【python爬虫】10.指挥浏览器自动工作(selenium)
文章目录
- 前言
- selenium是什么
- 怎么用
- 设置浏览器引擎
- 获取数据
- 解析与提取数据
- 自动操作浏览器
- 实操运用
- 确认目标
- 分析过程
- 代码实现
- 本关总结
前言
上一关,我们认识了cookies和session。
分别学习了它们的用法,以及区别。

还做了一个项目:带着小饼干登录,然后在博客中发表评论。
除了上一关所讲的登录问题,在爬虫过程中,我们还可能会遇到各种各样棘手的问题——
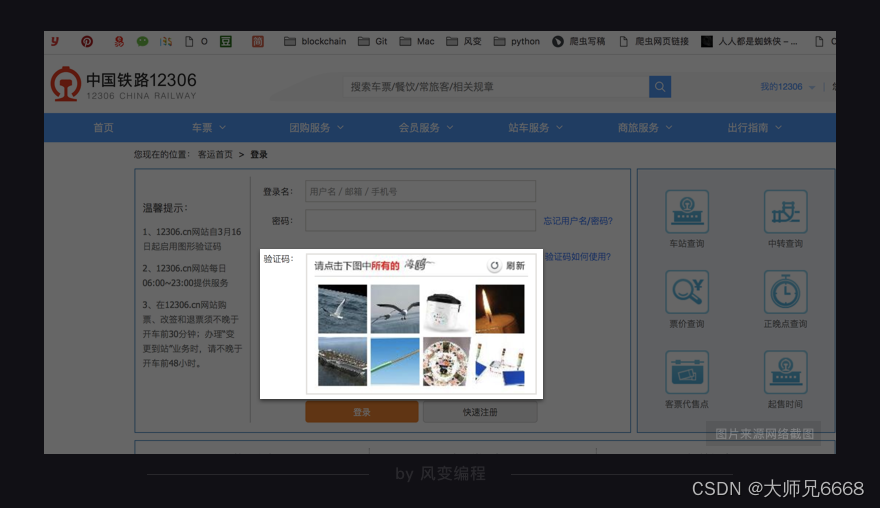
有的网站登录很复杂,验证码难以破解,比如大名鼎鼎的12306。
有的网站页面交互复杂,所使用的技术难以被爬取,比如,腾讯文档。
还有的网站,对URL的加密逻辑很复杂,比如,第4关爬过的QQ音乐歌曲评论,URL的参数变量找起来挺费劲的。
以上这些情况,想要攻破这些网站的反爬虫技术会有一些难度。
不过,你也不用担心,在本关,我将为你传授一个终极武器——selenium,通过它,可以解决以上所有问题。
selenium是什么
selenium是什么呢?它是一个强大的Python库。
它可以做什么呢?它可以用几行代码,控制浏览器,做出自动打开、输入、点击等操作,就像是有一个真正的用户在操作一样。
来看一小段录屏吧,文字在视频面前会显得苍白。
这就是我用selenium写的脚本,让浏览器自动打开网页,然后输入文字,点击提交按钮。这里用到的代码我都会在后面讲到。
这里要表扬一个我之前教过的用户,他们公司内网的登录和操作很繁琐,登录之后的操作又机械重复,他学会了selenium之后,就去写了一个Python程序。
他每天上班的第一件事,就是打开电脑运行自己写的脚本,让浏览器自动打开公司内网完成登录,那些重复的工作也紧跟着一起完成。而他自己,则是坐在那里悠闲地喝茶。
selenium能控制浏览器,这对解决我们刚刚提出的那几个问题,有什么帮助呢?
首先,当你遇到验证码很复杂的网站时,selenium允许让人去手动输入验证码,然后把剩下的操作交给机器。
而对于那些交互复杂、加密复杂的网站,selenium问题简化,爬动态网页如爬静态网页一样简单。
什么是动态网页,什么又是静态网页呢?其实两种网页你都已经接触过了。
第2关教你用html写出的网页,就是静态网页。我们使用BeautifulSoup爬取这类型网页,因为网页源代码中就包含着网页的所有信息,因此,网页地址栏的URL就是网页源代码的URL。
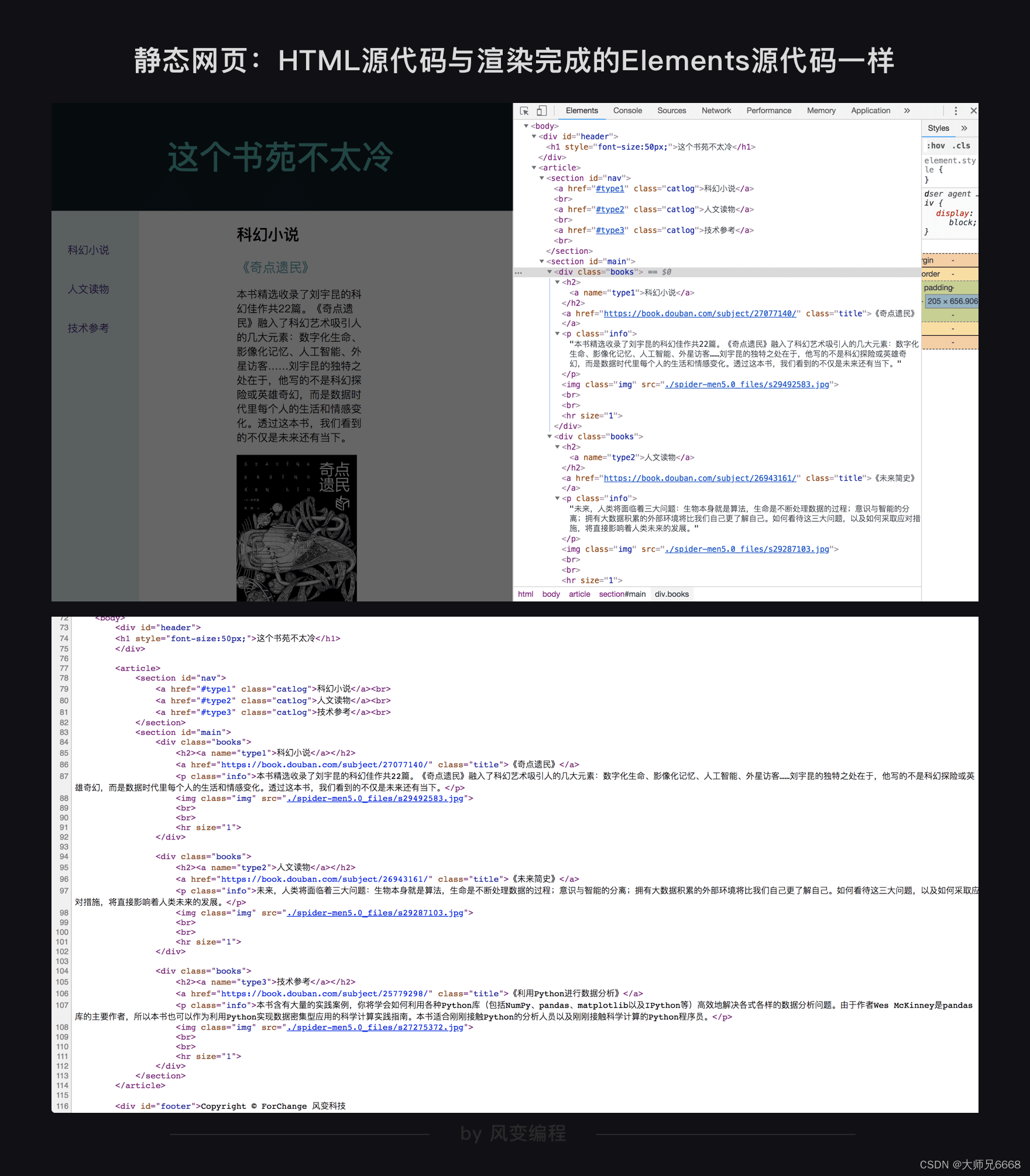
后来,你开始接触更复杂的网页,比如QQ音乐,要爬取的数据不在HTML源代码中,而是在json中,你就不能直接使用网址栏的URL了,而需要找到json数据的真实URL。这就是一种动态网页。

不论数据存在哪里,浏览器总是在向服务器发起各式各样的请求,当这些请求完成后,它们会一起组成开发者工具的Elements中所展示的,渲染完成的网页源代码。
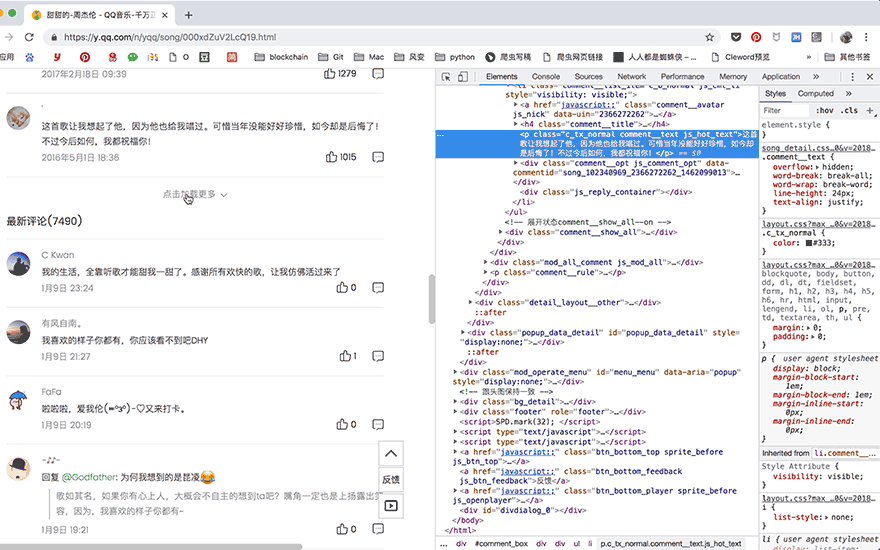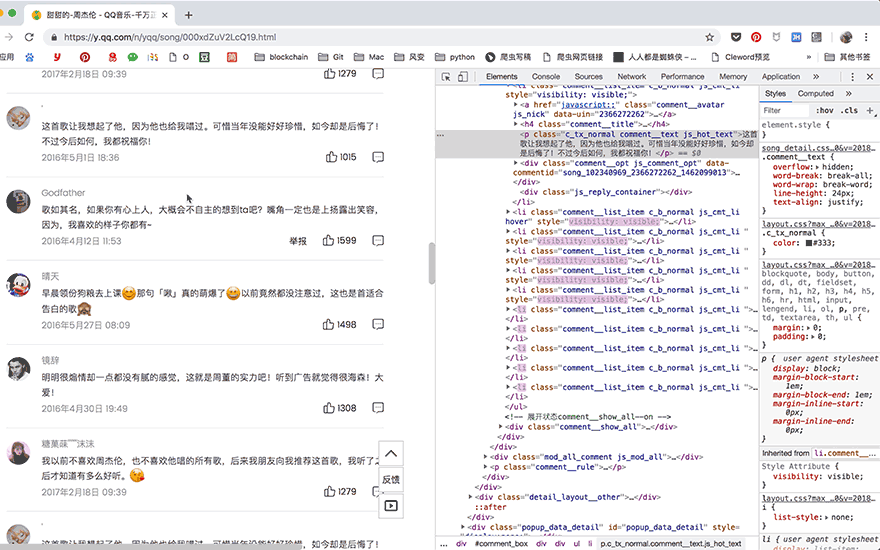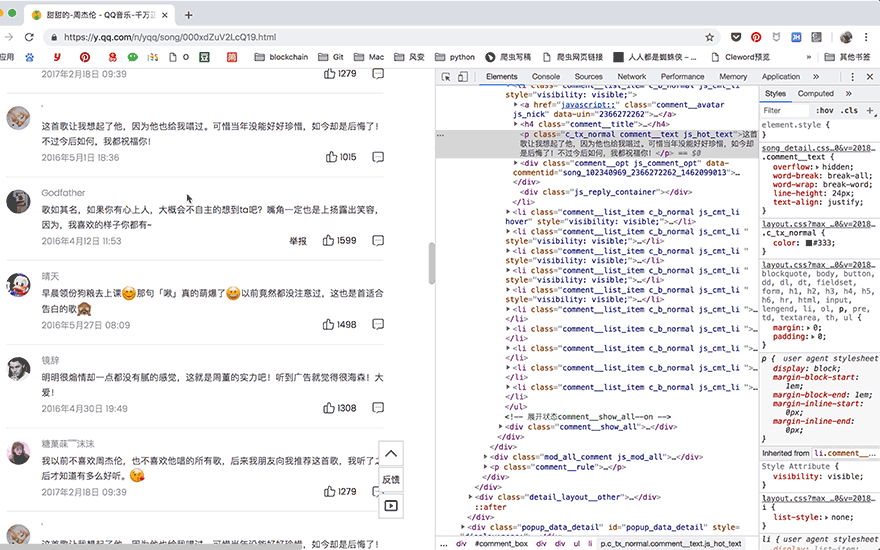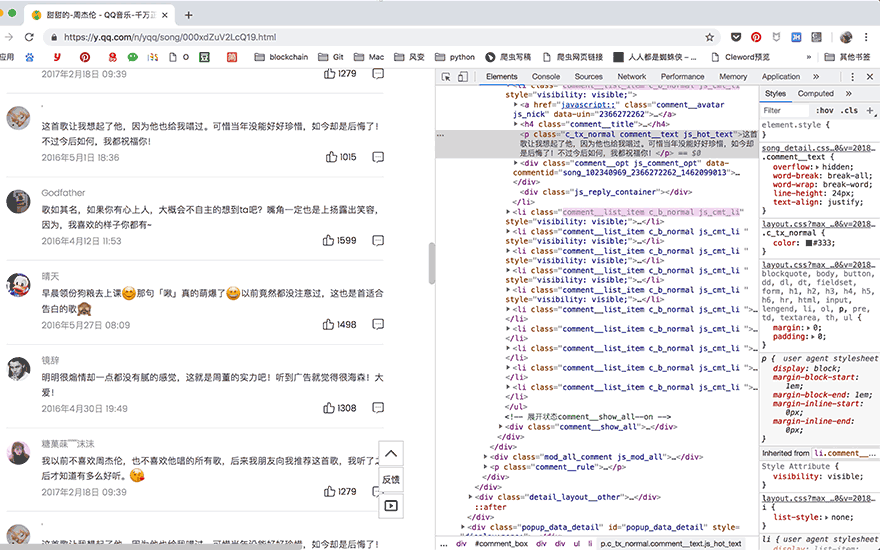
在遇到页面交互复杂或是URL加密逻辑复杂的情况时,selenium就派上了用场,它可以真实地打开一个浏览器,等待所有数据都加载到Elements中之后,再把这个网页当做静态网页爬取就好了。
说了这么多优点,使用selenium时,当然也有美中不足之处。
由于要真实地运行本地浏览器,打开浏览器以及等待网渲染完成需要一些时间,selenium的工作不可避免地牺牲了速度和更多资源,不过,至少不会比人慢。
知道了它的优缺点,我们就开始学习如何使用selenium吧。
怎么用
首先,和其它所有Python库一样,selenium需要安装,方法也很简单, 使用pip安装。
pip install selenium # Windows电脑安装selenium
pip3 install selenium # Mac电脑安装selenium
selenium的脚本可以控制所有常见浏览器的操作,在使用之前,需要安装浏览器的驱动。
我推荐的是Chrome浏览器,打开下面的链接,就可以下载Chrome的安装包了,Windows和Mac都有。
https://localprod.pandateacher.com/python-manuscript/crawler-html/chromedriver/ChromeDriver.html
我强烈建议你现在立刻马上就下载它,并且在自己的电脑中安装好浏览器驱动,因为这个关卡比较特别,需要你边学习,边在本地环境中运行代码。
这是因为,我只能用一些动图为你展示它的运行效果。
由此造成的影响是,在学习本关的内容时,如果你想更直观地看到浏览器的操作过程,就要在本地电脑中运行脚本。
在正式开始知识的讲解之前,我想首先让你体验一下selenium脚本程序在你的本地终端运行的效果。因为在学习selenium之初,如果能亲自看到浏览器自动弹出后的操作效果,对你后续的学习会有很大帮助。
下面的代码就是本节课开头动图的代码。你现在不需要去理解具体的意思,等会儿就会学到每一行的用法。
现在只需要把这段代码复制到本地的代码编辑器中运行,体验一下你的浏览器为你自动工作的效果。当然,前提是你已经安装好了selenium库以及Chrome浏览器驱动。
# 本地Chrome浏览器设置方法
from selenium import webdriver
import timedriver = webdriver.Chrome()
driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/')
time.sleep(4)teacher = driver.find_element_by_id('teacher')
teacher.send_keys('必须是吴枫呀')
assistant = driver.find_element_by_name('assistant')
assistant.send_keys('都喜欢')
time.sleep(1)
button = driver.find_element_by_class_name('sub')
time.sleep(1)
button.click()
time.sleep(1)
driver.close()
除了看程序运行,不如手动打开这个网站看看,做一遍和程序中一样的操作,URL给你:
https://localprod.pandateacher.com/python-manuscript/hello-spiderman/
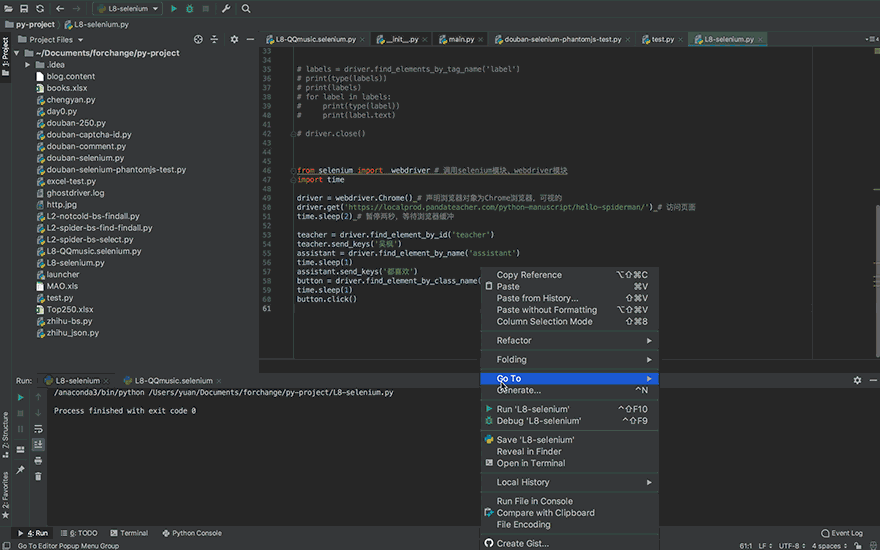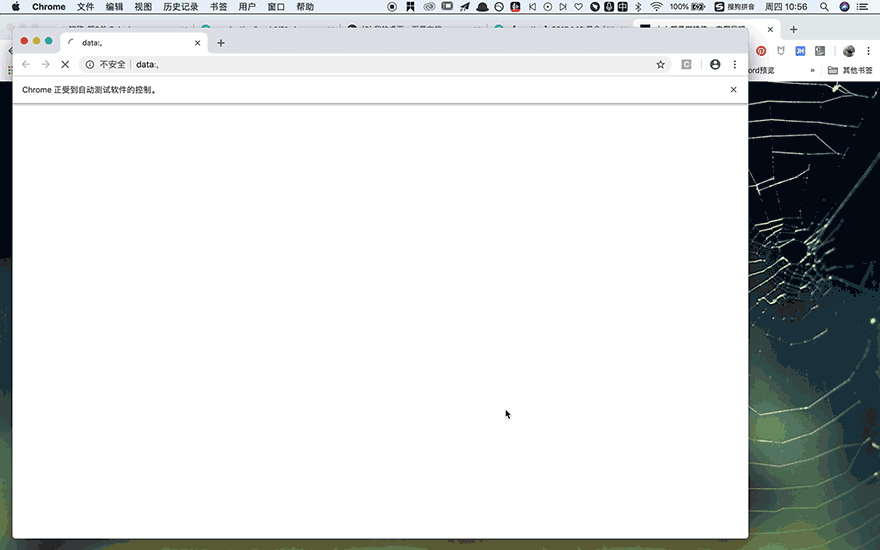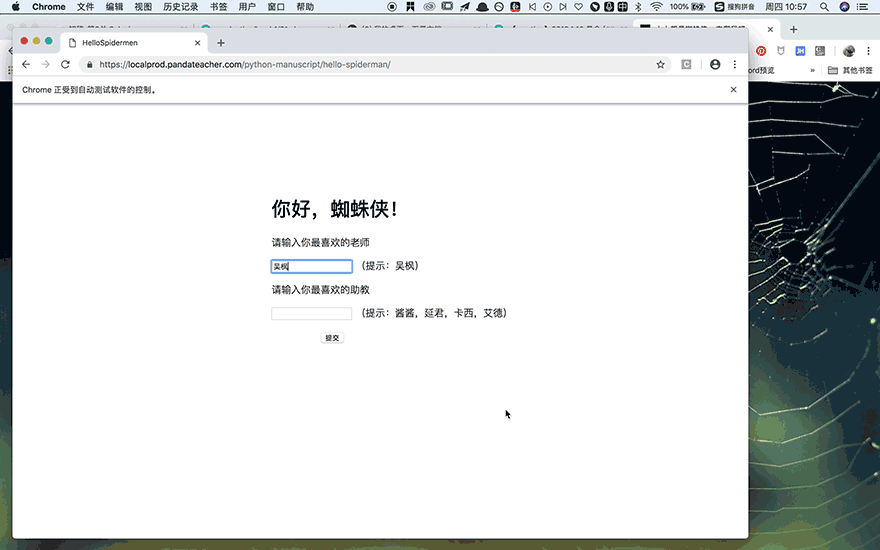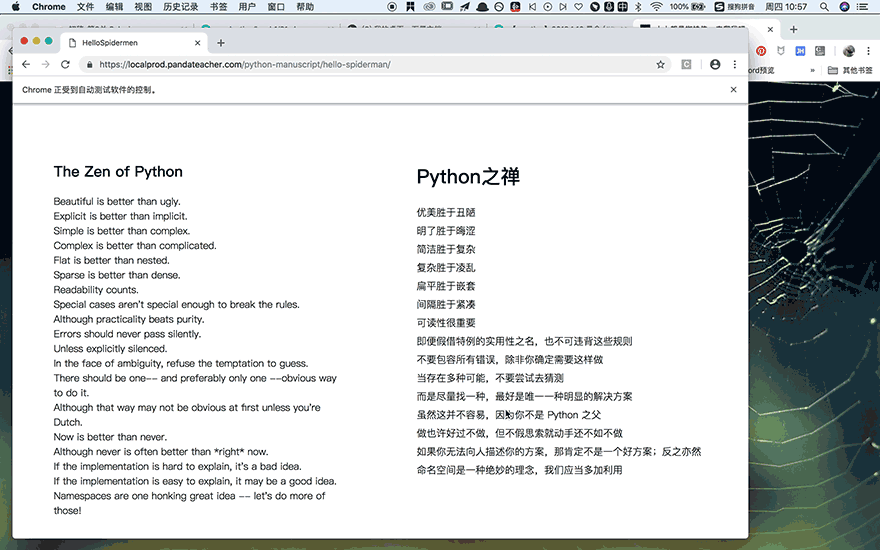
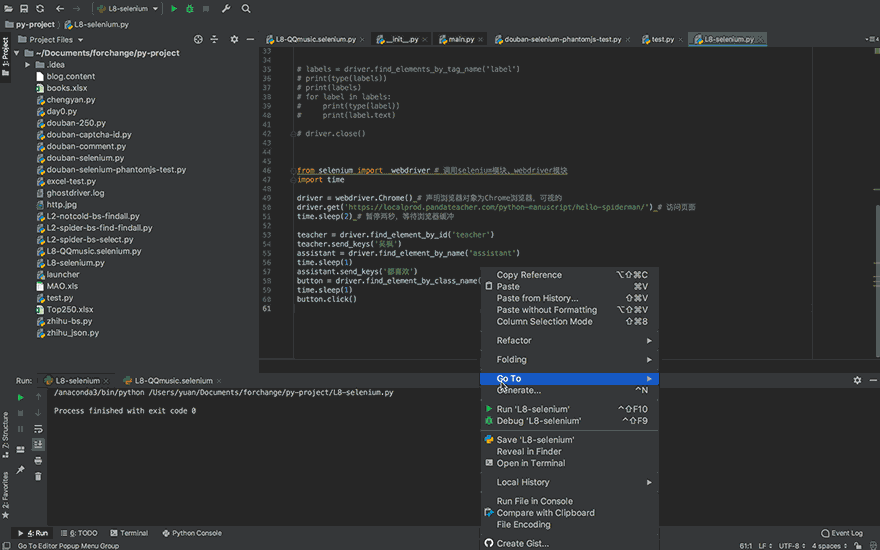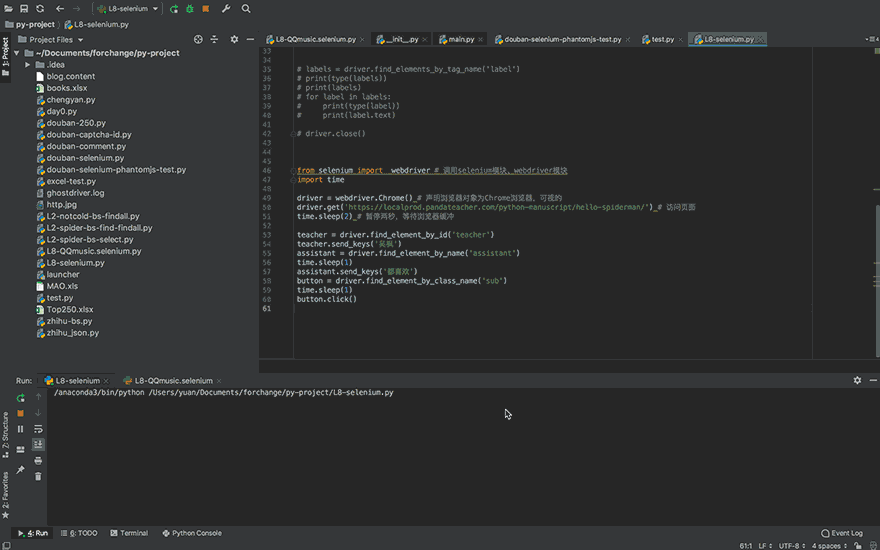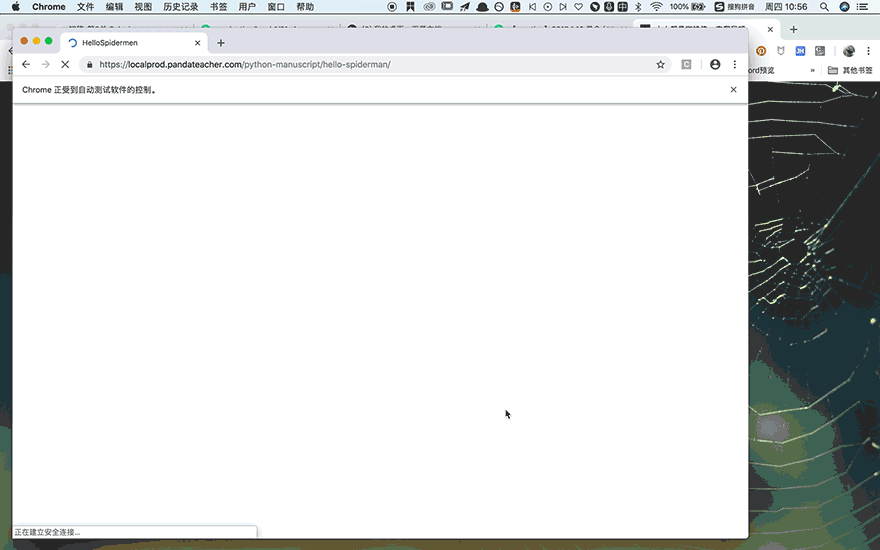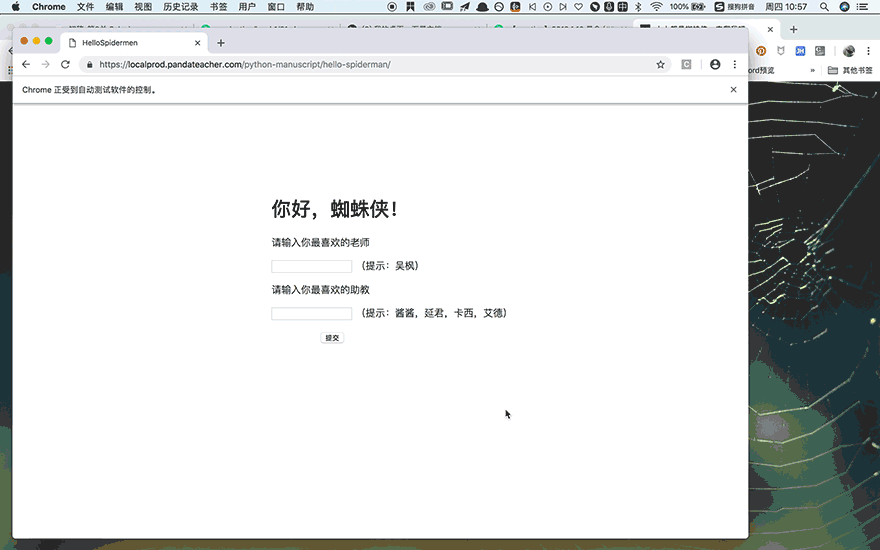
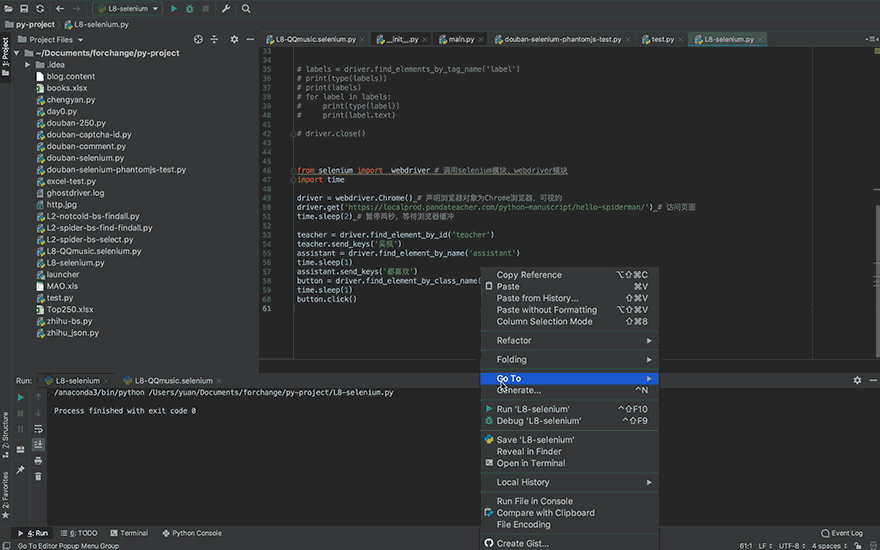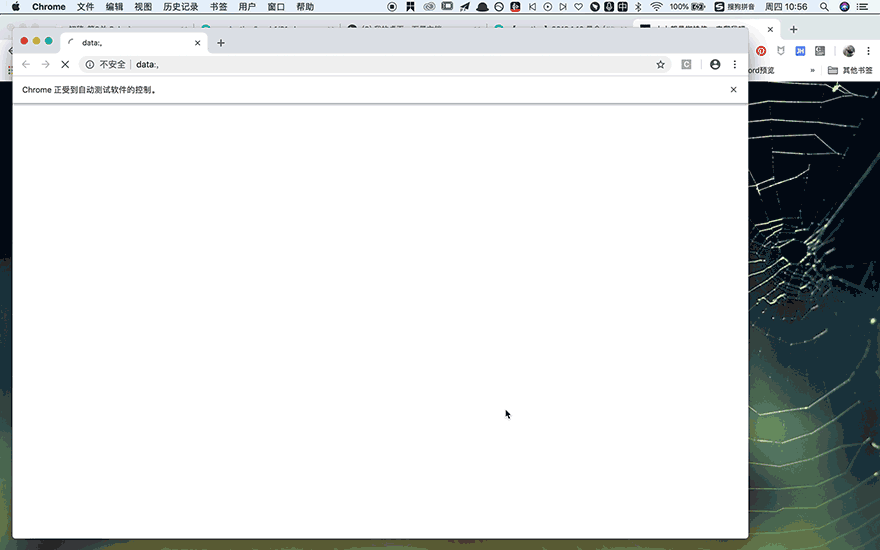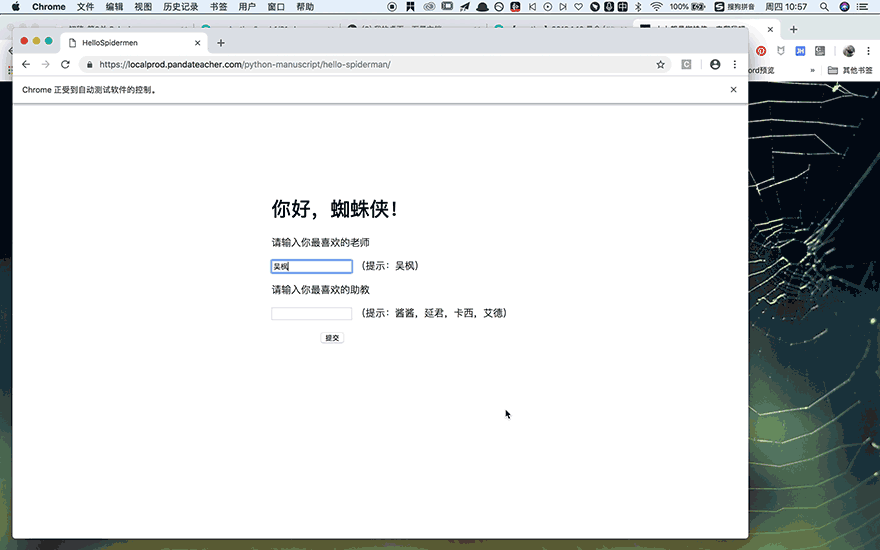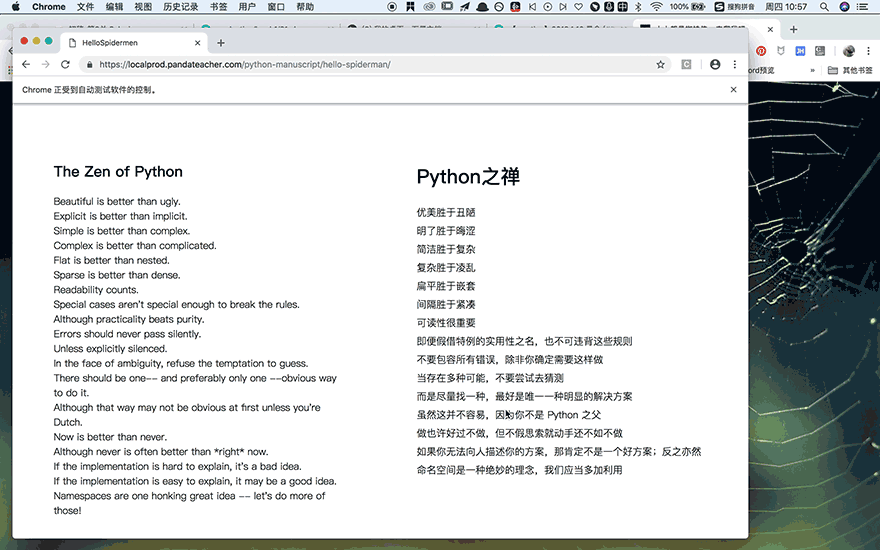
首先引入眼帘的是【你好,蜘蛛侠!】几个大字,一秒之后,它会自动跳转到一个新的页面,请你输入最喜欢的老师和助教,你点击提交之后,它又会跳转到Python之禅的中英对照页面。
仔细看,你会发现,在这个过程中,网页URL一直没有变化,可见【你好,蜘蛛侠!】是个动态网页。
体验了selenium之后,我们接下来正式开始代码的讲解。
设置浏览器引擎
和以前一样,使用一个新的Python库,首先要调用它。selenium有点不同,除了调用,还需要设置浏览器引擎。
# 本地Chrome浏览器设置方法
from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器
以上就是浏览器的设置方式:把Chrome浏览器设置为引擎,然后赋值给变量driver。driver是实例化的浏览器,在后面你会总是能看到它的影子,这也可以理解,因为我们要控制这个实例化的浏览器为我们做一些事情。
配置好了浏览器,就可以开始让它帮我们干活啦!
接下来,我们学习selenium的具体用法,这个部分的知识讲解,都会以你已经见到好几次的,【你好蜘蛛侠!】这个网站为例:
https://localprod.pandateacher.com/python-manuscript/hello-spiderman/
我们还是按照爬虫四步来讲解selenium的用法,看看selenium如何获取、解析与提取数据。由于本关中提取出的数据都不太复杂,直接在终端打印就好,不会涉及到储存数据这一步。

获取数据
首先看一下获取数据的代码怎么写吧。
import time# 本地Chrome浏览器设置方法
from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 打开网页
time.sleep(1)
driver.close() # 关闭浏览器
前面三行代码都是你学过的,调用模块,并且设置浏览器,只有后两行代码是新的。
get(URL)是webdriver的一个方法,它的使命是为你打开指定URL的网页。
刚才说过driver在这里是一个实例化的浏览器,因此,就是通过这个浏览器打开网页。
当一个网页被打开,网页中的数据就加载到了浏览器中,也就是说,数据被我们获取到了。
driver.close()是关闭浏览器驱动,每次调用了webdriver之后,都要在用完它之后加上一行driver.close()用来关闭它。
就像是,每次打开冰箱门,把东西放进去之后,都要记得关上门,使用selenium调用了浏览器之后也要记得关闭浏览器。
把上面的代码复制粘贴在你的本地电脑中运行,你可以看到,一个浏览器自动启动,并为你打开一个网页,停留一秒之后,浏览器关闭。
下一步,我们要让浏览器解析并提取数据,然后打印出来,让我们看到返回的运行结果。
解析与提取数据
我们在前面花两个关卡学习了使用BeautifulSoup解析网页源代码,然后提取其中的数据。
selenium库同样也具备解析数据、提取数据的能力。它和BeautifulSoup的底层原理一致,但在一些细节和语法上有所出入。
首先明显的一个不同即是:selenium所解析提取的,是Elements中的所有数据,而BeautifulSoup所解析的则只是Network中第0个请求的响应。
本关开头我说过,用selenium把网页打开,所有信息就都加载到了Elements那里,之后,就可以把动态网页用静态网页的方法爬取了。
selenium是如何解析与提取数据的呢?我们现在来试试提取【你好蜘蛛侠!】网页中,<label>元素的内容吧。
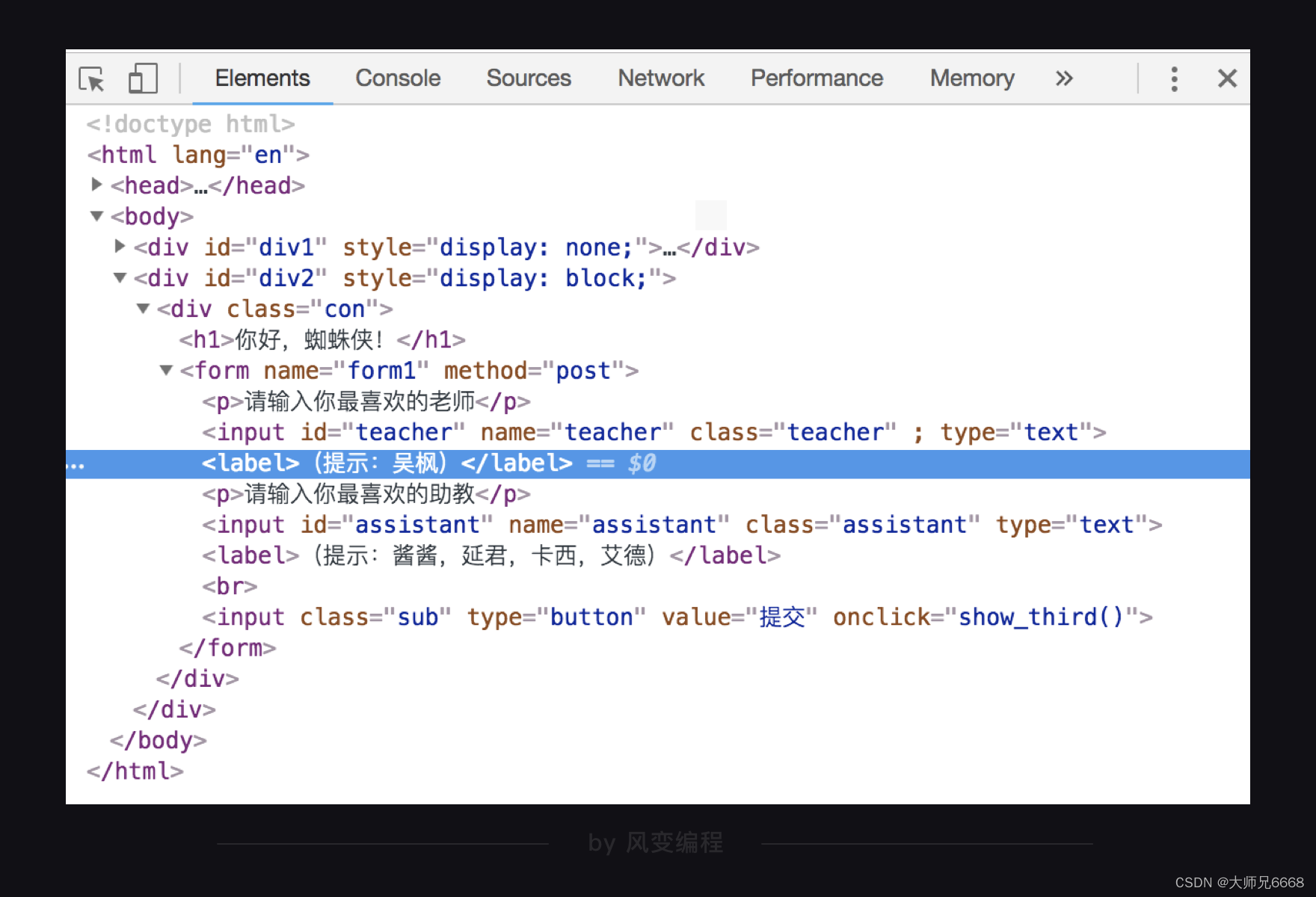
代码我写好了,你可以运行看看吧!提示:如果出现参考代码运行报错请复制后自己修改运行!
from selenium import webdriver # 从selenium库中调用webdriver模块
from bs4 import BeautifulSoup # 调用BeautifulSoup库
import timechrome_options = webdriver.ChromeOptions() # 实例化Option对象
chrome_options.add_argument('--headless') # 对浏览器的设置
driver = webdriver.Chrome(options=chrome_options) # 声明浏览器对象driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 访问页面
time.sleep(2) # 等待2秒
label = driver.find_element_by_tag_name('label') # 解析网页并提取第一个<label>标签
print(label.text) # 打印label的文本
driver.close() # 关闭浏览器
输出结果:
(提示:吴枫)
从运行结果中可以看到,我们提取出了<label>(提示:吴枫)</label>中的文本(提示:吴枫)。
上面这段代码只有最后几行代码是新增的,第11行:等待2秒;第12行:然后解析网页并提取网页中第一个<label>标签;第13行:打印label的文本内容。
用time.sleep(3)等待三秒,是由于浏览器缓冲加载网页需要耗费一些时间,以及我在这个网页中设置了一秒之后才从首页跳转到输入页面,所以,等待三秒再去解析和提取比较稳妥。
这样来看,解析与提取数据,在这里其实只用了一行代码:
label = driver.find_element_by_tag_name('label') # 解析网页并提取第一个<label>标签中的文字
你能否看出,是哪部分在做解析,哪部分在做提取?
先回想下,使用BeautifulSoup解析提取数据时,首先要把Response对象解析为BeautifulSoup对象,然后再从中提取数据。
而在selenium中,获取到的网页存在了driver中,而后,解析与提取是同时做的,都是由driver这个实例化的浏览器完成。
所以,上个问题的答案是:解析数据是由driver自动完成的,提取数据是driver的一个方法。
清楚了解析与提取的本质,我们接下来详细讲解析数据的方法。
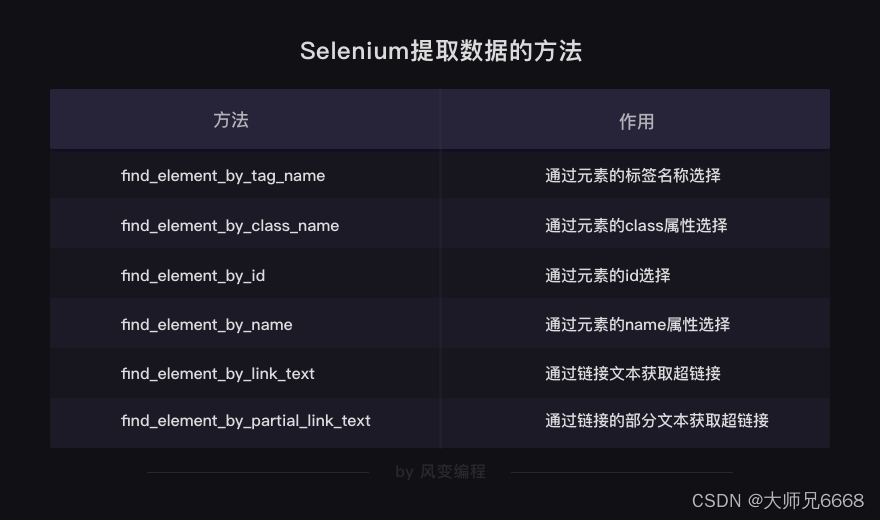
selenium当然不光能通过标签来提取数据,还有很多查找和提取元素的方法,都是非常直截了当的方法。

你可以看出,提取数据的方法都是英文直译的意思。举例给你看看它们的用法,请仔细阅读下面代码的注释:
# 以下方法都可以从网页中提取出'你好,蜘蛛侠!'这段文字find_element_by_tag_name:通过元素的名称选择
# 如<h1>你好,蜘蛛侠!</h1>
# 可以使用find_element_by_tag_name('h1')find_element_by_class_name:通过元素的class属性选择
# 如<h1 class="title">你好,蜘蛛侠!</h1>
# 可以使用find_element_by_class_name('title')find_element_by_id:通过元素的id选择
# 如<h1 id="title">你好,蜘蛛侠!</h1>
# 可以使用find_element_by_id('title')find_element_by_name:通过元素的name属性选择
# 如<h1 name="hello">你好,蜘蛛侠!</h1>
# 可以使用find_element_by_name('hello')#以下两个方法可以提取出超链接find_element_by_link_text:通过链接文本获取超链接
# 如<a href="spidermen.html">你好,蜘蛛侠!</a>
# 可以使用find_element_by_link_text('你好,蜘蛛侠!')find_element_by_partial_link_text:通过链接的部分文本获取超链接
# 如<a href="https://localprod.pandateacher.com/python-manuscript/hello-spiderman/">你好,蜘蛛侠!</a>
# 可以使用find_element_by_partial_link_text('你好')
以上就是提取单个元素的方法了。
那么,我们提取出的元素是什么类呢?这种对象有什么属性和方法呢?我们现在就来看看。请阅读下面的代码,然后点击运行:
from selenium import webdriver # 从selenium库中调用webdriver模块
from bs4 import BeautifulSoup # 调用BeautifulSoup库
import timeoptions = webdriver.ChromeOptions()
options.add_argument('--headless') # 开启无头模式chrome_options = webdriver.ChromeOptions() # 实例化Option对象
chrome_options.add_argument('--headless') # 对浏览器的设置
driver = webdriver.Chrome(options=chrome_options) # 声明浏览器对象driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 访问页面
time.sleep(2) # 等待2秒
label = driver.find_element_by_tag_name('label') # 解析网页并提取第一个<label>标签中的文字
print(type(label)) # 打印label的数据类型
print(label.text) # 打印label的文本
print(label) # 打印label
driver.close() # 关闭浏览器
运行结果:
<class 'selenium.webdriver.remote.webelement.WebElement'>
(提示:吴枫)
<selenium.webdriver.remote.webelement.WebElement (session="6d400c6ad6f0aa4f5a241b4332ea0c4c", element="0.9387651316030954-1")>
运行结果有3行
可见,提取出的数据属于WebElement类对象,如果直接打印它,返回的是一串对它的描述。
而它与BeautifulSoup中的Tag对象类似,也有一个属性.text,可以把提取出的元素用字符串格式显示。
还想补充的是,WebElement类对象与Tag对象类似,它也有一个方法,可以通过属性名提取属性的值,这个方法是.get_attribute()。

我们来举个例子:
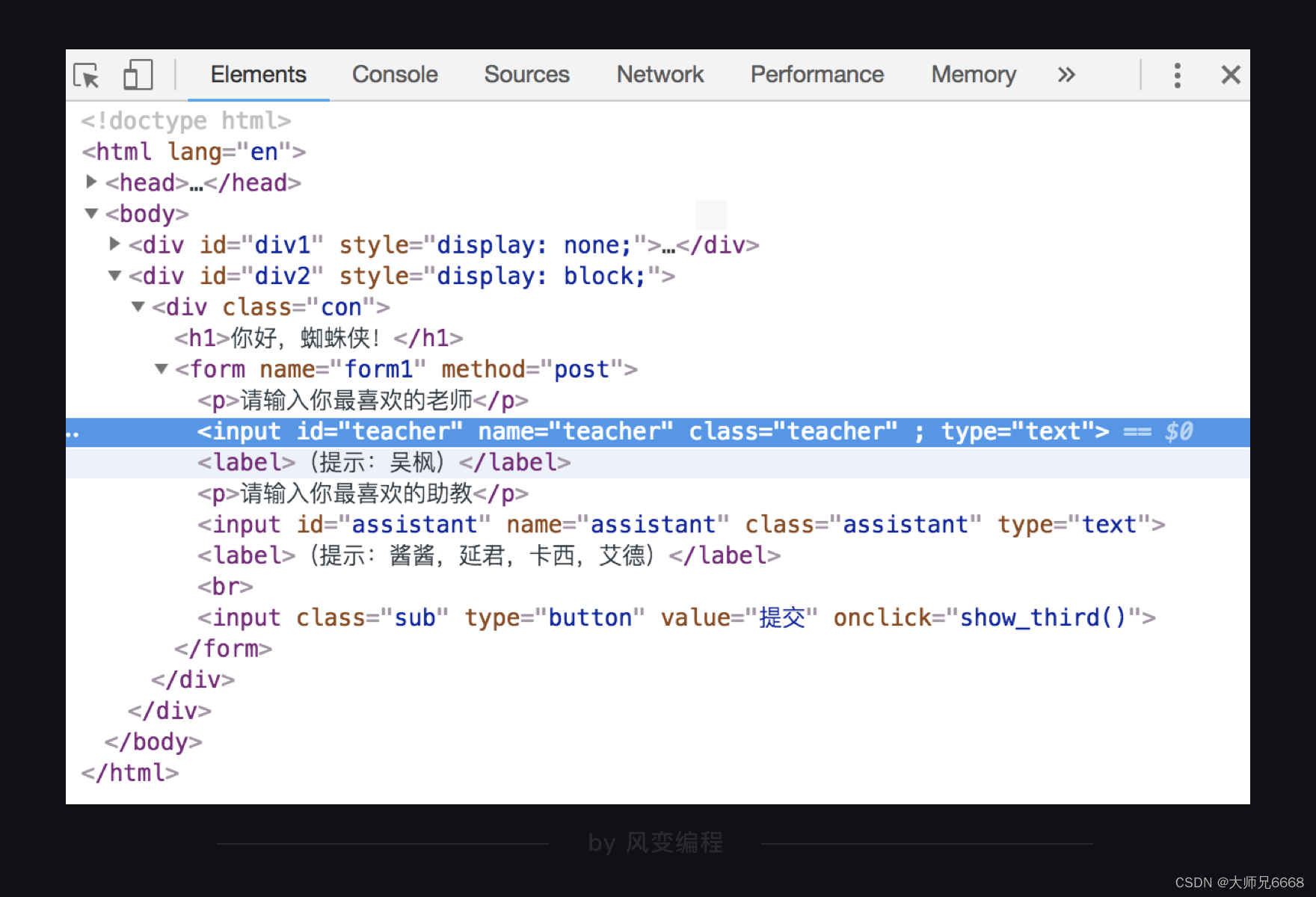
我们试试,通过class="teacher"定位到上图中标亮的元素,然后提取出type这个属性的值text。
from selenium import webdriver # 从selenium库中调用webdriver模块
from bs4 import BeautifulSoup # 调用BeautifulSoup库
import timeoptions = webdriver.ChromeOptions()
options.add_argument('--headless') # 开启无头模式chrome_options = webdriver.ChromeOptions() # 实例化Option对象
chrome_options.add_argument('--headless') # 对浏览器的设置
driver = webdriver.Chrome(options=chrome_options) # 声明浏览器对象driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 访问页面
time.sleep(2) # 等待2秒
label = driver.find_element_by_class_name('teacher') # 根据类名找到元素
print(type(label)) # 打印label的数据类型
print(label.get_attribute('type')) # 获取type这个属性的值
driver.close() # 关闭浏览器
运行结果:
<class 'selenium.webdriver.remote.webelement.WebElement'>
text
因此,我们可以总结出,selenium解析与提取数据的过程中,我们操作的对象转换:

刚才,我们做的都是提取出网页中的第一个符合要求的数据,接下来,我们就看看提取多个元素的方法吧。
find_element_by_与BeautifulSoup中的find类似,可以提取出网页中第一个符合要求的元素;既然BeautifulSoup有提取所有元素的方法find_all,selenium也同样有方法。
方法也一样很简单,把刚才的element换成复数elements就好了。
我们来试试提取出【你好,蜘蛛侠!】的所有label标签中的文字。
from selenium import webdriver # 从selenium库中调用webdriver模块
from bs4 import BeautifulSoup # 调用BeautifulSoup库
import timeoptions = webdriver.ChromeOptions()
options.add_argument('--headless') # 开启无头模式chrome_options = webdriver.ChromeOptions() # 实例化Option对象
chrome_options.add_argument('--headless') # 对浏览器的设置
driver = webdriver.Chrome(options=chrome_options) # 声明浏览器对象driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 访问页面
time.sleep(2) # 等待2秒labels = driver.find_elements_by_tag_name('label') # 根据标签名提取所有元素
print(type(labels)) # 打印labels的数据类型
print(labels) # 打印labels
driver.close() # 关闭浏览器
运行结果:
<class 'list'>
[<selenium.webdriver.remote.webelement.WebElement (session="87d373c4e7a09aef4dd31f5940f8cf84", element="0.794826797904179-1")>, <selenium.webdriver.remote.webelement.WebElement (session="87d373c4e7a09aef4dd31f5940f8cf84", element="0.794826797904179-2")>]
从运行结果可以看到,提取出的是一个列表,<class ‘list’>。而列表的内容就是WebElements对象,这些符号是对象的描述,我们刚才学过,需要用.text才能返回它的文本内容。
既然得到了列表,就可以和find_all返回的结果类似,同样用for循环遍历列表就可以提取出列表中的每一个值了。
那么,请你写一下这个代码吧:
参考代码:
labels=driver.find_elements_by_tag_name('label')
for i in labels:print(i.text)
以上就是selenium的解析与提取数据的方法了。
除了用selenium解析与提取数据,还有一种解决方案,那就是,使用selenium获取网页,然后交给BeautifulSoup解析和提取。
接下来,我们就看看,selenium与BeautifulSoup如何快乐地合作。
我们回顾一下BeautifulSoup的工作方式吧。
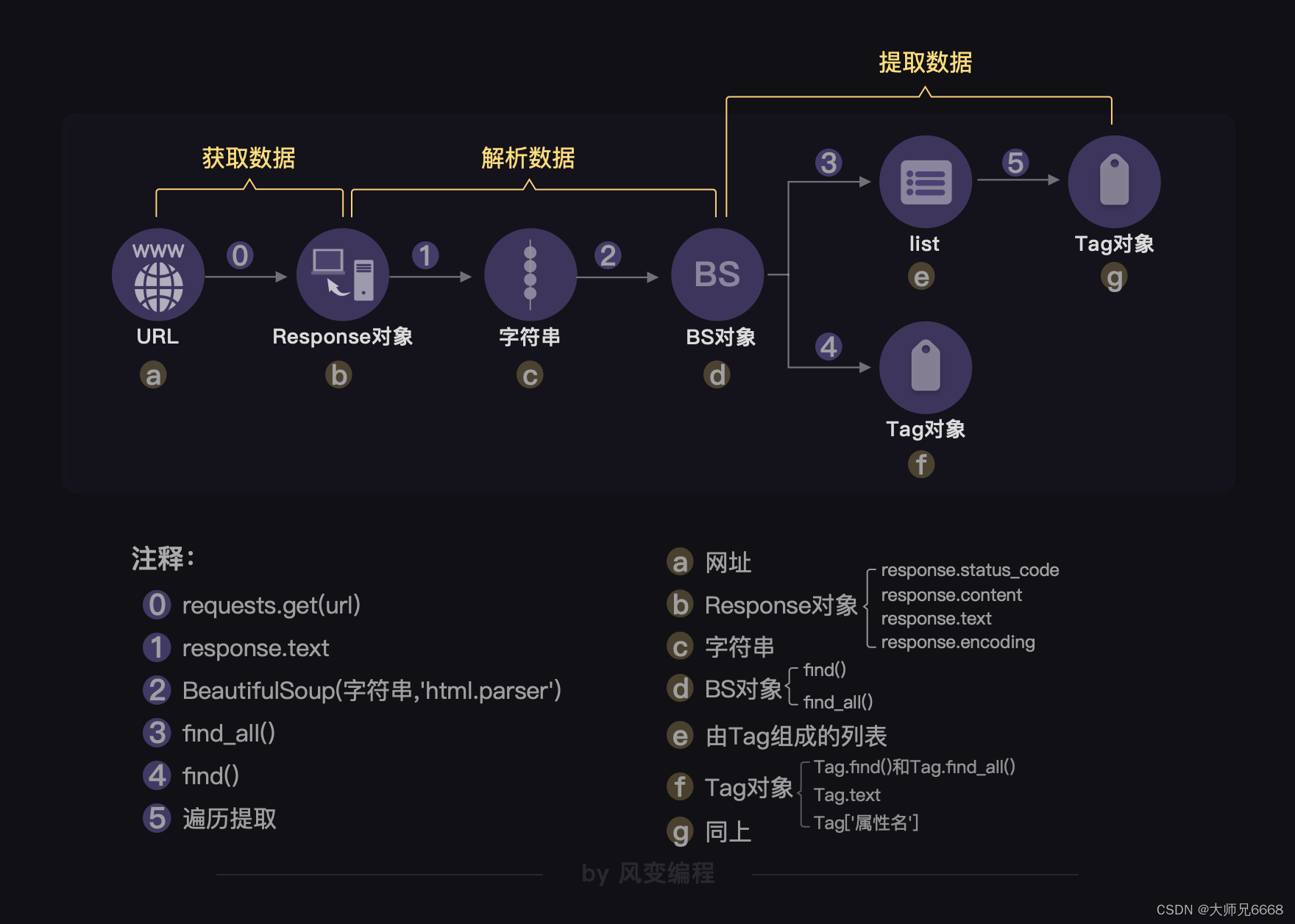
BeautifulSoup需要把字符串格式的网页源代码解析为BeautifulSoup对象,然后再从中提取数据。
selenium刚好可以获取到渲染完整的网页源代码。
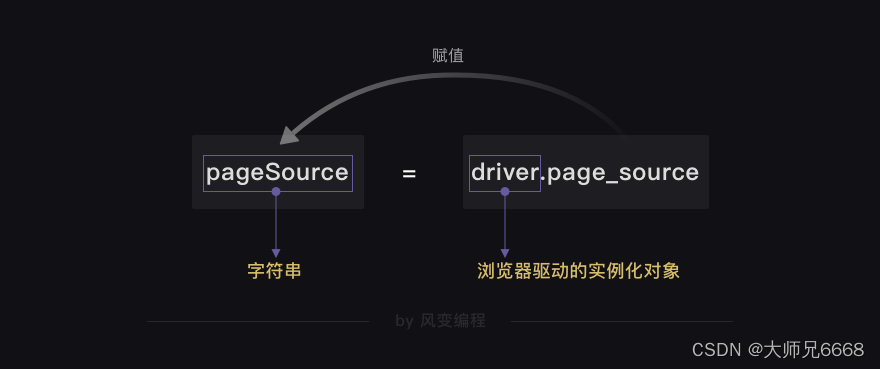
如何获取呢?也是使用driver的一个方法:page_source。
HTML源代码字符串 = driver.page_source
我们现在就来实操一下,获取【你好,蜘蛛侠!】的网页源代码:
from selenium import webdriver # 从selenium库中调用webdriver模块
from bs4 import BeautifulSoup # 调用BeautifulSoup库
import timeoptions = webdriver.ChromeOptions()
options.add_argument('--headless') # 开启无头模式chrome_options = webdriver.ChromeOptions() # 实例化Option对象
chrome_options.add_argument('--headless') # 对浏览器的设置
driver = webdriver.Chrome(options=chrome_options) # 声明浏览器对象driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 访问页面
time.sleep(2) # 等待2秒pageSource = driver.page_source # 获取完整渲染的网页源代码
print(type(pageSource)) # 打印pageSource的类型
print(pageSource) # 打印pageSource
driver.close() # 关闭浏览器
我们成功获取并打印出了网页源代码O(∩_∩)O~~而且它的数据类型是<class 'str'>。
你还记不记得,用requests.get()获取到的是Response对象,在交给BeautifulSoup解析之前,需要用到.text的方法才能将Response对象的内容以字符串的形式返回。
而使用selenium获取到的网页源代码,本身已经是字符串了。
获取到了字符串格式的网页源代码之后,就可以用BeautifulSoup解析和提取数据了,这是我留给你的一个课后作业。
到这里,解析与提取数据的方法就讲解完了。
关于selenium的用法,还有什么没有讲呢?对!就是我们在本关开头演示的功能,控制浏览器自动输入文本,并且点击提交。
网页URL再给你一次:
https://localprod.pandateacher.com/python-manuscript/hello-spiderman/
我现在就为你解开这个谜底。
自动操作浏览器
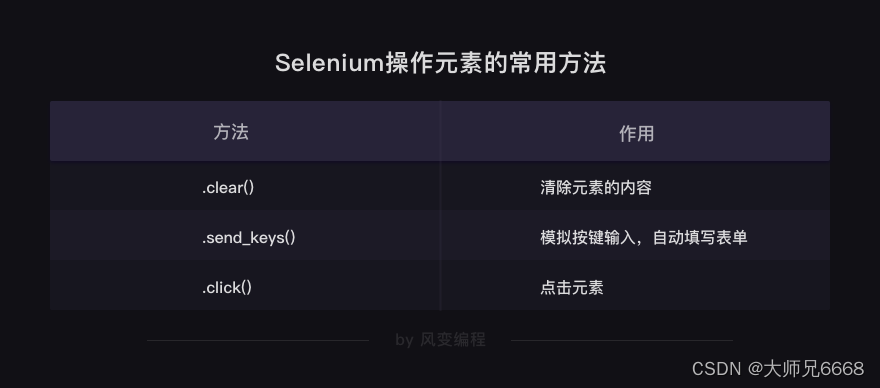
其实,要做到上面动图中显示的效果,你只需要新学两个方法就好了:
.send_keys() # 模拟按键输入,自动填写表单
.click() # 点击元素
用这两行代码,再搭配刚才所讲的解析提取数据的方法,就可以完成操作浏览器的效果了。
学到这里,我们就可以写下全部代码了,这也正是我在开头给你的,让你复制到本地运行过的代码。
# 本地Chrome浏览器设置方法
from selenium import webdriver # 从selenium库中调用webdriver模块
import time # 调用time模块
driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 访问页面
time.sleep(3) # 暂停三秒,等待浏览器缓冲teacher = driver.find_element_by_id('teacher') # 找到【请输入你喜欢的老师】下面的输入框位置
teacher.send_keys('必须是吴枫呀') # 输入文字
assistant = driver.find_element_by_name('assistant') # 找到【请输入你喜欢的助教】下面的输入框位置
assistant.send_keys('都喜欢') # 输入文字
button = driver.find_element_by_class_name('sub') # 找到【提交】按钮
button.click() # 点击【提交】按钮
time.sleep(1)
driver.close() # 关闭浏览器
由于这个代码的命令都是控制浏览器做一些操作,因此终端不会返回任何结果。
你在抄写的时候,有没有发现,最后的6行代码是两两对应的,在每一次输入和点击之前,都要先定位到对应的位置,查找定位用的方法就是前面学过的,解析与提取数据的方法。
比如,在输入你喜欢的老师之前,首先要在网页源代码中找到输入框的位置,方法还是我们之前学过的方法,点击开发者工具左上角的小箭头,然后把鼠标放在网页的空格处。
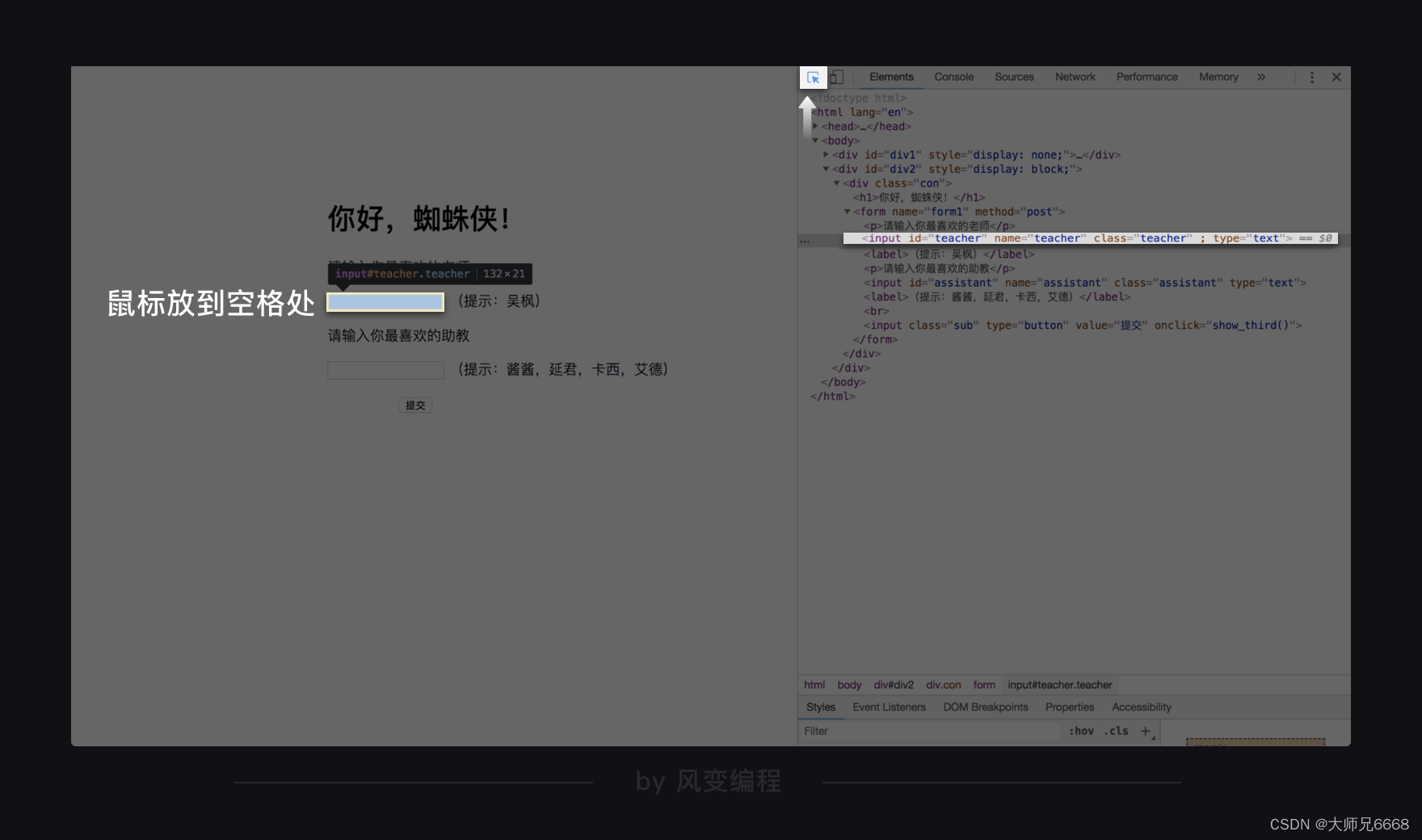
从网页源代码可以看出,可以根据id=“teacher”,或者class="teacher"查找定位到这里。
把提取到的位置信息赋值给teacher,然后再用teacher.send_keys()的方法输入你想填到这个空里的文本。
这样就完成了一个完整的操作,后面的两个操作,方法都是类似的。由此,整个代码也就写出来了。
还想补充一个小知识,除了输入和点击的两个方法,经常配合它们会用到的,还有一个方法.clear(),用于清除元素的内容。
假如,在刚才的空格中,已经输入了【蜘蛛侠】,如果你想改成【吴枫】,就需要先用.clear()清除掉【蜘蛛侠】这几个文字,再填写新的文字。
到这里,本关知识讲解的部分就全部完成了,我们接下来一起做一个项目吧~
每次学到新知识,都要及时通过实操练习,巩固所学的知识,这样才能对知识形成更深的理解和记忆。
实操运用
确认目标
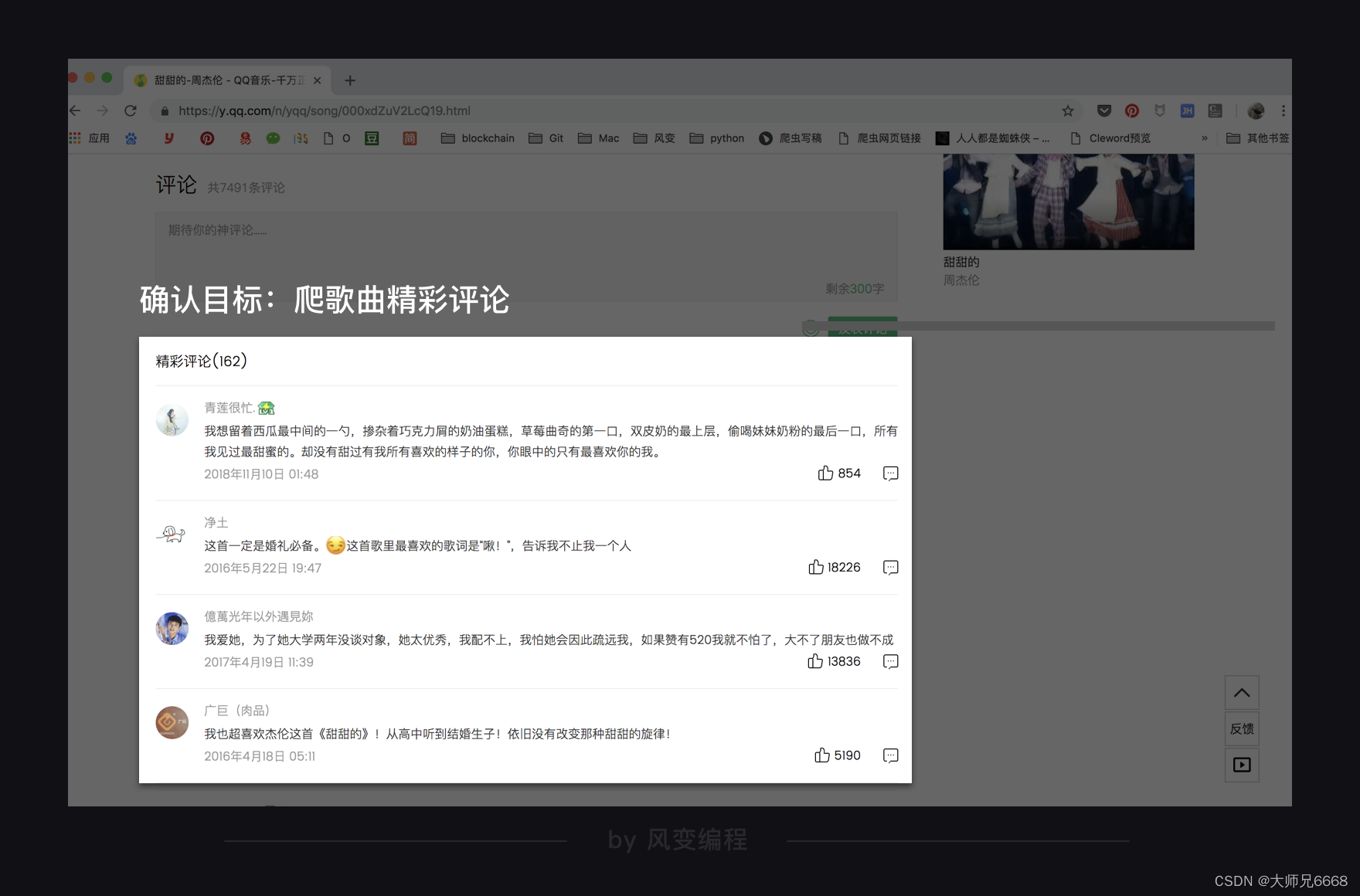
我们这次试试用selenium爬取QQ音乐的歌曲评论,我选的歌是《甜甜的》。
https://y.qq.com/n/yqq/song/000xdZuV2LcQ19.html
不知道你还有没有印象,在第5关学json时,爬过QQ音乐的歌曲最新评论,我们这次来爬精彩评论,两种评论的爬取方法本质是一样的。
现在带你用selenium再做一次之前做过的项目,当然不是我偷懒拍脑袋的决定,而是经过了深思熟虑,因为,同一个项目可以做两次,甚至可以做很多次。
使用不同的路径,到达相同的目的,这种学习和训练方法,会帮你把知识搞得更加透彻。
确认了目标,我们就开始行动吧!照旧,在写代码之前,要先分析思路。
分析过程
依旧按照爬虫的四个步骤来分析。
首先是获取数据:
通过第5关的学习,你已经知道,网页源代码中没有我们想要的评论,而是存在了Json中,需要通过查看XHR,找到每一页评论的Json数据真实URL,才能获取到数据。
我们这次是用selenium,就不需要花费精力去查找和破解URL了,因为,通过selenium打开浏览器的操作,数据就被加载到elements中了。
获取更多的评论的方法,也变得非常简单,直接使用selenium控制浏览器点击【点击加载更多】的按钮,评论数据自然就都加载到elements中了,简直完美:
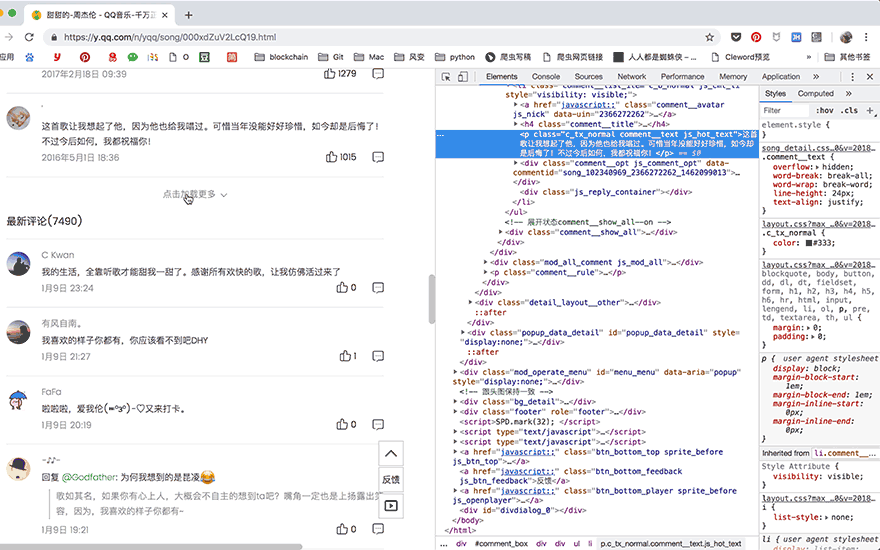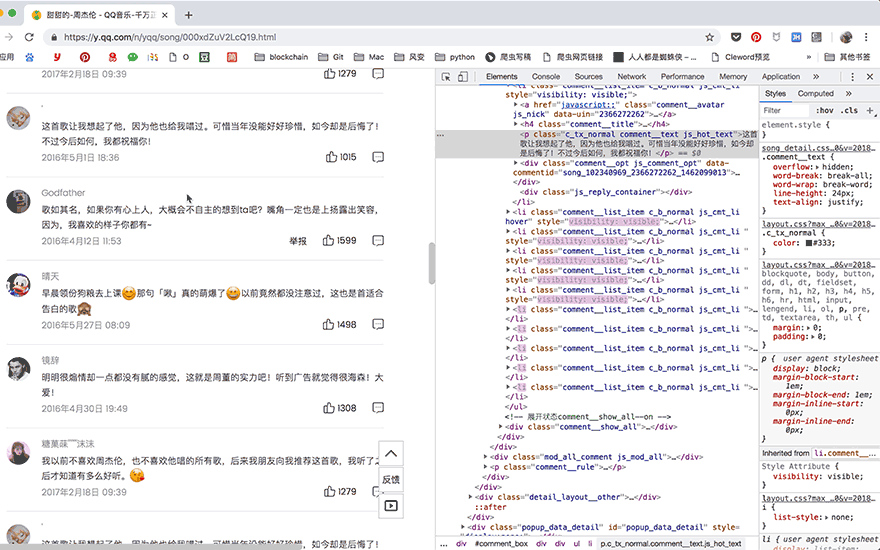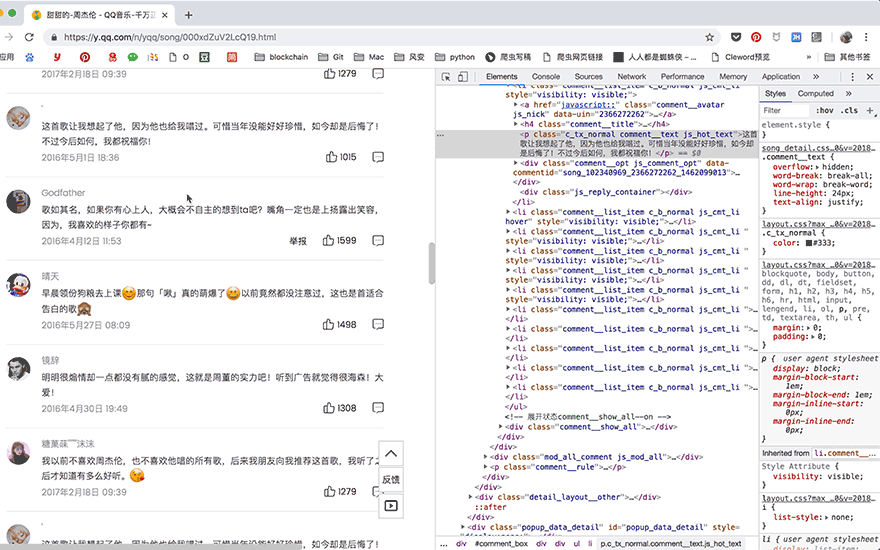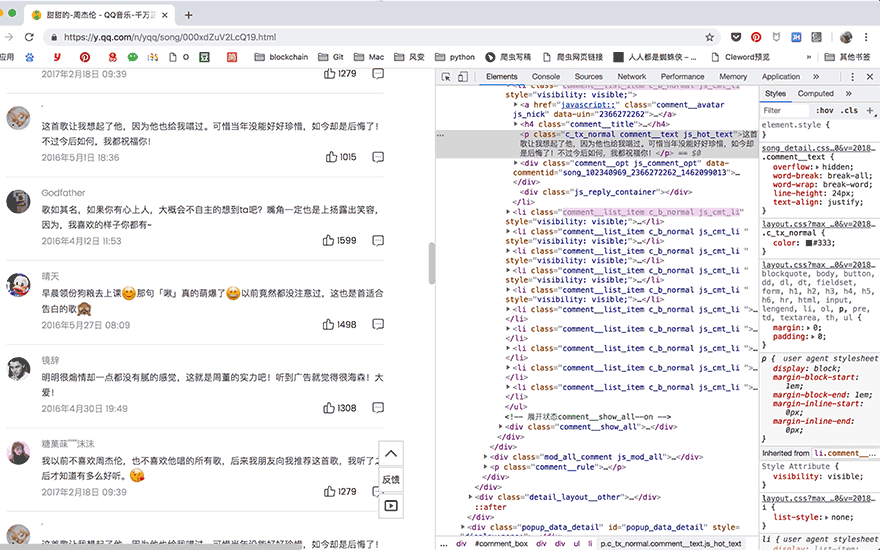
接下来是解析与提取数据:
第一种解决思路是使用selenium提取数据的方法。
第二种解决思路是,先获取到完整网页源代码,然后用BeautifulSoup抓取。这两种方法都能完成解析提取的工作。
最后的存储数据这一步我们跳过不做了,直接在终端打印。
梳理清楚了全部过程,就可以开始写!代!码!啦!
代码实现
首先,调用所有需要的模块,设置好Chrome浏览器引擎,访问网页,获取数据。
from selenium import webdriver # 从selenium库中调用webdriver模块
from bs4 import BeautifulSoup # 调用BeautifulSoup库options = webdriver.ChromeOptions()
options.add_argument('--headless') # 开启无头模式chrome_options = webdriver.ChromeOptions() # 实例化Option对象
chrome_options.add_argument('--headless') # 对浏览器的设置
driver = webdriver.Chrome(options=chrome_options) # 声明浏览器对象driver.get('https://y.qq.com/n/yqq/song/000xdZuV2LcQ19.html') # 访问页面
然后,用selenium的解析提取方法,获取歌曲评论并打印。
需要注意的是,在获取到网页之后,解析与提取之前,要加上time.sleep(2),因为网页的加载需要零点几秒的时间,保险起见,我们等待2秒。
提取数据的时候,首先需要知道数据存在了网页的什么位置,还是老办法,【右键-检查】,把鼠标放在歌曲精彩评论那里,找到Elements中对应的位置:
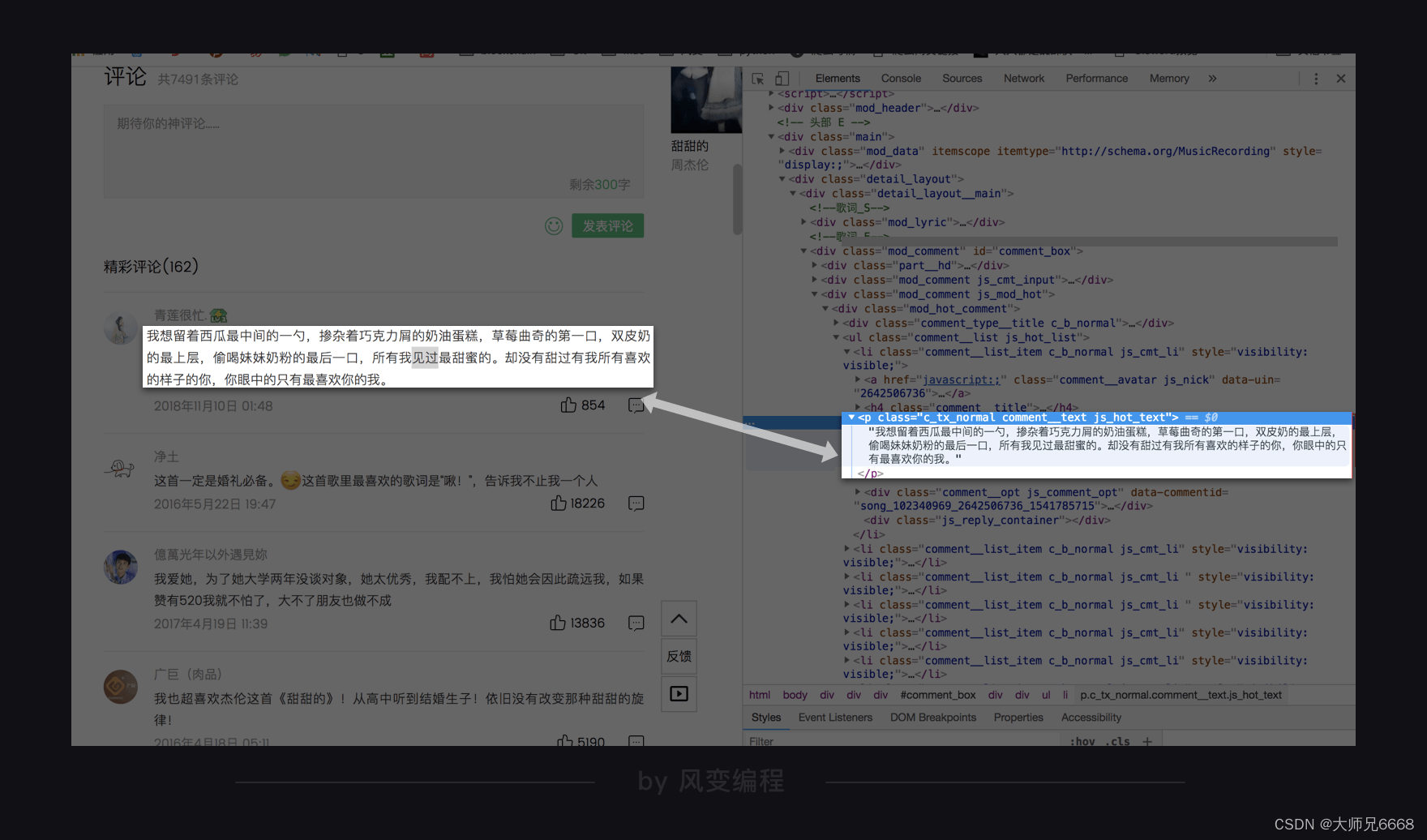
这里要注意的是,这个网页源代码中,评论所在的元素中,class属性就有好多个,而使用selenium时,只能用其中一个属性来提取数据。
通过分析网页结构,我们选择用class_name与tag_name来提取数据。获取这首歌曲第一页精彩评论的代码就可以写出来了:
from selenium import webdriver # 从selenium库中调用webdriver模块
from bs4 import BeautifulSoup # 调用BeautifulSoup库
import timeoptions = webdriver.ChromeOptions()
options.add_argument('--headless') # 开启无头模式chrome_options = webdriver.ChromeOptions() # 实例化Option对象
chrome_options.add_argument('--headless') # 对浏览器的设置
driver = webdriver.Chrome(options=chrome_options) # 声明浏览器对象driver.get('https://y.qq.com/n/yqq/song/000xdZuV2LcQ19.html') # 访问页面
time.sleep(2)comments = driver.find_element_by_class_name('js_hot_list').find_elements_by_class_name('js_cmt_li') # 使用class_name找到评论
print(len(comments)) # 打印获取到的评论个数
for comment in comments: # 循环sweet = comment.find_element_by_tag_name('p') # 找到评论print ('评论:%s\n ---\n'%sweet.text) # 打印评论
driver.close() # 关闭浏览器
运行结果:
15
评论:想起那晚我在你耳边轻轻的的说爱你,你一脸害羞的看着我并且点点头,你此时此刻的笑像夹心饼干,双手捂着嘴,而你的脸庞笑的却如此可爱,这或许就是恋爱最甜甜的趣事吧 Jay在录制这一首歌的时候,就考虑到这歌曲风格甜美是否适合自己以往的演唱,但想到这首歌能表达出Jay对学生时代那种单纯感觉的怀念,于是造就了现在的经典 那一晚过后,我们的每次相约,你的眼中只有我,望着我的样子眼神中充满满满宠溺,我用拥抱给了你一切的回应 我喜欢的样子你都有---评论:我想留着西瓜最中间的一勺,掺杂着巧克力屑的奶油蛋糕,草莓曲奇的第一口,双皮奶的最上层,偷喝妹妹奶粉的最后一口,所有我见过最甜蜜的。却没有甜过有我所有喜欢的样子的你,你眼中的只有最喜欢你的我。---评论:这首一定是婚礼必备。这首歌里最喜欢的歌词是“啾!”,告诉我不止我一个人---评论:我也超喜欢杰伦这首《甜甜的》!从高中听到结婚生子!依旧没有改变那种甜甜的旋律!---评论:第一次实在广告里面听的,然后就开始找啊找,找的好辛苦啊。。。。一听钟情!---评论:这首甜甜的 满满的都是中学时代的回忆。 那时候还很懵懂,那时候还不懂什么是爱情,就是喜欢某个女生 喜欢和她一起的那个时光, 午后的操场 六楼的钢琴室 学校周边的街道 … 如今再也回不去了,但是这首歌里满满的都是回忆。---评论:听到这首歌想起了初中的时候,每个人心中都住着那么一个人,不是爱,也不是喜欢,但是每次见到哪怕是提到他的名字就会怦然心动的感觉,要怪就怪当时没有提起勇气告诉他,也许有些人就是用来怀念的---评论:这首歌!!真的炒鸡炒鸡甜!炒鸡甜!甜到掉牙!好了,我要去看书了---评论:刘霞,你在哪里。我为你跑了很远很远。我知道你喜欢周董,希望你能看到。我相信缘分,,,,---评论:歌如其名,如果你有心上人,大概会不自主的想到ta吧?嘴角一定也是上扬露出笑容,因为,我喜欢的样子你都有~---评论:听到这首歌想起了初中的时候,每个人心中都住着那么一个人,不是爱,是喜欢,但是每次见到哪怕是提到她的名字就会怦然心动的感觉,要怪就怪当时没有提起勇气告诉她,也许有些人就是用来怀念的---评论:早晨领份狗粮去上课那句「啾」真的萌爆了以前竟然都没注意过,这也是首适合告白的歌---评论:又啥都没干听了两小时周杰伦了…---评论:明明很煽情却一点都没有腻的感觉,这就是周董的实力吧!听到广告就觉得很海森!大爱!---评论:如果用周杰伦的歌代表我对感情的认知,应该是从情窦初开的<简单爱>到热恋期的<甜甜的>,俩个人的世界满满的好<星晴>,然而异地恋开始了,我们中间隔了一片<珊瑚海>。最后我选择了<退后>,失去了关于你的<轨迹>,但我承认这一切都是我的错,是我<搁浅>了我们之间的感情。再后来我们失去了联系,而<一路向北>也成了我的单曲循环。---
这次提取出了15个评论,下一步,我们要获取更多评论。点击网页中的【点击加载更多】,就会加载出新的15个评论的数据。
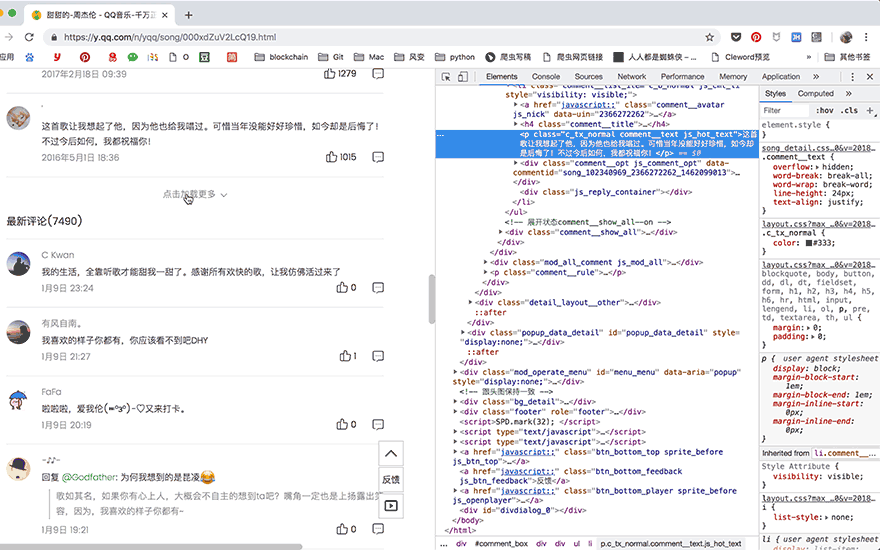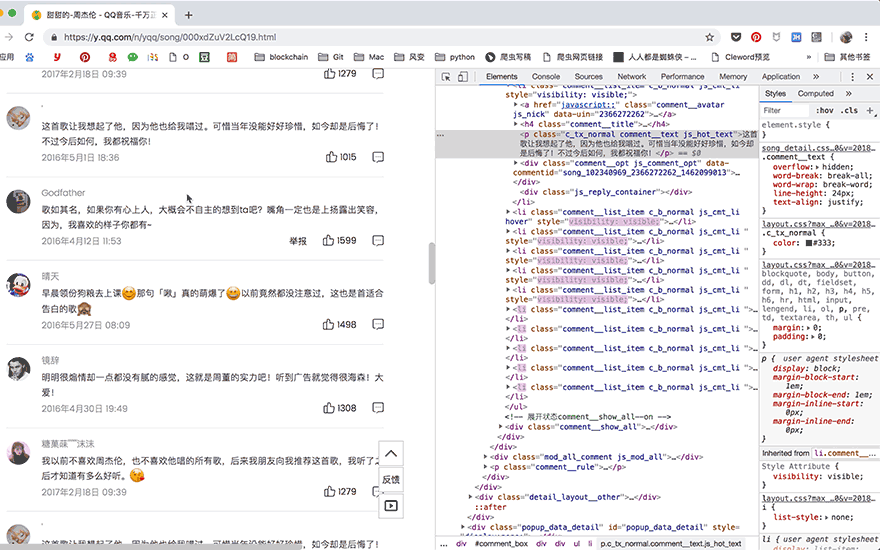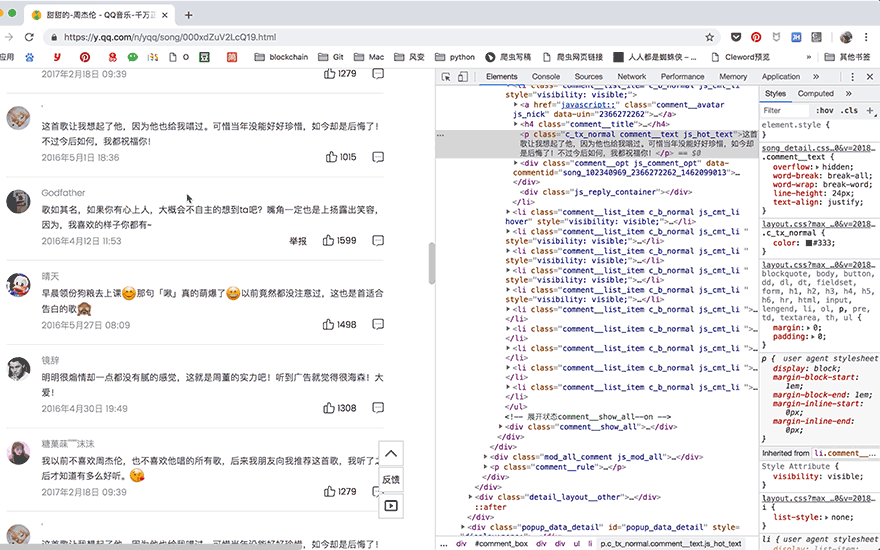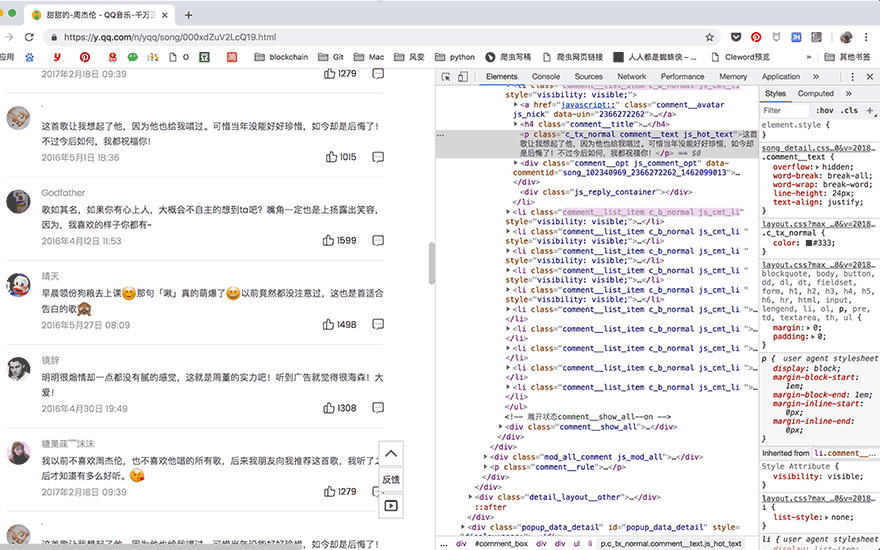
这时候,写代码的方法就很明朗了,首先找到【点击加载更多】在网页源代码中的位置,点击它,等待源代码加载完成之后就可以把全部30个评论提取出来了。
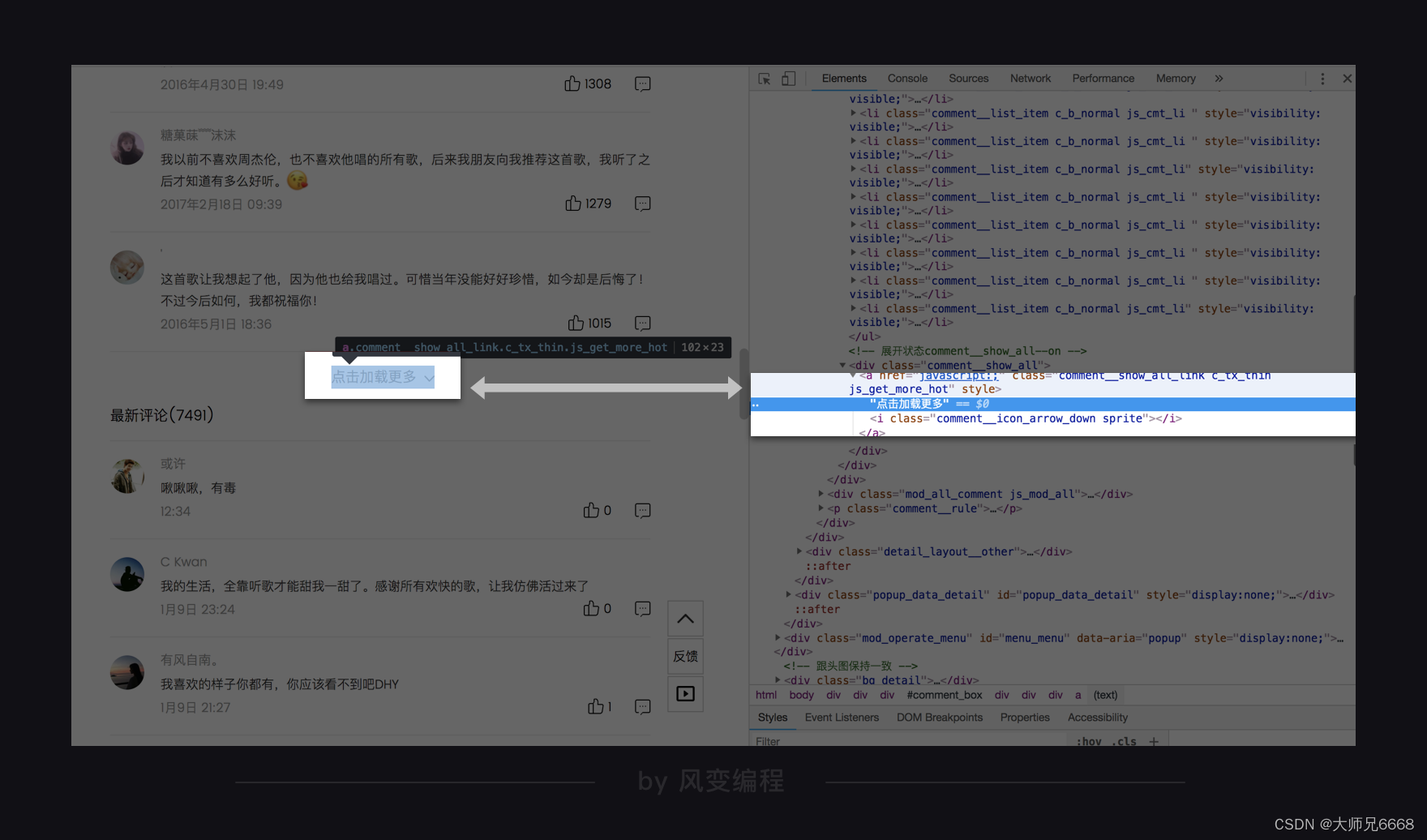
请你尝试把后面的补全吧:
参考代码:
from selenium import webdriver # 从selenium库中调用webdriver模块
from bs4 import BeautifulSoup # 调用BeautifulSoup库
import timeoptions = webdriver.ChromeOptions()
options.add_argument('--headless') # 开启无头模式chrome_options = webdriver.ChromeOptions() # 实例化Option对象
chrome_options.add_argument('--headless') # 对浏览器的设置
driver = webdriver.Chrome(options=chrome_options) # 声明浏览器对象driver.get('https://y.qq.com/n/yqq/song/000xdZuV2LcQ19.html') # 访问页面
time.sleep(2)loadmore=driver.find_element_by_class_name('comment__show_all').find_element_by_tag_name('a')
loadmore.click()
time.sleep(2)
comments = driver.find_element_by_class_name('js_hot_list').find_elements_by_class_name('js_cmt_li')for i in comments:txt=i.find_element_by_tag_name('p')print(txt.text)
成功获取到了两页的评论,掌声给你~
如果你还想获取更多评论,再加上一个循环,和一个条件判断——能否找到点击翻页的选项,就可以实现啦。代码我在这里就不写了,你可以自己在课后练习,练习的目的是学会方法,而没有必要真的把上千条评论全部获取到。
刚才用的是第一种解析与提取的方法,当然还可以使用第二种方法:selenium和BeautifulSoup结合。
先用selenium获取完整的网页源代码,然后使用你已经熟悉的BeautifulSoup解析和提取数据。
代码我写好了,和刚才的区别就是最后几行代码:
from selenium import webdriver # 从selenium库中调用webdriver模块
from bs4 import BeautifulSoup # 调用BeautifulSoup库
import timeoptions = webdriver.ChromeOptions()
options.add_argument('--headless') # 开启无头模式chrome_options = webdriver.ChromeOptions() # 实例化Option对象
chrome_options.add_argument('--headless') # 对浏览器的设置
driver = webdriver.Chrome(options=chrome_options) # 声明浏览器对象driver.get('https://y.qq.com/n/yqq/song/000xdZuV2LcQ19.html') # 访问页面
time.sleep(2)button = driver.find_element_by_class_name('js_get_more_hot') # 根据类名找到【点击加载更多】
button.click() # 点击
time.sleep(2) # 等待两秒pageSource = driver.page_source # 获取Elements中渲染完成的网页源代码
soup = BeautifulSoup(pageSource,'html.parser') # 使用bs解析网页
comments = soup.find('ul',class_='js_hot_list').find_all('li',class_='js_cmt_li') # 使用bs提取元素
print(len(comments)) # 打印comments的数量for comment in comments: # 循环sweet = comment.find('p') # 提取评论print ('评论:%s\n ---\n'%sweet.text) # 打印评论
driver.close() # 关闭浏览器 # 关闭浏览器
到这里,代码就全部写完了。
我们用了与第5关不同的方法,完成了相同的项目。而且,在解析与提取数据的时候,也采用了两种方法去实现。
学会了这么多种方法,以后再遇到类似问题,就可以根据实际情况来评估,用哪些方法可以实现,然后挑选其中一种方法去做项目了。
本关总结
感谢努力的你,学完了全部知识,还做了项目,我们现在又到了关卡快要结束的时刻了。
在这一关,我教你安装了selenium与Chrome驱动,然后介绍了浏览器的设置方法:
# 本地Chrome浏览器的可视模式设置:
from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器
这种设置方法可以让你看到浏览器的操作过程。我想在这里补充的是,在本地的操作环境中,你还可以把自己电脑中的Chrome浏览器设置为静默模式,也就是说,让浏览器只是在后台运行,并不在电脑中打开它的可视界面。
因为在做爬虫时,通常不需要打开浏览器,爬虫的目的是爬到数据,而不是观看浏览器的操作过程,在这种情况下,就可以使用浏览器的静默模式,
它的设置方法是这样的:
# 本地Chrome浏览器的静默模式设置:
from selenium import webdriver #从selenium库中调用webdriver模块
from selenium.webdriver.chrome.options import Options # 从options模块中调用Options类chrome_options = Options() # 实例化Option对象
chrome_options.add_argument('--headless') # 把Chrome浏览器设置为静默模式
driver = webdriver.Chrome(options = chrome_options) # 设置引擎为Chrome,在后台默默运行
与上面浏览器的可视设置相比,3、5、6行代码是新增的,首先调用了一个新的类——Options,然后通过它的方法和属性,给浏览器输入了一个参数——headless。第7行代码中,把刚才所做的浏览器设置传给了Chrome浏览器。
浏览器的可视模式与静默模式的设置,就是以上四行代码的区别。你懂的,这之后所有代码都是一样的。
嘱咐好了所有要讲给你的知识,那就继续每一关结尾例行的总结吧~
我们刚才学习了使用selenium获取数据的方法:.get(‘URL’)。
解析与提取数据的方法:
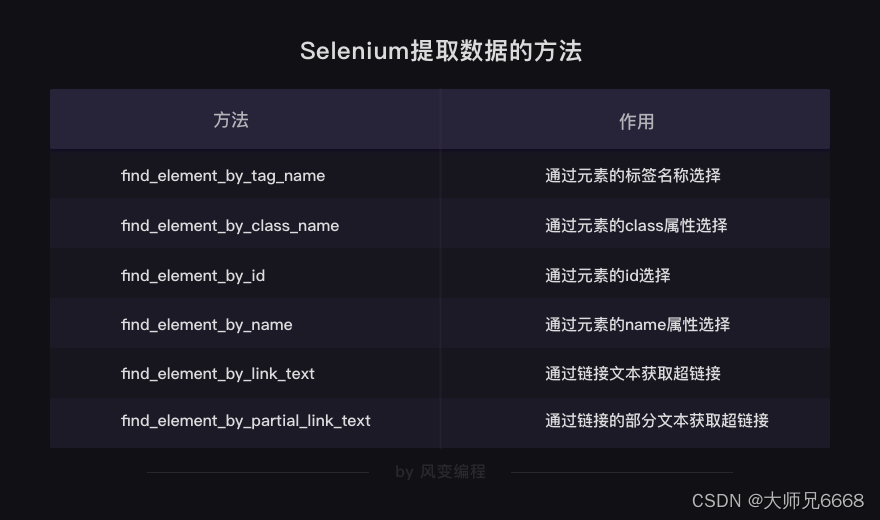
以及在这个过程中,对象的转换过程:

除了上面的方法,selenium还可以搭配BeautifulSoup解析提取数据,前提是先获取字符串格式的网页源代码。
HTML源代码字符串 = driver.page_source
以及自动操作浏览器的一些方法。
还有,在用完浏览器之后,要记得关闭它,以免资源浪费,在代码的结尾处加一行driver.close()就好。
到这里,你应该能感受到,Selenium是一个强大的网络数据采集工具,它的优势是简单直观,而它当然也有缺点。
由于是真实地模拟人操作浏览器,需要等待网页缓冲的时间,在爬取大量数据的时候,速度会比较慢。
通常情况,在爬虫项目中,selenium都是用在其它方法无法解决,或是很难解决的问题时,才会用到。
当然,除了爬虫,selenium的使用场景还有很多。比如:它可以控制网页中图片文件的显示、控制CSS和JavaScript的加载与执行等等。
我们的课程只是带你入门,讲了一些简单常用的操作,还想进一步学习的话,可以通过selenium的官方文档链,目前只有英文版:
https://seleniumhq.github.io/selenium/docs/api/py/api.html
还可以参考这个中文文档:
https://selenium-python-zh.readthedocs.io/en/latest/
下一关,我们还会讲一个实用的方法,定时与通知,期待与你相见!
相关文章:
【python爬虫】10.指挥浏览器自动工作(selenium)
文章目录 前言selenium是什么怎么用设置浏览器引擎获取数据解析与提取数据自动操作浏览器 实操运用确认目标分析过程代码实现 本关总结 前言 上一关,我们认识了cookies和session。 分别学习了它们的用法,以及区别。 还做了一个项目:带着小…...
QT文件对话框,将标签内容保存至指定文件
一、主要步骤 首先,通过getSaveFileName过去想要保存的文件路径及文件名,其次,通过QFile类实例化一个文件对象,再读取文本框中的内容,最后将读取到的内容写入到文件中,最后关闭文件。 1.txt即为完成上述操作…...
C#,《小白学程序》第十一课:阶乘(Factorial)的计算方法与代码
1 文本格式 /// <summary> /// 阶乘的非递归算法 /// </summary> /// <param name"a"></param> /// <returns></returns> private int Factorial_Original(int a) { int r 1; for (int i a; i > 1; i--) { …...
MySQL 数据库常用命令大全(完整版)
文章目录 1. MySQL命令2. MySQL基础命令3. MySQL命令简介4. MySQL常用命令4.1 MySQL准备篇4.1.1 启动和停止MySQL服务4.1.2 修改MySQL账户密码4.1.3 MySQL的登陆和退出4.1.4 查看MySQL版本 4.2 DDL篇(数据定义)4.2.1 查询数据库4.2.2 创建数据库4.2.3 使…...

【数学】【书籍阅读笔记】【概率论】应用随机过程概率论模型导论 by Sheldon M.Ross 第一章 概率论引总结与习题题解 【更新中】
文章目录 前言1 第一章 概率论引论 总结1.1 样本空间与事件1.2 定义在事件上的概率1.3 条件概率1.4 独立事件 2 一些有用的重要结论/公式/例题3 重要例题例 1.11 3 习题题解题1题2 4 习题总结 前言 1 第一章 概率论引论 总结 第一章从事件的角度引出样本空间、事件、概率的基本…...
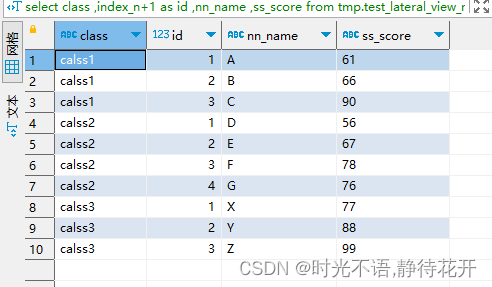
posexplode函数实战总结
目录 1、建表和准备数据 2、炸裂实践 3、错误炸裂方式 4、当字段类型为string,需要split一下 对单列array类型的字段进行炸裂时,可以使用lateral view explode。 对多列array类型的字段进行炸裂时,可以使用lateral view posexplode。 1…...
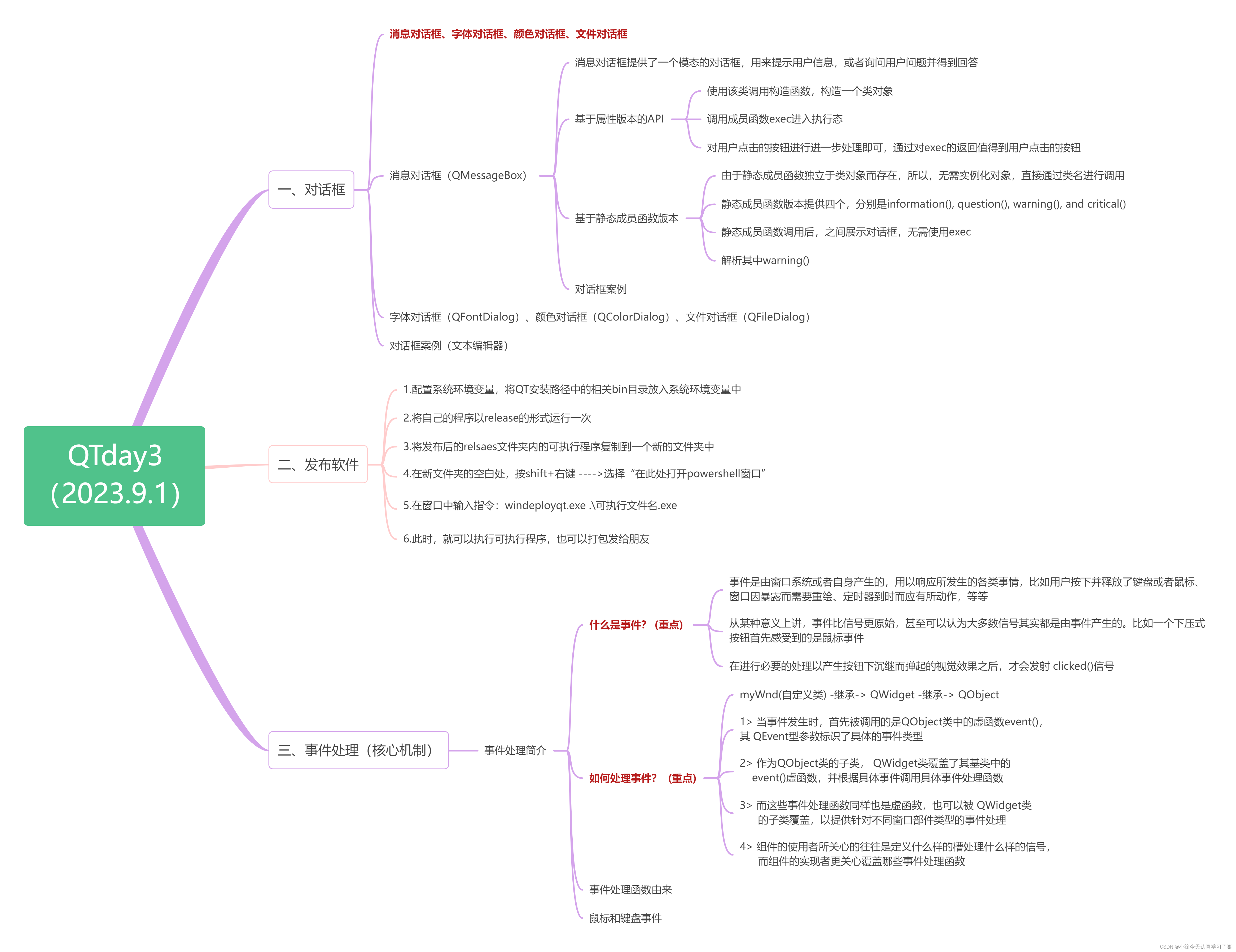
QTday3(对话框、发布软件、事件处理核心机制)
一、Xmind整理: 二、上课笔记整理: 1.消息对话框(QMessageBox) ①基于属性版本的API QMessageBox::QMessageBox( //有参构造函数名QMessageBox::Icon icon, //图标const Q…...
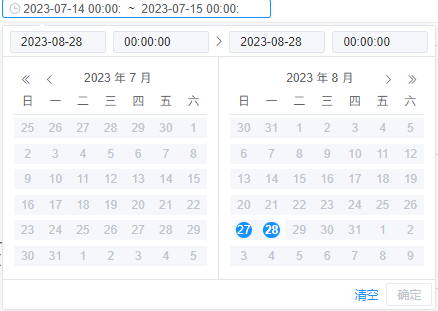
el-date-picker限制选择的时间范围
<el-date-pickersize"mini"v-model"dateTime"value-format"yyyy-MM-dd HH:mm:ss"type"datetimerange"range-separator"~"start-placeholder"开始日期"end-placeholder"结束日期":picker-options&quo…...

Scala中的Actor模型
Scala中的Actor模型 概念 Actor Model是用来编写并行计算或分布式系统的高层次抽象(类似java中的Thread)让程序员不必为多线程模式下共享锁而烦恼。Actors将状态和行为封装在一个轻量的进程/线程中,但是不和其他Actors分享状态,…...
Java使用pdfbox将pdf转图片
前言 目前比较主流的两种转pdf的方式,就是pdfbox和icepdf,两种我都尝试了下,icepdf解析出来有时候会出现中文显示不出来,网上的解决方式又特别麻烦,不是安装字体,就是重写底层类,所以我选择了p…...

大规模场景下对Istio的性能优化
简介 当前istio下发xDS使用的是全量下发策略,也就是网格里的所有sidecar(envoy),内存里都会有整个网格内所有的服务发现数据。这样的结果是,每个sidecar内存都会随着网格规模增长而增长。 Aeraki-mesh aeraki-mesh项目下有一个子项目专门用来…...

数字化新零售平台系统提供商,门店商品信息智慧管理-亿发进销存
传统的批发零售业务模式正面临着市场需求变化的冲击。用户日益注重个性化、便捷性和体验感,新兴的新零售模式迅速崛起,改变了传统的零售格局。如何在保持传统业务的基础上,变革发展,成为了业界亟需解决的问题。 在这一背景下&…...
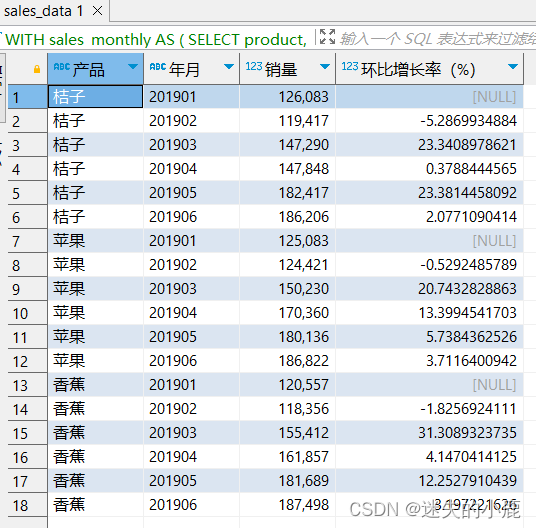
postgresql-窗口函数
postgresql-窗口函数 简介窗口函数的定义分区选项(PARTITION BY)排序选项(ORDER BY)窗口选项(frame_clause) 聚合窗口函数排名窗口函数演示了 CUME_DIST 和 NTILE 函数 取值窗口函数 简介 常见的聚合函数&…...
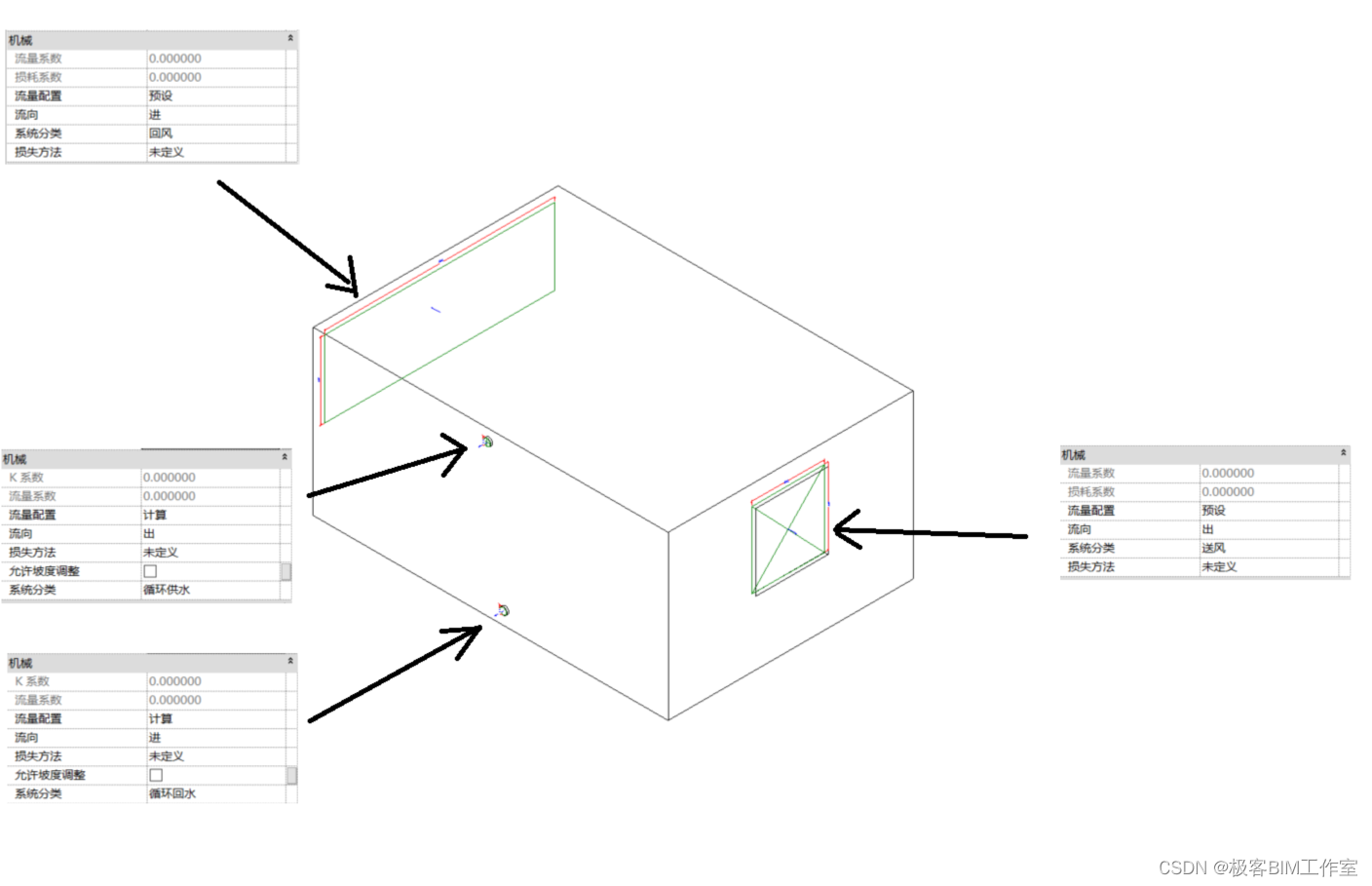
Revit SDK 介绍:CreateAirHandler 创建户式风管机
前言 这个例子介绍如何通过 API 创建一个户式风管机族的内容,包含几何和接头。 内容 效果 核心逻辑 必须打开机械设备的族模板创建几何实体来表示风管机创建风机的接头 创建几何实体来表示风管机 例子中创建了多个拉伸,下面仅截取一段代码ÿ…...

微信小程序云开发-云函数发起https请求简易封装函数
一、前言 在日常的开发中,经常会遇到需要请求第三方API的情况,例如请求实名认证接口、IP转换地址接口等等。这些请求放在小程序前端的话,就需要把密钥放在客户端,在安全性上没这么高。 因此,一般是放在云函数端去访问…...

深入探索PHP编程:连接数据库的完整指南
深入探索PHP编程:连接数据库的完整指南 在现代Web开发中,与数据库进行交互是不可或缺的一部分。PHP作为一种强大的服务器端编程语言,提供了丰富的工具来连接和操作各种数据库系统。本篇教程将带您了解如何在PHP中连接数据库,执行…...
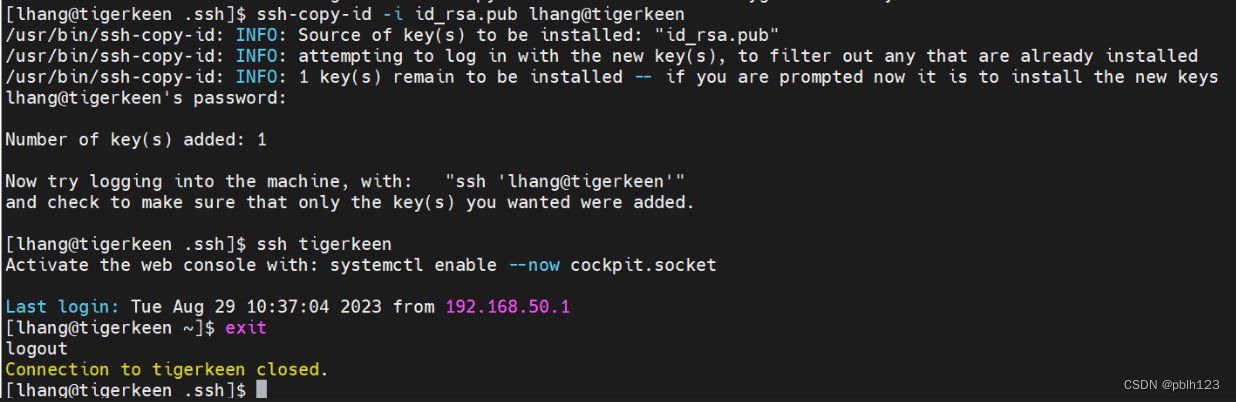
【Centos8配置节点免密登陆】
登录Centos8 配置免密登录 为什么需要配置免密登录,玩大数据,玩集群的朋友们,都需要使用RPC通讯,完成集群命令同步,数据操作通讯。要实现RPC通讯,就需要配置节点之间的免密登录。 # 配置登录秘钥 ssh-key…...
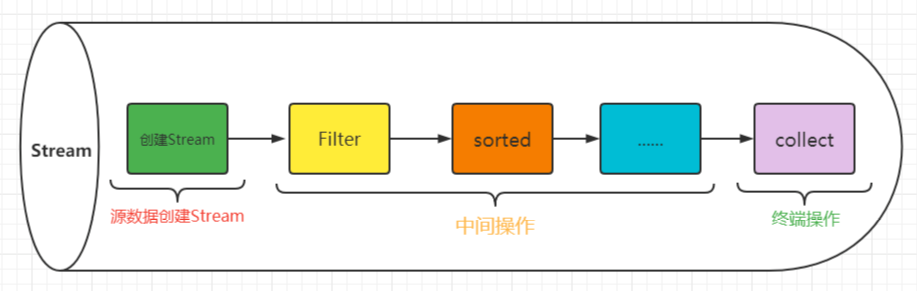
不可变集合、Lambda表达式、Stream流
不可变集合、Lambda表达式、Stream流 创建不可变集合 不能被修改的集合 应用场景 如果某个数据不能被修改,把它防御性的拷贝到不可变集合中是个很好的实践。 当集合对象被不可信的库调用时,不可变形式是安全的。 创建不可变集合 在List、Set、Map接口中…...

Three.js GLTF模型加载
在Three.js中,要加载三维模型文件,可以使用GLTF格式。GLTF是一种基于JSON的开放标准,用于3D模型的交换和运行时加载。本篇文章将详细讲解如何使用Three.js加载GLTF模型。 ## 1. 下载GLTF模型 在开始之前,请确保您已经有一个GLTF模…...
外包干了2个月,技术退步明显...
先说一下自己的情况,大专生,18年通过校招进入湖南某软件公司,干了接近4年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能测试…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

oracle与MySQL数据库之间数据同步的技术要点
Oracle与MySQL数据库之间的数据同步是一个涉及多个技术要点的复杂任务。由于Oracle和MySQL的架构差异,它们的数据同步要求既要保持数据的准确性和一致性,又要处理好性能问题。以下是一些主要的技术要点: 数据结构差异 数据类型差异ÿ…...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

MySQL JOIN 表过多的优化思路
当 MySQL 查询涉及大量表 JOIN 时,性能会显著下降。以下是优化思路和简易实现方法: 一、核心优化思路 减少 JOIN 数量 数据冗余:添加必要的冗余字段(如订单表直接存储用户名)合并表:将频繁关联的小表合并成…...
基于Springboot+Vue的办公管理系统
角色: 管理员、员工 技术: 后端: SpringBoot, Vue2, MySQL, Mybatis-Plus 前端: Vue2, Element-UI, Axios, Echarts, Vue-Router 核心功能: 该办公管理系统是一个综合性的企业内部管理平台,旨在提升企业运营效率和员工管理水…...
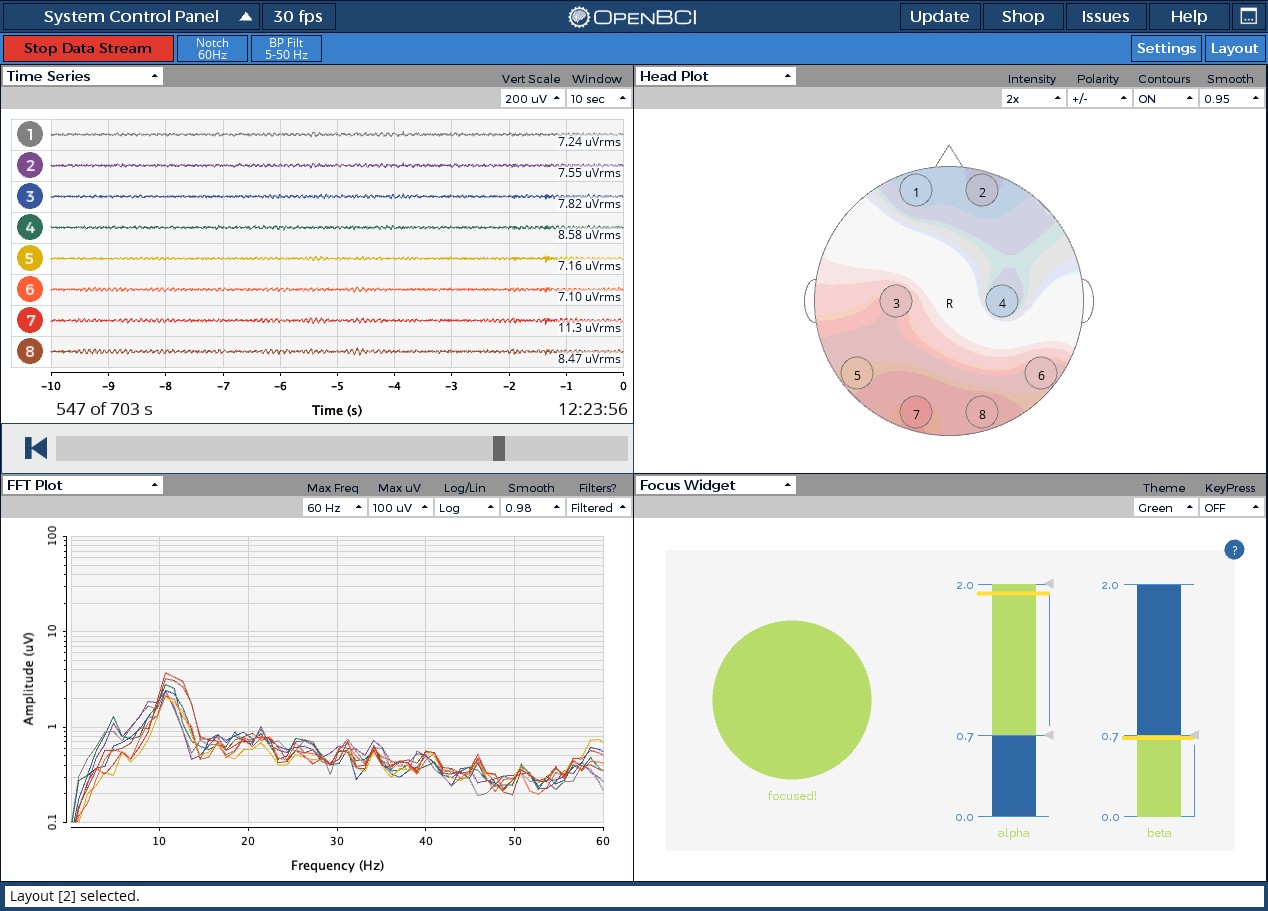
脑机新手指南(七):OpenBCI_GUI:从环境搭建到数据可视化(上)
一、OpenBCI_GUI 项目概述 (一)项目背景与目标 OpenBCI 是一个开源的脑电信号采集硬件平台,其配套的 OpenBCI_GUI 则是专为该硬件设计的图形化界面工具。对于研究人员、开发者和学生而言,首次接触 OpenBCI 设备时,往…...

离线语音识别方案分析
随着人工智能技术的不断发展,语音识别技术也得到了广泛的应用,从智能家居到车载系统,语音识别正在改变我们与设备的交互方式。尤其是离线语音识别,由于其在没有网络连接的情况下仍然能提供稳定、准确的语音处理能力,广…...