自然语言处理2-NLP
目录
自然语言处理2-NLP
如何把词转换为向量
如何让向量具有语义信息
在CBOW中
在Skip-gram中
skip-gram比CBOW效果更好
CBOW和Skip-gram的算法实现
Skip-gram的理想实现
Skip-gram的实际实现
自然语言处理2-NLP
在自然语言处理任务中,词向量(Word Embedding)是表示自然语言里单词的一种方法,即把每个词都表示为一个N维空间内的点,即一个高维空间内的向量。通过这种方法,实现把自然语言计算转换为向量计算。
如 图1 所示的词向量计算任务中,先把每个词(如queen,king等)转换成一个高维空间的向量,这些向量在一定意义上可以代表这个词的语义信息。再通过计算这些向量之间的距离,就可以计算出词语之间的关联关系,从而达到让计算机像计算数值一样去计算自然语言的目的。

图1:词向量计算示意图
因此,大部分词向量模型都需要回答两个问题:
- 如何把词转换为向量?
自然语言单词是离散信号,比如“香蕉”,“橘子”,“水果”在我们看来就是3个离散的词。
如何把每个离散的单词转换为一个向量?
- 如何让向量具有语义信息?
比如,我们知道在很多情况下,“香蕉”和“橘子”更加相似,而“香蕉”和“句子”就没有那么相似,同时“香蕉”和“食物”、“水果”的相似程度可能介于“橘子”和“句子”之间。
那么,我们该如何让词向量具备这样的语义信息?
如何把词转换为向量
自然语言单词是离散信号,比如“我”、“ 爱”、“人工智能”。如何把每个离散的单词转换为一个向量?通常情况下,我们可以维护一个如 图2 所示的查询表。表中每一行都存储了一个特定词语的向量值,每一列的第一个元素都代表着这个词本身,以便于我们进行词和向量的映射(如“我”对应的向量值为 [0.3,0.5,0.7,0.9,-0.2,0.03] )。给定任何一个或者一组单词,我们都可以通过查询这个excel,实现把单词转换为向量的目的,这个查询和替换过程称之为Embedding Lookup。

图2:词向量查询表
上述过程也可以使用一个字典数据结构实现。事实上如果不考虑计算效率,使用字典实现上述功能是个不错的选择。然而在进行神经网络计算的过程中,需要大量的算力,常常要借助特定硬件(如GPU)满足训练速度的需求。GPU上所支持的计算都是以张量(Tensor)为单位展开的,因此在实际场景中,我们需要把Embedding Lookup的过程转换为张量计算,如 图3 所示。
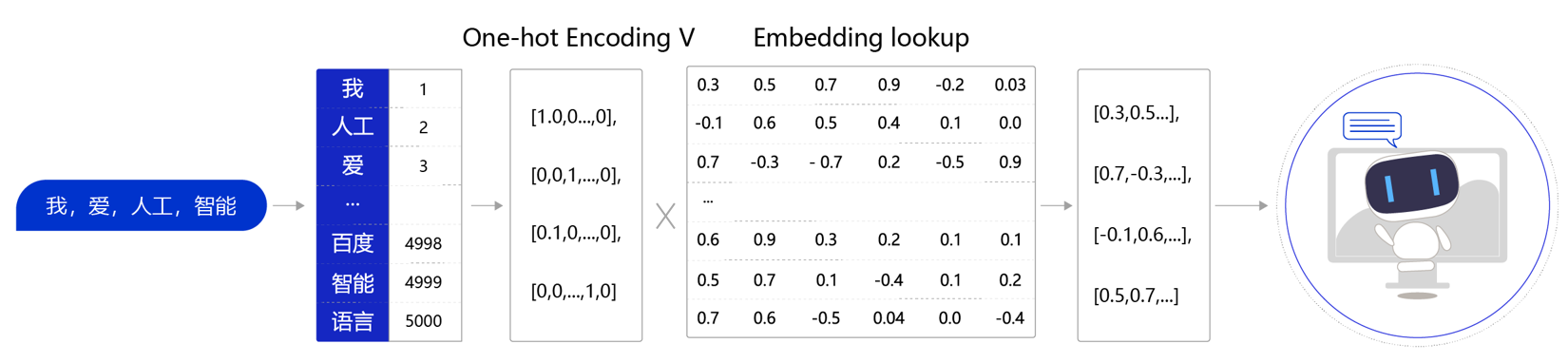
图3:张量计算示意图
假设对于句子"我,爱,人工,智能",把Embedding Lookup的过程转换为张量计算的流程如下:
-
通过查询字典,先把句子中的单词转换成一个ID(通常是一个大于等于0的整数),这个单词到ID的映射关系可以根据需求自定义(如图3中,我=>1, 人工=>2,爱=>3,…)。
-
得到ID后,再把每个ID转换成一个固定长度的向量。假设字典的词表中有5000个词,那么,对于单词“我”,就可以用一个5000维的向量来表示。由于“我”的ID是1,因此这个向量的第一个元素是1,其他元素都是0([1,0,0,…,0]);
-
同样对于单词“人工”,第二个元素是1,其他元素都是0。
-
用这种方式就实现了用一个向量表示一个单词。由于每个单词的向量表示都只有一个元素为1,而其他元素为0,因此我们称上述过程为One-Hot Encoding。
-
经过One-Hot Encoding后,句子“我,爱,人工,智能”就被转换成为了一个形状为 4×5000的张量,记为V。在这个张量里共有4行、5000列,从上到下,每一行分别代表了“我”、“爱”、“人工”、“智能”四个单词的One-Hot Encoding。最后,我们把这个张量V和另外一个稠密张量W相乘,其中W张量的形状为5000 × 128(5000表示词表大小,128表示每个词的向量大小)。经过张量乘法,我们就得到了一个4×128的张量,从而完成了把单词表示成向量的目的。
如何让向量具有语义信息
得到每个单词的向量表示后,我们需要思考下一个问题:比如在多数情况下,“香蕉”和“橘子”更加相似,而“香蕉”和“句子”就没有那么相似;同时,“香蕉”和“食物”、“水果”的相似程度可能介于“橘子”和“句子”之间。那么如何让存储的词向量具备这样的语义信息呢?
我们先学习自然语言处理领域的一个小技巧。在自然语言处理研究中,科研人员通常有一个共识:使用一个单词的上下文来了解这个单词的语义,比如:
“苹果手机质量不错,就是价格有点贵。”
“这个苹果很好吃,非常脆。”
“菠萝质量也还行,但是不如苹果支持的APP多。”
在上面的句子中,我们通过上下文可以推断出第一个“苹果”指的是苹果手机,第二个“苹果”指的是水果苹果,而第三个“菠萝”指的应该也是一个手机。事实上,
在自然语言处理领域,使用上下文描述一个词语或者元素的语义是一个常见且有效的做法。
我们可以使用同样的方式训练词向量,让这些词向量具备表示语义信息的能力。
2013年,Mikolov提出的经典word2vec算法就是通过上下文来学习语义信息。word2vec包含两个经典模型:CBOW(Continuous Bag-of-Words)和Skip-gram,如 图4 所示。
- CBOW:通过上下文的词向量推理中心词。
- Skip-gram:根据中心词推理上下文。
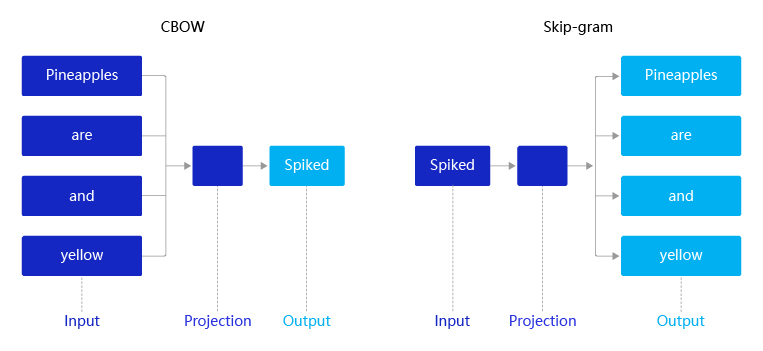
图4:CBOW和Skip-gram语义学习示意图
假设有一个句子“Pineapples are spiked and yellow”,两个模型的推理方式如下:
-
在CBOW中
-
先在句子中选定一个中心词,并把其它词作为这个中心词的上下文。如 图4 CBOW所示,把“Spiked”作为中心词,把“Pineapples、are、and、yellow”作为中心词的上下文。在学习过程中,使用上下文的词向量推理中心词,这样中心词的语义就被传递到上下文的词向量中,如“Spiked → pineapple”,从而达到学习语义信息的目的。
-
在Skip-gram中
-
同样先选定一个中心词,并把其他词作为这个中心词的上下文。如 图4 Skip-gram所示,把“Spiked”作为中心词,把“Pineapples、are、and、yellow”作为中心词的上下文。不同的是,在学习过程中,使用中心词的词向量去推理上下文,这样上下文定义的语义被传入中心词的表示中,如“pineapple → Spiked”, 从而达到学习语义信息的目的。
说明:
一般来说,CBOW比Skip-gram训练速度快,训练过程更加稳定,原因是CBOW使用上下文average的方式进行训练,每个训练step会见到更多样本。
而在生僻字(出现频率低的字)
skip-gram比CBOW效果更好
原因是skip-gram不会刻意回避生僻字(CBOW结构中输入中存在生僻字时,生僻字会被其它非生僻字的权重冲淡)。
CBOW和Skip-gram的算法实现
我们以这句话:“Pineapples are spiked and yellow”为例分别介绍CBOW和Skip-gram的算法实现。
如 图5 所示,CBOW是一个具有3层结构的神经网络,分别是:

图5:CBOW的算法实现
- 输入层: 一个形状为C×V的one-hot张量,其中C代表上线文中词的个数,通常是一个偶数,我们假设为4;V表示词表大小,我们假设为5000,该张量的每一行都是一个上下文词的one-hot向量表示,比如“Pineapples, are, and, yellow”。
- 隐藏层: 一个形状为V×N的参数张量W1,一般称为word-embedding,N表示每个词的词向量长度,我们假设为128。输入张量和word embedding W1进行矩阵乘法,就会得到一个形状为C×N的张量。综合考虑上下文中所有词的信息去推理中心词,因此将上下文中C个词相加得一个1×N的向量,是整个上下文的一个隐含表示。
- 输出层: 创建另一个形状为N×V的参数张量,将隐藏层得到的1×N的向量乘以该N×V的参数张量,得到了一个形状为1×V的向量。最终,1×V的向量代表了使用上下文去推理中心词,每个候选词的打分,再经过softmax函数的归一化,即得到了对中心词的推理概率:
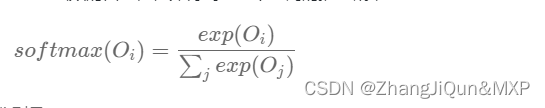
如 图6 所示,Skip-gram是一个具有3层结构的神经网络,分别是:
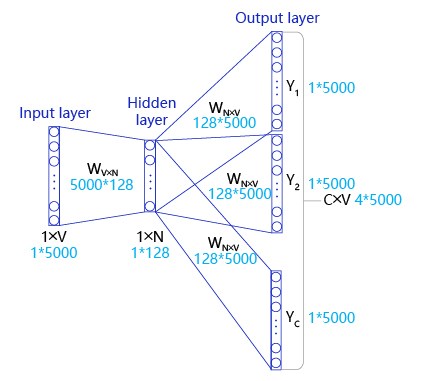
图6:Skip-gram算法实现

在实际操作中,使用一个滑动窗口(一般情况下,长度是奇数),从左到右开始扫描当前句子。每个扫描出来的片段被当成一个小句子,每个小句子中间的词被认为是中心词,其余的词被认为是这个中心词的上下文。
Skip-gram的理想实现

Skip-gram的实际实现


相关文章:
自然语言处理2-NLP
目录 自然语言处理2-NLP 如何把词转换为向量 如何让向量具有语义信息 在CBOW中 在Skip-gram中 skip-gram比CBOW效果更好 CBOW和Skip-gram的算法实现 Skip-gram的理想实现 Skip-gram的实际实现 自然语言处理2-NLP 在自然语言处理任务中,词向量(…...
穿上App外衣,保持Web灵魂——PWA温故
早在2015年,设计师弗朗西斯贝里曼和Google Chrome的工程师亚历克斯罗素提出“PWA(渐进式网络应用程序)”概念,将网络之长与应用之长相结合,其核心目标就是提升 Web App 的性能,改善 Web App以媲美Native的流…...
)
【跟小嘉学 Rust 编程】二十六、Rust的序列化解决方案(Serde)
系列文章目录 【跟小嘉学 Rust 编程】一、Rust 编程基础 【跟小嘉学 Rust 编程】二、Rust 包管理工具使用 【跟小嘉学 Rust 编程】三、Rust 的基本程序概念 【跟小嘉学 Rust 编程】四、理解 Rust 的所有权概念 【跟小嘉学 Rust 编程】五、使用结构体关联结构化数据 【跟小嘉学…...
:函数)
菜鸟教程《Python 3 教程》笔记(14):函数
菜鸟教程《Python 3 教程》笔记(14) 14 函数14.1 参数传递14.1.1 可更改(mutable)与不可更改(immutable)对象14.1.2 python 传不可变对象实例 14.2 参数14.2.1 必需参数14.2.2 关键字参数14.2.3 默认参数14.2.4 不定长参数 14.3 匿名函数14.4 强制位置参…...

SEC推迟ETF,BTC跌破26k,十年之约#6逢跌加仓
今日荐读:8.31教链内参《美证监会推迟所有的BTC现货ETF申请》。刘教链Pro《BTC的流速》。 * * * 刘教链 原创 * * * 原本是9.2的截止日,美SEC昨晚就忙不迭地放出了话,所有现货比特币ETF的申请,推迟,统统推迟。不管你什…...

c++20 多线程并发 latch barrier semaphore
背景: c20 关于多线程并发新增了 latch, barrier, semaphore ,接下来就按照一个一个进行介绍 latch latch 是一次性使用的线程协调点, 一旦给定数量的线程达到latch点时, 所有线程都会解除阻塞, 并继续执行. 基本上它是一个计数器, 在每个线程到达latch点时倒数, 一旦计数器达…...

【8 排序】简单选择排序。
顺序表: void Swap(int &a,int &b){int temp;tempa;ab;btemp; } void SelectSort(int A[],int n){int min,i,j;for(i0;i<n-1;i){mini;for(ji1;j<n;j)if(A[j]<A[min])minj;if(min!i)Swap(A[i],A[min]);} } 单链表: void SelectSort…...

中国太保首席数据库专家林春:先难后易,核心系统数据库升级复盘
P17 是中国太平洋保险(以下简称太保)关联关系最为复杂、商业数据库绑定程度最深、业务影响最多的核心系统之一。但就是这样一个对太保业务至关重要的系统却被选为数据库升级的“实验品”。当然,说是“实验品”只是因为这是太保第一次对关键的…...

数字孪生智慧工厂:电缆厂 3D 可视化管控系统
近年来,我国各类器材制造业已经开始向数字化生产转型,使得生产流程变得更加精准高效。通过应用智能设备、物联网和大数据分析等技术,企业可以更好地监控生产线上的运行和质量情况,及时发现和解决问题,从而提高生产效率…...

使用WebSocket实现聊天功能
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、数据库设计二、实现代码1.SessionWrap2.websocket3.insertMessage4.清除未读 前言 使用WebSocket实现一对一的聊天功能与未读消息功能 一、数据库设计 会话…...

Ubuntu升级Cmake、gcc、g++
背景 最近要安装llvm,我选择的是从源码安装,所以要使用Cmake进行构建项目。但是服务器上的Cmake、gcc、g的版本都太低了,不符合要求,所以要对此进行升级。在本博客中采用的升级方法不一定是最好的方法(因为我也是参考…...
8月28日上课内容 第四章 MySQL备份与恢复
本章结构 前言:日志⭐⭐ MySQL 的日志默认保存位置为 /usr/local/mysql/data ##配置文件 vim /etc/my.cnf [mysqld] ##错误日志,用来记录当MySQL启动、停止或运行时发生的错误信息,默认已开启 log-error/usr/local/mysql/data/mysql_error.l…...

es字段查询加keyword和不加keyword的区别
在ES(Elasticsearch)中,查询字段名后面加上"keyword"和不加"keyword"有着不同的含义和用途。 当字段名后面加上"keyword"时,表示该字段是一个keyword类型的字段。Keyword类型的字段会将文本作为一…...

前端JavaScript将数据转换成JSON字符串以及将JSON字符串转换成对象的两个API
在前端 JavaScript 中,你可以使用 JSON.stringify() 方法将 JavaScript 数据转换成 JSON 字符串,以及使用 JSON.parse() 方法将 JSON 字符串转换成 JavaScript 对象。下面是这两个 API 的详细说明和示例: JSON.stringify(): 用于…...
Spring——Spring Boot基础
文章目录 第一个helloword项目新建 Spring Boot 项目Spring Boot 项目结构分析SpringBootApplication 注解分析新建一个 Controller大功告成,运行项目 简而言之,从本质上来说,Spring Boot 就是 Spring,它做了那些没有它你自己也会去做的 Spri…...

Python基础之基础语法(二)
Python基础之基础语法(二) 语言类型 静态语言 如:C C Java ina a 100 a 100 a abc # 不可以静态语言需要指定声明标识符的类型,之后不可以改变类型赋值。静态语言变异的时候要检查类型,编写源代码,编译时检查错误。 动态语…...
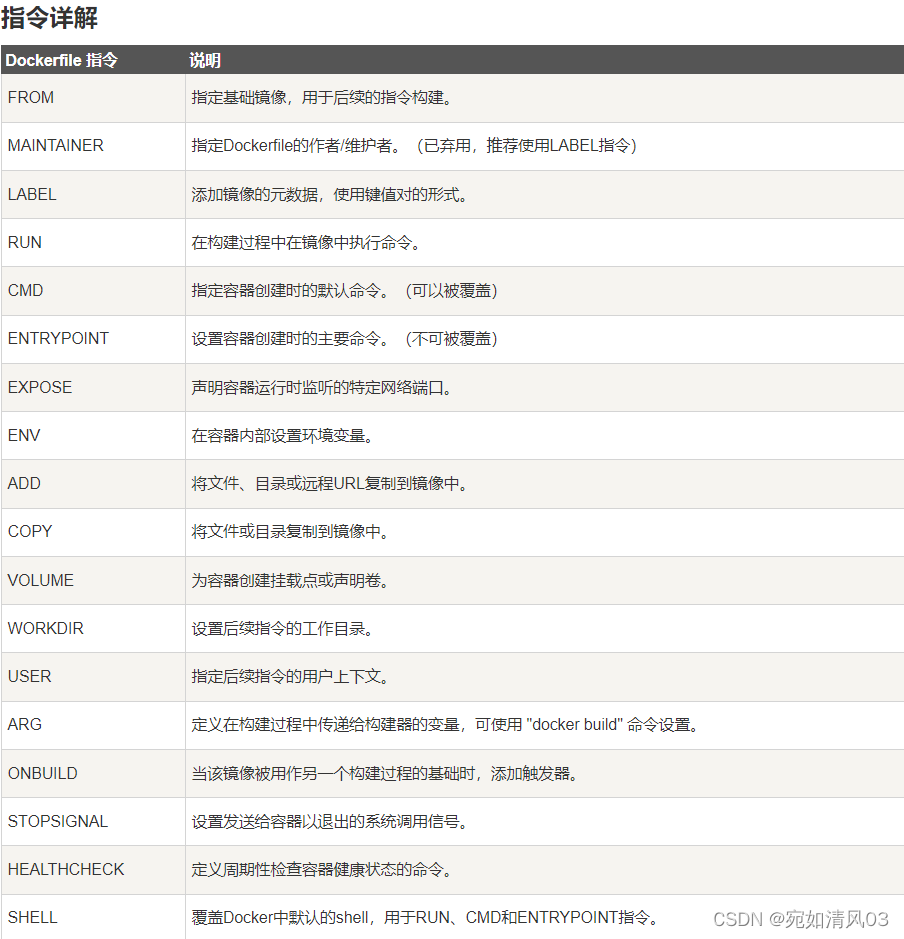
docker常见面试问题详解
在面试的时候,面试官常常会问一些问题: docker是什么,能做什么?docker和虚拟机的区别是什么呢?docker是用什么做隔离的?docke的网络类型?docker数据之间是如何通信的?docker的数据保…...

Auto-GPT 学习笔记
Auto-GPT 学习笔记 Auto-GPT 简介 Auto-GPT 是一个基于 GPT-4 的自主智能体实验项目。它展示了大规模语言模型的规划、记忆和工具使用能力。Auto-GPT 的目标是实现一个完全自主的 AI 代理。GitHub 仓库 Auto-GPT 核心模块 规划(Planning) 使用强化学习策略进行多跳思考。通…...

代码随想录 - Day30 - 修剪二叉树,转换二叉树 + 二叉树总结
代码随想录 - Day30 - 修剪二叉树,转换二叉树 二叉树总结 669. 修剪二叉搜索树 有点像是删除二叉搜索树的变形,改变了删除条件而已。 递归法: class Solution:def trimBST(self, root: Optional[TreeNode], low: int, high: int) -> O…...

[音视频] sdl 渲染到外部创建的窗口上
API SDL_CreateWindowFrom # 在外部窗口上创建窗口 其他 api 调用,按照之前的 代码 ui.setupUi(this); sdl_width ui.label->width(); sdl_height ui.label->height(); SDL_Init(SDL_INIT_VIDEO); sdl_win SDL_CreateWindowFrom((void*)ui.label->wi…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...

AI书签管理工具开发全记录(十九):嵌入资源处理
1.前言 📝 在上一篇文章中,我们完成了书签的导入导出功能。本篇文章我们研究如何处理嵌入资源,方便后续将资源打包到一个可执行文件中。 2.embed介绍 🎯 Go 1.16 引入了革命性的 embed 包,彻底改变了静态资源管理的…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

零基础在实践中学习网络安全-皮卡丘靶场(第九期-Unsafe Fileupload模块)(yakit方式)
本期内容并不是很难,相信大家会学的很愉快,当然对于有后端基础的朋友来说,本期内容更加容易了解,当然没有基础的也别担心,本期内容会详细解释有关内容 本期用到的软件:yakit(因为经过之前好多期…...

Java + Spring Boot + Mybatis 实现批量插入
在 Java 中使用 Spring Boot 和 MyBatis 实现批量插入可以通过以下步骤完成。这里提供两种常用方法:使用 MyBatis 的 <foreach> 标签和批处理模式(ExecutorType.BATCH)。 方法一:使用 XML 的 <foreach> 标签ÿ…...