Java 大厂面试 —— 常见集合篇 List HashMap 红黑树
23Java面试专题 八股文面试全套真题(含大厂高频面试真题)多线程_软工菜鸡的博客-CSDN博客
常见集合篇-01-集合面试题-课程介绍

02-算法复杂度分析



2 List相关面试题
2.1 数组
2.1.1 数组概述
数组(Array)是一种用连续的内存空间存储相同数据类型数据的线性数据结构。
int[] array = {22,33,88,66,55,25};我们定义了这么一个数组之后,在内存的表示是这样的:

现在假如,我们通过arrar[1],想要获得下标为1这个元素,但是现在栈内存中指向的堆内存数组的首地址,它是如何获取下标为1这个数据的?

2.1.2 寻址公式
为了方便大家理解,我们把数组的内存地址稍微改了一下,都改成了数字,如下图
在数组在内存中查找元素的时候,是有一个寻址公式的,如下:

arr:指的是数组
i:指的是数组的下标
有了寻址公式以后,我们再来获取一下下标为1的元素,这个是原来的数组, 套入公式:
array[1] =10 + i * 4 = 14获取到14这个地址,就能获取到下标为1的这个元素了。

2.1.3 操作数组的时间复杂度
1.随机查询(根据索引查询)
数组元素的访问是通过下标来访问的,计算机通过数组的首地址和寻址公式能够很快速的找到想要访问的元素
public int test01(int[] a,int i){return a[i];// a[i] = baseAddress + i \* dataSize
}代码的执行次数并不会随着数组的数据规模大小变化而变化,是常数级的,所以查询数据操作的时间复杂度是O(1)
2. 未知索引查询O(n)或O(log2n)
情况一:查找数组内的元素,查找55号数据,遍历数组时间复杂度为O(n)

情况二:查找排序后数组内的元素,通过二分查找算法查找55号数据时间复杂度为O(logn)

3.插入O(n)
数组是一段连续的内存空间,因此为了保证数组的连续性会使得数组的插入和删除的效率变的很低。
假设数组的长度为 n,现在如果我们需要将一个数据插入到数组中的第 k 个位置。为了把第 k 个位置腾出来给新来的数据,我们需要将第 k~n 这部分的元素都顺序地往后挪一位。如下图所示:
新增之后的数据变化,如下

所以:
插入操作,最好情况下是O(1)的,最坏情况下是O(n)的,平均情况下的时间复杂度是O(n)。
4.删除O(n)
同理可得:如果我们要删除第 k 个位置的数据,为了内存的连续性,也需要搬移数据,不然中间就会出现空洞,内存就不连续了,时间复杂度仍然是O(n)。
2.2 ArrayList源码分析
分析ArrayList源码主要从三个方面去翻阅:成员变量,构造函数,关键方法
以下 源码都来源于jdk1.8
2.2.1 成员变量

DEFAULT_CAPACITY = 10; 默认初始的容量**(CAPACITY)
EMPTY_ELEMENTDATA = {}; 用于空实例的共享空数组实例
DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};用于默认大小的空实例的共享空数组实例
Object[] elementData; 存储元素的数组缓冲区
int size; ArrayList的大小(它包含的元素数量)
2.2.2 三个构造方法

第一个构造是带初始化容量的构造函数,可以按照指定的容量初始化数组
第二个是无参构造函数,默认创建一个空集合
将 collection对象转换成数组,然后将数组的地址的赋给elementData
2.2.3 ArrayList源码分析
添加数据的流程
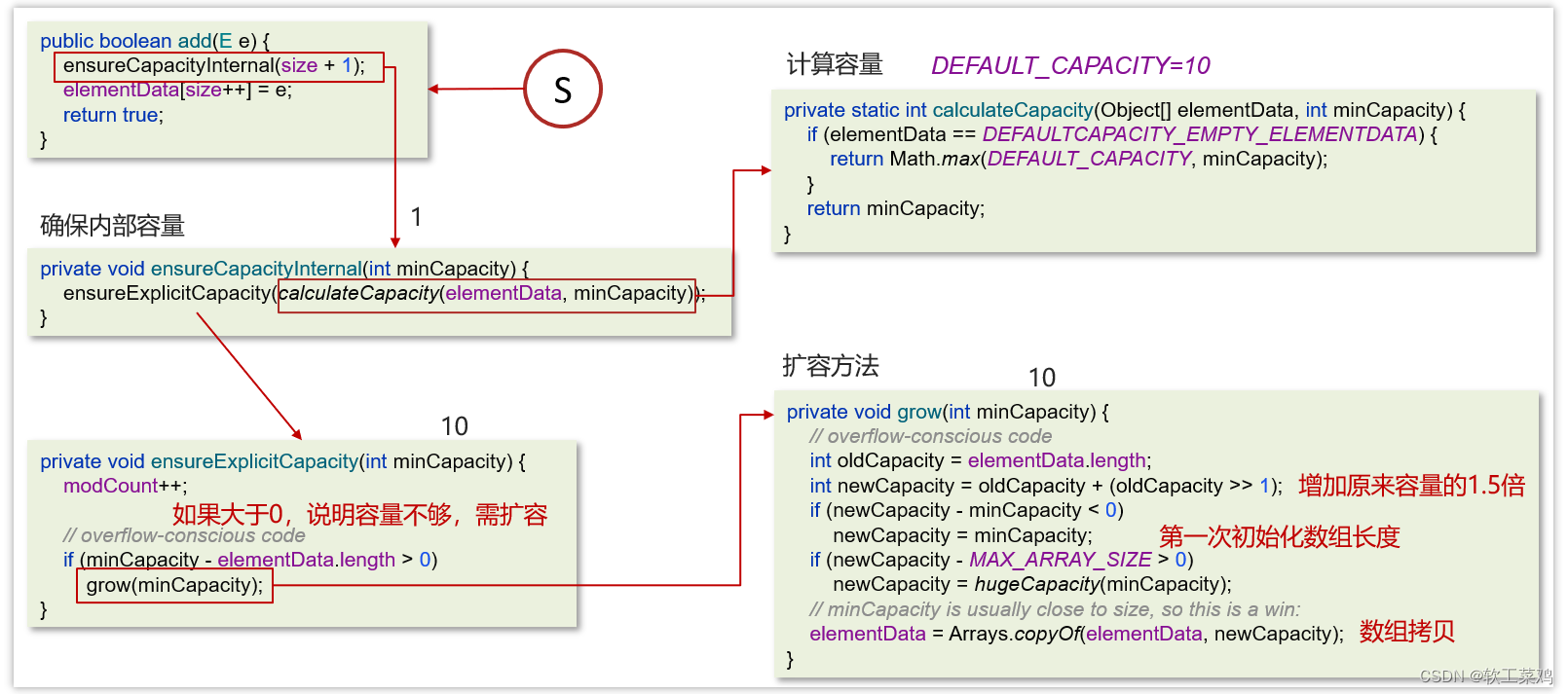
结论:
-
底层数据结构
ArrayList底层是用动态的数组实现的
-
初始容量
ArrayList初始容量为0,当第一次添加数据的时候才会初始化容量为10
-
扩容逻辑
ArrayList在进行扩容的时候是原来容量的1.5倍,每次扩容都需要拷贝数组
-
添加逻辑
-
确保数组已使用长度(size)加1之后足够存下下一个数据
-
计算数组的容量,如果当前数组已使用长度+1后的大于当前的数组长度,则调用grow方法扩容(原来的1.5倍)
-
确保新增的数据有地方存储之后,则将新元素添加到位于size的位置上。
-
返回添加成功布尔值。
2.2.4 ArrayList底层的实现原理是什么-面试题
难易程度:☆☆☆☆
出现频率:☆☆☆

2.2.5 ArrayList list=new ArrayList(10)中的list扩容几次-面试题
难易程度:☆☆☆
出现频率:☆☆

参考回答:
该语句只是声明和实例了一个 ArrayList,指定了容量为 10,未扩容
2.2.6 面试题-如何实现数组和List之间的转换
难易程度:☆☆☆
出现频率:☆☆
如下代码:

参考回答:
-
数组转List ,使用JDK中java.util.Arrays工具类的asList方法
-
List转数组,使用List的toArray方法。
无参toArray方法返回 Object数组,传入初始化长度的数组对象,返回该对象数组
面试官再问:
1,用Arrays.asList转List后,如果修改了数组内容,list受影响吗
2,List用toArray转数组后,如果修改了List内容,数组受影响吗

数组转List受影响; List转数组不受影响
再答:
1,用Arrays.asList转List后,如果修改了数组内容,list受影响吗
Arrays.asList转换list之后,如果修改了数组的内容,list会受影响,因为它的底层使用的Arrays类中的一个内部类ArrayList来构造的集合,在这个集合的构造器中,把我们传入的这个集合进行了包装而已,最终指向的都是同一个内存地址
2,List用toArray转数组后,如果修改了List内容,数组受影响吗
list用了toArray转数组后,如果修改了list内容,数组不会影响,当调用了toArray以后,在底层是它是进行了数组的拷贝,跟原来的元素就没啥关系了,所以即使list修改了以后,数组也不受影响
2.3 链表
2.3.1 单向链表

-
代码实现参考:

2.3.2 单向链表时间复杂度分析
(1)查询操作

-
只有在查询头节点的时候不需要遍历链表,时间复杂度是O(1)
-
查询其他结点需要遍历链表,时间复杂度是O(n)
(2)插入和删除操作

-
只有在添加和删除头节点的时候不需要遍历链表,时间复杂度是O(1)
-
添加或删除其他结点需要遍历链表找到对应节点后,才能完成新增或删除节点,时间复杂度是O(n)
2.3.3 双向链表
而双向链表,顾名思义,它支持两个方向
-
每个结点不止有一个后继指针 next 指向后面的结点
-
有一个前驱指针 prev 指向前面的结点
参考代码


对比单链表:
-
双向链表需要额外的两个空间来存储后继结点和前驱结点的地址
-
支持双向遍历,这样也带来了双向链表操作的灵活性
2.3.4 双向链表时间复杂度分析

(1)查询操作
-
查询头尾结点的时间复杂度是O(1)
-
平均的查询时间复杂度是O(n)
-
给定节点找前驱节点的时间复杂度为O(1)
(2)增删操作
-
头尾结点增删的时间复杂度为O(1)
-
其他部分结点增删的时间复杂度是 O(n)
-
给定节点增删的时间复杂度为O(1)
2.3.5 面试题-ArrayList和LinkedList的区别是什么?
-
底层数据结构
-
ArrayList 是动态数组的数据结构实现
-
LinkedList 是双向链表的数据结构实现
-
操作数据效率
-
ArrayList按照下标查询的时间复杂度O(1)【内存是连续的,根据寻址公式】, LinkedList不支持下标查询
-
查找(未知索引): ArrayList需要遍历,链表也需要链表,时间复杂度都是O(n)
-
新增和删除
-
ArrayList尾部插入和删除,时间复杂度是O(1);其他部分增删需要挪动数组,时间复杂度是O(n)
-
LinkedList头尾节点增删时间复杂度是O(1),其他都需要遍历链表,时间复杂度是O(n)
-
内存空间占用
-
ArrayList底层是数组,内存连续,节省内存
-
LinkedList 是双向链表需要存储数据,和两个指针,更占用内存
-
线程安全
-
ArrayList和LinkedList都不是线程安全的
-
如果需要保证线程安全,有两种方案:
-
在方法内使用,局部变量(每个线程都有一份局部变量)则是线程安全的;
-
使用线程安全的ArrayList和LinkedList ;加锁性能下降

3 HashMap相关面试题

3.1 二叉树
3.1.1 二叉树概述
二叉树,顾名思义,每个节点最多有两个“叉”,两个子节点,分别是左/右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只有左/右子节点。
二叉树每个节点的左子树和右子树也分别满足二叉树的定义。

Java中有两个方式实现二叉树:数组存储,链式存储。
基于链式存储的树的节点可定义如下:

3.1.2 二叉搜索树BST
在二叉树中,比较常见的二叉树有:
-
满二叉树
-
完全二叉树
-
二叉搜索树
-
红黑树
我们重点讲解二叉搜索树和红黑树
(1)二叉搜索树概述

(2)二叉搜索树-时间复杂度分析
实际上由于二叉查找树的形态各异,时间复杂度也不尽相同,我画了几棵树我们来看一下插入,查找,删除的时间复杂度

查找,的时间复杂度O(logn);插入,删除需要用到查找 所以也是O(logn);
极端情况下二叉搜索的时间复杂度

3.1.3 红黑树
(1)概述
红黑树(Red Black Tree):也是一种自平衡的二叉搜索树(BST),之前叫做平衡二叉B树(Symmetric Binary B-Tree)

(2)红黑树的特质

在添加或删除节点的时候,如果不符合这些性质会发生旋转,以达到所有的性质,保证红黑树的平衡

(3)红黑树的复杂度
-
查找:
-
红黑树也是一棵BST(二叉搜索树)树,查找操作的时间复杂度为:O(log n)
-
添加:
-
添加先要从根节点开始找到元素添加的位置,时间复杂度O(log n)
-
添加完成后涉及到复杂度为O(1)的旋转调整操作
-
故整体复杂度为:O(log n)
-
删除:
-
首先从根节点开始找到被删除元素的位置,时间复杂度O(log n)
-
删除完成后涉及到复杂度为O(1)的旋转调整操作
-
故整体复杂度为:O(log n)
3.2 散列表
在HashMap中的最重要的一个数据结构就是散列表,在散列表中又使用到了红黑树和链表
3.2.1 散列表(Hash Table)概述
散列表(Hash Table)又名哈希表/Hash表,是根据键(Key)直接访问在内存存储位置值(Value)的数据结构,它是由数组演化而来的,利用了数组支持按照下标进行随机访问数据的特性
举个例子:
假设有100个人参加马拉松,编号是1-100,如果要编程实现根据选手的编号迅速找到选手信息?
可以把选手信息存入数组中,选手编号就是数组的下标,数组的元素就是选手的信息。
当我们查询选手信息的时候,只需要根据选手的编号到数组中查询对应的元素就可以快速找到选手的信息,如下图:

现在需求升级了:

我们目前是把选手的信息存入到数组中,不过选手的编号不能直接作为数组的下标,不过,可以把选手的选号进行转换,转换为数值就可以继续作为数组的下标了?
转换可以使用散列函数进行转换
3.2.2 散列函数和散列冲突
将键(key)映射为数组下标的函数叫做散列函数。可以表示为:hashValue = hash(key)
散列函数的基本要求:
-
散列函数计算得到的散列值必须是≥0的正整数,因为hashValue需要作为数组的下标。
-
如果key1==key2,那么经过hash后得到的哈希值也必相同即:hash(key1) == hash(key2)
-
如果key1 != key2,那么经过hash后得到的哈希值也必不相同即:hash(key1) != hash(key2)
实际的情况下想找一个散列函数能够做到对于不同的key计算得到的散列值都不同几乎是不可能的,即便像著名的MD5,SHA等哈希算法也无法避免这一情况,这就是散列冲突(或者哈希冲突,哈希碰撞,就是指多个key映射到同一个数组下标位置)

3.2.3 散列冲突-链表法(拉链)
在散列表中,数组的每个下标位置我们可以称之为桶(bucket)或者槽(slot),每个桶(槽)会对应一条链表,所有散列值相同的元素我们都放到相同槽位对应的链表中。

简单就是,如果有多个key最终的hash值是一样的,就会存入数组的同一个下标中,下标中挂一个链表存入多个数据
3.2.4 时间复杂度-散列表
1,插入操作,通过散列函数计算出对应的散列槽位,将其插入到对应链表中即可,插入的时间复杂度是 O(1)

通过计算就可以找到元素
2,当查找、删除一个元素时,我们同样通过散列函数计算出对应的槽,然后遍历链表查找或者删除
-
平均情况下基于链表法解决冲突时查询的时间复杂度是O(1)
-
散列表可能会退化为链表,查询的时间复杂度就从 O(1) 退化为 O(n)

-
将链表法中的链表改造为其他高效的动态数据结构,比如红黑树,查询的时间复杂度是 O(logn)

将链表法中的链表改造红黑树还有一个非常重要的原因,可以防止DDos攻击
DDos 攻击:
分布式拒绝服务攻击(英文意思是Distributed Denial of Service,简称DDoS)
指处于 不同位置的多个攻击者同时向一个或数个目标发动攻击,或者 一个攻击者控制了位于不同位置的多台机器并利用这些机器对受害者同时实施攻击。由于攻击的发出点是分布在不同地方的,这类攻击称为分布式拒绝服务攻击,其中的攻击者可以有多个
3.3 面试题-说一下HashMap的实现原理?

面试官追问:HashMap的jdk1.7和jdk1.8有什么区别

3.4 面试题-HashMap的put方法的具体流程
3.4.1 hashMap常见属性

3.4.2 源码分析

-
HashMap是懒惰加载,在创建对象时并没有初始化数组
-
在无参的构造函数中,设置了默认的加载因子DEFA..是0.75
添加数据流程图
具体的jdk8源码:
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;//判断数组是否未初始化if ((tab = table) == null || (n = tab.length) == 0)//如果未初始化,调用resize方法 进行初始化n = (tab = resize()).length;//通过 & 运算求出该数据(key)的数组下标并判断该下标位置是否有数据if ((p = tab[i = (n - 1) & hash]) == null)//如果没有,直接将数据放在该下标位置tab[i] = newNode(hash, key, value, null);//该数组下标有数据的情况else {Node<K,V> e; K k;//判断该位置数据的key和新来的数据是否一样if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))//如果一样,证明为修改操作,该节点的数据赋值给e,后边会用到e = p;//判断是不是红黑树else if (p instanceof TreeNode)//如果是红黑树的话,进行红黑树的操作e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);//新数据和当前数组既不相同,也不是红黑树节点,证明是链表else {//遍历链表for (int binCount = 0; ; ++binCount) {//判断next节点,如果为空的话,证明遍历到链表尾部了if ((e = p.next) == null) {//把新值放入链表尾部p.next = newNode(hash, key, value, null);//因为新插入了一条数据,所以判断链表长度是不是大于等于8if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st//如果是,进行转换红黑树操作treeifyBin(tab, hash);break;}//判断链表当中有数据相同的值,如果一样,证明为修改操作if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;//把下一个节点赋值为当前节点p = e;}}//判断e是否为空(e值为修改操作存放原数据的变量)if (e != null) { // existing mapping for key//不为空的话证明是修改操作,取出老值V oldValue = e.value;//一定会执行 onlyIfAbsent传进来的是falseif (!onlyIfAbsent || oldValue == null)//将新值赋值当前节点e.value = value;afterNodeAccess(e);//返回老值return oldValue;}}//计数器,计算当前节点的修改次数++modCount;//当前数组中的数据数量如果大于扩容阈值if (++size > threshold)//进行扩容操作resize();//空方法afterNodeInsertion(evict);//添加操作时 返回空值return null;
}
HashMap的put方法的具体流程
-
判断键值对数组table是否为空或为null,否则执行resize()进行扩容(初始化)
-
根据键值key计算hash值得到数组索引
-
判断table[i]==null,条件成立,直接新建节点添加
-
如果table[i]==null ,不成立
4.1 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value
4.2 判断table[i] 是否为treeNode,即table[i 是否是红黑树,如果是红黑树,则直接在树中插入键值对
4.3 遍历table[i],链表的尾部插入数据,然后判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操 作,遍历过程中若发现key已经存在直接覆盖value
-
插入成功后,判断实际存在的键值对数量size是否超过了最大容量threshold(数组长度*0.75),如果超过,进行扩容。
!3.5 面试题-讲一讲HashMap的扩容机制

扩容的流程:

源码:
//扩容、初始化数组
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;//如果当前数组为null的时候,把oldCap老数组容量设置为0int oldCap = (oldTab == null) ? 0 : oldTab.length;//老的扩容阈值int oldThr = threshold;int newCap, newThr = 0;//判断数组容量是否大于0,大于0说明数组已经初始化if (oldCap > 0) {//判断当前数组长度是否大于最大数组长度if (oldCap >= MAXIMUM_CAPACITY) {//如果是,将扩容阈值直接设置为int类型的最大数值并直接返回threshold = Integer.MAX_VALUE;return oldTab;}//如果在最大长度范围内,则需要扩容 OldCap << 1等价于oldCap*2//运算过后判断是不是最大值并且oldCap需要大于16else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold 等价于oldThr*2}//如果oldCap<0,但是已经初始化了,像把元素删除完之后的情况,那么它的临界值肯定还存在, 如果是首次初始化,它的临界值则为0else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;//数组未初始化的情况,将阈值和扩容因子都设置为默认值else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}//初始化容量小于16的时候,扩容阈值是没有赋值的if (newThr == 0) {//创建阈值float ft = (float)newCap * loadFactor;//判断新容量和新阈值是否大于最大容量newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}//计算出来的阈值赋值threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})//根据上边计算得出的容量 创建新的数组 Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//赋值table = newTab;//扩容操作,判断不为空证明不是初始化数组if (oldTab != null) {//遍历数组for (int j = 0; j < oldCap; ++j) {Node<K,V> e;//判断当前下标为j的数组如果不为空的话赋值个e,进行下一步操作if ((e = oldTab[j]) != null) {//将数组位置置空oldTab[j] = null;//判断是否有下个节点if (e.next == null)//如果没有,就重新计算在新数组中的下标并放进去newTab[e.hash & (newCap - 1)] = e;//有下个节点的情况,并且判断是否已经树化else if (e instanceof TreeNode)//进行红黑树的操作((TreeNode<K,V>)e).split(this, newTab, j, oldCap);//有下个节点的情况,并且没有树化(链表形式)else {//比如老数组容量是16,那下标就为0-15//扩容操作*2,容量就变为32,下标为0-31//低位:0-15,高位16-31//定义了四个变量// 低位头 低位尾Node<K,V> loHead = null, loTail = null;// 高位头 高位尾Node<K,V> hiHead = null, hiTail = null;//下个节点Node<K,V> next;//循环遍历do {//取出next节点next = e.next;//通过 与操作 计算得出结果为0if ((e.hash & oldCap) == 0) {//如果低位尾为null,证明当前数组位置为空,没有任何数据if (loTail == null)//将e值放入低位头loHead = e;//低位尾不为null,证明已经有数据了else//将数据放入next节点loTail.next = e;//记录低位尾数据loTail = e;}//通过 与操作 计算得出结果不为0else {//如果高位尾为null,证明当前数组位置为空,没有任何数据if (hiTail == null)//将e值放入高位头hiHead = e;//高位尾不为null,证明已经有数据了else//将数据放入next节点hiTail.next = e;//记录高位尾数据hiTail = e;}} //如果e不为空,证明没有到链表尾部,继续执行循环while ((e = next) != null);//低位尾如果记录的有数据,是链表if (loTail != null) {//将下一个元素置空loTail.next = null;//将低位头放入新数组的原下标位置newTab[j] = loHead;}//高位尾如果记录的有数据,是链表if (hiTail != null) {//将下一个元素置空hiTail.next = null;//将高位头放入新数组的(原下标+原数组容量)位置newTab[j + oldCap] = hiHead;}}}}}//返回新的数组对象return newTab;}-
在添加元素或初始化的时候需要调用resize方法进行扩容,第一次添加数据初始化数组长度为16,以后每次每次扩容都是达到了扩容阈值(数组长度 * 0.75)
-
每次扩容的时候,都是扩容之前容量的2倍;
-
扩容之后,会新创建一个数组,需要把老数组中的数据挪动到新的数组中
-
没有hash冲突的节点,则直接使用 e.hash & (newCap - 1) 计算新数组的索引位置
-
如果是红黑树,走红黑树的添加
-
如果是链表,则需要遍历链表,可能需要拆分链表,判断(e.hash & oldCap)是否为0,该元素的位置要么停留在原始位置,要么移动到原始位置+增加的数组大小这个位置上
3.6 面试题-hashMap的寻址算法

3.9 面试题-HashTable与HashMap的区别
难易程度:☆☆
出现频率:☆☆
主要区别:
| 区别 | HashTable | HashMap |
| 数据结构 | 数组+链表 | 数组+链表+红黑树 |
| 是否可以为null | Key和value都不能为null | 可以为null |
| hash算法 | key的hashCode() | 二次hash |
| 扩容方式 | 当前容量翻倍 +1 | 当前容量翻倍 |
| 线程安全 | 同步(synchronized)的,线程安全 | 非线程安全 |
在实际开中不建议使用HashTable,在多线程环境下可以使用ConcurrentHashMap类
3 真实面试还原
3.1 Java常见的集合类
面试官:说一说Java提供的常见集合?(画一下集合结构图)
候选人:
嗯~~,好的。
在java中提供了量大类的集合框架,主要分为两类:
第一个是Collection 属于单列集合,第二个是Map 属于双列集合
在Collection中有两个子接口List和Set。在我们平常开发的过程中用的比较多像list接口中的实现类ArrarList和LinkedList。 在Set接口中有实现类HashSet和TreeSet。
在map接口中有很多的实现类,平时比较常见的是HashMap、TreeMap,还有一个线程安全的map:ConcurrentHashMap
3.2 List
面试官:ArrayList底层是如何实现的?
候选人:
嗯~,我阅读过arraylist的源码,我主要说一下add方法吧
第一:确保数组已使用长度(size)加1之后足够存下下一个数据
第二:计算数组的容量,如果当前数组已使用长度+1后的大于当前的数组长度,则调用grow方法扩容(原来的1.5倍)
第三:确保新增的数据有地方存储之后,则将新元素添加到位于size的位置上。
第四:返回添加成功布尔值。
面试官:ArrayList list=new ArrayList(10)中的list扩容几次
候选人:
是new了一个ArrarList并且给了一个构造参数10,对吧?(问题一定要问清楚再答)
面试官:是的
候选人:
好的,在ArrayList的源码中提供了一个带参数的构造方法,这个参数就是指定的集合初始长度,所以给了一个10的参数,就是指定了集合的初始长度是10,这里面并没有扩容。
面试官:如何实现数组和List之间的转换
候选人:
嗯,这个在我们平时开发很常见
数组转list,可以使用jdk自动的一个工具类Arrars,里面有一个asList方法可以转换为数组
List 转数组,可以直接调用list中的toArray方法,需要给一个参数,指定数组的类型,需要指定数组的长度。
面试官:用Arrays.asList转List后,如果修改了数组内容,list受影响吗?List用toArray转数组后,如果修改了List内容,数组受影响吗
候选人:
Arrays.asList转换list之后,如果修改了数组的内容,list会受影响,因为它的底层使用的Arrays类中的一个内部类ArrayList来构造的集合,在这个集合的构造器中,把我们传入的这个集合进行了包装而已,最终指向的都是同一个内存地址
list用了toArray转数组后,如果修改了list内容,数组不会影响,当调用了toArray以后,在底层是它是进行了数组的拷贝,跟原来的元素就没啥关系了,所以即使list修改了以后,数组也不受影响
面试官:ArrayList 和 LinkedList 的区别是什么?
候选人:
嗯,它们两个主要是底层使用的数据结构不一样,ArrayList 是动态数组,LinkedList 是双向链表,这也导致了它们很多不同的特点。
1,从操作数据效率来说
ArrayList按照下标查询的时间复杂度O(1)【内存是连续的,根据寻址公式】, LinkedList不支持下标查询
查找(未知索引): ArrayList需要遍历,链表也需要链表,时间复杂度都是O(n)
新增和删除
ArrayList尾部插入和删除,时间复杂度是O(1);其他部分增删需要挪动数组,时间复杂度是O(n)
LinkedList头尾节点增删时间复杂度是O(1),其他都需要遍历链表,时间复杂度是O(n)
2,从内存空间占用来说
ArrayList底层是数组,内存连续,节省内存
LinkedList 是双向链表需要存储数据,和两个指针,更占用内存
3,从线程安全来说,ArrayList和LinkedList都不是线程安全的
面试官:嗯,好的,刚才你说了ArrayList 和 LinkedList 不是线程安全的,你们在项目中是如何解决这个的线程安全问题的?
候选人:
嗯,是这样的,主要有两种解决方案:
第一:我们使用这个集合,优先在方法内使用,定义为局部变量,这样的话,就不会出现线程安全问题。
第二:如果非要在成员变量中使用的话,可以使用线程安全的集合来替代
ArrayList可以通过Collections 的 synchronizedList 方法将 ArrayList 转换成线程安全的容器后再使用。
LinkedList 换成ConcurrentLinkedQueue来使用
3.4 HashMap
面试官:说一下HashMap的实现原理?
候选人:
嗯。它主要分为了一下几个部分:
1,底层使用hash表数据结构,即数组+(链表 | 红黑树)
2,添加数据时,计算key的值确定元素在数组中的下标
key相同则替换
不同则存入链表或红黑树中
3,获取数据通过key的hash计算数组下标获取元素
面试官:HashMap的jdk1.7和jdk1.8有什么区别
候选人:
JDK1.8之前采用的拉链法,数组+链表
JDK1.8之后采用数组+链表+红黑树,链表长度大于8且数组长度大于64则会从链表转化为红黑树
面试官:好的,你能说下HashMap的put方法的具体流程吗?
候选人:
嗯好的。
判断键值对数组table是否为空或为null,否则执行resize()进行扩容(初始化)
根据键值key计算hash值得到数组索引
判断table[i]==null,条件成立,直接新建节点添加
如果table[i]==null ,不成立
4.1 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value
4.2 判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对
4.3 遍历table[i],链表的尾部插入数据,然后判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操 作,遍历过程中若发现key已经存在直接覆盖value
插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold(数组长度*0.75),如果超过,进行扩容。
面试官:好的,刚才你多次介绍了hsahmap的扩容,能讲一讲HashMap的扩容机制吗?
候选人:
好的
在添加元素或初始化的时候需要调用resize方法进行扩容,第一次添加数据初始化数组长度为16,以后每次每次扩容都是达到了扩容阈值(数组长度 * 0.75)
每次扩容的时候,都是扩容之前容量的2倍;
扩容之后,会新创建一个数组,需要把老数组中的数据挪动到新的数组中
没有hash冲突的节点,则直接使用 e.hash & (newCap - 1) 计算新数组的索引位置
如果是红黑树,走红黑树的添加
如果是链表,则需要遍历链表,可能需要拆分链表,判断(e.hash & oldCap)是否为0,该元素的位置要么停留在原始位置,要么移动到原始位置+增加的数组大小这个位置上
面试官:好的,刚才你说的通过hash计算后找到数组的下标,是如何找到的呢,你了解hashMap的寻址算法吗?
候选人:
这个哈希方法首先计算出key的hashCode值,然后通过这个hash值右移16位后的二进制进行按位 异或运算得到最后的hash值。
在putValue的方法中,计算数组下标的时候使用hash值与数组长度取模得到存储数据下标的位置,hashmap为了性能更好,并没有直接采用取模的方式,而是使用了数组长度-1 得到一个值,用这个值按位与运算hash值,最终得到数组的位置。
面试官:为何HashMap的数组长度一定是2的次幂?
候选人:
嗯,好的。hashmap这么设计主要有两个原因:
第一:
计算索引时效率更高:如果是 2 的 n 次幂可以使用位与运算代替取模
第二:
扩容时重新计算索引效率更高:在进行扩容是会进行判断 hash值按位与运算旧数组长租是否 == 0
如果等于0,则把元素留在原来位置 ,否则新位置是等于旧位置的下标+旧数组长度
面试官:好的,我看你对hashmap了解的挺深入的,你知道hashmap在1.7情况下的多线程死循环问题吗?
候选人:
嗯,知道的。是这样
jdk7的的数据结构是:数组+链表
在数组进行扩容的时候,因为链表是 头插法,在进行数据迁移的过程中,有可能导致死循环
比如说,现在有两个线程
线程一: 读取到当前的hashmap数据,数据中一个链表,在准备扩容时,线程二介入
线程二也读取hashmap,直接进行扩容。因为是头插法,链表的顺序会进行颠倒过来。比如原来的顺序是AB,扩容后的顺序是BA,线程二执行结束。
当线程一再继续执行的时候就会出现死循环的问题。
线程一先将A移入新的链表,再将B插入到链头,由于另外一个线程的原因,B的next指向了A,所以B->A->B,形成循环。
当然,JDK 8 将扩容算法做了调整,不再将元素加入链表头(而是保持与扩容前一样的顺序), 尾插法,就避免了jdk7中死循环的问题。
面试官:好的,hashmap是线程安全的吗?
候选人:不是线程安全的
面试官:那我们想要使用线程安全的map该怎么做呢?
候选人:我们可以采用ConcurrentHashMap进行使用,它是一个线程安全的HashMap
面试官:那你能聊一下ConcurrentHashMap的原理吗?
候选人:好的,请参考《多线程相关面试题》中的ConcurrentHashMap部分的讲解
面试官:HashSet与HashMap的区别?
候选人:嗯,是这样。
HashSet底层其实是用HashMap实现存储的, HashSet封装了一系列HashMap的方法. 依靠HashMap来存储元素值,(利用hashMap的key键进行存储), 而value值默认为Object对象. 所以HashSet也不允许出现重复值, 判断标准和HashMap判断标准相同, 两个元素的hashCode相等并且通过equals()方法返回true.
面试官:HashTable与HashMap的区别
候选人:
嗯,他们的主要区别是有几个吧
第一,数据结构不一样,hashtable是数组+链表,hashmap在1.8之后改为了数组+链表+红黑树
第二,hashtable存储数据的时候都不能为null,而hashmap是可以的
第三,hash算法不同,hashtable是用本地修饰的hashcode值,而hashmap经常了二次hash
第四,扩容方式不同,hashtable是当前容量翻倍+1,hashmap是当前容量翻倍
第五,hashtable是线程安全的,操作数据的时候加了锁synchronized,hashmap不是线程安全的,效率更高一些
在实际开中不建议使用HashTable,在多线程环境下可以使用ConcurrentHashMap类
相关文章:
Java 大厂面试 —— 常见集合篇 List HashMap 红黑树
23Java面试专题 八股文面试全套真题(含大厂高频面试真题)多线程_软工菜鸡的博客-CSDN博客 常见集合篇-01-集合面试题-课程介绍 02-算法复杂度分析 2 List相关面试题 2.1 数组 2.1.1 数组概述 数组(Array)是一种用连续的内存空…...

剪枝基础与实战(5): 剪枝代码详解
对模型进行剪枝,我们只对有参数的层进行剪枝,我们基于BatchNorm2d对通道重要度 γ \gamma γ参数进行稀释训练。对BatchNorm2d及它的前后层也需要进行剪枝。主要针对有参数的层:Conv2d、BatchNorm2d、Linear。但是我们不会对Pool2d 层进行剪枝,因为Pool2d只用来做下采样,没…...
)
Acwing 897. 最长公共子序列 (每日一题)
最长公共子序列 题目描述 给定两个长度分别为 N 和 M 的字符串 A 和 B,求既是 A 的子序列又是 B 的子序列的字符串长度最长是多少。 输入格式 第一行包含两个整数 N和 M。 第二行包含一个长度为 N 的字符串,表示字符串 A。 第三行包含一个长度为 M …...
CSS中border-radius的来美化table的实战方案
border-radius是一种CSS属性,用于设置元素的边框的圆角程度。其具体的用法如下: 设置一个值:可以为元素设置一个单一的圆角半径,这个半径将应用于元素的四个角。例如: div {border-radius: 10px; }设置四个值&#x…...
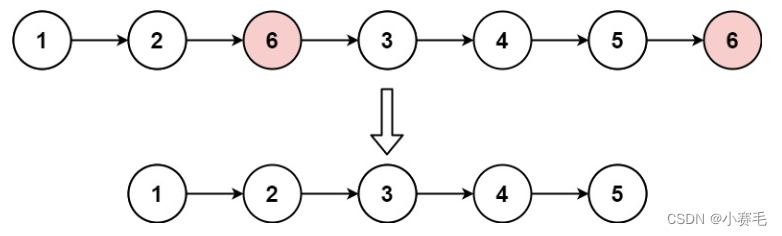
移除链表元素_每日一题
“路虽远,行则将至” ❤️主页:小赛毛 ☕今日份刷题:移除链表元素 题目描述: 给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val val 的节点,并返回 新的头节点 。 示例1&…...
spring boot + Consul 示例 (Kotlin版)
文章目录 1.docker 安装consul2.创建基于springboot的client2.1 依赖版本2.2 pom.xml2.3 启动类2.4 application.properties 3 搭建完成4. 总结 1.docker 安装consul docker-compose.yaml version: "3"services:consul:image: consul:1.4.4container_name: consule…...

Git企业开发控制理论和实操-从入门到深入(四)|Git的远程操作|Gitee
前言 那么这里博主先安利一些干货满满的专栏了! 首先是博主的高质量博客的汇总,这个专栏里面的博客,都是博主最最用心写的一部分,干货满满,希望对大家有帮助。 高质量博客汇总 然后就是博主最近最花时间的一个专栏…...
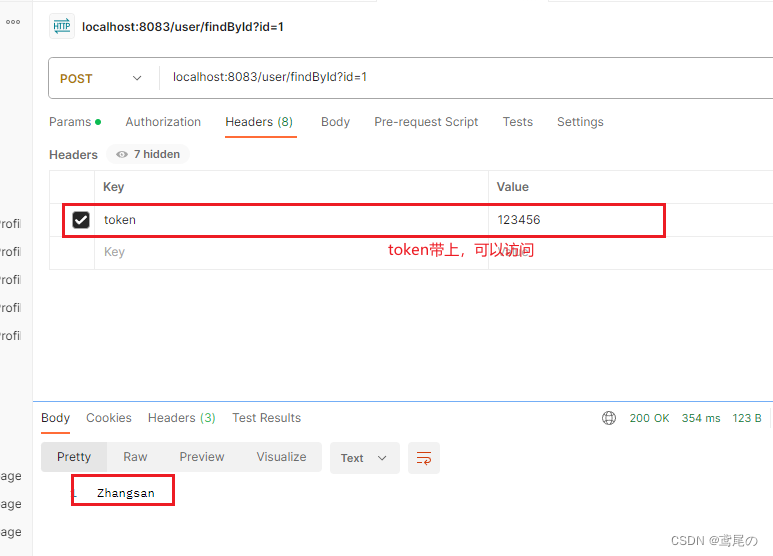
SpringCloudAlibaba Gateway(二)详解-内置Predicate、Filter及自定义Predicate、Filter
Predicate(断言) Predicate(断言),用于进行判断,如果返回为真,才会路由到具体服务。SpirnngCloudGateway由路由断言工厂实现,直接配置即生效,当然也支持自定义路由断言工厂。 内置路由断言工厂实现 SpringClo…...

调用chat-gpt
调用chat-gpt 依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifact…...

Element组件浅尝辄止6:Dialog 对话框组件
Dialog 对话框组件:在保留当前页面状态的情况下,告知用户并承载相关操作。 大白话就是弹窗组件,日常开发中比较常见 1.怎样使用? //触发方式 <el-button type"text" click"dialogVisible true">打开&…...

Bert和LSTM:情绪分类中的表现
一、说明 这篇文章的目的是评估和比较 2 种深度学习算法(BERT 和 LSTM)在情感分析中进行二元分类的性能。评估将侧重于两个关键指标:准确性(衡量整体分类性能)和训练时间(评估每种算法的效率)。…...

【面试经典150题】跳跃游戏
题目链接 给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。 1 < nums…...

【Rust】003-基础语法:流程控制
【Rust】003-基础语法:流程控制 文章目录 【Rust】003-基础语法:流程控制一、概述二、if 表达式1、语法格式2、多个3、获取表达式的值 三、循环1、loop:无限循环,可跳出无限循环跳出循环返回值 2、while:条件循环&…...
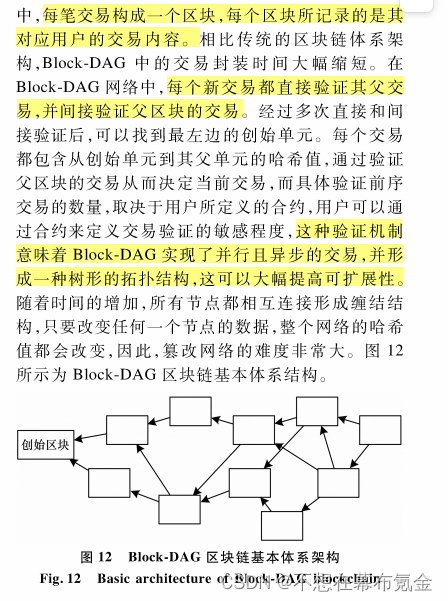
0829【综述】面向时空数据的区块链研究综述
摘要:时空数据包括时间和空间2个维度,常被应用于物流、供应链等领域。传统的集中式存储方式虽然具有一定的便捷性,但不能充分满足时空数据存储及查询等要求,而区块链技术采用去中心化的分布式存储机制,并通过共识协议来保证数据的安全性。研究现有区块链1.0、2.0和以Block-DAG为…...
MySQL高级篇(SQL优化、索引优化、锁机制、主从复制)
目录 0 存储引擎介绍1 SQL性能分析2 常见通用的JOIN查询 SQL执行加载顺序七种JOIN写法3 索引介绍 3.1 索引是什么3.2 索引优劣势3.3 索引分类和建索引命令语句3.4 索引结构与检索原理3.5 哪些情况适合建索引3.6 哪些情况不适合建索引4 性能分析 4.1 性能分析前提知识4.2 Expla…...

YOLOV8模型使用-检测-物体追踪
这个最新的物体检测模型,很厉害的样子,还有物体追踪的功能。 有官方的Python代码,直接上手试试就好,至于理论,有想研究在看论文了╮(╯_╰)╭ 简单介绍 YOLOv8 中可用的模型 YOLOv8 模型的每个类别中有五个模型用于检…...

springmvc:设置后端响应给前端的json数据转换成String格式
设置spring-mvc.xml: xml <?xml version"1.0" encoding"UTF-8"?> <beans xmlns"http://www.springframework.org/schema/beans"xmlns:context"http://www.springframework.org/schema/context"xmlns:xsi"http://www.w…...

Mac安装brew、mysql、redis
mac安装brew mac安装brewmac安装mysql并配置开机启动mac安装redis并配置开机启动 mac安装brew 第一步:执行. /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"第二步:输入开机密码 第三…...
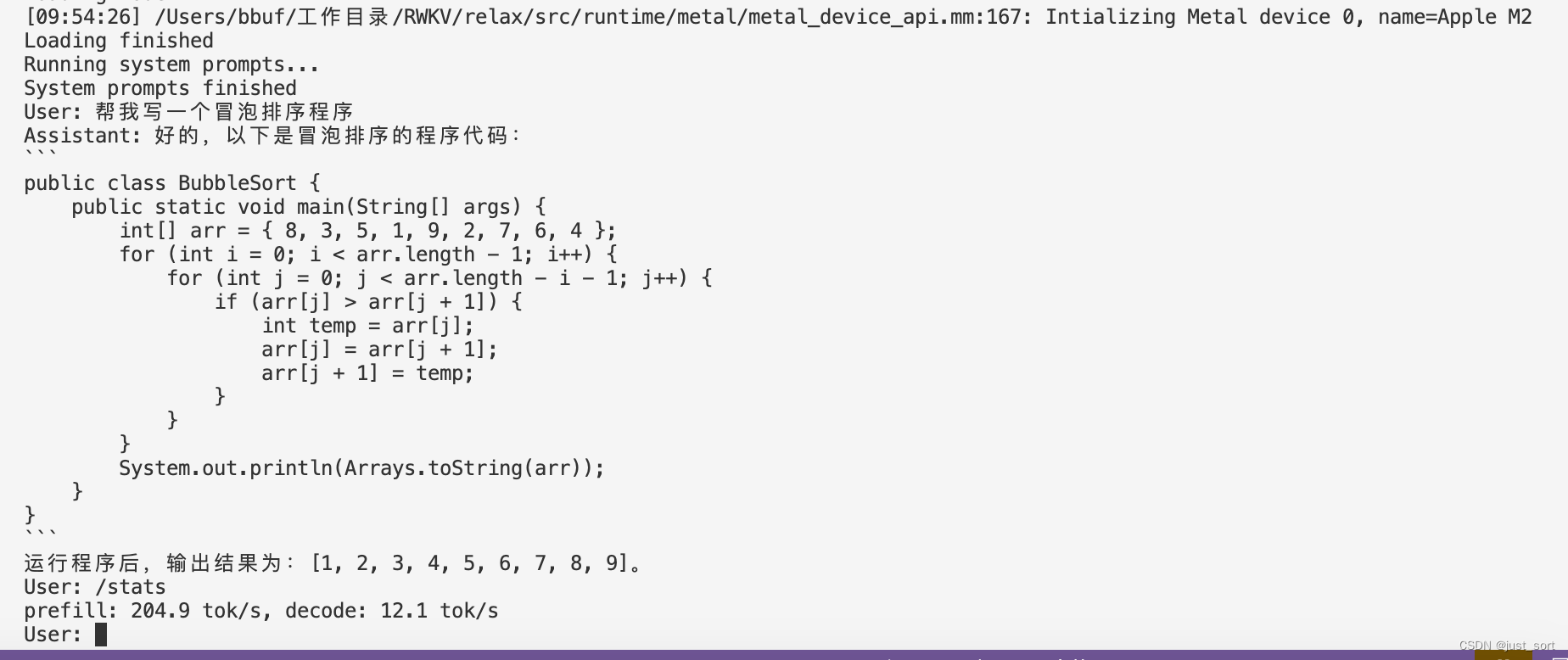
MLC-LLM 部署RWKV World系列模型实战(3B模型Mac M2解码可达26tokens/s)
0x0. 前言 我的 ChatRWKV 学习笔记和使用指南 这篇文章是学习RWKV的第一步,然后学习了一下之后决定自己应该做一些什么。所以就在RWKV社区看到了这个将RWKV World系列模型通过MLC-LLM部署在各种硬件平台的需求,然后我就开始了解MLC-LLM的编译部署流程和…...

Unity 之 参数类型之值类型参数的用法
文章目录 基本数据类型结构体结构体的进一步补充 总结: 当谈论值类型参数时,我们可以从基本数据类型和结构体两个方面详细解释。值类型参数指的是以值的形式传递给函数或方法的数据,而不是引用。 基本数据类型 基本数据类型的值类型参数&…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...

【配置 YOLOX 用于按目录分类的图片数据集】
现在的图标点选越来越多,如何一步解决,采用 YOLOX 目标检测模式则可以轻松解决 要在 YOLOX 中使用按目录分类的图片数据集(每个目录代表一个类别,目录下是该类别的所有图片),你需要进行以下配置步骤&#x…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...

消防一体化安全管控平台:构建消防“一张图”和APP统一管理
在城市的某个角落,一场突如其来的火灾打破了平静。熊熊烈火迅速蔓延,滚滚浓烟弥漫开来,周围群众的生命财产安全受到严重威胁。就在这千钧一发之际,消防救援队伍迅速行动,而豪越科技消防一体化安全管控平台构建的消防“…...

Python实现简单音频数据压缩与解压算法
Python实现简单音频数据压缩与解压算法 引言 在音频数据处理中,压缩算法是降低存储成本和传输效率的关键技术。Python作为一门灵活且功能强大的编程语言,提供了丰富的库和工具来实现音频数据的压缩与解压。本文将通过一个简单的音频数据压缩与解压算法…...
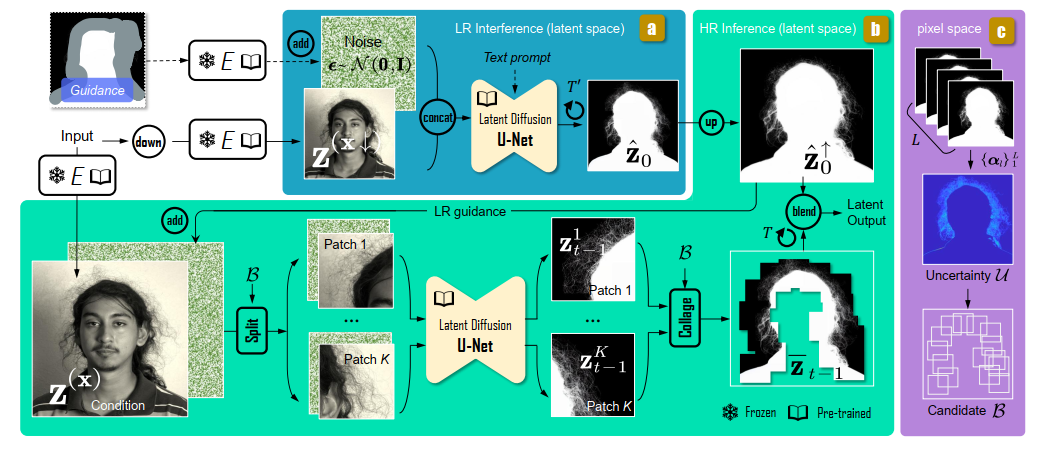
论文阅读:Matting by Generation
今天介绍一篇关于 matting 抠图的文章,抠图也算是计算机视觉里面非常经典的一个任务了。从早期的经典算法到如今的深度学习算法,已经有很多的工作和这个任务相关。这两年 diffusion 模型很火,大家又开始用 diffusion 模型做各种 CV 任务了&am…...