PixelSNAIL论文代码学习(1)——总体框架和平移实现因果卷积
文章目录
- 引言
- 正文
- 目录解析
- README.md阅读
- Setup配置
- Training the model训练模型
- Pretrained Model Check Point预训练的模型
- 训练方法
- train.py文件的阅读
- model.py文件阅读
- h12_noup_smallkey_spec模型定义
- _base_noup_smallkey_spec模型实现
- 一、定义因果卷积过程
- 通过平移实现因果卷积的原理讲解
- 一维向量实现因果卷积
- 二维矩阵实现因果卷积
- 平移实现因果卷积
- nn.down_shifted_conv2d下卷积
- 填充实现
- 权重归一化二维卷积实现
- 自定义实现权重归一化卷积层
- 使用pytorch自带的权重归一化修饰器
- nn.down_right_shifted_conv2d:右下移卷积
- nn.down_shift:下移
- nn.right_shift:右移
- 二、门控残差网络
- 三、因果自注意力机制实现
- 四、使用pytorch实现
- 总结
引言
- 阅读了PixelSNAIL的相关论文,具体链接如下,论文学习链接
- 这篇文章是一个自回归神经网络,将自注意力机制和因果卷积进行结合,我们在PixelCNN中学习过因果卷积的具体实现,并且结合了相关代码进行阅读,这里给出链接:
- PixelCNN的论文和代码学习连接
- PixelSNAIL的效果是远比PixelCNN的效果好的,而且,这里并不知道如何实现自注意力机制,所以需要好学习一下他的代码。
- 很烦,之前弄得深度学习环境因为系统快照的问题,需要重新安装,所以在做这个代码分析之前,还是得重新安装对应的tensorflow深度学习环境。
- 对应github项目的连接
正文
目录解析
- data
- cifar10_data.py 下载并加载相关的数据集
- cifar10_plotdata.py 绘制对应的图片
- imagenet_data.py 下载并加载相关的数据集
- pixel_cnn_pp
- linearize.py 优化tensorflow计算图的执行顺序
- model.py 模型定义函数
- nn.py 实现pixelCNN ++模型的实用函数和层,包括了自定义的损失函数
- plotting.py 绘制训练图
- train.py 训练以及测试文件
README.md阅读
Setup配置
- 需要运行这个代码,需要具有如下的内容
- 具有多个GPU的机器
- python3以上的编译器
- Numpy,TensorFlow
Training the model训练模型
- 使用train.py脚本去训练模型
Pretrained Model Check Point预训练的模型
- 直接在对应的连接上进行下载
- CIFAR10 model
- ImageNet model
训练方法
- CIFAR-10的训练脚本
python train.py \--data_set=cifar \--model=h12_noup_smallkey \--nr_logistic_mix=10 \--nr_filters=256 \--batch_size=8 \--init_batch_size=8 \--dropout_p=0.5 \--polyak_decay=0.9995 \--save_interval=10
- ImageNet的训练脚本
python train.py \--data_set=imagenet \--model=h12_noup_smallkey \--nr_logistic_mix=32 \--nr_filters=256 \--batch_size=8 \--init_batch_size=8 \--learning_rate=0.001 \--dropout_p=0.0 \--polyak_decay=0.9997 \--save_interval=1
train.py文件的阅读
-
这个代码写的真的不敢苟同,所有的处理逻辑都放在一个train.p中,看起来很混乱。他的代码是tensorflow的,而且是1.0系列的代码,可读性并不是那么好,所以这里就不 投入太多关注了,仅仅阅读模型的生成部分。
-
调用并生成模型的代码
- 这里是调用了一个模型模板,传入了model文件,然后具体的模型名称是在训练脚本中指名的,是参数"model=h12_noup_smallkey"这个键值对
# 创建模型
model_opt = {'nr_resnet': args.nr_resnet, 'nr_filters': args.nr_filters,'nr_logistic_mix': args.nr_logistic_mix, 'resnet_nonlinearity': args.resnet_nonlinearity}
# 生成一个模型模板,模型可以多次重复使用,不需要重复创建变量
model = tf.make_template('model', getattr(pxpp_models, args.model + "_spec"))# 用于依赖于数据的参数初始化
with tf.device('/gpu:0'):gen_par = model(x_init, h_init, init=True,dropout_p=args.dropout_p, **model_opt)
- 综上所述,所以具体使用的模型是"h12_noup_smallkey_spec"
model.py文件阅读
- 鉴于上一个文件,这里直接从h12_noup_smallkey_spec这个函数开始看。
h12_noup_smallkey_spec模型定义
- 定义h12_noup_smallkey_spec的代码:
- functools.partial:用于固定某个函数的一些参数,然后生成一个新的函数
- 实现:创建了一个h12_noup_smalleky_spec的函数,这个函数的逻辑和_base_noup_smallkey_spc的逻辑一样,但是参数attn_rep是固定的12
h12_noup_smallkey_spec = functools.partial(_base_noup_smallkey_spec, attn_rep=12)
h12_pool2_smallkey_spec = functools.partial(_base_noup_smallkey_spec, attn_rep=12, att_downsample=2)
h8_noup_smallkey_spec = functools.partial(_base_noup_smallkey_spec, attn_rep=8)
- 所以,下一步,是仔细看_base_noup_smallkey_spec的具体实现逻辑。
_base_noup_smallkey_spec模型实现
-
参照论文,我们看一下整个模型基本的定义图,具体如下,主要是两个模块,分别是
- 门控残差网络的实现(左下角蓝色的模块)
- 自注意力机制的实现(右下角蓝色的模块)
-
具体执行逻辑如下图
- 将图片进行2*2的因果卷积得到A
- 重复执行一下模块M次
- 将A重复执行4次门控残差模块得到B,两步执行
- 步骤一:对B执行1*卷积,得到C
- 步骤二:对B执行因果注意力模块,得到D
- 将C和D进行拼接,程序例又执行了一次因果卷积,得到E,将E保存起来
- 然后最终进行输出
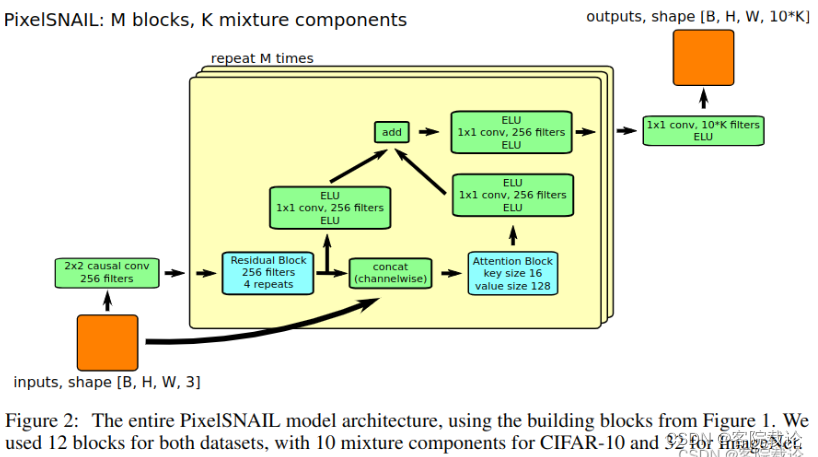
- 将A重复执行4次门控残差模块得到B,两步执行
-
下述为原程序代码
def h6_shift_spec(x, h=None, init=False, ema=None, dropout_p=0.5, nr_resnet=5, nr_filters=160, nr_logistic_mix=10, resnet_nonlinearity='concat_elu'):"""We receive a Tensor x of shape (N,H,W,D1) (e.g. (12,32,32,3)) and producea Tensor x_out of shape (N,H,W,D2) (e.g. (12,32,32,100)), where each fiberof the x_out tensor describes the predictive distribution for the RGB atthat position.'h' is an optional N x K matrix of values to condition our generative model on"""counters = {}with arg_scope([nn.conv2d, nn.deconv2d, nn.gated_resnet, nn.dense, nn.nin, nn.mem_saving_causal_shift_nin], counters=counters, init=init, ema=ema, dropout_p=dropout_p):# parse resnet nonlinearity argumentif resnet_nonlinearity == 'concat_elu':resnet_nonlinearity = nn.concat_eluelif resnet_nonlinearity == 'elu':resnet_nonlinearity = tf.nn.eluelif resnet_nonlinearity == 'relu':resnet_nonlinearity = tf.nn.reluelse:raise('resnet nonlinearity ' +resnet_nonlinearity + ' is not supported')with arg_scope([nn.gated_resnet], nonlinearity=resnet_nonlinearity, h=h):# // up pass through pixelCNN xs = nn.int_shape(x)background = tf.concat([((tf.range(xs[1], dtype=tf.float32) - xs[1] / 2) / xs[1])[None, :, None, None] + 0. * x,((tf.range(xs[2], dtype=tf.float32) - xs[2] / 2) / xs[2])[None, None, :, None] + 0. * x,],axis=3)# add channel of ones to distinguish image from padding later onx_pad = tf.concat([x, tf.ones(xs[:-1] + [1])], 3)ul_list = [nn.causal_shift_nin(x_pad, nr_filters)] # stream for up and to the leftfor attn_rep in range(6):for rep in range(nr_resnet):ul_list.append(nn.gated_resnet(ul_list[-1], conv=nn.mem_saving_causal_shift_nin))ul = ul_list[-1]hiers = [1, ]hier = hiers[attn_rep % len(hiers)]raw_content = tf.concat([x, ul, background], axis=3)key, mixin = tf.split(nn.nin(nn.gated_resnet(raw_content, conv=nn.nin), nr_filters * 2 // 2), 2, axis=3)raw_q = tf.concat([ul, background], axis=3)if hier != 1:raw_q = raw_q[:, ::hier, ::hier, :]query = nn.nin(nn.gated_resnet(raw_q, conv=nn.nin), nr_filters // 2)if hier != 1:key = tf.nn.pool(key, [hier, hier], "AVG", "SAME", strides=[hier, hier])mixin = tf.nn.pool(mixin, [hier, hier], "AVG", "SAME", strides=[hier, hier])mixed = nn.causal_attention(key, mixin, query, causal_unit=1 if hier == 1 else xs[2] // hier)if hier != 1:mixed = tf.depth_to_space(tf.tile(mixed, [1, 1, 1, hier * hier]), hier)ul_list.append(nn.gated_resnet(ul, mixed, conv=nn.nin))x_out = nn.nin(tf.nn.elu(ul_list[-1]), 10 * nr_logistic_mix)return x_out
-
函数参数说明
- x:输入张量,形状为(N,H,W,D1),N为batch_size,H,W为图像的高和宽,D1为图像的通道数
- h:可选的N x K矩阵,用于在生成模型上进行条件,默认是不使用的。
- init:是否初始化,默认不进行初始化
- ema:是否使用指数移动平均,默认不进行指数平均
- dropout_p:dropout概率,默认为0.5
- nr_resnet:残差网络的数量,默认为5
- nr_filters:卷积核的数量,默认为256
- attn_rep:注意力机制的重复次数,默认重复12次
- nr_logistic_mix:logistic混合的数量,默认混合采样10次
- att_downsample:注意力机制的下采样,默认下采样一次
- resnet_nonlinearity:残差网络的非线性激活函数,默认使用“concat_elu”
-
下述将根据代码和流程图,列出因果卷积、门控残差网络和因果注意力模块的具体实现
一、定义因果卷积过程
-
这里因果卷积的定义方式和PixelCNN不一样,他是定义掩码,这里是定义了四种不同的卷积方式来实现因果卷积的,分别是,这个过程复杂的很。
- nn.down_shifted_conv2d:下移卷积:
- nn.down_right_shifted_conv2d:右下移卷积
- nn.down_shift:下移
- nn.right_shift:右移
-
在二维因果卷积过程中,要确保每一个输出像素仅受其左侧和上方元素的影响,通常经过一下几种方式实现
- 零填充:卷积之前,将输入矩阵的周围填充零,卷积操作从图像边缘开始,不会看到未来消息。
- 平移:在卷积之后,输出矩阵通常会沿着某个方向进行平移,确保因果性。这个平移是需要将原来移空的位置设置为0.
-
在作者的代码通过了两个方法来确保每一个像素点只能获得上面和左边的信息。
- 对矩阵的上面进行padding,然后再将,矩阵下移,来确保每一个元素只能获得上边的元素信息
- 对矩阵的左面进行padding,然后再将矩阵右移,来确保每一个元素只能获得左边的元素信息
-
通过上述两个方法的结合,确保元素只能获得左上部的未来信息。
通过平移实现因果卷积的原理讲解
一维向量实现因果卷积
-
一维输入序列 x = [ x 0 , x 1 , . . . , x n − 1 ] x = [x_0,x_1,...,x_{n-1}] x=[x0,x1,...,xn−1]
-
一维卷积核 h = [ h 0 , h 1 , . . . . , h m − 1 ] h = [h _0,h_1,....,h_{m-1}] h=[h0,h1,....,hm−1]
-
因果卷积的输出 y y y定义如下, y t = ∑ i = 0 m − 1 h i x t − i t > = i y_t = \sum_{i = 0}^{m-1} h_i x_{t-i} \ \ \ \ \ \ \ \ \ \ \ \ \ t >= i yt=i=0∑m−1hixt−i t>=i
-
具体样例如下
- 一维输入序列 x = [ x 0 , x 1 , x 2 , x 3 , x 4 ] x = [x_0,x_1,x_2,x_3,x_4] x=[x0,x1,x2,x3,x4]
- 一维卷积核 h = [ h 2 , h 1 , h 1 ] h = [h _2,h_1,h_1] h=[h2,h1,h1]
- 这个在卷积过程中,完全是按他的公式进行卷积的

二维矩阵实现因果卷积
- 二维卷积:因果性意味着输出矩阵中每一个元素只能依赖于其上方和左方的输入元素,通过pading和平移实现。

- 就是通过填充和平移来实现。
平移实现因果卷积
nn.down_shifted_conv2d下卷积
- 这里使用了自定义的Conv2d卷积,还有填充模式,这里逐个进行分析
填充实现
def down_shifted_conv2d(x, num_filters, filter_size=[2, 3], stride=[1, 1], **kwargs):# 这里是对数据进行填充,总共有四个维度,分别是N,H,W,C# 第一个维度不进行填充,他是batch_size# 第二个维度H进行填充,开始的地方填充的大小是filter_size[0] - 1,结束的地方填充的大小是0,也就是仅仅扩充上部分# 第三个宽度是W进行填充,开始的地方填充的大小是int((filter_size[1] - 1) / 2),结束的地方填充的大小是int((filter_size[1] - 1) / 2),也就是仅仅扩充左右两边# 第四个维度不进行填充,他是channelx = tf.pad(x, [[0, 0], [filter_size[0] - 1, 0], [int((filter_size[1] - 1) / 2), int((filter_size[1] - 1) / 2)], [0, 0]])# return conv2d(x, num_filters, filter_size=filter_size, pad='VALID', stride=stride, **kwargs)
- 假设原始输入的矩阵是68的,卷积核的大小是34,原矩阵、填充之后的矩阵和卷积之后的单个矩阵,效果如下
- 原矩阵,6*8

- 填充之后的矩阵8*10
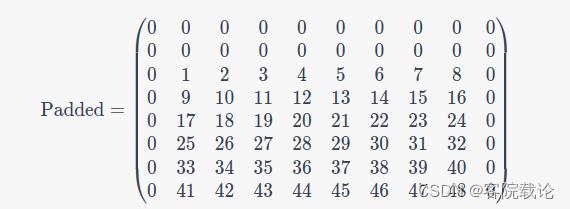
- 卷积之后的矩阵6*7

- 原矩阵,6*8
- 这里对于生成的序列在于需要将生成之后的矩阵和原来的矩阵进行对齐,然后按照位置进行比对的,这里有个样例将很好。具体截图如下。
- 上面一行是卷积之后的输出,下面一行是原始的数据集
- 左图是正确的,timeB的时间序列仅仅获取timeA和timeB的序列,但是右图就获取了timeC未来序列的数据,所以左图是符合因果卷积的效果的。
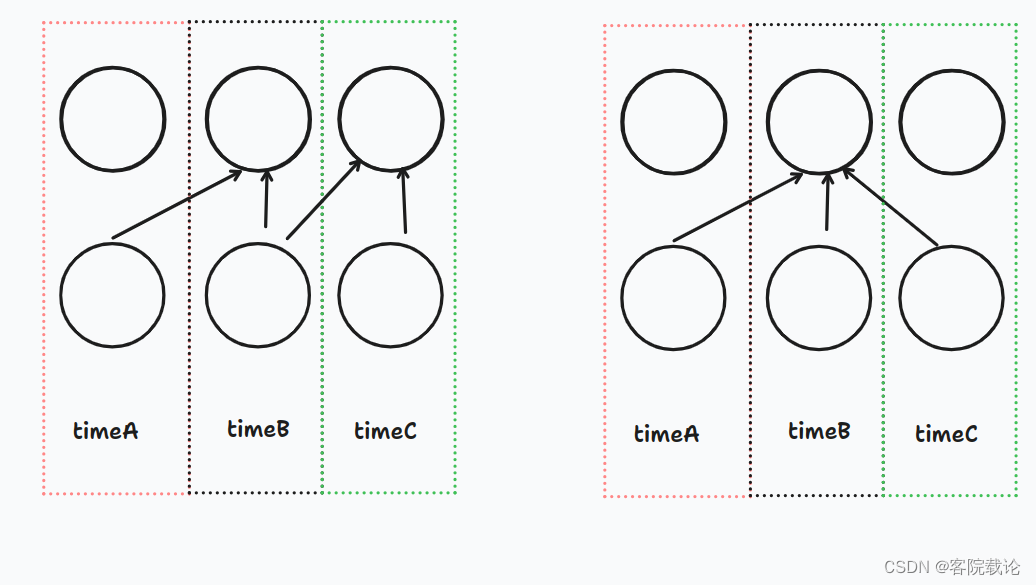
权重归一化二维卷积实现
-
这里作者自己定义了一个带有权重归一化的二维卷积层,因为正常卷积并不包含权重归一化的效果。
-
带权重归一化的二维卷积层的优势:
- 训练稳定:权重归一化之后,模型的训练更加稳定
- 快速收敛:权重归一化能够加速模型收敛
- 改进泛化:在特定的任务中,权重归一化有注意模型泛化
-
正常二维卷积的优势:
- 效率更高、操作简单、广泛应用
-
缩放因子 g g g和偏置权重 b b b的作用:
- 缩放因子 g g g:
-
使用广播机制,将放缩因子与权重矩阵中的每一个数字按位相乘 S c a l e d W e i g h t = g × N o r m a l i z e d W e i g h t Scaled \ Weight = g \times Normalized \ Weight Scaled Weight=g×Normalized Weight
-
主要是权重归一化之后,所有权重的范围 都是单位范围内,加上缩放因子能够适应更多范数。
-
注意,权重归一化,是在输出通道上进行操作的
-
- 偏置权重 b b b
- 是在卷积结果之后,加上偏置,让模型输出一个非零的值
- 具体公式如下 O u t p u t = C o n v 2 D ( x , S c a l e d W e i g h t ) + b Output = Conv2D(x,Scaled \ Weight) + b Output=Conv2D(x,Scaled Weight)+b
- 缩放因子 g g g:
-
这里我进行了两种实现方法,一种是通过pytorch自定义权重归一化卷积层,还有一种是通过pytorch内置的权重归一化装饰器实现类似的功能。
自定义实现权重归一化卷积层
- 这里需要继承nn.Moudle模块,自己定义forward模块实现相关功能
- 需要实现的基本步骤:
- 基本的init初始化函数
- forward前向传播函数自定义
- 计算缩放因子和偏置初值的函数,具体计算公式如下

# 权重归一化卷积层
class WeightNormConv2d(nn.Module):def __init__(self, in_channels, out_channels,kernel_size, stride=1, padding=0, nonlinearity=None, init_scale=1.):super(WeightNormConv2d, self).__init__()# 指定非线性激活函数self.nonlinearity = nonlinearityself.init_scale = init_scale# 定义卷积层self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)# 定义缩放因子g和偏置b# 将g和b声明为需要优化的参数,卷积层默认的权重是(C-out,C-in,H,W)这四个维度self.g = nn.Parameter(torch.ones(out_channels, 1, 1, 1))self.b = nn.Parameter(torch.zeros(out_channels))# 声明初始化参数self.reset_parameters()# 数据依赖的参数初始化def reset_parameters(self):# 初始化权重为正太分布init.normal_(self.conv.weight, mean=0, std=0.05)# 初始化偏置为0init.zeros_(self.conv.bias)# 使用一次随机输入,进行一次前向传播,以计算初始的g和bwith torch.no_grad():x_init = F.conv2d(torch.randn(1, *self.conv.weight.shape[1:]), self.conv.weight)m_init, v_init = x_init.mean(), x_init.var()# 计算缩放因子scale_init = self.init_scale / torch.sqrt(v_init + 1e-8)self.g.data.fill_(scale_init)# 计算偏置# 将张量所有的元素都设定为特定的元素# data属性仅仅是修改对应的值,但是不会计入梯度的改变self.b.data.fill_(-m_init * scale_init)def forward(self, x):# 应用权重归一化W = self.conv.weight * (self.g / torch.sqrt((self.conv.weight ** 2).sum([1, 2, 3], keepdim=True)))# 执行卷积操作x = F.conv2d(x, W, self.b, self.conv.stride, self.conv.padding)# 应用非线性激活if self.nonlinearity is not None:x = self.nonlinearity(x)return x# 测试函数
conv_layer = WeightNormConv2d(3, 16, [3, 3], stride=1, nonlinearity=F.relu)
x = torch.randn(8, 3, 64, 64) # NCHW格式
out = conv_layer(x)
print(out.shape)
使用pytorch自带的权重归一化修饰器
- 直接调用nn.utils中的weight.norm组件,包括原来的卷积层即可,具体如下
# 使用pytorch自定义的权重归一化层
import torch
from torch import nn
from torch.nn.utils import weight_norm# 创建一个标准的 Conv2d 层
conv_layer = nn.Conv2d(3, 16, 3, 1)# 应用权重归一化
conv_layer = weight_norm(conv_layer)# 测试该层
x = torch.randn(8, 3, 64, 64) # 输入张量,形状为 [batch_size, channels, height, width]
out = conv_layer(x)print(out.shape) # 输出张量的形状应为 [8, 16, 62, 62]
nn.down_right_shifted_conv2d:右下移卷积
- 这个和上一个方式基本上都是相同的,只不过对于W和这个维度而言,仅仅是填充了左边,并没有填充右边。就是在原来的代码上进行修改,同时填充的数量也不一样。具体不再讲解
@add_arg_scope
def down_right_shifted_conv2d(x, num_filters, filter_size=[2, 2], stride=[1, 1], **kwargs):x = tf.pad(x, [[0, 0], [filter_size[0] - 1, 0],[filter_size[1] - 1, 0], [0, 0]])return conv2d(x, num_filters, filter_size=filter_size, pad='VALID', stride=stride, **kwargs)
nn.down_shift:下移
- 使用原始数据的一部分用零来替代,确保最终生成的数据是。将原始的张量往下移动n行,然后前n行全部替换成0
nn.right_shift:右移
- 具体实现和上面相同,仅仅是在矩阵的作伴部分进行添加,然后返回最终的矩阵
def right_shift(x, step=1):xs = int_shape(x)return tf.cobncat([tf.zeros([xs[0], xs[1], step, xs[3]]), x[:, :, :xs[2] - step, :]], 2)
二、门控残差网络
- 由于篇幅有限,这里具体看这篇文章和博客
- 门控残差网络的具体实现
三、因果自注意力机制实现
- 看对应文章的链接
- 因果自注意力机制实现
四、使用pytorch实现
- 之前每一个章节都有pytorch实现的版本,这里将对所有的内容进行汇总,使用pytorch对pixelSNAIL模型进行重构,具体代码如下
# 实现最终的模型
class PixelSNAIL(nn.Module):'''pixelSNAIL模型'''def __init__(self,nr_resnet=5, nr_filters=32, attn_rep=12, nr_logistic_mix=10, att_downsample=1):super(PixelSNAIL,self).__init__()# 声明类成员self.nr_resnet = nr_resnetself.nr_filters = nr_filtersself.attn_rep = attn_repself.nr_logistic_mix = nr_logistic_mixself.att_downsample = att_downsample# 声明定义模型对象# 声明因果卷积的网络self.down_shifted_conv2d = weight_norm(nn.Conv2d(3, self.nr_filters, kernel_size=(1, 3)))self.down_right_shifted_conv2d = weight_norm(nn.Conv2d(3, self.nr_filters, kernel_size=(2, 1)))# 声明包含若干门控残差网络的modulelistself.gated_resnets = nn.ModuleList([GatedResNet(self.nr_filters) for _ in range(self.nr_resnet)])# 声明线性模型self.nin1 = nn.Linear(self.nr_filters, self.nr_filters // 2 + 16) # 假设q_size = 16self.nin2 = nn.Linear(self.nr_filters, 16) # 假设q_size = 16# 声明因果注意力模块self.causal_attentions = nn.ModuleList([CausalAttention() for _ in range(self.attn_rep)])# 最终的卷积网络self.final_conv = nn.Conv2d(self.nr_filters, 10 * self.nr_logistic_mix, kernel_size=1)def forward(self, x):ul_list = []# 加上一个是四个# 按照左右上下的方式进行填充down_shifted = F.pad(x, (1, 1, 0, 0)) # 自定义下移和右移操作right_shifted = F.pad(x, (0, 0, 1, 0))# 因果卷积ds_conv = self.down_shifted_conv2d(down_shifted)drs_conv = self.down_right_shifted_conv2d(right_shifted)ul = ds_conv + drs_convul_list.append(ul)# 下采样,从右下角开始for causal_attention in self.causal_attentions:for gated_resnet in self.gated_resnets:ul = gated_resnet(ul)ul_list.append(ul)print('attention module')# 注意力机制last_ul = ul_list[-1]# 准备原始内容raw_content = torch.cat([x, last_ul], dim=1) # 假设背景信息已经添加到x中# 生成key和valueprint(raw_content.shape)raw = self.nin1(raw_content)print('raw data shape',raw.shape)key, mixin = raw.split(18, dim=1) # 假设q_size = 16# 生成query查询键raw_q = last_ulquery = self.nin2(raw_q)# 计算注意力print(mixin.shape)print(query.shape)mixed = causal_attention(key, mixin, query)ul_list.append(mixed)x_out = F.elu(ul_list[-1])x_out = self.final_conv(x_out)return x_outx = torch.randn(64,3,32,32)
model = PixelSNAIL()
x_out = model(x)
print(x_out.shape)
- 这个代码多多少少有一点问题, 但是我并不想在投入时间了,因为我感觉我已经滞后了很多,有点慌张,这个模型完整的都已经知道了,具体的实现细节。pytorch的大概实现逻辑也给了,后续有空了,可以继续调整。
总结
- 激活函数,可以试一下concat_elu,能够识别更加复杂的特征。
- 这个PixelSNAIL用了差不多一周看完,虽然没有跑起来,没有调试,但是大部分代码自己都进行了重构,学到了很多。
- 以后在处理序列数据,可以使用因果注意力机制,而不仅仅是使用因果卷积。除此之外,对于query、key和value的生成理解还有一些问题,总是觉得怪怪的,门控残差进行卷积一定次数之后,设定特定的filter_num,直接输出,直接进行拆分,就可以获得key和value,然后在点乘,我想知道这个操作是怎么想出来的。
- 我想将我所有的代码都放到我的github上,现在还缺数据加载和最终生成模型的评价指标,下一步还是回归我们的那个基础的模型,然后将之模块化,主要是为了适应以后的模块替换。
相关文章:
PixelSNAIL论文代码学习(1)——总体框架和平移实现因果卷积
文章目录 引言正文目录解析README.md阅读Setup配置Training the model训练模型Pretrained Model Check Point预训练的模型训练方法 train.py文件的阅读model.py文件阅读h12_noup_smallkey_spec模型定义_base_noup_smallkey_spec模型实现一、定义因果卷积过程通过平移实现因果卷…...

Python大数据处理利器之Pyspark详解
摘要: 在现代信息时代,数据是最宝贵的财富之一,如何处理和分析这些数据成为了关键。Python在数据处理方面表现得尤为突出。而pyspark作为一个强大的分布式计算框架,为大数据处理提供了一种高效的解决方案。本文将详细介绍pyspark…...

S905L3A(M401A)拆解, 运行EmuELEC和Armbian
关于S905L3A / S905L3AB S905Lx系列没有公开资料, 猜测是Amlogic用于2B的芯片型号, 最早的 S905LB 是 S905X 的马甲, 而这个 S905L3A/S905L3AB 则是 S905X2 的马甲, 因为在性能评测里这两个U的得分几乎一样. S905L3A/S905L3AB 和 S905X2, S905X3 一样 GPU 是 G31, 相比前一代的…...
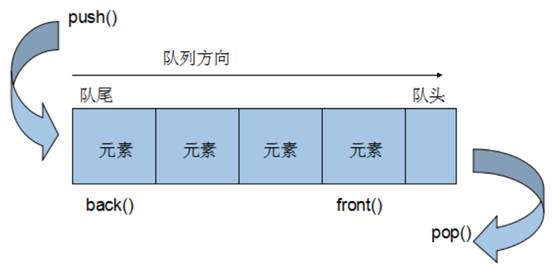
stack和queue容器
1 stack 基本概念 概念:stack是一种先进后出(First In Last Out,FILO)的数据结构,它只有一个出口 栈中只有顶端的元素才可以被外界使用,因此栈不允许有遍历行为 栈中进入数据称为 — 入栈 push 栈中弹出数据称为 — 出栈 pop 2 stack 常用…...
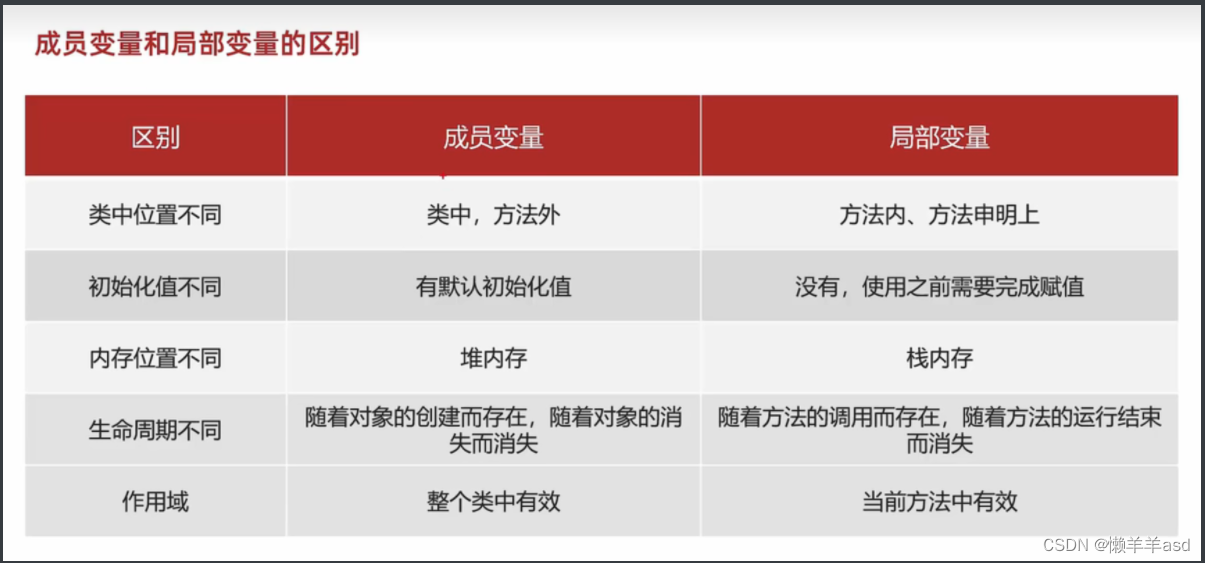
面向对象基础
文章目录 面向对象基础一.面向对象介绍二.设计对象并使用三.封装四.This关键字五.构造方法六.标准的Javabean类七.对象内存图八.基本数据类型和引用数据类型九.成员和局部 面向对象基础 一.面向对象介绍 面向:拿,找 对象:能干活的东西 面向对象编程:找东西来做对应的事情 …...
spring集成mybatis
1、新建一个javaEE web项目 2、加入相关依赖的坐标 <dependencies><!--数据系列:mybatis,mysgl,druid数据源,junit--><!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java --><dependency><groupId>mysql</grou…...

抽象轻松c语言
目 c语言 c程序 c语言的核心在于语言,语言的作用是进行沟通,人与人之间的信息交换 人与人之间的信息交换是会有信息空白(A表达信息,B接受信息,B对信息的处理会与A所以表达的信息具有差距,这段差距称为信…...
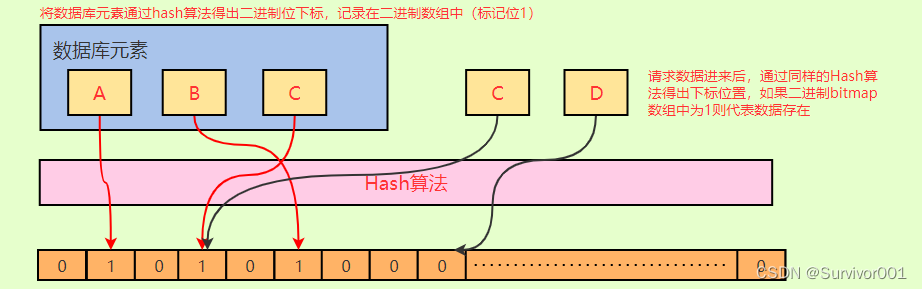
Redis布隆过滤器原理
其实布隆过滤器本质上要解决的问题,就是防止很多没有意义的、恶意的请求穿透Redis(因为Redis中没有数据)直接打入到DB。它是Redis中的一个modules,其实可以理解为一个插件,用来拓展实现额外的功能。 可以简单理解布隆…...

写代码时候的命名规则、命名规范、命名常用词汇
版权声明 这个大部分笔记是观看up主红桃A士的视频记录下来的,因为本人在学习的过程中也经常出现类似的问题,并且觉得Up主的视频讲解很好,做此笔记反复学习,若有侵权请联系删除,此推荐视频地址:【改善丑陋的…...
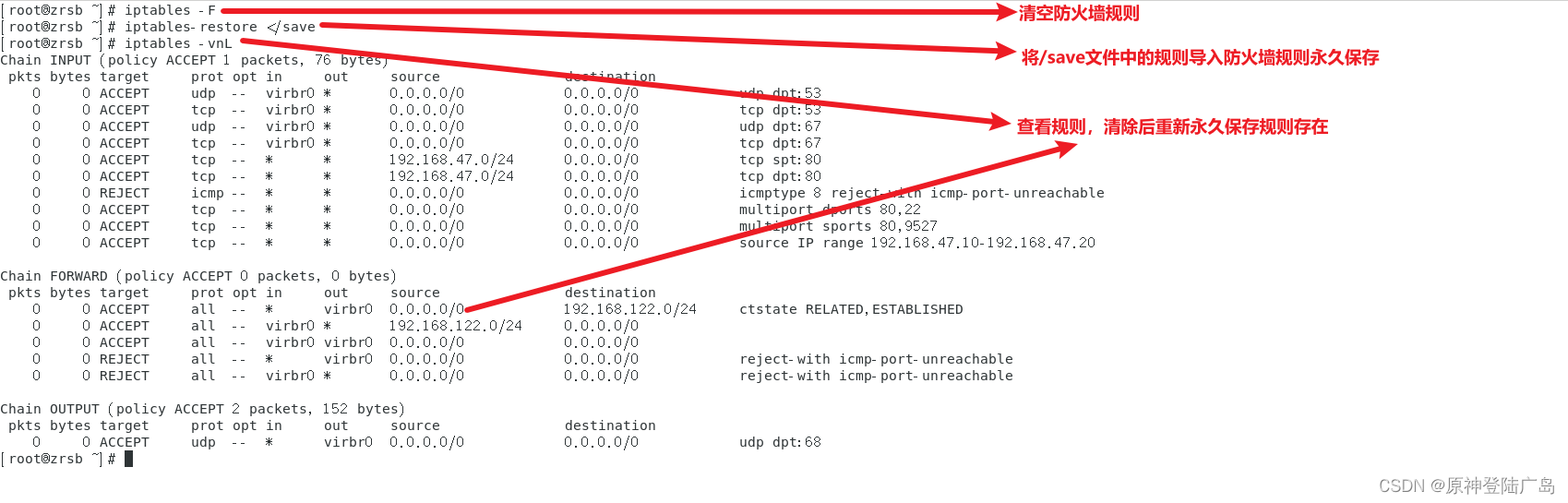
Linux之iptables防火墙
一.网络安全技术 ①入侵检测系统(Intrusion Detection Systems):特点是不阻断任何网络访问,量化、定位来自内外网络的威胁情况,主要以提供报警和事后监督为主,提供有针对性的指导措施和安全决策依据,类 似于…...

启动服务报错:Command line is too long Shorten command line for xxx or also for Spri
ommand line is too long. Shorten command line for ProjectApprovalApplication or also for Spring Boot default configuration. 启动springboot 项目的时候报错 解决方案: 点击提示中的:default:然后在弹出窗口中选择:JAR xx…...

docker安装elasticsearch、kibana
安装过程中,遇到最大的问题就是在安装kibana的时候发现 一直连接不上 elasticsearch。最后解决的问题就是 我通过 ifconfig en0 | grep inet| awk {print $2} 在mac中找到本机的ip,然后去到kibana容器中 修改 vi config/kibana.yml中的elasticsearch.hos…...

前端 CSS - 如何隐藏右侧的滚动条 -关于出现过多的滚动条导致界面不美观
1、配置 HTML 标签,隐藏右侧的滚动条 CSS 配置:下面两个一起写进进去,适配 IE、火狐、谷歌浏览器 html {/*隐藏滚动条,当IE下溢出,仍然可以滚动*/-ms-overflow-style:none;/*火狐下隐藏滚动条*/overflow:-moz-scroll…...
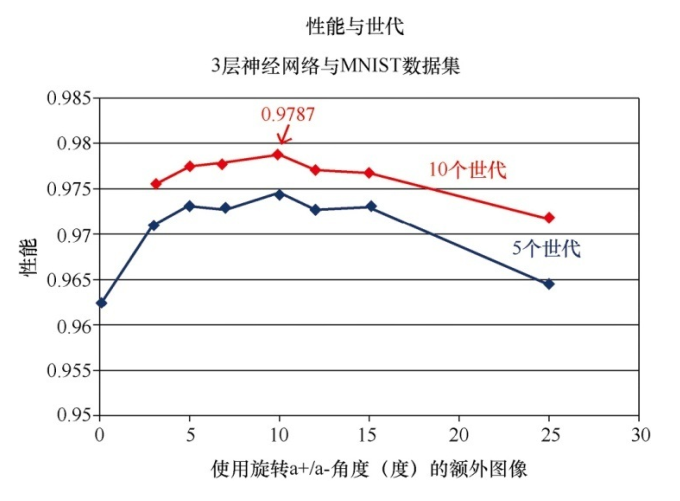
2.神经网络的实现
创建神经网络类 import numpy # scipy.special包含S函数expit(x) import scipy.special # 打包模块 import pickle# 激活函数 def activation_func(x):return scipy.special.expit(x)# 用于创建、 训练和查询3层神经网络 class neuralNetwork:# 初始化神经网络def __init__(se…...
合宙Air724UG LuatOS-Air LVGL API控件-键盘 (Keyboard)
键盘 (Keyboard) LVGL 可以添加触摸键盘,但是很明显,使用触摸键盘的话必须要使用触摸的输入方式,否则无法驱动键盘。 示例代码 function keyCb(obj, e)-- 默认处理事件lvgl.keyboard_def_event_cb(keyBoard, e)if(e lvgl.EVENT_CANCEL)the…...

pytorch深度学习实践
B站-刘二大人 参考-PyTorch 深度学习实践_错错莫的博客-CSDN博客 线性模型 import numpy as np import matplotlib.pyplot as pltx_data [1.0, 2.0, 3.0] y_data [2.0, 4.0, 6.0]def forward(x):return x * wdef loss(x, y):y_pred forward(x)return (y_pred - y) ** 2# …...
)
直方图反向投影(Histogram Backprojection)
直方图反向投影(Histogram Backprojection)是一种在计算机视觉中用于对象检测和图像分割的技术。它的原理基于图像的颜色分布,允许我们在一幅图像中找到与给定对象颜色分布相匹配的区域。这个技术常常用于图像中的目标跟踪、物体识别和图像分…...

day32 泛型 数据结构 List
一、泛型 概述 JDK1.5同时推出了两个和集合相关的特性:增强for循环,泛型 泛型可以修饰泛型类中的属性,方法返回值,方法参数, 构造函数的参数 Java提供的泛型类/接口 Collection, List, Set,Iterator 等 …...

DW-AHB Central DMAC
文章目录 AHB Central DMAC —— Design Ware AHB Central DMAC —— Design Ware AHB(Adavenced High-performace BUS) Central DMAC(Direct Memory Access Controller) : 一个高性能总线系统。 作用:在嵌入式系统种连接高速设备,如处理器内存&#x…...

JavaScript设计模式(四)——策略模式、代理模式、观察者模式
个人简介 👀个人主页: 前端杂货铺 🙋♂️学习方向: 主攻前端方向,正逐渐往全干发展 📃个人状态: 研发工程师,现效力于中国工业软件事业 🚀人生格言: 积跬步…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...

【电力电子】基于STM32F103C8T6单片机双极性SPWM逆变(硬件篇)
本项目是基于 STM32F103C8T6 微控制器的 SPWM(正弦脉宽调制)电源模块,能够生成可调频率和幅值的正弦波交流电源输出。该项目适用于逆变器、UPS电源、变频器等应用场景。 供电电源 输入电压采集 上图为本设计的电源电路,图中 D1 为二极管, 其目的是防止正负极电源反接, …...

Qemu arm操作系统开发环境
使用qemu虚拟arm硬件比较合适。 步骤如下: 安装qemu apt install qemu-system安装aarch64-none-elf-gcc 需要手动下载,下载地址:https://developer.arm.com/-/media/Files/downloads/gnu/13.2.rel1/binrel/arm-gnu-toolchain-13.2.rel1-x…...
的打车小程序)
基于鸿蒙(HarmonyOS5)的打车小程序
1. 开发环境准备 安装DevEco Studio (鸿蒙官方IDE)配置HarmonyOS SDK申请开发者账号和必要的API密钥 2. 项目结构设计 ├── entry │ ├── src │ │ ├── main │ │ │ ├── ets │ │ │ │ ├── pages │ │ │ │ │ ├── H…...
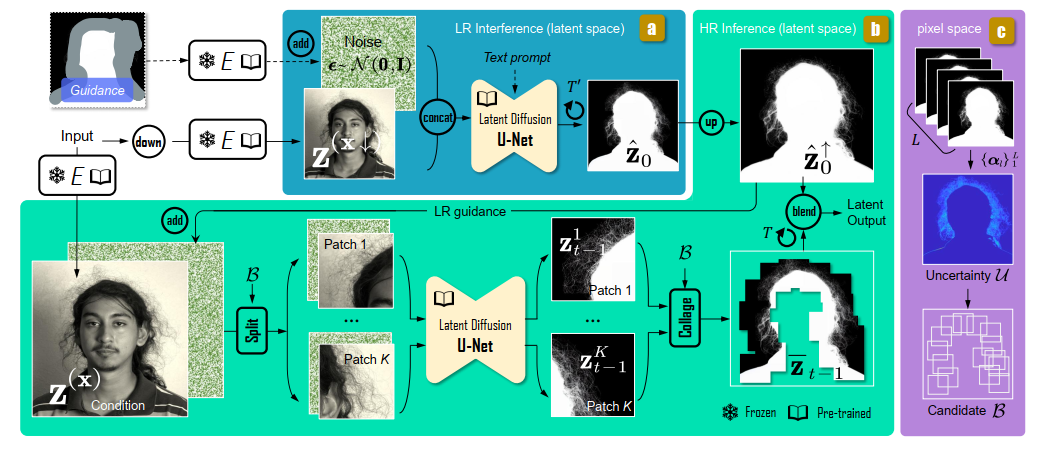
论文阅读:Matting by Generation
今天介绍一篇关于 matting 抠图的文章,抠图也算是计算机视觉里面非常经典的一个任务了。从早期的经典算法到如今的深度学习算法,已经有很多的工作和这个任务相关。这两年 diffusion 模型很火,大家又开始用 diffusion 模型做各种 CV 任务了&am…...
QT开发技术【ffmpeg + QAudioOutput】音乐播放器
一、 介绍 使用ffmpeg 4.2.2 在数字化浪潮席卷全球的当下,音视频内容犹如璀璨繁星,点亮了人们的生活与工作。从短视频平台上令人捧腹的搞笑视频,到在线课堂中知识渊博的专家授课,再到影视平台上扣人心弦的高清大片,音…...

DeepSeek越强,Kimi越慌?
被DeepSeek吊打的Kimi,还有多少人在用? 去年,月之暗面创始人杨植麟别提有多风光了。90后清华学霸,国产大模型六小虎之一,手握十几亿美金的融资。旗下的AI助手Kimi烧钱如流水,单月光是投流就花费2个亿。 疯…...