【100天精通Python】Day51:Python 数据分析_数据分析入门基础与Anaconda 环境搭建
目录
1 科学计算和数据分析概述
2. 数据收集和准备
2.1 数据收集
2.1.1 文件导入:
2.1.2 数据库连接:
2.1.3 API请求:
2.1.4 网络爬虫:
2.2 数据清洗
2.2.1 处理缺失值:
2.2.2 去除重复值:
2.2.3 数据类型转换:
2.2.4 异常值处理:
2.2.5 日期和时间处理:
2.2.6 数据格式规范化:
3. 数据分析工具
4. 数据分析过程
4.1 定义问题和目标
4.2 数据收集
4.3 数据清洗
4.4 数据探索和可视化
4.5 特征工程
4.6 建模和分析
4.7 模型评估和验证
4.8 结果解释和报告
5 数据科学工具的安装与环境设置
5.1 安装 Python
5.2 安装 Anaconda
5.3 配置虚拟环境
5.4 使用虚拟环境
1 科学计算和数据分析概述
Python 科学计算和数据分析是使用 Python 编程语言进行科学研究、数据处理和分析的领域。它们为科学家、工程师、数据分析师和研究人员提供了强大的工具和库,用于处理、分析和可视化各种数据,从而从数据中提取有价值的见解和信息。
Python 科学计算和数据分析可应用于各种领域,包括:
商业和市场分析:帮助企业做出决策,优化销售策略、市场营销和客户关系管理。
生物学和医学:用于基因组学研究、药物发现、疾病预测和医疗影像分析。
物理学和工程学:用于模拟、数据分析、实验设计和信号处理。
社会科学:用于调查研究、社会网络分析、舆情分析和心理学研究。
金融:用于风险评估、投资组合优化、量化交易和市场预测。等等,
2. 数据收集和准备
数据分析的第一步是数据的收集和准备。数据可以来自各种来源,包括实验、调查、传感器、文件、数据库和网络。在这个阶段,数据通常需要进行清洗、去重、处理缺失值和转换成适合分析的格式。
2.1 数据收集
数据收集是从不同来源获取数据的过程,这些来源可以包括数据库、文件、API、传感器、网络爬虫等。下面是一些常见的数据收集方法:
2.1.1 文件导入:
从本地文件(如CSV、Excel、文本文件)中导入数据。Python 中使用 Pandas 库可以轻松实现。
import pandas as pd# 从CSV文件导入数据
data = pd.read_csv('data.csv')
2.1.2 数据库连接:
通过数据库连接从关系型数据库中获取数据。可以使用库如 SQLAlchemy 或专用数据库库来连接数据库。
from sqlalchemy import create_engine# 创建数据库连接
engine = create_engine('sqlite:///mydatabase.db')# 查询数据库
data = pd.read_sql_query('SELECT * FROM mytable', engine)
2.1.3 API请求:
通过API请求获取数据。使用 Python 的 requests 库来发送HTTP请求并获取数据。
import requestsurl = 'https://api.example.com/data'
response = requests.get(url)
data = response.json()
2.1.4 网络爬虫:
使用爬虫工具(如 BeautifulSoup 或 Scrapy)从网页上抓取数据。
from bs4 import BeautifulSoup
import requestsurl = 'https://example.com/page'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 提取数据
2.2 数据清洗
一旦数据被收集,通常需要进行数据清洗,以确保数据质量和一致性。数据清洗的任务包括:
2.2.1 处理缺失值:
检测和处理数据中的缺失值,可以填充缺失值、删除包含缺失值的行或列。
# 填充缺失值
data['column_name'].fillna(value, inplace=True)# 删除包含缺失值的行
data.dropna(inplace=True)
2.2.2 去除重复值:
检测并删除重复的数据行。
data.drop_duplicates(inplace=True)
2.2.3 数据类型转换:
将数据转换为正确的数据类型,如将字符串转换为数字。
data['column_name'] = data['column_name'].astype(float)
2.2.4 异常值处理:
检测和处理异常值,可以根据数据的分布使用统计方法或可视化工具来识别异常值。
2.2.5 日期和时间处理:
如果数据包含日期和时间,可以解析它们并进行适当的处理。
data['date_column'] = pd.to_datetime(data['date_column'])
2.2.6 数据格式规范化:
确保数据在整个数据集中保持一致的格式。
数据收集和准备是数据分析的基础,确保你有高质量的数据可用于后续的分析和建模工作。这些步骤通常需要花费大量的时间,但它们对于获得准确、可信的分析结果至关重要。
3. 数据分析工具
Python 是一种非常强大的编程语言,具有丰富的数据分析工具和库。以下是一些常用的 Python 数据分析工具和库:
-
NumPy:NumPy(Numerical Python)是用于数值计算的基础库。它提供了多维数组对象和一组数学函数,使你能够高效地执行数值操作。
-
Pandas:Pandas 是用于数据处理和分析的库,提供了高性能、易于使用的数据结构,如 Series 和 DataFrame,以及数据操作工具。它是数据分析中的常用工具,用于数据清洗、转换、分组和聚合等任务。
-
Matplotlib:Matplotlib 是一个用于绘制各种类型的图表和图形的库。它用于数据可视化,可以创建折线图、散点图、柱状图、饼图等。
-
Seaborn:Seaborn 是建立在 Matplotlib 基础上的高级数据可视化库。它提供了更漂亮的默认样式和更简单的接口,用于创建统计图形和信息可视化。
-
Scipy:Scipy 是一个用于科学计算的库,包括了一系列高级数学、科学和工程计算的功能,如优化、插值、积分、线性代数等。
-
Scikit-Learn:Scikit-Learn 是用于机器学习和数据挖掘的库,提供了各种分类、回归、聚类、降维等算法,以及用于模型评估和选择的工具。
-
Statsmodels:Statsmodels 是用于统计建模和假设检验的库,可进行线性模型、非线性模型、时间序列分析等。
-
NLTK(Natural Language Toolkit):NLTK 是用于自然语言处理的库,提供了处理文本数据、分析语言结构和进行情感分析的工具。
-
Beautiful Soup:Beautiful Soup 是一个用于解析HTML和XML文档的库,常用于网络爬虫和数据抓取。
-
Jupyter Notebook:Jupyter Notebook 是一个交互式的计算环境,允许你在浏览器中创建和共享文档,其中可以包含代码、图形、文本和数学方程式。
-
Pillow:Pillow 是一个用于图像处理的库,用于打开、操作和保存各种图像文件。
这些工具和库可以帮助你进行各种数据分析任务,包括数据清洗、可视化、统计分析、机器学习和深度学习等。根据你的具体需求和项目,你可以选择合适的工具来完成工作。这些库的文档和社区资源丰富,可以帮助你深入学习和应用它们。
4. 数据分析过程
数据分析是一个系统性的过程,旨在从数据中提取有用的信息、洞察和模式。
数据探索:了解数据的基本特征,包括描述性统计、可视化、数据分布和相关性分析。
特征工程:选择和转换数据中的特征,以便用于建模和分析。
建模:选择适当的分析技术,例如回归、分类、聚类或时间序列分析,然后训练模型。
评估和验证:评估模型的性能,使用交叉验证、指标和图表来验证模型的准确性。
结果解释:解释分析结果,以便在业务或研究背景下做出决策。
4.1 定义问题和目标
在开始数据分析之前,首先要明确问题和分析的目标。这可以是回答一个特定的业务问题、识别市场趋势、预测销售或执行科学研究。例如,假设我们是一家电子商务公司,我们的问题是: "如何提高网站的购物车转化率?"
4.2 数据收集
一旦问题和目标明确,下一步是收集相关的数据。数据可以来自多个来源,包括数据库、文件、API、传感器等。在示例中,我们将使用一个模拟的电子商务网站数据集:
import pandas as pd# 从CSV文件导入数据
data = pd.read_csv('ecommerce_data.csv')
4.3 数据清洗
数据清洗是确保数据质量和可用性的关键步骤。它包括处理缺失值、去重、异常值处理等任务。
处理缺失值:
# 检查缺失值
missing_values = data.isnull().sum()# 填充缺失值或删除缺失值所在的行/列
data['column_name'].fillna(value, inplace=True)
data.dropna(inplace=True)
去除重复值:
# 检查和删除重复值
data.drop_duplicates(inplace=True)
4.4 数据探索和可视化
数据探索的目标是理解数据的基本特征、分布和关系。这通常涉及使用统计指标和可视化工具来分析数据。
描述性统计:
# 查看数据的基本统计信息
summary_stats = data.describe()# 计算相关系数
correlation_matrix = data.corr()
数据可视化:
import matplotlib.pyplot as plt
import seaborn as sns# 创建直方图
plt.hist(data['column_name'], bins=20)# 创建散点图
sns.scatterplot(x='column1', y='column2', data=data)
4.5 特征工程
特征工程涉及选择、构建和转换数据中的特征,以用于建模和分析。这可能包括创建新特征、编码分类变量等。
# 创建新特征
data['total_revenue'] = data['quantity'] * data['price']# 对分类变量进行独热编码
data = pd.get_dummies(data, columns=['category'])
4.6 建模和分析
在选择适当的分析技术后,可以开始建模和分析。这可能包括回归、分类、聚类、时间序列分析等。
from sklearn.linear_model import LinearRegression# 创建线性回归模型
model = LinearRegression()
model.fit(data[['feature1', 'feature2']], data['target'])
4.7 模型评估和验证
在建模后,需要评估模型的性能和准确性。这可以通过交叉验证、指标(如均方误差、准确度、召回率)和可视化来完成。
from sklearn.metrics import mean_squared_error# 用测试数据集评估模型
predictions = model.predict(test_data[['feature1', 'feature2']])
mse = mean_squared_error(test_data['target'], predictions)
4.8 结果解释和报告
最后,解释分析结果并制作报告,以便向相关利益相关者传达结果和洞察。
# 解释模型系数
coefficients = model.coef_# 制作数据分析报告
这是一个通用的数据分析过程,每个步骤都需要仔细思考和定制,以满足具体的问题和目标。数据分析是一个反复迭代的过程,通常需要多次探索、建模和验证,以逐渐提高模型的准确性和可解释性。
5 数据科学工具的安装与环境设置
5.1 安装 Python
首先,安装 Python。你可以从 Python 官方网站 下载需要版本的python安装程序。Download Python | Python.orgThe official home of the Python Programming Language![]() https://www.python.org/downloads/ 并按照官方文档中的说明进行安装。请注意,如果你已经安装了 Anaconda,通常不需要再单独安装 Python,因为 Anaconda 包含了 Python。
https://www.python.org/downloads/ 并按照官方文档中的说明进行安装。请注意,如果你已经安装了 Anaconda,通常不需要再单独安装 Python,因为 Anaconda 包含了 Python。
参考:【100天精通python】Day1:python入门_初识python,搭建python环境,运行第一个python小程序_python入门小程序_LeapMay的博客-CSDN博客
5.2 安装 Anaconda
如果你想使用 Anaconda 来管理 Python 环境和库,可以按照以下步骤安装 Anaconda:
-
访问 Anaconda 官方网站 Free Download | AnacondaAnaconda's open-source Distribution is the easiest way to perform Python/R data science and machine learning on a single machine.
 https://www.anaconda.com/download
https://www.anaconda.com/download -
下载适用你操作系统的Anaconda 发行版(通常是 Anaconda 或 Miniconda)。
-
下载后,按照官方文档中的说明运行安装程序,并在安装过程中选择 "Add Anaconda to my PATH environment variable" 选项以便能够在命令行中使用 Anaconda。
5.3 配置虚拟环境
使用 Anaconda,你可以轻松地创建和管理虚拟环境。虚拟环境可以帮助你隔离不同项目所需的库和依赖项。以下是创建虚拟环境的示例:
(1)创建一个名为 "myenv" 的虚拟环境:
conda create --name myenv
(2)激活虚拟环境:
在 Windows 上:
conda activate myenv
在 macOS 和 Linux 上:
source activate myenv
(3)安装库和依赖项(在虚拟环境中):
conda install numpy pandas matplotlib
现在,你的虚拟环境已配置并包含了 NumPy、Pandas 和 Matplotlib。
5.4 使用虚拟环境
每次你开始一个新项目时,都可以创建一个新的虚拟环境并在其中安装项目所需的库。这样可以保持项目之间的库隔离,避免版本冲突。
(1)创建项目虚拟环境
conda create --name myprojectenv
(2)激活项目虚拟环境
conda activate myprojectenv #在 Windows 上source activate myprojectenv #在 macOS 和 Linux 上
(3)在项目虚拟环境中安装项目所需的库
conda install numpy pandas matplotlib requests
也可以使用 pip 安装库:
pip install package_name
(4)在虚拟环境中运行项目
在虚拟环境中安装了所需的库后,你可以在其中运行你的项目,使用虚拟环境的 Python 解释器和库。当你完成工作后,可以退出虚拟环境。
进入项目目录:
使用终端进入你的项目目录,即包含项目文件的文件夹
cd /path/to/your/project
运行项目:
一旦进入了项目目录,你可以使用虚拟环境中的 Python 解释器来运行项目的脚本或应用程序。
python your_project_script.py
这将运行项目中的 Python 脚本,并且任何需要的依赖项都将从虚拟环境中加载。
(5)退出虚拟环境
conda deactivate # 使用 conda
这样,你可以在不同的虚拟环境中维护不同的项目,并根据需要自由切换虚拟环境。
通过上述步骤,你可以安装 Python、Anaconda、配置虚拟环境,并安装科学计算库来开始进行数据科学和数据分析的工作。在实际项目中,你还可能需要安装其他库和工具,具体取决于你的需求。安装包和库时,可以使用 Anaconda 的环境管理功能,使整个过程更加简单和可控。
相关文章:
【100天精通Python】Day51:Python 数据分析_数据分析入门基础与Anaconda 环境搭建
目录 1 科学计算和数据分析概述 2. 数据收集和准备 2.1 数据收集 2.1.1 文件导入: 2.1.2 数据库连接: 2.1.3 API请求: 2.1.4 网络爬虫: 2.2 数据清洗 2.2.1 处理缺失值: 2.2.2 去除重复值: 2.2…...

网络安全(黑客)自学路线
很多人上来就说想学习黑客,但是连方向都没搞清楚就开始学习,最终也只是会无疾而终!黑客是一个大的概念,里面包含了许多方向,不同的方向需要学习的内容也不一样。 算上从学校开始学习,已经在网安这条路上走…...
HTML5
写在前面 一、简单认识HTML 1.1 什么是网页【2023/08/31】 网站是指因特网上根据一定的规则,使用HTML等制作的用于展示特定内容相关的网页集合。 网页是网站中的一“页”,通常是HTML格式的文件,它要通过浏览器来阅读。 网页是构成网站的…...

Vue+Element-ui实现表格本地导入
表格文件存储在前端 如图,表格文件template.xlsx存储在public下的static文件夹下 注意这里的路径容易报错 a链接下载文件失败的问题(未发现文件) a.href ‘./static/template.xlsx’ 写的时候不能带public,直接这么写就可以 DownloadTemp…...

Golang参数输入
Golang参数输入 1.命令行参数(os.Args) package mainimport ("fmt""os""strconv" )func main() {for i, num : range os.Args[1:] {fmt.Println("参数"strconv.Itoa(i)": ", num)} } //输入&#x…...

2023年8月第4周大模型荟萃
2023年8月第4周大模型荟萃 2023.8.31版权声明:本文为博主chszs的原创文章,未经博主允许不得转载。 1、美国法官最新裁定:纯AI生成的艺术作品不受版权保护 美国华盛顿一家法院近日裁定,根据美国政府的法律,在没有任何…...

Kafka监控工具,LinkedIn详解
Kafka监控工具包括以下几种: Kafka Manager:这是一个开源的Kafka集群管理工具,可以监控Kafka集群的健康和性能,并提供可视化的用户界面。 Kafka Monitor:这是LinkedIn开发的一个监控工具,可以监控Kafka集群…...

如何处理 Flink 作业频繁重启问题?
分析&回答 Flink 实现了多种重启策略 固定延迟重启策略(Fixed Delay Restart Strategy)故障率重启策略(Failure Rate Restart Strategy)没有重启策略(No Restart Strategy)Fallback重启策略ÿ…...
Windows 安装 RabbitMq
Windows 上安装 RabbitMQ 的步骤 RabbitMQ 是一个强大的开源消息队列系统,广泛用于构建分布式、可扩展的应用程序。本教程将带您一步一步完成在 Windows 系统上安装 RabbitMQ 的过程。无需担心,即使您是初学者,也能够轻松跟随这些简单的步骤…...
Mybatis的关系关联配置
前言 MyBatis是一个流行的Java持久化框架,它提供了一种简单而强大的方式来映射Java对象和关系数据库之间的数据。在MyBatis中,关系关联配置是一种用于定义对象之间关系的方式,它允许我们在查询数据库时同时获取相关联的对象。 在MyBatis中&…...
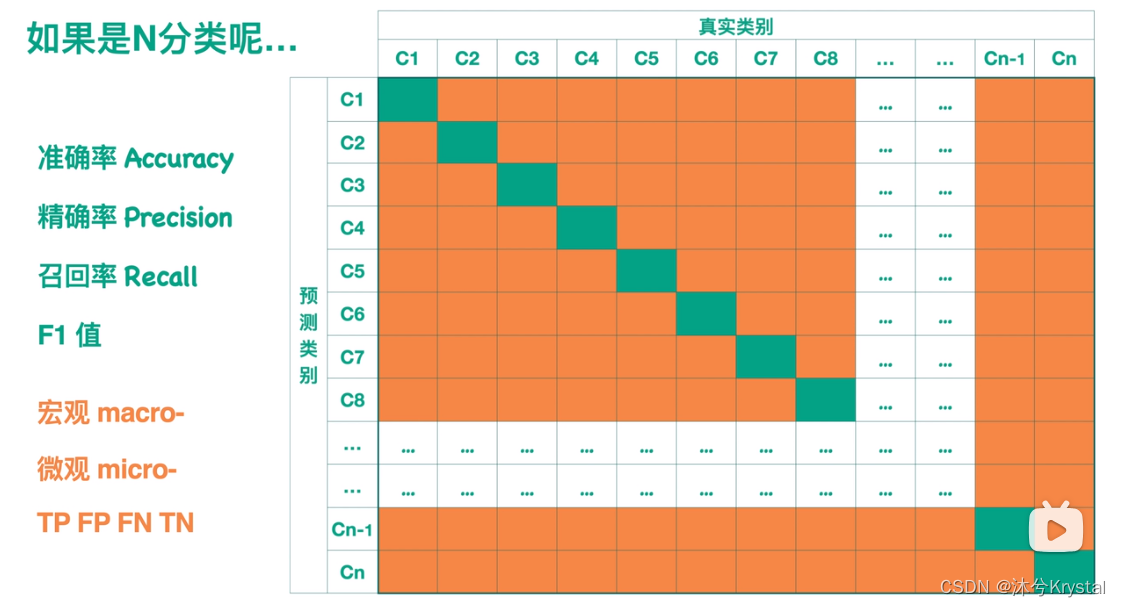
【知识积累】准确率,精确率,召回率,F1值
二分类的混淆矩阵(预测图片是否是汉堡) 分类器到底分对了多少? 预测的图片中正确的有多少? 有多少张应该预测为是的图片没有找到? 精确率和召回率在某种情况下会呈现此消彼长的状况。举个极端的例子…...

什么是分布式系统?
分布式系统是由多个独立的计算机或计算节点组成的系统,这些节点通过消息传递或共享数据的方式进行协调和通信,以实现共同的目标。分布式系统的设计目标是提高系统的可靠性、可扩展性、性能和容错性。 在一个分布式系统中,各个计算机节点之间…...

[AGC043D] Merge Triplets
题目传送门 引 很有意思的计数题 解法 考虑经过操作后得到的排列的性质 性质1: 设 p r e ( i ) pre(i) pre(i):前i个位置的最大值,则不会出现超过3个的连续位置的 p r e pre pre相同 必要性: 考虑反证,若有超过 3 3 3个的连续…...

2023年人工智能开源项目前20名
推荐:使用 NSDT场景编辑器快速搭建3D应用场景 1. Tensorflow 2. Hugging Face Transformers 3. Opencv 4. Pytorch 5. Keras 6. Stable Diffusion 7. Deepfacelab 8. Detectron2 9. Apache Mxnet 10. Fastai 11. Open Assistant 12. Mindsdb 13. Dall E…...

ThinkPHP 集成 jwt 技术 token 验证
ThinkPHP 集成 jwt 技术 token 验证 一、思路流程二、安装 firebase/php-jwt三、封装token类四、创建中间件,检验Token校验时效性五、配置路由中间件六、写几个测试方法,通过postman去验证 一、思路流程 客户端使用用户名和密码请求登录服务端收到请求&…...
gerrit 如何提交进行review
前言 本文主要介绍如何使用gerrit进行review。 下述所有流程都是参考: https://gerrit-review.googlesource.com/Documentation/intro-gerrit-walkthrough.html 先给一个commit后但是还没有push上去的一个办法: git reset --hard HEAD^可以多次reset.…...

罗勇军 →《算法竞赛·快冲300题》每日一题:“游泳” ← DFS+剪枝
【题目来源】http://oj.ecustacm.cn/problem.php?id1753http://oj.ecustacm.cn/viewnews.php?id1023【题目描述】 游泳池可以等分为n行n列的小区域,每个区域的温度不同。 小明现在在要从游泳池的左上角(1, 1)游到右下角(n, n),小明只能向上下左右四个方…...

【教程】PyTorch Timer计时器
转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn] OpenCV的Timer计时器可以看这篇:Python Timer和TimerFPS计时工具类 Timer作用说明:统计某一段代码的运行耗时。 直接上代码,开箱即用。 import time import torch import os …...
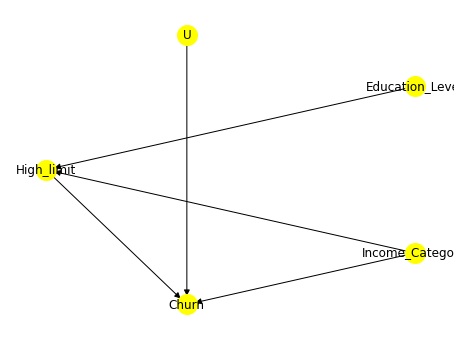
因果推断(六)基于微软框架dowhy的因果推断
因果推断(六)基于微软框架dowhy的因果推断 DoWhy 基于因果推断的两大框架构建:「图模型」与「潜在结果模型」。具体来说,其使用基于图的准则与 do-积分来对假设进行建模并识别出非参数化的因果效应;而在估计阶段则主要…...

探索隧道ip如何助力爬虫应用
在数据驱动的世界中,网络爬虫已成为获取大量信息的重要工具。然而,爬虫在抓取数据时可能会遇到一些挑战,如IP封禁、访问限制等。隧道ip(TunnelingProxy)作为一种强大的解决方案,可以帮助爬虫应用更高效地获…...
详解)
后进先出(LIFO)详解
LIFO 是 Last In, First Out 的缩写,中文译为后进先出。这是一种数据结构的工作原则,类似于一摞盘子或一叠书本: 最后放进去的元素最先出来 -想象往筒状容器里放盘子: (1)你放进的最后一个盘子(…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

回溯算法学习
一、电话号码的字母组合 import java.util.ArrayList; import java.util.List;import javax.management.loading.PrivateClassLoader;public class letterCombinations {private static final String[] KEYPAD {"", //0"", //1"abc", //2"…...
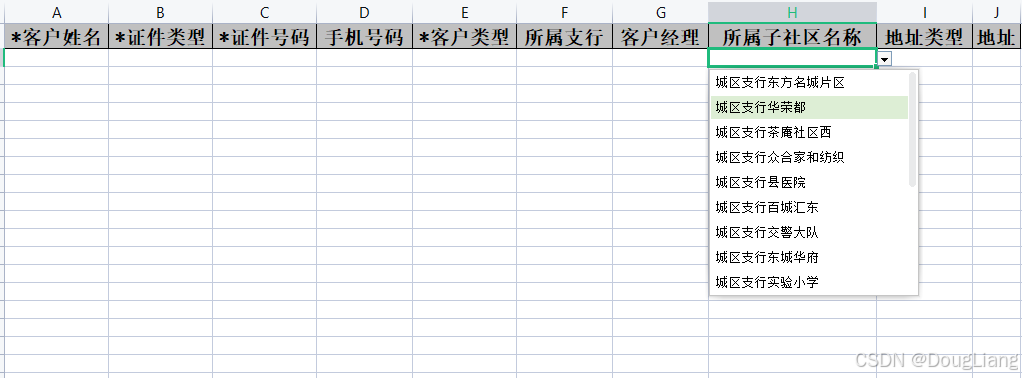
关于easyexcel动态下拉选问题处理
前些日子突然碰到一个问题,说是客户的导入文件模版想支持部分导入内容的下拉选,于是我就找了easyexcel官网寻找解决方案,并没有找到合适的方案,没办法只能自己动手并分享出来,针对Java生成Excel下拉菜单时因选项过多导…...

【Veristand】Veristand环境安装教程-Linux RT / Windows
首先声明,此教程是针对Simulink编译模型并导入Veristand中编写的,同时需要注意的是老用户编译可能用的是Veristand Model Framework,那个是历史版本,且NI不会再维护,新版本编译支持为VeriStand Model Generation Suppo…...

Vue 3 + WebSocket 实战:公司通知实时推送功能详解
📢 Vue 3 WebSocket 实战:公司通知实时推送功能详解 📌 收藏 点赞 关注,项目中要用到推送功能时就不怕找不到了! 实时通知是企业系统中常见的功能,比如:管理员发布通知后,所有用户…...