【python爬虫】14.Scrapy框架讲解
文章目录
- 前言
- Scrapy是什么
- Scrapy的结构
- Scrapy的工作原理
- Scrapy的用法
- 明确目标与分析过程
- 代码实现——创建项目
- 代码实现——编辑爬虫
- 代码实现——定义数据
- 代码实操——设置
- 代码实操——运行
- 复习
前言
前两关,我们学习了能提升爬虫速度的进阶知识——协程,并且通过项目实操,将协程运用于抓取薄荷网的食物数据。
可能你在体验开发一个爬虫项目的完整流程时,会有这样的感觉:原来要完成一个完整的爬虫程序需要做这么多琐碎的工作。
比如,要导入不同功能的模块,还要编写各种爬取流程的代码。而且根据不同的项目,每次要编写的代码也不同。
不知道你会不会有这样的想法:能不能有一个现成的爬虫模板,让我们拿来就能套用,就像PPT模板一样。我们不需要管爬虫的全部流程,只要负责填充好爬虫的核心逻辑代码就好。要是有的话,我们编写代码一定会很方便省事。
其实,在Python中还真的存在这样的爬虫模板,只不过它的名字是叫框架。
一个爬虫框架里包含了能实现爬虫整个流程的各种模块,就像PPT模板一开始就帮你设置好了主题颜色和排版方式一样。
这一关,我们要学习的就是一个功能强大的爬虫框架——Scrapy。
Scrapy是什么
以前我们写爬虫,要导入和操作不同的模块,比如requests模块、gevent库、csv模块等。而在Scrapy里,你不需要这么做,因为很多爬虫需要涉及的功能,比如麻烦的异步,在Scrapy框架都自动实现了。
我们之前编写爬虫的方式,相当于在一个个地在拼零件,拼成一辆能跑的车。而Scrapy框架则是已经造好的、现成的车,我们只要踩下它的油门,它就能跑起来。这样便节省了我们开发项目的时间。
下面,我们来了解Scrapy的基础知识,包括Scrapy的结构及其工作原理。
Scrapy的结构
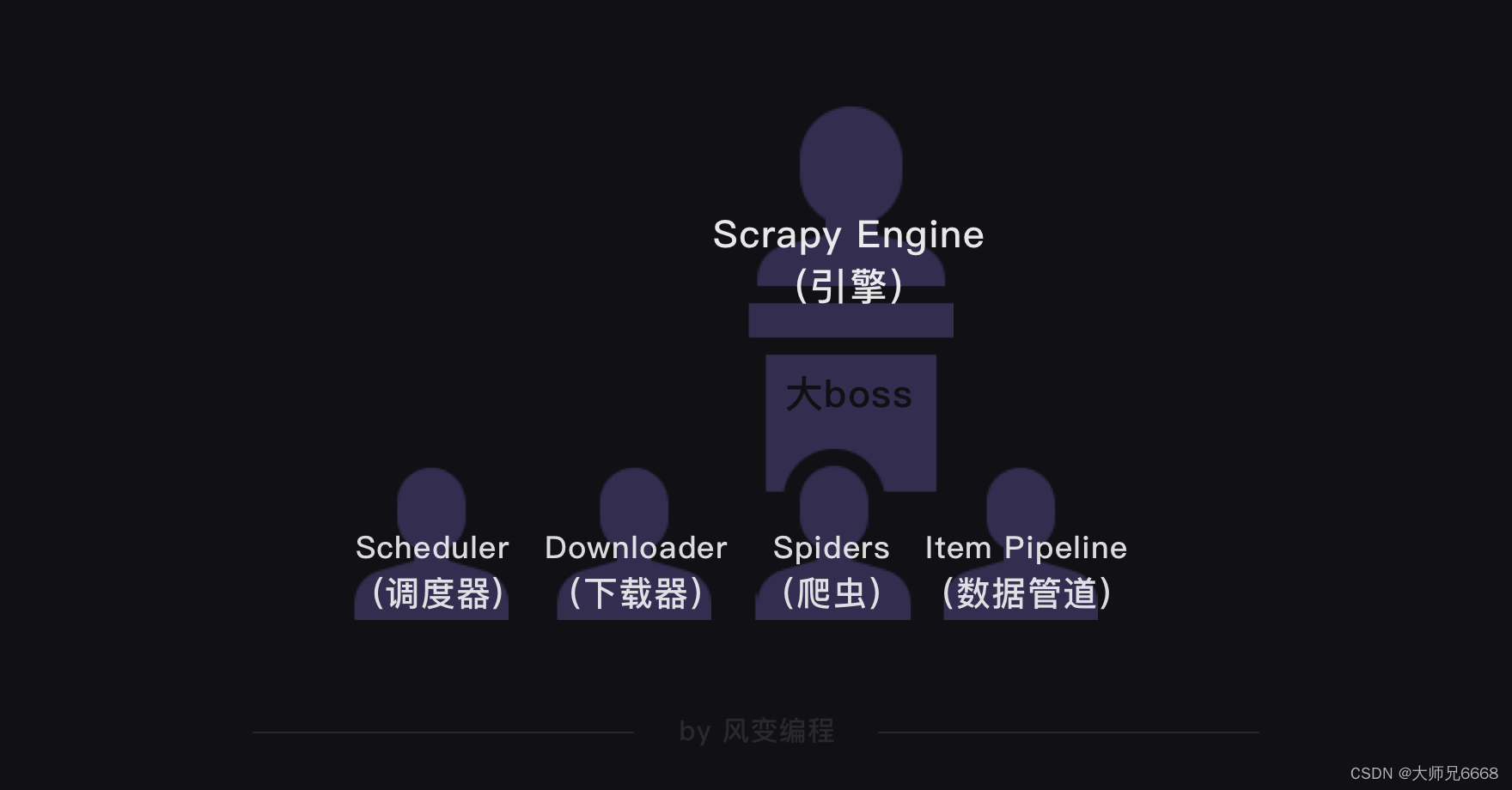
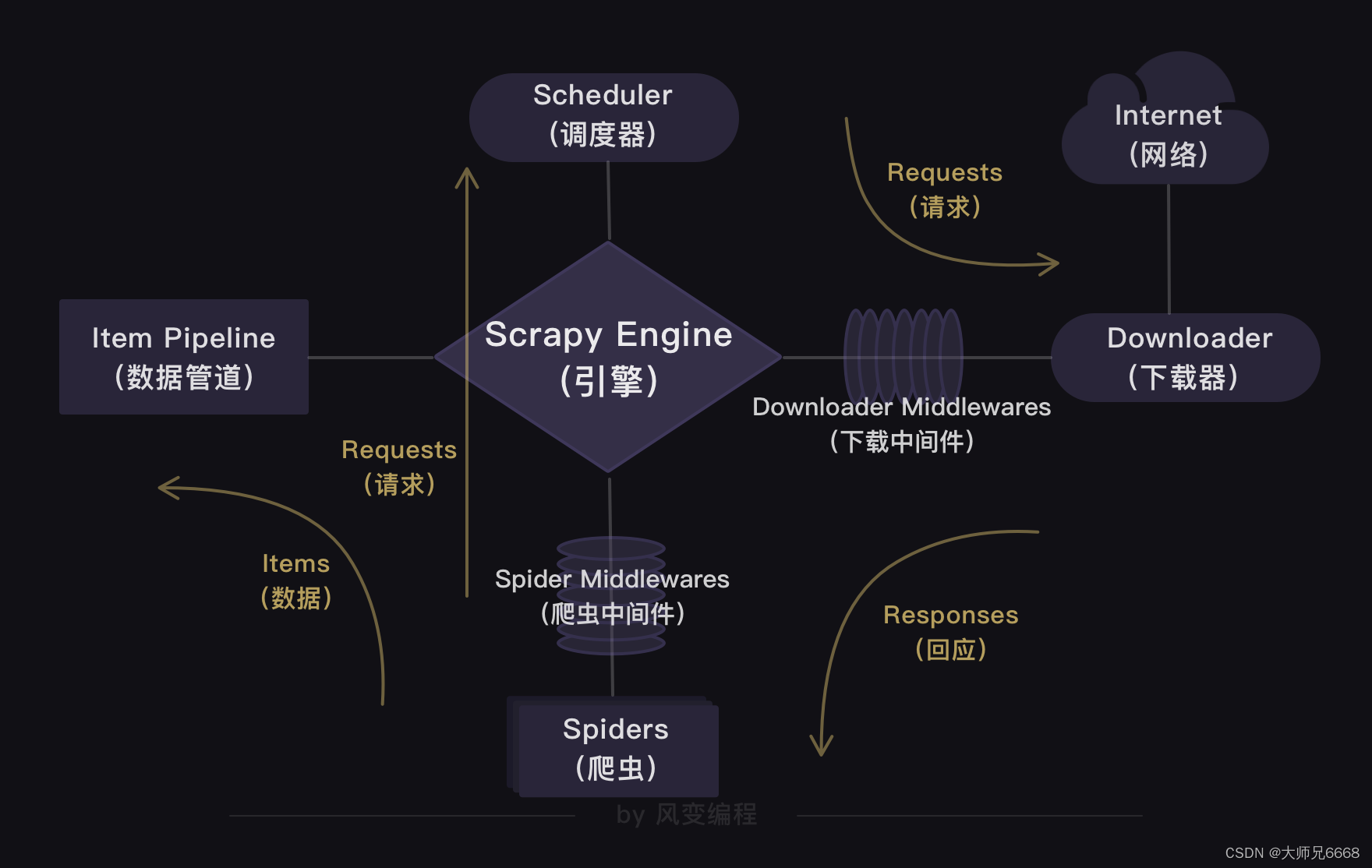
上面的这张图是Scrapy的整个结构。你可以把整个Scrapy框架看成是一家爬虫公司。最中心位置的Scrapy Engine(引擎)就是这家爬虫公司的大boss,负责统筹公司的4大部门,每个部门都只听从它的命令,并只向它汇报工作。
我会以爬虫流程的顺序来依次跟你介绍Scrapy爬虫公司的4大部门。
Scheduler(调度器)部门主要负责处理引擎发送过来的requests对象(即网页请求的相关信息集合,包括params,data,cookies,request headers…等),会把请求的url以有序的方式排列成队,并等待引擎来提取(功能上类似于gevent库的queue模块)。
Downloader(下载器)部门则是负责处理引擎发送过来的requests,进行网页爬取,并将返回的response(爬取到的内容)交给引擎。它对应的是爬虫流程【获取数据】这一步。
Spiders(爬虫)部门是公司的核心业务部门,主要任务是创建requests对象和接受引擎发送过来的response(Downloader部门爬取到的内容),从中解析并提取出有用的数据。它对应的是爬虫流程【解析数据】和【提取数据】这两步。
Item Pipeline(数据管道)部门则是公司的数据部门,只负责存储和处理Spiders部门提取到的有用数据。这个对应的是爬虫流程【存储数据】这一步。
Downloader Middlewares(下载中间件)的工作相当于下载器部门的秘书,比如会提前对引擎大boss发送的诸多requests做出处理。
Spider Middlewares(爬虫中间件)的工作则相当于爬虫部门的秘书,比如会提前接收并处理引擎大boss发送来的response,过滤掉一些重复无用的东西。
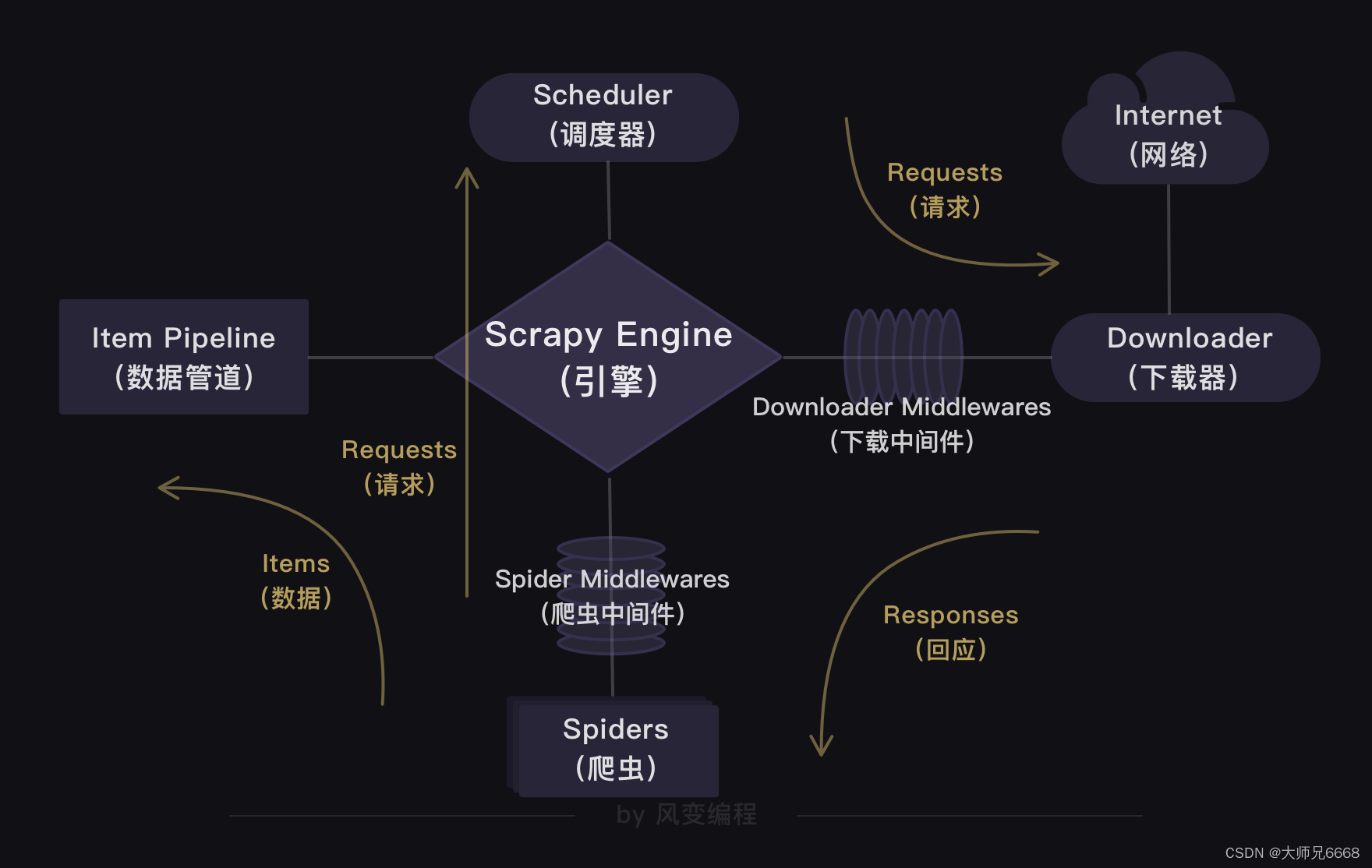
Scrapy的工作原理
你会发现,在Scrapy爬虫公司里,每个部门都各司其职,形成了很高效的运行流程。
这套运行流程的逻辑很简单,就是:引擎大boss说的话就是最高需求。
上图展现出的也是Scrapy框架的工作原理——引擎是中心,其他组成部分由引擎调度。
在Scrapy里,整个爬虫程序的流程都不需要我们去操心,且Scrapy中的程序全部都是异步模式,所有的请求或返回的响应都由引擎自动分配去处理。
哪怕有某个请求出现异常,程序也会做异常处理,跳过报错的请求,继续往下运行程序。
在一定程度上,Scrapy可以说是非常让人省心的一套爬虫框架。
Scrapy的用法
现在,你已经初步了解Scrapy的结构以及工作原理。接下来,为了让你熟悉Scrapy的用法,我们使用它来完成一个小项目——爬取豆瓣Top250图书。
明确目标与分析过程
依旧是遵循写代码的三个步骤:明确目标、分析过程、代码实现来完成项目。我会在代码实现的步骤重点讲解Scrapy的用法。
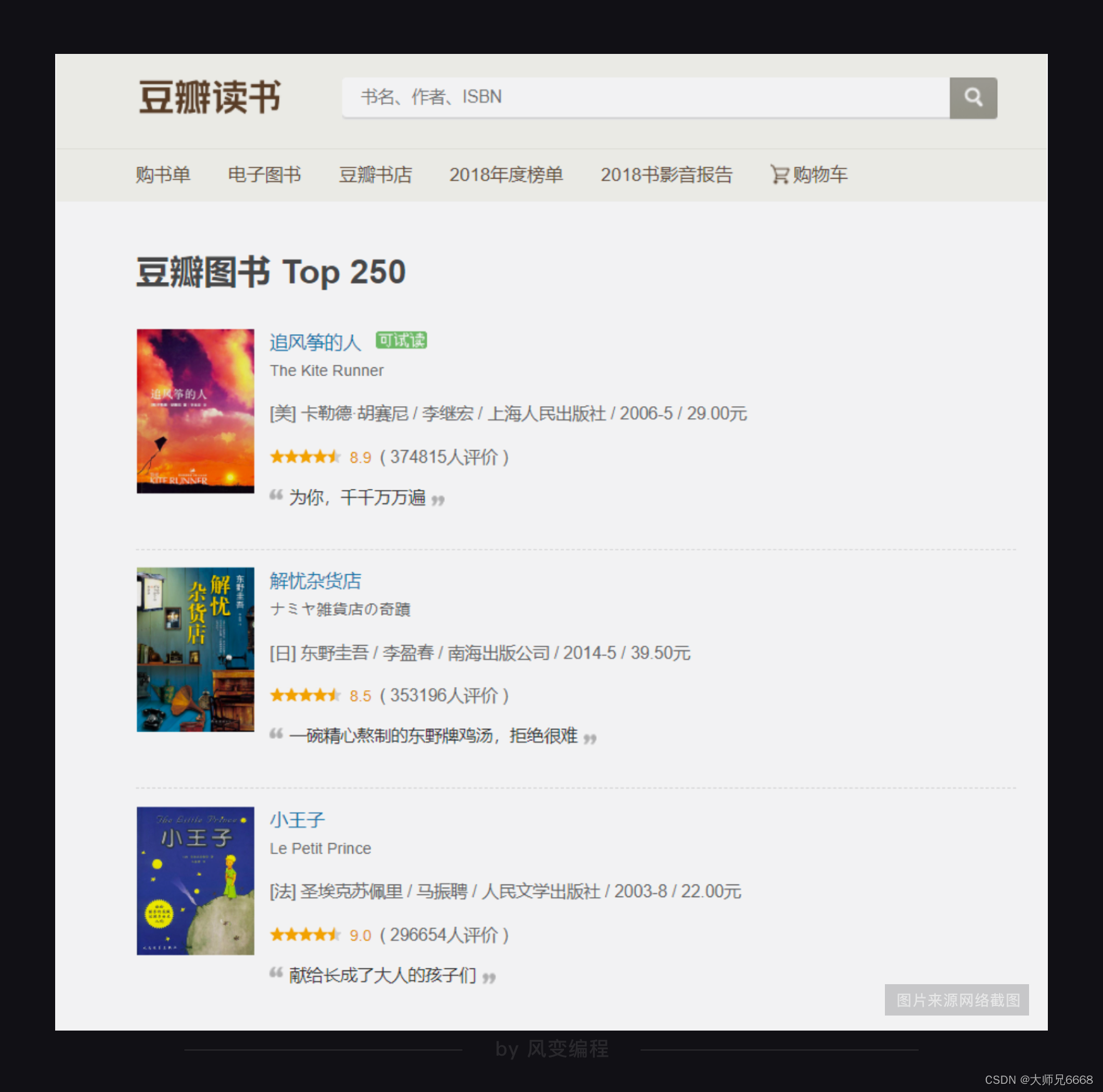
首先,要明确目标。请你务必打开以下豆瓣Top250图书的链接。
https://book.douban.com/top250
豆瓣Top250图书一共有10页,每页有25本书籍。我们的目标是:先只爬取前三页书籍的信息,也就是爬取前75本书籍的信息(包含书名、出版信息和书籍评分)。
接着,我们来分析网页。既然我们要爬取书籍信息,我们就得先判断这些信息被存在了哪里。
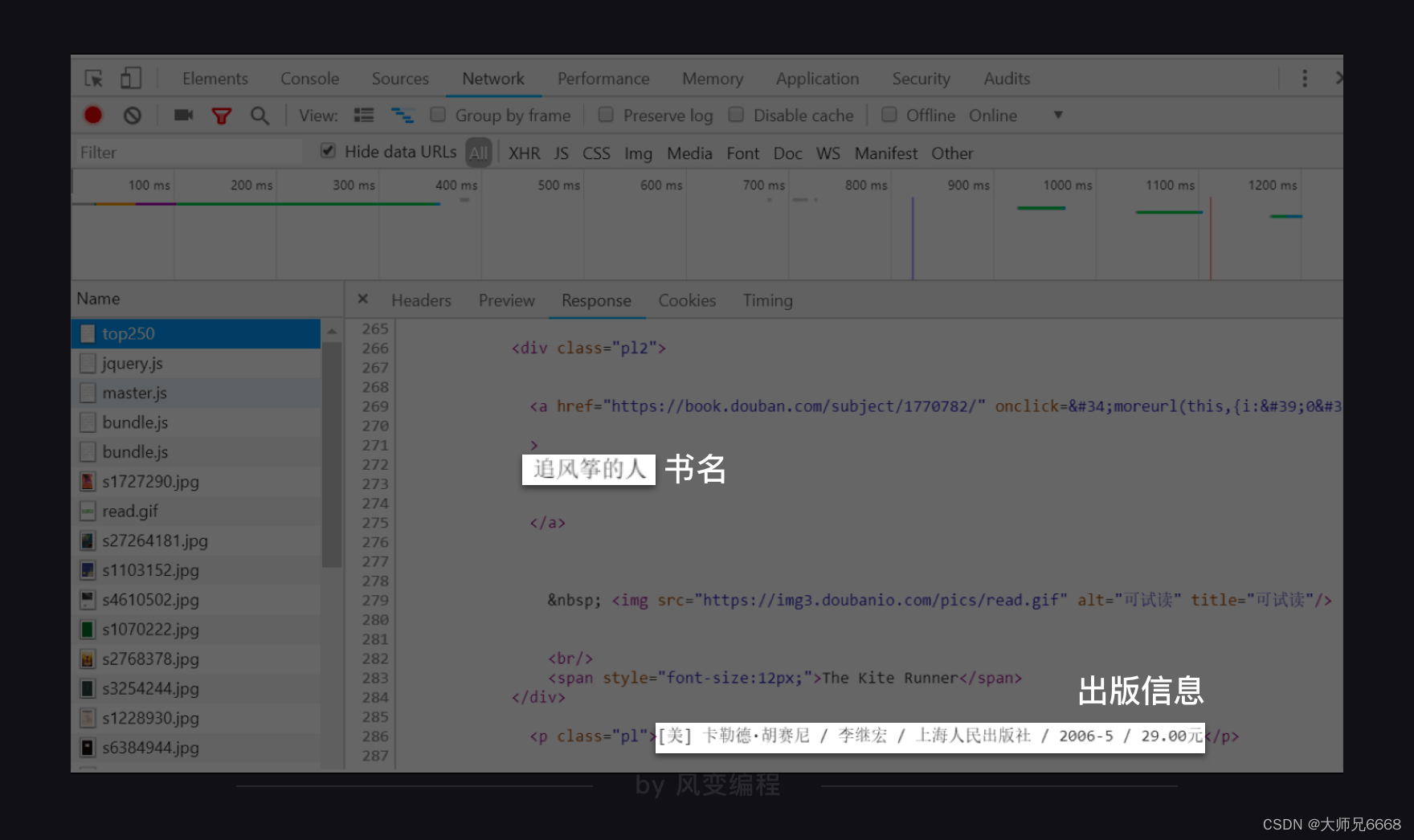
判断的方法你应该了然于胸。赶紧右击打开“检查”工具,点开Network,刷新页面,然后点击第0个请求top250,看Response.
我们能在里面翻找到书名、出版信息,说明我们想要的书籍信息就藏在这个网址的HTML里。
确定书籍信息有存在这个网址的HTML后,我们就来具体观察一下这个网站。
你点击翻到豆瓣Top250图书的第2页。
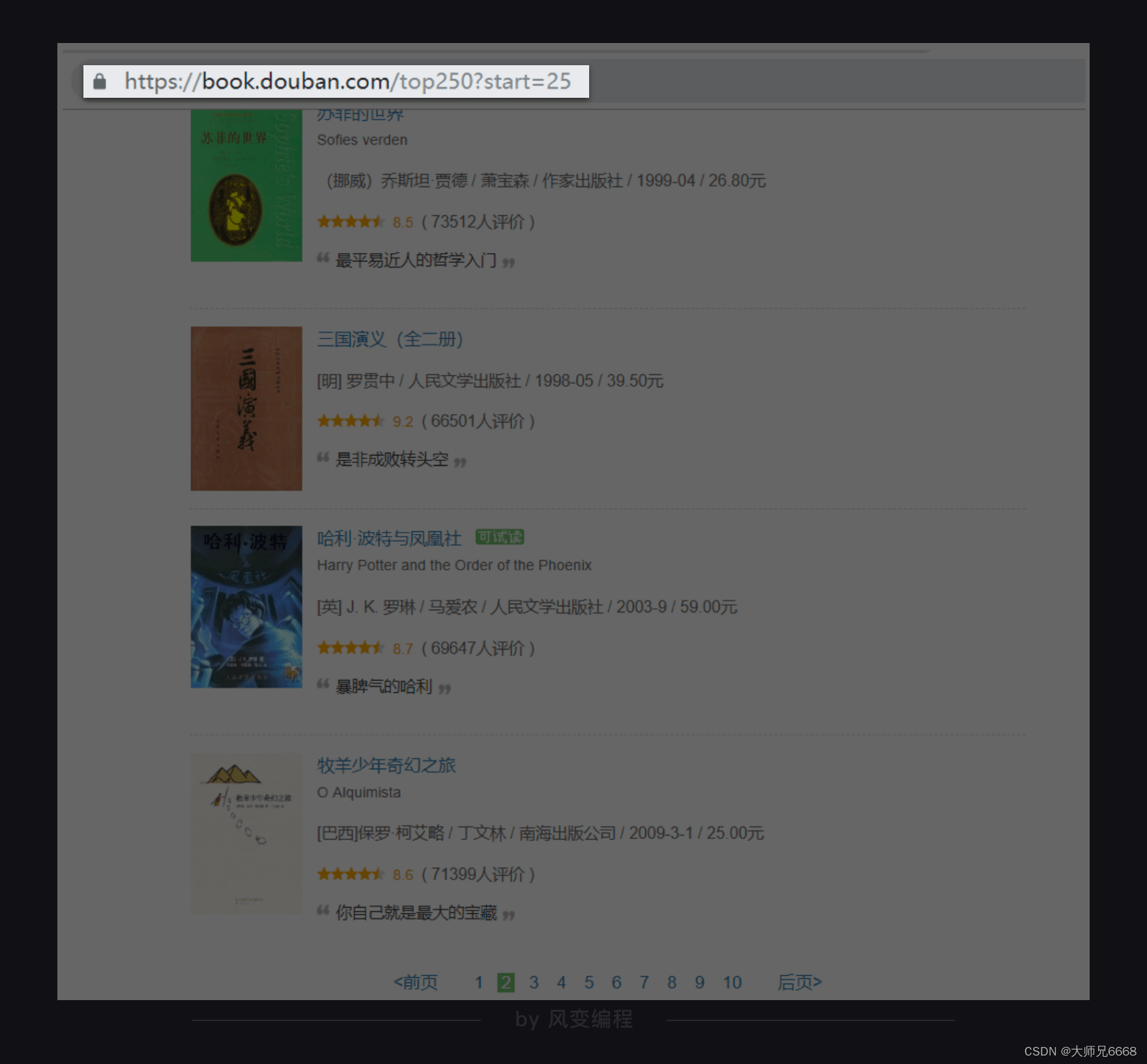
你会观察到,网址发生了变化,后面多了?start=25。我们猜想,后面的数字是代表一页的25本书籍。
你可以翻到第3页,验证一下我们的猜想是不是正确的。
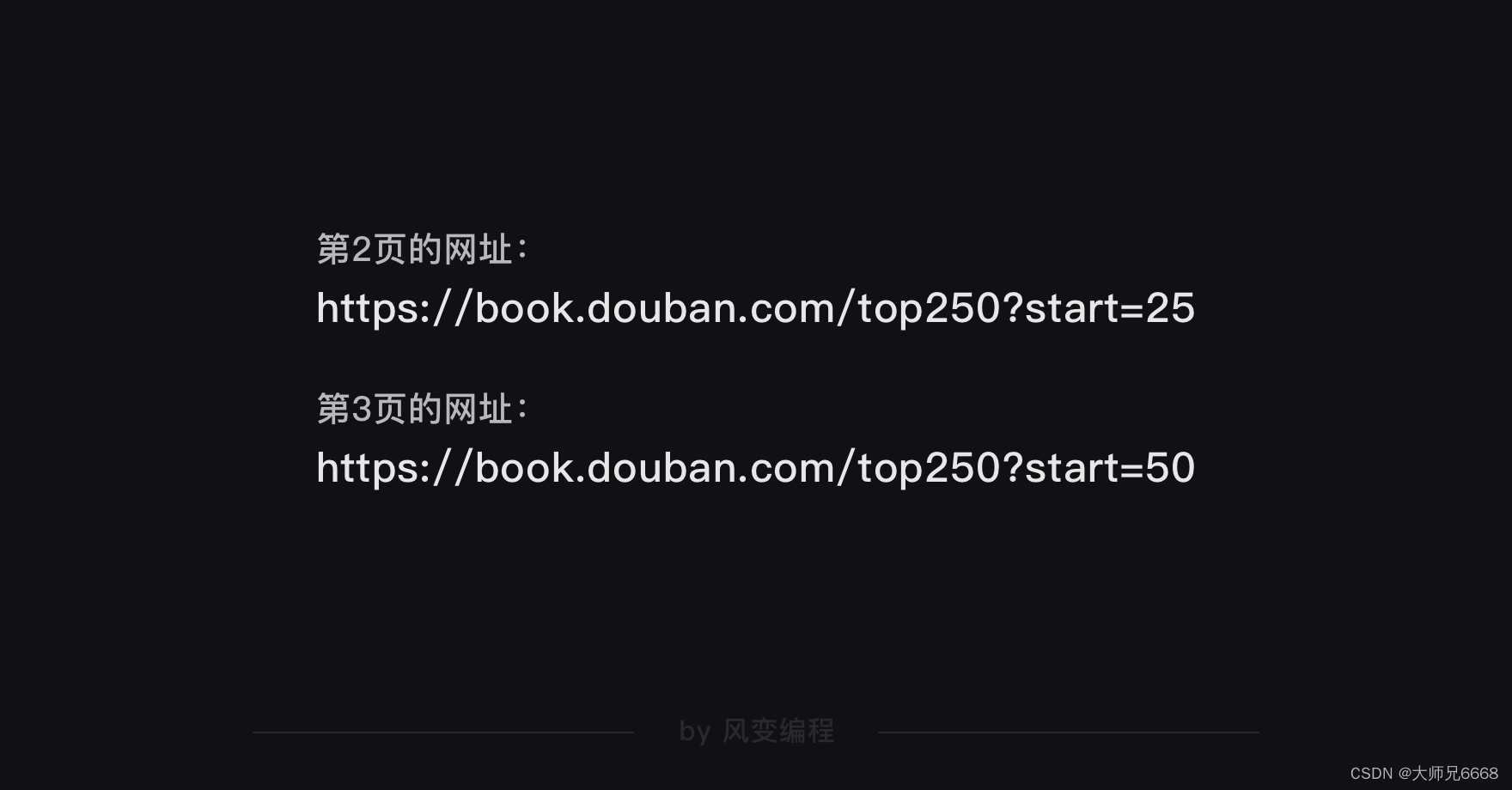
事实证明,我们猜对了。每翻一页,网址后面的数字都会增加25,说明这个start的参数就是代表每页的25本书籍。
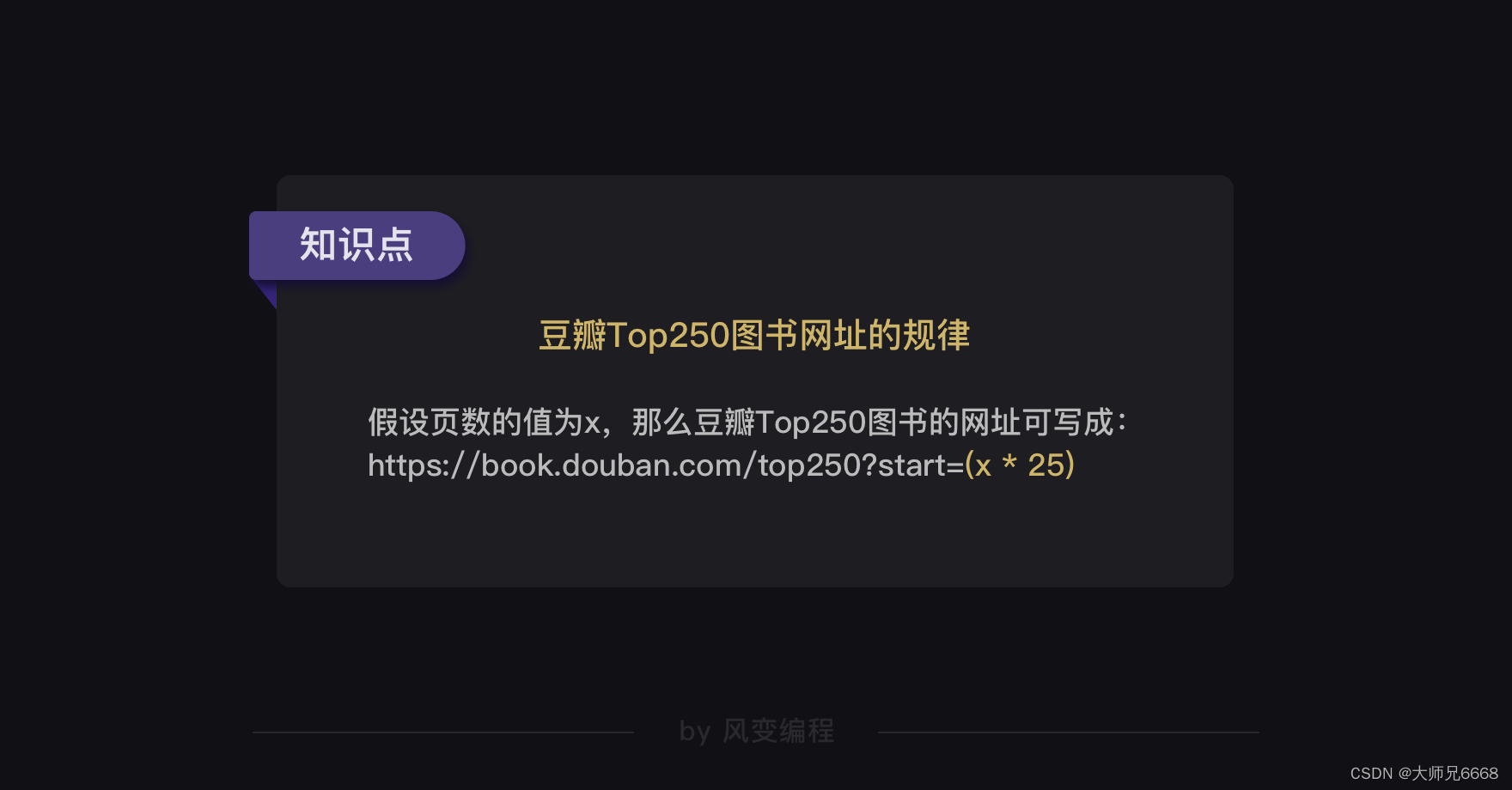
这么一观察,我们要爬取的网址的构造规律就出来了。只要改变?start=后面的数字(翻一页加25),我们就能得到每一页的网址。
找到了网址的构造规律,我们可以重点来分析HTML的结构,看看等下怎么才能提取出我们想要的书籍信息。
仍旧是右击打开“检查”工具,点击Elements,再点击光标,把鼠标依次移到书名、出版信息、评分处,就能在HTML里找到这些书籍信息。如下图,《追风筝的人》的书籍信息就全部放在<table width="100%">标签里。
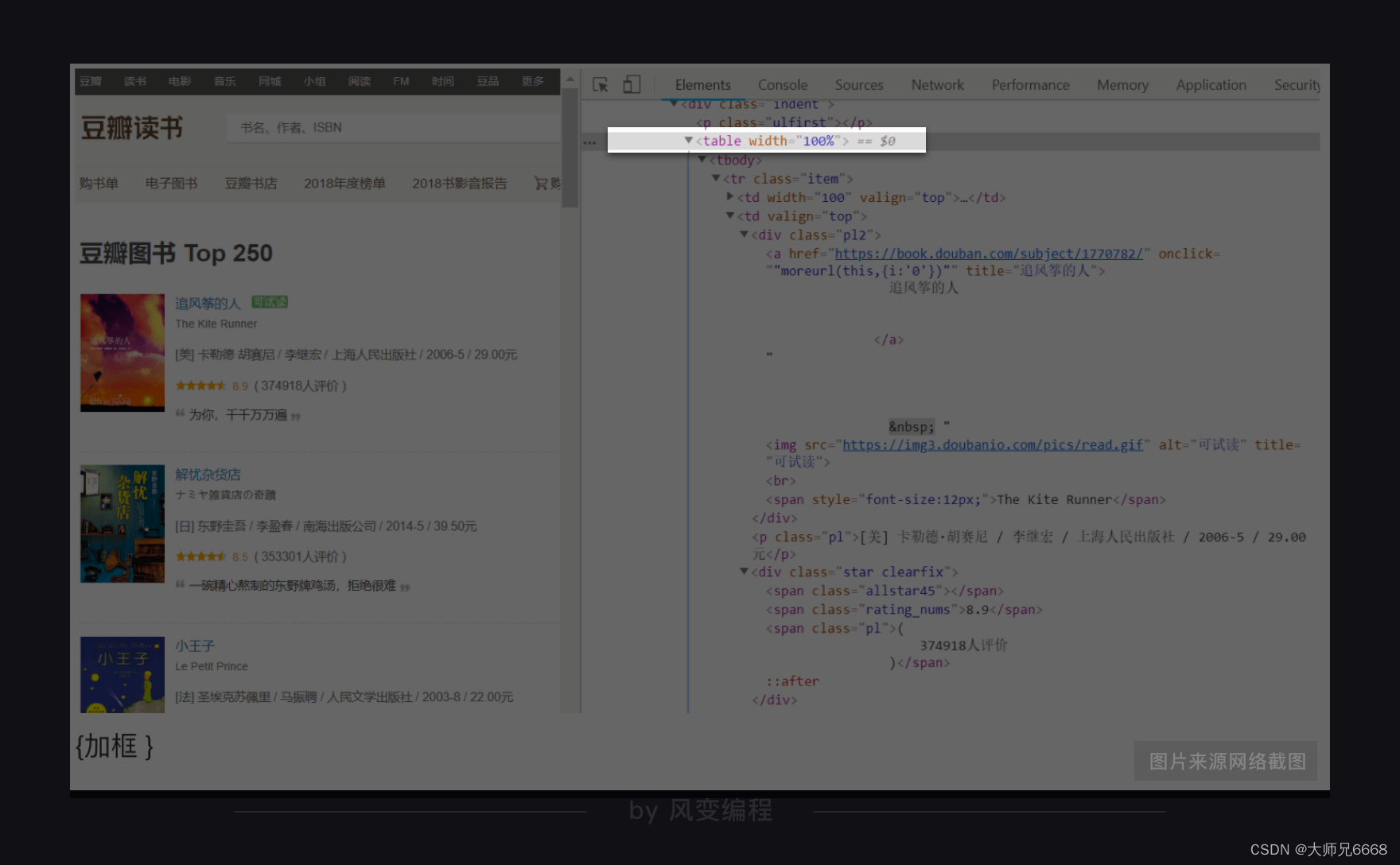
很快,你就会发现,其实每一页的25本书籍信息都分别藏在了一个<table width="100%">标签里。不过这个标签没有class属性,也没有id属性,不方便我们提取信息。
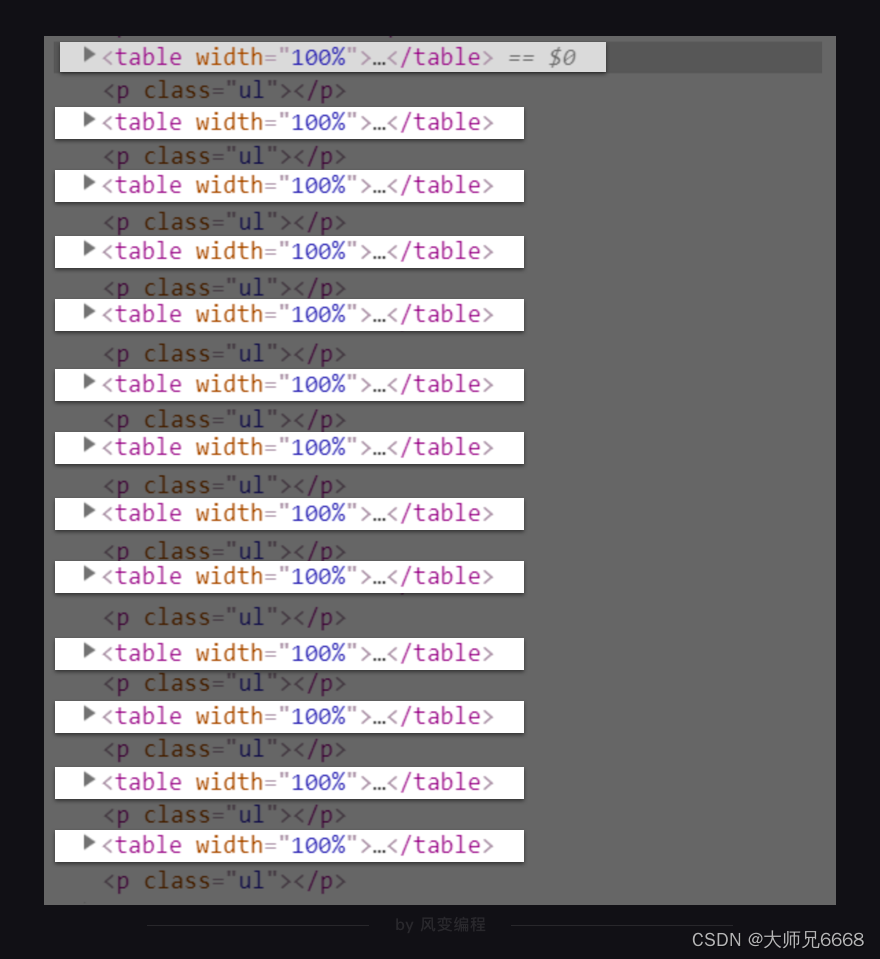
我们得再找一个既方便我们提取,又能包含所有书籍信息的标签。
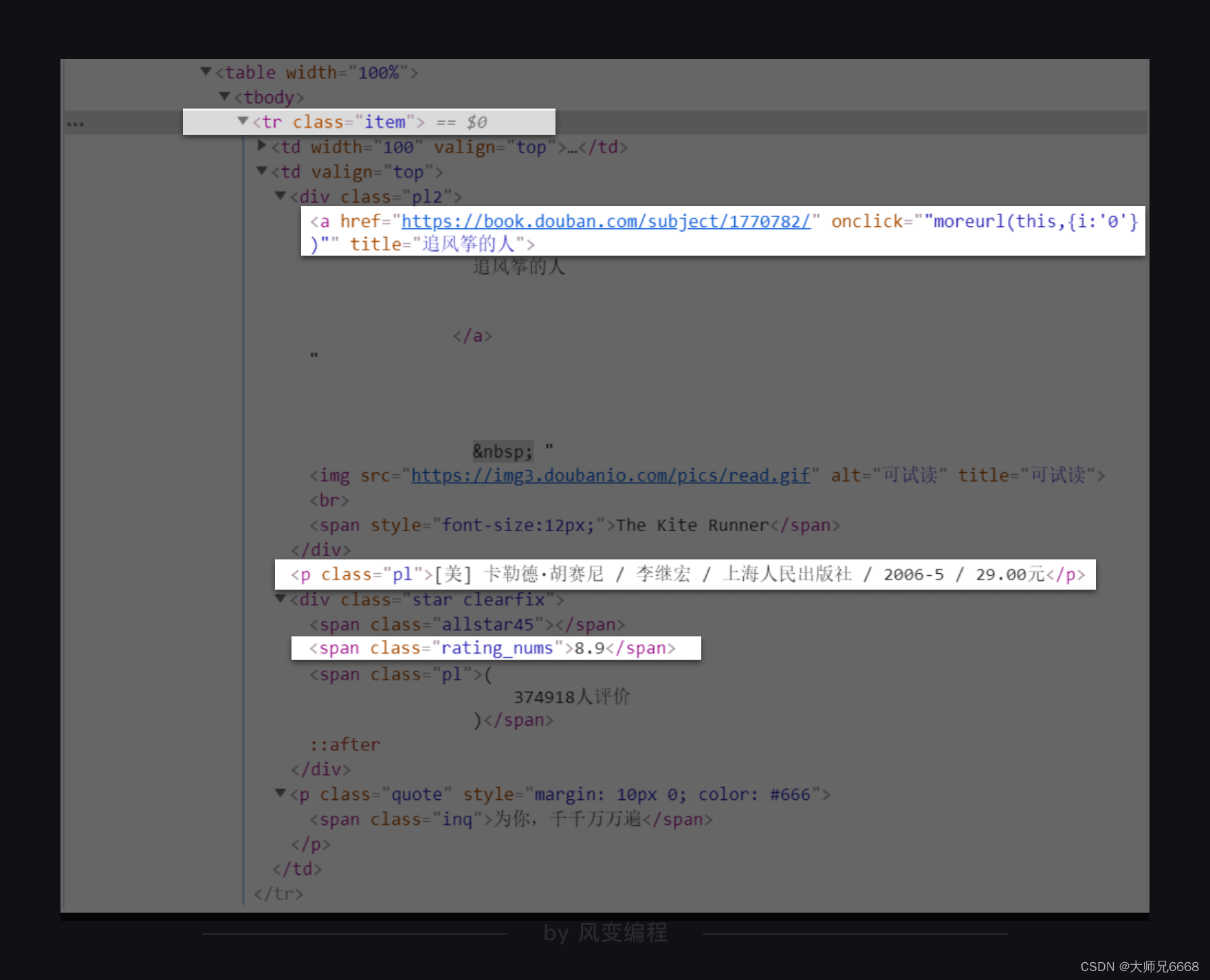
在<table width="100%">标签下的<tr class="item">元素刚好都能满足我们的要求,既有class属性,又包含了书籍的信息。
我们只要取出<tr class="item">元素下<a>元素的title属性的值、<p class="pl">元素、<span class="rating_nums">元素,就能得到书名、出版信息和评分的数据。
页面分析完毕,接着进入代码实现的步骤。
代码实现——创建项目
从这里开始,我会带你使用Scrapy编写我们的项目爬虫。其中会涉及到很多Scrapy的用法,请你一定要认真地看!
如果你想在自己本地的电脑使用Scrapy,需要提前安装好它。(安装方法:Windows:在终端输入命令:pip install scrapy;mac:在终端输入命令:pip3 install scrapy,按下enter键)
首先,要在本地电脑打开终端(windows:Win+R,输入cmd;mac:command+空格,搜索“终端”),然后跳转到你想要保存项目的目录下。
假设你想跳转到E盘里名为Python文件夹中的Pythoncode子文件夹。你需要再命令行输入e:,就会跳转到e盘,再输入cd Python,就能跳转到Python文件夹。接着输入cd Pythoncode,就能跳转到Python文件夹里的Pythoncode子文件夹。
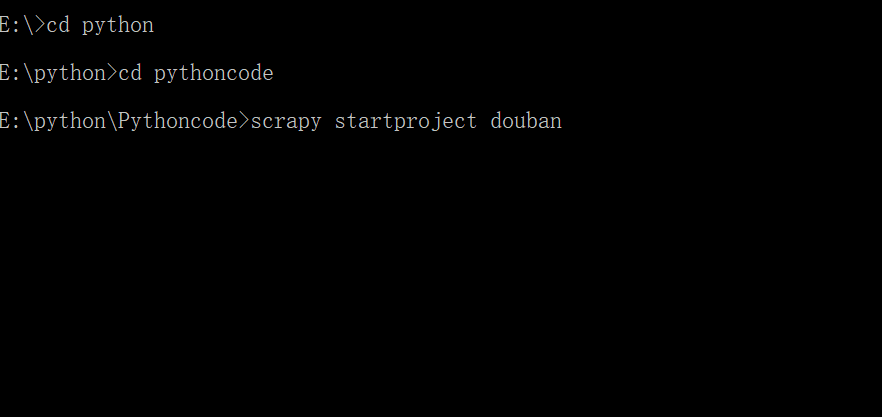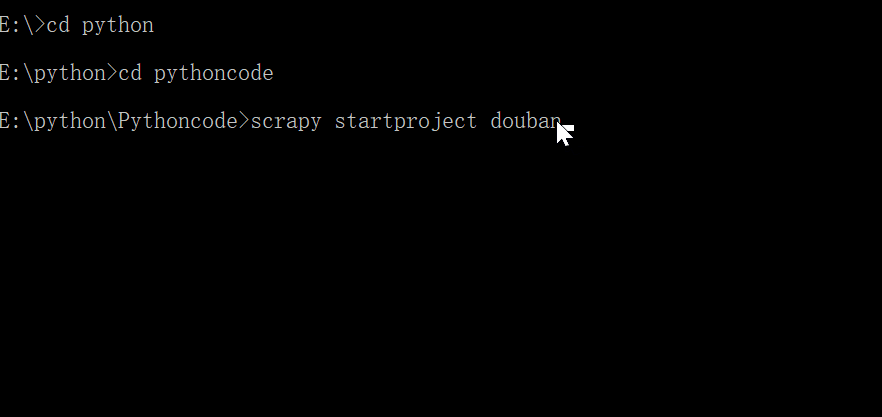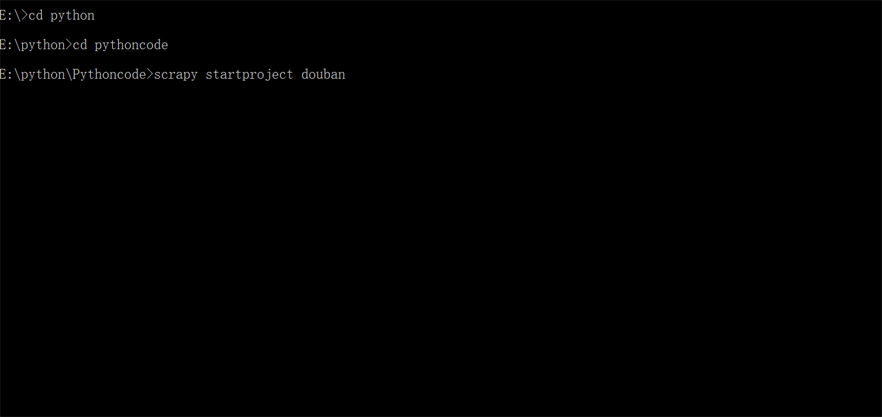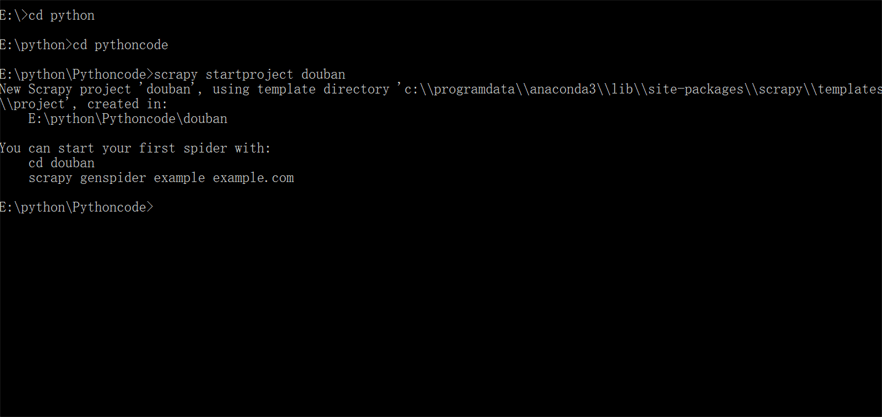
然后,再输入一行能帮我们创建Scrapy项目的命令:scrapy startproject douban,douban就是Scrapy项目的名字。按下enter键,一个Scrapy项目就创建成功了。
整个scrapy项目的结构,如下图所示:
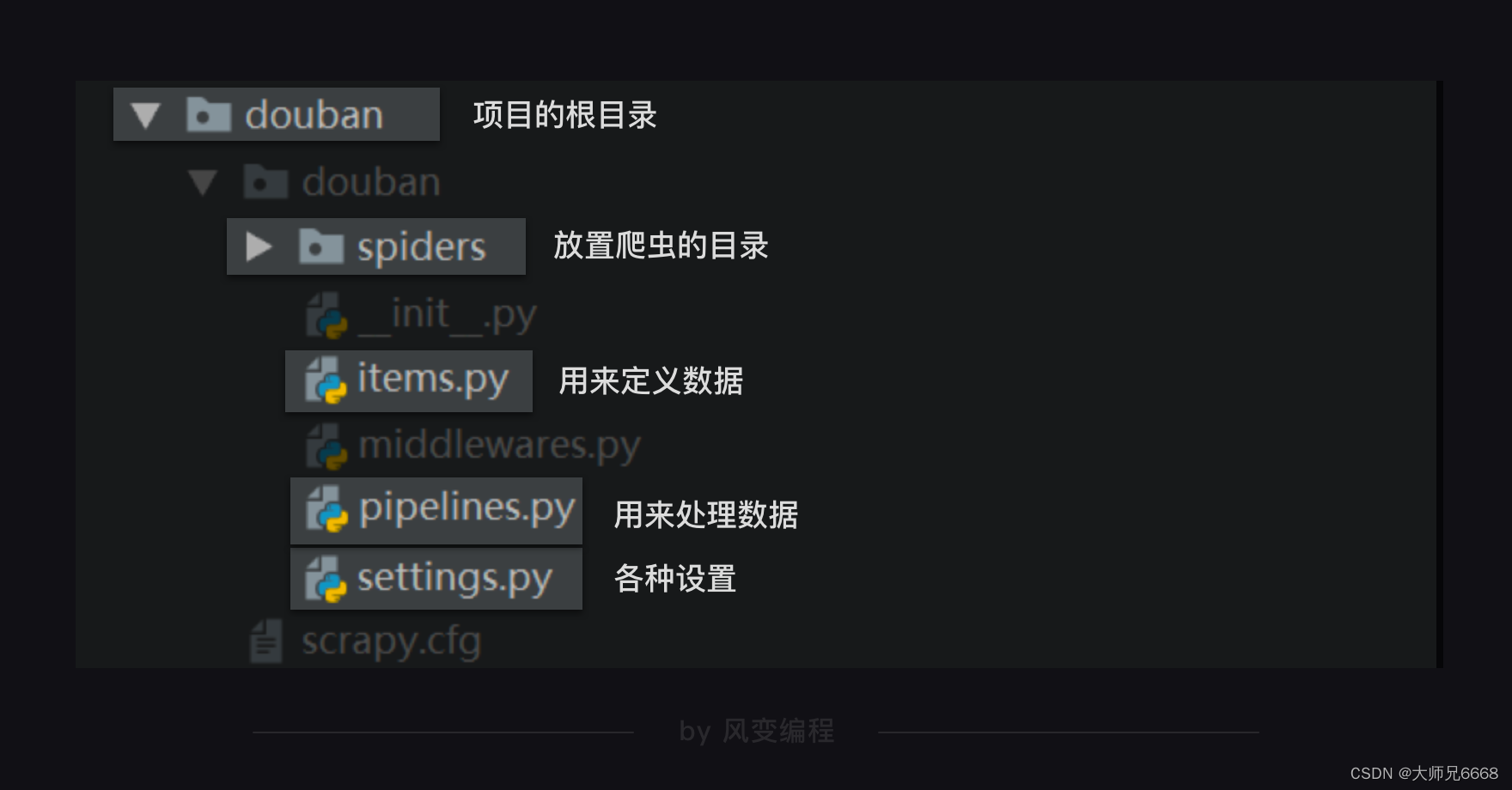
Scrapy项目里每个文件都有特定的功能,比如settings.py 是scrapy里的各种设置。items.py是用来定义数据的,pipelines.py是用来处理数据的,它们对应的就是Scrapy的结构中的Item Pipeline(数据管道)。
现在或许你还看不懂它们,没关系,事情将会一点点变清晰。我们来讲解它们。
代码实现——编辑爬虫
如前所述,spiders是放置爬虫的目录。我们可以在spiders这个文件夹里创建爬虫文件。我们来把这个文件,命名为top250。后面的大部分代码都需要在这个top250.py文件里编写。
先在top250.py文件里导入我们需要的模块。
import scrapy
import bs4
导入BeautifulSoup用于解析和提取数据,这个应该不需要我多做解释。在第2关、第3关的时候你就已经对它非常熟稔。
导入scrapy是待会我们要用创建类的方式写这个爬虫,我们所创建的类将直接继承scrapy中的scrapy.Spider类。这样,有许多好用属性和方法,就能够直接使用。
接着我们开始编写爬虫的核心代码。
在Scrapy中,每个爬虫的代码结构基本都如下所示:
class DoubanSpider(scrapy.Spider):name = 'douban'allowed_domains = ['book.douban.com']start_urls = ['https://book.douban.com/top250?start=0']def parse(self, response):print(response.text)
第1行代码:定义一个爬虫类DoubanSpider。就像我刚刚讲过的那样,DoubanSpider类继承自scrapy.Spider类。
第2行代码:name是定义爬虫的名字,这个名字是爬虫的唯一标识。name = 'douban’意思是定义爬虫的名字为douban。等会我们启动爬虫的时候,要用到这个名字。
第3行代码:allowed_domains是定义允许爬虫爬取的网址域名(不需要加https://)。如果网址的域名不在这个列表里,就会被过滤掉。
为什么会有这个设置呢?当你在爬取大量数据时,经常是从一个URL开始爬取,然后关联爬取更多的网页。比如,假设我们今天的爬虫目标不是爬书籍信息,而是要爬豆瓣图书top250的书评。我们会先爬取书单,再找到每本书的URL,再进入每本书的详情页面去抓取评论。
allowed_domains就限制了,我们这种关联爬取的URL,一定在book.douban.com这个域名之下,不会跳转到某个奇怪的广告页面。
第4行代码:start_urls是定义起始网址,就是爬虫从哪个网址开始抓取。在此,allowed_domains的设定对start_urls里的网址不会有影响。
第6行代码:parse是Scrapy里默认处理response的一个方法,中文是解析。
你或许会好奇,这里是不是少了一句类似requests.get()这样的代码?的确是,在这里,我们并不需要写这一句。scrapy框架会为我们代劳做这件事,写好你的请求,接下来你就可以直接写对响应如何做处理,我会在后面为你做示例。
了解完爬虫代码的基础结构,我们继续来完善爬取豆瓣Top图书的代码。
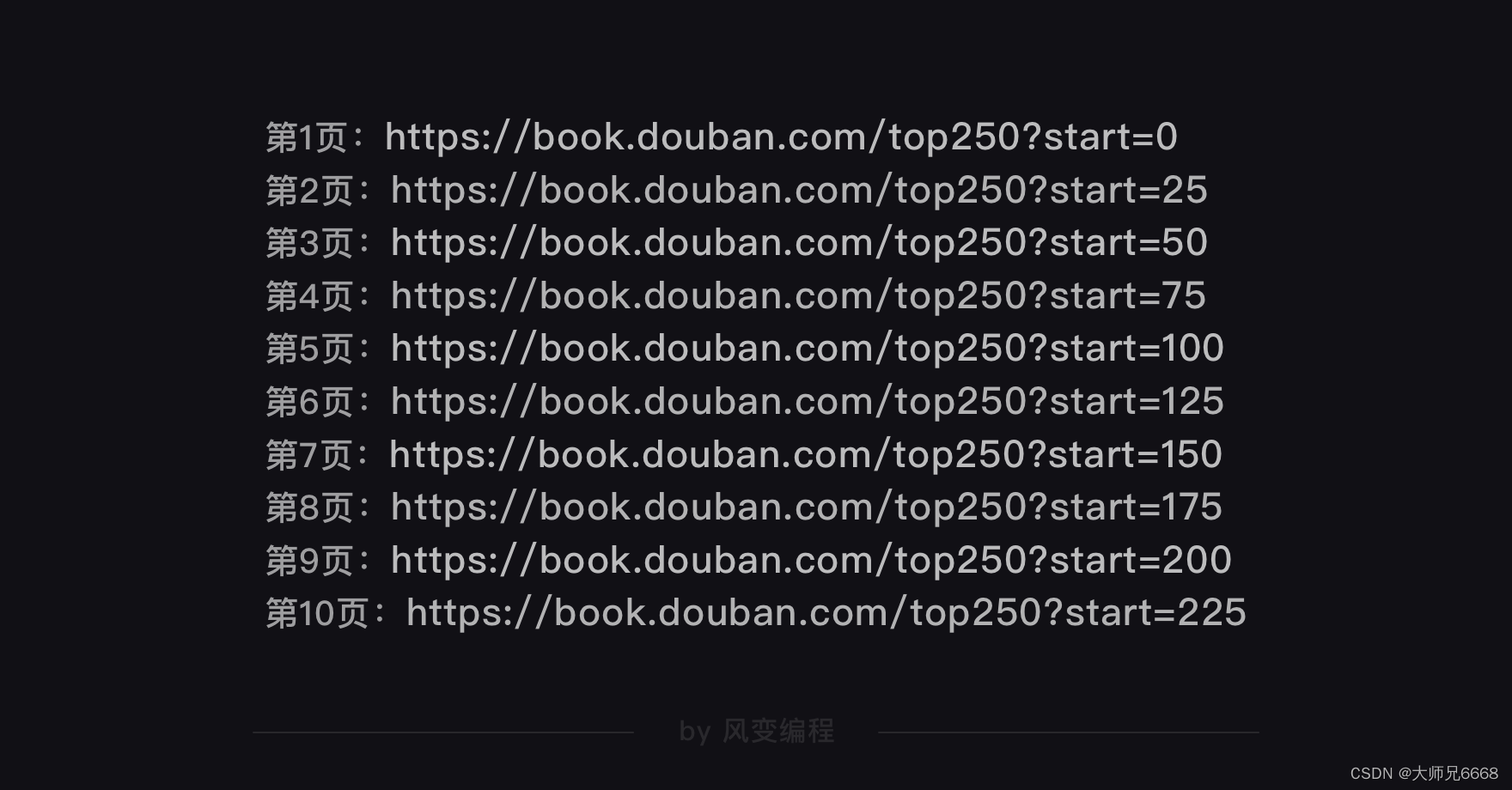
豆瓣Top250图书一共有10页,每一页的网址我们都知道。我们可以选择把10页网址都塞进start_urls的列表里。
但是这样的方式并不美观,而且如果要爬取的是上百个网址,全部塞进start_urls的列表里的话,代码就会非常长。
其实,我们可以利用豆瓣Top250图书的网址规律,用for循环构造出每个网址,再把网址添加进start_urls的列表里。这样代码会美观得多。
完善后的代码如下:
class DoubanSpider(scrapy.Spider):name = 'douban'allowed_domains = ['book.douban.com']start_urls = []for x in range(3):url = 'https://book.douban.com/top250?start=' + str(x * 25)start_urls.append(url)
我们只先爬取豆瓣Top250前3页的书籍信息。
接下来,只要再借助parse方法处理response,借助BeautifulSoup来取出我们想要的书籍信息的数据,代码即可完成。
我们前面在分析项目过程的时候,已经知道书籍信息都藏在了哪些元素里,现在可以利用find_all和find方法提取出来。比如,书名是元素下元素的title属性的值;出版信息在
元素里;评分在
按照过去的知识,我们可能会把代码写成这个模样:
import scrapy
import bs4
from ..items import DoubanItemclass DoubanSpider(scrapy.Spider):
#定义一个爬虫类DoubanSpider。name = 'douban'#定义爬虫的名字为douban。allowed_domains = ['book.douban.com']#定义爬虫爬取网址的域名。start_urls = []#定义起始网址。for x in range(3):url = 'https://book.douban.com/top250?start=' + str(x * 25)start_urls.append(url)#把豆瓣Top250图书的前3页网址添加进start_urls。def parse(self, response):#parse是默认处理response的方法。bs = bs4.BeautifulSoup(response.text,'html.parser')#用BeautifulSoup解析response。datas = bs.find_all('tr',class_="item")#用find_all提取<tr class="item">元素,这个元素里含有书籍信息。for data in datas:#遍历datas。title = data.find_all('a')[1]['title']#提取出书名。publish = data.find('p',class_='pl').text#提取出出版信息。score = data.find('span',class_='rating_nums').text#提取出评分。print([title,publish,score])#打印上述信息。按照过去,我们会把书名、出版信息、评分,分别赋值,然后统一做处理——或是打印,或是存储。但在scrapy这里,事情却有所不同。
spiders(如top250.py)只干spiders应该做的事。对数据的后续处理,另有人负责。
代码实现——定义数据
在scrapy中,我们会专门定义一个用于记录数据的类。
当我们每一次,要记录数据的时候,比如前面在每一个最小循环里,都要记录“书名”,“出版信息”,“评分”。我们会实例化一个对象,利用这个对象来记录数据。
每一次,当数据完成记录,它会离开spiders,来到Scrapy Engine(引擎),引擎将它送入Item Pipeline(数据管道)处理。
定义这个类的py文件,正是items.py。
我们已经知道,我们要爬取的数据是书名、出版信息和评分,我们来看看如何在items.py里定义这些数据。代码如下:
import scrapy
#导入scrapy
class DoubanItem(scrapy.Item):
#定义一个类DoubanItem,它继承自scrapy.Itemtitle = scrapy.Field()#定义书名的数据属性publish = scrapy.Field()#定义出版信息的数据属性score = scrapy.Field()#定义评分的数据属性
第1行代码,我们导入了scrapy。目的是,我们等会所创建的类将直接继承scrapy中的scrapy.Item类。这样,有许多好用属性和方法,就能够直接使用。比如到后面,引擎能将item类的对象发给Item Pipeline(数据管道)处理。
第3行代码:我们定义了一个DoubanItem类。它继承自scrapy.Item类。
第5、7、9行代码:我们定义了书名、出版信息和评分三种数据。scrapy.Field()这行代码实现的是,让数据能以类似字典的形式记录。你可能不太明白这句话的含义,没关系。我带你来体验一下,你就能感受到是怎样一回事:
import scrapy
#导入scrapy
class DoubanItem(scrapy.Item):
#定义一个类DoubanItem,它继承自scrapy.Itemtitle = scrapy.Field()#定义书名的数据属性publish = scrapy.Field()#定义出版信息的数据属性score = scrapy.Field()#定义评分的数据属性book = DoubanItem()
# 实例化一个DoubanItem对象
book['title'] = '海边的卡夫卡'
book['publish'] = '[日] 村上春树 / 林少华 / 上海译文出版社 / 2003'
book['score'] = '8.1'
print(book)
print(type(book))运行结果:
{'publish': '[日] 村上春树 / 林少华 / 上海译文出版社 / 2003','score': '8.1','title': '海边的卡夫卡'}
<class '__main__.DoubanItem'>
你会看到打印出来的结果的确和字典非常相像,但它却并不是dict,它的数据类型是我们定义的DoubanItem,属于“自定义的Python字典”。我们可以利用类似上述代码的样式,去重新写top250.py。如下所示:
import scrapy
import bs4
from ..items import DoubanItem
# 需要引用DoubanItem,它在items里面。因为是items在top250.py的上一级目录,所以要用..items,这是一个固定用法。class DoubanSpider(scrapy.Spider):
#定义一个爬虫类DoubanSpider。name = 'douban'#定义爬虫的名字为douban。allowed_domains = ['book.douban.com']#定义爬虫爬取网址的域名。start_urls = []#定义起始网址。for x in range(3):url = 'https://book.douban.com/top250?start=' + str(x * 25)start_urls.append(url)#把豆瓣Top250图书的前3页网址添加进start_urls。def parse(self, response):#parse是默认处理response的方法。bs = bs4.BeautifulSoup(response.text,'html.parser')#用BeautifulSoup解析response。datas = bs.find_all('tr',class_="item")#用find_all提取<tr class="item">元素,这个元素里含有书籍信息。for data in datas:#遍历data。item = DoubanItem()#实例化DoubanItem这个类。item['title'] = data.find_all('a')[1]['title']#提取出书名,并把这个数据放回DoubanItem类的title属性里。item['publish'] = data.find('p',class_='pl').text#提取出出版信息,并把这个数据放回DoubanItem类的publish里。item['score'] = data.find('span',class_='rating_nums').text#提取出评分,并把这个数据放回DoubanItem类的score属性里。print(item['title'])#打印书名。yield item#yield item是把获得的item传递给引擎。
在3行,我们需要引用DoubanItem,它在items里面。因为是items在top250.py的上一级目录,所以要用…items,这是一个固定用法。
当我们每一次,要记录数据的时候,比如前面在每一个最小循环里,都要记录“书名”,“出版信息”,“评分”。我们会实例化一个item对象,利用这个对象来记录数据。
每一次,当数据完成记录,它会离开spiders,来到Scrapy Engine(引擎),引擎将它送入Item Pipeline(数据管道)处理。这里,要用到yield语句。
yield语句你可能还不太了解,这里你可以简单理解为:它有点类似return,不过它和return不同的点在于,它不会结束函数,且能多次返回信息。
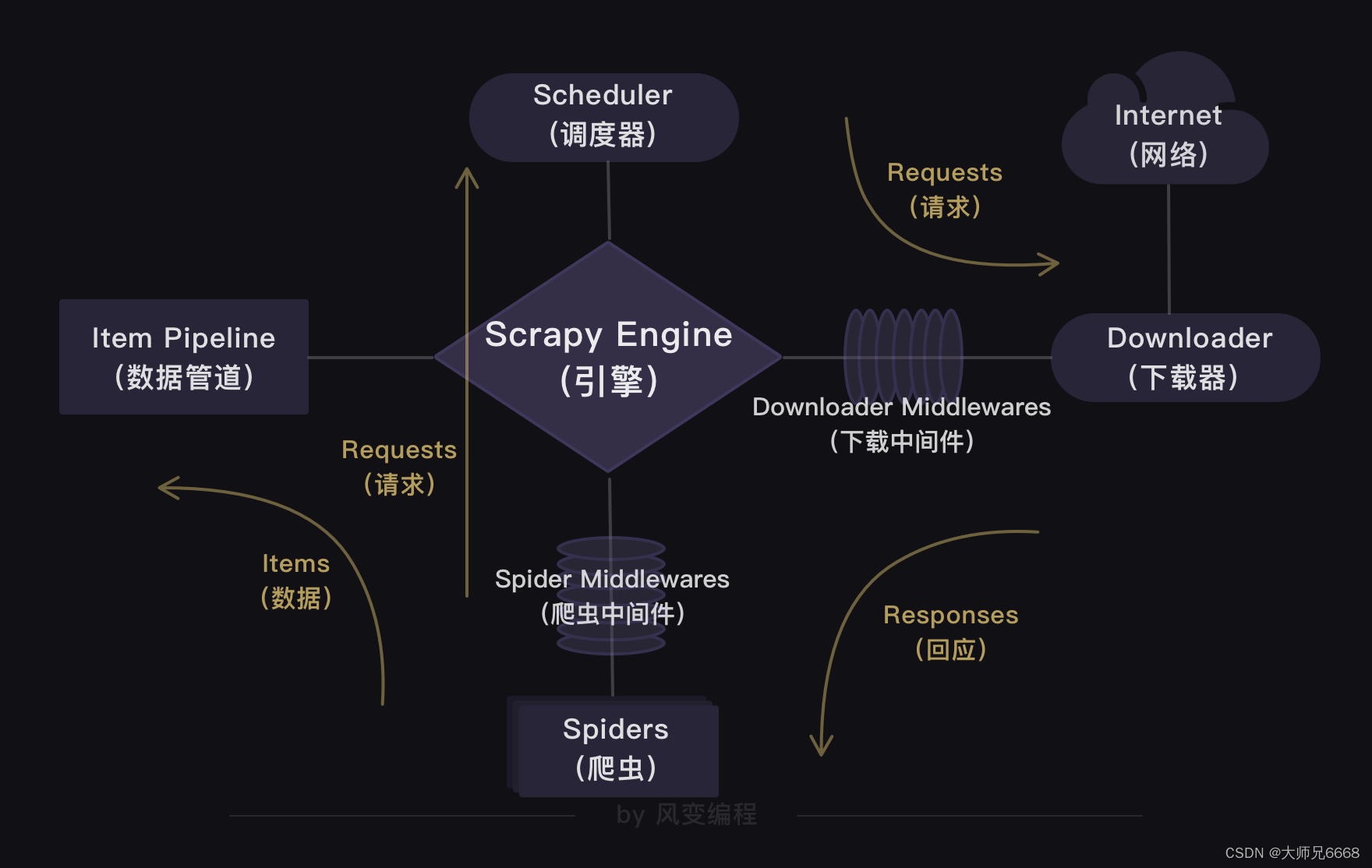
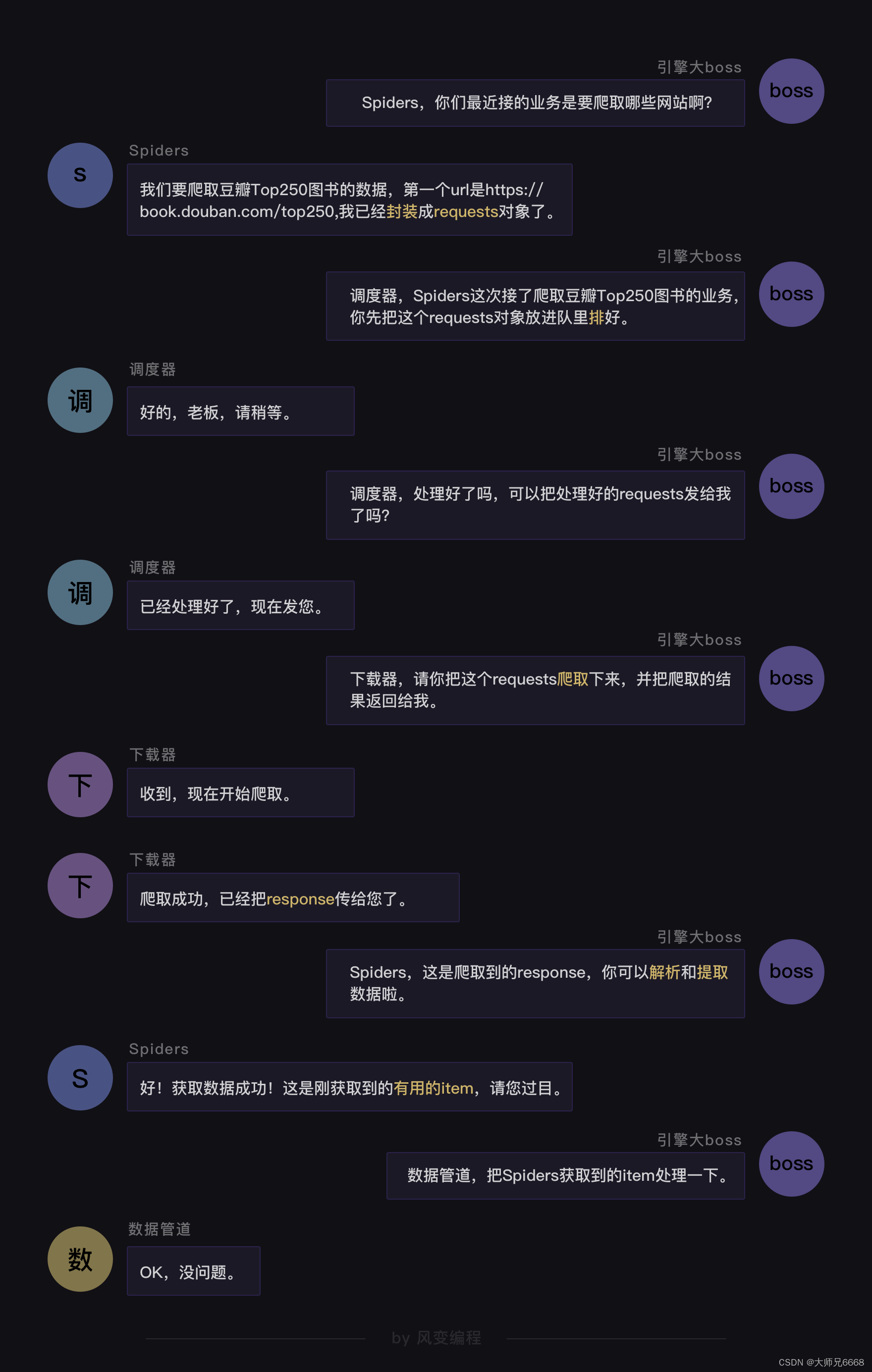
如果用可视化的方式来呈现程序运行的过程,就如同上图所示:爬虫(Spiders)会把豆瓣的10个网址封装成requests对象,引擎会从爬虫(Spiders)里提取出requests对象,再交给调度器(Scheduler),让调度器把这些requests对象排序处理。
然后引擎再把经过调度器处理的requests对象发给下载器(Downloader),下载器会立马按照引擎的命令爬取,并把response返回给引擎。
紧接着引擎就会把response发回给爬虫(Spiders),这时爬虫会启动默认的处理response的parse方法,解析和提取出书籍信息的数据,使用item做记录,返回给引擎。引擎将它送入Item Pipeline(数据管道)处理。
代码实操——设置
到这里,我们就用代码编写好了一个爬虫。不过,实际运行的话,可能还是会报错。
原因在于Scrapy里的默认设置没被修改。比如我们需要修改请求头。点击settings.py文件,你能在里面找到如下的默认设置代码:
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'douban (+http://www.yourdomain.com)'# Obey robots.txt rules
ROBOTSTXT_OBEY = True
请你把USER _AGENT的注释取消(删除#),然后替换掉user-agent的内容,就是修改了请求头。
又因为Scrapy是遵守robots协议的,如果是robots协议禁止爬取的内容,Scrapy也会默认不去爬取,所以我们还得修改Scrapy中的默认设置。
把ROBOTSTXT_OBEY=True改成ROBOTSTXT_OBEY=False,就是把遵守robots协议换成无需遵从robots协议,这样Scrapy就能不受限制地运行。
修改后的代码应该如下所示:
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'# Obey robots.txt rules
ROBOTSTXT_OBEY = False
现在,我们已经编写好了spider,也修改好了setting。万事俱备,只欠东风——运行Scrapy。
代码实操——运行
想要运行Scrapy有两种方法,一种是在本地电脑的终端跳转到scrapy项目的文件夹(跳转方法:cd+文件夹的路径名),然后输入命令行:scrapy crawl douban(douban 就是我们爬虫的名字)。
另一种运行方式需要我们在最外层的大文件夹里新建一个main.py文件(与scrapy.cfg同级)。
我们只需要在这个main.py文件里,输入以下代码,点击运行,Scrapy的程序就会启动。
from scrapy import cmdline
#导入cmdline模块,可以实现控制终端命令行。
cmdline.execute(['scrapy','crawl','douban'])
#用execute()方法,输入运行scrapy的命令。
第1行代码:在Scrapy中有一个可以控制终端命令的模块cmdline。导入了这个模块,我们就能操控终端。
第3行代码:在cmdline模块中,有一个execute方法能执行终端的命令行,不过这个方法需要传入列表的参数。我们想输入运行Scrapy的代码scrapy crawl douban,就需要写成[‘scrapy’,‘crawl’,‘douban’]这样。
至此,Scrapy的用法我们学完啦。
值得一提的是,在本关卡中为了教学方便理解,先写了爬虫,再定义数据。但是,在实际项目实战中,常常顺序却是相反的——先定义数据,再写爬虫。所以,流程图应如下:

细心的你可能会发现,这一关的内容没有涉及到存储数据的步骤。
是的,存储数据需要修改pipelines.py文件。这一关的内容已经很充实,所以这个知识点我们留到下一关再讲。
复习
最后,是这一关的重点知识的复习。
Scrapy的结构——
Scrapy的工作原理——

Scrapy的用法——

下一关,我们准备用Scrapy来实操一个大项目——爬取人气企业的招聘信息。
下关见啦~
相关文章:
【python爬虫】14.Scrapy框架讲解
文章目录 前言Scrapy是什么Scrapy的结构Scrapy的工作原理 Scrapy的用法明确目标与分析过程代码实现——创建项目代码实现——编辑爬虫代码实现——定义数据代码实操——设置代码实操——运行 复习 前言 前两关,我们学习了能提升爬虫速度的进阶知识——协程…...

功率放大器主要作用是什么呢
功率放大器是一种电子设备,主要作用是将输入信号的功率增加到更高的水平,以便能够驱动高功率负载。在许多应用中,信号源产生的信号往往具有较低的功率,无法直接满足一些要求较高的设备或系统的需求。而功率放大器则可以增强信号的…...

SpringBoot ApplicationEvent详解
ApplicationStartingEvent 阶段 LoggingApplicationListener#onApplicationStartingEvent 初始化日志工厂,LoggingSystemFactory接口,可以通过spring.factories进行定制 可以通过System.setProperty("org.springframework.boot.logging.LoggingSystem",&q…...

WebSocket 报java.io.IOException: 远程主机强迫关闭了一个现有的连接。
在客户端强制关闭时,或者窗口强制关闭时,后端session没有关闭。 有时还会报:java.io.EOFException: 这个异常 前端心跳没有收到信息,还在心跳。 CloseReason close new CloseReason(CloseReason.CloseCodes.NORMAL_CLOSURE, &…...
关于git约定式提交IDEA
背景 因为git提交的消息不规范导致被乱喷,所以领导统一规定了约定式提交 官话 约定式提交官网地址 约定式提交规范是一种基于提交信息的轻量级约定。 它提供了一组简单规则来创建清晰的提交历史; 这更有利于编写自动化工具。 通过在提交信息中描述功能…...
【计算机网络】http协议
目录 前言 认识URL URLEncode和URLDecode http协议格式 http方法 GET POST GET与POST的区别 http状态码 http常见header 简易的http服务器 前言 我们在序列化和反序列化这一章中,实现了一个网络版的计算器。这个里面设计到了对协议的分析与处…...

仓库太大,clone 后,git pull 老分支成功,最新分支失败
由于 git 仓库太大,新加入的小伙伴在拉取时,无法切换到最新的分支,报错如下: fetch-pack: unexpected disconnect while reading sideband packet fatal: early EOF fatal: fetch-pack: invalid index-pack output在此记录解决步…...

javafx Dialog无法关闭
// 生成二维码图片String qrCodeText "https://example.com";DialogPane grid new DialogPane();grid.setPadding(new Insets(5));VBox vBox new VBox();vBox.setAlignment(Pos.CENTER);Image qrCodeImage generateQRCodeImage(qrCodeText);ImageView customImag…...
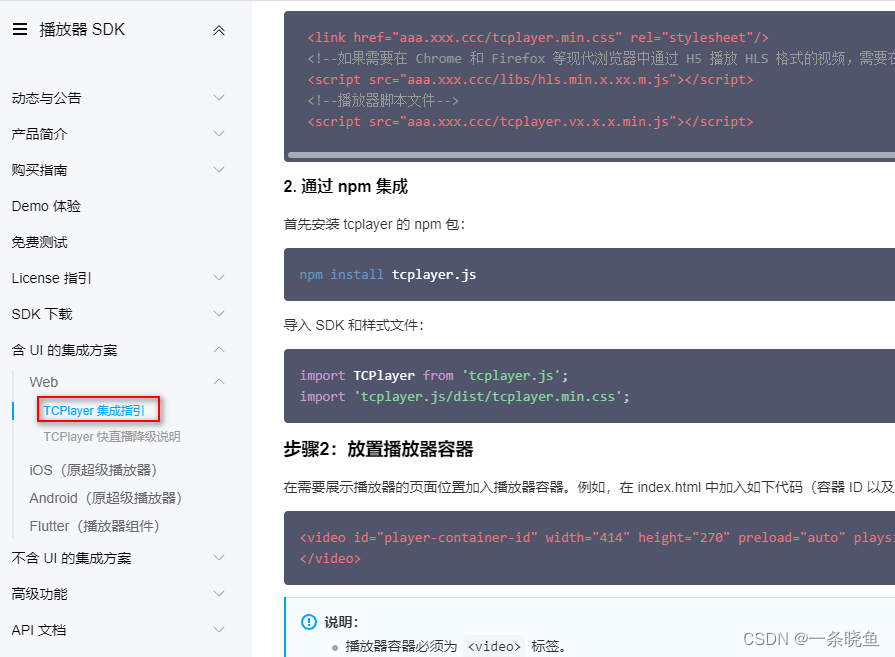
vue3中TCplayer应用
环境win10:vitevue3elementUI 1 安装 npm install tcplayer.js2 使用 <template><div><video id"player-container-id" width"414" height"270" preload"auto" playsinline webkit-playsinline></video>&l…...
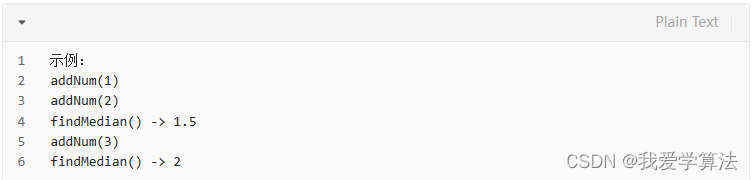
算法通关村14关 | 数据流中位数问题
1. 数据流中位数问题 题目 LeetCode295: 中位数是有序列表中间的数,如果列表长度是偶数,中位数是中间两个数的平均值, 例如:[2,3,4]的中位数是3, [2,3]中位数是(23)/ 2 2.5 设计一个数据结构: …...

工厂模式 与 抽象工厂模式 的区别
工厂模式: // 抽象产品接口 interface Product {void showInfo(); }// 具体产品A class ConcreteProductA implements Product {Overridepublic void showInfo() {System.out.println("This is Product A");} }// 具体产品B class ConcreteProductB impl…...
安装虚拟机+安装/删除镜像
安装虚拟机 注意,官网可能无法登录,导致无法从官网下载,就自己去网上搜靠谱的下载,我用的16.2.3 删除镜像 Vm虚拟机怎么删除已经创建的系统?Vm虚拟机创建好之后iso删除方法 - 系统之家 (xitongzhijia.net) 安装镜像…...
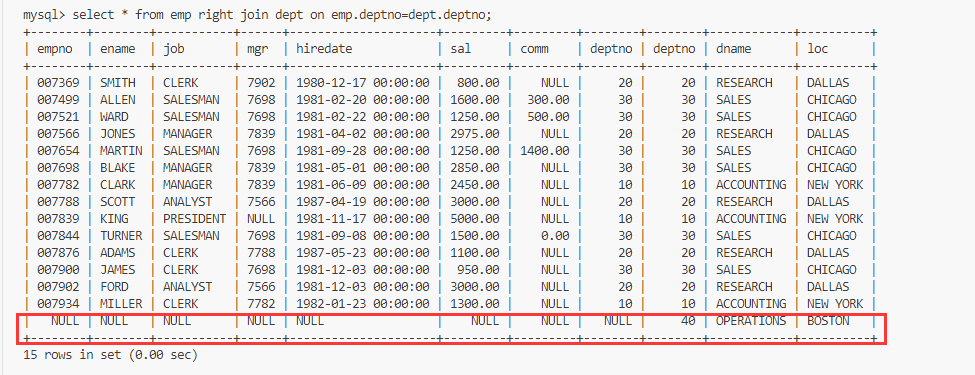
MySQL的内置函数复合查询内外连接
文章目录 内置函数时间函数字符串函数数学函数其他函数 复合查询多表笛卡尔积自连接在where中使用子查询多列子查询在from中使用子查询 内连接外连接左外连接右外连接 内置函数 时间函数 函数描述current_date()当前日期current_time()当前时间current_timestamp()当前时间戳…...
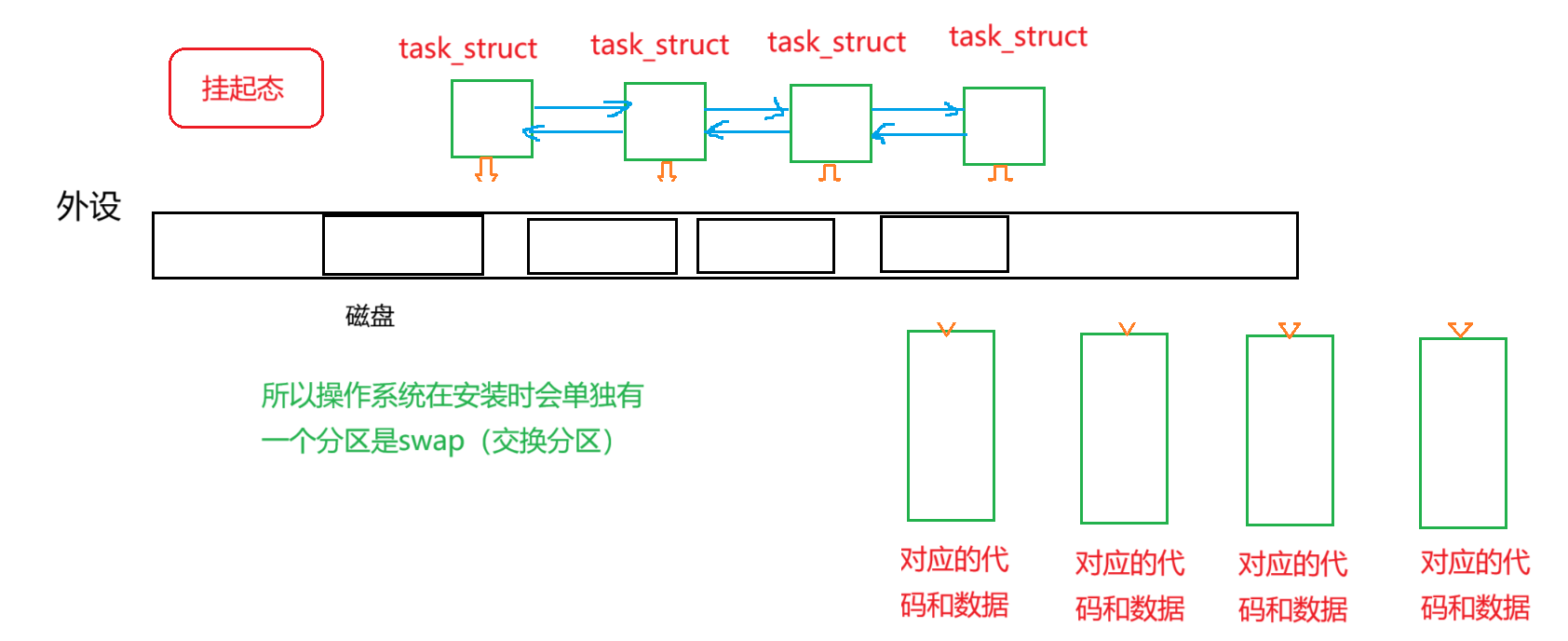
操作系统(OS)与系统进程
操作系统(OS)与系统进程 冯诺依曼体系结构操作系统(Operator System)进程基本概念进程的描述(PCB)查看进程通过系统调用获取进程标示符(PID)通过系统调用创建进程(fork)进程状态&…...
)
防重复提交:自定义注解 + 拦截器(HandlerInterceptor)
防重复提交:自定义注解 拦截器(HandlerInterceptor) 一、思路: 1、首先自定义注解; 2、创建拦截器实现类(自定义类名称),拦截器(HandlerInterceptor); 3…...
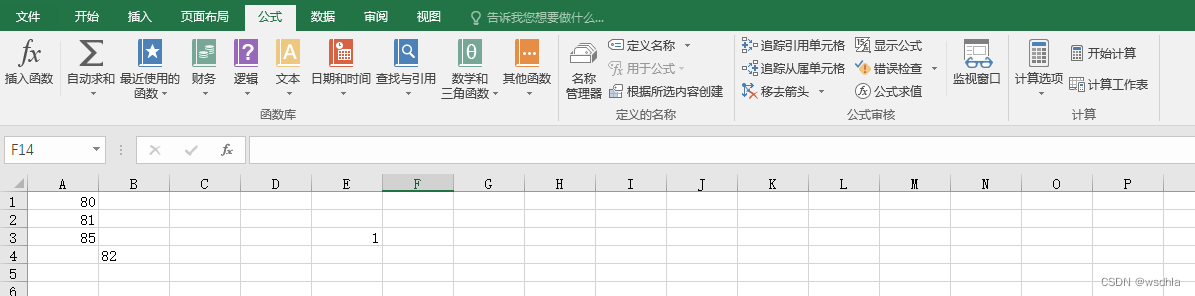
Excel中将文本格式的数值转换为数字
在使用excel时,有时需要对数字列进行各种计算,比如求平均值,我们都知道应该使用AVERAGE()函数,但是很多时候结果却“不尽如人意”。 1 问题: 使用AVERAGE函数: 结果: 可以看到单元格左上角有个…...
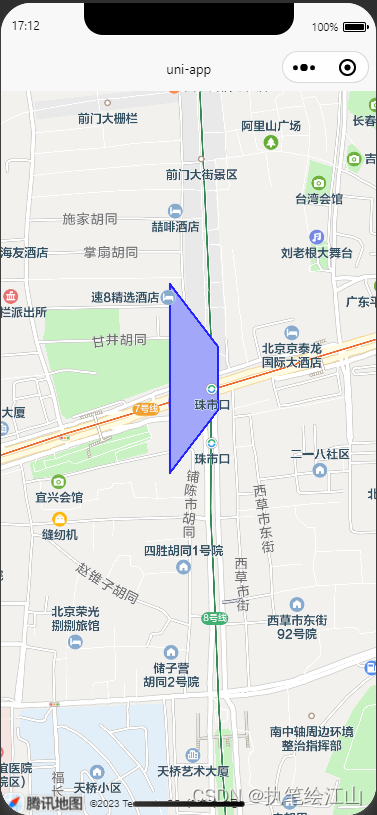
uni-app开发小程序中遇到的map地图的点聚合以及polygon划分区域问题
写一篇文章来记录以下我在开发小程序地图过程中遇到的两个小坑吧,一个是点聚合,用的是joinCluster这个指令,另一个是polygon在地图上划分多边形的问题: 1.首先说一下点聚合问题,由于之前没有做过小程序地图问题&#…...

【笔记】软件测试的艺术
软件测试的心理学和经济学 测试是为发现错误而执行程序的过程,所以它是一个破坏性的过程,测试是一个“施虐”的过程。 软件测试的10大原则 1、测试用例需要对预期输出的结果有明确的定义 做这件事的前提是能够提前知晓需求和效果图,如果不…...
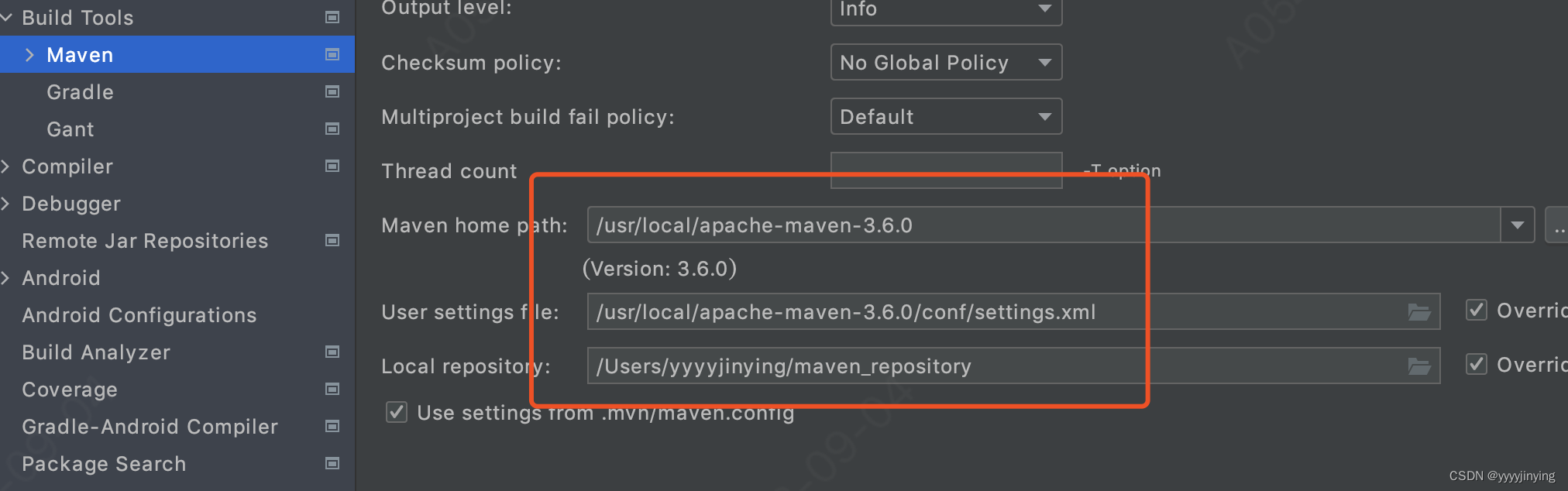
配置本地maven
安装maven安装包 修改环境变量 vim ~/.bash_profile export JMETER_HOME/Users/yyyyjinying/apache-jmeter-5.4.1 export GOROOT/usr/local/go export GOPATH/Users/yyyyjinying/demo-file/git/backend/go export GROOVY_HOME/Users/yyyyjinying/sortware/groovy-4.0.14 exp…...

C# 按钮的AcceptButton和CancelButton属性
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

【AI学习】三、AI算法中的向量
在人工智能(AI)算法中,向量(Vector)是一种将现实世界中的数据(如图像、文本、音频等)转化为计算机可处理的数值型特征表示的工具。它是连接人类认知(如语义、视觉特征)与…...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...

第7篇:中间件全链路监控与 SQL 性能分析实践
7.1 章节导读 在构建数据库中间件的过程中,可观测性 和 性能分析 是保障系统稳定性与可维护性的核心能力。 特别是在复杂分布式场景中,必须做到: 🔍 追踪每一条 SQL 的生命周期(从入口到数据库执行)&#…...

【学习笔记】erase 删除顺序迭代器后迭代器失效的解决方案
目录 使用 erase 返回值继续迭代使用索引进行遍历 我们知道类似 vector 的顺序迭代器被删除后,迭代器会失效,因为顺序迭代器在内存中是连续存储的,元素删除后,后续元素会前移。 但一些场景中,我们又需要在执行删除操作…...

Python 训练营打卡 Day 47
注意力热力图可视化 在day 46代码的基础上,对比不同卷积层热力图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pypl…...
:工厂方法模式、单例模式和生成器模式)
上位机开发过程中的设计模式体会(1):工厂方法模式、单例模式和生成器模式
简介 在我的 QT/C 开发工作中,合理运用设计模式极大地提高了代码的可维护性和可扩展性。本文将分享我在实际项目中应用的三种创造型模式:工厂方法模式、单例模式和生成器模式。 1. 工厂模式 (Factory Pattern) 应用场景 在我的 QT 项目中曾经有一个需…...