算法面试-深度学习基础面试题整理(2023.8.29开始,每天下午持续更新....)
一、无监督相关(聚类、异常检测)
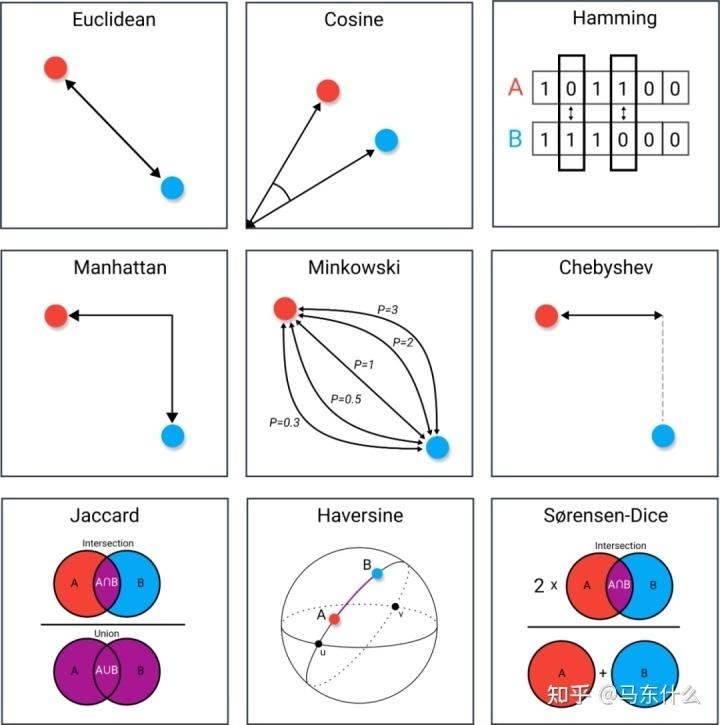
1、常见的距离度量方法有哪些?写一下距离计算公式。
1)连续数据的距离计算:
闵可夫斯基距离家族:

当p = 1时,为曼哈顿距离;p= 2时,为欧式距离;p ->∞时,就是切比雪夫距离。
余弦距离:
![]()
其中,A 和B是要比较的两个向量,⋅ 表示向量的点积(内积),∥A∥ 和 ∥B∥ 分别表示向量 A 和 B的欧几里德范数(也称为 L2 范数)。余弦距离的值范围在[0,2],取值越小表示两个向量越相似,取值越大表示两个向量越不相似。如果两个向量方向相同,则余弦距离为 0,表示完全相似;如果两个向量方向相反,则余弦距离为 2,表示完全不相似。请注意,有时也可以用余弦相似性(Cosine Similarity)来衡量向量的相似性,它是余弦距离的补数,即1−Cosine Distance。余弦相似性的取值范围在 [-1, 1],取值越大表示两个向量越相似,取值越小表示越不相似。
2)离散数据的距离计算
杰卡尔德(Jaccard)距离:A,B集合的交集/A,B集合的并集
汉明距离:表示两个等长字符串在对应位置上不同字符的数目
2、常见的聚类算法有哪些?
主要有基于划分、基于密度、基于网络、层次聚类等,除此之外聚类和其他领域也有很多结合形成的交叉领域比如半监督聚类、深度聚类、集成聚类等。
3、Kmeans的原理是什么?
Kmeans是一种基于划分的聚类,中心思想是类内距离尽量小,类间距离尽量大,主要算法过程如下:
- 初始K个质心,作为初始的K个簇的中心点,K为人工设定的超参数;
- 所有样本点n分别计算和K个质心的距离,这里的距离是人工定义的可以是不同距离计算方法,每个样本点和k个质心中最近的质心划分为1类簇;
- 重新计算质心,方法是针对簇进行聚合计算,kmeans中使用简单平均的方法进行聚合计算,也可以使用中位数等方式进行计算;
- 重复上述过程直到达到预定的迭代次数或质心不再发生明显变化。
- kmeans的损失函数是:

其中,||xi - cj|| 表示数据点 xi 到簇中心 cj 的欧氏距离,I(condition) 是一个指示函数,当 condition 成立时为 1,否则为 0。J越小,说明样本聚合程度越高。
4、Kmeans的初始点怎么选择,不同的初始点选择有哪些缺陷?该怎么解决?
- 随机初始化:随机选取K个样本点作为初始质心,缺陷在于如果选择到的质心距离很接近落在同个簇内,则迭代的结果可能比较差,因为最终迭代出来的质心点会落在簇内。最理想的状态是K个质心正好是K个簇,由于随机初始化的随机性,可以考虑多次进行随机初始化,选择聚合结果最优的一次。
- 随机分取初始化:即将所有样本点随机赋予1个簇的编号,则所有样本点最后会有K个编号,然后进行组平均,即对于同一个簇的样本进行平均得到初始化质心。相对于随机初始化,初始化质心会更鲁棒一些,但是仍旧存在随机初始化的缺陷,仅仅是缓解。
5、Kmeans聚的是特征还是样本?特征的距离如何计算?
一般情况下是对样本聚类,如果对特征聚类则处理方式也简单,对原始的输出进行转置。其目的和做相关系数类似,如果两个特征高度相关,例如收入和资产水平,则两个特征的距离相对较小,但是一般不可行,因为转置后维度很高,例如有100万个样本则有100万的维度,计算上不现实,高维数据的距离度量也是无效的,不如直接计算相关系数。
6、Kmeans如何调优?
- 初始化策略调参
- k的大小调参,手工方法,手肘法为代表
- 数据归一化和异常样本的处理
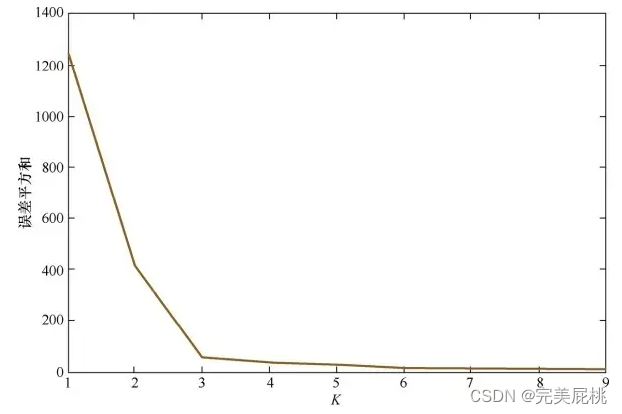
7、介绍一下手肘法。
手肘法纵轴是聚类效果的评估指标,根据具体的问题而定,如果聚类是作为单独的任务存在则使用SSE(损失函数)或轮廓系数这类的metric作为纵坐标,然后找到metric最好且k最小的结果,对应的k为最终的选择。手肘法自动化时,只需计算k = n 和 k = n+1之间的斜率,当斜率n和n-1,斜率n+1和斜率n,斜率n+2和斜率n+1的差值均小于固定阈值时即可停止。
8、kmeans的缺点如何解决?
- 对异常样本很敏感,簇心会因为异常样本被拉得很远。异常样本是指在某些维度上取值特别大或者特别小的样本,欧式距离中默认所有特征是相互独立的,异常样本会产生影响。解决方法是做好预处理,将异常样本剔除或者修正。
- K值很难确定。解决方法是针对k调参。
- 只能拟合球形簇,对于流形簇等不规则簇可能存在簇重叠的问题,效果差。这种情况可能不再适用于Kmeans算法,考虑换算法。
- 无法处理离散特征,缺失特征。
- 无法保证全局最优。解决方法是跑多次,取不同的局部最优里的最优。
9、余弦距离和欧氏距离的区别,什么场景下要使用余弦相似度?
- 欧式距离体现在数值上的绝对差异,余弦距离体现方向上的相对差异。
- 例如,统计两部剧的用户观看行为,用户A的观看向量为(0,1),用户B为(1,0),此时二者的余弦距离很大,而欧式距离很小;我们分析两个用户对于不同视频的偏好,更关注相关差异,显然应当使用余弦距离。而在分析用户活跃度,以登陆次数和平均观看时长为特征时,余弦距离会认为(1,10)、(10,100)两个用户距离很近,但显然这两个用户活跃度有差异,需用欧式距离。
10、余弦距离是否是一个严格定义的距离?一个度量标准要满足什么要求才能算是距离?
- 距离的定义:在一个集合中,如果每一对元素均可唯一确定一个实数,使得三条距离公理(正定性,对称性,三角不等式)成立,则该实数称为这对元素之间的距离。
- 余弦距离满足正定性和对称性,但是不满足三角不等式,因此它并不是严格定义的距离。
11、Kmeans中我想聚成100类,结果发现只能聚成98类,为什么?
- 迭代过程中出现空簇,原因在于K太大,实际簇数量小于K;
- 初始化策略不会导致空簇的问题,因为即使最简单的随机初始化也是从原始样本点中选择部分样本点作为质心。如果出现空粗,可以在初始质心中引入异常样本,这个异常点会自成一个簇而不会出现空簇的问题。
12、Kmeans, GMM, EM之间有什么关系?
- Kmeans是基于划分的聚类算法,GMM是基于模型的聚类算法,EM是估计GMM的参数使用的优化算法。
- Kmeans可以看作GMM的一种特例,Kmeans聚类为球形,Kmeans聚类为椭球形。
- Kmeans使用hard EM求解,GMM使用Soft EM求解。
13、高斯混合模型GMM的核心思想是什么?GMM和多元高斯有什么区别?多元高斯函数的期望是什么?
- GMM是多个相关多元高斯的加权求和。
- 高斯混合模型GMM是多元高斯分布之上的概念,他认为现实世界的数据是由多个不同参数的相关多元高斯模型以不同的权重累积求和构成的。(独立多元高斯模型可以看作相关多元高斯模型的特例)
14、GMM如何迭代计算?为什么kmeans, GMM, EM满足上面描述的方式?
- EM算法原理:EM算法和梯度下降一样,都可以用来优化极大似然函数,当极大似然函数存在隐变量时,EM算法是一种常用的优化算法。EM算法((Expectation-Maximization Algorithm)一般分为两步,首先是期望步(E步),另一个是极大步(M步)。
15、KNN算法是否存在损失函数?
不存在,KNN属于懒惰学习(lazy learning)的算法,对应的有eager learning。
- lazy learning: 只存储数据集而不从中学习,不需要模型训练;收到测试数据后开始根据存储数据集对数据进行分类或回归;
- eager learning:从收集的数据中学习,需要模型训练;收到测试数据后直接完成分类或回归。
二、不均衡学习
1、数据不均衡如何解决,抽样得到的分类准确率如何转换为原准确率?
将采样后的预测的类别按照采样比例进行相应的增大或减少,例如对类别A下采样了50%,则预测结果中类别A的预测数量为m,令m=m/0.5=2m,然后计算分类准确率;这种数据处理方式是不准确的,合理的方式应该是直接对原始数据进行评估指标的计算。
2、如果把不平衡的训练集(正负样本1:3)通过降采样平衡后,那么平衡后的AUC值和预测概率会有什么变化?
- ROC_AUC曲线对类别数量的变化不敏感,因此AUC的计算结果整体不会发生明显变化;
- 通过下采样平衡后变相增大了正样本数量,分类决策边界远离正样本,预测概率整体变大。
3、class_weight的思想是什么?
class_weight对应的简单加权法是代价敏感学习最简单的一种方法,思想就是小类样本加权,使其再loss中比重变大。
4、不均衡学习的原理是什么?
目前主流的不均衡学习主要是关于分类问题的不均衡。所谓的不均衡分类,指的是样本不同类别的数量差异越来越大的情况下,模型越来越偏向于预测大类样本的现象,因此,模型的分类性能越来越差。
单纯从样本不均衡的角度出发(不考虑分布变化,小样本学习,分类问题的困难程度等其他问题),不均衡的类别对模型造成影响的原因:
- 目标函数优化的方法,使用梯度下降优化目标函数的模型对于不均衡问题更敏感;而tree模型纯粹基于贪心策略进行分裂的方法则对此并不敏感;
- 目标函数的使用,hinge loss和交叉熵对于不均衡的敏感度不同。
5、上采样(过采样)和生成样本的区别?
上采样不一定是生成样本,例如简单的repeat式的上采样,通过复制不涉及样本生成的过程,但生成样本一定是一种上采样。
三、模型的损失函数、评价指标和优化方法
1、如何评价聚类结果的好坏?轮廓系数是什么?
- 可以使用SSE函数评价聚类结果的好坏:
- 轮廓系数是为每个样本定义的,由两个分数组成:a是样本与同一类簇中所有点的平均距离;b是样本与下一个最近的类簇中所有其他点之间的平均距离。对于单个样本而言轮廓系数如下,对于模型评估而言,取所有样本的轮廓系数的均值作为模型聚类效果的评估指标:
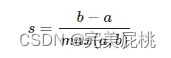
2、准确率的局限性是什么?
- 不同分类阈值下准确率会发生变化,评估起来比较麻烦;
- 对样本不均衡问题特别敏感,例如当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率。
- 公式:分类正确的样本数/总样本数
3、ROC曲线如何绘制?ROC与PRC的异同点,准确率(accuracy),精确率(precision), 召回率(recall)各自的定义和缺陷;PR曲线的绘制,如何使用PR曲线判断模型好坏;ROC曲线横坐标纵坐标意义。
- TP, FP, TN, FN是混淆矩阵(confudion matrix)中的组成部分,用来衡量分类模型在不同类别上的表现的工具。TP真正例,表示模型正确地将正类别样本预测为正类别的样本数量;FP假正例,表示模型错误地将负类别样本预测为正类别的样本数量;TN真反例,表示模型正确地将负类别样本预测为负类别的样本数量;FN假反例,表示模型错误地将正类别样本预测为负类别。
- 准确率acc=(TP+TN)/Total,分类正确的样本数量/总样本数。
- 精确率pre=TP/(TP+FP)分子为正确预测的正样本的样本数量,分母为预测为正样本的样本数量。
- 召回率=TP/(TP+FN)分子为正确预测的正样本的样本数量,分母为所有样本数量。
- 误杀率:FP/(FP+TN)分子为错误预测的正样本数量,分母为所有负样本的样本数量。
- 缺陷:①在数据量极度不平衡情况下,模型将所有样本预测为大类则准确率就能提高;②分类阈值接近0,则模型将所有样本预测为正样本则召回率接近100%;分类阈值接近1,则模型将极少样本预测为正样本则精确率接近100%;即召回率和精确率受分类阈值的影响较大。

- 模型的PR曲线,以召回率为横坐标,精确率为纵坐标。如果一个模型的PR曲线被另一个模型的PR曲线完全包住,则可认为后者的性能优于前者,如下图IG优于AC。
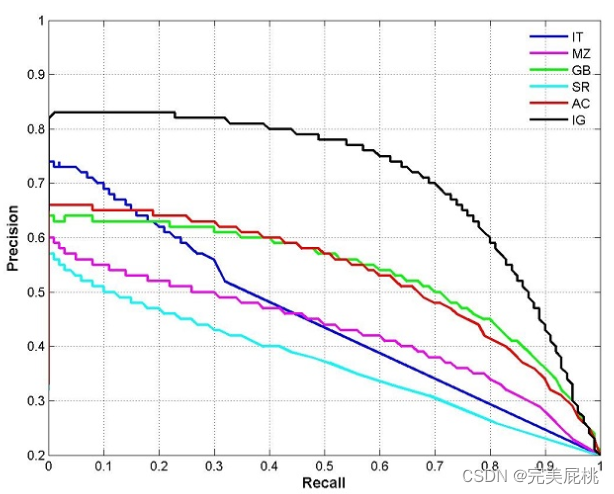
- 一般使用平衡点来评估无法直接比较的情况,例如上图的IT和MZ,平衡点(BEP)是P=R时的取值,如果这个值较大,则说明模型性能较好。而F1=2*recall*precision/(recall+precision), F1值越大,我们认为模型性能越好。
- ROC曲线和PR曲线相似,其纵坐标是精确率,但横坐标是误杀率。下方图的第一行ab均为原数据的图,左边为ROC曲线,右边为PR曲线。第二行cd为负样本增大10倍后两个曲线的图,可以看出ROC曲线基本没有变化,但PR曲线震荡剧烈。因此在面对正负样本数量非常不均衡的场景下,ROC曲线会是一个更加稳定能反映模型好坏的指标。
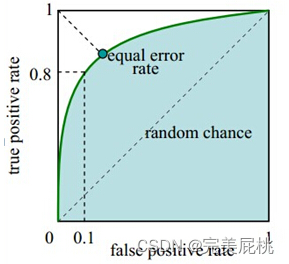

4、ROC曲线和PR曲线的区别,适用场景,各自优缺点。
- ROC曲线对于正负样本比例不敏感。因为ROC曲线纵坐标是精确率,横坐标是误杀率,改变了标签中类别的分布之后,预测正确的正样本/预测为正样本的样本数量会同时发生同向的变化,预测为错误的负样本/所有负样本数量也会发生同向的变化,即ROC的横纵坐标的计算是独立的,分别针对正样本和负样本独立计算,两个坐标的计算不会发生互相影响,因此类别比例发生变化时,ROC也不会剧烈抖动。
- PR曲线纵坐标是精确率,横坐标是召回率。PR横纵坐标的计算结果是存在相互关系的,他们都是针对正样本进行计算,两个坐标的计算发生互相影响,从而使得PR曲线对类别的变化很敏感。
- ROC聚焦于二分类模型整体对正负样本的预测能力,所以适用于评估模型整体的性能;如果主要关注正样本的预测能力而不care负样本的预测能力,则PR曲线更合适。
5、AUC的意义,AUC的计算公式?
- AUC是ROC的曲线下面积。
- AUC的实际意义:正负样本对中预测结果的rank值的比较,假设正样本有x1个,负样本有x0个,则统计正样本*负样本的样本对中,正样本的预测概率大于负样本的预测概率的样本数量z,然后用z/x0*x1就可以得到AUC了,计算的时间复杂度为O(N^2),这里的n指的是样本总数量。 即AUC表示任意选定一个正负样本对,正样本的预测结果大于负样本的预测结果的概率。
5、F1, F2....Fn值是什么,Fβ怎么计算?
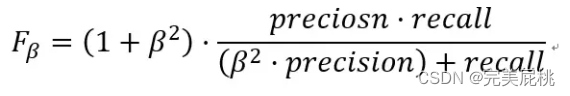
当β等于1时,Fβ等于F1,当β等于n时,Fβ等于Fn。β用于定义召回率和精确率的相对重要性,越大,则召回率越重要,当β趋于无穷大时,Fβ等于召回率;越小,则精确率越重要,当β**2趋于0时,Fβ等于精确率。
6、常见的损失函数有哪些?
- 0-1损失函数,非凸函数,直接优化困难。
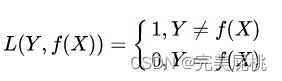
- logloss(交叉熵),多分类损失函数,最常用的损失函数,相对hinge loss对噪声敏感,噪声是指无意义的hard sample。
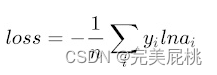
- Cross-entropy(二元交叉熵),logloss在二分类的特例,当使用sigmoid作为激活函数的时候,常用交叉熵损失函数而不用均方误差损失函数,因为它可以完美解决平方损失函数权重更新过慢的问题,具有“误差大的时候,权重更新快;误差小的时候,权重更新慢”的良好特性。
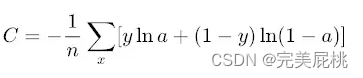
- exponential loss,对噪声敏感,adaboost中使用过,其他情况很少使用。

- hingeloss, 对噪声健壮性强。

- MSE, MAE, RMSE, MAPE, SMAPE。①其中,MSE, MAE, RMSE对标签Y取值特别大的样本鲁棒性都较差,MAE和RMSE相对有所缓解; ②MAPE范围是[0, +∞), MAPE为0%表示完美模型,MAPE大于100%则表示劣质模型,MAPE是MAE多了个字母;③真实值有数据等于0时,存在分母0除问题,需要做平滑;④MAPE对标签Y取值特别大的样本的鲁棒性较强,因为通过除以真实标签(即分母项),对单个异常样本的loss进行了放缩;缺陷在于对标签y取值接近0的样本鲁棒性很差,一点点的偏差就会使得单个样本的MAPE的loss的计算结果很大;⑤SMAPE是针对MAPE的对异常小样本的鲁棒性很差的问题进行了修正,可以较好的避免mape因为真实值yi小而计算结果太大的问题;同时对异常大的样本的鲁棒性也较好;⑥MAPE和SMAPE都可以作为损失函数进行优化。

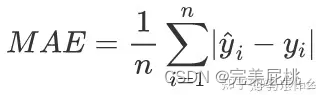
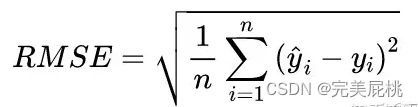
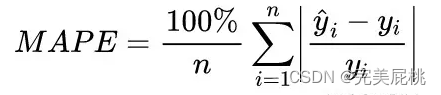

7、MSE均方误差对于异常样本的鲁棒性差的问题怎么解决?
- 如果异常样本无意义,则对异常样本进行平滑等方式处理成正常样本,如果异常样本很稀少,直接删除也行。
- 如果异常样本有意义,例如双十一销量,需要模型把这些有意义的异常考虑进来,则从模型侧考虑使用表达能力更强的模型或复合模型或分群建模等。
- 选择更加鲁棒的损失函数,例如SMAPE。
8、二分类为什么用二元交叉熵?为什么不用MSE?
sigmoid对模型输出进行压缩到(0, 1)区间的条件下,根据二元交叉熵得到的梯度更新公式中不包含sigmoid的求导项,根据MSE的得到的梯度更新公式则会包含。
- 使用MSE推导出的梯度更新量如下,因为sigmoid的性质导致σ′(x)在z取大部分值时会很小(如下图的两端,几乎接近于平坦),这样会使得η(a−y)σ′(z)很小,导致参数w和b更新非常慢。


- 根据二元交叉熵推导出来的梯度更新公式如下,不包含sigmoid的求导项,没这个问题:
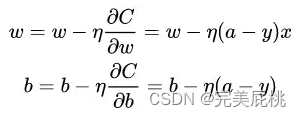
9、信息量,信息熵,相对熵(KL散度),交叉熵,条件熵,互信息,联合熵分别表示什么?
- 信息量:信息量用来度量一个事件的不确定性程度,不确定性越高则信息量越大,一般通过事件发生的概率来定义不确定性,信息量则是基于基于概率密度函数的log运算,公式如下,其中p(x)可以是离散数据的概率,也可以是连续数据的概率密度函数:

- 信息熵:衡量的是一个事件集合的不确定性程度,就是事件集合中所有事件的不确定的期望,公式如下:
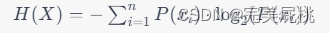
- 相对熵(KL散度):KL散度,从概率统计角度出发,表示用于两个概率分布的差异的非对称衡量,KL散度也可以从信息理论的角度出发,从这个角度出发的KL散度也称为相对熵,实际上描述的是两个概率分布的信息熵的差值。
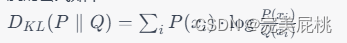 对于离散和连续的随机变量分布都可以使用KL散度进行定义,KL和余弦距离一样,不满足距离的严格定义,其具有非负性和不对称性。
对于离散和连续的随机变量分布都可以使用KL散度进行定义,KL和余弦距离一样,不满足距离的严格定义,其具有非负性和不对称性。 - 交叉熵:交叉熵是真值分布的信息熵与KL散度的和,而真值的熵是确定的,与模型的参数θ 无关,所以梯度下降求导时,优化交叉熵和优化KL散度是一样的。

- 联合熵:联合熵实际上衡量的是两个事件集合,经过组合之后形成的新的大的事件集合的信息熵。
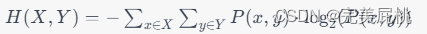
- 互信息:互信息=事件集合X的信息熵-事件集合X在已知事件集合Y下的条件熵=事件集Y的信息熵-事件集合Y在已知事件集合X下的条件熵。
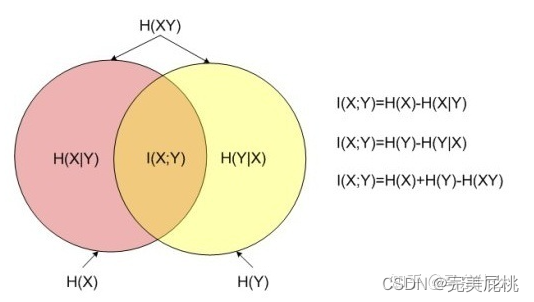
10、怎么衡量两个分布的差异?KL散度和交叉熵损失有什么不同?关系是什么?
- 衡量两个分布的差异可以用KL散度和js散度。
- 交叉熵=真实的标签分布的信息熵+相对熵(KL散度)
11、距离的定义?哪些度量方法不符合距离的定义?
- 定义:在一个结合汇总,如果每一对元素均可唯一确定一个实数,使得三条距离公理(正定性,对称性,三角不等式)成立,则该实数可称为这对元素之间的距离。①正定性:d(x,y)>=0,仅当x=y则不等式等号成立,如果样本A和样本B的距离为0,则样本A和样本B可以看作同一个样本;②对称性:d(x,y)=d(y,x),样本A到样本B的距离等于样本B到样本A的距离;③d(x,y)<d(x,z)+d(z,y),即样本A到样本B的距离小于样本A到样本C的距离+样本B到样本C的距离。
- 余弦距离不满足三角不等式,KL散度不满足对称性,二者都不是严格意义上的距离的定义。
12、交叉熵的设计思想是什么?
优化交叉熵等价于优化KL散度![]() ,其中p是真实分布,它的信息熵H(p)是一个定值,对于模型来说是一个不可优化的常数项,可以把它替换成包括1、Π在内的任何常数,对优化都没有影响。在这种问题中优化交叉熵和优化KL散度是等价的。在多分类问题中,这两者完全一致,因为对于onehot标签来说
,其中p是真实分布,它的信息熵H(p)是一个定值,对于模型来说是一个不可优化的常数项,可以把它替换成包括1、Π在内的任何常数,对优化都没有影响。在这种问题中优化交叉熵和优化KL散度是等价的。在多分类问题中,这两者完全一致,因为对于onehot标签来说![]() ,所以交叉熵是希望模型的预测结果能够尽量和标签的分布保持一致。
,所以交叉熵是希望模型的预测结果能够尽量和标签的分布保持一致。
13、梯度下降的表达式。
- 批量梯度下降:

- 随机梯度下降

14、机器学习中哪些是凸优化问题?哪些是非凸优化问题?请各举例。
- 凸函数的定义为,函数L(.)是凸函数当且仅当对定义域中的任意两点x, y和
总有
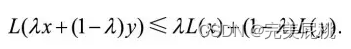
该不等式的一个直观解释是,凸函数曲面上任意两点而成的线段,其上的任意两点连接而成的线段,其上的任意一点都不会处于该函数曲面的下方。

- 凸优化问题包括支持向量机SVM、线性回归等线性模型。
- 非凸优化包括低秩模型(如矩阵分解)、深度神经网络模型等。
15、什么是偏差和方差?
- 偏差:所有采样得到的大小为m的训练数据集训练出的所有模型的输出的平均值和真实模型输出之间的差异。偏差通常是由于我们对学习算法做了错误的假设所导致的,比如真实模型是某个二次函数,但我们假设模型是一次函数,由偏差带来的误差通常在训练误差上就能体现出来。
- 方差:所有采样得到的大小为m的训练数据集训练出的所有模型的输出的方差。方差通常是由于模型的复杂度相对于训练样本数m过高导致的,比如有100个训练样本,而我们假设模型是阶数不大于200的多项式函数,由方差带来的误差通常体现在测试误差相对于训练误差的增量上。
16、特征选择的方法有哪些?
过滤式、包裹式、嵌入式特征选择。过滤式特征选择主要采用独立于模型的评估指标来评估特征的好坏,计算快,能够方便迅速的对特征进行粗筛,缺陷在于评估指标的计算与模型解耦,很多时候精度都不好。
17、什么是过拟合和欠拟合?
- 欠拟合:模型在训练和预测时表现都不够好。
- 过拟合:模型对于训练数据拟合过当,在训练集上表现很好,但在测试集和新数据上的表现较差。
18、如何解决过拟合和欠拟合问题?
- 过拟合:①数据层面:增加样本缓解过拟合;②特征层面:减少特征缓解过拟合;③模型层面:约束模型的复杂程度,如l1,l2,限制树深,学习率缩放,早停,dropout,BN正则,模型集成。
19、为什么需要对数值类型的特征做归一化?
通过梯度下降法求解的模型通常时需要归一化的,包括线性回归、逻辑回归、基于梯度下降法视角下的支持向量机、神经网络等模型,主要原因在于归一化能够大大加快梯度下降法收敛的速度。因为具有相似尺寸的特征可以帮助梯度下降更好更快地收敛;具有不同程度的幅度和范围的特征将导致每个特征的步长不同。为了确保梯度下降更平滑,更快速地收敛,我们需要缩放我们的特征,使他们共享相似的尺寸。
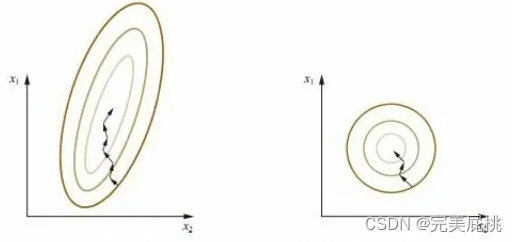
20、逻辑回归损失函数中为啥要加1/N?
1/N(N表示样本数量)可以融合到学习率里去理解,torch的损失函数里面也设计了对loss进行平均和对loss进行求和,平均不求和的差异就在于每一个step对参数W的梯度更新量的差异为N(样本数量)倍,数据量很大时,会导致梯度更新量非常大,权重的变化会非常的剧烈,收敛困难,当学习率缩小n倍达到的效果是一样的。梯度表达式前面的以乘数的形式存在的常数项对梯度下降法的收敛没有任何的影响,本质上可以理解为学习率的变化。
21、逻辑回归使用梯度下降的时候停止条件是什么?
- 达到最大迭代次数
- 所有的权重的梯度更新量的值都小于预先设定的阈值
- 早停
22、逻辑回归是线性模型还是非线性模型?
- 我们将逻辑回归视为线性模型。
- 逻辑回归的输出在进入sigmoid函数之前是线性值,sigmoid将模型输出映射成非线性的值,所以从决策平面来说逻辑回归是线性模型,从输出看逻辑回归是非线性模型。但一般从决策平面来定义线性和非线性,所以还是将逻辑回归视为线性模型。
23、L0、l1、l2范数分别指什么?
- L0范数:向量中非0元素的个数
- L1范数:向量中各个元素绝对值的和
- L2范数:向量中各元素平方和再求平方根。
- 其中L0和L1能够使参数稀疏,但L0范数很难优化,L1范数是L0范数的最优凸近似,而且它比L0范数更容易优化求解;L2范数不但可以防止过拟合,提高模型的泛化能力,还可以让我们的优化求解变得稳定和快速。
相关文章:
算法面试-深度学习基础面试题整理(2023.8.29开始,每天下午持续更新....)
一、无监督相关(聚类、异常检测) 1、常见的距离度量方法有哪些?写一下距离计算公式。 1)连续数据的距离计算: 闵可夫斯基距离家族: 当p 1时,为曼哈顿距离;p 2时,为欧…...
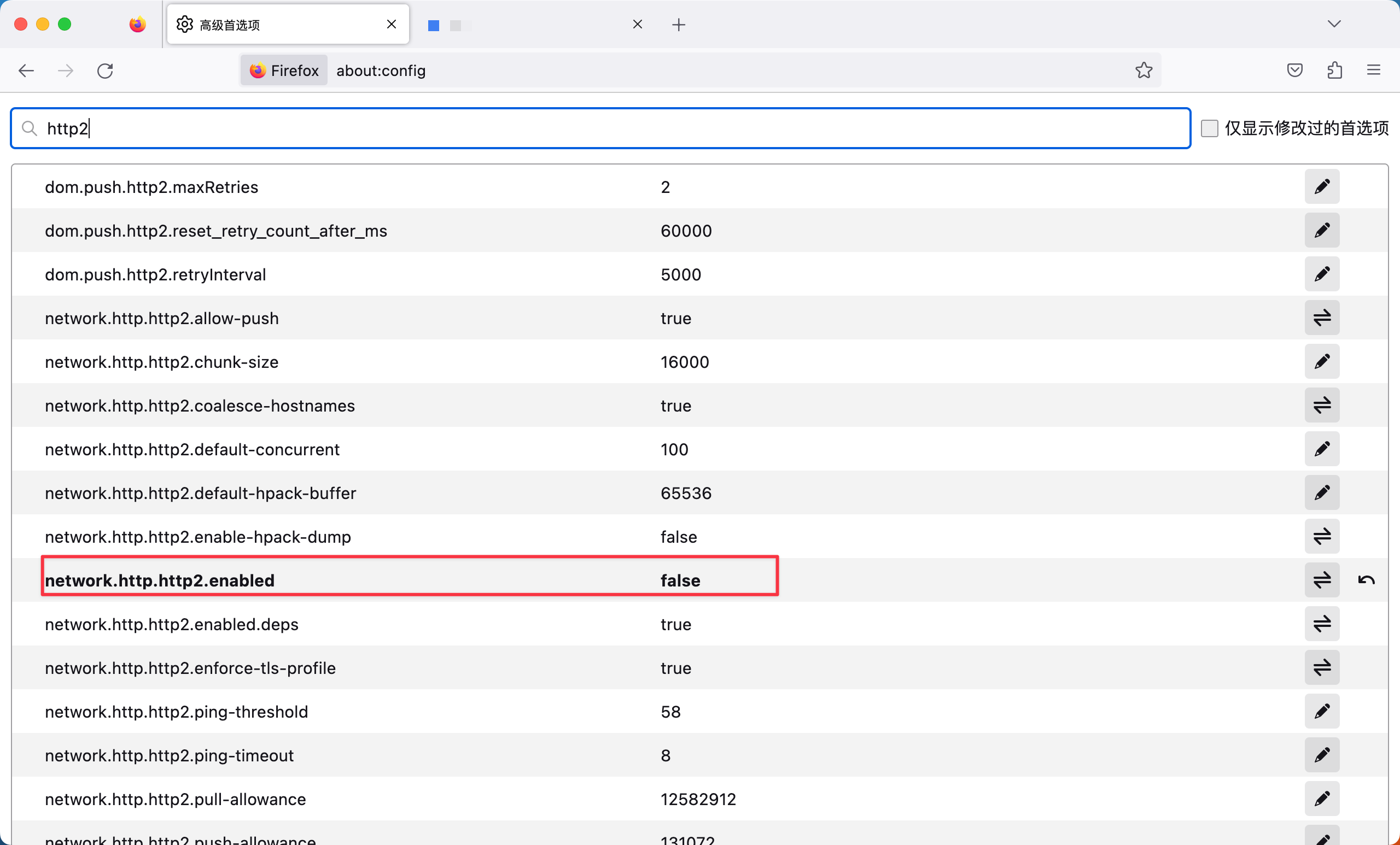
FireFox禁用HTTP2
问题 最近需要调试接口,但是,Chrome都是强制使用h2协议,即HTTP/2协议。为了排除h2协议排除对接口调用的影响,需要强制浏览器使用HTTP1协议。 解决 FireFox 设置firefox的network.http.http2.enabled为禁用,这样就禁…...

搭建HTTPS服务器
HTTPS代理服务器的作用与价值 HTTPS代理服务器可以帮助我们实现网络流量的转发和加密,提高网络安全性和隐私保护。本文将指导您从零开始搭建自己的HTTPS代理服务器,让您更自由、安全地访问互联网。 1. 准备工作:选择服务器与操作系统 a. 选…...

无人化在线静电监控系统的组成
无人化在线静电监控系统是一种用于检测和监控静电情况的系统,它可以自动地实时监测各个区域的静电水平,并在出现异常情况时发出报警信号。静电监控报警器则是该系统中的一个重要组成部分,用于接收和传达报警信号。 无人化在线静电监控系统通…...

element ui级联选择器数据处理
后端同事返回的级联选择器数据的children是childrens,而组件渲染只识别children,所以需要props自定义传入,代码如下 <el-form-item label"应用页面:" prop"appId"><el-cascader:props"{ child…...

zookeeper-3.6.4集群搭建
1、上传zookeeper安装包并解压 上传路径:/opt/software/ 解压路径:/opt/module/ 2、创建数据目录及日志目录 #数据目录:/data/zookeeper/data/ #3台机器创建存储目录: sudo mkdir -p /data/zookeeper/data#日志目录:…...

15种下载文件的方法文件下载方法汇总超大文件下载
15种下载文件的方法&文件下载方法汇总&超大文件下载 15种下载文件的方法Pentesters经常将文件上传到受感染的盒子以帮助进行权限提升,或者保持在计算机上的存在。本博客将介绍将文件从您的计算机移动到受感染系统的15种不同方法。对于那些在盒子上存在且需要…...
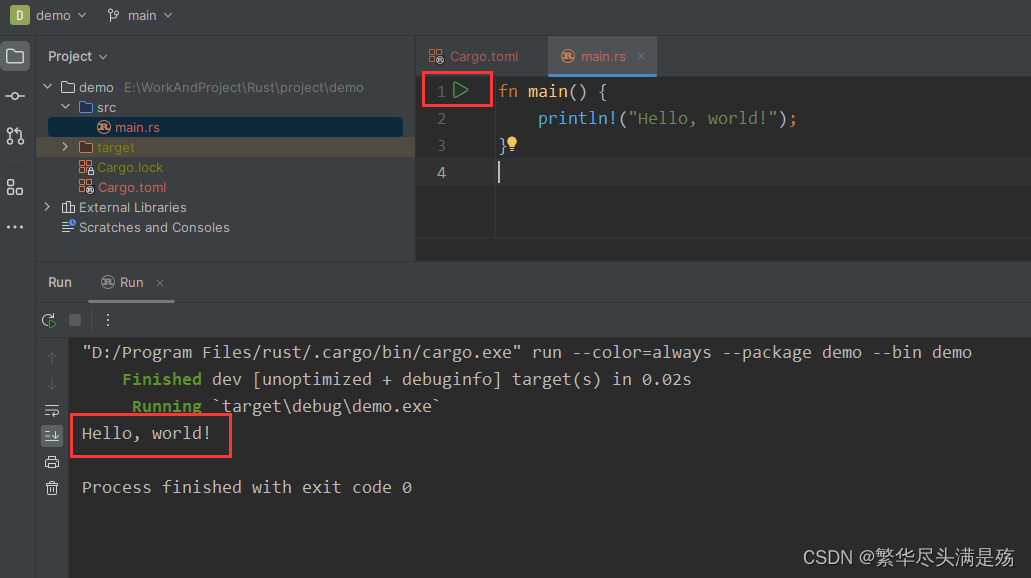
Windows安装配置Rust(附CLion配置与运行)
Windows安装配置Rust(附CLion配置与运行) 前言一、下载二、安装三、配置标准库!!!四、使用 CLion 运行 rust1、新建rust项目2、配置运行环境3、运行 前言 本文以 windows 安装为例,配置编译器为 minGW&…...

【ROS】例说mapserver静态地图参数(对照Rviz、Gazebo环境)
文章目录 例说mapserver静态地图参数1. Rviz中显示的地图2. mapserver保存地图详解3. 补充实验 例说mapserver静态地图参数 1. Rviz中显示的地图 在建图过程中,rviz会显示建图的实时情况,其输出来自于SLAM,浅蓝色区域为地图大小,…...
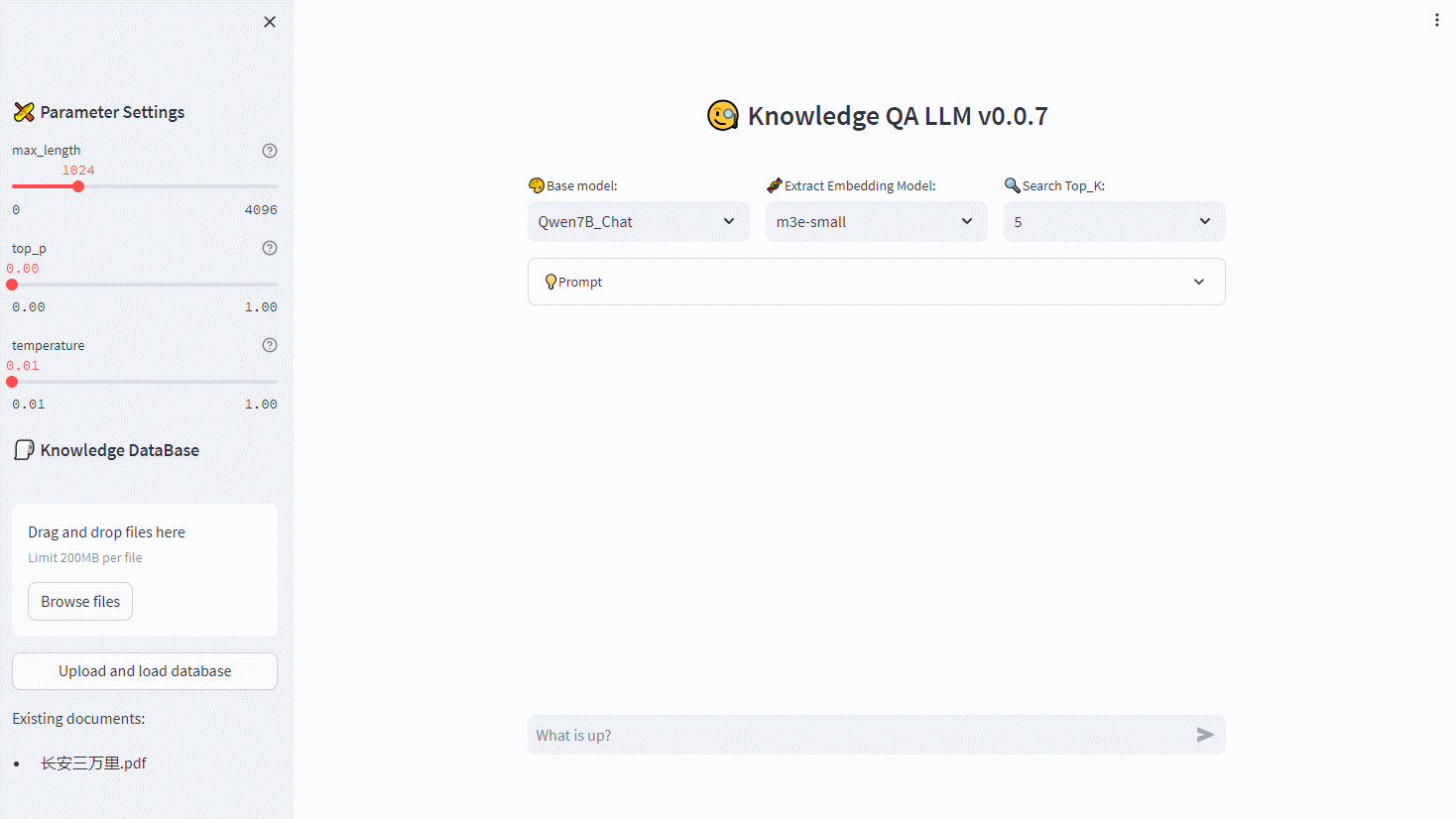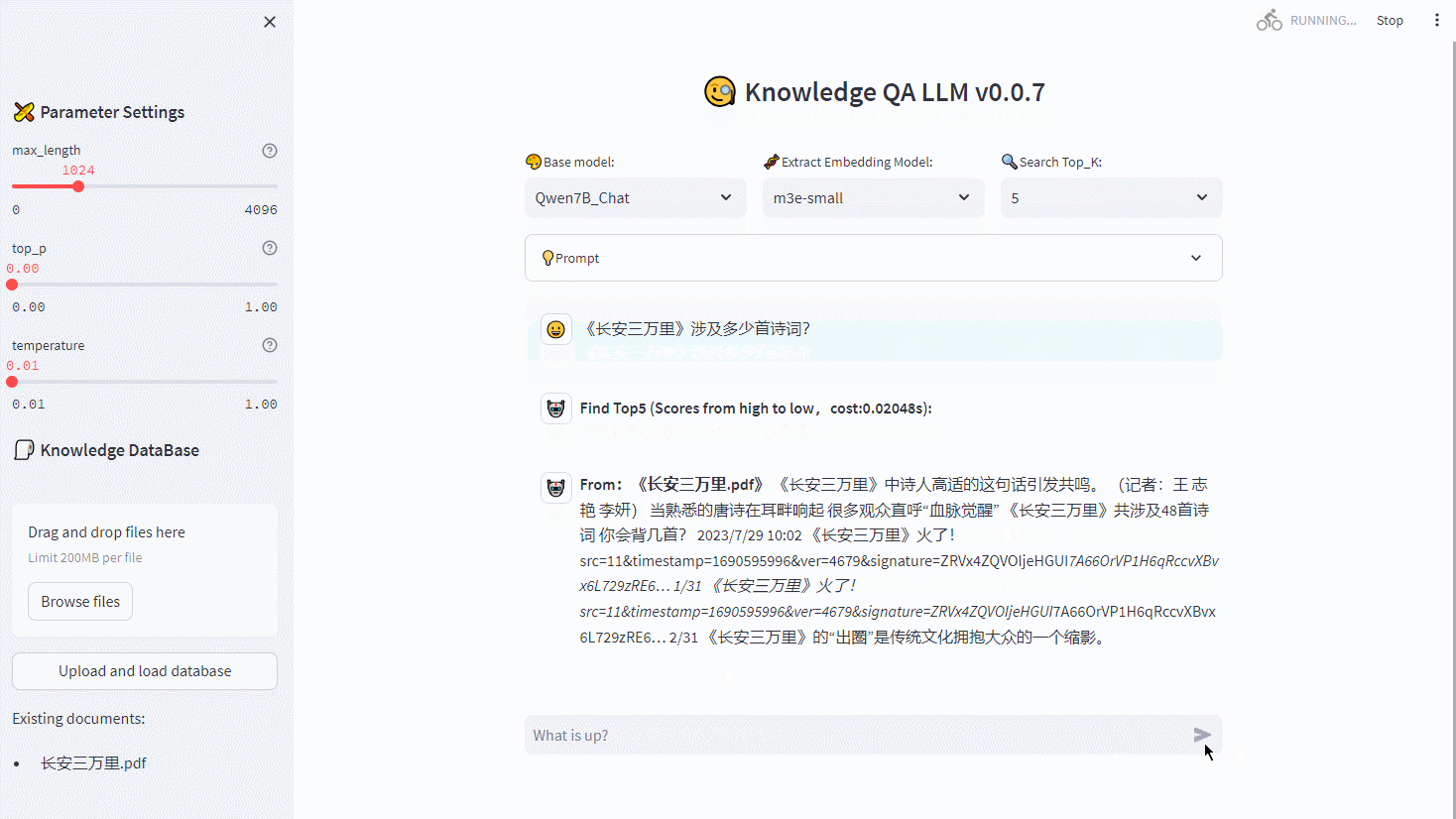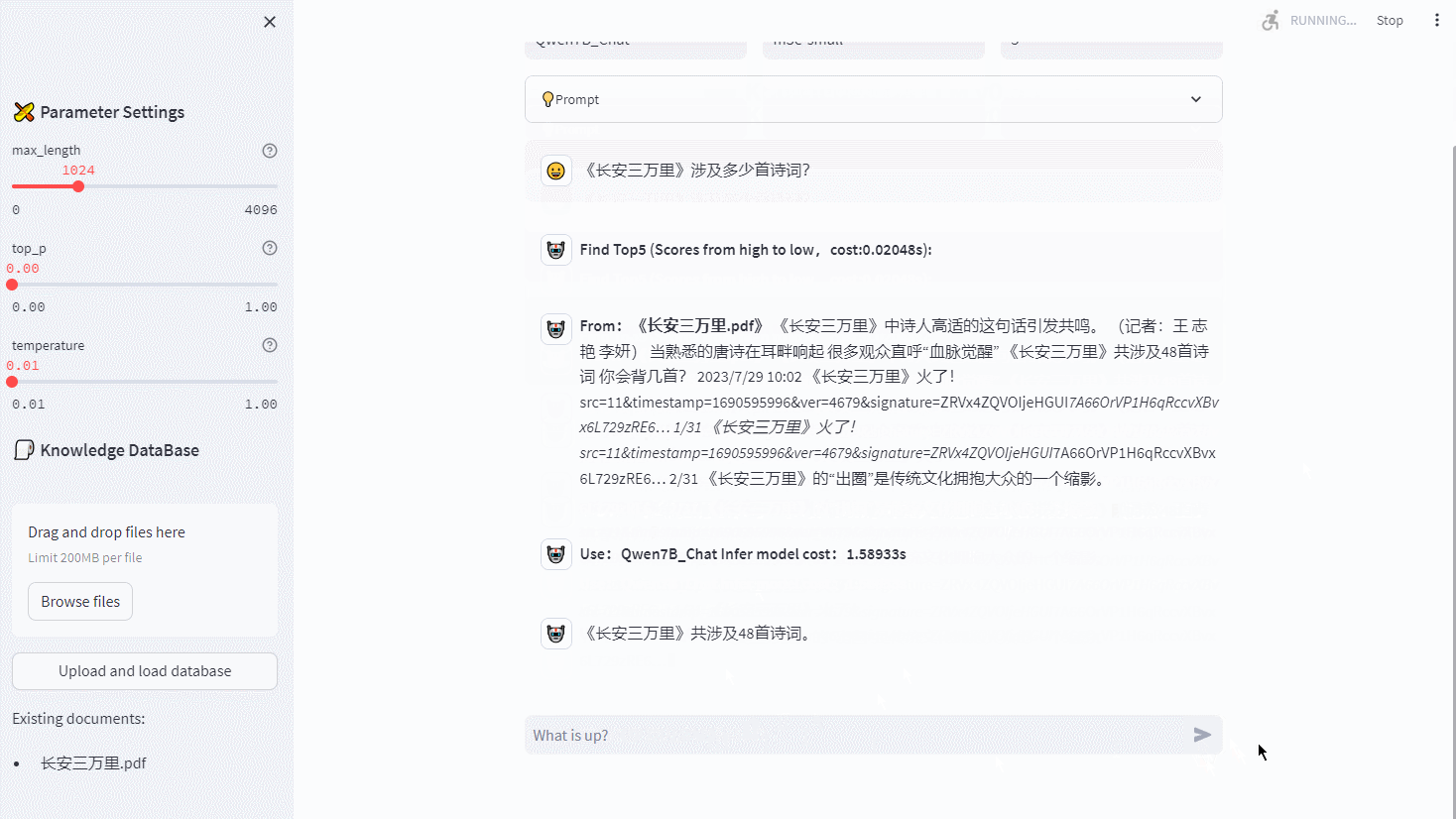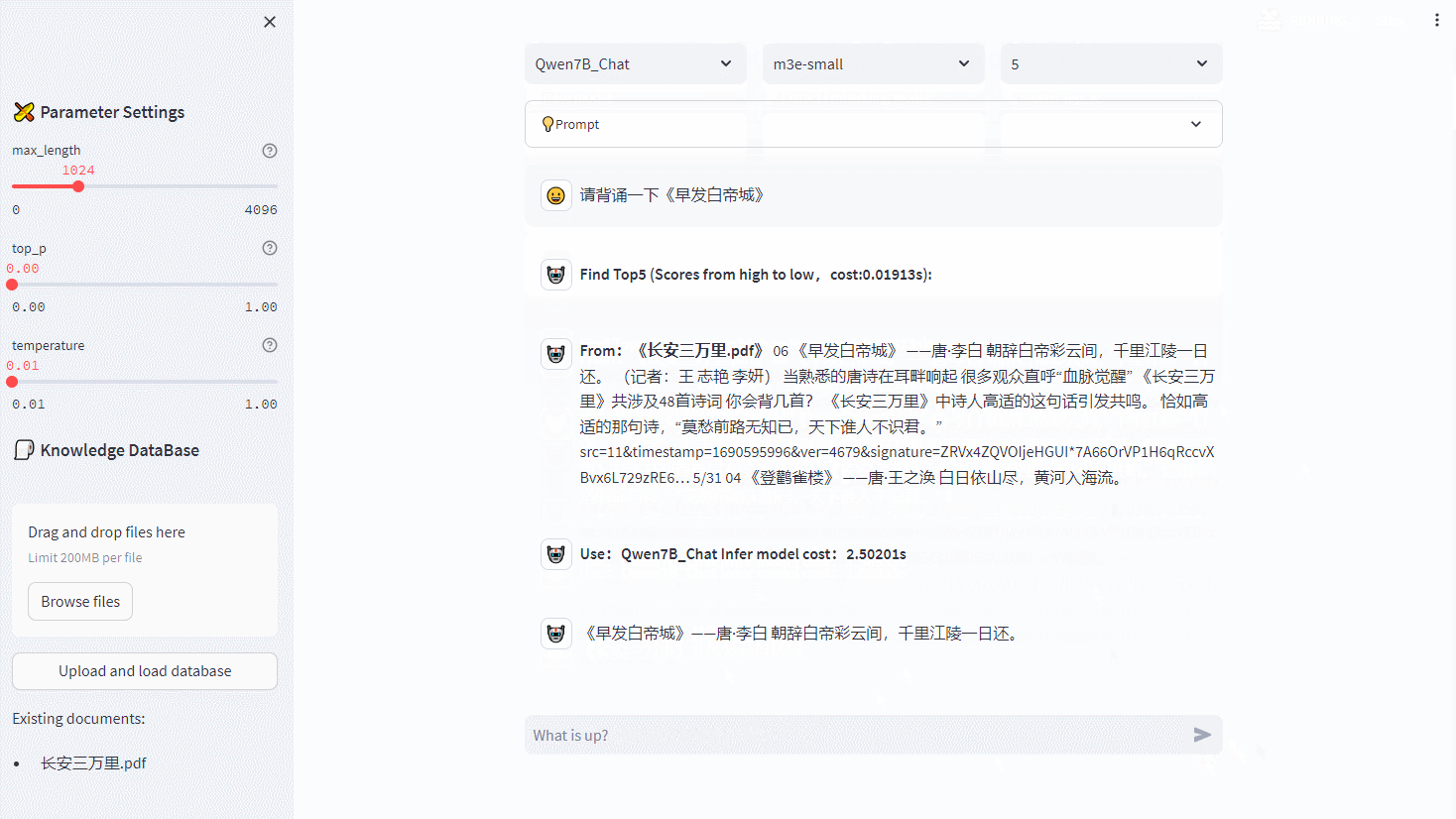
【RapidAI】P0 项目总览
RapidAI 项目总览 ** 内容介绍 ** Author: SWHL、omahs Github: https://github.com/RapidAI/Knowledge-QA-LLM/ CSDN Author: 脚踏实地的大梦想家 UI Demo: ** 读者须知 ** 本系列博文,主要内容为将 RapidAI 项目逐…...
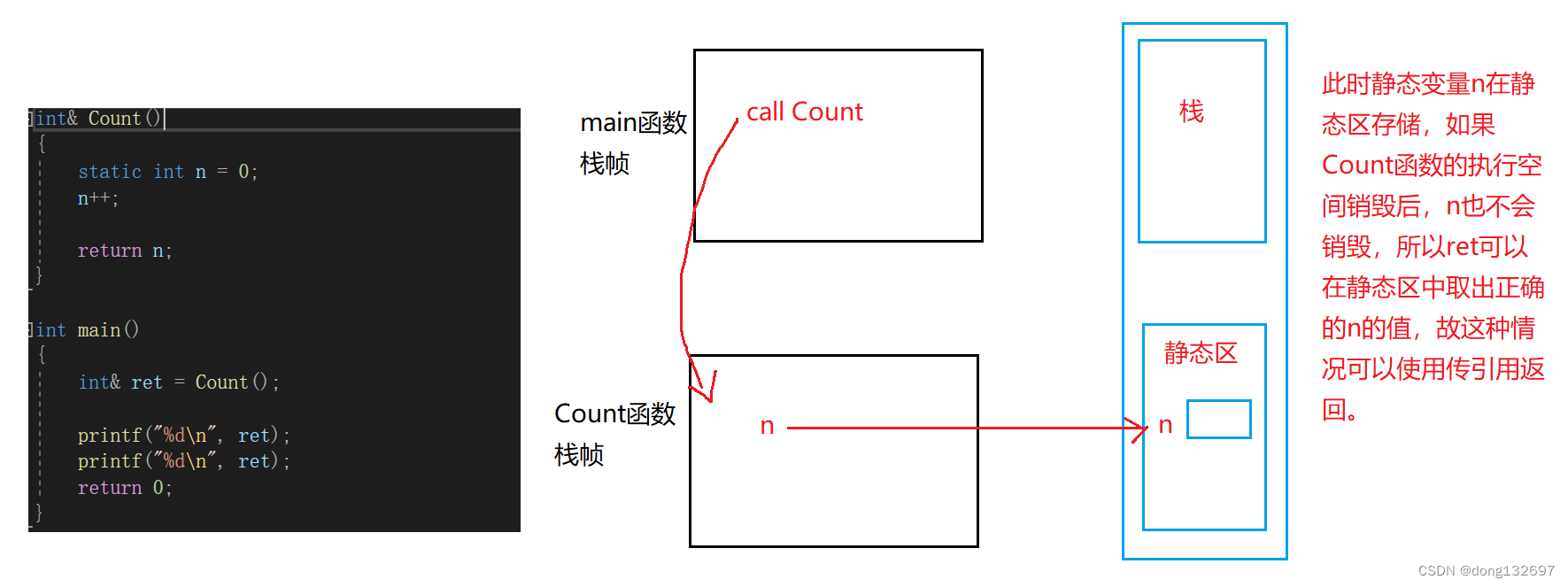
初识c++
文章目录 前言一、C命名空间1、命名空间2、命名空间定义 二、第一个c程序1、c的hello world2、std命名空间的使用惯例 三、C输入&输出1、c输入&输出 四、c中缺省参数1、缺省参数概念2、缺省参数分类3、缺省参数应用 五、c中函数重载1、函数重载概念2、函数重载应用 六、…...

【面试经典150题】跳跃游戏Ⅱ
题目链接 给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。 每个元素 nums[i] 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i j] 处: 0 < j < nums[i]i j < n 返回到达 nums[n…...

20230831-完成登录框的按钮操作,并在登录成功后进行界面跳转
登录框的按钮操作,并在登录成功后进行界面跳转 app.cpp #include "app.h" #include <cstdio> #include <QDebug> #include <QLineEdit> #include <QLabel> #include <QPainter> #include <QString> #include <Q…...

039 - sql逻辑操作符
前提: 做两个表employee和movie,用来练习使用; 表一:employee -- 创建表employee CREATE TABLE IF NOT EXISTS employee(id INT NOT NULL AUTO_INCREMENT,first_name VARCHAR(100) NOT NULL,last_name VARCHAR(100) NOT NULL,t…...

DbLInk使用
DbLInk介绍 DbLink是一种数据库连接技术,在不同的数据库之间进行数据传输和共享。它提供了一种透明的方法,让一个数据库访问另一个数据库的数据。 DbLink的优点是可以在多个数据库间实现数据共享,并且为不同数据库间的数据访问提供了便捷的…...

2.3 Vector 动态数组(迭代器)
C数据结构与算法 目录 本文前驱课程 1 C自学精简教程 目录(必读) 2 Vector<T> 动态数组(模板语法) 本文目标 1 熟悉迭代器设计模式; 2 实现数组的迭代器; 3 基于迭代器的容器遍历; 迭代器语法介绍 对迭…...
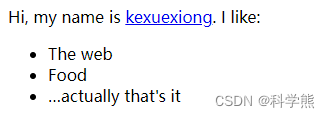
【ES6】Proxy的高级用法,实现一个生成各种 DOM 节点的通用函数dom
下面的例子则是利用get拦截,实现一个生成各种 DOM 节点的通用函数dom。 <body> </body><script>const dom new Proxy({}, {get(target, property) {return function(attrs {}, ...children) {const el document.createElement(property);for …...

气象站是什么设备?功能是什么?
气象站是一种用于测量和记录气象数据的设备。它通常是由各种传感器及其数据传输设备、固定设备和供电设备组成,可以测量风速、风向、温度、湿度、气压、降水量等气象要素,并将这些数据记录下来,以便进一步分析和研究。 气象站通常设置在广阔…...

227. 基本计算器 II Python
文章目录 一、题目描述示例 1示例 2示例 3 二、代码三、解题思路 一、题目描述 给你一个字符串表达式 s ,请你实现一个基本计算器来计算并返回它的值。 整数除法仅保留整数部分。 你可以假设给定的表达式总是有效的。所有中间结果将在 [-2^31, 2^31 - 1]的范围内…...

python中字典常用函数
字典常用函数 cmp(dict1,dict2) (已删除,直接用>,<,即可) 如果两个字典的元素相同返回0,如果字典dict1大于字典dict2返回1,如果字典dict1小于字典dict2返回-1。 先比较字典的长度,然后比较键&#x…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...

MFC 抛体运动模拟:常见问题解决与界面美化
在 MFC 中开发抛体运动模拟程序时,我们常遇到 轨迹残留、无效刷新、视觉单调、物理逻辑瑕疵 等问题。本文将针对这些痛点,详细解析原因并提供解决方案,同时兼顾界面美化,让模拟效果更专业、更高效。 问题一:历史轨迹与小球残影残留 现象 小球运动后,历史位置的 “残影”…...
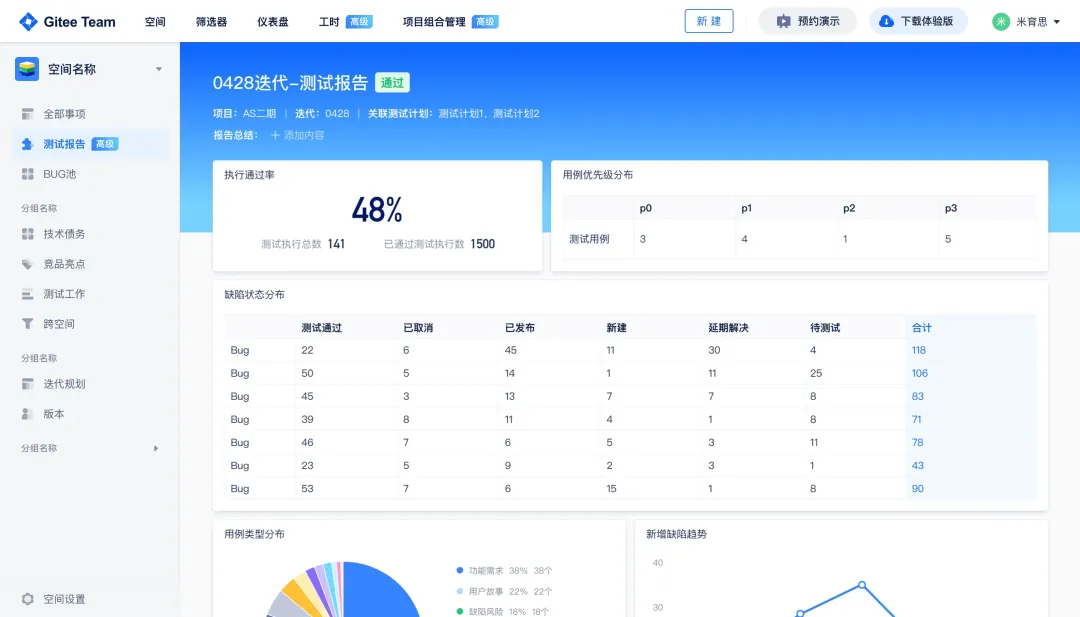
从“安全密码”到测试体系:Gitee Test 赋能关键领域软件质量保障
关键领域软件测试的"安全密码":Gitee Test如何破解行业痛点 在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的"神经中枢"。从国防军工到能源电力,从金融交易到交通管控,这些关乎国计民生的关键领域…...

从面试角度回答Android中ContentProvider启动原理
Android中ContentProvider原理的面试角度解析,分为已启动和未启动两种场景: 一、ContentProvider已启动的情况 1. 核心流程 触发条件:当其他组件(如Activity、Service)通过ContentR…...

Kafka主题运维全指南:从基础配置到故障处理
#作者:张桐瑞 文章目录 主题日常管理1. 修改主题分区。2. 修改主题级别参数。3. 变更副本数。4. 修改主题限速。5.主题分区迁移。6. 常见主题错误处理常见错误1:主题删除失败。常见错误2:__consumer_offsets占用太多的磁盘。 主题日常管理 …...