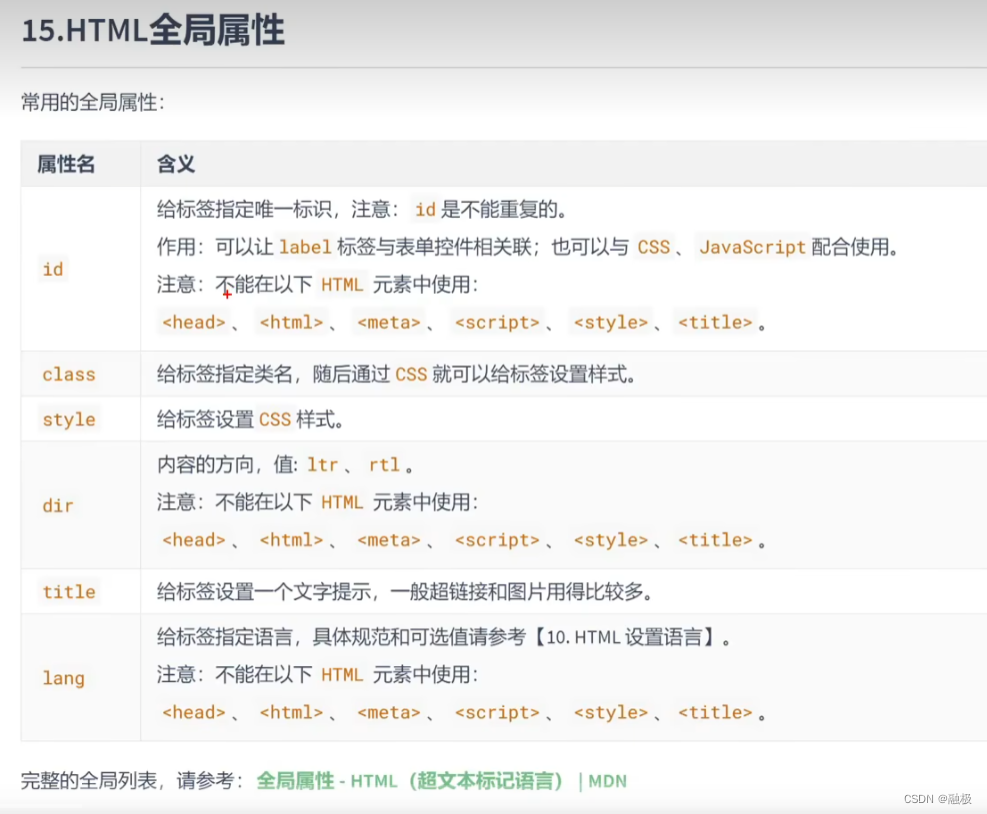
知识图谱项目实践
目录
步骤
SpaCy
Textacy——Text Analysis for Cybersecurity
Networkx
Dateparser
导入库
写出页面的名称
编辑
自然语言处理
词性标注
可能标记的完整列表
依存句法分析(Dependency Parsing,DEP)
可能的标签完整列表
实例理解POS与DEP
可视化注释
Spacy还可执行命名实体识别
可能的所有标签的完整列表
Spacy图形工具
实体和关系抽取
构建图表
网络图
使用Python和自然语言处理构建知识图谱。
知识图谱被视为自然语言处理领域的一部分,因为要构建“知识”,需要进行“语义增强”过程。由于没有人想要手动执行此任务,因此我们需要使用机器和自然语言处理算法来完成此任务。
我们将解析维基百科并提取一个页面,用作本数据集。
俄乌战争-维基百科
步骤
- 设置:使用维基百科API进行网页爬取以读取包和数据。
- NLP使用SpaCy:对文本进行分句、词性标注、依存句法分析和命名实体识别。
- 提取实体及其关系:使用Textacy库来识别实体并建立它们之间的关系。
- 网络图构建:使用NetworkX库来创建和操作图形结构。
- 时间轴图:使用DateParser库来解析日期信息并生成时间轴图。
SpaCy
"spaCy" 这个名称是从 "Space"(空间) 这个词汇中来的,它代表了 spaCy 设计的初衷,即为了提供一个轻量级、高性能的自然语言处理(NLP)库。
SpaCy是一个自然语言处理(NLP)库和工具包,用于处理和分析文本数据。它被设计成高效、快速且易用的工具,具有许多功能,包括分词、命名实体识别、依存关系分析、文本分类等。SpaCy支持多种语言,并提供了预训练的词向量模型。它广泛用于文本挖掘、信息检索、自动化文本分类、情感分析、实体识别、机器翻译等领域。
Textacy——Text Analysis for Cybersecurity
Textacy的名称来源于"Text Analysis for Cybersecurity"(网络安全文本分析),这个名称强调了该库最初的用途,即在网络安全领域中对文本数据进行分析。然而,随着时间的推移,Textacy的功能扩展到了更广泛的自然语言处理和文本挖掘任务,包括情感分析、实体识别、主题建模等,因此它的名称也逐渐演化成了更通用的文本分析工具。
Networkx
NetworkX是一个用于创建、操作和研究复杂网络(图)的Python库。它提供了丰富的功能和工具,使用户能够轻松地构建、分析和可视化各种类型的网络,包括社交网络、网络拓扑、生物网络、交通网络等。
Dateparser
"dateparser" 是一个Python库,用于解析日期和时间字符串。它的主要功能是将各种格式的日期和时间字符串转换成Python的datetime对象,以便在程序中进行日期和时间的处理和计算。
导入库
## for data
import pandas as pd #1.1.5
import numpy as np #1.21.0## for plotting
import matplotlib.pyplot as plt #3.3.2## for text
import wikipediaapi #0.5.8
import nltk #3.8.1
import re## for nlp
import spacy #3.5.0
from spacy import displacy
import textacy #0.12.0## for graph
import networkx as nx #3.0 (also pygraphviz==1.10)## for timeline
import dateparser #1.1.7Wikipedia-api是一个Python库,可轻松解析Wikipedia页面。我们将使用这个库来提取所需的页面,但会排除页面底部的所有“注释”和“参考文献”内容。
写出页面的名称
topic = "Russo-Ukrainian War"wiki = wikipediaapi.Wikipedia('en')
page = wiki.page(topic)
txt = page.text[:page.text.find("See also")]
txt[0:500] + " ..."
topic = "Russo-Ukrainian War":在这一行中,定义了一个名为topic的变量,其中存储了要查询的维基百科主题,即 "Russo-Ukrainian War"(俄乌战争)。wiki = wikipediaapi.Wikipedia('en'):在这一行中,创建了一个名为wiki的维基百科API的实例,使用了英语语言版('en'表示英语)。page = wiki.page(topic):这一行使用wiki实例的page方法来获取与主题topic相关的维基百科页面。这将返回一个包含页面内容的对象,存储在名为page的变量中。txt = page.text[:page.text.find("See also")]:这一行代码从获取的维基百科页面文本中提取了感兴趣的部分。它使用了字符串切片和.find()方法,首先查找文本中 "See also"(通常表示相关链接的部分)的位置,然后将文本截断到这个位置之前,从而得到了页面的一部分文本。这部分文本存储在名为txt的变量中。txt[0:500] + " ...":最后一行代码将前500个字符的文本内容提取出来,然后附加了 " ...",以表示文本的截断。这个结果存储在txt变量中,它包含了从维基百科页面提取的前500个字符的内容。
自然语言处理
#python -m spacy download en_core_web_smnlp = spacy.load("en_core_web_sm")
doc = nlp(txt)#python -m spacy download en_core_web_sm:这是一个注释行,用于表示在终端或命令行中执行的操作。它指示用户下载spaCy的英语语言模型"en_core_web_sm"。这个模型包括了一些用于处理英语文本的语言数据和算法。nlp = spacy.load("en_core_web_sm"):在这一行代码中,首先导入了spaCy库(前提是已经安装了spaCy库)。然后,使用spacy.load()函数加载了之前下载的英语语言模型"en_core_web_sm"。加载后的模型被存储在名为nlp的变量中,以便后续对文本数据进行处理。doc = nlp(txt):在这一行代码中,使用已加载的模型nlp对文本数据txt进行处理。nlp(txt)将文本数据传递给已加载的模型,返回一个Doc对象,其中包含了对文本进行了分词、词性标注、命名实体识别等自然语言处理任务的结果。这个Doc对象存储了文本的各种信息,可以用于进一步的文本分析和处理。

看SpaCy将文本分成了多少个句子:
lst_docs = [sent for sent in doc.sents]
print("tot sentences:", len(lst_docs))lst_docs = [sent for sent in doc.sents]:这一行代码使用了列表推导式(List Comprehension)来遍历doc对象中的每个句子,并将它们存储在一个名为lst_docs的列表中。列表推导式的语法是[expression for item in iterable],在这里,expression是用于生成列表元素的表达式,item是迭代的每个元素,iterable是要迭代的对象。因此,这行代码遍历doc.sents,它是doc对象中句子的一个生成器(generator),并将每个句子添加到lst_docs列表中。

![]()
词性标注
即用适当的语法标签标记句子中的每个单词的过程
可能标记的完整列表
- ADJ: 形容词,例如big,old,green,incomprehensible,first
- ADP: 介词,例如in,to,during
- ADV: 副词,例如very,tomorrow,down,where,there
- AUX: 助动词,例如is,has(done),will(do),should(do)
- CONJ: 连词,例如and,or,but
- CCONJ: 并列连词,例如and,or,but
- DET: 限定词,例如a,an,the
- INTJ: 感叹词,例如psst,ouch,bravo,hello
- NOUN: 名词,例如girl,cat,tree,air,beauty
- NUM: 数词,例如1,2017,one,seventy-seven,IV,MMXIV
- PART: 助词,例如's,not
- PRON: 代词,例如I,you,he,she,myself,themselves,somebody
- PROPN: 专有名词,例如Mary,John,London,NATO,HBO
- PUNCT: 标点符号,例如.,(,),?
- SCONJ: 从属连词,例如if,while,that
- SYM: 符号,例如$,%,§,©,+,-,×,÷,=,:),表情符号
- VERB: 动词,例如run,runs,running,eat,ate,eating
- X: 其他,例如sfpksdpsxmsa
- SPACE: 空格
依存句法分析(Dependency Parsing,DEP)
模型还会尝试理解单词对之间的关系。
可能的标签完整列表
- ACL:作为名词从句的修饰语
- ACOMP:形容词补语
- ADVCL:状语从句修饰语
- ADVMOD:状语修饰语
- AGENT:主语中的动作执行者
- AMOD:形容词修饰语
- APPOS:同位语
- ATTR:主谓结构中的谓语部分
- AUX:助动词
- AUXPASS:被动语态中的助动词
- CASE:格标记
- CC:并列连词
- CCOMP:从句补足语
- COMPOUND:复合修饰语
- CONJ:连接词
- CSUBJ:主语从句
- CSUBJPASS:被动语态中的主语从句
- DATIVE:与双宾语动词相关的间接宾语
- DEP:未分类的依赖
- DET:限定词
- DOBJ:直接宾语
- EXPL:人称代词
- INTJ:感叹词
- MARK:标记
- META:元素修饰语
- NEG:否定修饰语
- NOUNMOD:名词修饰语
- NPMOD:名词短语修饰语
- NSUBJ:名词从句主语
- NSUBJPASS:被动语态中的名词从句主语
- NUMMOD:数字修饰语
- OPRD:宾语补足语
- PARATAXIS:并列结构
- PCOMP:介词的补足语
- POBJ:介词宾语
- POSS:所有格修饰语
- PRECONJ:前置连词
- PREDET:前置限定词
- PREP:介词修饰语
- PRT:小品词
- PUNCT:标点符号
- QUANTMOD:量词修饰语
- RELCL:关系从句修饰语
- ROOT:句子主干
- XCOMP:开放性从句补足语
实例理解POS与DEP
i = 3
list_docs[3]![]()
检查 NLP 模型预测的 POS 和 DEP 标签
for token in lst_docs[i]:print(token.text, "-->", "pos: "+token.pos_, "|", "dep: "+token.dep_, "")token.text:token对象的text属性表示词汇的原始文本内容,即单词或标点符号的字符串。"-->":这部分代码只是一个字符串,用于分隔词汇信息的不同部分,以便输出更易读。"pos: "+token.pos_:token对象的pos_属性表示词汇的词性(Part-of-Speech,POS)。该部分将词汇的词性标签添加到输出中,例如:"pos: NOUN" 表示名词。"|":这部分代码只是一个字符串,用于分隔不同词汇信息。"dep: "+token.dep_:token对象的dep_属性表示词汇与句子中其他词汇的依存关系。该部分将词汇的依存关系标签添加到输出中,例如:"dep: nsubj" 表示名词主语。

可视化注释
SpaCy提供了一个图形工具来可视化这些注释
from spacy import displacydisplacy.render(lst_docs[i], style="dep", options={"distance":100})displacy.render(lst_docs[i], style="dep", options={"distance":100}):这是用于渲染句子依存关系图的函数调用。它包括以下参数:
-
lst_docs[i]:这是要可视化的文本数据,通常是一个Doc对象,或者在这里是句子的Doc对象,表示要可视化的句子。 -
style="dep":这个参数指定了可视化的样式。在这里,我们选择了"dep",表示依存关系图。 -
options={"distance":100}:这是一个字典参数,用于配置可视化选项。在这里,我们设置了"distance"参数,以控制词汇之间的水平距离。较大的距离可以使图更易于阅读。您可以根据需要自定义其他可视化选项。
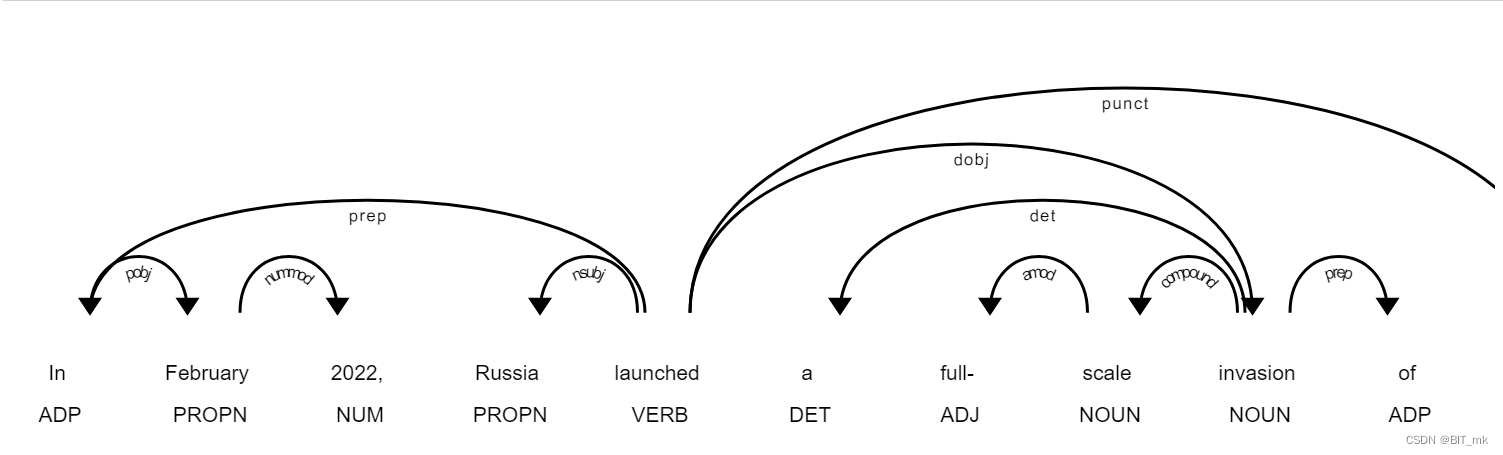
- 最重要的标记是动词 ( POS=VERB ),因为它是句子中含义的词根 ( DEP=ROOT )。
- 助词,如副词和副词 ( POS=ADV/ADP ),通常作为修饰语 ( *DEP=mod ) 与动词相关联,因为它们可以修饰动词的含义。例如,“ travel to ”和“ travel from ”具有不同的含义,即使词根相同(“ travel ”)。
- 在与动词相连的单词中,必须有一些名词(POS=PROPN/NOUN)作为句子的主语和宾语( *DEP=nsubj/obj )。
- 名词通常位于形容词 ( POS=ADJ ) 附近,作为其含义的修饰语 ( DEP=amod )。例如,在“好人”和“坏人”中,形容词赋予名词_“人”相反的含义。
Spacy还可执行命名实体识别
可能的所有标签的完整列表
- 人名: 包括虚构人物。
- 国家、宗教或政治团体:民族、宗教或政治团体。
- 地点:建筑、机场、高速公路、桥梁等。
- 公司、机构等:公司、机构等。
- 地理位置:国家、城市、州。
- 地点:非国家地理位置,山脉、水域等。
- 产品:物体、车辆、食品等(不包括服务)。
- 事件:命名飓风、战斗、战争、体育赛事等。
- 艺术作品:书籍、歌曲等的标题。
- 法律:成为法律的指定文件。
- 语言:任何命名的语言。
- 日期:绝对或相对日期或期间。
- 时间:小于一天的时间。
- 百分比:百分比,包括“%”。
- 货币:货币价值,包括单位。
- 数量:衡量重量或距离等。
- 序数: “第一”,“第二”等。
- 基数:不属于其他类型的数字。
for ent in lst_docs[i].ents:print(tag.text, f"({tag.label_})")print(tag.text, f"({tag.label_})"):在每次迭代中,使用 print() 函数打印每个实体的文本内容和实体类型标签。
-
tag.text:这是实体对象的text属性,表示实体的原始文本内容。 -
f"({tag.label_})":这是一个格式化字符串,用于将实体的类型标签添加到输出中。在字符串中使用了f开头的字符串字面值,它允许在字符串中插入表达式,这里插入了实体的类型标签,标签位于括号中。 -
花括号
{}在格式化字符串中用于表示占位符,可以在运行时将变量或表达式的值插入到字符串中。
在spaCy中,实体(命名实体)对象通常包含两个重要的属性:ent.text 和 ent.label_,它们分别表示实体的文本内容和实体类型标签。

Spacy图形工具
displacy.render(lst_docs[i], style="ent")
实体和关系抽取
对于每个句子,我们将提取主语和宾语以及它们的修饰语、复合词和它们之间的标点符号。
## extract entities and relations
dic = {"id":[], "text":[], "entity":[], "relation":[], "object":[]}for n,sentence in enumerate(lst_docs):lst_generators = list(textacy.extract.subject_verb_object_triples(sentence)) for sent in lst_generators:subj = "_".join(map(str, sent.subject))obj = "_".join(map(str, sent.object))relation = "_".join(map(str, sent.verb))dic["id"].append(n)dic["text"].append(sentence.text)dic["entity"].append(subj)dic["object"].append(obj)dic["relation"].append(relation)## create dataframe
dtf = pd.DataFrame(dic)## example
dtf[dtf["id"]==i]
构建图表
网络图
Python标准库中用于创建和操作图网络的是NetworkX。我们可以从整个数据集开始创建图形,但如果节点太多,可视化将变得混乱:
## create full graph
G = nx.from_pandas_edgelist(dtf, source="entity", target="object", edge_attr="relation", create_using=nx.DiGraph())## plot
plt.figure(figsize=(15,10))pos = nx.spring_layout(G, k=1)
node_color = "skyblue"
edge_color = "black"nx.draw(G, pos=pos, with_labels=True, node_color=node_color, edge_color=edge_color, cmap=plt.cm.Dark2, node_size=2000, connectionstyle='arc3,rad=0.1')nx.draw_networkx_edge_labels(G, pos=pos, label_pos=0.5, edge_labels=nx.get_edge_attributes(G,'relation'),font_size=12, font_color='black', alpha=0.6)
plt.show()G = nx.from_pandas_edgelist(dtf, source="entity", target="object", edge_attr="relation", create_using=nx.DiGraph()):这行代码使用 NetworkX 库创建了一个有向图(DiGraph)。具体解释如下:nx.from_pandas_edgelist(dtf, source="entity", target="object", edge_attr="relation", create_using=nx.DiGraph()):这个函数将 Pandas 数据帧dtf转换为一个有向图。在有向图中,实体作为节点,关系作为有向边,而 "entity" 列和 "object" 列包含了节点之间的连接,"relation" 列包含了边的属性(关系)。plt.figure(figsize=(15,10)):这行代码创建一个新的图形画布,指定了画布的大小为 15x10 像素。pos = nx.spring_layout(G, k=1):这行代码使用 NetworkX 的spring_layout函数布局图形中的节点位置,其中G是创建的有向图。k=1控制了节点之间的相互排斥力,影响图形的布局。node_color和edge_color:这两行代码定义了节点和边的颜色。nx.draw(...):这个函数用于绘制图形。以下是参数的含义:G:要绘制的图形。pos=pos:节点位置的布局。with_labels=True:是否显示节点的标签。node_color=node_color:节点的颜色。edge_color=edge_color:边的颜色。cmap=plt.cm.Dark2:用于定义节点颜色映射的颜色映射。nx.draw_networkx_edge_labels(...):这个函数用于在图形上绘制边的标签。以下是参数的含义:pos=pos:节点位置的布局。label_pos=0.5:标签相对于边的位置。edge_labels=nx.get_edge_attributes(G,'relation'):从图中获取边的属性(关系)作为标签。font_size=12:标签的字体大小。font_color='black':标签的字体颜色。alpha=0.6:标签的透明度。plt.show():这行代码用于显示绘制好的图形。

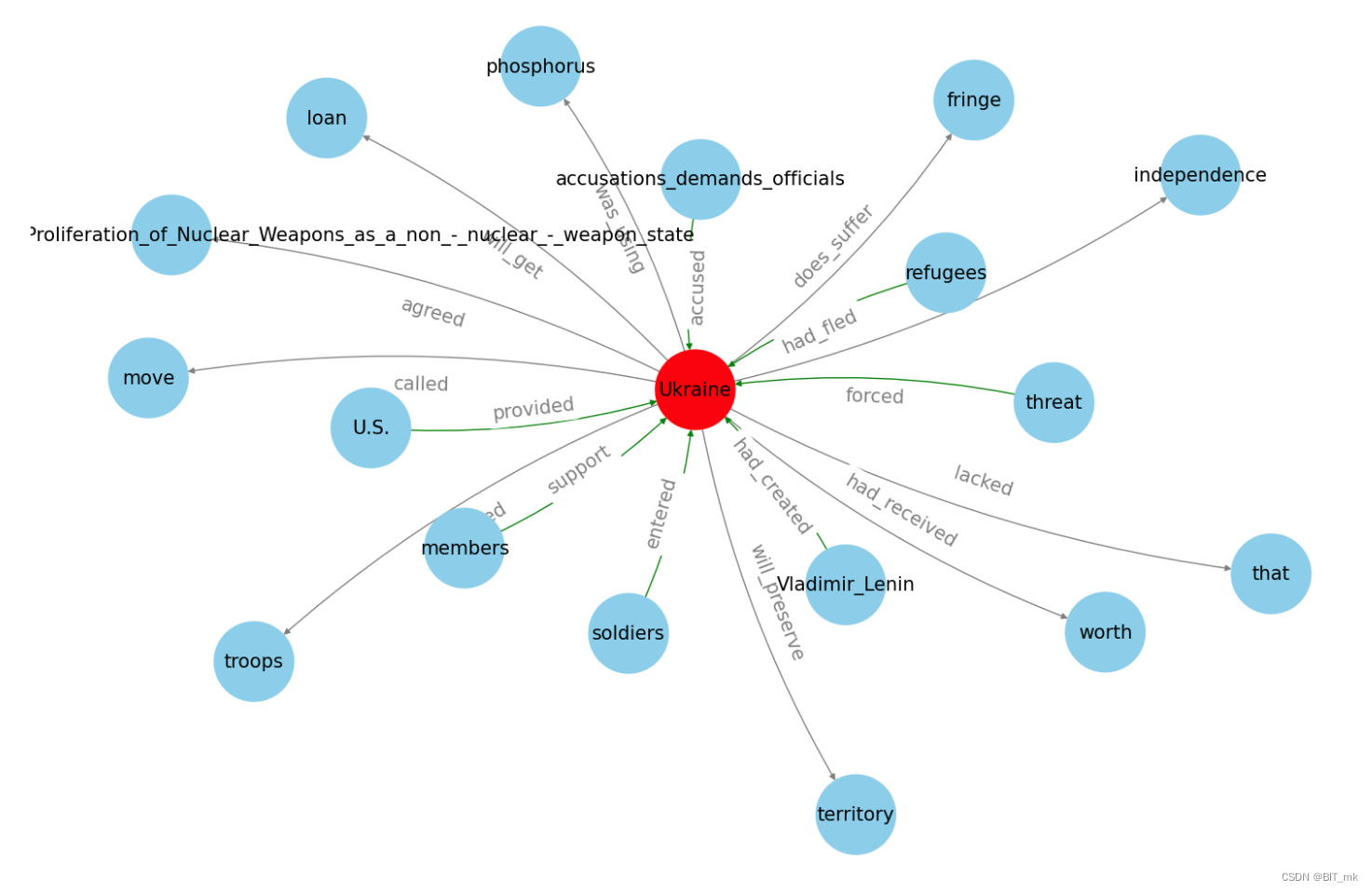
知识图谱可以让我们从大局的角度看到所有事物的相关性,但是如果直接看整张图就没有什么用处。因此,最好根据我们所需的信息应用一些过滤器。对于这个例子,我将只选择涉及最常见实体的部分(基本上是最多连接的节点):
先找出最多连接的节点
dtf["entity"].value_counts().head()
然后进行过滤操作并进行可视化
## filter
f = "Russia"
tmp = dtf[(dtf["entity"]==f) | (dtf["object"]==f)]## create small graph
G = nx.from_pandas_edgelist(tmp, source="entity", target="object", edge_attr="relation", create_using=nx.DiGraph())## plot
plt.figure(figsize=(15,10))pos = nx.spring_layout(G, k=0.5)
node_color = ["red" if node==f else "skyblue" for node in G.nodes]
edge_color = ["red" if edge[0]==f else "black" for edge in G.edges]nx.draw(G, pos=pos, with_labels=True, node_color=node_color, edge_color=edge_color, cmap=plt.cm.Dark2, node_size=800, node_shape="o", width=1.0, connectionstyle='arc3,rad=0.1', font_size=8)nx.draw_networkx_edge_labels(G, pos=pos, label_pos=0.5, edge_labels=nx.get_edge_attributes(G,'relation'),font_size=8, font_color='black', alpha=0.6)
plt.show()
对于Ukraine的效果图
相关文章:
知识图谱项目实践
目录 步骤 SpaCy Textacy——Text Analysis for Cybersecurity Networkx Dateparser 导入库 写出页面的名称 编辑 自然语言处理 词性标注 可能标记的完整列表 依存句法分析(Dependency Parsing,DEP) 可能的标签完整列表 实例理…...

stable diffusion实践操作-提示词-人物属性
系列文章目录 stable diffusion实践操作-提示词 文章目录 系列文章目录前言一、提示词汇总1.1 人物属性11.2 人物属性2 前言 本文主要收纳总结了提示词-人物属性。 一、提示词汇总 1.1 人物属性1 角色类型人物身材胸部头发-发型头发-发色[女仆][霊烏路空][大腿][乳房][呆毛…...

RabbitMQ的安装和配置
将RabbitMQ文件夹传到linux根目录 开启管理界面及配置...

WebRTC 日志
WebRTC 日志 flyfish WebRTC支持的日志等级 // // The meanings of the levels are: // LS_VERBOSE: This level is for data which we do not want to appear in the // normal debug log, but should appear in diagnostic logs. // LS_INFO: Chatty level used in de…...
【python爬虫】16.爬虫知识点总结复习
文章目录 前言爬虫总复习工具解析与提取(一)解析与提取(二)更厉害的请求存储更多的爬虫更强大的爬虫——框架给爬虫加上翅膀 爬虫进阶路线指引解析与提取 存储数据分析与可视化更多的爬虫更强大的爬虫——框架项目训练 反爬虫应对…...
Windows系统中Apache Http服务器简单使用
1 简介 Apache HTTP服务器是一个开源的、跨平台的Web服务器软件。它由Apache软件基金会开发和维护。Apache HTTP服务器可以在多种操作系统上运行,如Windows、Linux、Unix等,并且支持多种编程语言和技术,如PHP、Perl、Python、Java等。…...
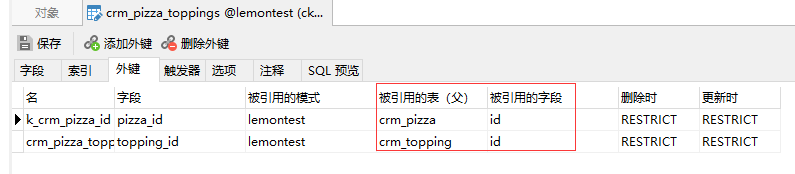
Django ORM 框架中的表关系,你真的弄懂了吗?
Django ORM 框架中的表关系 为了说清楚问题,我们设计一个 crm 系统,包含五张表: 1.tb_student 学生表 2.tb_student_detail 学生详情表 3.tb_salesman 课程顾问表 4.tb_course 课程表 5.tb_entry 报名表 表关系和字段如下图:…...

第五课:C++实现加密PDF文档解密
请注意,未经授权的加密PDF文件解密是非法的,本文仅为学术和研究目的提供参考。 打开加密的PDF文件并获取密钥 在C++中,可以使用pdfium库打开加密的PDF文件。使用pdfium库中的FPDF_LoadCustomDocument函数可以打开具有自定义访问权限的加密文件。该函数接受一个IFX_FileRead*…...

罗马数字转整数
罗马数字转整数 题目: 罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M …...
processflow流程图多人协作预热
前言 在线上办公如火如荼的今天,多人协作功能是每个应用绕不开的门槛。processflow在线流程图(前身基于drawio二次开发)沉寂两年之久,经过长时间设计开发,调整,最终完成了多人协作的核心模块设计。废话不多…...
)
PCL点云处理之快速计算多个点到同一直线的距离(二百零五)
PCL点云处理之快速计算多个点到同一直线的距离(二百零五) 一、算法简介二、具体实现1.代码2.结果一、算法简介 点到直线的距离计算,是一种常用的算法,在点云处理中,经常遇到需要计算多个点云到同一条直线的距离计算需求,此时若是逐点计算将耗费大量的时间,熟悉点到直线…...

xxl-job 任务调度搭建及简单使用
xxl-job是开源架构,可以通过它实现调度中心和执行器。 git地址和 官网中进行了详细的技术说明。 xxl-job支持单机部署和集群式部署,在集群式部署中又可以实现调度中心集群式部署和执行器集群式部署。本文主要针对调度中心和执行器分离单机部署方式进…...
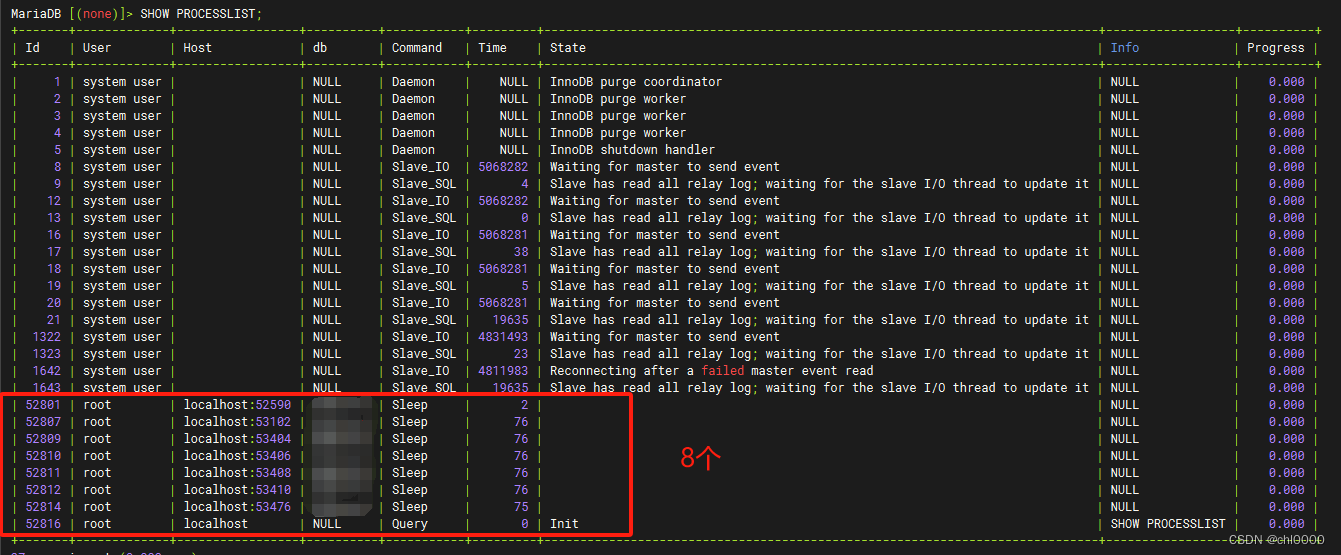
mysql数据库使用技巧整理
查看当前数据库已建立的client连接 > SHOW VARIABLES LIKE max_connections; -- 查看数据库允许的最大连接数,不是实时正在使用的连接数 > SHOW STATUS LIKE Threads_connected; -- 查看当前数据库client的连接数 > SHOW PROCESSLIST; -- 查看具体的连接...

车规微控制器的ECC机制及EMU外设
车规微控制器的ECC机制及EMU外设 文章目录 车规微控制器的ECC机制及EMU外设引言ECC的基本原理ECC RAM的访问方式ECC RAM的初始化SRAM ECC错误注入及EMU外设Flash ECC校验参考文献 引言 ECC是微控制器系统中,用于保障信息安全的常用机制,主要是避免存储设…...

Less的强大变量用法
less中的变量应用十分强大,可以灵活的应用到各种不同需求的场景。 一,属性值变量 声明:sass声明变量是用$符号,而less声明变量是用符号 作用域:也区分为全局变量和局部变量,如果引用的变量有定义局部变量&…...

【相机标定】opencv python 标定相机内参时不计算 k3 畸变参数
文章目录 1. 背景2. 完整的 opencv python 标定相机内参过程3. 选择是否计算畸变参数 k3 1. 背景 畸变参数 k3 通常用于描述径向畸变的更高阶效应,即在需要高精度的应用中可以用到,一般的应用中 k1, k2 足矣。 常见的应用中, orbslam3 中是否…...
html 标签简介
概述 标签的效果不重要,重要的是标签的语义。 文本标签 文本标签用于包裹:词汇、短语等。排版标签,比如div,p,h1等。排版标签更宏观(大段的文字),文本标签更微观(词汇、短语)。文…...

dos汇编总结
前言: 计组课本需要学习汇编,可惜自己看不太懂。这里发现一个学习方法交给大家。其实新手可能一些抽象表示难理解,这里我把我学习的疑问点以及思路记录一下。 要点: 这里我以题为例给大家分析 输出输入对应大写字母的小写字母 …...

四川玖璨电子商务有限公司:短视频有什么运营
根据短视频有什么运营,短视频的拍摄工具多种多样。无论是在手机上拍摄还是使用专业摄影设备,拍摄短视频的目的都是为了吸引观众的注意力和提升内容的质量。从小花费到高投入,在不断发展的短视频行业中,拍摄方法也得到了不断创新和…...
混合查询多家快递,快速掌握物流信息
在现代社会,快递服务已成为我们日常生活的重要组成部分。无论是购物还是文件传递,我们都需要快递服务的帮助。然而,不同的快递公司需要不同的查询方法,这无疑增加了我们的查询难度。因此,有没有一种方法可以让我们一次…...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

基于Java Swing的电子通讯录设计与实现:附系统托盘功能代码详解
JAVASQL电子通讯录带系统托盘 一、系统概述 本电子通讯录系统采用Java Swing开发桌面应用,结合SQLite数据库实现联系人管理功能,并集成系统托盘功能提升用户体验。系统支持联系人的增删改查、分组管理、搜索过滤等功能,同时可以最小化到系统…...

NXP S32K146 T-Box 携手 SD NAND(贴片式TF卡):驱动汽车智能革新的黄金组合
在汽车智能化的汹涌浪潮中,车辆不再仅仅是传统的交通工具,而是逐步演变为高度智能的移动终端。这一转变的核心支撑,来自于车内关键技术的深度融合与协同创新。车载远程信息处理盒(T-Box)方案:NXP S32K146 与…...

LLMs 系列实操科普(1)
写在前面: 本期内容我们继续 Andrej Karpathy 的《How I use LLMs》讲座内容,原视频时长 ~130 分钟,以实操演示主流的一些 LLMs 的使用,由于涉及到实操,实际上并不适合以文字整理,但还是决定尽量整理一份笔…...