pytorch-构建卷积神经网络
构建卷积神经网络
- 卷积网络中的输入和层与传统神经网络有些区别,需重新设计,训练模块基本一致
import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F from torchvision import datasets,transforms import matplotlib.pyplot as plt import numpy as np %matplotlib inline首先读取数据
- 分别构建训练集和测试集(验证集)
- DataLoader来迭代取数据
# 定义超参数 input_size = 28 #图像的总尺寸28*28 num_classes = 10 #标签的种类数 num_epochs = 3 #训练的总循环周期 batch_size = 64 #一个撮(批次)的大小,64张图片# 训练集 train_dataset = datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) # 测试集 test_dataset = datasets.MNIST(root='./data', train=False, transform=transforms.ToTensor())# 构建batch数据 train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True) test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=True)卷积网络模块构建
- 一般卷积层,relu层,池化层可以写成一个套餐
- 注意卷积最后结果还是一个特征图,需要把图转换成向量才能做分类或者回归任务
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.conv1 = nn.Sequential( # 输入大小 (1, 28, 28)nn.Conv2d(in_channels=1, # 灰度图out_channels=16, # 要得到几多少个特征图kernel_size=5, # 卷积核大小stride=1, # 步长padding=2, # 如果希望卷积后大小跟原来一样,需要设置padding=(kernel_size-1)/2 if stride=1), # 输出的特征图为 (16, 28, 28)nn.ReLU(), # relu层nn.MaxPool2d(kernel_size=2), # 进行池化操作(2x2 区域), 输出结果为: (16, 14, 14))self.conv2 = nn.Sequential( # 下一个套餐的输入 (16, 14, 14)nn.Conv2d(16, 32, 5, 1, 2), # 输出 (32, 14, 14)nn.ReLU(), # relu层nn.Conv2d(32, 32, 5, 1, 2),nn.ReLU(),nn.MaxPool2d(2), # 输出 (32, 7, 7))self.conv3 = nn.Sequential( # 下一个套餐的输入 (16, 14, 14)nn.Conv2d(32, 64, 5, 1, 2), # 输出 (32, 14, 14)nn.ReLU(), # 输出 (32, 7, 7))self.out = nn.Linear(64 * 7 * 7, 10) # 全连接层得到的结果def forward(self, x):x = self.conv1(x)x = self.conv2(x)x = self.conv3(x)x = x.view(x.size(0), -1) # flatten操作,结果为:(batch_size, 32 * 7 * 7)output = self.out(x)return output准确率作为评估标准
def accuracy(predictions, labels):pred = torch.max(predictions.data, 1)[1] rights = pred.eq(labels.data.view_as(pred)).sum() return rights, len(labels)训练网络模型
# 实例化 net = CNN() #损失函数 criterion = nn.CrossEntropyLoss() #优化器 optimizer = optim.Adam(net.parameters(), lr=0.001) #定义优化器,普通的随机梯度下降算法#开始训练循环 for epoch in range(num_epochs):#当前epoch的结果保存下来train_rights = [] for batch_idx, (data, target) in enumerate(train_loader): #针对容器中的每一个批进行循环net.train() output = net(data) loss = criterion(output, target) optimizer.zero_grad() loss.backward() optimizer.step() right = accuracy(output, target) train_rights.append(right) if batch_idx % 100 == 0: net.eval() val_rights = [] for (data, target) in test_loader:output = net(data) right = accuracy(output, target) val_rights.append(right)#准确率计算train_r = (sum([tup[0] for tup in train_rights]), sum([tup[1] for tup in train_rights]))val_r = (sum([tup[0] for tup in val_rights]), sum([tup[1] for tup in val_rights]))print('当前epoch: {} [{}/{} ({:.0f}%)]\t损失: {:.6f}\t训练集准确率: {:.2f}%\t测试集正确率: {:.2f}%'.format(epoch, batch_idx * batch_size, len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.data, 100. * train_r[0].numpy() / train_r[1], 100. * val_r[0].numpy() / val_r[1]))当前epoch: 0 [0/60000 (0%)] 损失: 2.300918 训练集准确率: 10.94% 测试集正确率: 10.10% 当前epoch: 0 [6400/60000 (11%)] 损失: 0.204191 训练集准确率: 78.06% 测试集正确率: 93.31% 当前epoch: 0 [12800/60000 (21%)] 损失: 0.039503 训练集准确率: 86.51% 测试集正确率: 96.69% 当前epoch: 0 [19200/60000 (32%)] 损失: 0.057866 训练集准确率: 89.93% 测试集正确率: 97.54% 当前epoch: 0 [25600/60000 (43%)] 损失: 0.069566 训练集准确率: 91.68% 测试集正确率: 97.68% 当前epoch: 0 [32000/60000 (53%)] 损失: 0.228793 训练集准确率: 92.85% 测试集正确率: 98.18% 当前epoch: 0 [38400/60000 (64%)] 损失: 0.111003 训练集准确率: 93.72% 测试集正确率: 98.16% 当前epoch: 0 [44800/60000 (75%)] 损失: 0.110226 训练集准确率: 94.28% 测试集正确率: 98.44% 当前epoch: 0 [51200/60000 (85%)] 损失: 0.014538 训练集准确率: 94.78% 测试集正确率: 98.60% 当前epoch: 0 [57600/60000 (96%)] 损失: 0.051019 训练集准确率: 95.14% 测试集正确率: 98.45% 当前epoch: 1 [0/60000 (0%)] 损失: 0.036383 训练集准确率: 98.44% 测试集正确率: 98.68% 当前epoch: 1 [6400/60000 (11%)] 损失: 0.088116 训练集准确率: 98.50% 测试集正确率: 98.37% 当前epoch: 1 [12800/60000 (21%)] 损失: 0.120306 训练集准确率: 98.59% 测试集正确率: 98.97% 当前epoch: 1 [19200/60000 (32%)] 损失: 0.030676 训练集准确率: 98.63% 测试集正确率: 98.83% 当前epoch: 1 [25600/60000 (43%)] 损失: 0.068475 训练集准确率: 98.59% 测试集正确率: 98.87% 当前epoch: 1 [32000/60000 (53%)] 损失: 0.033244 训练集准确率: 98.62% 测试集正确率: 99.03% 当前epoch: 1 [38400/60000 (64%)] 损失: 0.024162 训练集准确率: 98.67% 测试集正确率: 98.81% 当前epoch: 1 [44800/60000 (75%)] 损失: 0.006713 训练集准确率: 98.69% 测试集正确率: 98.17% 当前epoch: 1 [51200/60000 (85%)] 损失: 0.009284 训练集准确率: 98.69% 测试集正确率: 98.97% 当前epoch: 1 [57600/60000 (96%)] 损失: 0.036536 训练集准确率: 98.68% 测试集正确率: 98.97% 当前epoch: 2 [0/60000 (0%)] 损失: 0.125235 训练集准确率: 98.44% 测试集正确率: 98.73% 当前epoch: 2 [6400/60000 (11%)] 损失: 0.028075 训练集准确率: 99.13% 测试集正确率: 99.17% 当前epoch: 2 [12800/60000 (21%)] 损失: 0.029663 训练集准确率: 99.26% 测试集正确率: 98.39% 当前epoch: 2 [19200/60000 (32%)] 损失: 0.073855 训练集准确率: 99.20% 测试集正确率: 98.81% 当前epoch: 2 [25600/60000 (43%)] 损失: 0.018130 训练集准确率: 99.16% 测试集正确率: 99.09% 当前epoch: 2 [32000/60000 (53%)] 损失: 0.006968 训练集准确率: 99.15% 测试集正确率: 99.11%
相关文章:

pytorch-构建卷积神经网络
构建卷积神经网络 卷积网络中的输入和层与传统神经网络有些区别,需重新设计,训练模块基本一致 import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F from torchvision import datasets,transforms impor…...
)
点云从入门到精通技术详解100篇-点云滤波算法及单木信息提取(续)
目录 3.3 点云滤波算法原理概述 3.3.1 坡度滤波算法 3.3.2 基于不规则三角网滤波 3.3.3 数学形态学滤波...

Gartner发布中国科技报告:数据编织和大模型技术崭露头角
近日,全球知名科技研究和咨询机构Gartner发布了关于中国数据分析与人工智能技术的最新报告。报告指出,中国正迎来数据分析与人工智能领域的蓬勃发展,预计到2026年,将有超过30%的白领工作岗位重新定义,生成式人工智能技…...

java八股文面试[数据库]——explain
使用 EXPLAIN 关键字可以模拟优化器来执行SQL查询语句,从而知道MySQL是如何处理我们的SQL语句的。分析出查询语句或是表结构的性能瓶颈。 MySQL查询过程 通过explain我们可以获得以下信息: 表的读取顺序 数据读取操作的操作类型 哪些索引可以被使用 …...

Kafka3.0.0版本——增加副本因子
目录 一、服务器信息二、启动zookeeper和kafka集群2.1、先启动zookeeper集群2.2、再启动kafka集群 三、增加副本因子3.1、增加副本因子的概述3.2、增加副本因子的示例3.2.1、创建topic(主题)3.2.2、手动增加副本存储 一、服务器信息 四台服务器 原始服务器名称原始服务器ip节点…...
升级iOS 17出现白苹果、不断重启等系统问题怎么办?
iOS 17发布后了,很多果粉都迫不及待的将iphone/ipad升级到最新iOS17系统,体验新系统功能。 但部分果粉因硬件、软件的各种情况,导致升级系统后出现故障,比如白苹果、不断重启、卡在系统升级界面等等问题。 如果遇到了这些系统问题…...

6. `Java` 并发基础之`ReentrantReadLock`
前言:随着多线程程序的普及,线程同步的问题变得越来越常见。Java中提供了多种同步机制来确保线程安全,其中之一就是ReentrantLock。ReentrantLock是Java中比较常用的一种同步机制,它提供了一系列比synchronized更加灵活和可控的操…...
float浮动布局大战position定位布局
华子目录 布局方式普通文档流布局浮动布局(浮动主要针对与black,inline元素)float属性浮动用途浮动元素父级高度塌陷 position属性定位篇相对定位(relative为属性值,配合left属性,和top属性使用)…...
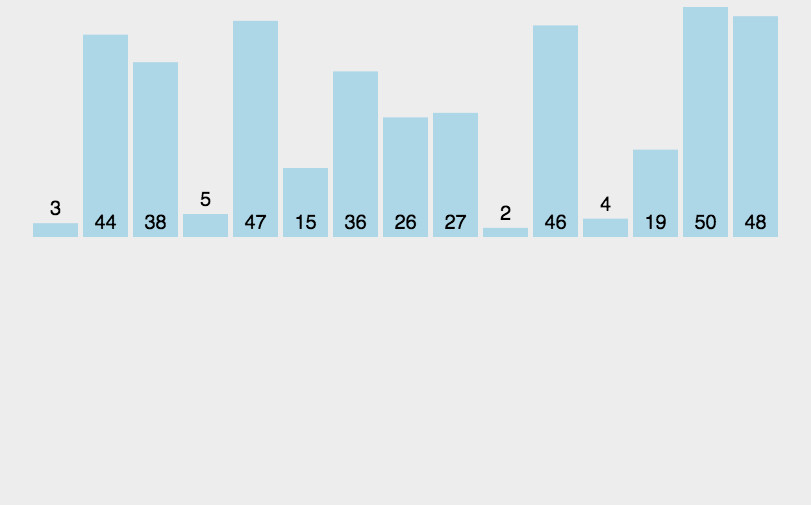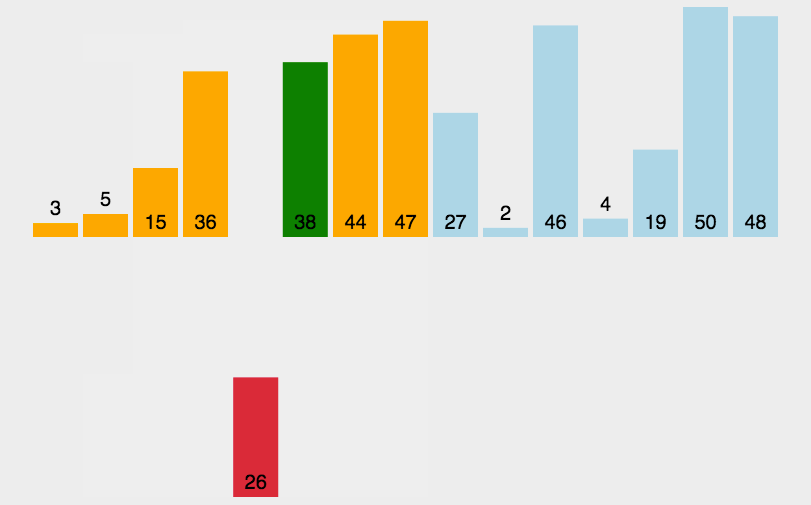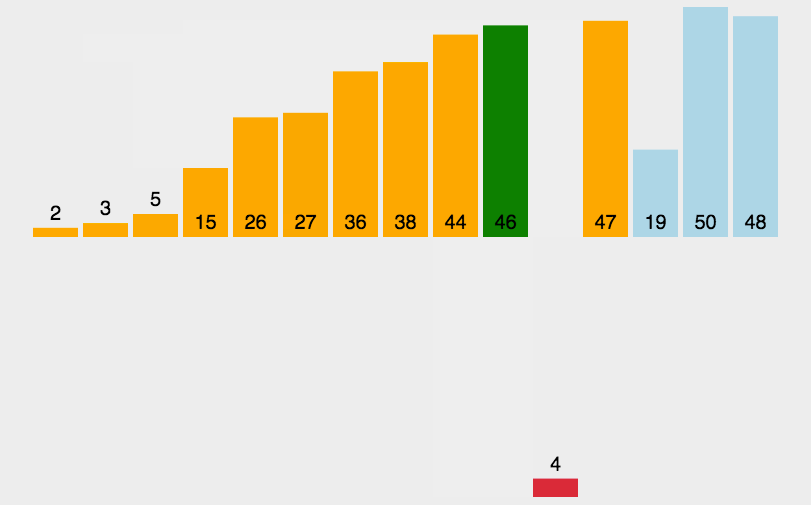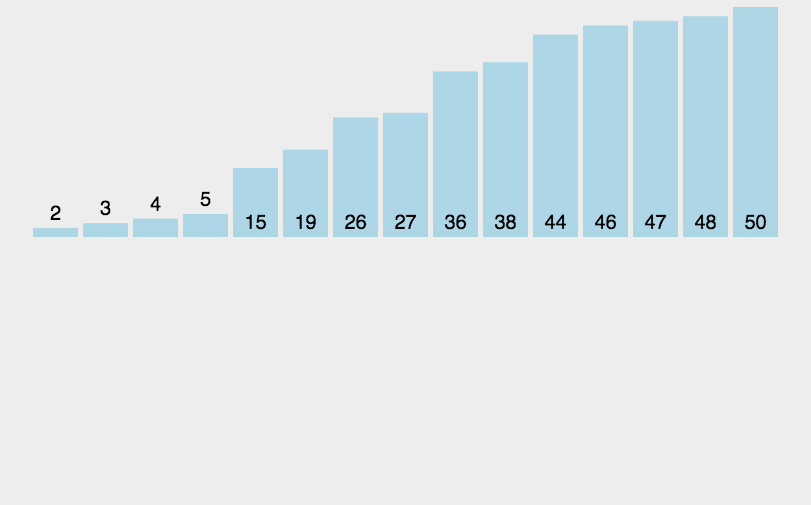
算法 数据结构 递归插入排序 java插入排序 递归求解插入排序算法 如何用递归写插入排序 插入排序动图 插入排序优化 数据结构(十)
1. 插入排序(insertion-sort): 是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入 算法稳定性: 对于两个相同的数,经过…...
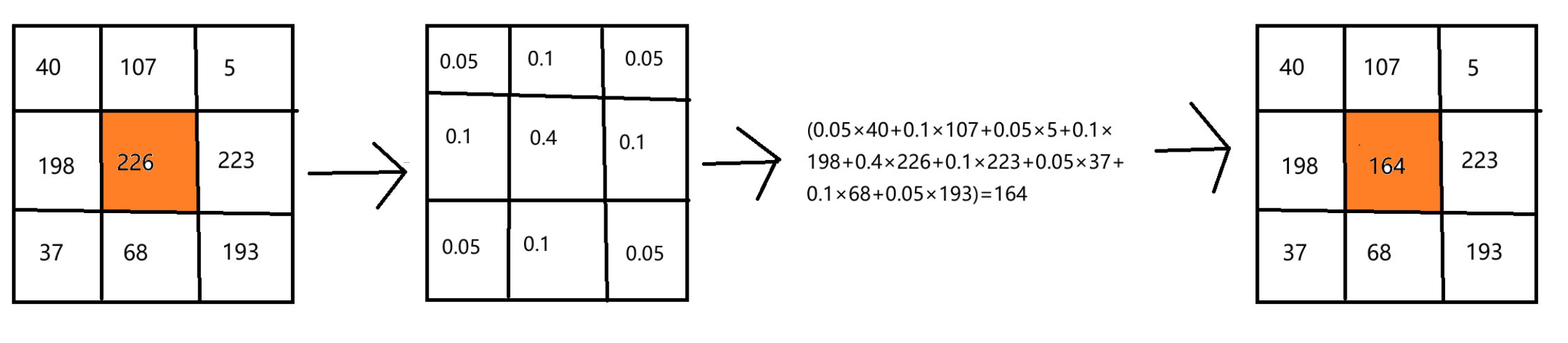
OpenCV(二十二):均值滤波、方框滤波和高斯滤波
目录 1.均值滤波 2.方框滤波 3.高斯滤波 1.均值滤波 OpenCV中的均值滤波(Mean Filter)是一种简单的滤波技术,用于平滑图像并减少噪声。它的原理非常简单:对于每个像素,将其与其周围邻域内像素的平均值作为新的像素值…...
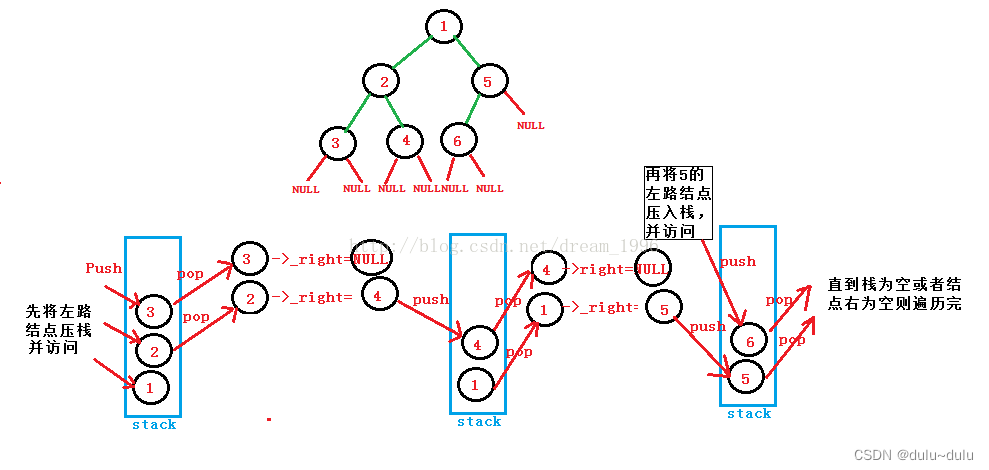
二叉树的递归遍历和非递归遍历
目录 一.二叉树的递归遍历 1.先序遍历二叉树 2.中序遍历二叉树 3.后序遍历二叉树 二.非递归遍历(栈) 1.先序遍历 2.中序遍历 3.后序遍历 一.二叉树的递归遍历 定义二叉树 #其中TElemType可以是int或者是char,根据要求自定 typedef struct BiNode{TElemType data;stru…...

JDK17:未来已来,你准备好了吗?
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

K8s和Docker
Kubernetes(简称为K8s)和Docker是两个相关但又不同的技术。 一、Docker 1、Docker是一种容器化平台,用于将应用程序及其依赖项打包成可移植的容器。 2、Docker容器可以在任何支持Docker的操作系统上运行 好处:提供了一种轻量级…...

使用物理机服务器应该注意的事项
使用物理机服务器应该注意的事项 如今云计算的发展已经遍布各大领域,尽管现在的云服务器火遍全网,但是仍有一些大型企业依旧选择使用独立物理服务器,你知道这是为什么吗?壹基比小鑫来告诉你吧。 独立物理服务器托管业务适合大中…...

py脚本解决ArcGIS Server服务内存过大的问题
在一台服务器上,使用ArcGIS Server发布地图服务,但是地图服务较多,在发布之后,服务器的内存持续处在95%上下的高位状态,导致服务器运行状态不稳定,经常需要重新启动。重新启动后重新进入这种内存高位的陷阱…...

Go语言Web开发入门指南
Go语言Web开发入门指南 欢迎来到Go语言的Web开发入门指南。Go语言因其出色的性能和并发支持而成为Web开发的热门选择。在本篇文章中,我们将介绍如何使用Go语言构建简单的Web应用程序,包括路由、模板、数据库连接和静态文件服务。 准备工作 在开始之前…...

保姆级教程——VSCode如何在Mac上配置C++的运行环境
vscode官方下载: 点击官网链接,下载对应的pkg,安装打开; https://code.visualstudio.com/插件安装 点击箭头所指插件商店按钮,yyds; 下载C/C 插件; 
Java 操作FTP服务器进行下载文件
用Java去操作FTP服务器去做下载,本文章里面分为单个下载和批量下载,批量下载只不过多了一层循环,为了方便参考,我代码都贴出来了。 不管单个下载还是多个,一定要记得,远程服务器的直接写文件夹路径…...

物理机服务器应该注意的事
物理机服务器应该注意的事 1、选址 服务器是个非常重要的硬件产品,对机房的也是有一定的要求的,比如温度、安全性,噪音、电源稳定性等等问题都需要解决!但是不是每个人都会选择自己建立一个机房,毕竟各方面加起来的成本都太高。这…...

信息化发展24
信息技术的发展 1 )在计算机软硬件方面, 计算机硬件技术将向超高速、超小型、平行处理、智能化的方向发展, 计算机硬件设备的体积越来越小、速度越来越高、容量越来越大、功耗越来越低、可靠性越来越高。 2 )计算机软件越来越丰富…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

镜像里切换为普通用户
如果你登录远程虚拟机默认就是 root 用户,但你不希望用 root 权限运行 ns-3(这是对的,ns3 工具会拒绝 root),你可以按以下方法创建一个 非 root 用户账号 并切换到它运行 ns-3。 一次性解决方案:创建非 roo…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

C++中string流知识详解和示例
一、概览与类体系 C 提供三种基于内存字符串的流,定义在 <sstream> 中: std::istringstream:输入流,从已有字符串中读取并解析。std::ostringstream:输出流,向内部缓冲区写入内容,最终取…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...