accelerate 分布式技巧(一)
accelerate分布式技巧
简单使用
Accelerate是一个来自Hugging Face的库,它简化了将单个GPU的PyTorch代码转换为单个或多台机器上的多个GPU的代码。
Accelerate精确地抽象了与多GPU/TPU/fp16相关的模板代码,并保持Pytorch其余代码不变。
import torchimport torch.nn.functional as Ffrom datasets import load_dataset
+ from accelerate import Accelerator+ accelerator = Accelerator()
- device = 'cpu'
+ device = accelerator.devicemodel = torch.nn.Transformer().to(device)optimizer = torch.optim.Adam(model.parameters())dataset = load_dataset('my_dataset')data = torch.utils.data.DataLoader(dataset, shuffle=True)+ model, optimizer, data = accelerator.prepare(model, optimizer, data)model.train()for epoch in range(10):for source, targets in data:source = source.to(device)targets = targets.to(device)optimizer.zero_grad()output = model(source)loss = F.cross_entropy(output, targets)- loss.backward()
+ accelerator.backward(loss)optimizer.step()
通过添加上面5行代码,可以在任何类型的单节点或分布式节点设置(单CPU、单GPU、多GPU和TPU)上运行,也可以使用或不使用混合精度(fp16)如:Accelerator(cpu=args.cpu, mixed_precision=args.mixed_precision)。
+ eval_dataloader = accelerator.prepare(eval_dataloader)predictions, labels = [], []for source, targets in eval_dataloader:with torch.no_grad():output = model(source)- predictions.append(output.cpu().numpy())
- labels.append(targets.cpu().numpy())
+ predictions.append(accelerator.gather(output).cpu().numpy())
+ labels.append(accelerator.gather(targets).cpu().numpy())predictions = np.concatenate(predictions)labels = np.concatenate(labels)+ predictions = predictions[:len(eval_dataloader.dataset)]
+ labels = label[:len(eval_dataloader.dataset)]metric_compute(predictions, labels)
config参数
您需要配置 Accelerate以了解当前系统是如何为训练设置的。为此,运行以下命令并回答提示给您的问题:
accelerate config --config_file xxx
## accelerate config --help
options:-h, --help show this help message and exit--config_file CONFIG_FILEThe path to use to store the config file. Will default to a file nameddefault_config.yaml in the cache location, which is the content of the environment`HF_HOME` suffixed with 'accelerate', or if you don't have such an environmentvariable, your cache directory ('~/.cache' or the content of `XDG_CACHE_HOME`)suffixed with 'huggingface'.subcommands:{default,update}default Create a default config file for Accelerate with only a few flags set.update Update an existing config file with the latest defaults while maintaining the oldconfiguration.
要编写不包括DeepSpeed配置或在tpu上运行等选项的裸机配置,您可以快速运行:
python -c "from accelerate.utils import write_basic_config; write_basic_config(mixed_precision='fp16')"
得到default_config.yaml文件:
{"compute_environment": "LOCAL_MACHINE","debug": false,"distributed_type": "MULTI_GPU","downcast_bf16": false,"machine_rank": 0,"main_training_function": "main","mixed_precision": "fp16","num_machines": 1,"num_processes": 4,"rdzv_backend": "static","same_network": false,"tpu_use_cluster": false,"tpu_use_sudo": false,"use_cpu": false
}
要检查您的配置是否正常,请运行
accelerate env
- `Accelerate` version: 0.22.0
- Platform: Linux-3.10.0-1160.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.10.12
- Numpy version: 1.25.2
- PyTorch version (GPU?): 2.0.1 (True)
- PyTorch XPU available: False
- PyTorch NPU available: False
- System RAM: 503.65 GB
- GPU type: NVIDIA A10
- `Accelerate` default config:Not found
一旦完成,您就可以通过运行来测试设置上的一切是否正常:
accelerate test --config_file path_to_config.yaml
accelerate launch 启动
accelerate launch --config_file default_config.yaml \path_to_script.py \--args_for_the_script
API 说明
导入Accelerator主类并在accelerate 对象中实例化一个, 该类的所有参数可以参考https://huggingface.co/docs/accelerate/v0.22.0/en/package_reference/accelerator#accelerate.Accelerator
from accelerate import Accelerator
accelerator = Accelerator()
将所有与训练相关的对象(优化器、模型、训练数据加载器、学习率调度器)传递给prepare()方法。这将确保一切为训练做好准备。
model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(model, optimizer, train_dataloader, lr_scheduler
)
特别是,您的训练数据加载器将在所有可用的 GPU/TPU 核心上进行分片,以便每个核心都能看到训练数据集的不同部分。此外,所有进程的随机状态将在每次迭代开始时通过数据加载器进行同步,以确保数据以相同的方式进行洗牌(如果您决定使用 shuffle=True 或任何类型的随机采样器)。
训练的实际批大小将是使用的设备数量乘以您在脚本中设置的批大小:例如,在4个gpu上进行训练,在创建训练数据加载器时,批大小为16,将以实际批大小为64进行训练。
或者,您可以在创建和初始化加速器时使用选项 split_batches=True,在这种情况下,无论您在 1、2、4 还是 64 个 GPU 上运行脚本,批处理大小将始终保持不变。
Replace the lineloss.backward()by accelerator.backward(loss).
分布式评估
validation_dataloader = accelerator.prepare(validation_dataloader)
至于您的训练数据加载器,这意味着(如果您在多个设备上运行脚本)每个设备将只能看到部分评估数据。这意味着您需要将您的预测组合在一起。使用gather_for_metrics()方法非常容易做到这一点。
for inputs, targets in validation_dataloader:predictions = model(inputs)# Gather all predictions and targetsall_predictions, all_targets = accelerator.gather_for_metrics((predictions, targets))# Example of use with a *Datasets.Metric*metric.add_batch(all_predictions, all_targets)
只在一个进程上执行一条语句
if accelerator.is_local_main_process: # 本机多进程# Is executed once per server
另一个例子是进度条:为了避免在输出中出现多个进度条,您应该只在本地主进程中显示一个
from tqdm.auto import tqdmprogress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
如果你在两台有多个gpu的服务器上运行你的训练,指令将在每台服务器上执行一次。如果您只需要对所有进程(而不是每台机器)执行一次,例如,将最终模型上载到模型中心,那么将其封装在这样的测试中
if accelerator.is_main_process:# Is executed once only
推迟执行
当您运行常规脚本时,指令是按顺序执行的。使用Accelerate同时在多个gpu上部署脚本会带来一些复杂性:虽然每个进程按顺序执行所有指令,但有些进程可能比其他进程更快。
在执行给定的指令之前,可能需要等待所有进程到达某个点。例如,在确定每个过程都通过训练完成之前,您不应该保存模型。为此,只需在代码中编写以下行代码
accelerator.wait_for_everyone()
该指令将阻塞所有先到达的进程,直到所有其他进程到达该点(如果您只在一个GPU或CPU上运行脚本,这将不会做任何事情)。
保存训练的模型可能需要一些调整:首先,您应该等待所有进程都达到脚本中的该点,如上所示,然后,您应该在保存模型之前解开模型。这是因为在执行prepare()方法时,您的模型可能已被放置在一个更大的模型中,该模型处理分布式训练。这反过来意味着,在不采取任何预防措施的情况下保存模型状态字典将考虑到潜在的额外层,并且最终将得到无法加载回基本模型的权重。 save_model() 方法将帮助您实现这一目标。它将解开您的模型并保存模型状态字典。
Saving/loading a model
accelerator.wait_for_everyone()
accelerator.save_model(model, save_directory)
save_model()方法还可以将模型保存到分片检查点或使用安全系数格式。如下例子:
accelerator.wait_for_everyone()
accelerator.save_model(model, save_directory, max_shard_size="1GB", safe_serialization=True)
如果您的脚本包含加载检查点的逻辑,我们还建议您在展开的模型中加载权重(这仅在您使模型经过prepare()后使用加载函数时才有用)。这是一个例子:
unwrapped_model = accelerator.unwrap_model(model)
path_to_checkpoint = os.path.join(save_directory,"pytorch_model.bin")
unwrapped_model.load_state_dict(torch.load(path_to_checkpoint))
请注意,由于所有模型参数都是对张量的引用,因此这会将您的权重加载到模型中。
如果您想将分片检查点或安全张量格式的检查点加载到具有特定设备的模型中,我们建议您使用 load_checkpoint_in_model() 函数加载它。这是一个例子:
load_checkpoint_in_model(unwrapped_model, save_directory, device_map={"":device})
Saving/loading entire states
训练模型时,您可能希望保存模型、优化器、随机生成器和潜在的 LR 调度器的当前状态,以便在同一脚本中恢复。您可以分别使用 save_state() 和 load_state() 来执行此操作。
要进一步自定义通过 save_state() 保存状态的位置和方式,可以使用 ProjectConfiguration 类。例如,如果启用automatic_checkpoint_naming,则每个保存的检查点将位于Accelerator.project_dir/checkpoints/checkpoint_{checkpoint_number}.
from accelerate.utils import ProjectConfiguration
accelerator_project_config = ProjectConfiguration(total_limit=args.checkpoints_total_limit
)
accelerator = Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps,mixed_precision=args.mixed_precision,log_with=args.report_to,logging_dir=logging_dir,project_config=accelerator_project_config,
)如果您已通过 register_for_checkpointing() 注册了要存储的任何其他有状态项目,它们也将被保存和/或加载。
from accelerate import Acceleratoraccelerator = Accelerator()
# Assume `CustomObject` has a `state_dict` and `load_state_dict` function.
obj = CustomObject()
accelerator.register_for_checkpointing(obj)
accelerator.save_state("checkpoint.pt")
传递给
register_for_checkpointing()的每个对象都必须有一个要存储的load_state_dict和state_dict函数
梯度裁剪
如果您在脚本中使用梯度裁剪,则应分别将对 torch.nn.utils.clip_grad_norm_ 或 torch.nn.utils.clip_grad_value_ 的调用替换为clipgrad_norm() 和clipgrad_value() 。
from accelerate import Acceleratoraccelerator = Accelerator(gradient_accumulation_steps=2)
dataloader, model, optimizer, scheduler = accelerator.prepare(dataloader, model, optimizer, scheduler)for input, target in dataloader:optimizer.zero_grad()output = model(input)loss = loss_func(output, target)accelerator.backward(loss)if accelerator.sync_gradients: # 在每个训练步骤中同步梯度, 目前是否在所有过程中同步梯度accelerator.clip_grad_norm_(model.parameters(), max_grad_norm)optimizer.step()
混合精度训练
如果您使用 Accelerate 在混合精度中运行训练,您将在模型内部计算损失(例如在 Transformer 模型中),从而获得最佳结果。模型外部的每个计算都将以全精度执行(这通常是损失计算所需的,特别是当它涉及 softmax 时)。但是,您可能希望将损失计算放入 autocast() 上下文管理器中:
from accelerate import Acceleratoraccelerator = Accelerator(mixed_precision="fp16")
with accelerator.autocast():train()
混合精度训练的另一个警告是,梯度在开始时和有时在训练过程中会跳过一些更新:由于动态损失缩放策略,训练期间存在梯度溢出的点,并且损失缩放因子减小为避免在下一步中再次发生这种情况。
这意味着您可以在没有更新时更新您的学习率调度程序,这通常很好,但当您的训练数据很少或调度程序的第一个学习率值非常重要时,可能会产生影响。在这种情况下,当优化器步骤未完成时,您可以跳过学习率调度程序更新,如下所示:
if not accelerator.optimizer_step_was_skipped:lr_scheduler.step()
梯度累积
要执行梯度累积,请使用accumulate()并指定gradient_accumulation_steps。这还将自动确保在多设备训练时梯度同步或不同步,检查是否应该实际执行该步骤,并自动缩放损失:
accelerator = Accelerator(gradient_accumulation_steps=2)
model, optimizer, training_dataloader = accelerator.prepare(model, optimizer, training_dataloader)for input, label in training_dataloader:with accelerator.accumulate(model):predictions = model(input)loss = loss_function(predictions, label)accelerator.backward(loss)optimizer.step()scheduler.step()optimizer.zero_grad()
参数、属性和方法说明
- 设备类型
distributed_type
class DistributedType(str, enum.Enum):# Subclassing str as well as Enum allows the `DistributedType` to be JSON-serializable out of the box.NO = "NO"MULTI_CPU = "MULTI_CPU"MULTI_GPU = "MULTI_GPU"MULTI_NPU = "MULTI_NPU"MULTI_XPU = "MULTI_XPU"DEEPSPEED = "DEEPSPEED"FSDP = "FSDP"TPU = "TPU"MEGATRON_LM = "MEGATRON_LM"
init_trackers初始化跟踪器,
from accelerate import Accelerator
accelerator = Accelerator(log_with="tensorboard")
accelerator.init_trackers(project_name="my_project",config={"learning_rate": 0.001, "batch_size": 32},init_kwargs={"tensorboard": {"flush_secs": 60}},)tensorboard_tracker = accelerator.get_tracker("tensorboard")
end_training结束训练
在这里插入代码片
其他接口参考: https://huggingface.co/docs/accelerate/v0.22.0/en/package_reference/accelerator
进阶
指定GPU和最大显存
当一张显卡容不下一个模型时,我们需要用多张显卡来推理。
假如我们现在模型是一个Llama33B,那么我们推理一般需要使用66G的显存,假如我们想要使用6号和7号卡,每张卡允许使用的显存是35G。那么我们代码可以这样写:
from transformers import LlamaConfig,LlamaForCausalLM,LlamaTokenizer
from accelerate import init_empty_weights,infer_auto_device_map,load_checkpoint_in_model,dispatch_model, load_checkpoint_and_dispatch
import torchcuda_list = '1,2'.split(',')
memory = '8GiB'
model_path = './custom_model/hf_llama_7b'
no_split_module_classes = LlamaForCausalLM._no_split_modules
print(no_split_module_classes)
max_memory = {int(cuda):memory for cuda in cuda_list}
config = LlamaConfig.from_pretrained(model_path)
with init_empty_weights():model = LlamaForCausalLM._from_config(config, torch_dtype=torch.float16) #加载到meta设备中,不需要耗时,不需要消耗内存和显存device_map = infer_auto_device_map(model, max_memory=max_memory,no_split_module_classes=no_split_module_classes) #自动划分每个层的设备
load_checkpoint_in_model(model, model_path,device_map=device_map) #加载权重
model = dispatch_model(model, device_map=device_map) #并分配到具体的设备上tokenizer = LlamaTokenizer.from_pretrained(model_path)
if tokenizer.pad_token is None:tokenizer.pad_token = tokenizer.eos_token
torch.set_grad_enabled(False)
model.eval()
sents=['你是谁']
ids = tokenizer(sents, max_length=1800, padding=True, truncation=True, return_tensors="pt")
ids = ids.to(model.device)
outputs = model.generate(**ids, do_sample=False)
print(outputs)
但是里面写的不是很齐全,如果用了infer_auto_device_map,就不需要用load_checkpoint_and_dispatch了,否则其他显卡还是会被占用少量显存,而且也不需要手动指定如何分割,挺方便的。
相关文章:
)
accelerate 分布式技巧(一)
accelerate分布式技巧 简单使用 Accelerate是一个来自Hugging Face的库,它简化了将单个GPU的PyTorch代码转换为单个或多台机器上的多个GPU的代码。 Accelerate精确地抽象了与多GPU/TPU/fp16相关的模板代码,并保持Pytorch其余代码不变。 import torchim…...
密码找回安全
文章目录 密码找回安全任意秘密重置 密码找回安全 用户提交修改密码请求;账号认证:服务器发送唯一ID (例如信验证码)只有账户所有者才能看的地方,完成身份验证;身份验证:用户提交验证码完成身份验证;修改密码:用户修改密码。 任意秘密重置 登录metinfo4…...

Spring Boot + Vue的网上商城之商品管理
Spring Boot Vue的网上商城之商品管理 在网上商城中,商品管理是一个非常重要的功能。它涉及到商品的添加、编辑、删除和展示等操作。本文将介绍如何使用Spring Boot和Vue来实现一个简单的商品管理系统。 下面是一个实现Spring Boot Vue的网上商城之商品管理的思路…...

B站:提高你的词汇量:如何用英语谈论驾驶
视频链接:提高你的词汇量:如何用英语谈论驾驶_哔哩哔哩_bilibili 英文音标中文hood/hʊd/n. 汽车的引擎盖go over仔细检查;认真讨论;用心思考There are plenty of videos go over this.有很多关于这个的视频unlockvt. 发现;揭开&…...

大前端面试注意要点
前端面试:从IT专家角度全面解析 在数字时代,前端开发工程师的角色变得越来越重要。随着网站和应用程序的复杂性和交互性越来越高,对具有专业技能的前端开发人员的需求也在不断增长。对于正在寻找前端开发职位的开发者,或者正在寻…...
)
稻盛和夫-如是说(读书笔记)
本书解答的核心问题: “今天,我们需要的不是短期有效的处方。作为人,何谓正确?作为人,应该如何度过人生?这才是一切问题的根源。 有几个要点和认知比较深的地方谈一谈。 1、利他 类似于阳明心学࿰…...

Jmeter是用来做什么的?
JMeter是一个开源的Java应用,主要用于性能测试和功能测试。它最初由Apache软件基金会设计用于测试Web应用程序,但现在已经扩展到其他测试功能。JMeter的主要功能如下: 性能测试:性能测试是JMeter的核心功能,主要分为两…...

Docker基础教程
Docker基础教程 Docker简介 Docker基本操作 Docker应用 Docker自定义镜像 Docker compose 为什么使用DockerDocker简介安装DockerDocker的中央仓库Docker镜像操作Docker容器操作准备一个web项目创建MySQL容器创建Tomcat容器将项目部署到TomcatDocker数据卷DockerfileDock…...

Linux命令200例:who用于显示当前登录到系统的用户信息
🏆作者简介,黑夜开发者,CSDN领军人物,全栈领域优质创作者✌。CSDN专家博主,阿里云社区专家博主,2023年6月csdn上海赛道top4。 🏆数年电商行业从业经验,历任核心研发工程师࿰…...
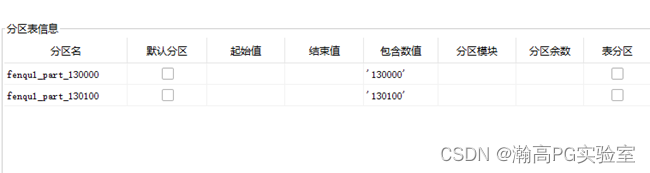
HGDB-修改分区表名称及键值
瀚高数据库 目录 环境 文档用途 详细信息 环境 系统平台:N/A 版本:4.5.7 文档用途 使用存储过程拼接SQL,修改分区名称、分区键值、并重新加入主表,适用于分区表较多场景。 详细信息 说明:本文档为测试过程࿱…...

1分钟了解音频、语音数据和自然语言处理的关系
机器学习在日常场景中的应用 音频、语音数据和自然语言处理这三者正在不断促进人工智能技术的发展,人机交互也逐渐渗透进生活的每个角落。在各行各业包括零售业、银行、食品配送服务商)的多样互动中,我们都能通过与某种形式的AI(…...
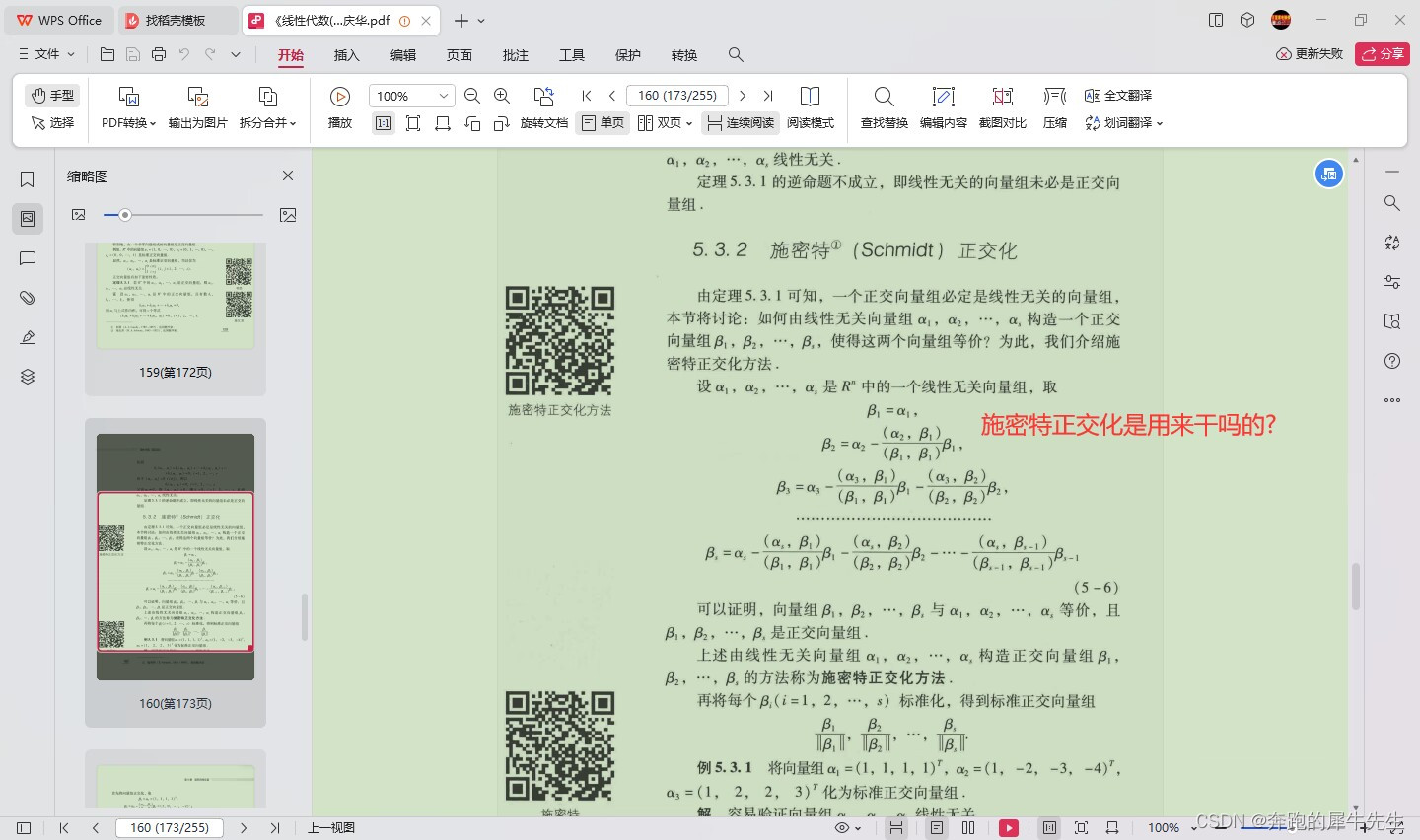
线性代数的学习和整理20,关于向量/矩阵和正交相关,相似矩阵等
目录 1 什么是正交 1.1 正交相关名词 1.2 正交的定义 1.3 正交向量 1.4 正交基 1.5 正交矩阵的特点 1.6 正交矩阵的用处 1 什么是正交 1.1 正交相关名词 orthogonal set 正交向量组正交变换orthogonal matrix 正交矩阵orthogonal basis 正交基orthogonal decompositio…...
OpenCV之ellipse函数
ellipse函数用来在图片中绘制椭圆、扇形,有两个重载函数。 函数原型1: void cv::ellipse( InputOutputArray img,Point center,Size axes,double angle,double startAngle,double …...
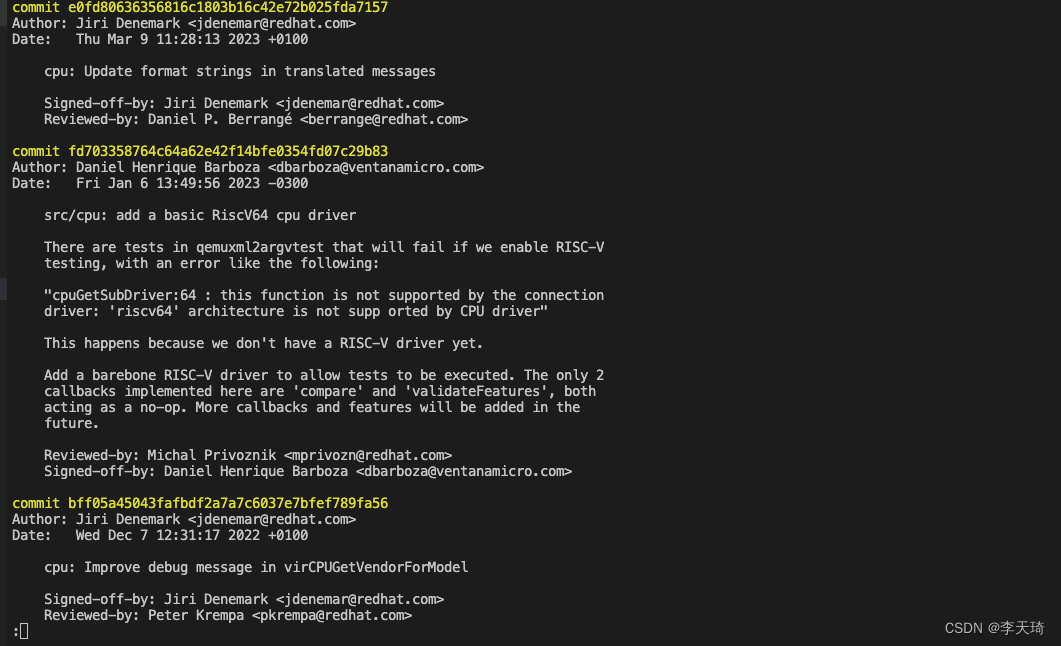
git快速查看某个文件修改的所有commit
1. git blame file git blame 可以显示历史修改的每一行记录,有时候我们只想了解某个文件一共提交几次commit,只显示commit列表,这种方式显然不满足要求。 2.git log常规使用 (1)显示整个project的所有commit (2)显示某个文件的所有commit 这是git log不添加参数的常规…...
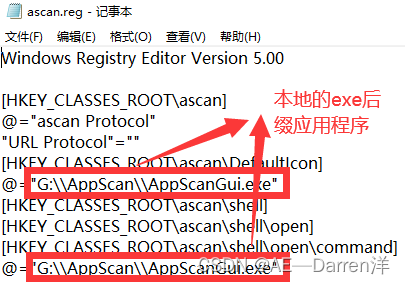
加强版python连接飞书通知——本地电脑PC端通过网页链接打开本地已安装软件(调用注册表形式,以漏洞扫描工具AppScan为例)
前言 如果你想要通过超链接来打开本地应用,那么你首先你需要将你的应用添入windows注册表中(这样网页就可以通过指定代号来调用程序),由于安全性的原因所以网页无法直接通过输入绝对路径来调用本地文件。 一、通过创建reg文件自动配置注册表 创建文本文档,使用记事本打开…...
Jmeter进阶使用指南-使用断言
Apache JMeter是一个流行的开源负载和性能测试工具。在JMeter中,断言(Assertions)是用来验证响应数据是否符合预期的一个重要组件。它是对请求响应的一种检查,如果响应不符合预期,那么断言会标记为失败。 以下是如何在…...

44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例--网上有些说法好像是错误的
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

电脑入门: 路由器初学者完全教程
路由器初学者完全教程 本文以Cisco2620为例,讲述了路由器的初始化配置以及远程接入的配置方法,探讨了如何使用内部网络的DHCP服务功能为远程拨入的用户分配地址信息以及路由器常见故障的排除技巧。 (本文假定Cisco2620路由器为提供远…...
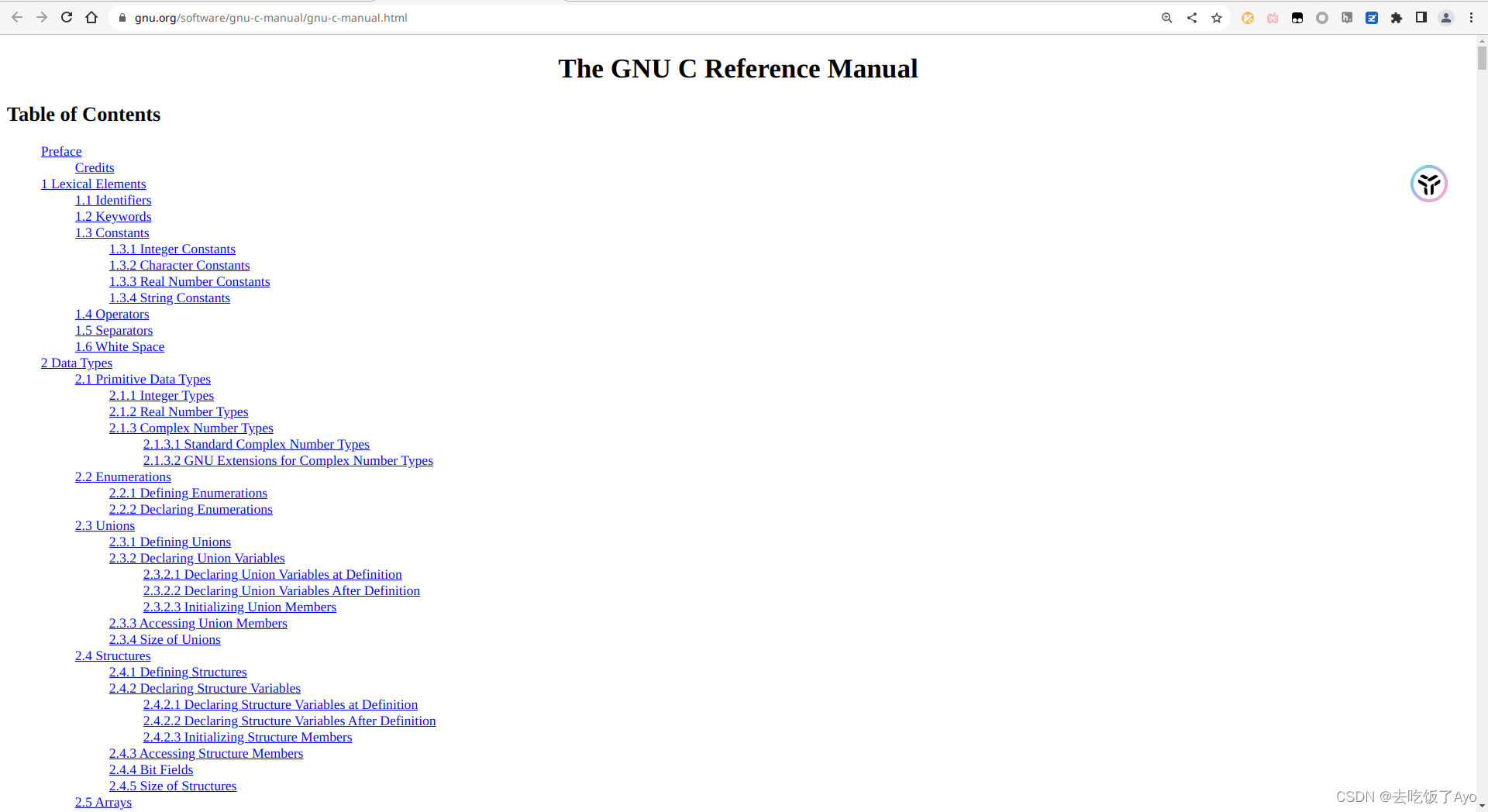
如何查找GNU C语言参考手册
快捷通道 标准C/C参考手册 GNU C参考手册HTML版 GNU C参考手册PDF版本 HTML版本部分目录预览 从GNU官网找那个GNU C参考手册 访问gnu.org 点击软件 下滑找到gnu-c-manual或者在这个页面Ctrl-f搜索"manual" 点进去即可看到HTML版本和PDF版本...
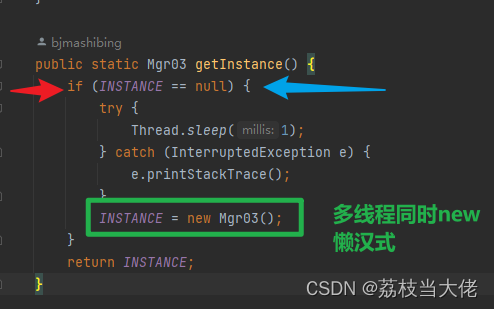
弄懂软件设计模式(一):单例模式和策略模式
前言 软件设计模式和设计原则是十分重要的,所有的开发框架和组件几乎都使用到了,比如在这小节中的单例模式就在SpringBean中被使用。在这篇文章中荔枝将会仔细梳理有关单例模式和策略模式的相关知识点,其中比较重要的是掌握单例模式的常规写法…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测;从基础到高级,涵盖ArcGIS数据处理、ENVI遥感解译与CLUE模型情景模拟等
🔍 土地利用/土地覆盖数据是生态、环境和气象等诸多领域模型的关键输入参数。通过遥感影像解译技术,可以精准获取历史或当前任何一个区域的土地利用/土地覆盖情况。这些数据不仅能够用于评估区域生态环境的变化趋势,还能有效评价重大生态工程…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

嵌入式学习笔记DAY33(网络编程——TCP)
一、网络架构 C/S (client/server 客户端/服务器):由客户端和服务器端两个部分组成。客户端通常是用户使用的应用程序,负责提供用户界面和交互逻辑 ,接收用户输入,向服务器发送请求,并展示服务…...
: 一刀斩断视频片头广告)
快刀集(1): 一刀斩断视频片头广告
一刀流:用一个简单脚本,秒杀视频片头广告,还你清爽观影体验。 1. 引子 作为一个爱生活、爱学习、爱收藏高清资源的老码农,平时写代码之余看看电影、补补片,是再正常不过的事。 电影嘛,要沉浸,…...

WebRTC从入门到实践 - 零基础教程
WebRTC从入门到实践 - 零基础教程 目录 WebRTC简介 基础概念 工作原理 开发环境搭建 基础实践 三个实战案例 常见问题解答 1. WebRTC简介 1.1 什么是WebRTC? WebRTC(Web Real-Time Communication)是一个支持网页浏览器进行实时语音…...
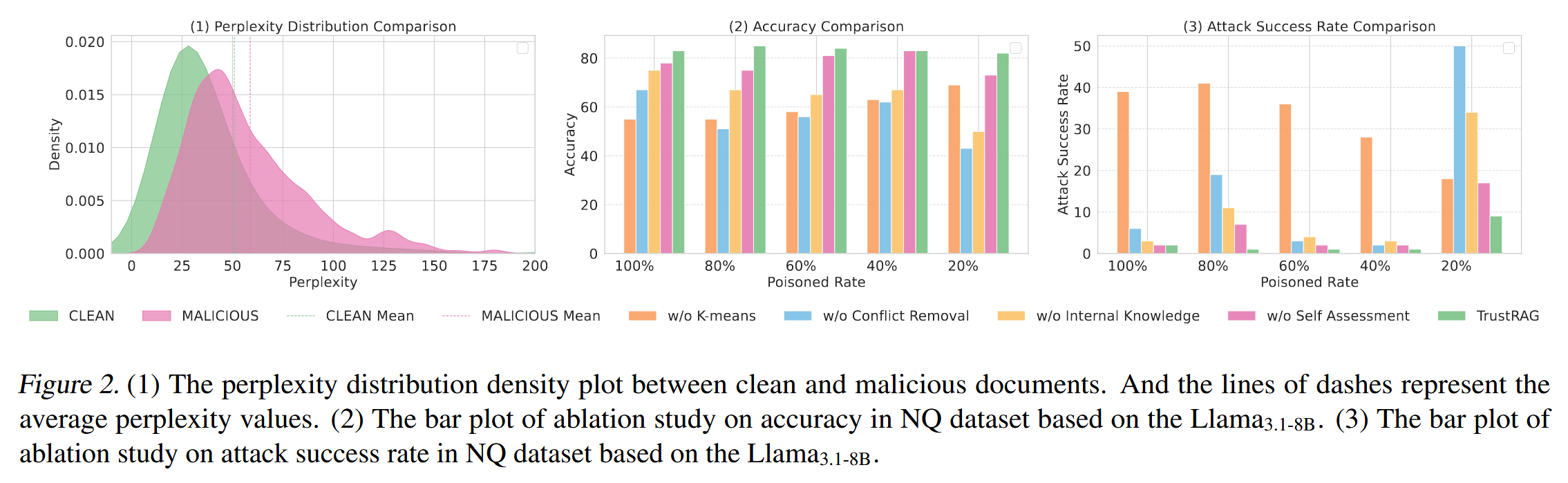
[论文阅读]TrustRAG: Enhancing Robustness and Trustworthiness in RAG
TrustRAG: Enhancing Robustness and Trustworthiness in RAG [2501.00879] TrustRAG: Enhancing Robustness and Trustworthiness in Retrieval-Augmented Generation 代码:HuichiZhou/TrustRAG: Code for "TrustRAG: Enhancing Robustness and Trustworthin…...