19-springcloud(中)
一 服务注册发现
1 什么是服务治理

为什么需要服务治理
在没有进行服务治理前,服务之间的通信是通过服务间直接相互调用来实现的。

过程:
武当派直接调用峨眉派和华山派,同样,华山派直接调用武当派和峨眉派。如果系统不复杂,这样调用没什么问题。但在复杂的微服务系统中,采用这样的调用方法就会产生问题。
微服务系统中服务众多,这样会导致服务间的相互调用非常不便, 因为要记住提供服务的IP地址、名称、端口号等。这时就需要中间代理,通过中间代理来完成调用。
服务治理的解决方案

服务治理责任:
- 你是谁:服务注册 - 服务提供方自报家门
- 你来自哪里:服务发现 - 服务消费者拉取注册数据
- 你好吗:心跳检测,服务续约和服务剔除,一套由服务提供方和注册中心配合完成的去伪存真的过程
- 当你死的时候:服务下线 - 服务提供方发起主动下线
服务治理技术选型

注意:
在架构选型的时候,我们需要注意一下切记不能为了新而新, 忽略了对于当前业务的支持,虽然Eureka2.0不开源了,但是谁知道以后会不会变化,而且1.0也是可以正常使用的,也有一些贡献者在维护这个项目,所以我们不必要过多的担心这个问题,要针对于业务看下该技术框架是否支持在做考虑。
2 Eureka概述

Spring Cloud Eureka 是Netflix 开发的注册发现组件,本身是一个 基于 REST 的服务。提供注册与发现,同时还提供了负载均衡、故障转移等能力。
Eureka3个角色
- 服务中心
- 服务提供者
- 服务消费者。

注意:
- Eureka Server:服务器端。它提供服务的注册和发现功能,即实现服务的治理。
- Service Provider:服务提供者。它将自身服务注册到Eureka Server中,以便“服务消费者” 能够通过服务器端提供的服务清单(注册服务列表)来调用它。
- Service Consumer:服务消费者。它从 Eureka 获取“已注册的服务列表”,从而消费服务。
比Zookeeper好在哪里呢

当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的注册信息,但不能接受服务直接down掉不可用。也就是说,服务注册功能对可用性的要求要高于一致性。

注意:
Zookeeper会出现这样一种情况,当Master节点因为网络故障 与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30~120s,且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。
结论
Eureka看明白了这一点,因此在设计时就优先保证可用性。
3 微服务聚合父工程构建
New Project

聚合总工程名称

字符编码

注解生效激活

Java编译版本选择

File Type过滤

父工程POM
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.lxx</groupId><artifactId>cloud</artifactId><version>1.0-SNAPSHOT</version><packaging>pom</packaging><!-- 统一管理jar包版本 --><properties><project.build.sourceEncoding>UTF8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><spring-cloud.version>2021.0.0</spring-cloud.version><spring-boot.version>2.6.3</spring-boot.version></properties><!-- pom import 解决maven单继承问题 --><dependencyManagement><dependencies><!--spring boot 2.6.3--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>${spring-boot.version}</version><type>pom</type><scope>import</scope></dependency><!--spring cloud 2021.0.0--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>${spring-cloud.version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement>
</project>
IDEA开启Dashboard
2022-06-16更新idea后面的版本将Dashboard改成了Services
1.在idea中打开Services窗口,View > Tool Windows > Services 或者直接快捷键 Alt + 8
2.添加service服务
4 搭建单机Eureka注册中心
创建cloud-eureka-server7001模块

pom添加依赖
<dependencies><!-- 服务注册发现Eureka--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-server</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies>
写yml文件
server:port: 7001
eureka:instance:# eureka服务端的实例名字hostname: localhostclient:# 表示是否将自己注册到Eureka Serverregister-with-eureka: false# 表示是否从Eureka Server获取注册的服务信息fetch-registry: false# 设置与 Eureka server交互的地址查询服务和注册服务都需要依赖这个地址service-url:defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
主启动类
@Slf4j
@SpringBootApplication
@EnableEurekaServer
public class EurekaMain7001 {public static void main(String[] args) {SpringApplication.run(EurekaMain7001.class, args);log.info("*************** Eureka 服务启动成功 端口 7001 ***********");}
}
测试
访问浏览器localhost:7001

5 解读Eureka注册中心UI界面

参数:
- Environment: 环境,默认为test,该参数在实际使用过程中,可以不用更改
- Data center: 数据中心,使用的是默认的是 “MyOwn”
- Current time:当前的系统时间
- Uptime:已经运行了多少时间
- Lease expiration enabled:是否启用租约过期 ,自我保护机制关闭时,该值默认是true, 自我保护机制开启之后为false。
- Renews threshold: 每分钟最少续约数,Eureka Server 期望每分钟收到客户端实例续约的 总数。
- Renews (last min): 最后一分钟的续约数量(不含当前,1分钟更新一次),Eureka Server 最后 1 分钟收到客户端实例续约的总数。
DS Replicas

参数:
这个下面的信息是这个Eureka Server相邻节点,互为一个集群。注册到这个服务上的实例信息
Instances currently registered with Eureka
注册到Eureka服务上的实例信息。

参数:
- Application:服务名称。配置的spring.application.name属性
- AMIs:n/a (1),字符串n/a+实例的数量,我不了解
- Availability Zones:实例的数量
- Status:实例的状态 + eureka.instance.instance‐id的值。
实例的状态分为UP、DOWN、STARTING、 OUT_OF_SERVICE、UNKNOWN.
- UP: 服务正常运行,特殊情况当进入自我保护模式,所有的服务依然是UP状态,所以需要做好熔断重试等容错机制应对灾难性网络出错情况
- OUT_OF_SERVICE : 不再提供服务,其他的Eureka Client将调用不到该服务,一般有人为的调用接口设置的,如:强制下线。
- UNKNOWN: 未知状态
- STARTING : 表示服务正在启动中
- DOWN: 表示服务已经宕机,无法继续提供服务
General Info

参数:
- total-avail-memory : 总共可用的内存
- environment : 环境名称,默认test
- num-of-cpus : CPU的个数
- current-memory-usage : 当前已经使用内存的百分比
- server-uptime : 服务启动时间
- registered-replicas : 相邻集群复制节点
- unavailable-replicas :不可用的集群复制节点,如何确定不可用? 主要是server1 向 server2和server3发送接口查询自身的注册信息。
- available-replicas :可用的相邻集群复制节点
Instance Info

参数:
- ipAddr:eureka服务端IP
- status:eureka服务端状态
6 创建服务提供者

创建cloud-provider-payment8001模块

pom文件添加依赖
<!-- 引入Eureka client依赖 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency>
写yml文件
server:port: 8001eureka:client:service-url:# Eureka Server 地址defaultZone: http://localhost:7001/eureka/
编写主启动类
/*** 主启动类*/
@EnableEurekaClient
@SpringBootApplication
@Slf4j
public class PaymentMain8001 {public static void main(String[] args) {SpringApplication.run(PaymentMain8001.class, args);log.info("********* 服务提供者启动成功 ******");}
}
测试
先启动EurekaServer服务,访问http://locahost:7001

注意:
application名字未定义。
修改yml文件
spring:application:# 设置应用名词name: cloud-payment-provider

7 创建服务消费者

创建cloud-consumer-order80模块

pom文件添加依赖
<!-- 引入Eureka client依赖 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency>
写yml文件
spring:application:# 设置应用名字name: cloud-order-consumerserver:port: 80eureka:client:service-url:# Eureka Server地址defaultZone: http://localhost:7001/eureka/编写主启动类
@SpringBootApplication
@EnableEurekaClient
@Slf4j
public class OrderMain80 {public static void main(String[] args) {SpringApplication.run(OrderMain80.class, args);log.info("*************** 订单服务消费者启动成功 ***********");}
}
测试
先启动EurekaServer服务,访问http://locahost:7001

8 服务自保和服务剔除机制

服务剔除,服务自保,这两套功法一邪一正,俨然就是失传多年的 上乘心法的上卷和下卷。但是往往你施展了服务剔除便无法施展服务自保,而施展了服务自保,便无法施展服务剔除。也就是说,注册中心在同一时刻,只能施展一种心法,不可两种同时施展。
服务剔除

注意:
服务剔除把服务节点果断剔除,即使你的续约请求晚了一步也毫不留情,招式凌厉,重在当断则断,忍痛割爱。
心法总决简明扼要:
欲练此功,必先自宫
服务自保

注意:
服务自保把当前所有节点保留,一个都不能少,绝不放弃任何队友。心法的指导思想是,即便主动删除,也许并不能解决问题,且放之任之,以不变应万变。
心法总决引人深思:
宫了以后,未必成功
如果不宫,或可成功
心法总纲
在实际应用里,并不是所有无心跳的服务都不可用,也许因为短暂的网络抖动等原因,导致服务节点与注册中心之间续约不上,但服务节点之间的调用还是属于可用状态,这时如果强行剔除服务节点,可能会造成大范围的业务停滞。
Euraka服务自保的触发机关
自动开关
注意:
服务自保模式往往是为了应对短暂的网络环境问题,在理想情况下服务节点的续约成功率应该接近100%,如果突然发生网络问题,比如一部分机房无法连接到注册中心,这时候续约成功 率有可能大幅降低。但考虑到Eureka采用客户端的服务发现模式,客户端手里有所有节点的地址,如果服务节点只是因为网络原因无法续约但其自身服务是可用的,那么客户端仍然可以成功发起调用请求。这样就避免了被服务剔除给错杀。
手动开关
这是服务自保的总闸,以下配置将强制关闭服务自保,即便上面的自动开关被触发,也不能开启自保功能。
eureka:server:# 参数来关闭保护机制,以确保注册中心可以将不可用的实例正确剔除,默认为true。enable-self-preservation: false
9 actuator微服务信息完善

SpringCloud体系里的,服务实体向eureka注册时,注册名默认是 IP名:应用名:应用端口名。

问题:
自定义服务在Eureka上的实例名怎么弄呢
在服务提供者和消费者pom中配置Actuator依赖
<!-- actuator监控信息完善 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency>
在服务提供者生产者application.yml中加入
eureka:instance:#实例名称(根据需要自己起名字)instance-id: cloud-payment-provider8001
在服务提供者消费者application.yml中加入
eureka:instance:# 实例名称instance-id: cloud-order-consumer80
测试

10 服务发现Discovery

编写payment8001的Controller
@Slf4j
@RestController
@RequestMapping("/payment")
public class PaymentController {@Autowiredprivate DiscoveryClient discoveryClient;// 获取所有微服务信息@GetMapping("/discovery")public Object discovery() {List<String> services = discoveryClient.getServices();for (String service : services) {log.info("server:={}", service);}return this.discoveryClient;}}RestTemplate介绍
RestTemplate 是从 Spring3.0 开始支持的一个HTTP 请求工具,它 提供了常见的REST请求方案的模版,例如 GET 请求、POST 请求、 PUT 请求、DELETE 请求以及一些通用的请求执行方法 exchange 以及 execute。
在配置类中的restTemplate添加@LoadBalanced注解
这个注解会 给这个组件 有负载均衡的功能
@Configuration
public class CloudConfig {@LoadBalanced@Beanpublic RestTemplate restTemplate(){return new RestTemplate();}
}
修改payment8001工程controller
@Slf4j
@RestController
@RequestMapping("/payment")
public class PaymentController {//测试服务调用@GetMapping("/index")public String index() {return "payment + successs";}}
编写order80工程Controller
@RestController
@RequestMapping("/order")
public class OrderController {//发现服务@Autowiredprivate DiscoveryClient discoveryClient;// HTTP 请求工具@Autowiredprivate RestTemplate restTemplate;/*** 测试服务发现接口** @return*/@GetMapping("/index")public String index() {//服务生产者名字String hostName = "CLOUD-PAYMENT-PROVIDER";//远程调用方法具体URLString url = "/payment/index";//1.从Eureka服务的发现中获取服务生产者的实例List<ServiceInstance> instances = discoveryClient.getInstances(hostName);//2.获取到具体的服务生产者实例ServiceInstance serviceInstance = instances.get(0);//3.发起远程调用String forObject = restTemplate.getForObject(serviceInstance.getUri() + url, String.class);return forObject;}}11 高可用Eureka注册中心

在微服务架构这样的分布式环境中,我们需要充分考虑发生故障的情况,所以在生产环境中必须对各个组件进行高可用部署,对于微服务如此,对于服务注册中心也一样。

问题:
Spring-Cloud为基础的微服务架构,所有的微服务都需要注册到注册中心,如果这个注册中心阻塞或者崩了,那么整个系统都无法继续正常提供服务,所以,这里就需要对注册中心搭 建,高可用(HA)集群。
Eureka Server的设计一开始就考虑了高可用问题,在Eureka的服 务治理设计中,所有节点即是服务提供方,也是服务消费方,服务 注册中心也不例外。是否还记得在单节点的配置中,我们设置过下 面这两个参数,让服务注册中心不注册自己:
eureka:client:# 表示是否将自己注册到Eureka Serverregister-with-eureka: false# 表示是否从Eureka Server获取注册的服务信息fetch-registry: false
12 高可用Eureka注册中心搭建
构建cloud-eureka-server7002工程

pom文件添加依赖
<!-- 服务注册发现Eureka--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-server</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency>
修改7001YML文件
server:port: 7001
eureka:server:# 参数来关闭保护机制,以确保注册中心可以将不可用的实例正确剔除,默认为true。enable-self-preservation: falseinstance:# eureka服务端的实例名字hostname: eureka7001.comclient:# 表示是否将自己注册到Eureka Serverregister-with-eureka: false# 表示是否从Eureka Server获取注册的服务信息fetch-registry: false# 设置与 Eureka server交互的地址查询服务和注册服务都需要依赖这个地址service-url:defaultZone: http://localhost:7002/eureka/修改7002YML文件
server:port: 7002
eureka:server:# 关闭保护机制enable-self-preservation: falseinstance:# eureka服务端的实例名字hostname: eureka7002.comclient:# 表示是否将自己注册到Eureka Serverregister-with-eureka: false# 表示是否从Eureka Server获取注册的服务信息fetch-registry: false# 设置与 Eureka server交互的地址查询服务和注册服务都需要依赖这个地址service-url:defaultZone: http://localhost:7001/eureka/编写主启动类
@Slf4j
@SpringBootApplication
@EnableEurekaServer
public class EurekaMain7002 {public static void main(String[] args) {SpringApplication.run(EurekaMain7002.class, args);log.info("*************** Eureka 服务启动成功 端口 7002 ***********");}
}
将支付微服务8001发布到Eureka集群上
spring:application:# 设置应用名词name: cloud-payment-providerserver:port: 8001eureka:client:service-url:# 单机 Eureka Server 地址#defaultZone: http://localhost:7001/eureka/# 集群 Eureka Server 地址defaultZone: http://localhost:7001/eureka/,http://localhost:7002/eureka/instance:#实例名称(根据需要自己起名字)instance-id: cloud-payment-provider8001
将订单微服务80发布到Eureka集群上
spring:application:# 设置应用名字name: cloud-order-consumerserver:port: 80eureka:client:service-url:# Eureka Server地址defaultZone: http://localhost:7001/eureka/,http://localhost:7002/eureka/instance:# 实例名称instance-id: cloud-order-consumer80
测试
- 先启动EurekaServer集群
- 在启动服务提供者provider服务
- 在启动消费者服务

二 客户端负载均衡
1 什么是负载均衡

为什么需要负载均衡
俗话说在生产队薅羊毛不能逮着一只羊薅,在微服务领域也是这个 道理。面对一个庞大的微服务集群,如果你每次发起服务调用都只盯着那一两台服务器,在大用户访问量的情况下,这几台被薅羊毛的服务器一定会不堪重负。
负载均衡要干什么事情
负载均衡有两大门派,服务端负载均衡和客户端负载均衡。我们先来聊聊这两个不同门派的使用场景,再来看看本节课的主角Spring Cloud Loadbalancer 属于哪门哪派。
服务端负载均衡
在服务集群内设置一个中心化负载均衡器,比如Nginx。发起服务间调用的时候,服务请求并不直接发向目标服务器,而是发给这个全局负载均衡器,它再根据配置的负载均衡策略将请求转发到目标服务。

优点:
- 服务端负载均衡应用范围非常广,它不依赖于服务发现技术,客户端并不需要拉取完整的服务列表;同时,发起服务调用的客户端也不用操心该使用什么负载均衡策略。
劣势:
- 网络消耗
- 复杂度和故障率提升
Spring Cloud Loadbalancer 可以很好地弥补上面的劣势,那么它是如何做到的呢?
客户端负载均衡
Spring Cloud Loadbalancer 采用了客户端负载均衡技术,每个发起服务调用的客户端都存有完整的目标服务地址列表,根据配置的负载均衡策略,由客户端自己决定向哪台服务器发起调用。

优势:
- 网络开销小
- 配置灵活
劣势:
需要满足⼀个前置条件,发起服务调用的客户端需要获取所有目标服务的地址,这样它才能使用负载均衡规则选取要调用的服务。也就是说,客户端负载均衡技术往往需要依赖服务发现技术来获取服务列表。
负载均衡需要解决两个最基本的问题:
第一个是从哪里选服务实例
在Spring Cloud的Eureka微服务系统中,维护微服务实例清单的是 Eureka服务治理中心,而具体微服务实例会执行服务获取,获得微服务实例清单,缓存到本地,同时,还会按照一个时间间隔更新这份实例清单(因为实例清单也是在不断维护和变化的)。
第二个是如何选择服务实例
通过过负载均衡的策略从服务实例清单列表中选择具体实例。
注意:
Eurka和Loadbalancer 自然而然地到了一起,一个通过服务发现获取服务列表,另一个使用负载均衡规则选出目标服务器,然后过着没羞没躁的生活。
什么是Spring Cloud Ribbon
Spring Cloud Ribbon是NetFlix发布的负载均衡器,它有助于Http 和Tcp的客户端行为。可以根据负载均衡算法(轮询、随机或自定义)自动帮助消费者请求,默认就是轮询。
问题:
- 状态 - 停更进维
- 替代方案 - Spring Cloud Loadbalancer
什么是Spring Cloud LoadBalancer
但是由于Ribbon已经进入维护模式,并且Ribbon 2并不与Ribbon 1 相互兼容,所以Spring Cloud全家桶在Spring Cloud Commons项 目中,添加了Spring cloud Loadbalancer作为新的负载均衡器,并且做了向前兼容,就算你的项目中继续用 Spring Cloud Netflix套 装(包括Ribbon,Eureka,Zuul,Hystrix等等)让你的项目中有这些依赖,你也可以通过简单的配置,把Ribbon替换成Spring Cloud LoadBalancer。
2 服务端负载均衡和客户端负载均衡的区别
服务端负载均衡示意图:

客户端负载均衡示意图:

通过上面两个图的对比,可以发现,服务端负载均衡和客户端负载均衡的主要区别就在于负载均衡发生的位置的不同,服务端负载均衡是发生在服务提供方,比如常见的nginx负载均衡。而客户端负载均衡则是发生在发起请求的消费者方,消费者作为客户端在发起请求时就已经选好处理该请求的实例了,像微服务中的远程调用,就是把注册中心的服务列表缓存在本地,然后发起请求时直接选择一个服务实例提供服务。
总结
其实简单点想,服务列表或者说服务信息保存在哪一方,是客户端还是服务端?那负载均衡对应的就是客户端负载均衡或者服务端负载均衡。
3 负载均衡策略

以前的Ribbon有多种负载均衡策略
RandomRule - 随性而为

解释:
随机
RoundRobinRule - 按部就班

解释:
轮询
RetryRule - 卷土重来

解释:
先按照RoundRobinRule的策略获取服务,如果获取服务失败则在指定时间内会进行重试。
WeightedResponseTimeRule - 能者多劳
这个Rule继承自RoundRibbonRule,他会根据服务节点的响应时间计算权重,响应时间越长权重就越低,响应越快则权重越高,权重 的高低决定了机器被选中概率的高低。也就是说,响应时间越小的机器,被选中的概率越大。

解释:
对RoundRobinRule的扩展,响应速度越快的实例选择权重越大,越容易被选择
BestAvailableRule - 让最闲的人来

解释:
应该说这个Rule有点智能的味道了,在过滤掉故障服务以后, 它会基于过去30分钟的统计结果选取当前并发量最小的服务节点,也就是最“闲”的节点作为目标地址。如果统计结果尚未生成,则采用轮询的方式选定节点。
AvailabilityFilteringRule - 我是有底线的
这个规则底层依赖RandomRobinRule来选取节点,但并非来者不拒,它也是有一些底线的,必须要满足它的最低要求的节点才会被选中。如果节点满足了要求,无论其响应时间或者当前并发量是什么,都会被选中。

解释:
每次AvailabilityFilteringRule(简称AFR)都会请求RobinRule 挑选一个节点,然后对这个节点做以下两步检查:是否处于不可用,节点当前的active请求连接数超过阈值,超过了则表示节点目前太忙,不适合接客,如果被选中的server不幸挂掉了检查,那么AFR会自动重试(次数最多10次),让RobinRule重新选择一个服务节点。
ZoneAvoidanceRule - 我的地盘我做主

解释:
默认规则,复合判断server所在区域的性能和server的可用性选择服务器
但LoadBalancer只提供了两种负载均衡器
- RandomLoadBalancer 随机
- RoundRobinLoadBalancer 轮询
注意:
不指定的时候默认用的是轮询
三 服务接口调用
1 OpenFeign概述

OpenFeign是什么
Spring Cloud OpenFeign用于Spring Boot应用程序的声明式REST客户端。

OpenFeign能干嘛
Feign旨在使编写Java Http客户端变得更容易。前面在使用RestTemplate时,利用RestTemplate对http请求的封装处理,形成了一套模版化的调用方法。

OpenFeign和Feign两者区别
Feign是一个声明式WebService客户端。使用Feign能让编写Web Service客户端更加简单。它的使用方法是定义一个服务接口然后在上面添加注解。Feign也支持可拔插式的编码器和解码器。Spring Cloud对Feign进行了封装,使其支持了Spring MVC标准注解和HttpMessageConverters。
| Feign | OpenFeign |
|---|---|
| Feign是Spring Cloud组件中的一个轻量级RESTful的HTTP服务,客户端Feign内置了Ribbon,用来做客户端负载均衡,去调用服务注册中心的服务。 | OpenFeign是Spring Cloud在Feign的基础上支持了 SpringMVC的注解,如@RequesMapping等等。OpenFeign 的@Feignclient可以解析SpringMVC的@RequestMapping注解下的接口,并通过动态代理的方式产生实现类,实现类中做负载均衡并调用其他服务。 |
| Spring-cloud-starter-feign | spring-cloud-starter-openfeign |
注意:
接口+注解。
2 入门案列
构建cloud-consumer-feign-order80工程

修改POM文件
<!-- 引入Eureka 客户端依赖 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency><!-- 引入服务调用依赖 OpenFigen --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><!-- actuator监控信息完善 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency>编写YML文件
spring:application:# 设置应用名词name: cloud-openfeign-order-consumer
server:port: 80eureka:client:# Eureka Server地址service-url:defaultZone: http://localhost:7001/eureka,http://localhost:7002/eurekainstance:instance-id: cloud-openfeign-order-consumer80
编写主启动类
@Slf4j
@SpringBootApplication
@EnableFeignClients
public class OrderFeignMain80 {public static void main(String[] args) {SpringApplication.run(OrderFeignMain80.class,args);log.info("************** OrderFeignMain80 服务启动成功 **********");}
}
编写业务逻辑接口PaymentFeignService
/*** 支付远程调用Feign接口*/
// 声明为OpenFeign客户端 (value = 调用的服务生产者名字)
@FeignClient(value = "CLOUD-PAYMENT-PROVIDER")
public interface PaymentFeignService {@GetMapping("/payment/index")String index();
}编写控制层Controller
/*** 订单控制层*/
@RestController
@RequestMapping("/order")
public class OrderController {@Autowiredprivate PaymentFeignService paymentFeignService;/*** 测试OpenFeign接口调用** @return*/@GetMapping("/index")public String get() {return paymentFeignService.index();}
}
测试
- 先启动2个Eureka集群7001/7002
- 在启动服务提供者payment8001
- 在启动服务消费者cloud-consumer-feign-order
- 浏览器访问http://localhost/order/index
3 日志增强

OpenFeign虽然提供了日志增强功能,但是默认是不显示任何日志的,不过开发者在调试阶段可以自己配置日志的级别。
OpenFeign的日志级别如下:
- NONE:默认的,不显示任何日志;
- BASIC:仅记录请求方法、URL、响应状态码及执行时间;
- HEADERS:除了BASIC中定义的信息之外,还有请求和响应的头信息;
- FULL:除了HEADERS中定义的信息之外,还有请求和响应的正文及元数据。
配置类中配置日志级别
@Configuration
public class OpenFeignConfig{/*** 日志级别定义*/@BeanLogger.Level feignLoggerLevel(){return Logger.Level.FULL;}
}
注意:
这里的logger是feign包里的。
yaml文件中设置接口日志级别
logging:level:com.lxx.service: debug
注意:
这里的 com.lxx.service 是openFeign接口所在的包名,当然你也可以配置一个特定的openFeign接口。
测试
请求http://localhost/order/index

4 超时机制

超时机制

问题:
- 服务消费者在调用服务提供者的时候发生了阻塞、等待的情形,这个时候,服务消费者会一直等待下去。
- 在某个峰值时刻,大呈的请求都在同时请求服务消费者,会造成线程的大呈堆积,势必会造成雪崩。
- 利用超时机制来解决这个问题,设置一个超时时间,在这个时间段内,无法完成服务访问, 则自动断开连接。
服务消费方80配置超时时间
feign:client:config:default:connectTimeout: 2000 # 连接超时时间readTimeout: 2000 # 读取超时时间
服务提供方8001故意写超时程序
@GetMapping("/timeout")public String timeout() {try {Thread.sleep(5000);} catch (InterruptedException e) {throw new RuntimeException(e);}return "timeout";}
服务消费方80添加超时方法PaymentFeignService
@FeignClient(value = "CLOUD-PAYMENT-PROVIDER")
public interface PaymentFeignService {@GetMapping("/payment/timeout")String timeout();
}
服务消费方80添加超时方法OrderController
/*** 订单控制层*/
@RestController
@RequestMapping("/order")
public class OrderController {@Autowiredprivate PaymentFeignService paymentFeignService;/*** 测试超时机制* @return*/@GetMapping("/timeout")public String timeout() {return paymentFeignService.timeout();}
}四 服务断路器
1 什么是灾难性雪崩效应

什么是灾难性雪崩效应
假设我们有两个访问量比较大的服务A和B,这两个服务分别依赖C 和D,C和D服务都依赖E服务。

A和B不断的调用C,D处理客户请求和返回需要的数据。当E服务不能供服务的时候,C和D的超时和重试机制会被执行

由于新的调用不断的产生,会导致C和D对E服务的调用大量的积压,产生大量的调用等待和重试调用,慢慢会耗尽C和D的资源比如内存或CPU,然后也down掉。

A和B服务会重复C和D的操作,资源耗尽,然后down掉,最终整个服务都不可访问。

结论:
服务与服务之间的依赖性,故障会传播,造成连锁反应,会对整个微服务系统造成灾难性的严重后果,这就是服务故障的“雪崩”效应。
造成雪崩原因是什么
- 服务提供者不可用(硬件故障、程序bug、缓存击穿、用户大量请求)
- 重试加大流量(用户重试,代码逻辑重试)
- 服务调用者不可用(同步等待造成的资源耗尽)
注意:
在高并发访问下,系统所依赖的服务的稳定性对系统的影响非常大,依赖有很多不可控的因素,比如网络连接变慢,资源突然繁忙,暂时不可用,服务脱机等。我们要构建稳定、可靠的分布式系统,就必须要有一套容错方法。
2 服务雪崩解决方案之服务熔断

保险丝:电路中正确安置保险丝,保险丝就会在电流异常升高到一定的高度和热度的时候,自身熔断切断电流,保护了电路安全运行。
什么是熔断
熔断就跟保险丝一样,当一个服务请求并发特别大,服务器已经招架不住了,调用错误率飙升,当错误率达到一定阈值后,就将这个服务熔断了。熔断之后,后续的请求就不会再请求服务器了,以减缓服务器的压力。

注意:
当失败率(如因网络故障/超时造成的失败率高)达到阀值自动触发降级,熔断器触发的快速失败会进行快速恢复。
3 服务雪崩解决方案之服务降级

什么是服务降级

两种场景:
- 当下游的服务因为某种原因响应过慢,下游服务主动停掉一些不太重要的业务,释放出服务器资源,增加响应速度!
- 当下游的服务因为某种原因不可用,上游服务主动调用本地的一些降级逻辑,避免卡顿,迅速返回给用户!
服务降级 fallback
概念:服务器繁忙,请稍后重试,不让客户端等待并立即返回一个友好的提示。
出现服务降级的情况:
- 程序运行异常
- 超时
- 服务熔断触发服务降级
- 线程池/信号量打满也会导致服务降级
4 服务雪崩解决方案之服务隔离

那显而易见,做服务隔离的目的就是避免服务之间相互影响。毕竟谁也不能说自己的微服务百分百可用,如果不做隔离,一旦一个服务出现了问题,整个系统的稳定性都会受到影响! 因此,做服务隔离是很有必要的。
什么是线程池隔离
将用户请求线程和服务执行线程分割开来,同时约定了每个服务最多可用线程数。

使用线程池隔离后

解释:
动物园有了新规矩-线程隔离,就是说每个服务单独设置一个小房间(独立线程池),把大厅区域和服务区域隔离开来,每个服务房间也有接待数量限制,比如我设置了熊猫馆最多接纳10 人,犀牛管最多5人,大象馆20人。这样,即便来了20个人想看熊猫,我们也只能接待10人,剩下的10个人就会收到Thread Pool Rejects。如此一来,也不会耽搁动物园为用户提供其他服务。
什么是信号量隔离
小时候我们就知道“红灯停,绿灯行”,跟着交通信号的指示过马路。信号量也是这么一种放行、禁行的开关作用。它和线程池技术一样,控制了服务可以被同时访问的并发数量。

线程池隔离和信号量隔离区别
| 隔离方式 | 是否支持超时 | 是否支持熔断 | 隔离原理 | 是否是异步调用 | 资源消耗 |
|---|---|---|---|---|---|
| 线程池隔离 | 支持,可直接返回 | 支持,当线程池到达 maxSize后,再请求会触发 fallback接口进行熔断 | 每 服务 单独 用线 程池 | 可以是异步, 也可以是同 步。看调用的 方法 | 大,大量线程的 上下文切换,容 易造成机器负载 高 |
| 信号量隔离 | 不支持,如果阻塞,只能 通过调用协议(如: socket超时才能返回) | 支持,当信号量达到 maxConcurrentRequests 后。再请求会触发fallback | 通过信号量的 计数器 | 同步调用,不 支持异步 | 小,只是个计数 器 |
5 服务雪崩解决方案之服务限流

服务熔断和服务隔离都属于出错后的容错处理机制,而限流模式则可以称为预防模式。

限流模式主要是提前对各个类型的请求设置最高的QPS阈值,若高于设置的阈值则对该请求直接返回,不再调用后续资源。
注意:
限流的目的是通过对并发访问/请求进行限速,或者对一个时间窗口内的请求进行限速来保护系统,一旦达到限制速率则可以拒绝服务、排队或等待、降级等处理。
流量控制
- 网关限流:防止大量请求进入系统,Mq实现流量消峰
- 用户交流限流:提交按钮限制点击频率限制等
6 Resilience4j介绍

什么是Hystrix
我们耳熟能详的就是Netflix Hystrix,这个断路器是SpringCloud中最早支持的一种容错方案,现在这个断路器已经处于维护状态,已经不再更新了,你仍然可以使用这个断路器,但是呢,我不建议你去使用,因为这个已经不再更新,所以Spring官方已经出现了Netflix Hystrix的替换方案。

什么是Resilience4j
Resilience4j是一个轻量级的容错组件,其灵感来自于Hystrix,但主要为Java 8和函数式编程所设计,也就是我们的lambda表达式。轻量级体现在其只用 Vavr 库(前身是 Javaslang),没有任何外部依赖。而Hystrix依赖了Archaius ,Archaius本身又依赖很多第三方包,例如 Guava、Apache Commons Configuration 等。
Resilience4j官网
https://resilience4j.readme.io/
Resilience4J 提供了一系列增强微服务的可用性功能:
- resilience4j-circuitbreaker:熔断
- resilience4j-ratelimiter:限流
- resilience4j-bulkhead:隔离
- resilience4j-retry:自动重试
- resilience4j-cache:结果缓存
- resilience4j-timelimiter:超时处理
注意:
在使用Resilience4j的过程中,不用引入所有的依赖,只引入需要用到的依赖即可。
7 Resilience4j的断路器

断路器(CircuitBreaker)相对于前面几个熔断机制更复杂, CircuitBreaker通常存在三种状态(CLOSE、OPEN、 HALF_OPEN),并通过一个时间或数量窗口来记录当前的请求成功率或慢速率,从而根据这些指标来作出正确的容错响应。

6种状态:
- CLOSED: 关闭状态,代表正常情况下的状态,允许所有请求通过,能通过状态转换为OPEN
- HALF_OPEN: 半开状态,即允许一部分请求通过,能通过状态转换为CLOSED和OPEN
- OPEN: 熔断状态,即不允许请求通过,能通过状态转为为HALF_OPEN
- DISABLED: 禁用状态,即允许所有请求通过,出现失败率达到给定的阈值也不会熔断,不会发生状态转换。
- METRICS_ONLY: 和DISABLED状态一样,也允许所有请求通过不会发生熔断,但是会记录失败率等信息,不会发生状态转换。
- FORCED_OPEN: 与DISABLED状态正好相反,启用CircuitBreaker,但是不允许任何请求通 过,不会发生状态转换。
主要介绍3种状态
- closed -> open : 关闭状态到熔断状态, 当失败的调用率(比如超时、异常等)默认50%,达到一 定的阈值服务转为open状态,在open状态下,所有的请求都被拦截。
- open-> half_open: 当经过一定的时间后,CircubitBreaker中默认为60s服务调用者允许一定的请求到达服务提供者。
- half_open -> open: 当half_open状态的调用失败率超过给定的阈值,转为open状态
- half_open -> closed: 失败率低于给定的阈值则默认转换为closed状态
8 Resilience4j超时降级
创建模块cloud-consumer-resilience4j-order80

POM引入依赖
<dependencies><!-- 引入Eureka 客户端依赖 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency><!-- 引入服务调用依赖 OpenFigen --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><!-- actuator监控信息完善 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!-- 引入断路器依赖 resilience4j--><dependency><groupId>io.github.resilience4j</groupId><artifactId>resilience4j-spring-cloud2</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-circuitbreaker-resilience4j</artifactId></dependency></dependencies>
修改YML文件
spring:application:# 设置应用名词name: cloud-resilience4j-order-consumer
server:port: 80eureka:client:# Eureka Server地址service-url:defaultZone: http://localhost:7001/eureka,http://localhost:7002/eurekainstance:instance-id: cloud-resilience4j-order-consumer80resilience4j:# 超时机制timelimiter:instances:delay:# 设置超时时间 2秒timeoutDuration: 2
编写服务提供者提供超时方法(沿用cloud-provider-payment8001服务提供者)
@Slf4j
@RestController
@RequestMapping("/payment")
public class PaymentController {@GetMapping("/timeout")public String timeout() {try {Thread.sleep(5000);} catch (InterruptedException e) {throw new RuntimeException(e);}return "timeout";}}编写服务消费者主启动类
@Slf4j
@SpringBootApplication
@EnableFeignClients
public class OrderResilience4jMain80 {public static void main(String[] args) {SpringApplication.run(OrderResilience4jMain80.class, args);log.info("************** OrderResilience4jMain80 服务启动成功 **********");}
}
编写服务消费者业务逻辑接口PaymentFeignService
@FeignClient(value = "CLOUD-PAYMENT-PROVIDER")
public interface PaymentFeignService {@GetMapping("/payment/timeout")String timeout();
}
编写服务消费者Controller
@RestController
@RequestMapping("/order")
@Slf4j
public class OrderController {@Autowiredprivate PaymentFeignService paymentFeignService;/*** 测试超时降级** @return*/@GetMapping("/timeout")/*** name = "delay"* 跟application.yaml中得配置对应(我在配置中取名为delay)* resilience4j:* timelimiter:* instances:* delay:* timeoutDuration: 2*/@TimeLimiter(name = "delay", fallbackMethod = "timeoutFallback")public CompletableFuture<String> timeout() {log.info("********* 进入方法 ******");//异步操作CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> (paymentFeignService.timeout()));log.info("********* 离开方法 ******");return completableFuture;}
}编写服务降级方法
/*** 超时服务降级方法* @param e* @return*/public CompletableFuture<ResponseEntity> timeoutFallback(Exception e) {e.printStackTrace();return CompletableFuture.completedFuture(ResponseEntity.ok("超时啦"));}测试

9 Resilience4j重试机制

重试机制比较简单,当服务端处理客户端请求异常时,服务端将会开启重试机制,重试期间内,服务端将每隔一段时间重试业务逻辑处理。 如果最大重试次数内成功处理业务,则停止重试,视为处理成功。如果在最大重试次数内处理业务逻辑依然异常,则此时系统将拒绝该请求。
修改YML文件
resilience4j:# 重试机制retry:instances:backendA:# 最大重试次数maxRetryAttempts: 3# 固定的重试间隔waitDuration: 10senableExponentialBackoff: trueexponentialBackoffMultiplier: 2
编写服务提供者提供测试重试机制方法(沿用cloud-provider-payment8001服务提供者)
@Slf4j
@RestController
@RequestMapping("/payment")
public class PaymentController {//测试服务调用@GetMapping("/index")public String index() {//模拟服务异常int i = 1 / 0;return "payment + successs";}
}
编写服务消费者业务逻辑接口PaymentFeignService
@FeignClient(value = "CLOUD-PAYMENT-PROVIDER")
public interface PaymentFeignService {@GetMapping("/payment/index")String index();
}
编写服务消费者Controller
@RestController
@RequestMapping("/order")
@Slf4j
public class OrderController {@Autowiredprivate PaymentFeignService paymentFeignService;/*** 重试机制* @return*/@GetMapping("/retry")//对应配置文件中的resilience4j.retry.instances.backendA@Retry(name = "backendA")public CompletableFuture<String> retry() {log.info("********* 进入方法 ******");//异步操作CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> (paymentFeignService.index()));log.info("********* 离开方法 ******");return completableFuture;}
}
10 Resilience4j异常比例熔断降级
修改yml文件
resilience4j.circuitbreaker:configs:default:# 熔断器打开的失败阈值failureRateThreshold: 30# 默认滑动窗口大小,circuitbreaker使用基于计数和时间范围滑动窗口聚合统计失败率slidingWindowSize: 10# 计算比率的最小值,和滑动窗口大小去最小值,即当请求发生5次才会计算失败率minimumNumberOfCalls: 5# 滑动窗口类型,默认为基于计数的滑动窗口slidingWindowType: TIME_BASED# 半开状态允许的请求数permittedNumberOfCallsInHalfOpenState: 3# 是否自动从打开到半开automaticTransitionFromOpenToHalfOpenEnabled: true# 熔断器从打开到半开需要的时间waitDurationInOpenState: 2srecordExceptions:- java.lang.Exceptioninstances:backendA:baseConfig: default
编写服务提供者方法(沿用cloud-provider-payment8001服务提供者)
@Slf4j
@RestController
@RequestMapping("/payment")
public class PaymentController {@GetMapping("/index")public String index() {return "payment + successs";}}
编写服务消费者业务逻辑接口PaymentFeignService
@FeignClient(value = "CLOUD-PAYMENT-PROVIDER")
public interface PaymentFeignService {@GetMapping("/payment/index")String index();
}
编写服务消费者Controller
@RestController
@RequestMapping("/order")
@Slf4j
public class OrderController {@Autowiredprivate PaymentFeignService paymentFeignService;/*** 异常比例熔断降级* @return*/@GetMapping("/circuitBreaker")@CircuitBreaker(name = "backendA")public String CircuitBreaker() {log.info("************ 进入方法 ***********");String index = paymentFeignService.index();log.info("************ 离开方法 ***********");return index;}
} 使用JMeter进行压力测试
修改语言

创建线程组

创建取样器HTTP请求

添加查看结果树

修改线程数量

修改HTTP请求参数

关闭服务提供者模拟发生异常,此时半开状态只有三次请求

编写降级方法
/*** 异常比例熔断降级** @return*/@GetMapping("/circuitBreaker")@CircuitBreaker(name = "backendA", fallbackMethod = "circuitBreakerFallback")public String CircuitBreaker() {log.info("************ 进入方法 ***********");String index = paymentFeignService.index();log.info("************ 离开方法 ***********");return index;}/*** 服务降级方法** @param e* @return*/public String circuitBreakerFallback(Throwable e) {e.printStackTrace();return "客官服务繁忙,稍等一会。。。。";}

测试降级方法
- 关闭服务提供者
- 服务消费者发起请求
产生服务降级

11 Resilience4j慢调用比例熔断降级
编写yml文件(添加backendB)
resilience4j.circuitbreaker:configs:default:# 熔断器打开的失败阈值failureRateThreshold: 30# 默认滑动窗口大小,circuitbreaker使用基于计数和时间范围欢动窗口聚合统计失败率slidingWindowSize: 10# 计算比率的最小值,和滑动窗口大小去最小值,即当请求发生5次才会计算失败率minimumNumberOfCalls: 5# 滑动窗口类型,默认为基于计数的滑动窗口slidingWindowType: TIME_BASED# 半开状态允许的请求数permittedNumberOfCallsInHalfOpenState: 3# 是否自动从打开到半开automaticTransitionFromOpenToHalfOpenEnabled: true# 熔断器从打开到半开需要的时间waitDurationInOpenState: 2srecordExceptions:- java.lang.Exceptioninstances:backendA:baseConfig: defaultbackendB:# 熔断器打开的失败阈值failureRateThreshold: 50# 慢调用时间阈值 高于这个阈值的slowCallDurationThreshold: 2s# 慢调用百分比阈值,断路器慢调用时间大于slowslowCallRateThreshold: 30slidingWindowSize: 10slidingWindowType: TIME_BASEDminimumNumberOfCalls: 2
编写服务消费者Controller
/*** 慢调用比例熔断降级** @return*/@GetMapping("/slowCircuitBreaker")@CircuitBreaker(name = "backendB", fallbackMethod = "slowCircuitBreakerFallback")public String slowCircuitBreaker() {log.info("************ 进入方法 ***********");try {TimeUnit.SECONDS.sleep(10);} catch (InterruptedException e) {e.printStackTrace();}String index = paymentFeignService.index();log.info("************ 离开方法 ***********");return index;}public String slowCircuitBreakerFallback(Throwable e) {e.printStackTrace();return "太慢了。。。。";}
12 Resilience4j信号量隔离实现
POM引入依赖
<dependency><groupId>io.github.resilience4j</groupId><artifactId>resilience4j-bulkhead</artifactId><version>1.7.0</version></dependency>
信号量隔离修改YML文件
resilience4j:#信号量隔离bulkhead:instances:backendA:# 隔离允许并发线程执行的最大数量maxConcurrentCalls: 5# 当达到并发调用数量时,新的线程的阻塞时间maxWaitDuration: 20ms
编写controller
/*** 测试信号量隔离** @return*/@Bulkhead(name = "backendA", type = Bulkhead.Type.SEMAPHORE)@GetMapping("/bulkhead")public String bulkhead() throws InterruptedException {log.info("************** 进入方法 *******");TimeUnit.SECONDS.sleep(10);String index = paymentFeignService.index();log.info("************** 离开方法 *******");return index;}
测试
配置隔离并发线程最大数量为5

13 Resilience4j线程池隔离实现
线程池隔离配置修改YML文件
resilience4j:
#线程池隔离thread-pool-bulkhead: instances:backendA:# 最大线程池大小maxThreadPoolSize: 4# 核心线程池大小coreThreadPoolSize: 2# 队列容量queueCapacity: 2
编写controller
/*** 测试线程池服务隔离** @return*/@Bulkhead(name = "backendA", type = Bulkhead.Type.THREADPOOL)@GetMapping("/thread")public CompletableFuture threadPoolBulkhead() {log.info("********** 进入方法 *******");try {TimeUnit.SECONDS.sleep(10);} catch (InterruptedException e) {e.printStackTrace();}log.info("********** 离开方法 *******");return CompletableFuture.supplyAsync(() -> "线程池隔离信息......");}
测试
配置文件设置核心线程2个最大4个服务会一次处理4个请求

14 Resilience4j限流
限流YML配置
resilience4j:# 限流ratelimiter:instances:backendA:# 限流周期时长。 默认:500纳秒limitRefreshPeriod: 5s# 周期内允许通过的请求数量。 默认:50limitForPeriod: 2
编写Controller
/*** 限流** @return*/@GetMapping("/limiter")@RateLimiter(name = "backendA")public CompletableFuture<String>RateLimiter() {log.info("********* 进入方法 ******");//异步操作CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> (paymentFeignService.index()));log.info("********* 离开方法 ******");return completableFuture;}
JMeter压测
线程数 - 5

五 服务网关Gateway
1 微服务中的应用

没有服务网关

问题:
1 地址太多
2 安全性
3 管理问题
为什么要使用服务网关
网关是微服务架构中不可或缺的部分。使用网关后,客户端和微服务之间的网络结构如下。

注意:
网关统一向外部系统(如访问者、服务)提供REST API。在 SpringCloud 中,使用Zuul、Spring Cloud Gateway等作为API Gateway来实现动态路由、监控、回退、安全等功能。
认识Spring Cloud Gateway
Spring Cloud Gateway 是 Spring Cloud生态系统中的网关,它是 基于Spring 5.0、SpringBoot 2.0和Project Reactor等技术开发的, 旨在为微服务架构提供一种简单有效的、统一的API路由管理方式, 并为微服务架构提供安全、监控、指标和弹性等功能。其目标是替代Zuul。

注意:
Spring Cloud Gateway 用"Netty + Webflux"实现,不要加入 Web依赖,否则会报错,它需要加入Webflux依赖。
什么是WebFlux
Webflux模式替换了旧的Servlet线程模型。用少量的线程处理 request和response io操作,这些线程称为Loop线程,而业务交给响应式编程框架处理,响应式编程是非常灵活的,用户可以将业务中阻塞的操作提交到响应式框架的work线程中执行,而不阻塞的操作依然可以在Loop线程中进行处理,大大提高了Loop线程的利用率。

注意:
Webflux虽然可以兼容多个底层的通信框架,但是一般情况下, 底层使用的还是Netty,毕竟,Netty是目前业界认可的最高性能的通信框架。而Webflux的Loop线程,正好就是著名的Reactor模式IO处理模型的Reactor线程,如果使用的是高性能的通信框架Netty。
温馨提示:
什么是Netty,Netty 是一个基于NIO的客户、服务器端的编程框架。提供异步的、事件驱动的网络应用程序框架和工具,用以快速开发高性能、高可靠性的网络服务器和客户端程序。
Spring Cloud Gateway特点
- 易于编写谓词( Predicates )和过滤器( Filters ) 。其Predicates和Filters可作用于特定路由。
- 支持路径重写。
- 支持动态路由。
- 集成了Spring Cloud DiscoveryClient。
2 三大核心概念

路由(Route)
这是网关的基本构建块。它由一个ID,一个目标URI,一组断言和一组过滤器定义。如果断言为真,则路由匹配。
断言(predicate)
输入类型是一个ServerWebExchange。我们可以使用它来匹配来自HTTP请求的任何内容,例如headers或参数。
过滤器(filter)
可以在请求被路由前或者之后对请求进行修改。

举个例子:
你想去动物园游玩,那么你买了一张熊猫馆的门票,只能进入熊猫馆的区域,而不能去犀牛管瞎转。因为没有犀牛馆的门票,进不去,就算走到门口,机器也不能识别。这里门票就相当于请求URL,熊猫馆相当于路由,而门口识别门卡的机器就是断言。然后我进入熊猫馆里面看到工作人员我想很有可能是过滤器,结果还真是,他在我进入馆之前拿手持设备对我全身扫描看看有没有危险品(请求前改代码),并且在我出熊猫馆之后要求再次检察看看我是否携带熊猫出馆(请求后改动代码)。这个工作人员相当于过滤器。
总结
首先任何请求进来,网关都会把它们拦住。根据请求的URL把它们分配到不同的路由上,路由上面会有断言,来判断请求能不能进来。进来之后会有一系列的过滤器对请求被转发前或转发后进行改动。 具体怎么个改动法,那就根据业务不同而自定义了。一般就是监控,限流,日志输出等等。
3 入门案例
创建cloud-gateway-gateway9527工程

pom文件引入依赖
<dependencies><!-- 引入网关Gateway依赖 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency></dependencies>
新增application.yaml
server:port: 9527spring:cloud:gateway:# 路由配置routes:# 路由ID,没有固定规则但要求唯一,建议配合服务名- id: cloud-payment-provider# 目标服务地址uri: http://localhost:8001# 路由条件 断言会接收一个输入的参数,会返回一个布尔结果值predicates:# 路径相匹配的进行路由 # /**表示匹配所有子级请求- Path=/payment/**
主启动类
@Slf4j
@SpringBootApplication
public class GatewayMain {public static void main(String[] args) {SpringApplication.run(GatewayMain.class, args);log.info("********** GatewayMain 服务启动成功 *********");}
}
测试
启动注册中心 7001,7002
启动服务提供者8001
启动网关服务9527
请求http://localhost:9527/payment/index

4 Java API构建路由

代码注入RouteLocator
@Configuration
public class GatewayConfig {@Beanpublic RouteLocator routeLocator(RouteLocatorBuilder routeLocatorBuilder) {//获取路由RouteLocatorBuilder.Builder routes = routeLocatorBuilder.routes();//设置路由routes.route("cloud-payment-provider",r -> r.path("/payment/**").uri("http://localhost:8001")).build();return routes.build();}}
测试
5 路由规则


Gateway 的路由规则主要有三个部分,分别是路由、断言(谓词)和过滤器。
路由
路由是 Gateway 的⼀个基本单元。
断言
也称谓词,实际上是路由的判断规则。一个路由中可以添加多个谓词的组合。
提示:
打个比方,你可以为某个路由设置⼀条谓词规则,约定访问路径的匹配规则为Path=/bingo/*,在这种情况下只有以 /bingo 打头的请求才会被当前路由选中。
过滤器

Gateway 组件使用了⼀种 FilterChain的模式对请求进行处理,每一个服务请求(Request)在发送到目标标服务之前都要被一串FilterChain处理。同理,在 Gateway接收服务响应(Response) 的过程中也会被FilterChain 处理⼀把。
6 动态路由

默认情况下Gateway会根据注册中心的服务列表,以注册中心上微服务名为路径创建动态路由进行转发,从而实现动态路由的功能。
添加eureka依赖
<!-- 引入Eureka client依赖 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency>
yml配置
server:port: 9527spring:cloud:gateway:# 路由配置routes:# 路由ID,没有固定规则但要求唯一,建议配合服务名- id: cloud-payment-provider# 目标服务地址 lb后边是微服务名字uri: lb://CLOUD-PAYMENT-PROVIDER# 路由条件 断言会接收一个输入的参数,会返回一个布尔结果值predicates:# 路径相匹配的进行路由- Path=/payment/**application:# 设置应用名词name: cloud-gatewayeureka:client:service-url:defaultZone: http://localhost:7001/eureka/,http://localhost:7002/eureka/instance:#实例名称instance-id: cloud-gateway9527
**注意: **
需要注意的是uri的协议lb,表示启用Gateway的负载均衡的功能。
服务提供者payemt8001和payment8002工程controller添加方法
@Slf4j
@RestController
@RequestMapping("/payment")
public class PaymentController {@Value("${server.port}")private String port;@GetMapping("/lb")public String lb() {return port;}}

测试
启动eureka服务注册发现 7001,7002
启动服务提供者payment8001,8002
启动网关服务测试

7 断言功能详解

一个请求在抵达网关层后,首先就要进行断言匹配,在满足所有断言之后才会进入Filter阶段。说白了Predicate就是一种路由规则, 通过Gateway中丰富的内置断言的组合,我们就能让一个请求找到对应的Route来处理。
After路由断言 Factory
After Route Predicate Factory采用一个参数——日期时间。在该日期时间之后发生的请求都将被匹配。
YML文件添加配置
predicates:# 路径相匹配的进行路由- Path=/payment/**- After=2030-02-15T14:54:23.317+08:00[Asia/Shanghai]
注意:
UTC时间格式的时间参数。
UTC时间格式的时间参数时间生成方法
public static void main(String[] args) {ZonedDateTime now = ZonedDateTime.now();System.out.println(now); }
Before路由断言 Factory
Before Route Predicate Factory采用一个参数——日期时间。在该日期时间之前发生的请求都将被匹配。
YML文件添加配置
predicates:- Before=2030-02-15T14:54:23.317+08:00[Asia/Shanghai]
Between 路由断言 Factory
Between 路由断言 Factory有两个参数,datetime1和datetime2。 在datetime1和datetime2之间的请求将被匹配。datetime2参数的实际时间必须在datetime1之后。
YML文件添加配置
predicates:- Between=2020-02-15T14:54:23.317+08:00[Asia/Shanghai],2030-02-15T14:54:23.317+08:00[Asia/Shanghai]
Cookie路由断言 Factory
顾名思义,Cookie验证的是Cookie中保存的信息,Cookie断言和上 面介绍的两种断言使用方式大同小异,唯一的不同是它必须连同属性值一同验证,不能单独只验证属性是否存在。
YML文件添加配置
predicates:# 路径相匹配的进行路由- Cookie=username,lxx
使用postman测试

Header路由断言 Factory
这个断言会检查Header中是否包含了响应的属性,通常可以用来验证请求是否携带了访问令牌。
YML文件添加配置
# 请求头要有X-Request-Id属性并且值为整数的正则表达式
predicates:- Header=X-Request-Id,\d+
测试

Host路由断言 Factory
Host 路由断言 Factory包括一个参数:host name列表。使用Ant 路径匹配规则, . 作为分隔符。访问的主机匹配http或者https, baidu.com 默认80端口, 就可以通过路由。 多个 , 号隔开。
YML文件添加配置
predicates:- Host=lxx.com
Host文件新增配置
127.0.0.1 lxx.com
Method路由断言 Factory
这个断言是专门验证HTTP Method的,在下面的例子中,我们把 Method断言和Path断言通过一个and连接符合并起来,共同作用于路由判断,当我们访问“/gateway/sample”并且HTTP Method是 GET的时候,将适配下面的路由。
YML文件添加配置
predicates:# 路径相匹配的进行路由- Path=/payment/**- Method=GET
Query路由断言 Factory
请求断言也是在业务中经常使用的,它会从ServerHttpRequest中 的Parameters列表中查询指定的属性,有如下两种不同的使用方式。
YML文件添加配置
predicates:# 路径相匹配的进行路由- Path=/payment/**# 要有参数名称并且是正整数才能路由- Query=username,\d+
测试

8 过滤器详解

微服务系统中的服务非常多。如果每个服务都自己做鉴权、限流、 日志输出,则非常不科学。所以,可以通过网关的过滤器来处理这些工作。在用户访问各个服务前,应在网关层统一做好鉴权、限流等工作。
Filter的生命周期
根据生命周期可以将Spring Cloud Gateway中的Filter分 为"PRE"和"POST"两种。
- PRE:代表在请求被路由之前执行该过滤器,此种过滤器可用来实现参数校验、权限校验、流量监控、日志输出、协议转换等功能。
- POST:代表在请求被路由到微服务之后执行该过滤器。此种过滤器可用来实现响应头的修改(如添加标准的HTTP Header )、收集统计信息和指标、将响应发送给客户端、输出日志、流量监控等功能。
Filter分类
根据作用范围,Filter可以分为以下两种。
- GatewayFilter:网关过滤器,此种过滤器只应用在单个路由或者一个分组的路由上。
- GlobalFilter:全局过滤器,此种过滤器会应用在所有的路由上。
9 网关过滤器GatewayFilter

网关过滤器( GatewayFilter )允许以某种方式修改传入的HTTP请求, 或输出的HTTP响应。网关过滤器作用于特定路由。Spring Cloud Gateway内置了许多网关过滤器工厂来编写网关过滤器。
| 过滤器工厂 | 作用 | 参数 |
|---|---|---|
| AddRequestHeader | 为原始请求添加Header | Header的名称及值 |
| AddRequestParameter | 为原始请求添加请求参数 | 参数名称及值 |
| AddResponseHeader | 为原始响应添加Header | Header的名称及值 |
| DedupeResponseHeader | 剔除响应头中重复的值 | 需要去重的Header名称及去重策略 |
| Hystrix | 为路由引入Hystrix的断路器保护 | HystrixCommand的名称 |
| FallbackHeaders | 为fallbackUri的请求头中添加具体的异常信息 | Header的名称 |
| PrefixPath | 为原始请求路径添加前缀 | 前缀路径 |
| PreserveHostHeader | 为请求添加一个preserveHostHeader=true的属性,路由过滤器 会检查该属性以决定是否要发送原始的Host | 无 |
| RequestRateLimiter | 用于对请求限流,限流算法为令牌桶 | keyResolver、rateLimiter、statusCode、 denyEmptyKey、emptyKeyStatus |
| RedirectTo | 将原始请求重定向到指定的URL | http状态码及重定向的url |
| RemoveHopByHopHeadersFilter | 为原始请求删除IETF组织规定的一系列Header | 默认就会启用,可以通过配置指定仅删除哪些 Header |
| RemoveRequestHeader | 为原始请求删除某个Header | Header名称 |
| RemoveResponseHeader | 为原始响应删除某个Header | Header名称 |
| RewritePath | 重写原始的请求路径 | 原始路径正则表达式以及重写后路径的正则表达式 |
| RewriteResponseHeader | 重写原始响应中的某个Header | Header名称,值的正则表达式,重写后的值 |
| SaveSession | 在转发请求之前,强制执行WebSession::save操作 | 无 |
| secureHeaders | 为原始响应添加一系列起安全作用的响应头 | 无,支持修改这些安全响应头的值 |
| SetPath | 修改原始的请求路径 | 修改后的路径 |
| SetResponseHeader | 修改原始响应中某个Header的值 | Header名称,修改后的值 |
| SetStatus | 修改原始响应的状态码 | HTTP 状态码,可以是数字,也可以是字符串 |
| StripPrefix | 用于截断原始请求的路径 | 使用数字表示要截断的路径的数量 |
| Retry | 针对不同的响应进行重试 | retries、statuses、methods、series |
| RequestSize | 设置允许接收最大请求包的大小。如果请求包大小超过设置的值,则返回 413 Payload Too Large | 请求包大小,单位为字节,默认值为5M |
| ModifyRequestBody | 在转发请求之前修改原始请求体内容 | 修改后的请求体内容 |
| ModifyResponseBody | 修改原始响应体的内容 | 修改后的响应体内容 |
| Default | 为所有路由添加过滤器 | 过滤器工厂名称及值 |
常用内置过滤器的使用
#过滤器,请求在传递过程中可以通过过滤器对其进行一定的修改
filters:- SetStatus=250 # 修改原始响应的状态码
启动测试

10 自定义网关过滤器

需求:通过过滤器,配置是否在控制台输出日志信息,以及是否记录日志。
实现步骤:
1、类名必须叫做XxxGatewayFilterFactory,注入到Spring容器后使用时的名称就叫做Xxx。
2、创建一个静态内部类Config, 里面的属性为配置文件中配置的参数, - 过滤器名称=参数 1,参数2… 2、类必须继承 AbstractGatewayFilterFactory,让父类帮实现配置参数的处理。
3、重写shortcutFieldOrder()方法,返回List参数列表为Config中属性集合。return Arrays.asList(“参数1”,参数2…)
4、无参构造方法中super(Config.class)
5、编写过滤逻辑 public GatewayFilter apply(Config config)
在配置文件中,添加一个Log的过滤器配置
# 过滤器,请求在传递过程中可以通过过滤器对其进行一定的修改
filters: # 控制日志是否开启- Log=true
自定义一个过滤器工厂,实现里面的方法
/*** 自定义局部过滤器*/
@Component
public class LogGatewayFilterFactory extends AbstractGatewayFilterFactory<LogGatewayFilterFactory.Config> {public LogGatewayFilterFactory() {super(Config.class);}@Overridepublic List<String> shortcutFieldOrder() {return Arrays.asList("consoleLog");}@Overridepublic GatewayFilter apply(Config config) {return ((exchange, chain) -> {if (config.consoleLog) {System.out.println("console 日志已开启...");}return chain.filter(exchange);});}@Datapublic static class Config {private boolean consoleLog;}
}
运行测试
请求http://localhost:9527/payment/lb

11 过滤器之全局过滤器

全局过滤器作用于所有路由,无需配置。通过全局过滤器可以实现对权限的统一校验,安全性验证等功能。
内置的全局过滤器
SpringCloud Gateway内部也是通过一系列的内置全局过滤器对整个路由转发进行处理的。
- 路由过滤器(Forward)
- 路由过滤器(LoadBalancerClient)
- Netty路由过滤器 Netty
- 写响应过滤器(Netty Write Response F)
- RouteToRequestUrl 过滤器
- 路由过滤器 (Websocket Routing Filter)
- 网关指标过滤器(Gateway Metrics Filter)
- 组合式全局过滤器和网关过滤器排序(Combined Global Filter and GatewayFilter Ordering)
- 路由(Marking An Exchange As Routed)
自定义全局过滤器

开发中的鉴权逻辑
- 当客户端第一次请求服务时,服务端对用户进行信息认证(登录) 认证通过,
- 将用户信息进行加密形成token,返回给客户端,作为登录凭证
- 以后每次请求,客户端都携带认证的token
- 服务端对token进行解密,判断是否有效。
对于验证用户是否已经登录及鉴权的过程,可以在网关统一校验。
下面我们通过自定义一个GlobalFIlter,去校验所有请求的请求参数 中是否包含“token”,如果不包含请求参数“token”则不转发路由, 否则执行正常逻辑。
@Component
public class AuthGlobalFilter implements GlobalFilter, Ordered {@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {String token = exchange.getRequest().getQueryParams().getFirst("token");if (StringUtils.isEmpty(token)) {System.out.println("鉴权失败。确少token参数。");exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);return exchange.getResponse().setComplete();}if (!"jack".equals(token)) {System.out.println("token无效...");exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);return exchange.getResponse().setComplete();}// 继续执行filter链return chain.filter(exchange);}/*** 顺序,数值越小,优先级越高** @return*/@Overridepublic int getOrder() {return 0;}
}测试

12 网关的cors跨域配置

为什么会出现跨域问题
出于浏览器的同源策略限制。同源策略是一种约定,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,则浏览器的正常功能可能都会受到影响。可以说Web是构建在同源策略基础之上的,浏览器只是针对同源策略的一种实现。
什么是跨域
当一个请求url的协议、域名、端口三者之间任意一个与当前页面url 不同即为跨域
跨域问题演示
编写index页面
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Title</title>
</head>
<body>
</body>
<scriptsrc="http://libs.baidu.com/jquery/2.0.0/jquery.min.js"></script>
<script>$.get("http://localhost:9527/payment/lb?token = jack", function (data, status) {alert("Data: " + data + "\nStatus: " + status);});
</script>
</html>

用idea内置服务器打开该页面
问题出现

Gateway解决如何允许跨域

CORS
- 如何允许跨域,一种解决方法就是目的域告诉请求者允许什么来源域来请求,那么浏览器就会知道 B域是否允许A域发起请求。
- CORS(“跨域资源共享”(Cross-origin resource sharing))就是这样一种解决手段。
CORS使得浏览器在向目的域发起请求之前先发起一个OPTIONS方式的请求到目的域获取目的域的信息,比如获取目的域允许什么域来请求的信息。
spring:cloud:gateway:globalcors:cors-configurations:'[/**]':allowCredentials: trueallowedOriginPatterns: "*"allowedMethods: "*"allowedHeaders: "*"add-to-simple-url-handler-mapping: true
六 服务网关Gateway实现用户鉴权
1 什么是JWT

什么是JWT
JWT是一种用于双方之间传递安全信息的简洁的、URL安全的声明规范。定义了一种简洁的,自包含的方法用于通信双方之间以Json对象的形式安全的传递信息。特别适用于分布式站点的单点登录 (SSO)场景。
什么是SSO单点登录
SSO(Single Sign On)单点登录。SSO是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统。它包括可以将这次主要的登录映射到其他应用中用于同一个用户的登录的机制。它是目前比较流行的企业业务整合的解决方案之一。
当用户第一次访问应用系统1的时候,因为还没有登录,会被引导到认证系统中进行登录;根据用户提供的登录信息,认证系统进行身份校验,如果通过校验,应该返回给用户一个认证的凭据--ticket;用户再访问别的应用的时候就会将这个ticket带上,作为自己认证的凭据,应用系统接受到请求之后会把ticket送到认证系统进行校验,检查ticket的合法性。如果通过校验,用户就可以在不用再次登录的情况下访问应用系统2和应用系统3了。
传统的session认证
每次提到无状态的 JWT 时相信都会看到另一种基于 Session 的用户认证方案介绍,这里也不例外,Session 的认证流程通常会像这样:

缺点:
安全性:CSRF攻击因为基于cookie来进行用户识别, cookie如果被截获,用户就会很容易受 到跨站请求伪造的攻击。
扩展性:对于分布式应用,需要实现 session 数据共享
性能:每一个用户经过后端应用认证之后,后端应用都要在服务端做一次记录,以方便用户 下次请求的鉴别,通常而言session都是保存在内存中,而随着认证用户的增多,服务端的开 销会明显增大,与REST风格不匹配。因为它在一个无状态协议里注入了状态。
JWT方式

优点:
- 无状态
- 适合移动端应用
- 单点登录友好
2 JWT原理

JWT 的原理是,服务器认证以后,生成一个 JSON 对象,发回给用户,就像下面这样。
{"姓名": "张三","角色": "管理员","到期时间": "2030年7月1日0点0分"
}
注意:
用户与服务端通信的时候,都要发回这个 JSON 对象。服务器完全只靠这个对象认定用户身份。为了防止用户篡改数据,服务器在生成这个对象的时候会加上签名,服务器就不保存任何 session 数据了,也就是说,服务器变成无状态了,从而比较容易实现扩展。
JWT的结构

注意:
它是一个很长的字符串,中间用点( . )分隔成三个部分。注 意,JWT 内部是没有换行的,这里只是为了便于展示,将它写成了几行。
JWT 的三个部分依次如下:
- 头部(header)
- 载荷(payload)
- 签证(signature)
Header
JSON对象,描述 JWT 的元数据。其中 alg 属性表示签名的算法 (algorithm),默认是 HMAC SHA256(写成 HS256);typ属性表示这个令牌(token)的类型(type),统一写为 JWT。
{"alg": "HS256","typ": "JWT"
}
注意:
上面代码中, alg 属性表示签名的算法(algorithm),默认是 HMAC SHA256(写成 HS256); typ 属性表示这个令牌 (token)的类型(type),JWT 令牌统一写为 JWT 然后将头部进行Base64编码构成了第一部分,Base64是一种用64个字符来表示任意二进制数据的方法,Base64是一种任意二进制到文本字符串的编码方法,常用于在URL、Cookie、网页中传输少量二进制数据。
Payload
内容又可以分为3种标准
- 标准中注册的声明
- 公共的声明
- 私有的声明
payload-标准中注册的声明 (建议但不强制使用) :
- iss: jwt签发者
- sub: jwt所面向的用户
- aud: 接收jwt的一方
- exp: jwt的过期时间,这个过期时间必须要大于签发时间
- nbf: 定义在什么时间之前,该jwt都是不可用的.
- iat: jwt的签发时间
- jti: jwt的唯一身份标识,主要用来作为一次性token,从而回避重放攻击。
payload-公共的声明 :
公共的声明可以添加任何的信息。一般这里我们会存放一下用户的基本信息(非敏感信息)。
payload-私有的声明 :
私有声明是提供者和消费者所共同定义的声明。需要注意的是,不要存放敏感信息,不要存放敏感信息,不要存放敏感信息!!!
因为:这里也是base64编码,任何人获取到jwt之后都可以解码!!
{"sub": "1234567890","name": "John Doe","iat": 1516239022
}
注意:
sub和iat是标准声明,分别代表所面向的用户和jwt签发时间。
- sub:这个是发给一个账号是1234567890的用户(也许是ID)
- name:名字叫John Doe
- iat:签发时间是1516239022(2030/1/18 9:30:22)
Signature
这部分就是 JWT 防篡改的精髓,其值是对前两部分 base64UrlEncode 后使用指定算法签名生成,以默认 HS256 为例,指定一个密钥(secret),就会按照如下公式生成:
HMACSHA256(base64UrlEncode(header) + "." + base64UrlEncode(payload), secret,
)
注意:
算出签名以后,把 Header、Payload、Signature 三个部分拼成一个字符串,每个部分之间用"点"( . )分隔,就可以返回给用户。
JWT 的使用方式

流程:
客户端收到服务器返回的 JWT,可以储存在 Cookie 里面,也可以储存在 localStorage。此后,客户端每次与服务器通信,都要带上这个 JWT。你可以把它放在 Cookie 里面自动发送,但是这样不能跨域,所以更好的做法是放在 HTTP 请求的头信息 Authorization 字段里面。
3 用户微服务

创建cloud-auth-user6500工程

引入POM依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- eureka client 依赖 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency>
创建主启动类
@EnableEurekaClient
@SpringBootApplication
@Slf4j
public class AuthUserMain6500 {public static void main(String[] args) {SpringApplication.run(AuthUserMain6500.class, args);log.info("********* 认证用户启动成功 ******");}
}
4 JWT工具类
引入JWT依赖
<dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.79</version></dependency><dependency><groupId>com.auth0</groupId><artifactId>java-jwt</artifactId><version>3.7.0</version></dependency>
创建JWT工具类JWTUtils
/*** JWT工具类*/
public class JWTUtils {// 签发人private static final String ISSUSER = "lxx";// 过期时间 5分钟private static final long TOKEN_EXPIRE_TIME = 5 * 60 * 1000;// 秘钥private static final String KEY = "wer21w3e2r904923";/*** 生成令牌** @return*/public static String token() {Date now = new Date();// key 用来加密数据签名秘钥Algorithm algorithm = Algorithm.HMAC256(KEY);// 1. 创建JWTString token = JWT.create()//签发人.withIssuer(ISSUSER)// 签发时间.withIssuedAt(now)// 过期时间.withExpiresAt(new Date(now.getTime() + TOKEN_EXPIRE_TIME)).sign(algorithm);return token;}/*** 验证令牌** @return*/public static boolean verify(String token) {try {Algorithm algorithm = Algorithm.HMAC256(KEY);// 1. 验证令牌JWTVerifier verifier = JWT.require(algorithm)// 签发人.withIssuer(ISSUSER).build();// 如果校验有问题会抛出异常verifier.verify(token);return true;} catch (IllegalArgumentException e) {e.printStackTrace();} catch (JWTVerificationException e) {e.printStackTrace();}return false;}public static void main(String[] args) {//1. 生成令牌
// String token = token();
// System.out.println(token);//eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJpc3MiOiJpdGJhaXpoYW4iLCJleHAiOjE2NDU5NDQzMjEsImlhdCI6MTY0NTk0NDAyMX0.BLHAKsHsVW4NUo7K_yZgaIq-64eI4R7_ewCl4svGntg// 令牌String token = "eyJ0eXAiOiJKVCJhbGciOiJIUzI1NiJ9.eyJpc3MiOiJpdCJleHAiOjE2NDU5NDQzMjEsImlhdCI6MTY0NTk0NDAyMX0.BLHAKsHsVW4NUo7K_yZgaIq-64eI4R7_ewCl4svGntg";boolean verify = verify(token);System.out.println(verify);}}
5 用户服务实现JWT鉴权
编写统一返回实体类
/*** 统一返回实体类*/
@AllArgsConstructor
@NoArgsConstructor
@Data
@Builder
public class Result {// 返回状态码private int code;// 返回描述信息private String msg;// 返回token信息 令牌private String token;}
编写LoginController类,编写用户登录接口
@RequestMapping("/user")
@RestController
@Slf4j
public class LoginController {/*** 登录** @param username 用户名* @param password 密码*/@PostMapping("/login")public Result login(String username, String password) {// 1. 验证用户名和密码// TODO 模拟数据库操作if ("admin".equals(username) && "123456".equals(password)) {// 2. 生成令牌String token = JWTUtils.token();return Result.builder().code(200).msg("succes").token(token).build();} else {return Result.builder().code(500).msg("用户名或密码不正确").build();}}}
YML文件编写
spring:application:# 设置应用名词name: cloud-auth-userserver:port: 6500eureka:client:service-url:# 单机 Eureka Server 地址defaultZone: http://localhost:7001/eureka/instance:#实例名称(根据需要自己起名字)instance-id: cloud-auth-user65006 网关全局过滤器加入JWT 鉴权

在cloud-gateway-gateway9527工程中操作
配置跳过验证路由
org:my:jwt:# 跳过认证路由skipAuthUrls:- /user/login
创建UserAuthGlobalFilter全局过滤器
Data
@ConfigurationProperties("org.my.jwt")
@Component
@Slf4j
public class UserAuthGlobalFilter implements GlobalFilter, Ordered {private String[] skipAuthUrls;/*** 过滤器逻辑** @param exchange* @param chain* @return*/@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {// user/login// 获取请求url地址String path = exchange.getRequest().getURI().getPath();// 跳过不需要验证的路径if (null != skipAuthUrls && isSkip(path)) {return chain.filter(exchange);}// 1. 从请求头中获取tokenString token = exchange.getRequest().getHeaders().getFirst("token");// 2. 判断tokenif (StringUtils.isEmpty(token)) {// 3. 设置响应ServerHttpResponse response = exchange.getResponse();// 4. 设置响应状态码response.setStatusCode(HttpStatus.OK);// 5. 设置响应头response.getHeaders().add("Content-Type", "application/json;charset=UTF-8");// 6. 创建响应对象Response res = new Response(200, "token 参数缺失");// 7. 对象转字符串byte[] bytes = JSONObject.toJSONString(res).getBytes(StandardCharsets.UTF_8);// 8. 数据流返回数据DataBuffer wrap = response.bufferFactory().wrap(bytes);return response.writeWith(Flux.just(wrap));}// 验证tokenboolean verify = JWTUtils.verify(token);if (!verify) {// 3. 设置响应ServerHttpResponse response = exchange.getResponse();// 4. 设置响应状态码response.setStatusCode(HttpStatus.OK);// 5. 设置响应头response.getHeaders().add("Content-Type", "application/json;charset=UTF-8");// 6. 创建响应对象Response res = new Response(200, "token 失效");// 7. 对象转字符串byte[] bytes = JSONObject.toJSONString(res).getBytes(StandardCharsets.UTF_8);// 8. 数据流返回数据DataBuffer wrap = response.bufferFactory().wrap(bytes);return response.writeWith(Flux.just(wrap));}// 如果各种判断都通过。。return chain.filter(exchange);}@Overridepublic int getOrder() {return 0;}/*** 判断当前访问的url是否开头URI是在配置的忽略url列表中** @param url* @return*/private boolean isSkip(String url) {for (String skipurl : skipAuthUrls) {if (url.startsWith(skipurl)) {return true;}}return false;}}测试


相关文章:
19-springcloud(中)
一 服务注册发现 1 什么是服务治理 为什么需要服务治理 在没有进行服务治理前,服务之间的通信是通过服务间直接相互调用来实现的。 过程: 武当派直接调用峨眉派和华山派,同样,华山派直接调用武当派和峨眉派。如果系统不复杂,这样…...
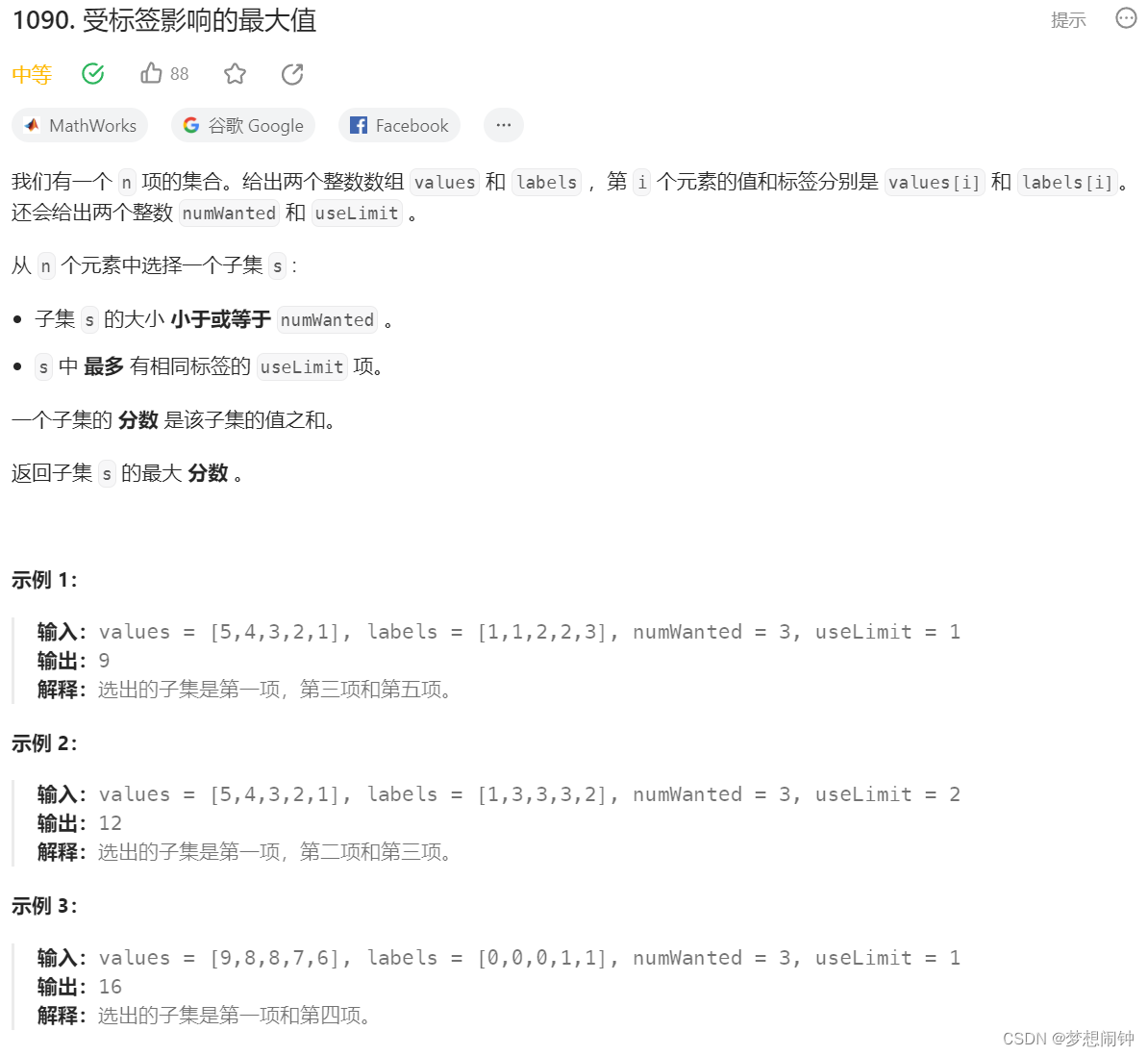
Leetcode1090. 受标签影响的最大值
思路:根据值从大到小排序,然后在加的时候判断是否达到标签上限即可,一开始想用字典做,但是题目说是集合却连续出现两个8,因此使用元组SortedList进行解决 class Solution:def largestValsFromLabels(self, values: li…...
第七章:敏捷开发工具方法-part2-CI/CD工具介绍
文章目录 前言一、CI-持续集成1.1 安装部署gitlab 二、gitlab CI配置三、jenkins实现CI / CD3.1 安装jenkins3.2 配置CI3.3 配置CD3.4 其他构建方式1、定时构建2、指定参数构建3、webhook自动根据git事件进行构建 前言 什么是CI/Cd? CI-Continuous integration&…...
【自学开发之旅】Flask-回顾--对象拆分-蓝图(二)
url-统一资源定位符-不同的url对应不同的资源 作为服务端,url和视图函数的映射关系就是路由。 定义传递参数的方式: 1.创建动态url app.route("/login2/<username>/<passwd>") def login2(username, passwd):if username "…...

自动驾驶中间件
自动驾驶中间件 1. 什么是中间件2. 中间件的分类3. 自动驾驶为什么需要中间件4. 通信中间件 Reference: 自动驾驶中间件:量产落地的关键技术通俗易懂的告诉你什么是中间件 对于初入自动驾驶行业的人来说,各色各样的新型传感器、线控系统、芯…...
移植javacpp)
鲲鹏920(ARM64)移植javacpp
JavaCPP JavaCPP 使得Java 应用可以在高效的访问本地C++方法,JavaCPP底层使用了JNI技术,可以广泛的用在Java SE应用中(也包括安卓),以下两个特性是JavaCPP的关键,稍后咱们会用到: 提供一些注解,将Java代码映射为C++代码提供一个jar,用java -jar命令可以将C++代码转为…...

python打包exe实用版
pyinstaller模块用于将python项目打包成exe文件,以方便地在没有安装python环境的机器上运行。该模块使用 pip install pyinstaller 安装即可。 参数命令含义-Dpyinstaller -D demo.py默认选项。除了主程序demo.exe外,还会在在dist文件夹中生成很多依赖文…...
?解释反向代理的作用和常见应用。)
什么是反向代理(Reverse Proxy)?解释反向代理的作用和常见应用。
1、什么是反向代理(Reverse Proxy)?解释反向代理的作用和常见应用。 反向代理是一种代理服务器模型,它位于客户端和后端服务器之间。它允许将请求转发到后端服务器,并将响应返回给客户端。反向代理的主要作用如下&…...

算法通关村第十二关——不简单的字符串转换问题
前言 字符串是我们在日常开发中最常处理的数据,虽然它本身不是一种数据结构,但是由于其可以包含所有信息,所以通常作为数据的一种形式出现,由于不同语言创建和管理字符串的方式也各有差异,因此针对不同语言特征又产生…...

PROSOFT PTQ-PDPMV1网络接口模块
通信接口:PROSOFT PTQ-PDPMV1 网络接口模块通常配备了多种通信接口,以便与不同类型的设备和网络进行通信。常见的接口包括以太网、串行端口(如RS-232和RS-485)、Profibus、DeviceNet 等。 协议支持:该模块通常支持多种…...
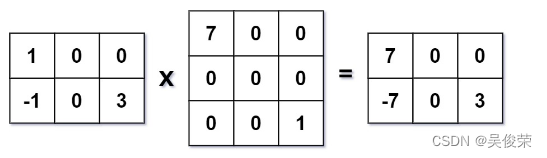
力扣(LeetCode)算法_C++——稀疏矩阵的乘法
给定两个 稀疏矩阵 :大小为 m x k 的稀疏矩阵 mat1 和大小为 k x n 的稀疏矩阵 mat2 ,返回 mat1 x mat2 的结果。你可以假设乘法总是可能的。 示例 1: 输入:mat1 [[1,0,0],[-1,0,3]], mat2 [[7,0,0],[0,0,0],[0,0,1]] 输出&am…...

华为云API人脸识别服务FRS的感知力—偷偷藏不住的你
云服务、API、SDK,调试,查看,我都行 阅读短文您可以学习到:人工智能AI人脸的识别、检测、搜索、比对 1、IntelliJ IDEA 之API插件介绍 API插件支持 VS Code IDE、IntelliJ IDEA等平台、以及华为云自研 CodeArts IDE,…...

产品技术体系
产品,是一个企业或公司针对市场客户推出的一系列相关的功能或者服务,为对应的客户解决实际问题,进而产生对应的商业、社会价值。有了这些实际的价值,企业就会获得相应的利益或者利润回报。正常来讲,这应该是一个良性的…...

Docker从认识到实践再到底层原理(二-3)|LXC容器
前言 那么这里博主先安利一些干货满满的专栏了! 首先是博主的高质量博客的汇总,这个专栏里面的博客,都是博主最最用心写的一部分,干货满满,希望对大家有帮助。 高质量博客汇总 然后就是博主最近最花时间的一个专栏…...

[运维|docker] ubuntu镜像更新时报E: Problem executing scripts APT::Update::Post-Invoke错误
参考文献 docker-ce在ubuntu:22.04进行apt update时报错E: Problem executing scripts APT::Update::Post-Invoke 详细报错信息 E: Problem executing scripts APT::Update::Post-Invoke rm -f /var/cache/apt/archives/*.deb /var/cache/apt/archives/partial/*.deb /var/c…...
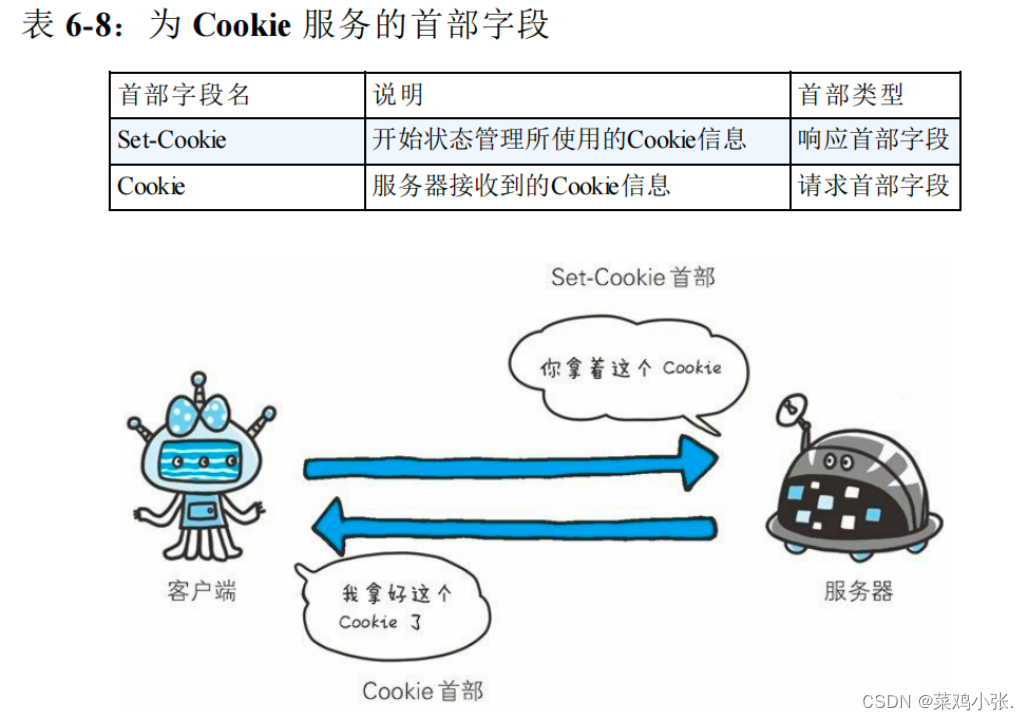
计算机网络的故事——HTTP首部
HTTP首部 在HTTP协议通信交互中使用的首部字段。不限于RFC2616中定义的47种首部字段,还有Cookie、setCookie和Content-Disposition等 HTTP 首部字段将定义成缓存代理和非缓存代理的行为,分成 2 种类型。端到端首部和逐跳首部...

js农历与阳历转换使用笔记
1、新建utils/dateChange.js /*** 1900-2100区间内的公历、农历互转* charset UTF-8* Author jiangjiazhi* 公历转农历:calendar.solar2lunar(1987,11,01); //[you can ignore params of prefix 0]* 农历转公历:calendar.lunar2solar(1987,09,10); //[…...

苹果与芯片巨头Arm达成20年新合作协议,将继续采用芯片技术
9月6日消息,据外媒报道,芯片设计巨头Arm宣布在当地时间周二提交给美国证券交易委员会(SEC)的最新IPO文件中,透露与苹果达成了一项长达20年的新合作协议,加深了双方之间的合作关系。 报道称,虽然…...

Linux下systemd深入指南:如何优化Java服务管理与开机自启配置
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

PMOS阵列(PMOS阵列代替)
pmos阵列没有找到,不过高压侧驱动芯片倒是可以使用VN340SP Datasheet - VN340SP-E & VN340SP-33-E - Quad high-side smart power solid-state relayhttps://www.st.com/resource/en/datasheet/vn340sp-33-e.pdf VN340SP-E - 四通道高侧智能功率固态继电器 - 意…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

AGain DB和倍数增益的关系
我在设置一款索尼CMOS芯片时,Again增益0db变化为6DB,画面的变化只有2倍DN的增益,比如10变为20。 这与dB和线性增益的关系以及传感器处理流程有关。以下是具体原因分析: 1. dB与线性增益的换算关系 6dB对应的理论线性增益应为&…...

vulnyx Blogger writeup
信息收集 arp-scan nmap 获取userFlag 上web看看 一个默认的页面,gobuster扫一下目录 可以看到扫出的目录中得到了一个有价值的目录/wordpress,说明目标所使用的cms是wordpress,访问http://192.168.43.213/wordpress/然后查看源码能看到 这…...

为什么要创建 Vue 实例
核心原因:Vue 需要一个「控制中心」来驱动整个应用 你可以把 Vue 实例想象成你应用的**「大脑」或「引擎」。它负责协调模板、数据、逻辑和行为,将它们变成一个活的、可交互的应用**。没有这个实例,你的代码只是一堆静态的 HTML、JavaScript 变量和函数,无法「活」起来。 …...

libfmt: 现代C++的格式化工具库介绍与酷炫功能
libfmt: 现代C的格式化工具库介绍与酷炫功能 libfmt 是一个开源的C格式化库,提供了高效、安全的文本格式化功能,是C20中引入的std::format的基础实现。它比传统的printf和iostream更安全、更灵活、性能更好。 基本介绍 主要特点 类型安全:…...

字符串哈希+KMP
P10468 兔子与兔子 #include<bits/stdc.h> using namespace std; typedef unsigned long long ull; const int N 1000010; ull a[N], pw[N]; int n; ull gethash(int l, int r){return a[r] - a[l - 1] * pw[r - l 1]; } signed main(){ios::sync_with_stdio(false), …...
大模型——基于Docker+DeepSeek+Dify :搭建企业级本地私有化知识库超详细教程
基于Docker+DeepSeek+Dify :搭建企业级本地私有化知识库超详细教程 下载安装Docker Docker官网:https://www.docker.com/ 自定义Docker安装路径 Docker默认安装在C盘,大小大概2.9G,做这行最忌讳的就是安装软件全装C盘,所以我调整了下安装路径。 新建安装目录:E:\MyS…...
Element-Plus:popconfirm与tooltip一起使用不生效?
你们好,我是金金金。 场景 我正在使用Element-plus组件库当中的el-popconfirm和el-tooltip,产品要求是两个需要结合一起使用,也就是鼠标悬浮上去有提示文字,并且点击之后需要出现气泡确认框 代码 <el-popconfirm title"是…...