【爬虫】实验项目二:模拟登录和数据持久化
目录
一、实验目的
二、实验预习提示
三、实验内容
实验要求
基本要求:
改进要求A:
改进要求B:
四、实验过程
基本要求:
源码如下:
改进要求A:
源码如下:
改进要求B:
源码如下:
五、资料
1.实验框架代码:
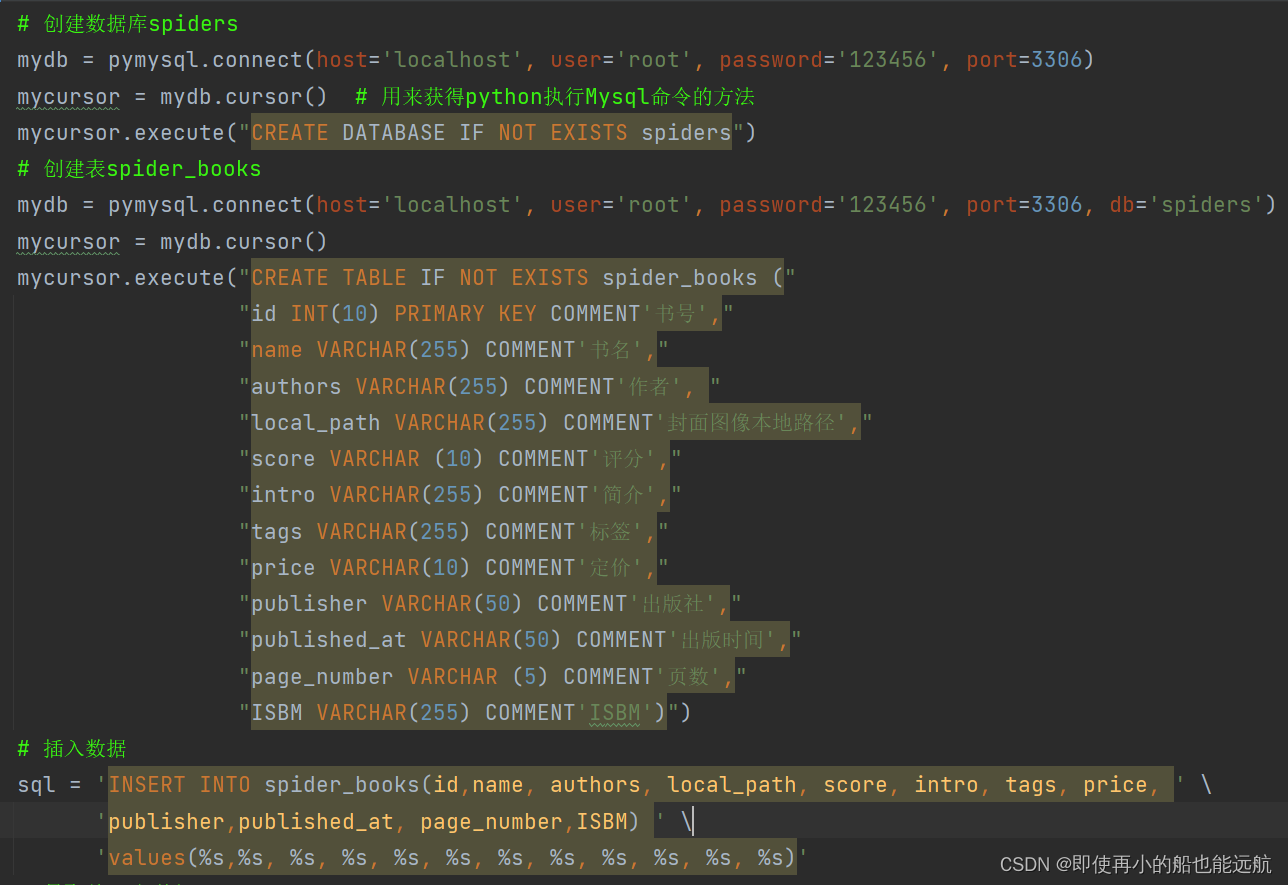
2.MySQL存储:
3.实验小提示
一、实验目的
部分网站的数据需要用户登录后才能查看,因此爬虫程序需要模拟用户进行登录操作才能获取到数据。这次需要熟悉两种常见的登录模式:基于Session与Cookie的登录,基于JWT登录。同时掌握使用MySQL数据库基本操作,来持久化爬取的数据。
二、实验预习提示
1、安装Mysql和相应的python库:pymysql
2、为Python安装selenium、pyquery库,安装Chrome和对应ChromeDriver(见实验一)
三、实验内容
爬取网站1:https://login2.scrape.center/
爬取网站2:https://login3.scrape.center/login 
使用浏览器开发者工具(F12),分析网站登录请求,在登录后再分析获取数据的请求。根两种登录模式,写出相应的相应登录请求,获取数据并持久化到MySQL数据库中。基于Session与Cookie的登录代码已在资料给出。
实验要求
基本要求:
实现基于JWT登录模式,实现对爬取网站2数据的爬取,并把数据持久化到MySQL,存储的表名为:spider_books,字段名称自定义,存储的字段信息包含:书名、作者、封面图像本地路径、评分、简介、标签、定价、出版社、出版时间、页数、ISBM

请把封面图像保存到本地文件夹中,因此封面图像本地路径为封面图像保存到本地的路径,而不是原始URL链接。
改进要求A:
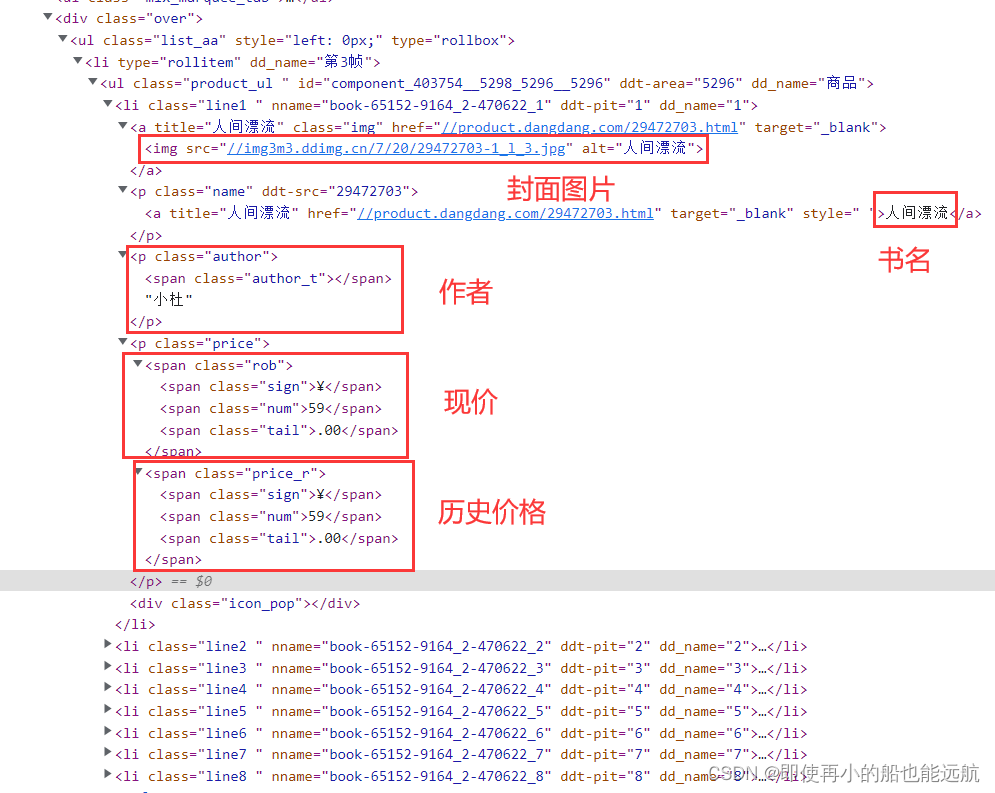
在完成基本要求的基础上,选项一:实现对当当网的新书上架内容数据(https://book.dangdang.com/)爬取(红框内的所有数据):

书籍信息需要保存到MySQL中,表名和字段名自定义,注意红框内为一个Tab展示列表,实际内容有4页,而不是8只有本书,应该有4*8本书。选项二:分析给出豆瓣、淘宝等网站是如何实现登录请求的,以及登陆后再次请求需要携带哪些信息,给出一个案例分析即可,不需要代码实现,必须给出分析思路和图片说明。
改进要求B:
在完成基本要求的基础上,实现一个常见网站模拟登录代码,并输出需要登录访问的信息,无需持久化,输出至控制台即可,必须给出分析思路和图片说明。
四、实验过程
基本要求:
模拟登录爬取网页内容,首先分析网站登录请求,在登录后再分析获取数据的请求。
如下图所示:

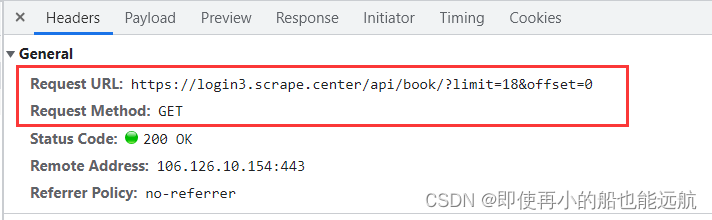
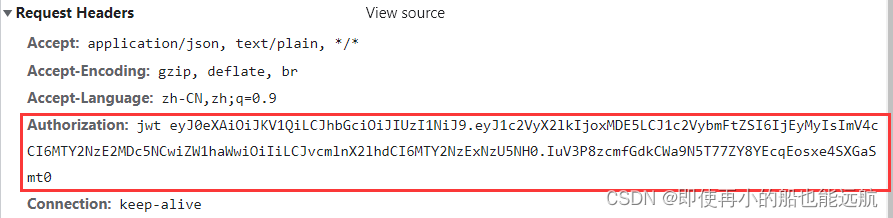
Authorization主要用作http协议的认证。
1. 构造JWT获取网站的一级页面,并把每次数据请求加入相应的token即可
目的:找到每本书的书号
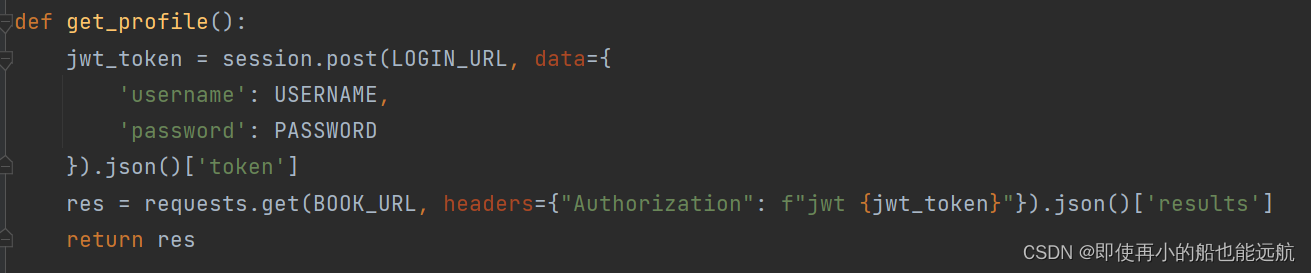
得到结果如下图所示:

2. 通过书号获取书的详细信息的JSON数据
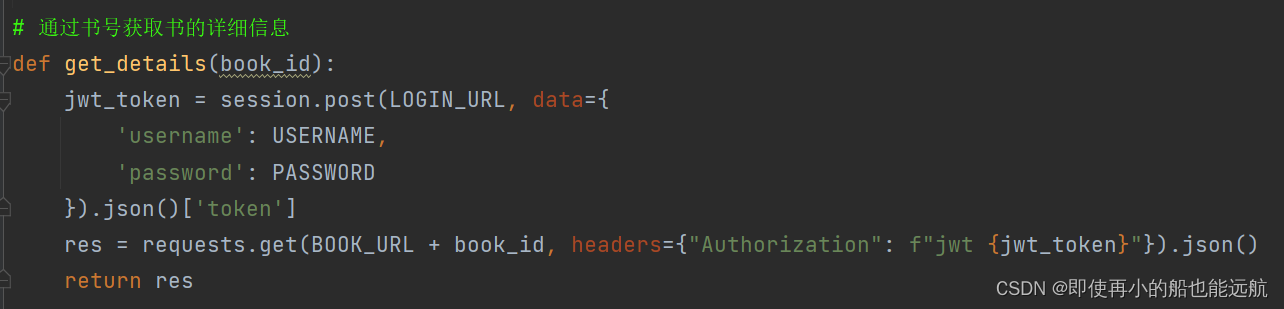
得到结果如下图所示:
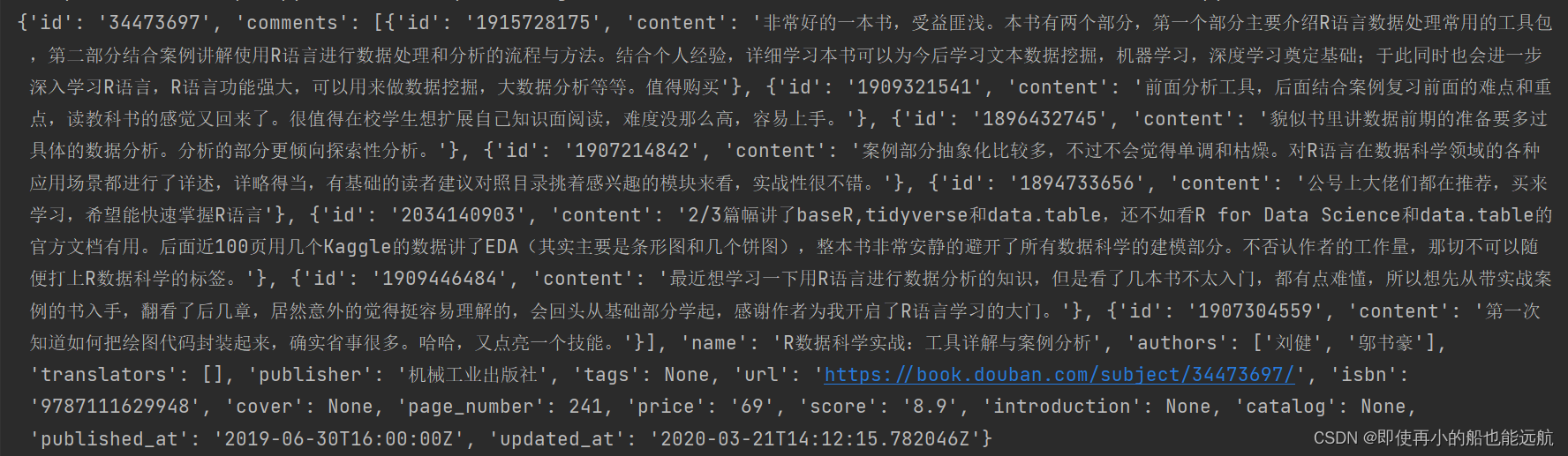
总结:因为书籍信息部分缺失,所以很多用None代替了,后续会把这些数据特殊处理
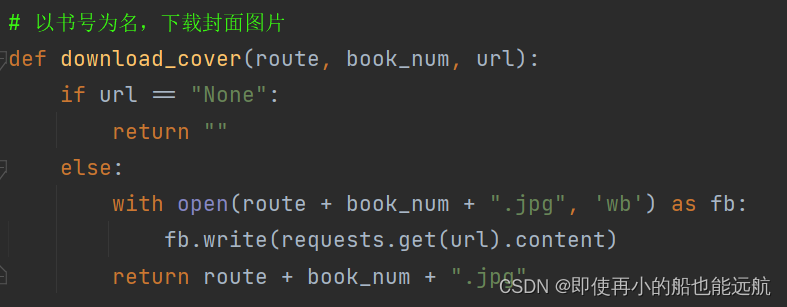
3. 现在已经得到了相关数据信息,只需保存即可,把封面图像保存到本地文件夹中
4. 将爬下来的数据进行特殊处理并存储到变量中,None用空代替,这里只展示了书名与作者,其他数据都类似,都是用的三目运算符

5. 最后将数据保存到mysql数据库中即可
6. 数据库数据展示如下:
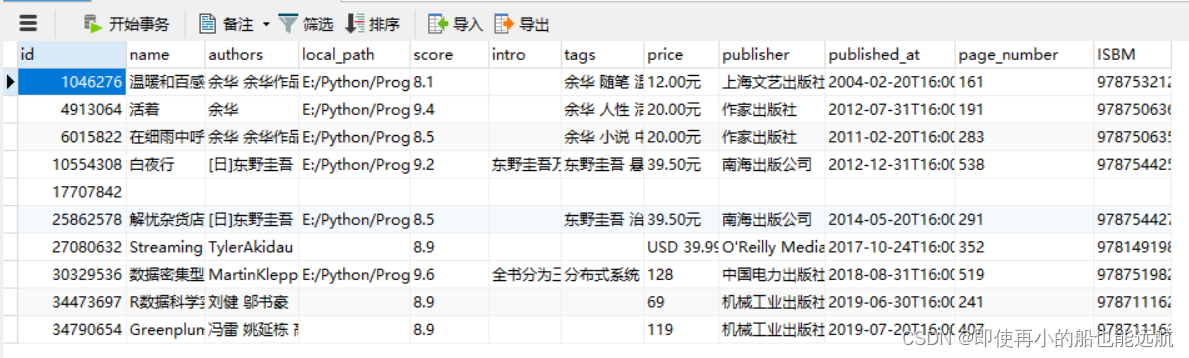
总结: 有些字段本来可以用int或float的,但是由于该字段有些缺失数据,所以所有字段都用字符串,把缺失字段都用空来替代。
源码如下:
# coding=UTF-8
import pymysql
import requests
from urllib.parse import urljoin# 存储封面图像本地路径
# LOCAL_PATH = "/usr/local/images/"
LOCAL_PATH = "D:\images\\"BASE_URL = 'https://login3.scrape.center/'
LOGIN_URL = urljoin(BASE_URL, '/api/login')
BOOK_URL = urljoin(BASE_URL, '/api/book/')
USERNAME = 'admin'
PASSWORD = 'admin'
session = requests.Session()
"""requests库的session会话对象可以跨请求保持某些参数。说白了,就是比如你使用session成功的登录了某个网站,则再次使用该session对象对该网站的其他网页访问时都会默认使用该session之前使用的cookie等参数。
"""# Authorization主要用作http协议的认证。
# 构造JWT获取网站的一级页面,并把每次数据请求加入相应的token即可
# 获取网站的一级页面 目的:找到每本书的书号
def get_profile():jwt_token = session.post(LOGIN_URL, data={'username': USERNAME,'password': PASSWORD}).json()['token']res = requests.get(BOOK_URL, headers={"Authorization": f"jwt {jwt_token}"}).json()['results']return res# 通过书号获取书的详细信息
def get_details(book_id):jwt_token = session.post(LOGIN_URL, data={'username': USERNAME,'password': PASSWORD}).json()['token']res = requests.get(BOOK_URL + book_id, headers={"Authorization": f"jwt {jwt_token}"}).json()return res# 将爬下来的数据进行处理并存储到变量中
def get_info(id):global name, authors, local_path, score, intro, tags, price, publisher, published_at, page_number, isbndetail = get_details(id)name = detail['name'] if detail['name'] is not None else ""authors = " ".join(map(lambda x: x.strip().replace(" ", ""), detail['authors'])) \if detail['authors'] is not None else ""cover = detail['cover'] if detail['cover'] is not None else "None"local_path = download_cover(LOCAL_PATH, id, cover)score = eval(detail['score']) if detail['score'] is not None else ""intro = detail['introduction'][:255] if detail['introduction'] is not None else ""tags = " ".join(detail['tags']) if detail['tags'] is not None else ""price = detail['price'] if detail['price'] is not None else ""publisher = detail['publisher'] if detail['publisher'] is not None else ""published_at = detail['published_at'] if detail['published_at'] is not None else ""page_number = int(detail['page_number']) if detail['page_number'] is not None else ""isbn = detail['isbn'] if detail['isbn'] is not None else ""# 以书号为名,下载封面图片
def download_cover(route, book_num, url):if url == "None":return ""else:with open(route + book_num + ".jpg", 'wb') as fb:fb.write(requests.get(url).content) # content返回的是bytes,二进制数据return route + book_num + ".jpg"# 将数据持久化到MySQL数据库中
if __name__ == '__main__':infos = get_profile()# 创建数据库spiders connect:连接mydb = pymysql.connect(host='localhost', user='root', password='123456', port=3306)mycursor = mydb.cursor() # 用来获得python执行Mysql命令的方法 cursor:游标 指针mycursor.execute("CREATE DATABASE IF NOT EXISTS spiders") # execute:执行# 创建表spider_booksmydb = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders')mycursor = mydb.cursor()mycursor.execute("CREATE TABLE IF NOT EXISTS spider_books (""id INT(10) PRIMARY KEY COMMENT'书号',""name VARCHAR(255) COMMENT'书名',""authors VARCHAR(255) COMMENT'作者', ""local_path VARCHAR(255) COMMENT'封面图像本地路径',""score VARCHAR (10) COMMENT'评分',""intro VARCHAR(255) COMMENT'简介',""tags VARCHAR(255) COMMENT'标签',""price VARCHAR(10) COMMENT'定价',""publisher VARCHAR(50) COMMENT'出版社',""published_at VARCHAR(50) COMMENT'出版时间',""page_number VARCHAR (5) COMMENT'页数',""ISBM VARCHAR(255) COMMENT'ISBM')")# 插入数据sql = 'INSERT INTO spider_books values(%s,%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)'# 只取前10条数据for info in infos[0:10]:book_id = info['id']get_info(book_id)try:mycursor.execute(sql,(book_id, name, authors, local_path, score, intro, tags, price, publisher, published_at,page_number, isbn))mydb.commit()print('Insert successfully')except Exception as err:mydb.rollback() # 数据回滚print("Failed To Insert")print(err)mydb.close()
改进要求A:
1. 此处实现的是选项一:实现对当当网的新书上架内容数据爬取,话不多说,分析网页数据,如图所示:
2. 利用ChromeDriver获取数据
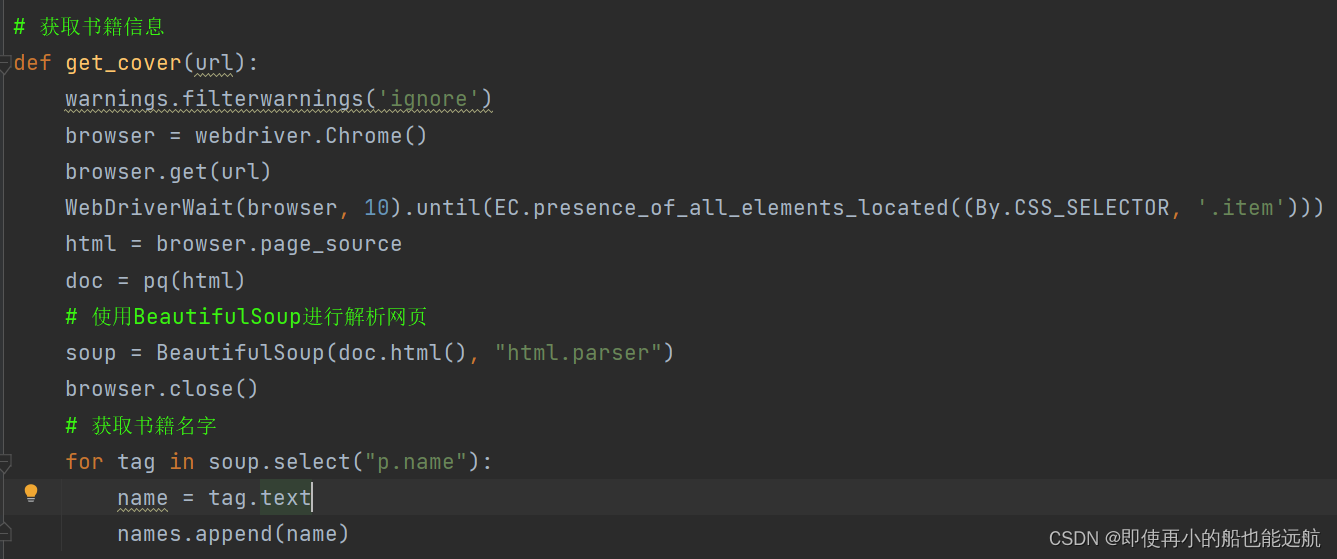
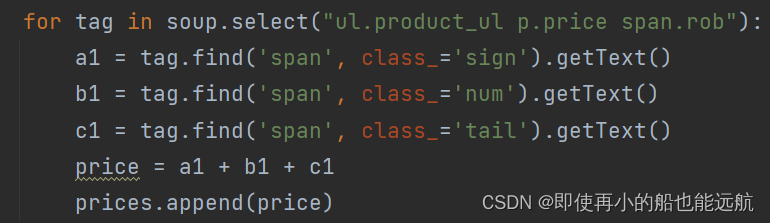
书名,作者,封面三者类似,重点看看爬取现价与历史价格,从分析图可以看出每一项都在span标签中,可以取出来合并
- 获取现价
- 获取历史价格

3. 将书籍存储MySQL数据库中
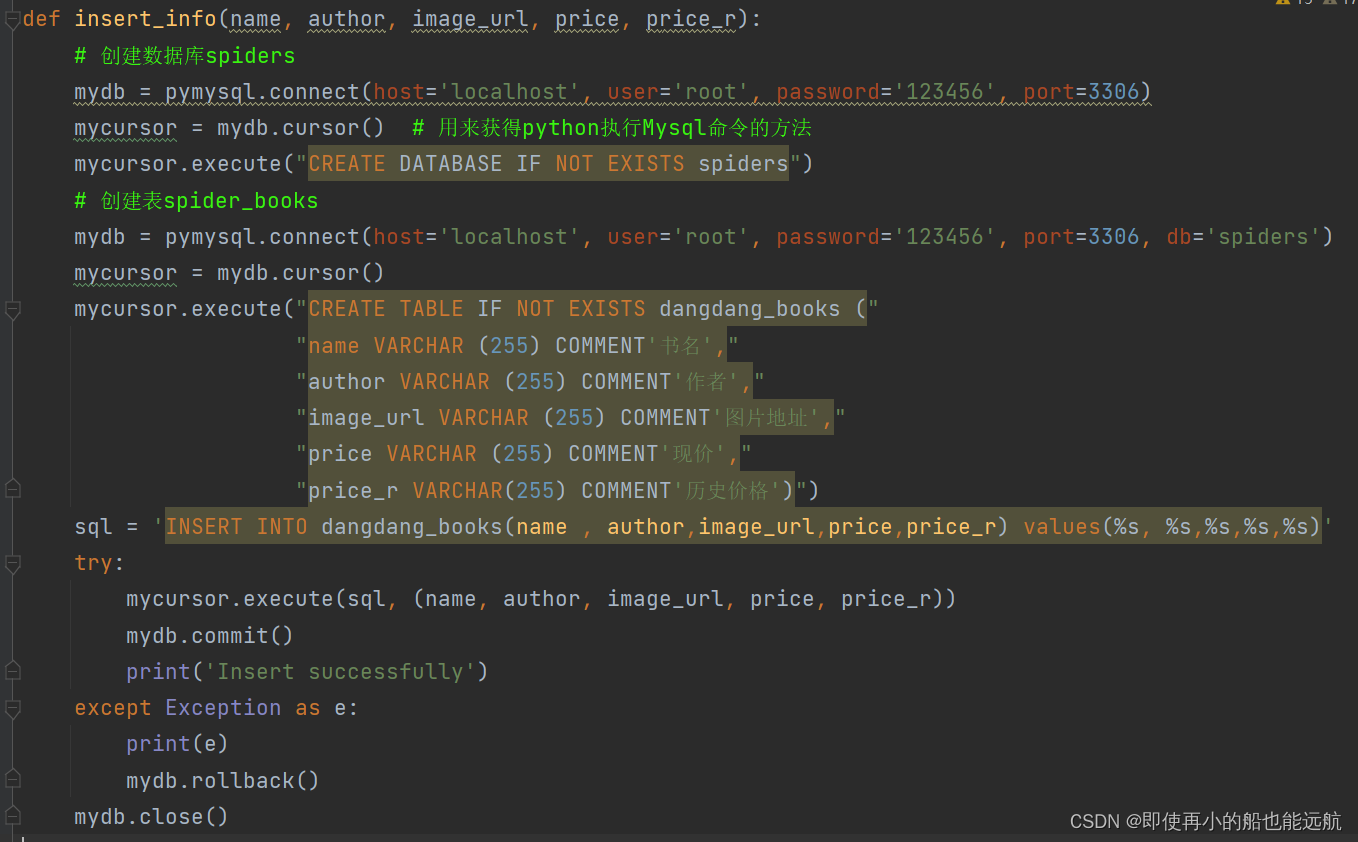
4. 主函数,遍历取出数据给MySQL函数
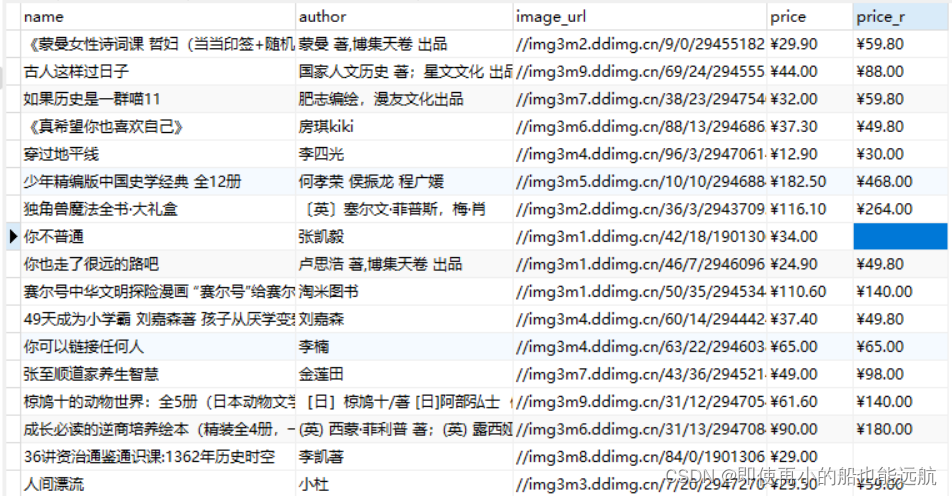
5. 数据库数据展示如下:
源码如下:
import pymysql
import warnings
from selenium import webdriver
from pyquery import PyQuery as pq
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from bs4 import BeautifulSoup# 定义容器用来存储书籍的信息
names = [] # 书籍名字
authors = [] # 书籍作者
image_urls = [] # 书籍封面图片
prices = [] # 现价
price_rs = [] # 历史价格# 获取书籍信息
def get_cover(url):warnings.filterwarnings('ignore')browser = webdriver.Chrome()browser.get(url)WebDriverWait(browser, 10).until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.item')))html = browser.page_sourcedoc = pq(html)# 使用BeautifulSoup进行解析网页soup = BeautifulSoup(doc.html(), "html.parser")browser.close()# 获取书籍名字for tag in soup.select("p.name"):name = tag.textnames.append(name)# 获取作者名字for tag in soup.select("p.author"):author = tag.textauthors.append(author)# 获取书籍封面图片urlfor tag in soup.select("ul.product_ul li a img"):image_url = tag.attrs['src']image_urls.append(image_url)# 获取现价for tag in soup.select("ul.product_ul p.price span.rob"):a1 = tag.find('span', class_='sign').getText()b1 = tag.find('span', class_='num').getText()c1 = tag.find('span', class_='tail').getText()price = a1 + b1 + c1prices.append(price)# 获取历史价格(每个界面最后一本书没有历史价格,所以if一下)for tag in soup.select("ul.product_ul p.price"):if not tag.find('span', class_='price_r'):price = ''price_rs.append(price)else:tag = tag.find('span', class_='price_r')a1 = tag.find('span', class_='sign').getText()b1 = tag.find('span', class_='num').getText()c1 = tag.find('span', class_='tail').getText()price = a1 + b1 + c1price_rs.append(price)return names, authors, image_urls, prices, price_rsdef insert_info(name, author, image_url, price, price_r):# 创建数据库spidersmydb = pymysql.connect(host='localhost', user='root', password='123456', port=3306)mycursor = mydb.cursor() # 用来获得python执行Mysql命令的方法mycursor.execute("CREATE DATABASE IF NOT EXISTS spiders")# 创建表spider_booksmydb = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders')mycursor = mydb.cursor()mycursor.execute("CREATE TABLE IF NOT EXISTS dangdang_books (""name VARCHAR (255) COMMENT'书名',""author VARCHAR (255) COMMENT'作者',""image_url VARCHAR (255) COMMENT'图片地址',""price VARCHAR (255) COMMENT'现价',""price_r VARCHAR(255) COMMENT'历史价格')")sql = 'INSERT INTO dangdang_books(name , author,image_url,price,price_r) values(%s, %s,%s,%s,%s)'try:mycursor.execute(sql, (name, author, image_url, price, price_r))mydb.commit()print('Insert successfully')except Exception as e:print(e)mydb.rollback()mydb.close()if __name__ == '__main__':url = "https://book.dangdang.com/"get_cover(url)for i in range(len(image_urls)):name = names[i]author = authors[i]image_url = image_urls[i]price = prices[i]price_r = price_rs[i]insert_info(name, author, image_url, price, price_r)
改进要求B:
这里模拟淘宝网站自动登录
显然只需用利用selenium打开Chrome Driver模拟点击及输入,下面来分析网站来获取用户名、密码的input及其登录button,分析如下:

代码实现部分:
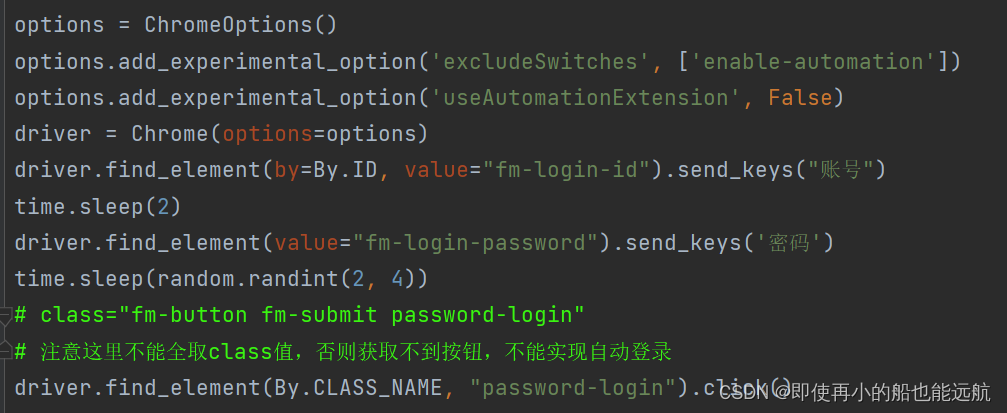
模拟后才发现还有滑块验证问题,如下:
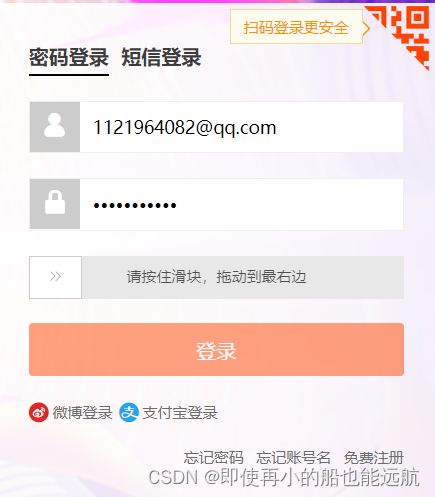
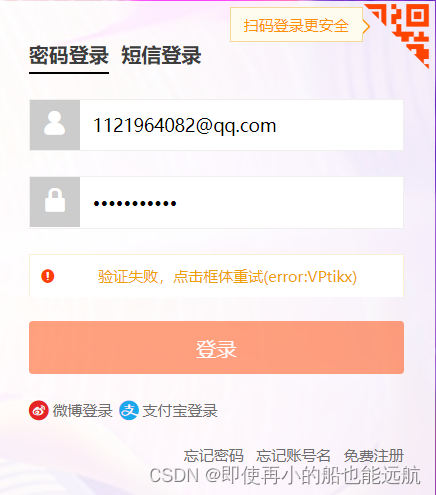
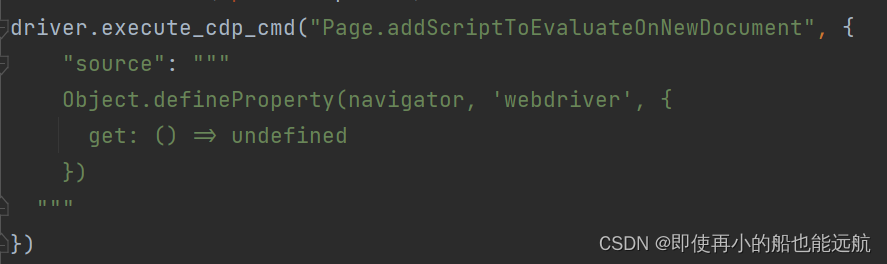
解决代码如下:
现在就可以模拟自动登录了,但是滑块还是的手动去操作,能力有限,先就这样吧。后面都改为手机淘宝验证了
准备爬取该页面,找到对应属性即可爬取
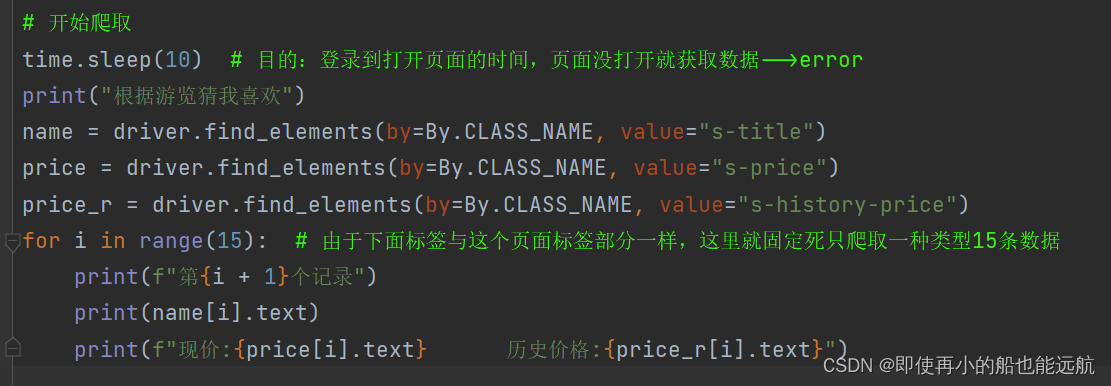
下面开始爬取数据:
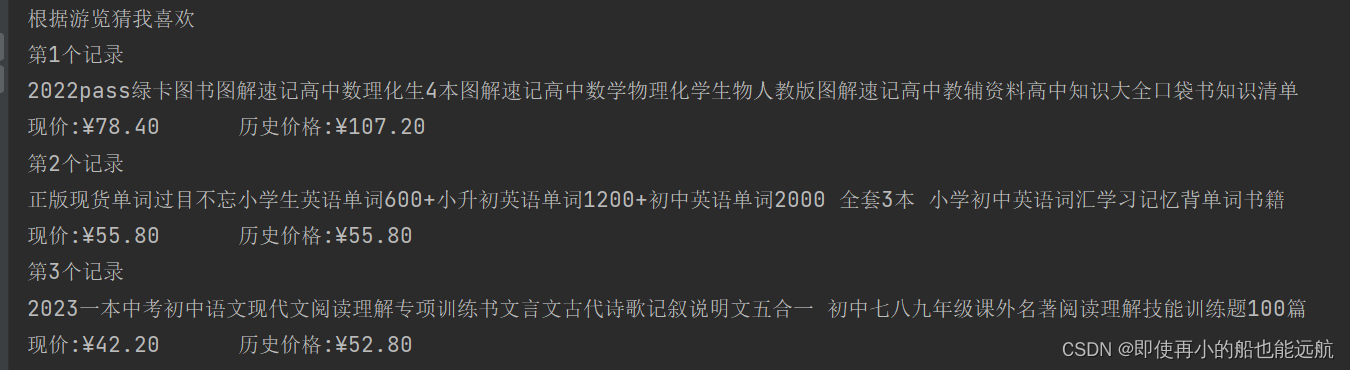
控制台爬取数据展示如下:
总结:其实模拟登录可以分为以下几部分:
1.打开游览器 2.打开网址 3.点击密码登录
4.定位账号跟密码 5.输入内容 6.点击登录该网站
源码如下:
新建steting.py放入自己的账号密码,如下:
username = 'xxx'
password = 'xxx'import random
import time
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
from selenium.webdriver.common.by import By
from selenium import webdriver
# 导入自己的账号和密码
from steting import username, password"""
# options = ChromeOptions()
# options.add_experimental_option('excludeSwitches', ['enable-automation'])
# options.add_experimental_option('useAutomationExtension', False)
# driver = Chrome(options=options)
"""
# 打开游览器
driver = webdriver.Chrome()# 解决滑块验证失败问题
# 由于selenium被淘宝识别,然后跳出滑动验证问题。这里需要添加参数,让淘宝无法检测出selenium。
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"""
})
# 打开网站
driver.get('https://login.taobao.com/member/login.jhtml')
# 定位账号跟密码 # 输入内容
driver.find_element(by=By.ID, value="fm-login-id").send_keys(username)
time.sleep(2)
driver.find_element(value="fm-login-password").send_keys(password)
time.sleep(random.randint(2, 4))
# class="fm-button fm-submit password-login"
# 注意这里不能全取class值,否则获取不到按钮,不能实现自动登录
# 点击登录
driver.find_element(By.CLASS_NAME, "password-login").click()# 开始爬取
time.sleep(10) # 目的:登录到打开页面的时间,页面没打开就获取数据-->error
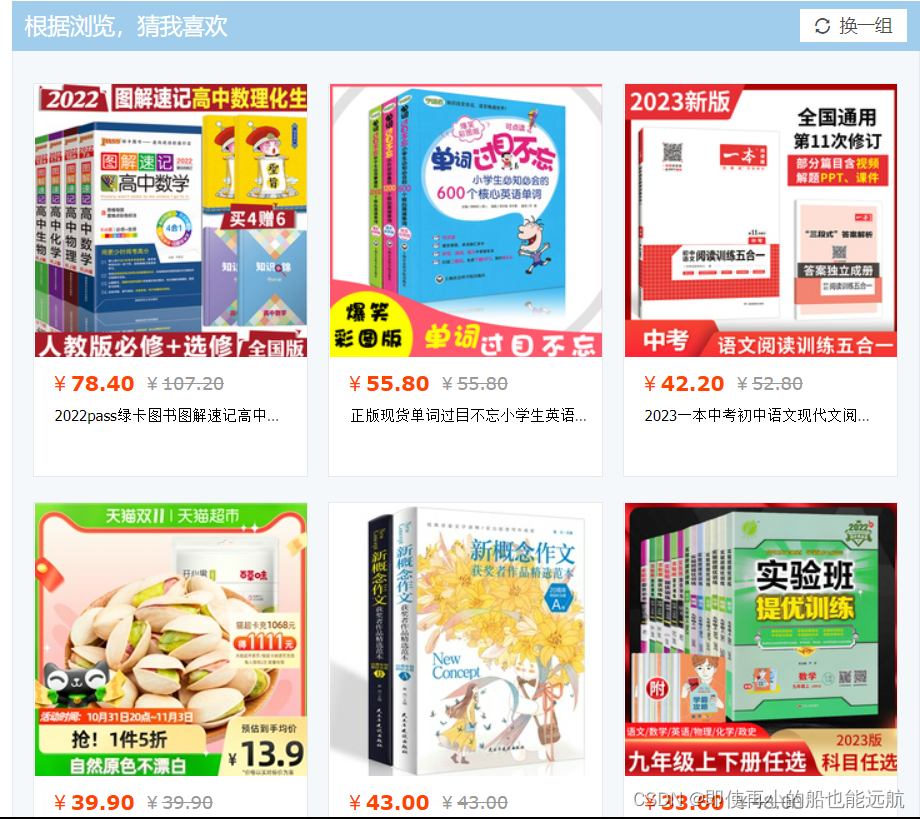
print("根据游览猜我喜欢")
name = driver.find_elements(by=By.CLASS_NAME, value="s-title")
price = driver.find_elements(by=By.CLASS_NAME, value="s-price")
price_r = driver.find_elements(by=By.CLASS_NAME, value="s-history-price")
for i in range(15): # 由于下面标签与这个页面标签部分一样,这里就固定死只爬取一种类型15条数据print(f"第{i + 1}个记录")print(name[i].text)print(f"现价:{price[i].text} 历史价格:{price_r[i].text}")
# 爬取完成自动关闭游览器
driver.quit()五、资料
1.实验框架代码:
BASE_URL = 'https://login2.scrape.center'
LOGIN_URL = urljoin(BASE_URL, '/login')
INDEX_URL = urljoin(BASE_URL, '/page/1')
USERNAME = 'admin'
PASSWORD = 'admin'
session = requests.Session()
response_login = session.post(LOGIN_URL, data={'username': USERNAME,'password': PASSWORD
})
cookies = session.cookies
print('Cookies', cookies)
response_index = session.get(INDEX_URL)
print('Response Status', response_index.status_code)
print('Response URL', response_index.url)2.MySQL存储:
import pymysql
id = '20120001'
user = 'Bob'
age = 20
db = pymysql.connect(host='localhost', user='root',password=None, port=3306, db='spiders')
cursor = db.cursor()
sql = 'INSERT INTO students(id, name, age) values(%s, %s, %s)'
try:cursor.execute(sql, (id, user, age))db.commit()print('Insert successfully')
except:db.rollback()
db.close()3.实验小提示
两种登录模式都是保存相应的登录token,并把每次数据请求加入相应的token即可。
下一篇文章: 实验项目三:验证码处理与识别
相关文章:
【爬虫】实验项目二:模拟登录和数据持久化
目录 一、实验目的 二、实验预习提示 三、实验内容 实验要求 基本要求: 改进要求A: 改进要求B: 四、实验过程 基本要求: 源码如下: 改进要求A: 源码如下: 改进要求B: 源码如下&…...
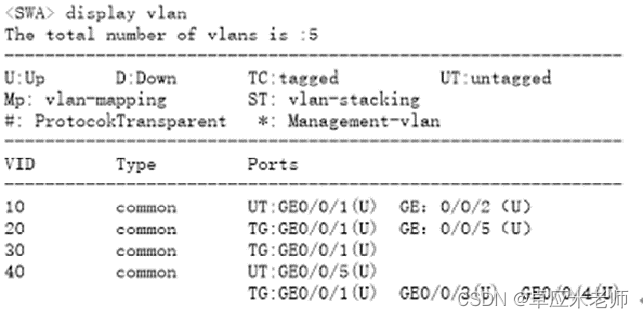
图文版:以太网二层接口类型(含配套习题)
常见的以太网二层接口类型包括以下三种: 一、Access接口 access链路类型端口,一种交换机的主干道模式,2台交换机的2个端口之间是否能够建立干道连接,取决于这2个端口模式的组合。 Access端口在收到以太网帧后打开VLAN标签&#…...
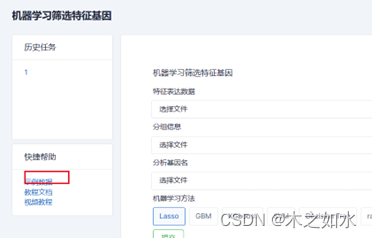
生信豆芽菜-机器学习筛选特征基因
网址:http://www.sxdyc.com/mlscreenfeature 一、使用方法 1、准备数据 第一个文件:特征表达数据 第二个文件:分组信息,第一列为样本名,第二列为患者分组 第三个文件:分析基因名 2、选择机器学习的方…...
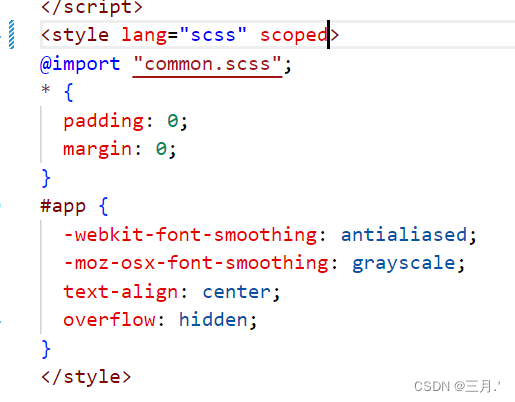
v-html富文本里面的图片设置宽高不起作用的原因
把scoped去掉...
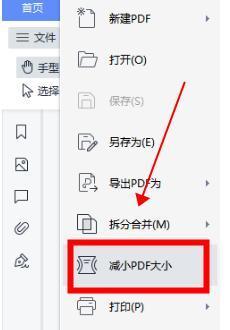
pdf文档怎么压缩小一点?文件方法在这里
在日常工作和生活中,我们经常会遇到需要上传或者发送pdf文档的情况。但是,有时候pdf文档的大小超出了限制,需要我们对其进行压缩。那么,如何将pdf文档压缩得更小一点呢?下面,我将介绍三种方法,让…...
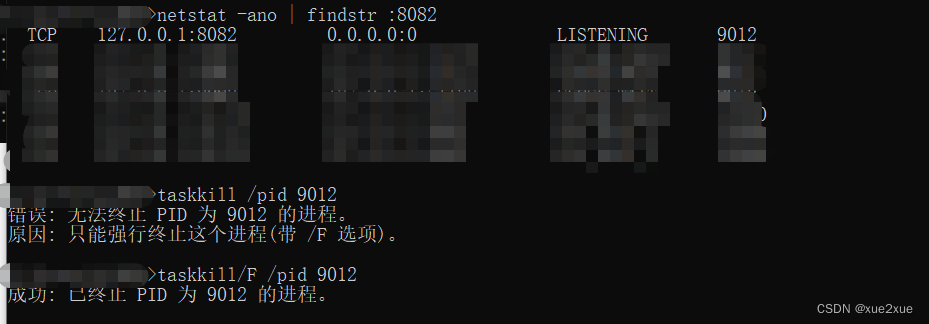
CMD关闭占用端口
1. netstat -ano | findstr :xxxx 2. taskkill /pid xxxx 3. 强制关闭taskkill/F /pid xxxx...
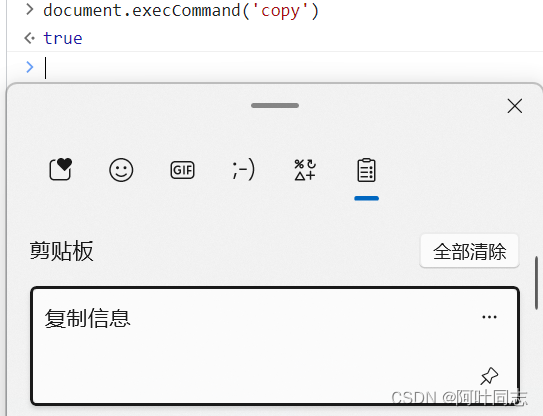
复制粘贴是怎么实现的
在上面的代码中,command 和 select 是自定义的函数。它们的作用如下: 实现复制粘贴的思路: 创建一个 textarea 标签将 textarea 移出可视区域给这个 textarea 赋值将这个 textarea 标签添加到页面中调用 textarea 的 select 方法调用 docum…...
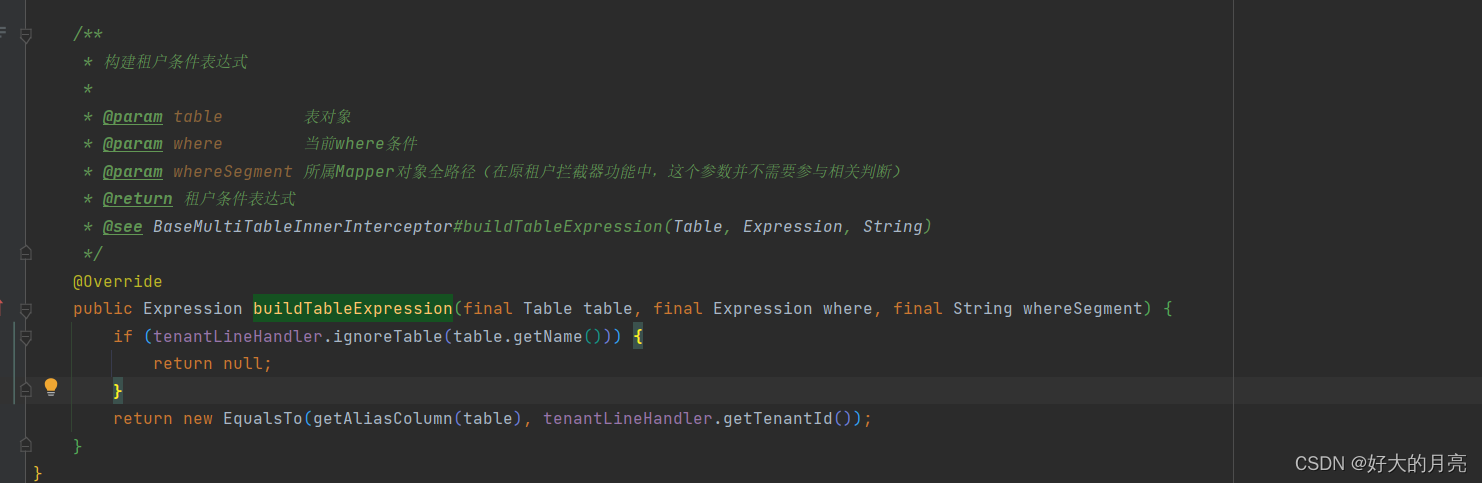
mybatisplus多租户原理略解
概述 当前mybatisPlus版本 <dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.3.2</version> </dependency>jdk版本:17 springboot版本:…...

Spring整合RabbitMQ-配制文件方式-1-消息生产者
Spring-amqp是对AMQP的一些概念的一些抽象,Spring-rabbit是对RabbitMQ操作的封装实现。 主要有几个核心类RabbitAdmin、RabbitTemplate、SimpleMessageListenerContainer等 RabbitAdmin类完成对Exchange、Queue、Binding的操作,在容器中管理 了RabbitA…...
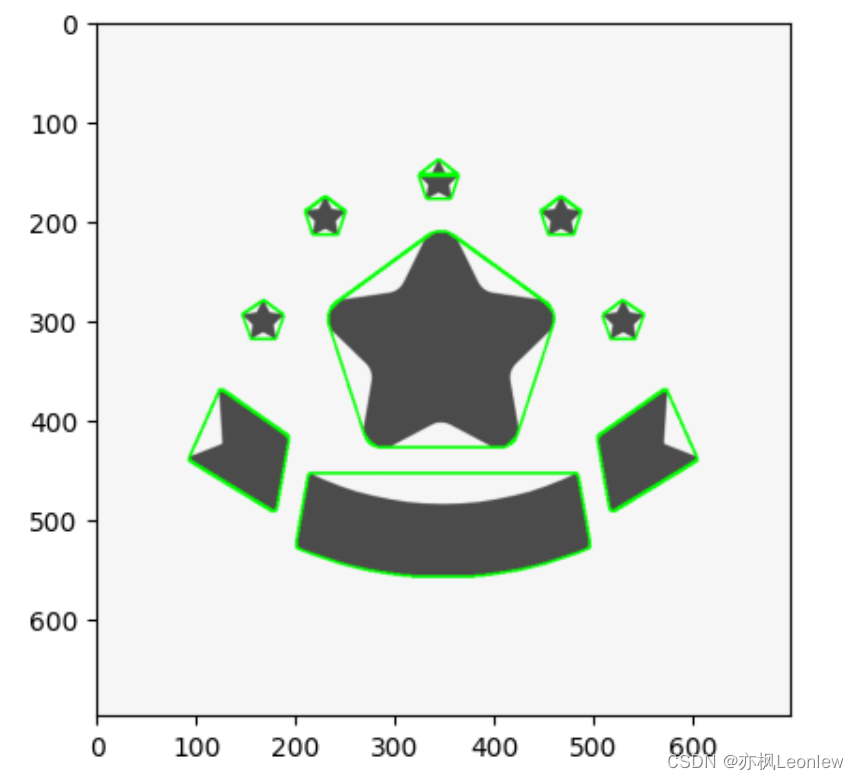
Python Opencv实践 - 凸包检测(ConvexHull)
import cv2 as cv import numpy as np import matplotlib.pyplot as pltimg cv.imread("../SampleImages/stars.png") plt.imshow(img[:,:,::-1])img_contour img.copy() #得到灰度图做Canny边缘检测 img_gray cv.cvtColor(img_contour, cv.COLOR_BGR2GRAY) edges…...

IP网络广播系统有哪些优点
IP网络广播系统有哪些优点 IP网络广播系统有哪些优点? IP网络广播系统是基于 TCP/IP 协议的公共广播系统,采用 IP 局域网或 广域网作为数据传输平台,扩展了公共广播系统的应用范围。随着局域网络和 网络的发展 , 使网络广播的普及变为可能 …...

【LeetCode】83. 删除排序链表中的重复元素
83. 删除排序链表中的重复元素(简单) 方法:一次遍历 思路 由于给定的链表是排好序的,因此重复的元素在链表中出现的位置是连续的,因此我们只需要对链表进行一次遍历,就可以删除重复的元素。 从指针 cur 指…...
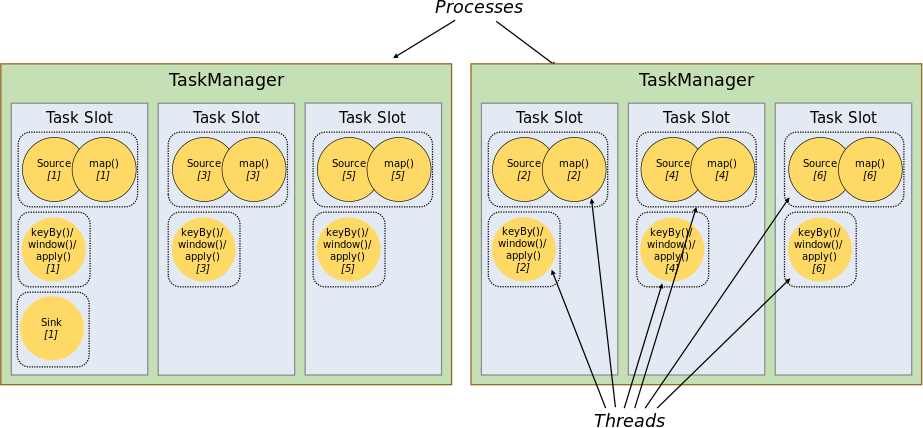
【大数据】Flink 详解(七):源码篇 Ⅱ
本系列包含: 【大数据】Flink 详解(一):基础篇【大数据】Flink 详解(二):核心篇 Ⅰ【大数据】Flink 详解(三):核心篇 Ⅱ【大数据】Flink 详解(四…...

stable diffusion实践操作-SD原理
系列文章目录 本文专门开一节写SD原理相关的内容,在看之前,可以同步关注: stable diffusion实践操作 文章目录 系列文章目录前言一、原理说明1.1、出图原理1.1.1 AI画画不是和人一样,从0开始,而是一个去噪点的过程&am…...

C++ Primer Plus第十三章编程练习答案
1,以下面的类声明为基础: // base class class Cd{ // represents a CD disk private: char performers[50] ; char label[20]; int selections;// number of selections double playtime; // playing time in minutes public: Cd(char * sl,char * s2,int n,double…...
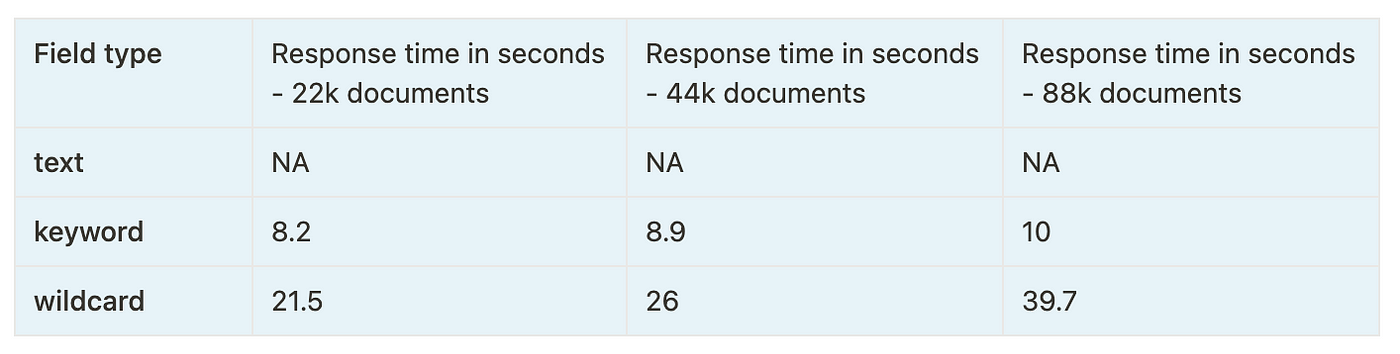
Elasticsearch:wildcard - 通配符搜索
Elasticsearch 是一个分布式、免费和开放的搜索和分析引擎,适用于所有类型的数据,例如文本、数字、地理空间、结构化和非结构化数据。 它基于 Apache Lucene 构建,Apache Lucene 是一个全文搜索引擎,可用于各种编程语言。 由于其速…...

配置类安全问题学习小结
目录 一、前言 二、漏洞类型 目录 一、前言 二、漏洞类型 2.1 Strict Transport Security Not Enforced 2.2 SSL Certificate Cannot Be Trusted 2.3 SSL Anonymous Cipher Suites Supported 2.4 "Referrer Policy”Security 头值不安全 2.5 “Content-Security-…...

IMX6ULL移植篇-uboot源码目录
一. uboot 源码分析前提 由于 uboot 会使用到一些经过编译才会生成的文件,因此,我们在分析 uboot的时候,需要先编译一下 uboot 源码工程。 这里所用的开发板是 nand-flash版本。 二. uboot 源码目录及编译 1. uboot 源码目录 uboot源码目…...
SAP MM学习笔记27- 购买依赖(采购申请)
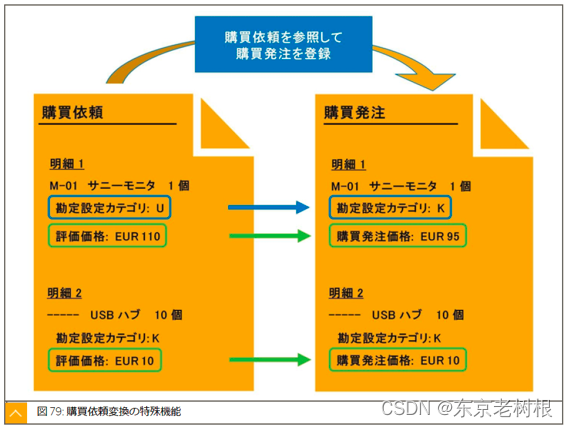
前面已经努力的学习了 购买发注,入库,请求书照合 等功能,还是蛮多内容的哈。 剩下的功能,比如 右侧的 所要量决定,供给元决定,仕入先选择 还没学。 从这章开始,要开始学习它们了。 这一章先来…...
)
C++零碎记录(八)
14. 运算符重载简介 14.1 运算符重载简介 ① 运算符重载:对已有的运算符重新进行定义,赋予其另一种功能,以适应不同的数据类型。 ② 对于内置的数据类型的表达式的运算符是不可能改变的。 14.2 加号运算符重载 ① 加号运算符作用&#x…...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...

微服务商城-商品微服务
数据表 CREATE TABLE product (id bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 商品id,cateid smallint(6) UNSIGNED NOT NULL DEFAULT 0 COMMENT 类别Id,name varchar(100) NOT NULL DEFAULT COMMENT 商品名称,subtitle varchar(200) NOT NULL DEFAULT COMMENT 商…...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...

Redis:现代应用开发的高效内存数据存储利器
一、Redis的起源与发展 Redis最初由意大利程序员Salvatore Sanfilippo在2009年开发,其初衷是为了满足他自己的一个项目需求,即需要一个高性能的键值存储系统来解决传统数据库在高并发场景下的性能瓶颈。随着项目的开源,Redis凭借其简单易用、…...

Linux安全加固:从攻防视角构建系统免疫
Linux安全加固:从攻防视角构建系统免疫 构建坚不可摧的数字堡垒 引言:攻防对抗的新纪元 在日益复杂的网络威胁环境中,Linux系统安全已从被动防御转向主动免疫。2023年全球网络安全报告显示,高级持续性威胁(APT)攻击同比增长65%,平均入侵停留时间缩短至48小时。本章将从…...