02-打包代码与依赖
打包代码与依赖说明
在开发中,我们写的应用程序通常需要依赖第三方的库(即程序中引入了既不在 org.apache.spark包,也不再语言运行时的库的依赖),我们就需要确保所有的依赖在Spark应用运行时都能被找到
- 对于Python而言,安装第三方库的方法有很多种
- 可以通过包管理器(如pip)在集群中所有机器上安装所依赖的库,或者手动将依赖安装到python安装目录下的site-packages/目录在
- 我们也可以通过spark-submit 的 --py-Files 参数提交独立的库
- 如果我们没有在集群上安装包的权限,可以手动添加依赖库,但是要防范与已经安装在集群上的那些包发生冲突
注意:
提交应用时,绝不要把spark本身放在提交的依赖中。spark-submit会自动确保spark在你的程序的运行路径中
- 对于Java 和 Scala,可以通过spark-submit 的 --jars 标记提交独立的jar包依赖
- 当只有一两个库的简单依赖,并且这些库不依赖与其他库时,这种方式比较合适
- 当需要依赖很多库的使用,这种方式很笨拙,不太适用。
- 此时的常规做法时使用构建工具(如maven、sbt)生成一个比较大的jar包,这个jar包中包含应用的所有的传递依赖。
使用Maven构建Java编写的Spark Application
参考POM
<repositories><!-- 指定仓库的位置,依次为aliyun、cloudera、jboss --><repository><id>aliyun</id><url>http://maven.aliyun.com/nexus/content/groups/public/</url></repository><repository><id>cloudera</id><url>https://repository.cloudera.com/artifactory/cloudera-repos/</url></repository><repository><id>jboss</id><url>https://repository.jboss.com/nexus/content/groups/public/</url></repository>
</repositories><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><scala.version>2.12.15</scala.version><scala.binary.version>2.12</scala.binary.version><hadoop.version>3.1.3</hadoop.version><spark.version>3.2.0</spark.version><spark.scope>compile</spark.scope>
</properties><dependencies><!-- 依赖Scala语言--><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><!-- Spark Core 依赖 --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_${scala.binary.version}</artifactId><version>${spark.version}</version></dependency><!-- Hadoop Client 依赖 --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency>
</dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.10.1</version><configuration><source>${maven.compiler.source}</source><!-- 源代码使用的JDK版本 --><target>${maven.compiler.target}</target><!-- 需要生成的目标class文件的编译版本 --><encoding>${project.build.sourceEncoding}</encoding><!-- 字符集编码 --></configuration></plugin></plugins>
</build>
使用Maven构建Scala编写的Spark Application
参考POM
<repositories><!-- 指定仓库的位置,依次为aliyun、cloudera、jboss --><repository><id>aliyun</id><url>http://maven.aliyun.com/nexus/content/groups/public/</url></repository><repository><id>cloudera</id><url>https://repository.cloudera.com/artifactory/cloudera-repos/</url></repository><repository><id>jboss</id><url>https://repository.jboss.com/nexus/content/groups/public/</url></repository>
</repositories><properties><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><scala.version>2.13.5</scala.version><scala.binary.version>2.13</scala.binary.version><spark.version>3.2.0</spark.version><hadoop.version>3.1.3</hadoop.version>
</properties><dependencies><!-- 依赖Scala语言--><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><!-- Spark Core 依赖 --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_${scala.binary.version}</artifactId><version>${spark.version}</version></dependency><!-- Hadoop Client 依赖 --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency>
</dependencies><build><plugins><!--maven的打包插件--><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.0.0</version><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin><!--该插件用于将scala代码编译成class文件--><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.2.2</version><executions><!--绑定到maven的编译阶段--><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin></plugins>
</build>
使用sbt构建Scala编写的Spark Application
目前未使用,暂时未记录
依赖冲突
当我们的Spark Application与Spark本身依赖于同一个库时可能会发生依赖冲突,导致程序崩溃。
依赖冲突通常表现为:
- NoSuchMethodError
- ClassNotFoundException
- 或其他与类加载相关的JVM异常
对于这类问题,主要的两种解决方式:
1)修改Spark Application,使其使用的依赖库版本与Spark所使用的相同
2)通常使用”shading“的方式打包我们的Spark Application
相关文章:

02-打包代码与依赖
打包代码与依赖说明 在开发中,我们写的应用程序通常需要依赖第三方的库(即程序中引入了既不在 org.apache.spark包,也不再语言运行时的库的依赖),我们就需要确保所有的依赖在Spark应用运行时都能被找到 对于Python而…...

Kotlin(五) 循环语句
目录 For循环 关键字 until step downTo Java中主要有两种循环语句:while循环和for循环。而Kotlin也提供了while循环和for循环,其中while循环不管是在语法还是使用技巧上都和Java中的while循环没有任何区别,因此我们就直接跳过不进行讲解…...

数字孪生产品:数字化时代的变革引擎
数字孪生技术,作为一项前沿的科技创新,正在不断改变我们的世界。它为各行各业的发展提供了无限的可能性,成为了当今数字化时代的一大亮点。数字孪生产品,作为数字孪生技术的具体应用,将在未来发挥越来越重要的作用。 数…...
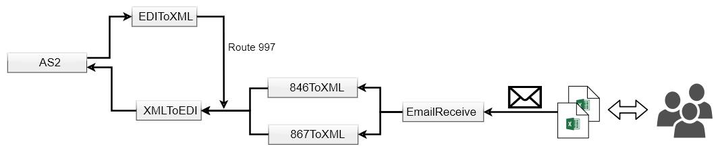
对接西部数据Western Digital EDI 系统
近期我们为国内某知名电子产品企业提供EDI解决方案,采用知行之桥 EDI 系统作为核心组件,成功与西部数据Western Digital(简称西数)建立EDI连接,实现数据安全且自动化传输。 EDI实施需求 EDI连接 传输协议:A…...
ClickHouse进阶(十):Clickhouse数据查询-4
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 📌订阅…...

FPGA原理与结构——FIFO IP核的使用与测试
一、前言 本文介绍FIFO Generator v13.2 IP核的具体使用与例化,在学习一个IP核的使用之前,首先需要对于IP核的具体参数和原理有一个基本的了解,具体可以参考: FPGA原理与结构——FIFO IP核原理学习https://blog.csdn.net/apple_5…...

ABB CMA120 3DDE300400面板
人机界面:ABB CMA120 3DDE300400 面板通常具有用户友好的人机界面,可用于监视和控制连接设备和系统的操作。 图形显示:该面板通常具有高分辨率的液晶显示屏,用于显示图形界面和实时数据,以便操作员更容易理解和管理工…...

【代码随想录day25】动态规划:01背包理论基础
题目 有n件物品和一个最多能背重量为w 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品只能用一次,求解将哪些物品装入背包里物品价值总和最大。 代码 dp[i][j]: 表示从0~i个物品中选物品放到容量为j的背包中所能获得的最大价值 …...
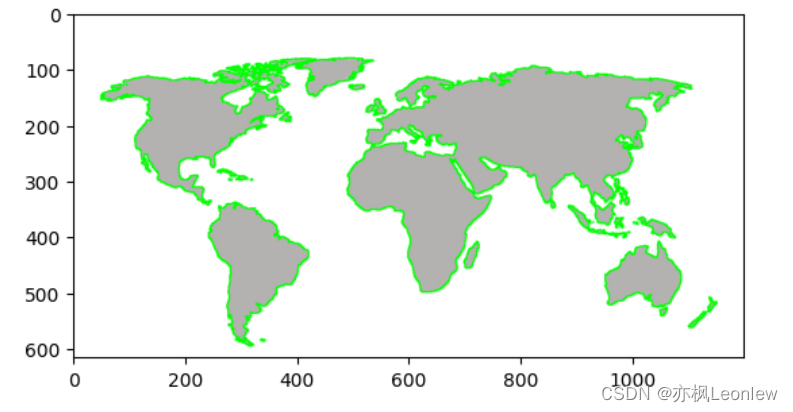
Python Opencv实践 - 轮廓检测
import cv2 as cv import numpy as np import matplotlib.pyplot as pltimg cv.imread("../SampleImages/map.jpg") print(img.shape) plt.imshow(img[:,:,::-1])#Canny边缘检测 edges cv.Canny(img, 127, 255, 0) plt.imshow(edges, cmapplt.cm.gray)#查找轮廓 #c…...

c#保留两位小数
1.使用ToString()方法和格式字符串 double number 3.1415926; string result number.ToString(“F2”); // 将number转换为字符串,并保留两位小数 Console.WriteLine(result); // 输出结果为 “3.14” 2.使用字符串插值和格式字符串 double number 3.1415926;…...
[machineLearning]非监督学习unsupervised learning
1.什么是非监督学习 常见的神经网络是一种监督学习,监督学习的主要特征即为根据输入来对输出进行预测,最终会得到一个输出数值.而非监督学习的目的不在于输出,而是在于对读入的数据进行归类,选取特征,打标签,通过对于数据结构的分析来完成这些操作, 很少有最后的输出操作. 从…...

C语言深入理解指针(非常详细)(四)
目录 字符指针变量数组指针变量数组指针变量是什么数组指针变量怎么初始化 二维数组传参的本质函数指针变量函数指针变量的创建函数指针变量的使用代码typedef关键字 函数指针数组转移表 字符指针变量 字符指针在之前我们有提到过,(字符)&am…...
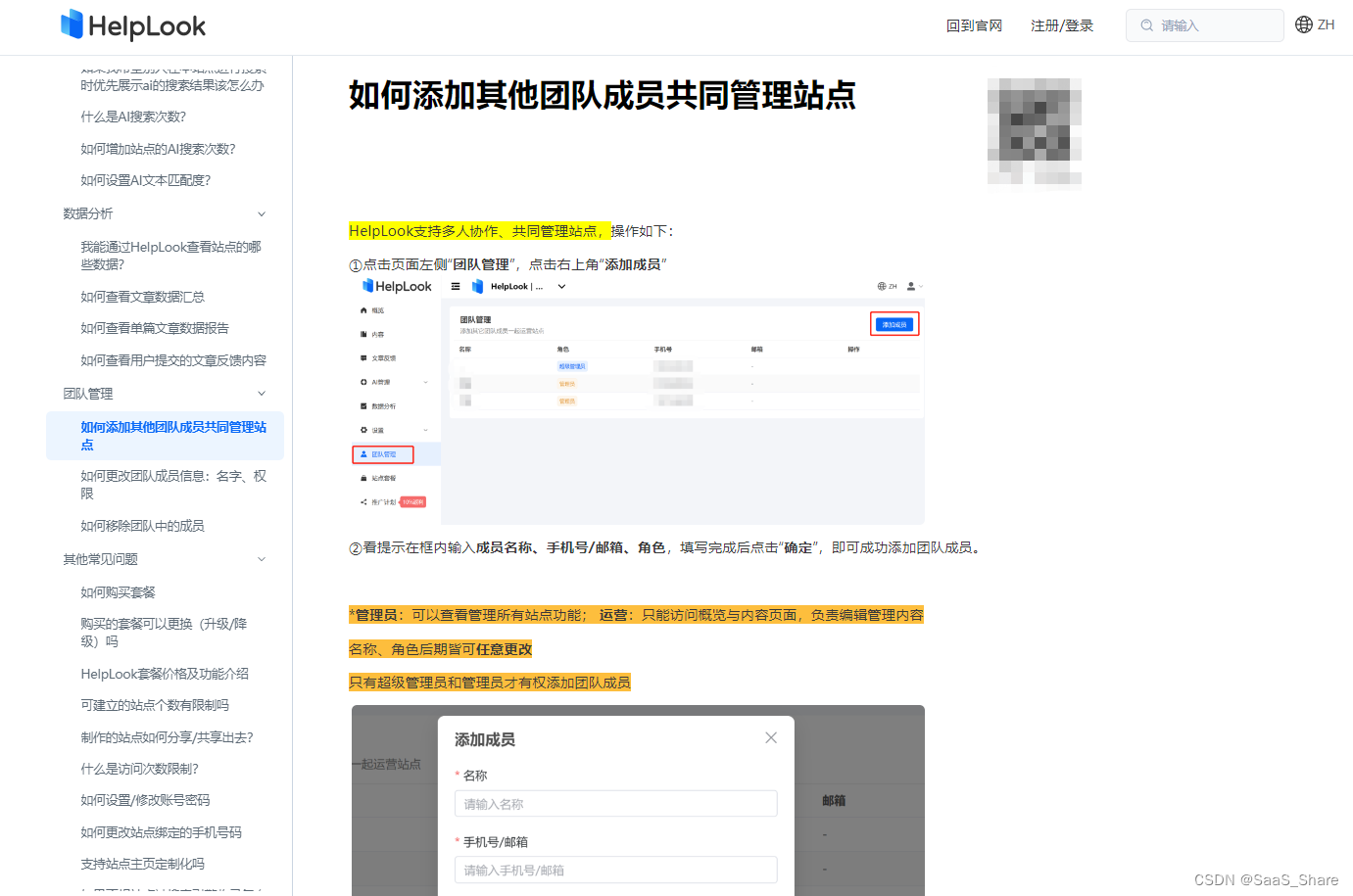
知识库建设:从0到1搞定知识库建设的方法论分享
如果我们想要搭建一个知识库,前提是我们要明确知道这个知识库是干什么用的,只有了解知识库的应用场景才能知道如何去建设知识库。 知识库建设 以常见的电商客服为例,客户会经常咨询什么时候发货,怎么退货,怎么换货………...
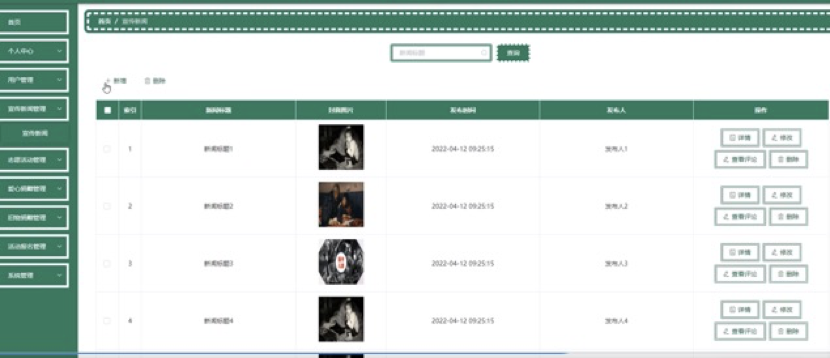
SpringBoot+Vue 的留守儿童系统的研究与实现,2.0 版本,附数据库、教程
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝30W,Csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 文章目录 1.研究背景2. 技术栈3.系统分析4系统设计5系统的详细设计与实现5.1系统功能模块5.2管理员功能模块…...

28.考试
Description 小学期马上就要结束了,为了检验大家的学习成果,老师进行了一次考试。然而小徐前两周半都忙于练习篮球,几乎没有学习,因此考试时很可能做不完所有题目。 但小徐仍然想要拿到尽可能高的分数,因此在做题时需要…...

浏览器窗口间的通信
一、汇总 二、同源策略 三、webSocket (无跨域限制) 优点:无跨域限制 缺点:成本高 四、客户端存储 1、localStorage onStorage 例子: 2、定时器 客户端存储 例子: 缺点: 五、postMessage (无跨域…...

MATLAB 的 plot 绘图
文章目录 SyntaxDescriptionplot(X,Y)plot(X,Y,LineSpec)plot(X1,Y1,…,Xn,Yn)plot(X1,Y1,LineSpec1,...,Xn,Yn,LineSpecn)plot(Y)plot(Y,LineSpec)plot(tbl,xvar,yvar)plot(tbl,yvar)plot(ax,___)plot(___,Name,Value)p plot(___) plot: 2-D line plot Syntax plot(X,Y)plo…...
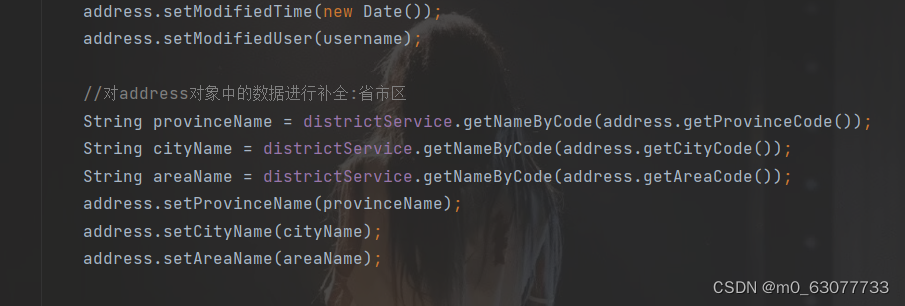
SpringBoot项目--电脑商城【获取省市区列表】
1.易错点 1.错误做法 新增收货地址页面的三个下拉列表的内容展示没有和数据库进行交互,而是通过前端实现的(将代码逻辑放在了distpicker.data.js文件中),实现方法是在加载新增收货地址页面时加载该js文件,这种做法不可取 2.正确做法 把这些数据保存到数据库中,用户点击下拉…...

使用git把本地项目关联远程代码仓库,并推送到远程仓库
你在本地新建了一个项目,写好了代码,但是没有关联远程仓库,怎么关联并上传呢? 你要先去gitee创建一个代码仓库,然后复制http地址。 首次提交项目代码到一个新建的远程仓库: 1、通过命令 git init 把这个…...
Spring+MyBatis使用collection标签的两种使用方法
目录 项目场景: 实战操作: 1.创建菜单表 2.创建实体 3.创建Mapper 4.创建xml 属性描述: 效率比较: 项目场景: 本文说明了Spring BootMyBatis使用collection标签的两种使用方法 1. 方法一: 关联查询 2. 方法…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

网络编程(UDP编程)
思维导图 UDP基础编程(单播) 1.流程图 服务器:短信的接收方 创建套接字 (socket)-----------------------------------------》有手机指定网络信息-----------------------------------------------》有号码绑定套接字 (bind)--------------…...

基于Java Swing的电子通讯录设计与实现:附系统托盘功能代码详解
JAVASQL电子通讯录带系统托盘 一、系统概述 本电子通讯录系统采用Java Swing开发桌面应用,结合SQLite数据库实现联系人管理功能,并集成系统托盘功能提升用户体验。系统支持联系人的增删改查、分组管理、搜索过滤等功能,同时可以最小化到系统…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...

Java毕业设计:WML信息查询与后端信息发布系统开发
JAVAWML信息查询与后端信息发布系统实现 一、系统概述 本系统基于Java和WML(无线标记语言)技术开发,实现了移动设备上的信息查询与后端信息发布功能。系统采用B/S架构,服务器端使用Java Servlet处理请求,数据库采用MySQL存储信息࿰…...

jmeter聚合报告中参数详解
sample、average、min、max、90%line、95%line,99%line、Error错误率、吞吐量Thoughput、KB/sec每秒传输的数据量 sample(样本数) 表示测试中发送的请求数量,即测试执行了多少次请求。 单位,以个或者次数表示。 示例:…...

什么是VR全景技术
VR全景技术,全称为虚拟现实全景技术,是通过计算机图像模拟生成三维空间中的虚拟世界,使用户能够在该虚拟世界中进行全方位、无死角的观察和交互的技术。VR全景技术模拟人在真实空间中的视觉体验,结合图文、3D、音视频等多媒体元素…...

论文阅读:LLM4Drive: A Survey of Large Language Models for Autonomous Driving
地址:LLM4Drive: A Survey of Large Language Models for Autonomous Driving 摘要翻译 自动驾驶技术作为推动交通和城市出行变革的催化剂,正从基于规则的系统向数据驱动策略转变。传统的模块化系统受限于级联模块间的累积误差和缺乏灵活性的预设规则。…...