【计算机视觉项目实战】中文场景识别

✨专栏介绍: 经过几个月的精心筹备,本作者推出全新系列《深入浅出OCR》专栏,对标最全OCR教程,具体章节如导图所示,将分别从OCR技术发展、方向、概念、算法、论文、数据集等各种角度展开详细介绍。
👨💻面向对象: 本篇前言知识主要介绍深度学习知识,全面总结知知识点,方便小白或AI爱好者学习基础知识。
💚友情提醒: 本文内容可能未能含概深度学习所有知识点,其他内容可以访问本人主页其他文章或个人博客,同时因本人水平有限,文中如有错误恳请指出,欢迎互相学习交流!
💙个人主页: GoAI |💚 公众号: GoAI的学习小屋 | 💛交流群: 704932595 |💜个人简介 : 掘金签约作者、百度飞桨PPDE、领航团团长、开源特训营导师、CSDN、阿里云社区人工智能领域博客专家、新星计划计算机视觉方向导师等,专注大数据与人工智能知识分享。
💻文章目录

💻文章目录
《深入浅出OCR》前言知识(二):深度学习基础总结 (✨文末有深度学习总结导图福利!)
《深入浅出OCR》前言知识(一):机器学习基础总结 (✨文末有机器学习总结导图福利!)
【计算机视觉OCR项目实战】中文文字识别
💻本篇导读:在上节深度学习知识总结,本人对手写识别项目进行实战,为了进一步学习计算机视觉知识,我们本次以计算机视觉的OCR方向为例,完成中文场景识别,从头到尾帮助大家学习并完成中文文字识别实战任务,方便学习者学习计算机视觉项目流程。
一、项目背景
随着OCR领域在结构化数据中取得不错成果及应用,中文场景文字识别技术在人们的日常生活中受到广泛关注,在文档识别、身份证识别、银行卡识别、病例识别、名片识别等领域广泛应用.但由于中文场景中的文字容易受光照变化、低分辨率、字体以及排布多样性、中文字符种类多等影响,对识别经典有一定影响,如何解决这一问题是目前值得关注的。
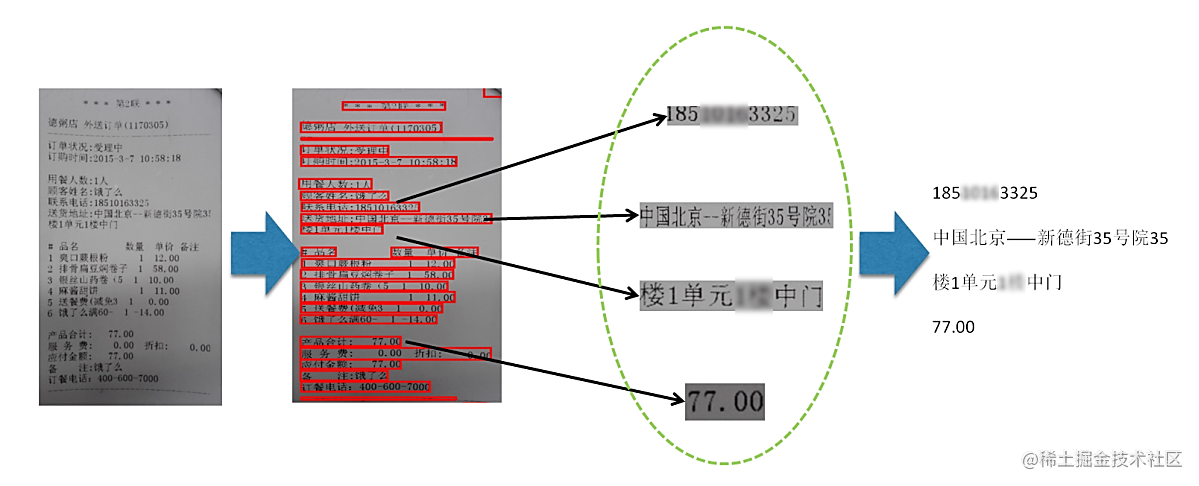
二、项目简介:
本项目为基于PaddleOCR的中文场景文字识别,项目主要以CRNN网络为基础框架,结合数据增强及模型微调,采用ResNet34和MobileNetV3模型作为骨干网络,进行训练及预测。以准确度为评价指标,最终生成的预测文件为work中的result.txt文件。
三、数据集介绍:
项目提供的数据训练集(train_img)是5w张,测试集(test_img)为1w张。训练集原始标注文件(train.list)。
- 数据集采自中国街景,并由街景图片中的文字行区域(例如店铺标牌、地标等等)截取出来而形成
- 所有图像都经过一些预处理,将文字区域利用仿射变化,等比映射为一张高为48像素的图片。
数据集样例如下:


标注文件
本数据集提供的标注文件为.txt文件格式。标注文件中的四列分别是图片的宽、高、文件名和文字标注。标注文件信息如下:
| h | w | name | value |
|---|---|---|---|
| 128 | 48 | img_1.jpg | 文本1 |
| 56 | 48 | img_2.jpg | 文本2 |
四、相关框架及技术
PaddleOCR框架: https://github.com/PaddlePaddle/PaddleOCR
PaddleOCR是一款超轻量、中英文识别模型,目标是打造丰富、领先、实用的文本识别模型/工具库
3.5M实用超轻量OCR系统,支持在服务器,移动,嵌入式和IoT设备之间进行培训和部署
同时支持中英文识别;支持倾斜、竖排等多种方向文字识别,支持GPU、CPU预测,同时可运行于Linux、Windows、MacOS等多种系统。
本次项目以开源的百度飞桨PaddleOCR为框架,采用CRNN+CTC网络为主体,具体结构如下图:

五、项目流程:
深度学习OCR通用流程
项目分析:针对中文场景下的数据预处理(包括:把繁体字转成简体字,大写->小写,删除空格,删除符号等操作),结合相应的中文字典来提升文字识别的准确率。并且在飞桨框架下采用当前业界最经典的CRNN算法架构来建模与求解,以保证模型的性能。
基于上述分析,我将本次项目大致分为以下几个流程:
1.PaddleOCR环境安装
2.数据处理
3.模型调整
4.训练与预测
六、环境安装
6.1 项目环境安装
本次项目环境需要先克隆PaddleOCR项目,具体命令:
!cd ~/work && git clone -b develop <https://gitee.com/paddlepaddle/PaddleOCR.git>
其次,需要安装PaddleOCR项目提供环境文件requirements.txt,具体命令:
!cd ~/work/PaddleOCR
!pip install -r ./requirements.txt && python setup.py install
6.2 PaddleOCR识别测试
另外,在正式开始介绍项目前,我们尝试可以快速开始体验PaddleOCR,将其应用到自己的领域进行图片识别测试。同样需要我们在自己电脑上安装如下环境
1.1 安装PaddlePaddle
如果大家没有基础的Python运行环境,请参考运行环境准备。
-
您的机器安装的是CUDA9或CUDA10,请运行以下命令安装
python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple -
您的机器是CPU,请运行以下命令安装
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
更多的版本需求,请参照飞桨官网安装文档中的说明进行操作。
1.2 安装PaddleOCR whl包
pip install "paddleocr>=2.0.1" # 推荐使用2.0.1+版本
在安装好环境后,为了大家能够更好的直观体验PaddleOCR识别效果,我们可以直接调用PaddleOCR框架提供的接口进行测试,本人帮大家整理好了相关代码,大家可以自行更换图片路径。
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr supports Chinese, English, French, German, Korean and Japanese.
# You can set the parameter `lang` as `ch`, `en`, `fr`, `german`, `korean`, `japan` to switch the language model in order.
ocr = PaddleOCR(use_angle_cls=True, lang='en', #选择语种use_gpu=False, #是否调用GPUdet_model_dir="/root/.paddleocr/whl/det/en/en_PP-OCRv3_det_infer/", # 检测模型cls_model_dir="/root/.paddleocr/whl/cls/ch_ppocr_mobile_v2.0_cls_infer/", # 分类模型rec_model_dir="/root/.paddleocr/whl/rec/en/en_PP-OCRv3_rec_infer/" # 识别模型
) # need to run only once to download and load model into memoryimg_path = './1.jpg' #更换自己的图片路径
result = ocr.ocr(img_path, cls=True)
for line in result:print(line)# draw result
from PIL import Image
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='./fonts/simfang.ttf') # 字体需要准备
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
七、数据处理及增广合成
7.1 解压数据集
解压训练集与测试集
!cd ~/data/data62842/ && unzip train\_images.zip
!cd ~/data/data62843/ && unzip test\_images.zip
重命名处理
!cd ~/data/data62842/ && mv train\_images ../ && mv train\_label.csv ../
!cd ~/data/data62843/ && mv test\_images ../
查看前十条数据样例
%cd data/data62842
!cat train\_label.csv | head -n 10
2.2数据增广
首先,考虑使用轻量模型会有一定精度损失,采用经典网络ResNet34。
其次,为了进一步增强识别效果及模型泛化行,参考其他项目使用text_render进行数据增广。
最后,使用text_renderer进行数据增广,修改text_render/configs/default.yaml配置,以下为更改后的模版,主要将三项做修改,分别是font_color的enable设为True,img_bg的enable设为False,seamless_clone的enable设为True。
数据增广参考: 链接
本次数据增广参数配置信息如下:
# Small font_size will make text looks like blured/prydown
font_size:min: 14max: 23# choose Text color range
# color boundary is in R,G,B format
font_color:enable: Trueblue:fraction: 0.5l_boundary: [0,0,150]h_boundary: [60,60,255]brown:fraction: 0.5l_boundary: [139,70,19]h_boundary: [160,82,43]# By default, text is drawed by Pillow with (https://stackoverflow.com/questions/43828955/measuring-width-of-text-python-pil)
# If `random_space` is enabled, some text will be drawed char by char with a random space
random_space:enable: falsefraction: 0.3min: -0.1 # -0.1 will make chars very close or even overlappedmax: 0.1# Do remap with sin()
# Currently this process is very slow!
curve:enable: falsefraction: 0.3period: 360 # degree, sin 函数的周期min: 1 # sin 函数的幅值范围max: 5# random crop text height
crop:enable: falsefraction: 0.5# top and bottom will applied equallytop:min: 5max: 10 # in pixel, this value should small than img_heightbottom:min: 5max: 10 # in pixel, this value should small than img_height# Use image in bg_dir as background for text
img_bg:enable: falsefraction: 0.5# Not work when random_space applied
text_border:enable: falsefraction: 0.5# lighter than word colorlight:enable: truefraction: 0.5# darker than word colordark:enable: truefraction: 0.5# https://docs.opencv.org/3.4/df/da0/group__photo__clone.html#ga2bf426e4c93a6b1f21705513dfeca49d
# https://www.cs.virginia.edu/~connelly/class/2014/comp_photo/proj2/poisson.pdf
# Use opencv seamlessClone() to draw text on background
# For some background image, this will make text image looks more real
seamless_clone:enable: truefraction: 0.5perspective_transform:max_x: 25max_y: 25max_z: 3blur:enable: truefraction: 0.03# If an image is applied blur, it will not be applied prydown
prydown:enable: truefraction: 0.03max_scale: 1.5 # Image will first resize to 1.5x, and than resize to 1xnoise:enable: truefraction: 0.3gauss:enable: truefraction: 0.25uniform:enable: truefraction: 0.25salt_pepper:enable: truefraction: 0.25poisson:enable: truefraction: 0.25line:enable: falsefraction: 0.05random_over:enable: truefraction: 0.2under_line:enable: falsefraction: 0.2table_line:enable: falsefraction: 0.3middle_line:enable: falsefraction: 0.3line_color:enable: falseblack:fraction: 0.5l_boundary: [0,0,0]h_boundary: [64,64,64]blue:fraction: 0.5l_boundary: [0,0,150]h_boundary: [60,60,255]# These operates are applied on the final output image,
# so actually it can also be applied in training process as an data augmentation method.# By default, text is darker than background.
# If `reverse_color` is enabled, some images will have dark background and light text
reverse_color:enable: falsefraction: 0.5emboss:enable: falsefraction: 0.1sharp:enable: falsefraction: 0.1
2.3数据预处理
- 读取train.list标签文件,生成图片的信息字典。
- get_aspect_ratio函数设定图片信息(宽、高、比例、最长字符串、类别等信息)。
- 对标签label进行预处理,进行“繁体->简体”、“大写->小写”、“删除空格”、“删除符号”等操作。
import glob
import os
import cv2def get_aspect_ratio(img_set_dir):m_width = 0m_height = 0width_dict = {}height_dict = {}images = glob.glob(img_set_dir+'*.jpg')for image in images:img = cv2.imread(image)width_dict[int(img.shape[1])] = 1 if (int(img.shape[1])) not in width_dict else 1 + width_dict[int(img.shape[1])]height_dict[int(img.shape[0])] = 1 if (int(img.shape[0])) not in height_dict else 1 + height_dict[int(img.shape[0])]m_width += img.shape[1]m_height += img.shape[0]m_width = m_width/len(images)m_height = m_height/len(images)aspect_ratio = m_width/m_heightwidth_dict = dict(sorted(width_dict.items(), key=lambda item: item[1], reverse=True))height_dict = dict(sorted(height_dict.items(), key=lambda item: item[1], reverse=True))return aspect_ratio,m_width,m_height,width_dict,height_dict
aspect_ratio,m_width,m_height,width_dict,height_dict = get_aspect_ratio("/home/aistudio/data/train_images/")
print("aspect ratio is: {}, mean width is: {}, mean height is: {}".format(aspect_ratio,m_width,m_height))
print("Width dict:{}".format(width_dict))
print("Height dict:{}".format(height_dict))
import pandas as pddef Q2B(s):"""全角转半角"""inside_code=ord(s)if inside_code==0x3000:inside_code=0x0020else:inside_code-=0xfee0if inside_code<0x0020 or inside_code>0x7e: #转完之后不是半角字符返回原来的字符return sreturn chr(inside_code)def stringQ2B(s):"""把字符串全角转半角"""return "".join([Q2B(c) for c in s])def is_chinese(s):"""判断unicode是否是汉字"""for c in s:if c < u'\u4e00' or c > u'\u9fa5':return Falsereturn Truedef is_number(s):"""判断unicode是否是数字"""for c in s:if c < u'\u0030' or c > u'\u0039':return Falsereturn Truedef is_alphabet(s):"""判断unicode是否是英文字母"""for c in s:if c < u'\u0061' or c > u'\u007a':return Falsereturn Truedef del_other(s):"""判断是否非汉字,数字和小写英文"""res = str()for c in s:if not (is_chinese(c) or is_number(c) or is_alphabet(c)):c = ""res += creturn resdf = pd.read_csv("/home/aistudio/data/train_label.csv", encoding="gbk")
name, value = list(df.name), list(df.value)
for i, label in enumerate(value):# 全角转半角label = stringQ2B(label)# 大写转小写label = "".join([c.lower() for c in label])# 删除所有空格符号label = del_other(label)value[i] = label# 删除标签为""的行
data = zip(name, value)
data = list(filter(lambda c: c[1]!="", list(data)))
# 保存到work目录
with open("/home/aistudio/data/train_label.txt", "w") as f:for line in data:f.write(line[0] + "\t" + line[1] + "\n")# 记录训练集中最长标签
label_max_len = 0
with open("/home/aistudio/data/train_label.txt", "r") as f:for line in f:name, label = line.strip().split("\t")if len(label) > label_max_len:label_max_len = len(label)print("label max len: ", label_max_len)
def create_label_list(train_list):classSet = set()with open(train_list) as f:next(f)for line in f:img_name, label = line.strip().split("\t")for e in label:classSet.add(e)# 在类的基础上加一个blankclassList = sorted(list(classSet))with open("/home/aistudio/data/label_list.txt", "w") as f:for idx, c in enumerate(classList):f.write("{}\t{}\n".format(c, idx))# 为数据增广提供词库with open("/home/aistudio/work/text_renderer/data/chars/ch.txt", "w") as f:for idx, c in enumerate(classList):f.write("{}\n".format(c))return classSetclassSet = create_label_list("/home/aistudio/data/train_label.txt")
print("classify num: ", len(classSet))
这里我们需要通过上述代码对数据集进行信息统计,设置识别算法参数,具体统计结果如下:
宽高比等信息:
aspect ratio is: 3.451128333333333, mean width is: 165.65416, mean height is: 48.0
Width dict:{48: 741, 96: 539, 44: 392, 42: 381, 144: 365, 45: 345, 43: 323, 72: 318, 88: 318, 40: 312, 52: 301, 36: 298, 50: 297, 120: 294, 54: 288, 84: 286, 51: 283, 32: 283, 24: 281, 100: 277, 64: 276, 80: 276, 76: 275, 102: 272, 81: 270, 90: 269, 56: 268, 66: 267, 78: 266, 37: 262, 82: 261, 41: 259, 89: 25.....
词典规格:
Height dict:{48: 50000}
最长字符长度:
label max len: 77
类别数:
classify num: 3096
八、模型调整
- 加载官方提供的CRNN预训练模型。
- 改变默认输入图片尺寸,高度height设为48,宽度width设为256。
- 优化学习率策略,通过cosine_decay和warmup策略加快模型收敛。
CRNN模型介绍
本项目模型采用文字识别经典CRNN模型(CNN+RNN+CTC),其中部分模型代码经过PaddleOCR源码改编,完成识别模型的搭建、训练、评估和预测过程。训练时可以手动更改config配置文件(数据训练、加载、评估验证等参数),默认采用优化器采用Adam,使用CTC损失函数。本项目采用ResNet34作为骨干网络。
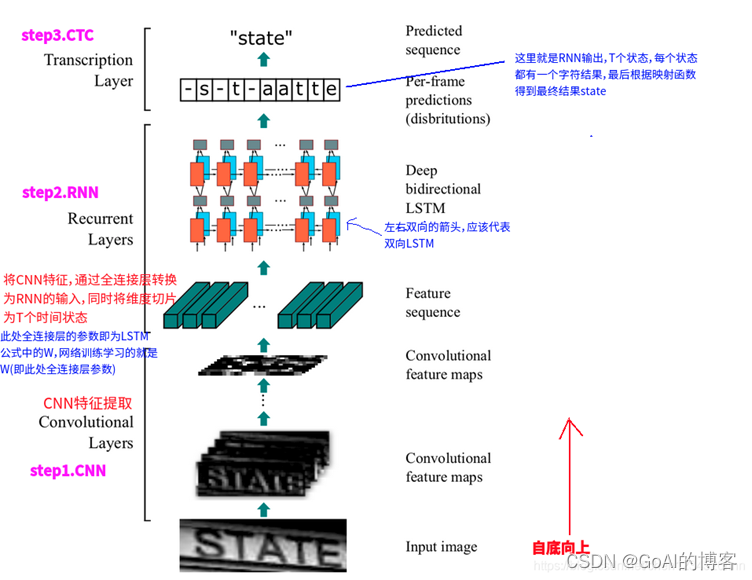
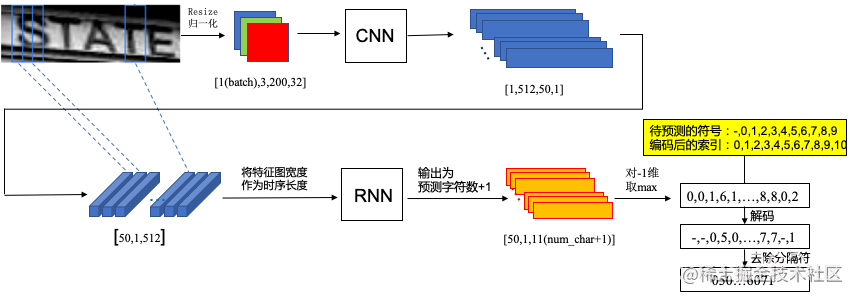
CRNN网络结构包含三部分,从下到上依次为:
(1)卷积层。作用是从输入图像中提取特征序列。
(2)循环层。作用是预测从卷积层获取的特征序列的标签(真实值)分布。
(3)转录层。作用是把从循环层获取的标签分布通过去重整合等操作转换成最终的识别结果。
CRNN网络详细流程:
下载PaddleOCR提供的训练权重
!cd ~/work/PaddleOCR && mkdir pretrain_weights && cd pretrain_weights && wget https://paddleocr.bj.bcebos.com/20-09-22/server/rec/ch_ppocr_server_v1.1_rec_pre.tar
解压训练权重文件
!cd ~/work/PaddleOCR/pretrain_weights && tar -xf ch_ppocr_server_v1.1_rec_pre.tar
PaddleOCR通过将训练参数统一为配置文件进行训练,具体位置在PaddleOCR/configs/rec中,添加训练配置文件 my_rec_ch_train.yml和my_rec_ch_reader.yml
#my_rec_ch_train.yml
Global:algorithm: CRNNuse_gpu: trueepoch_num: 201log_smooth_window: 20print_batch_step: 10save_model_dir: ./output/my_rec_chsave_epoch_step: 50eval_batch_step: 1000train_batch_size_per_card: 64test_batch_size_per_card: 64image_shape: [3, 48, 256]max_text_length: 80character_type: chcharacter_dict_path: ./ppocr/utils/ppocr_keys_v1.txtloss_type: ctcdistort: trueuse_space_char: truereader_yml: ./configs/rec/my_rec_ch_reader.ymlpretrain_weights: ./pretrain_weights/ch_ppocr_server_v1.1_rec_pre/best_accuracycheckpoints:save_inference_dir: infer_img:Architecture:function: ppocr.modeling.architectures.rec_model,RecModelBackbone:function: ppocr.modeling.backbones.rec_resnet_vd,ResNetlayers: 34Head:function: ppocr.modeling.heads.rec_ctc_head,CTCPredictencoder_type: rnnfc_decay: 0.00004SeqRNN:hidden_size: 256Loss:function: ppocr.modeling.losses.rec_ctc_loss,CTCLossOptimizer:function: ppocr.optimizer,AdamDecaybase_lr: 0.0001l2_decay: 0.00004beta1: 0.9beta2: 0.999decay:function: cosine_decay_warmupstep_each_epoch: 1000total_epoch: 201warmup_minibatch: 2000
#my_rec_ch_reader.yml
TrainReader:reader_function: ppocr.data.rec.dataset_traversal,SimpleReadernum_workers: 1img_set_dir: /home/aistudio/data/train_imageslabel_file_path: /home/aistudio/data/train_label.txtEvalReader:reader_function: ppocr.data.rec.dataset_traversal,SimpleReaderimg_set_dir: /home/aistudio/data/train_imageslabel_file_path: /home/aistudio/data/train_label.txtTestReader:reader_function: ppocr.data.rec.dataset_traversal,SimpleReader
参数解读:
| Parameter | Description | Default value |
|---|---|---|
| use_gpu | 是否启用GPU | TRUE |
| gpu_mem | GPU memory size used for initialization | 8000M |
| image_dir | The images path or folder path for predicting when used by the command line | |
| det_algorithm | 选择的检测算法类型 | DB |
| det_model_dir | 文本检测推理模型文件夹。 参数传递有两种方式:None:自动将内置模型下载到 /root/.paddleocr/det ; 自己转换的推理模型的路径,模型和params文件必须包含在模型路径中 | None |
| det_max_side_len | 图像长边的最大尺寸。 当长边超过这个值时,长边会调整到这个大小,短边会按比例缩放 | 960 |
| det_db_thresh | Binarization threshold value of DB output map | 0.3 |
| det_db_box_thresh | The threshold value of the DB output box. Boxes score lower than this value will be discarded | 0.5 |
| det_db_unclip_ratio | The expanded ratio of DB output box | 2 |
| det_east_score_thresh | Binarization threshold value of EAST output map | 0.8 |
| det_east_cover_thresh | The threshold value of the EAST output box. Boxes score lower than this value will be discarded | 0.1 |
| det_east_nms_thresh | The NMS threshold value of EAST model output box | 0.2 |
| rec_algorithm | 选择的识别算法类型 | CRNN(卷积循环神经网络) |
| rec_model_dir | 文本识别推理模型文件夹。 参数传递有两种方式:None:自动将内置模型下载到 /root/.paddleocr/rec ; 自己转换的推理模型的路径,模型和params文件必须包含在模型路径中 | None |
| rec_image_shape | 图像形状识别算法 | “3,32,320” |
| rec_batch_num | When performing recognition, the batchsize of forward images | 30 |
| max_text_length | 识别算法可以识别的最大文本长度 | 25 |
| rec_char_dict_path | the alphabet path which needs to be modified to your own path when rec_model_Name use mode 2 | ./ppocr/utils/ppocr_keys_v1.txt |
| use_space_char | 是否识别空格 | TRUE |
| drop_score | 按分数过滤输出(来自识别模型),低于此分数的将不返回 | 0.5 |
| use_angle_cls | 是否加载分类模型 | FALSE |
| cls_model_dir | 分类推理模型文件夹。 参数传递有两种方式:None:自动下载内置模型到 /root/.paddleocr/cls ; 自己转换的推理模型的路径,模型和params文件必须包含在模型路径中 | None |
| cls_image_shape | 图像形状分类算法 | “3,48,192” |
| label_list | label list of classification algorithm | [‘0’,‘180’] |
| cls_batch_num | When performing classification, the batchsize of forward images | 30 |
| enable_mkldnn | 是否启用 mkldnn | FALSE |
| use_zero_copy_run | Whether to forward by zero_copy_run | FALSE |
| lang | 支持语言,目前只支持中文(ch)、English(en)、French(french)、German(german)、Korean(korean)、Japanese(japan) | ch |
| det | ppocr.ocr 函数执行时启用检测 | TRUE |
| rec | ppocr.ocr func exec 时启用识别 | TRUE |
| cls | Enable classification when ppocr.ocr func exec((Use use_angle_cls in command line mode to control whether to start classification in the forward direction) | FALSE |
| show_log | Whether to print log | FALSE |
| type | Perform ocr or table structuring, 取值在 [‘ocr’,‘structure’] | ocr |
| ocr_version | OCR型号版本号,目前模型支持列表如下:PP-OCRv3支持中英文检测、识别、多语言识别、方向分类器模型;PP-OCRv2支持中文检测识别模型;PP-OCR支持中文检测、识别 和方向分类器、多语言识别模型 | PP-OCRv3 |
九、训练与预测
9.1 训练模型
- 根据修改后的配置文件,输入以下命令就可以开始训练。
!pwd
!cd ~/work/PaddleOCR && python tools/train.py -c configs/rec/my_rec_ch_train.yml
9.2导出模型
通过export_model.py导出模型,设置配置文件及导出路径。
!cd ~/work/PaddleOCR && python tools/export_model.py -c configs/rec/my_rec_ch_train.yml -o Global.checkpoints=./output/my_rec_ch/iter_epoch_27 Global.save_inference_dir=./inference/CRNN_R34
2022-09-30 22:57:53,971-INFO: {'Global': {'debug': False, 'algorithm': 'CRNN', 'use_gpu': True, 'epoch_num': 201, 'log_smooth_window': 20, 'print_batch_step': 10, 'save_model_dir': './output/my_rec_ch', 'save_epoch_step': 3, 'eval_batch_step': 1000, 'train_batch_size_per_card': 64, 'test_batch_size_per_card': 64, 'image_shape': [3, 48, 256], 'max_text_length': 80, 'character_type': 'ch', 'character_dict_path': './ppocr/utils/ppocr_keys_v1.txt', 'loss_type': 'ctc', 'distort': True, 'use_space_char': True, 'reader_yml': './configs/rec/my_rec_ch_reader.yml', 'pretrain_weights': './pretrain_weights/ch_ppocr_server_v1.1_rec_pre/best_accuracy', 'checkpoints': './output/my_rec_ch/iter_epoch_27', 'save_inference_dir': './inference/CRNN_R34', 'infer_img': None}, 'Architecture': {'function': 'ppocr.modeling.architectures.rec_model,RecModel'}, 'Backbone': {'function': 'ppocr.modeling.backbones.rec_resnet_vd,ResNet', 'layers': 34}, 'Head': {'function': 'ppocr.modeling.heads.rec_ctc_head,CTCPredict', 'encoder_type': 'rnn', 'fc_decay': 4e-05, 'SeqRNN': {'hidden_size': 256}}, 'Loss': {'function': 'ppocr.modeling.losses.rec_ctc_loss,CTCLoss'}, 'Optimizer': {'function': 'ppocr.optimizer,AdamDecay', 'base_lr': 0.0001, 'l2_decay': 4e-05, 'beta1': 0.9, 'beta2': 0.999, 'decay': {'function': 'cosine_decay_warmup', 'step_each_epoch': 1000, 'total_epoch': 201, 'warmup_minibatch': 2000}}, 'TrainReader': {'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'num_workers': 8, 'img_set_dir': '/home/aistudio/data/train_images', 'label_file_path': '/home/aistudio/data/train_label.txt'}, 'EvalReader': {'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'img_set_dir': '/home/aistudio/data/train_images', 'label_file_path': '/home/aistudio/data/train_label.txt'}, 'TestReader': {'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader'}}
W0930 22:57:54.222055 22198 device_context.cc:252] Please NOTE: device: 0, CUDA Capability: 70, Driver API Version: 11.2, Runtime API Version: 9.0
W0930 22:57:54.227607 22198 device_context.cc:260] device: 0, cuDNN Version: 7.6.
2022-09-30 22:57:57,220-INFO: Finish initing model from ./output/my_rec_ch/iter_epoch_27
inference model saved in ./inference/CRNN_R34/model and ./inference/CRNN_R34/params
save success, output_name_list: ['decoded_out', 'predicts']
9.3预测结果
修改模型路径,运行predict.py:
import sys
import osfrom paddleocr import PaddleOCR
import numpy as np
import glob
import time
if __name__=='__main__':# Preferenceimg_set_dir = os.path.join('..','data','test_images','')# Load modeluse_gpu = True use_angle_cls = False det = Falsedet_model_dir = os.path.join('PaddleOCR','inference','ch_ppocr_mobile_v1.1_det_infer')cls_model_dir = os.path.join('PaddleOCR','inference','ch_ppocr_mobile_v1.1_cls_infer')rec_model_dir = os.path.join('PaddleOCR','inference','CRNN_R34')ocr = PaddleOCR(use_angle_cls=use_angle_cls, lang="ch",use_gpu=use_gpu,use_space_char=False,gpu_mem=4000,det = det,rec_image_shape = '3, 48, 256', rec_algorithm = 'CRNN',max_text_length = 80,det_model_dir = det_model_dir,cls_model_dir = cls_model_dir,rec_model_dir = rec_model_dir)# Load data in a folderimages = glob.glob(img_set_dir+'*.jpg')log_file_name = time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime())# Print result to a filewith open(log_file_name+'.txt','w') as fid:print('new_name\tvalue',file=fid)#Inference in a folderfor image in images:result = ocr.ocr(image, cls=use_angle_cls,det=det)if result is None:print('Test {} failed.'.format(image.replace(img_set_dir,'')))continuefor info in result:pred_label = info[0]print('{}\t{}'.format(image.replace(img_set_dir,''),pred_label),file=fid)print("Finished predicting {} images!".format(len(images)))!pwd
!python ~/work/predict.py
最终结果以txt文件保存,命名格式Y-%m-%d-%H-%M-%S,保存在在/home/aistudio/目录下。
#查看结果 txt文件生成
%cd /home/aistudio/
!cat 2022-09-30-22-58-06.txt | head -n 10
十、总结与后续优化:
1.目前只用resnet网络,后续考虑更换更多轻量级网络测试效果;
2.后续继续对数据进行增强操作或结合更多相关数据集,增加模型的泛化性;
3.继续精调整学习率大小及训练策略调整,提升模型的收敛速度及准确度。
本篇总结: 本篇主要介绍OCR实战项目,以PaddleOCR框架完成计算机视觉中文场景识别任务,尽可能详细介绍代码及项目流程,如有错误请指正,后续本人也将介绍更多实战项目,欢迎大家交流学习。
参考资料
- PaddleOCR官方教程
相关文章:
【计算机视觉项目实战】中文场景识别
✨专栏介绍: 经过几个月的精心筹备,本作者推出全新系列《深入浅出OCR》专栏,对标最全OCR教程,具体章节如导图所示,将分别从OCR技术发展、方向、概念、算法、论文、数据集等各种角度展开详细介绍。 👨&…...

Java 中 Map 初始化的几种方法
# 传统方式 Map<String, String> map new HashMap<>(); map.put("k1", "v1"); map.put("k2", "v2");# java8新特性-双括号初始化 Map<String, String> map1 new HashMap<>() {{put("k1", "v…...

【学习方法论】学习的三种境界、三种习惯、三个要点,三个心态
学习的三种境界、三种习惯、三个要点,三个心态 三种学习境界 苦学 古人云:“头悬梁、锥刺股”,勤学苦练是第一境界。处于这种层次的同学,觉得学习枯燥无味,对他们来说学习是一种被迫行为,体会不到学习中的…...
[管理与领导-67]:IT基层管理者 - 辅助技能 - 4- 职业发展规划 - 评估你与公司的八字是否相合
目录 前言: 一、概述 二、八字相合的步骤 2.1 企业文化是否相合 2.2.1 企业文化对职业选择的意义 2.2.2 个人与企业三观不合的结果 2.2.3 什么样的企业文化的公司不能加入 2.2 公司的发展前景 2.3 公司所处行业发展 2.4 创始人的三观 2.5 创始人与上司的…...

【PMO项目管理】深入了解项目管理 | Stakeholder 利益相关者 | 利益相关者之间的立场差异
💭 写在前面:本文将带您深入了解项目管理的核心概念和关键要素。我们将从项目管理的基本理解开始,逐步探讨其领域、复杂性和变化的重点,以及项目管理的具体过程。我们还将研究项目的性质以及成功项目所必备的条件。在此过程中&…...

设计模式-原则篇-01.开闭原则
简介 可以把设计模式理解为一套比较成熟并且成体系的建筑图纸,经过多次编码检验目前看来使用效果还不错的软件设计方案。适用的场景也比较广泛,在使用具体的设计模式之前先要学习软件设计的基础 “软件设计原则”,后面的23个设计模式都是…...

JAVA毕业设计096—基于Java+Springboot+Vue的在线教育系统(源码+数据库+18000字论文)
基于JavaSpringbootVue的在线教育系统(源码数据库18000字论文)096 一、系统介绍 本系统前后端分离 本系统分为管理员、用户两种角色(管理员角色权限可自行分配) 用户功能: 注册、登录、课程预告、在线课程观看、学习资料下载、学习文章预览、个人信息管理、消息…...

windows环境搭建ELK
目录 资源下载(8.9.1) ES安装、注册、使用 Kibana安装、注册、使用 Logstash安装、注册、使用 Filebeat安装、使用(如果只有一个数据流,则不需要使用filebeat,直接上logstash即可) 资源下载࿰…...

langchain介绍之-Prompt
LangChain 是一个基于语言模型开发应用程序的框架。它使得应用程序具备以下特点:1.数据感知:将语言模型与其他数据源连接起来。2.代理性:允许语言模型与其环境进行交互 LangChain 的主要价值在于:组件:用于处理语言模型…...
汇编语言Nasmide编辑软件
用来编写汇编语言源程序,Windows 记事本并不是一个好工具。同时,在命令行编译源程序也令很多人迷糊。毕竟,很多年轻的朋友都是用着 Windows 成长起来的,他们缺少在 DOS和 UNIX 下工作的经历。 我一直想找一个自己中意的汇编语言编…...

用python开发一个炸金花小游戏
众所周知扑克牌可谓是居家旅行、桌面交友的必备道具, 今天我们用 Python 来实现一个类似炸金花的扑克牌小游戏,先来看一下基本的游戏规则。 炸(诈)金花又叫三张牌,是在全国广泛流传的一种民间多人纸牌游戏…...

Uniapp中使用uQRCode二维码跳转小程序页面
下载插件 uQRCode官网地址 引入插件 文件如下 //--------------------------------------------------------------------- // github https://github.com/Sansnn/uQRCode //---------------------------------------------------------------------let uQRCode = {};(functio…...
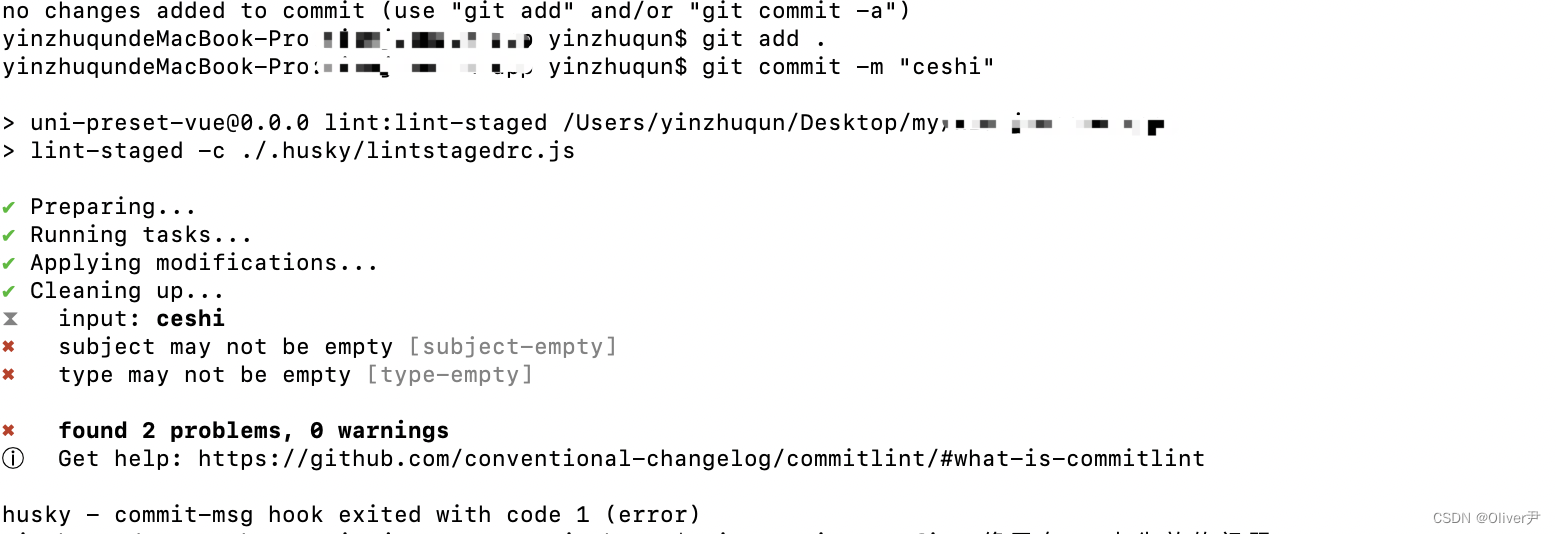
解决husky在mac下不生效的问题
目录 一、问题 1.1 问题描述 二、解决 2.1 解决 一、问题 1.1 问题描述 本文主要解决的问题是,husky在windows上正常生肖,但放到mac下后不生效的问题! 为了确保团队中提交代码的一致性,因此使用了 husky 作为提交的检测工具…...
如何在自动化测试中使用MitmProxy获取数据返回?
背景介绍 当我们在接口或UI自动化项目中,常常会出现这种现象——明明是正常请求,却无法获取到想要的数据返回。 比如: 场景A:页面是动态数据,第一次进入页面获取到的数据,和下次进入页面获取到的数据完全…...
达之云BI平台助力中国融通集团陕西军民服务社有限公司实现数字化运营
中国融通集团陕西军民服务社是一家大型综合类零售购物中心,公司目前管理系统运行了10年左右,面临系统新零售支持发展严重滞后,行业主流应用落地困难,如线上业务、到家业务、全渠道营销、电子发票、自助收银、扫码购、无感停车、未…...
Private market:借助ZK实现的任意计算的trustless交易
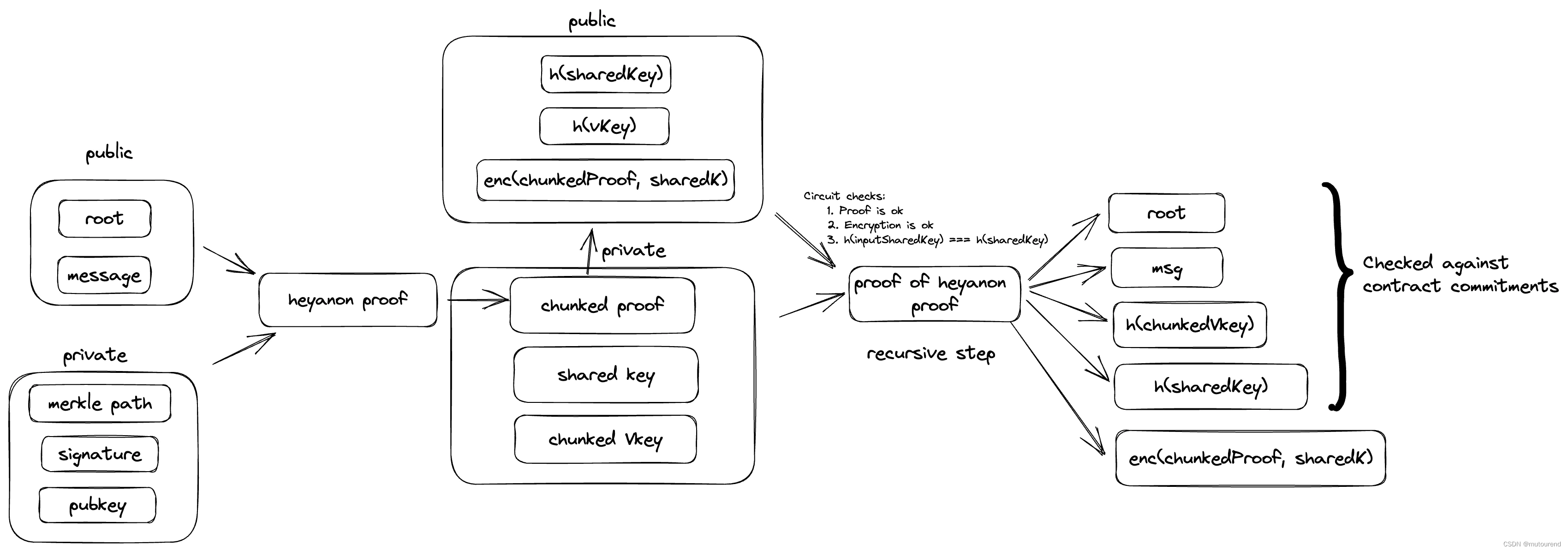
1. 引言 Private market,借助zk-SNARKs和以太坊来 隐私且trustlessly selling: 1)以太坊地址的私钥(ECDSA keypair)2)EdDSA签名3)Groth16 proof:借助递归性来匿名交易Groth16 proo…...
反序列化漏洞复现(typecho)
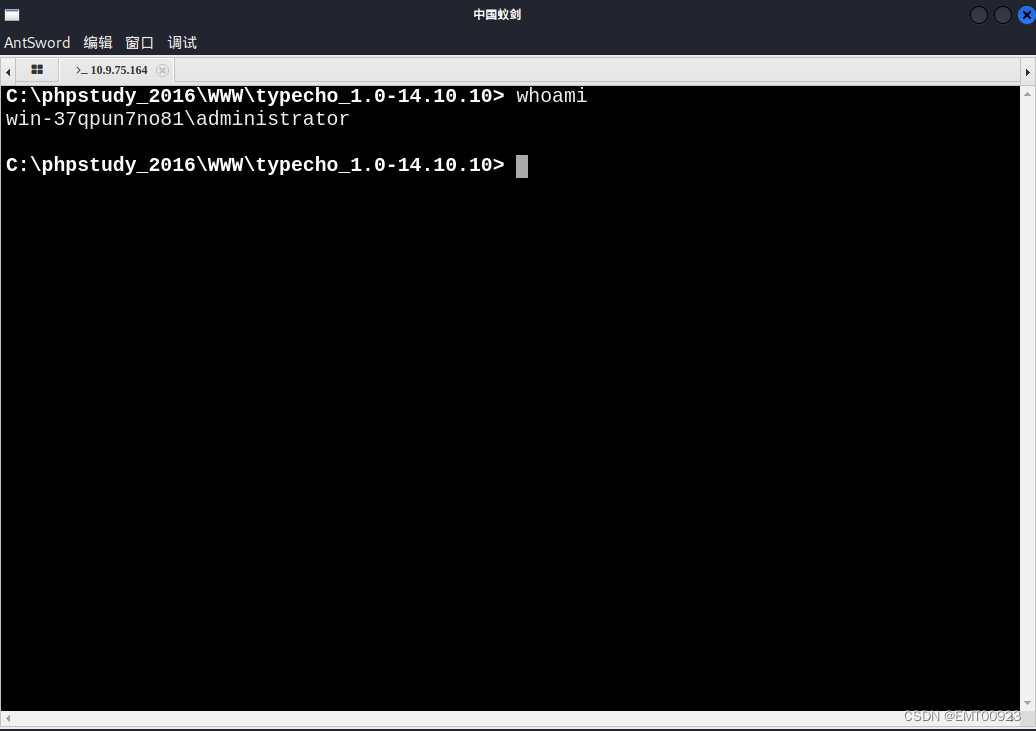
文章目录 执行phpinfogetshell 执行phpinfo 将下面这段代码复制到一个php文件,命名为typecho_1.0-14.10.10_unserialize_phpinfo.php,代码中定义的类名与typecho中的类相同,是它能识别的类: <?php class Typecho_Feed{const…...

QT设计一个小闹钟
设置一个闹钟,左侧窗口显示当前时间,右侧设置时间,以及控制闹钟的开关,下方显示闹钟响时的提示语。当按启动按钮时,设置时间与闹钟提示语均不可再改变。当点击停止时,关闭闹钟并重新启用设置时间与闹钟提示…...

MybatisPlus(3)
前言🍭 ❤️❤️❤️SSM专栏更新中,各位大佬觉得写得不错,支持一下,感谢了!❤️❤️❤️ Spring Spring MVC MyBatis_冷兮雪的博客-CSDN博客 一、查询投影🍭 查询投影是指在查询操作中,只选择…...

安全计算环境技术测评要求项
1.身份鉴别-在应用系统及各类型设备中确认操作者身份的过程(身份鉴别和数据保密) 1-2/2-3/3-4/4-4 a)应对登录的用户进行身份标识和鉴别,身份标识具有唯一性,身份鉴别信息具有复杂度要求并定期更换 b)应具有…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

如何理解 IP 数据报中的 TTL?
目录 前言理解 前言 面试灵魂一问:说说对 IP 数据报中 TTL 的理解?我们都知道,IP 数据报由首部和数据两部分组成,首部又分为两部分:固定部分和可变部分,共占 20 字节,而即将讨论的 TTL 就位于首…...

STM32---外部32.768K晶振(LSE)无法起振问题
晶振是否起振主要就检查两个1、晶振与MCU是否兼容;2、晶振的负载电容是否匹配 目录 一、判断晶振与MCU是否兼容 二、判断负载电容是否匹配 1. 晶振负载电容(CL)与匹配电容(CL1、CL2)的关系 2. 如何选择 CL1 和 CL…...

使用SSE解决获取状态不一致问题
使用SSE解决获取状态不一致问题 1. 问题描述2. SSE介绍2.1 SSE 的工作原理2.2 SSE 的事件格式规范2.3 SSE与其他技术对比2.4 SSE 的优缺点 3. 实战代码 1. 问题描述 目前做的一个功能是上传多个文件,这个上传文件是整体功能的一部分,文件在上传的过程中…...
与文本切分器(Splitter)详解《二》)
LangChain 中的文档加载器(Loader)与文本切分器(Splitter)详解《二》
🧠 LangChain 中 TextSplitter 的使用详解:从基础到进阶(附代码) 一、前言 在处理大规模文本数据时,特别是在构建知识库或进行大模型训练与推理时,文本切分(Text Splitting) 是一个…...

aardio 自动识别验证码输入
技术尝试 上周在发学习日志时有网友提议“在网页上识别验证码”,于是尝试整合图像识别与网页自动化技术,完成了这套模拟登录流程。核心思路是:截图验证码→OCR识别→自动填充表单→提交并验证结果。 代码在这里 import soImage; import we…...