8月31日-9月1日 第六章 案例:MySQL主从复制与读写分离(面试重点,必记)
本章结构

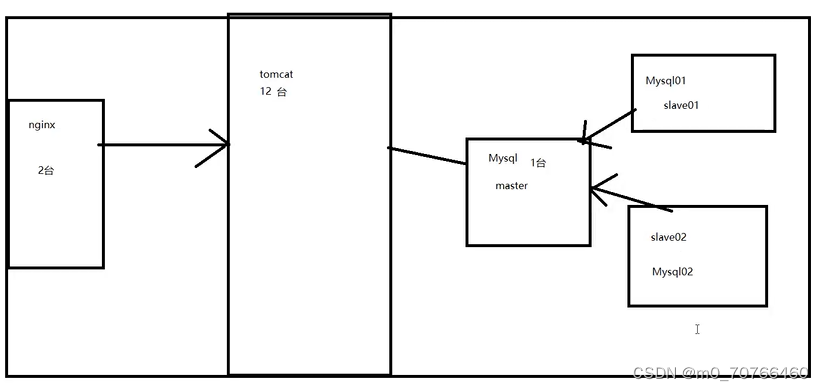
案例概述

案例前置知识点
详细图示
1、什么是读写分离?
读写分离,基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
2、为什么要读写分离呢?
因为数据库的“写”(写10000条数据可能要3分钟)操作是比较耗时的。
但是数据库的“读”(读10000条数据可能只要5秒钟)。
所以读写分离,解决的是,数据库的写入,影响了查询的效率。
3、什么时候要读写分离?
数据库不一定要读写分离,如果程序使用数据库较多时,而更新少,查询多的情况下会考虑使用。利用数据库主从同步,再通过读写分离可以分担数据库压力,提高性能。
4、主从复制与读写分离
在实际的生产环境中,对数据库的读和写都在同一个数据库服务器中,是不能满足实际需求的。无论是在安全性、高可用性还是高并发等各个方面都是完全不能满足实际需求的。因此,通过主从复制的方式来同步数据,再通过读写分离来提升数据库的并发负载能力。有点类似于rsync,但是不同的是rsync是对磁盘文件做备份,而mysql主从复制是对数据库中的数据、语句做备份。
5、mysq支持的复制类型
(1)STATEMENT:基于语句的复制。在服务器上执行sql语句,在从服务器上执行同样的语句,mysql默认采用基于语句的复制,执行效率高。
(2)ROW:基于行的复制。把改变的内容复制过去,而不是把命令在从服务器上执行一遍。
(3)MIXED:混合类型的复制。默认采用基于语句的复制,一旦发现基于语句无法精确复制时,就会采用基于行的复制。
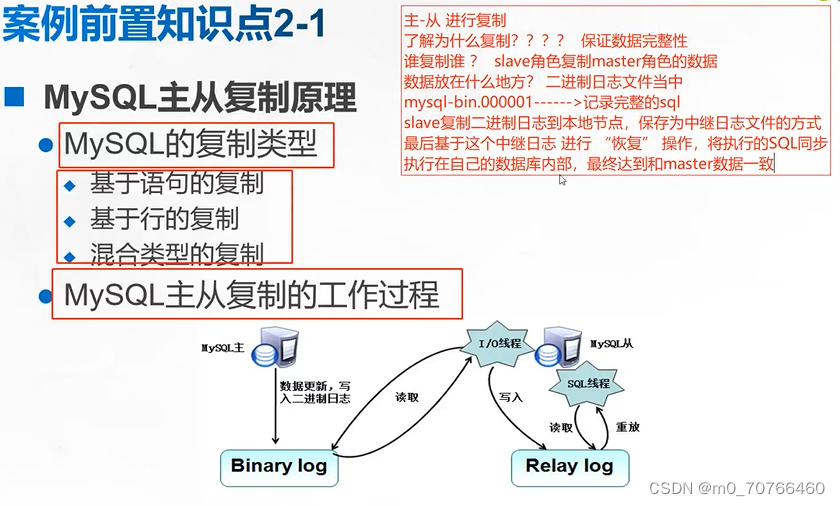
6、主从复制的工作过程(重点)
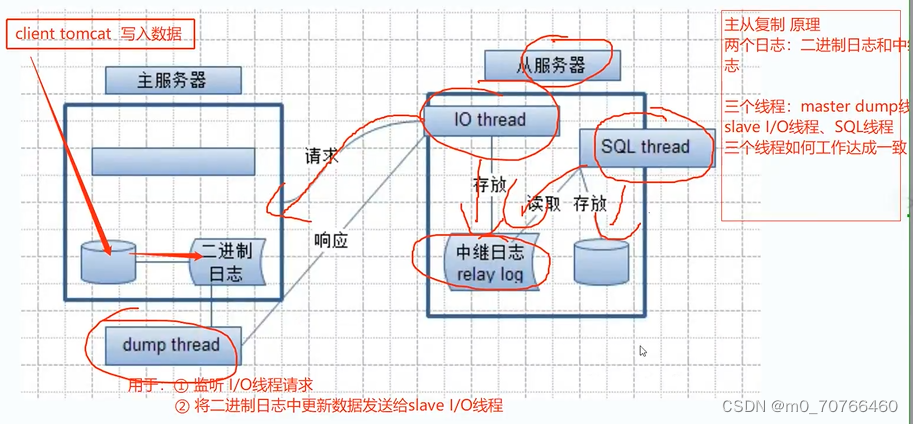
(1)Master节点将数据的改变记录成二进制日志(bin log),当Master上的数据发生改变时,则将其改变写入二进制日志中。
(2)Slave节点会在一定时间间隔内对Master的二进制日志进行探测其是否发生改变,如果发生改变,则开始一个I/O线程请求 Master的二进制事件。
(3)同时Master节点为每个I/O线程启动一个dump线程,用于向其发送二进制事件,并保存至Slave节点本地的中继日志(Relay log)中,Slave节点将启动SQL线程从中继日志中读取二进制日志,在本地重放,即解析成 sql 语句逐一执行,使得其数据和 Master节点的保持一致,最后I/O线程和SQL线程将进入睡眠状态,等待下一次被唤醒。
注:
●中继日志通常会位于 OS 缓存中,所以中继日志的开销很小。
●复制过程有一个很重要的限制,即复制在 Slave上是串行化的,也就是说 Master上的并行更新操作不能在 Slave上并行操作。
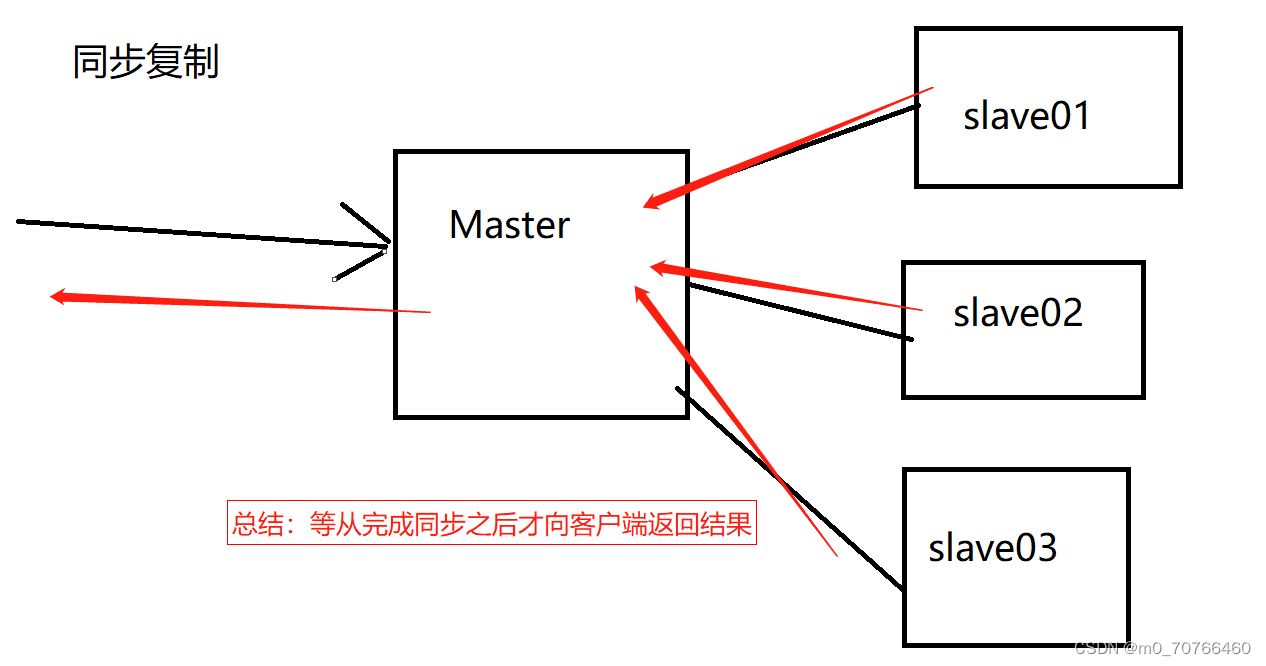
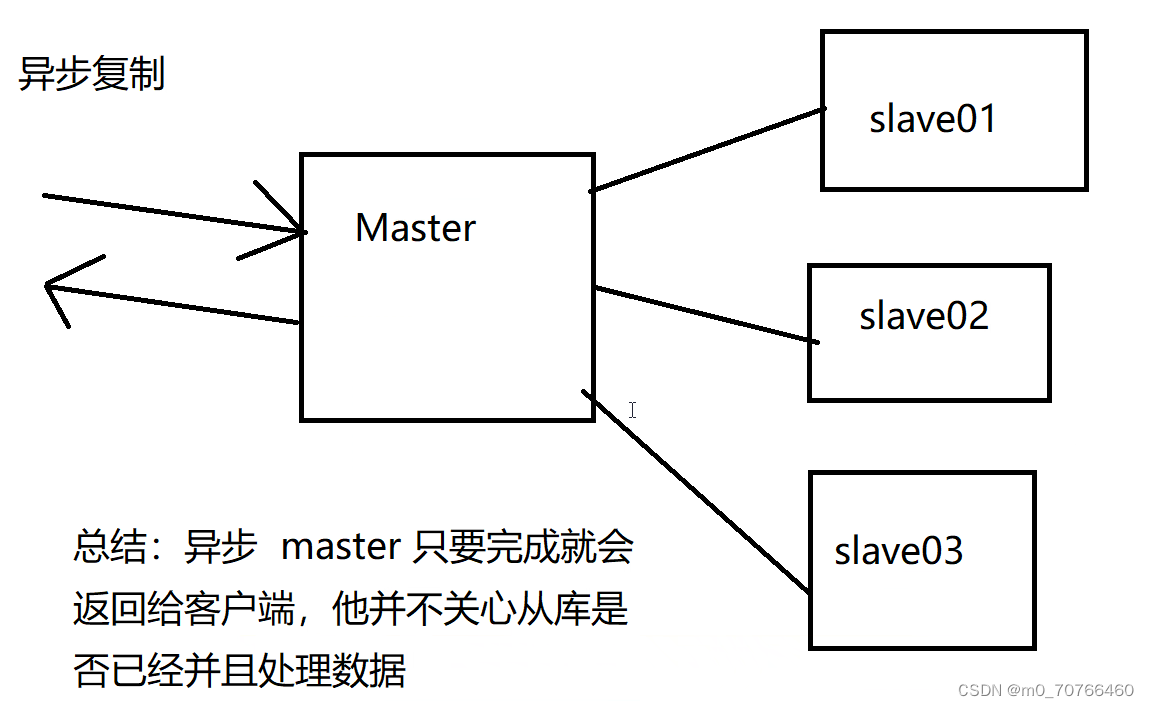
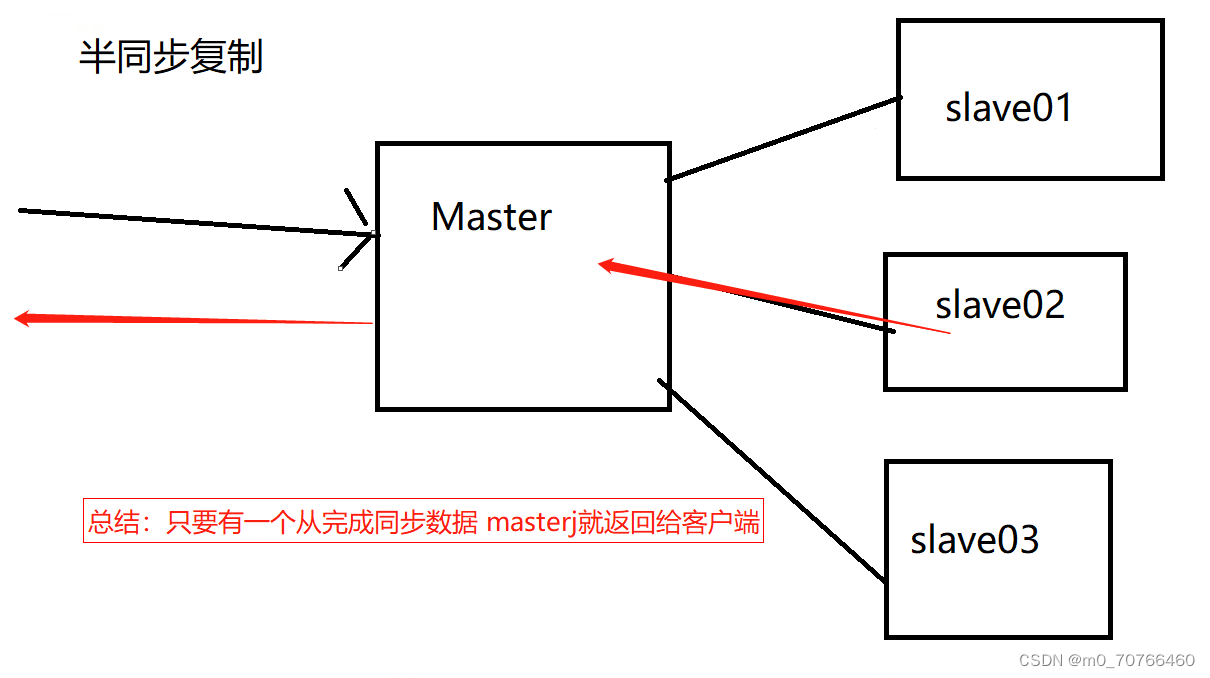
MySQL主从复制延迟(重点)
1、master服务器高并发,形成大量事务
2、网络延迟
3、主从硬件设备导致
cpu主频、内存io、硬盘io
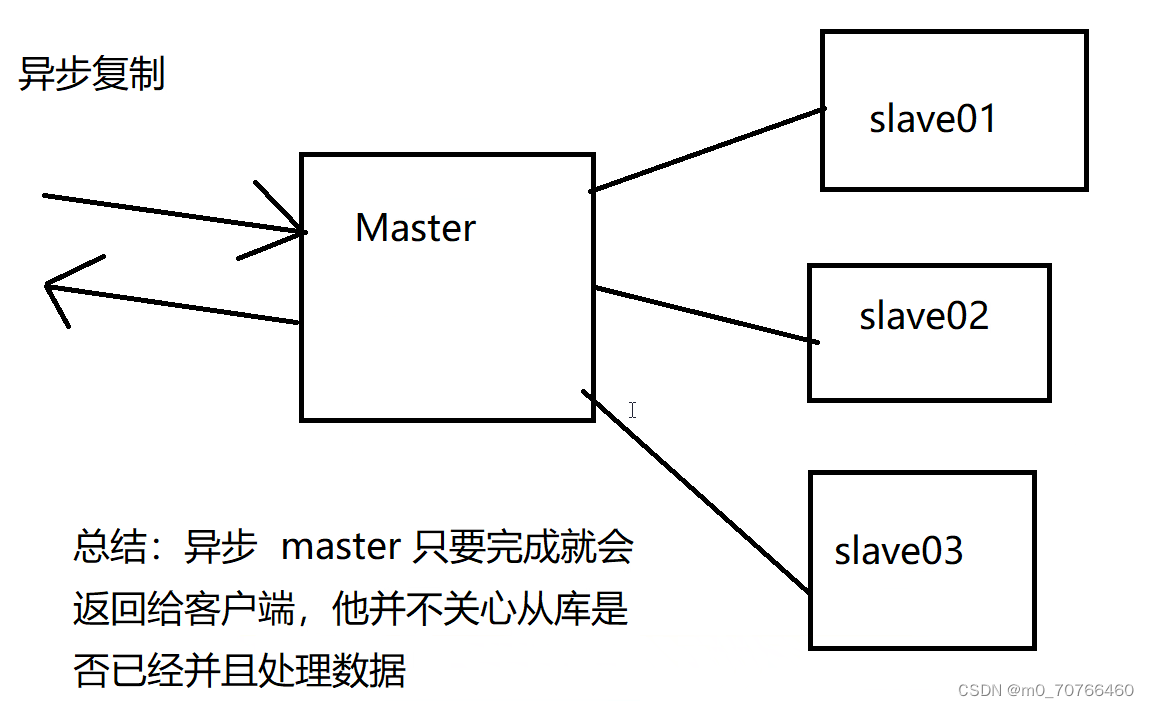
4、本来就不是同步复制、而是异步复制
从库优化Mysql参数。比如增大innodb_buffer_pool_size,让更多操作在Mysql内存中完成,减少磁盘操作。
从库使用高性能主机。包括cpu强悍、内存加大。避免使用虚拟云主机,使用物理主机,这样提升了i/o方面性。
从库使用SSD磁盘
网络优化,避免跨机房实现同步
异步复制
同步复制
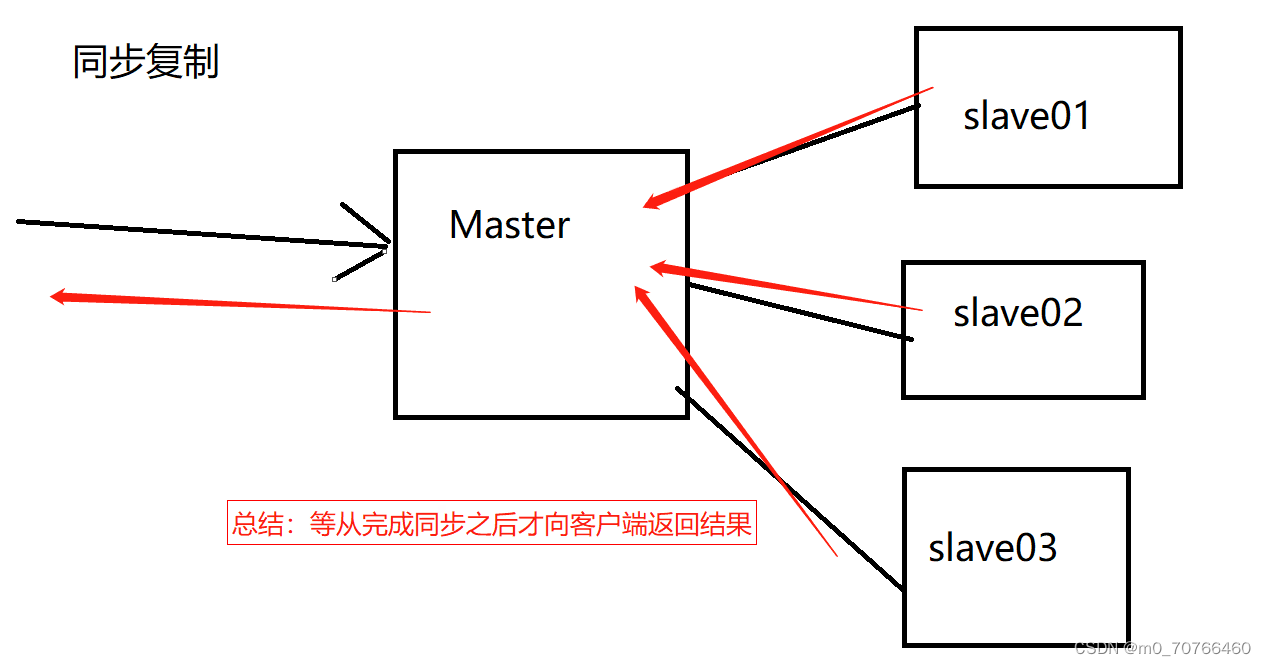
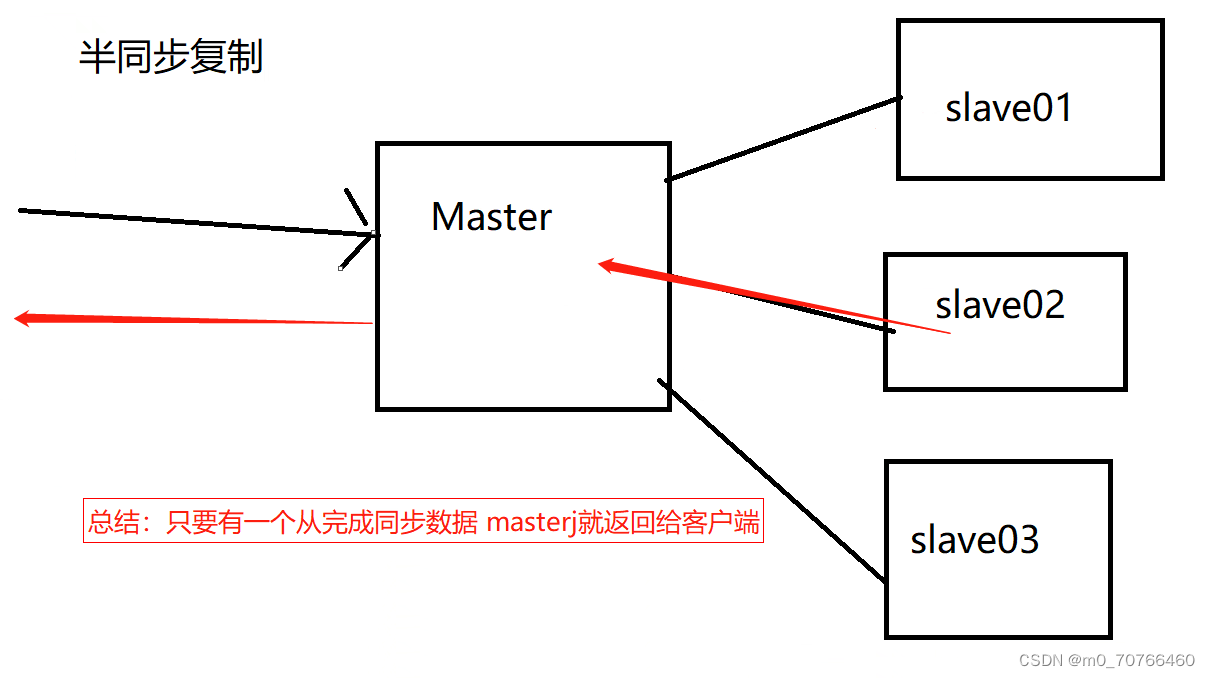
半同步复制
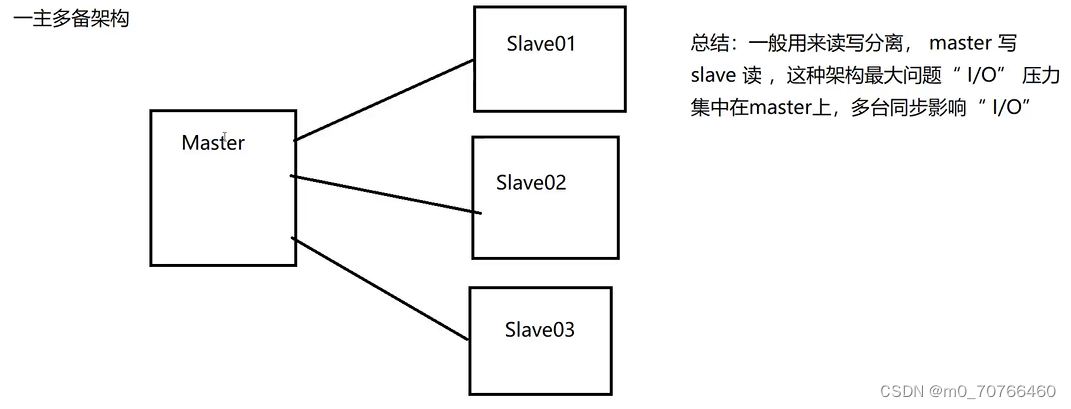
7、MySQL 读写分离原理
读写分离就是只在主服务器上写,只在从服务器上读。基本的原理是让主数据库处理事务性操作,而从数据库处理 select 查询。数据库复制被用来把主数据库上事务性操作导致的变更同步到集群中的从数据库。
8、目前较为常见的 MySQL 读写分离分为以下两种:
1)基于程序代码内部实现
在代码中根据 select、insert 进行路由分类,这类方法也是目前生产环境应用最广泛的。
优点是性能较好,因为在程序代码中实现,不需要增加额外的设备为硬件开支;缺点是需要开发人员来实现,运维人员无从下手。
但是并不是所有的应用都适合在程序代码中实现读写分离,像一些大型复杂的Java应用,如果在程序代码中实现读写分离对代码改动就较大。
2)基于中间代理层实现
代理一般位于客户端和服务器之间,代理服务器接到客户端请求后通过判断后转发到后端数据库,有以下代表性程序。
(1)MySQL-Proxy。MySQL-Proxy 为 MySQL 开源项目,通过其自带的 lua 脚本进行SQL 判断。
(2)Atlas。是由奇虎360的Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目。它是在mysql-proxy 0.8.2版本的基础上,对其进行了优化,增加了一些新的功能特性。360内部使用Atlas运行的mysql业务,每天承载的读写请求数达几十亿条。支持事物以及存储过程。
(3)Amoeba。由陈思儒开发,作者曾就职于阿里巴巴。该程序由Java语言进行开发,阿里巴巴将其用于生产环境。但是它不支持事务和存储过程。
由于使用MySQL Proxy 需要写大量的Lua脚本,这些Lua并不是现成的,而是需要自己去写。这对于并不熟悉MySQL Proxy 内置变量和MySQL Protocol 的人来说是非常困难的。
Amoeba是一个非常容易使用、可移植性非常强的软件。因此它在生产环境中被广泛应用于数据库的代理层。
Master 服务器:192.168.10.15 mysql5.7
Slave1 服务器:192.168.10.14 mysql5.7
Slave2 服务器:192.168.10.16 mysql5.7
Amoeba 服务器:192.168.10.13 jdk1.6、Amoeba
客户端 服务器:192.168.10.13 mysql
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
搭建 MySQL主从复制
Mysql主从服务器时间同步
##主服务器设置##
yum install ntp -y
vim /etc/ntp.conf
--末尾添加--
server 127.127.80.0 #设置本地是时钟源,注意修改网段 127.127.10.0
fudge 127.127.80.0 stratum 8 #设置时间层级为8(限制在15内)
service ntpd start
主一定要装好ntpdate

##从服务器设置##
yum install ntp ntpdate -y
service ntpd start
/usr/sbin/ntpdate 192.168.80.10 #进行时间同步 192.168.10.15
crontab -e
*/30 * * * * /usr/sbin/ntpdate 192.168.80.10
从可以直接同步时间

----主服务器的mysql配置-----
vim /etc/my.cnf
server-id = 11
log-bin=master-bin #添加,主服务器开启二进制日志
binlog_format = MIXED
log-slave-updates=true #添加,允许slave从master复制数据时可以写入到自己的二进制日志
systemctl restart mysqld
mysql -u root -pabc123
GRANT REPLICATION SLAVE ON *.* TO 'myslave'@'192.168.10.%' IDENTIFIED BY '123456'; #给从服务器授权
FLUSH PRIVILEGES;
show master status;
//如显示以下
+-------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+-------------------+----------+--------------+------------------+
| master-bin.000001 | 603 | | |
+-------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
#File 列显示日志名,Position 列显示偏移量
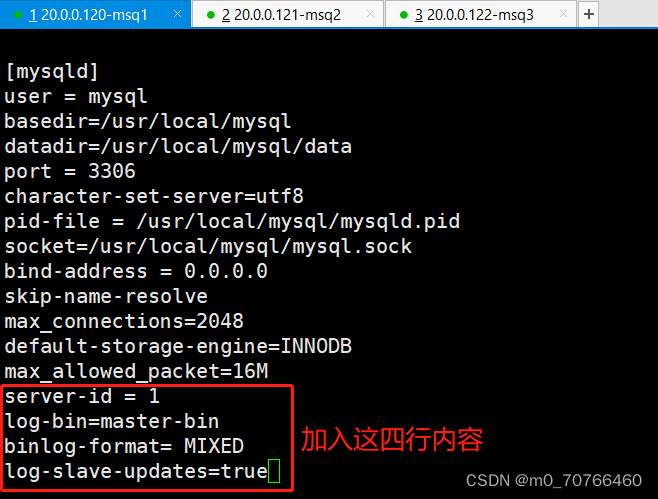

----从服务器的mysql配置----
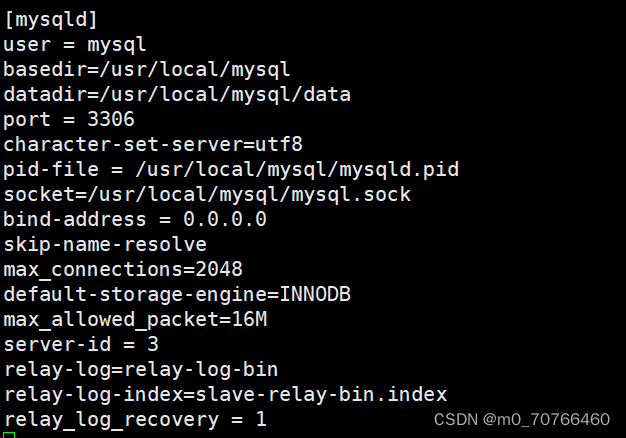
vim /etc/my.cnf
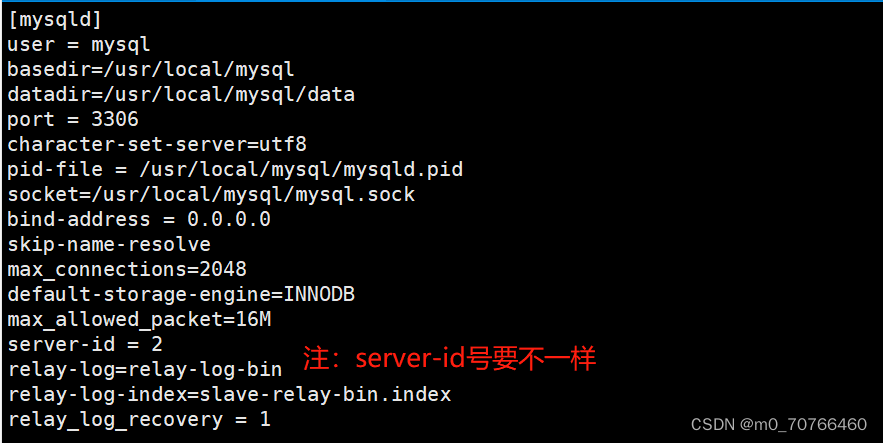
server-id = 22 #修改,注意id与Master的不同,两个Slave的id也要不同
relay-log=relay-log-bin #添加,开启中继日志,从主服务器上同步日志文件记录到本地
relay-log-index=slave-relay-bin.index #添加,定义中继日志文件的位置和名称,一般和relay-log在同一目录
relay_log_recovery = 1 #选配项
#当 slave 从库宕机后,假如 relay-log 损坏了,导致一部分中继日志没有处理,则自动放弃所有未执行的 relay-log,并且重新从 master 上获取日志,这样就保证了relay-log 的完整性。默认情况下该功能是关闭的,将 relay_log_recovery 的值设置为 1 时, 可在 slave 从库上开启该功能,建议开启。
systemctl restart mysqld
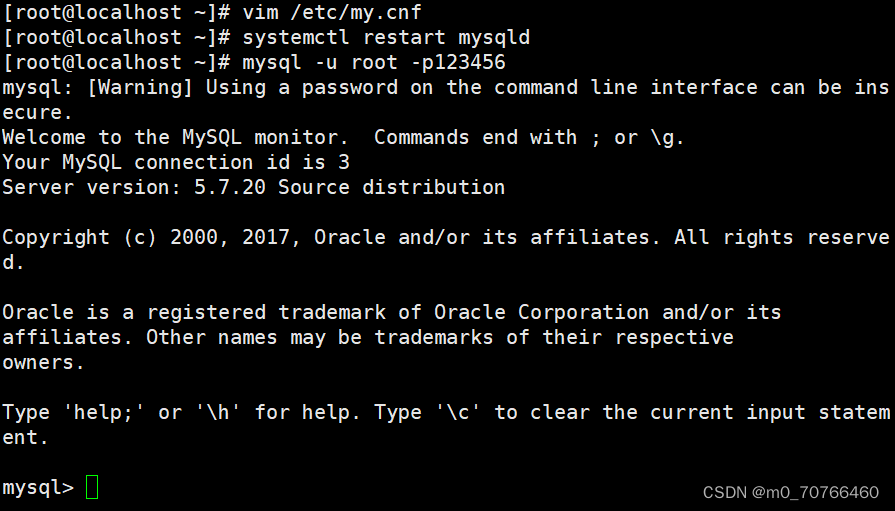
mysql -u root -pabc123
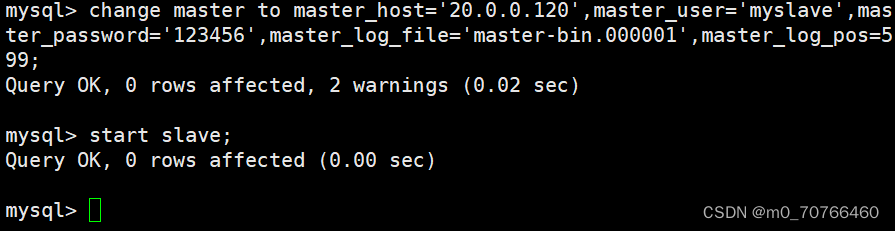
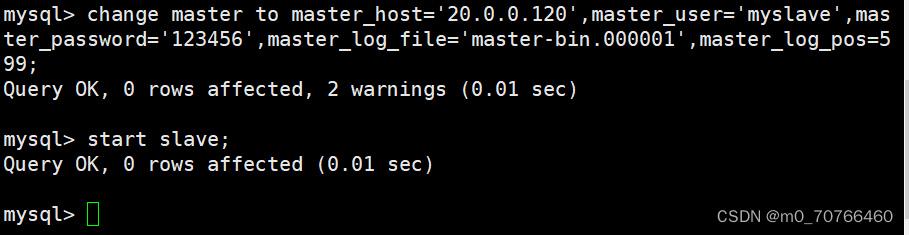
CHANGE master to master_host='192.168.80.10',master_user='myslave',master_password='123456',master_log_file='master-bin.000002',master_log_pos=339; #配置同步,注意 master_log_file 和 master_log_pos 的值要与Master查询的一致
CHANGE master to master_host='192.168.10.15',master_user='myslave',master_password='123456',master_log_file='master-bin.000001',master_log_poss=603;
start slave; #启动同步,如有报错执行 reset slave;
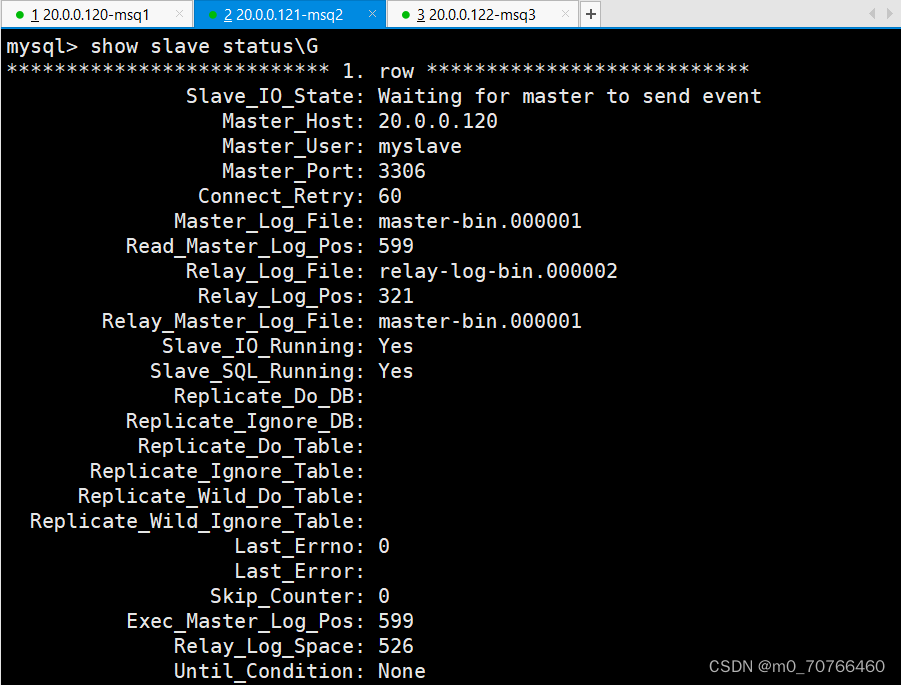
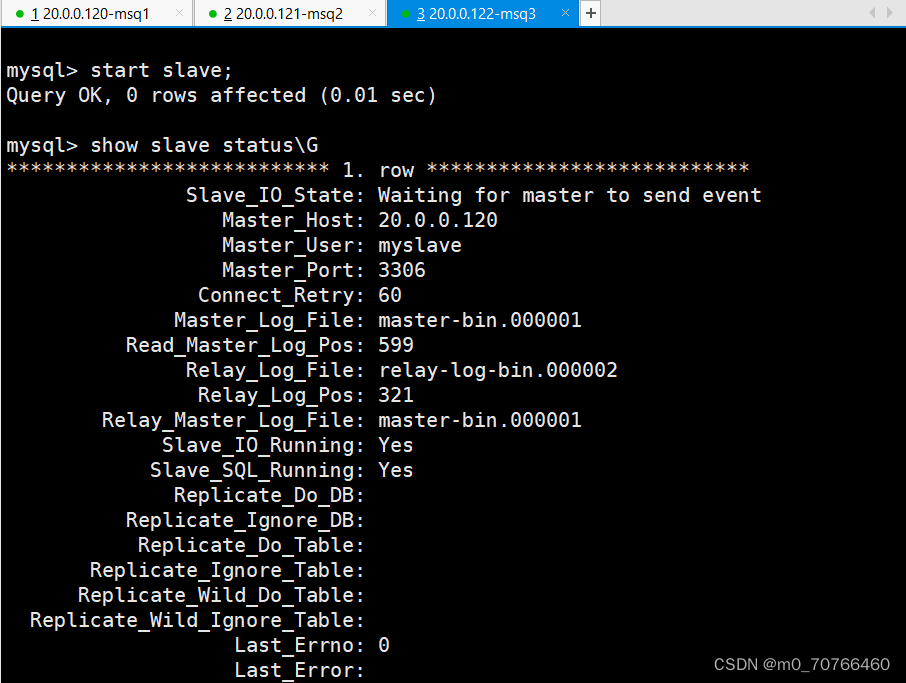
show slave status\G #查看 Slave 状态
//确保 IO 和 SQL 线程都是 Yes,代表同步正常。
Slave_IO_Running: Yes #负责与主机的io通信
Slave_SQL_Running: Yes #负责自己的slave mysql进程
这两个必须是yes才行,不是yes找到no的error原因
从1:
查看连接状态
从2:
#一般 Slave_IO_Running: No 的可能性:
1、网络不通
2、my.cnf配置有问题
3、密码、file文件名、pos偏移量不对
4、防火墙没有关闭
----验证主从复制效果----
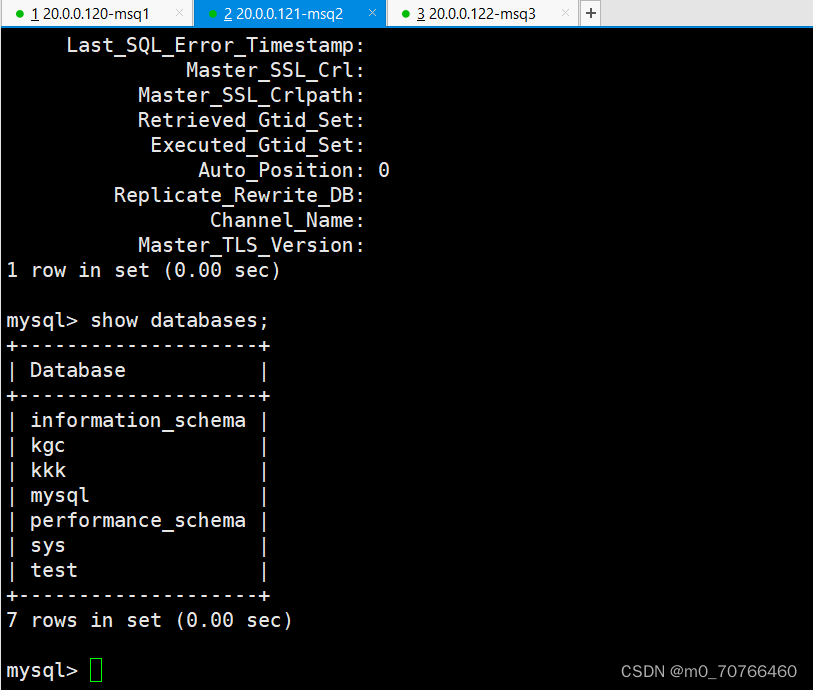
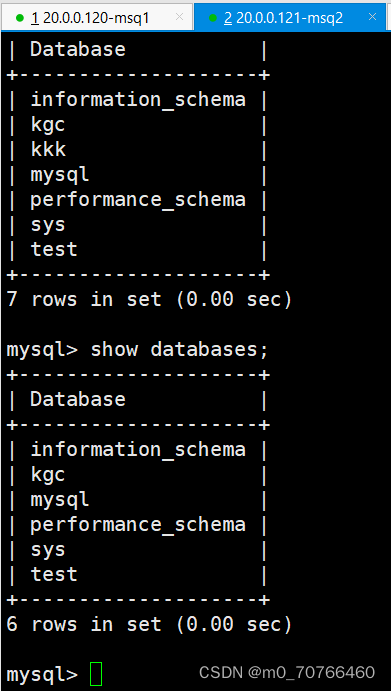
主服务器上进入执行 create database db_test;
去从服务器上查看 show databases;
注:如数据中途加入主从复制的库 需要导出主服务器库 的库文件并且导入到从服务器中
主:创建
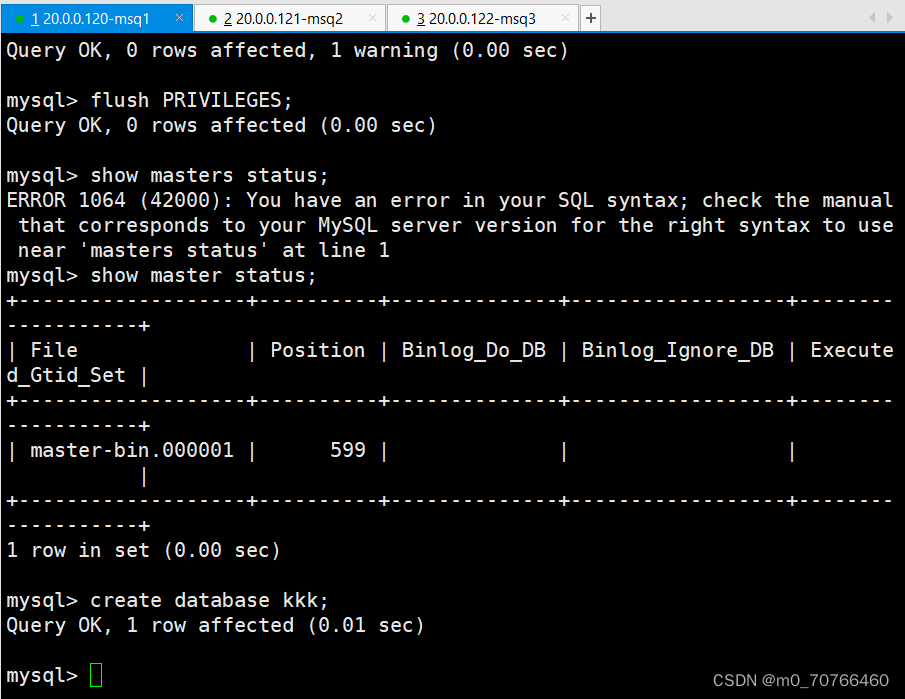
从:同步
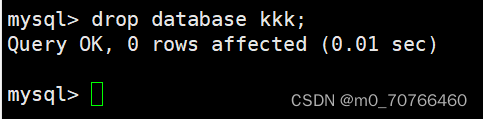
删除一样同步
搭建 MySQL读写分离
----Amoeba服务器配置----
##安装 Java 环境##
因为 Amoeba 基于是 jdk1.5 开发的,所以官方推荐使用 jdk1.5 或 1.6 版本,高版本不建议使用。
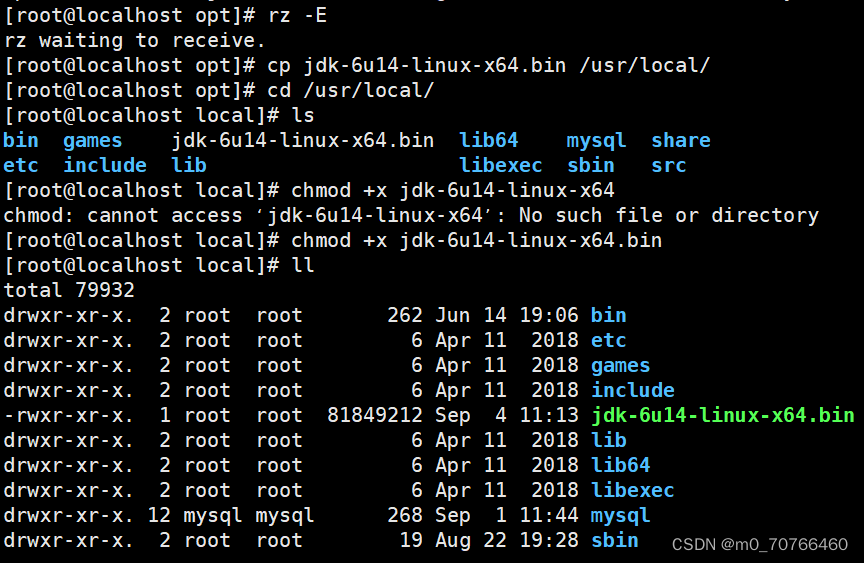
cd /opt/
cp jdk-6u14-linux-x64.bin /usr/local/
cd /usr/local/
chmod +x jdk-6u14-linux-x64
./jdk-6u14-linux-x64.bin
//按yes,按enter
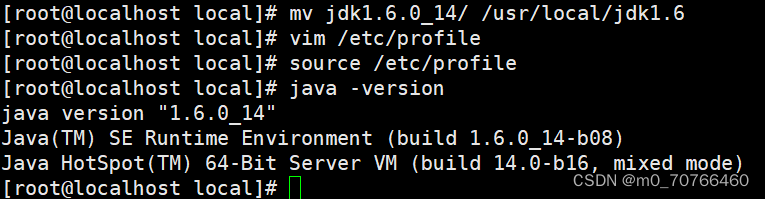
mv jdk1.6.0_14/ /usr/local/jdk1.6
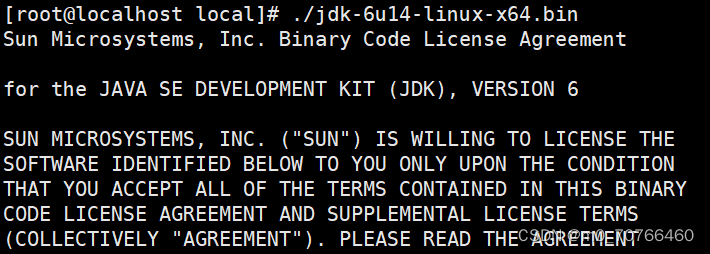

vim /etc/profile
export JAVA_HOME=/usr/local/jdk1.6
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/bin/:$PATH:$HOME/bin
export AMOEBA_HOME=/usr/local/amoeba
export PATH=$PATH:$AMOEBA_HOME/bin
source /etc/profile
java -version
##安装 Amoeba软件##
mkdir /usr/local/amoeba
tar zxvf amoeba-mysql-binary-2.2.0.tar.gz -C /usr/local/amoeba/
chmod -R 755 /usr/local/amoeba/
/usr/local/amoeba/bin/amoeba
//如显示amoeba start|stop说明安装成功
##配置 Amoeba读写分离,两个 Slave 读负载均衡##
#先在Master、Slave1、Slave2 的mysql上开放权限给 Amoeba 访问
grant all on *.* to test@'192.168.80.%' identified by '123.com';
grant all on *.* to test@'192.168.10.%' identified by '123456';

#再回到amoeba服务器配置amoeba服务:
cd /usr/local/amoeba/conf/
cp amoeba.xml amoeba.xml.bak
修改amoeba配置文件
vim amoeba.xml #修改amoeba配置文件
--30行--
<property name="user">amoeba</property>
--32行--
<property name="password">123456</property>
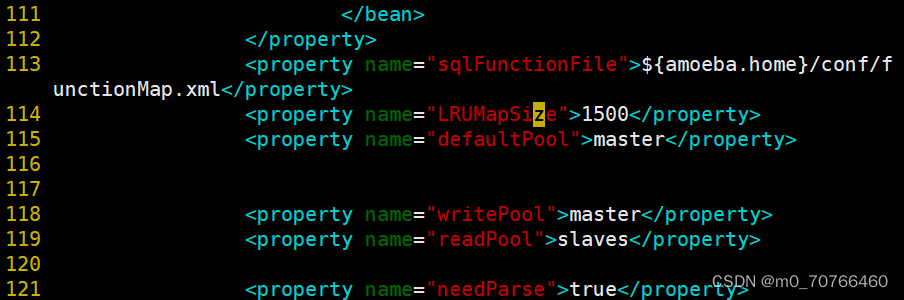
--115行--
<property name="defaultPool">master</property>
--117-去掉注释-
<property name="writePool">master</property>
<property name="readPool">slaves</property>

cp dbServers.xml dbServers.xml.bak
修改数据库配置文件
vim dbServers.xml #修改数据库配置文件
--23行--注释掉 作用:默认进入test库 以防mysql中没有test库时,会报错
<!-- <property name="schema">test</property> -->
--26--修改
<property name="user">test</property>
--28-30--去掉注释
<property name="password">123456</property>
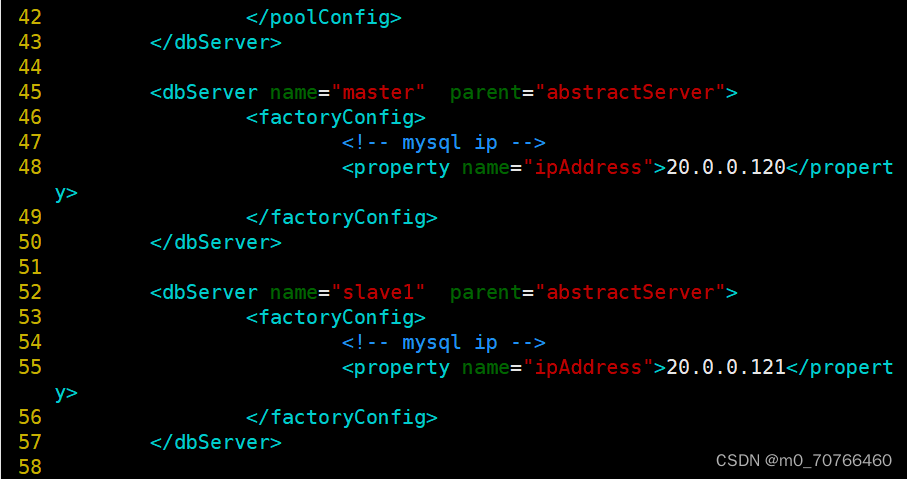
--45--修改,设置主服务器的名Master
<dbServer name="master" parent="abstractServer">
--48--修改,设置主服务器的地址
<property name="ipAddress">192.168.10.15</property>
--52--修改,设置从服务器的名slave1
<dbServer name="slave1" parent="abstractServer">
--55--修改,设置从服务器1的地址
<property name="ipAddress">192.168.10.14</property>
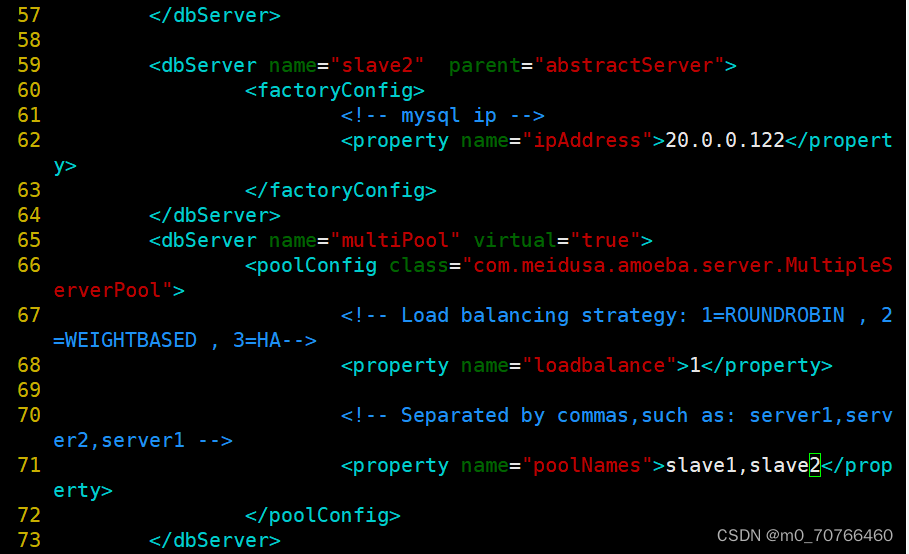
--58--复制上面6行粘贴,设置从服务器2的名slave2和地址
<dbServer name="slave2" parent="abstractServer">
<property name="ipAddress">192.168.10.16</property>
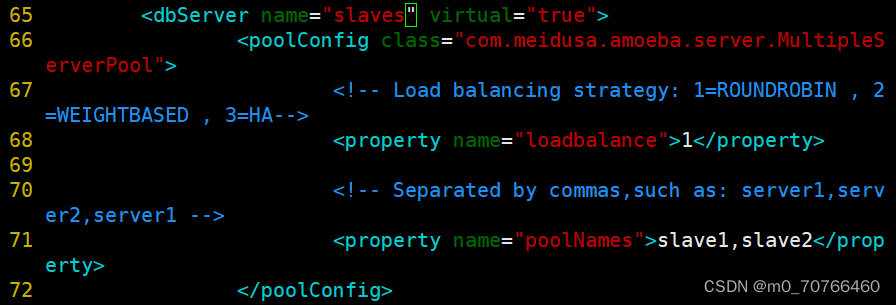
--65行--修改
<dbServer name="slaves" virtual="true">
--71行--修改
<property name="poolNames">slave1,slave2</property>

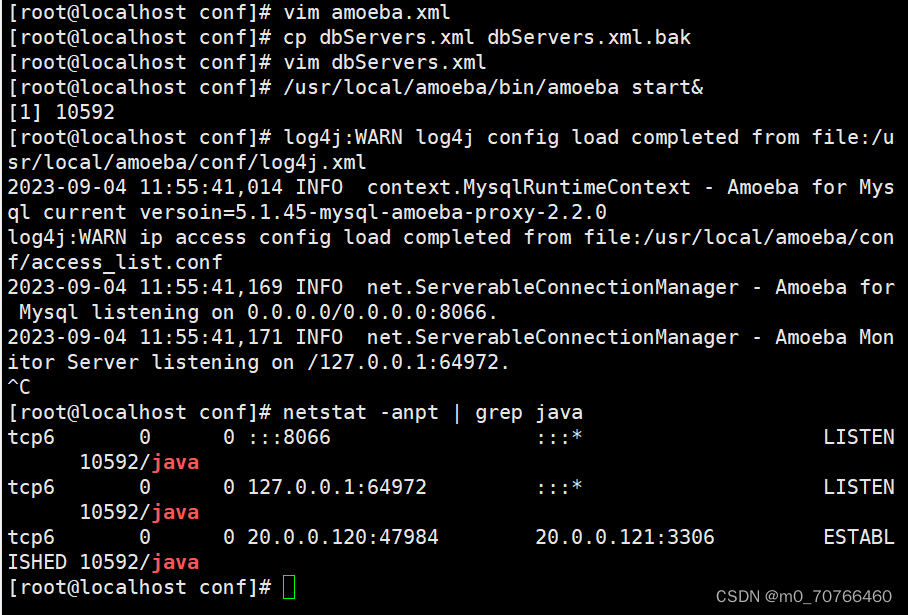
/usr/local/amoeba/bin/amoeba start& #启动Amoeba软件,按ctrl+c 返回
netstat -anpt | grep java #查看8066端口是否开启,默认端口为TCP 8066
----测试读写分离 ----
yum install -y mariadb-server mariadb
systemctl start mariadb.service
在客户端服务器上测试:
mysql -u amoeba -p123456 -h 192.168.10.13 -P8066
//通过amoeba服务器代理访问mysql ,在通过客户端连接mysql后写入的数据只有主服务会记录,然后同步给从--从服务器
在主服务器上:
use db_test;
create table test (id int(10),name varchar(10),address varchar(20));
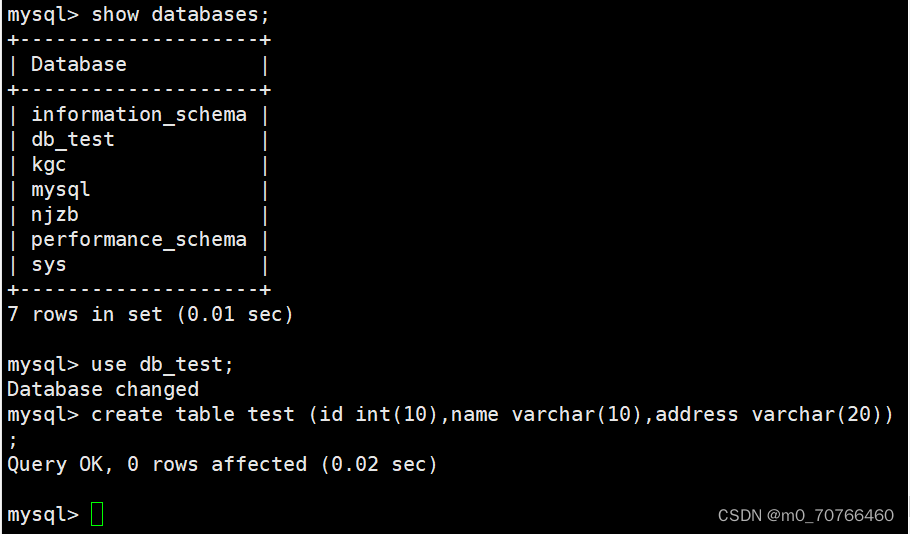
在两台从服务器上:
stop slave; #关闭同步
use db_test;
//在slave1上:
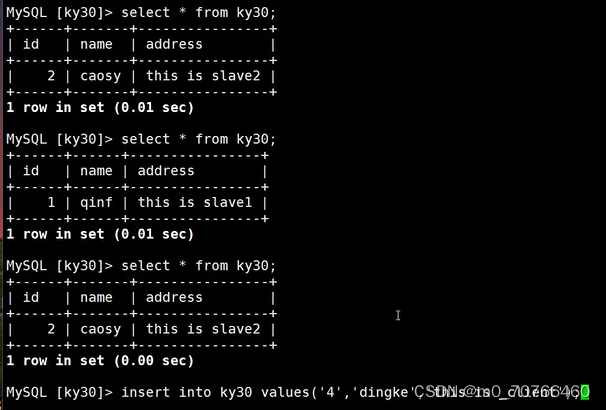
insert into test values('1','zhangsan','this_is_slave1');
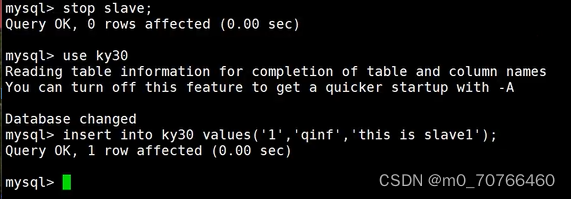
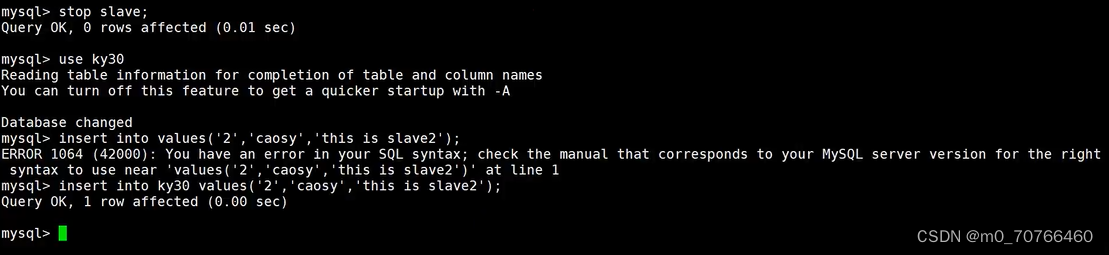
//在slave2上:
insert into test values('2','lisi','this_is_slave2');
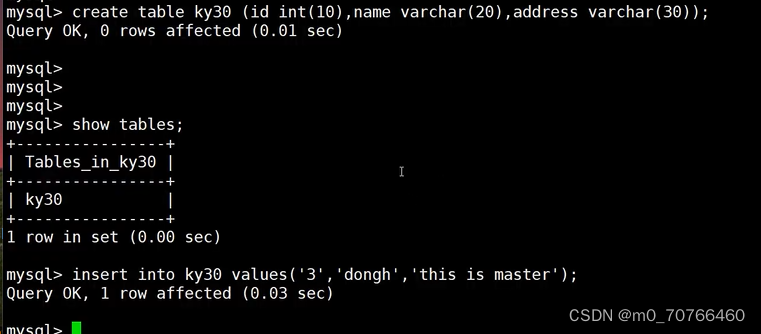
//在主服务器上:
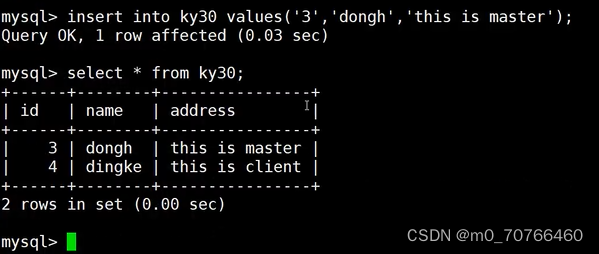
insert into test values('3','wangwu','this_is_master');
//在客户端服务器上:
use db_test;
select * from test; //客户端会分别向slave1和slave2读取数据,显示的只有在两个从服务器上添加的数据,没有在主服务器上添加的数据
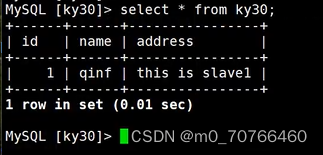
insert into test values('4','qianqi','this_is_client'); //只有主服务器上有此数据
从上面没有,只有主有
//在两个从服务器上执行 start slave; 即可实现同步在主服务器上添加的数据
start slave;
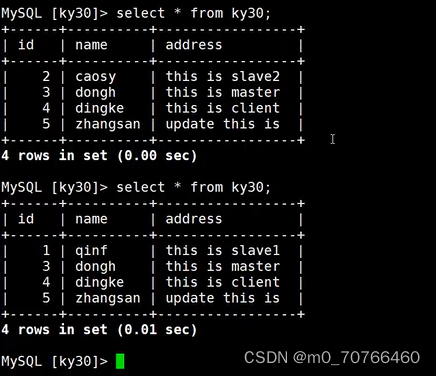
实现只在主服务器上写,只在从服务器上读
总结+面试题
1、主从同步复制原理
2、读写分离你们使用什么方式? amoeba 代理 mycat 代码 sql_proxy
通过amoeba代理服务器,实现只在主服务器上写,只在从服务器上读;
主数据库处理事务性查询,从数据库处理select 查询;
数据库复制被用来把事务查询导致的变更同步的集群中的从数据库
3、如何查看主从同步状态是否成功
在从服务器上内输入 show slave status\G 查看主从信息查看里面有IO线程的状态信息,还有master服务器的IP地址、端口事务开始号。
当 Slave_IO_Running和Slave_SQL_Running都是YES时 ,表示主从同步状态成功
4、如果I/O不是yes呢,你如何排查?
首先排查网络问题,使用ping 命令查看从服务器是否能与主服务器通信
再查看防火墙和核心防护是否关闭(增强功能)
接着查看从服务slave是否开启
两个从服务器的server-id 是否相同导致只能连接一台
master_log_file master_log_pos的值跟master值是否一致
5、show slave status能看到哪些信息(比较重要)
IO线程的状态信息
master服务器的IP地址、端口、事务开始的位置
最近一次的错误信息和错误位置
最近一次的I/O报错信息和ID
最近一次的SQL报错信息和id
6、主从复制慢(延迟)会有哪些可能?怎么解决?
主服务器的负载过大,被多个睡眠或 僵尸线程占用 导致系统负载过大,从库硬件比主库差,导致复制延迟
主从复制单线程,如果主库写作并发太大,来不及传送到从库,就会到导致延迟
慢sql语句过多
网络延迟
注
mysql主从复制
若主从版本不一致,从的版本一定要高于主,保证可以向下兼容
因为若主的版本更新,低版本的从无法兼容的。
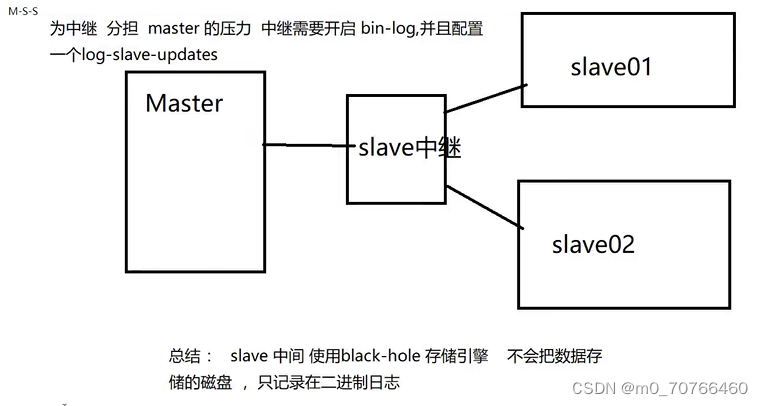
附:
主从复制
主流架构框架

相关文章:
8月31日-9月1日 第六章 案例:MySQL主从复制与读写分离(面试重点,必记)
本章结构 案例概述 案例前置知识点 详细图示 1、什么是读写分离? 读写分离,基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导…...

Oracle RAC 删除CRS集群配置失败
1.错误现象 [gridrac1~]$ /u01/app/11.2.0/grid/crs/install/rootcrs.pl -deconfig -force -verbose Cant locate Env.pm in INC (INC contains: /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64 /app/11.2.0/grid/crs/install) at /u01/app/11.2.0/grid/crs/insta…...

Kafka3.0.0版本——消费者(消费者总体工作流程图解)
一、消费者总体工作流程图解 角色划分:生产者、zookeeper、kafka集群、消费者、消费者组。如下图所示: 生产者发送消息给leader,followerr主动从leader同步数据,一个消费者可以消费某一个分区数据或者一个消费者可以消费多个分区数据。如下图…...
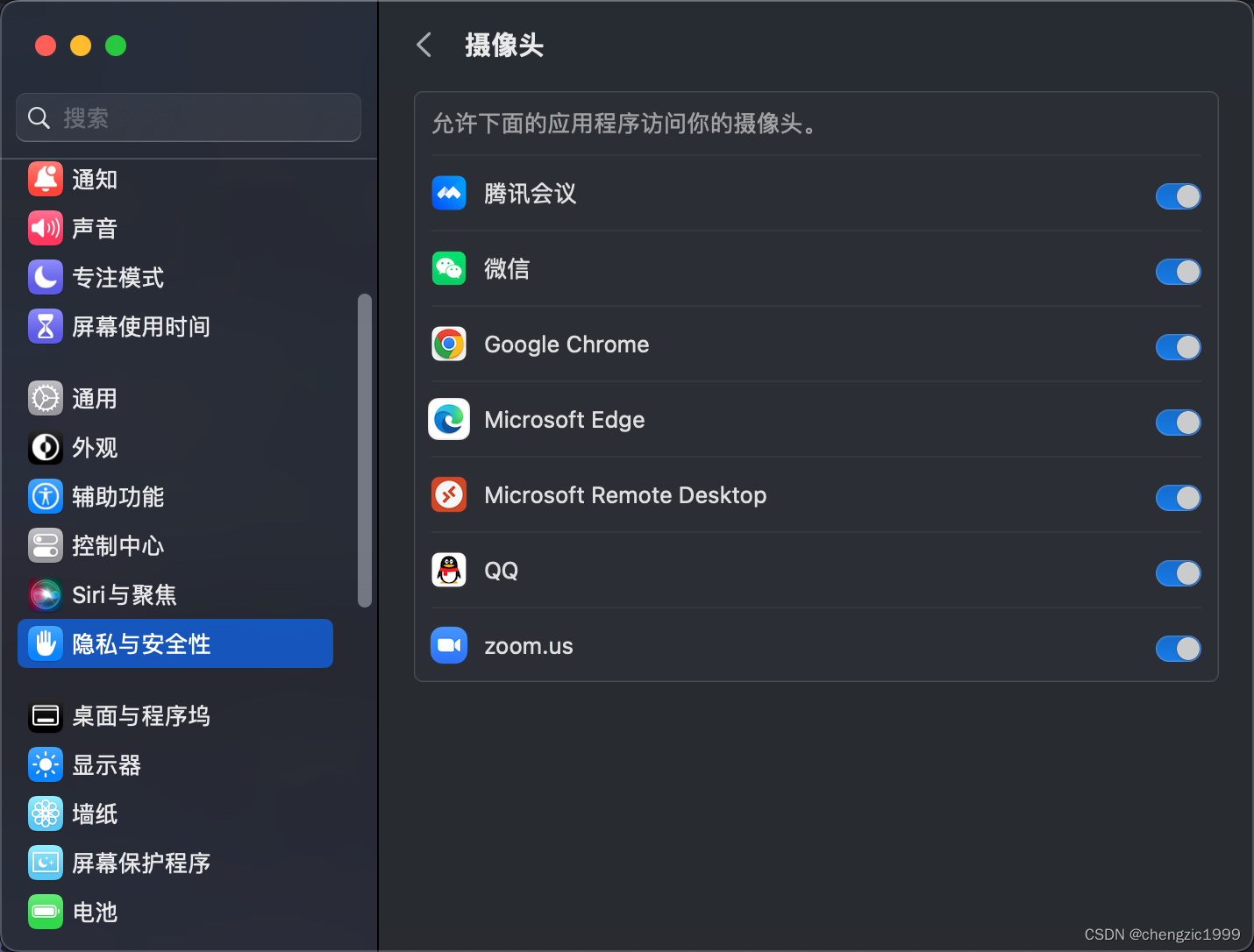
MacOS 为指定应用添加指定权限(浏览器无法使用摄像头、麦克风终极解决方案)
起因:需要浏览器在线做一些测评,但我的 Chrome 没有摄像头/麦克风权限,并且在设置中是没有手动添加按钮的。 我尝试了重装软件,更新系统(上面的 13.5 就是这么来的,我本来都半年懒得更新系统了)…...

Mysql 流程控制
简介 我们可以在存储过程和函数中实现比较复杂的业务逻辑,但是需要对应的流程控制语句来控制,就像Java中分支和循环语句一样,在MySQL中也提供了对应的语句,接下来就详细的介绍下。 1.分支结构 1.1 IF语句 IF 表达式1 THEN 操作1…...

Java学习笔记之----I/O(输入/输出)二
【今日】 孩儿立志出乡关,学不成名誓不还。 文件输入/输出流 程序运行期间,大部分数据都在内存中进行操作,当程序结束或关闭时,这些数据将消失。如果需要将数据永久保存,可使用文件输入/输出流与指定的文件建立连接&a…...
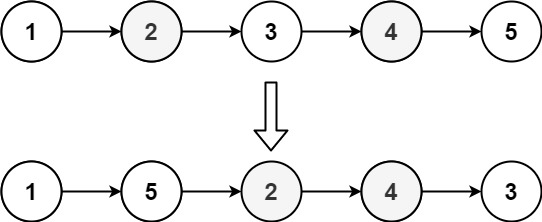
2024字节跳动校招面试真题汇总及其解答(一)
1. 【算法题】重排链表 给定一个单链表 L 的头节点 head ,单链表 L 表示为: L0 → L1 → … → Ln - 1 → Ln请将其重新排列后变为: L0 → Ln → L1 → Ln - 1 → L2 → Ln - 2 → … 不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。 示例 1: 输入:hea…...
【Nginx23】Nginx学习:响应头与Map变量操作
Nginx学习:响应头与Map变量操作 响应头是非常重要的内容,浏览器或者客户端有很多东西可能都是根据响应头来进行判断操作的,比如说最典型的 Content-Type ,之前我们也演示过,直接设置一个空的 types 然后指定默认的数据…...

前端代理报错Error occured while trying to proxy to: localhost:端口
webpack配置进行前端代理时, 报错信息如下:(DEPTH_ZERO_SELF_SIGNED_CERT) 需设置:secure为false即可解决此报错 // webpack配置前端代理config["/test"]{target: https://xxxx.com,changeOrigin: true,secure: false // 这个配置…...
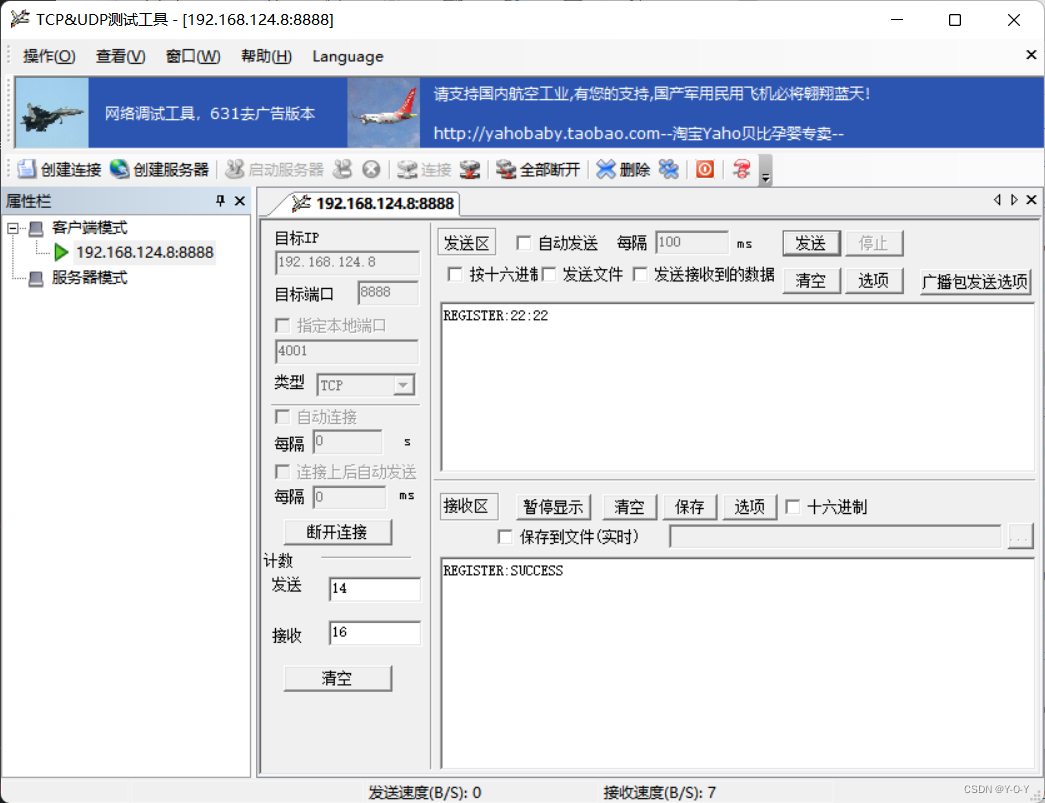
QT DAY6
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this);socket new QTcpSocket(this);//如果连接服务器成功,该客户端就会发射一个connected的信号。//我们…...
Slint学习文档
Slint学习文档 Slint Learn如何学习本文档学习顺序标志说明 Slint With VSCodeSlint With Rust依赖👎定义宏 Slint与Rust分离1.添加编译依赖(slint-build)2.编写slint文件3.编写build.rs4.编写main.rs 普通组件主窗体Windowexample 文本Texte…...
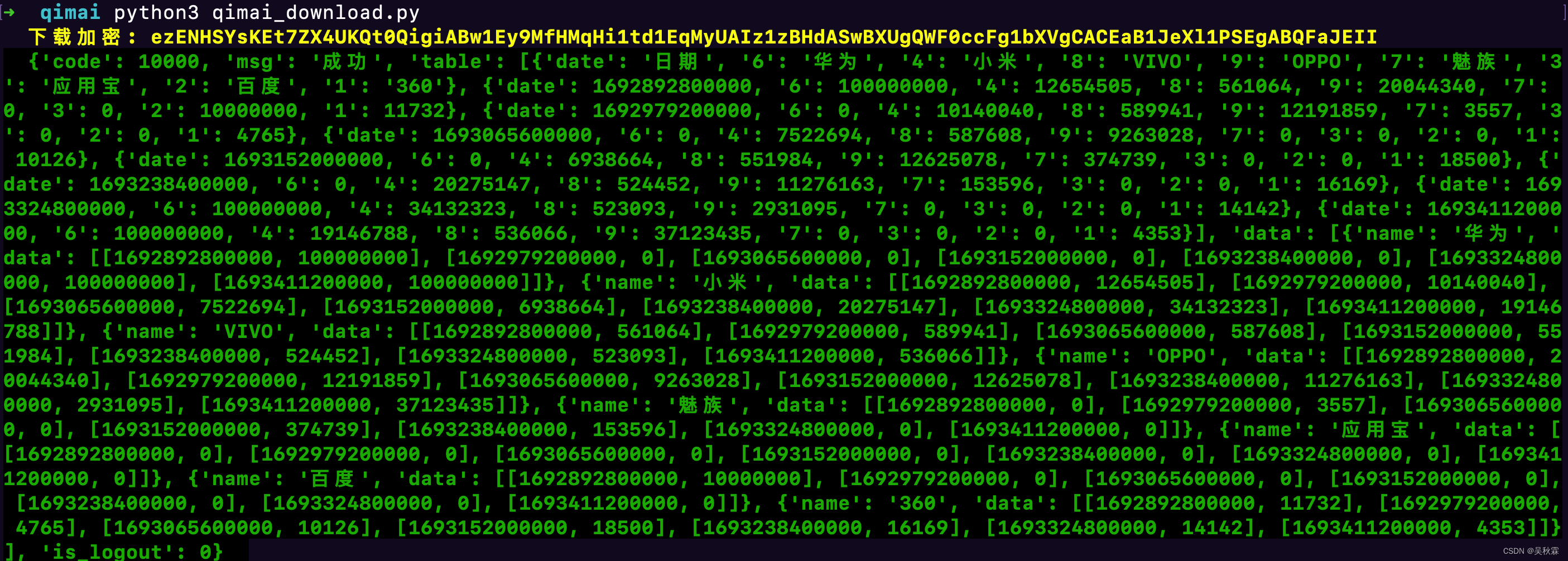
【最新!七麦下载量analysis参数】逆向分析与Python实现加密算法
文章目录 1. 写在前面2. 请求分析3. 加密分析4. 算法实现 1. 写在前面 之前出过一个关于榜单analysis的分析,有兴趣的可以查看这篇文章:七麦榜单analysis加密分析 最近运营团队那边有同事找到我们,说工作中偶尔需要统计分析一下某APP在一些主…...
)
蓝桥杯练习题(3的倍数)
问题描述 小蓝对 3 的倍数很感兴趣。现在他手头有三个不同的数 a,b,c, 他想知道, 这三个数中是不是有两个数的和是 3 的倍数。 例如, 当 a3,b4,c6 时, 可以找到 a 和 c 的和是 3 的倍数。 例如, 当 a3,b4,c7 时, 没办法找到两个数的和是 3 的倍数。 输入格式 输入三行, 每行…...

安装Qe-7.2细节
编译 直接编译报错,发现要使用gpu加速。 检查linux的GPU: nvidia-smi lspci |grep -i nvidia module load cuda ./configure make all 安装curl mkdir build cd build …/configure --prefix/home/bin/local/curl make make install 加入路径: expor…...
3.运行项目
克隆项目 使用安装的git克隆vue2版本的若依项目,博主使用的版本是3.8.6. git clone https://gitee.com/y_project/RuoYi-Vue.git目录结构如下图所示,其中ruoyi-ui是前端的内容,其它均为后端的内容。 配置mysql数据库 在数据库里新建一个…...

【算法题】2651. 计算列车到站时间
题目: 给你一个正整数 arrivalTime 表示列车正点到站的时间(单位:小时),另给你一个正整数 delayedTime 表示列车延误的小时数。 返回列车实际到站的时间。 注意,该问题中的时间采用 24 小时制。 示例 1…...

Mybatis传递实体对象只能直接获取,不能使用对象.属性方式获取
mybatis的自动识别参数功能很强大,pojo实体类可以直接写进mapper接口里面,不需要在mapper.xml文件中添加paramType,但是加了可以提高mybatis的效率 不加Param注解,取值的时候直接写属性 //这里是单参数,可以不加param!…...

flink 写入数据到 kafka 后,数据过一段时间自动删除
版本 flink 1.16.0kafka 2.3 流程描述: flink利用KafkaSource,读取kafka的数据,然后经过一系列的处理,通过KafkaSink,采用 EXACTLY_ONCE 的模式,将处理后的数据再写入到新的topic中。 问题描述࿱…...
golong基础相关操作--一
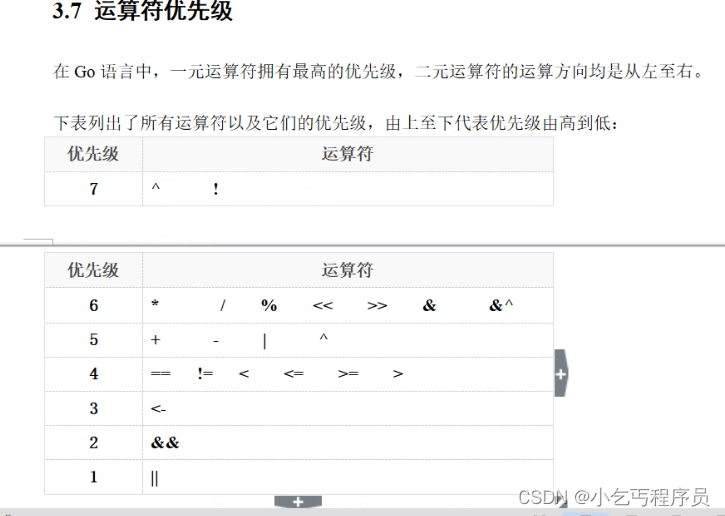
package main//go语言以包作为管理单位,每个文件必须先声明包 //程序必须有一个main包 // 导入包,必须要要使用 // 变量声明了,必须要使用 import ("fmt" )/* * 包内部的变量 */ var aa 3var ss "kkk"var bb truevar …...
【深度学习】基于卷积神经网络的铁路信号灯识别方法
基于卷积神经网络的铁路信号灯识别方法 摘 要:1 引言2 卷积神经网络模型2.1 卷积神经网络结构2.2.1 卷积层2.2.2 池化层2.2.3 全连接层 3 卷积神经网络算法实现3.1 数据集制作3.2 卷积神经网络的训练过程3.2.1 前向传播过程 4 实验5 结语 摘 要: 目前中…...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

【2025年】解决Burpsuite抓不到https包的问题
环境:windows11 burpsuite:2025.5 在抓取https网站时,burpsuite抓取不到https数据包,只显示: 解决该问题只需如下三个步骤: 1、浏览器中访问 http://burp 2、下载 CA certificate 证书 3、在设置--隐私与安全--…...

OPenCV CUDA模块图像处理-----对图像执行 均值漂移滤波(Mean Shift Filtering)函数meanShiftFiltering()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在 GPU 上对图像执行 均值漂移滤波(Mean Shift Filtering),用于图像分割或平滑处理。 该函数将输入图像中的…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...

在 Spring Boot 项目里,MYSQL中json类型字段使用
前言: 因为程序特殊需求导致,需要mysql数据库存储json类型数据,因此记录一下使用流程 1.java实体中新增字段 private List<User> users 2.增加mybatis-plus注解 TableField(typeHandler FastjsonTypeHandler.class) private Lis…...
【若依】框架项目部署笔记
参考【SpringBoot】【Vue】项目部署_no main manifest attribute, in springboot-0.0.1-sn-CSDN博客 多一个redis安装 准备工作: 压缩包下载:http://download.redis.io/releases 1. 上传压缩包,并进入压缩包所在目录,解压到目标…...
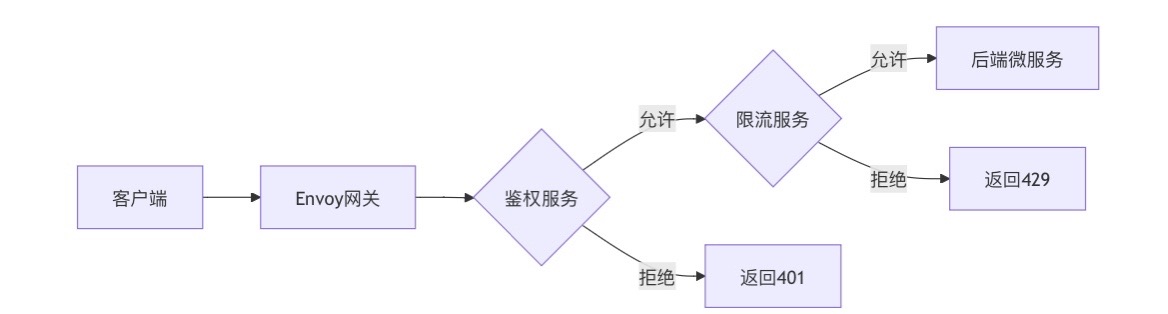
云原生安全实战:API网关Envoy的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关 作为微服务架构的统一入口,负责路由转发、安全控制、流量管理等核心功能。 2. Envoy 由Lyft开源的高性能云原生…...

Python第七周作业
Python第七周作业 文章目录 Python第七周作业 1.使用open以只读模式打开文件data.txt,并逐行打印内容 2.使用pathlib模块获取当前脚本的绝对路径,并创建logs目录(若不存在) 3.递归遍历目录data,输出所有.csv文件的路径…...