questions
1.JDK 和 JRE 有什么区别?
JDK:Java Development Kit 的简称,java 开发工具包,提供了 java 的开发环境和运行环境
JRE:Java Runtime Environment 的简称,java 运行环境,为 java 的运行提供了所需环境
具体来说 JDK 其实包含了 JRE,同时还包含了编译 java 源码的编译器 javac,还包含了很多 java 程序调试和分析的工具。简单来说:如果你需要运行 java 程序,只需安装 JRE 就可以了,如果你需要编写 java 程序,需要安装 JDK。
2.如何理解类
类是对现实生活中一类具有共同属性和行为的事物的抽象
类的特点:
•类是对象的数据类型
•类是具有相同属性和行为的一组对家的集合
3.类和对象的关系
4.如何理解封装
- 封装概述
是面向对象三大特征之一(封装,继承,多态)
是面向对象编程语言对客观世界的模拟,客观世界里成员变量都是隐藏在对象内部的,外界是无法直接操作的 - 封装原则
将类的某些信息隐藏在类内部,不允许外部程序直接访问,而是通过该类提供的方法来实现对隐藏信息的操作和访问
成员变量private,提供对应的getXxx()/setxxx()方法
3.封装好处
通过方法来控制成员变量的操作,提高了代码的安全性
把代码用方法进行封装,提高了代码的复用性
5.泛型是什么
6.ClassLoad是什么,解释一下原理和过程
类加载器是加载class文件到内存中,供其他class文件调用。
加载过程是:加载->链接(验证、准备、解析)->初始化->使用->卸载
ClassLoad(类加载器)是Java虚拟机(JVM)的一部分,它负责将Java字节码(编译后的Java源代码)加载到内存中并转换成可执行的Java类。类加载器是Java的一个重要概念,它允许应用程序在运行时动态加载类,这是Java语言的一个重要特性之一,也是实现Java的动态扩展和模块化的基础。
类加载器的原理和过程:
- 加载(Loading):在这个阶段,类加载器会查找并读取.class文件(Java字节码文件)。这些文件可以来自本地文件系统、网络、JAR文件等资源。类加载器会将字节码数据加载到内存中,并创建一个代表这个类的
java.lang.Class对象。 - 链接(Linking):类加载过程的链接阶段包括三个步骤:
- 验证(Verification):在这一步,类加载器会验证加载的字节码是否符合Java虚拟机规范,以确保它是合法的、安全的。这包括类型检查、字节码验证、符号引用验证等。
- 准备(Preparation):在这一步,类加载器会为类的静态变量分配内存空间,并初始化这些变量的默认初始值(通常为零值)。这些静态变量被存储在类的静态存储区域中。
- 解析(Resolution):在这一步,类加载器会将符号引用替换为直接引用,以确保类、方法和字段的引用都能正确地连接到已加载的类或接口。这是一个可选步骤,不是所有类都需要解析。
- 初始化(Initialization):在这个阶段,类加载器会执行类的初始化代码,包括执行静态初始化块(
static块)和静态字段初始化。这是类加载过程的最后一步,只有在初始化完成后,类才会真正准备好使用。
Java虚拟机提供了默认的类加载器,但也可以通过编写自定义类加载器来实现更复杂的加载策略。自定义类加载器通常用于实现类隔离、动态加载模块、热部署等功能。
总之,类加载器是Java中实现动态加载和运行时扩展的关键部分,它确保了Java的灵活性和可扩展性,允许应用程序在运行时根据需要加载新的类和资源。
7.常用的网络协议
HTTP协议:超文本传输协议,是万维网数据通信基础。
TCP协议:传输控制协议,传送数据,需要经过三次握手,是一种可靠的传输,适用于如文件传输,网络数据库,分布式高精度计算系统的数据传输
三次握手:
客户端发起连接请求:
服务器确认连接请求:
客户端确认连接请求:
8.JVM是什么?及原理
JVM (Java Virtual Machine) 是 Java 编程语言的关键组成部分之一,它是一个虚拟机,用于执行 Java 程序。JVM 的主要任务是将 Java 源代码编译成字节码(Bytecode),然后在运行时执行这些字节码。以下是 JVM 的一些重要特点和功能:
字节码执行:JVM 通过解释或即时编译(Just-In-Time Compilation,JIT)方式执行 Java 字节码。即时编译将字节码转换成本地机器代码,以提高执行速度。
平台无关性:Java 程序编写一次,可以在支持 JVM 的任何平台上运行,只要有相应的 JVM 实现。这个特性使得 Java 成为跨平台的编程语言。
内存管理:JVM 负责内存管理,包括分配和回收内存。它具有垃圾回收机制,可自动释放不再使用的内存,以减少内存泄漏的风险。
安全性:JVM 提供了一系列安全性功能,如字节码验证,以确保代码的合法性和防止恶意代码执行。
多线程支持:JVM 具有内置的多线程支持,可以轻松创建和管理多线程应用程序。
性能优化:现代的 JVM 实现包括各种性能优化技术,以提高 Java 程序的执行速度。
异常处理:JVM 提供了强大的异常处理机制,使开发人员能够有效地处理错误和异常情况。
类加载器:JVM 使用类加载器(Class Loader)来加载类和资源文件,它们可以动态地从不同的来源加载类,如本地文件系统、网络等。
总的来说,JVM 允许开发人员编写一次 Java 代码,并在不同的平台上运行,同时提供了许多强大的功能,包括内存管理、多线程支持和安全性,以简化和增强 Java 应用程序的开发和执行。不同的 Java 实现(例如Oracle HotSpot、OpenJ9、GraalVM等)提供了不同的性能特性和优化,以满足不同应用程序的需求。
JVM的生命周期:
1.启动。启动一个java程序的时候就产生了一个jvm实例
2.运行。Main方法是程序的入口,任何其他线程均有它启动
3.消亡。当程序中所有非守护线程都终止时,JVM才退出。若安全管理器允许,程序也可以使用Runtime类或者System.exit()来退出程序。
JVM的组成:
JVM是由类加载器,字节码执行引擎,运行时数据区(堆,栈,本地方法栈,方法区,程序计数器)组成的
JVM的优点:
一次编写跨平台运行
提供自动内存管理机制
9.Git提交代码命令 用指令
git commit -m [massage] 将暂存区所有文件添加到本地仓库
git branch [branch-name] 创建分支
git fetch 拉取远程分支最新的commit到本地仓库的origin/[branch-name]
git pull 从远程仓库拉取代码到工作空间
git branch 查看当前分支
git checkout [branch] 切换分支
git remote 查看远程分支
git revert 版本号 回退到这个版本号
git init 初始化本地库,在当前目录创建了一个空的存储库
10.Linux常用命令和基本操作
切换目录 cd
查看目录 ls
-l 列出文件详细信息 或者直接ll
-a 列出当前目录下所有文件及目录,包括隐藏的a(all)
创建目录 mkdir
查看目录大小 du -h /home (带有单位显示目录信息)
查看磁盘大小 df -h (带有单位显示磁盘信息)
查看网络情况 ifconfig
测试网络连通 ping
显示网络状态信息 netstat
创建空文件 touch
复制文件 cp
移动或重命名 mv
删除文件 rm
-r 递归删除,可删除子目录及文件
-f 强制删除
11.Mysql的默认引擎
在MysqL 5.5之前,当您创建表而未明确指定存储引擎时,MyISAM是默认存储引擎。从版本5.5开始,MysqL使用InnoDB作为默认存储引擎。
数据库的存储引擎决定了表在计算机的存储方式,不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能
12.讲讲平时怎么用索引,以及联合索引
联合索引又叫复合索引,是指两个及两个以上的字段创建索引,符合最左原则
13.mybatis-plus比Mybatis相比,优点是什么
MyBatis:
所有SQL语句全部自己写
手动解析实体关系映射转换为MyBatis内部对象注入容器
不支持Lambda形式调用
Mybatis Plus:
强大的条件构造器,满足各类使用需求
内置的Mapper,通用的Service,少量配置即可实现单表大部分CRUD操作
支持Lambda形式调用
提供了基本的CRUD功能,连SQL语句都不需要编写
自动解析实体关系映射转换为MyBatis内部对象注入容器
14.Mybatis分页
借助数组进行分页
借助Sql语句进行分页
拦截器分页:MybatisPlusInterceptor
RowBounds实现分页
15.什么是io
从磁盘读到内存,从内存写到磁盘
按功能来分:输入流(input)、输出流(output)。
按类型来分:字节流和字符流。
字节流和字符流的区别是:字节流按 8 位传输以字节为单位输入输出数据,字符流按 16 位传输以字符为单位输入输出数据。
16.讲一下公平锁和非公平锁
公平锁―是指多个线程按照申请锁的顺序来获取锁,类似排队打饭,先来后到。 非公平锁是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁
17.大量数据并发时,怎么解决
18.创建docker镜像命令
Docker pull
19.进入docker命令
docker exec -it <容器名称或容器ID> /bin/bash
20.IOC和di的区别
ioc是控制反转,是一种思想,
di是依赖注入,往对象里注入值
21.链表的拓展
22.Java怎么使用PLC通讯
23.Socket通讯技术
24.TCP通讯技术
TCP的三次握手和四次挥手实质就是TCP通信的连接和断开。
三次握手:为了对每次发送的数据量进行跟踪与协商,确保数据段的发送和接收同步,根据所接收到的数据量而确认数据发送、接收完毕后何时撤消联系,并建立虚连接。
四次挥手:即终止TCP连接,就是指断开一个TCP连接时,需要客户端和服务端总共发送4个包以确认连接的断开。
原文链接:https://blog.csdn.net/m0_38106923/article/details/108292454
25.Mqtt通讯技术
26.List list = new ArrayList()和ArrayList list = new ArrayList();
第一个是面向接口,第二个是面向对象
27.简历一个springboot项目+mybatis构建
28.说说面向对象
29.数据库的外键是
30.将list里面的数组里数据过滤,只留下偶数
31.集合分类
iMap,Collection两大类
Map分为hashMap和TreeMap
Collection分为Set和List
32.同步io和异步io
同步IO是指,读写IO时代码必须等待数据返回后才继续执行后续代码,它的优点是代码编写简单,缺点是CPU执行效率低。
而异步IO是指,读写IO时仅发出请求,然后立刻执行后续代码,它的优点是CPU执行效率高,缺点是代码编写复杂。
System.out.println(2 >> 32)是多少
是2
HashMap和HashSet的区别
HashMap和HashSet是Java集合框架中的两种不同的数据结构,它们有一些重要的区别:
-
数据结构:
HashMap:是一种键值对(key-value)映射表,用于存储一组键值对,每个键都唯一,可以用于快速查找和访问值。HashSet:是一种集合,用于存储一组唯一的元素,不允许重复值。
-
元素类型:
HashMap:包含键值对,其中键和值可以是任意类型的对象。HashSet:包含唯一的元素,通常是对象,但也可以包含基本数据类型的值,因为它们会被自动装箱。
-
存储方式:
HashMap:使用哈希表来存储键值对,通过键的哈希码来定位值的存储位置,允许通过键来查找值。HashSet:也使用哈希表来存储唯一元素,通过元素的哈希码来确定存储位置,允许通过元素来查找。
-
操作:
HashMap:提供了put(key, value)来插入键值对,get(key)来根据键获取值,以及其他与键相关的操作。HashSet:提供了add(element)来添加元素,contains(element)来检查是否包含特定元素,以及其他与元素相关的操作。
-
重复值:
HashMap:允许不同键对应相同的值,但不允许重复的键。HashSet:不允许重复的元素,如果试图添加重复的元素,它将被忽略。
-
迭代顺序:
HashMap:不保证键值对的顺序,可以通过LinkedHashMap来保持插入顺序。HashSet:不保证元素的顺序,可以通过LinkedHashSet来保持插入顺序。
-
线程安全性:
HashMap和HashSet都不是线程安全的。如果在多线程环境中使用它们,需要采取额外的同步措施或使用线程安全的集合类。
总之,HashMap用于存储键值对,而HashSet用于存储唯一元素。它们有不同的用途和适用场景,因此在选择使用哪个取决于您的需求。如果需要键值对映射,HashMap更合适;如果需要存储唯一元素的集合,HashSet更适合。
synchronized锁住的静态方法和普通方法有什么区别
spring的请求流程
Spring框架是一个广泛用于构建Java企业级应用程序的框架,其中Spring MVC(Model-View-Controller)是Spring框架的一部分,用于构建Web应用程序。以下是Spring MVC的请求处理流程:
-
客户端发起请求:
- 客户端(通常是浏览器)向Web服务器发送HTTP请求,请求特定的URL,例如
http://example.com/myapp/somePage。
- 客户端(通常是浏览器)向Web服务器发送HTTP请求,请求特定的URL,例如
-
前端控制器(DispatcherServlet)接收请求:
- 在Spring MVC中,一个名为
DispatcherServlet的前端控制器充当所有请求的入口点。DispatcherServlet会拦截到所有请求,然后根据配置将它们路由到适当的处理程序(Controller)。
- 在Spring MVC中,一个名为
-
处理程序映射:
DispatcherServlet使用处理程序映射器(Handler Mapping)来确定请求应该由哪个处理程序(Controller)来处理。处理程序映射器将请求URL映射到一个具体的处理程序。
-
处理程序执行:
- 一旦确定了请求的处理程序,
DispatcherServlet调用相应的处理程序方法来执行业务逻辑。处理程序方法通常会访问模型(Model)来存储和获取数据,并返回视图(View)名称。
- 一旦确定了请求的处理程序,
-
业务逻辑执行:
- 处理程序方法执行业务逻辑,可能包括从数据库获取数据、处理请求参数、调用服务层等操作。
-
模型更新:
- 处理程序方法可以将数据添加到模型中,以便在视图中显示。模型是一个数据容器,通常包含在视图中渲染的数据。
-
视图解析:
DispatcherServlet使用视图解析器(View Resolver)来解析处理程序返回的视图名称,以确定要使用哪个视图模板来呈现响应。
-
视图呈现:
- 视图模板负责将模型中的数据渲染到HTML页面或其他响应格式中,生成最终的响应内容。
-
响应发送:
DispatcherServlet将视图生成的响应发送回客户端,通常是浏览器。这是通过HTTP响应完成的。
-
请求生命周期结束:
- 整个请求-响应周期结束后,请求生命周期也随之结束。
Spring MVC提供了丰富的配置选项,允许您自定义处理程序、拦截器、视图解析器等,以适应不同的应用程序需求。这个流程提供了一个清晰的结构,使得构建和维护Web应用程序变得更加容易。
以下结果 += 和 + 不同
byte c = 2;c += 1;//合法 相当于c = (byte)(c + 1);byte a = 1;a = a + 1;//不合法 这里结果是int类型 int g = a + 1;//合法
索引有哪几种
在MySQL中,有几种常见的索引类型,每种类型都有其特定的用途和性能特点。以下是MySQL中常见的索引类型:
-
B-tree 索引:B-tree(平衡树)索引是MySQL中最常用的索引类型。它适用于各种查询,包括等值查询、范围查询和排序。B-tree索引可以用于所有存储引擎,包括InnoDB和MyISAM。
-
哈希索引:哈希索引适用于等值查询,但不适用于范围查询或排序。它们通常在内存表上使用,例如MEMORY存储引擎。InnoDB存储引擎也支持自动创建哈希索引以加速特定类型的查询。
-
全文索引:全文索引用于在文本数据上执行全文搜索。它们主要用于MyISAM存储引擎,并且支持全文搜索功能,以查找匹配的文本。
-
空间索引:空间索引用于处理空间数据类型,例如地理信息系统(GIS)数据。MySQL支持用于空间索引的特定类型,如R-tree。
-
前缀索引:前缀索引允许您只索引列值的一部分。这可以用于减小索引的大小,但也会降低查询性能。前缀索引通常用于处理大文本列。
-
复合索引:复合索引是包含多个列的索引。它们用于优化需要多个列的查询,例如多列的等值查询或范围查询。复合索引的列顺序非常重要,因为它们影响查询性能。
-
唯一索引:唯一索引确保索引列的值是唯一的,不允许重复值。这种索引用于实现唯一性约束,以确保表中的数据不包含重复记录。
-
主键索引:主键索引是一种特殊的唯一索引,它唯一标识表中的每一行,并且每个表只能有一个主键索引。主键索引通常与主键列关联,用于快速查找和引用表中的特定行。
-
外键索引:外键索引是用于实现外键关系的索引。它们用于维护表之间的引用完整性,确保在关联表中的数据一致性。
-
全列索引:全列索引是包含表中所有列的索引。通常,它们用于覆盖索引,以避免回表操作,从而提高性能。
每种索引类型都有其适用场景和性能考虑因素,根据您的查询需求和数据模型来选择适当的索引类型非常重要。不正确的索引策略可能会导致性能问题。
B-tree索引怎么使用
B-tree(平衡树)索引是MySQL中最常用的索引类型之一,用于加速各种查询操作,包括等值查询、范围查询和排序。下面是如何使用B-tree索引的一些示例:
-
创建B-tree索引:
您可以在表的列上创建B-tree索引,以加速对该列的查询。例如,假设您有一个名为
users的表,并且要在username列上创建索引:CREATE INDEX idx_username ON users(username);这将在
username列上创建一个B-tree索引,以加速与username相关的查询。 -
等值查询:
B-tree索引特别适用于等值查询,例如:
SELECT * FROM users WHERE username = 'john_doe';在这种情况下,MySQL可以使用B-tree索引快速查找
username等于’john_doe’的行。 -
范围查询:
B-tree索引还可以用于范围查询,例如:
SELECT * FROM orders WHERE order_date BETWEEN '2023-01-01' AND '2023-12-31';在这种情况下,MySQL可以使用B-tree索引快速查找
order_date在指定范围内的订单。 -
排序:
B-tree索引也有助于加速排序操作,因为它们存储了索引列的数据的有序副本。例如,如果您需要按
user_id列对用户表进行升序排序:SELECT * FROM users ORDER BY user_id ASC;B-tree索引可以加速这个排序操作。
-
覆盖索引:
如果您的查询只需要从索引中获取数据,而不需要回到表中检索其他列的值,那么可以使用覆盖索引来提高性能。例如:
SELECT username FROM users WHERE user_id = 123;如果在
user_id列上有一个B-tree索引,并且只需获取username列的值,MySQL可以完全使用索引,而不需要回到表中查找。
请注意,创建索引会增加插入、更新和删除操作的开销,因此需要根据查询需求和数据库的使用模式仔细考虑索引的创建。同时,还要定期维护索引以确保其性能。使用EXPLAIN语句可以帮助您分析查询的执行计划,以确定是否有效地使用了B-tree索引。
如何知道正确使用了索引
注意事项
使用索引时,有以下一些技巧和注意事项:
1.索引不会包含有null值的列
只要列中包含有null值都将不会被包含在索引中,复合索引中只要有一列含有null值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为null。
2.使用短索引
对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个char(255)的列,如果在前10个或20个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
3.索引列排序
查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。
4.like语句操作
一般情况下不推荐使用like操作,如果非使用不可,如何使用也是一个问题。like “%aaa%” 不会使用索引而like “aaa%”可以使用索引。
5.不要在列上进行运算
这将导致索引失效而进行全表扫描,例如
SELECT * FROM table_name WHERE YEAR(column_name)<2017;
6.不使用not in和<>操作
35.索引的缺点
1.虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行insert、update和delete。因为更新表时,不仅要保存数据,还要保存一下索引文件。
2.建立索引会占用磁盘空间的索引文件。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会增长很快。
索引只是提高效率的一个因素,如果有大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询语句。
接口里面可以定义常量吗?
可以的
public interface Book {String abc = "open";Shop getShopName(Shop shop);
}
public class TestMain {public static void main(String[] args) {System.out.println(Book.abc);}
}
结果是:open
请注意,尽管在接口中定义字段是合法的,但这种做法通常不被推荐,因为接口的主要目的是定义方法签名,而不是存储数据。通常情况下,应该使用常量类或枚举来定义常量,而不是将常量放在接口中。
接口可以实现抽象方法吗?
不能
在Java中,接口(interface)和抽象类(abstract class)是两种不同的概念,它们有不同的用途和特性。
-
接口(Interface):接口是一种抽象类型,它可以包含抽象方法的声明,但不能包含方法的实现。接口通常用于定义一组方法签名,而不提供具体的实现。类可以实现(implements)一个或多个接口,实现接口的类必须提供接口中声明的所有方法的实现。
-
抽象类(Abstract Class):抽象类也是一种抽象类型,但它可以包含抽象方法的声明以及方法的实现。抽象类用于定义具有一些通用实现的类,但允许派生类覆盖(override)其中的方法,也可以包含非抽象的方法。
接口不能直接实现抽象类,因为它们是不同的概念。一个类可以同时实现一个接口并扩展一个抽象类,这是允许的。例如:
// 接口
interface MyInterface {void methodA();
}// 抽象类
abstract class MyAbstractClass {abstract void methodB();
}// 实现接口并扩展抽象类的类
class MyClass extends MyAbstractClass implements MyInterface {@Overridevoid methodB() {// 实现抽象方法}@Overridepublic void methodA() {// 实现接口方法}
}
在上述示例中,MyClass类同时实现了MyInterface接口和扩展了MyAbstractClass抽象类。它必须提供抽象类中的抽象方法和接口中的方法的实现。
总之,接口和抽象类都有其用途,它们可以在Java中用于不同的情景和需求。您可以根据具体的设计需求来选择使用哪个或同时使用两者。
Java中int型的数据能表示汉字吗
不能表示
汉字可以用char类型或者String类型表示
Java中int型数据能表示字母吗
可以表示
char letter = 'A'; // 字母字符 'A'
int intValue = (int) letter; // 将字母字符 'A' 转换为 int 值System.out.println(intValue); // 输出 65Java中的基本数据类型各占几个字节
在Java中,基本数据类型的大小是规定的,但具体的大小可能因不同的JVM实现和平台而有所不同。通常情况下,Java中的基本数据类型的大小如下:
- byte:占用1个字节(8位)。
- short:占用2个字节(16位)。
- int:占用4个字节(32位)。
- long:占用8个字节(64位)。
- float:占用4个字节(32位),但请注意,浮点数的精度和表示不同于整数。
- double:占用8个字节(64位),双精度浮点数的精度更高。
- char:占用2个字节(16位),用于表示Unicode字符。
- boolean:通常不明确规定大小,但其存储大小通常是虚拟机和平台相关的。
需要注意的是,这些基本数据类型的大小是Java语言规范中定义的标准大小。然而,不同的Java虚拟机(JVM)实现和不同的平台可能会有微小的差异,但这些差异通常很小,不会对大多数Java程序产生显著影响。
此外,Java的基本数据类型在内存中的布局也可以受到虚拟机的实现和平台的影响,例如,字节对齐等。因此,如果需要严格控制内存布局,可以考虑使用Java的ByteBuffer等机制。
springmvc的流程是什么
Spring MVC 是 Spring 框架的一个模块,用于开发基于模型-视图-控制器(MVC)设计模式的 Web 应用程序。Spring MVC 的典型工作流程如下:
-
客户端请求:当用户通过浏览器或其他客户端发送 HTTP 请求时,请求被传递到 Spring MVC 应用程序的前端控制器(通常是
DispatcherServlet)。 -
前端控制器处理请求:
DispatcherServlet是 Spring MVC 应用程序的中心控制器,它接收所有的 HTTP 请求并将它们路由到适当的处理程序(Controller)。 -
处理程序映射:
DispatcherServlet使用处理程序映射器(Handler Mapping)来确定请求应该由哪个处理程序来处理。处理程序映射器将请求 URL 映射到一个具体的控制器类和方法。 -
调用控制器方法:一旦确定了请求的处理程序,
DispatcherServlet调用相关的控制器方法来执行业务逻辑。控制器方法可以访问模型、调用服务层、处理请求参数等。 -
处理方法返回:控制器方法执行完后,它可以返回一个模型和视图名称。模型是要传递给视图的数据,视图名称告诉 Spring MVC 哪个视图应该用于呈现响应。
-
视图解析和呈现:
DispatcherServlet使用视图解析器(View Resolver)来解析视图名称,找到实际的视图对象。视图对象负责呈现模型数据,通常生成 HTML 页面或其他响应格式。 -
返回响应:视图呈现模型数据后,
DispatcherServlet将响应发送回客户端,通常是浏览器。这是通过 HTTP 响应完成的,可以包括 HTML 页面、JSON 数据等。 -
渲染视图:客户端(浏览器)接收到响应后,会渲染视图并显示在用户界面上。
-
请求生命周期结束:整个请求-响应周期完成后,请求生命周期结束。
这是 Spring MVC 的基本工作流程。Spring MVC 提供了丰富的配置选项,允许您自定义处理程序、拦截器、视图解析器等,以适应不同的应用程序需求。它还提供了强大的支持,包括数据绑定、表单处理、国际化、文件上传等功能,使得开发 Web 应用程序更加方便和灵活。
36.将本地文件上传到git空仓库
初始化项目
git init
将当前目录下所有需要上传的文件代码等资源添加到缓存区
添加一个或多个文件到暂存区:
git add [file1] [file2]
添加指定目录到暂存区,包括子目录:
git add [dir]
添加当前目录下的所有文件到暂存区:
git add .
提交缓存区里面的主要内容到本地仓库
git commit -m “提交说明”
添加一个远程仓库的地址
git remote add origin https://gitee.com/xxxxxxx(远程仓库的地址)
将远程仓库进行下拉,获取同步
git pull --rebase origin master
提交本地仓库到远程仓库
git push -u origin master
因为第一次提交 所以要加一个 -u
37.Mysql数据库的锁
表锁,页锁,行锁
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低,使用表级锁定的有MyISAM,MEMORY,CSV等一些非事务性存储引擎;
行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高,使用行级锁定的主要是InnoDB存储引擎;
页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般,使用页级锁定的主要是BerkeleyDB存储引擎。
对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加排他锁(X);对于普通SELECT语句,InnoDB不会加任何锁;事务可以通过以下语句显示给记录集加共享锁或排他锁。
共享锁(S):SELECT * FROM table_name WHERE … LOCK IN SHARE MODE
排他锁(X):SELECT * FROM table_name WHERE … FOR UPDATE
说两个维度:
共享锁(简称S锁)和排他锁(简称X锁)
读锁是共享的,可以通过lock in share mode实现,这时候只能读不能写。写锁是排他的,它会阻塞其他的写锁和读锁。从颗粒度来区分,可以分为表锁和行锁两种。
表锁和行锁
表锁会锁定整张表并且阻塞其他用户对该表的所有读写操作,比如alter修改表结构的时候会锁表。
行锁又可以分为乐观锁和悲观锁
悲观锁可以通过for update实现
乐观锁则通过版本号实现。
著作权归@pdai所有 原文链接:https://pdai.tech/md/interview/x-interview.html
38.Mysql缓存
39.线程池什么是线程池?为什么要使用线程池?
线程池是一种用于管理和复用线程的机制,它可以预先创建一组线程,然后将任务分配给这些线程执行。通过使用线程池,可以避免频繁地创建和销毁线程,从而降低线程开销,提高系统性能和资源利用率。
40.Java 中如何创建线程池?请介绍一下 Executor 和 ExecutorService 接口。
在Java中,你可以使用Executor框架来创建线程池,以管理和执行多个任务。线程池可以帮助你更有效地使用系统资源,并提高多线程应用程序的性能。以下是创建线程池的一些常见方式:
-
使用
Executors工厂方法创建线程池:java.util.concurrent.Executors类提供了一些工厂方法,用于创建不同类型的线程池。以下是一些示例:-
创建一个固定大小的线程池:
ExecutorService executor = Executors.newFixedThreadPool(5); // 创建一个包含5个线程的固定大小线程池 -
创建一个单线程的线程池:
ExecutorService executor = Executors.newSingleThreadExecutor(); // 创建一个单线程的线程池 -
创建一个缓存线程池:
ExecutorService executor = Executors.newCachedThreadPool(); // 创建一个根据需求自动调整线程数的线程池
-
-
手动创建线程池:
你也可以手动创建一个
ThreadPoolExecutor,以更精细地控制线程池的属性,如核心线程数、最大线程数、线程空闲时间等。以下是一个示例:int corePoolSize = 5; int maxPoolSize = 10; long keepAliveTime = 5000; // 5秒 TimeUnit unit = TimeUnit.MILLISECONDS; BlockingQueue<Runnable> workQueue = new LinkedBlockingQueue<>();ExecutorService executor = new ThreadPoolExecutor(corePoolSize, maxPoolSize, keepAliveTime, unit, workQueue); -
执行任务:
无论你选择哪种方式创建线程池,一旦创建完成,你可以使用
execute()方法提交任务供线程池执行,或者使用submit()方法提交任务并获取Future对象以便跟踪任务的执行进度和结果。executor.execute(() -> {// 在这里执行你的任务逻辑 }); -
关闭线程池:
最后,不要忘记在程序结束时关闭线程池,以释放资源。
executor.shutdown(); // 关闭线程池
以上是创建和使用线程池的基本步骤。你可以根据自己的需求和项目的复杂性来选择不同类型的线程池,并配置线程池的属性以优化性能。确保在使用完线程池后关闭它,以避免资源泄漏。
41.常见的线程池实现有哪些?比较它们的区别。
42.线程池中的核心线程数、最大线程数、队列等参数的作用是什么?
核心线程数:线程池中保持的活动线程数量,即使它们是空闲的。
最大线程数:线程池能容纳的最大线程数量,包括核心线程和非核心线程。
队列:存储待执行任务的队列,可以是无界队列(如LinkedBlockingQueue)或有界队列(如ArrayBlockingQueue)。
43.线程池的工作原理是怎样的?线程池是如何管理线程的生命周期的?
44.线程池中的任务队列有哪些类型?它们的特点和适用场景是什么?
45.什么是线程池的拒绝策略?请列举一些内置的拒绝策略。
46.在什么情况下会使用自定义的线程池和拒绝策略?可以举例说明吗?
47.如何优雅地关闭线程池?
48.在使用线程池时,有哪些需要注意的问题,如避免死锁、线程安全等?
49.你有没有遇到过线程池使用不当导致的问题?如何解决的?
50.线程池与并发集合有何区别?什么时候选择使用线程池而不是并发集合?
51.如何评估线程池的性能和效率?有哪些衡量指标?
52.在使用线程池的过程中,有哪些常见的线程安全问题,如何避免?
53.什么是线程池的线程复用和线程复用的优势?
54.线程池的线程数量怎样选择?过多或过少的线程数量会有什么问题?
55.在 Java 中,线程池是否会自动回收闲置的线程?如果不会,怎么解决?
56.Springboot创建定时任务几种写法
在Spring Boot中创建定时任务有多种写法,其中最常用的是使用@Scheduled注解和实现SchedulingConfigurer接口。以下是几种创建定时任务的写法:
-
使用@Scheduled注解:
使用
@Scheduled注解是最简单的方式之一,它可以直接标注在需要定时执行的方法上。您可以在方法上设置定时任务的触发时间、周期、延迟等属性。import org.springframework.scheduling.annotation.Scheduled; import org.springframework.stereotype.Component;@Component public class MyScheduledTasks {@Scheduled(fixedRate = 5000) // 每5秒执行一次public void myTask() {// 定时任务的逻辑} } -
使用Cron表达式:
使用Cron表达式可以更灵活地定义定时任务的执行时间,例如每天凌晨执行、每周某一天的某个时间执行等。
import org.springframework.scheduling.annotation.Scheduled; import org.springframework.stereotype.Component;@Component public class MyScheduledTasks {@Scheduled(cron = "0 0 0 * * ?") // 每天凌晨执行public void myTask() {// 定时任务的逻辑} } -
实现SchedulingConfigurer接口:
通过实现
SchedulingConfigurer接口,您可以更灵活地配置定时任务。这种方式适用于需要动态配置定时任务的情况。import org.springframework.context.annotation.Configuration; import org.springframework.scheduling.annotation.EnableScheduling; import org.springframework.scheduling.annotation.SchedulingConfigurer; import org.springframework.scheduling.config.ScheduledTaskRegistrar;@Configuration @EnableScheduling public class MySchedulingConfig implements SchedulingConfigurer {@Overridepublic void configureTasks(ScheduledTaskRegistrar taskRegistrar) {taskRegistrar.addCronTask(() -> {// 定时任务的逻辑}, "0 0 0 * * ?"); // 每天凌晨执行} }
4.使用Quartz Scheduler:
5.单利线程池
如果需要更高级的调度功能,可以集成Quartz Scheduler。Quartz提供了更复杂的调度和任务管理功能,适用于大型和复杂的定时任务需求。
以上是几种在Spring Boot中创建定时任务的常见写法。您可以根据项目的需求和复杂度选择适合的方式。
57.Mysql的数据库事务四大特性
Atomicity(原子性):一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
Consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
Isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
Durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失
58.@Autowired与@Resource注解的区别
@Autowired注解由Spring提供,只按照byType注入;@resource注解由J2EE提供,默认按照byName自动注入。
@Autowired功能虽说非常强大,但是也有些不足之处。比如:比如它跟spring强耦合了,如果换成了JFinal等其他框架,功能就会失效。而@Resource是JSR-250提供的,它是Java标准,绝大部分框架都支持。
除此之外,有些场景使用@Autowired无法满足的要求,改成@Resource却能解决问题。接下来,我们重点看看@Autowired和@Resource的区别。
@Autowired默认按byType自动装配,而@Resource默认byName自动装配。
@Autowired只包含一个参数:required,表示是否开启自动准入,默认是true。而@Resource包含七个参数,其中最重要的两个参数是:name 和 type。
@Autowired如果要使用byName,需要使用@Qualifier一起配合。而@Resource如果指定了name,则用byName自动装配,如果指定了type,则用byType自动装配。
@Autowired能够用在:构造器、方法、参数、成员变量和注解上,而@Resource能用在:类、成员变量和方法上。
59.什么是Redis,为什么用Redis?
Redis是一种支持key-value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存,可持久化。
读写性能优异
Redis能读的速度是110000次/s,写的速度是81000次/s (测试条件见下一节)。
数据类型丰富
Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
原子性
Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
丰富的特性
Redis支持 publish/subscribe, 通知, key 过期等特性。
持久化
Redis支持RDB, AOF等持久化方式
发布订阅
Redis支持发布/订阅模式
分布式
Redis Cluster
60.暂定Redis 一般有哪些使用场景?
热点数据的缓存:缓存是Redis最常见的应用场景,之所有这么使用,主要是因为Redis读写性能优异。而且逐渐有取代memcached,成为首选服务端缓存的组件。而且,Redis内部是支持事务的,在使用时候能有效保证数据的一致性。
限时业务的运用:redis中可以使用expire命令设置一个键的生存时间,到时间后redis会删除它。利用这一特性可以运用在限时的优惠活动信息、手机验证码等业务场景。
计数器相关问题:redis由于incrby命令可以实现原子性的递增,所以可以运用于高并发的秒杀活动、分布式序列号的生成、具体业务还体现在比如限制一个手机号发多少条短信、一个接口一分钟限制多少请求、一个接口一天限制调用多少次等等。
分布式锁:这个主要利用redis的setnx命令进行,setnx:"set if not exists"就是如果不存在则成功设置缓存同时返回1,否则返回0 ,这个特性在俞你奔远方的后台中有所运用,因为我们服务器是集群的,定时任务可能在两台机器上都会运行,所以在定时任务中首先 通过setnx设置一个lock,如果成功设置则执行,如果没有成功设置,则表明该定时任务已执行。 当然结合具体业务,我们可以给这个lock加一个过期时间,比如说30分钟执行一次的定时任务,那么这个过期时间设置为小于30分钟的一个时间就可以,这个与定时任务的周期以及定时任务执行消耗时间相关。
61.Spring注入bean的值有几种方式
Set方法注入
构造器注入
静态工厂注入
实例工厂注入
62.Springboot的注入bean有几种方式
63.@Value的用法
在使用上述配置文件时,可以直接@Value(“${user.userName}”)等等。
可以注入基本类型
64.实体字段有数据库没有的字段用哪些注解
@TableField(exist = false):表示该属性不为数据库表字段,但又是必须使用的。 @TableField(exist = true):表示该属性为数据库表字段。
65.Springboot的主要注解是哪个?有哪些注解组成
@SpringBootApplication
这是 Spring Boot 最最最核心的注解,用在 Spring Boot 主类上,标识这是一个 Spring Boot 应用,用来开启 Spring Boot 的各项能力。
三个注解的组合,也可以用这三个注解来代替 @SpringBootApplication 注解。
@SpringBootConfiguration:@SpringBootConfiguration继承自@Configuration,二者功能也一致,标注当前类是配置类。
@EnableAutoConfiguration:启用Spring的自动加载配置。
@ComponentScan:该注解定义了Spring将自动扫描包主类所在包及其子包下的bean
如果你项目中所有的类都定义在主类包及其子包下,那你不需要做任何事,如果有别的类不在,需要注解后面配置当前包位置,和主类包位置
66.Spring定义bean的注解和装配bean的注解
定义:
@Component
@Bean
@Controller
@Service
@Repository
装备:
@Autowire:只按照类型
@Resources:默认按照名称找,找不到按照类型找
67.Java规范
类名要大写
包名要小写
方法名驼峰式命名,第一个单词用动词
一个方法不能超过50行
复杂功能要写注释
格式化对其
抽取公共方法
数据库连接的表不能超过五个
68.@ComponentScan和@MapperScan的区别
首先,@ComponentScan是组件扫描注解,用来扫描@Controller @Service @Repository这类,主要就是定义扫描的路径从中找出标志了需要装配的类到Spring容器中
其次,@MapperScan 是扫描mapper类的注解,配置包的路径,就不用在每个mapper类上加@Mapper
69.反射的理解
将一个类的组成部分封装成其他对象,可以在程序运行的时候操控这些对象,有三种方式
第一种:Class.forName(“全类名”):将字节码加载进缓存,返回class对象,多用于配置文件
第二种:类名.class,通过类名的属性class获取,多用于参数的传递
第三种:对象.getClass():getClass方法在Object类中定义着,多用于对象的获取字节码方式
70.多线程
71.TCP协议
72.并行和并发有什么区别?
并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔发生。
并行是在不同实体上的多个事件,并发是在同一实体上的多个事件。
在一台处理器上“同时”处理多个任务,在多台处理器上同时处理多个任务。如hadoop分布式集群。
所以并发编程的目标是充分的利用处理器的每一个核,以达到最高的处理性能。
73.线程和进程的区别?
进程是资源分配的最小单位,线程是CPU调度的最小单位。一个进程包含多个线程,一个线程只能属于一个进程。进程在执行过程中拥有内存单元。进程比线程消耗更多的资源。
74.暂定守护线程是什么?
守护线程(即daemon thread),准确地来说就是服务其他的线程。
75.创建线程有哪几种方式?
①. 继承Thread类创建线程类
定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务。因此把run()方法称为执行体。
创建Thread子类的实例,即创建了线程对象。
调用线程对象的start()方法来启动该线程。
②. 通过Runnable接口创建线程类
定义runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。
创建 Runnable实现类的实例,并依此实例作为Thread的target来创建Thread对象,该Thread对象才是真正的线程对象。
调用线程对象的start()方法来启动该线程。
③. 通过Callable和Future创建线程
创建Callable接口的实现类,并实现call()方法,该call()方法将作为线程执行体,并且有返回值。
创建Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值。
使用FutureTask对象作为Thread对象的target创建并启动新线程。
调用FutureTask对象的get()方法来获得子线程执行结束后的返回值。
76.说一下 runnable 和 callable 有什么区别?
Runnable接口中的run()方法的返回值是void,它做的事情只是纯粹地去执行run()方法中的代码而已;
Callable接口中的call()方法是有返回值的,是一个泛型,和Future、FutureTask配合可以用来获取异步执行的结果。
77.线程有哪些状态?
线程通常都有五种状态,创建、就绪、运行、阻塞和死亡。
创建状态。在生成线程对象,并没有调用该对象的start方法,这是线程处于创建状态。
就绪状态。当调用了线程对象的start方法之后,该线程就进入了就绪状态,但是此时线程调度程序还没有把该线程设置为当前线程,此时处于就绪状态。在线程运行之后,从等待或者睡眠中回来之后,也会处于就绪状态。
运行状态。线程调度程序将处于就绪状态的线程设置为当前线程,此时线程就进入了运行状态,开始运行run函数当中的代码。
阻塞状态。线程正在运行的时候,被暂停,通常是为了等待某个时间的发生(比如说某项资源就绪)之后再继续运行。sleep,suspend,wait等方法都可以导致线程阻塞。
死亡状态。如果一个线程的run方法执行结束或者调用stop方法后,该线程就会死亡。对于已经死亡的线程,无法再使用start方法令其进入就绪
78.sleep() 和 wait() 有什么区别?
sleep():方法是线程类(Thread)的静态方法,让调用线程进入睡眠状态,让出执行机会给其他线程,等到休眠时间结束后,线程进入就绪状态和其他线程一起竞争cpu的执行时间。因为sleep() 是static静态的方法,他不能改变对象的机锁,当一个synchronized块中调用了sleep() 方法,线程虽然进入休眠,但是对象的机锁没有被释放,其他线程依然无法访问这个对象。
wait():wait()是Object类的方法,当一个线程执行到wait方法时,它就进入到一个和该对象相关的等待池,同时释放对象的机锁,使得其他线程能够访问,可以通过notify,notifyAll方法来唤醒等待的线程
79.notify()和 notifyAll()有什么区别?
如果线程调用了对象的 wait()方法,那么线程便会处于该对象的等待池中,等待池中的线程不会去竞争该对象的锁。
当有线程调用了对象的 notifyAll()方法(唤醒所有 wait 线程)或 notify()方法(只随机唤醒一个 wait 线程),被唤醒的的线程便会进入该对象的锁池中,锁池中的线程会去竞争该对象锁。也就是说,调用了notify后只要一个线程会由等待池进入锁池,而notifyAll会将该对象等待池内的所有线程移动到锁池中,等待锁竞争。
优先级高的线程竞争到对象锁的概率大,假若某线程没有竞争到该对象锁,它还会留在锁池中,唯有线程再次调用 wait()方法,它才会重新回到等待池中。而竞争到对象锁的线程则继续往下执行,直到执行完了 synchronized 代码块,它会释放掉该对象锁,这时锁池中的线程会继续竞争该对象锁。
80.线程的 run()和 start()有什么区别?
每个线程都是通过某个特定Thread对象所对应的方法run()来完成其操作的,方法run()称为线程体。通过调用Thread类的start()方法来启动一个线程。
start()方法来启动一个线程,真正实现了多线程运行。这时无需等待run方法体代码执行完毕,可以直接继续执行下面的代码; 这时此线程是处于就绪状态, 并没有运行。 然后通过此Thread类调用方法run()来完成其运行状态, 这里方法run()称为线程体,它包含了要执行的这个线程的内容, Run方法运行结束, 此线程终止。然后CPU再调度其它线程。
run()方法是在本线程里的,只是线程里的一个函数,而不是多线程的。 如果直接调用run(),其实就相当于是调用了一个普通函数而已,直接待用run()方法必须等待run()方法执行完毕才能执行下面的代码,所以执行路径还是只有一条,根本就没有线程的特征,所以在多线程执行时要使用start()方法而不是run()方法。
81.建线程池有哪几种方式?
①. newFixedThreadPool(int nThreads)
创建一个固定长度的线程池,每当提交一个任务就创建一个线程,直到达到线程池的最大数量,这时线程规模将不再变化,当线程发生未预期的错误而结束时,线程池会补充一个新的线程。
②. newCachedThreadPool()
创建一个可缓存的线程池,如果线程池的规模超过了处理需求,将自动回收空闲线程,而当需求增加时,则可以自动添加新线程,线程池的规模不存在任何限制。
③. newSingleThreadExecutor()
这是一个单线程的Executor,它创建单个工作线程来执行任务,如果这个线程异常结束,会创建一个新的来替代它;它的特点是能确保依照任务在队列中的顺序来串行执行。
④. newScheduledThreadPool(int corePoolSize)
创建了一个固定长度的线程池,而且以延迟或定时的方式来执行任务,类似于Timer。
线程池的作用:
降低资源消耗
高效管理线程
82.线程池的几种状态
线程池有5种状态:Running、ShutDown、Stop、Tidying、Terminated。
83.线程池的submit()和execute()有什么区别?
execute():只能执行 Runnable 类型的任务。
submit():可以执行 Runnable 和 Callable 类型的任务。
Callable 类型的任务可以获取执行的返回值,而 Runnable 执行无返回值。
84.Synchronized在 java 程序中怎么保证多线程的运行安全?
线程安全在三个方面体现:
原子性:提供互斥访问,同一时刻只能有一个线程对数据进行操作,(atomic,synchronized);
可见性:一个线程对主内存的修改可以及时地被其他线程看到,(synchronized,volatile);
有序性:一个线程观察其他线程中的指令执行顺序,由于指令重排序,该观察结果一般杂乱无序,(happens-before原则)。
85.多线程锁的升级原理是什么
在Java中,锁共有4种状态,级别从低到高依次为:无状态锁,偏向锁,轻量级锁和重量级锁状态,这几个状态会随着竞争情况逐渐升级。锁可以升级但不能降级。
Java SE 1.6 为了减少获得锁和释放锁带来的性能消耗,引入了 “偏向锁” 和 “轻量级锁”:锁一共有 4 种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态。锁可以升级但不能降级。
偏向锁:大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁。当一个线程访问同步块并获取锁时,会在对象头和栈帧中记录存储锁偏向的线程ID,以后该线程在进入同步块时先判断对象头的Mark Word里是否存储着指向当前线程的偏向锁,如果存在就直接获取锁。
轻量级锁:当其他线程尝试竞争偏向锁时,锁升级为轻量级锁。线程在执行同步块之前,JVM会先在当前线程的栈帧中创建用于存储锁记录的空间,并将对象头中的MarkWord替换为指向锁记录的指针。如果成功,当前线程获得锁,如果失败,标识其他线程竞争锁,当前线程便尝试使用自旋来获取锁。
重量级锁:锁在原地循环等待的时候,是会消耗CPU资源的。所以自旋必须要有一定的条件控制,否则如果一个线程执行同步代码块的时间很长,那么等待锁的线程会不断的循环反而会消耗CPU资源。默认情况下锁自旋的次数是10 次,可以使用-XX:PreBlockSpin参数来设置自旋锁等待的次数。10次后如果还没获取锁,则升级为重量级锁。
86.什么是死锁?
死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
87.怎么防止死锁?
死锁的四个必要条件:
互斥条件:进程对所分配到的资源不允许其他进程进行访问,若其他进程访问该资源,只能等待,直至占有该资源的进程使用完成后释放该资源
请求和保持条件:进程获得一定的资源之后,又对其他资源发出请求,但是该资源可能被其他进程占有,此事请求阻塞,但又对自己获得的资源保持不放
不可剥夺条件:是指进程已获得的资源,在未完成使用之前,不可被剥夺,只能在使用完后自己释放
环路等待条件:是指进程发生死锁后,若干进程之间形成一种头尾相接的循环等待资源关系
这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之 一不满足,就不会发生死锁。
理解了死锁的原因,尤其是产生死锁的四个必要条件,就可以最大可能地避免、预防和 解除死锁。
所以,在系统设计、进程调度等方面注意如何不让这四个必要条件成立,如何确 定资源的合理分配算法,避免进程永久占据系统资源。
此外,也要防止进程在处于等待状态的情况下占用资源。因此,对资源的分配要给予合理的规划。
88.ThreadLocal 是什么?有哪些使用场景?
线程局部变量是局限于线程内部的变量,属于线程自身所有,不在多个线程间共享。
经典的使用场景是为每个线程分配一个 JDBC 连接 Connection。这样就可以保证每个线程的都在各自的 Connection 上进行数据库的操作,不会出现 A 线程关了 B线程正在使用的 Connection; 还有 Session 管理 等问题。
89.说一下 synchronized 底层实现原理?
synchronized 用的锁是存在 Java 对象头里的。在 JVM 中,对象在内存中的布局分为三块区域:对象头、实例数据和对齐填充。
同步方法通过ACC_SYNCHRONIZED 关键字隐式的对方法进行加锁。当线程要执行的方法被标注上ACC_SYNCHRONIZED时,需要先获得锁才能执行该方法。
同步代码块通过monitorenter和monitorexit执行来进行加锁。当线程执行到monitorenter的时候要先获得锁,才能执行后面的方法。当线程执行到monitorexit的时候则要释放锁。每个对象自身维护着一个被加锁次数的计数器,当计数器不为0时,只有获得锁的线程才能再次获得锁。
Java中的每个对象都可以作为锁,锁的是当前实例对象。具体表现为以下三种方式:
对于普通方法,锁的是当前对象
对于静态同步方法,锁的是当前类的class对象
对于同步方法块,锁住的是synchronized里括号里配置的内容
synchronized关键字可以保证并发编程的三大特性:原子性、可见性、有序性,而volatile关键字只能保证可见性和有序性,不能保证原子性,也称为是轻量级的synchronized。
原子性:一个或多个操作全部执行成功或者全部执行失败。synchronized关键字可以保证只有一个线程拿到锁,访问共享资源。
可见性:当一个线程对共享变量进行修改后,其他线程可以立刻看到。
执行synchronized时,会对应执行lock、unlock原子操作,保证可见性。
有序性:程序的执行顺序会按照代码的先后顺序执行。
synchronized关键字可以实现什么类型的锁?
悲观锁:synchronized关键字实现的是悲观锁,每次访问共享资源时都会上锁。
非公平锁:synchronized关键字实现的是非公平锁,即线程获取锁的顺序并不一定是按照线程阻塞的顺序。
可重入锁:synchronized关键字实现的是可重入锁,即已经获取锁的线程可以再次获取锁。
独占锁或者排他锁:synchronized关键字实现的是独占锁,即该锁只能被一个线程所持有,其他线程均被阻塞。
为什么说Synchronized是一个重量级锁?
Synchronized 是通过对象内部的一个叫做监视器锁(monitor)来实现的,监视器锁本质又是依赖于底层的操作系统的 Mutex Lock(互斥锁)来实现的。而操作系统实现线程之间的切换需要从用户态转换到核心态,这个成本非常高,状态之间的转换需要相对比较长的时间,这就是为什么 Synchronized 效率低的原因。因此,这种依赖于操作系统 Mutex Lock 所实现的锁我们称之为 “重量级锁”。
90.synchronized 和 volatile 的区别是什么?
1,作用的位置不同
synchronized是修饰方法,代码块。
volatile是修饰变量。
2,作用不同
synchronized,可以保证变量修改的可见性及原子性,可能会造成线程的阻塞;synchronized在锁释放的时候会将数据写入主内存,保证可见性;
volatile仅能实现变量修改的可见性,但无法保证原子性,不会造成线程的阻塞;volatile修饰变量后,每次读取都是去主内存进行读取,保证可见性
synchronized是修饰方法,代码块。
volatile是修饰变量。
91.synchronized 和 Lock 有什么区别?
首先synchronized是java内置关键字,在jvm层面,Lock是个java类;
synchronized无法判断是否获取锁的状态,Lock可以判断是否获取到锁;
synchronized会自动释放锁(a 线程执行完同步代码会释放锁 ;b 线程执行过程中发生异常会释放锁),Lock需在finally中手工释放锁(unlock()方法释放锁),否则容易造成线程死锁;
用synchronized关键字的两个线程1和线程2,如果当前线程1获得锁,线程2线程等待。如果线程1阻塞,线程2则会一直等待下去,而Lock锁就不一定会等待下去,如果尝试获取不到锁,线程可以不用一直等待就结束了;
synchronized的锁可重入、不可中断、非公平,而Lock锁可重入、可判断、可公平(两者皆可);
Lock锁适合大量同步的代码的同步问题,synchronized锁适合代码少量的同步问题。
92.synchronized 和 ReentrantLock 区别是什么?
Synchronized是关键字,ReentrantLock是类
ReentrantLock可以替代synchronized进行同步;
ReentrantLock获取锁更安全,不会无限等待,造成死锁;
必须先获取到锁,再进入try {…}代码块,最后使用finally(unlock())保证释放锁;
93.说一下 atomic 的原理?
Atomic包中的类基本的特性就是在多线程环境下,当有多个线程同时对单个(包括基本类型及引用类型)变量进行操作时,具有排他性,即当多个线程同时对该变量的值进行更新时,仅有一个线程能成功,而未成功的线程可以向自旋锁一样,继续尝试,一直等到执行成功。
Atomic系列的类中的核心方法都会调用unsafe类中的几个本地方法。我们需要先知道一个东西就是Unsafe类,全名为:sun.misc.Unsafe,这个类包含了大量的对C代码的操作,包括很多直接内存分配以及原子操作的调用,而它之所以标记为非安全的,是告诉你这个里面大量的方法调用都会存在安全隐患,需要小心使用,否则会导致严重的后果,例如在通过unsafe分配内存的时候,如果自己指定某些区域可能会导致一些类似C++一样的指针越界到其他进程的问题。
SpringBoot
94.什么是docker
docker是一个用Go语言实现的开源项目,可以让我们方便的创建和使用容器,docker将程序以及程序所有的依赖都打包到docker container,这样你的程序可以在任何环境都会有一致的表现,这里程序运行的依赖也就是容器就好比集装箱,容器所处的操作系统环境就好比货船或港口,程序的表现只和集装箱有关系(容器),和集装箱放在哪个货船或者哪个港口(操作系统)没有关系。docker可以屏蔽环境差异,也就是说,只要你的程序打包到了docker中,那么无论运行在什么环境下程序的行为都是一致的
95.Docker常用命令
查看正在运行容器列表
docker ps1
查看所有容器 -----包含正在运行 和已停止的
docker ps -a
停止容器
docker stop 容器ID/容器名
重启容器
docker restart 容器ID/容器名
启动容器
docker start 容器ID/容器名
查看容器日志
docker logs -f --tail=要查看末尾多少行 默认all 容器ID
docker logs <容器ID或名称>:查看容器的日志输出。
docker exec -it <容器ID或名称> /bin/bash:进入容器的shell或命令行。
docker pull <镜像名称>:从Docker仓库中拉取一个镜像。
docker images 或 docker image ls:列出本地已经下载的镜像。
docker rmi <镜像ID或名称>:删除本地的一个或多个镜像。
96.什么是规则引擎Drools
97.什么是spring
Spring是一种轻量级框架,旨在提高开发人员的开发效率以及系统的可维护性。
98.Spring由几大模块组成
1、 Core Container(核心容器)
Spring的核心容器是其他模块建立的基础,它主要由Beans模块、Core模块、Context模块、Context-support模块和SpEL(Spring Expression Language,Spring表达式语言)模块组成,具体介绍如下。
·Beans模块:提供了BeanFactory,是工厂模式的经典实现,Spring将管理对象称为Bean。
·Core核心模块:提供了Spring框架的基本组成部分,可以说spring的其他所有功能都依赖该类库。包括控制反转IoC和DI功能。
·Context上下文模块:建立在Core和Beans模块的基础之上,它是访问定义和配置的任何对象的媒介。其中ApplicationContext接口是上下文模块的焦点。
·Context-support 模块:提供了对第三方库嵌入 Spring 应用的集成支持,比如缓存(EhCache、Guava、JCache)、邮件服务(JavaMail)、任务调度(CommonJ、Quartz)和模板引擎(FreeMarker、JasperReports、速率)。
·SpEL模块:是Spring 3.0后新增的模块,它提供了Spring Expression Language支持,是运行时查询和操作对象图的强大的表达式语言。
2、 Data Access/Integration(数据访问/集成)
数据访问/集成层包括JDBC、ORM、OXM、JMS和Transactions模块,具体介绍如下。
·JDBC模块:提供了一个JDBC的抽象层,大幅度地减少了在开发过程中对数据库操作的编码。
·ORM模块:对流行的对象关系映射API,包括JPA、JDO和Hibernate提供了集成层支持。
·OXM模块:提供了一个支持对象/ XML映射的抽象层实现,如JAXB、Castor、XMLBeans、JiBX和XStream。
·JMS 模块:指 Java 消息传递服务,包含使用和产生信息的特性,自 4.1 版本后支持与Spring-message模块的集成。
·Transactions事务模块:支持对实现特殊接口以及所有POJO类的编程和声明式的事务管理。
3、 Web
Spring的Web层包括WebSocket、Servlet、Web和Portlet模块,具体介绍如下。
·WebSocket模块:Spring 4.0以后新增的模块,它提供了WebSocket 和SockJS的实现,以及对STOMP的支持。
·Servlet模块:也称为Spring-webmvc模块,包含了Spring的模型—视图—控制器(MVC)和REST Web Services实现的Web应用程序。
·Web模块:提供了基本的Web开发集成特性,例如:多文件上传功能、使用Servlet***来初始化IoC容器以及Web应用上下文。
·Portlet模块:提供了在Portlet环境中使用MVC实现,类似Servlet模块的功能。
4、 其他模块
Spring的其他模块还有AOP、Aspects、Instrumentation以及Test模块,具体介绍如下。
·AOP 模块:提供了面向切面编程实现,允许定义方法拦截器和切入点,将代码按照功能进行分离,以降低耦合性。
·Aspects 模块:提供了与AspectJ的集成功能,AspectJ是一个功能强大且成熟的面向切面编程(AOP)框架。
·Instrumentation 模块:提供了类工具的支持和类加载器的实现,可以在特定的应用服务器中使用。
·Messaging模块:Spring 4.0以后新增的模块,它提供了对消息传递体系结构和协议的支持。
·Test模块:提供了对单元测试和集成测试的支持。
99.DI(Dependency Injection)和IoC(Inversion of Control)是两个相关但不同的概念,它们通常一起使用,但它们的焦点和作用不同。
- DI(Dependency Injection,依赖注入):
- DI 是一种设计模式,用于管理组件之间的依赖关系。
- 在DI中,一个组件(通常是一个类或对象)不再负责创建或查找它所依赖的其他组件,而是通过外部的机制将这些依赖项注入到它内部。
- DI有助于降低组件之间的耦合度,使代码更易于测试、维护和扩展。
- DI可以通过构造函数注入、setter方法注入或接口注入等方式实现。
- IoC(Inversion of Control,控制反转):
- IoC是一种设计原则,强调将控制权从应用程序代码转移到框架或容器中。
- 在IoC中,应用程序不再控制组件的创建和生命周期,而是将这些控制权委托给IoC容器,容器负责创建、配置和管理组件。
- IoC的目标是解耦应用程序的各个组件,使其更灵活、可维护和可测试。
- DI是IoC的一种具体实现方式,它是IoC的一部分,用于实现依赖注入。
总结:
- IoC是一种更广泛的概念,它描述了应用程序的控制权的转移和组件之间的松耦合。
- DI是IoC的一种具体实现方式,它关注如何管理组件之间的依赖关系,以实现IoC的原则。
- 使用DI,依赖关系是通过注入而不是硬编码在组件内部实现的,这使得组件更容易被替换和测试。
- Spring框架是一个典型的IoC容器,它提供了依赖注入的功能,帮助开发者实现IoC原则。
100.IOC是什么?
IOC(Inversion Of Controll,控制反转,又叫依赖注入)是一种设计思想,就是将原本在程序中手动创建对象的控制权,交给IOC容器来管理,并由IOC容器完成对象的注入。这样可以很大程度上简化应用的开发,把应用从复杂的依赖关系中解放出来。IOC容器就像是一个工厂一样,当我们需要创建一个对象的时候,只需要配置好配置文件/注解即可,完全不用考虑对象是如何被创建出来的。
Spring 中的 IoC 的实现原理就是工厂模式加反射机制。
101.Aop是什么?
AOP(Aspect-Oriented Programming,面向切面编程)AOP(Aspect-Oriented Programming,面向切面编程)是一种编程范式,用于增强和扩展应用程序的功能。
能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可扩展性和可维护性。
Spring AOP是基于动态代理的,如果要代理的对象实现了某个接口,那么Spring AOP就会使用JDK动态代理去创建代理对象;而对于没有实现接口的对象,就无法使用JDK动态代理,转而使用CGlib动态代理生成一个被代理对象的子类来作为代理。
当然也可以使用AspectJ,Spring AOP中已经集成了AspectJ,AspectJ应该算得上是Java生态系统中最完整的AOP框架了。使用AOP之后我们可以把一些通用功能抽象出来,在需要用到的地方直接使用即可,这样可以大大简化代码量。我们需要增加新功能也方便,提高了系统的扩展性。日志功能、事务管理和权限管理等场景都用到了AOP。
102.Aop包含的几个概念
Jointpoint(连接点):具体的切面点点抽象概念,可以是在字段、方法上,Spring中具体表现形式是PointCut(切入点),仅作用在方法上。
Advice(通知): 在连接点进行的具体操作,如何进行增强处理的,分为前置、后置、异常、最终、环绕五种情况。
目标对象:被AOP框架进行增强处理的对象,也被称为被增强的对象。
AOP代理:AOP框架创建的对象,简单的说,代理就是对目标对象的加强。Spring中的AOP代理可以是JDK动态代理,也可以是CGLIB代理。
Weaving(织入):将增强处理添加到目标对象中,创建一个被增强的对象的过程
总结为一句话就是:在目标对象(target object)的某些方法(jointpoint)添加不同种类的操作(通知、增强操处理),最后通过某些方法(weaving、织入操作)实现一个新的代理目标对象。
103.Aop有哪些应用场景
记录日志,权限控制,事务管理,监控性能
104.有哪些aop的Advice通知类型
特定 JoinPoint 处的 Aspect 所采取的动作称为 Advice。Spring AOP 使用一个 Advice 作为拦截器,在 JoinPoint “周围”维护一系列的拦截器。
前置通知(Before advice) : 这些类型的 Advice 在 joinpoint 方法之前执行,并使用 @Before 注解标记进行配置。
后置通知(After advice) :这些类型的 Advice 在连接点方法之后执行,无论方法退出是正常还是异常返回,并使用 @After 注解标记进行配置。
返回后通知(After return advice) :这些类型的 Advice 在连接点方法正常执行后执行,并使用@AfterReturning 注解标记进行配置。
环绕通知(Around advice) :这些类型的 Advice 在连接点之前和之后执行,并使用 @Around 注解标记进行配置。
抛出异常后通知(After throwing advice) :仅在 joinpoint 方法通过抛出异常退出并使用 @AfterThrowing 注解标记配置时执行。
105.Aop有哪些实现方式
实现 AOP 的技术,主要分为两大类:
静态代理 - 指使用 AOP 框架提供的命令进行编译,从而在编译阶段就可生成 AOP 代理类,因此也称为编译时增强;
编译时编织(特殊编译器实现)
类加载时编织(特殊的类加载器实现)。
动态代理 - 在运行时在内存中“临时”生成 AOP 动态代理类,因此也被称为运行时增强。
JDK 动态代理
JDK Proxy 是 Java 语言自带的功能,无需通过加载第三方类实现;
Java 对 JDK Proxy 提供了稳定的支持,并且会持续的升级和更新,Java 8 版本中的 JDK Proxy 性能相比于之前版本提升了很多;
JDK Proxy 是通过拦截器加反射的方式实现的;
JDK Proxy 只能代理实现接口的类;
JDK Proxy 实现和调用起来比较简单;
CGLIB
CGLib 是第三方提供的工具,基于 ASM 实现的,性能比较高;
CGLib 无需通过接口来实现,它是针对类实现代理,主要是对指定的类生成一个子类,它是通过实现子类的方式来完成调用的。
106.谈谈对cgLIB的理解
JDK 动态代理机制只能代理实现接口的类,一般没有实现接口的类不能进行代理。使用 CGLib 实现动态代理,完全不受代理类必须实现接口的限制。
CGLib 的原理是对指定目标类生成一个子类,并覆盖其中方法实现增强,但因为采用的是继承,所以不能对 final 修饰的类进行代理。
107.Spring aop和aspectJ aop有什么区别?
Spring AOP是属于运行时增强,而AspectJ是编译时增强。Spring AOP基于代理(Proxying),而AspectJ基于字节码操作(Bytecode Manipulation)。
Spring AOP已经集成了AspectJ,AspectJ应该算得上是Java生态系统中最完整的AOP框架了。AspectJ相比于Spring AOP功能更加强大,但是Spring AOP相对来说更简单。
如果我们的切面比较少,那么两者性能差异不大。但是,当切面太多的话,最好选择AspectJ,它比SpringAOP快很多。
108.SpringBean的作用域
singleton:唯一bean实例,Spring中的bean默认都是单例的。
prototype:每次请求都会创建一个新的bean实例。
request:每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP request内有效。
session:每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP session内有效。
109.Bean的生命周期
分为四个阶段:
实例化,属性设置,初始化,销毁
实例化:对于beanFactory容器,会调用createBean进行实例化
对于applicationContext容器,当容器启动后,会实例化所有bean
设置属性(依赖注入):实例化后的对象放在beanWrapper中,spring会根据beanDefinition的信息进行依赖注入
在Spring框架中,Bean(即Spring容器管理的对象)的生命周期通常包括以下阶段:
- 实例化(Instantiation):在这个阶段,Spring容器创建Bean的实例。这通常是通过构造函数或工厂方法进行的。Bean的定义信息通常在XML配置文件中指定。
- 属性注入(Property Injection):一旦Bean实例化完成,Spring容器会将相关的属性注入到Bean中。这可以通过属性注入、构造函数注入或方法注入(例如
@Autowired注解)来实现。 - Bean的初始化方法调用(Initialization):在Bean实例化和属性注入之后,容器会调用Bean的初始化方法(如果有定义的话)。可以使用
@PostConstruct注解或XML配置中的init-method属性来指定初始化方法。 - Bean的使用(In Use):在Bean初始化完成后,它可以被其他Bean或应用程序组件使用。
- Bean的销毁方法调用(Destruction):在Bean不再需要时,容器可以调用Bean的销毁方法来释放资源。可以使用
@PreDestroy注解或XML配置中的destroy-method属性来指定销毁方法。 - Bean的销毁(Disposal):在销毁方法调用后,Bean会被销毁,从Spring容器中移除。这时,Bean的实例将被垃圾回收。
请注意,Bean的生命周期可以受到Spring配置、注解和XML文件的影响。您可以选择使用合适的方法和注解来管理Bean的生命周期,以满足应用程序的需求。
110.Spring用了哪些设计模式
1.工厂设计模式:Spring使用工厂模式通过BeanFactory和ApplicationContext创建bean对象。
2.代理设计模式:Spring AOP功能的实现。
3.单例设计模式:Spring中的bean默认都是单例的。
4.模板方法模式:Spring中的jdbcTemplate、hibernateTemplate等以Template结尾的对数据库操作的类,它们就使用到了模板模式。
5.包装器设计模式:我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
6.观察者模式:Spring事件驱动模型就是观察者模式很经典的一个应用。
7.适配器模式:Spring AOP的增强或通知(Advice)使用到了适配器模式、Spring MVC中也是用到了适配器模式适配Controller。
111.@Component和@Bean的区别是什么
作用对象不同。@Component注解作用于类,而@Bean注解作用于方法。
112.将一个类声明为spring的bean注解有哪些?
我们一般使用@Autowired注解去自动装配bean。而想要把一个类标识为可以用@Autowired注解自动装配的bean,可以采用以下的注解实现:
1.@Component注解。通用的注解,可标注任意类为Spring组件。如果一个Bean不知道属于哪一个层,可以使用@Component注解标注。
2.@Repository注解。对应持久层,即Dao层,主要用于数据库相关操作。
3.@Service注解。对应服务层,即Service层,主要涉及一些复杂的逻辑,需要用到Dao层(注入)。
4.@Controller注解。对应Spring MVC的控制层,即Controller层,主要用于接受用户请求并调用Service层的方法返回数据给前端页面。
113.Spring事务管理的方式有几种
1.编程式事务:在代码中硬编码(不推荐使用)。
2.声明式事务:在配置文件中配置(推荐使用),分为基于XML的声明式事务和基于注解的声明式事务。
114.Spring事务中的隔离级别有哪几种
115.Spring中Bean Factory和ApplicationContext有什么区别?
116.可以通过多少种方式完成依赖注入
构造函数注入
Setter注入
接口注入
117.说说对spring Mvc的工作原理
1.客户端(浏览器)发送请求,直接请求到DispatcherServlet。
2.DispatcherServlet根据请求信息调用HandlerMapping,解析请求对应的Handler。
3.解析到对应的Handler(也就是我们平常说的Controller控制器)。
4.HandlerAdapter会根据Handler来调用真正的处理器来处理请求和执行相对应的业务逻辑。
5.处理器处理完业务后,会返回一个ModelAndView对象,Model是返回的数据对象,View是逻辑上的View。
6.ViewResolver会根据逻辑View去查找实际的View。
7.DispatcherServlet把返回的Model传给View(视图渲染)。
8.把View返回给请求者(浏览器)。
118.什么是spring boot
Spring Boot 是 Spring 开源组织下的子项目,是 Spring 组件一站式解决方案,主要是简化了使用 Spring 的难度,简省了繁重的配置,提供了各种启动器,开发者能快速上手。
用来简化Spring应用的初始搭建以及开发过程,使用特定的方式来进行配置
创建独立的Spring引用程序main方法运行
嵌入的tomcat无需部署war文件
简化maven配置
自动配置Spring添加对应的功能starter自动化配置
SpringBoot来简化Spring应用开发,约定大于配置,去繁化简
119.Springboot的原理
120.为什么使用spring boot(优点)
独立运行
Spring Boot 而且内嵌了各种 servlet 容器,Tomcat、Jetty 等,现在不再需要打成war 包部署到容器中,Spring Boot 只要打成一个可执行的 jar 包就能独立运行,所有的依赖包都在一个 jar 包内。
简化配置
spring-boot-starter-web 启动器自动依赖其他组件,简少了 maven 的配置。
自动配置
Spring Boot 能根据当前类路径下的类、jar 包来自动配置 bean,如添加一个 spring
boot-starter-web 启动器就能拥有 web 的功能,无需其他配置。
无代码生成和XML配置
Spring Boot 配置过程中无代码生成,也无需 XML 配置文件就能完成所有配置工作,这一切都是借助于条件注解完成的,这也是 Spring4.x 的核心功能之一。
应用监控
Spring Boot 提供一系列端点可以监控服务及应用,做健康检测。
121.请解释一下工厂模式
工厂模式将目的将创建对象的具体过程屏蔽隔离起来,从而达到更高的灵活性,工厂模式可以分为三类:
简单工厂模式(Simple Factory)
简单工厂模式的核心是定义一个创建对象的接口,将对象的创建和本身的业务逻辑分离,降低系统的耦合度,使得两个修改起来相对容易些,当以后实现改变时,只需要修改工厂类即可。
优缺点: 简单工厂模式提供专门的工厂类用于创建对象,实现了对象创建和使用的职责分离,客户端不需知道所创建的具体产品类的类名以及创建过程,只需知道具体产品类所对应的参数即可,通过引入配置文件,可以在不修改任何客户端代码的情况下更换和增加新的具体产品类,在一定程度上提高了系统的灵活性。
但缺点在于不符合“开闭原则”,每次添加新产品就需要修改工厂类。在产品类型较多时,有可能造成工厂逻辑过于复杂,不利于系统的扩展维护,并且工厂类集中了所有产品创建逻辑,一旦不能正常工作,整个系统都要受到影响。
工厂方法模式(Factory Method)
工厂方法模式将工厂抽象化,并定义一个创建对象的接口。每增加新产品,只需增加该产品以及对应的具体实现工厂类,由具体工厂类决定要实例化的产品是哪个,将对象的创建与实例化延迟到子类,这样工厂的设计就符合“开闭原则”了,扩展时不必去修改原来的代码。在使用时,用于只需知道产品对应的具体工厂,关注具体的创建过程,甚至不需要知道具体产品类的类名,当我们选择哪个具体工厂时,就已经决定了实际创建的产品是哪个了。
但缺点在于,每增加一个产品都需要增加一个具体产品类和实现工厂类,使得系统中类的个数成倍增加,在一定程度上增加了系统的复杂度,同时也增加了系统具体类的依赖。
抽象工厂模式(Abstract Factory)
抽象工厂模式主要用于创建相关对象的家族,通过抽象工厂模式,所有的具体工厂都实现了抽象工厂中定义的公共接口,因此只需要改变具体工厂的实例,就可以在某程度上改变整个行为。
但该模式的缺点在于添加新的行为时比较麻烦,如果需要添加一个新产品族对象时,需要更改接口及其下所有子类,这必然会带来很大的麻烦。
工厂模式小结:
工厂方法模式与抽象工厂模式的区别在于:
(1)工厂方法只有一个抽象产品类和一个抽象工厂类,但可以派生出多个具体产品类和具体工厂类,每个具体工厂类只能创建一个具体产品类的实例。
(2)抽象工厂模式拥有多个抽象产品类(产品族)和一个抽象工厂类,每个抽象产品类可以派生出多个具体产品类;抽象工厂类也可以派生出多个具体工厂类,同时每个具体工厂类可以创建多个具体产品类的实例
122.请解释一下单例模式
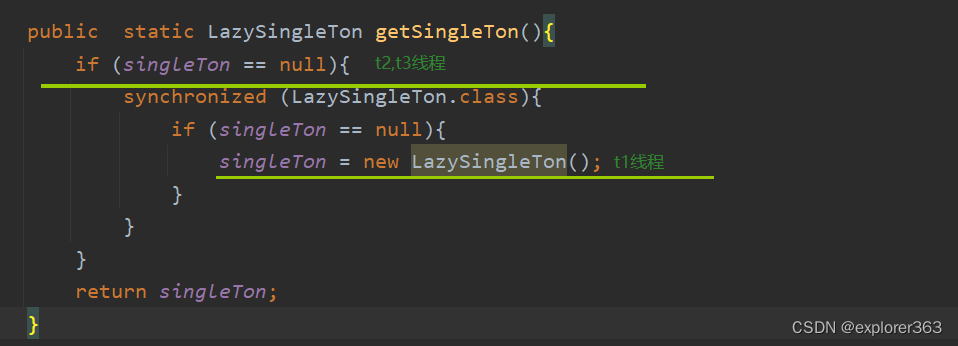
懒汉模式:在第一次调用的时候实例
饿汉模式:饿汉就是类一旦加载,就把单例初始化完成,保证getInstance的时候,单例是已经存在的了。
123.请解释一下代理模式
结构型设计模式, 代理模式是常见的设计模式之一,顾名思义,代理模式就是代理对象具备真实对象的功能,并代替真实对象完成相应操作,并能够在操作执行的前后,对操作进行增强处理。(为真实对象提供代理,然后供其他对象通过代理访问真实对象)
静态代理:
动态代理:
124.简单说下Redis
125.消息队列
126.单元测试
127.zpl语言
ZPL(Zebra Programming Language)是一种专门用于打印标签和条形码的标签打印机编程语言。ZPL是由斑马技术(Zebra Technologies)开发的,并且广泛用于各种标签打印机和条形码打印机上。
ZPL语言的主要目的是控制标签打印机的行为,包括文本、条形码、图像、位置和格式等方面。通过编写ZPL命令,用户可以自定义标签的外观和内容,并将这些命令发送给标签打印机,以在标签上生成所需的标识信息。
以下是一些常见的ZPL语言元素和命令:
^XA // 标签开始
^XZ // 标签结束
128.Redis
相关文章:

questions
1.JDK 和 JRE 有什么区别? JDK:Java Development Kit 的简称,java 开发工具包,提供了 java 的开发环境和运行环境 JRE:Java Runtime Environment 的简称,java 运行环境,为 java 的运行提供了所需…...
MojoTween:使用「Burst、Jobs、Collections、Mathematics」优化实现的Unity顶级「Tween动画引擎」
MojoTween是一个令人惊叹的Tween动画引擎,针对C#和Unity进行了高度优化,使用了Burst、Jobs、Collections、Mathematics等新技术编码。 MojoTween提供了一套完整的解决方案,将Tween动画应用于Unity Objects的各个方面,并可以通过E…...

Vue3响应式源码实现
Vue3响应式源码实现 初始化项目结构 vue-proxy ├── effect.js ├── effect.ts ├── index.html ├── index.js ├── package.json ├── reactive.js ├── reactive.ts └── webpack.config.jsreactive.ts import { track, trigger } from "./effect&q…...

【RapidAI】P1 中文文本切割程序
中文文本切割程序 基本信息代码解析相关包获取 yaml 关键文件类的构造函数切分语句部分特殊处理 PDF重点切分去除数组中空字符串再度切分后长度 附录附录一:完整代码附录二:可继续思考问题 基本信息 文件名: chinese_text_splitter.py 文件地…...

4、QT中的网络编程
一、Linux中的网络编程 1、子网和公网的概念 子网网络:局域网,只能进行内网的通信公网网络:因特网,服务器等可以进行远程的通信 2、网络分层模型 4层模型:应用层、传输层、网络层、物理层 应用层:用户自…...
单例模式(饿汉式单例 VS 懒汉式单例)
所谓的单例模式就是保证某个类在程序中只有一个对象 一、如何控制只产生一个对象? 1.构造方法私有化(保证对象的产生个数) 创建类的对象,要通过构造方法产生对象 构造方法若是public权限,对于类的外部,可…...

Oracle数据库连接之TNS-12541异常
在进行数据库开发的时候,通常需要使用PLSQL Developer开发工具连接Oralce数据库,在进行连接时,经常性的会提示TNS-12541:TNS:no listener(没有监听),从而导致PLSQL Developer 无法连接到数据库实例…...
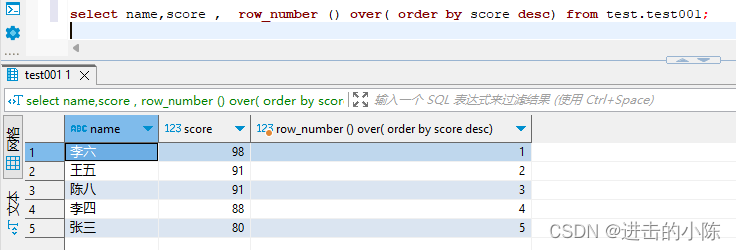
sql中的排序函数dense_rank(),RANK()和row_number()
dense_rank(),RANK()和row_number()是SQL中的排序函数。 为方便后面的函数差异比对清晰直观,准备数据表如下: 1.dense_rank() 函数语法:dense_rank() over( order by 列名 【desc/asc】) DENSE_RANK()是连续排序,比如…...

Flask狼书笔记 | 05_数据库
文章目录 5 数据库5.1 数据库的分类5.2 ORM5.3 使用Flask_SQLAlchemy5.4 数据库操作5.5 定义关系5.6 更新数据库表5.7 数据库进阶小结 5 数据库 这一章学习如何在Python中使用DBMS(数据库管理系统),来对数据库进行管理和操作。本书使用SQLit…...

HJ70 矩阵乘法计算量估算
Powered by:NEFU AB-IN Link 文章目录 HJ70 矩阵乘法计算量估算题意思路代码 HJ70 矩阵乘法计算量估算 题意 矩阵乘法的运算量与矩阵乘法的顺序强相关。 例如: A是一个5010的矩阵,B是1020的矩阵,C是205的矩阵 计算ABC有两种顺序:…...

Doris数据库使用记录
新建表 create table tonly_attendance(vin varchar(64),diggings_name varchar(256),area varchar(64),diggings_type varchar(256),work_time decimal(20,2),engine_run_time decimal(20,2),upload_time varchar(64))DUPLICATE KEY (vin)distributed by hash (vin)删除之…...

华为OD机试真题【篮球比赛】
1、题目描述 【篮球比赛】 一个有N个选手参加比赛,选手编号为1~N(3<N<100),有M(3<M<10)个评委对选手进行打分。 打分规则为每个评委对选手打分,最高分10分,最低分1分。…...
sublime text 格式化json快捷键配置
以 controlcommandj 为例。 打开Sublime Text,依次点击左上角菜单Sublime Text->Preferences->Key Bindings,出现以下文件: 左边的是Sublime Text默认的快捷键,不可编辑。右边是我们自定义快捷键的地方,在中括号…...

Spring Cloud 面试题总结
Spring Cloud和各子项目版本对应关系 Spring Cloud 是一个用于构建分布式系统的开发工具包,它基于Spring Boot提供了一组模块和功能,用于构建微服务架构中的分布式应用程序。Spring Cloud的不同子项目有各自的版本,下面是一些常见的Spring C…...

如何实现24/7客户服务自动化?
传统的客服制胜与否的法宝在于人,互联网时代,对于产品线广的大型企业来说:单靠人力,成本大且效率低,相对于产品相对单一的中小型企业来说:建设传统客服系统的成本难以承受,企业客户服务的转型已…...

2022年12月 C/C++(六级)真题解析#中国电子学会#全国青少年软件编程等级考试
C/C++编程(1~8级)全部真题・点这里 第1题:区间合并 给定 n 个闭区间 [ai; bi],其中i=1,2,…,n。任意两个相邻或相交的闭区间可以合并为一个闭区间。例如,[1;2] 和 [2;3] 可以合并为 [1;3],[1;3] 和 [2;4] 可以合并为 [1;4],但是[1;2] 和 [3;4] 不可以合并。 我们的任务是…...

【Spring Cloud系列】 雪花算法原理及实现
【Spring Cloud系列】 雪花算法原理及实现 文章目录 【Spring Cloud系列】 雪花算法原理及实现一、概述二、生成ID规则部分硬性要求三、ID号生成系统可用性要求四、解决分布式ID通用方案4.1 UUID4.2 数据库自增主键4.3 基于Redis生成全局id策略 五、SnowFlake(雪花算…...

Postgresql 阿里云部署排雷
启动服务bug: 根据你的输出,可以看到 PostgreSQL 服务启动失败,并且显示以下错误消息: pg_ctl: cannot be run as root Please log in (using, e.g., "su") as the (unprivileged) user that will own the server proc…...
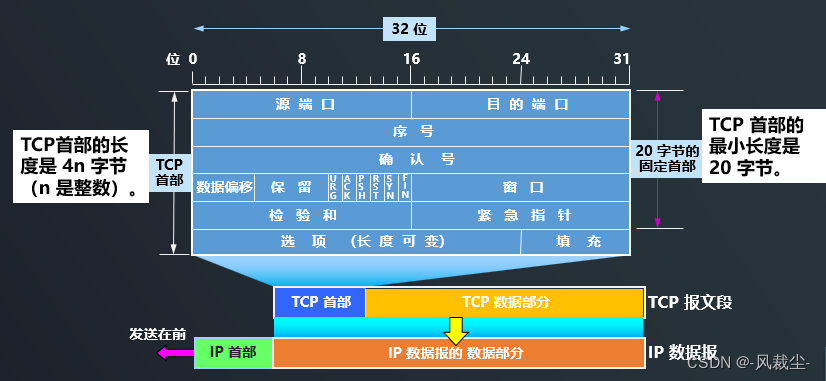
l8-d10 TCP协议是如何实现可靠传输的
一、TCP主要特点 TCP 是面向连接的运输层协议,在无连接的、不可靠的 IP 网络服务基础之上提供可靠交付的服务。为此,在 IP 的数据报服务基础之上,增加了保证可靠性的一系列措施。 TCP主要特点 1.TCP 是面向连接的运输层协议。 每一条 TCP 连…...

9月9日扒面经
堆和栈的区别? 分配方式:堆内存是由程序员手动分配和释放的,而栈内存是由编译器自动分配和释放的。内存管理:堆内存需要手动管理内存的分配和释放,程序员需要显式地调用malloc()或new来分配内存,并使用fre…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

回溯算法学习
一、电话号码的字母组合 import java.util.ArrayList; import java.util.List;import javax.management.loading.PrivateClassLoader;public class letterCombinations {private static final String[] KEYPAD {"", //0"", //1"abc", //2"…...

Yolov8 目标检测蒸馏学习记录
yolov8系列模型蒸馏基本流程,代码下载:这里本人提交了一个demo:djdll/Yolov8_Distillation: Yolov8轻量化_蒸馏代码实现 在轻量化模型设计中,**知识蒸馏(Knowledge Distillation)**被广泛应用,作为提升模型…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...

【Linux】自动化构建-Make/Makefile
前言 上文我们讲到了Linux中的编译器gcc/g 【Linux】编译器gcc/g及其库的详细介绍-CSDN博客 本来我们将一个对于编译来说很重要的工具:make/makfile 1.背景 在一个工程中源文件不计其数,其按类型、功能、模块分别放在若干个目录中,mak…...

k8s从入门到放弃之HPA控制器
k8s从入门到放弃之HPA控制器 Kubernetes中的Horizontal Pod Autoscaler (HPA)控制器是一种用于自动扩展部署、副本集或复制控制器中Pod数量的机制。它可以根据观察到的CPU利用率(或其他自定义指标)来调整这些对象的规模,从而帮助应用程序在负…...

DiscuzX3.5发帖json api
参考文章:PHP实现独立Discuz站外发帖(直连操作数据库)_discuz 发帖api-CSDN博客 简单改造了一下,适配我自己的需求 有一个站点存在多个采集站,我想通过主站拿标题,采集站拿内容 使用到的sql如下 CREATE TABLE pre_forum_post_…...