论文精读 —— Gradient Surgery for Multi-Task Learning
文章目录
- Multi-task Learning和 PCGrad 方法简介
- 论文信息
- 论文核心图
- 摘要翻译
- 引言翻译
- 2 使用PCGrad进行多任务学习
- 2.1 基本概念:问题和符号表示
- 2.2 三重悲剧:冲突的梯度,主导的梯度,高曲率
- 2.3 PCGrad:解决梯度冲突
- 2.4 PCGrad的理论分析
- 3 PCGrad在实际应用中
- 参考文章
Multi-task Learning和 PCGrad 方法简介
多任务学习 (Multi-task Learning, MTL) 是机器学习中的一个热门研究领域,其中单一模型同时学习多个相关任务。这种方法的核心动机是,不同的任务可以相互辅助并提高学习效率,因为它们可能共享某些底层的表示或特征。但是,当任务的梯度更新方向冲突时,这可能会导致训练困难。
论文 “Gradient Surgery for Multi-task Learning” 中提出的 PCGrad 方法应对了这个问题。当多个任务的梯度在更新时相互冲突时,PCGrad 主要考虑如何修整这些梯度,使它们不再互相矛盾。具体地,它通过将每个任务的梯度投影到与其他任务梯度冲突方向的正交平面上,来消除梯度之间的冲突。
这种方法的直观理解是:如果两个任务产生的梯度相互冲突(例如,一个任务可能会推动模型权重向一个方向移动,而另一个任务则推动它向相反方向移动),那么这种冲突可能会妨碍模型的学习。为了缓解这种情况,PCGrad 会对梯度进行修整,确保每个任务的梯度在与其他任务的梯度冲突的方向上为零。这样,每个任务只在不与其他任务冲突的方向上更新模型权重。
该论文中的实验证明,这种方法在多任务场景中是有效的,无论是在多任务监督学习还是在多任务强化学习 (RL) 中。
解释——“它通过将每个任务的梯度投影到与其他任务梯度冲突方向的正交平面上,来消除梯度之间的冲突”:
使用一个简化的二维示例来理解这个概念:
假设我们有两个任务A和B,并且我们正在二维空间中考虑梯度。所以,每个任务有一个梯度向量。
- 示例情况:
- 任务A的梯度向量为 g A ⃗ \vec{g_A} gA,指向右上方。
- 任务B的梯度向量为 g B ⃗ \vec{g_B} gB,指向右下方。
这两个向量在水平方向上是一致的(都推动模型权重向右移动),但在垂直方向上是相反的(一个向上,一个向下)。
-
找出冲突:
- 由于两个梯度在垂直方向上存在冲突,我们需要解决这个冲突。
-
解决冲突的方法 - 投影到正交平面:
- 对于任务A,我们想要消除与任务B梯度冲突的部分。具体来说,我们需要找到一个向量,它与 g B ⃗ \vec{g_B} gB正交,并且与 g A ⃗ \vec{g_A} gA在同一方向。这个向量是 g A ⃗ \vec{g_A} gA在 g B ⃗ \vec{g_B} gB的正交方向上的投影。
- 同理,对于任务B,我们会找到一个向量,它与 g A ⃗ \vec{g_A} gA正交,并且与 g B ⃗ \vec{g_B} gB在同一方向。这个向量是 g B ⃗ \vec{g_B} gB在 g A ⃗ \vec{g_A} gA的正交方向上的投影。
-
结果:
- 两个任务现在有了修正后的梯度向量。这两个新向量仍然在原来的方向上,但它们在与另一个任务的梯度冲突的方向上没有分量。
图解:
想象一个坐标系。在这个坐标系上,任务A的梯度是一个从原点指向第一象限的向量。任务B的梯度是一个从原点指向第四象限的向量。为了消除垂直方向上的冲突,我们会找到一个新的向量,它是任务A梯度在水平方向(任务B梯度的正交方向)上的投影。这样,我们就得到了一个完全在水平方向上的向量,与任务B的梯度没有冲突。
同样,任务B的梯度也会被投影到水平方向,得到一个新的梯度向量,与任务A的梯度没有冲突。
这样,两个任务就可以同时进行梯度更新,而不会相互干扰。

计算一个向量在另一个向量的正交方向上的投影:

论文信息
| 论文标题 | Gradient Surgery for Multi-Task Learning |
|---|---|
| 作者 | Tianhe Yu 1 ^1 1, Saurabh Kumar 1 ^1 1, Abhishek Gupta 2 ^2 2, Sergey Levine 2 ^2 2, Karol Hausman 3 ^3 3, Chelsea Finn 1 ^1 1 |
| 科研机构 | Stanford University 1 ^1 1, UC Berkeley 2 ^2 2, Robotics at Google e ^e e |
| 会议 | NeurlIPS |
| 发表年份 | 2020 |
| 论文链接 | https://proceedings.neurips.cc/paper/2020/file/3fe78a8acf5fda99de95303940a2420c-Paper.pdf |
| 开源代码 | https://paperswithcode.com/paper/gradient-surgery-for-multi-task-learning-1 |
| 论文贡献 | 在这篇论文中,作者确定了三种导致不良梯度干扰的多任务优化环境条件,并开发了一种简单而通用的方法,以避免任务梯度之间的这种干扰。作者提出了一种梯度手术形式,将任务的梯度投影到任何其他具有冲突梯度的任务的梯度的法平面上。在一系列具有挑战性的多任务监督和多任务RL问题上,这种方法带来了效率和性能的大幅提升。此外,它与模型无关,并且可以与先前提出的多任务架构结合,以增强性能。 |
论文核心图

摘要翻译
尽管深度学习和深度强化学习(RL)系统在图像分类、游戏玩耍和机器人控制等领域展示了令人印象深刻的成果,但数据效率仍然是一个重大的挑战。多任务学习已经崭露头角,成为一个有前景的方法,它允许在多个任务之间共享结构,实现更高效的学习。但是,多任务设置带来了一系列的优化问题,这使得与单独学习任务相比,难以获得大幅度的效率提升。与单任务学习相比,为什么多任务学习如此有挑战性,这个问题尚未得到完全解释。在这项研究中,我们确定了三种多任务优化情境下导致不良梯度干扰的条件,并开发了一种简单但通用的方法来避免这种任务梯度间的干扰。我们提出了一种梯度手术方法,将一个任务的梯度投影到其他任何存在冲突梯度任务的梯度的法线平面上。在一系列具有挑战性的多任务监督和多任务RL问题中,这种方法使效率和性能大大提高。而且,它与模型无关,并可以与之前提议的多任务架构相结合,从而进一步提高性能。
引言翻译

图1:在2D多任务优化问题上的PCGrad可视化。 (a) 是一个多任务目标景观。 (b)和©是组成(a)的单个任务目标的等高线图。 (d)是使用Adam优化器对多任务目标进行梯度更新的轨迹。轨迹结束时两个任务的梯度矢量分别由蓝色和红色箭头表示,其中相对长度是对数尺度。 (e)是使用Adam和PCGrad对多任务目标进行梯度更新的轨迹。在(d)和(e)中,优化轨迹的颜色从黑色渐变为黄色。
尽管深度学习和深度强化学习(RL)在使系统学习复杂任务方面表现出了巨大的潜力,但当前方法的数据需求使得从零开始分别学习每项任务变得困难。面对这种多任务学习问题,一种直观的方法是对所有任务进行联合训练,旨在找到任务之间的共享结构,以期比单独解决任务时实现更高的效率和性能。但是,同时学习多个任务变成了一个复杂的优化问题,有时这比单独学习每个任务的效果还要差[42,50]。这些优化问题如此普遍,以至于许多多任务RL算法首先单独进行培训,然后再将这些独立的模型整合到一个多任务模型中[32,42,50,21,56],虽然得到了一个多任务模型,但在独立培训方面的效率提升被牺牲了。如果我们能有效地解决多任务学习的优化挑战,可能真的可以实现多任务学习的预期优势,而不影响最终的表现。
尽管已进行了大量的多任务学习研究[6,49],但其中的优化挑战并不为人所知。先前的工作指出不同任务的学习速度差异[8,26]和优化过程中的高原现象[52]可能是造成这一问题的原因,而其他研究则侧重于模型架构[40,33]。**在这项工作中,我们提出一个假设,即多任务学习中的主要优化问题源于来自不同任务的梯度相互冲突,从而阻碍了学习进度。如果两个梯度的方向相反(即,它们的余弦相似度为负),我们认为这两个梯度是冲突的。**当a)冲突的梯度与b)高正曲率和c)大的梯度幅度差异同时出现时,这种冲突会变得不利。
例如,考虑图1a-c中两个任务目标的2D优化景观。每个任务的优化景观中都有一个深谷,这是在神经网络优化中观察到的现象[22],而每个谷底都具有高正曲率和大的任务梯度幅度差异。在这种情况下,一个任务的梯度会主导多任务梯度,牺牲了另一个任务的性能。由于曲率高,主导任务的改进可能被高估,而非主导任务的性能劣化可能被低估。
因此,优化器难以在优化目标上取得进展。在图1d中,优化器达到了任务1的深谷,但由于存在冲突的梯度、高曲率和大的梯度幅度差异,无法穿越谷底(如图1d中所示的梯度)。在5.3节中,我们实验证明,在更高维的神经网络多任务学习问题中,这种情况也会发生。
**这项工作的主要贡献是一种通过直接修改梯度来减轻梯度干扰的方法,即“梯度手术”。如果两个梯度发生冲突,我们会通过将它们投影到彼此的正交平面上来调整这些梯度,从而阻止梯度的干扰部分作用于网络。我们称这种特定的梯度手术为“投影冲突梯度”(PCGrad)。**PCGrad不依赖于特定模型,只需对梯度的应用进行一次修改。因此,它可以轻松应用于各种问题设置,包括多任务监督学习和多任务强化学习,并可以与其他多任务学习方法(例如,修改架构的方法)结合使用。我们从理论上证明了PCGrad在何种局部条件下能够优于标准的多任务梯度下降,并在多种具有挑战性的问题上对PCGrad进行了实证评估,包括多任务CIFAR分类、多目标场景理解、具有挑战性的多任务RL领域和目标条件下的RL。整体而言,与先前的方法相比,我们发现PCGrad在数据效率、优化速度和最终性能方面都取得了显著的提高,包括在多任务强化学习问题中实现了超过30%的绝对改进。此外,对于多任务监督学习任务,PCGrad可以与先前的多任务学习方法结合使用,以获得更高的性能。
2 使用PCGrad进行多任务学习
尽管从原则上来说,多任务问题可以通过使用标准的单任务算法并为模型提供适当的任务标识符,或者使用简单的多头或多输出模型来解决,但是之前的一些工作 [42, 50, 53] 发现这个问题相当困难。在本节中,我们将引入符号标记,识别多任务优化的困难之处,提出一个简单且通用的方法来缓解这些困难,并对这个方法进行理论分析。
2.1 基本概念:问题和符号表示
多任务学习的目标是找到模型 f θ f_{\theta} fθ 的参数 θ \theta θ,以便在从任务分布 p ( T ) p(\mathcal{T}) p(T) 中抽取的所有训练任务中实现高平均性能。更正式地说,我们的目标是解决以下问题:
min θ E T i ∼ p ( T ) [ L i ( θ ) ] \min_{\theta} \mathbb{E}_{\mathcal{T}_{i} \sim p(\mathcal{T})}\left[\mathcal{L}_{i}(\theta)\right] minθETi∼p(T)[Li(θ)],
其中 L i \mathcal{L}_{i} Li 是我们希望最小化的第 i i i 个任务 T i \mathcal{T}_{i} Ti 的损失函数。对于一组任务 { T i } \left\{\mathcal{T}_{i}\right\} {Ti},我们将多任务损失表示为 L ( θ ) = ∑ i L i ( θ ) \mathcal{L}(\theta)=\sum_{i} \mathcal{L}_{i}(\theta) L(θ)=∑iLi(θ),并将每个任务的梯度表示为 g i = ∇ L i ( θ ) \mathbf{g}_{i}=\nabla \mathcal{L}_{i}(\theta) gi=∇Li(θ),对于特定的 θ \theta θ。为了获得一个能够解决来自任务分布 p ( T ) p(\mathcal{T}) p(T) 中特定任务的模型,我们定义了一个任务条件模型 f θ ( y ∣ x , z i ) f_{\theta}\left(y \mid x, z_{i}\right) fθ(y∣x,zi),其中输入为 x x x,输出为 y y y,编码为 z i z_{i} zi 代表任务 T i \mathcal{T}_{i} Ti,可以以独热编码或任何其他形式提供。
解释这个式子—— f θ ( y ∣ x , z i ) f_{\theta}\left(y \mid x, z_{i}\right) fθ(y∣x,zi):
这个式子表示一个条件概率模型,分解式子来更清楚地解释。
- 函数形式: f θ f_{\theta} fθ
这是一个函数,由参数 θ \theta θ参数化。通常,在深度学习或机器学习的上下文中, f θ f_{\theta} fθ可能是一个神经网络或其他类型的模型,其中 θ \theta θ表示模型的参数,例如权重和偏置。
- 条件符号: ∣ \mid ∣
这个符号表示“给定”或“条件于”,经常用于表示条件概率。在这里,它表示我们想要预测 y y y,但这个预测是基于给定的 x x x和 z i z_{i} zi。
- 变量: y , x , z i y, x, z_{i} y,x,zi
-
y y y:这是我们想要预测或输出的变量。
-
x x x:这是输入变量或特征。在许多机器学习任务中, x x x代表的是我们基于其做出预测的数据。
-
z i z_{i} zi:这是任务 T i \mathcal{T}_{i} Ti的编码。从原文中我们可以看到,这个编码可能是一个one-hot向量或其他形式,用来指示或描述任务 T i \mathcal{T}_{i} Ti。这种编码在多任务学习中是很常见的,它告诉模型应该对哪个特定任务进行优化。
总结: f θ ( y ∣ x , z i ) f_{\theta}\left(y \mid x, z_{i}\right) fθ(y∣x,zi)表示的是一个由参数 θ \theta θ参数化的模型,它试图预测 y y y,基于给定的输入 x x x和任务编码 z i z_{i} zi。这种形式通常出现在多任务学习的场景中,其中模型需要知道它正在处理哪个具体的任务,以便正确地进行预测。
2.2 三重悲剧:冲突的梯度,主导的梯度,高曲率
我们假设多任务学习中的一个关键优化问题源自于冲突的梯度,即不同任务的梯度相互指向对方,如由负内积测量的那样。然而,冲突的梯度本身并不是有害的。事实上,简单地平均任务梯度应该能够提供降低多任务目标的合适解决方案。然而,在某些情况下,这种冲突的梯度会导致性能大幅下降。考虑一个具有两个任务的优化问题。如果一个任务的梯度的幅度远大于另一个任务的梯度,它将主导平均梯度。如果在任务梯度方向上还有高正曲率,则来自主导任务的性能提升可能会被大大高估,而来自被主导任务的性能下降可能会被大大低估。因此,我们可以这样描述这三个条件的共同出现:(a) 多个任务的梯度相互冲突,(b) 梯度幅度的差异很大,导致某些任务梯度主导其他任务梯度,并且 © 多任务优化景观中存在高曲率。在下面,我们正式定义了这三个条件。
定义 1. \textbf{定义 1.} 定义 1. 我们定义 ϕ i j \phi_{ij} ϕij 为两个任务梯度 g i \mathbf{g}_{i} gi 和 g j \mathbf{g}_{j} gj 之间的夹角。当 cos ϕ i j < 0 \cos \phi_{ij}<0 cosϕij<0 时,我们定义这些梯度之间存在冲突。
定义 2. \textbf{定义 2.} 定义 2. 我们定义两个梯度 g i \mathbf{g}_{i} gi 和 g j \mathbf{g}_{j} gj 之间的梯度幅度相似性为
Φ ( g i , g j ) = 2 ∥ g i ∥ 2 ∥ g j ∥ 2 ∥ g i ∥ 2 2 + ∥ g j ∥ 2 2 . \Phi(\mathbf{g}_{i}, \mathbf{g}_{j})=\frac{2\|\mathbf{g}_{i}\|_{2}\|\mathbf{g}_{j}\|_{2}}{\|\mathbf{g}_{i}\|_{2}^{2}+\|\mathbf{g}_{j}\|_{2}^{2}}. Φ(gi,gj)=∥gi∥22+∥gj∥222∥gi∥2∥gj∥2.
当两个梯度的幅度相同时,这个值等于1。当梯度的幅度差异增大时,这个值趋近于零。
定义 3. \textbf{定义 3.} 定义 3. 我们定义多任务曲率为
H ( L ; θ , θ ′ ) = ∫ 0 1 ∇ L ( θ ) T ∇ 2 L ( θ + a ( θ ′ − θ ) ) ∇ L ( θ ) d a \mathbf{H}(\mathcal{L}; \theta, \theta^{\prime})=\int_{0}^{1} \nabla \mathcal{L}(\theta)^{T} \nabla^{2} \mathcal{L}(\theta+a(\theta^{\prime}-\theta)) \nabla \mathcal{L}(\theta) \, da H(L;θ,θ′)=∫01∇L(θ)T∇2L(θ+a(θ′−θ))∇L(θ)da,
这是在多任务梯度 ∇ L ( θ ) \nabla \mathcal{L}(\theta) ∇L(θ) 的方向上, L \mathcal{L} L 在 θ \theta θ 和 θ ′ \theta^{\prime} θ′ 之间的平均曲率。
当 H ( L ; θ , θ ′ ) > C \mathbf{H}(\mathcal{L}; \theta, \theta^{\prime})>C H(L;θ,θ′)>C 对于某个大的正常数 C C C,对于模型参数 θ \theta θ 和 θ ′ \theta^{\prime} θ′ 在当前和下一个迭代时,我们将优化景观描述为具有高曲率。
我们的目标是研究这三重悲剧,并通过两个例子来观察这三个条件的存在。首先,考虑图1a所示的二维优化景观,其中每个任务目标的景观对应于一个深深的山谷,具有大的曲率(见图1b和1c)。这个多任务目标的最优解对应于这两个山谷相遇的地方。关于优化景观的更多细节,请参见附录D。这个优化景观的某些特定点展现了上述三个条件,我们观察到,Adam优化器 [30] 恰好在其中一个点上停滞,阻止它达到最优解。这为我们的假设提供了一些经验性的证据。我们在第5.3节的实验进一步表明,这种现象在使用深度网络的多任务学习中确实发生。受到这些观察的启发,我们开发了一个算法,旨在减轻由冲突的梯度、主导的梯度和高曲率引起的优化挑战,接下来我们将描述这个算法。
2.3 PCGrad:解决梯度冲突
我们的目标是通过直接修改梯度来打破悲剧三重奏的其中一个条件,以避免冲突。在本节中,我们将概述如何修改梯度的方法。在下一节中,我们将从理论上证明,在存在主导梯度和高曲率的情况下,解决梯度冲突可以有益于多任务学习。
为了达到最大的效果并广泛适用,我们的目标是以一种可以在任务梯度之间产生积极互动且不会对模型形式做出假设的方式来修改梯度。因此,当梯度不冲突时,我们不改变梯度。当梯度发生冲突时,PCGrad的目标是为每个任务修改梯度,以尽量减少与其他任务梯度的负面冲突,这将进一步缓解由高曲率引起的低估和高估问题。
为了在优化过程中解决梯度冲突,PCGrad采用了一个简单的程序:如果两个任务之间的梯度发生冲突,即它们的余弦相似度为负,则我们将每个任务的梯度投影到另一个任务的梯度的法向平面上。这相当于为任务去除了梯度的冲突组件,从而减少了任务之间的梯度干扰。这个想法的图解如图2所示。


图2:冲突梯度和PCGrad。在(a)中,任务i和j具有冲突的梯度方向,这可能导致破坏性的干扰。在(b)和©中,我们说明了当梯度冲突时的PCGrad算法。PCGrad将任务i的梯度投影到任务j的梯度的法向量上,反之亦然。非冲突任务梯度(d)在PCGrad下不会改变,允许有建设性的互动。
假设任务 T i \mathcal{T}_{i} Ti的梯度是 g i \mathbf{g}_{i} gi,任务 T j \mathcal{T}_{j} Tj的梯度是 g j \mathbf{g}_{j} gj。PCGrad如下进行:
(1) 首先,通过计算向量 g i \mathbf{g}_{i} gi和 g j \mathbf{g}_{j} gj之间的余弦相似度来确定 g i \mathbf{g}_{i} gi是否与 g j \mathbf{g}_{j} gj冲突,其中负值表示冲突梯度。
(2) 如果余弦相似度为负,则我们用 g i \mathbf{g}_{i} gi在 g j \mathbf{g}_{j} gj的法向平面上的投影替换 g i \mathbf{g}_{i} gi: g i = g i − g i ⋅ g j ∥ g j ∥ 2 g j \mathbf{g}_{i}=\mathbf{g}_{i}-\frac{\mathbf{g}_{i} \cdot \mathbf{g}_{j}}{\left\|\mathbf{g}_{j}\right\|^{2}} \mathbf{g}_{j} gi=gi−∥gj∥2gi⋅gjgj。如果梯度没有冲突,即余弦相似度为非负,则原始梯度 g i \mathbf{g}_{i} gi保持不变。
(3) PCGrad重复这个过程,从当前批次 T j \mathcal{T}_{j} Tj中随机选择的所有其他任务中,对于所有的 j ≠ i j \neq i j=i,产生应用于任务 T i \mathcal{T}_{i} Ti的梯度 g i P C \mathbf{g}_{i}^{\mathrm{PC}} giPC。
我们对批次中的所有任务执行相同的程序,以获得它们各自的梯度。完整的更新程序在算法1中描述,而关于使用随机任务顺序的讨论则包含在附录H中。
这个程序虽然实现简单,但确保了我们为每个任务每批应用的梯度与批次中的其他任务干扰最少,从而减少了梯度冲突问题,产生了多目标设置中的标准一阶梯度下降的变体。在实践中,PCGrad可以与任何基于梯度的优化器结合使用,包括常用的方法如带动量的SGD和Adam [30],只需将计算出的更新传递给相应的优化器,而不是原始梯度。我们的实验结果验证了这一过程可以减少梯度冲突问题的假设,并发现,因此,学习进度得到了大幅度的改进。
2.4 PCGrad的理论分析
在本节中,我们将从理论上分析PCGrad在处理两个任务时的性能:
定义4. 考虑两个任务损失函数 L 1 : R n → R \mathcal{L}_{1}: \mathbb{R}^{n} \rightarrow \mathbb{R} L1:Rn→R 和 L 2 : R n → R \mathcal{L}_{2}: \mathbb{R}^{n} \rightarrow \mathbb{R} L2:Rn→R。我们定义两任务学习目标为 L ( θ ) = L 1 ( θ ) + L 2 ( θ ) \mathcal{L}(\theta)=\mathcal{L}_{1}(\theta)+\mathcal{L}_{2}(\theta) L(θ)=L1(θ)+L2(θ),对于所有的 θ ∈ R n \theta \in \mathbb{R}^{n} θ∈Rn,其中 g 1 = ∇ L 1 ( θ ) \mathbf{g}_{1}=\nabla \mathcal{L}_{1}(\theta) g1=∇L1(θ), g 2 = ∇ L 2 ( θ ) \mathbf{g}_{2}=\nabla \mathcal{L}_{2}(\theta) g2=∇L2(θ),且 g = g 1 + g 2 \mathbf{g}=\mathbf{g}_{1}+\mathbf{g}_{2} g=g1+g2。
首先,我们目标是验证在简化的假设下,PCGrad的更新对应一个合理的优化程序。我们在凸集设置下分析PCGrad的收敛性,基于定理1中的标准假设。关于收敛性的进一步分析,包括非凸设置、多于两个任务,以及基于动量的优化器,请参见附录A.1和A.4。
定理1. 假设 L 1 \mathcal{L}_{1} L1 和 L 2 \mathcal{L}_{2} L2 是凸的且可微的。假设 L \mathcal{L} L 的梯度是 L L L Lipschitz 且 L > 0 L>0 L>0。那么,使用步长 t ≤ 1 L t \leq \frac{1}{L} t≤L1 的 PCGrad 更新规则将收敛于 (1) 优化景观中的一个位置,其中 cos ( ϕ 12 ) = − 1 \cos \left(\phi_{12}\right)=-1 cos(ϕ12)=−1 或 (2) 最优值 L ( θ ∗ ) \mathcal{L}\left(\theta^{*}\right) L(θ∗)。
证明. 参见附录A.1。
简单来说,定理1 指出,在凸环境下,对于两个任务的多任务损失函数 L \mathcal{L} L,应用PCGrad更新会导致一个位置,要么是 L \mathcal{L} L 的最小值,要么是梯度完全冲突的次优位置。这意味着,如果两任务的梯度方向正好相反,则PCGrad的梯度更新为零,这可能导致次优解。但实际上,因为我们使用的是SGD,它仅是真实梯度的一个含噪声的估计,所以两个任务的梯度在一个小批次中的相似度很难恰好为-1,这避免了这种情况。值得注意的是,理论上,如果两个梯度之间的角度非常接近直角,那么收敛可能会变慢。但在实际应用中,我们并没有观察到这种情况,如附录B的学习曲线所示。
现在我们已经检查了PCGrad的合理性,我们的目标是了解PCGrad与悲剧三重奏中的三个条件之间的关系。特别地,我们导出了在一个更新之后,PCGrad达到更低损失的充分条件。在这里,我们仍然分析两任务设置,但不再假设损失函数的凸性。
定义5. 我们定义多任务曲率界定度量为
ξ ( g 1 , g 2 ) = ( 1 − cos 2 ϕ 12 ) ∥ g 1 − g 2 ∥ 2 2 ∥ g 1 + g 2 ∥ 2 2 \xi\left(\mathbf{g}_{1}, \mathbf{g}_{2}\right)=(1-\cos^{2} \phi_{12}) \frac{\|\mathbf{g}_{1}-\mathbf{g}_{2}\|_{2}^{2}}{\|\mathbf{g}_{1}+\mathbf{g}_{2}\|_{2}^{2}} ξ(g1,g2)=(1−cos2ϕ12)∥g1+g2∥22∥g1−g2∥22
基于上述定义,我们提出了我们的下一个定理:
定理2. 假设 L \mathcal{L} L 是可微的,且 L \mathcal{L} L 的梯度是具有常数 L > 0 L>0 L>0 的Lipschitz连续的。设 θ M T \theta^{MT} θMT 和 θ PCGrad \theta^{\text{PCGrad}} θPCGrad 分别为对 θ \theta θ 使用 g \mathbf{g} g 和 PCGrad修改过的梯度 g P C \mathbf{g}^{PC} gPC 之后的参数,步长为 t > 0 t>0 t>0。此外,假设对于某个常数 ℓ ≤ L \ell \leq L ℓ≤L 有 H ( L ; θ , θ M T ) ≥ ℓ ∥ g ∥ 2 2 \mathbf{H}\left(\mathcal{L} ; \theta, \theta^{MT}\right) \geq \ell\|\mathbf{g}\|_{2}^{2} H(L;θ,θMT)≥ℓ∥g∥22,即多任务曲率是下界的。那么,如果满足 (a) cos ϕ 12 ≤ − Φ ( g 1 , g 2 ) \cos \phi_{12} \leq -\Phi\left(\mathbf{g}_{1}, \mathbf{g}_{2}\right) cosϕ12≤−Φ(g1,g2),(b) ℓ ≥ ξ ( g 1 , g 2 ) L \ell \geq \xi\left(\mathbf{g}_{1}, \mathbf{g}_{2}\right) L ℓ≥ξ(g1,g2)L,和 © t ≥ 2 ℓ − ξ ( g 1 , g 2 ) L t \geq \frac{2}{\ell-\xi\left(\mathbf{g}_{1}, \mathbf{g}_{2}\right) L} t≥ℓ−ξ(g1,g2)L2,则 L ( θ PCGrad ) ≤ L ( θ M T ) \mathcal{L}\left(\theta^{\text{PCGrad}}\right) \leq \mathcal{L}\left(\theta^{MT}\right) L(θPCGrad)≤L(θMT)。
证明. 参见附录A.2。
直观地说,定理2 意味着,在单个梯度更新后,与标准的多任务学习梯度下降相比,PCGrad可以实现更低的损失值,当 (i) 任务梯度之间的角度不是太小,即两个任务需要有足够的冲突(条件(a)),(ii) 差异的大小需要足够大(条件(a)),(iii) 多任务梯度的曲率应该很大(条件(b)),(iv) 学习速率应该足够大,以便大的曲率会导致对主导任务的性能改进的高估和对被主导任务的性能退化的低估(条件©)。这前三点 (i-iii) 完全对应于2.2节中概述的三重奏的条件,而后者条件 (iv) 是期望的,因为我们希望快速学习。我们通过5.3节的图4实证验证,第一三点,(i-iii),在神经网络多任务学习问题中经常被满足。关于PCGrad更新比原生多任务梯度更优的完整的充分和必要条件的进一步分析,请参见附录A.3。
3 PCGrad在实际应用中
我们在监督学习和强化学习中使用PCGrad处理多任务或多目标问题。下面,我们将讨论PCGrad在这些场景中的实际应用方法。
在多任务的监督学习中,每一个任务 T i ∼ p ( T ) \mathcal{T}_{i} \sim p(\mathcal{T}) Ti∼p(T)都有其对应的训练数据集 D i \mathcal{D}_{i} Di,它由标注的训练样本组成,即 D i = { ( x , y ) n } \mathcal{D}_{i}=\left\{(x, y)_{n}\right\} Di={(x,y)n}。在这种监督环境中,每个任务的目标定义为 L i ( θ ) = E ( x , y ) ∼ D i [ − log f θ ( y ∣ x , z i ) ] \mathcal{L}_{i}(\theta)=\mathbb{E}_{(x, y) \sim \mathcal{D}_{i}}\left[-\log f_{\theta}\left(y \mid x, z_{i}\right)\right] Li(θ)=E(x,y)∼Di[−logfθ(y∣x,zi)],这里的 z i z_{i} zi是任务 T i \mathcal{T}_{i} Ti的独热编码。在每一个训练步骤,我们从所有数据集 ⋃ i D i \bigcup_{i} \mathcal{D}_{i} ⋃iDi中随机选取一批数据 B \mathcal{B} B,然后将这些随机样本根据其任务编码分组,形成每个任务 T i \mathcal{T}_{i} Ti的小批次数据 B i \mathcal{B}_{i} Bi。我们记 B \mathcal{B} B中的任务集合为 B T \mathcal{B}_{\mathcal{T}} BT。取样之后,我们为 B T \mathcal{B}_{\mathcal{T}} BT中的每一个任务预先计算梯度,形式为 ∇ θ L i ( θ ) = E ( x , y ) ∼ B i [ − ∇ θ log f θ ( y ∣ x , z i ) ] \nabla_{\theta} \mathcal{L}_{i}(\theta)=\mathbb{E}_{(x, y) \sim \mathcal{B}_{i}}\left[-\nabla_{\theta} \log f_{\theta}\left(y \mid x, z_{i}\right)\right] ∇θLi(θ)=E(x,y)∼Bi[−∇θlogfθ(y∣x,zi)]。有了这些预先计算的梯度,我们还预先计算集合中所有梯度对的余弦相似度。利用这些预先计算的梯度和它们的相似度,我们可以按照算法1得到PCGrad的更新,无需再次计算任务梯度或对网络进行反向传播。由于PCGrad仅在优化过程中修改共享参数的梯度,因此它不依赖于任何特定模型,并可以应用于任何有共享参数的架构。在第5节中,我们针对多种架构验证了PCGrad的实际效果。
对于多任务的强化学习和基于目标的强化学习,可以直接将PCGrad应用到策略梯度方法上,这是通过直接更新每个任务计算出的策略梯度来实现的,这与监督学习的情境是相似的。对于actor-critic算法,应用PCGrad也很直接:我们只需用通过PCGrad计算出的梯度替换actor和critic的任务梯度即可。更多关于强化学习的实际实施细节,请查看附录C。
(待续)
参考文章
-
多任务学习——【ICLR 2020】PCGrad
-
论文阅读:Gradient Surgery for Multi-Task Learning
相关文章:
论文精读 —— Gradient Surgery for Multi-Task Learning
文章目录 Multi-task Learning和 PCGrad 方法简介论文信息论文核心图摘要翻译引言翻译2 使用PCGrad进行多任务学习2.1 基本概念:问题和符号表示2.2 三重悲剧:冲突的梯度,主导的梯度,高曲率2.3 PCGrad:解决梯度冲突2.4 …...
【VS Code插件开发】常见自定义命令(七)
🐱 个人主页:不叫猫先生,公众号:前端舵手 🙋♂️ 作者简介:前端领域优质作者、阿里云专家博主,共同学习共同进步,一起加油呀! 📢 资料领取:前端…...

Spring Cloud服务发现与注册的原理与实现
Spring Cloud服务发现与注册的原理与实现 一、简介1 服务发现的定义2 服务发现的意义 二、Spring Cloud服务注册与发现的实现1 Spring Cloud服务注册1.1 服务注册的基本框架1.2 服务注册的实现方式 2 Spring Cloud服务发现2.1 服务发现的基本框架2.2 服务发现的实现方式 三、Sp…...

FFmpeg入门之简单介绍
FFmpeg是什么意思: Fast Forward Moving Picture Experts Group ffmpeg相关文档: Documentation FFmpeg ffmpeg源码下载: https://git.videolan.org/git/ffmpeg.git https://github.com/FFmpeg/FFmpeg.git FFmpeg能做什么? 多种媒体格式的封装与解封装 : 1.多种音…...

新版DBeaver调整编辑窗口字体大小
网上有DBeave字体设置了,但看了下,目前最新版的已经更改了首选项分组,层级发生了变化,这里记录一下2022.08.21版的设置。 默认字体是10,比较小,改为11或更大会好看些。...
《vue3实战》运用push()方法实现电影评价系统的添加功能
目录 前言 电影评价系统的添加功能是什么? 电影评价系统的添加功能有什么作用? 一、push()方法是什么?它有什么作用? 含义: 作用: 二、功能实现 这段是添加开始时点击按钮使…...
JavaScript学习笔记02
JavaScript笔记02 数据类型详解 字符串 在 JavaScript 中正常的字符串都使用单引号 或者双引号" "包裹:例: 转义字符 在 JavaScript 字符串中也可用使用转义字符(参考:详解转义字符):例&…...
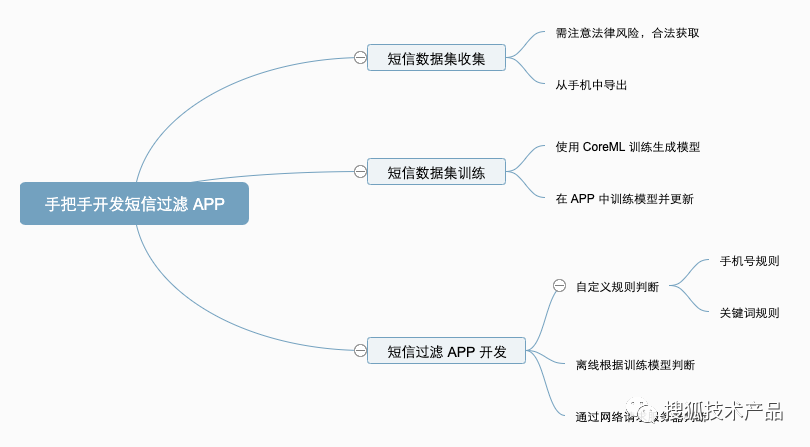
短信过滤 APP 开发
本文字数:7033字 预计阅读时间:42分钟 一直想开发一个自己的短信过滤 APP,但是一直没有具体实施,现在终于静下心来,边开发边记录下整体的开发过程。 01 垃圾短信样本 遇到的第一个问题是,既然要过滤垃圾短信…...

【计算机基础知识7】垃圾回收机制与内存泄漏
目录 前言 一、垃圾回收机制的工作原理 1. 标记-清除算法的基本原理 2. 垃圾回收器的类型及其工作方式 3. 垃圾回收的回收策略和触发机制 三、内存泄漏的定义和原因 1. 内存泄漏的概念和影响 2. 常见的内存泄漏情况及其原因 四、如何避免和处理内存泄漏 1. 使用合适…...

[学习笔记]CS224W
资料: 课程网址 斯坦福CS224W图机器学习、图神经网络、知识图谱【同济子豪兄】 斯坦福大学CS224W图机器学习公开课-同济子豪兄中文精讲 图的基本表示 图是描述各种关联现象的通用语言。与传统数据分析中的样本服从独立同分布假设不一样,图数据自带关联…...
华为云API对话机器人CBS的魅力—实现简单的对话操作
云服务、API、SDK,调试,查看,我都行 阅读短文您可以学习到:人工智能AI智能的问答管理、全面的对话管理、高效训练部署 1.IntelliJ IDEA 之API插件介绍 API插件支持 VS Code IDE、IntelliJ IDEA等平台、以及华为云自研 CodeArts …...

精益制造、质量管控,盛虹百世慧共同启动MOM(制造运营管理)
百世慧科技依托在电池智能制造行业中的丰富经验,与盛虹动能达成合作,为其提供MOM制造运营管理平台,并以此为起点,全面提升盛虹动能的制造管理水平与运营体系。 行业困境 中国动力电池已然发展为全球最大的电池产业,但…...
【科研论文配图绘制】task7密度图绘制
【科研论文配图绘制】task7密度图绘制 task7 了解密度图的定义,清楚密度图是常用使用常见,掌握密度图绘制。 1.什么是密度图 密度图(Density Plot)是一种用于可视化数据分布的图表类型。它通过在数据中创建平滑的概率密度曲线…...

Python3 集合
Python3 集合 集合(set)是一个无序的不重复元素序列。 可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。 创建格式: parame …...

【山河送书第十期】:《Python 自动化办公应用大全》参与活动,送书两本!!
【山河送书第十期】:《Python 自动化办公应用大全》参与活动,送书两本!! 前言一书籍亮点二作者简介三内容简介四购买链接五参与方式六往期赠书回顾 前言 在过去的 5 年里,Python 已经 3 次获得 TIOBE 指数年度大奖&am…...

Java多线程——同步
同步是什么? 当两个线程同时对一个变量进行修改时,不同的访问顺序会造成不一样的结果,这时候就需要同步保证结果的唯一性。 未同步时 新建Bank类,transfer()用于在两个账户之间转账金额 class Bank {private double[] account…...
Vue+NodeJS实现邮件发送
一.邮箱配置 这里以QQ邮箱为例,网易邮箱类似. 设置->账号 二.后端服务搭建 index.js const express require(express) const router require(./router); const app express()// 使用路由文件 app.use(/,router);app.listen(3000, () > {console.log(server…...
TCP粘包)
Go语言网络编程(socket编程)TCP粘包
1、TCP粘包 服务端代码如下: // socket_stick/server/main.gofunc process(conn net.Conn) {defer conn.Close()reader : bufio.NewReader(conn)var buf [1024]bytefor {n, err : reader.Read(buf[:])if err io.EOF {break}if err ! nil {fmt.Println("read…...
【再识C进阶2(中)】详细介绍指针的进阶——函数指针数组、回调函数、qsort函数
前言 💓作者简介: 加油,旭杏,目前大二,正在学习C,数据结构等👀 💓作者主页:加油,旭杏的主页👀 ⏩本文收录在:再识C进阶的专栏…...
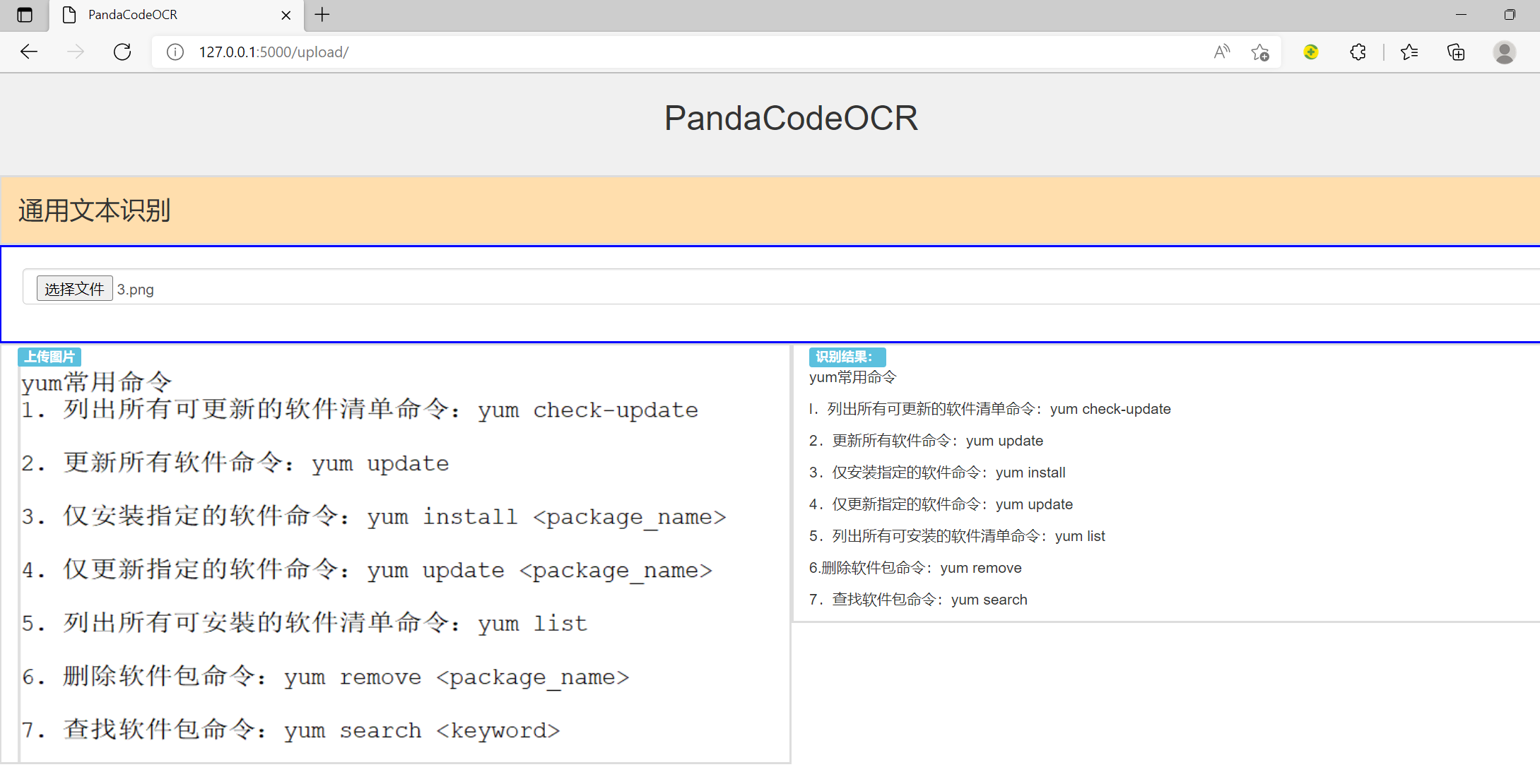
PaddleOCR学习笔记3-通用识别服务
今天优化了下之前的初步识别服务的python代码和html代码。 采用flask paddleocr bootstrap快速搭建OCR识别服务。 代码结构如下: 模板页面代码文件如下: upload.html : <!DOCTYPE html> <html> <meta charset"utf-8"> …...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

Java如何权衡是使用无序的数组还是有序的数组
在 Java 中,选择有序数组还是无序数组取决于具体场景的性能需求与操作特点。以下是关键权衡因素及决策指南: ⚖️ 核心权衡维度 维度有序数组无序数组查询性能二分查找 O(log n) ✅线性扫描 O(n) ❌插入/删除需移位维护顺序 O(n) ❌直接操作尾部 O(1) ✅内存开销与无序数组相…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...