mysql(九)mysql主从复制
目录
- 前言
- 概述
- 提出问题
- 主从复制的用途
- 工作流程
- 主从复制的配置
- 创建复制账号
- 配置主库和从库
- 启动主从复制
- 从另一个服务器开始主从复制
- 主从复制时推荐的配置
- sync_binlog
- innodb_flush_logs_at_trx_commit
- innodb_support_xa=1
- innodb_safe_binlog
- 主从复制的原理
- 基于语句复制
- 优点:
- 缺点:
- 基于行复制
- 优点:
- 缺点:
- 主从复制用到的文件
- mysql-bin.index
- mysql-relay-bin-index
- master.info
- relay-log.info
- 发送复制事件到其他的从库
- 主从复制拓扑
- 一主库多从库
- 用途
- 主动-主动模式下的主-主复制
- 主动-被动模式下的主-主复制
- 拥有从库的主-主结构
- 主库,分发主库以及从库
- 树或金字塔型
- 定制的复制方案
- 选择性复制
- 分离功能
- 数据归档
- 只读从库
- 复制和容量规划
- 如何测量从库延迟
- 检查主从是否一致
- 从主库重新同步从库
前言
MySQL的内建功能是构建基于MySQL的大规模,高性能应用的基础,这类应用使用所谓的“水平扩展”的架构。我们可以通过为服务器配置一个或多个从库的方式来进行数据同步,复制功能不仅有利于构建高性能的应用,同时也是高可用,可扩展性,灾难恢复,备份以及数据仓库等工作的基础。
概述
复制解决的基本问题是让一台服务器的数据与其他服务器保持同步。一台主库的数据可以同步到多台设备上,从库本身也可以被配置到另外一台服务器的书库。主库和从库可以有多种不同的组合方式。
MySQL支持两种复制方式
- 基于行的复制
- 基于语句的复制
这两种方式都是通过在主库上记录二进制日志,在从库重放日志的方式来实现异步的数据复制。这意味着,在同一时间点从库上的数据可能与主库存在不一致,并且无法保证主从之间的延迟。一些大的语句可能导致从库产生几秒,几分钟甚至几个小时的延迟。
MySQL通常是向后兼容的,新版本的服务器可以作为老版本服务器的从库,但反过来,将老版本作为新版本服务器的从库通常是不行的,因为它可能无法解析新版本所采用的的新的特性或语法,另外所使用的的二进制文件的格式也可能不太相同。
主从复制通常不会增加主库的开销,主要是启用二进制日志带来的开销,但是出于备份或及时从崩溃中恢复的目的,这点开销也是必要的。除此之外,每个从库也会对主库增加一些负载(例如I/O开销),尤其当从库请求从主库读取旧的二进制日志文件时,可能会造成更高的I/O开销。另外锁竞争也可能阻碍事务的提交。最后,如果是从一个高吞吐量(例如5000或者更高的TPS)的主库上复制到多个从库,唤醒多个线程发送事件的开销将会累加。
通过主从复制可以将读操作指向从库来获得更好的读扩展,但是对于写操作,除非设计得当,否则并不适合通过主从复制来扩展写操作。在一主库多从库的架构中,写操作会被执行多次,这个时候整个系统的性能取决于写入最慢的那部分
提出问题
此时我们想一想,当使用一主库多从库的时候,可能会造成一些浪费,因为本质上它会复制大量不必要的重复数据。例如,对于一台主库和十台从库的时候,会有十一份数据拷贝,并且这十一台服务器的缓存中储存了大部分相同的数据。这和服务器上有十一路RAID 1类似。这不是一种经济的硬件使用方式。但这种复制架构却很常见,稍后我们会讨论解决这个问题的方法。
主从复制的用途
- 数据分布
MySQL主从复制通常不会对贷款造成很大压力,但是在5.1版本引入的基于行的复制会比传统的基于语句的复制模式带来的贷款压力更大。你可以随意的停止或者开始复制,并在不同的地理位置来分布数据备份。但如果为了保持很低的复制延迟,最好有一个稳定的,低延迟的连接 - 负载均衡
通过主从复制可以将读操作分布到多个服务器上,实现对密集型应用的优化,并且实现很方便,通过简单的代码修改就能实现基本的负载均衡。对于小规模的应用,可以简单的对机器名做硬编码或使用DNS轮询(将一个机器名指向多个IP地址)。当然也可以使用更复杂的方法,例如网络负载均衡这一类的标准负载均衡解决方案,能够很好的将负载分配到不同的MySQL服务器上。 - 备份
对于备份来说,复制是一项很有意义的技术补充,但复制既不是备份也不能够取代备份 - 高可用和故障切换
复制能够帮助应用避免MySQL单点失败,一个包含复制的设计良好的故障切换系统能够明显得缩短宕机时间 - MySQL升级测试
这种做法比较普遍,使用一个更高版本的MySQL作为从库,保证在升级全部实例前,查询能够在从库按照预期执行。
工作流程
MySQL实际上是如何复制数据的。总的来说,分为如下三个步骤:
- 在主库上记录二进制日志(Binary Log)。在每次准备提交事务完成数据更新前,主库将数据更新的事件记录到二进制日志(Binary Log)中,MySQL会按照事务提交的顺序而非每条语句的执行顺序来记录二进制日志。在记录二进制日志后,主库会告诉存储引擎可以提交事务了。
- 从库将主库的二进制日志(Binary Log)复制到其本地的中继日志(Relay Log)当中。首先,从库会启动一个工作线程,成为I/O线程,I/O线程跟主库建立一个普通的客服端连接,然后在主库上启动一个特殊的二进制转储(binlog dump)线程(该线程没有对应的SQL命令),这个二进制转储线程会读取主库上二进制日志(Binary Log)中的事件。他不会对事件进行轮询。如果该线程追赶上了主库,它将进入睡眠状态,直到主库发送信号量通知其有的新的事件产生时才会被唤醒,备库I/O线程会将接收到的事件记录到中继日志中。
- 从库的SQL线程会执行最后一步。该线程从中继日志(Relay Log)中读取事件并在从库中执行,从而实现从库的数据更新。当SQL线程追赶上I/O线程时,中继日志(Relay Log)通常已经在系统缓存中,所以中继日志(Relay Log)的开销很低。SQL线程执行的事件也可以通过配置选项来决定是否写入其自己的二进制日志(Binary Log)中,它对我们稍后提到的场景非常有用
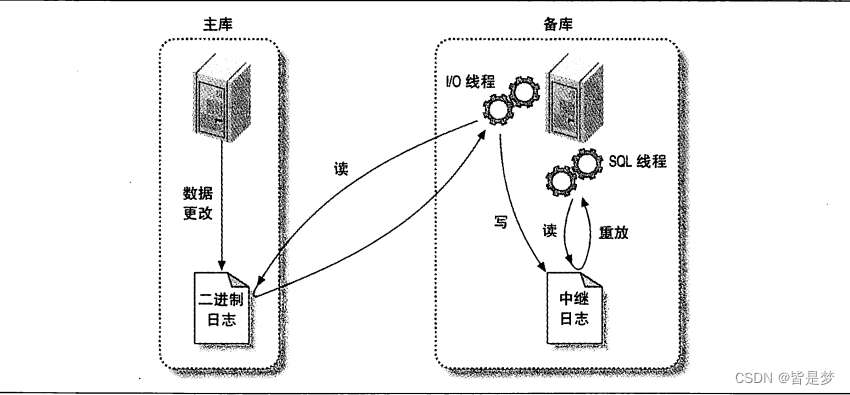
上图中显示了在从库中有两个运行的线程,在主库中也有一个运行的线程,这种复制架构实现了获取事件和重放时间的解耦,允许这两个过程异步进行。也是就说I/O线程能工独立于SQL线程之外工作。这种架构也限制了复制的过程,其中很重要的一点是在主库上并发运行的查询在从库只能串行化执行,因为只有一个SQL线程来重放中继日志中的事件,这个会是很多工作负载的性能瓶颈所在。
主从复制的配置
为MySQL服务器配置非常简单。但由于场景不同。基本的步骤有所差异。最基本的场景是新安装的主库和从库,总的来说分为以下几步:
- 在每台服务器上注册新的账号
- 配置主库和从库
- 通知从库连接到主库并从主库上复制数据
这里我们假定大部分配置采用默认值即可,在主库和从库都是全新安装并且拥有同样的数据时这样的假设是合理的。
创建复制账号
MySQL会赋予一些特殊的权限给复制线程。在从库运行的I/O线程会建立一个到主库的TCP/IP连接,这意味着必须在主库创建一个用户,并赋予权限。从库I/O线程以该用户名连接到主库并读取其二进制日志
mysql> CREATE USER 'repl'@'%' IDENTIFIED BY 'Dxl199522@';
mysql> GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'repl'@'%';
mysql> flush privileges;
-
REPLICATION SLAVE: 这是一个权限选项,表示授予用户主从复制的权限。主从复制是 MySQL 数据库中的一种特性,它允许一个 MySQL 服务器(从服务器)从另一个 MySQL 服务器(主服务器)复制数据。
-
REPLICATION CLIENT: 这是另一个权限选项,表示授予用户复制客户端的权限。复制客户端权限允许用户查看复制相关的状态和信息。

我们在主库和从库都创建该账号
复制账户事实上只需要有主库上的REPLICATION SLAVE权限,并不一定需要每一端服务器都有REPLICATION CLIENT权限,那为什么我们要把这两种权限给主/从库都赋予呢?这有两个原因:
1.用来监控和管理复制的账号需要 REPLICATION CLIENT权限,并且针对这两种目的使用同一个账号更加容易 (而不是为某个目的单独创建一个账号)。
2.如果在主库上建立了账号,然后从主库将数据克隆到备库上时,备库也就设置好了一一变成主库所需要的配置。这样后续有需要可以方便地交换主备库的角色。
配置主库和从库
首先在主库上开启一些设置,需要打开二进制日志并指定一个独一无二服务器ID,在主库的my.cnf文件中增加或者修改如下内容并重启:
log_bin=mysql-bin
server_id=10
必须明确的指定一个唯一的服务器ID,默认服务器ID通常为1。使用默认值可能会导致和其他服务器的ID冲突,因此这里我们选择10来作为服务器ID。一种通用的做法是使用服务器IP地址的末8位,但要保证它是唯一不变的。最好选择一些有意义的约定并遵循。
此时使用命令
mysql> show master status;

从库上也需要在my.cnf中增加类似的配置,并且同样需要重启服务器
log_bin=mysql-bin
server_id=2
relay_log=/var/lib/mysql/mysql-relay-bin
log_slave_updates=1
read_only=1
从技术上,这些选项只有server_id是必须的。这里我们也使用了log_bin,并赋予了一个明确的名字。默认情况下,它是根据机器名来命名的,但如果机器名变化了可能会导致问题。为了简便起见,我们将主库和从库上的log_bin设置为相同的值。
除此之外我们还增加了两个配置选项:
- relay_log:指定中继日志的位置和命名
- log_updates:允许从库将其重放的事件也记录到自身的二进制日志中,此选项会给从库增加额外的工作,但是在文章会提到为什么要添加改配置
启动主从复制
告诉从库如何连接到主库并重放进其二进制日志。
mysql> CHANGE MASTER TO MASTER_HOST='192.168.99.145',
MASTER_USER='repl',
MASTER_PASSWORD='Dxl199522@',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=0;
MASTER_LOG_POS参数被设置成0,因为要从日志的开头读起。当在从库中执行完这条语句之后,可以通过
mysql> show slave status\G
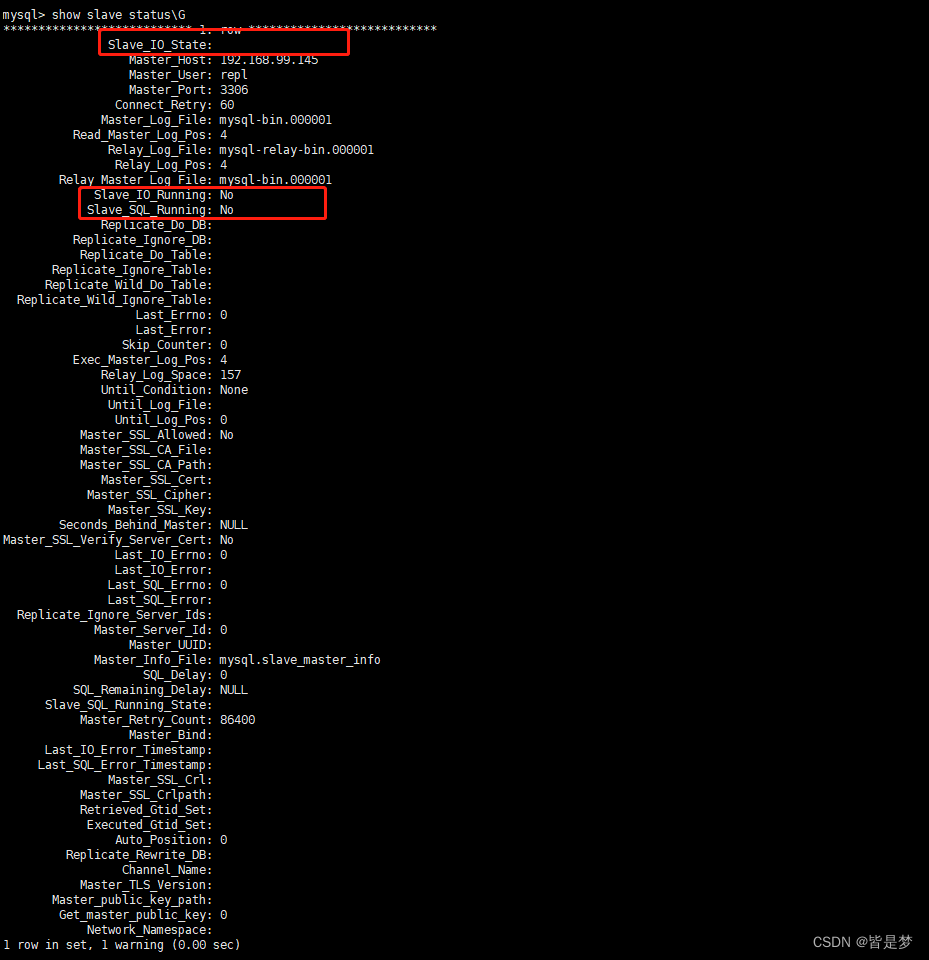
图中参数显示当前从库复制尚未运行
运行命令开始复制
mysql> start slave;
执行该命令后没有显示错误,然后使用show slave status查看状态显示
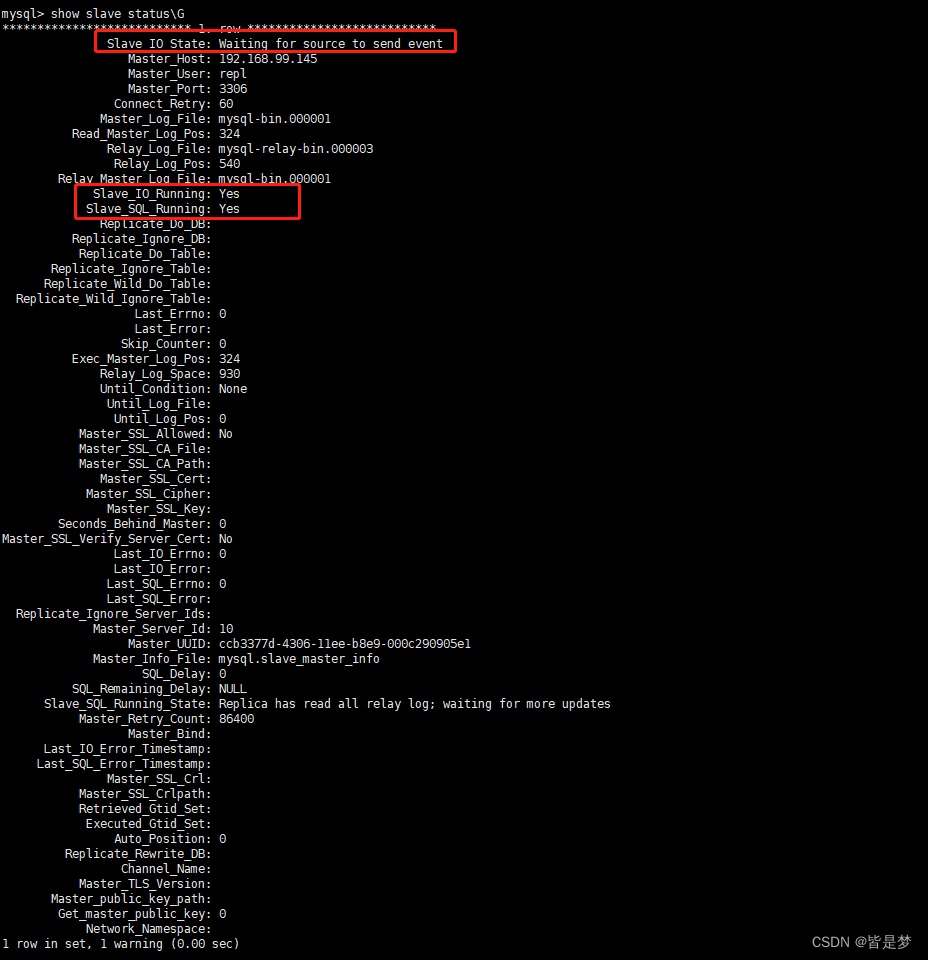
从输出上看出I/O和SQL线程都开始运行,此时已经完成最基本场景的主从复制了。
从另一个服务器开始主从复制
上述的设置主库和从库都是刚刚安装切都是默认的数据,也就是说两台服务器上的数据已经相同,并且知道当前主库的二进制文件。但是现实的场景往往是已经运行了一段时间的主库,然后用一台新安装的从库与之同步,此时这台设备还没有数据。那么如何初始化从库呢
需要有三个条件来让主库和从库保持数据同步:
- 在某个时间点的主库的数据快照
- 主库当前的二进制日志文件,和获得数据快照时在该二进制日志文件中的偏移量,我们把这两个值称为日志文件坐标(log file coordinates)。通过这两个值可以确定二进制日志的位置。可以通过show master status命令来获得
- 从快照时间到现在的二进制日志
例举初始化从库的方法
- 使用冷备份
最基本的方式就是关闭主库,把数据复制到主库。重启主库后,会使用一个新的二进制日志文件,我们在从库通过执行CHANGE MASTER TO指向这个文件的起始处。但这个方式缺点很明显,在复制数据的时候,需要关闭主库。 - 使用mysqldump
如果只包含InnoDB表,那么可以使用以下命令来转储主数据库数据并将其加载到从库,然后设置相应的二进制日志坐标
mysqldump --single-transaction --all-databases --master-data=1 --host=server1 | mysql --host=server2- single-transaction:这个选项告诉 mysqldump 使用单个事务来获取数据,以确保备份的数据是一致的。这对于生产环境中的备份非常有用,因为它避免了对数据库的读锁,使得数据库在备份期间可以正常提供读取服务。- all-databases:这个选项指示 mysqldump 备份所有数据库,而不仅仅是一个单独的数据库。- master-data=1:这个选项告诉 mysqldump 在备份文件中添加二进制日志文件和位置的信息,这将用于初始化从库。
- 使用快照或备份
只要知道对应的二进制日志标,就可以使用主库的快照或者备份来初始化从库 (如果使用备份,需要确保从备份的时间点开始的主库二进制日志都要存在)。只需要把备份或快照恢复到从库,然后使用CHANGE MASTER TO指定二进制日志的坐标 - 使用另外的从库
可以使用任何一种提及的克隆或者拷贝技术来从任意一台从库上将数据克隆到另外一台服务器。但是如果使用的是 mysgldump,–master-data 选项就会不起作用。此外,不能使用SHOW MASTER STATUS来获得主库的二进制日志标,而是在获取快照时使用SHOW SLAVE STATUS来获取从库在主库上的执行位置。使用另外的从库进行数据克隆最大的缺点是,如果这台从库的数据已经和主库不同步,克隆得到的就是脏数据。
主从复制时推荐的配置
sync_binlog
该配置是主库上二进制日志最重要的选项
- sync_binlog=0:表示不同步写入二进制日志文件。这意味着 MySQL 不会等待操作在二进制日志文件中写入磁盘后才返回,而是立即返回。这样可能会提高性能,但也会增加风险,因为未同步的数据可能在宕机等情况下丢失。
- sync_binlog=1:表示每次写入二进制日志都会等待操作在日志文件中同步到磁盘后才返回。这样可以确保数据的持久性,但也会对性能产生一些影响。
- sync_binlog=N:表示每 N 次写入操作后才进行同步。这可以在一定程度上权衡性能和数据持久性。
需要注意的是,选择适当的 sync_binlog 设置取决于你的应用需求以及对性能和数据安全性的权衡考虑。如果应用对数据的持久性要求较高,可以选择较小的值,甚至是 sync_binlog=1。如果对性能要求较高,可以选择较大的值或者关闭同步。
如果使用InnoDB,强烈推荐设置如下选项:
innodb_flush_logs_at_trx_commit
这个参数用于控制事务的日志刷新行为。它有三个可能的值:
- 0:表示事务提交时不会将日志刷新到磁盘,而是定期刷新。这可能会在故障时丢失一些事务。
- 1:表示事务提交时会立即将日志刷新到磁盘。这可以保证事务的持久性,但会对性能产生一定影响。
- 2:表示事务提交时将日志写入操作系统的缓存,但不会立即刷新到磁盘。这在某些情况下可以提高性能,但在操作系统崩溃的情况下可能会丢失一些事务。
innodb_support_xa=1
这个参数用于控制是否支持分布式事务(XA 事务)。如果设置为 1,表示 InnoDB 存储引擎支持 XA 事务,可以与其他数据库或应用协调执行分布式事务。
innodb_safe_binlog
这个参数用于控制是否在事务提交时将日志写入二进制日志。如果设置为 1,表示在每个事务提交时将操作写入二进制日志,以确保日志和数据的一致性。如果设置为 0,表示只有在事务完成时才将操作写入二进制日志
我们推荐明确指定二进制日志的名字,以保证二进制日志名在所有服务器上是一致的,避免因为服务器名的变化导致的日志文件名变化。你可能认为以服务器名来命名二进制日志无关紧要,但经验表明,当在服务器间转移文件、克隆新的从库、转储备份或者其他一些你想象不到的场景下,可能会导致很多问题。为了避免这些问题,需要给 log_bin 选项指定一个参数。可以随意地给一个绝对路径,但必须明确地指定基本的命名(正如之前讨论的)。
log_bin=/var/lib/mysq1/mysql-bin
在从库上,我们同样推荐开启如下配置选项,为中继日志指定绝对路径
relay_log=/path/to/logs/relay-bin
skip_slave_start
read_only
通过设置 relay_log 可以避免中继日志文件基于机器名来命名,防止之前提到的可能在主库发生的问题。指定绝对路径可以避免多个 MySQL版本中存在的 Bug,这些 Bug可能会导致中继日志在一个意料外的位置创建。skip _slave_start 选项能够阻止从库在崩溃后自动启动复制。这可以给你一些机会来修复可能发生的问题。如果从库在崩溃后自动启动并且处于不一致的状态,就可能会导致更多的损坏,最后将不得不把所有数据丢弃,并重新开始配置从库
read_only 选项可以阻止大部分用户更改非临时表,除了复制SOL 线程和其他拥有超级权限的用户之外,这也是要尽量避免给正常账号授予超级权限的原因之一。
主从复制的原理
主从复制有两种方式:
- 基于语句复制
- 基于行复制
基于语句复制
在基于语句复制中,主库执行的每个 SQL 语句都会被记录到二进制日志,并且从库会解析并在从库上执行相同的 SQL 语句来复制数据。这意味着从库上的数据会与主库上的数据在逻辑上保持一致。
优点:
- 简单明了:复制的是 SQL 语句,不需要复制整个行的数据。
- 节省网络带宽:当一条 SQL 修改多行数据时,只需要复制一条语句,节省了网络传输的带宽。
缺点:
- 不适用于非确定性函数:如果主库上使用了随机函数或时间函数,从库上的执行结果可能与主库不一致。
- 不适用于不可重复读问题:在从库上执行与主库不同的查询顺序时,可能导致结果不一致。
- 主库版本限制:一些特定版本的 MySQL 主库可能不支持基于语句的复制。
基于行复制
在基于行复制中,主库上每次修改数据的操作都会被记录为修改行的详细信息,包括修改前和修改后的数据。从库会接收这些行级别的变更并在从库上应用相同的修改操作。
优点:
- 更准确的复制:避免了基于语句复制的一些问题,如非确定性函数和不可重复读问题。
- 可用于更广泛的情况:适用于所有 SQL 语句,包括复杂的更新操作。
缺点:
- 增加了网络传输和存储开销:需要传输和存储更多的数据,可能增加网络带宽和磁盘空间的占用。
主从复制用到的文件
mysql-bin.index
当在服务器上开启二进制日志时,同时会生成一个和二进制日志同名的但以index作为后缀的文件,该文件用于记录磁盘上的二进制日志文件。这里的“index”并不是指表的索引,而是说这个文件的每一行包含了二进制文件的文件名。你可能认为这个文件是多余的,可以被删除 (毕竟 MySQL可以在磁盘上找到它要的文件)。事实上并非如此,MySQL 依赖于这个文件,除非在这个文件里有记录,否则MySOL识别不了二进制日志文件。
mysql-relay-bin-index
这个文件是中继日志的索引文件,和 mysgl-bin.index 的作用类似
master.info
这个文件用于保存从库连接到主库所需要的信息,格式为纯文本(每行一个值),不同的 MySQL 版本,其记录的信息也可能不同。此文件不能删除,否则从库在重启后无法连接到主库。这个文件以文本的方式记录了复制用户的密码,所以要注意此文件的权限控制。
relay-log.info
这个文件包含了当前从库复制的二进制日志和中继日志坐标(例如,从库复制在主库上的位置),同样也不要删除这个文件,否则在从库重启后将无法获知从哪个位置开始复制,可能会导致重放已经执行过的语句。
发送复制事件到其他的从库
log_slave_updates 选项可以让从库变成其他服务器的主库。在设置该选项后,MySQL会将其执行过的事件记录到它自己的二进制日志中。这样它的从库就可以从其日志中检索并执行事件。
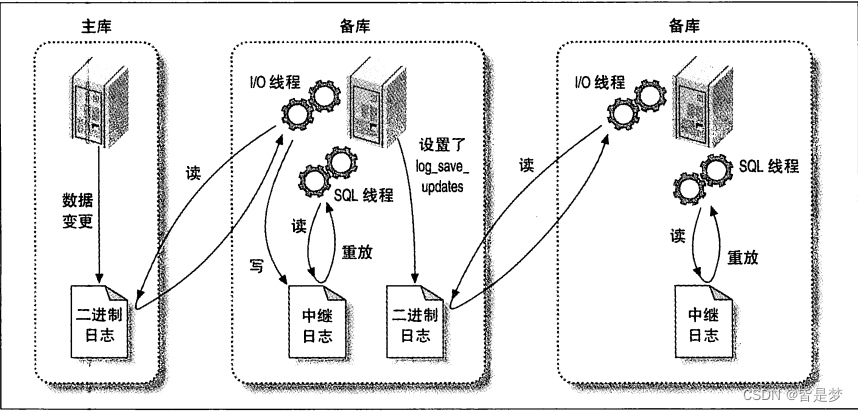
在这种场景下,主库将数据更新事件写入二进制日志,第一个从库提取并执行这个事件这时候一个事件的生命周期应该已经结束了,但由于设置了 log_slave_updates,从库会将这个事件写到它自己的二进制日志中。这样第二个从库就可以将事件提取到它的中继日志中并执行。这意味着作为源服务器的主库可以将其数据变化传递给没有与其直接相连的从库上。默认情况下这个选项是被打开的,这样在连接到从库时就不需要重启服务器。
当第一个从库将从主库获得的事件写入到其二进制日志中时,这个事件在从库二进制日志中的位置与其在主库二进制日志中的位置肯定是不相同的,可能在不同的日志文件或文件内不同的位置。这意味着你不能假定所有拥有同一逻辑复制点的服务器拥有相同的日志坐标。稍后我们会提到,这种情况会使某些任务更加复杂,例如,修改一个从库的主库或将从库提升为主库。
除非你已经注意到要给每个服务器分配一个唯一的服务器 ID,否则按照这种方式配置从库会导致一些奇怪的错误,甚至还会导致复制停止。一个更常见的问题是 :为什么要指定服务器ID,难道MySQL 在不知道复制命来源的情况下不能执行吗?为什么MySQL 要在意服务器ID是全局唯一的。问题的答案在于 MySOL 在复制过中如何防止无限循环。当复制SQL 线程读中继日志时,会丢弃事件中记录的服务器ID 和该服务器本身ID相同的事件,从而打破了复制过程中的无限循环。在某些复制拓扑结构下打破无限循环非常重要,例如主 -主复制结构
主从复制拓扑
可以在任意个主库和从库之间建立复制,只有一个限制:每一个从库只能有一个主库。有很多复杂的拓扑结构,但即使是最简单的也可能会非常灵活。一种拓扑可以有多种用途。
我们已经讨论了如何为主库设置一个从库,接下来讨论其他比较普遍的拓扑结构以及它们的优缺点。记住下面的基本原则:
- 一个MySQL从库实例只能有一个主库
- 每个从库必须有一个唯一的服务器 ID
- 一个主库可以有多个从库 (或者相应的,一个从库可以有多个兄弟从库)。
- 如果打开了 log_slave_updates 选项,一个从库可以把其主库上的数据变化传播到其他从库。
一主库多从库
这是最简单的拓扑结构。在有少量写和大量读时,这种配置是非常有用的。可以把读分摊到多个从库上,直到从库给主库造成了太大的负担,或者主从之间的带宽成为瓶颈为止。你可以按照之前介绍的方法一次性设置多个从库,或者根据需要增加从库
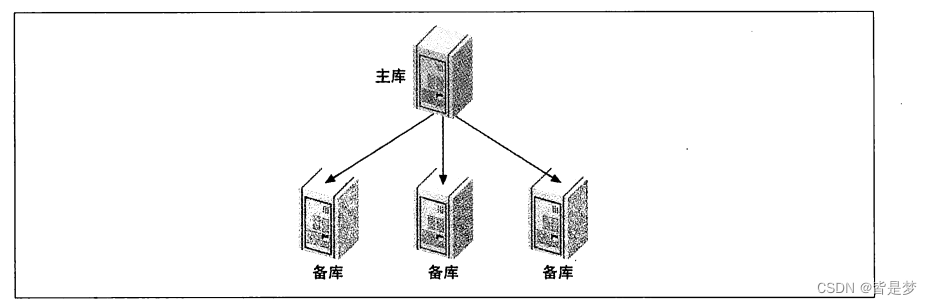
用途
- 为不同的角色使用不同的从库 (例如添加不同的索或使用不同的存储)
- 把一台从库当作待用的主库,除了复制没有其他数据传输。
- 将一台从库放到远程数据中心,用作灾难恢复。
- 延迟一个或多个从库,以备灾难恢复。
- 使用其中一个从库,作为备份、培训、开发或者测试使用服务器
主动-主动模式下的主-主复制
主-主复制(也叫双主复制或者双向复制)包含两台服务器,每一个都被配置成对方的主库和从库,换句话说,他们是一对主库

主动-主动模式下主- 主复制有一些应用场景,但通常用于特殊的目的。一个可能的应用场景是两个处于不同地理位置的办公室,并且都需要一份可写的数据拷贝。
这种配置最大的问题是如何解决冲突,两个可写的互主服务器导致的问题非常多。这通常发生在两台服务器同时修改一行记录,或同时在两台服务器上向一个包含 AUTO_INCREMENT列的表里插入数据
主动-被动模式下的主-主复制
这是前面描述的主-主结构的变体,它能够避免我们之前讨论的问题。这也是构建容错性和高可用性系统的非常强大的方式,主要区别在于其中的一台服务器是只读的被动服务器

这种方式使得反复切换主动和被动服务器非常方便,因为服务器的配置是对称的。这使得故障转移和故障恢复很容易。它也可以让你在不关闭服务器的情况下执行维护、优化表、升级操作系统(或者应用程序、硬等) 或其他任务。
例如,执行 ALTER TABLE操作可能会锁住整个表,阻塞对表的读和写,这可能会花费很长时间并导致服务中断。然而在主-主配置下,可以先停止主动服务器上的从库复制线程(这样就不会在被动服务器上执行任何更新),然后在被动服务器上执行ALTER操作交换角色,最后在先前的主动服务器上启动复制线程。这个服务器将会读取中继日志并执行相同的 ALTER语句。这可能花费很长时间,但不要紧,因为该服务器没有为任何活跃查询提供服务。
主动-被动模式的主-主结构能够帮助回避许多 MySOL的问题和限制
让我们看看如何配置主-主服务器对,在两台服务器上执行如下设置后,会使其拥有对称的设置:
- 确保两台服务器上有相同的数据
- 启用二进制日志,选择唯一的服务器 ID,并创建复制账号
- 启用从库更新的日志记录,后面将会看到,这是故障转移和故障恢复的关键把被动服务器配置成只读,防止可能与主动服务器上的更新产生冲突,这一点是可选的。
- 启动每个服务器的MySQL实例
- 将每个主库设置为对方的从库,使用新创建的二进制日志开始工作
设置主动- 被动的主-主拓扑结构在某种意义上类似于创建一个热备份,但是可以使用这个“备份”来提高性能,例如,用它来执行读操作、备份、“离线”维护以及升级等。真正的热备份做不了这些事情。然而,你不会获得比单台服务器更好的写性能。
拥有从库的主-主结构
另外一种相关的配置是为每个主库增加一个从库
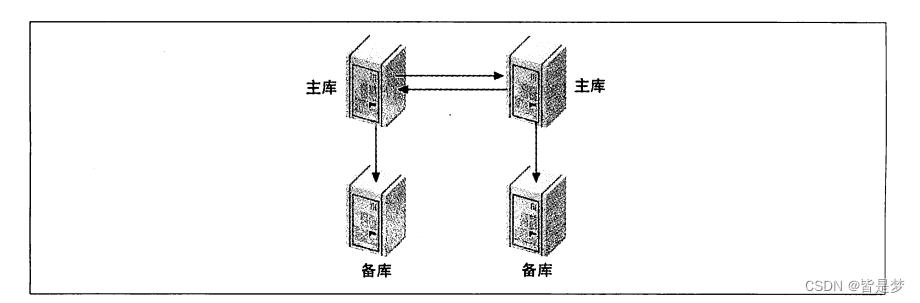
这种配置的优点是增加了冗余,对于不同地理位置的复制拓扑,能够消除站点单点失效的问题。你也可以像平常一样,将读查询分配到从库上。
如果在本地为了故障转移使用主 - 主结构,这种配置同样有用。当主库失效时,用从库来代替主库还是可行的,虽然这有点复杂。同样也可以把从库指向一个不同的主库,但需要考虑增加的复杂度
主库,分发主库以及从库
我们之前提到当从库足够多时,会对主库造成很大的负载。每个从库会在主库上创建一个线程,并执行 binlog dump 命令。该命令会读取二进制日志文件中的数据并将其发送给从库。每个从库都会重复这样的工作,它们不会共享 binlog dump 的资源
如果有很多从库,并且有大的事件时,例如一次很大的 LOAD DATA INFILE操作,主库上的负载会显著上升,甚至可能由于从库同时请求同样的事件而耗尽内存并崩溃。另一方面,如果从库请求的数据不在文件系统的缓存中,可能会导致大量的磁盘检索,这同样会影响主库的性能并增加锁的竞争。
因此,如果需要多个从库,一个好办法是从主库移除负载并使用分发主库。分发主库事实上也是一个从库,它的唯一目的就是提取和提供主库的二进制日志。多个从库连接到分发主库,这使原来的主库摆脱了负担。为了避免在分发主库上做实际的查询,可以将它的表修改为 blackhole 存储引擎
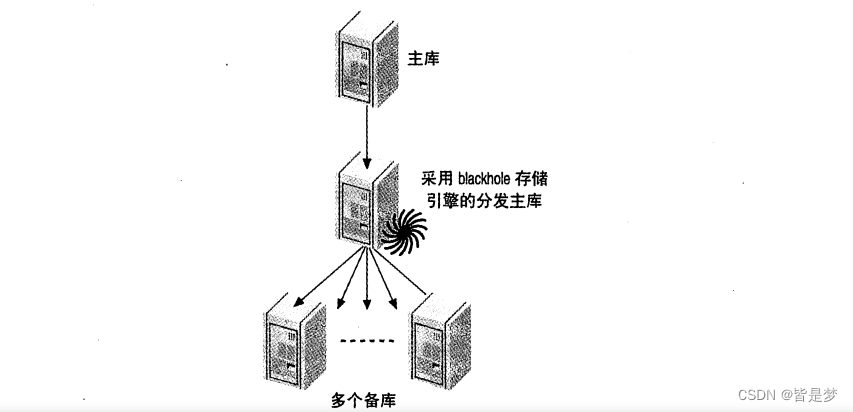
很难说当从库数据达到多少时需要一个分发主库。按照通用准则,如果主库接近满负载不应该为其建立 10 个以上的从库。如果有少量的写操作,或者只复制其中一部分表,主库就可以提供更多的复制。另外,也不一定只使用一个分发主库。如果需要的话,可以使用多个分发主库向大量的从库进行复制,或者使用金字塔状的分发主库。在某些情况下,可以通过设置slave_compressed_protocol来节约一些主库带宽。这对跨数据中心复制很有好处。
还可以通过分发主库实现其他目的,例如,对二进制日志事件执行过滤和重写规则。这比在每个从库上重复进行日志记录、重写和过滤要高效得多。
如果在分发主库上使用 blackhole 表,可以支持更多的从库。虽然会在分发主库执行查询但其代价非常小,因为 blackhole 表中没有任何数据。blockhole 表的缺点是其存在 Bug,例如在某些情况下会忘记将自增ID 写入到二进制日志中。所以要小心使用 blackhole表
一个比较常见的问题是如何确保分发服务器上的每个表都是 blackhole 存储引警。如果有人在主库创建了一个表并指定了不同的存储引擎呢?确实,不管什么时候,在从库上使用不同的存储引擎总会导致同样的问题。常见的解决方案是设置服务器的 storage_engine选项:
storage_engine = blackhole
这只会影响那些没有指定存储引警的CREATE TABLE的语句如果有一个无法控制的应用这种拓扑结构可能会非常脆弱。可以通过 skip_innodb 选项禁止InnoDB,将表退化为MyISAM。但你无法禁止 MyISAM 或者Memory 引擎。
使用分发主库另外一个主要的缺点是无法使用一个从库来代替主库。因为由于分发主库的存在,导致各个从库与原始主库的二进制日志坐标已经不相同
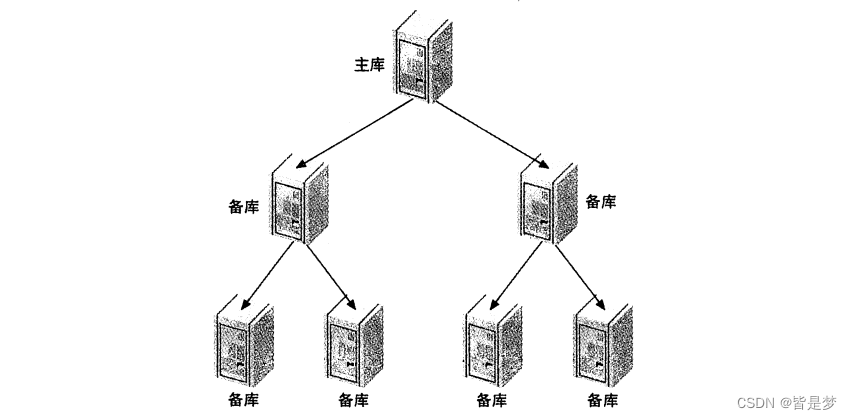
树或金字塔型
如果正在将主库复制到大量的从库中。不管是把数据分发到不同的地方,还是提供更高的读性能,使用金字塔结构都能够更好地管理
这种设计的好处是减轻了主库的负担,就像前一节提到的分发主库一样。它的缺点是中间层出现的任何错误都会影响到多个服务器。如果每个从库和主库直接相连就不会存在这样的问题。同样,中间层次越多,处理故障会更困难、更复杂。
定制的复制方案
MySQL的复制非常灵活,可以根据需要定制解决方案。典型的定制方案包括 组合,过滤,分发和向不同的存储引擎复制。也可以使用“黑客手段”,例如,从一个使用 blackhole存储引擎的服务器上复制或复制到这样的服务器上。可以根据需要任意设计。这其中最大的限制是合理的监控和管理,以及所拥有资源约束(网络带宽,CPU能力等)
选择性复制
为了利用访问局部性原理 (locality of reference),并将需要读的工作集驻留在内存中可以复制少量数据到从库中。如果每个从库只拥有主库的一部分数据,并且将读分配给从库,就可以更好地利用从库的内存。并且每个从库也只有主库一部分的写入负载,这样主库的能力更强并能保证从库延迟
它的优势在于主库包含了所有的数据集,这意味着无须为了一条写入查询去访问多个服务器。如果读操作无法在从库上找到数据,还可以通过主库来查询。即使不能从从库上读取所有数据,可以移除大量的主库读负担。
最简单的方法是在主库上将数据划分到不同的数据库里。然后将每个数据库复制到不同的从库上。例如,若需要将公司的每一个部门的数据复制到不同的从库,可以创建名为sales、marketing、procurement 等的数据库,每个从库通过选项 replicate_wild_dotable选项来限制给定数据库的数据。下面是 sales 数据库的配置:
replicate_wild_do_table = sales.%
#replicate_wild_do_table 是 MySQL 复制中的一个配置选项,
#用于指定要复制的表。sales.% 表示要复制 sales 数据库下的所有表(以 % 通配符表示)到从库。
也可以通过一台分发主库进行分发。举个例子,如果想通过一个很慢或者非常昂贵的网络,从一台负载很高的数据库上复制一部分数据,就可以使用一个包含 blackhole 表和过滤规则的本地分发主库,分发主库可以通过复制过滤移除不需要的日志。这可以避免在主库上进行不安全的日志选项设定,并且无须传输所有的数据到远程从库
分离功能
许多应用都混合了在线事务处理 (OLTP)和在线数据分析(OLAP)的查询。OLTP查询比较短并且是事务型的,OLAP 查询则通常很大,也很慢,并且不要求绝对最新的数据这两种查询给服务器带来的负担完全不同,因此它们需要不同的配置,其至可能使用不同的存储引擎或者硬件。
一个常见的办法是将 OLTP 服务器的数据复制到专门为 OLAP 工作负载准备的备库上这些备库可以有不同的硬件、配置、索引或者不同的存储引擎。如果决定在备库上执行OLAP 查询,就可能需要忍受更大的复制延迟或降低备库的服务质量。这意味着在一个非专用的备库上执行一些任务时,可能会导致不可接受的性能,例如执行一条长时间运行的查询。
数据归档
可以在从库上实现数据归档,也就是说可以在从库上保留主库上删除过的数据,在主库上通过 delete 语句删除数据是确保 delete 语句不传递到从库就可以实现。有两种通常的办法:一种是在主库上选择性地禁止二进制日志,另一种是在备库上使用 replicate_ignore_db规则(是的,两种方法都很危险)。
第一种方法需要先将SQL_LOG_BIN设置为0,然后再进行数据清理。这种方法的好处是不需要在从库进行任何配置,由于SQL语根本没有记录到二进制日志中,效率会稍微有所提升。最大缺点也正因为没有将在主库的修改记录下来,因此无法使用二进制日志来进行审计或者做按时间点的数据恢复。另外还需要 SUPER 权限
第二种方法是在清理数据之前对主库上特定的数据库使用USE语句。例如,可以创建一个名为 purge的数据库,然后在从库的 my.cnf文件里设置 replicate_ignore_db=purge并重启服务器。从库将会忽略使用了 USE语句指定的数据库。这种方法没有第一种方法的缺点,但有另一个小小的缺点:从库需要去读取它不需要的事件。另外,也可能有人在 purge数据库上执行非清理查询,从而导致从库无法重放该事件。
只读从库
将从库设置为只读,以防止在从库进行的无意识修改导致复制中断。可以通过设置 read_only 选项来实现。它会禁止大部分写操作,除了复制线程和拥有超级权限的用户以及临时表操作。只要不给也不应该给普通用户超级权限,这应该就是很完美的方法
复制和容量规划
写操作通常是复制的瓶颈,并且很难使用复制来扩展写操作。当计划为系统增加复制容量时,需要确保进行了正确的计算,否则很容易犯一些复制相关的错误。
例如,假设工作负载为 20% 的写以及80% 的读 。为了计算简单,假设有以下前提 :
- 读和写查询包含同样的工作量。
- 所有的服务器是等同的,每秒能进行 1000次查询。
- 从库和主库有同样的性能特征。
- 可以把所有的读操作转移到从库。
如果当前有一个服务器能支持每秒 1 000 次查询,那么应该增加多少从库才能处理当前两倍的负载,并将所有的读查询分配给从库?
看上去应该增加两个从库并将1600的读操作平分给他们。但是不要忘记,写入负载同样增加到了400次每秒,并且无法在主从服务器之间进行分摊。每个从库每秒必须处理400次写入,这意味着每个从库写入占了40%,只能每秒为600次查询提供服务。因此,需要三台而不是两台从库来处理双倍负载。
如何测量从库延迟
主从同步一个普遍的问题是如何监控从库落后主库的延迟有多大,虽然SHOW_SLAVE _STATUS输出的Seconds_behind _master列理论上显示了从库的延时,但是由于各种原因,并不是精确的:
- 从库Seconds_behind_master值是通过将服务器当前的时间戳与二进制日志中的事件的时间戳相对比得到的,所以只有在执行事件时才能报告延迟。
- 如果从库复制线程没有运行,就会报延迟为 NULL。
- 一些错误(例如主从的 max_allowed_packet 不匹配,或者网络不稳定)可能中断复制并且/或者停止复制线程,但 Seconds_behind_master将显示为0而不是显示错误
- 即使从库线程正在运行,从库有时候可能无法计算延时。如果发生这种情况,从库会报0或者NULL。
- 一个大事务可能会导致延迟波动,例如,有一个事务更新数据长达一个小时,最后提交。这条更新将比它实际发生时间要晚一个小时才记录到二进制日志中。当从库执行这条语句时,会临时地报告从库延迟为一个小时,然后又很快变成0。
- 如果分发主库落后了,并且其本身也有已经追赶上它的从库,从库的延迟将显示为 0,而事实上和源主库之间是有延迟的
解决这些问题的办法是忽略 Seconds_behind_master的值,并使用一些可以直接观察和衡量的方式来监控从库延迟。最好的解决办法是使用heartbeat record ,这是一个在主库上会每秒更新一次的时间戳。为了计算延时,可以直接用从库当前的时间戳减去心跳记录的值。这个方法能够解决刚刚我们提到的所有问题,另外一个额外的好处是我们还可以通过时间戳知道从库当前的复制状况。包含在 Percona Toolkit 里的 pt-heartbeat 脚本是“复制心跳”最流行的一种实现
心跳还有其他好处,记录在二进制日志中的心跳记录拥有许多用途,例如在一些很难解决的场景下可以用于灾难恢复。
检查主从是否一致
使用Percona Toolkit 里的 pt-table-checksum能够验证主从数据是否一致。其主要特性是用于确认从库与主库的数据是否一致。工作方式是通过在主库上执行 INSERT…SELECT查询
这些查询对数据进行校验并将结果插入到一个表中。这些语句通过复制传递到从库,并在从库执行一遍,然后可以比较主从上的结果是否一样。由于该方法是通过复制工作的它能够给出一致的结果而 无须同时把主从上的表都锁上。
通常情况下可以在主库上运行该工具,参数如下 :
$ pt-table-checksum --replicate=test.checksum <master host>
该命令将检查所有的表,并将结果插入到 test.checksum 表中。当查询在从库执行完后就可以简单地比较主从之间的不同了。pt-table-checksum 能够发现服务器所有的从库在每台从库上运行查询,并自动地输出结果
从主库重新同步从库
当使用校验工具发现了数据不一致,或者是因为已经知道是从库忽略了某条查询或者有人在从库上修改了数据,此时就需要出路未被同步的从库。
- 关闭从库,重新从主库上复制一份数据。该方式缺点是不太方便,特别是数据量很大的时候。
- 使用mysqldump转储受影响的数据并重新导入。可以在主库上简单的锁住表然后进行转储,再等待从库赶上主库。然后将数据导入到从库中。(需要等待从库赶上主库,这样就不会为其他的表引入新的不一致)。此种方式在表很大或者网络带宽受限的情况下,转储和重载数据的代价依然很高
- pt-table-sync 是 Percona Toolkit 中的另外一个工具,可以解决该问题。该工具能够高效地查找并解决表之间的不同。它同样通过复制工作,在主库上执行查询,在从库上重新同步,这样就没有竞争条件。它是结合 pt-table-checksum 生成的 checksum 表来工作的所以只能操作那些已知不同步的表的数据块。但该工具不是在所有场景下都有效。为了正确地同步主库和从库,该工具要求复制是正常的,否则就无法工作。pt-table-sync设计得很高效,但当数据量非常大时效率还是会很低。比较主库和从库上 1TB 的数据不可避免地会带来额外的工作。尽管如此,在那些合适的场景中,该工具依然能节约大量的时间和工作。
相关文章:
mysql(九)mysql主从复制
目录 前言概述提出问题主从复制的用途工作流程 主从复制的配置创建复制账号配置主库和从库启动主从复制从另一个服务器开始主从复制主从复制时推荐的配置sync_binloginnodb_flush_logs_at_trx_commitinnodb_support_xa1innodb_safe_binlog 主从复制的原理基于语句复制优点&…...
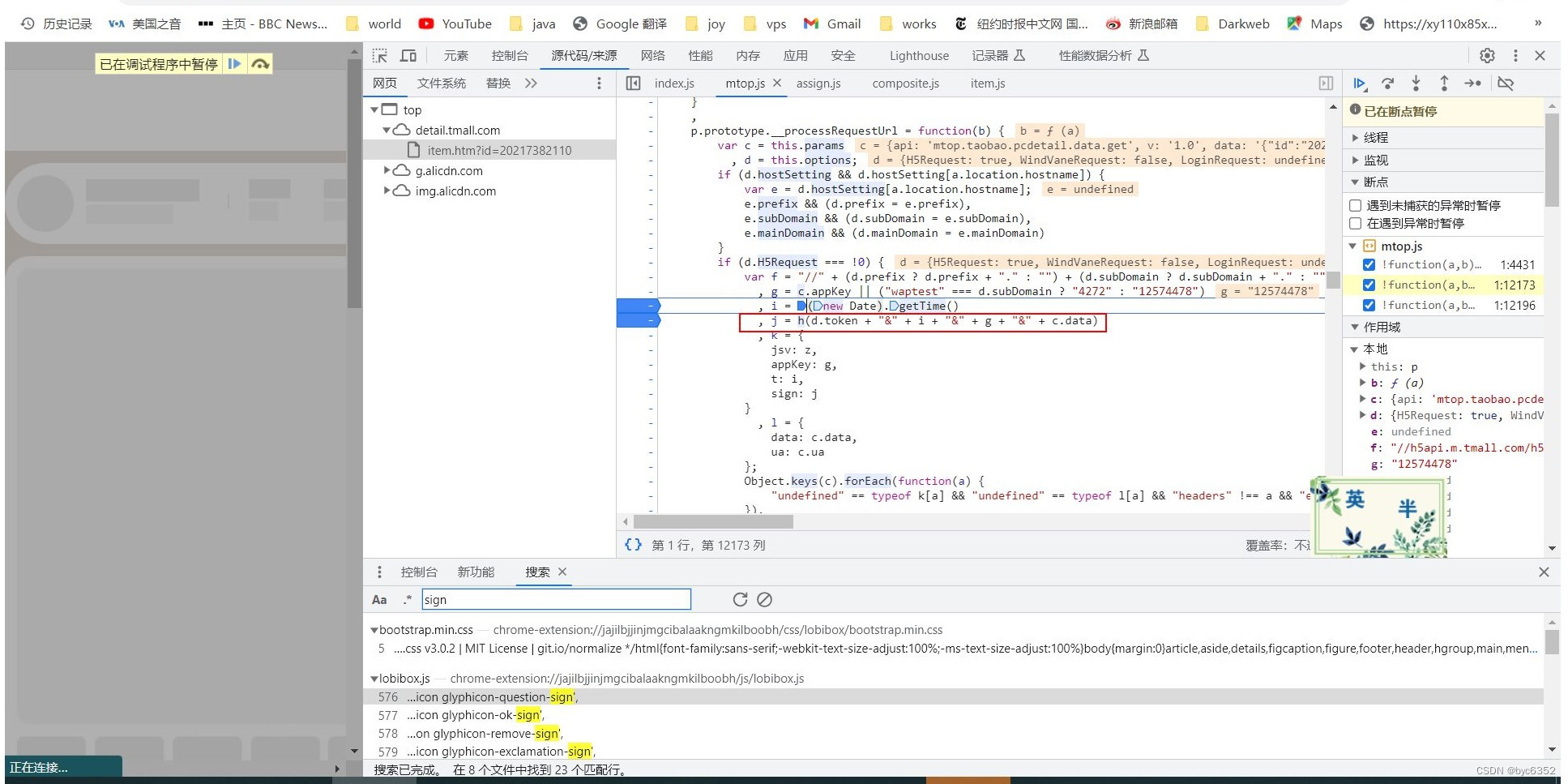
nodejs采集淘宝、天猫网商品详情数据以及解决_m_h5_tk令牌及sign签名验证(2023-09-09)
一、淘宝、天猫sign加密算法 淘宝、天猫对于h5的访问采用了和APP客户端不同的方式,由于在h5的js代码中保存appsercret具有较高的风险,mtop采用了随机分配令牌的方式,为每个访问端分配一个token,保存在用户的cookie中,通…...
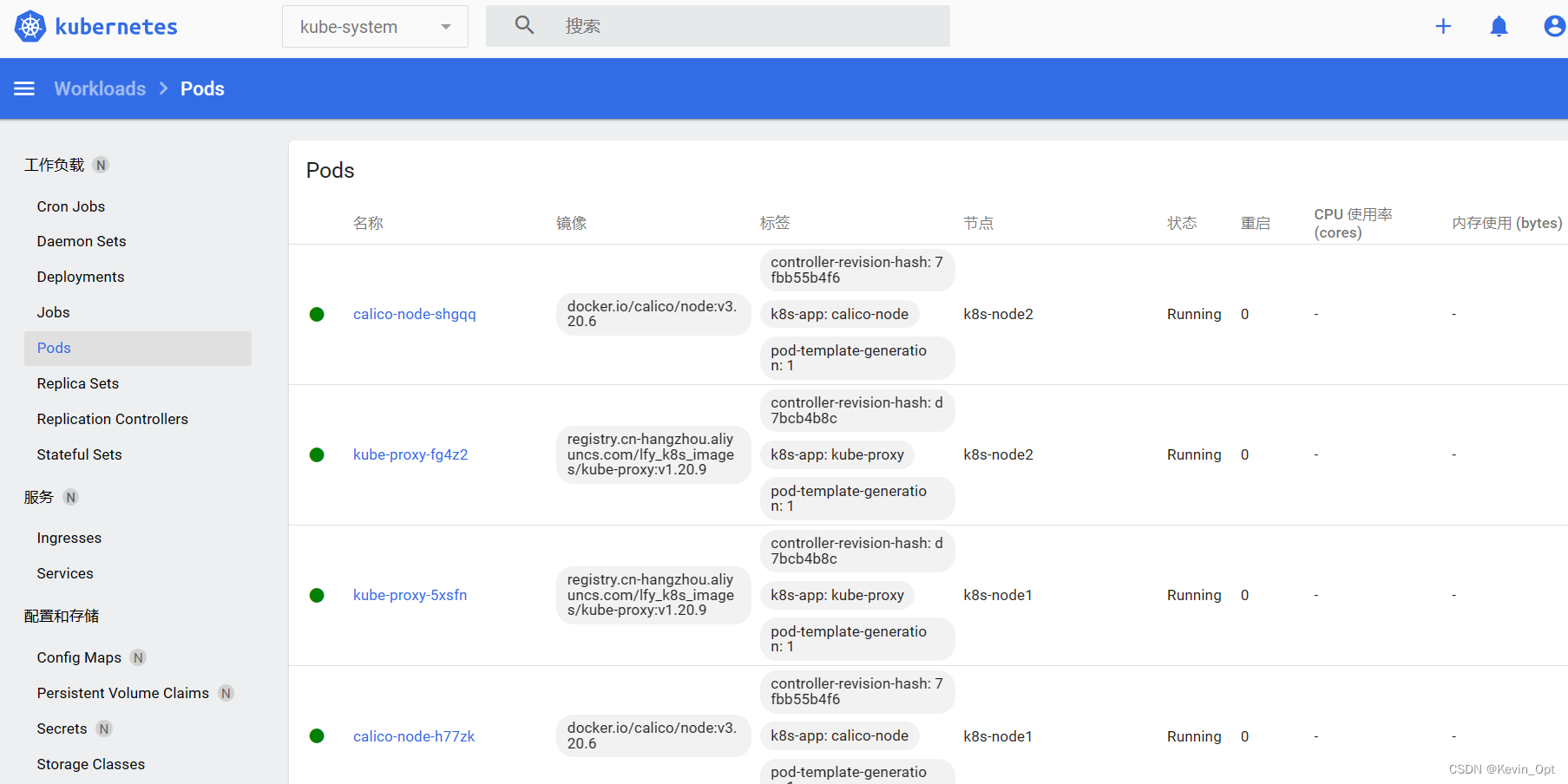
虚拟机上部署K8S集群
虚拟机上部署K8S集群 安装VM Ware安装Docker安装K8S集群安装kubeadm使用kubeadm引导集群 安装VM Ware 参考:http://www.taodudu.cc/news/show-2034573.html?actiononClick 安装Docker 参考:https://www.yuque.com/leifengyang/oncloud/mbvigg#2ASxH …...

设计模式 - 责任链
一、前言 相信大家平时或多或少都间接接触过责任链设计模式,只是可能有些同学自己不知道此处用的是该设计模式,比如说 Java Web 中的 Filter 过滤器,就是非常经典的责任链设计模式的例子。 那么什么是责任链设计模式呢? …...
【小沐学Unity3d】3ds Max 骨骼动画制作(CAT、Character Studio、Biped、骨骼对象)
文章目录 1、简介2、 CAT2.1 加载 CATRig 预设库2.2 从头开始创建 CATRig 3、character studio3.1 基本描述3.2 Biped3.3 Physique 4、骨骼系统4.1 创建方法4.2 简单示例 结语 1、简介 官网地址: https://help.autodesk.com/view/3DSMAX/2018/CHS https://help.aut…...
CUDA说明和安装[window]
文章目录 1、查看版本信息查看GPU查看cuda版本其他方法 2区分 了解cudaCUDA ToolkitNVCCcuDNN 3/ 安装过程4/版本的问题CUDA Toolkit和 显卡驱动 的版本对应CUDA / CUDA Toolkit和cuDNN的版本对应 5/关于CUDA和Cudnn**5.1 CUDA的命名规则****5.2 如何查看自己所安装的CUDA的版本…...
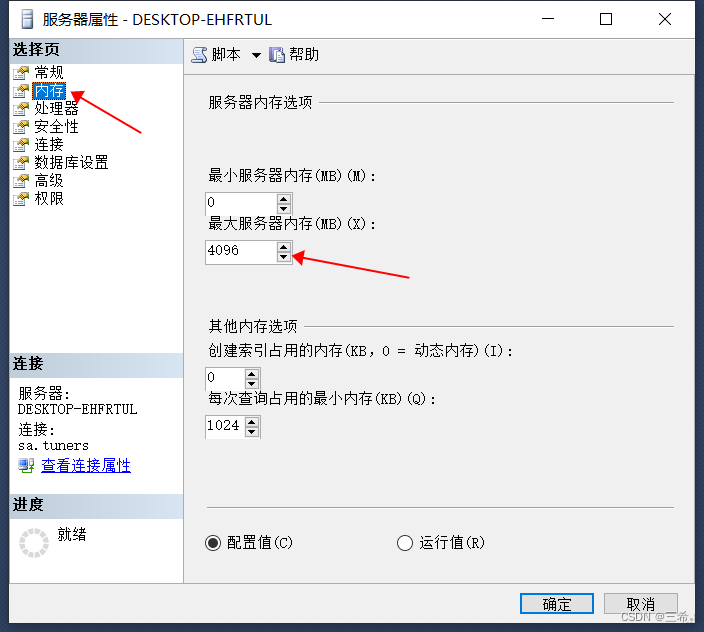
sqlserver2012性能优化配置:设置性能相关的服务器参数
前言 sqlserver2012 长时间运行的话会将服务器的内存占满 解决办法 通过界面设置 下图中设置最大服务器内存 通过执行脚本设置 需要先开发开启高级选项配置才能设置成功 设置完成之后将高级选择配置关闭,还原成跟之前一样 --可以配置高级选项 EXEC sp_conf…...
介绍 dubbo-go 并在Mac上安装,完成一次自己定义的接口RPC调用
目录 RPC 远程调用的说明作用:像调用本地方法一样调用远程方法和直接HTTP调用的区别:调用模型图示: Dubbo 框架说明Dubbo Go 介绍应用 Dubbo Go环境安装(Mac 系统)安装 Go语言环境安装 序列化工具protoc安装 dubbogo-c…...
)
目标检测数据集:摄像头成像吸烟检测数据集(自己标注)
1.专栏介绍 ✨✨✨✨✨✨目标检测数据集✨✨✨✨✨✨ 本专栏提供各种场景的数据集,主要聚焦:工业缺陷检测数据集、小目标数据集、遥感数据集、红外小目标数据集,该专栏的数据集会在多个专栏进行验证,在多个数据集进行验证mAP涨点明显,尤其是小目标、遮挡物精度提升明显的…...
Unity的UI管理器
1、代码 public class UIManager {private static UIManager instance new UIManager();public static UIManager Instance > instance;//存储显示着的面板脚本(不是面板Gameobject),每显示一个面板就存入字典//隐藏的时候获取字典中对…...

Mp4文件提取详细H.264和MP3文件
文章目录 Mp4文件提取为H.264和MP3文件**提取视频为H.264:****提取音频为MP3:** 点赞收藏加关注,追求技术不迷路!!!欢迎评论区互动。 Mp4文件提取为H.264和MP3文件 要将视频分开为H.264(视频编…...
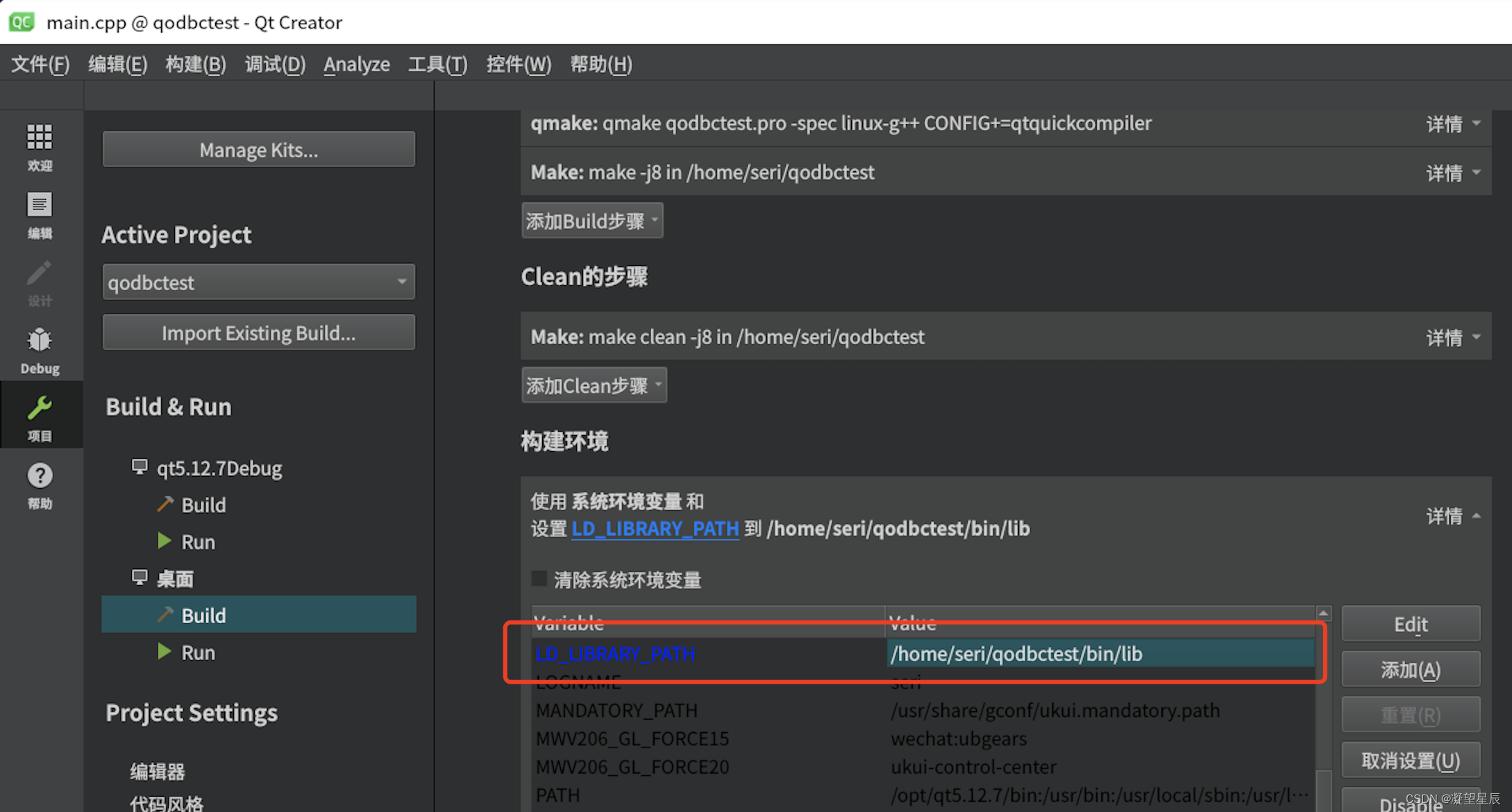
Qt应用程序连接达梦数据库-飞腾PC麒麟V10
目录 前言1 安装ODBC1.1 下载unixODBC源码1.2 编译安装1.4 测试 2 编译QODBC2.1 修改 qsqldriverbase.pri 文件2.2 修改 odbc.pro 文件2.3 编译并安装QODBC 3 Qt应用程序连接达梦数据库测试4 优化ODBC配置,方便程序部署4.1 修改pro文件,增加DESTDIR 变量…...

2023-09-03 LeetCode每日一题(消灭怪物的最大数量)
2023-09-03每日一题 一、题目编号 1921. 消灭怪物的最大数量二、题目链接 点击跳转到题目位置 三、题目描述 你正在玩一款电子游戏,在游戏中你需要保护城市免受怪物侵袭。给你一个 下标从 0 开始 且长度为 n 的整数数组 dist ,其中 dist[i] 是第 i …...

绘图 | MATLAB
目的语法注意事项图片中出现网格grid on放在plot后面在同一图片中绘制多个图例hold on在图形中添加图例legend LineSpec 线性 线型描述线型描述" - "实线" : "点线" - - "虚线" -. "点划线 标记 标记描述标记描述“o”圆圈“squa…...
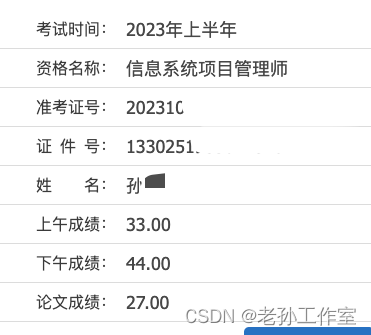
2023年下半年高项考试学习计划
之前总结 2023年上半年的考试,对于我自己,就是虎头蛇尾,也谈不上太过自信,好好学习了一段时间之后,也就是不再发博文,截止到2022年11月的时候,自己就算是放弃了,没有再主动学习。 结…...

SpringBoot中CommandLineRunner的使用
开发中,你有没有遇到这样的场景,项目启动后,立即需要进行一些操作。比如:加载一些初始化数据、执行一段逻辑代码。你可以使用SpringBoot中CommandLineRunner。它可以在项目启动后,执行CommandLineRunner接口实现类的相…...
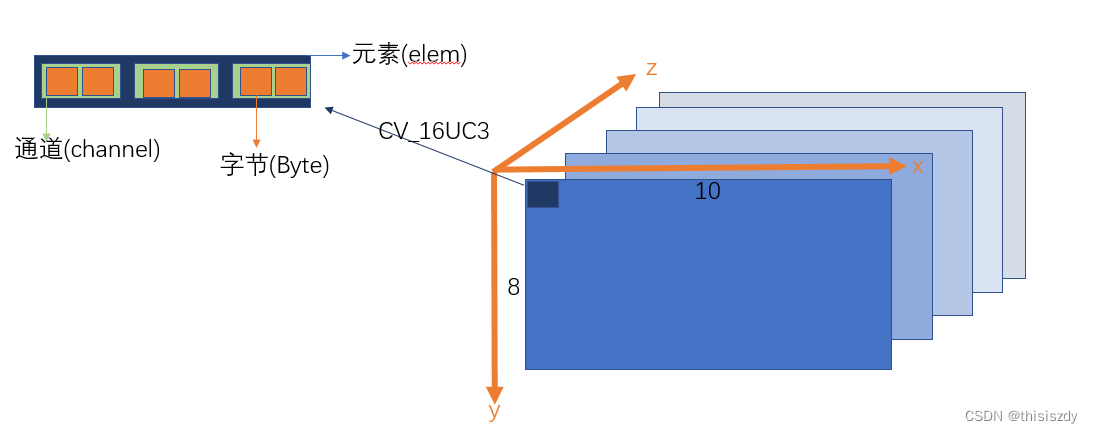
<OpenCV> Mat属性
OpenCV的图像数据类型可参考之前的博客:https://blog.csdn.net/thisiszdy/article/details/120238017 OpenCV-Mat类型的部分属性如下: size:矩阵的大小, s i z e ( c o l s , r o w s ) size(cols,rows) size(cols,rows)…...

LAMP 综合实验
LAMP 综合实验 一.实验目标 实验目标如下: 实现 LAMP 架构 实现数据库主从复制 实现 NFS 服务器存储 wordpress 文件 实现备份服务器实时备份 NFS 服务器文件 实现日志集中存储 实现 loganalyzer 分析展示日志 二.实验准备 2.1 实验环境 实验环境: 虚拟机版本: VM…...

JavaScript发展历程
目录 一、起源(1995-1997) 二、发展(1997-2005) 三、进化——Ajax与Web 2.0(2005-2010年) 四、移动互联网与现代化(2010年至今) 结论 JavaScript是一种广泛使用的网络编程语言&…...

LP(六十九)智能文档助手升级
本文在笔者之前研发的大模型智能文档问答项目中,开发更进一步,支持多种类型文档和URL链接,支持多种大模型接入,且使用更方便、高效。 项目介绍 在文章NLP(六十一)使用Baichuan-13B-Chat模型构建智能文档中…...

【Axure高保真原型】引导弹窗
今天和大家中分享引导弹窗的原型模板,载入页面后,会显示引导弹窗,适用于引导用户使用页面,点击完成后,会显示下一个引导弹窗,直至最后一个引导弹窗完成后进入首页。具体效果可以点击下方视频观看或打开下方…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

论文笔记——相干体技术在裂缝预测中的应用研究
目录 相关地震知识补充地震数据的认识地震几何属性 相干体算法定义基本原理第一代相干体技术:基于互相关的相干体技术(Correlation)第二代相干体技术:基于相似的相干体技术(Semblance)基于多道相似的相干体…...

基于 TAPD 进行项目管理
起因 自己写了个小工具,仓库用的Github。之前在用markdown进行需求管理,现在随着功能的增加,感觉有点难以管理了,所以用TAPD这个工具进行需求、Bug管理。 操作流程 注册 TAPD,需要提供一个企业名新建一个项目&#…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...

Kafka入门-生产者
生产者 生产者发送流程: 延迟时间为0ms时,也就意味着每当有数据就会直接发送 异步发送API 异步发送和同步发送的不同在于:异步发送不需要等待结果,同步发送必须等待结果才能进行下一步发送。 普通异步发送 首先导入所需的k…...
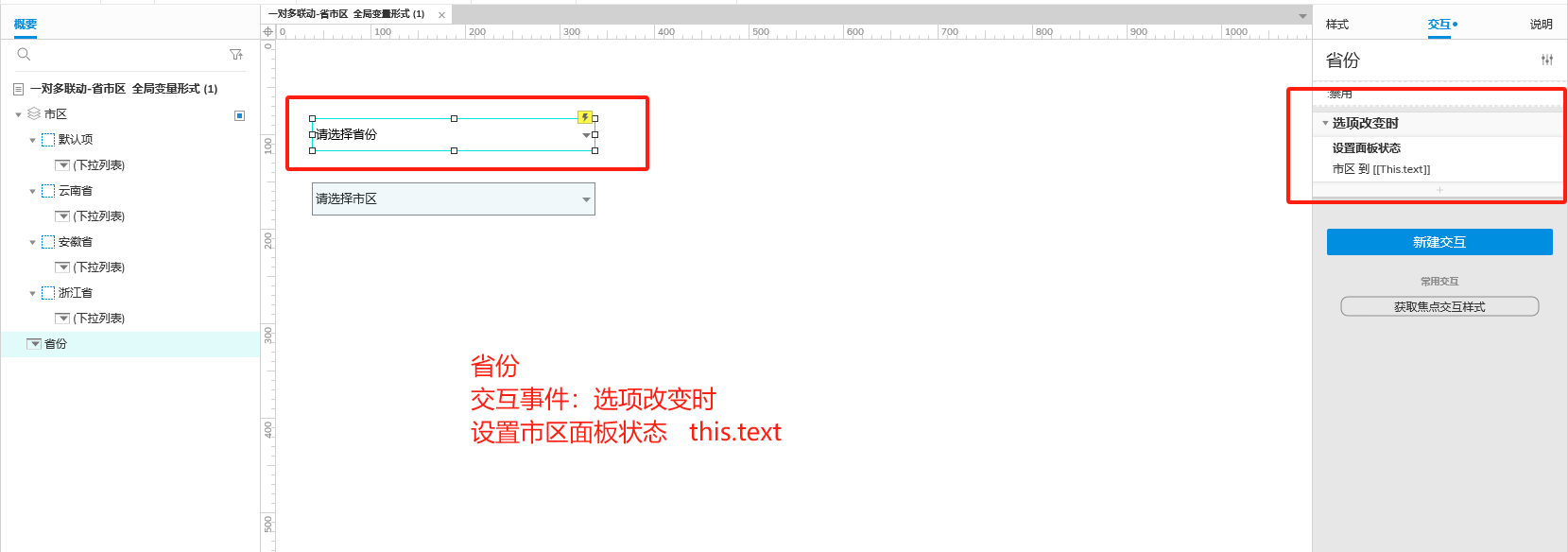
Axure 下拉框联动
实现选省、选完省之后选对应省份下的市区...

高防服务器价格高原因分析
高防服务器的价格较高,主要是由于其特殊的防御机制、硬件配置、运营维护等多方面的综合成本。以下从技术、资源和服务三个维度详细解析高防服务器昂贵的原因: 一、硬件与技术投入 大带宽需求 DDoS攻击通过占用大量带宽资源瘫痪目标服务器,因此…...