Apache Hive之数据查询
文章目录
- 版权声明
- 数据查询
- 环境准备
- 基本查询
- 准备数据
- select基础查询
- 分组、聚合
- JOIN
- RLIKE正则匹配
- UNION联合
- Sampling采用
- Virtual Columns虚拟列
版权声明
- 本博客的内容基于我个人学习黑马程序员课程的学习笔记整理而成。我特此声明,所有版权属于黑马程序员或相关权利人所有。本博客的目的仅为个人学习和交流之用,并非商业用途。
- 我在整理学习笔记的过程中尽力确保准确性,但无法保证内容的完整性和时效性。本博客的内容可能会随着时间的推移而过时或需要更新。
- 若您是黑马程序员或相关权利人,如有任何侵犯版权的地方,请您及时联系我,我将立即予以删除或进行必要的修改。
- 对于其他读者,请在阅读本博客内容时保持遵守相关法律法规和道德准则,谨慎参考,并自行承担因此产生的风险和责任。本博客中的部分观点和意见仅代表我个人,不代表黑马程序员的立场。
数据查询
环境准备
- hdfs启动
start-dfs.sh - yarn启动
start-yarn.sh - HiveServer2服务 启动
#先启动metastore服务 然后启动hiveserver2服务 nohup bin/hive --service metastore >> logs/metastore.log 2>&1 & nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
基本查询
- 查询语句的基本语法
select [all | distinct] select_expr, select_expr, ..
from table_reference
[WHERE where_condition]
[group by col_list]
[having where_condition]
[order by col_list]
[ cluster by col_list|[DISTRIBUTE BY col_list] [SORT by col_list]
]
[LIMIT number]
准备数据
- 准备数据:订单表
create database itheima;
use itheima;
CREATE TABLE itheima.orders (orderId bigint COMMENT '订单id',orderNo string COMMENT '订单编号',shopId bigint COMMENT '门店id',userId bigint COMMENT '用户id',orderStatus tinyint COMMENT '订单状态 -3:用户拒收 -2:未付款的订单 -1:用户取消 0:待发货 1:配送中 2:用户确认收货',goodsMoney double COMMENT '商品金额',deliverMoney double COMMENT '运费',totalMoney double COMMENT '订单金额(包括运费)',realTotalMoney double COMMENT '实际订单金额(折扣后金额)',payType tinyint COMMENT '支付方式,0:未知;1:支付宝,2:微信;3、现金;4、其他',isPay tinyint COMMENT '是否支付 0:未支付 1:已支付',userName string COMMENT '收件人姓名',userAddress string COMMENT '收件人地址',userPhone string COMMENT '收件人电话',createTime timestamp COMMENT '下单时间',payTime timestamp COMMENT '支付时间',totalPayFee int COMMENT '总支付金额'
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';-- 上传数据到linux,导入数据
load data local inpath '/home/hadoop/itheima_orders.txt' into table itheima.orders;
- 准备数据:用户表
CREATE TABLE itheima.users (userId int,loginName string,loginSecret int,loginPwd string,userSex tinyint,userName string,trueName string,brithday date,userPhoto string,userQQ string,userPhone string,userScore int,userTotalScore int,userFrom tinyint,userMoney double,lockMoney double,createTime timestamp,payPwd string,rechargeMoney double
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
-- 导入数据
load data local inpath '/home/hadoop/itheima_users.txt' into table itheima.users;
select基础查询
-- 查询全表数据
SELECT * FROM itheima.orders;-- 查询单列信息
SELECT orderid, userid, totalmoney FROM itheima.orders;-- 查询表有多少条数据
SELECT COUNT(*) FROM itheima.orders;-- 过滤广东省的订单
SELECT * FROM itheima.orders
WHERE useraddress LIKE '%广东%';-- 找出广东省单笔营业额最大的订单
SELECT * FROM itheima.orders
WHERE useraddress LIKE '%广东%'
ORDER BY totalmoney DESC LIMIT 1;
分组、聚合
-- 统计未支付、已支付各自的人数
SELECT ispay, COUNT(*)
FROM itheima.orders
GROUP BY ispay;-- 在已付款的订单中,统计每个用户最高的一笔消费金额
SELECT userid, MAX(totalmoney)
FROM itheima.orders
WHERE ispay = 1 GROUP BY userid;SELECT usr.username, MAX(ord.totalmoney)
FROM itheima.orders ord,itheima.users usr
WHERE ord.userId=usr.userId and ord.ispay = 1
GROUP BY usr.username;-- 统计每个用户的平均订单消费额
SELECT userid, AVG(totalmoney)
FROM itheima.orders
GROUP BY userid;-- 统计每个用户的平均订单消费额,并过滤大于10000的数据
SELECT userid, AVG(totalmoney) AS avg_money
FROM itheima.orders
GROUP BY userid
HAVING avg_money > 10000;
JOIN
-- 订单表和用户表JOIN 找出用户username
SELECT o.orderid, o.userid, u.username
FROM itheima.orders o JOIN itheima.users u
ON o.userid = u.userid;
-- 左外连接
SELECT o.orderid, o.userid, u.username
FROM itheima.orders o
LEFT JOIN itheima.users uON o.userid = u.userid;
RLIKE正则匹配
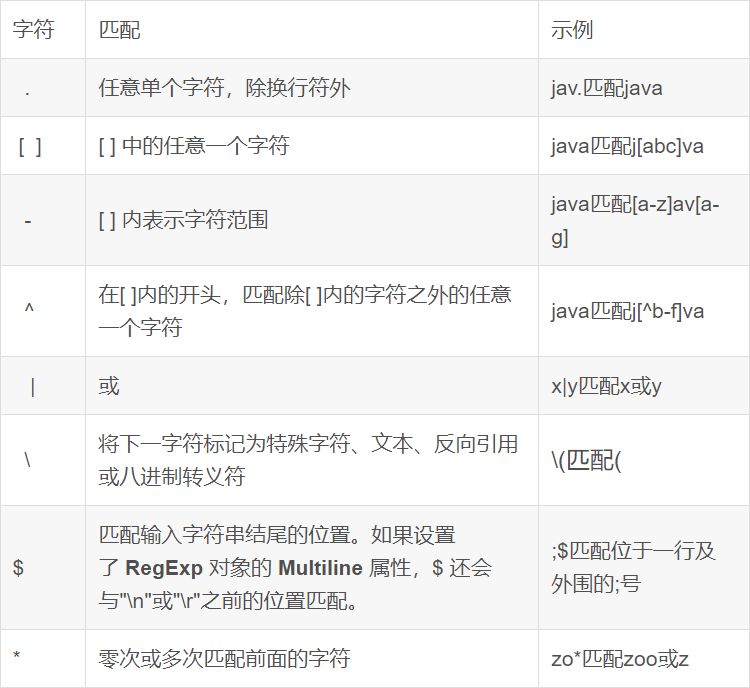
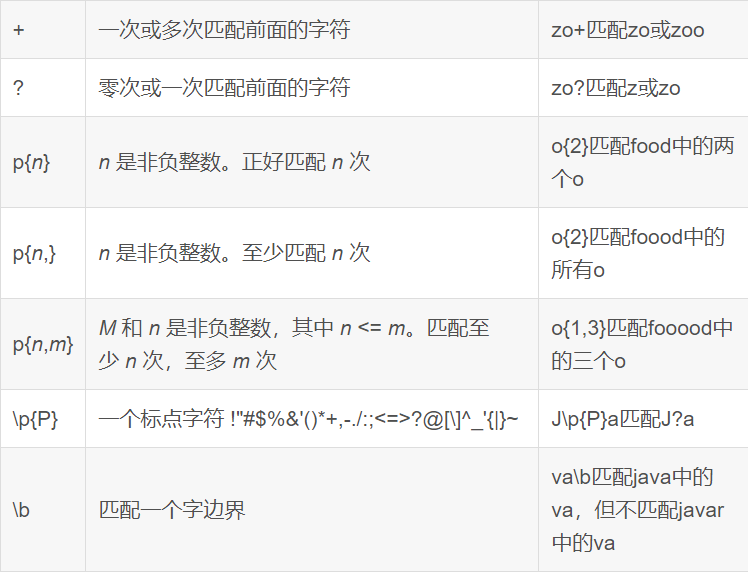
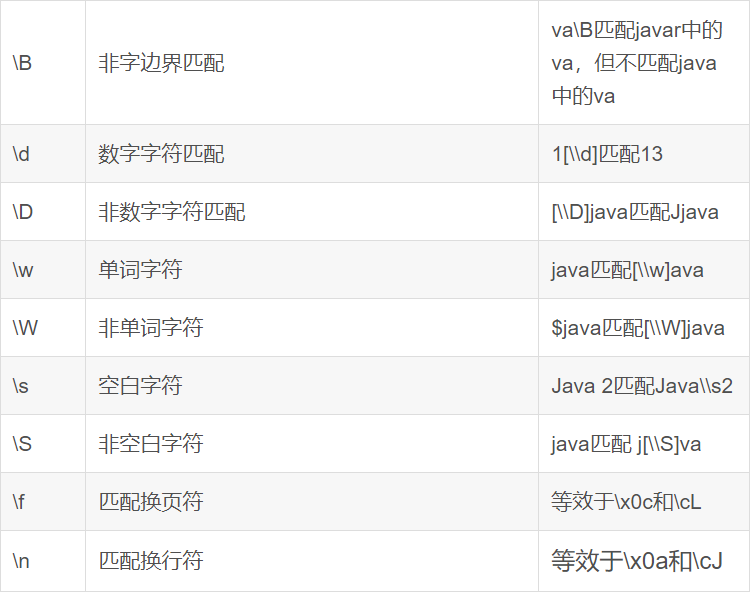
- 正则表达式是一种规则集合,通过特定的规则字符描述,来判断字符串是否符合规则。
-- 查找广东省数据
SELECT * FROM itheima.orders WHERE useraddress RLIKE '.*广东.*';
-- 查找用户地址是:xx省 xx市 xx区
SELECT * FROM itheima.orders WHERE useraddress RLIKE '..省 ..市 ..区';
-- 查找用户姓为:张、王、邓
SELECT * FROM itheima.orders WHERE username RLIKE '[张王邓]\\S*+';
-- 查找手机号符合:188****0*** 规则
SELECT * FROM itheima.orders WHERE userphone RLIKE '188\\S{4}0[0-9]{3}';
UNION联合
- UNION 用于将多个SELECT语句的结果组合成单个结果集。
- 每个select语句返回的列的数量和名称必须相同。否则,将引发架构错误。
- UNION关键字的作用是?
- 将多个SELECT的结果集合并成一个
- 多个SELECT的结果集需要架构一致,否则无法合并
- 自带去重效果,如果无需去重,需要使用UNIONALL
- UNION用在何处
- 可以用在任何需要SELECT发挥的地方(包括子查询、ISNERTSELECT等)
- 基础语法
select ...union [all] select ...
CREATE TABLE itheima.course(c_id string,c_name string,t_id string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';LOAD DATA LOCAL INPATH '/home/hadoop/course.txt' INTO TABLE itheima.course;-- 基础UNION
SELECT * FROM itheima.course WHERE t_id = '周杰轮'
UNION
SELECT * FROM itheima.course WHERE t_id = '王力鸿';-- 去重演示
SELECT * FROM itheima.course
UNION
SELECT * FROM itheima.course;-- 不去重
SELECT * FROM itheima.course
UNION ALL
SELECT * FROM itheima.course;-- UNION写在FROM中 UNION写在子查询中
SELECT t_id, COUNT(*) FROM(SELECT * FROM itheima.course WHERE t_id = '周杰轮'UNION ALLSELECT * FROM itheima.course WHERE t_id = '王力鸿') AS u GROUP BY t_id;
Sampling采用

TABLE SAMPLE (BUCKET <x> OUT OF <y> [ON <col_name> | rand()])
- x,y:必填。将源表中的数据划分为y个桶,取其中的第x个桶,桶从1开始编号。
- col_name:分桶列名即要进行采样的列名。当表不是聚簇表时,col_name与rand()函数必须二选一,当使用rand()函数时表示对输入的数据随机进行分桶。ON语句中最多支持指定10个列。
语法2,基于数据块抽样
SELECT ... FROM tbl TABLESAMPLE(num ROWS I num PERCENT I num(KM|G));
- num ROWS 表示抽样num条数据
- num PERCENT表示抽样num百分百比例的数据
- num(K | M |G)表示抽取num大小的数据,单位可以是K、M、G表示KB、MB、GB
- 注意:
- 使用这种语法抽样,条件不变的话,每一次抽样的结果都一致
- 即无法做到随机,只是按照数据顺序从前向后取。
- TABLESAMPLE函数的使用
- 桶抽样方式,
TABLESAMPLE(BUCKET x OUT OF y ON(colname rand() ) ),推荐,完全随机,速度略慢块抽样,使用分桶表可以加速 - 块抽样方式,
TABLESAMPLE(num ROWS/num PERCENT」num(K|M|G))速度快于桶抽样方式,但不随机,只是按照数据顺序从前向后取。
- 桶抽样方式,
-- 随机桶抽取, 分配桶是有规则的
-- 可以按照列的hash取模分桶
-- 按照完全随机分桶
-- 其它条件不变的话,每一次运行结果一致
SELECT username, orderId, totalmoney
FROM itheima.orders tablesample(bucket 3 out of 10 on orders.username);-- 完全随机,每一次运行结果不同
select * from itheima.orders
tablesample(bucket 3 out of 10 on rand());-- 数据块抽取,按顺序抽取,每次条件不变,抽取结果不变
-- 抽取100条
select * from itheima.orderstablesample(100 rows);-- 取1%数据
select * from itheima.orderstablesample(20 percent);-- 取 1KB数据
select * from itheima.orders tablesample(1K);Virtual Columns虚拟列
- 虚拟列是Hive内置的可以在查询语句中使用的特殊标记,可以查询数据本身的详细参数
-
Hive自前可用3个虚拟列:
INPUT_FILE_NAME,显示数据行所在的具体文件BLOCK_OFFSET_INSIDE_FILE,显示数据行所在文件的偏移量ROW_OFFSET_INSIDE__BLOCK,显示数据所在HDFS块的偏移量- 此虚拟列需要设置:
SET hive.exec.rowoffset=true才可使用
- 此虚拟列需要设置:
-
虚拟列的作用
- 查看行级别的数据详细参数
- 可以用于WHERE、GROUPBY等各类统计计算中
- 可以协助进行错误排查工作
--虚拟列
SET hive.exec.rowoffset=true;SELECT orderid, username, INPUT__FILE__NAME, BLOCK__OFFSET__INSIDE__FILE, ROW__OFFSET__INSIDE__BLOCK FROM itheima.orders;SELECT *, BLOCK__OFFSET__INSIDE__FILE FROM itheima.orders WHERE BLOCK__OFFSET__INSIDE__FILE < 1000;SELECT orderid, username, INPUT__FILE__NAME, BLOCK__OFFSET__INSIDE__FILE, ROW__OFFSET__INSIDE__BLOCK FROM itheima.orders_bucket;SELECT INPUT__FILE__NAME, COUNT(*) FROM itheima.orders_bucket GROUP BY INPUT__FILE__NAME;
相关文章:
Apache Hive之数据查询
文章目录 版权声明数据查询环境准备基本查询准备数据select基础查询分组、聚合JOINRLIKE正则匹配UNION联合Sampling采用Virtual Columns虚拟列 版权声明 本博客的内容基于我个人学习黑马程序员课程的学习笔记整理而成。我特此声明,所有版权属于黑马程序员或相关权利…...

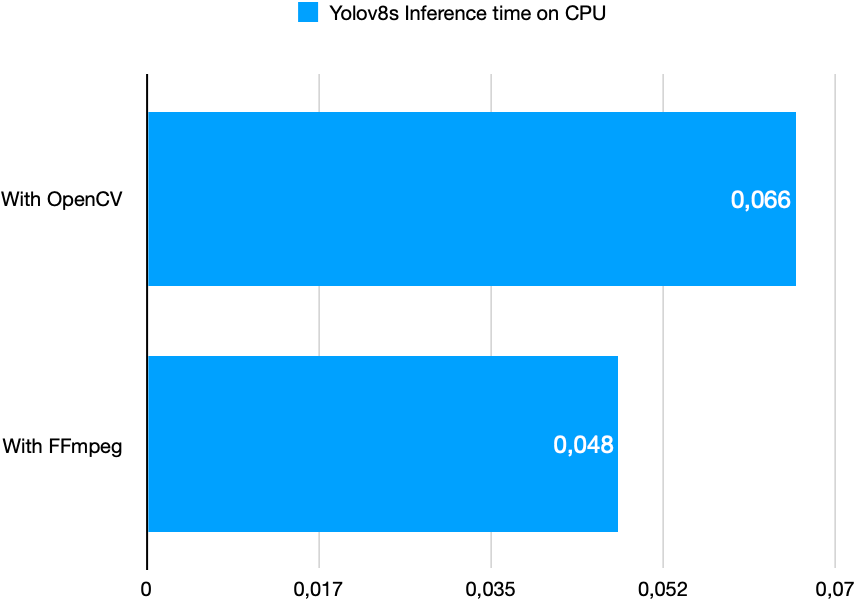
OpenCV---视频操作
用摄像头捕获视频 import cv2 as cv import numpy cap cv.VideoCapture(0) while(cap.isOpened()):ret, frame cap.read() # read() 它返回两个值,第一个是布尔值,表示是否成功读取到一帧,第二个是帧本身。cv.imshow(Video, frame)if c…...

《TCP/IP网络编程》阅读笔记--进程间通信
目录 1--进程间通信 2--pipe()函数 3--代码实例 3-1--pipe1.c 3-2--pipe2.c 3-3--pipe3.c 3-4--保存信息的回声服务器端 1--进程间通信 为了实现进程间通信,使得两个不同的进程间可以交换数据,操作系统必须提供两个进程可以同时访问的内存空间&am…...

mysql中show status参数介绍
Uptime_since_flush_status, 2159061:自上次刷新状态以来的服务器运行时间(以秒为单位)。Uptime, 2159061:服务器的总运行时间(以秒为单位)。Threads_running, 2:当前正在运行的客户端线程数。T…...

Tomcat服务的部署及配置优化
文章目录 1. Tomcat的相关介绍1.1 Tomcat简介1.2 Tomcat的核心组件1.2.1 Web容器1.2.2 Servlet容器1.2.3 JSP容器 1.3 Tomcat的功能组件1.3.1 connector连接器1.3.2 container容器1.3.2.1 子容器及其相关功能 1.4 主要作用1.5 Tmocat处理请求的过程 2. Tomcata服务部署2.1 安装…...

入门力扣自学笔记279 C++ (题目编号:1123)
1123. 最深叶节点的最近公共祖先 题目: 给你一个有根节点 root 的二叉树,返回它 最深的叶节点的最近公共祖先 。 回想一下: 叶节点 是二叉树中没有子节点的节点树的根节点的 深度 为 0,如果某一节点的深度为 d,那它…...

【AIGC专题】Stable Diffusion 从入门到企业级实战0402
一、概述 本章是《Stable Diffusion 从入门到企业级实战》系列的第四部分能力进阶篇《Stable Diffusion ControlNet v1.1 图像精准控制》第02节, 利用Stable Diffusion ControlNet Openpose模型精准控制图像生成。上一节,我们介绍了《Stable Diffusion C…...
)
【Spring事务】Spring事务的传播机制(通俗易懂)
目录 什么是spring事务 Spring事务的传播机制 什么是spring事务 封装在数据库事务之上的一种事务处理机制。其管理方法有两种,分别是编程式事务以及声明式事务。一般我们使用Transactional进行声明式事务。 Spring事务的传播机制 Spring的事务传播机制种类 传播行…...
使用 Python 的高效相机流
一、说明 让我们谈谈在Python中使用网络摄像头。我有一个简单的任务,从相机读取帧,并在每一帧上运行神经网络。对于一个特定的网络摄像头,我在设置目标 fps 时遇到了问题(正如我现在所理解的——因为相机可以用 mjpeg 格式运行 30…...

pycharm使用
在使用pycharm时,有时一个回车或者一个tab键,缩进的长度不符合预期可以调整设置tab键缩进的长度: 平时工作中,不同的人在编辑代码缩进的时候,有的人喜欢按四个或者六个空格,有的人喜欢按tab键,而…...

C++项目实战——基于多设计模式下的同步异步日志系统-②-相关技术补充(不定参函数)
文章目录 专栏导读不定参函数C风格不定参函数不定参宏函数 专栏导读 🌸作者简介:花想云 ,在读本科生一枚,C/C领域新星创作者,新星计划导师,阿里云专家博主,CSDN内容合伙人…致力于 C/C、Linux 学…...
iOS开发Swift-10-位置授权, cocoapods,API,天气获取,城市获取-和风天气App首页代码
1.获取用户当前所在的位置 在infi中点击加号,选择权限:当用户使用app的时候获取位置权限. 填写使用位置权限的目的. 2.获取用户的经纬度. ViewController: import UIKit import CoreLocationclass ViewController: UIViewController, CLLocationManagerDelegate { //遵循CLL…...

CNN(七):ResNeXt-50算法的思考
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊|接辅导、项目定制 在进行ResNeXt-50实战练习时,我也跟其他学员一样有这个疑惑,如下图所示: 反复查看代码,仍然有…...

【人月神话】深入了解软件工程和项目管理
文章目录 👨⚖️《人月神话》的主要观点👨🏫《人月神话》的主要内容👨💻作者介绍 🌸🌸🌸🌷🌷🌷💐💐💐&a…...
52、基于函数式方式开发 Spring WebFlux 应用
★ Spring WebFlux的两种开发方式 1. 采用类似于Spring MVC的注解的方式来开发。此时开发时感觉Spring MVC差异不大,但底层依然是反应式API。2. 使用函数式编程来开发★ 使用函数式方式开发Web Flux 使用函数式开发WebFlux时需要开发两个组件: ▲ Han…...
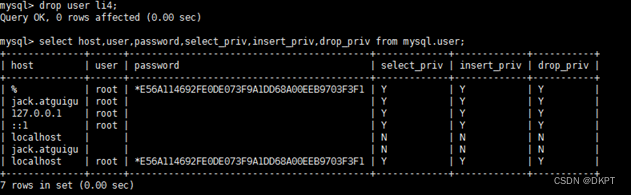
MySQL的用户管理
1、MySQL的用户管理 (1)创建用户 create user zhang3 identified by 123123;表示创建名称为zhang3的用户,密码设为123123。 (2)了解user表 1)查看用户 select host,user,authentication_string,select…...

LeetCode //C - 114. Flatten Binary Tree to Linked List
114. Flatten Binary Tree to Linked List Given the root of a binary tree, flatten the tree into a “linked list”: The “linked list” should use the same TreeNode class where the right child pointer points to the next node in the list and the left child …...

利用transform和border 创造简易图标,以适应uniapp中多字体大小情况下的符号问题
heml: <text class"icon-check"></text> css: .icon-check {border: 2px solid black;border-left: 0;border-top: 0;height: 12px;width: 6px;transform-origin: center;transform: rotate(45deg);} 实际上就是声明一个带边框的div 将其中相邻的两边去…...

C/C++指针函数与函数指针
一、指针函数 指针函数:本质为一个函数,返回值为指针指针函数:如果一个函数的返回值是指针类型,则称为指针函数用指针作为函数的返回值的好处:可以从被调函数向主函数返回大量的数据,常用于返回结构体指针。…...
30天入门Python(基础篇)——第1天:为什么选择Python
文章目录 专栏导读作者有话说为什么学习Python原因1(总体得说)原因2(就业说) Python的由来(来自百度百科)Python的版本 专栏导读 🔥🔥本文已收录于《30天学习Python从入门到精通》 🉑🉑本专栏专门针对于零基础和需要重新复习巩固…...

深入解析C++ STL容器:从底层实现到高效应用
1. STL容器基础概念与分类 第一次接触C STL容器时,我被它的强大功能震撼到了。记得当时写一个学生管理系统,原本需要几百行代码实现的链表操作,用list容器十几行就搞定了。STL(Standard Template Library)是C标准库的核…...

WebGL/Three.js性能优化实战:你的3D模型为什么卡?从理解栅格化与渲染管线开始
WebGL/Three.js性能优化实战:从栅格化原理到渲染管线调优 当你用Three.js加载一个精致的3D模型时,是否遇到过页面突然卡顿、风扇狂转的情况?这背后往往与浏览器如何将矢量图形转换为屏幕像素的过程密切相关。今天我们就从栅格化的底层原理出发…...

ARM单片机位带操作原理与应用详解
1. ARM单片机位带操作基础回顾在嵌入式开发中,位带操作(Bit-Banding)是Cortex-M系列处理器提供的一个非常实用的功能特性。简单来说,它允许开发者通过访问特定内存地址的方式,直接操作某个寄存器的单个比特位,而无需进行传统的&qu…...

fa‘s‘d‘f
fa’s’d’fa’d...

告别卡顿:在Windows10上通过QEMU与WHPX硬件加速高效部署Ubuntu20.04开发环境
1. 为什么选择QEMUWHPX方案? 很多开发者都遇到过这样的困境:在Windows系统上运行Linux虚拟机时,要么性能拉胯到让人抓狂,要么配置复杂得让人望而却步。我之前用VMware跑Ubuntu时,光是开个浏览器就能让CPU飙到100%&…...

5个技巧让你高效畅玩Switch游戏:开源Ryujinx模拟器全攻略
5个技巧让你高效畅玩Switch游戏:开源Ryujinx模拟器全攻略 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx Ryujinx是一款采用C#语言开发的开源Nintendo Switch模拟器&#x…...

如何高效构建Steam游戏DRM解除自动化解决方案:开源框架技术实现
如何高效构建Steam游戏DRM解除自动化解决方案:开源框架技术实现 【免费下载链接】Steam-auto-crack Steam Game Automatic Cracker 项目地址: https://gitcode.com/gh_mirrors/st/Steam-auto-crack Steam游戏DRM解除自动化解决方案为技术爱好者提供了一套完整…...

01_Neo4j知识体系之原生图数据库架构全景与技术定位
01_Neo4j知识体系之原生图数据库架构全景与技术定位 体系 基础概念层:原生图数据库定位、属性图模型、索引自由邻接、与关系型数据库对比延伸阅读方向:Cypher 查询、图数据科学、向量索引、GraphRAG、企业级集群适用对象:架构师、数据平台负…...

解锁Intel GPU的CUDA能力:从零开始的跨硬件计算实践
解锁Intel GPU的CUDA能力:从零开始的跨硬件计算实践 【免费下载链接】ZLUDA CUDA on non-NVIDIA GPUs 项目地址: https://gitcode.com/GitHub_Trending/zl/ZLUDA 当实验室电脑只有Intel集成显卡却需要运行CUDA加速程序时,当笔记本的Iris Xe显卡面…...

第6章 数据类型转换-6.8 转换为集合
通过使用set()函数可以将字符串、列表或元组转换为可变集合。其语法格式如下: set([x]) 其中,参数x为可选参数,表示字符串、列表或元组,如果省略该参数,则该函数返回空集合。示例代码如下: # 资源包\Cod…...