【redis进阶】基础知识简要回顾
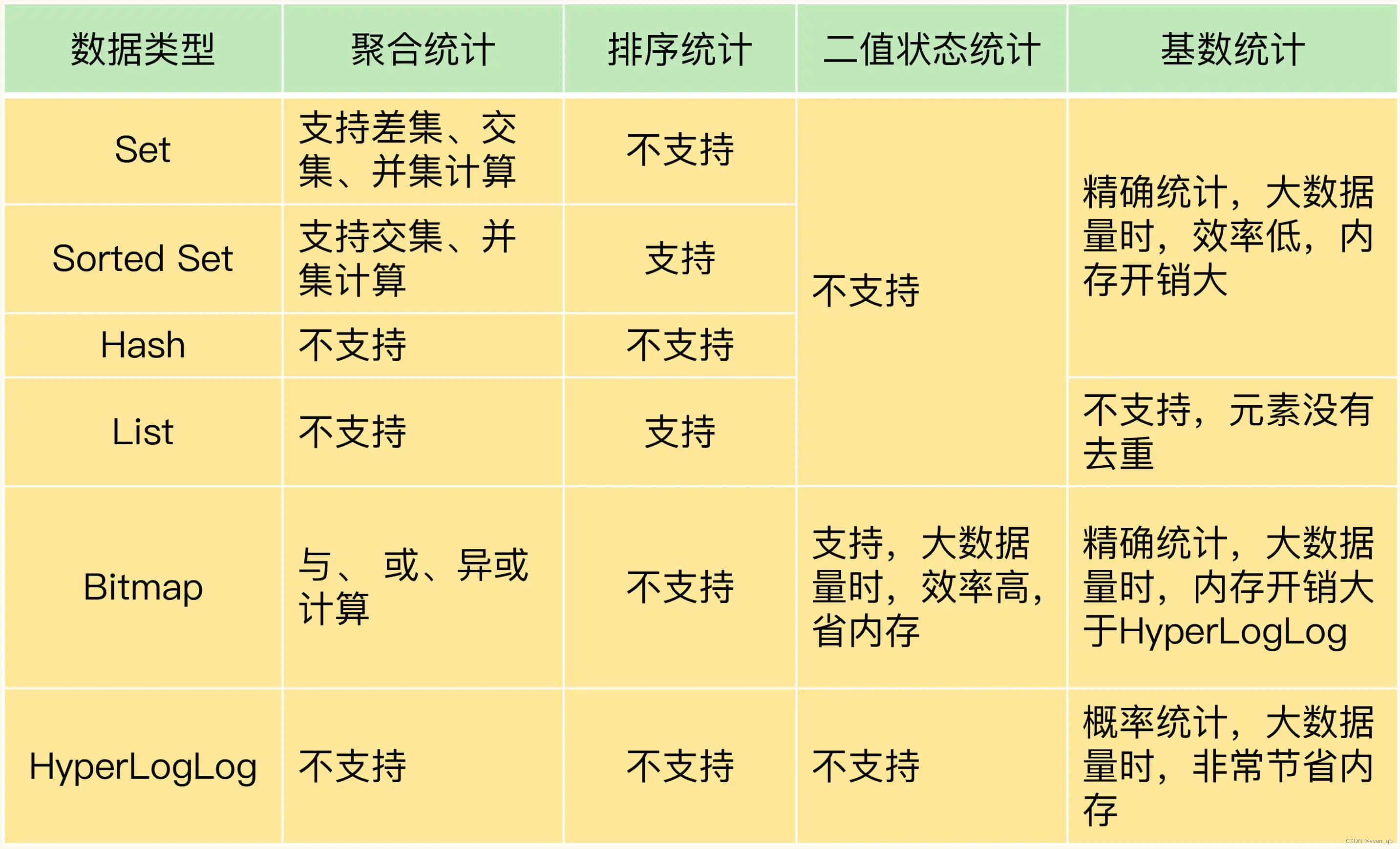
1. 常见功能介绍
聚合统计
使用list集合的差集、并集来统计
排序统计
SortedSet(ZSet)统计,再利用分页列出权重高的元素
二值状态统计
BitMap存储,获取并统计
SETBIT uid:sign:3000:202008 2 1 GETBIT uid:sign:3000:202008 2 统计8月份签到情况
BITCOUNT uid:sign:3000:202008基数统计
数据量小的时候可以用Set或hash
数据量大的时候可以HyperLogLog
PFADD page1:uv user1 user2 user3 user4 user5PFCOUNT page1:uv注意:HyperLogLog 的统计规则是基于概率完成的,所以它给出的统计结果是有一定误差的,标准误算率是 0.81%。这也就意味着,你使用 HyperLogLog 统计的 UV 是 100 万,但实际的 UV 可能是 101 万。虽然误差率不算大,但是,如果你需要精确统计结果的话,最好还是继续用 Set 或 Hash 类型。
2. 一个键值数据库应该包含什么?
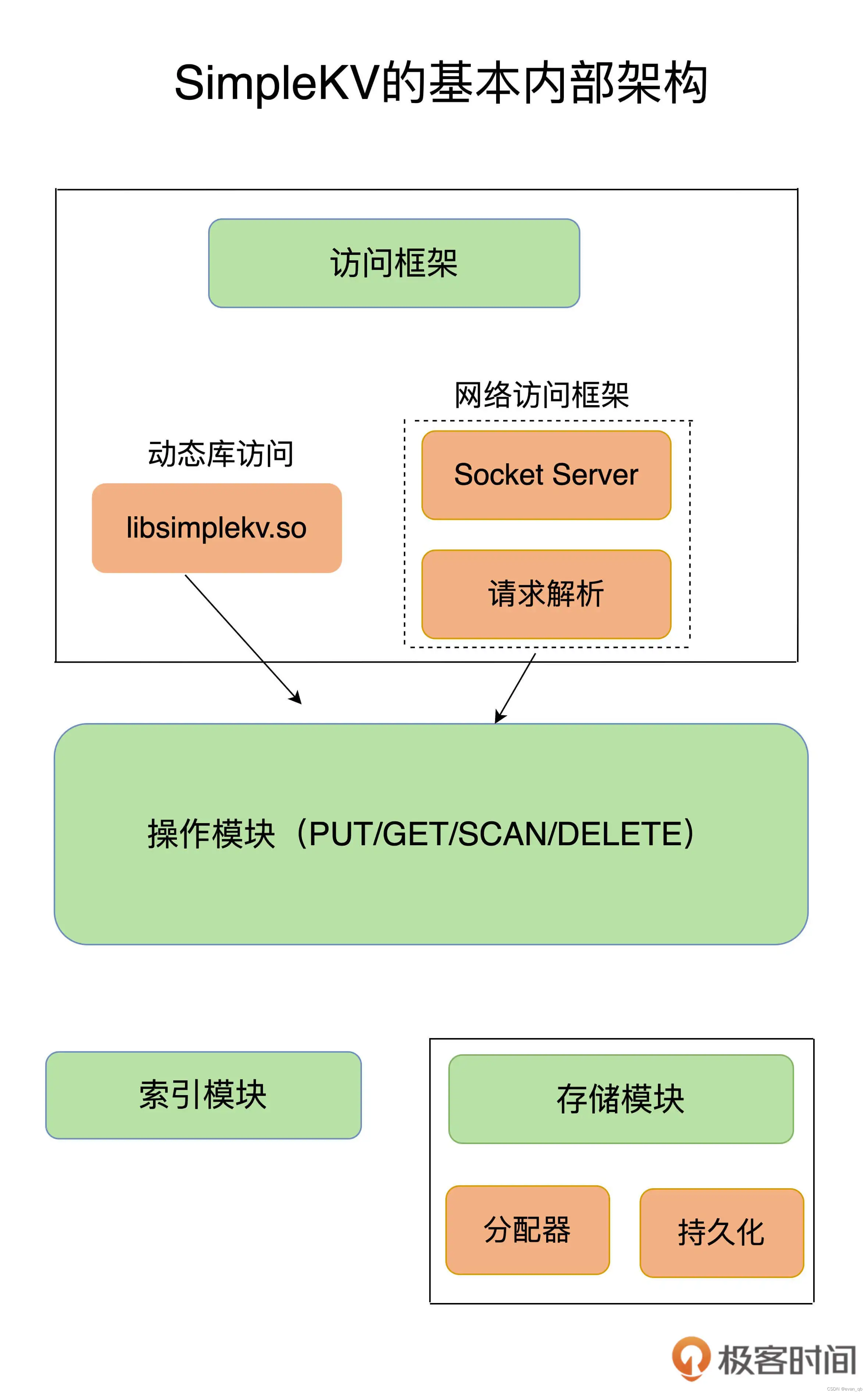
Redis 主要通过网络框架进行访问,而不再是动态库了,这也使得 Redis 可以作为一个基础性的网络服务进行访问,扩大了 Redis 的应用范围。
Redis 的持久化模块能支持两种方式:日志(AOF)和快照(RDB),这两种持久化方式具有不同的优劣势,影响到 Redis 的访问性能和可靠性。
Redis 支持高可靠集群和高可扩展集群,因此,Redis 中包含了相应的集群功能支撑模块。
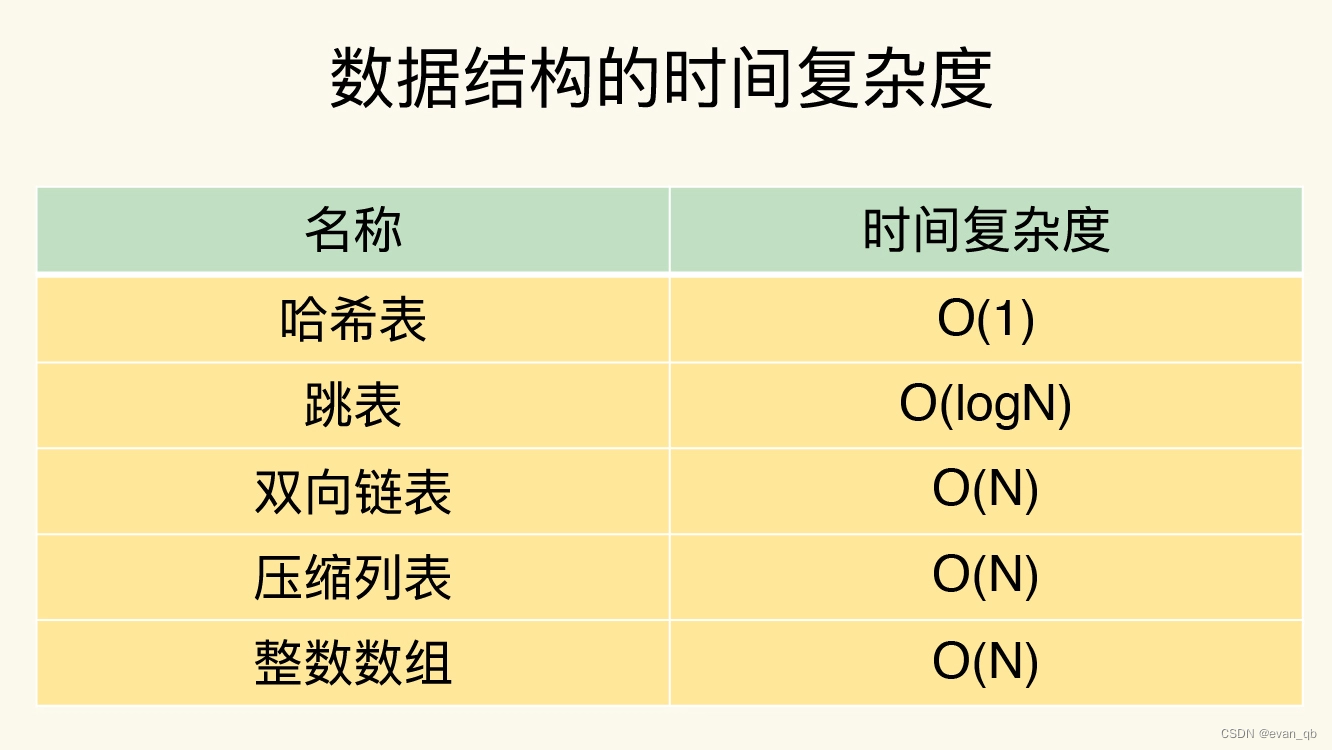
3. redis常见的数据结构
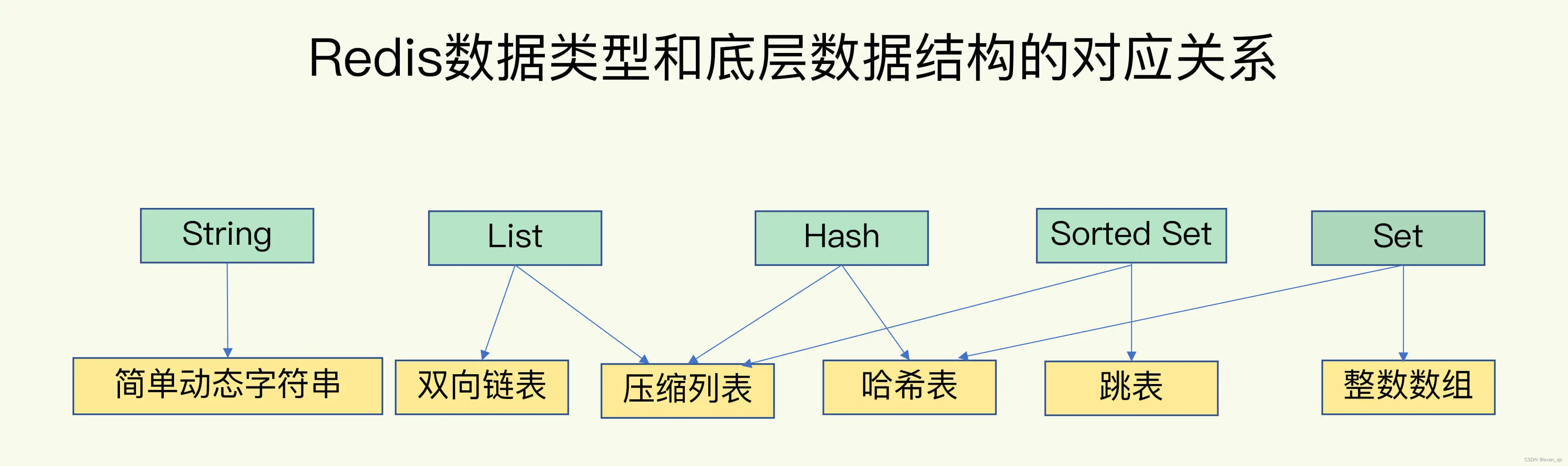
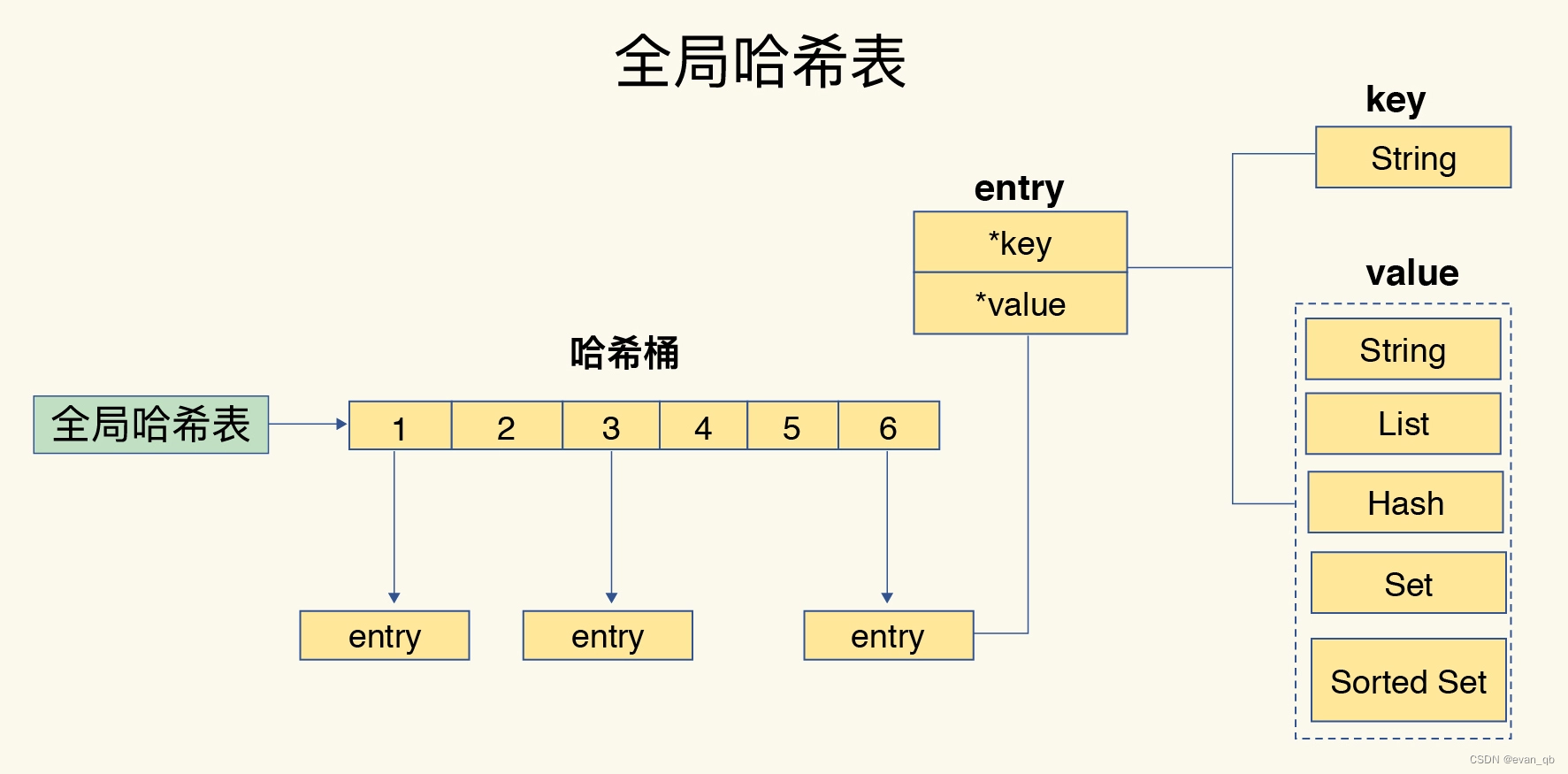
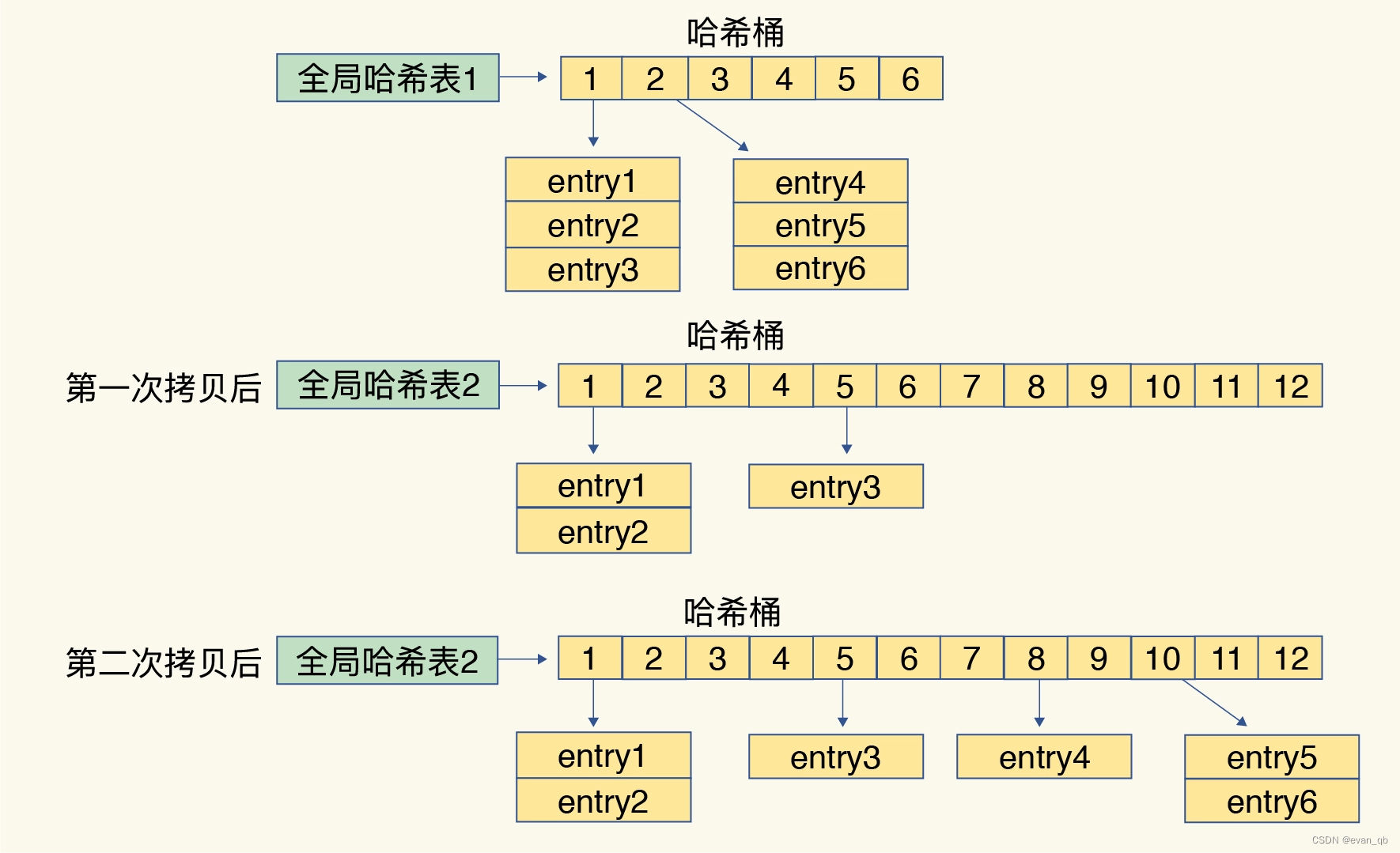
redis渐进式rehash
压缩列表

zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量和列表中的 entry 个数
第一个元素和最后一个元素复杂度为O(1),其他为O(N)
跳表
在链表的基础上加了多级索引
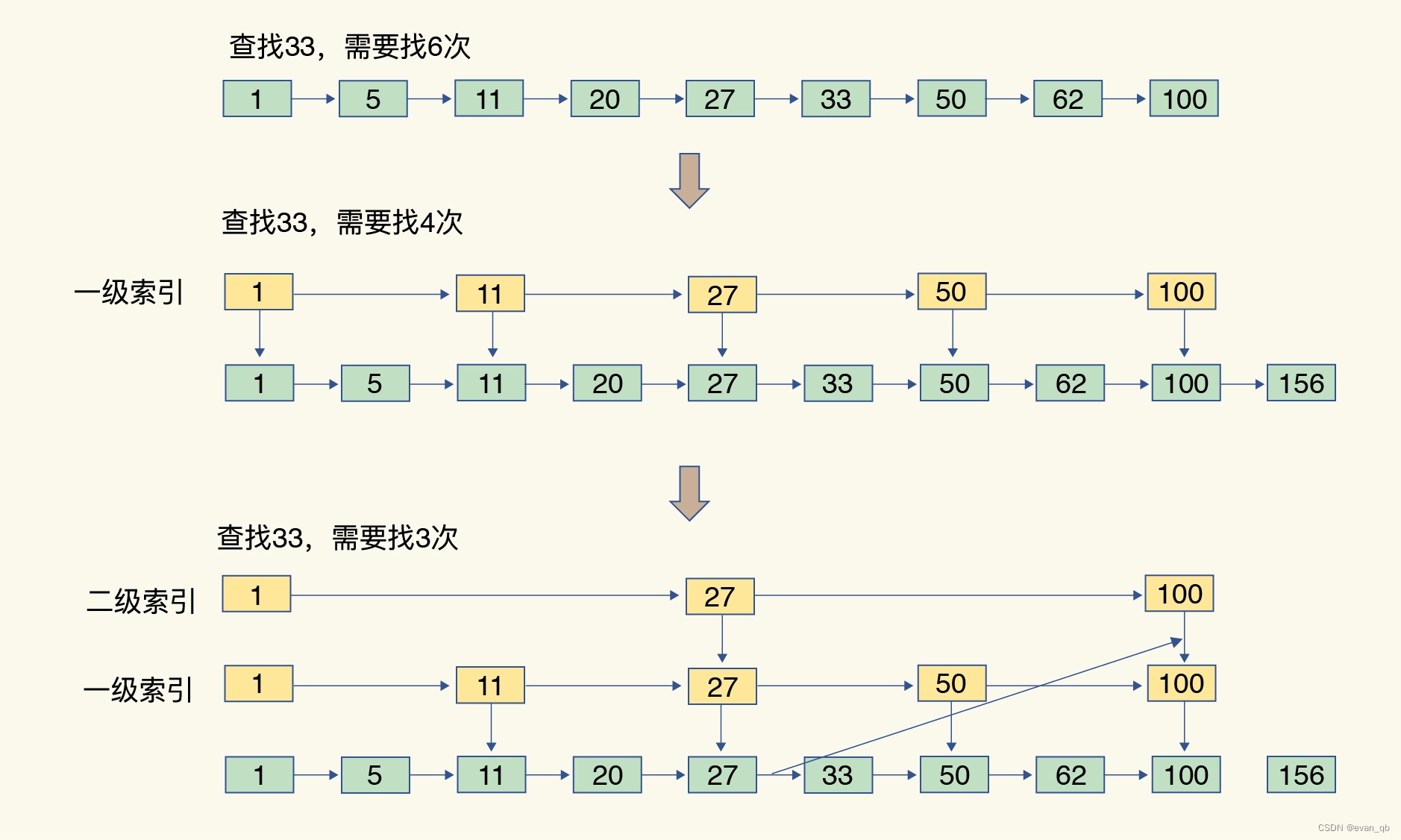
查找复杂度为O(logN)
思考
整数数组和压缩列表在查找时间复杂度方面并没有很大的优势,那为什么 Redis 还会把它们作为底层数据结构呢?
1、内存利用率,数组和压缩列表都是非常紧凑的数据结构,它比链表占用的内存要更少。Redis是内存数据库,大量数据存到内存中,此时需要做尽可能的优化,提高内存的利用率。
2、数组对CPU高速缓存支持更友好,所以Redis在设计时,集合数据元素较少情况下,默认采用内存紧凑排列的方式存储,同时利用CPU高速缓存不会降低访问速度。当数据元素超过设定阈值后,避免查询时间复杂度太高,转为哈希和跳表数据结构存储,保证查询效率。
如果在数组上是随机访问,对CPU高速缓存还友好不?
如果在数组上是随机访问,会造成 CPU 高速缓存整个缓存行失效,命中率降低。(取决于数组的大小)
4. 高性能IO模型:为什么单线程Redis能那么快?
为什么使用单线程?
大部分线程也在等待获取访问共享资源的互斥锁,并行变串行,系统吞吐率并没有随着线程的增加而增加。
采用多线程开发一般会引入同步原语来保护共享资源的并发访问,这也会降低系统代码的易调试性和可维护性。为了避免这些问题,Redis 直接采用了单线程模式。
单线程Redis为什么那么快?
- 内存操作
- 数据结构,hash表、跳表提高访问效率
- 多路复用机制
多路复用模型
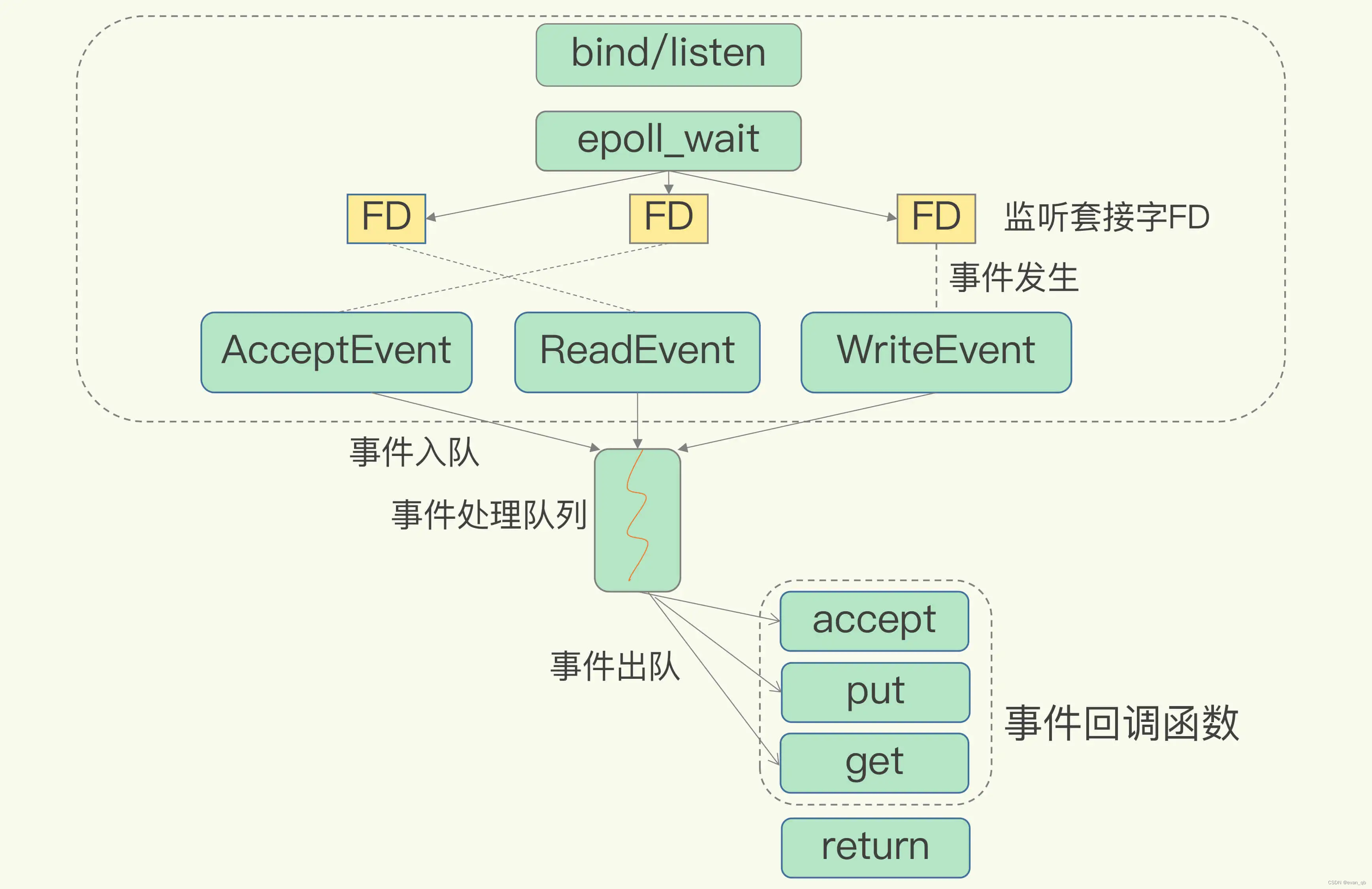
为了在请求到达时能通知到 Redis 线程,select/epoll 提供了基于事件的回调机制,即针对不同事件的发生,调用相应的处理函数。select/epoll 一旦监测到 FD 上有请求到达时,就会触发相应的事件。
事件驱动,两个请求分别对应 Accept 事件和 Read 事件,Redis 分别对这两个事件注册 accept 和 get 回调函数。当 Linux 内核监听到有连接请求或读数据请求时,就会触发 Accept 事件和 Read 事件,此时,内核就会回调 Redis 相应的 accept 和 get 函数进行处理。
问题
“Redis 基本 IO 模型”图中,你觉得还有哪些潜在的性能瓶颈吗?如何进行解决?
Redis单线程处理IO请求性能瓶颈主要包括2个方面:
1、任意一个请求在server中一旦发生耗时,都会影响整个server的性能,也就是说后面的请求都要等前面这个耗时请求处理完成,自己才能被处理到。耗时的操作包括以下几种:
a、操作bigkey:写入一个bigkey在分配内存时需要消耗更多的时间,同样,删除bigkey释放内存同样会产生耗时;
b、使用复杂度过高的命令:例如SORT/SUNION/ZUNIONSTORE,或者O(N)命令,但是N很大,例如lrange key 0 -1一次查询全量数据;
c、大量key集中过期:Redis的过期机制也是在主线程中执行的,大量key集中过期会导致处理一个请求时,耗时都在删除过期key,耗时变长;
d、淘汰策略:淘汰策略也是在主线程执行的,当内存超过Redis内存上限后,每次写入都需要淘汰一些key,也会造成耗时变长;
e、AOF刷盘开启always机制:每次写入都需要把这个操作刷到磁盘,写磁盘的速度远比写内存慢,会拖慢Redis的性能;
f、主从全量同步生成RDB:虽然采用fork子进程生成数据快照,但fork这一瞬间也是会阻塞整个线程的,实例越大,阻塞时间越久;
2、并发量非常大时,单线程读写客户端IO数据存在性能瓶颈,虽然采用IO多路复用机制,但是读写客户端数据依旧是同步IO,只能单线程依次读取客户端的数据,无法利用到CPU多核。
针对问题1,一方面需要业务人员去规避,一方面Redis在4.0推出了lazy-free机制,把bigkey释放内存的耗时操作放在了异步线程中执行,降低对主线程的影响。
针对问题2,Redis在6.0推出了多线程,可以在高并发场景下利用CPU多核多线程读写客户端数据,进一步提升server性能,当然,只是针对客户端的读写是并行的,每个命令的真正操作依旧是单线程的。
5. AOF日志:宕机了,Redis如何避免数据丢失?
AOF写磁盘的风险
1. 命令没有持久化,redis宕机可能会导致数据丢失
2. AOF会导致下一个命令阻塞
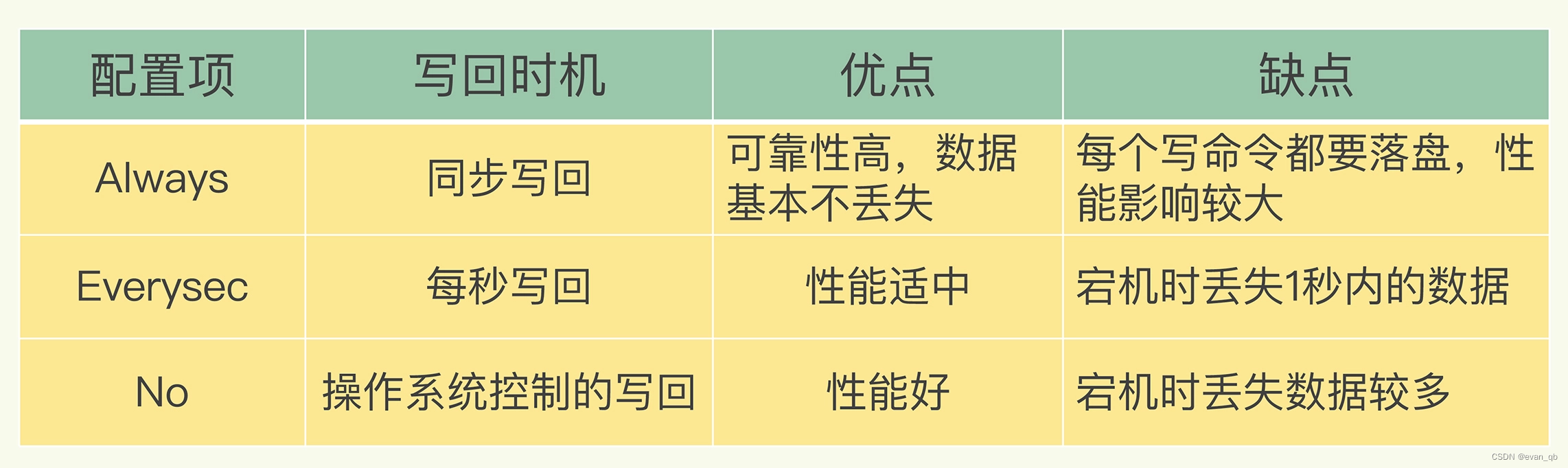
写磁盘策略
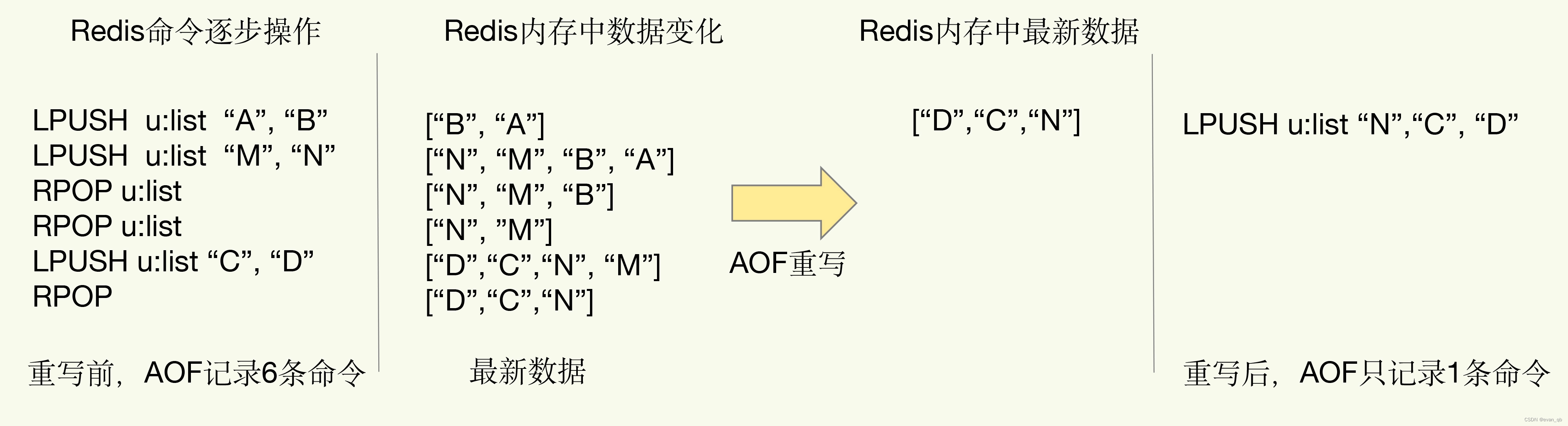
重写机制
AOF重写会阻塞吗?
AOF非阻塞的重写过程
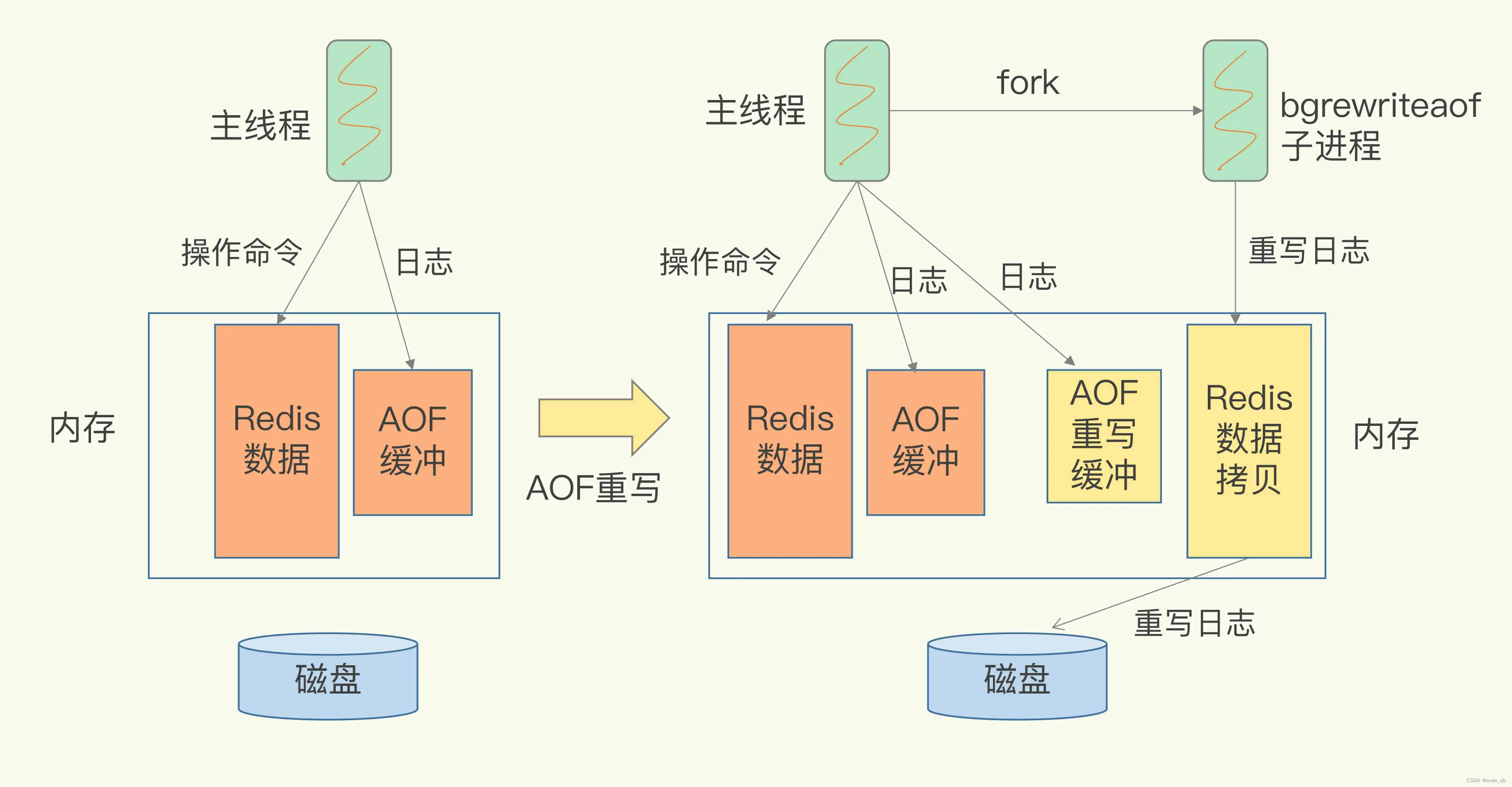
一个拷贝:
每次执行重写时,主线程 fork 出后台的 bgrewriteaof 子进程。此时,fork 会把主线程的内存拷贝一份给 bgrewriteaof 子进程,这里面就包含了数据库的最新数据。然后,bgrewriteaof 子进程就可以在不影响主线程的情况下,逐一把拷贝的数据写成操作,记入重写日志。
两处日志:
因为主线程未阻塞,仍然可以处理新来的操作。此时,如果有写操作,第一处日志就是指正在使用的 AOF 日志,Redis 会把这个操作写到它的缓冲区。这样一来,即使宕机了,这个 AOF 日志的操作仍然是齐全的,可以用于恢复。
而第二处日志,就是指新的 AOF 重写日志。这个操作也会被写到重写日志的缓冲区。这样,重写日志也不会丢失最新的操作。等到拷贝数据的所有操作记录重写完成后,重写日志记录的这些最新操作也会写入新的 AOF 文件,以保证数据库最新状态的记录。此时,我们就可以用新的 AOF 文件替代旧文件了。
总结来说,每次 AOF 重写时,Redis 会先执行一个内存拷贝,用于重写;然后,使用两个日志保证在重写过程中,新写入的数据不会丢失。而且,因为 Redis 采用额外的线程进行数据重写,所以,这个过程并不会阻塞主线程
有两个配置项在控制AOF重写的触发时机:
为了减小aof文件的体量,可以手动发送“bgrewriteaof”指令,通过子进程生成更小体积的aof,然后替换掉旧的、大体量的aof文件。
也可以自动触发:
1. auto-aof-rewrite-min-size: 表示运行AOF重写时文件的最小大小,默认为64MB
2. auto-aof-rewrite-percentage: 这个值的计算方法是:当前AOF文件大小和上一次重写后AOF文件大小的差值,再除以上一次重写后AOF文件大小。也就是当前AOF文件比上一次重写后AOF文件的增量大小,和上一次重写后AOF文件大小的比值。
AOF文件大小同时超出上面这两个配置项时,会触发AOF重写。
问题
1. AOF 日志重写的时候,是由 bgrewriteaof 子进程来完成的,不用主线程参与,我们今天说的非阻塞也是指子进程的执行不阻塞主线程。但是,你觉得,这个重写过程有没有其他潜在的阻塞风险呢?如果有的话,会在哪里阻塞?
Redis采用fork子进程重写AOF文件时,潜在的阻塞风险包括:fork子进程 和 AOF重写过程中父进程产生写入的场景,下面依次介绍。
a、fork子进程,fork这个瞬间一定是会阻塞主线程的(注意,fork时并不会一次性拷贝所有内存数据给子进程,文章写的是拷贝所有内存数据给子进程,个人认为是有歧义的),fork采用操作系统提供的写实复制(Copy On Write)机制,就是为了避免一次性拷贝大量内存数据给子进程造成的长时间阻塞问题,但fork子进程需要拷贝进程必要的数据结构,其中有一项就是拷贝内存页表(虚拟内存和物理内存的映射索引表),这个拷贝过程会消耗大量CPU资源,拷贝完成之前整个进程是会阻塞的,阻塞时间取决于整个实例的内存大小,实例越大,内存页表越大,fork阻塞时间越久。拷贝内存页表完成后,子进程与父进程指向相同的内存地址空间,也就是说此时虽然产生了子进程,但是并没有申请与父进程相同的内存大小。那什么时候父子进程才会真正内存分离呢?“写实复制”顾名思义,就是在写发生时,才真正拷贝内存真正的数据,这个过程中,父进程也可能会产生阻塞的风险,就是下面介绍的场景。
b、fork出的子进程指向与父进程相同的内存地址空间,此时子进程就可以执行AOF重写,把内存中的所有数据写入到AOF文件中。但是此时父进程依旧是会有流量写入的,如果父进程操作的是一个已经存在的key,那么这个时候父进程就会真正拷贝这个key对应的内存数据,申请新的内存空间,这样逐渐地,父子进程内存数据开始分离,父子进程逐渐拥有各自独立的内存空间。因为内存分配是以页为单位进行分配的,默认4k,如果父进程此时操作的是一个bigkey,重新申请大块内存耗时会变长,可能会产阻塞风险。另外,如果操作系统开启了内存大页机制(Huge Page,页面大小2M),那么父进程申请内存时阻塞的概率将会大大提高,所以在Redis机器上需要关闭Huge Page机制。Redis每次fork生成RDB或AOF重写完成后,都可以在Redis log中看到父进程重新申请了多大的内存空间。
在AOF重写期间,Redis运行的命令会被积累在缓冲区,待AOF重写结束后会进行回放,在高并发情况下缓冲区积累可能会很大,这样就会导致阻塞,Redis后来通过Linux管道技术让aof期间就能同时进行回放,这样aof重写结束后只需要回放少量剩余的数据即可
2. AOF 重写也有一个重写日志,为什么它不共享使用 AOF 本身的日志呢?
AOF重写不复用AOF本身的日志,一个原因是父子进程写同一个文件必然会产生竞争问题,控制竞争就意味着会影响父进程的性能。二是如果AOF重写过程中失败了,那么原本的AOF文件相当于被污染了,无法做恢复使用。所以Redis AOF重写一个新文件,重写失败的话,直接删除这个文件就好了,不会对原先的AOF文件产生影响。等重写完成之后,直接替换旧文件即可。
6. 内存快照:宕机后,Redis如何实现快速恢复?
写时复制机制保证快照期间数据可修改
优点:恢复速度快
缺点:性能开销大
RDB和AOF最佳实践
数据不能丢失时,内存快照和 AOF 的混合使用是一个很好的选择
如果允许分钟级别的数据丢失,可以只使用 RDB
如果只用 AOF,优先使用 everysec 的配置选项,因为它在可靠性和性能之间取了一个平衡。
问题
使用一个 2 核 CPU、4GB 内存、500GB 磁盘的云主机运行 Redis,Redis 数据库的数据量大小差不多是 2GB,我们使用了 RDB 做持久化保证。当时 Redis 的运行负载以修改操作为主,写读比例差不多在 8:2 左右,也就是说,如果有 100 个请求,80 个请求执行的是修改操作。你觉得,在这个场景下,用 RDB 做持久化有什么风险吗?
产生的风险主要在于 CPU资源 和 内存资源
a、内存资源风险:Redis fork子进程做RDB持久化,由于写的比例为80%,那么在持久化过程中,“写时复制”会重新分配整个实例80%的内存副本,大约需要重新分配1.6GB内存空间,这样整个系统的内存使用接近饱和,如果此时父进程又有大量新key写入,很快机器内存就会被吃光,如果机器开启了Swap机制,那么Redis会有一部分数据被换到磁盘上,当Redis访问这部分在磁盘上的数据时,性能会急剧下降,已经达不到高性能的标准(可以理解为武功被废)。如果机器没有开启Swap,会直接触发OOM,父子进程会面临被系统kill掉的风险。
b、CPU资源风险:虽然子进程在做RDB持久化,但生成RDB快照过程会消耗大量的CPU资源,虽然Redis处理处理请求是单线程的,但Redis Server还有其他线程在后台工作,例如AOF每秒刷盘、异步关闭文件描述符这些操作。由于机器只有2核CPU,这也就意味着父进程占用了超过一半的CPU资源,此时子进程做RDB持久化,可能会产生CPU竞争,导致的结果就是父进程处理请求延迟增大,子进程生成RDB快照的时间也会变长,整个Redis Server性能下降。
c、另外,可以再延伸一下,问题没有提到Redis进程是否绑定了CPU,如果绑定了CPU,那么子进程会继承父进程的CPU亲和性属性,子进程必然会与父进程争夺同一个CPU资源,整个Redis Server的性能必然会受到影响!所以如果Redis需要开启定时RDB和AOF重写,进程一定不要绑定CPU。
7. redis cluster集群
数据切片和实例的对应分布关系
一个切片集群共有 16384 个哈希槽,这些哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中。
首先根据键值对的 key,按照CRC16 算法计算一个 16 bit 的值;然后,再用这个 16bit 值对 16384 取模,得到 0~16383 范围内的模数,每个模数代表一个相应编号的哈希槽。

数据迁移客户端如何重新定位数据?
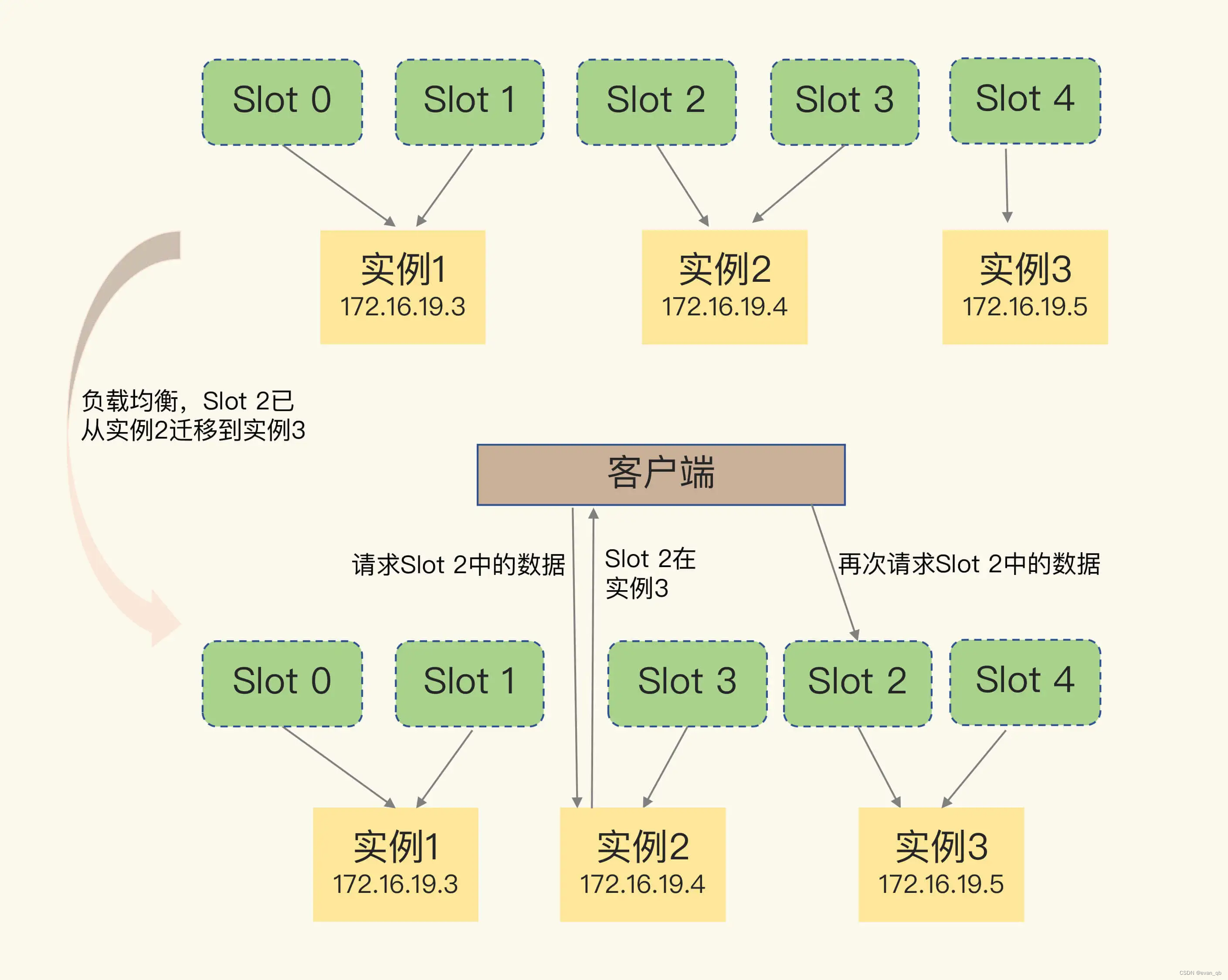
部分迁移情况,重定向
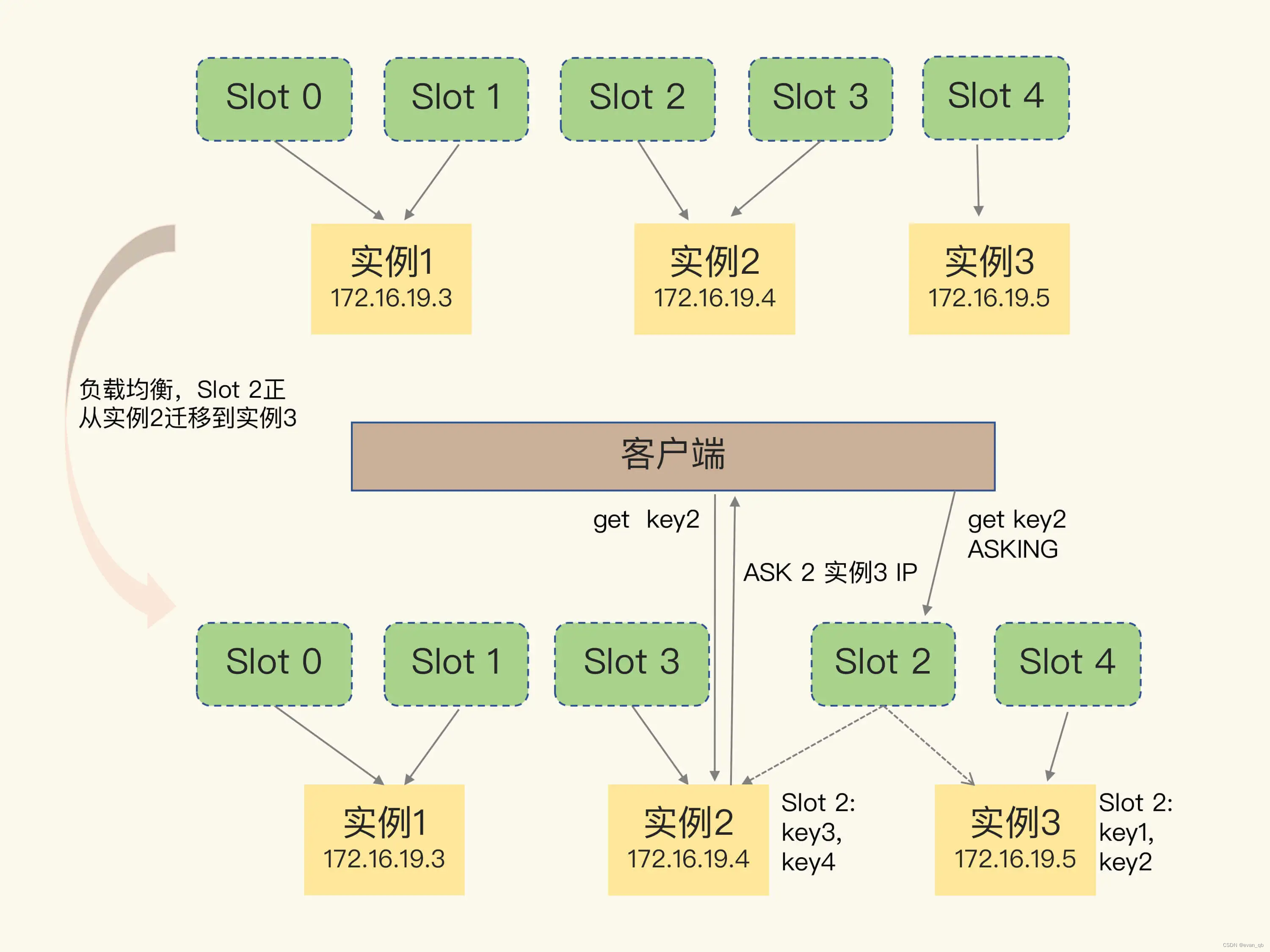
Moved命令和ASK命令
MOVED 命令不同,ASK 命令并不会更新客户端缓存的哈希槽分配信息。所以,在上图中,如果客户端再次请求 Slot 2 中的数据,它还是会给实例 2 发送请求。这也就是说,ASK 命令的作用只是让客户端能给新实例发送一次请求,而不像 MOVED 命令那样,会更改本地缓存,让后续所有命令都发往新实例。
问题
Redis Cluster不采用把key直接映射到实例的方式,而采用哈希槽的方式原因?
1、整个集群存储key的数量是无法预估的,key的数量非常多时,直接记录每个key对应的实例映射关系,这个映射表会非常庞大,这个映射表无论是存储在服务端还是客户端都占用了非常大的内存空间。
2、Redis Cluster采用无中心化的模式(无proxy,客户端与服务端直连),客户端在某个节点访问一个key,如果这个key不在这个节点上,这个节点需要有纠正客户端路由到正确节点的能力(MOVED响应),这就需要节点之间互相交换路由表,每个节点拥有整个集群完整的路由关系。如果存储的都是key与实例的对应关系,节点之间交换信息也会变得非常庞大,消耗过多的网络资源,而且就算交换完成,相当于每个节点都需要额外存储其他节点的路由表,内存占用过大造成资源浪费。
3、当集群在扩容、缩容、数据均衡时,节点之间会发生数据迁移,迁移时需要修改每个key的映射关系,维护成本高。
4、在中间增加一层哈希槽,可以把数据和节点解耦,key通过Hash计算,只需要关心映射到了哪个哈希槽,然后再通过哈希槽和节点的映射表找到节点,相当于消耗了很少的CPU资源,不但让数据分布更均匀,还可以让这个映射表变得很小,利于客户端和服务端保存,节点之间交换信息时也变得轻量。
5、当集群在扩容、缩容、数据均衡时,节点之间的操作例如数据迁移,都以哈希槽为基本单位进行操作,简化了节点扩容、缩容的难度,便于集群的维护和管理。
另外:
Redis使用集群方案就是为了解决单个节点数据量大、写入量大产生的性能瓶颈的问题。多个节点组成一个集群,可以提高集群的性能和可靠性,但随之而来的就是集群的管理问题,最核心问题有2个:请求路由、数据迁移(扩容/缩容/数据平衡)。
1、请求路由:一般都是采用哈希槽的映射关系表找到指定节点,然后在这个节点上操作的方案。
Redis Cluster在每个节点记录完整的映射关系(便于纠正客户端的错误路由请求),同时也发给客户端让客户端缓存一份,便于客户端直接找到指定节点,客户端与服务端配合完成数据的路由,这需要业务在使用Redis Cluster时,必须升级为集群版的SDK才支持客户端和服务端的协议交互。
其他Redis集群化方案例如Twemproxy、Codis都是中心化模式(增加Proxy层),客户端通过Proxy对整个集群进行操作,Proxy后面可以挂N多个Redis实例,Proxy层维护了路由的转发逻辑。操作Proxy就像是操作一个普通Redis一样,客户端也不需要更换SDK,而Redis Cluster是把这些路由逻辑做在了SDK中。当然,增加一层Proxy也会带来一定的性能损耗。
2、数据迁移:当集群节点不足以支撑业务需求时,就需要扩容节点,扩容就意味着节点之间的数据需要做迁移,而迁移过程中是否会影响到业务,这也是判定一个集群方案是否成熟的标准。
Twemproxy不支持在线扩容,它只解决了请求路由的问题,扩容时需要停机做数据重新分配。而Redis Cluster和Codis都做到了在线扩容(不影响业务或对业务的影响非常小),重点就是在数据迁移过程中,客户端对于正在迁移的key进行操作时,集群如何处理?还要保证响应正确的结果?
Redis Cluster和Codis都需要服务端和客户端/Proxy层互相配合,迁移过程中,服务端针对正在迁移的key,需要让客户端或Proxy去新节点访问(重定向),这个过程就是为了保证业务在访问这些key时依旧不受影响,而且可以得到正确的结果。由于重定向的存在,所以这个期间的访问延迟会变大。等迁移完成之后,Redis Cluster每个节点会更新路由映射表,同时也会让客户端感知到,更新客户端缓存。Codis会在Proxy层更新路由表,客户端在整个过程中无感知。
除了访问正确的节点之外,数据迁移过程中还需要解决异常情况(迁移超时、迁移失败)、性能问题(如何让数据迁移更快、bigkey如何处理),这个过程中的细节也很多。
Redis Cluster的数据迁移是同步的,迁移一个key会同时阻塞源节点和目标节点,迁移过程中会有性能问题。而Codis提供了异步迁移数据的方案,迁移速度更快,对性能影响最小,当然,实现方案也比较复杂。
总结
问题 1:rehash 的触发时机和渐进式执行机制
Redis 什么时候做 rehash?
Redis 会使用装载因子(load factor)来判断是否需要做 rehash。装载因子的计算方式是,哈希表中所有 entry 的个数除以哈希表的哈希桶个数。Redis 会根据装载因子的两种情况,来触发 rehash 操作:
装载因子≥1,同时,哈希表被允许进行 rehash;
装载因子≥5。
在第一种情况下,如果装载因子等于 1,同时我们假设,所有键值对是平均分布在哈希表的各个桶中的,那么,此时,哈希表可以不用链式哈希,因为一个哈希桶正好保存了一个键值对。
但是,如果此时再有新的数据写入,哈希表就要使用链式哈希了,这会对查询性能产生影响。在进行 RDB 生成和 AOF 重写时,哈希表的 rehash 是被禁止的,这是为了避免对 RDB 和 AOF 重写造成影响。如果此时,Redis 没有在生成 RDB 和重写 AOF,那么,就可以进行 rehash。否则的话,再有数据写入时,哈希表就要开始使用查询较慢的链式哈希了。
在第二种情况下,也就是装载因子大于等于 5 时,就表明当前保存的数据量已经远远大于哈希桶的个数,哈希桶里会有大量的链式哈希存在,性能会受到严重影响,此时,就立马开始做 rehash。
如果装载因子小于 1,或者装载因子大于 1 但是小于 5,同时哈希表暂时不被允许进行 rehash(例如,实例正在生成 RDB 或者重写 AOF),此时,哈希表是不会进行 rehash 操作的。
2. 采用渐进式 hash 时,如果实例暂时没有收到新请求,是不是就不做 rehash 了?
Redis 会执行定时任务,定时任务中就包含了 rehash 操作。所谓的定时任务,就是按照一定频率(例如每 100ms/ 次)执行的任务。在 rehash 被触发后,即使没有收到新请求,Redis 也会定时执行一次 rehash 操作,而且,每次执行时长不会超过 1ms,以免对其他任务造成影响。
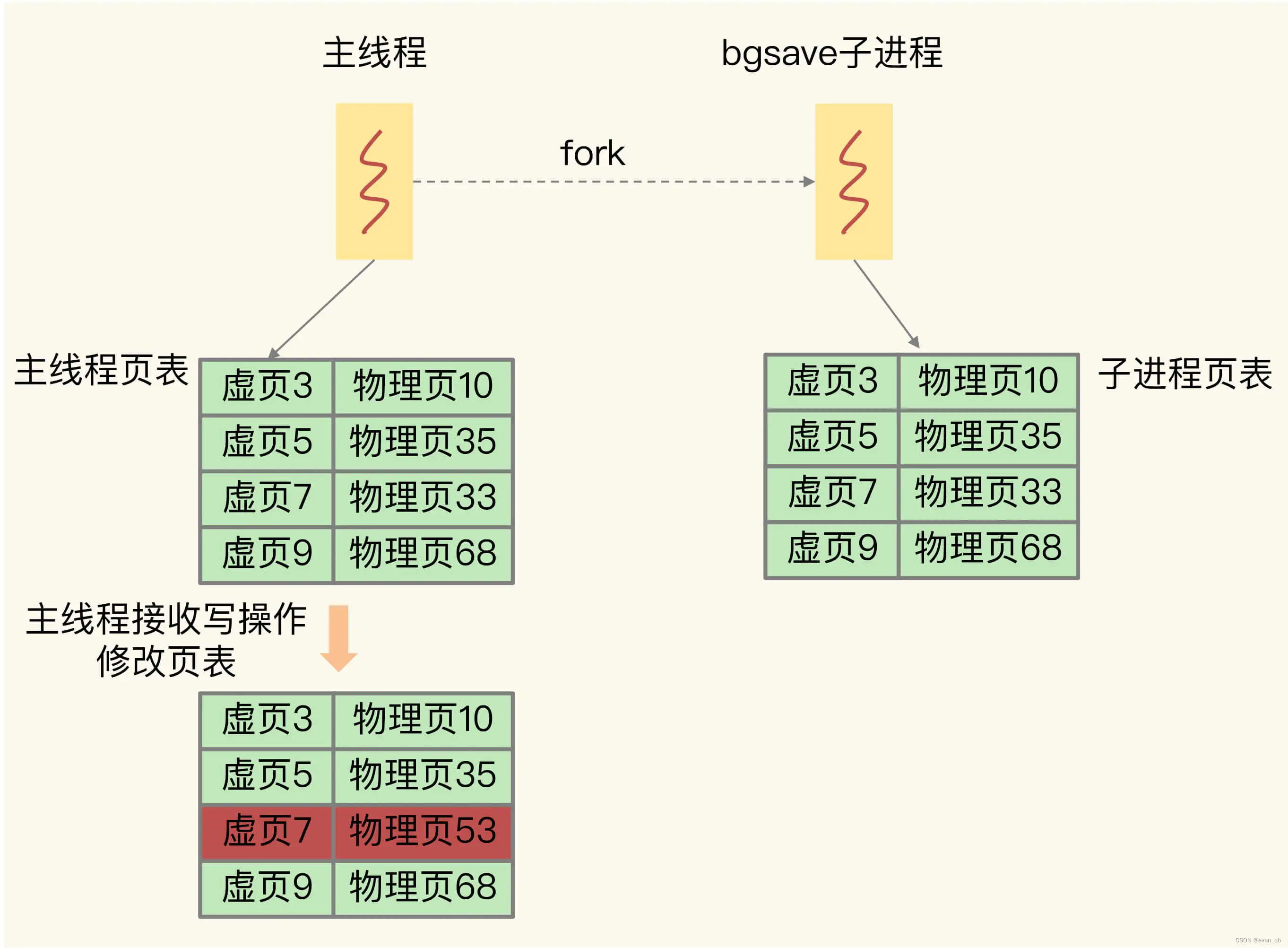
问题 2:写时复制的底层实现机制
bgsave 子进程复制主线程的页表以后,假如主线程需要修改虚页 7 里的数据,那么,主线程就需要新分配一个物理页(假设是物理页 53),然后把修改后的虚页 7 里的数据写到物理页 53 上,而虚页 7 里原来的数据仍然保存在物理页 33 上。这个时候,虚页 7 到物理页 33 的映射关系,仍然保留在 bgsave 子进程中。所以,bgsave 子进程可以无误地把虚页 7 的原始数据写入 RDB 文件。
相关文章:
【redis进阶】基础知识简要回顾
1. 常见功能介绍 聚合统计 使用list集合的差集、并集来统计 排序统计 SortedSet(ZSet)统计,再利用分页列出权重高的元素 二值状态统计 BitMap存储,获取并统计 SETBIT uid:sign:3000:202008 2 1 GETBIT uid:sign:3000:202008 2…...
HTML5-3-表格
文章目录 属性边框属性标题跨行和跨列单元格边距 HTML 表格由 <table> 标签来定义。 tr:tr 是 table row 的缩写,表示表格的一行。td:td 是 table data 的缩写,表示表格的数据单元格。th:th 是 table header的缩…...

Spring Boot + Vue的前后端项目结构及联调查询
Spring Boot Vue的前后端项目结构及联调查询 当你刚开始学习前后端开发时,可能会感到有些困惑和不知所措。下面是一些建议,希望能为你的学习之旅提供一些启示: 建立坚实的基础知识:学习前后端开发的第一步是建立坚实的基础知识。…...
Transformer貌似也是可以使用state递归解码和训练的
import paddle import numpy as npclass HeadLoss(paddle.nn.Layer):def __init__(self):super(HeadLoss, self).__init__()...

振弦采集仪应用地铁隧道安全监测详细解决方案
振弦采集仪应用地铁隧道安全监测详细解决方案 随着城市化进程的不断加快,地铁作为一种高效、便捷、环保的交通方式已经成为现代城市不可或缺的一部分。因此,对地铁的安全性也越来越重视,一般二三线以上的城市在不断发展中,地铁做…...
2023 IntelliJ IDEA下载、安装教程, 附详细图解
文章目录 下载与安装IDEA推荐阅读 下载与安装IDEA 首先先到官网下载最新版的IntelliJ IDEA, 下载后傻瓜式安装就好了 官网下载地址:https://www.jetbrains.com/ 1、下载完后在本地找到该文件,双击运行 idea 安装程序 2、点击 Next 3、选择安装路径&…...

波卡生态重要动态一览:w3ndi 推出,首尔、新加坡、里斯本活动接踵而至
Web3 市场冷却,但新的社区合作与推进仍在发生,技术和产品依然不断迭代。OneBlock 为你介绍波卡生态近期值得你关注的动态,以及接下来重要的行业活动。 波卡生态重要进展 1、最新 Referendum#110,提议对验证器配置进行多项修改&a…...

成都瀚网科技有限公司:抖音商家怎么免费入驻?
随着抖音成为全球最受欢迎的短视频平台之一,越来越多的商家开始关注抖音上的商机。抖音商家的进驻可以帮助商家扩大品牌影响力和销售渠道。那么,如何免费进入抖音成为商家呢?下面就为大家介绍一下具体步骤。 1、抖音商家如何免费注册…...
vue Router从入门到精通
文章目录 介绍使用多级路由实例 路由的query参数传递参数接收参数实例 命名路由作用使用 params参数声明接收params参数传参接收参数实例 props配置实例 router-link的replace属性编程式路由导航作用使用实例 缓存路由组件两个新的生命周期钩子实例 路由守卫作用分类全局守卫独…...

【100天精通Python】Day56:Python 数据分析_Pandas数据清洗和处理(删除填充插值,数据类型转换,去重,连接与合并)
目录 数据清洗和处理 1.处理缺失值 1.1 删除缺失值: 1.2 填充缺失值: 1.3 插值: 2 数据类型转换 2.1 数据类型转换 2.2 日期和时间的转换: 2.3 分类数据的转换: 2.4 自定义数据类型的转换: 3 数…...
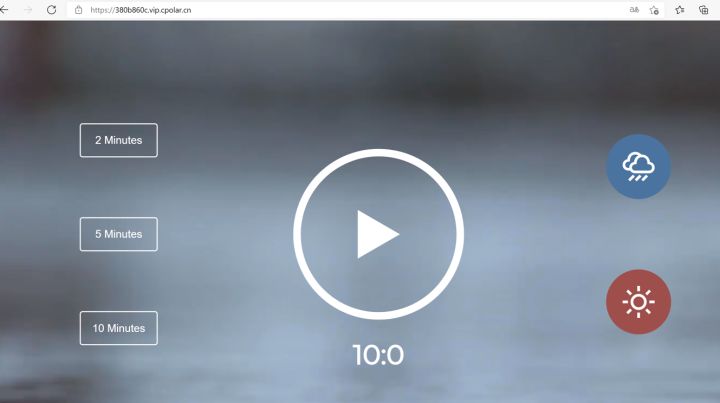
phpstudy本地快速搭建网站,并外网访问【无公网IP】
文章目录 使用工具1. 本地搭建web网站1.1 下载phpstudy后解压并安装1.2 打开默认站点,测试1.3 下载静态演示站点1.4 打开站点根目录1.5 复制演示站点到站网根目录1.6 在浏览器中,查看演示效果。 2. 将本地web网站发布到公网2.1 安装cpolar内网穿透2.2 映…...
WebSocket的那些事(5-Spring STOMP支持之连接外部消息代理)
目录 一、序言二、开启RabbitMQ外部消息代理三、代码示例1、Maven依赖项2、相关实体3、自定义用户认证拦截器4、Websocket外部消息代理配置5、ChatController6、前端页面chat.html 四、测试示例1、群聊、私聊、后台定时推送测试2、登录RabbitMQ控制台查看队列信息 五、结语 一、…...
【数据结构】单链表详解
当我们学完顺序表的时候,我们发现了好多问题如下: 中间/头部的插入删除,时间复杂度为O(N)增容需要申请新空间,拷贝数据,释放旧空间。会有不小的消耗。增容一般是呈2倍的增长,势必会有一定的空间浪费。例如当…...

dql的执行顺序
在 SQL 查询语言中,DQL(Data Query Language)是用于从数据库中检索数据的部分。SQL 查询的执行顺序通常按照以下步骤进行: FROM 子句:查询首先确定要从哪些表中检索数据。在 FROM 子句中列出的表格被称为源表ÿ…...

java的动态代理如何实现
一. JdkProxy jdkproxy动态代理必须基于接口(interface)实现 接口UserInterface.java public interface UserService {String getUserName(String userCde); }原始实现类:UseServiceImpl.java public class UserServiceImpl implements UserSerice {Overridepub…...

Java--日志管理
日志管理 作用: 设置日志级别,决定什么日志信息应该被输出、什么日志信息应该被忽略。 基本工具 见的日志管理用具有:JDK logging(配置文件:logging.properties) 和log4j(配置文件:log4j.properties) 。…...
Pygame中Sprite类的使用2
4 让僵尸动起来 让僵尸能够动起来,也就是让僵尸从屏幕右边走到屏幕左边,此时只需要使用while循环,改变僵尸图片的x轴坐标即可,代码如下所示。 while True:screen.fill((255,255,255))z1.rect.x - 5z1.draw(screen)z1.update()if…...

排队时延与流量强度
流量强度 设R为传输速率,a表示分组到达队列的平均速率,假定所有分组都是由L比特组成的,则比特到达队列的平均速率为La。比率 L a R \frac{La}{R} RLa被成为流量强度。 根据流量强度的定义,我们可以很直观的得出以下结论&#x…...

mysql:如何设计互相关注业务场景
目录 业务场景 业务问题: 数据库表设计: like(关注表): friend(朋友表) 并发场景下,SQL语句执行逻辑 比较 A 和 B 的大小,如果 A执行下面的逻辑:<&…...

AI伦理:科技发展中的人性之声
文章目录 AI伦理的关键问题1. 隐私问题2. 公平性问题3. 自主性问题4. 伦理教育问题 隐私问题的拓展分析数据收集和滥用隐私泄露和数据安全 公平性问题的拓展分析历史偏见和算法模型可解释性 自主性问题的拓展分析自主AI决策伦理框架 伦理教育的拓展分析伦理培训 结论 …...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

蓝桥杯3498 01串的熵
问题描述 对于一个长度为 23333333的 01 串, 如果其信息熵为 11625907.5798, 且 0 出现次数比 1 少, 那么这个 01 串中 0 出现了多少次? #include<iostream> #include<cmath> using namespace std;int n 23333333;int main() {//枚举 0 出现的次数//因…...