linux之perf(2)list事件
Linux之perf(2)list事件
Author:Onceday Date:2023年9月3日
漫漫长路,才刚刚开始…
参考文档:
- Tutorial - Perf Wiki (kernel.org)
- perf-list(1) - Linux manual page (man7.org)
1. 概述
perf list用于列出可用的性能事件,这些事件可以用于 perf record 和其他 perf 子命令的性能分析。性能事件包括硬件事件(如 CPU 周期、缓存未命中等)、软件事件(如上下文切换、页面错误等)和跟踪点事件(如内核函数调用、用户空间应用程序的跟踪等)。
Usage: perf list [<options>] [hw|sw|cache|tracepoint|pmu|sdt|metric|metricgroup|event_glob]-d, --desc Print extra event descriptions. --no-desc to not print.-j, --json JSON encode events and metrics-v, --long-desc Print longer event descriptions.--debug Enable debugging output--deprecated Print deprecated events.--details Print information on the perf event names and expressions used internally by events.--unit <PMU name>Limit PMU or metric printing to the specified PMU.
上面是在linux kernel6.2版本的perf list帮助输出,perf工具和linux内核以及硬件高度绑定,因此不同的内核版本,虚拟机,硬件环境下,perf list的输出会有较大差别。许多性能事件是否可用,需要取决于当前硬件和软件环境。
perf工具支持一系列可测量的事件。该工具和底层内核接口可以测量来自不同来源的事件。例如,有些事件是纯内核计数器,在这种情况下称为软件事件。例如:上下文切换、小故障。
事件的另一个来源是处理器本身及其性能监控单元(PMU)。它提供了一个事件列表来测量微体系结构事件,如周期数、指令退役、L1缓存缺失等。这些事件被称为PMU硬件事件或简称硬件事件。它们因处理器类型和型号而异。
perf_events接口还提供了一组常用的硬件事件名称。在每个处理器上,如果这些事件存在,则将它们映射到CPU提供的实际事件上,否则无法使用事件。有些令人困惑的是,这些事件也称为硬件事件(hardware event)和硬件缓存事件(hardware cache event)。
最后,还有由内核ftrace基础设施实现的tracepoint事件。这些仅在2.6.3 3x和更新的内核中可用。
PMU硬件事件是特定于CPU的,并由CPU供应商记录。如果链接到libpfm4, perf工具库会提供一些事件的简短描述。有关Intel和AMD处理器的PMU硬件事件列表,请参见:
- Intel® 64 and IA-32 Architectures Developer’s Manual: Vol. 3B
- BIOS and Kernel Developer’s Guide (BKDG) For AMD Family 10h Processors
perf list列出来的这些事件就是本机设备上受支持性能事件,后面中括号里面就是具体的事件类型,这些事件可能会非常多,不同的账户权限执行的结果也会有些不同。
对于非root用户,通常只有上下文切换的PMU事件可用。这通常只是cpu PMU中的事件、预定义的事件(如周期和指令)以及一些软件事件。其他pmu和全局测量通常仅为root可用。一些事件限定符,如“any”,也是root限定符。这可以通过设置kernel.perf_event_paranoid为-1来修改(使用sysctl),允许非root用户使用这些事件。为了访问跟踪点事件,perf需要对/sys/kernel/debug/tracing具有读访问权限,即使perf_event_paranoid处于宽松设置中也是如此。
1.1 打印指定PMU单元的事件
--unit <PMU name> 选项在使用 perf list 时用于将事件或指标的输出限制为特定的性能监视单元(Performance Monitoring Unit,PMU)。PMU 是处理器的一个组件,它可以计数硬件事件,如执行的指令、遭受的缓存未命中或错误预测的分支。它们为应用程序分析提供了基础,可以追踪动态控制流并识别热点。
以下是如何使用它的示例:
perf list --unit cpu
此命令将列出 CPU PMU 可用的所有事件或指标。PMU 名称需要事先知道,具体取决于硬件和内核的支持。一些常见的 PMU 名称包括 cpu、cache、bus 和 software。
请记住,根据您的硬件和内核配置,可能并非所有 PMU 都可用。
1.2 事件描述格式
--details会额外打印符号事件(cycles, cache-misses等)的内部表达形式,如下:
cache-misses OR cpu/cache-misses/ [Kernel PMU event]cpu/event=0x64,umask=0x9/cpu-cycles OR cpu/cpu-cycles/ [Kernel PMU event]cpu/event=0x76/
事件是用它们的符号名和可选的单位掩码和修饰符来指定的。事件名称(Event names)、单元掩码(unit masks)和修饰符(modifiers)不区分大小写。一般的情况下,可以使用cache-misses这种符号形式来代替cpu/event=0x64,umask=0x9/这种格式。
默认情况下,事件是在用户和内核级别度量的:
perf stat -e cycles dd if=/dev/zero of=/dev/null count=100000
若要仅在用户级别进行度量,则需要传递一个修饰符(u):
perf stat -e cycles:u dd if=/dev/zero of=/dev/null count=100000
要测量用户和内核(显式地):
perf stat -e cycles:uk dd if=/dev/zero of=/dev/null count=100000
事件可以通过附加冒号和一个或多个修饰符来选择具有修饰符。修饰符允许用户限制何时对事件进行计数。修饰符如下:
| 名称标识 | 描述 |
|---|---|
| u | user-space counting,用户空间 |
| k | kernel counting,内核空间 |
| h | hypervisor counting,虚拟机 |
| I | non idle counting,非空闲时 |
| G | guest counting (in KVM guests),KVM虚拟机 |
| H | host counting (not in KVM guests),KVM主机 |
| p | precise level,硬件事件精度级别 |
| P | use maximum detected precise level,使用最大检测精度水平 |
| S | read sample value (PERF_SAMPLE_READ)读取样本值 |
| D | pin the event to the PMU,将事件绑定到PMU上 |
| W | 组是弱的,如果不可调度,将退回到非组 |
| e | 群组或事件是排他性的,不共享PMU |
p修饰符可用于指定指令地址的精确程度。p修饰符可以被指定多次:
- 0 - SAMPLE_IP可以任意滑动
- 1 - SAMPLE_IP必须有恒定的滑动
- 2 - SAMPLE_IP要求有O滑块
- 3 - SAMPLE_IP必须有0滑块,或者使用随机化来避免样本副作用效果。
对于英特尔系统,精确事件采样是用PEBS实现的,它支持精确级别2,在某些特殊情况下支持精确级别3。
在AMD系统上,它是使用IBS实现的(最高精确级别到2)。精确修饰符与事件类型0x76 (cpu-cycles,CPU时钟未停止)和0xC1(micro-ops retired)一起工作。
2. 详细信息
2.1 perf list性能事件分类
默认情况下,perf list列出所有的已知事件。也可以通过下面的类别来列出其中某一类事件:
| 事件类名称 | 描述 |
|---|---|
| hw or hardware | 列出硬件事件,如cache-misses |
| sw or software | 列出软件事件,例如上下文切换(context switches) |
| cache or hwcache | 列出硬件缓存事件,如L1-dcache-loads |
| tracepoint | 列出所有的tracepoint事件,也可使用subsys_glob:event_glob去过滤子系统追踪点事件,如sched、block等。 |
| pmu | 打印内核提供的PMU事件 |
| sdt | 列出所有静态定义的跟踪点事件(Statically Defined Tracepoint) |
| metric | 指标列表(度量事件) |
| metricgroup | 列出带有指标的指标组 |
| –raw-dump | 显示所有事件的原始格式信息,该选项后面可以接[hw|sw|cache|tracepoint|pmu|event_glob] |
2.2 测量特定硬件上的PMU事件
本章详细内容可以参考文档: perf-list(1) - Linux manual page (man7.org)
即使现在在perf中没有符号形式的事件,也可以用特定于每个处理器的方式对其进行编码。
比如对于X86CPUs,要测量CPU硬件供应商文档中提供的实际PMU,可以传递十六进制参数代码:
perf stat -e r1a8 -a sleep 1
perf record -e r1a8 ...
有些处理器,比如AMD的处理器,支持大于一个字节的事件代码和单元掩码。在这种情况下,与事件配置参数对应的位可以参考下面命令的结果:
cat /sys/bus/event_source/devices/cpu/format/event
比如可能的命令如下:
perf record -e r20000038f -a sleep 1
perf record -e cpu/r20000038f/ ...
perf record -e cpu/r0x20000038f/ ...
有关于特定硬件上的PMU事件,需要参考处理器的说明文档来确定使用方法。
在下面的路径可以查看可用的PMUs和它们的原始参数:
ls /sys/devices/*/format
一些pmu不与核心相关联,而是与整个CPU socket相关联。这些pmu上的事件通常不能采样,只能使用perf stat -a进行全局计数。它们可以绑定到一个逻辑CPU,但是会测量同一个插槽中的所有CPU。
本例在Intel Xeon系统的socket 0上的第一个内存控制器上每秒测量内存带宽:
perf stat -C 0 -a uncore_imc_0/cas_count_read/,uncore_imc_0/cas_count_write/ -I 1000 ...
每个内存控制器都有自己的PMU。测量整个系统带宽需要指定所有imc pmu(请参阅perf list output),并将这些值相加。为了简化多个事件的创建,在PMU名称中支持前缀和全局匹配,并且在执行匹配时也忽略前缀uncore_。因此,上面的命令可以通过使用以下语法扩展到所有内存控制器:
perf stat -C 0 -a imc/cas_count_read/,imc/cas_count_write/ -I 1000 ...
perf stat -C 0 -a *imc*/cas_count_read/,*imc*/cas_count_write/ -I 1000 ...
2.3 参数化的性能事件
有一些pmu事件列出来的时候,其显示字符中带有?号。如下:
hv_gpci/dtbp_ptitc,phys_processor_idx=?/
这意味着当作为事件提供时,?所指示的内容必须也可提供。
perf stat -C 0 -e 'hv_gpci/dtbp_ptitc,phys_processor_idx=0x2/' ...
此外还有可能指定额外的事件修饰符(percore):
perf stat -e cpu/event=0,umask=0x3,percore=1/
上面命令即汇总一个核心中所有硬件线程的事件计数。
2.4 事件组测量
当活动事件的数量超过硬件性能计数器的数量时,Perf支持基于时间的事件复用。当工作负载更改其执行配置文件时,多路复用可能导致测量错误。
当使用来自事件计数的公式计算度量时,确保始终将一些事件作为一个组一起测量以最小化多路错误是很有用的。事件组可以使用{}指定。
perf stat -e '{instructions,cycles}' ...
可用性能计数器的数量取决于CPU。一个组不能包含比可用计数器更多的事件。例如,Intel Core cpu通常有四个通用的核心性能计数器,加上三个固定的instructions、cycles和ref-cycles计数器。一些特殊事件对它们可以调度的计数器有限制,并且可能不支持单个组中的多个实例。当组中指定的事件太多时,其中一些事件将无法测量。
全局固定事件可以限制其他组可用的计数器数量。在x86系统上,NMI看门狗默认固定一个计数器。NMI看门狗可以在root用户下禁用:
echo 0 > /proc/sys/kernel/nmi_watchdog
来自多个不同pmu的事件不能混合在一个组中,软件事件除外。
perf还支持使用:S说明符进行组领导抽样(group leader sampling)。
perf record -e '{cycles,instructions}:S' ...
perf report --group
通常情况下,所有事件都在一个事件组样本中,但是使用:S时,只有第一个事件(leader)进行采样,它只读取组中其他事件的值。然而,在AUX区域事件(例如Intel PT或CoreSight)的情况下,AUX区域事件必须是先导事件,因此第二个事件采样,而不是第一个事件。
相关文章:
list事件)
linux之perf(2)list事件
Linux之perf(2)list事件 Author:Onceday Date:2023年9月3日 漫漫长路,才刚刚开始… 参考文档: Tutorial - Perf Wiki (kernel.org)perf-list(1) - Linux manual page (man7.org) 1. 概述 perf list用于列出可用的性能事件,这…...

将多个EXCEL 合并一个EXCEL多个sheet
合并老版本xls using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Windows.Forms; using NPOI.HSSF.UserModel; …...

【送书活动】揭秘分布式文件系统大规模元数据管理机制——以Alluxio文件系统为例
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 「推荐专栏」: ★java一站式服务 ★ ★ React从入门到精通★ ★前端炫酷代码分享 ★ ★ 从0到英雄,vue成神之路★ ★ uniapp-从构建到提升★ ★ 从0到英雄ÿ…...

微信小程序——数据绑定
在微信小程序中,可以通过以下代码实现数据绑定: 在WXML中,使用双大括号{{}}绑定数据,将数据渲染到对应的视图中。 <view>{{message}}</view>在JS中,定义一个数据对象,并将其绑定到页面的data…...

libbpf-bootstrap安卓aarch64适配交叉编译
1.为什么移植 疑惑 起初我也认为,像libbpf-bootstrap这样在ebpf程序开发中很常用的框架,理应支持不同架构的交叉编译。尤其是向内核态的ebpf程序本身就是直接通过clang的-target btf直接生成字节码,各个内核上的ebpf虚拟机大同小异…...

【剑指Offer】24.反转链表
题目 定义一个函数,输入一个链表的头节点,反转该链表并输出反转后链表的头节点。 示例: 输入: 1->2->3->4->5->NULL 输出: 5->4->3->2->1->NULL限制: 0 < 节点个数 < 5000 解答 源代码 /*** Defin…...

04-docker compose容器编排
Docker Compose简介 Docker Compose是什么 Compose 是Docker公司推出的一个工具软件,可以管理多个Dokcer容器组成一个应用。你需要定义一个YAML格式的配置文件 docker-compose.yml,写好多个容器之间的调用关系。然后,只要一个命令&#…...

通过位运算打多个标记
通过位运算打多个标记 如何在一个字段上,记录多个标记? 如何在一个字段上,记录不同类型的多个标记? 如何用较少的字段,记录多个标记? 如何在不增加字段的要求下,记录新增的标记? 在实…...
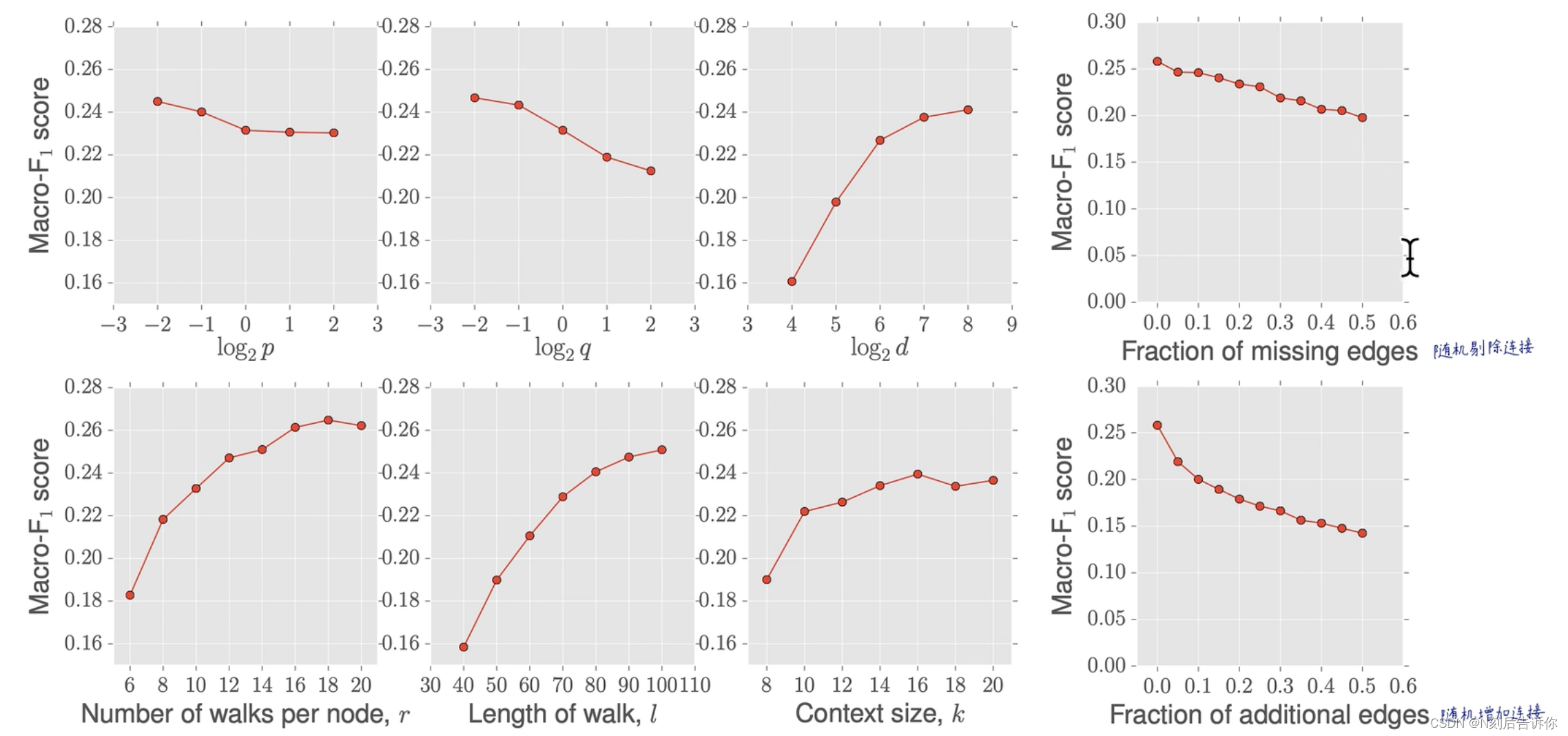
[学习笔记]Node2Vec图神经网络论文精读
参考资料:https://www.bilibili.com/video/BV1BS4y1E7tf/?p12&spm_id_frompageDriver Node2vec简述 DeepWalk的缺点 用完全随机游走,训练节点嵌入向量,仅能反应相邻节点的社群相似信息,无法反映节点的功能角色相似信息。 …...

C# Linq源码分析之Take(五)
概要 本文在C# Linq源码分析之Take(四)的基础上继续从源码角度分析Take的优化方法,主要分析Where.Select.Take的使用案例。 Where.Select.Take的案例分析 该场景模拟我们显示中将EF中与数据库关联的对象进行过滤,然后转换成Web…...
性能监控-grafana+prometheus+node_exporter
Prometheus是一个开源的系统监控和报警工具。它由SoundCloud开发并于2012年发布,后来成为了一个独立的开源项目,并得到了广泛的应用和支持。 Prometheus的主要功能包括采集和存储各种系统和应用程序的监控数据,并提供强大的查询语言PromQL来…...
(STM32H5系列)STM32H573RIT6、STM32H573RIV6、STM32H573ZIT6嵌入式微控制器基于Cortex®-M33内核
一、应用 工业(PLC、工业电机控制、泵和压缩机) 智能家居(空调、冰箱、冰柜、中央警报系统、洗衣机) 个人电子产品(键盘、智能手机、物联网标签、跟踪设备) 智能城市(工业通信、照明控制、数字…...

mysql配置bind-address不生效
1、前言 因为要ip直接访问mysql,故去修改bind-address参数,按照mysql配置文件查找顺序是:/etc/my.cnf、/etc/mysql/my.cnf、~/.my.cnf,服务器上没有 /etc/my.cnf文件,故去修改 /etc/mysql/my.cnf文件,但是一…...

Linux相关指令(下)
cat指令 查看目标文件的内容 常用选项: -b 对非空输出行编号 -n 对输出的所有行编号 -s 不输出多行空行 一个重要思想:linux下一切皆文件,如显示器文件,键盘文件 cat默认从键盘中读取数据再打印 退出可以ctrlc 输入重定向<…...
(A - F))
Codeforces Round 855 (Div 3)(A - F)
Codeforces Round 855 (Div. 3)(A - F) Codeforces Round 855 (Div. 3) A. Is It a Cat?(思维) 思路:先把所有字母变成小写方便判断 , 然后把每一部分取一个字母出来 , 判断和‘meow’是否相同即可。 复杂度 O ( n…...
:社交媒体金融的未来,真的如此美好吗?)
Friend.tech(FT):社交媒体金融的未来,真的如此美好吗?
Friend.tech(FT)是一个在2023年8月10日正式推出的社交金融平台,它的特点在于允许用户购买和出售创作者的股票(shares),这些股票赋予用户访问创作者内容的权利。FT的推出引发了广泛的关注,吸引了…...
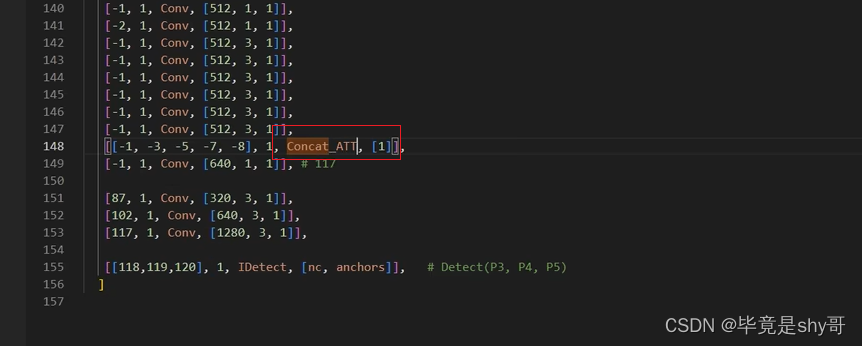
yolov7中Concat之后加注意力模块(最复杂的情况)
1、common.py中找到Concat模块,复制一份 2、要传参进来,dim通道数 3、然后找yolo.py模块,添加 4、yaml里替换 5、和加的位置也有关系...
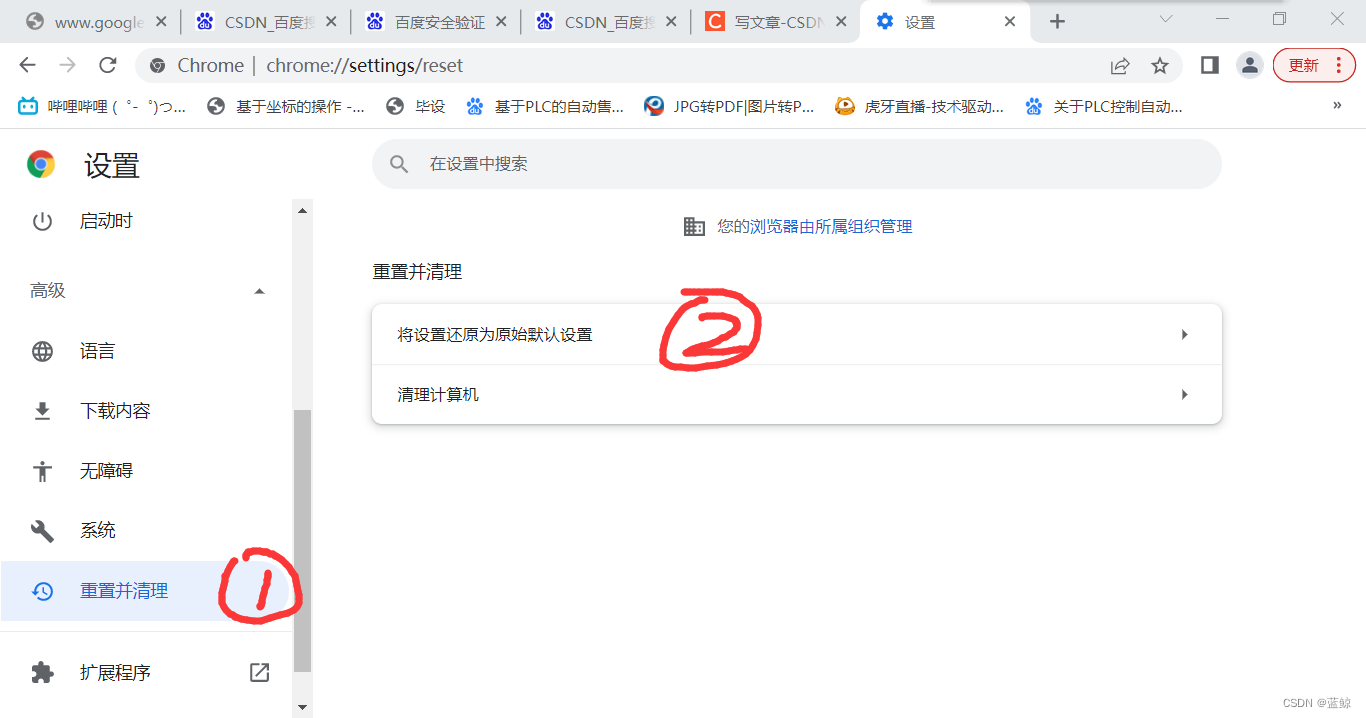
解除百度安全验证
使用chrome浏览器用百度浏览时,一直弹百度安全验证: 在设置里进行重置: 然后重启浏览器就可以了。...
(A - F))
Codeforces Round 731 (Div 3)(A - F)
Codeforces Round 731 (Div. 3)(A - F) Dashboard - Codeforces Round 731 (Div. 3) - Codeforces A. Shortest Path with Obstacle(思维) 思路:显然要计算 A → B 之间的曼哈顿距离 , 要绕开 F 当且仅当 AB形成的直线平行于坐…...
与sorted()函数详解)
Python的sort()与sorted()函数详解
目录 sort()函数 sorted()函数 key参数 区别 sort()函数 sort()方法:该方法用于原地对列表进行排序,即直接在原始列表上进行排序操作,并不返回一个新的列表。 my_l…...

为什么养鱼高手都换创牌无管件鱼缸?创牌无溢流区,到底强在哪?
创牌无管件鱼缸:它凭什么成为新一代鱼缸主流。创牌无管件无溢流区鱼缸 颜值更高 空间更大 过滤更强 更好打理 更安全。从“能用”升级到“好看、好用、高级”,一步到位。家有一缸,风生水起。干净、高级、好养的创牌无管件鱼缸࿰…...

开源番茄小说下载工具:让数字阅读摆脱平台依赖的完整方案
开源番茄小说下载工具:让数字阅读摆脱平台依赖的完整方案 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 当你在通勤途中想继续阅读昨晚未看完的小说,却发现网络信号…...

TensorFlow 2.x数据管道优化:TF Data模块的5个高效技巧
TensorFlow 2.x数据管道优化:TF Data模块的5个高效技巧 【免费下载链接】TensorFlow Project containig related material for my TensorFlow articles 项目地址: https://gitcode.com/gh_mirrors/ten/TensorFlow TensorFlow 2.x数据管道优化是提升模型训练效…...

5分钟解锁中文版Figma:设计师亲手翻译的完整汉化方案
5分钟解锁中文版Figma:设计师亲手翻译的完整汉化方案 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的英文界面而烦恼吗?FigmaCN为你带来完美解决方…...

Ostrakon-VL像素终端实战:生成符合ISO 20252市场调研报告
Ostrakon-VL像素终端实战:生成符合ISO 20252市场调研报告 1. 项目背景与价值 在零售与餐饮行业,市场调研数据的采集和分析一直是一项耗时耗力的工作。传统方法需要人工记录货架商品、价格标签、店铺环境等信息,不仅效率低下,还容…...

2026届最火的六大降AI率神器横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 维普平台已正式引进AIGC检测模块,可借之识别学术论文里由人工智能生成的内容&…...

Phi-4-reasoning-vision-15B入门必看:视觉推理模型prompt工程要点
Phi-4-reasoning-vision-15B入门必看:视觉推理模型prompt工程要点 如果你刚接触Phi-4-reasoning-vision-15B,可能会发现一个奇怪的现象:有时候它像个博学的学者,能精准分析复杂的图表;有时候却像个固执的程序员&#…...

Magnum音频处理框架终极指南:OpenAL集成与沉浸式3D音效实现
Magnum音频处理框架终极指南:OpenAL集成与沉浸式3D音效实现 【免费下载链接】magnum Lightweight and modular C11 graphics middleware for games and data visualization 项目地址: https://gitcode.com/gh_mirrors/mag/magnum Magnum是一个轻量级、模块化…...

Git-RSCLIP快速上手教程:Jupyter替换端口+7860界面双功能实测
Git-RSCLIP快速上手教程:Jupyter替换端口7860界面双功能实测 想试试用一句话就让AI看懂卫星图吗?比如,你上传一张城市航拍图,告诉它“找找看哪里有新建的住宅区”,它就能帮你把相关的区域圈出来。听起来像科幻片&…...
)
保姆级教程:在RK3566 Android 11上搞定ES7202 ADC录音(附驱动修复与PDM协议详解)
RK3566 Android 11平台ES7202 ADC录音全流程实战:从硬件原理到驱动修复 在嵌入式音频开发领域,RK3566凭借其出色的性价比和丰富的接口资源,成为众多智能硬件产品的首选平台。但当遇到ES7202这类仅支持ADC功能的编解码芯片时,如何在…...