04 卷积神经网络搭建
一、数据集
MNIST数据集是从NIST的两个手写数字数据集:Special Database 3 和Special Database 1中分别取出部分图像,并经过一些图像处理后得到的[参考]。
MNIST数据集共有70000张图像,其中训练集60000张,测试集10000张。所有图像都是28×28的灰度图像,每张图像包含一个手写数字。

1.1 准备数据
将数据集分为训练集、验证集和测试集
#训练集有60000张图片,前5000张图片作为验证集,后55000作为训练集
1. `x_train_all` 和 `y_train_all`:
- `x_train_all` 包含了完整的训练数据集的图像数据,这些图像用于训练深度学习模型。
- `y_train_all` 包含了完整的训练数据集的标签,即与 `x_train_all` 中的图像相对应的类别标签。
2. `x_test` 和 `y_test`:
- `x_test` 包含了测试数据集的图像数据,这些图像用于评估深度学习模型的性能。
- `y_test` 包含了测试数据集的标签,即与 `x_test` 中的图像相对应的类别标签。
from tensorflow import keras
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltfashion_mnist = keras.datasets.fashion_mnist
(x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]print(x_valid.shape, y_valid.shape)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)1.2 标准化
# 标准化
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
x_valid_scaled = scaler.transform(x_valid.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)x_test_scaled = scaler.transform(x_test.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)1.3 数据集
def make_dataset(data, target, epochs, batch_size, shuffle=True):dataset = tf.data.Dataset.from_tensor_slices((data, target))if shuffle:dataset = dataset.shuffle(10000)dataset = dataset.repeat(epochs).batch(batch_size).prefetch(50)return datasetbatch_size = 64
epochs = 20
train_dataset = make_dataset(x_train_scaled, y_train, epochs, batch_size)1.4 搭建模型
model = keras.models.Sequential()
# 卷积
model.add(keras.layers.Conv2D(filters = 32, kernel_size = 3, padding = 'same',activation='relu',# batch_size, height, width, channelsinput_shape=(28, 28, 1))) # (28, 28, 32)model.add(keras.layers.Conv2D(filters = 32, kernel_size = 3, padding = 'same',activation='relu'))
# 池化
model.add(keras.layers.MaxPool2D()) # (14, 14, 32)model.add(keras.layers.Conv2D(filters = 64, kernel_size = 3, padding = 'same',activation='relu')) # (14, 14, 64)
model.add(keras.layers.Conv2D(filters = 64, kernel_size = 3, padding = 'same',activation='relu'))
# 池化
model.add(keras.layers.MaxPool2D()) # (7, 7, 64)
model.add(keras.layers.Conv2D(filters = 128, kernel_size = 3, padding = 'same',activation='relu')) # (7, 7, 128)
model.add(keras.layers.Conv2D(filters = 128, kernel_size = 3, padding = 'same',activation='relu')) # (7, 7, 128)
# 池化, 向下取整
model.add(keras.layers.MaxPooling2D()) # (3, 3, 128)model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(512, activation='relu'))
model.add(keras.layers.Dense(256, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))model.compile(loss='sparse_categorical_crossentropy',optimizer='adam',metrics=['accuracy'])print(model.summary())keras.models.Sequential()`是使用 Keras 构建神经网络模型的开始。`keras.models.Sequential()` 创建了一个 Sequential 模型对象,这是 Keras 中的一种常见模型类型。Sequential 模型是一个线性的、层叠的神经网络模型,适用于顺序层的堆叠,其中每一层都是依次添加到模型中。
一旦创建了 Sequential 模型,你可以使用 `.add()` 方法来逐层添加神经网络层,从输入层到输出层。每个层都可以通过实例化 Keras 中的层类来创建,例如
`keras.layers.Dense` 用于全连接层,
`keras.layers.Conv2D` 用于卷积层等。
以下是一个简单的例子,演示如何使用 Sequential 模型创建一个简单的前馈神经网络:
from tensorflow import keras# 创建一个 Sequential 模型 model = keras.models.Sequential()# 添加输入层和第一个隐藏层 model.add(keras.layers.Input(shape=(input_shape,))) # 输入层,input_shape 根据你的数据维度定义 model.add(keras.layers.Dense(units=128, activation='relu')) # 隐藏层1# 添加第二个隐藏层 model.add(keras.layers.Dense(units=64, activation='relu')) # 隐藏层2# 添加输出层 model.add(keras.layers.Dense(units=num_classes, activation='softmax')) # 输出层,num_classes 是输出类别的数量# 编译模型 model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])上面的代码创建了一个具有两个隐藏层和一个输出层的前馈神经网络模型,并使用了 ReLU 激活函数和 softmax 激活函数。这只是一个简单的示例,你可以根据你的任务和数据来构建更复杂的模型。一旦模型构建完成,你可以使用 `.fit()` 方法来训练模型。
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
是 Keras 中用于编译深度学习模型的代码,它设置了模型的损失函数、优化器和评估指标。让我为你解释每个参数的含义:
- `loss='sparse_categorical_crossentropy'`: 这里设置了模型的损失函数。`sparse_categorical_crossentropy` 是一种用于多类别分类问题的损失函数。它适用于目标变量是整数形式(类别标签)的情况,而不需要将目标变量进行独热编码(one-hot encoding)。模型的目标是最小化这个损失函数,从而使预测结果尽可能接近真实标签。
- `optimizer='adam'`: 这里设置了优化器,用于模型的参数更新。`'adam'` 是一种常用的优化算法,它基于梯度下降的方法,具有自适应学习率和动量的特性,通常在深度学习中表现良好。优化器的作用是最小化损失函数,从而调整模型的权重和参数以使模型更好地拟合数据。
- `metrics=['accuracy']`: 这里设置了评估指标,用于在模型训练期间监测模型性能。
`['accuracy']` 表示模型在训练期间将计算并输出准确度(accuracy),即正确分类的样本数与总样本数的比率。准确度通常用于分类问题的性能评估。
一旦模型编译完成,你可以使用 `model.fit()` 方法来训练模型,该方法会使用上述设置的损失函数、优化器和评估指标来进行训练。例如:
```python
model.fit(x_train, y_train, epochs=10, validation_data=(x_valid, y_valid))
```
1.5 train
eval_dataset = make_dataset(x_valid_scaled, y_valid, epochs=1, batch_size=32, shuffle=False)history = model.fit(train_dataset, steps_per_epoch=x_train_scaled.shape[0] // batch_size,epochs=10,validation_data=eval_dataset)
1.6 模型评估
model.evaluate(eval_dataset)
1.7 可视化
def plot_learning_curves(history):pd.DataFrame(history.history).plot(figsize=(8, 5))plt.grid(True)plt.gca().set_ylim(0, 1)plt.show()plot_learning_curves(history)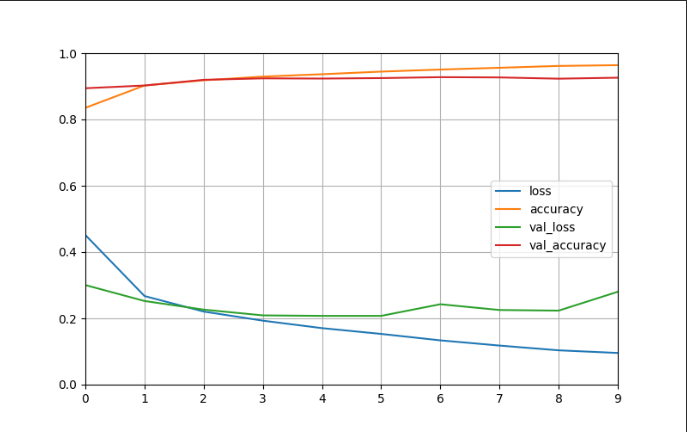
相关文章:
04 卷积神经网络搭建
一、数据集 MNIST数据集是从NIST的两个手写数字数据集:Special Database 3 和Special Database 1中分别取出部分图像,并经过一些图像处理后得到的[参考]。 MNIST数据集共有70000张图像,其中训练集60000张,测试集10000张。所有图…...

【hadoop运维】running beyond physical memory limits:正确配置yarn中的mapreduce内存
文章目录 一. 问题描述二. 问题分析与解决1. container内存监控1.1. 虚拟内存判断1.2. 物理内存判断 2. 正确配置mapReduce内存2.1. 配置map和reduce进程的物理内存:2.2. Map 和Reduce 进程的JVM 堆大小 3. 小结 一. 问题描述 在hadoop3.0.3集群上执行hive3.1.2的任…...
)
数据结构--6.5二叉排序树(插入,查找和删除)
目录 一、创建 二、插入 三、删除 二叉排序树(Binary Sort Tree)又称为二叉查找树,它或者是一棵空树,或者是具有下列性质的二叉树: ——若它的左子树不为空,则左子树上所有结点的值均小于它的根结构的值…...
无需公网IP,在家SSH远程连接公司内网服务器「cpolar内网穿透」
文章目录 1. Linux CentOS安装cpolar2. 创建TCP隧道3. 随机地址公网远程连接4. 固定TCP地址5. 使用固定公网TCP地址SSH远程 本次教程我们来实现如何在外公网环境下,SSH远程连接家里/公司的Linux CentOS服务器,无需公网IP,也不需要设置路由器。…...

Java工具类
一、org.apache.commons.io.IOUtils closeQuietly() toString() copy() toByteArray() write() toInputStream() readLines() copyLarge() lineIterator() readFully() 二、org.apache.commons.io.FileUtils deleteDirectory() readFileToString() de…...

makefile之使用函数wildcard和patsubst
Makefile之调用函数 调用makefile机制实现的一些函数 $(function arguments) : function是函数名,arguments是该函数的参数 参数和函数名用空格或Tab分隔,如果有多个参数,之间用逗号隔开. wildcard函数:让通配符在makefile文件中使用有效果 $(wildcard pattern) 输入只有一个参…...

算法通关村第十八关——排列问题
LeetCode46.给定一个没有重复数字的序列,返回其所有可能的全排列。例如: 输入:[1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]] 元素1在[1,2]中已经使…...

基于STM32设计的生理监测装置
一、项目功能要求 设计并制作一个生理监测装置,能够实时监测人体的心电图、呼吸和温度,并在LCD液晶显示屏上显示相关数据。 随着现代生活节奏的加快和环境的变化,人们对身体健康的关注程度越来越高。为了及时掌握自身的生理状况,…...

Go-Python-Java-C-LeetCode高分解法-第五周合集
前言 本题解Go语言部分基于 LeetCode-Go 其他部分基于本人实践学习 个人题解GitHub连接:LeetCode-Go-Python-Java-C Go-Python-Java-C-LeetCode高分解法-第一周合集 Go-Python-Java-C-LeetCode高分解法-第二周合集 Go-Python-Java-C-LeetCode高分解法-第三周合集 G…...
)
【前端知识】前端加密算法(base64、md5、sha1、escape/unescape、AES/DES)
前端加密算法 一、base64加解密算法 简介:Base64算法使用64个字符(A-Z、a-z、0-9、、/)来表示二进制数据的64种可能性,将每3个字节的数据编码为4个可打印字符。如果字节数不是3的倍数,将会进行填充。 优点࿱…...
leetcode 925. 长按键入
2023.9.7 我的基本思路是两数组字符逐一对比,遇到不同的字符,判断一下typed与上一字符是否相同,不相同返回false,相同则继续对比。 最后要分别判断name和typed分别先遍历完时的情况。直接看代码: class Solution { p…...

[CMake教程] 循环
目录 一、foreach()二、while()三、break() 与 continue() 作为一个编程语言,CMake也少不了循环流程控制,他提供两种循环foreach() 和 while()。 一、foreach() 基本语法: foreach(<loop_var> <items>)<commands> endfo…...
Mojo安装使用初体验
一个声称比python块68000倍的语言 蹭个热度,安装试试 系统配置要求: 不支持Windows系统 配置要求: 系统:Ubuntu 20.04/22.04 LTSCPU:x86-64 CPU (with SSE4.2 or newer)内存:8 GiB memoryPython 3.8 - 3.10g or cla…...

艺术与AI:科技与艺术的完美融合
文章目录 艺术创作的新工具生成艺术艺术与数据 AI与互动艺术虚拟现实(VR)与增强现实(AR)机器学习与互动性 艺术与AI的伦理问题结语 🎉欢迎来到AIGC人工智能专栏~艺术与AI:科技与艺术的完美融合 ☆* o(≧▽≦…...
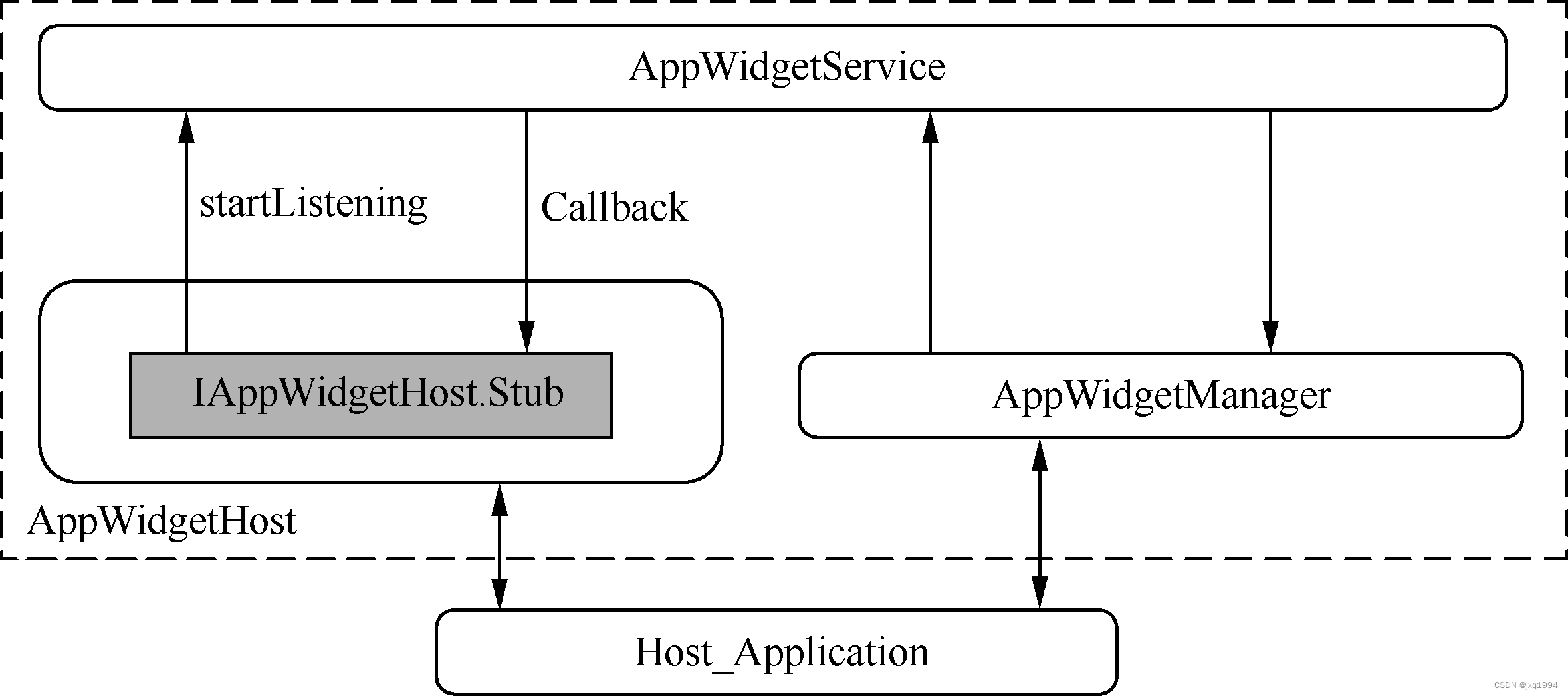
Android常用的工具“小插件”——Widget机制
Widget俗称“小插件”,是Android系统中一个很常用的工具。比如我们可以在Launcher中添加一个音乐播放器的Widget。 在Launcher上可以添加插件,那么是不是说只有Launcher才具备这个功能呢? Android系统并没有具体规定谁才能充当“Widget容器…...

探索在云原生环境中构建的大数据驱动的智能应用程序的成功案例,并分析它们的关键要素。
文章目录 1. Netflix - 个性化推荐引擎2. Uber - 实时数据分析和决策支持3. Airbnb - 价格预测和优化5. Google - 自然语言处理和搜索优化 🎈个人主页:程序员 小侯 🎐CSDN新晋作者 🎉欢迎 👍点赞✍评论⭐收藏 ✨收录专…...

jupyter 添加中文选项
文章目录 jupyter 添加中文选项1. 下载中文包2. 选择中文重新加载一下,页面就变成中文了 jupyter 添加中文选项 1. 下载中文包 pip install jupyterlab-language-pack-zh-CN2. 选择中文 重新加载一下,页面就变成中文了 这才是设置中文的正解ÿ…...

系列十、Java操作RocketMQ之批量消息
一、概述 RocketMQ可以一次性发送一组消息,那么这一组消息会被当做一个消息进行消费。 二、案例代码 2.1、pom 同系列五 2.2、RocketMQConstant 同系列五 2.3、BatchConsumer package org.star.batch.consumer;import cn.hutool.core.util.StrUtil; import lom…...

leetcode1两数之和
题目: 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。 你…...

近年GDC服务器分享合集(四): 《火箭联盟》:为免费游玩而进行的扩展
如今,网络游戏采用免费游玩(Free to Play)加内购的比例要远大于买断制,这是因为前者能带来更低的用户门槛。甚至有游戏为了获取更多的用户,选择把原来的买断制改为免费游玩,一个典型的例子就是最近的网易的…...

多模态数据挖掘前沿:生物医学与情感分析领域论文深度解析
多模态数据挖掘前沿:生物医学与情感分析领域论文深度解析 在人工智能与大数据技术飞速发展的当下,多模态数据因能更全面、立体地刻画研究对象,已成为科研领域的核心研究方向。本文将深度解析两篇聚焦多模态数据挖掘的重磅论文——《多模态生物…...

彻底解决Windows 11系统稳定性问题:ExplorerPatcher核心技术解析与实战指南
彻底解决Windows 11系统稳定性问题:ExplorerPatcher核心技术解析与实战指南 【免费下载链接】ExplorerPatcher 提升Windows操作系统下的工作环境 项目地址: https://gitcode.com/GitHub_Trending/ex/ExplorerPatcher 当你的Windows 11系统频繁出现界面无响应…...


例子-子网划分问题
...

5步实现Switch控制器PC全功能适配:从连接到精通的设备适配指南
5步实现Switch控制器PC全功能适配:从连接到精通的设备适配指南 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitc…...

TikTok零/低播放突围:跨境账号实战破局指南
图片来源:TK云大师0播放或低播放是TikTok跨境从业者的高频痛点——行业数据显示,超68%新手账号遇初始零播放,45%带货账号因持续低播放停摆。耗时制作的内容无人问津,既耗资源又乱节奏。结合实操经验,本文从排查、挽救、…...

Gradio项目快速公网演示:除了share=True,你还有这几种轻量级内网穿透方案
Gradio项目快速公网演示:5种轻量级内网穿透方案横向评测 当你开发了一个酷炫的机器学习模型演示,或是精心设计的数据可视化界面,最迫切的需求往往是如何快速分享给同事或客户。Gradio的shareTrue参数可能是大多数开发者首先想到的方案&#x…...

Charticulator:数据可视化的自由创作平台与技术革命
Charticulator:数据可视化的自由创作平台与技术革命 【免费下载链接】charticulator Interactive Layout-Aware Construction of Bespoke Charts 项目地址: https://gitcode.com/gh_mirrors/ch/charticulator 当数据分析师面对预设模板无法表达复杂数据关系时…...

Meshroom三维重建实战指南:从图像到模型的全流程解析
Meshroom三维重建实战指南:从图像到模型的全流程解析 【免费下载链接】Meshroom 3D Reconstruction Software 项目地址: https://gitcode.com/gh_mirrors/me/Meshroom Meshroom作为一款开源的3D重建软件,通过摄影测量技术将2D图像转化为精确的三维…...

iText7中文渲染完全指南:从乱码到完美显示的技术突破
iText7中文渲染完全指南:从乱码到完美显示的技术突破 【免费下载链接】itext7-chinese-font 项目地址: https://gitcode.com/gh_mirrors/it/itext7-chinese-font 在数字化文档处理领域,PDF格式以其跨平台一致性成为信息传递的首选。然而…...