hivesql执行过程
语法解析
SemanticAnalyzer
SemanticAnalyzer是Hive中的语义分析器,负责检查Hive SQL程序的语义是否正确。SemanticAnalyzer会对Hive SQL程序进行以下检查:
检查过程
语法检查
SemanticAnalyzer会检查Hive SQL程序的语法是否正确,包括关键字、运算符、字符串、数字等。
类型检查
SemanticAnalyzer会检查Hive SQL程序中的变量、常量、表达式等的类型是否正确。
范围检查
SemanticAnalyzer会检查Hive SQL程序中的变量是否在定义的范围内使用。
约束检查
SemanticAnalyzer会检查Hive SQL程序中的约束是否满足。
SemanticAnalyzer的检查结果会记录在Hive的错误日志中。如果SemanticAnalyzer发现语义错误,则Hive SQL程序将无法执行。
原理
SemanticAnalyzer的原理如下:
- SemanticAnalyzer首先会使用ANTLR解析器来解析Hive SQL程序,生成抽象语法树 (AST)。AST是Hive SQL程序的结构化表示,它包含了Hive SQL程序的语法信息。
- SemanticAnalyzer会使用Resolver来解析AST,将AST中的变量、常量、表等引用解析为具体的值。
- SemanticAnalyzer会使用Checker来检查AST,检查AST中的语义是否正确。
Checker是SemanticAnalyzer的核心组件,它负责检查AST的语义。Checker会对AST进行以下检查:
- 语法检查:Checker会检查AST是否满足Hive的语法规则。
- 类型检查:Checker会检查AST中的变量、常量、表达式等的类型是否正确。
- 范围检查:Checker会检查AST中的变量是否在定义的范围内使用。
- 约束检查:Checker会检查AST中的约束是否满足。
如果Checker发现语义错误,则会记录在Hive的错误日志中。
SemanticAnalyzer的检查过程是递归的,它从AST的根节点开始,逐级检查子节点。如果发现语义错误,则会中止检查,并返回错误信息。
Checker
SemanticAnalyzer中的Checker是用来检查源代码语义是否正确的组件。它通常是基于一个类型系统来实现的。类型系统定义了程序中的各种类型,以及这些类型之间的关系。Checker会使用类型系统来检查程序中的表达式、语句和函数是否符合语义规则。
Checker的实现可以分为以下几个步骤:
- 构建符号表。符号表是存储程序中所有符号及其类型信息的数据结构。Checker需要使用符号表来查找符号的类型。
- 检查表达式。Checker会检查表达式的类型是否正确。例如,如果表达式的类型是整数,那么其值必须是一个整数。
- 检查语句。Checker会检查语句的语义是否正确。例如,如果语句是赋值语句,那么其左值和右值的类型必须是兼容的。
- 检查函数。Checker会检查函数的参数类型和返回类型是否正确。
以下是一个简单的Checker的实现示例:
class Checker:def __init__(self, symbol_table):self.symbol_table = symbol_tabledef check_expression(self, expression):# 检查表达式的类型是否正确expression_type = self.symbol_table.get_type(expression)if expression_type is None:raise SemanticError("Unknown symbol: " + expression)# 检查表达式的值是否正确if expression_type == "int":if not isinstance(expression, int):raise SemanticError("Expression is not an integer: " + expression)elif expression_type == "float":if not isinstance(expression, float):raise SemanticError("Expression is not a float: " + expression)def check_statement(self, statement):# 检查语句的语义是否正确if isinstance(statement, AssignmentStatement):# 检查赋值语句的左值和右值的类型是否兼容variable_type = self.symbol_table.get_type(statement.variable)value_type = self.check_expression(statement.value)if variable_type != value_type:raise SemanticError("Type mismatch: " + statement)elif isinstance(statement, IfStatement):# 检查条件表达式的类型是否是布尔值condition_type = self.check_expression(statement.condition)if condition_type != "bool":raise SemanticError("Condition is not a boolean: " + statement)elif isinstance(statement, WhileStatement):# 检查条件表达式的类型是否是布尔值condition_type = self.check_expression(statement.condition)if condition_type != "bool":raise SemanticError("Condition is not a boolean: " + statement)def check_function(self, function):# 检查函数的参数类型是否正确for parameter in function.parameters:parameter_type = self.symbol_table.get_type(parameter)if parameter_type is None:raise SemanticError("Unknown symbol: " + parameter)# 检查函数的返回类型是否正确return_type = self.symbol_table.get_type(function.return_type)if return_type is None:raise SemanticError("Unknown symbol: " + function.return_type)这个Checker可以检查简单的表达式、语句和函数。它使用了一个简单的符号表来存储程序中所有符号及其类型信息。它还使用了一些简单的规则来检查表达式、语句和函数的语义。
HiveServer2
HiveServer2 是 Hive 的一种服务器模式,它允许用户通过 JDBC 或 ODBC 连接到 Hive。HiveServer2 在 Hive 的后端运行,它将用户的查询发送到 Hive 的执行引擎。HiveServer2 还负责处理用户的连接和认证。
HiveServer2 相对于 Hive 的其他模式有以下优点:
- 它提供了一个可扩展的连接管理器,可以处理多个用户同时连接到 Hive。
- 它提供了一个安全的连接管理器,可以使用用户名和密码来认证用户。
- 它提供了一个标准的 JDBC 和 ODBC 接口,可以通过任何支持这些接口的客户端工具来连接到 Hive。
HiveServer2 是 Hive 的默认服务器模式。它是使用 Hive 的推荐方式。
HiveServer2 的工作原理如下:
- 用户使用 JDBC 或 ODBC 连接到 HiveServer2。
- HiveServer2 会验证用户的连接,并为用户创建一个会话。
- 用户向 HiveServer2 发送查询。
- HiveServer2 将查询发送到 Hive 的执行引擎。
- Hive 的执行引擎执行查询,并将结果返回给 HiveServer2。
- HiveServer2 将结果返回给用户。
HiveServer2 的架构如下:
+-------------------------------------------------------+
| HiveServer2 |
+-------------------------------------------------------+
| |
| Hive Driver |
| |
+-------------------------------------------------------+
| |
| JDBC/ODBC Client |
| |
+-------------------------------------------------------+
HiveServer2 由以下组件组成:
- HiveServer2 服务器:HiveServer2 服务器是 HiveServer2 的核心组件,它负责处理用户的连接、认证和查询。
- Hive 执行引擎:Hive 执行引擎负责执行 Hive 的查询。
- Hive JDBC/ODBC 驱动程序:Hive JDBC/ODBC 驱动程序提供 JDBC 和 ODBC 接口,可以通过任何支持这些接口的客户端工具来连接到 Hive。
HiveServer2 服务器
Hive 执行引擎
Hive 执行引擎是 Hive 的核心组件,它负责执行 Hive 的查询。Hive 执行引擎可以使用不同的计算引擎来执行查询,包括 MapReduce、Tez 和 Spark。
Hive 执行引擎的功能如下:
- 解析查询语句。
- 生成执行计划。
- 执行执行计划。
- 生成查询结果。
Hive 执行引擎的实现可以分为以下几个阶段:
- 解析阶段:Hive 执行引擎首先会解析查询语句,并生成语法树。
- 优化阶段:Hive 执行引擎会对语法树进行优化,以提高查询的性能。
- 编译阶段:Hive 执行引擎会将优化后的语法树转换为执行计划。
- 执行阶段:Hive 执行引擎会根据执行计划来执行查询。
- 结果阶段:Hive 执行引擎会将查询结果返回给用户。
Hive 执行引擎的架构如下:
+-------------------------------------------------------+
| Hive 执行引擎 |
+-------------------------------------------------------+
| |
| Parser |
| |
+-------------------------------------------------------+
| |
| Optimizer |
| |
+-------------------------------------------------------+
| |
| HivePlanner |
| |
+-------------------------------------------------------+
| |
| HiveExecDriver |
| |
+-------------------------------------------------------+
| |
| HiveExecMapper |
| |
+-------------------------------------------------------+
| |
| HiveExecReducer |
| |
+-------------------------------------------------------+
Hive 执行引擎由以下组件组成:
- Parser:Parser 负责解析查询语句,并生成语法树。
- Optimizer:Optimizer 负责对语法树进行优化,以提高查询的性能。
- HivePlanner:HivePlanner 负责将优化后的语法树转换为执行计划。
- HiveExecDriver:HiveExecDriver 负责执行查询。
- HiveExecMapper:HiveExecMapper 负责执行 MapReduce 阶段的任务。
- HiveExecReducer:HiveExecReducer 负责执行 Reduce 阶段的任务。
Hive 执行引擎的优化策略可以分为以下几个方面:
- 逻辑优化:逻辑优化是指对查询的语法树进行优化,以提高查询的性能。例如,Hive 执行引擎可以通过以下方式来进行逻辑优化:
- 常量折叠:将查询中出现的常量值折叠到表达式中,以减少计算量。
- 子查询优化:将子查询合并到外层查询中,以减少查询的次数。
- 谓词下推:将查询中的谓词下推到表扫描之前,以减少扫描的数据量。
- 物理优化:物理优化是指对查询的执行计划进行优化,以提高查询的性能。例如,Hive 执行引擎可以通过以下方式来进行物理优化:
- 合并 Map 任务:将多个 Map 任务合并到一个 Map 任务中,以提高 Map 任务的并行度。
- 合并 Reduce 任务:将多个 Reduce 任务合并到一个 Reduce 任务中,以减少 Reduce 任务的数量。
- 选择合适的计算引擎:根据查询的特点,选择合适的计算引擎,以提高查询的性能。
Hive JDBC/ODBC 驱动程序
Hive JDBC/ODBC 驱动程序是 Hive 提供的一种连接器,它允许用户通过 JDBC 或 ODBC 连接到 Hive。Hive JDBC/ODBC 驱动程序提供标准的 JDBC 和 ODBC 接口,可以通过任何支持这些接口的客户端工具来连接到 Hive。
Hive JDBC/ODBC 驱动程序的功能如下:
- 支持 JDBC 和 ODBC 接口。
- 支持 Hive 的所有功能,包括查询、DDL、DML 等。
- 支持 Hive 的所有数据类型,包括表、视图、UDF 等。
- 支持 Hive 的所有安全功能,包括用户名、密码、Kerberos 等。
Hive JDBC/ODBC 驱动程序可以通过以下方式下载:
- 从 Hive 的官方网站下载。
- 从 Hive 的源代码中编译。
Hive JDBC/ODBC 驱动程序的使用方法如下:
- 使用 JDBC 连接到 HiveServer2。
- 使用 ODBC 连接到 HiveServer2。
Hive JDBC/ODBC 驱动程序的示例代码如下:
// 使用 JDBC 连接到 HiveServer2
Connection connection = DriverManager.getConnection("jdbc:hive2://localhost:10000/default", "user", "password");// 使用 ODBC 连接到 HiveServer2
Connection connection = DriverManager.getConnection("jdbc:hive2://localhost:10000/default;user=user;password=password");
Hive JDBC/ODBC 驱动程序的优势如下:
- 提供了一种标准的连接方式,可以通过任何支持 JDBC 或 ODBC 的客户端工具来连接到 Hive。
- 提供了一种安全的连接方式,可以使用用户名、密码、Kerberos 等来认证用户。
- 提供了一种灵活的连接方式,可以通过 JDBC 或 ODBC 接口来访问 Hive 的所有功能。
Optimizer
Hive中的Optimizer是负责优化Hive SQL程序执行计划的组件。Optimizer会对Hive SQL程序的执行计划进行以下优化:
优化过程
- 逻辑优化:Optimizer会对Hive SQL程序的逻辑执行计划进行优化,例如:
- 推导常量
- 合并子查询
- 重写表达式
- 物理优化:Optimizer会对Hive SQL程序的物理执行计划进行优化,例如:
- 选择合适的分布策略
- 选择合适的算子
- 合并MapReduce任务
原理
Optimizer的原理如下:
- Optimizer会首先使用语义分析器来检查Hive SQL程序的语义是否正确。如果语义错误,则会中止优化,并返回错误信息。
- Optimizer会使用逻辑优化器来对Hive SQL程序的逻辑执行计划进行优化。逻辑优化器会根据Hive的语义规则,对Hive SQL程序的逻辑执行计划进行改写,以提高执行效率。
- Optimizer会使用物理优化器来对Hive SQL程序的物理执行计划进行优化。物理优化器会根据Hive的执行机制,对Hive SQL程序的物理执行计划进行改写,以提高执行效率。
Optimizer的作用是提高Hive SQL程序的执行效率。Optimizer可以通过对Hive SQL程序的执行计划进行优化,减少不必要的计算和I/O操作,从而提高Hive SQL程序的执行效率。
在Hive 3.0中,Optimizer进行了一些改进,包括:
- 支持更加复杂的优化规则
- 支持更加灵活的优化策略
- 支持更多的优化算法
这些改进使得Hive 3.0的Optimizer更加高效,能够对Hive SQL程序进行更加有效的优化。
Hive Metastore
Hive Metastore 是 Hive 的元数据存储系统,它存储了 Hive 的所有元数据,包括表、列、分区、外部表、UDF 等。Hive Metastore 是一个关系型数据库,可以使用 MySQL、PostgreSQL 等数据库来实现。
Hive Metastore 的主要功能如下:
- 存储 Hive 的所有元数据。
- 提供对 Hive 元数据的访问接口。
- 实现 Hive 元数据的版本控制。
- 实现 Hive 元数据的安全访问控制。
Hive Metastore 的架构如下:
+-------------------------------------------------------+
| Hive Metastore |
+-------------------------------------------------------+
| |
| MySQL/PostgreSQL |
| |
+-------------------------------------------------------+
Hive Metastore 由以下组件组成:
- Hive Metastore Server:Hive Metastore Server 是 Hive Metastore 的核心组件,它负责处理对 Hive 元数据的访问请求。
- MySQL/PostgreSQL:MySQL/PostgreSQL 是 Hive Metastore 的存储组件,它存储 Hive 的所有元数据。
Hive Metastore 的优点如下:
- 提供了一个集中式、可靠的元数据存储系统。
- 提供了对 Hive 元数据的访问接口,可以通过 HiveQL 或 JDBC 来访问 Hive 元数据。
- 实现了 Hive 元数据的版本控制,可以追踪 Hive 元数据的变更历史。
- 实现了 Hive 元数据的安全访问控制,可以根据用户的权限来访问 Hive 元数据。
Hive Metastore 的缺点如下:
- 是一个单点故障系统,如果 Hive Metastore Server 发生故障,可能会导致 Hive 无法使用。
- 需要额外维护一个关系型数据库,增加了系统的复杂度。
总体而言,Hive Metastore 是一个重要的 Hive 组件,它提供了对 Hive 元数据的集中式、可靠的存储。
总结
也就是说,hive sql在客户端被编写之后会发送到hive的服务端,服务端首先会对编写的sql进行词法解析和语法解析,检测语法的正确性,然后会对sql进行语义分析,如果语义分析没有问题,则进行下一步sql优化工作,优化工作完毕之后,会生成sql的执行计划,然后最终会生成一系列map reduce任务,从而得到结果。
相关文章:

hivesql执行过程
语法解析 SemanticAnalyzer SemanticAnalyzer是Hive中的语义分析器,负责检查Hive SQL程序的语义是否正确。SemanticAnalyzer会对Hive SQL程序进行以下检查: 检查过程 语法检查 SemanticAnalyzer会检查Hive SQL程序的语法是否正确,包括关…...

C语言学习:8、深入数据类型
数据超过类型规定的大小怎么办 C语言中,如果需要用的整数大于int类型的最大值了怎么办? 我们知道int能表示的最大数是2147483647,最小的数是-2147483648,为什么? 因为字32位系统中,寄存器是32位的&#…...
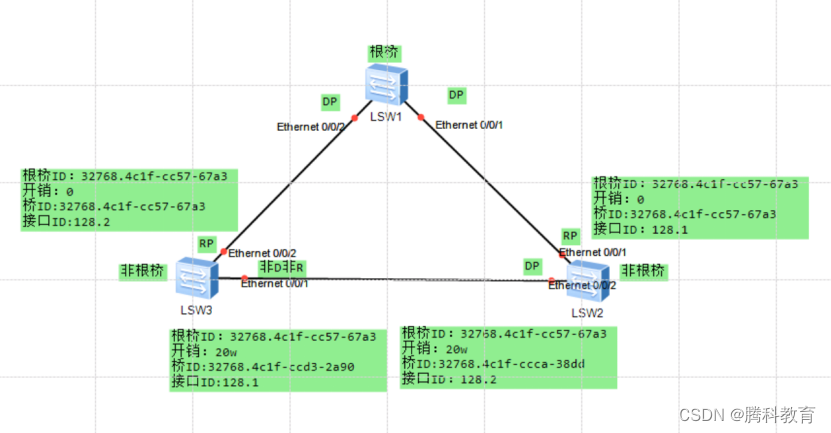
生成树协议 STP(spanning-tree protocol)
一、STP作用 1、消除环路:通过阻断冗余链路来消除网络中可能存在的环路。 2、链路备份:当活动路径发生故障时,激活备份链路,及时恢复网络连通性。 二、STP选举机制 1、目的:找到阻塞的端口 2、STP交换机的角色&am…...

【LeetCode】312.戳气球
题目 有 n 个气球,编号为0 到 n - 1,每个气球上都标有一个数字,这些数字存在数组 nums 中。 现在要求你戳破所有的气球。戳破第 i 个气球,你可以获得 nums[i - 1] * nums[i] * nums[i 1] 枚硬币。 这里的 i - 1 和 i 1 代表和…...

商业数据分析概论
🐳 我正在和鲸社区参加“商业数据分析训练营活动” https://www.heywhale.com/home/competition/6487de6649463ee38dbaf58b ,以下是我的学习笔记: 学习主题:波士顿房价数据快速查看 日期:2023.9.4 关键概念/知识点&…...

Golang GUI框架
Golang GUI框架fyne fyne简介第一个fyne应用fyne应用程序和运行循环fyne更新GUI内容fyne窗口处理fyne解决中文乱码问题fyne应用打包fyne画布和画布对象fyne容器和布局fyne绘制和动画fyne盒子布局fyne网格grid布局fyne网格包裹布局fyne边框布局fyne表单布局fyne中心布局fyne ma…...

LeetCode刷题笔记【24】:贪心算法专题-2(买卖股票的最佳时机II、跳跃游戏、跳跃游戏II)
文章目录 前置知识122.买卖股票的最佳时机II题目描述贪心-直观写法贪心-优化代码更简洁 55. 跳跃游戏题目描述贪心-借助ability数组贪心-只用int far记录最远距离 45.跳跃游戏II题目描述回溯算法贪心算法 总结 前置知识 参考前文 参考文章: LeetCode刷题笔记【23】…...

游戏出现卡顿有哪些因素
一、服务器CPU内存占用过大会导致卡顿,升级CPU内存或者优化自身程序占用都可以解决。 二、带宽跑满导致卡,可以升级带宽解决。 二、平常不卡,有大型的活动的时候会卡,这方面主要是服务器性能方面不够导致的,性能常说…...

学习Bootstrap 5的第八天
目录 加载器 彩色加载器 实例 闪烁加载器 实例 加载器大小 实例 加载器按钮 实例 分页 分页的基本结构 实例 活动状态 实例 禁用状态 实例 分页大小 实例 分页对齐 实例 面包屑(Breadcrumbs) 实例 加载器 彩色加载器 在 Bootstr…...

vue中自定义指令
什么是指令 在Vue.js中,指令是一种特殊的 token,用于在模板中以声明式方式将响应式数据绑定到 DOM 元素上,从而实现与 DOM 元素的交互和操作。指令以 “v-” 前缀开始,后跟指令的名称,例如 v-model、v-bind 和 v-on。…...
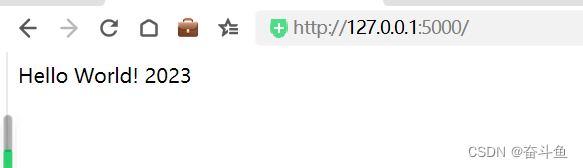
Python:安装Flask web框架hello world
安装easy_install pip install distribute 安装pip easy_install pip 安装 virtualenv pip install virtualenv 激活Flask pip install Flask 创建web页面demo.py from flask import Flask app Flask(__name__)app.route(/) def hello_world():return Hello World! 2023if _…...

小程序点击复制功能制作
在wxml文件中添加一个按钮或需要点击的元素,并绑定点击事件监听器2 <button bindtap"copyText">点击复制</button> 2 在对应的js文件中定义点击事件处理函数,并在函数中调用小程序的API进行复制操作, copyText(e){co…...
20230909java面经整理
1.java常用集合 ArrayList动态数组,动态调整大小,实现List接口 LinkedList双向链表,实现list和queue接口,适用于频繁插入和删除操作 HashSet无序,使用哈希表实现 TreeSet有序,使用红黑树实现 HashMap无序&…...

常用的css命名规则
一、命名规则说明: 1)、所有的命名最好都小写 2)、属性的值一定要用双引号(“”)括起来 3)、给图片加上alt标签 4)、尽量使用英文命名原则 5)、尽量不缩写,除非一看就明白的单词 二、相对网页外…...
)
【Linux编程Shell自动化脚本】03 shell四剑客(find、sed、grep、awk)
文章目录 一、find1. 常用expression2. 时间参数3. 其他选项参数3.1 查找深度3.2 执行命令 二、sed1. 常用命令选项2. 常用动作脚本命令2.1 s 替换2.2 已匹配字符串标记&2.3 在当前行前后插入文本 a\ 和 i\2.4 p 打印指定行2.5 匹配行的方式2.5.1 以数字形式指定行区间2.5.…...

java的springboot框架中使用logback日志框架使用RabbitHandler注解为什么获取不到消费的traceId信息?
当使用 Logback 日志框架和 RabbitMQ 的 RabbitHandler 注解时,如果无法获取消费的 traceId 信息,可能是因为在处理 RabbitMQ 消息时,没有正确地将 traceId 传递到日志中。 为了将 traceId 传递到日志中,你可以利用 MDCÿ…...

初探Vue.js及Vue-Cli
一、使用vue框架的简单示例 我们本次的vue系列就使用webstorm来演示: 对于vue.js的安装我们直接使用script的cdn链接来实现 具体可以参考如下网址: https://www.bootcdn.cn/ 进入vue部分,可以筛选版本,我这里使用的是2.7.10版本的ÿ…...

大数据课程K21——Spark的SparkSQL基础语法
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 掌握Spark的SparkSQL通过方法来使用; ⚪ 掌握Spark的SparkSQL通过sql语句来调用; 一、SparkSQL基础语法——通过方法来使用 1. 查询 df.select("id","name").show()…...

【实践篇】Redis最强Java客户端(三)之Redisson 7种分布式锁使用指南
文章目录 0. 前言1. Redisson 7种分布式锁使用指南1.1 简单锁:1.2 公平锁:1.3 可重入锁:1.4 红锁:1.5 读写锁:1.6 信号量:1.7 闭锁: 2. Spring boot 集成Redisson 验证分布式锁3. 参考资料4. 源…...

卫星通话过后,卫星导航产业被彻底激活
华为新手机发布后,其主打的卫星通话功能备受热议。在卫星产业链发展的背后,下一个大产业在哪里让人颇为好奇。 目前,卫星导航颇被看好,或将引领下一个技术狂潮。它的特点是产业大、发展快、参与者多。继电动汽车、新能源和芯片产…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

聊一聊接口测试的意义有哪些?
目录 一、隔离性 & 早期测试 二、保障系统集成质量 三、验证业务逻辑的核心层 四、提升测试效率与覆盖度 五、系统稳定性的守护者 六、驱动团队协作与契约管理 七、性能与扩展性的前置评估 八、持续交付的核心支撑 接口测试的意义可以从四个维度展开,首…...

JavaScript 数据类型详解
JavaScript 数据类型详解 JavaScript 数据类型分为 原始类型(Primitive) 和 对象类型(Object) 两大类,共 8 种(ES11): 一、原始类型(7种) 1. undefined 定…...

【学习笔记】erase 删除顺序迭代器后迭代器失效的解决方案
目录 使用 erase 返回值继续迭代使用索引进行遍历 我们知道类似 vector 的顺序迭代器被删除后,迭代器会失效,因为顺序迭代器在内存中是连续存储的,元素删除后,后续元素会前移。 但一些场景中,我们又需要在执行删除操作…...

WebRTC从入门到实践 - 零基础教程
WebRTC从入门到实践 - 零基础教程 目录 WebRTC简介 基础概念 工作原理 开发环境搭建 基础实践 三个实战案例 常见问题解答 1. WebRTC简介 1.1 什么是WebRTC? WebRTC(Web Real-Time Communication)是一个支持网页浏览器进行实时语音…...

从面试角度回答Android中ContentProvider启动原理
Android中ContentProvider原理的面试角度解析,分为已启动和未启动两种场景: 一、ContentProvider已启动的情况 1. 核心流程 触发条件:当其他组件(如Activity、Service)通过ContentR…...

git: early EOF
macOS报错: Initialized empty Git repository in /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core/.git/ remote: Enumerating objects: 2691797, done. remote: Counting objects: 100% (1760/1760), done. remote: Compressing objects: 100% (636/636…...

第八部分:阶段项目 6:构建 React 前端应用
现在,是时候将你学到的 React 基础知识付诸实践,构建一个简单的前端应用来模拟与后端 API 的交互了。在这个阶段,你可以先使用模拟数据,或者如果你的后端 API(阶段项目 5)已经搭建好,可以直接连…...