kafka学习-消费者
目录
1、消费者、消费组
2、心跳机制
3、消费者常见参数配置
4、订阅
5、反序列化
基本概念
自定义反序列化器
6、位移提交
6.1、自动提交
6.2、手动提交
同步提交
异步提交
7、再均衡
7.1、定义与基本概念
7.2、缺陷
7.3、如何避免再均衡
7.4、如何进行组内分区分配
7.5、谁来执行再均衡和消费组管理
8、消费者拦截器
作用
自定义消费者拦截器
1、消费者、消费组
- 消费者从订阅的主题消费消息,消费消息的偏移量保存在kafka中的__consumer_offsets的主题中。
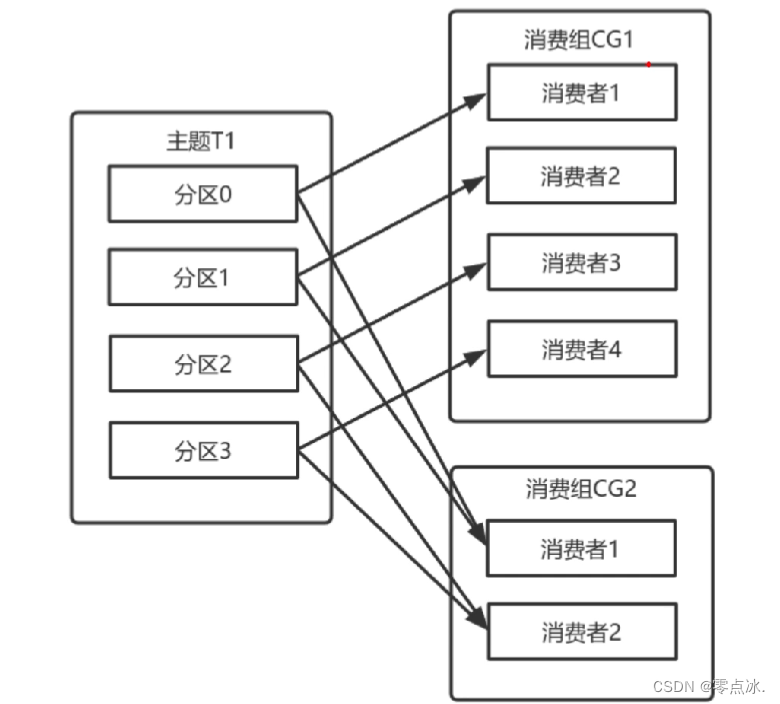
- 多个消费同一个主题的消费者,可以通过group.id配置,加入到同一个消费组中。消费组均衡地给消费者分配分区,每个分区只由消费组中的一个消费者消费,防止重复消费。
- 同一个消费组里:一个分区只会对应一个消费者,但一个消费者可以消费多个分区。
- group_id一半设置为应用或者业务的逻辑名称。
2、心跳机制

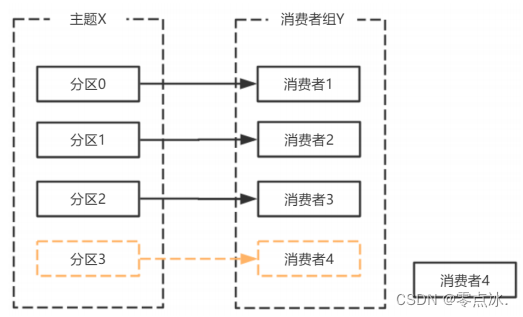
- 消费者宕机,退出消费组,触发再平衡,重新给消费组中的消费者分配分区;
- broker宕机,分区3重选leader副本,出发再平衡,重新分配分区3消息。
心跳机制,就是consumer和broker之间的健康检查。consumer和broker之间保持长连接,通过心跳机制检测对方是否健康。心跳检测相关参数如下所示:

在broker端,可配置sessionTimeoutMs参数,如果consumer心跳超期,broker会把消费者从消费组中移除,并触发再平衡,重新分配分区;
在consumer端,可配置sessionTimeoutMs和rebalanceTimeoutMs参数,如果broker心跳超期,consumer则会告知broker主动退出消费组,并触发再平衡。
3、消费者常见参数配置

4、订阅
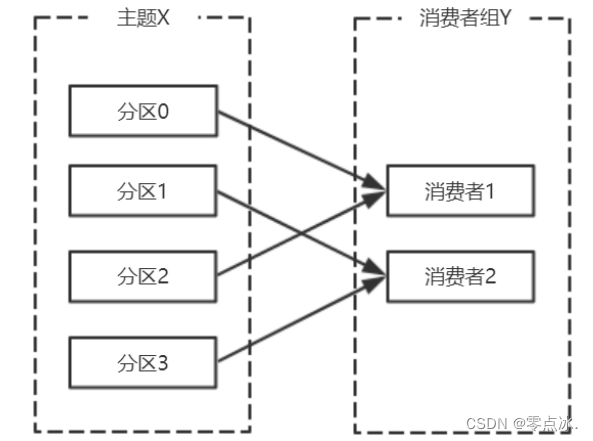
主题、分区(leader和follower分区)、消费者、消费组、订阅。
- 主题:topic,用于分类管理消息的逻辑单元,可以用于区分业务类型;
- 分区:partition,同一个topic的消息,会被分散到多个分区中,不同分区通常在不同broker上,方便水平扩展。分区可分为leader分区和follower分区,leader分区用于与生产者/消费者通信,follower分区用于备份leader分区的数据;
- 消费者:与分区长连接,用于消费分区中的消息;
- 消费组:消费组中可能会有多个消费者,保证一个消费组获取到特定主题的全部消息。消费组可以保证一个主题的分区只会被消费组中的一个消费者消费;
- 订阅:消费者订阅主题,并将消费者加入到消费组中,采用pull模式,从broker分区中读取消息。kafka的消费者只有pull模式,该模式下消费者可以自主控制消费消息的速率。
5、反序列化
基本概念
- 在Kafka中保存的数据都是字节数组。
- 消息者接收消息后,需要将消息反序列化为指定的数据格式进行处理。
- 消费者通过key.deserializer和value.deserializer指定key和value的序列化器。
- Kafka使用org.apache.kafka.common.serialization.Deserializer<T>接口定义序列化器。
- Kafka已实现的序列化器有:ByteArrayDeserializer、ByteBufferDeserializer、BytesDeserializer、DoubleDeserializer、FloatDeserializer、IntegerDeserializer、StringDeserializer、LongDeserializer、ShortDeserializer。
自定义反序列化器
实现org.apache.kafka.common.serialization.Deserializer<T>接口,并实现其中的deserializer方法。
public class UserDeserializer implements Deserializer<User> {@Overridepublic void configure(Map<String, ?> configs, boolean isKey) {}@Overridepublic User deserialize(String topic, byte[] data) {ByteBuffer allocate = ByteBuffer.allocate(data.length);allocate.put(data);allocate.flip();int userId = allocate.getInt();int length = allocate.getInt();System.out.println(length);String username = new String(data, 8, length);return new User(userId, username);}@Overridepublic void close() {}
}6、位移提交
- 位移 = kafka分区消息的偏移量。
- kafka中有一个主题,专门用于保存消费者的偏移量。
- 消费者与分区一一对应,消费者在消费分区消息时,需要向kafka提交自己的位移(偏移量)信息,kafka只记录该消费者在对应分区的偏移量信息。
- 消费者向kafka提交偏移量的过程,叫做位移提交。
- 位移提交,分为自动提交和手动提交;也分为同步提交和异步提交。
6.1、自动提交
- 开启⾃动提交: enable.auto.commit=true,kafka默认为自动提交。
- 配置⾃动提交间隔:Consumer端: auto.commit.interval.ms ,默认 5s。
- Consumer 每 5s 提交一次offset
- 假设提交 offset 后的 3s 发⽣了 Rebalance
- Rebalance 之后的所有 Consumer 从上⼀次提交的 offset 处继续消费
- 因此 Rebalance 发⽣前 3s 的消息会被重复消费
6.2、手动提交
同步提交
while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));process(records); // 处理消息try {consumer.commitSync();} catch (CommitFailedException e) {handle(e); // 处理提交失败异常}
}- 使⽤ KafkaConsumer#commitSync(),会提交 KafkaConsumer#poll() 返回的最新 offset
- ⼿动同步提交可以控制offset提交的时机和频率
- 调⽤ commitSync 时,Consumer 处于阻塞状态,直到 Broker 返回结果
- 会影响 TPS
- 如果提交间隔过长,consumer重启后,会有更多的消息被重复消费。
异步提交
while (true) {ConsumerRecords<String, String> records = consumer.poll(3_000);process(records); // 处理消息consumer.commitAsync((offsets, exception) -> {if (exception != null) {handle(exception);}});
}- 使⽤ KafkaConsumer#commitAsync():会提交 KafkaConsumer#poll() 返回的最新 offset
- commitAsync出现问题不会⾃动重试,可通过异步提交与同步提交相结合的方式解决。
7、再均衡
7.1、定义与基本概念
也叫做重平衡,主要是为了让消费组下的消费者来重新分配主题下的每一个分区。再均衡的触发条件有如下三个:
- 消费组内成员变更(增加和减少消费者),⽐如消费者宕机退出消费组,或者新增一个消费者。
- 主题的分区数发⽣变更,kafka⽬前只⽀持增加分区,当增加的时候就会触发再均衡。
- 订阅的主题发⽣变化,比如消费者组使⽤正则表达式订阅主题,⽽恰好⼜新建了对应的主题,就会触发再均衡。
7.2、缺陷
7.3、如何避免再均衡
- session.timout.ms:控制⼼跳超时时间,推荐设置为6s;
- heartbeat.interval.ms:控制⼼跳发送频率,频率越高越不容易误判,但也会消耗更多资源,推荐设置为2s;
- max.poll.interval.ms:控制poll的间隔,消费者poll数据后,需要⼀些处理,再进⾏拉取。如果两次拉取时间间隔超过这个参数设置的值,那么消费者就会被踢出消费者组。推荐为消费者处理消息最长耗时 + 1分钟。
7.4、如何进行组内分区分配
有三种分配策略:RangeAssignor和RoundRobinAssignor以及StickyAssignor。
7.5、谁来执行再均衡和消费组管理
kafka里有一个角色,叫做Group Coordinator,用于执行消费组的管理。
Group Coordinator——每个消费组分配一个消费组协调器⽤于组管理和位移管理。当消费组的第一个消费者启动的时候,它会去和Kafka Broker确定谁是它们组的组协调器。之后该消费组内所有消费者和该组协调器协调通信。
8、消费者拦截器
作用
- 消费者在拉取了分区消息后,会先通过反序列化对key和value进行处理;
- 然后可通过设置消费者拦截器对消息进行处理,允许更改消费者接收到的消息,或者做一些监控、日志处理;
- 应用程序处理消费者拉取的分区消息;
自定义消费者拦截器
ConsumerInterceptor方法抛出的异常会被捕获、记录,但是不会向下传播。如果用户配置了错误的key或value类型参数,消费者不会抛出异常,而仅仅是记录下来。
自定义消费者拦截器需要实现org.apache.kafka.clients.consumer.ConsumerInterceptor<K, V> 接口,并实现其中的configure()、onConsume()、onCommit()、close()方法,其中:
- onConsume():该方法在poll方法返回之前调用,调用结束后poll方法就返回消息了。可通过该方法修改消费者消息,返回新的消息。
- onCommit():当消费者提交偏移量时,调用该方法。
- close():用于关闭该拦截器用到的资源,如打开的文件、连接的数据库等。
- configure():用于获取消费者的参数配置。
public class MyInterceptor implements ConsumerInterceptor<String, String> {@Overridepublic ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> records) {// poll方法返回结果之前最后要调用的方法System.out.println("MyInterceptor -- 开始");// 消息不做处理,直接返回return records;}@Overridepublic void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets) {// 消费者提交偏移量的时候,经过该方法System.out.println("MyInterceptor -- 结束");}@Overridepublic void close() {// 用于关闭该拦截器用到的资源,如打开的文件,连接的数据库等}@Overridepublic void configure(Map<String, ?> configs) {// 用于获取消费者的设置参数configs.forEach((k, v) -> {System.out.println(k + "\t" + v);});}
}以上内容为个人学习理解,如有问题,欢迎在评论区指出。
部分内容截取自网络,如有侵权,联系作者删除。
相关文章:
kafka学习-消费者
目录 1、消费者、消费组 2、心跳机制 3、消费者常见参数配置 4、订阅 5、反序列化 基本概念 自定义反序列化器 6、位移提交 6.1、自动提交 6.2、手动提交 同步提交 异步提交 7、再均衡 7.1、定义与基本概念 7.2、缺陷 7.3、如何避免再均衡 7.4、如何进行组内分…...
Alibaba(商品详情)API接口
为了进行电商平台 的API开发,首先我们需要做下面几件事情。 1)开发者注册一个账号 2)然后为每个alibaba应用注册一个应用程序键(App Key) 。 3)下载alibaba API的SDK并掌握基本的API基础知识和调用 4)利…...

OLED透明屏触控:引领未来科技革命的创新力量
OLED透明屏触控技术作为一项颠覆性的创新,正在引领新一轮科技革命。它将OLED显示技术与触摸技术相结合,实现了透明度和触控功能的完美融合。 在这篇文章中,尼伽将通过引用最新的市场数据、报告和行业动态,详细介绍OLED透明屏触控…...
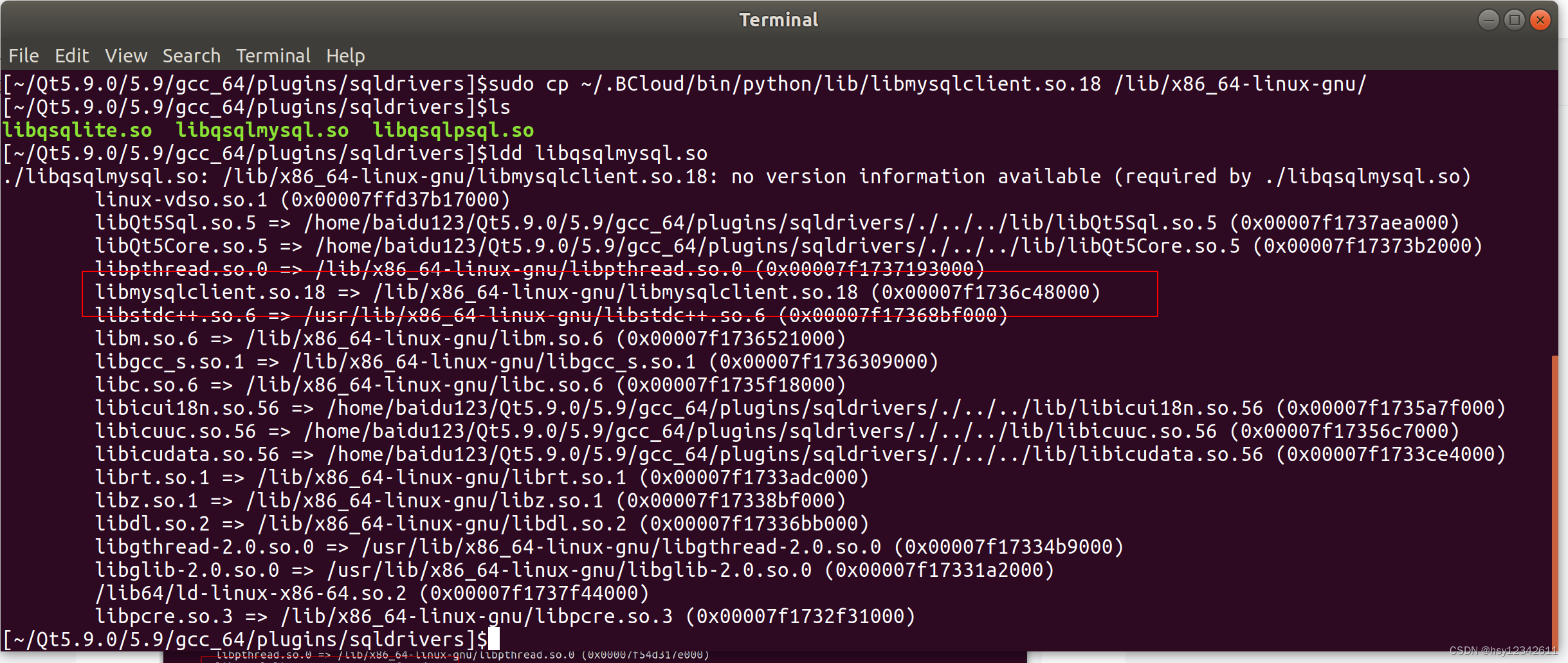
Ubuntu下QT操作Mysql数据库
本篇总结一下一下Ubuntu下QT操作Mysql数据库。 目录 1. 启动Mysql数据库服务器 2.查看QT支持的数据库驱动 3.连接数据库 4. 增加表和记录 5. 删除记录 6. 修改记录 7. 查询记录 8.完整代码和运行效果 常见错误总结: (1) 数据库服务没启动报错信息 (2) 有…...
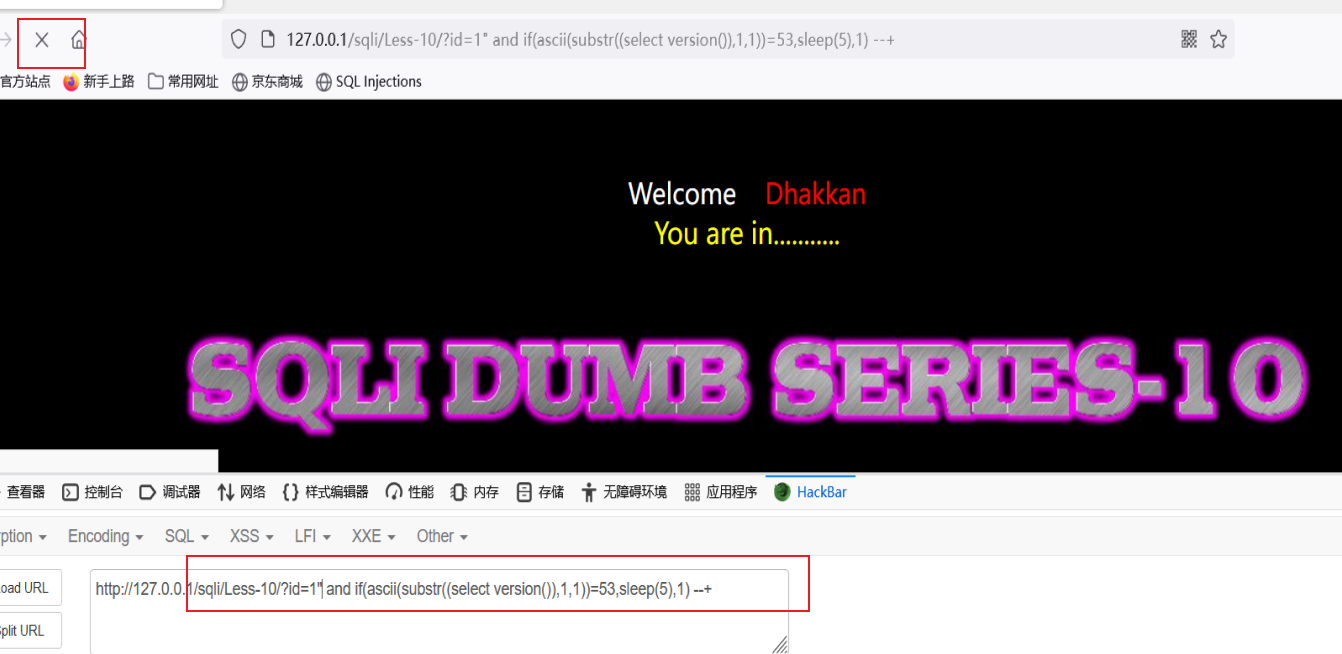
sqli --【1--10】
Less-1(联合查询) 1.查看是否有回显 2.查看是否有报错 3.使用联合查询(字符注入) 3.1判断其列数 3.2 判断显示位置 3.3敏感信息查询 Less-2(联合查询) 1.查看是否有回显 2.查看是否有报错 3.使用…...

《自然语言处理(NLP)的最新进展:Transformers与GPT-4的浅析》
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

Wireshark 用命令行分析数据包
1,那些情况需要使用命令行 Wireshark一次性提供了太多的信息。使用命令行工具可以限制打印出的信息,最后只显示相关数据,比如用单独一行来显示IP地址。命令行工具适用于过滤数据包捕获文件,并提供结果给另一个支持UNIX管道的工具…...
LVS DR模式负载均衡群集部署
目录 1 LVS-DR 模式的特点 1.1 数据包流向分析 1.2 DR 模式的特点 2 DR模式 LVS负载均衡群集部署 2.1 配置负载调度器 2.1.1 配置虚拟 IP 地址 2.1.2 调整 proc 响应参数 2.1.3 配置负载分配策略 2.2 部署共享存储 2.3 配置节点服务器 2.3.1 配置虚拟 IP 地址 2.3.2…...

探讨前后端分离开发的优势、实践以及如何实现更好的用户体验?
随着互联网技术的迅猛发展,前后端分离开发已经成为现代软件开发的一种重要趋势。这种开发模式将前端和后端的开发工作分开,通过清晰的接口协议进行通信,旨在优化开发流程、提升团队协作效率,并最终改善用户体验。本文将深入探讨前…...

微博一面:JVM预热,你的方案是啥?
说在前面 在40岁老架构师 尼恩的读者社区(50)中,最近有小伙伴拿到了一线互联网企业如微博、阿里、汽车之家、极兔、有赞、希音、百度、网易、滴滴的面试资格,遇到一几个很重要的面试题: JVM预热,你的方案是啥?Springb…...

open与fopen的区别
1. 来源 从来源的角度看,两者能很好的区分开,这也是两者最显而易见的区别: open是UNIX系统调用函数(包括LINUX等),返回的是文件描述符(File Descriptor),它是文件在文件…...

Unity记录一些glsl和hlsl的着色器Shader逆向代码
以下内容一般基于 GLSL 300 之后 以下某些代码行,是“伪代码“,绝大部分是renderDoc 逆向产生标准代码 本人OpenlGL零基础,也不打算重头学 目录 Clip() 剔除函数 discard; FS最终颜色输出 out 和最终颜色相加方程…...
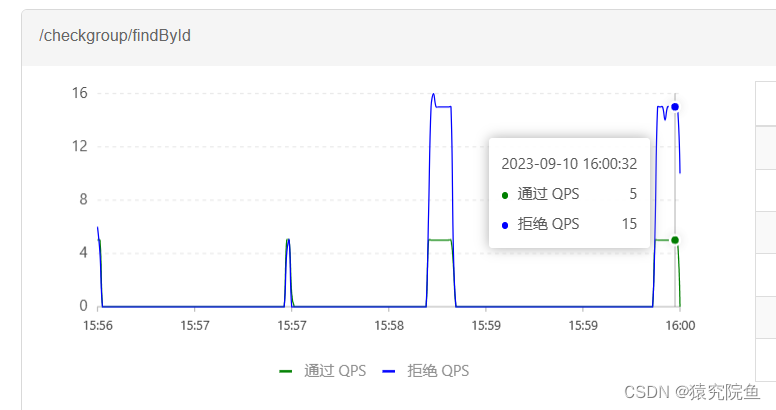
基于Sentinel的微服务保护
前言 Sentinel是Alibaba开源的一款微服务流控组件,用于解决分布式应用场景下服务的稳定性问题。Sentinel具有丰富的应用场景,它基于流量提供一系列的服务保护措施,例如多线程秒杀情况下的系统承载,并发访问下的流量控制ÿ…...

Collectors类作用:
一、Collectors类: 1.1、Collectors介绍 Collectors类,是JDK1.8开始提供的一个的工具类,它专门用于对Stream操作流中的元素各种处理操作,Collectors类中提供了一些常用的方法,例如:toList()、toSet()、to…...
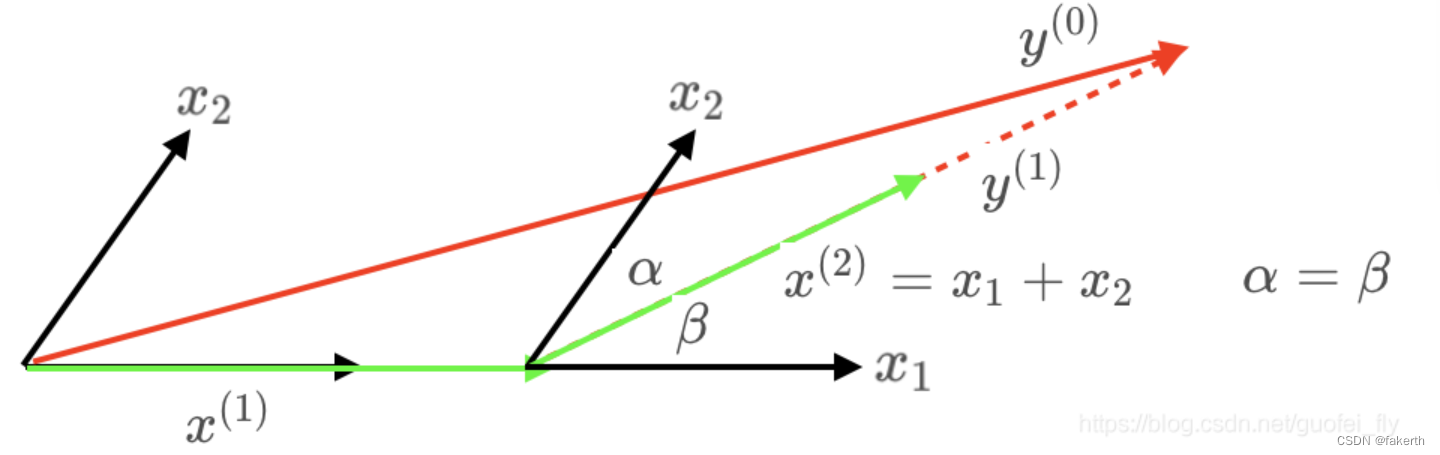
LASSO回归
LASSO回归 LASSO(Least Absolute Shrinkage and Selection Operator,最小绝对值收敛和选择算子算法)是一种回归分析技术,用于变量选择和正则化。它由Robert Tibshirani于1996年提出,作为传统最小二乘回归方法的替代品。 损失函数 1.线性回…...

机器学习中的 K-均值聚类算法及其优缺点。
K-均值聚类算法是一种常见的无监督学习算法,它可以将数据集分成 K 个簇,每个簇内部的数据点尽可能相似,而不同簇之间的数据点应尽可能不同。下面详细讲解 K-均值聚类算法的优缺点: 优点: 简单易用:K-均值…...
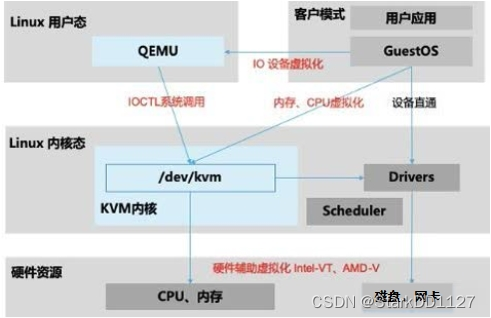
云计算与虚拟化
一、概念 什么是云计算? 云计算(cloud computing)是分布式计算的一种,指的是通过网络“云”将巨大的数据计算处理程序分解成无数个小程序,然后,通过多部服务器组成的系统进行处理和分析这些小程序得到结果…...

Linux常见进程类别
目录 常见进程类别 守护进程&精灵进程 任务管理 进程组 作业 作业 | 进程组 会话 w命令 守护进程 守护进程的创建 setsid()函数 daemon()函数 模拟实现daemon函数 前台进程 | 后台进程 僵尸进程 | 孤儿进程 僵尸进程的一些细节 守护进程 | 后台进程 守护…...

智能小车之蓝牙控制并测速小车、wife控制小车、4g控制小车、语音控制小车
目录 1. 蓝牙控制小车 2. 蓝牙控制并测速小车 3. wifi控制测速小车 4. 4g控制小车 5. 语音控制小车 1. 蓝牙控制小车 使用蓝牙模块,串口透传蓝牙模块,又叫做蓝牙串口模块 串口透传技术: 透传即透明传送,是指在数据的传输过…...
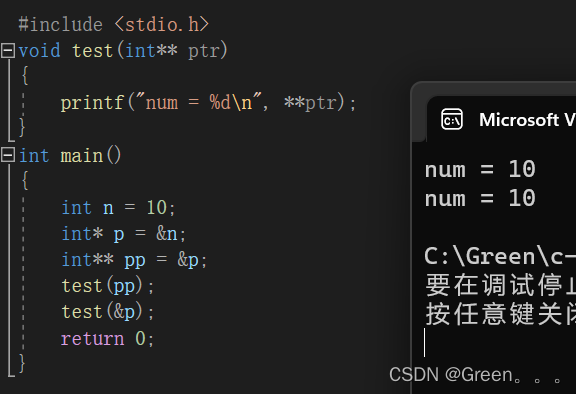
指针进阶(一)
指针进阶 1. 字符指针面试题 2. 指针数组3. 数组指针3.1 数组指针的定义3.2 &数组名VS数组名 3.3 数组指针的使用4. 数组传参和指针传参4.1 一维数组传参4.2 二维数组传参4.3 一级指针传参4.4 二级指针传参 前言 指针的主题,我们在初级阶段的《指针》章节已经接…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...
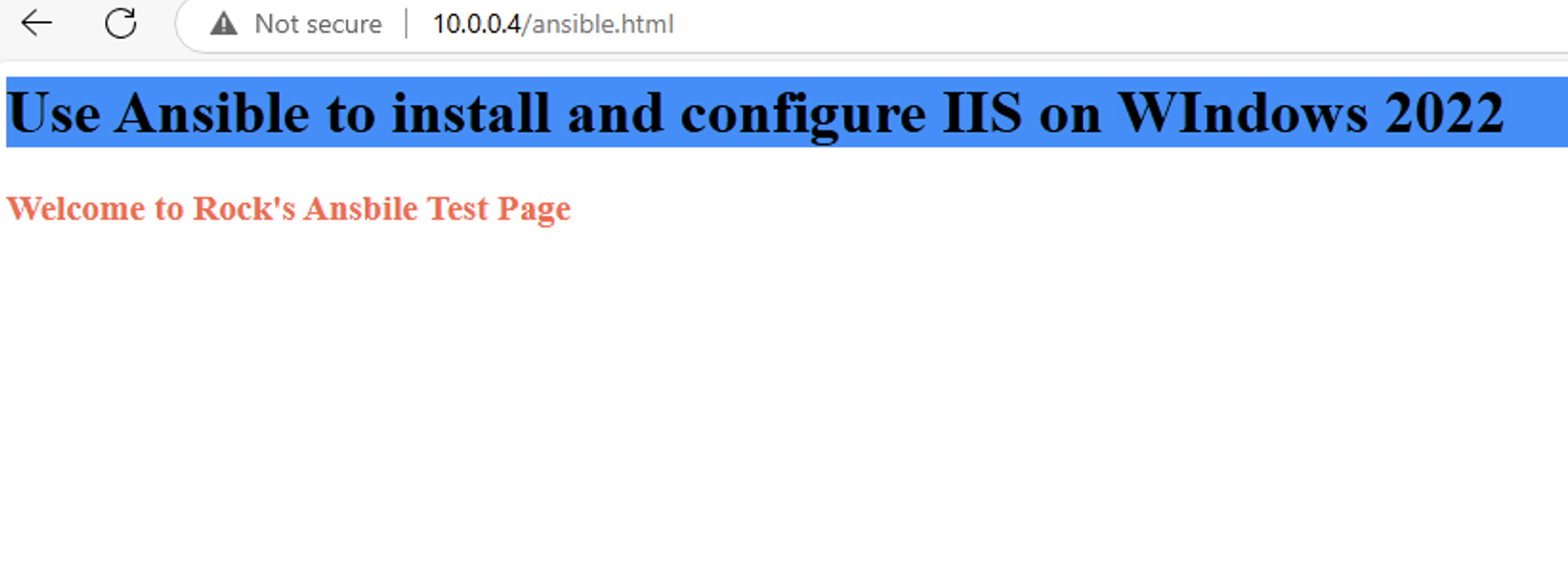
通过 Ansible 在 Windows 2022 上安装 IIS Web 服务器
拓扑结构 这是一个用于通过 Ansible 部署 IIS Web 服务器的实验室拓扑。 前提条件: 在被管理的节点上安装WinRm 准备一张自签名的证书 开放防火墙入站tcp 5985 5986端口 准备自签名证书 PS C:\Users\azureuser> $cert New-SelfSignedCertificate -DnsName &…...

水泥厂自动化升级利器:Devicenet转Modbus rtu协议转换网关
在水泥厂的生产流程中,工业自动化网关起着至关重要的作用,尤其是JH-DVN-RTU疆鸿智能Devicenet转Modbus rtu协议转换网关,为水泥厂实现高效生产与精准控制提供了有力支持。 水泥厂设备众多,其中不少设备采用Devicenet协议。Devicen…...
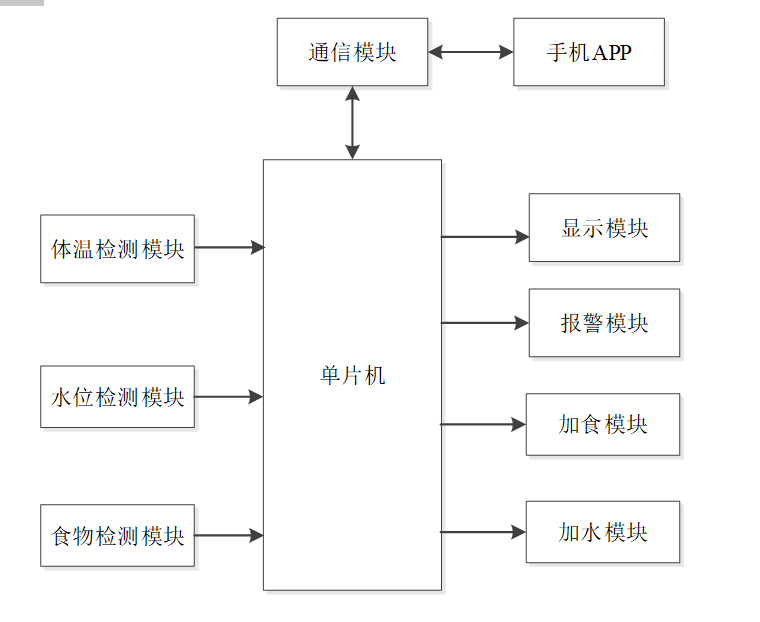
基于单片机的宠物屋智能系统设计与实现(论文+源码)
本设计基于单片机的宠物屋智能系统核心是实现对宠物生活环境及状态的智能管理。系统以单片机为中枢,连接红外测温传感器,可实时精准捕捉宠物体温变化,以便及时发现健康异常;水位检测传感器时刻监测饮用水余量,防止宠物…...
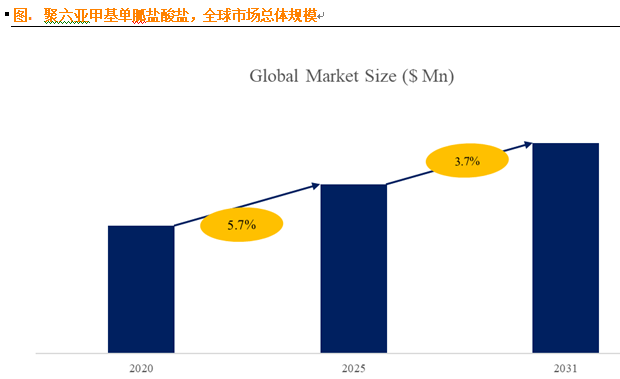
聚六亚甲基单胍盐酸盐市场深度解析:现状、挑战与机遇
根据 QYResearch 发布的市场报告显示,全球市场规模预计在 2031 年达到 9848 万美元,2025 - 2031 年期间年复合增长率(CAGR)为 3.7%。在竞争格局上,市场集中度较高,2024 年全球前十强厂商占据约 74.0% 的市场…...