Hadoop的HDFS的集群安装部署
注意:主机名不要有/_等特殊的字符,不然后面会出问题。有问题可以看看第5点(问题)。
1、下载
1.1、去官网,点下载
下载地址:https://hadoop.apache.org/
1.2、选择下载的版本
1.2.1、最新版
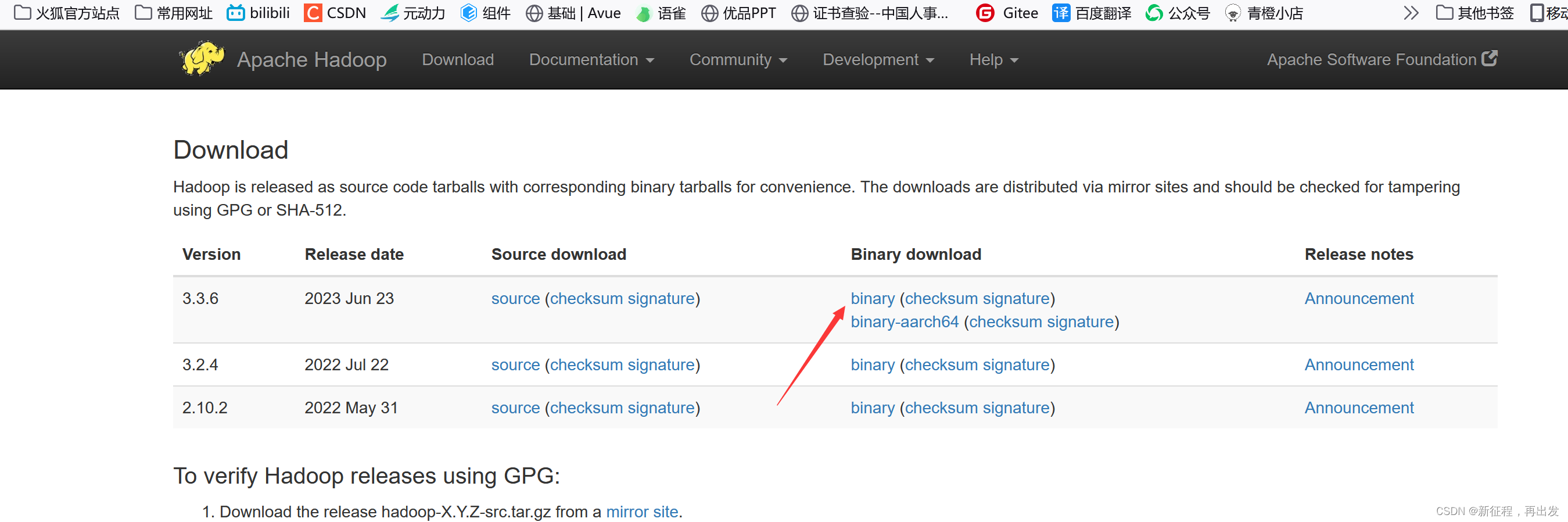
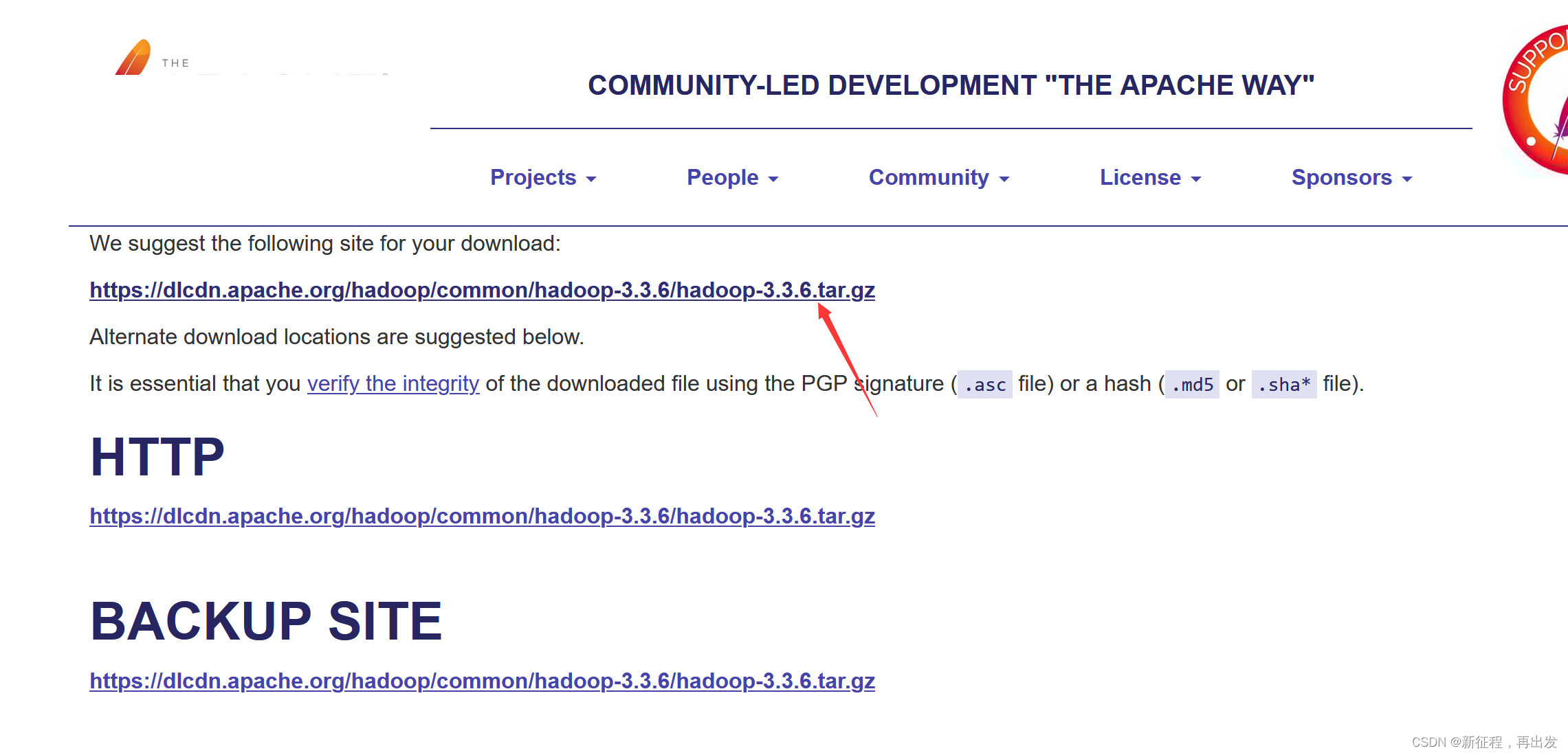
1.2.2、其他版本,我这里选择3.3.4
1.3、上传,解压
HDFS是主从模式,所以在node1节点安装即可
1.3.1、上传安装包node1节点

1.3.2、解压到/export/server下
tar -zxvf hadoop-3.3.4.tar.gz -C /export/server
1.3.3、构建软链接
ln -s /export/server/hadoop-3.3.4 hadoop

2、配置
配置HDFS集群,我们主要涉及到如下文件的修改:
- workers: 配置从节点(DataNode)有哪些
- hadoop-env.sh: 配置Hadoop的相关环境变量
- core-site.xml: Hadoop核心配置文件
- hdfs-site.xml: HDFS核心配置文件
这些文件均存在与$HADOOP_HOME/etc/hadoop文件夹中。
进入etc下的Hadoop目录
cd ./etc/hadoop
2.1、配置workers文件
2.1.1、进入Hadoop目录
cd ./etc/hadoop

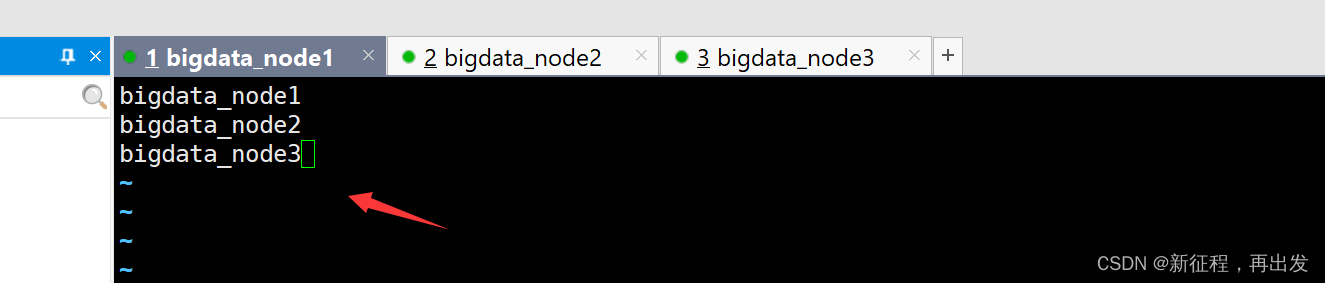
2.1.2、编辑workers文件
vim workers
配置主机名
填入的bigdata_node1,2,3是三台主机的名称
表明集群记录了三个从节点(DataNode)
2.2、配置hadoop-env.sh文件
vim hadoop-env.sh
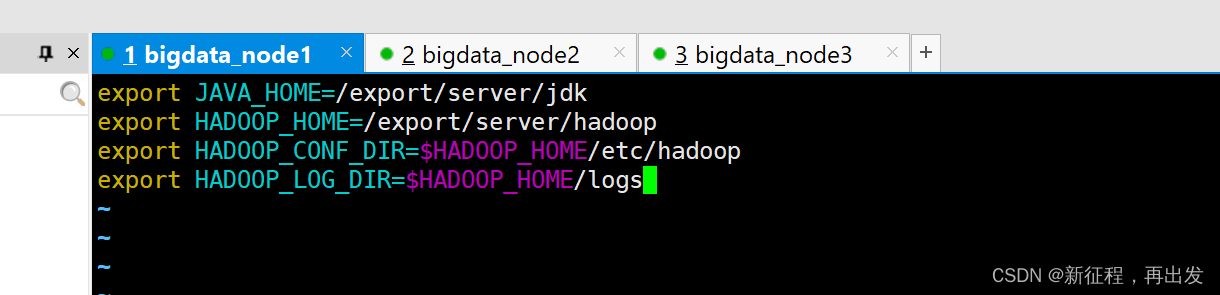
# 填入如下内容
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
- JAVA_HOME,指明JDK环境的位置在哪
- HADOOP_HOME,指明Hadoop安装位置
- HADOOP_CONF_DIR,指明Hadoop配置文件目录位置
- HADOOP_LOG_DIR,指明Hadoop运行日志目录位置
2.3、配置core-site.xml文件
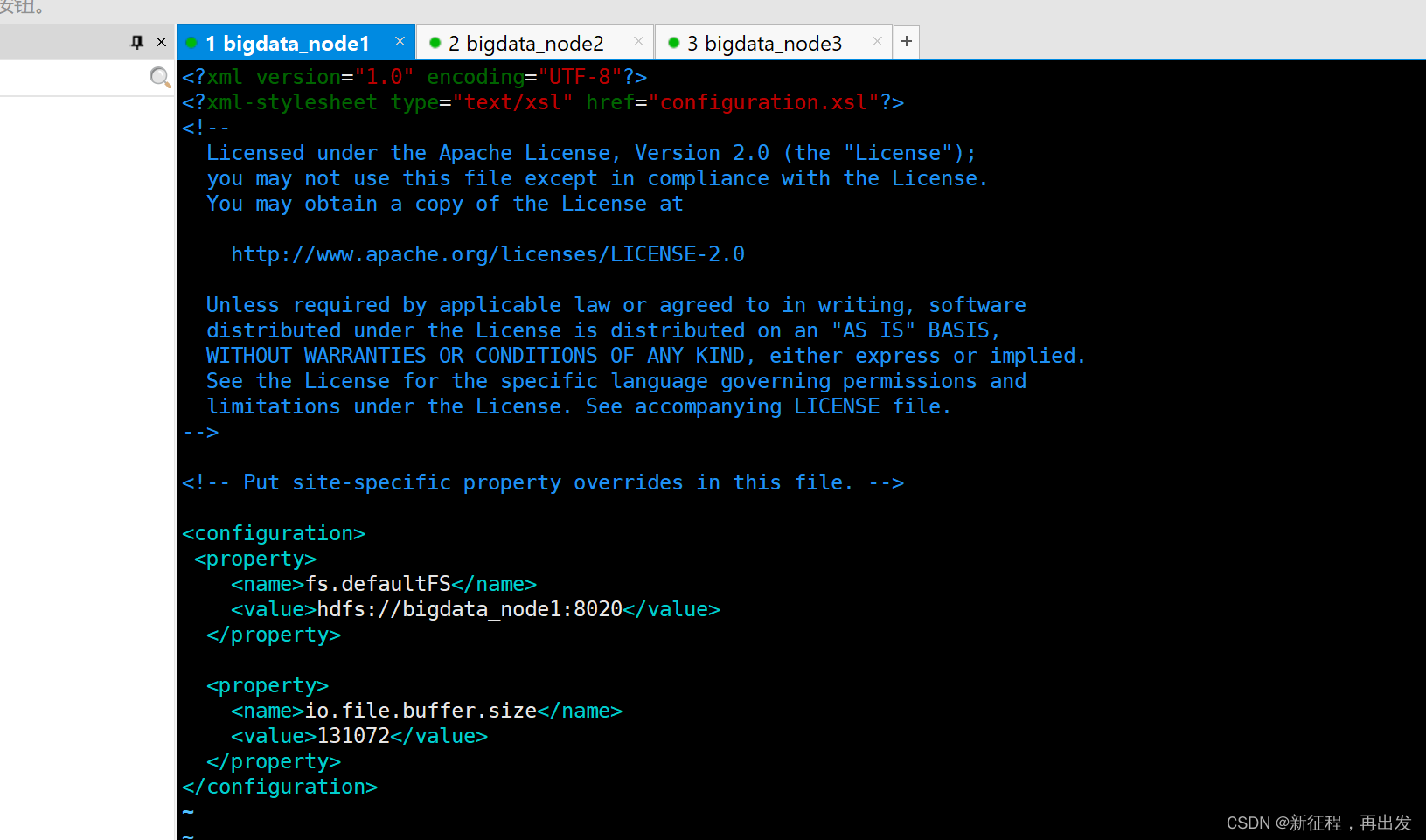
vim core-site.xml
在文件内部填入如下内容
<configuration><property><name>fs.defaultFS</name><value>hdfs://bigdata_node1:8020</value></property><property><name>io.file.buffer.size</name><value>131072</value></property>
</configuration>
-
key:fs.defaultFS
含义:HDFS文件系统的网络通讯路径 -
值:hdfs://node1:8020
协议为hdfs://
namenode为bigdata_node1
namenode通讯端口为8020 -
key:io.file.buffer.size
含义:io操作文件缓冲区大小 -
值:131072 bit
hdfs://bigdata_node1:8020为整个HDFS内部的通讯地址,应用协议为hdfs://(Hadoop内置协议)。
表明DataNode将和node1的8020端口通讯,bigdata_node1是NameNode所在机器。
此配置固定了bigdata_node1必须启动NameNode进程。
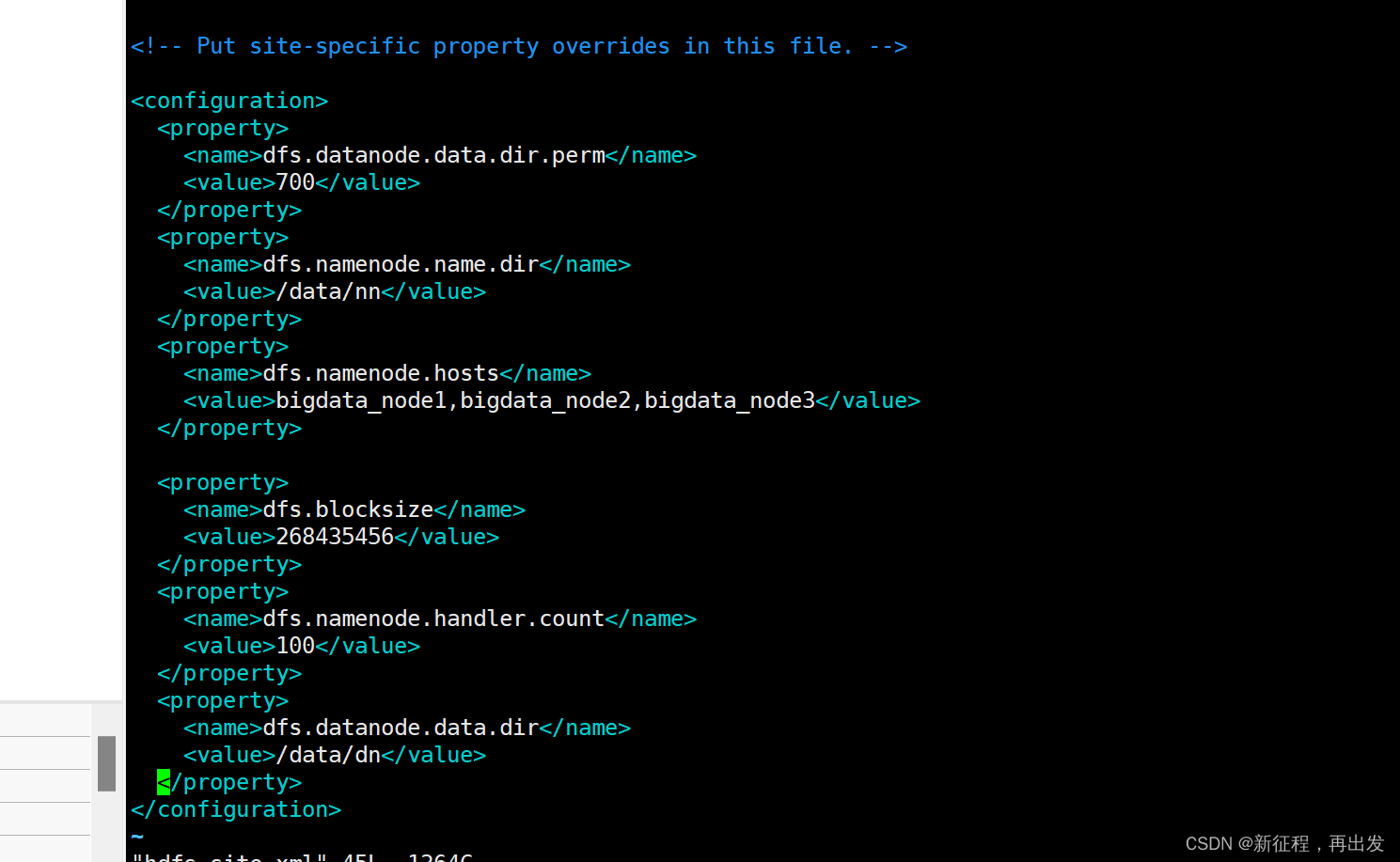
2.4、配置hdfs-site.xml文件
vim hdfs-site.xml
# 在文件内部填入如下内容
<configuration><property><name>dfs.datanode.data.dir.perm</name><value>700</value></property><property><name>dfs.namenode.name.dir</name><value>/data/nn</value></property><property><name>dfs.namenode.hosts</name><value>bigdata_node1,bigdata_node2,bigdata_node3</value></property><property><name>dfs.blocksize</name><value>268435456</value></property><property><name>dfs.namenode.handler.count</name><value>100</value></property><property><name>dfs.datanode.data.dir</name><value>/data/dn</value></property>
</configuration>
-
key:dfs.datanode.data.dir.perm
含义:hdfs文件系统,默认创建的文件权限设置 -
值:700,即:rwx------
-
key:dfs.namenode.name.dir
含义:NameNode元数据的存储位置 -
值:/data/nn,在bigdata_node1节点的/data/nn目录下
-
key:dfs.namenode.hosts
含义:NameNode允许哪几个节点的DataNode连接(即允许加入集群) -
值:bigdata_node1,bigdata_node2,bigdata_node3这三台服务器被授权
-
key:dfs.blocksize
含义:hdfs默认块大小 -
值:268435456(256MB)
-
key:dfs.namenode.handler.count
含义:namenode处理的并发线程数 -
值:100,以100个并行度处理文件系统的管理任务
-
key:dfs.datanode.data.dir
含义:从节点DataNode的数据存储目录 -
值:/data/dn,即数据存放在bigdata_node1,bigdata_node2,bigdata_node3三台机器的/data/dn内
2.5、根据下述2个配置项:


- namenode数据存放bigdata_node1的/data/nn
- datanode数据存放bigdata_node1,bigdata_node2,bigdata_node3的/data/dn
所以应该
-
在bigdata_node1节点:
mkdir -p /data/nn
mkdir -p /data/dn

-
在bigdata_node2和bigdata_node3节点:
mkdir -p /data/dn


2.6、分发Hadoop文件夹
已经基本完成Hadoop的配置操作,可以从bigdata_node1将hadoop安装文件夹远程复制到bigdata_node2、bigdata_node3。
在bigdata_node1执行如下命令
cd /export/server
scp -r hadoop-3.3.4 bigdata_node2:`pwd`/
scp -r hadoop-3.3.4 bigdata_node3:`pwd`/


2.7、为hadoop配置软链接
2.7.1、在bigdata_node2执行
ln -s /export/server/hadoop-3.3.4 /export/server/hadoop

2.7.2、在bigdata_node3执行
ln -s /export/server/hadoop-3.3.4 /export/server/hadoop

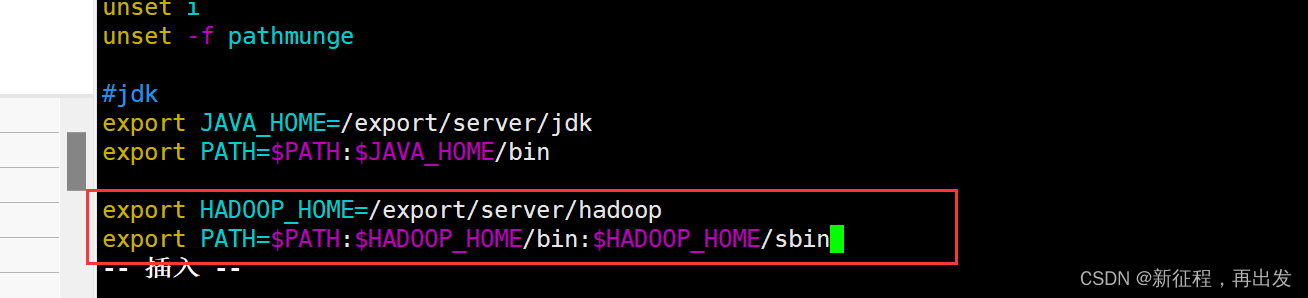
2.8、配置环境变量
2.8.1、添加配置
为了方便我们操作Hadoop,可以将Hadoop的一些脚本、程序配置到PATH中,方便后续使用。
在Hadoop文件夹中的bin、sbin两个文件夹内有许多的脚本和程序,现在来配置一下环境变量。
vim /etc/profile
在/etc/profile文件底部追加如下内容
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
2.8.2、配置生效
source /etc/profile

三台服务器都要配置。
3、授权为hadoop用户
hadoop部署的准备工作基本完成。
为了确保安全,hadoop系统不以root用户启动,我们以普通用户hadoop来启动整个Hadoop服务
所以,现在需要对文件权限进行授权。
ps:请确保已经提前创建好了hadoop用户,并配置好了hadoop用户之间的免密登录。
以root身份,在bigdata_node1、bigdata_node2、bigdata_node3三台服务器上均执行如下命令
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export
三台服务器都要。


4、格式化,启动,访问
前期准备全部完成,现在对整个文件系统执行初始化。
4.1、格式化namenode
确保以hadoop用户执行
su hadoop
格式化namenode
hadoop namenode -format



4.2、启动
一键启动hdfs集群
start-dfs.sh

一键关闭hdfs集群
stop-dfs.sh如果遇到命令未找到的错误,表明环境变量未配置好,可以以绝对路径执行
/export/server/hadoop/sbin/start-dfs.sh
/export/server/hadoop/sbin/stop-dfs.sh
4.3、访问
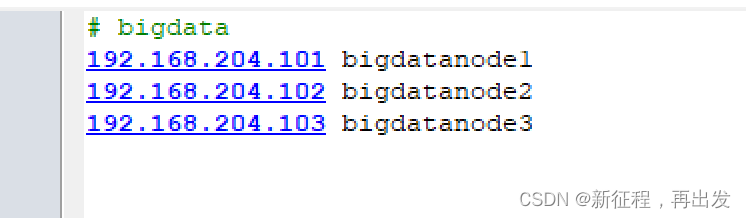
- 在本地系统配置host的文件,就可以直接使用域名访问。

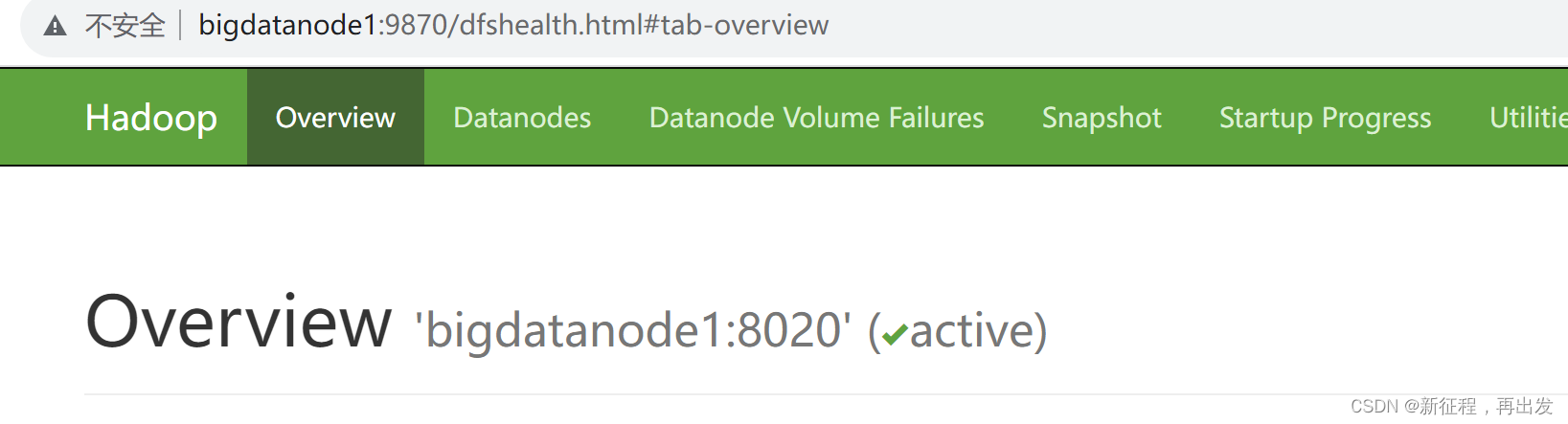
- http://bigdatanode1:9870,即可查看到hdfs文件系统的管理网页。
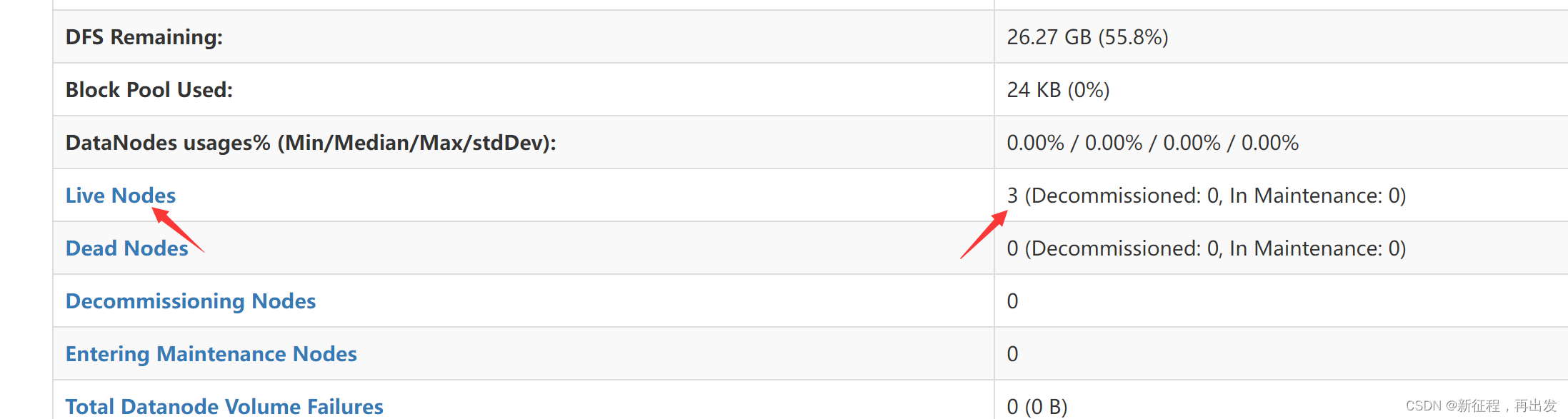
5、问题
5.1、一键启动hdfs集群后,jps查看没有启动的服务

5.2、检查日志log
java.lang.IllegalArgumentException: Does not contain a valid host:port authority: bigdata_node1:8020at org.apache.hadoop.net.NetUtils.createSocketAddr(NetUtils.java:232)at org.apache.hadoop.net.NetUtils.createSocketAddr(NetUtils.java:189)at org.apache.hadoop.net.NetUtils.createSocketAddr(NetUtils.java:169)at org.apache.hadoop.hdfs.DFSUtilClient.getNNAddress(DFSUtilClient.java:766)at org.apache.hadoop.hdfs.DFSUtilClient.getNNAddress(DFSUtilClient.java:792)at org.apache.hadoop.hdfs.DFSUtilClient.getNNAddressCheckLogical(DFSUtilClient.java:810)at org.apache.hadoop.hdfs.DFSUtilClient.getNNAddress(DFSUtilClient.java:772)at org.apache.hadoop.hdfs.server.namenode.NameNode.getRpcServerAddress(NameNode.java:578)at org.apache.hadoop.hdfs.server.namenode.NameNode.loginAsNameNodeUser(NameNode.java:718)at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:738)at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:1020)at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:995)at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1769)at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1834)
2023-09-11 00:28:53,873 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1: java.lang.IllegalArgumentException: Does not contain a valid host:port authority: bigdata_node1:8020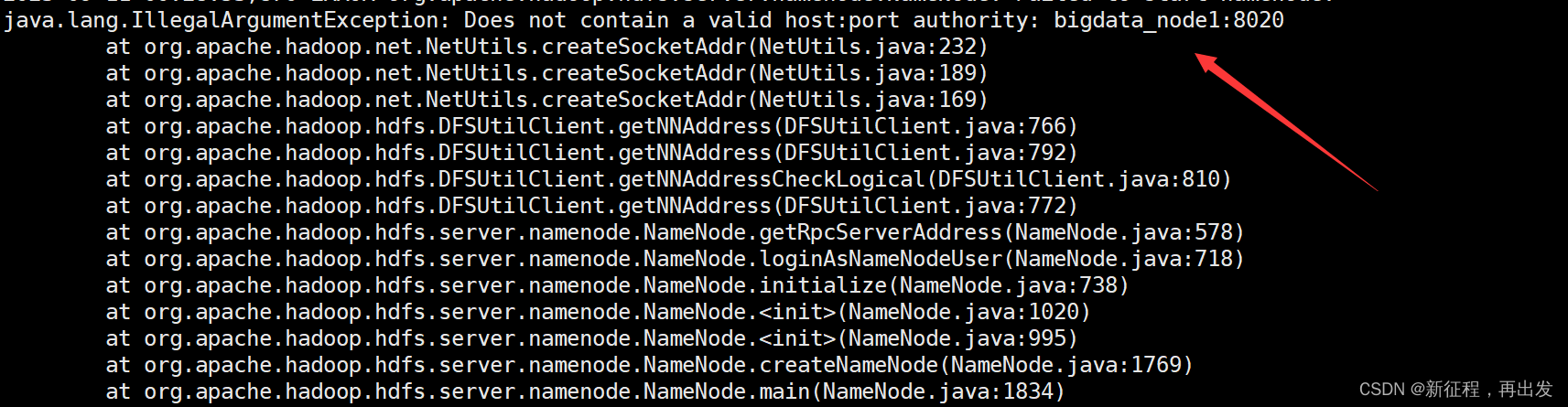
5.3、问题原因
说是我主机与端口不对
5.3.1、ping端口号
ping bigdata_node1
5.3.2、说是端口号没放开
telnet bigdata_node1 8020
5.3.3、自己的真实原因
主机使用的hostname不合法,修改为不包含着‘.’ ‘/’ '_'等非法字符的主机名。
5.3.4、修改主机名,并把之前的配置的主机名全部改了
hostnamectl set-hostname bigdatanode1
vim /etc/hosts
vim workers
vim core-site.xml
vim hdfs-site.xml
5.4、重启启动,成功
5.4.1、先格式化namenode
hadoop namenode -format
5.4.2、再启动
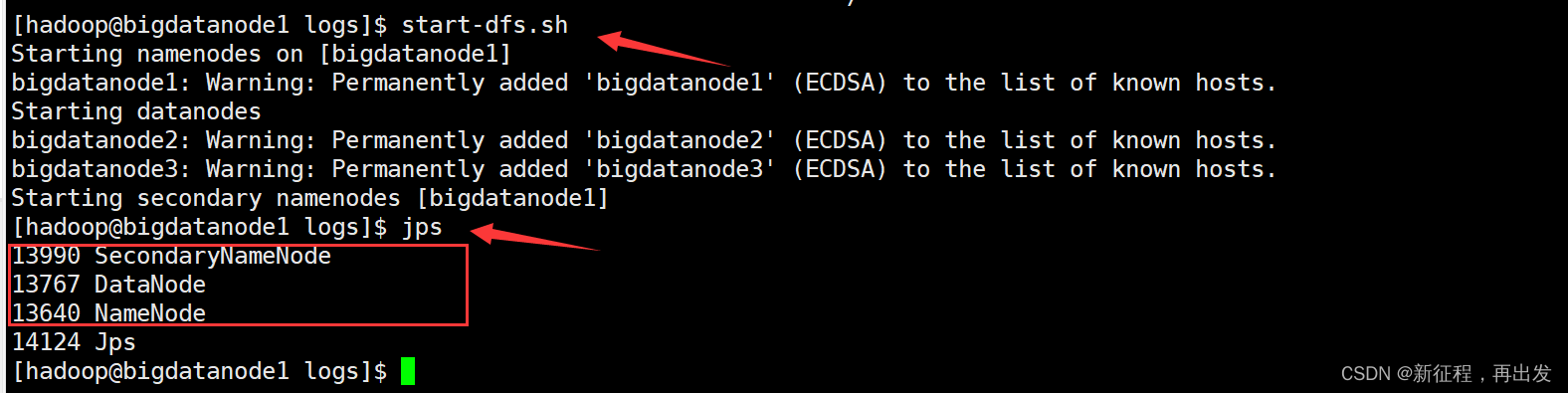


结束!!!!!!!
hy:33
为什么害怕独处?因为人在独处的时候,总是会听到心灵深处的声音。
相关文章:
Hadoop的HDFS的集群安装部署
注意:主机名不要有/_等特殊的字符,不然后面会出问题。有问题可以看看第5点(问题)。 1、下载 1.1、去官网,点下载 下载地址:https://hadoop.apache.org/ 1.2、选择下载的版本 1.2.1、最新版 1.2.2、其…...
uniapp 在 onLoad 事件中 this.$refs 娶不到的问题
现象 本人想在主页面加载的时候调用子组件的方法。示例代码如下: 运行,发现 this.$refs 取不到。如下图所示: 解决方法,把onLoad 换为 onReady 就可以了。...

常見算法時間複雜度分析
当我们进行算法分析时,通常会忽略掉常数倍数的因子和低阶项,只考虑最高阶的项。这是因为在大规模问题下,较小的项和常数倍数的因子相对于最高阶的项来说变得可以忽略不计。 以下是一些常见的示例,说明了常数倍数的因子和高阶项对…...

自学Python05-学会Python中的函数定义
亲爱的同学们,今天我们将开始学习 Python 中的函数。函数就像一个魔法盒子,可以让我们在程序中执行一段代码,并且可以反复使用。这样,我们的程序就可以变得更加简洁和易于理解。现在,让我们一起来学习如何使用函数吧&a…...
)
设计模式-组合模式(Composite)
文章目录 前言一、组合模式的概念二、组合模式的优缺点1.优点2.缺点 三、组合模式的实现总结 前言 组合模式(Composite Pattern)是一种结构型设计模式,它允许你将对象组合成树状结构以表示“整体-部分”的层次结构。组合模式使得客户端可以统…...

架构核心技术之微服务架构
小熊学Java:https://www.javaxiaobear.cn/,文末有免费资源 本文我们来学习微服务的架构设计 主要包括如下内容。 单体系统的困难:编译部署困难、数据库连接耗尽、服务复用困难、新增业务困难。 微服务框架:Dubbo 和 Spring Clou…...
SQL Server2022版+SSMS安装教程(保姆级)
SQL Server2022版SSMS安装教程(保姆级) 一,安装SQL Server数据库 1.下载安装包 (1)百度网盘下载安装包 链接:https://pan.baidu.com/s/1A-WRVES4EGv8EVArGNF2QQ?pwd6uvs 提取码:6uvs &…...
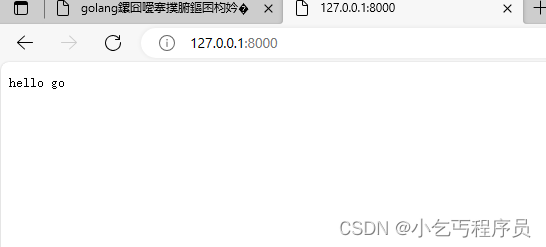
go语言基础---8
Http请求报文格式分析 package mainimport ("fmt""net" )func main() {//监听listener, err : net.Listen("tcp", ":8000")if err ! nil {fmt.Println("listener err", err)return}defer listener.Close()//阻塞等待用户的…...

Oracle的 dblink 学习笔记
文章目录 一、基础环境二、适用场景三、过程和方法四、参考资料 版权声明:本文为CSDN博主「杨群」的原创文章,遵循 CC 4.0 BY-SA版权协议,于2023年9月10日首发于CSDN,转载请附上原文出处链接及本声明。 原文链接:http…...

任意文件上传
1.任意文件上传概述 1.1 漏洞成因 服务器配置不当,开启了PUT 方法。 Web 应用开放了文件上传功能,没有对上传的文件做足够的限制和过滤。在程序开发部署时,没有考虑以下因素,导致限制被绕过: 代码特性 组件漏洞&am…...

【Unity3D】UI Toolkit自定义元素
1 前言 UI Toolkit 支持通过继承 VisualElement 实现自定义元素,便于通过脚本控制元素。另外,UI Toolkit 也支持将一个容器及其所有子元素作为一个模板,便于通过脚本复制模板。 如果读者对 UI Toolkit 不是太了解,可以参考以下内容…...
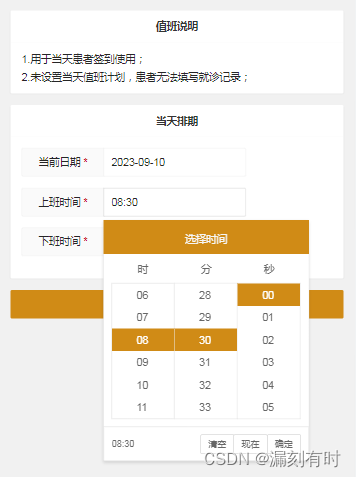
layui手机端使用laydate时间选择器被输入法遮挡的解决方案
在HTML中,你可以使用input元素的readonly属性来禁止用户输入,但是这将完全禁用输入,而不仅仅是禁止弹出输入法。如果你想允许用户在特定条件下输入,你可以使用JavaScript来动态地切换readonly属性。 readonly属性 增加readonly属…...

MVSNet CVPR-2018 学习总结笔记 译文 深度学习三维重建
文章目录 2 MVSNet CVPR-20182.0 主要特点2.1 过程2.2 MVSNet主要贡献2.3 论文简介2.3.1 深度特征提取2.3.2 构造匹配代价2.3.3 代价累计2.3.4 深度估计2.3.5 深度图优化2.4 MVSNet(pytorch版本)2 MVSNet CVPR-2018 MVSNet (pytorch版) 代码注释版 下载 (注释非常详细,代码…...
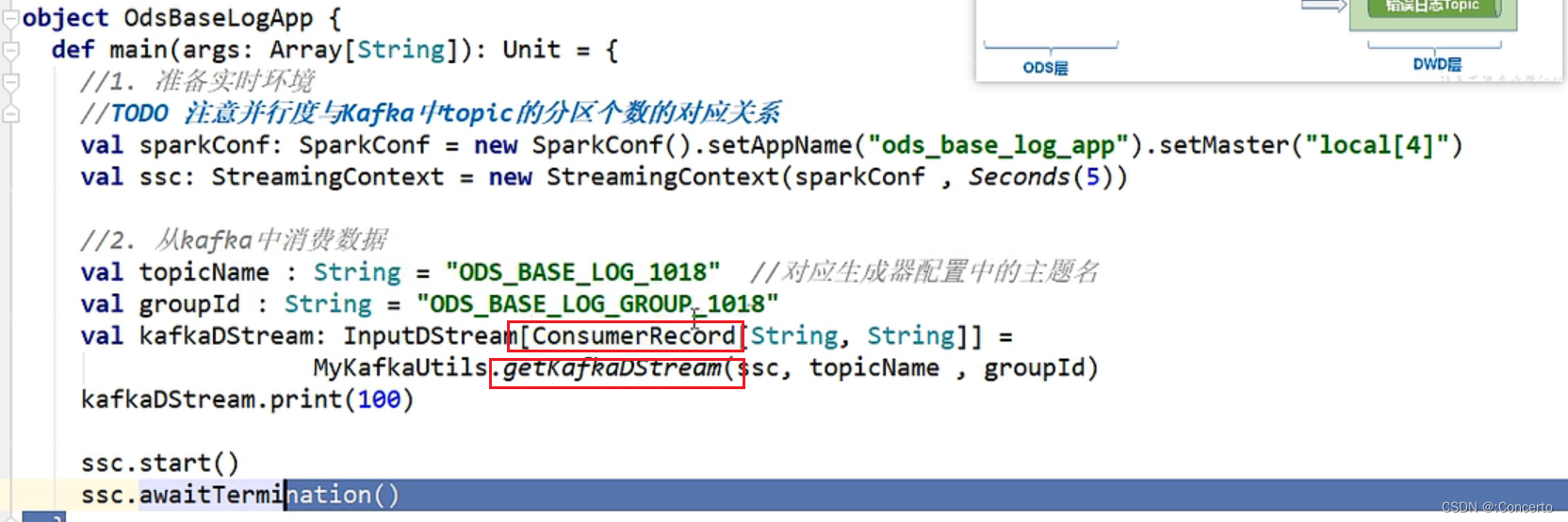
Kafka/Spark-01消费topic到写出到topic
1 Kafka的工具类 1.1 从kafka消费数据的方法 消费者代码 def getKafkaDStream(ssc : StreamingContext , topic: String , groupId:String ) {consumerConfigs.put(ConsumerConfig.GROUP_ID_CONFIG , groupId)val kafkaDStream: InputDStream[ConsumerRecord[String, Strin…...
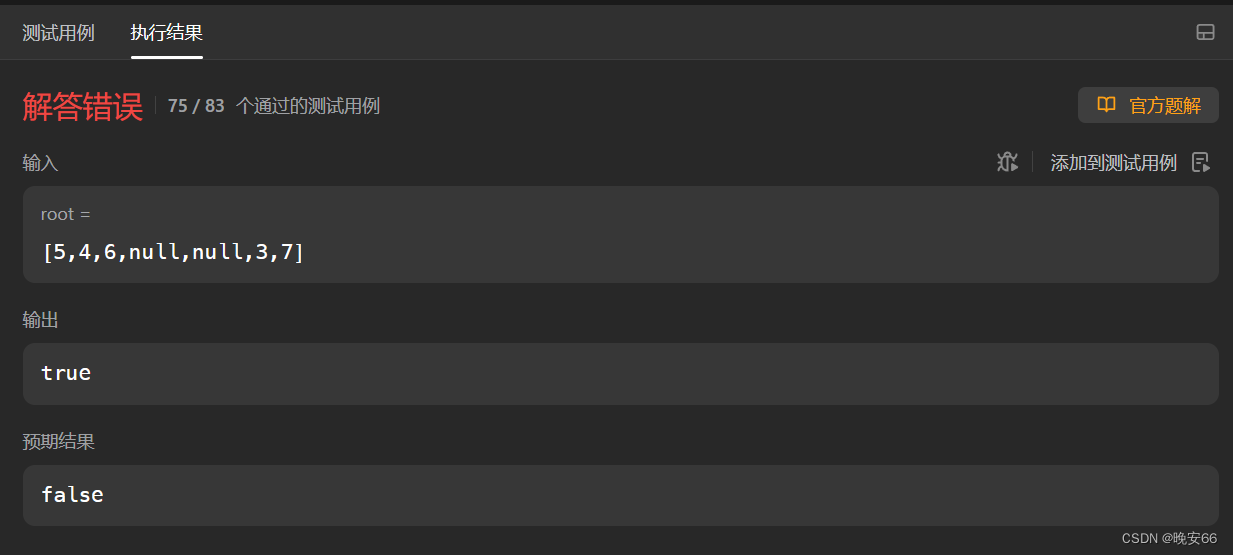
【算法与数据结构】98、LeetCode验证二叉搜索树
文章目录 一、题目二、解法三、完整代码 所有的LeetCode题解索引,可以看这篇文章——【算法和数据结构】LeetCode题解。 一、题目 二、解法 思路分析:注意不要落入下面你的陷阱,笔者本来想左节点键值<中间节点键值<右节点键值即可&…...
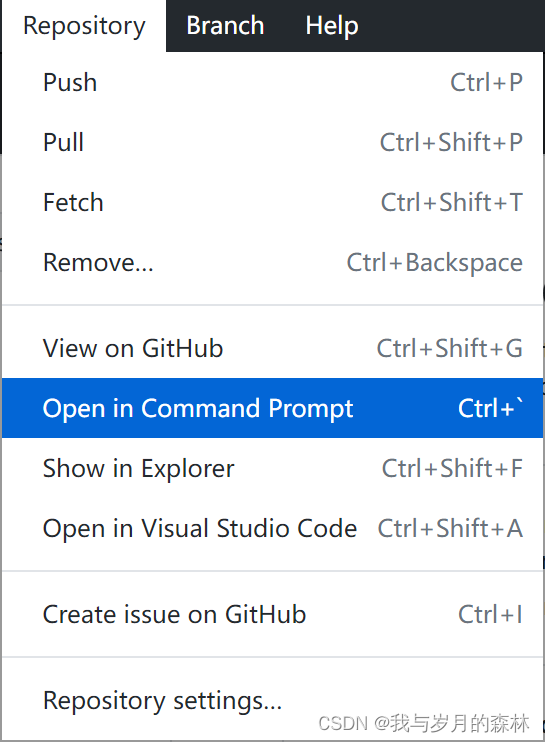
关于GitHub Desktop中的“Open in Git Bash”无法使用的问题
问题描述 在GitHub Desktop中选择Repository--Open in Git Bash(如图1),出现如图2所示结果。 图1 图2 解决办法(Windows10) 这个问题是由于Git的环境变量没有得到正确配置所导致的,所以需要正确设置环境变量…...

使用DeepSpeed加速大型模型训练(二)
使用DeepSpeed加速大型模型训练 在这篇文章中,我们将了解如何利用Accelerate库来训练大型模型,从而使用户能够利用DeeSpeed的 ZeRO 功能。 简介 尝试训练大型模型时是否厌倦了内存不足 (OOM) 错误?我们已经为您提供了保障。大型模型性能非…...

ASP.net web应用 GridView控件常用方法
GridView 控件是 ASP.NET Web Forms 中常用的数据展示控件之一。它提供了一个网格形式的表格,用于显示和编辑数据。GridView 控件对于包含大量数据、需要进行分页、排序和筛选的情况非常有用。 GridView 控件的主要特性包括: 数据绑定:GridV…...

MATLAB入门一基础知识
MATLAB入门一基础知识 此篇为课程学习笔记 链接: link 什么是MATLAB 平时所说的MATLAB既是一款软件又是一种编程语言,只是这种高级解释性语言是在配套的软件下进行开发的 MATLAB的一个特性 MATLAB的一个特性,如果一条语句以英文分号‘;’结尾&…...

SpringMVC实现文件上传和下载功能
文件下载 ResponseEntity用于控制器方法的返回值类型,该控制器方法的返回值就是响应到浏览器的响应报文。具体步骤如下: 获取下载文件的位置;创建流,读取文件;设置响应信息,包括响应头,响应体以…...

初识Git,带你深入学习Git相关的知识
在之前的博客中,我都会在博客的开头放一个gitee的链接。Gitee是什么呢?它是一个远程的代码托管库。在我们学习和项目管理的时候起着非常重要的作用。 本期我就带领着大家一起学习Git相关的知识内容。学习它的操作,了解其在企业级开发中的作用…...

TTI-Chicago等机构突破性研究:AI学会了一笔一划创作矢量草图
这项由芝加哥丰田技术研究院(TTI-Chicago)、芝加哥大学和麻省理工学院联合开展的研究发表于2026年,论文编号为arXiv:2603.19500v1。有兴趣深入了解技术细节的读者可以通过该编号查询完整论文。当我们看到一位画家创作时,他们通常不…...

MiniCPM-V-2_6嵌入式AI应用实战:STM32F103C8T6边缘推理集成
MiniCPM-V-2_6嵌入式AI应用实战:STM32F103C8T6边缘推理集成 最近几年,AI模型越来越“小”,开始往各种硬件设备里钻。你可能听说过在手机、树莓派上跑AI,但有没有想过,在一块只有指甲盖大小、主频72MHz、内存才20KB的S…...
LumiPixel开箱即用教程:快速上手这个专为人像设计的AI创作平台
LumiPixel开箱即用教程:快速上手这个专为人像设计的AI创作平台 1. 认识LumiPixel:纯净人像创作平台 LumiPixel: Canvas Quest是一款专注于人像创作的AI视觉平台,它将先进的Z-Image扩散模型与复古像素艺术美学完美结合。这个平台特别适合需要…...

无人值守智能图书借阅系统 Java 后端开发实战
在无人值守智能图书借阅系统的Java后端开发实战中,需围绕系统架构设计、核心功能实现、关键技术选型及部署优化等核心环节展开,以下为具体开发方案:一、系统架构设计分层架构体系:采用经典的四层架构设计,包括表现层、…...

GLM-Image技术验证:长宽比对构图影响实测数据
GLM-Image技术验证:长宽比对构图影响实测数据 1. 项目背景介绍 GLM-Image是由智谱AI开发的先进文本到图像生成模型,提供了一个美观易用的Web交互界面。这个界面基于Gradio构建,让用户能够轻松使用GLM-Image模型生成高质量的AI图像。 在实际…...

Z-Image-Turbo商业应用探索:稳定可靠的AI绘画方案推荐
Z-Image-Turbo商业应用探索:稳定可靠的AI绘画方案推荐 1. 商业级AI绘画的新选择 在数字内容创作需求爆炸式增长的今天,Z-Image-Turbo作为阿里通义实验室开源的文生图模型,凭借其卓越的稳定性和高效性,正在成为商业应用领域的新宠…...

高效一键构建:DoL-Lyra整合包的智能自动化构建系统解析
高效一键构建:DoL-Lyra整合包的智能自动化构建系统解析 【免费下载链接】DOL-CHS-MODS Degrees of Lewdity 整合 项目地址: https://gitcode.com/gh_mirrors/do/DOL-CHS-MODS 还在为Degrees of Lewdity游戏的美化整合包配置而烦恼吗?您是否曾因手…...

祝贺电影《得闲谨制》荣获2026亚洲艺术电影节 六项提名
电影《得闲谨制》荣获2026亚洲艺术电影节「金海燕奖」主竞赛单元六项提名: 祝贺导演孔笙 提名最佳导演; 祝贺编剧伍千万里四十八 提名最佳编剧; 祝贺演员肖战 提名最佳男主角; 祝贺演员尹正 提名最佳男配角; 祝贺美术指…...

AI动画创作新范式:Krita插件驱动的动态视觉叙事解决方案
AI动画创作新范式:Krita插件驱动的动态视觉叙事解决方案 【免费下载链接】krita-ai-diffusion Streamlined interface for generating images with AI in Krita. Inpaint and outpaint with optional text prompt, no tweaking required. 项目地址: https://gitco…...