使用DeepSpeed加速大型模型训练(二)
使用DeepSpeed加速大型模型训练
在这篇文章中,我们将了解如何利用Accelerate库来训练大型模型,从而使用户能够利用DeeSpeed的 ZeRO 功能。
简介
尝试训练大型模型时是否厌倦了内存不足 (OOM) 错误?我们已经为您提供了保障。大型模型性能非常好[1],但很难使用可用的硬件进行训练。为了充分利用可用硬件来训练大型模型,可以使用 ZeRO(零冗余优化器)[2] 来利用数据并行性。
下面是使用 ZeRO 的数据并行性的简短描述以及此博客文章中的图表
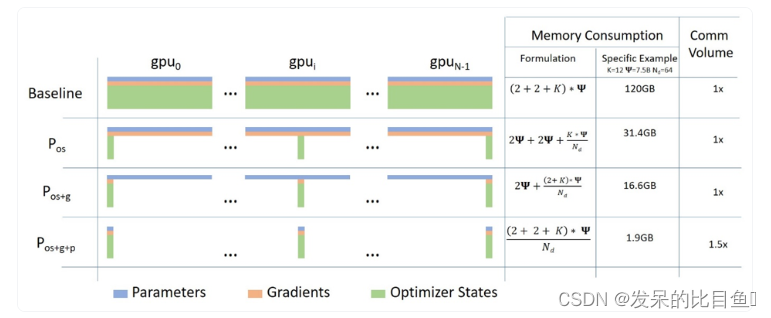
a. 第 1 阶段:分片优化器状态跨数据并行工作器/GPUs的状态
b. 第 2 阶段:分片优化器状态+梯度跨数据并行工作器/GPUs
c. 第 3 阶段:分片优化器状态+梯度+模型参数跨数据并行工作器/GPUs
d. 优化器卸载(Optimizer Offload):将梯度+优化器状态卸载到ZERO Stage 2之上的CPU/磁盘构建
e. 参数卸载(Param Offload):将模型参数卸载到ZERO Stage 3之上的CPU/磁盘构建
在这篇博文中,我们将看看如何使用ZeRO和Accelerate来利用数据并行性。DeepSpeed, FairScale和PyTorch fullyshardeddataparlparallel (FSDP)实现了ZERO论文的核心思想。伴随博客,通过DeepSpeed和FairScale 使用ZeRO适应更多和训练更快[4]和使用PyTorch完全分片并行数据加速大型模型训练[5], 这些已经集成在transformer Trainer和accelerate中。背后的解释可以看这些博客,主要集中在使用Accelerate来利用DeepSpeed ZeRO。
Accelerate :利用DeepSpeed ZeRO没有任何代码的变化
我们将研究只微调编码器模型用于文本分类的任务。我们将使用预训练microsoft/deberta-v2-xlarge-mnli (900M params) 用于对MRPC GLUE数据集进行微调。
代码可以在这里找到 run_cls_no_trainer.py它类似于这里的官方文本分类示例,只是增加了计算训练和验证时间的逻辑。让我们比较分布式数据并行(DDP)和DeepSpeed ZeRO Stage-2在多gpu设置中的性能。
要启用DeepSpeed ZeRO Stage-2而无需任何代码更改,请运行加速配置并利用 Accelerate DeepSpeed Plugin
ZeRO Stage-2 DeepSpeed Plugin 示例
配置
compute_environment: LOCAL_MACHINE
deepspeed_config:gradient_accumulation_steps: 1gradient_clipping: 1.0offload_optimizer_device: noneoffload_param_device: nonezero3_init_flag: falsezero_stage: 2
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false现在,运行下面的命令进行训练
accelerate launch run_cls_no_trainer.py \--model_name_or_path "microsoft/deberta-v2-xlarge-mnli" \--task_name "mrpc" \--ignore_mismatched_sizes \--max_length 128 \--per_device_train_batch_size 40 \--learning_rate 2e-5 \--num_train_epochs 3 \--output_dir "/tmp/mrpc/deepspeed_stage2/" \--with_tracking \--report_to "wandb" \在我们的单节点多gpu设置中,DDP支持的无OOM错误的最大批处理大小是8。相比之下,DeepSpeed Zero-Stage 2允许批量大小为40,而不会出现OOM错误。因此,与DDP相比,DeepSpeed使每个GPU能够容纳5倍以上的数据。下面是wandb运行的图表快照,以及比较DDP和DeepSpeed的基准测试表。


表1:DeepSpeed ZeRO Stage-2在DeBERTa-XL (900M)模型上的基准测试
使用更大的批处理大小,我们观察到总训练时间加快了3.5倍,而性能指标没有下降,所有这些都没有改变任何代码。
为了能够调整更多选项,您将需要使用DeepSpeed配置文件和最小的代码更改。我们来看看怎么做。
Accelerate :利用 DeepSpeed 配置文件调整更多选项
首先,我们将研究微调序列到序列模型以训练我们自己的聊天机器人的任务。具体来说,我们将facebook/blenderbot-400M-distill在smangrul/MuDoConv(多域对话)数据集上进行微调。该数据集包含来自 10 个不同数据源的对话,涵盖角色、基于特定情感背景、目标导向(例如餐厅预订)和一般维基百科主题(例如板球)。
代码可以在这里找到run_seq2seq_no_trainer.py。目前有效衡量聊天机器人的参与度和人性化的做法是通过人工评估,这是昂贵的[6]。对于本例,跟踪的指标是BLEU分数(这不是理想的,但却是此类任务的常规指标)。如果您可以访问支持bfloat16精度的gpu,则可以调整代码以训练更大的T5模型,否则您将遇到NaN损失值。我们将在10000个训练样本和1000个评估样本上运行一个快速基准测试,因为我们对DeepSpeed和DDP感兴趣。我们将利用DeepSpeed Zero Stage-2 配置 zero2_config_accelerate.json(如下所示)进行训练。有关各种配置特性的详细信息,请参阅DeeSpeed文档。
{"fp16": {"enabled": "true","loss_scale": 0,"loss_scale_window": 1000,"initial_scale_power": 15,"hysteresis": 2,"min_loss_scale": 1},"optimizer": {"type": "AdamW","params": {"lr": "auto","weight_decay": "auto","torch_adam": true,"adam_w_mode": true}},"scheduler": {"type": "WarmupDecayLR","params": {"warmup_min_lr": "auto","warmup_max_lr": "auto","warmup_num_steps": "auto","total_num_steps": "auto"}},"zero_optimization": {"stage": 2,"allgather_partitions": true,"allgather_bucket_size": 2e8,"overlap_comm": true,"reduce_scatter": true,"reduce_bucket_size": 2e8,"contiguous_gradients": true},"gradient_accumulation_steps": 1,"gradient_clipping": "auto","steps_per_print": 2000,"train_batch_size": "auto","train_micro_batch_size_per_gpu": "auto","wall_clock_breakdown": false
}要使用上述配置启用DeepSpeed ZeRO Stage-2,请运行accelerate config并提供配置文件路径。更多详细信息,请参考accelerate官方文档中的DeepSpeed配置文件。
ZeRO Stage-2 DeepSpeed配置文件示例
compute_environment: LOCAL_MACHINE
deepspeed_config:deepspeed_config_file: /path/to/zero2_config_accelerate.jsonzero3_init_flag: false
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false现在,运行下面的命令进行训练
accelerate launch run_seq2seq_no_trainer.py \--dataset_name "smangrul/MuDoConv" \--max_source_length 128 \--source_prefix "chatbot: " \--max_target_length 64 \--val_max_target_length 64 \--val_min_target_length 20 \--n_val_batch_generations 5 \--n_train 10000 \--n_val 1000 \--pad_to_max_length \--num_beams 10 \--model_name_or_path "facebook/blenderbot-400M-distill" \--per_device_train_batch_size 200 \--per_device_eval_batch_size 100 \--learning_rate 1e-6 \--weight_decay 0.0 \--num_train_epochs 1 \--gradient_accumulation_steps 1 \--num_warmup_steps 100 \--output_dir "/tmp/deepspeed_zero_stage2_accelerate_test" \--seed 25 \--logging_steps 100 \--with_tracking \--report_to "wandb" \--report_name "blenderbot_400M_finetuning"当使用DeepSpeed配置时,如果用户在配置中指定了优化器和调度器,用户将不得不使用accelerate.utils.DummyOptim和accelerate.utils.DummyScheduler。这些都是用户需要做的小改动。下面我们展示了使用DeepSpeed配置时所需的最小更改的示例
- optimizer = torch.optim.Adam(optimizer_grouped_parameters, lr=args.learning_rate)
+ optimizer = accelerate.utils.DummyOptim(optimizer_grouped_parameters, lr=args.learning_rate)- lr_scheduler = get_scheduler(
- name=args.lr_scheduler_type,
- optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps,
- num_training_steps=args.max_train_steps,
- )+ lr_scheduler = accelerate.utils.DummyScheduler(
+ optimizer, total_num_steps=args.max_train_steps, warmup_num_steps=args.num_warmup_steps
+ )

表2:DeepSpeed ZeRO Stage-2在BlenderBot (400M)模型上的基准测试
在我们的单节点多gpu设置中,DDP支持的无OOM错误的最大批处理大小是100。相比之下,DeepSpeed Zero-Stage 2允许批量大小为200,而不会出现OOM错误。因此,与DDP相比,DeepSpeed使每个GPU能够容纳2倍以上的数据。我们观察到训练加速了1.44倍,评估加速了1.23倍,因为我们能够在相同的可用硬件上容纳更多的数据。由于这个模型是中等大小,加速不是那么令人兴奋,但这将改善与更大的模型。你可以和使用Space smangrul/Chat-E上的全部数据训练的聊天机器人聊天。你可以给机器人一个角色,一个特定情感的对话,用于目标导向的任务或自由流动的方式。下面是与聊天机器人的有趣对话。您可以在这里找到使用不同上下文的更多对话的快照。

CPU/磁盘卸载,使训练庞大的模型将不适合GPU内存
在单个24GB NVIDIA Titan RTX GPU上,即使批量大小为1,也无法训练GPT-XL模型(1.5B参数)。我们将看看如何使用DeepSpeed ZeRO Stage-3与CPU卸载优化器状态,梯度和参数来训练GPT-XL模型。
我们将利用DeepSpeed Zero Stage-3 CPU卸载配置zero3_offload_config_accelerate.json (如下所示)进行训练。
{"fp16": {"enabled": true,"loss_scale": 0,"loss_scale_window": 1000,"initial_scale_power": 16,"hysteresis": 2,"min_loss_scale": 1},"optimizer": {"type": "AdamW","params": {"lr": "auto","weight_decay": "auto"}},"scheduler": {"type": "WarmupDecayLR","params": {"warmup_min_lr": "auto","warmup_max_lr": "auto","warmup_num_steps": "auto","total_num_steps": "auto"}},"zero_optimization": {"stage": 3,"offload_optimizer": {"device": "cpu","pin_memory": true},"offload_param": {"device": "cpu","pin_memory": true},"overlap_comm": true,"contiguous_gradients": true,"reduce_bucket_size": "auto","stage3_prefetch_bucket_size": "auto","stage3_param_persistence_threshold": "auto","sub_group_size": 1e9,"stage3_max_live_parameters": 1e9,"stage3_max_reuse_distance": 1e9,"stage3_gather_16bit_weights_on_model_save": true},"gradient_accumulation_steps": 1,"gradient_clipping": "auto","steps_per_print": 2000,"train_batch_size": "auto","train_micro_batch_size_per_gpu": "auto","wall_clock_breakdown": false
}ZeRO Stage-3 CPU Offload DeepSpeed配置文件示例
compute_environment: LOCAL_MACHINE
deepspeed_config:deepspeed_config_file: /path/to/zero3_offload_config_accelerate.jsonzero3_init_flag: true
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false现在,运行下面的命令进行训练

表3:在GPT-XL (1.5B)模型上对DeepSpeed ZeRO Stage-3 CPU Offload进行基准测试
即使批大小为1,DDP也会导致OOM错误。另一方面,使用DeepSpeed ZeRO Stage-3 CPU卸载,我们可以以16个batch_size大小进行训练。
最后,请记住,Accelerate只集成了DeepSpeed,因此,如果您对DeepSpeed的使用有任何问题或疑问,请向DeepSpeed GitHub提交问题。
相关文章:
使用DeepSpeed加速大型模型训练(二)
使用DeepSpeed加速大型模型训练 在这篇文章中,我们将了解如何利用Accelerate库来训练大型模型,从而使用户能够利用DeeSpeed的 ZeRO 功能。 简介 尝试训练大型模型时是否厌倦了内存不足 (OOM) 错误?我们已经为您提供了保障。大型模型性能非…...

ASP.net web应用 GridView控件常用方法
GridView 控件是 ASP.NET Web Forms 中常用的数据展示控件之一。它提供了一个网格形式的表格,用于显示和编辑数据。GridView 控件对于包含大量数据、需要进行分页、排序和筛选的情况非常有用。 GridView 控件的主要特性包括: 数据绑定:GridV…...

MATLAB入门一基础知识
MATLAB入门一基础知识 此篇为课程学习笔记 链接: link 什么是MATLAB 平时所说的MATLAB既是一款软件又是一种编程语言,只是这种高级解释性语言是在配套的软件下进行开发的 MATLAB的一个特性 MATLAB的一个特性,如果一条语句以英文分号‘;’结尾&…...

SpringMVC实现文件上传和下载功能
文件下载 ResponseEntity用于控制器方法的返回值类型,该控制器方法的返回值就是响应到浏览器的响应报文。具体步骤如下: 获取下载文件的位置;创建流,读取文件;设置响应信息,包括响应头,响应体以…...
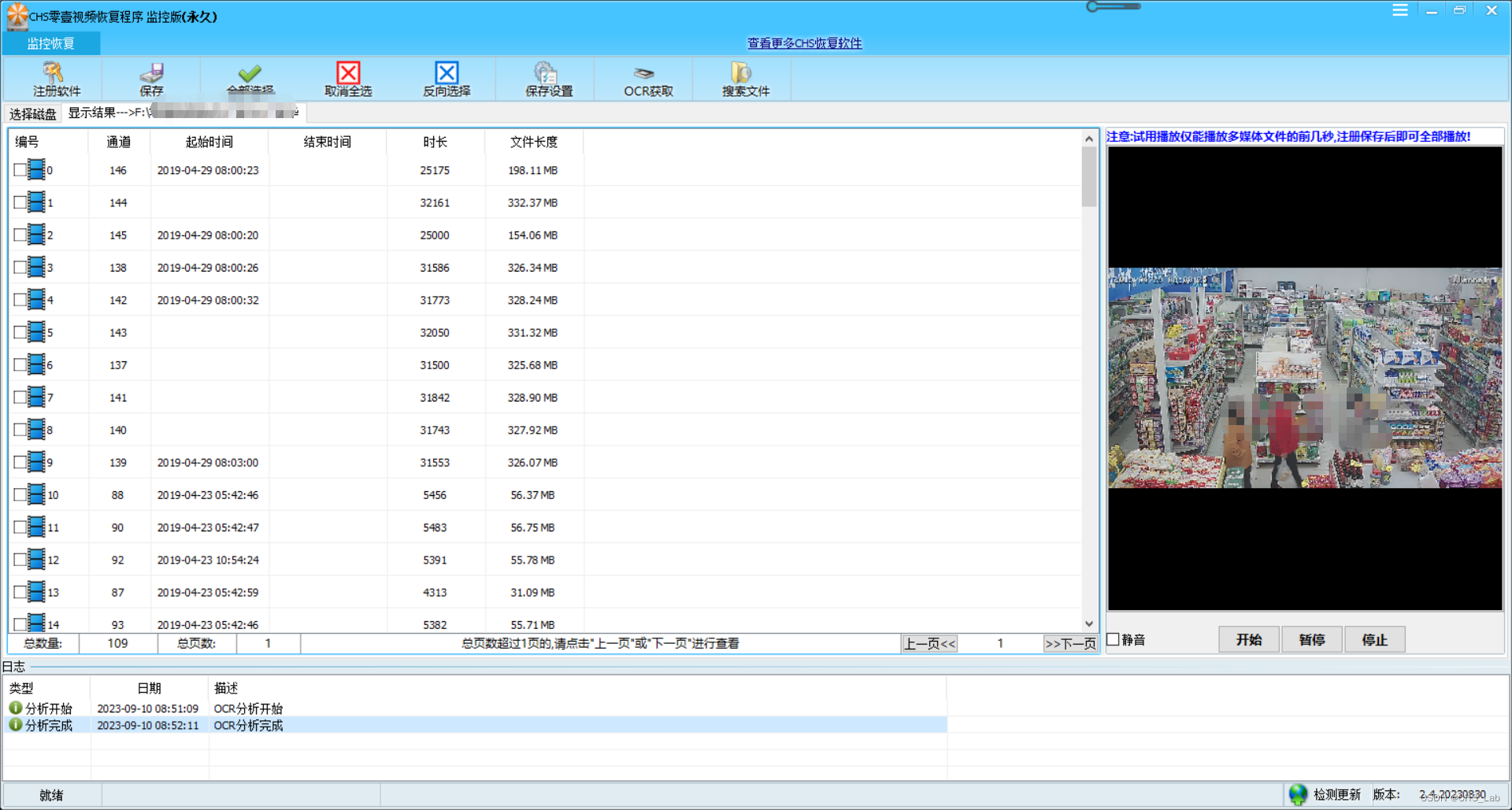
CHS零壹视频恢复程序OCR使用方法
目前CHS零壹视频恢复程序监控版、专业版、高级版已经支持了OCR,OCR是一种光学识别系统,通俗说就和扫描仪带的OCR软件一样的原理: 分析照片->OCR获取字符串->整理字符串->输出 使用方法如下(以CHS零壹视频恢复程序监控版…...

云备份——服务端客户端联合测试
一,准备工作 服务端清空备份文件信息、备份文件夹、压缩文件夹 客户端清空备份文件夹 二,开始测试 服务端配置文件 先启动服务端和客户端 向客户端指定文件夹放入稍微大点的文件,方便后续测试断点重传 2.1 上传功能测试 客户端自动上传成功…...
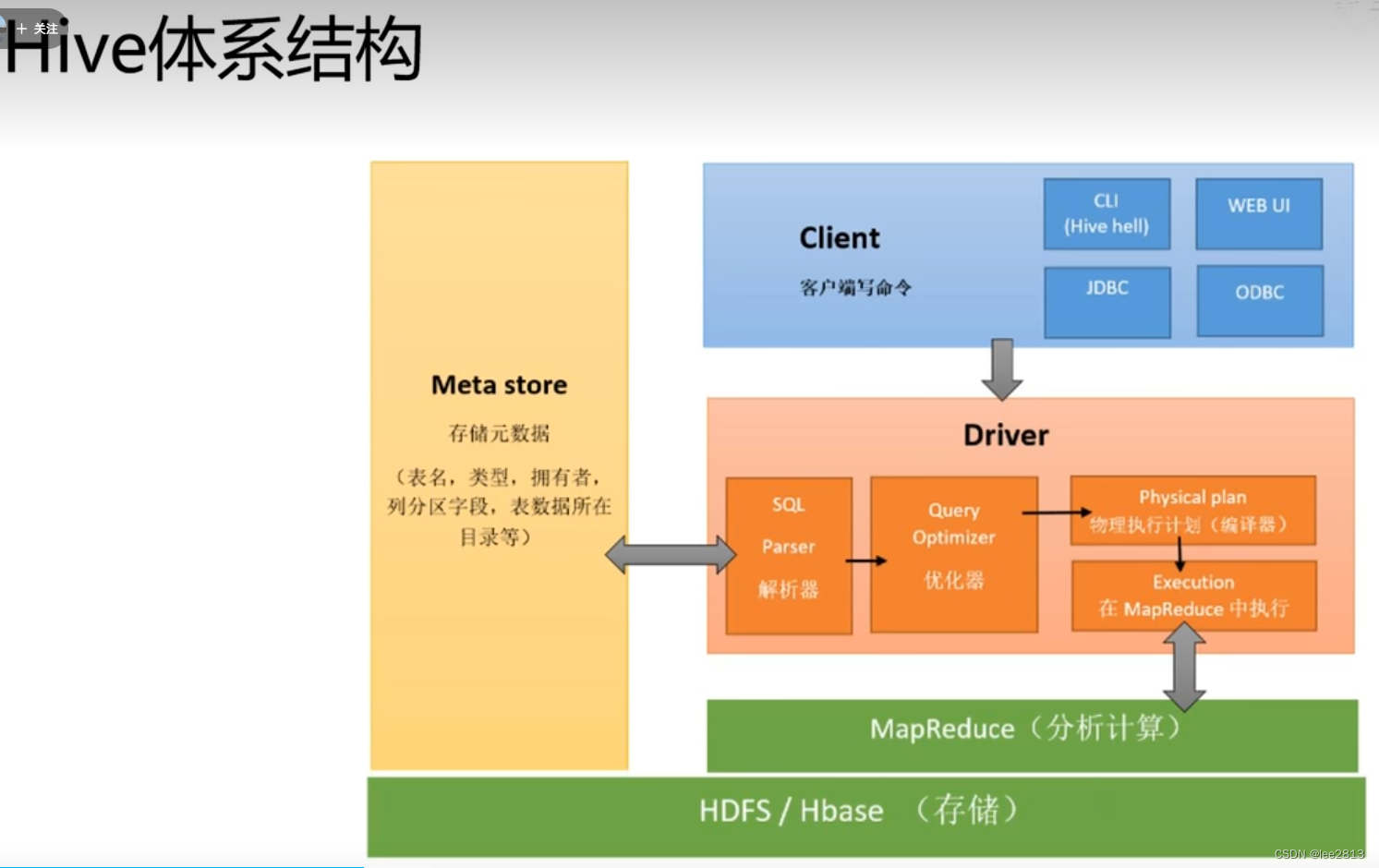
L2 数据仓库和Hive环境配置
1.数据仓库架构 数据仓库DW主要是一个用于存储,分析,报告的数据系统。数据仓库的目的是面向分析的集成化数据环境,分析结果为企业提供决策支持。-DW不产生和消耗数据 结构数据:数据库中数据,CSV文件 直接导入DW非结构…...
【iOS】MVC
文章目录 前言一、MVC各层职责1.1、controller层1.2、model层1.3、view层 二、总结三、优缺点3.1、优点3.2、缺点 四、代码示例 前言 MVC模式的目的是实现一种动态的程序设计,使后续对程序的修改和扩展简化,并且使程序某一部分的重复利用成为可能。除此…...

JavaScript-----jQuery
目录 前言: 1. jQuery介绍 2. 工厂函数 - $() jQuery通过选择器获取元素,$("选择器") 过滤选择器,需要结合其他选择器使用。 3.操作元素内容 4. 操作标签属性 5. 操作标签样式 6. 元素的创建,添加,删除 7.数据与对象遍历…...

Stream流
Stream操作流 在Java 8中,得益于Lambda所带来的函数式编程,引入了一个全新的Stream概念,用于解决已有集合类库既有的弊端。 1.1 集合的迭代 几乎所有的集合(如 Collection 接口或 Map 接口等)都支持直接或间接的迭代…...

javaee spring 声明式事务管理方式2 注解方式
spring配置文件 <?xml version"1.0" encoding"UTF-8"?> <beans xmlns"http://www.springframework.org/schema/beans"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xmlns:context"http://www.springframewo…...
基于SpringBoot+微信小程序的智慧医疗线上预约问诊小程序
✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背景介绍: 近年来,随…...

注意力机制讲解与代码解析
一、SEBlock(通道注意力机制) 先在H*W维度进行压缩,全局平均池化将每个通道平均为一个值。 (B, C, H, W)---- (B, C, 1, 1) 利用各channel维度的相关性计算权重 (B, C, 1, 1) --- (B, C//K, 1, 1) --- (B, C, 1, 1) --- sigmoid 与原特征相…...

微调 TrOCR – 训练 TrOCR 识别弯曲文本
TrOCR(基于 Transformer 的光学字符识别)模型是性能最佳的 OCR 模型之一。在我们之前的文章中,我们分析了它们在单行打印和手写文本上的表现。然而,与任何其他深度学习模型一样,它们也有其局限性。TrOCR 在处理开箱即用的弯曲文本时表现不佳。本文将通过在弯曲文本数据集上…...
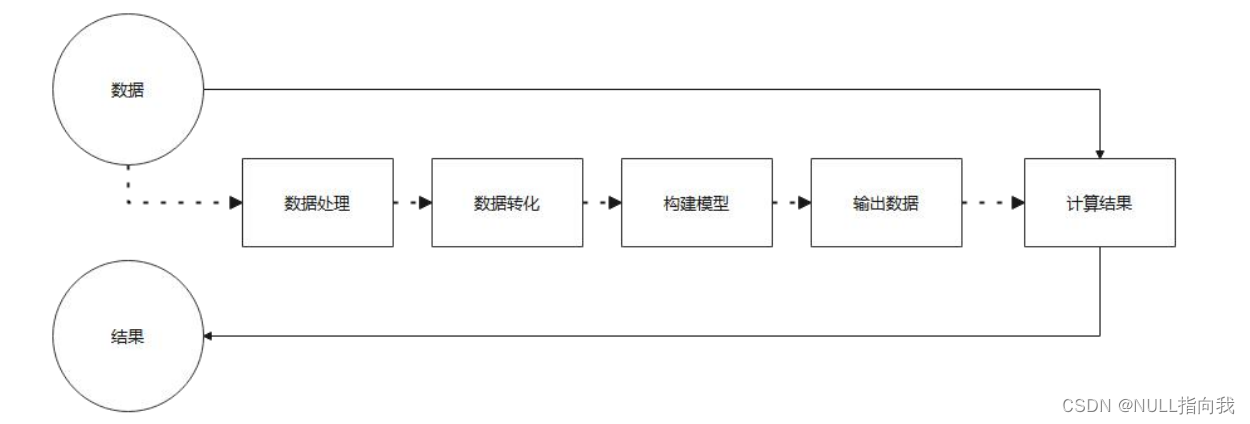
Jetsonnano B01 笔记7:Mediapipe与人脸手势识别
今日继续我的Jetsonnano学习之路,今日学习安装使用的是:MediaPipe 一款开源的多媒体机器学习模型应用框架。可在移动设备、工作站和服务 器上跨平台运行,并支持移动 GPU 加速。 介绍与程序搬运官方,只是自己的学习记录笔记&am…...
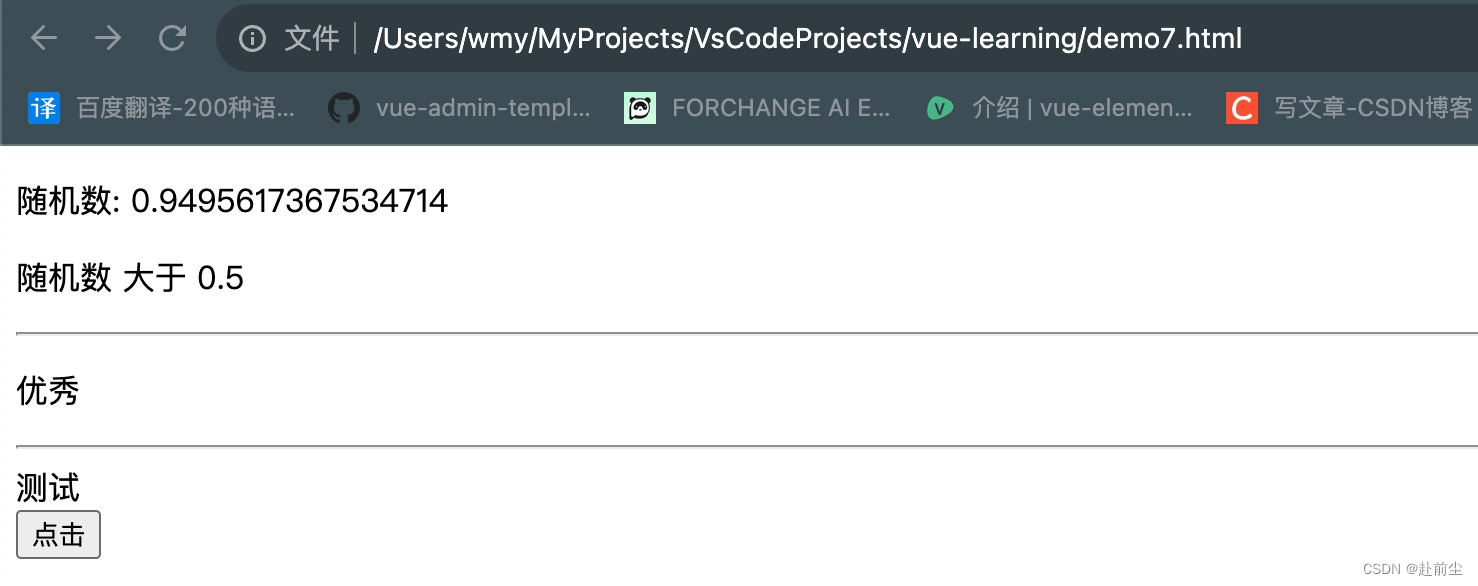
vue学习之v-if/v-else/v-else-if
v-else/v-else-if 创建 demo7.html,内容如下 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Docum…...
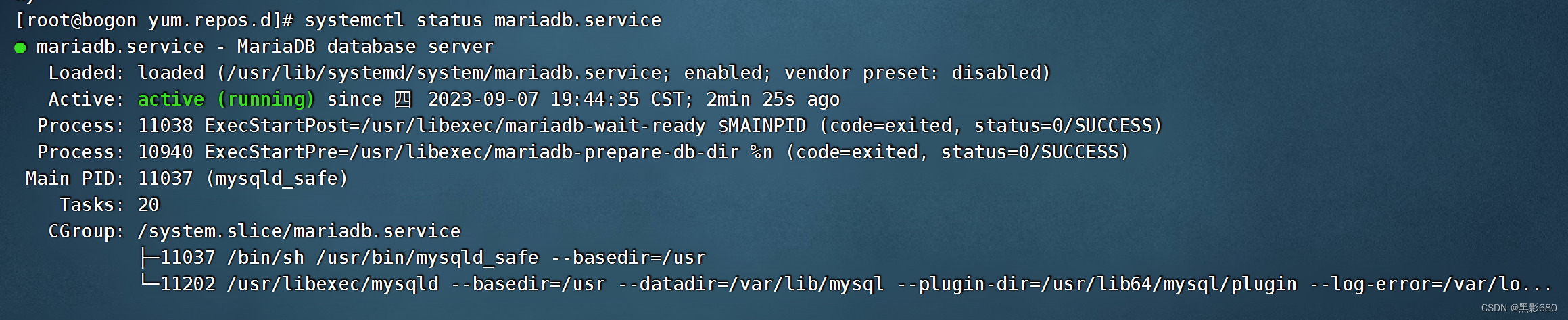
ansible的安装和简单的块使用
目录 一、概述 二、安装 1、选择源 2、安装ansible 3、模块查看 三、实验 1、拓扑编辑 2、设置组、ping模块 3、hostname模块 4、file模块 编辑 5、stat模块 6、copy模块(本地拷贝到远程) 7、fetch模块与copy模块类似,但作用…...

Android 状态栏显示运营商名称
Android 原生设计中在锁屏界面会显示运营商名称,用户界面中,大概是基于 icon 数量长度显示考虑,对运营商名称不作显示。但是国内基本都加上运营商名称。对图标显示长度优化基本都是:缩小运营商字体、限制字数长度、信号图标压缩上…...
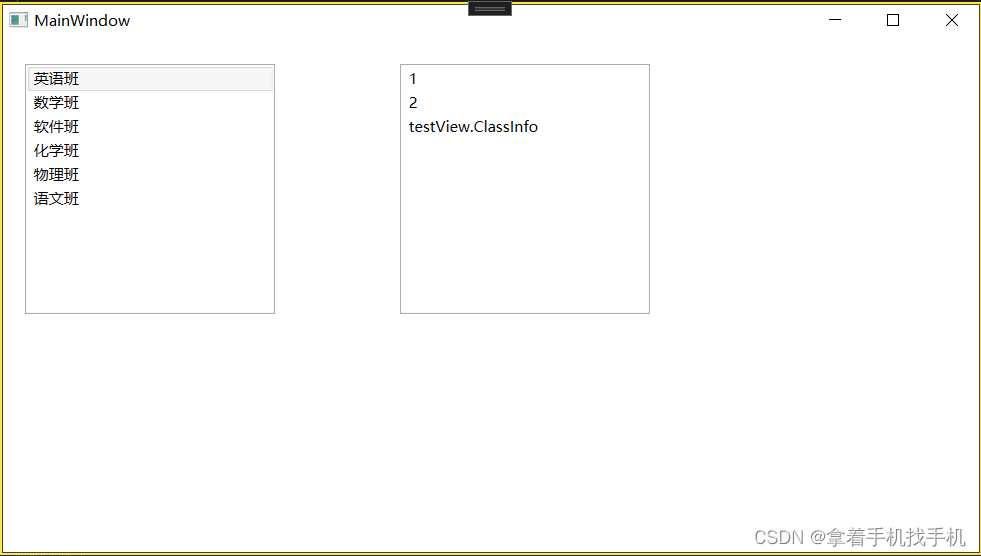
10.Xaml ListBox控件
1.运行界面 2.运行源码 a.Xaml 源码 <Grid Name="Grid1"><!--IsSelected="True" 表示选中--><ListBox x:Name="listBo...

基于vue3和element-plus的省市区级联组件
git地址:https://github.com/ht-sauce/elui-china-area-dht 使用:npm i elui-china-area-dht 默认使用 使用方法 <template><div class"app"><!--默认使用--><elui-china-area-dht change"onChange"></elui-china…...

解密SWAT模型中的土壤水分特性:如何用SPAW快速计算AWC与饱和导水率?
土壤水分特性在SWAT模型中的关键作用与SPAW实战指南 土壤水分参数对水文模拟的影响机制 在分布式水文建模领域,土壤水分特性参数犹如隐藏在水循环方程式中的密码钥匙。这些看似简单的数值背后,实则决定着水分在土壤剖面中的运移轨迹、植物根系的吸水效率…...

技术赋能B端拓客:号码核验行业的破局与价值重塑,氪迹科技法人股东号码筛选系统,阶梯式价格
2026年,B端拓客正式迈入智能内卷时代,“精准获客、降本增效”成为企业突破业绩瓶颈的核心关键词,而号码核验作为拓客流程的前置过滤环节,直接决定了线索质量与人力效能,成为影响拓客投入回报比的关键变量。当前&#x…...
)
【2026年蚂蚁集团暑期实习- 3月29日-开发岗-第二题- 质数合数】(题目+思路+JavaC++Python解析+在线测试)
题目内容 在数论中,质数是大于 $1 $且仅能被 $1 和自身整除的正整数;合数是大于和自身整除的正整数;合数是大于和自身整除的正整数;合数是大于 1$ 且除了 $1 $和自身外还有其他正因子的正整数。 给定一个长度为$ n$ 的数组 { a1,a2,…,ana_1,a_2,…,a_na...
精准对应翻译)
Hunyuan-MT-7B真实效果:法院判决书专业术语(如‘举证责任倒置’)精准对应翻译
Hunyuan-MT-7B真实效果:法院判决书专业术语(如‘举证责任倒置’)精准对应翻译 1. 引言:当法律翻译遇上AI 想象一下这样的场景:一份涉及跨国纠纷的法院判决书需要翻译,里面充满了"举证责任倒置"…...

【忍者算法】394 字符串解码:遇到嵌套时,栈最像“现场保存器”
【忍者算法】394 字符串解码:遇到嵌套时,栈最像“现场保存器” 接上题:这次栈里要存“上一层的现场” 前两题里,我们已经见过两种栈的用法: 《有效括号》:栈存“还没配对的左括号”。 《最小栈》:栈存数据,同时顺手维护“当前最小值”。 这一题会再往前走一步。 因为…...

如何通过DeepWiki实现本地部署的智能文档生成与数据安全保障?
如何通过DeepWiki实现本地部署的智能文档生成与数据安全保障? 【免费下载链接】deepwiki-open Open Source DeepWiki: AI-Powered Wiki Generator for GitHub Repositories 项目地址: https://gitcode.com/gh_mirrors/de/deepwiki-open 在数字化开发的浪潮中…...

OpenClaw故障排查指南:GLM-4.7-Flash模型连接常见问题解决
OpenClaw故障排查指南:GLM-4.7-Flash模型连接常见问题解决 1. 为什么需要这份指南 上周我在本地部署GLM-4.7-Flash模型时,连续遭遇了三次连接失败。每次错误提示都像谜语一样——"Connection timeout"、"Invalid response"这些报错…...

Spring WebFlux + Reactivate-Feign实战:如何用响应式编程提升微服务性能
Spring WebFlux Reactivate-Feign实战:构建高性能响应式微服务架构 在当今高并发、低延迟的应用场景中,传统同步阻塞式的微服务调用方式逐渐暴露出性能瓶颈。当系统面临突发流量时,线程资源迅速耗尽,响应时间急剧上升,…...
)
手把手教你用KVM在openEuler 22.03 LTS上安装华为FusionCompute 6.5.1 CNA(含VNC避坑指南)
深度实战:在openEuler 22.03 LTS上通过KVM部署FusionCompute CNA全流程解析 当企业需要构建私有云环境时,华为FusionCompute作为成熟的虚拟化平台常被列为首选方案。本文将完整呈现如何在openEuler 22.03 LTS系统中,通过KVM虚拟化技术实现Fus…...

Grok-1开源项目终极指南:从入门到精通完整教程
Grok-1开源项目终极指南:从入门到精通完整教程 【免费下载链接】grok-1 马斯克旗下xAI组织开源的Grok AI项目的代码仓库镜像,此次开源的Grok-1是一个3140亿参数的混合专家模型 项目地址: https://gitcode.com/GitHub_Trending/gr/grok-1 想要体验…...