Spark【RDD编程(三)键值对RDD】
简介
键值对 RDD 就是每个RDD的元素都是 (key,value)类型的键值对,是一种常见的 RDD,可以应用于很多场景。
因为毕竟通过我们之前Hadoop的学习中,我们就可以看到对数据的处理,基本都是以键值对的形式进行统一批处理的,因为MapReduce模型中,Mapper和Reducer之间的联系就是通过键和值进行连接产生关系的。
键值对RDD的创建
其实就是个RDD 的创建,无非就是通过并行集合创建和通过文件系统创建,然后文件系统又分为本地文件系统和HDFS。
常用的键值对RDD转换操作
1、reduceByKey(func)
和上一篇文章中的用法一致。
2、groupByKey(func)
和上一篇文章中的用法一致。
3、keys
返回键值对 RDD 中所有的key,构成一个新的 RDD。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object KV_RDD {def main(args: Array[String]): Unit = {//创建SparkContext对象val conf = new SparkConf()conf.setAppName("kv_rdd").setMaster("local")val sc:SparkContext = new SparkContext(conf)//通过并行集合创建RDDval arr = Array(("Spark",1),("Hadoop",1),("Spark",1),("Flink",1))val rdd: RDD[(String, Int)] = sc.parallelize(arr)val res: RDD[String] = rdd.keysres.foreach(println)//关闭SparkContextsc.stop()}
}
输出结果:
Spark
Hadoop
Spark
Flink4、values
返回键值对 RDD 中所有的key,构成一个新的 RDD。
//通过并行集合创建RDDval arr = Array(("Spark",1),("Hadoop",1),("Spark",1),("Flink",1))val rdd: RDD[(String, Int)] = sc.parallelize(arr)val res: RDD[Int] = rdd.valuesres.foreach(println)运行结果:
1
1
1
15、sortByKey(Boolean asce)
返回一个根据 key 排序(字典序)的RDD。
//通过并行集合创建RDDval arr = Array(("Spark",1),("Hadoop",1),("Spark",1),("Flink",1))val rdd: RDD[(String, Int)] = sc.parallelize(arr)val res: RDD[(String,Int)] = rdd.sortByKey()res.foreach(println)运行结果:
(Flink,1)
(Hadoop,1)
(Spark,1)
(Spark,1)设置升序/降序
默认我们sortByKey()方法是升序排序的,如果要降序可以传入一个false的值。
//通过并行集合创建RDDval arr = Array(("Spark",1),("Hadoop",1),("Spark",1),("Flink",1))val rdd: RDD[(String, Int)] = sc.parallelize(arr)//降序val res: RDD[(String,Int)] = rdd.sortByKey(false)res.foreach(println)运行结果:
(Spark,1)
(Spark,1)
(Hadoop,1)
(Flink,1)6、sortBy()
可以根据其他字段进行排序。
//通过并行集合创建RDDval arr = Array(("Spark",1),("Hadoop",5),("Hive",2),("Flink",3))val rdd: RDD[(String, Int)] = sc.parallelize(arr)//按照value升序排序val res: RDD[(String,Int)] = rdd.sortBy(kv=>kv._2,true)res.foreach(println)运行结果:
(Spark,1)
(Hive,2)
(Flink,3)
(Hadoop,5)7、mapValues(func)
之前我们处理的RDD 都是文本或数字类型的,之前我们的map(func)中的func函数是对整个RDD的元素进行处理。但是这里换成了mapValues(func),这里func函数处理的是我们(key,value)中的所有value,而key 不会发生变化。
//通过并行集合创建RDDval arr = Array(("Spark",1),("Hadoop",5),("Hive",2),("Flink",3))val rdd: RDD[(String, Int)] = sc.parallelize(arr)//所有的value+1val res: RDD[(String,Int)] = rdd.mapValues(value=>value+1)res.foreach(println)运行结果:
(Spark,2)
(Hadoop,6)
(Hive,3)
(Flink,4)8、join()
内连接,(K,V1)和(K,V2)进行内连接生成(K,(V1,V2))。
//通过并行集合创建RDDval arr1 = Array(("Spark",1),("Hadoop",5),("Hive",2),("Flink",3))val arr2 = Array(("Spark","fast"),("Hadoop","good"))val rdd1: RDD[(String,Int)] = sc.parallelize(arr1)val rdd2: RDD[(String,String)] = sc.parallelize(arr2)//所有的value+1
// val res: RDD[(String,(Int,Int))] = rdd1.join(rdd2)val res: RDD[(String, (Int, String))] = rdd1.join(rdd2)res.foreach(println)运行结果:
(Spark,(1,fast))
(Hadoop,(5,good))我们可以看到,返回的RDD 的元素都是满足连接表rdd2的K的。
9、combineByKey()
这个函数的参数比较多,下面做个介绍:
- createCombiner:用于将RDD中的每个元素转换为一个类型为C(V=>C)的值。这个函数在第一次遇到某个key的时候会被调用,用于创建一个累加器。
- mergeValue:用于将RDD中的每个value值合并到已经存在的累加器中。这个函数在遇到相同key的value时会被调用。
- mergeCombiners:用于将不同分区中的累加器值进行合并。这个函数在每个分区处理完后,将各个分区的累加器值进行合并。
案例-统计公司三个季度的总收入和平均收入
//通过并行集合创建RDDval arr = Array(("company-1",88),("company-1",96),("company-1",85),("company-2",94),("company-2",86),("company-2",74),("company-3",86),("company-3",88),("company-3",92))val rdd: RDD[(String, Int)] = sc.parallelize(arr,3)val res: RDD[(String,Int,Float)] = rdd.combineByKey(income=>(income,1),(acc:(Int,Int),income)=>(acc._1+income,+acc._2+1),(acc1:(Int,Int),acc2:(Int,Int))=>(acc1._1+acc2._1,acc1._2+acc2._2)).map({case (key,value) => (key,value._1,value._1/value._2.toFloat)})//重新分配分区 将3个分区合并为1个res.repartition(1).saveAsTextFile("data/kv_rdd/")运行结果中-part-00000文件内容:
(company-3,266,88.666664)
(company-1,269,89.666664)
(company-2,254,84.666664)其中,第一列为季度名称。第二列为总收入,第三列为平均收入。
参数解析
第一个参数的作用是:当我们取出的RDD元素是第一次遇到的key,那么就创建一个组合器函数createCombiner(),负责将我们的键值对(K:季度名称,V:收入额)中的 V:收入额转为 C格式(总收入额,1)的格式,其中的1代表当前已经累加了一个月的收入。
第二个参数是合并值函数 mergeValue(),它的作用是:如果遇到相同的key,比如都是"company-1",那么就对相同key的的value进行mergeValue()中定义的操作。
第三个参数的作用是 :由于我们开启了多个分区,所以最后要对不同分区的数据进行一个对总,这个函数中定义的就是对两个 C格式 的键值对进行的操作。
最后我们进行了一个模式匹配,对于结果返回的(k,v)形式的数据,其中 k 就是指季度名称, v 是一个键值对(总收入额,月份数),我们将它转为 (季度名称,总收入额,平均收入额)。
分区1:
1-调用createCombiner()函数
(company-1,88) => (company-1,(88,1))
2-调用mergeValue()函数
(company-1,96) => (company-1,(184,2))
分区2:
1-调用createCombiner()函数
(company-1,85) => (company-1,(85,1))3-调用mergeCombiners()函数
(company-1,(184,2)) + (company-1,(85,1)) => (company-1,(269,3))10、flatMapValues(fubc)
flatMapValues(func)的操作和mapValues(func)相似。它们都是对键值对类型的RDD进行操作,mapValues(func)是对(ke要,value)的value通过函数 func 进行一个处理,而key不变。而flatMapValues(func)则是对value先通过函数 func 进行处理,然后再处理后的值和key组成一系列新的键值对。
输入数据:
("k1","hadoop,spark,flink")
("k2","hadoop,hive,hbase")处理
//通过并行集合创建RDDval arr = Array(("k1","hadoop,spark,flink"),("k2","hadoop,hive,hbase"))val rdd: RDD[(String, String)] = sc.parallelize(arr)//flatMapValues(func)//val res: Array[(String, String)] = rdd.flatMapValues(value => value.split(",")).collect() //mapValues(func)val res: Array[(String, Array[String])] =rdd.mapValues(value => value.split(",")).collect()value.split(",")).collect()res.foreach(println)运行结果:
(k1,hadoop)
(k1,spark)
(k1,flink)
(k2,hadoop)
(k2,hive)
(k2,hbase)而我们的mapValues(func)执行后的RDD集合内为:
(k1,Array("hadoop","spark","flink"))
(k2,Array("hadoop","hive","hbase"))显然我们的flatMapValues(func)是多进行了一部扁平化的操作,将集合内的元素与key一一组成一系列心得键值对。
相关文章:
键值对RDD】)
Spark【RDD编程(三)键值对RDD】
简介 键值对 RDD 就是每个RDD的元素都是 (key,value)类型的键值对,是一种常见的 RDD,可以应用于很多场景。 因为毕竟通过我们之前Hadoop的学习中,我们就可以看到对数据的处理,基本都是以…...

从板凳围观到玩转行家:Moonbeam投票委托如何让普通用户一同参与
今年5月,Moonbeam发起了一项社区链上治理中投票委托反馈的调查。187位社区成员参与了这项调查,调查发现受访者对治理感兴趣,增加参与度只需要进行一些调整,即更简化的投票流程。 治理和去中心化是Web3的核心,随着Moon…...
SpringMVC的文件上传文件下载多文件上传---详细介绍
目录 前言: 一,文件上传 1.1 添加依赖 1.2 配置文件上传解析器 1.3 表单设置 1.4 文件上传的实现 二,文件下载 controller层 前端jsp 三,多文件上传 Controller层 运行 前言: Spring MVC 是一个基于 Java …...
综合案例】)
Spark【RDD编程(四)综合案例】
案例1-TOP N个数据的值 输入数据: 1,1768,50,155 2,1218,600,211 3,2239,788,242 4,3101,28,599 5,4899,290,129 6,3110,54,1201 7,4436,259,877 8,2369,7890,27 处理代码: def main(args: Array[String]): Unit {//创建SparkContext对象val conf…...

Golang报错mixture of field:value and value initializers
Golang报错mixture of field:value and value initializers 这个错误跟编程习惯(模式)有关,都知道golang 语言的编程与java /python 以及其他的编程语言相似 ,一通百通,易学万卷书。 编程中同一个结构中要保持唯一模…...

【网络教程】记一次使用Docker手动搭建BT宝塔面板的全过程(包含问题解决如:宝塔面板无法开启防火墙,ssh,nginx等)
文章目录 准备安装安装宝塔面板开启ssh和修改ssh的密码导出镜像问题解决宝塔面板无法开启防火墙无法启动ssh设置密码nginx安装失败设置开机启动相关服务准备 演示的系统环境:Ubuntu 22.04.3 LTS更新安装/升级docker到最新版本升级docker相关命令如下# 更新软件包列表并自动升级…...
【大虾送书第九期】速学Linux:系统应用从入门到精通
目录 🍭写在前面 🍭为什么学习Linux系统 🍭Linux系统的应用领域 🍬1.Linux在服务器的应用 🍬2.嵌入式Linux的应用 🍬3.桌面Linux的应用 🍭Linux的版本选择 &a…...

docker相关命令
####### 帮助启动类命令 ########## 启动docker systemctl start docker 停止docker systemctl stop docker 重启docker systemctl restart docker 查看docker状态 systemctl status docker 开机启动 systemctl enable docker 查看docker概要信息 docker info 查看…...

【Redis】4、rsync远程同步
与inodify结合使用,实现实时同步 rsync简介 rsync(Remote Sync,远程同步)是一个开源的快速备份工具,可以在不同主机之间镜像同步整个目录树,;支持增量备份,并保持链接和权限&#…...

无服务架构--Serverless
无服务架构 无服务架构(Serverless Architecture)即无服务器架构,也被称为函数即服务(Function as a Service,FaaS),是一种云计算模型,用于构建和部署应用程序,无需关心…...

2023-09-07 LeetCode每日一题(修车的最少时间)
2023-09-07每日一题 一、题目编号 2594. 修车的最少时间二、题目链接 点击跳转到题目位置 三、题目描述 给你一个整数数组 ranks ,表示一些机械工的 能力值 。ranksi 是第 i 位机械工的能力值。能力值为 r 的机械工可以在 r * n2 分钟内修好 n 辆车。 同时给你…...
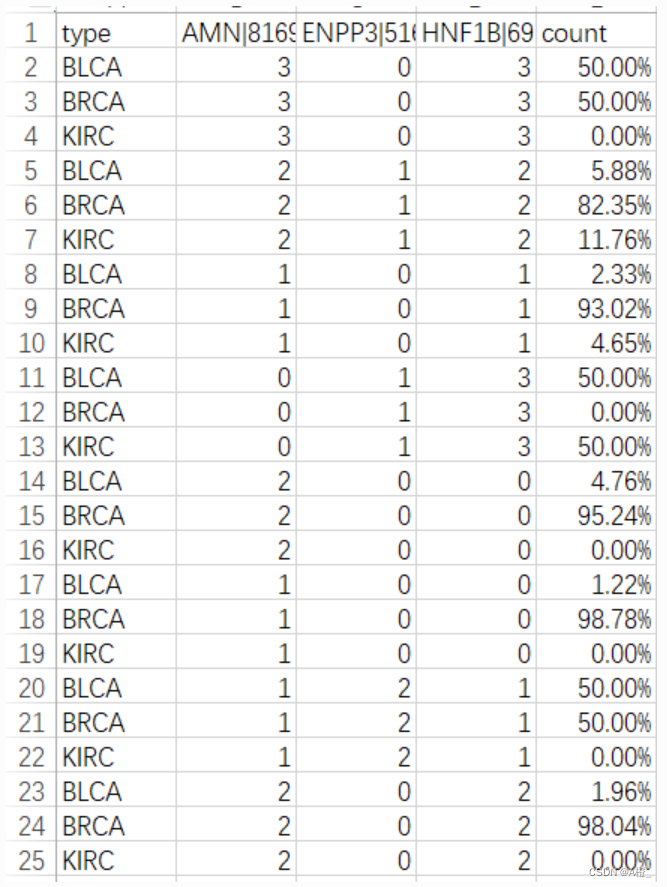
数据挖掘实验-主成分分析与类特征化
数据集&代码https://www.aliyundrive.com/s/ibeJivEcqhm 一.主成分分析 1.实验目的 了解主成分分析的目的,内容以及流程。 掌握主成分分析,能够进行编程实现。 2.实验原理 主成分分析的目的 主成分分析就是把原有的多个指标转化成少数几个代表…...
,322. 零钱兑换,279.完全平方数)
70. 爬楼梯 (进阶),322. 零钱兑换,279.完全平方数
代码随想录训练营第45天|70. 爬楼梯 (进阶,322. 零钱兑换,279.完全平方数 70.爬楼梯文章思路代码 322.零钱兑换文章思路代码 279.完全平方数文章思路代码 总结 70.爬楼梯 文章 代码随想录|0070.爬楼梯完全背包版本 思路 将楼梯长度视为背…...
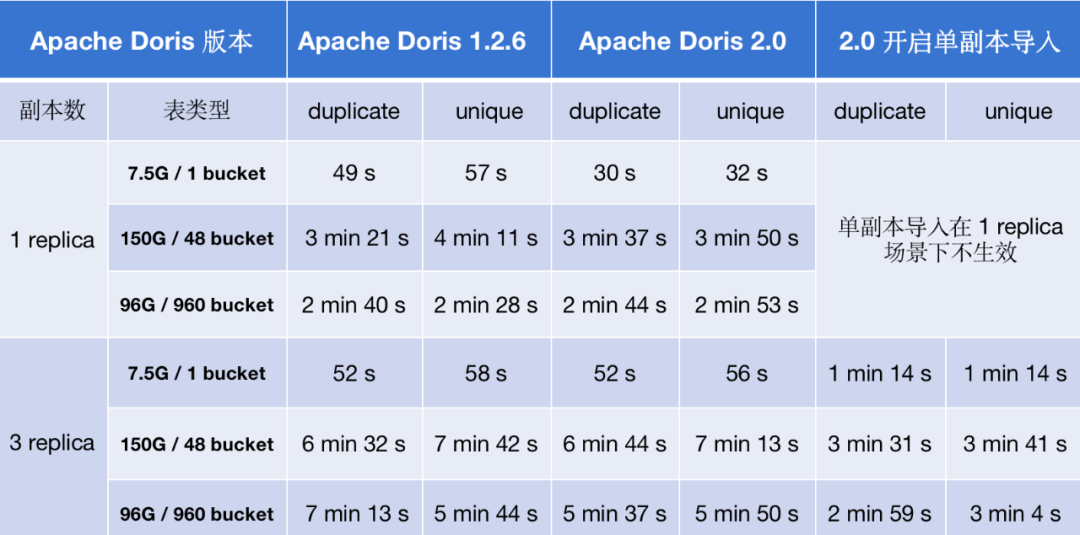
Apache Doris 2.0 如何实现导入性能提升 2-8 倍
数据导入吞吐是 OLAP 系统性能的重要衡量标准之一,高效的数据导入能力能够加速数据实时处理和分析的效率。随着 Apache Doris 用户规模的不断扩大, 越来越多用户对数据导入提出更高的要求,这也为 Apache Doris 的数据导入能力带来了更大的挑战…...

RabbitMQ: topic 结构
生产者 package com.qf.mq2302.topic;import com.qf.mq2302.utils.MQUtils; import com.rabbitmq.client.Channel; import com.rabbitmq.client.Connection;public class Pubisher {public static final String EXCHANGE_NAME"mypubilisher";public static void ma…...
信息系统项目管理教程(第4版):第二章 信息技术及其发展
请点击↑关注、收藏,本博客免费为你获取精彩知识分享!有惊喜哟!! 第二章 信息技术及其发展 2.1信息技术及其发展 信息技术是以微电子学为基础的计算机技术和电信技术的结合而形成的,对声音的、图像的、文字的、数字…...

有哪些适合初学者的编程语言?
C语言 那为什么我还要教你C语言呢?因为我想要让你成为一个更好、更强大的程序员。如果你要变得更好,C语言是一个极佳的选择,其原因有二。首先,C语言缺乏任何现代的安全功能,这意味着你必须更为警惕,时刻了…...

uni-app动态tabBar,根据不同用户展示不同的tabBar
1.uni框架的api实现 因为我们用的是uni-app框架开发,所以在创建项目的时候直接创建uni-ui的项目即可,这个项目模板中自带了uni的一些好用的组件和api。 起初我想着这个效果不难实现,因为官方也有api可以直接使用,所以我最开始尝试…...

手写Spring:第6章-资源加载器解析文件注册对象
文章目录 一、目标:资源加载器解析文件注册对象二、设计:资源加载器解析文件注册对象三、实现:资源加载器解析文件注册对象3.1 工程结构3.2 资源加载器解析文件注册对象类图3.3 类工具类3.4 资源加载接口定义和实现3.4.1 定义资源加载接口3.4…...

Redis 7 第八讲 集群模式(cluster)架构篇
集群架构 Redis 集群架构图 集群定义 Redis 集群是一个提供在多个Redis节点间共享数据的程序集;Redis集群可以支持多个master 应用场景 Redis集群支持多个master,每个master又可以挂载多个slave读写分离支持数据的高可用支持海量数据的读写存储操作集群自带Sentinel的故障…...

CSS 嵌套:编写更优雅的样式代码
CSS 嵌套:编写更优雅的样式代码让 CSS 结构更清晰,层次更分明,代码更易维护。一、CSS 嵌套的优势 作为一名把代码当散文写的 UI 匠人,我对代码的可读性和结构有着近乎偏执的要求。CSS 嵌套让我们能够按照 HTML 的层次结构来组织样…...

MATLAB频谱分析:从fft到fftshift的实战解读
1. 为什么我们需要频谱分析? 想象一下你正在调试一段音频,听到里面有奇怪的嗡嗡声。作为工程师,你不仅想知道"有杂音",更想知道这个杂音具体是哪个频率成分。这就是频谱分析的用武之地——它像是一把声音的显微镜&#…...

PINN 融合机器学习重构科学计算范式,物理先验赋能神经网络高效求解偏微分方程
PINN 即物理信息神经网络,将物理定律(如偏微分方程、边界条件)以约束损失形式嵌入机器学习框架,实现数据驱动与物理先验的融合。它依托神经网络的拟合能力,在训练中同时最小化观测数据误差与物理方程残差,无…...

2025届学术党必备的五大降AI率工具横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 要是想降低AIGC检测率,那就得从内容生成与后期修饰这两个关键的方面开始着手。在…...
)
新手必看:知乎话题数据采集从入门到精通(含代理IP配置与数据清洗技巧)
知乎数据采集实战指南:从零搭建合规爬虫系统 在信息爆炸的时代,知乎作为高质量内容社区,汇聚了大量行业见解和用户真实反馈。对于市场研究人员、产品经理或数据分析师而言,获取这些数据能为决策提供宝贵参考。本文将系统性地介绍如…...

Flutter Web:混合开发的最佳实践
Flutter Web:混合开发的最佳实践一次编写,多端运行。Flutter Web 让前端开发更加高效。一、Flutter Web 的优势 作为一名追求像素级还原的 UI 匠人,我对跨平台解决方案有着严格的要求。Flutter Web 不仅让我们能够使用相同的代码库构建 Andro…...

虚拟机网络救急指南:当ens33突然丢失IP时必做的6个检查项
虚拟机网络救急指南:当ens33突然丢失IP时必做的6个检查项 虚拟化环境中,ens33网卡突然丢失IP地址的情况并不罕见。这种突发状况往往让开发者措手不及,尤其是在远程连接或自动化部署的关键时刻。本文将系统性地梳理6个关键检查项,帮…...
)
博物馆展览门户|基于springboot + vue博物馆展览门户系统(源码+数据库+文档)
博物馆展览门户系统 目录 基于springboot vue博物馆展览门户系统 一、前言 二、系统功能演示 三、技术选型 四、其他项目参考 五、代码参考 六、测试参考 七、最新计算机毕设选题推荐 八、源码获取: 基于springboot vue博物馆展览门户系统 一、前言 博主…...

OpenClaw新手误区:Qwen3-32B部署中最易犯的5个配置错误
OpenClaw新手误区:Qwen3-32B部署中最易犯的5个配置错误 1. 前言:为什么OpenClaw新手容易踩坑? 第一次接触OpenClaw时,我被它"本地化AI智能体"的定位深深吸引。作为一个长期依赖云端API的开发者,能直接在本…...

m4s-converter:B站缓存视频本地化全解决方案
m4s-converter:B站缓存视频本地化全解决方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 1. 价值定位:解决B站缓存文件…...