目标检测笔记(十三): 使用YOLOv5-7.0版本对图像进行目标检测完整版(从自定义数据集到测试验证的完整流程))
文章目录
- 一、目标检测介绍
- 二、YOLOv5介绍
- 2.1 和以往版本的区别
- 三、代码获取
- 3.1 视频代码介绍
- 四、环境搭建
- 五、数据集准备
- 5.1 数据集转换
- 5.2 数据集验证
- 六、模型训练
- 七、模型验证
- 八、模型测试
- 九、评价指标
一、目标检测介绍
目标检测(Object Detection)是计算机视觉领域的一个重要研究方向,其主要任务是从图像或视频中识别并定位出感兴趣的目标对象。目标检测技术在许多实际应用中具有广泛的用途,如自动驾驶、视频监控、医学影像分析等。
目标检测的主要方法可以分为两大类:基于传统机器学习的方法和基于深度学习的方法。
-
基于传统机器学习的方法:这些方法主要依赖于手工设计的特征提取器和分类器。常用的特征提取器包括SIFT、SURF、HOG等,而分类器则可以是支持向量机(SVM)、随机森林(Random Forest)、K-近邻(KNN)等。这类方法通常需要大量的标注数据进行训练,但在一些特定场景下,它们仍具有一定的性能。
-
基于深度学习的方法:近年来,深度学习在目标检测领域取得了显著的进展。深度学习方法主要包括卷积神经网络(CNN)和区域卷积神经网络(R-CNN)。
- 卷积神经网络(CNN):CNN通过多层卷积层和池化层来自动学习图像的特征表示。著名的目标检测网络有Faster R-CNN、Faster R-CNN v2和YOLO(You Only Look Once)。这些网络可以生成候选框,然后使用非极大值抑制(NMS)等技术去除重叠的框,从而得到最终的目标检测结果。
- 区域卷积神经网络(R-CNN):R-CNN通过引入Region Proposal Network (RPN)来生成候选框。RPN首先在图像中生成一系列可能包含目标的区域,然后将这些区域送入CNN进行特征提取和分类。著名的R-CNN网络有Fast R-CNN、Faster R-CNN和Mask R-CNN。这些网络相较于传统的目标检测方法具有更高的准确率和速度。
随着深度学习技术的发展,目标检测的性能得到了显著提升,同时计算复杂度也得到了降低。这使得目标检测技术在各种应用场景中得到了广泛应用。
二、YOLOv5介绍
YOLOv5是一种目标检测算法,是YOLO(You Only Look Once)系列的较新版本。它由ultralytics团队开发的,采用PyTorch框架实现。
YOLOv5相较于之前的版本,有以下几个显著的改进:
- 更高的精度:YOLOv5在精度上有了显著提升,特别是在小目标检测方面。
- 更快的速度:YOLOv5相较于YOLOv4,速度更快,可以实时运行在较低的硬件设备上。
- 更小的模型:YOLOv5相较于YOLOv4,模型大小更小,占用更少的存储空间。
- 更好的可扩展性:YOLOv5可以很容易地进行模型的扩展和修改,以适应不同的任务和数据集。
YOLOv5的工作流程如下:
- 输入图像被分割成一系列的网格。
- 每个网格预测一系列的边界框,以及每个边界框属于不同类别的概率。
- 使用非极大值抑制(NMS)算法,去除重叠较多的边界框,并选择最终的检测结果。
YOLOv5可以用于各种目标检测任务,如人脸检测、车辆检测、行人检测等。它在许多计算机视觉竞赛中取得了优异的成绩,并且被广泛应用于实际应用中,如自动驾驶、视频监控等。
2.1 和以往版本的区别
YOLOv1:
- 主干部分主要由卷积层、池化层组成,输出部分由两个全连接层组成用来预测目标的位置和置信度。
- 原理:将每一张图片平均的分成7x7个网格,每个网格分别负责预测中心点落在该网格内的目标。
- 优点:检测速度快、迁移能力强
- 缺点:输入尺寸是固定的,有较大的定位误差
YOLOv2:
- 在继续保持处理速度的基础上,从预测更准确(Better),速度更快(Faster),**识别对象更多(Stronger)**这三个方面进行了改进
- 加入BN层,加速收敛;加入先验框解决物体漏检问题;多尺度训练,网络可自动改变尺寸等等
- 优点:收敛速度快、可自动改变训练尺寸。
- 缺点:对于小目标检测不友好
YOLOv3:
- 针对v2的缺点,1)加入了更好的主干网络(Darknet53),而不是VGG;2)为了提升小目标检测还加入了FPN网络;3)通过聚类生成先验框(一个框:长宽,根据纵横比和它的尺寸生成的先验框);4)加入了更好的分类器-二元交叉熵损失。
- 优点:增强了对于小目标的检测
- 缺点:参数量太大
YOLOv4:
- 差别:
- 特征提取网络的不同:1)Darknet53变成CSPDarknet53(降低了计算量,丰富了梯度信息,降低了梯度重用)相当于多个一个大残差边,再将这部分融合;2)加入了SPP-空间金字塔池化,增加感受野;3)加入了PAN操作,增加一条下采样操作
- 激活函数不同:由leakyrelu变为mish激活函数
- loss不同:余弦退火衰减,学习率会先上升再下降
- 数据增强方法:采用了Cutout(随机剪切框)、GridMask(图像的区域隐藏在网格中)、MixUp(两张图混合)、Mosaic(四张图混合)等方法
- 优点:激活函数无边界,从而避免饱和;融合了多种tricks提升网络性能;参数量相比v3更低,速度更快。
- 缺点:不够灵活,代码对用户体验不好
YOLOv5:
- 差别:
- 自定锚框定义:自动预先利用聚类自定义锚框
- 控制模型大小:通过控制深度和宽度来控制模型的大小,从而区分出s,m,l,x的不同尺寸的模型
- 优化函数:提供了两个优化函数Adam和SGD,并都预设了与之匹配的训练超参数
- 非极大值抑制:DIoU-nms变为加权nms。
- Focus操作:加入切片操作,提升训练速度
- 优点:灵活性更强,速度更快;使用Pytorch框架对用户更好,精度高。
- 缺点:Focus的切片操作对嵌入式并不友好,网络量化不支持Focus;精度和速度不平衡。
- 正负样本匹配策略:通过k-means聚类获得9个从小到大排列的anchor框,一个GT可以同时分配给多个anchor,它们是直接使用Anchor模板与GT Boxes进行粗略匹配,如果GT与某个anchor的iou大于给定的阈值,GT则分配给该Anchor,也就是说可以定位到对应cell的对应Anchor。以前是一个GT只分配给一个anchor。
- 坐标定义1:xyxy→通常为(x1, y1, x2, y2),先两个表示左上角的坐标,再两个表示右下角的坐标。具体来说,这里的‘x1’表示bbox左上角的横坐标,‘y1’表示bbox左上角的纵坐标,‘x2’表示bbox右下角的横坐标,‘y2’表示bbox右下角的纵坐标。
- 坐标定义2:xywh→通常为(x, y, w, h),也就是先两个表示bbox左上角的坐标,再两个表示bbox的宽和高,因此被称为 ‘xywh’ 表示。具体来说,这里的‘x’表示bbox左上角的横坐标,‘y’表示bbox左上角的纵坐标,‘w’表示bbox的宽度,‘h’表示bbox的高度。
三、代码获取
https://github.com/ultralytics/yolov5
3.1 视频代码介绍
可参考这个视频代码讲解:点击
四、环境搭建
安装ultralytics、cuda、pytorch、torchvision,然后执行pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
如果是cpu,则直接安装cpu对应的pytorch和torchvision,然后再执行后面的pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple。
参考这个博客:点击
五、数据集准备
首先我们可以通过labelImg来对图片进行标注,标注的适合我们可以选择保存为VOC或者YOLO格式的数据集,VOC对应为XML,YOLO对应为TXT。具体的准备过程可参考这篇博客:数据集学习笔记(六):目标检测和图像分割标注软件介绍和使用,并转换成YOLO系列可使用的数据集格式
5.1 数据集转换
参考这篇博客:数据集学习笔记(六):目标检测和图像分割标注软件介绍和使用,并转换成YOLO系列可使用的数据集格式
5.2 数据集验证
参考这篇博客:数据集学习笔记(六):目标检测和图像分割标注软件介绍和使用,并转换成YOLO系列可使用的数据集格式
import cv2
import os# 读取txt文件信息
def read_list(txt_path):pos = []with open(txt_path, 'r') as file_to_read:while True:lines = file_to_read.readline() # 整行读取数据if not lines:break# 将整行数据分割处理,如果分割符是空格,括号里就不用传入参数,如果是逗号, 则传入‘,'字符。p_tmp = [float(i) for i in lines.split(' ')]pos.append(p_tmp) # 添加新读取的数据# Efield.append(E_tmp)passreturn pos# txt转换为box
def convert(size, box):xmin = (box[1] - box[3] / 2.) * size[1]xmax = (box[1] + box[3] / 2.) * size[1]ymin = (box[2] - box[4] / 2.) * size[0]ymax = (box[2] + box[4] / 2.) * size[0]box = (int(xmin), int(ymin), int(xmax), int(ymax))return boxdef draw_box_in_single_image(image_path, txt_path):# 读取图像image = cv2.imread(image_path)pos = read_list(txt_path)for i in range(len(pos)):label = classes[int(str(int(pos[i][0])))]print('label is '+label)box = convert(image.shape, pos[i])image = cv2.rectangle(image,(box[0], box[1]),(box[2],box[3]),colores[int(str(int(pos[i][0])))],2)cv2.putText(image, label,(box[0],box[1]-2), 0, 1, colores[int(str(int(pos[i][0])))], thickness=2, lineType=cv2.LINE_AA)cv2.imshow("images", image)cv2.waitKey(0)if __name__ == '__main__':img_folder = "D:\Python\company\Object_detection\datasets\mask_detection/train\images"img_list = os.listdir(img_folder)img_list.sort()label_folder = "D:\Python\company\Object_detection\datasets\mask_detection/train/labels"label_list = os.listdir(label_folder)label_list.sort()classes = {0: "no-mask", 1: "mask"}colores = [(0,0,255),(255,0,255)]for i in range(len(img_list)):image_path = img_folder + "\\" + img_list[i]txt_path = label_folder + "\\" + label_list[i]draw_box_in_single_image(image_path, txt_path)六、模型训练
我们将所有的原图和TXT标签得到之后,为下图结构:
mask_detection
- images
- train
- val
- labels
- train
- val
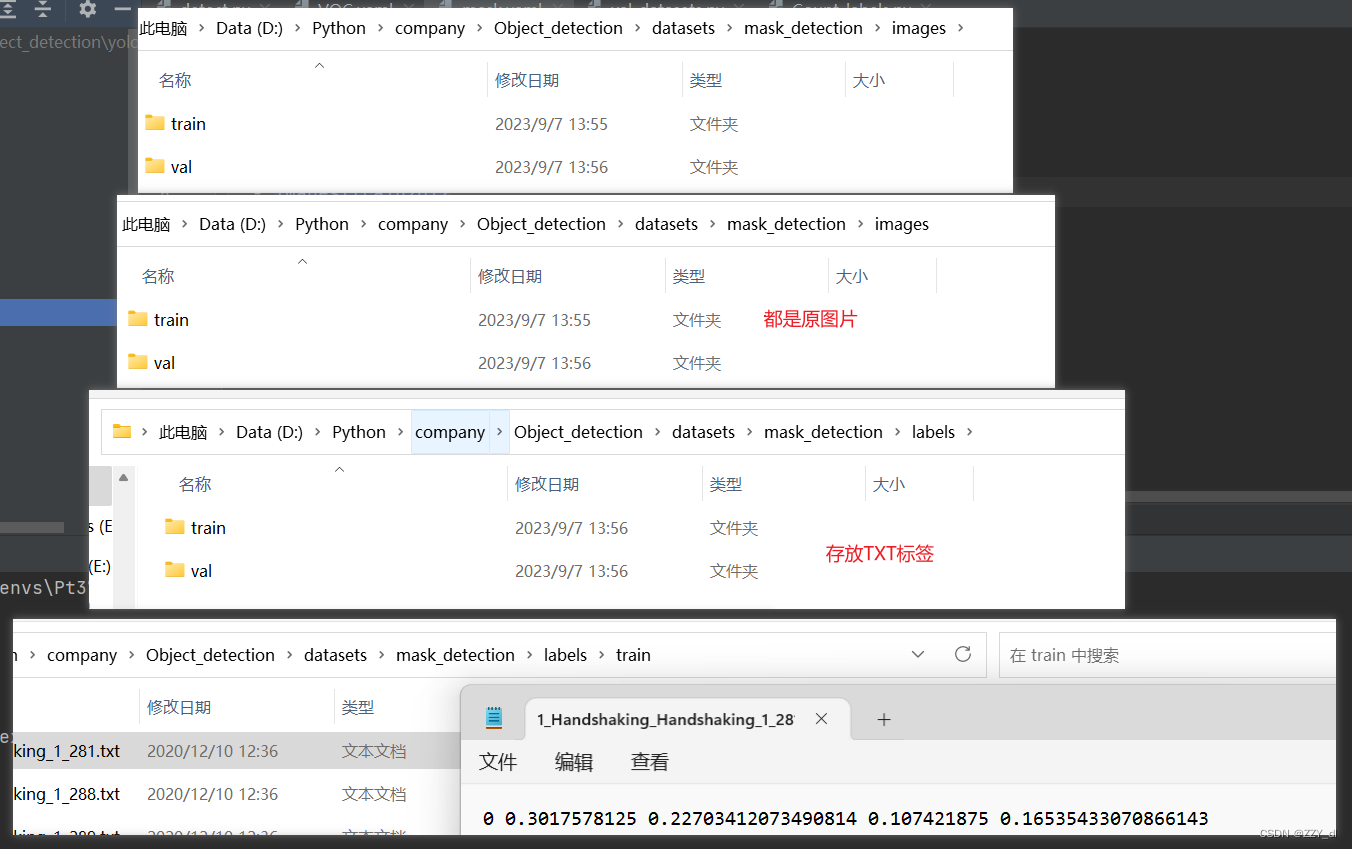
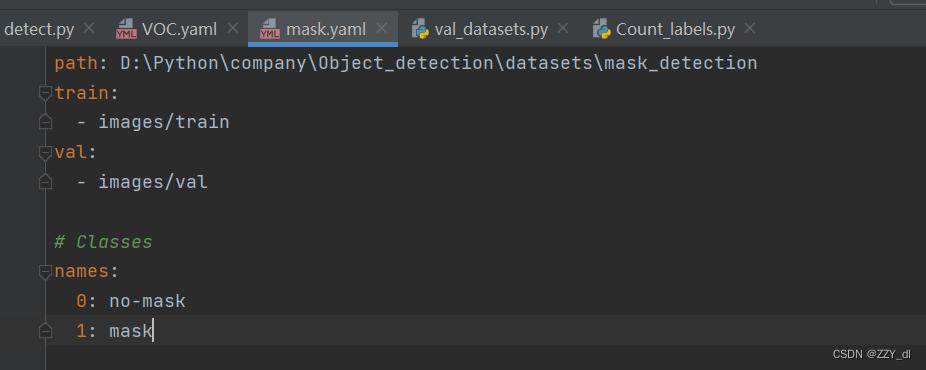
修改yaml数据集配置文件:
统计口罩佩戴的数量信息:
# 只需要修改txt路径和样本数和类别名
import ostxt_path = "D:\Python\company\Object_detection\datasets\mask_detection/train/labels" # txt所在路径
class_num = 2 # 样本类别数
classes = {0: "no-mask", 1: "mask"}
class_list = [i for i in range(class_num)]
class_num_list = [0 for i in range(class_num)]
labels_list = os.listdir(txt_path)
for i in labels_list:file_path = os.path.join(txt_path, i)file = open(file_path, 'r') # 打开文件file_data = file.readlines() # 读取所有行for every_row in file_data:class_val = every_row.split(' ')[0]class_ind = class_list.index(int(class_val))class_num_list[class_ind] += 1file.close()
# 输出每一类的数量以及总数
for i in classes:print(classes.get(i),":",class_num_list[i])
print('total:', sum(class_num_list))
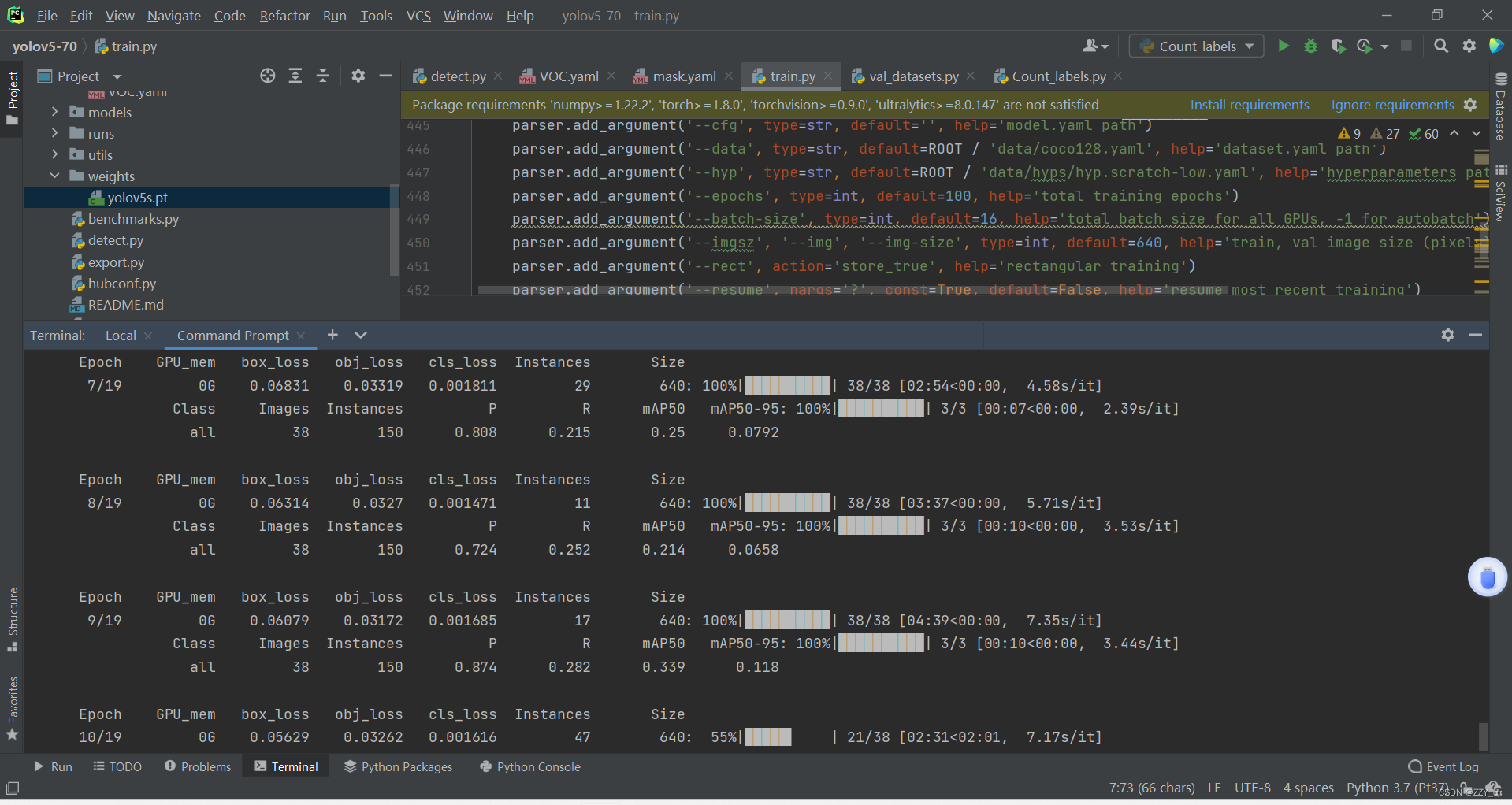
开始准备训练:
python train.py --data data/mask.yaml --weights weights/yolov5s.pt --img 640 --epochs 20 --workers 4 --batch-size 8
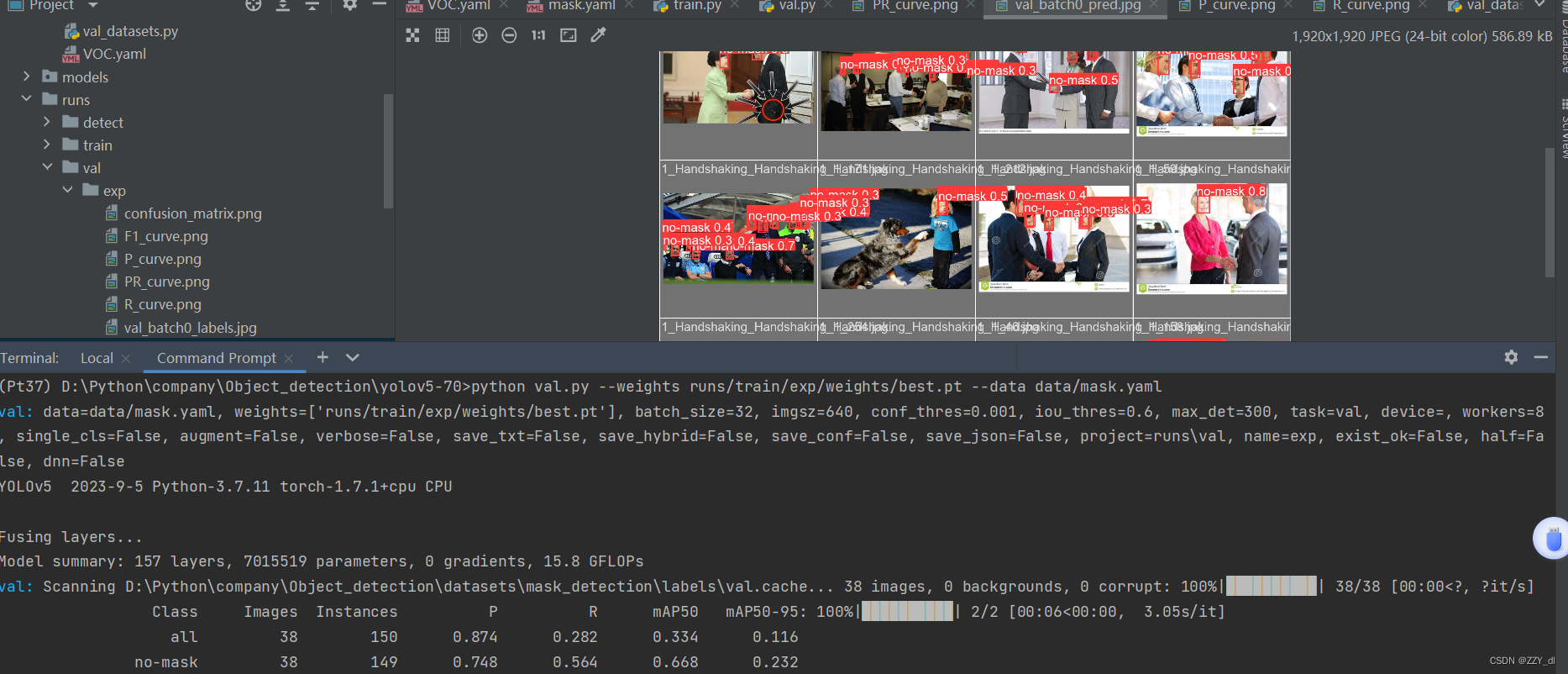
七、模型验证
python val.py --weights runs/train/exp/weights/best.pt --data data/mask.yaml
八、模型测试
python detect.py --weights runs/train/exp/weights/best.pt

九、评价指标
YOLOv5是一种用于目标检测的深度学习模型,它使用了YOLO(You Only Look Once)算法。评价指标是用来衡量模型性能的指标,以下是YOLOv5常用的评价指标介绍:
-
mAP(mean Average Precision):平均精度均值。mAP是目标检测中最常用的评价指标之一,它综合考虑了准确率和召回率。mAP的取值范围是0到1,数值越高表示模型性能越好。
- mAP50:是指平均精确度(mean Average Precision)的值,其中计算的是检测模型在IoU(Intersection over Union)阈值为0.5时的平均精确度。
- mAP50-95 : mAP50-95是指在计算平均精确度时,使用IoU阈值从0.5到0.95的范围进行计算,然后取平均值。这个指标可以更全面地评估检测模型在不同IoU阈值下的表现。
-
Precision(精确率):精确率是指模型预测为正例中真正为正例的比例。Precision的计算公式是预测为正例且正确的样本数除以预测为正例的样本数。
-
Recall(召回率):召回率是指真实为正例中被模型正确预测为正例的比例。Recall的计算公式是预测为正例且正确的样本数除以真实为正例的样本数。
-
F1-score:F1-score是精确率和召回率的调和平均值,它综合考虑了两者的性能。F1-score的计算公式是2 * (Precision * Recall) / (Precision + Recall)。
-
AP(Average Precision):平均精度。AP是mAP的组成部分,它是在不同的置信度阈值下计算得到的精度值的平均值。
-
IoU(Intersection over Union):交并比。IoU是计算预测框和真实框之间重叠部分的比例,用于判断预测框和真实框的匹配程度。一般情况下,当IoU大于一定阈值时,认为预测框和真实框匹配成功。
相关文章:
目标检测笔记(十三): 使用YOLOv5-7.0版本对图像进行目标检测完整版(从自定义数据集到测试验证的完整流程))
文章目录 一、目标检测介绍二、YOLOv5介绍2.1 和以往版本的区别 三、代码获取3.1 视频代码介绍 四、环境搭建五、数据集准备5.1 数据集转换5.2 数据集验证 六、模型训练七、模型验证八、模型测试九、评价指标 一、目标检测介绍 目标检测(Object Detectionÿ…...
【数据结构】设计环形队列
环形队列是一种线性数据结构,其操作表现基于 FIFO(先进先出)原则并且队尾被连接在队首之后以形成一个循环。它也被称为“环形缓冲器”。 环形队列的一个好处是我们可以利用这个队列之前用过的空间。在一个普通队列里,一旦一个队列…...

无涯教程-JavaScript - COUPDAYSNC函数
描述 COUPDAYSNC函数返回从结算日期到下一个息票日期的天数。 语法 COUPDAYSNC (settlement, maturity, frequency, [basis])争论 Argument描述Required/OptionalSettlement 证券的结算日期。 证券结算日期是指在发行日期之后将证券交易给买方的日期。 RequiredMaturity 证…...

python 随机生成emoji表情
问答板块觉得比较有意思的问题 当时搜了些网上的发现基本都不能用,不知道是版本的问题还是咋的就开始自己研究 python随机生成emoji 问题的产生解决官网文档数据类型实现思路实现前提:具体实现: 其他常见用法插入 Emoji 表情:解析…...

python关闭指定进程以excel为例
先说下环境: Excel版本: Python2.7.13和Python3.10.4并存。 2、打开两个excel工作簿 看进程是这样的: 3、用python编程kill进程 # -*- coding: utf-8 -*- import os proc_nameEXCEL.EXE if __name__ __main__:os.system(taskkill /im {} /…...

前后端中的异步和事件机制 | 前后端开发
前言 在前后端程序设计开发工作中,小伙伴们一定都接触过事件、异步这些概念。出现这些概念的原因之一是,我们的代码在执行过程中所涉及的逻辑在不同的场合下执行时间的期望是各不相同的。为了尽量做到充分利用CPU等资源做尽可能多的事,免不了…...

设计模式篇(Java):装饰者模式
👨💻本文专栏:设计模式篇-装饰者模式 👨💻本文简述:装饰者模式的详解以及jdk中的应用 👨💻上一篇文章: 设计模式篇(Java):桥接模式 👨&am…...
键值对RDD】)
Spark【RDD编程(三)键值对RDD】
简介 键值对 RDD 就是每个RDD的元素都是 (key,value)类型的键值对,是一种常见的 RDD,可以应用于很多场景。 因为毕竟通过我们之前Hadoop的学习中,我们就可以看到对数据的处理,基本都是以…...

从板凳围观到玩转行家:Moonbeam投票委托如何让普通用户一同参与
今年5月,Moonbeam发起了一项社区链上治理中投票委托反馈的调查。187位社区成员参与了这项调查,调查发现受访者对治理感兴趣,增加参与度只需要进行一些调整,即更简化的投票流程。 治理和去中心化是Web3的核心,随着Moon…...
SpringMVC的文件上传文件下载多文件上传---详细介绍
目录 前言: 一,文件上传 1.1 添加依赖 1.2 配置文件上传解析器 1.3 表单设置 1.4 文件上传的实现 二,文件下载 controller层 前端jsp 三,多文件上传 Controller层 运行 前言: Spring MVC 是一个基于 Java …...
综合案例】)
Spark【RDD编程(四)综合案例】
案例1-TOP N个数据的值 输入数据: 1,1768,50,155 2,1218,600,211 3,2239,788,242 4,3101,28,599 5,4899,290,129 6,3110,54,1201 7,4436,259,877 8,2369,7890,27 处理代码: def main(args: Array[String]): Unit {//创建SparkContext对象val conf…...

Golang报错mixture of field:value and value initializers
Golang报错mixture of field:value and value initializers 这个错误跟编程习惯(模式)有关,都知道golang 语言的编程与java /python 以及其他的编程语言相似 ,一通百通,易学万卷书。 编程中同一个结构中要保持唯一模…...

【网络教程】记一次使用Docker手动搭建BT宝塔面板的全过程(包含问题解决如:宝塔面板无法开启防火墙,ssh,nginx等)
文章目录 准备安装安装宝塔面板开启ssh和修改ssh的密码导出镜像问题解决宝塔面板无法开启防火墙无法启动ssh设置密码nginx安装失败设置开机启动相关服务准备 演示的系统环境:Ubuntu 22.04.3 LTS更新安装/升级docker到最新版本升级docker相关命令如下# 更新软件包列表并自动升级…...
【大虾送书第九期】速学Linux:系统应用从入门到精通
目录 🍭写在前面 🍭为什么学习Linux系统 🍭Linux系统的应用领域 🍬1.Linux在服务器的应用 🍬2.嵌入式Linux的应用 🍬3.桌面Linux的应用 🍭Linux的版本选择 &a…...

docker相关命令
####### 帮助启动类命令 ########## 启动docker systemctl start docker 停止docker systemctl stop docker 重启docker systemctl restart docker 查看docker状态 systemctl status docker 开机启动 systemctl enable docker 查看docker概要信息 docker info 查看…...

【Redis】4、rsync远程同步
与inodify结合使用,实现实时同步 rsync简介 rsync(Remote Sync,远程同步)是一个开源的快速备份工具,可以在不同主机之间镜像同步整个目录树,;支持增量备份,并保持链接和权限&#…...

无服务架构--Serverless
无服务架构 无服务架构(Serverless Architecture)即无服务器架构,也被称为函数即服务(Function as a Service,FaaS),是一种云计算模型,用于构建和部署应用程序,无需关心…...

2023-09-07 LeetCode每日一题(修车的最少时间)
2023-09-07每日一题 一、题目编号 2594. 修车的最少时间二、题目链接 点击跳转到题目位置 三、题目描述 给你一个整数数组 ranks ,表示一些机械工的 能力值 。ranksi 是第 i 位机械工的能力值。能力值为 r 的机械工可以在 r * n2 分钟内修好 n 辆车。 同时给你…...
数据挖掘实验-主成分分析与类特征化
数据集&代码https://www.aliyundrive.com/s/ibeJivEcqhm 一.主成分分析 1.实验目的 了解主成分分析的目的,内容以及流程。 掌握主成分分析,能够进行编程实现。 2.实验原理 主成分分析的目的 主成分分析就是把原有的多个指标转化成少数几个代表…...
,322. 零钱兑换,279.完全平方数)
70. 爬楼梯 (进阶),322. 零钱兑换,279.完全平方数
代码随想录训练营第45天|70. 爬楼梯 (进阶,322. 零钱兑换,279.完全平方数 70.爬楼梯文章思路代码 322.零钱兑换文章思路代码 279.完全平方数文章思路代码 总结 70.爬楼梯 文章 代码随想录|0070.爬楼梯完全背包版本 思路 将楼梯长度视为背…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...

Selenium常用函数介绍
目录 一,元素定位 1.1 cssSeector 1.2 xpath 二,操作测试对象 三,窗口 3.1 案例 3.2 窗口切换 3.3 窗口大小 3.4 屏幕截图 3.5 关闭窗口 四,弹窗 五,等待 六,导航 七,文件上传 …...

水泥厂自动化升级利器:Devicenet转Modbus rtu协议转换网关
在水泥厂的生产流程中,工业自动化网关起着至关重要的作用,尤其是JH-DVN-RTU疆鸿智能Devicenet转Modbus rtu协议转换网关,为水泥厂实现高效生产与精准控制提供了有力支持。 水泥厂设备众多,其中不少设备采用Devicenet协议。Devicen…...

Modbus RTU与Modbus TCP详解指南
目录 1. Modbus协议基础 1.1 什么是Modbus? 1.2 Modbus协议历史 1.3 Modbus协议族 1.4 Modbus通信模型 🎭 主从架构 🔄 请求响应模式 2. Modbus RTU详解 2.1 RTU是什么? 2.2 RTU物理层 🔌 连接方式 ⚡ 通信参数 2.3 RTU数据帧格式 📦 帧结构详解 🔍…...

node.js的初步学习
那什么是node.js呢? 和JavaScript又是什么关系呢? node.js 提供了 JavaScript的运行环境。当JavaScript作为后端开发语言来说, 需要在node.js的环境上进行当JavaScript作为前端开发语言来说,需要在浏览器的环境上进行 Node.js 可…...