多线程与高并发——并发编程(6)
文章目录
- 六、并发集合
- 1 ConcurrentHashMap
- 1.1 存储结构
- 1.2 存储操作
- 1.2.1 put方法
- 1.2.2 putVal方法-散列算法
- 1.2.3 putVal方法-添加数据到数组&初始化数组
- 1.2.4 putVal方法-添加数据到链表
- 1.3 扩容操作
- 1.3.1 treeifyBin方法触发扩容
- 1.3.2 tryPresize方法-针对putAll的初始化操作
- 1.3.3 tryPreSize方法-计算扩容戳&查看BUG
- 1.3.4 tryPreSize方法-对sizeCtl的修改&条件判断的BUG
- 1.3.5 transfer方法-计算每个线程迁移的长度
- 1.3.6 transfer方法-构建新数组&查看标识属性
- 1.3.7 transfer方法-线程领取迁移任务
- 1.3.8 transfer方法-迁移结束操作
- 1.3.9 transfer方法-迁移数据(链表)
- 1.3.10 helpThransfer方法-协助扩容
- 1.4 红黑树操作
- 1.4.1 什么是红黑树
- 1.4.2 treeifyBin方法-封装TreeNode和双向链表
- 1.4.3 TreeBin有参构造-双向链表转为红黑树
- 1.4.4 balanceInsertion方法-保证红黑树平衡以及特性
- 1.4.5 putTreeVal方法-添加节点
- 1.4.6 TreeBin的锁操作
- 1.4.7 transfer迁移数据
- 1.5 查询数据
- 1.5.1 get方法-查询数据的入口
- 1.5.2 ForwardingNode的find方法
- 1.5.3 ReservationNode的find方法
- 1.5.4 TreeBin的find方法
- 1.5.5 TreeNode的findTreeNode方法
- 1.6 ConcurrentHashMap其它方法
- 1.6.1 compute方法
- 1.6.2 compute方法源码分析
- 1.6.3 computeIfPresent、computeIfAbsent、compute的区别
- 1.6.4 replace方法详解
- 1.6.5 merge方法详解
- 1.7 ConcurrentHashMap计数器
- 1.7.1 addCount方法分析
- 1.7.2 size方法分析
- 1.8 JDK1.7的HashMap的环形链表问题
- 2 CopyOnWriteArrayList
- 2.1 CopyOnWriteArrayList介绍
- 2.2 核心属性&方法
- 2.3 读操作
- 2.4 写操作
- 2.5 移除数据
- 2.6 覆盖数据&清空集合
- 2.7 迭代器
六、并发集合
1 ConcurrentHashMap
1.1 存储结构
ConcurrentHashMap 是线程安全的 HashMap,在 JDK1.8 中是以 CAS + synchronized 实现的线程安全。
- CAS:在没有 hash 冲突时(Node 要放在数组上时)
- synchronized:在出现 hash 冲突时(Node 存放的位置已经有数据了)
- 存储结构:数组+链表+红黑树
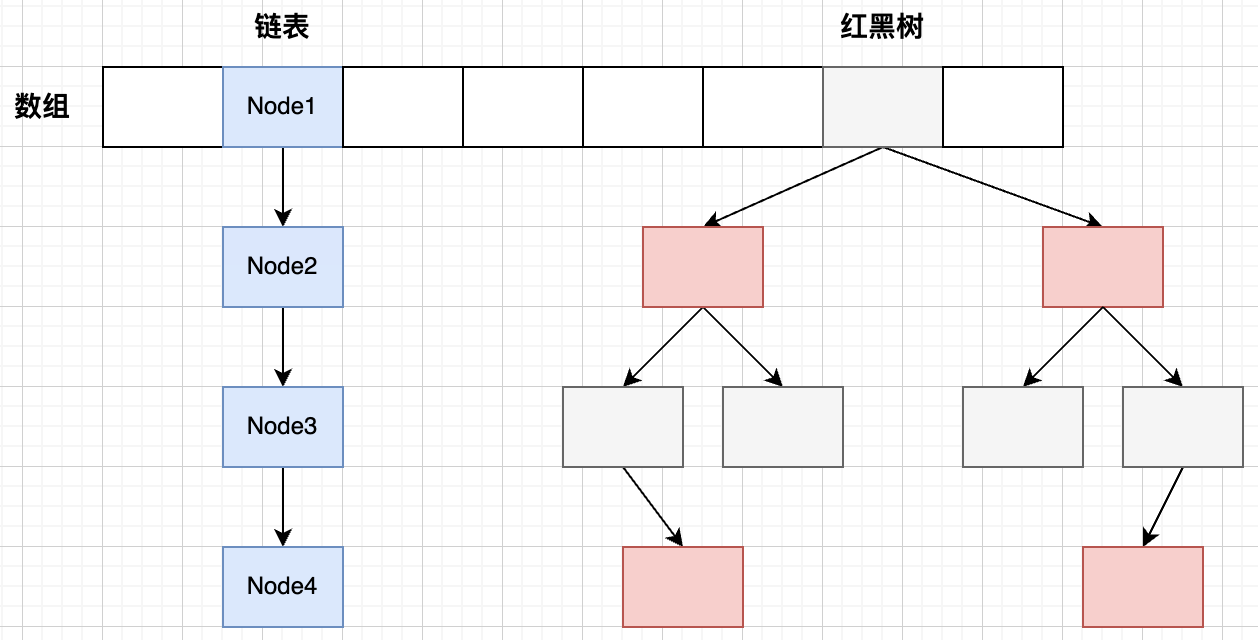
1.2 存储操作
1.2.1 put方法
public V put(K key, V value) {// 在调用put方法时,会调用putVal方法,第三个参数默认传递false// 在调用putIfAbsent时,会调用putVal方法,第三个参数传递true// false: 代表key一致时,直接覆盖数据// true: 代表key一致时,什么都不做,key不存在正常添加(类似Redis的setnx)return putVal(key, value, false);
}
1.2.2 putVal方法-散列算法
final V putVal(K key, V value, boolean onlyIfAbsent) {// ConcurrentHashMap不允许key或者value出现为null的值,跟HashMap的区别if (key == null || value == null) throw new NullPointerException();// 根据key的hashCode计算出一个hash值,后期得出当前key-value要存储在哪个数组索引位置int hash = spread(key.hashCode());int binCount = 0; // 一个标识,在后面有用// ...省略大量代码
}
// 计算当前Node的hash值的方法
static final int spread(int h) {// 将key的hashCode值的高低16位进行^运算,最终又与HASH_BITS进行了&运算// 将高位的hash也参与到计算索引位置的运算当中,尽可能将数据打散// 为什么HashMap、ConcurrentHashMap,都要求数组长度为2^n// HASH_BITS让hash值的最高位符号位肯定为0,代表当前hash值默认情况下一定是正数,因为hash值为负数时,有特殊的含义// static final int MOVED = -1; // 代表当前hash位置的数据正在扩容// static final int TREEBIN = -2; // 代表当前hash位置下挂载的是一个红黑树// static final int RESERVED = -3; // 预留当前索引位置return (h ^ (h >>> 16)) & HASH_BITS;// 计算数组放到哪个索引位置的方法 (f = tabAt(tab, i = (n - 1) & hash)// n:是数组的长度
}
运算方式
00000000 00000000 00000000 00001111 - 15 (n - 1)
&
((00001101 00001101 00101111 10001111 - h^00000000 00000000 00001101 00001101 - h >>> 16)&01111111 11111111 11111111 11111111 - HASH_BITS
)
1.2.3 putVal方法-添加数据到数组&初始化数组
- 添加数据到数组:CAS
- 初始化数组:DCL + CAS
final V putVal(K key, V value, boolean onlyIfAbsent) {// 省略部分代码...// 将Map的数组赋值给tab,死循环for (Node<K,V>[] tab = table;;) {// n: 数组长度;i: 当前Node需要存放的索引位置// f: 当前数组i索引位置的Node对象;fn: 当前数组i索引位置上数据的hash值Node<K,V> f; int n, i, fh;// 判断当前数组是否还没有初始化if (tab == null || (n = tab.length) == 0)tab = initTable(); // 将数组进行初始化// 基于 (n - 1) & hash 计算出当前Node需要存放在哪个索引位置// 基于tabAt获取到i位置的数据else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// 现在数组的i位置上没有数据,基于CAS的方式将数据存在i位置上if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))break; // 如果成功,执行break跳出循环,插入数据成功}// 判断当前位置数据是否正在扩容else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f); // 让当前插入数据的线程协助扩容// 省略部分代码...}addCount(1L, binCount);return null;
}
// 初始化数组方法
private final Node<K,V>[] initTable() {Node<K,V>[] tab; int sc;// 再次判断数组没有初始化,并且完成tab的赋值while ((tab = table) == null || tab.length == 0) {// sizeCtl:是数组在初始化和扩容操作时的一个控制变量。// -1: 代表当前数组正在初始化;// 小于-1: 低16位代表当前数组正在扩容的线程个数(如果1个线程扩容,值为-2,如果2个线程扩容,值为-3);// 0: 代表数组还没初始化;// 大于0: 代表当前数组的扩容阈值,或者是当前数组的初始化大小// 将sizeCtl赋值给sc变量,并判断是否小于0if ((sc = sizeCtl) < 0)Thread.yield(); // lost initialization race; just spin// 可以尝试初始化数组,线程会以CAS的方式,将sizeCtl修改为-1,代表当前线程可以初始化数组else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {try { // 尝试初始化// 再次判断当前数组是否已经初始化完毕if ((tab = table) == null || tab.length == 0) {// 开始初始化: 如果sizeCtl > 0,就初始化sizeCtl长度的数组;如果sizeCtl == 0,就初始化默认的长度16int n = (sc > 0) ? sc : DEFAULT_CAPACITY;// 初始化数组Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];// 将初始化的数组nt,赋值给tab和tabletable = tab = nt;// sc赋值为了数组长度 - 数组长度 右移 2位 16 - 4 = 12,将sc赋值为下次扩容的阈值sc = n - (n >>> 2);}} finally {// 将赋值好的sc,设置给sizeCtlsizeCtl = sc;}break;}}return tab;
}
1.2.4 putVal方法-添加数据到链表
- 添加数据到链表:利用 synchronized 基于当前索引位置的Node,作为锁对象
final V putVal(K key, V value, boolean onlyIfAbsent) {// 省略部分代码...int binCount = 0;for (Node<K,V>[] tab = table;;) {// n: 数组长度;i: 当前Node需要存放的索引位置// f: 当前数组i索引位置的Node对象;fn: 当前数组i索引位置上数据的hash值Node<K,V> f; int n, i, fh;// 省略部分代码...else {V oldVal = null; // 声明变量为oldValsynchronized (f) { // 基于当前索引位置的Node,作为锁对象// 判断当前位置的数据还是之前的f么……(避免并发操作的安全问题)if (tabAt(tab, i) == f) {if (fh >= 0) { // 再次判断hash值是否大于0(不是树)// binCount设置为1(在链表情况下,记录链表长度的一个标识)binCount = 1;// 死循环,每循环一次,对binCountfor (Node<K,V> e = f;; ++binCount) { K ek;// 当前i索引位置的数据,是否和当前put的key的hash值一致if (e.hash == hash &&// 如果当前i索引位置数据的key和put的key == 返回为true// 或者equals相等((ek = e.key) == key || (ek != null && key.equals(ek)))) {// key一致,可能需要覆盖数据,当前i索引位置数据的value赋值给oldValoldVal = e.val;// 如果传入的是false,代表key一致,覆盖value;如果传入的是true,代表key一致,什么都不做if (!onlyIfAbsent)e.val = value; // 覆盖valuebreak;}Node<K,V> pred = e; // 拿到当前指定的Node对象// 将e指向下一个Node对象,如果next指向的是一个null,可以挂在当前Node下面if ((e = e.next) == null) {// 将hash,key,value封装为Node对象,挂在pred的next上pred.next = new Node<K,V>(hash, key, value, null);break;}}}// 省略部分代码...}}if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD) // binCount是否大于8(链表长度是否 >= 8)// 尝试转为红黑树或者扩容// 基于treeifyBin方法和上面的if判断,可以得知链表想要转为红黑树,必须保证数组长度大于等于64,并且链表长度大于等于8// 如果数组长度没有达到64的话,会首先将数组扩容treeifyBin(tab, i);if (oldVal != null) // 如果出现了数据覆盖的情况,返回之前的值return oldVal;break;}}}// 省略部分代码...
}
为什么链表长度为8转换为红黑树,不是能其他数值嘛?
因为泊松分布
The main disadvantage of per-bin locks is that other update* operations on other nodes in a bin list protected by the same* lock can stall, for example when user equals() or mapping* functions take a long time. However, statistically, under* random hash codes, this is not a common problem. Ideally, the* frequency of nodes in bins follows a Poisson distribution* (http://en.wikipedia.org/wiki/Poisson_distribution) with a* parameter of about 0.5 on average, given the resizing threshold* of 0.75, although with a large variance because of resizing* granularity. Ignoring variance, the expected occurrences of* list size k are (exp(-0.5) * pow(0.5, k) / factorial(k)). The* first values are:** 0: 0.60653066* 1: 0.30326533* 2: 0.07581633* 3: 0.01263606* 4: 0.00157952* 5: 0.00015795* 6: 0.00001316* 7: 0.00000094* 8: 0.00000006* more: less than 1 in ten million
1.3 扩容操作
1.3.1 treeifyBin方法触发扩容
// 在链表长度大于等于8时,尝试将链表转为红黑树
private final void treeifyBin(Node<K,V>[] tab, int index) {Node<K,V> b; int n, sc;// 数组不能为空if (tab != null) {// 数组的长度n,是否小于64if ((n = tab.length) < MIN_TREEIFY_CAPACITY)// 如果数组长度小于64,不能将链表转为红黑树,先尝试扩容操作tryPresize(n << 1);// 省略部分代码……}
}
1.3.2 tryPresize方法-针对putAll的初始化操作
// size是将之前的数组长度 左移 1位得到的结果
private final void tryPresize(int size) {// 如果扩容的长度达到了最大值,就使用最大值,否则需要保证数组的长度为2的n次幂// 这块的操作,是为了初始化操作准备的,因为调用putAll方法时,也会触发tryPresize方法// 如果刚刚new的ConcurrentHashMap直接调用了putAll方法的话,会通过tryPresize方法进行初始化int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :tableSizeFor(size + (size >>> 1) + 1);// 这些代码和initTable一模一样int sc;// 将sizeCtl的值赋值给sc,并判断是否大于0,这里代表没有初始化操作,也没有扩容操作while ((sc = sizeCtl) >= 0) {// 将ConcurrentHashMap的table赋值给tab,并声明数组长度nNode<K,V>[] tab = table; int n;// 数组是否需要初始化if (tab == null || (n = tab.length) == 0) {// 进来执行初始化// sc是初始化长度,初始化长度如果比计算出来的c要大的话,直接使用sc,如果没有sc大,说明sc无法容纳下putAll中传入的map,使用更大的数组长度n = (sc > c) ? sc : c;// 设置sizeCtl为-1,代表初始化操作if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {try {// 再次判断数组的引用有没有变化if (table == tab) {// 初始化数组Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];// 数组赋值table = nt;// 计算扩容阈值sc = n - (n >>> 2);}} finally {// 最终赋值给sizeCtlsizeCtl = sc;}}}// 如果计算出来的长度c小于等于c,或者数组长度大于等于最大长度,直接退出循环结束方法else if (c <= sc || n >= MAXIMUM_CAPACITY)break;// 省略部分代码...}
}// 将c这个长度设置到最近的2的n次幂的值, 15 -> 16 17 -> 32
// c == size + (size >>> 1) + 1
// size = 17
00000000 00000000 00000000 00010001
+
00000000 00000000 00000000 00001000
+
00000000 00000000 00000000 00000001
// c = 26
00000000 00000000 00000000 00011010
private static final int tableSizeFor(int c) { // c = 26// 00000000 00000000 00000000 00011001int n = c - 1;// 00000000 00000000 00000000 00011001// 00000000 00000000 00000000 00001100// 00000000 00000000 00000000 00011101n |= n >>> 1;// 00000000 00000000 00000000 00011101// 00000000 00000000 00000000 00000111// 00000000 00000000 00000000 00011111n |= n >>> 2;// 00000000 00000000 00000000 00011111// 00000000 00000000 00000000 00000001// 00000000 00000000 00000000 00011111n |= n >>> 4;// 00000000 00000000 00000000 00011111// 00000000 00000000 00000000 00000000// 00000000 00000000 00000000 00011111n |= n >>> 8;// 00000000 00000000 00000000 00011111n |= n >>> 16;// 00000000 00000000 00000000 00100000return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
1.3.3 tryPreSize方法-计算扩容戳&查看BUG
private final void tryPresize(int size) {// n:数组长度while ((sc = sizeCtl) >= 0) {// 省略部分代码…// 判断当前的tab是否和table一致else if (tab == table) {// 计算扩容标识戳,根据当前数组的长度计算一个16位的扩容戳// 第一个作用是为了保证后面的sizeCtl赋值时,保证sizeCtl为小于-1的负数// 第二个作用用来记录当前是从什么长度开始扩容的int rs = resizeStamp(n);// BUG --- sc < 0,永远进不去if (sc < 0) { // 如果sc小于0,代表有线程正在扩容// 省略部分代码……协助扩容的代码(进不来~~~~)}// 代表没有线程正在扩容,我是第一个扩容的。else if (U.compareAndSwapInt(this, SIZECTL, sc,(rs << RESIZE_STAMP_SHIFT) + 2))// 省略部分代码……第一个扩容的线程……}}
}
// 计算扩容标识戳
// 32 = 00000000 00000000 00000000 00100000
// Integer.numberOfLeadingZeros(32) = 26
// 1 << (RESIZE_STAMP_BITS - 1)
// 00000000 00000000 10000000 00000000
// 00000000 00000000 00000000 00011010
// 00000000 00000000 10000000 00011010
static final int resizeStamp(int n) {return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}
1.3.4 tryPreSize方法-对sizeCtl的修改&条件判断的BUG
private final void tryPresize(int size) {// sc默认为sizeCtlwhile ((sc = sizeCtl) >= 0) {else if (tab == table) {// rs: 扩容戳 00000000 00000000 10000000 00011010int rs = resizeStamp(n);if (sc < 0) {// 说明有线程正在扩容,过来帮助扩容Node<K,V>[] nt;// 依然有BUG// 当前线程扩容时,老数组长度是否和我当前线程扩容时的老数组长度一致// 00000000 00000000 10000000 00011010if ((sc >>> RESIZE_STAMP_SHIFT) != rs // 10000000 00011010 00000000 00000010 // 00000000 00000000 10000000 00011010// 这两个判断都是有问题的,核心问题就应该先将rs左移16位,再追加当前值// 判断当前扩容是否已经即将结束|| sc == rs + 1 // sc == rs << 16 + 1 BUG// 判断当前扩容的线程是否达到了最大限度|| sc == rs + MAX_RESIZERS // sc == rs << 16 + MAX_RESIZERS BUG// 扩容已经结束了|| (nt = nextTable) == null // 记录迁移的索引位置,从高位往低位迁移,也代表扩容即将结束|| transferIndex <= 0)break;// 如果线程需要协助扩容,首先就是对sizeCtl进行+1操作,代表当前要进来一个线程协助扩容if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))// 上面的判断没进去的话,nt就代表新数组transfer(tab, nt);}// 是第一个来扩容的线程// 基于CAS将sizeCtl修改为 10000000 00011010 00000000 00000010 // 将扩容戳左移16位之后,符号位是1,就代码这个值为负数,低16位在表示当前正在扩容的线程有多少个// 为什么低位值为2时,代表有一个线程正在扩容// 每一个线程扩容完毕后,会对低16位进行-1操作,当最后一个线程扩容完毕后,减1的结果还是-1,当值为-1时,要对老数组进行一波扫描,查看是否有遗漏的数据没有迁移到新数组else if (U.compareAndSwapInt(this, SIZECTL, sc,(rs << RESIZE_STAMP_SHIFT) + 2))// 调用transfer方法,并且将第二个参数设置为null,就代表是第一次来扩容!transfer(tab, null);}}
}
1.3.5 transfer方法-计算每个线程迁移的长度
// 开始扩容 tab: oldTable
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {// n: 数组长度// stride: 每个线程一次性迁移多少数据到新数组int n = tab.length, stride;// 基于CPU的内核数量来计算,每个线程一次性迁移多少长度的数据最合理// NCPU = 4// 举个栗子:数组长度为1024 - 512 - 256 - 128 / 4 = 32// MIN_TRANSFER_STRIDE = 16,为每个线程迁移数据的最小长度// 根据CPU计算每个线程一次迁移多长的数据到新数组,如果结果大于16,使用计算结果。 如果结果小于16,就使用最小长度16if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)stride = MIN_TRANSFER_STRIDE; // 省略部分代码...
}
1.3.6 transfer方法-构建新数组&查看标识属性
// 以32长度数组扩容到64位例子
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {// 省略部分代码...// n: 老数组长度 32// stride: 步长 16// 第一个进来扩容的线程需要把新数组构建出来if (nextTab == null) {try {// 将原数组长度左移一位,构建新数组长度Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];// 赋值操作nextTab = nt;} catch (Throwable ex) { // 到这说明已经达到数组长度的最大取值范围sizeCtl = Integer.MAX_VALUE;// 设置sizeCtl后直接结束return;}// 对成员变量的新数组赋值nextTable = nextTab;// 迁移数据时,用到的标识,默认值为老数组长度transferIndex = n; // 32}// 新数组长度int nextn = nextTab.length; // 64// 在老数组迁移完数据后,做的标识ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);// 迁移数据时,需要用到的标识boolean advance = true;boolean finishing = false; // 省略部分代码...
}
1.3.7 transfer方法-线程领取迁移任务
// 以32长度扩容到64位为例子
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {// 省略部分代码…// n: 32// stride: 16int n = tab.length, stride;if (nextTab == null) { // 省略部分代码…nextTable = nextTab; // 新数组// transferIndex:0transferIndex = n;}// nextn:64int nextn = nextTab.length;ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);// advance:true,代表当前线程需要接收任务,然后再执行迁移;如果为false,代表已经接收完任务boolean advance = true;boolean finishing = false; // 是否迁移结束// i = 15 代表当前线程迁移数据的索引值for (int i = 0, bound = 0;;) {Node<K,V> f; int fh; // f = null,fh = 0while (advance) { // 当前线程要接收任务// nextIndex = 16,nextBound = 16int nextIndex, nextBound;// 对i进行--,并且判断当前任务是否处理完毕!if (--i >= bound || finishing) // 第一次进来,这两个判断肯定进不去advance = false;// 判断transferIndex是否小于等于0,代表没有任务可领取,结束了// 在线程领取任务会,会对transferIndex进行修改,修改为transferIndex - stride// 在任务都领取完之后,transferIndex肯定是小于等于0的,代表没有迁移数据的任务可以领取else if ((nextIndex = transferIndex) <= 0) {i = -1相关文章:
多线程与高并发——并发编程(6)
文章目录 六、并发集合1 ConcurrentHashMap1.1 存储结构1.2 存储操作1.2.1 put方法1.2.2 putVal方法-散列算法1.2.3 putVal方法-添加数据到数组&初始化数组1.2.4 putVal方法-添加数据到链表1.3 扩容操作1.3.1 treeifyBin方法触发扩容1.3.2 tryPresize方法-针对putAll的初始…...

Elasticsearch——Docker单机部署安装
文章目录 1 简介2 Docker安装与配置2.1 安装Docker2.2 配置Docker镜像加速器2.3 调整Docker资源限制 3 准备Elasticsearch Docker镜像3.1 下载Elasticsearch镜像3.2 自定义镜像配置3.3执行Docker Compose 4 运行Elasticsearch容器4.1 创建Elasticsearch容器4.2 修改配置文件4.3…...

基于AHP模型指标权重分析python整理
一 背景介绍 日常会有很多定量分析的场景,然而也会有一些定性分析的场景针对定性分析的场景,预测者只能通过主观判断分析能力来推断事物的性质和发展趋势然而针对个人的直觉和虽然能够有一定的协助判断效果,但是很难量化到指标做后期的复用 …...

用python实现基本数据结构【02/4】
*说明 如果需要用到这些知识却没有掌握,则会让人感到沮丧,也可能导致面试被拒。无论是花几天时间“突击”,还是利用零碎的时间持续学习,在数据结构上下点功夫都是值得的。那么Python 中有哪些数据结构呢?列表、字典、集…...
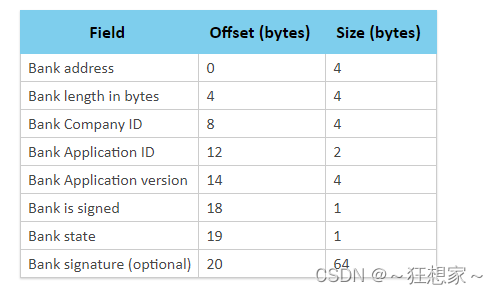
蓝牙Mesh专有DFU
蓝牙Mesh专有DFU Mesh专有DFU协议介绍特征DFU模式和类型角色并发传输混合设备的网络传输速率后台操作传输分区内存映射安全DFU固件IDApplication firmware IDSoftDevice firmware IDBootloader firmware ID 设备页面格式内容 Mesh专有DFU协议介绍 设备固件更新(Device Firmwar…...

浅谈综合管廊智慧运维管理平台应用研究
贾丽丽 安科瑞电气股份有限公司 上海嘉定 201801 摘要:为提升综合管廊运维管理水平,实现管理的数字化转型,采用综合监测系统、BIMGIS 可视化系统、智能机器人巡检、结构安全监测等技术,搭建实时监控、应急管理、数据分析等多功能…...

Httpservletrequest与Httpservletresponse
目录 一、Httpservletrequest 1.1什么是Httpservletrequest 1.2Httpservletrequest中的方法 二、Httpservletresponse 1.1什么是Httpservletresponse 1.2Httpservletresponse的方法 一、Httpservletrequest 1.1什么是Httpservletrequest HttpServletRequest(…...
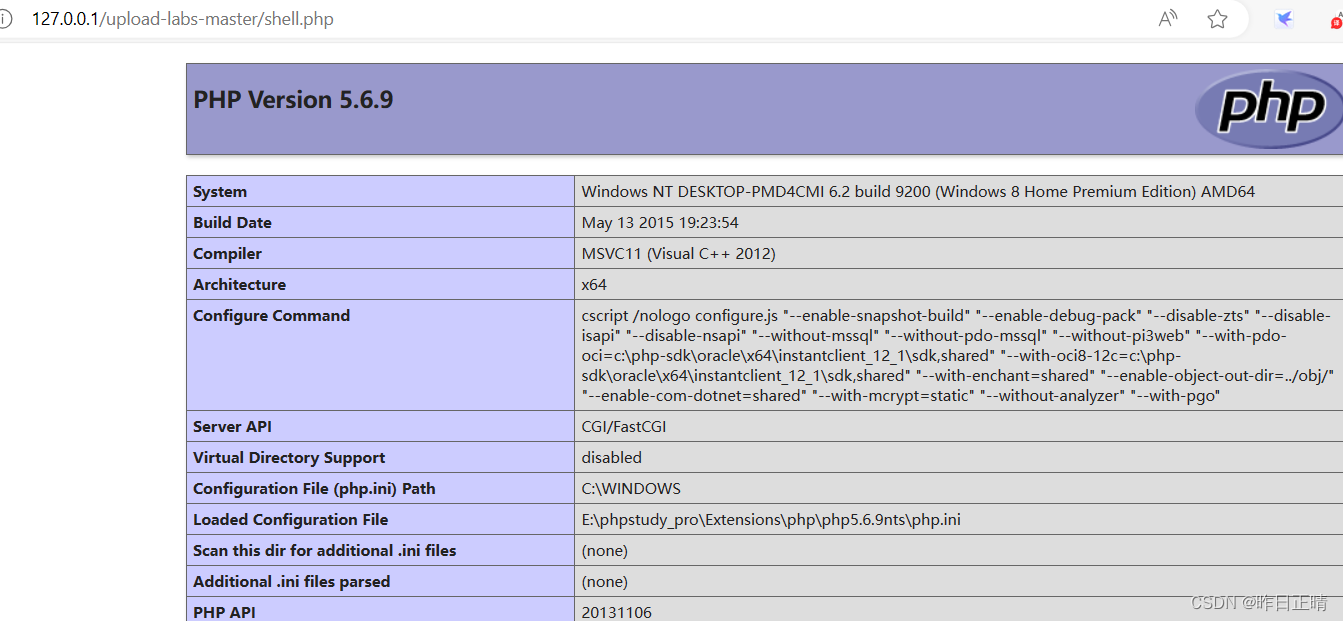
文件上传之图片码混淆绕过(upload的16,17关)
目录 1.upload16关 1.上传gif loadup17关(文件内容检查,图片二次渲染) 1.上传gif(同上面步骤相同) 2.条件竞争 1.upload16关 1.上传gif imagecreatefromxxxx函数把图片内容打散,,但是不会…...
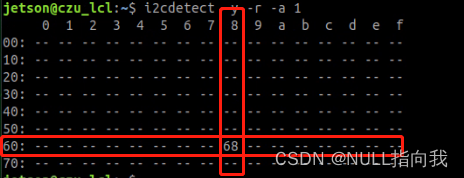
Jetsonnano B01 笔记5:IIC通信
今日继续我的Jetsonnano学习之路,今日学习的是IIC通信,并尝试使用Jetson读取MPU6050陀螺仪数据。文章提供源码。文章主要是搬运的官方PDF说明,这里结合自己实际操作作笔记。 目录 IIC通信: IIC硬件连线: 安装IIC库文…...

【网络爬虫笔记】爬虫Robots协议语法详解
Robots协议是指一个被称为Robots Exclusion Protocol的协议。该协议的主要功能是向网络蜘蛛、机器人等搜索引擎爬虫提供一个标准的访问控制机制,告诉它们哪些页面可以被抓取,哪些页面不可以被抓取。本文将进行爬虫Robots协议语法详解,同时提供…...
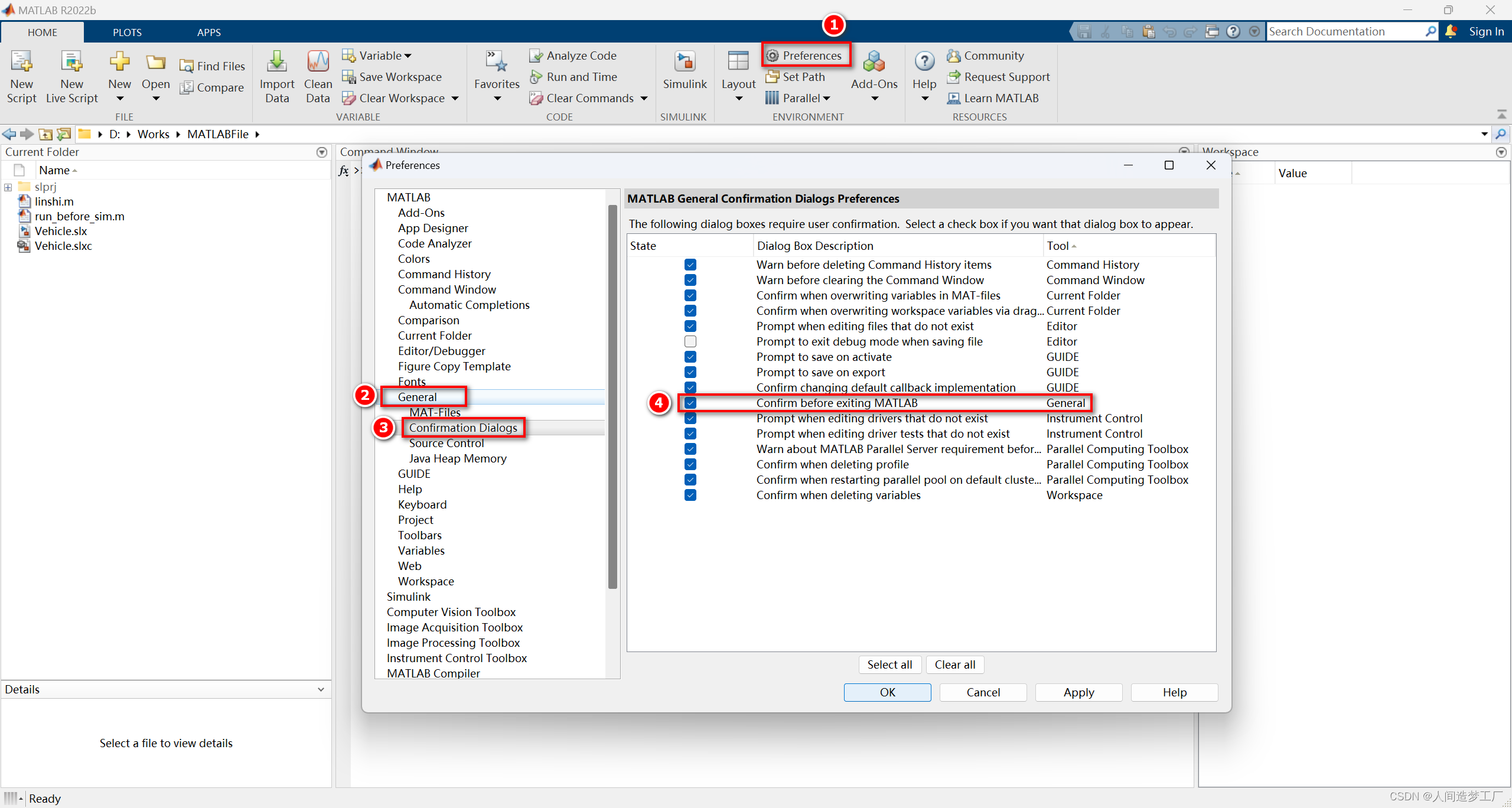
MATLAB 2022b 中设置关闭 MATLAB 之前进行询问
在 MATLAB 2022b 中可以进行设置,在关闭 MATLAB 之前进行询问,防止意外关闭 MATLAB。如图:...

在SpringBoot框架下,接口有读个实现类,在不改变任何源码的情况下,SpringBoot怎么知道给接口注入哪个实现类的依赖呢?
在Spring Boot框架下,当一个接口有多个实现类时,Spring Boot 默认情况下不知道要注入哪个实现类的依赖。因此,你需要使用一些方法来明确告诉Spring Boot应该注入哪个实现类的依赖。 以下是一些常用的方法: 1.使用Qualifier注解&a…...
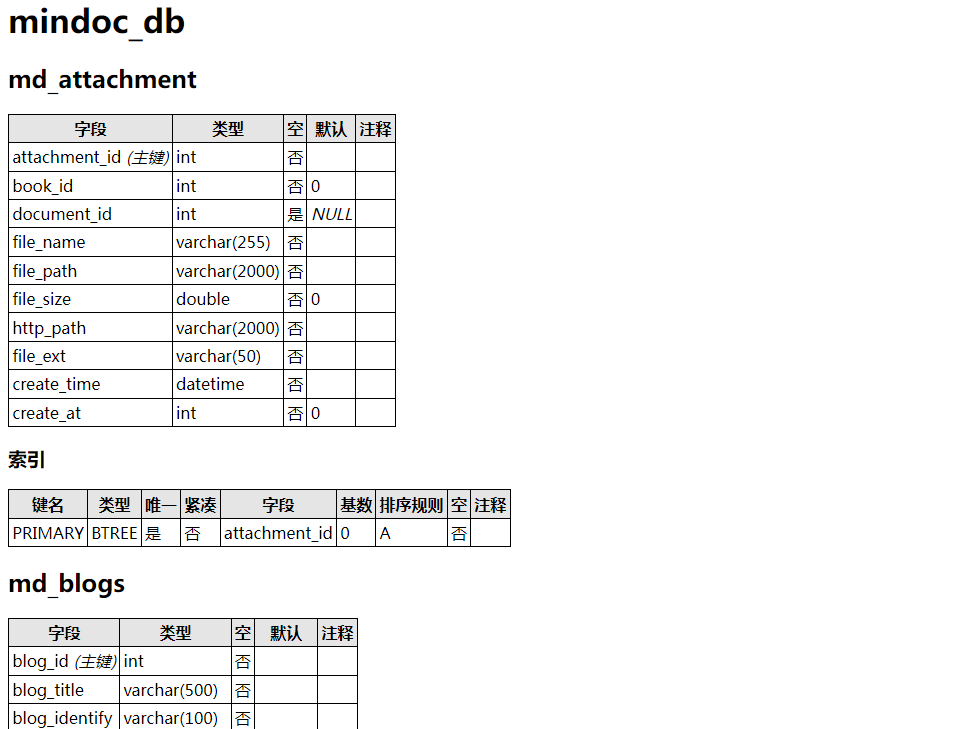
探索数据库管理的利器 - PHPMyAdmin
有一个项目,后端由博主独自负责,最近需要将项目交接给另一位同事。在项目初期,博主直接在数据库中使用工具创建了相关表格,并在完成后利用PhpMyAdmin生成了一份数据字典,供团队使用。然而,在随后的开发过程…...

大数据技术原理与应用学习笔记第1章
黄金组合访问地址:http://dblab.xmu.edu.cn/post/7553/ 1.《大数据技术原理与应用》教材 官网:http://dblab.xmu.edu.cn/post/bigdata/ 2.大数据软件安装和编程实践指南 官网林子雨编著《大数据技术原理与应用》教材配套大数据软件安装和编程实践指…...
算法从未放弃你,放弃你的只有你自己
在人生的旅程中,我们常常会遇到各种挫折和困难。有些人在面对困境时,会选择放弃,将责任归咎于命运或外部环境。然而,算法教给我们一个重要的道理:永远不要放弃 当我们遇到问题或挑战时,算法可以帮助我们找到…...

[Linux 基础] linux基础指令(1)
文章目录 1、Linux下基本指令1.ls指令2.pwd指令3.cd指令4.touch指令5.mkdir指令6.rmdir指令 && rm指令7.man指令8.cp指令9.mv指令10.cat指令11.more指令12.less指令 Linux学习笔记从今天开始不断更新了。第一篇我们从基础指令开始学起。 1、Linux下基本指令 好多人都说…...

ESP32蓝牙主从站模式:主站发送,从站接收,同时附加简单通信协议
主站发送:WXAiBj,六个字符 蓝牙模式是一个字符一个字符发送 主站和从站设置通信协议 使得六个字符一句话完整接收,同时打印出接收完成信息 硬件电路连接如下: 主从站为两个ESP32,只使用了其中的蓝牙功能 代码如下: 主站: //主机模式 #include <Arduino.h> …...

Redis布隆过滤亿级大数据
场景描述 小程序用户的openid作为最主要的业务查询字段,在做了缓存设计之后仍有非常高频的查询,通过埋点简单统计约在每日1000w次。 其中:由于有新增用户原因,导致请求的openid根本不存在MySQL数据库中,这部分统计约占…...
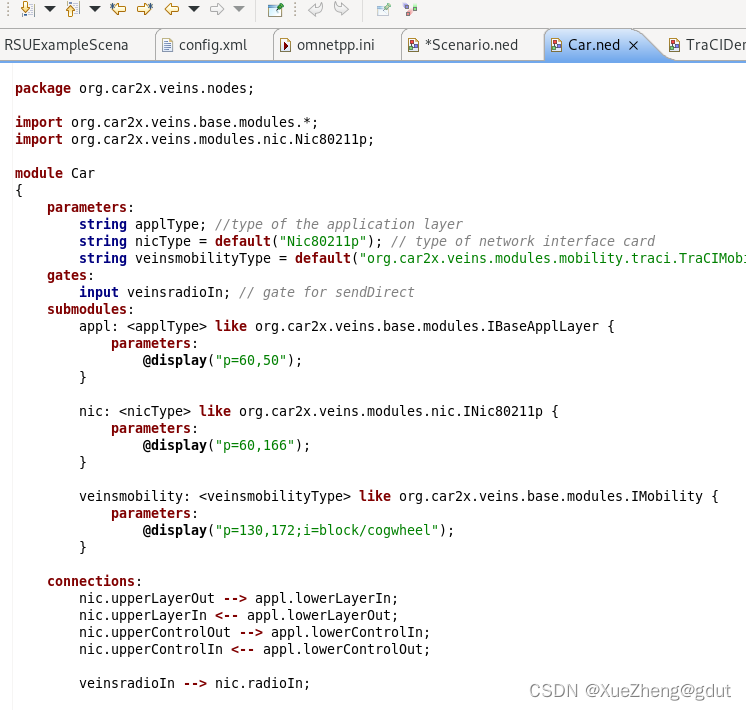
车联网仿真工具Veins学习1
准备条件 假如你是一个小白,先找到相关的参考资料(已根据上一篇博客安装好Veins),主要是官方文档和相关的博客,官方提供了一个example,我找到的资料如下: Frequently Asked Questions (FAQ) O…...

封闭岛屿数量 -- 二维矩阵的dfs算法
1254. 统计封闭岛屿的数目 这道题和 岛屿数量 – 二维矩阵的dfs算法 类似,区别在于不算边缘部分的岛屿,那其实很简单,把上⼀题中那些靠边的岛屿排除掉,剩下的就是「封闭岛屿」了。 关于岛屿的相似题目: 岛屿数量 –…...

从IMU初始化到点云去畸变:深入Fast-LIO2的传感器融合核心流程
从IMU初始化到点云去畸变:Fast-LIO2传感器融合全流程解析 在自动驾驶和机器人定位领域,激光雷达与IMU的紧耦合系统正成为高精度状态估计的主流方案。Fast-LIO2作为这一技术路线的代表,其核心创新在于将IMU的动力学特性与激光点云几何特征深度…...

【24年最新算法】首发CPO-XGBoost回归+交叉验证 基于冠豪猪优化算法-XGBoost多变量回归预测
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室👇 关注我领取海量matlab电子书和…...

Qwen3-0.6B-FP8多语言落地:支持粤语、闽南语、藏语等方言指令理解实测
Qwen3-0.6B-FP8多语言落地:支持粤语、闽南语、藏语等方言指令理解实测 1. 引言:当AI能听懂你的家乡话 想象一下,你正在用粤语和AI助手聊天,让它帮你写一份工作报告;或者用闽南语问它今天的天气,它不仅能听…...

Zotero文献管理终极指南:从混乱到高效的研究工作流
Zotero文献管理终极指南:从混乱到高效的研究工作流 【免费下载链接】zotero Zotero is a free, easy-to-use tool to help you collect, organize, annotate, cite, and share your research sources. 项目地址: https://gitcode.com/gh_mirrors/zo/zotero Z…...

Qwen3-VL-Reranker-8B应用场景:科研数据集图文代码混合检索
Qwen3-VL-Reranker-8B应用场景:科研数据集图文代码混合检索 1. 科研检索的痛点与解决方案 科研工作者在日常研究中经常面临这样的困境:手头有大量包含文本、图像、代码片段的研究资料,想要快速找到相关内容却异常困难。传统的文本检索工具只…...

探索Unity全功能的开源方案:UniHacker跨平台功能扩展工具深度指南
探索Unity全功能的开源方案:UniHacker跨平台功能扩展工具深度指南 【免费下载链接】UniHacker 为Windows、MacOS、Linux和Docker修补所有版本的Unity3D和UnityHub 项目地址: https://gitcode.com/GitHub_Trending/un/UniHacker Unity作为游戏开发领域的行业标…...

2024年App上架全攻略:从软著申请到应用市场发布
1. 2024年App上架必备条件全解析 想在2024年把App成功上架到各大应用市场,开发者需要跨过几道硬性门槛。最近帮几个创业团队走完上架流程,发现很多新手容易在这些基础环节卡壳。先说最重要的三件套:软件著作权证书、App备案号、应用市场要求的…...

OpenClaw技能扩展:安装百川2-13B-4bits专用插件提升自动化能力
OpenClaw技能扩展:安装百川2-13B-4bits专用插件提升自动化能力 1. 为什么需要为OpenClaw安装专用插件 去年冬天,我在处理一批技术文档归档任务时,发现OpenClaw的基础能力虽然强大,但在处理特定领域内容时总有些力不从心。比如让…...
)
深度学习 三次浪潮、三大驱动力与神经科学的恩怨(二)
1. 一个领域,多个名字 很多人以为"深度学习"是一个全新的领域。事实上,它的历史可以追溯到 20 世纪 40 年代——只不过在不同时期,它被叫过完全不同的名字: 1940s-1960s:被称为控制论(Cybernetic…...

python-flask-djangol框架的婚恋相亲交友网站
目录技术选型与框架对比核心功能模块设计数据库模型示例(Django ORM)安全防护措施部署方案开发路线图项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作技术选型与框架对比 Flask:轻量级框架&a…...