关于算法的时间复杂度(度量算法执行时间的两种方法、渐进时间复杂度、时间复杂度的几个性质、渐进估算、常见的渐进时间复杂度排序)
目录
度量算法执行时间的两种方法
事后统计法(Post Hoc Analysis):
事前统计法(Pre Hoc Analysis):
渐进时间复杂度
时间复杂度的几个性质
渐进估算
常见的渐进时间复杂度排序
度量算法执行时间的两种方法
算法的时间复杂度一般是指程序运行从开始到结束所需的时间。
算法执行时间需通过依据该算法编制的程序在计算机上运行所消耗的时间来度量,而度量算法执行时间通常有两种方法:事后统计法和事前估算法。
事后统计法是将算法实现后,计算其时间和空间开销,从而确定算法的效率。然而时间和空间开销的计算与计算机软硬件环境相关。同一个算法在不同的机器上执行所花的时间不同,可见这种方法存在明显缺陷,因此我们一般采用事前估算法来评估算法的效率。
事后统计法和事前统计法各自具有的一些优点和缺点:
事后统计法(Post Hoc Analysis):
**优点**:
1. 实用性:事后统计法适用于已经发生的事件和数据收集,因此在一些情况下,它是唯一可行的方法。
2. 数据充分:在使用事后统计法时,我们通常可以利用完整的数据集,包括详细的历史数据,以进行深入的分析。
3. 具体问题解决:可以使用事后统计法来解决具体的问题,如异常事件的分析、错误的原因追溯等。
**缺点**:
1. 反应性:事后统计法只能应用于已经发生的事件,也就是说我们必须先执行相关程序,因此我们无法预测未来事件,只能根据过去的经验做出决策。
2. 无法控制变量:在事后统计法中,我们不能直接控制或操纵变量,因此无法进行实验性的研究。
3. 样本偏差:根据已经发生的事件进行统计分析可能会受到样本选择偏差的影响,因此得出的结论可能不太可靠。
事前统计法(Pre Hoc Analysis):
**优点**:
1. 预测性:事前统计法允许我们在事件发生前进行分析和预测,从而可以采取预防措施或制定未来计划。
2. 控制变量:我们可以在事前统计法中控制和操纵变量,以便进行实验性的研究和测试不同的假设。
3. 减少偏见:通过在研究设计中考虑随机抽样和双盲试验等技术,我们可以减少样本选择偏见和实验者偏见。
**缺点**:
1. 不适用于所有情况:事前统计法需要提前计划和准备,因此可能不适用于某些突发事件或紧急情况。
2. 数据不足:在事前统计法中,我们可能没有足够的数据来支持分析或决策,特别是对于新兴领域或少见事件。
3. 成本高昂:事前统计法可能需要大量资源和时间来收集数据和进行实验,因此成本较高。
综上所述,事后统计法和事前统计法各有其适用的情况和限制。在决定使用哪种方法时,通常需要考虑问题的性质、可用数据、时间和资源等因素。在某些情况下,两种方法可以结合使用,以获得更全面的分析和决策支持。
渐进时间复杂度
要理解清楚渐进时间复杂度我们需要先了解几个概念。
首先,什么是问题规模?
你先思考一下有哪些会影响算法执行时间的因素?
我给你列出了几个(这里排序确实与重要程度有关):
1、算法选用的策略的优劣:
使用高效的算法策略可以显著减少执行时间。比如,一个具有较低时间复杂度的算法通常比一个时间复杂度较高的算法执行得更快。在某些情况下,选择最佳算法可能涉及到更多的内存使用,这可能会导致额外的计算时间来读取和写入内存。
2、问题规模,实例特征:
较小的问题规模通常意味着执行时间较短,因为算法需要处理的数据量更少。如果问题规模非常大,执行时间可能会显著增加,因为算法必须处理更多的数据。
算法的时间复杂度不仅与问题题规模相关,实例特征(如数据分布)也可以影响算法的执行时间。例如,在包含n个元素的数组中找给给定元素x,设算法从左向右搜索,如果待搜索的元素x正好是第一个元素,则所需的查找时间最短,这就是算法的最好情况;如果待搜索的元素x是最后一个元素或不在数组中,则是算法的最坏情况;如果需要多次在数组中查找概率检验每个数组元素,则是算法时间开销的平均情况。
3、使用的程序语言:
某些编程语言(如C++、Rust)具有更高的执行效率,因此可以使算法运行得更快。
选择较慢的编程语言(如Python)可能导致较长的执行时间,尤其是对于计算密集型任务。
4、编译程序产生的机器代码质量:
高质量的编译器可以将源代码优化为更有效率的机器代码,从而减少执行时间。
低质量的编译器可能无法实现最佳性能,导致执行时间增加。
5、计算机执行指令的速度:
更快的处理器和更快的内存访问速度可以加速算法的执行。新一代硬件通常比旧硬件执行得更快。如果硬件性能较低,算法执行时间可能较长。
前两者都是与设计方法有关的,而后三者与运行程序的计算机软硬件环境有关。
现在让我们抛开与计算机软硬件相关的因素,那么影响算法时间效率的最主要问题就是问题规模。
问题规模通常指算法的输入量,我们一般用整数 n 表示。例如:用相同的算法对10个元素进行处理和对10000000……个数据进行处理显然是不同的。
一个算法的时间开销与算法中语句的执行次数成正比。算法中语句执行次数越多,它的时间开销就越大。此时就涉及到语句频度的概念。
那么,什么是语句频度?
一个算法中的语句执行次数称为语句频度。
一般情况下,算法中基本运算执行次数用 T(n) 表示,若有问题规模 n 的某个函数 f(n),使存在自然数 n0,正常数 c,当 n >= n0 时,T(n) <= cf(n),则称 f(n) 是 T(n) 的渐进上界,记为:
T(n) = O( f(n) )
大O记号表示算法的一种渐进时间复杂度,也常简称为时间复杂度。
渐进时间复杂度用以表达一个算法运行时间的上界,估计算法的执行时间的数量级。
终于,我们可以得到渐进时间复杂度的具体定义了……
渐进时间复杂度是一种用于分析算法性能的概念,它描述了算法在处理不同规模的输入数据时所需的计算资源(主要是时间)的增长趋势。通常用大O记号(O-notation)来表示,它提供了算法运行时间的上界估计,表示算法的运行时间不会超过某个特定函数的增长速度。
时间复杂度的几个性质
1. 渐进性:时间复杂度是一种渐进性描述,它关注的是问题规模 n 趋向无穷大时的增长趋势。因此,我们通常关心的是算法在大规模数据上的性能表现,而不是精确的运行时间。
2. 上界估计:时间复杂度表示的是最坏情况下的运行时间上界,即在所有可能的输入情况下,算法的运行时间都不会超过 f(n)。这有助于我们对算法的性能有一个保守的估计。
3. 大O记号:大O记号(O-notation)是常用的表示时间复杂度的符号。例如,如果一个算法的时间复杂度为 O(n),则表示算法的运行时间与问题规模 n 成线性增长。
4. 简化比较:时间复杂度的目的是简化算法之间的比较,而不是精确测量运行时间。通过使用大O记号,我们可以更容易地确定哪个算法在大规模数据上更有效率,而不需要具体的测量。
5. 选择合适的算法:时间复杂度帮助我们选择最适合特定问题的算法。例如,如果一个算法的时间复杂度是 O(n^2),而另一个是 O(n logn),在大规模数据上,后者通常更快。
时间复杂度是算法分析的重要工具,它允许我们估计算法在不同规模的输入数据上的性能表现,并帮助我们选择最优算法以解决特定问题。在算法设计和分析中,理解时间复杂度是提高计算效率和优化算法的关键一步。
渐进估算
一般情况下,我们可以通过考察一个程序中的关键操作(对算法执行时间贡献最大的操作)的执行次数来计算算法的时间按复杂度。
了解了这一点,我们就可以来看看具体该如何计算一个算法的时间复杂度:
-
确定基本操作:首先,我们要确定算法中最主要、最耗时的操作——通常称为关键操作。这些操作是时间复杂度分析的核心。
-
建立基本操作的执行次数表达式:为了计算时间复杂度,我们需要建立一个表示关键操作执行次数的表达式,通常用 T(n) 来表示,其中 n 是问题规模。
-
简化表达式:在这一步,需要将表达式简化,去掉不必要的常数系数和低次项。这是为了关注算法在大规模数据上的增长趋势,而不是具体的执行时间。为了简化表达式,可以遵循以下规则:
-
常数系数可忽略:常数系数不影响算法的增长趋势,所以通常可以省略不写。例如,3n^2 和 n^2 在时间复杂度分析中被认为是相同的。
-
保留最高次项:只考虑表达式中的最高次项,因为在大规模数据上,它将主导增长趋势。其他次项、常数项和低次项都可以忽略。
-
-
确定时间复杂度符号:根据简化后的表达式,确定时间复杂度的大O记号。这是时间复杂度的最终表示,它表示算法在不同规模数据上的性能增长趋势。例如,如果简化后的表达式为 T(n) = 2n^2 + 3n + 1,那么时间复杂度可以表示为 O(n^2),因为 n^2 是最高次项。
好了,那么现在我就要向你就“简化表达式”提一个问题:
数程序步来判定算法的时间效率不是更精细吗?为啥还得在此基础上去掉低次幂和系数?
去掉低次幂还可以理解,因为随着问题规模趋向于正无穷大的时候,低次幂项值可以忽略
但是系数为何要去掉?
"程序步" :计算机科学和编程中的一个概念,通常用于描述算法或程序执行的基本操作或指令。程序步可以理解为算法执行的离散操作,每个步骤代表一个基本操作,例如赋值、条件判断、循环迭代、函数调用等。程序步用于描述算法的执行顺序和流程。
程序步的概念有助于分析和比较不同算法的性能。通过计算算法执行所需的程序步数,可以估算算法的时间复杂度。一般来说,执行步数越少,算法越高效。
在算法分析中,去掉低次幂项和系数的目的是为了关注算法的渐进行为,而不是关注具体输入大小或常数因子。这是因为算法的性能分析的主要关注点是如何随着输入规模的增长而变化,而不是具体的绝对性能。
去掉系数的原因是,系数通常取决于具体的实现、硬件、编程语言等因素,它们并不是算法本身的性质。通过去掉系数,我们可以更好地比较不同算法之间的性能,而不受特定实现的影响。
例如,如果有两个算法,一个算法A的运行时间是3n,另一个算法B的运行时间是1000n,如果我们只关注系数,似乎算法A更好。但如果我们去掉系数,它们的运行时间都是O(n),这意味着它们在输入规模增加时的性能表现是相同的。
因此,去掉系数和低次幂项是为了提供一种更通用、更抽象的方式来比较和分析不同算法的性能,以便更好地理解它们如何在大规模输入下表现。这有助于选择最适合特定问题的算法,而不受具体实现或硬件的限制。
常见的渐进时间复杂度排序
常见的渐进时间复杂度从小到大依次是:
1. O(1) —— 常数时间复杂度:
表示算法的执行时间是一个常数,不随问题规模的增加而变化。这通常是一些基本操作,如赋值、比较、算术运算等的执行时间。
2. O(log n) —— 对数时间复杂度:
表示算法的执行时间与问题规模的对数成正比。常见的例子是二分查找算法,其中问题规模每次减半。
3. O(n) —— 线性时间复杂度:
表示算法的执行时间与问题规模成线性关系。例如,对一个包含 n 个元素的数组进行线性扫描的操作。
4. O(n log n) —— 线性对数时间复杂度:
表示算法的执行时间介于线性时间和平方时间之间,通常出现在一些高效的排序算法中,如快速排序和归并排序。
5. O(n^2) —— 平方时间复杂度:
表示算法的执行时间与问题规模的平方成正比。通常出现在嵌套循环的情况下,如选择排序和插入排序。
6. O(n^k) —— 多项式时间复杂度:
表示算法的执行时间与问题规模的 k 次方成正比。k 可能是大于 2 的正整数,这意味着算法在大规模数据上的性能下降较快。
7. O(2^n) —— 指数时间复杂度:
表示算法的执行时间以指数方式增长,通常出现在某些穷举算法或递归算法中。
8. O(n!) —— 阶乘时间复杂度:
表示算法的执行时间与问题规模的阶乘成正比。这是一种极端情况,通常只出现在极其低效的算法中,对于大规模问题来说几乎不可行。
9. O(n^n) —— 指数级时间复杂度:
表示算法的执行时间与问题规模的 n 的 n 次方成正比。这是一种非常高的时间复杂度,通常只出现在极其低效的算法中,对于大规模问题来说几乎不可行。这种时间复杂度通常表明算法的性能随着问题规模的增加而急剧下降。
选择适当的时间复杂度是算法设计中的关键步骤,我们需要综合考虑问题规模、可用资源以及问题的特点。
通常,我们希望选择时间复杂度较低的算法,以在处理大规模数据时获得更高的效率。
然而,你需要记住,时间复杂度只是一个理论估计,实际的性能还受到硬件、编程语言、编译器等因素的影响。
相关文章:
)
关于算法的时间复杂度(度量算法执行时间的两种方法、渐进时间复杂度、时间复杂度的几个性质、渐进估算、常见的渐进时间复杂度排序)
目录 度量算法执行时间的两种方法 事后统计法(Post Hoc Analysis): 事前统计法(Pre Hoc Analysis): 渐进时间复杂度 时间复杂度的几个性质 渐进估算 常见的渐进时间复杂度排序 度量算法执行时间的两…...

SpringBoot项目--电脑商城【显示商品详情功能】
1.持久层[Mapper] 1规划需要执行的SQL语句 根据商品id显示商品详情的SQL语句 SELECT * FROM t_product WHERE id?2 设计接口和抽象方法 在ProductMapper接口中添加抽象方法 /*** 根据商品id查询商品详情* param id 商品id* return 匹配的商品详情,如果没有匹配…...
VLAN笔记
虚拟VLAN 什么是VLAN VLAN的作用 VLAN的优缺点 VLAN的配置方法 VLAN有哪些接口模式 access与trunk接口的区别 Hybrid接口 拓扑实验enspCiscoH3C 什么是VLAN VLAN(Virtual Local Area Network)又称虚拟局域网,是指在交换局域网的基础上&a…...

分类算法系列⑤:决策树
目录 1、认识决策树 2、决策树的概念 3、决策树分类原理 基本原理 数学公式 4、信息熵的作用 5、决策树的划分依据之一:信息增益 5.1、定义与公式 5.2、⭐手动计算案例 5.3、log值逼近 6、决策树的三种算法实现 7、API 8、⭐两个代码案例 8.1、决策树…...
)
前端面试(基础)
一、CSS 1.说一下CSS的盒模型。 在HTML页面中的所有元素都可以看成是一个盒子 盒子的组成:内容content、内边距padding、边框border、外边距margin 盒模型的类型: 标准盒模型 margin border padding content IE盒模型 margin content(border…...

element-ui switch开关组件二次封装,添加loading效果,点击时调用接口后改变状态
先看效果: element-ui中的switch开关无loading属性(在element-plus时加入了),而且点击时开关状态就会切换,这使得在需要调用接口后再改变开关状态变得比较麻烦。 思路:switch开关外包一层div,给…...

【GAN小白入门】Semi-Supervised GAN 理论与实战
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊🚀 文章来源:K同学的学习圈子论文原文:Semi-Supervised Learning with Generative Adversarial Networks.pdf在学习GAN的时候你有没有想过这样一个问题呢,如果我们生成的图像是带有标签的,例如数…...
Python自动化测试(1)-自动化测试及基本技术手段概述
生产力概述 在如今以google为首的互联网时代,软件的开发和生产模式都已经发生了变化, 在《参与感》一书提到:某位从微软出来的工程师很困惑,微软在google还有facebook这些公司发展的时候,为何为感觉没法有效还击&…...
小程序中如何查看会员的余额和变更记录
通过查看会员的余额和变更记录,可以帮助商家更好地管理会员资金,提供更好的服务和用户体验。下面将介绍小程序中如何查看会员的余额以及余额的变更记录。 1. 找到指定的会员卡。在管理员后台->会员管理处,找到需要查看余额和记录的会员…...

【项目经验】elementui--table表格自定义表头及bug
一.思路 首先我们肯定得循环表头,我们原生js封装的表格的实现原理就是这样。其次我们要把自己循环的label显示出来,对应的prop也要和表格数据相对应。用div标签循环都会出现错误(div里面套column),大家不要踩坑。第一…...

flink实现kafka、doris精准一次说明
前言说明:本文档只讨论数据源为kafka的情况实现kafka和doris的精准一次写入 flink的kafka连接器已经实现了自动提交偏移量到kafka,当flink中的数据写入成功后,flink会将这批次数据的offset提交到kafka,程序重启时,kafka中记录了当前groupId消费的offset位置,开始消费时将…...

【git】git commit、push之前自动执行脚本
可以使用 Git 的钩子(hooks)功能。Git 钩子是在特定事件发生时执行自定义脚本的方式。 下面是一个使用 pre-commit 钩子的例子,用于在执行 git commit 之前自动执行脚本: 进入你的 Git 仓库的根目录。进入 .git/hooks 目录&…...
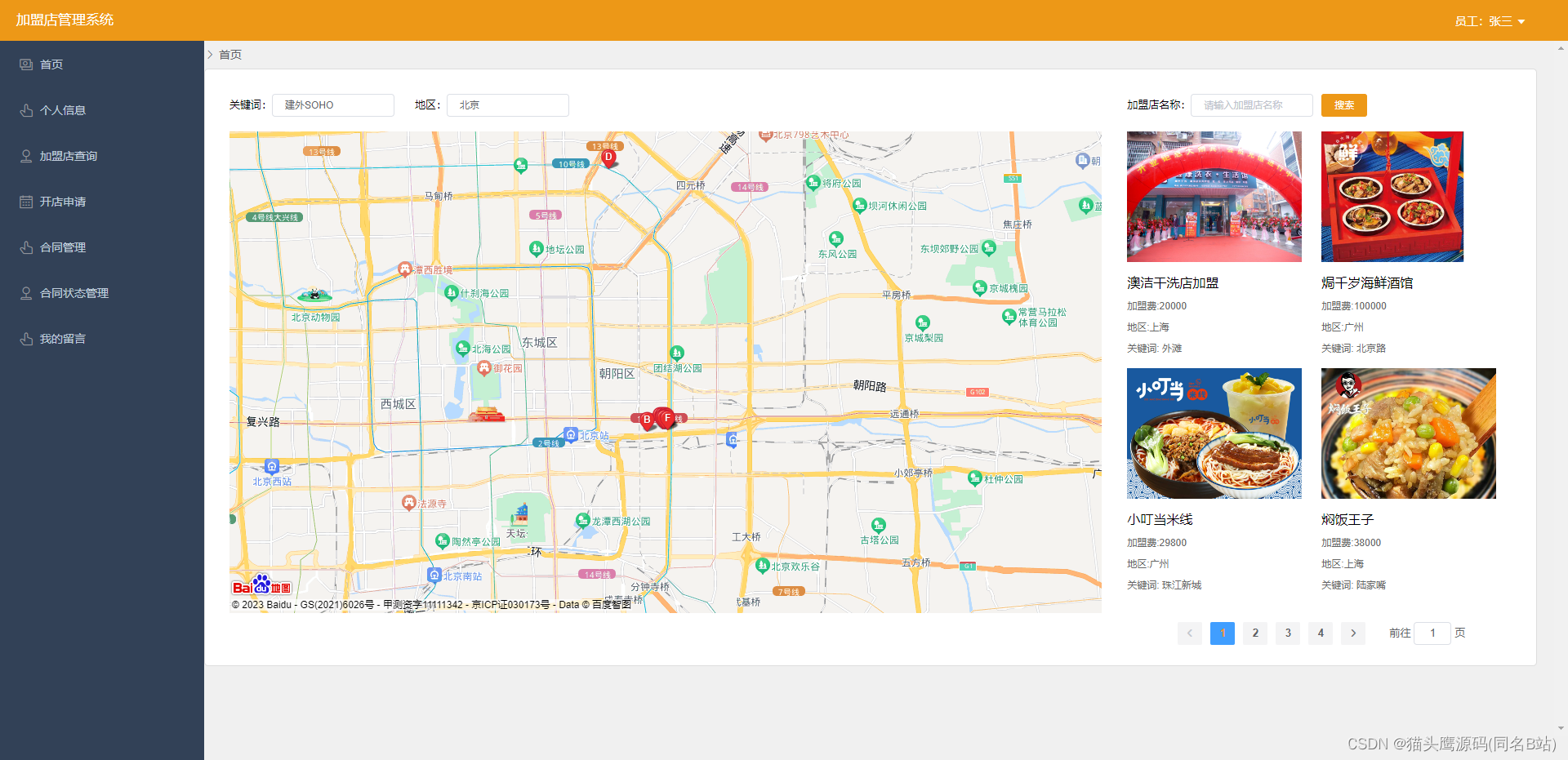
基于springboot+vue的加盟店管理系统(前后端分离)
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战 主要内容:毕业设计(Javaweb项目|小程序等)、简历模板、学习资料、面试题库、技术咨询 文末联系获取 项目介绍…...

Gin中的Cookie和Session的用法
Gin中的Cookie和Session的用法 文章目录 Gin中的Cookie和Session的用法介绍Cookie代码演示 Session代码展示 介绍 cookie 和 session 是 Web 开发中常用的两种技术,主要用于跟踪用户的状态信息。 Cookie func (c *Context) Cookie(name string, value string, max…...

【算法】反悔贪心
文章目录 反悔贪心力扣题目列表630. 课程表 III871. 最低加油次数LCP 30. 魔塔游戏2813. 子序列最大优雅度 洛谷题目列表P2949 [USACO09OPEN] Work Scheduling GP1209 [USACO1.3] 修理牛棚 Barn RepairP2123 皇后游戏(🚹省选/NOI− TODO) 相关…...
Hadoop的安装和使用,Windows使用shell命令简单操作HDFS
1,Hadoop简介 Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性。 高可靠性。 高效性。 高可扩展性。 高容错性。 成本低。 运行在Linux平台上。 支持多种编程…...

ubuntu上ffmpeg使用framebuffer显示video
这个主题是想验证使用fbdev(Linux framebuffer device),将video直接显示到Linux framebuffer上,在FFmpeg中对应的FFOutputFormat 就是ff_fbdev_muxer。 const FFOutputFormat ff_fbdev_muxer {.p.name "fbdev",.p.long_…...
82 # koa-bodyparser 中间件的使用以及实现
准备工作 安装依赖 npm init -y npm i koakoa 文档:https://koajs.cn/# koa 中不能用回调的方式来实现,因为 async 函数执行的时候不会等待回调完成 app.use(async (ctx, next) > {console.log(ctx.path, ctx.method);if (ctx.path "/login…...

计算一串输出数字的累加和
计算一个文件内数字的累加和 awk {sum$1}END{print sum} 直接抽取数据以后的打印是这样的 cat step-iostat.1125.log |grep sda |cut -c "49-56" |awk {sum$1}END{print sum}...

python包导入原理解析
原文链接: https://www.cnblogs.com/hi3254014978/p/15317976.html 根据编程经验的不同,我们在运行程序时可能经常或者偶尔碰到下面这些问题,仔细观察后会发现这些问题无一例外都出现了一个相同的短语,很容易就可以发现࿰…...

3个高效收藏技巧:用netease-cloud-music-dl构建个人无损音乐库
3个高效收藏技巧:用netease-cloud-music-dl构建个人无损音乐库 【免费下载链接】netease-cloud-music-dl Netease cloud music song downloader, with full ID3 metadata, eg: front cover image, artist name, album name, song title and so on. 项目地址: http…...

PushedSSD1306:跨平台零成本OLED显示驱动库
1. PushedSSD1306库概述PushedSSD1306是一个面向嵌入式平台的C SSD1306 OLED显示驱动库,专为12864和12832单色OLED显示屏设计。其核心定位是硬件抽象层无关性与字体资源灵活性,区别于多数Arduino生态中强耦合Wire.h、硬编码PROGMEM字体、或仅支持固定字库…...

Ollama部署本地大模型新体验:LFM2.5-1.2B-Thinking在Mac M系列芯片实测分享
Ollama部署本地大模型新体验:LFM2.5-1.2B-Thinking在Mac M系列芯片实测分享 1. 为什么要在Mac上部署本地大模型? 如果你正在寻找一个既强大又轻量的本地AI助手,LFM2.5-1.2B-Thinking模型绝对值得关注。这个仅有1.2B参数的模型,却…...

Java JDK 21 安装与开发环境一站式配置指南
1. Java JDK 21 安装全流程详解 Java开发环境的搭建是每个Java程序员的第一步。作为长期使用Java的老手,我经历过从JDK 1.4到现在的JDK 21的各个版本升级,深知一个正确的安装过程能避免后续开发中的很多麻烦。下面我就带大家一步步完成JDK 21的安装。 首…...

信捷XD与英威腾GD变频器通讯程序实战(XJXD - 14
信捷XD与英威腾GD变频器通讯程序(XJXD-14)可直接用于实际的程序带注释,并附送触摸屏有接线方式和设置,通讯地址说明等。 程序采用轮询,可靠稳定器件:信捷XD5的PLC,英威腾GD系列变频器,昆仑通态7022Ni 功能&…...

Gemma-3-12b-it多模态应用案例:科研论文图解问答、电商图片材质分析实战
Gemma-3-12b-it多模态应用案例:科研论文图解问答、电商图片材质分析实战 1. 工具概览 Gemma-3-12b-it是一款基于Google最新大模型技术开发的多模态交互工具,专为处理图文混合输入场景优化。不同于传统单一文本模型,它能同时理解图片内容和文…...

OpenClaw跨平台实战:Windows与macOS同步配置Qwen3-32B
OpenClaw跨平台实战:Windows与macOS同步配置Qwen3-32B 1. 为什么需要跨平台配置 去年我在团队内部推广OpenClaw时,遇到一个典型问题:开发同事清一色使用macOS,而运维同事则坚持Windows系统。当我们需要共享同一个Qwen3-32B模型时…...
Pixel Dimension Fissioner开源模型:MIT协议+完整推理代码开放说明
Pixel Dimension Fissioner开源模型:MIT协议完整推理代码开放说明 1. 项目概述 Pixel Dimension Fissioner(像素语言维度裂变器)是一款基于MT5-Zero-Shot-Augment核心引擎构建的创新型文本改写与增强工具。该项目采用MIT开源协议࿰…...

嵌入式C语言断言机制:从原理到工程化实践
1. C语言断言机制的工程化应用解析断言(Assertion)是嵌入式系统开发中一种被严重低估却极具价值的调试辅助机制。在资源受限、可靠性要求严苛的嵌入式环境中,合理运用断言不仅能显著提升代码质量与可维护性,更能构建起从开发调试到…...
)
线性代数实战:用Python快速计算特征值和特征向量(附完整代码)
线性代数实战:用Python快速计算特征值和特征向量(附完整代码) 在数据科学和机器学习领域,特征值和特征向量是理解矩阵本质的关键工具。它们不仅揭示了矩阵的深层结构特性,还在降维分析(如PCA)、…...