区块链世界的大数据入门之zkMapReduce简介
1. 引言
跨链互操作性的未来将围绕多链dapp之间的动态和数据丰富的关系构建。Lagrange Labs 正在构建粘合剂,以帮助安全地扩展基于零知识证明的互操作性。
2. ZK大数据栈
Lagrange Labs 的ZK大数据栈 为一种专有的证明结构,用于在任意动态分布式计算的同时生成大规模batch storage proof。ZK大数据堆栈可扩展到任何分布式计算框架,从MapReduce到RDD再到分布式SQL。
使用Lagrange Labs ZK大数据栈,可以从单个区块头生成证明,用于证明任意深度的历史storage slot 状态数组 和 对这些状态执行的分布式计算的结果。简而言之,每个证明都在一个步骤中结合了storage proof的验证 和 可验证的分布式计算。
在本文中,将讨论ZK-MapReduce(ZKMR)——Lagrange Labs ZK大数据栈 的第一个产品。
3. 何为MapReduce
在传统的顺序计算中,单个处理器按照线性路径执行整个程序,其中每条指令都按其在代码中出现的顺序执行。使用MapReduce和类似的分布式计算范式(如RDD),计算被划分为多个小任务,这些小任务可以在多个处理器上并行执行。
MapReduce的工作原理是将一个大数据集分解成更小的块,并将它们分布在一个机器集群中。大体上,这种计算遵循三个不同的步骤:
- 1)Map:每台机器对其数据块执行map操作,将其转换为一组键值(key-value)对。
- 2)Shuffle:对Map操作生成的键值对按键(key)进行shuffle和排序。
- 3)Reduce:Shuffle的结果被传递给Reduce操作,Reduce操作聚合数据并产生最终输出。
MapReduce的主要优点在于其可扩展性。由于计算分布在多台机器上,因此它可以处理无法按顺序处理的大规模数据集。此外,MapReduce的分布式特性允许计算在更多的机器上水平扩展,而不是在计算时间方面垂直扩展。

分布式计算范例(如MapReduce或RDD)通常用于Web 2.0架构中,用于处理和分析大型数据集。大多数大型web 2.0公司,如谷歌、亚马逊和脸书,都在很大程度上利用分布式计算来处理PB级的搜索数据和用户数据集。用于分布式计算的现代框架包括Hive、Presto和Spark。
3. zkMapReduce介绍
Lagrange的zkMapReduce(zkMR)为MapReduce的扩展,其利用递归证明来证明基于大量链上状态数据的分布式计算的正确性。通过在分布式计算作业的Map或Reduce步骤期间为每个给定worker生成计算正确性的证明来实现的。这些证明可以递归组合,构建整个分布式计算工作流有效性的单一证明。换句话说,可以将较小计算的证明组合起来,以创建整个计算的证明。
将worker computation的多个sub-proofs组合成单个zkMR proof的能力使其能够更有效地扩展到大型数据集上的复杂计算。

与zkVM相比,zkMR的主要优势之一在于,其能在合约现有和历史storage state基础之上执行动态计算。无需:
- 分别跨越一系列区块来证明storage inclusion
- 再基于aggregated data set之上证明一系列计算
zkMR(以及Lagrange的其它ZK大数据产品)支持将以上2者组合为单个proof。与其他设计相比,这样可大幅降低生成zkMR proof的证明时长。
3.1 zkMR示例
为理解递归证明的组合原理,先举个简单的例子。假设需计算某DEX内某资产对 在指定期间内的平均流动性。为此,必须:
- 对于每个区块,必须展示其correctness of an inclusion proof on the state root,以证明该DEX内的流动性数量。
- 必须对每个区块的流动性求和,再除以区块数。
这样的顺序计算类似为:
# Sequential Execution
func calculate_avg_eth_price_per_block(var mpt_paths, var liquidity_per_block){var sum = 0;for(int i=0; i<len(liquidity_per_block); i++){verify_inclusion(liquidity_per_block[i], mpt_path[i])sum += liquidity_per_block[i]}var avg_liquidity = sum / num_blocks// return the average liquidityreturn avg_liquidity
}
但是,随着所包含state数量的增加,该程序的性能将急速下降。以下图为例,展示每个链单位时间内的区块数。以Arbitrum上的单个DEX一个月内某单一DEX的平均流动性为例,其需要的数据需横跨约6500万个rollup区块。

但是,借助zkMR,可将该dataset切分为更小的chunks,并分发给多个处理器。每个机器执行map操作——计算Merkle-Patricia Trie(MPT)proof 并基于其chunk of data对流动性求和。该map操作会生成key-value pair,其中key为某constant string(如average_liquidity),value为a tuple containing the sum and count。
该map操作输出的为一组key-value pairs,可shuffled and sorted by key,然后传递给reduce操作。reduce接收的为key-value pair,其中key为average_liquidity,value为a list of tuples containing the sum and count of the liquidity from each map操作。该reduce操作将通过对单个sums和counts求和来聚合数据,然后将final sum除以final count,以获得最终的平均流动性。
示例代码为:
# Map step
func map(liquidity_data_chunk,mpt_path_chunk){var sum = 0for(int i=0; i<len(liquidity_data_chunk); i++){verify_inclusion(liquidity_data_chunk[i], mpt_path_chunk[i])sum += liquidity_data_chunk[i]}return ("average_liquidity", (sum, len(liquidity_data_chunk)))
}# Reduce step
func reduce(liquidity_data_chunk){var sum = 0var count = 0for(int i=0; i<len(liquidity_data_chunk); i++){sum += value[0]count += value[1]}return ("average_liquidity", sum/count)
}
广义上来说,可将开发者定义和消费zkMR proof的流程分为三步:
- 1)定义dataframe和computations:zkMR proof基于某dataframe来执行,所谓dataframe是指一定范围的区块,以及这些区块内的特定memory slots。如上例中,dataframe是指流动性求平均的区块方位,memory slot对应某DEX内某资产的流动性。
- 2)为batched storage生成证明 并 分发计算:zkMR proof会验证某特定dataframe input的计算结果。每个dataframe对应某个特定的区块头。组委验证计算的一部分,每个proof必须证明现有底层状态数据存在的同时,还需证明基于这些数据的动态计算结果。如上例中,所谓的动态计算设置求平均操作。
- 3)Proof verification:zkMR proof可提交并在任意EVM兼容链上验证(后续将支持更多的虚拟机)。

3.2 增加不可知传输层

zkMR proof(以及其他zk Big Data proof)的强大特性之一是其可实现传输层不可知。由于proof是基于初始的区块头input生成的,任何现有的传输层都可用于生成和relay zkMR proof。现有的传输层包含有;
- messaging protocol
- oracle
- bridge
- watcher/cron job
- 甚至untrusted or incentivized用户机制
zkMR proof的灵活性可大幅增加链间state的表达性,而不需要与现有的高性能传输基础设施竞争。
Lagrange SDK提供了简单的接口来将zk Big Data proof集成进任何现有的跨链messaging或bridging协议中。通过简单的函数调用,某协议可简单请求某指定区块头内某特定dataframe的任意计算结果的proof。
当与现有协议集成时,zkMR不设计为对用作proof input的区块头的有效性做assertion。通常当传输消息时,传输协议可证明或断言某区块头的有效性,也可额外包含基于某dataframe历史状态之上的动态计算。
值得指出的是,zkMR proof还支持将多个链的proof合并为单个final computation。
4. zkMR性能改进
现有的zkMR看起来要比传统的线性计算更复杂,其性能可随并行处理器/机器而水平扩展,而不是随时间垂直扩展。
最大并行化情况下,证明某zk MapReduce流程的时间复杂度为 O ( log ( n ) ) O(\log (n)) O(log(n)),而顺序执行需要的run-time为 O ( n ) O(n) O(n)。
例如,计算以太坊区块数据1天内的平均流动性。顺序执行需要循环6643 steps。具有recursive proof的分布式方式,仅需要单个map操作,高达6643个并行线程以及12个recursive reduction steps。从而可将rum-time复杂度reduce 约523倍。
对于扩容方案间的state storage碎片,如app chains、app rollup L3s、alt-L2s,链上数据以指数级增长并碎片化。很快就有关于:如何处理部署在100个不同app rollups上的某DEX的1周TWAP数据?
总之,zkMR是在分布式计算环境下、在zero-knowledge上下文中处理大规模数据集的强大范例。虽然顺序计算在通用应用程序开发中效率很高,表达能力很强,但在分析和处理大型数据集时,它的优化效果很差。分布式计算的效率使其成为主流Web2的许多大数据处理的标准。在zero-knowledge上下文中,可扩展性和容错性使其成为处理不可信大数据应用程序的理想支柱,如复杂的链上定价、波动性和流动性分析。
参考资料
[1] Lagrange Labs 2023年5月博客 A Big Data Primer: Introducing ZK MapReduce
相关文章:
区块链世界的大数据入门之zkMapReduce简介
1. 引言 跨链互操作性的未来将围绕多链dapp之间的动态和数据丰富的关系构建。Lagrange Labs 正在构建粘合剂,以帮助安全地扩展基于零知识证明的互操作性。 2. ZK大数据栈 Lagrange Labs 的ZK大数据栈 为一种专有的证明结构,用于在任意动态分布式计算的…...

Python流程控制语句-条件判断语句练习及应用详解
文章目录 简介条件判断语句(if语句)练习1:判断奇偶数练习2:判断闰年练习3:计算狗的年龄相当于人的年龄练习4:根据成绩奖励练习5:选择婚姻对象 小结 python 学习专栏推荐python基础知识ÿ…...
ElasticSearch高级使用【别名,重建索引,refresh操作,高亮查询,查询建议】)
(十)ElasticSearch高级使用【别名,重建索引,refresh操作,高亮查询,查询建议】
1.别名使用 1)别名作用 在开发中,随着业务需求的迭代,较⽼的业务逻辑就要⾯临更新甚⾄是重构,⽽对于es来说,为了 适应新的业务逻辑,可能就要对原有的索引做⼀些修改,⽐如对某些字段做调整&…...

基于小波神经网络的中药材价格预测,基于ANN的小波神经网络中药材价格预测
目标 背影 BP神经网络的原理 BP神经网络的定义 BP神经网络的基本结构 BP神经网络的神经元 BP神经网络的激活函数, BP神经网络的传递函数 小波神经网络(以小波基为传递函数的BP神经网络) 代码链接:基于小波神经网络的中药材价格预测,ANN小波神经网络中药材价格预测资源-CS…...

thinkPhp5返回某些指定字段
//去除掉密码$db new UserModel();$result $db->field(password,true)->where("username{$params[username]} AND password{$params[password]}")->find(); 或者指定要的字段的数组 $db new UserModel();$result $db->field([username,create_time…...

基于docker环境的tomcat开启远程调试
背景: Tomcat部署在docker环境中,使用rancher来进行管理,需要对其进行远程调试。 操作步骤: 1.将容器中的catalina.sh映射出来,便于对其修改,添加远程调试相关参数。 注意:/data/produce2201…...
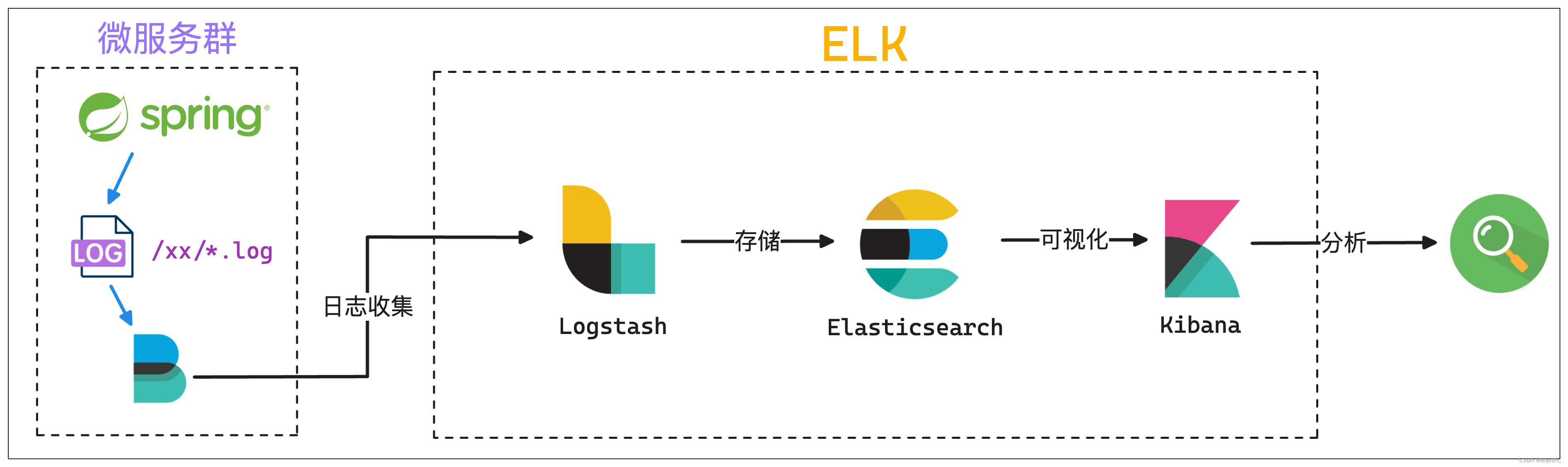
ELK日志框架图总结
ELK日志框架图总结 本文目录 ELK日志框架图总结Elastic Stack介绍模式分层图beatselasticsearchkibana模式logstashelasticsearchkibana模式beatslogstashelasticsearchkibana模式beats缓存/消息队列logstashelasticsearchkibana模式elkspringboot Elastic Stack介绍 官网&…...

go 每天定时任务 --chatGPT
问:clearLog(hour,cmds),定时执行shell 命令,hour 为每天的几点,cmds 为linux命令数组字符串(如 1,{"ls","cd"}) gpt: 要编写一个 Go 函数 clearLog,该函数可…...

Lightdb 23.3 plorasql函数支持DML
开篇立意 oracle在函数中使用dml语句时,有两者情况。即:(1)直接使用select调用该函数;(2)在匿名块中调用该函数。 针对第一种情况我们测试一下 简单的函数: create table nested_t…...
电容笔值不值得买?开学季比较好用的电容笔
眼看着新学期即将到来,到底应该选择什么样的电容笔?一款原装的苹果Pencil,就卖到了将近一千块,这对于很多人来说,都是一个十分昂贵的价格。事实上,由于平替电容笔的价格非常便宜,只要一二百元就…...
 分页)
Mybatis 框架 ( 五 ) 分页
4.6.分页 Mybatis-plus 内置分页插件, 并支持多种数据库 官网 : 分页插件 | MyBatis-Plus (baomidou.com) 4.6.1.增加拦截器 通过 MapperScan 指定 mapper接口的路径 import com.baomidou.mybatisplus.annotation.DbType; import com.baomidou.mybatisplus.extension.plug…...

Python模板注入
概念 发生在使用模板引擎解析用户提供的输入时。模板注入漏洞可能导致攻击者能够执行恶意代码或访问未授权的数据。 模板引擎可以让(网站)程序实现界面与数据分离,业务代码与逻辑代码分离。即也拓宽了攻击面,注入到模板中的代码可…...

Java常用的设计模式
单例模式(Singleton Pattern): 确保一个类只有一个实例,并提供一个全局访问点。示例:应用程序中的配置管理器。 工厂模式(Factory Pattern): 用于创建对象的模式,封装对象的创建过程。示例&…...
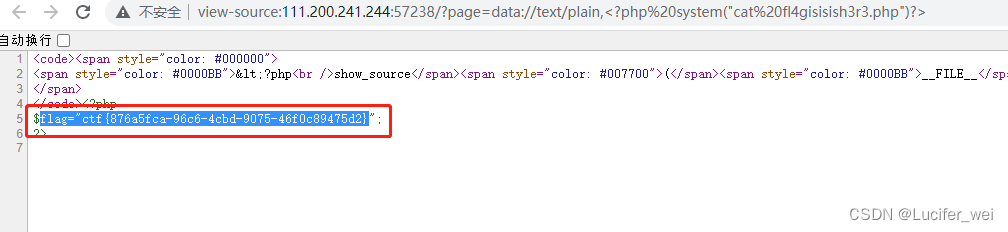
攻防世界-WEB-Web_php_include
打开靶机 通过代码审计可以知道,存在文件包含漏洞,并且对伪协议php://进行了过滤。 发现根目录下存在phpinfo 观察phpinfo发现如下: 这两个都为on 所以我们就可以使用data://伪协议 payload如下: - ?pagedata://text/plain,…...
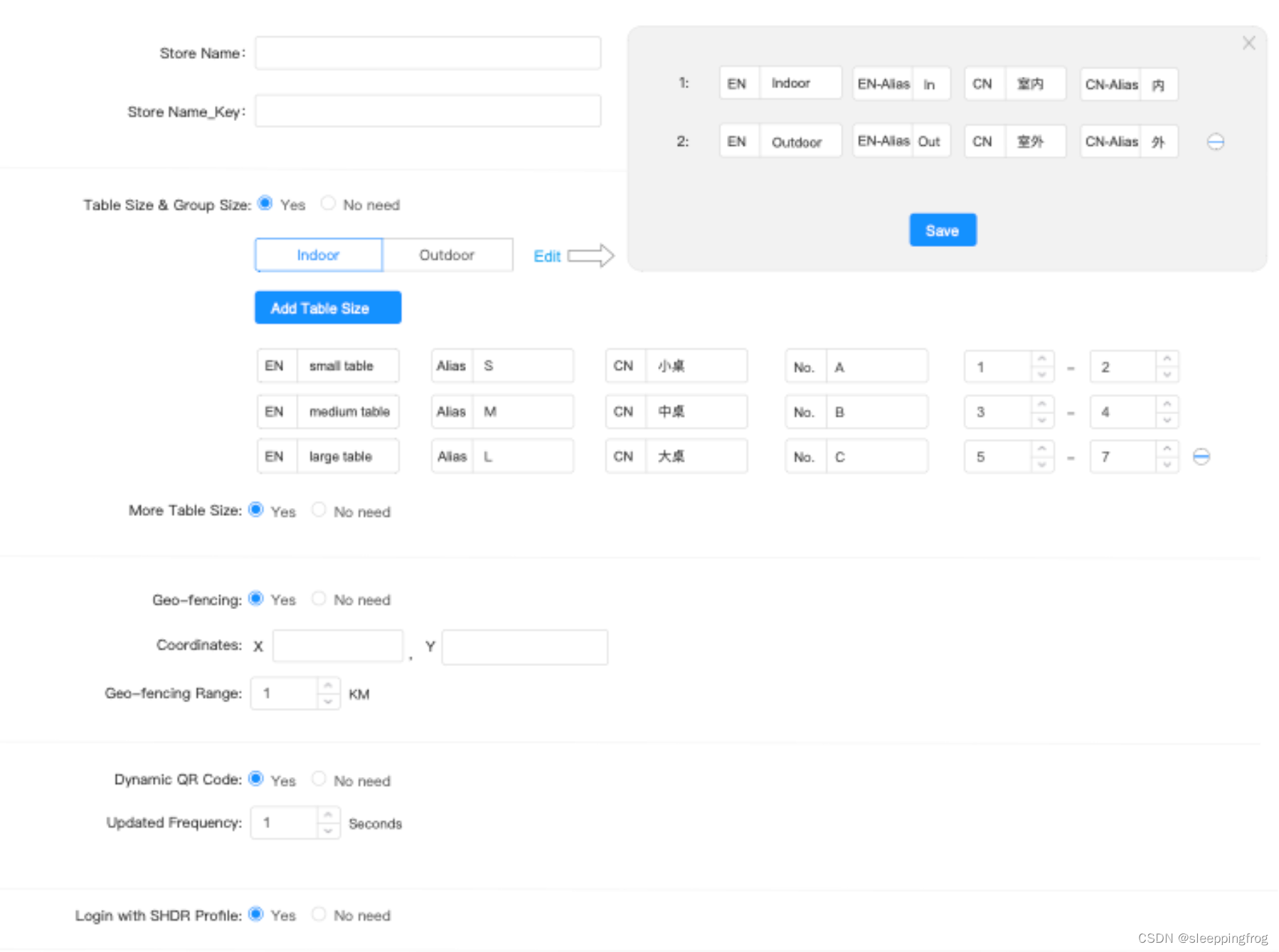
angular中多层嵌套结构的表单如何处理回显问题
最近在处理angular表单时,有一个4层结构的表单。而且很多元素时动态生成,如下: this.validateFormthis.fb.group({storeId: ["test12"],storeNameKey:[],config:this.fb.group({ tableSize:this.fb.group({toggle:[false],groupSiz…...
Leetcode646. 最长数对链
Every day a Leetcode 题目来源:646. 最长数对链 解法1:动态规划 定义 dp[i] 为以 pairs[i] 为结尾的最长数对链的长度。 初始化时,dp 数组需要全部赋值为 1。 计算 dp[i] 时,可以先找出所有的满足 pairs[i][0]>pairs[j]…...

Windows 下安装NPM
第一步: 下载node.js的windows版 当前最新版本是https://nodejs.org/dist/ 第二步:设置环境变量 把node.exe所在目录加入到PATH环境变量中。 配置成功后可以在CMD中通过node --version 看到node.js对应的版本号 C:\Users\fn>node --version v6.10.2 第三步: 安装git 直接…...

【ARM CoreLink 系列 2 -- CCI-400 控制器简介】
文章目录 CCI-400 介绍DVM 机制介绍DVM 消息传输过程TOKEN 机制介绍 下篇文章:ARM CoreLink 系列 3 – CCI-550 控制器介绍 CCI-400 介绍 CCI(Cache Coherent Interconnect)是ARM 中 的Cache一致性控制器。 CCI-400 将 Interconnect 和coh…...

LeetCode(力扣)77. 组合Python
LeetCode77. 组合 题目链接代码 题目链接 https://leetcode.cn/problems/combinations/description/ 代码 class Solution:def combine(self, n: int, k: int) -> List[List[int]]:result []return self.backtracking(n, k, 1, [], result)def backtracking(self, n, k…...
uniapp h5 微信缓存,解决版本更新还是旧版本
文章目录 一、微信缓存是什么?二、如何解决1.打包入口文件解决2.给请求url加时间戳3.给打包的js文件添加时间戳并修改打包后的css文件夹 总结 一、微信缓存是什么? 微信缓存是指微信客户端为了提高用户的使用体验,会在用户使用微信过程中将一…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...
与常用工具深度洞察App瓶颈)
iOS性能调优实战:借助克魔(KeyMob)与常用工具深度洞察App瓶颈
在日常iOS开发过程中,性能问题往往是最令人头疼的一类Bug。尤其是在App上线前的压测阶段或是处理用户反馈的高发期,开发者往往需要面对卡顿、崩溃、能耗异常、日志混乱等一系列问题。这些问题表面上看似偶发,但背后往往隐藏着系统资源调度不当…...

C#中的CLR属性、依赖属性与附加属性
CLR属性的主要特征 封装性: 隐藏字段的实现细节 提供对字段的受控访问 访问控制: 可单独设置get/set访问器的可见性 可创建只读或只写属性 计算属性: 可以在getter中执行计算逻辑 不需要直接对应一个字段 验证逻辑: 可以…...

STM32HAL库USART源代码解析及应用
STM32HAL库USART源代码解析 前言STM32CubeIDE配置串口USART和UART的选择使用模式参数设置GPIO配置DMA配置中断配置硬件流控制使能生成代码解析和使用方法串口初始化__UART_HandleTypeDef结构体浅析HAL库代码实际使用方法使用轮询方式发送使用轮询方式接收使用中断方式发送使用中…...

iview框架主题色的应用
1.下载 less要使用3.0.0以下的版本 npm install less2.7.3 npm install less-loader4.0.52./src/config/theme.js文件 module.exports {yellow: {theme-color: #FDCE04},blue: {theme-color: #547CE7} }在sass中使用theme配置的颜色主题,无需引入,直接可…...

windows系统MySQL安装文档
概览:本文讨论了MySQL的安装、使用过程中涉及的解压、配置、初始化、注册服务、启动、修改密码、登录、退出以及卸载等相关内容,为学习者提供全面的操作指导。关键要点包括: 解压 :下载完成后解压压缩包,得到MySQL 8.…...

在 Spring Boot 项目里,MYSQL中json类型字段使用
前言: 因为程序特殊需求导致,需要mysql数据库存储json类型数据,因此记录一下使用流程 1.java实体中新增字段 private List<User> users 2.增加mybatis-plus注解 TableField(typeHandler FastjsonTypeHandler.class) private Lis…...

c# 局部函数 定义、功能与示例
C# 局部函数:定义、功能与示例 1. 定义与功能 局部函数(Local Function)是嵌套在另一个方法内部的私有方法,仅在包含它的方法内可见。 • 作用:封装仅用于当前方法的逻辑,避免污染类作用域,提升…...