Java API 文档搜索引擎
1. 认识搜索引擎:
在搜狗搜索的搜索结果页中, 包含了若干条结果, 每一个结果包含了图标, 标题, 描述, 展示URL等
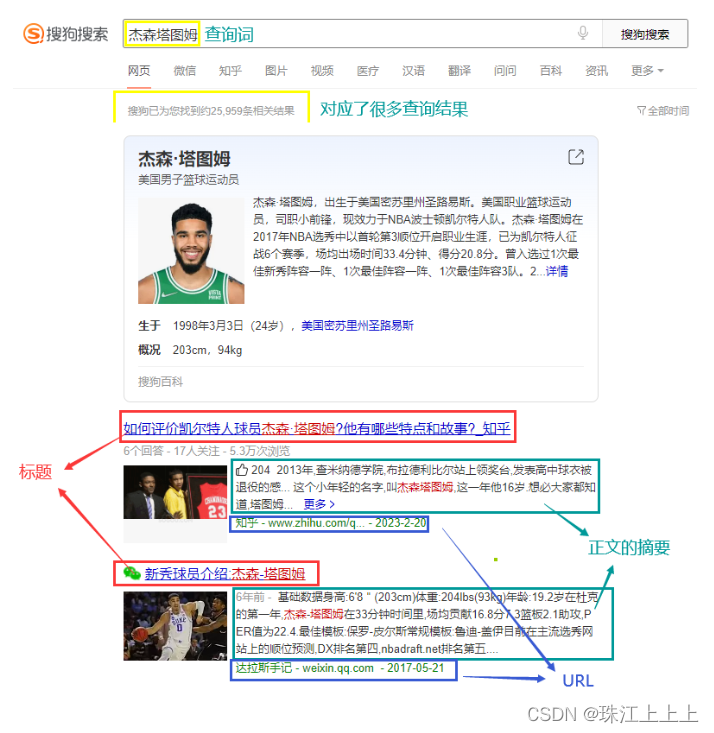
搜索引擎的本质:
输入一个查询词, 得到若干个搜索结果, 每个搜索结果包含了标题, 描述, 展示URL和点击URL
2. 搜索引擎思路:
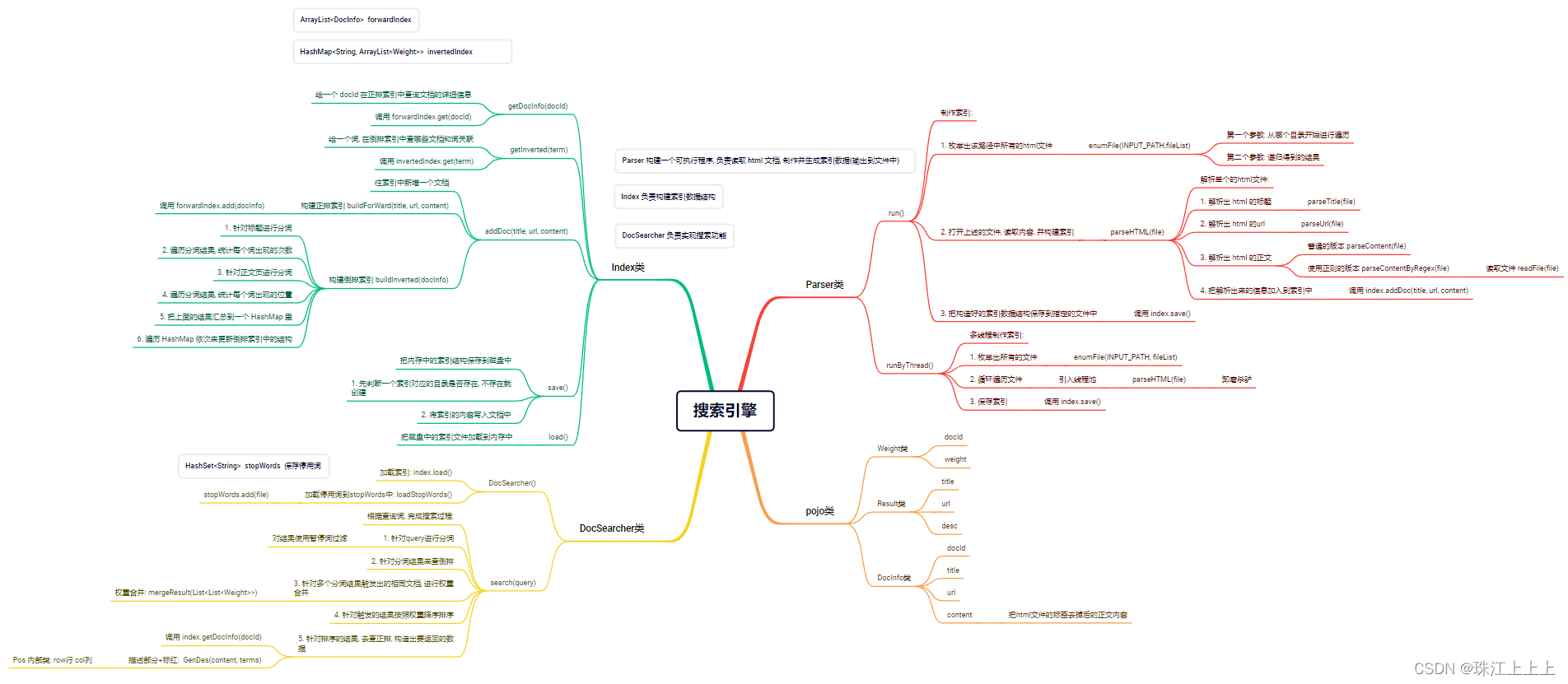
2.1 搜索的核心思路:
当前我们有很多的网页(假设上亿个), 每个网页我们称为是一个文档
如何高效进行检索? 查找出有哪些网页是和查询词具有一定的相关性呢?
我们可以认为, 网页中包含了查询词(或者查询词的一部分), 就认为具有相关性.
那么我们就有了一个直观的解决思路
方案一 -- 暴力搜索
每次处理搜索请求的时候, 拿着查询词去所有的网页中搜索一遍, 检查每个网页是否包含查询词字符串.
这个方法是否可行?
显然, 这个方案的开销非常大. 并且随着文档数量的增多, 这样的开销会线性增长. 而搜索引擎往往对于效率的要求非常高.
方案二 -- 倒排索引
这是一种专门针对搜索引擎场景而设计的数据结构.
文档(doc): 被检索的html页面(经过预处理)
正排索引: "一个文档包含了哪些词". 描述一个文档的基本信息, 包括文档标题, 文档正文, 文档标题和正文的分词 /断句结果
倒排索引: "一个词被哪些文档引用了". 描述了一个词的基本信息, 包括这个词都被哪些文档引用, 这个词在该文档 中的重要程度, 以及这个词的出现位置等.
2.2 项目目标:
实现一个 Java API 文档的简单的搜索引擎.
最终效果
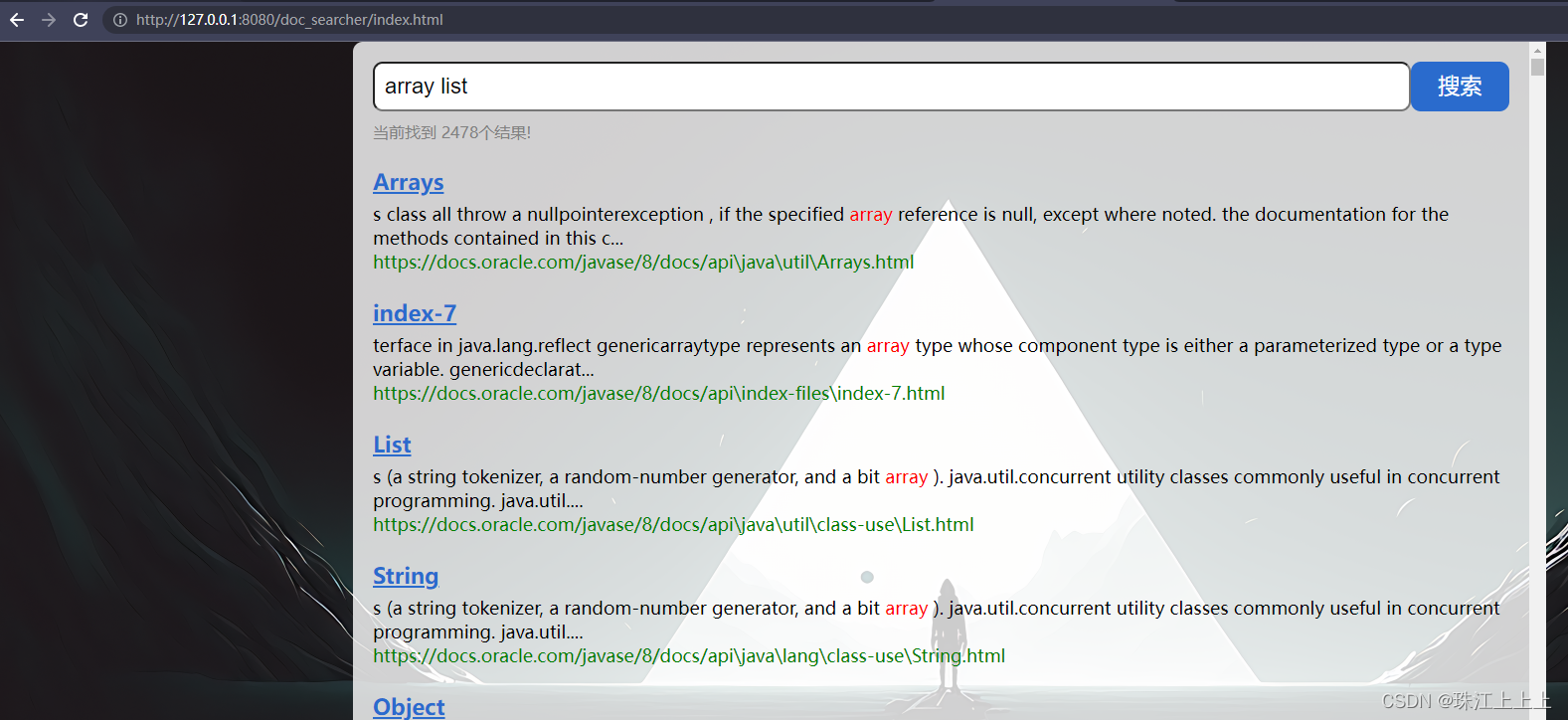
2.3 核心流程
索引模块: 扫描下载到的文档, 分析数据内容构建正排+倒排索引, 并保存到文件中.
搜索模块: 加载索引. 根据输入的查询词, 基于正排+倒排索引进行检索, 得到检索结果.
web模块: 编写一个简单的页面, 展示搜索结果. 点击其中的搜索结果能跳转到对应的 Java API 文档页面.
3. 实现搜索引擎:
3.. Weight, Result, DocInfo类
/*** 这个类就是把 文档id 和 文档与词的相关性 权重 进行一个包裹*/
@Data
public class Weight {private int docId;// 这个 weight 就表示 文档 和 词 之间的"相关性"// 这个值越大, 就认为相关性越强private int weight;
}/*** 这个类来表示一个搜索结果*/
@Data
public class Result {private String title;private String url;// 描述是正文的一段摘要private String desc;
}/*** 表示一个文档对象(HTML对象)* 根据这些内容后面才能制作索引, 完成搜索过程.*/
@Data
public class DocInfo {// docId 文档的唯一身份标识(不能重复)private int docId;// 该文档的标题. 简单粗暴的使用文件名来表示.// Collection.html => Collectionprivate String title;// 该文档对应的线上文档的 URL. 根据本地文件路径可以构造出线上文档的 URLprivate String url;// 该文档的正文. 把 html 文件中的 html 标签去掉, 留下的内容private String content;
}3.1 分词:
分词是搜索中的一个核心操作. 尤其是中文分词, 比较复杂(当然, 咱们此处暂不涉及中文分词)
我们可以使用现成的分词库 ansj.
注意: 当 ansj 对英文分词时, 会自动把单词转为小写.
导入依赖:
<dependency><groupId>org.ansj</groupId><artifactId>ansj_seg</artifactId><version>5.1.6</version>
</dependency>实例代码:
public static void main(String[] args) {// 准备一个比较长的话, 用来分词String str = "小明毕业于清华大学";// Term 就表示一个分词结果List<Term> terms = ToAnalysis.parse(str).getTerms();for (Term term : terms){System.out.println(term.getName());}
}3.2 实现 Parser 类:
Parser 构建一个可执行程序, 负责读取 html 文档, 制作并生成索引数据(输出到文件中)
从制定的路径中枚举出所有的文件
读取每个文件, 从文件中解析出 HTML 的标题, 正文, URL
先指定一个加载文档的路径
private static final String INPUT_PATH = "C:/Users/LEO/Desktop/jdk-8u361-docs-all/docs/api";创建一个 index 实例
private Index index = new Index();(1) run 方法
public void run(){long beg = System.currentTimeMillis();System.out.println("*** 索引制作开始! ***");// 整个 searcher.Parser 类的入口// 1. 根据上面指定的路径, 枚举出该路径中所有的文件(html), 这个过程需要把所有子目录中的文件都能获取到ArrayList<File> fileList = new ArrayList<>();enumFile(INPUT_PATH,fileList);/*** 获取到 INPUT_PATH 下的所有文件* System.out.println(fileList);* System.out.println(fileList.size());*/// 2. 针对上面罗列出的文件的路径, 打开文件, 读取文件内容, 并进行解析, 并构建索引for (File f : fileList){// 通过这个方法来解析单个的html文件System.out.println("开始解析: " + f.getAbsolutePath());parseHTML(f);}// 3. 把在内存中构造好的索引数据结构, 保存到指定的文件中index.save();long end = System.currentTimeMillis();System.out.println("**** 索引制作完成! " + (end - beg) + "ms ****");
}(2) enumFile() 枚举出该路径中所有的文件
// 第一个参数表示: 从哪个目录开始进行递归遍历
// 第二个参数表示: 递归得到的结果
// inputPath: C:/Users/LEO/Desktop/jdk-8u361-docs-all/docs/api
private void enumFile(String inputPath, ArrayList<File> fileList) {File rootPath = new File(inputPath);// listFiles 能够获取到 rootPath 当前目录下所包含的文件/目录// 使用 listFiles 只能看到一级目录, 看不到子目录里的内容// 要想看到子目录中的内容, 还需要进行递归File[] files = rootPath.listFiles();for (File f : files){// 根据当前 f 的类型, 来决定是否要递归// 如果 f 是一个普通文件, 就把 f 加入到 fileList 结果中// 如果 f 是一个目录, 就递归的调用 enumFile 方法, 进一步的获取子目录中的内容if(f.isDirectory()){enumFile(f.getAbsolutePath(), fileList);} else {// 排除非html文件// endsWith是String类的方法if(f.getAbsolutePath().endsWith(".html")){fileList.add(f);}}}
}(3) parseHTML() 通过这个方法来解析单个的html文件
private void parseHTML(File f) {// 1. 解析出 HTML 的标题String title = parseTitle(f);// 2. 解析出 HTML 对应的 URLString url = parseUrl(f);// 3. 解析出 HTML 对应的正文(有了正文才有后续的描述)
// String content = parseContent(f);String content = parseContentByRegex(f); // 使用正则的版本// 4. 把解析出来的这些信息加入到索引当中index.addDoc(title, url, content);
}(4) parseTitle() 解析出html文件的标题
private String parseTitle(File f) {String name = f.getName();return name.substring(0, name.length() - ".html".length());
}(5) parseUrl() 解析出html文件的URL
private String parseUrl(File f) {
// String part1 = "file:///C:/Users/LEO/Desktop/jdk-8u361-docs-all/docs/api/";String part11 = "https://docs.oracle.com/javase/8/docs/api";String part2 = f.getAbsolutePath().substring(INPUT_PATH.length());return part11 + part2;
}(6) parseContent() 解析出html文件的正文
// (边读边判断)
public String parseContent(File f) {
// 先按照一个字符一个字符的方式来读取, 以<和>来控制拷贝数据的开关
// BufferedReader bufferedReader = new BufferedReader(new FileReader(f),1024 * 1024);try {FileReader fileReader = new FileReader(f);// 加上一个是否要进行拷贝, 开关boolean isCopy = true;// 还得准备一个保存结果的 StringBuilderStringBuilder content = new StringBuilder();while(true){// 注意, 此处的 read 返回值是一个 int , 不是 char// 此处使用 int 作为返回值, 主要是为了表示一些非法情况// 如果读到了文件末尾, 继续读, 就会返回 -1int ret = fileReader.read();if(ret == -1){// 表示文件读完了break;}// 如果这个结果不是 -1, 那么就是一个合法的字符char c = (char) ret;if(isCopy) {// 开关打开的状态, 遇到普通字符就应该拷贝到 Stringbuilder 中if(c == '<'){// 关闭开关isCopy = false;continue;}if(c == '\n' || c == '\r'){// 目的是为了去掉换行, 把换行符替换成空格c = ' ';}// 其他字符, 直接进行拷贝即可, 把结果给拷贝到最终的 StringBuilder 中content.append(c);} else {// 开关关闭的状态, 就暂时不拷贝, 直到遇到 >if(c == '>'){isCopy = true;}}}fileReader.close();return content.toString();} catch (IOException e) {e.printStackTrace();}return "";
}(7) parseContentByRegex() 使用正则获取html的正文
基于正则表达式去除 script 标签的内容
// (先全部读取完, 然后替换) readFile 是 parseContentByRegex 需要的读取文件的方法
private String readFile(File f){try(BufferedReader bufferedReader = new BufferedReader(new FileReader(f))){StringBuilder content = new StringBuilder();while(true){int ret = bufferedReader.read();if(ret == -1){break;}char c = (char) ret;if(c == '\n' || c == '\r'){c = ' ';}content.append(c);}return content.toString();} catch (IOException e){e.printStackTrace();}return "";
}
// 这个方法内部就基于正则表达式, 实现去标签, 以及去除 script
public String parseContentByRegex(File f){// 1. 先把整个文件都读到 String 里面String content = readFile(f);// 2. 替换掉 script 标签content = content.replaceAll("<script.*?>(.*?)</script>", " ");// 3. 替换掉普通的 html 标签content = content.replaceAll("<.*?>", " ");// 4. 使用正则表达式把多个空格, 合并成一个空格content = content.replaceAll("\\s+", " ");return content;
}(8) 通过这个main方法实现整个制作索引的过程
要先将api文档扫描完并保存到磁盘上, 然后再启动tomcat
public static void main(String[] args) throws InterruptedException {// 通过main方法来实现整个制作索引的过程Parser parser = new Parser();// parser.run();parser.runByThread();
}3.3 实现 Index 类:
Index 负责构建索引数据结构
存放索引的路径
private static final String INDEX_PATH = "C:/Users/LEO/Desktop/jdk-8u361-docs-all/";objectMapper对象
private ObjectMapper objectMapper = new ObjectMapper();正排索引
// 使用数组下标表示: docId
private ArrayList<DocInfo> forwardIndex = new ArrayList<>();倒排索引
// 使用 哈希表 来表示倒排索引
// key 就是 词
// value 就是 一组和这个词关联的文章
private HashMap<String, ArrayList<Weight>> invertedIndex = new HashMap<>();锁对象
// 新创建俩个锁对象
private Object locker1 = new Object();
private Object locker2 = new Object();(1) getDocInfo() 根据 docId 查正排.
// 1. 给定一个 docId 在正排索引中, 查询文档的详细信息
public DocInfo getDocInfo(int docId) {return forwardIndex.get(docId);
}(2) getInverted() 根据关键词查倒排.
// 2. 给定一个词, 在倒排索引中, 查哪些文档和这个词关联
// List<Integer> 这里的返回值是Integer是否可以? 不行!
// 词和文档之间是存在一定的"相关性"的
public List<Weight> getInverted(String term) {return invertedIndex.get(term);
}(3) addDoc() 往索引中新增一个文档.
// 3. 往索引中新增一个文档
public void addDoc(String title, String url, String content) {// 新增文档操作, 需要同时给正排索引和倒排索引新增信息// 构建正排索引DocInfo docInfo = buildForWard(title, url, content);// 构建倒排索引buildInverted(docInfo);
}(4) buildForWard() 构建正排索引
// 3.2 构建正排索引
private DocInfo buildForWard(String title, String url, String content) {DocInfo docInfo = new DocInfo();docInfo.setTitle(title);docInfo.setUrl(url);docInfo.setContent(content);synchronized (locker1) {docInfo.setDocId(forwardIndex.size());forwardIndex.add(docInfo);}return docInfo;
}(5) buildInverted() 构建倒排索引
// 3.1 构建倒排索引
private void buildInverted(DocInfo docInfo) {class WordCnt {// 表示这个词在标题中出现的次数public int titleCount;// 表示这个词在正文中出现的次数public int contentCount;}// 这个数据结构用来统计词频HashMap<String, WordCnt> wordCntHashMap = new HashMap<>();// 1. 针对文档[标题]进行分词List<Term> terms = ToAnalysis.parse(docInfo.getTitle()).getTerms();// 2. 遍历分词结果, 统计每个词出现的次数for (Term term : terms) {// 先判定一下 term 是否存在String word = term.getName(); // 获取到分词结果具体的词的信息WordCnt wordCnt = wordCntHashMap.get(word);if (wordCnt == null) {// 如果不存在, 就创建一个新的键值对, 插入进去, titleCount 设为 1WordCnt newWordCnt = new WordCnt();newWordCnt.titleCount = 1;newWordCnt.contentCount = 0;wordCntHashMap.put(word, newWordCnt);} else {// 如果存在, 就找到之前的值, 然后把对应的 titleCount + 1wordCnt.titleCount += 1;}}// 3. 针对[正文]页进行分词terms = ToAnalysis.parse(docInfo.getContent()).getTerms();// 4. 遍历分词结果, 统计每个词出现的次数for (Term term : terms) {String word = term.getName(); // 获取词WordCnt wordCnt = wordCntHashMap.get(word);if (wordCnt == null) {WordCnt newWordCnt = new WordCnt();newWordCnt.titleCount = 0;newWordCnt.contentCount = 1;wordCntHashMap.put(word, newWordCnt);} else {wordCnt.contentCount += 1;}}// 5. 把上面的结果汇总到一个 HashMap 里面// 最终文档的权重, 就设定为 [标题中出现的次数 * 10 + 正文中出现的次数]// 6. 遍历刚才这个 HashMap 依次来更新倒排索引中的结构for (Map.Entry<String, WordCnt> entry : wordCntHashMap.entrySet()) {// 先根据这里的词, 去倒排索引中查一查// 倒排拉链synchronized (locker2) {List<Weight> invertedList = invertedIndex.get(entry.getKey());if (invertedList == null) {// 如果为空, 就插入一个新的键值对ArrayList<Weight> newInvertedList = new ArrayList<>();// 把新的文档(当前 searcher.DocInfo), 构造成 searcher.Weight 对象, 插入进来Weight weight = new Weight();weight.setDocId(docInfo.getDocId());// 权重计算公式: 标题中出现的次数 * 10 + 正文中出现的次数weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);newInvertedList.add(weight);invertedIndex.put(entry.getKey(), newInvertedList);} else {// 如果非空, 就把当前这个文档, 构造出一个 searcher.Weight 对象, 插入到倒排拉链的后面Weight weight = new Weight();weight.setDocId(docInfo.getDocId());// 权重计算公式: 标题中出现的次数 * 10 + 正文中出现的次数weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);invertedList.add(weight);}}}
}(6) save() 往磁盘中写索引数据
// 4. 把内存中的索引结构保存到磁盘中
public void save() {// 使用俩个文件, 分别保存正排和倒排long beg = System.currentTimeMillis();System.out.println("----- 保存索引开始! -----");// 1. 先判定一个索引对应的目录是否存在, 不存在就创建File indexPathFile = new File(INDEX_PATH);if(! indexPathFile.exists()){indexPathFile.mkdirs();}File forwardIndexFile = new File(INDEX_PATH + "forward.txt");File invertedIndexFile = new File(INDEX_PATH + "inverted.txt");try {objectMapper.writeValue(forwardIndexFile, forwardIndex);objectMapper.writeValue(invertedIndexFile, invertedIndex);} catch (IOException e) {e.printStackTrace();}long end = System.currentTimeMillis();System.out.println("----- 保存索引完成! 消耗时间: " + (end - beg) + " ms -----");
}(7) load() 从磁盘加载索引数据
// 5. 把磁盘中的索引数据加载到内存中
public void load() {long beg = System.currentTimeMillis();System.out.println("----- 加载索引开始! -----");// 1. 先设置一下加载索引的路径File forwardIndexFile = new File(INDEX_PATH + "forward.txt");File invertedIndexFile = new File(INDEX_PATH + "inverted.txt");try {forwardIndex = objectMapper.readValue(forwardIndexFile, new TypeReference<ArrayList<DocInfo>>() {});invertedIndex = objectMapper.readValue(invertedIndexFile, new TypeReference<HashMap<String, ArrayList<Weight>>>() {});} catch (IOException e) {e.printStackTrace();}long end = System.currentTimeMillis();System.out.println("----- 加载索引完成! 消耗时间: " + (end - beg) + " ms -----");
}3.4 实现 DocSearcher 类:
这个类负责实现搜索功能.
停用词文件的路径
private static final String STOP_WORD_PATH = "C:/Users/LEO/Desktop/jdk-8u361-docs-all/stop_word.txt";保存停用词
private HashSet<String> stopWords = new HashSet<>();创建一个index实例
// 此处要加上索引对象的实例
// 同时要完成索引加载的工作
private Index index = new Index();(1) DocSearcher() 构造方法
public DocSearcher() {index.load();loadStopWords();
}(2) searcher() 方法
// 根据查询词, 完成搜索过程
public List<Result> search(String query) {// 1. [分词] 针对 query 这个查询词进行分词List<Term> oldTerms = ToAnalysis.parse(query).getTerms();List<Term> terms = new ArrayList<>();// 针对分词结果, 使用暂停词表进行过滤for (Term term : oldTerms){if(stopWords.contains(term.getName())){continue;}terms.add(term);}// 2. [触发] 针对分词结果来查倒排// List<Weight> allTermResult = new ArrayList<>();// 搜索一个词的文档有 List<Weight> 个// 搜索n个分词结果的文档有 List<List<Weight>> 个List<List<Weight>> termResult = new ArrayList<>();for (Term term : terms) {String word = term.getName();// 虽然倒排索引中, 有很多的词, 但是这里的词一定都是之前的文档中存在的List<Weight> invertedList = index.getInverted(word);if (invertedList == null) {// 说明这个词在所有文档中都不存在continue;}termResult.add(invertedList);}// 3. [合并] 针对多个分词结果触发出的相同文档, 进行权重合并List<Weight> allTermResult = mergeResult(termResult);// 4. [排序] 针对触发的结果按照权重降序排序allTermResult.sort(new Comparator<Weight>() {@Overridepublic int compare(Weight o1, Weight o2) {// 如果是升序排序: return o1.getWeight() - o2.getWeight()// 如果是降序排序: return o2.getWeight() - o1.getWeight()return o2.getWeight() - o1.getWeight();}});// 5. [包装结果] 针对排序的结果, 去查正排, 构造出要返回的数据List<Result> results = new ArrayList<>();for (Weight weight : allTermResult) {DocInfo docInfo = index.getDocInfo(weight.getDocId());Result result = new Result();result.setTitle(docInfo.getTitle());result.setUrl(docInfo.getUrl());result.setDesc(GenDes(docInfo.getContent(), terms));results.add(result);}return results;
}(3) mergeResult() 权重合并
问题:
当搜索的查询词包含多个单词的时候, 可能同一个文档中, 会同时包含这多个分词结果.
像这样的文档应该要提高权重.
例如 查询词为 "array list"
某文档中同时存在 array 和 list, 这个时候这个文档的实际权重, 就要把 array 的权重和 list 的权重相加.
// 通过这个内部类, 来描述一个元素在二维数组中的位置
// Pos 类负责表示一个 Weight 的具体位置.
static class Pos{public int row; // 行private int col; // 列public Pos(int row, int col) {this.row = row;this.col = col;}
}private List<Weight> mergeResult(List<List<Weight>> source) {// 1. 先把每行的结果按照 id 升序排序for (List<Weight> row : source) {row.sort(new Comparator<Weight>() {@Overridepublic int compare(Weight o1, Weight o2) {return o1.getDocId() - o2.getDocId();}});}// 2. 借助优先队列, 进行归并ArrayList<Weight> target = new ArrayList<>();// 2.1 创建优先队列, 指定比较规则PriorityQueue<Pos> queue = new PriorityQueue<>(new Comparator<Pos>() {@Overridepublic int compare(Pos o1, Pos o2) {return source.get(o1.row).get(o1.col).getDocId() - source.get(o2.row).get(o2.col).getDocId();}});// 2.2 初始化队列, 放入每行的第一列元素for (int row = 0; row < source.size(); row++) {queue.offer(new Pos(row, 0));}// 2.3 循环从队列中取元素while (!queue.isEmpty()) {Pos curPos = queue.poll();Weight curWeight = source.get(curPos.row).get(curPos.col);if (target.size() != 0) {Weight lastWeight = target.get(target.size() - 1);if (curWeight.getDocId() == lastWeight.getDocId()) {// 合并 weight 的权重lastWeight.setWeight(lastWeight.getWeight() + curWeight.getWeight());} else {// 不合并, 直接插入target.add(curWeight);}} else {// 不合并, 直接插入target.add(curWeight);}Pos newPos = new Pos(curPos.row, curPos.col + 1);if (newPos.col >= source.get(newPos.row).size()) {// 当前行已经到达末尾了continue;}queue.offer(newPos);}return target;
}(4) GenDes() 制作描述部分 + 标红
private String GenDes(String content, List<Term> terms) {// 用分词结果中的第一个在描述能找到的词, 作为位置的中心// 先遍历分词结果, 看看哪个结果是在 content 中存在int firstPos = -1;for (Term term : terms) {// 别忘了, 分词库直接针对词进行转小写// 正因为如此, 就必须把正文也先转成小写, 然后再查询String word = term.getName();// 此处需要的是"全字匹配", 让word能够独立成词, 才要查出来, 而不是只作为词的一部分content = content.toLowerCase().replaceAll("\\b" + word + "\\b", " " + word + " "); // ... arraylist).firstPos = content.toLowerCase().indexOf(" " + word + " ");if (firstPos >= 0) {// 找到了位置break;}}if (firstPos == -1) {// 所有的分词结果都不在正文中存在// 极端情况, 标题有, 正文没有if(content.length() > 160){return content.substring(0, 160) + "...";}return content;}// 从 firstPos 作为基准位置, 往前找60个字符, 作为描述的起始位置String desc = "";int descBeg = firstPos < 60 ? 0 : firstPos - 60; // 描述的起始位置if (descBeg + 160 > content.length()) {desc = content.substring(descBeg); // 截取从descBeg位置开始到末尾结束} else {desc = content.substring(descBeg, descBeg + 160) + "...";}// [标红逻辑]// 在此处加上一个替换操作, 把描述中的和分词结果相同的部分, 给加上一层 <i> 标签, 就可以通过 replace 的方式来实现for (Term term : terms){String word = term.getName();// 注意. 此处要进行全字匹配, 也就是当查询词为 List 的时候, 不能把 ArrayList 中的 List 给单独标红desc = desc.replaceAll("(?i) " + word + " ", "<i> " + word + " </i>");}return desc;
}(5) loadStopWords() 加载停用词到stopWords中
// 加载停用词到stopWords中
public void loadStopWords(){try(BufferedReader bufferedReader = new BufferedReader(new FileReader(STOP_WORD_PATH))){while(true){String line = bufferedReader.readLine();if(line == null){// 读取文件完毕break;}stopWords.add(line);}} catch (IOException e){e.printStackTrace();}
}3.5 实现 Web 模块:
(1) doGet() 方法
@WebServlet("/searcher")
public class DocSearcherServlet extends HttpServlet {// 此处的 docSearcher 是全局唯一的, 因此需要 static 修饰private static DocSearcher docSearcher = new DocSearcher();private ObjectMapper objectMapper = new ObjectMapper();@Overrideprotected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {// 1. 先解析请求, 拿到用户提交的查询词String query = req.getParameter("query");if (query == null || query.equals("")){String msg = "您的参数非法! 没有获取到 query 的值!";System.out.println(msg);resp.sendError(404, msg);return;}// 2. 打印记录一下 query 的值System.out.println("query= " + query);// 3. 调用搜索模块, 进行搜索List<Result> results = docSearcher.search(query);// 4. 把当前的搜索结果进行打包resp.setContentType("application/json; charset=utf-8");objectMapper.writeValue(resp.getWriter(), results);}
}相关文章:
Java API 文档搜索引擎
1. 认识搜索引擎:在搜狗搜索的搜索结果页中, 包含了若干条结果, 每一个结果包含了图标, 标题, 描述, 展示URL等搜索引擎的本质:输入一个查询词, 得到若干个搜索结果, 每个搜索结果包含了标题, 描述, 展示URL和点击URL2. 搜索引擎思路:2.1 搜索的核心思路:当前我们有很多的网页(…...
2023美赛C题Wordle二三问分布预测和难度分类预测
文章目录前言题目介绍人数分布预测首先建立字母词典,加上时间特征数据预处理训练和预测函数保存模型函数位置编码模型及其参数设置模型训练以及训练曲线可视化预测人数分布难度分类预测总结前言 2023美赛选了C题,应该很多人会选,一看就好做&…...
gdb的简单练习
题目来自《ctf安全竞赛入门》1.用vim写代码vim gdb.c#include "stdio.h" #include "stdlib.h" void main() {int i 100;int j 101;if (i j){printf("bingooooooooo.");system("/bin/sh");}elseprintf("error............&quo…...

如何使用python AI快速比对两张人脸图像?
本篇文章的代码块的实现主要是为了能够快速的通过python第三方非标准库对比出两张人脸是否一样。 实现过程比较简单,但是第三方python依赖的安装过程较为曲折,下面是通过实践对比总结出来的能够支持的几个版本,避免大家踩坑。 python版本&a…...
C#传智:变量基础(第二天))
(2)C#传智:变量基础(第二天)
一、注释符 不写注释是流氓,名字瞎起是扯蛋。 注释作用:解释与注销 命名: 以字母、_、开头,里面只能有_与特殊符,其它不得出现如%*&^等。 不能与关键字重复。区分大小写,Num…...
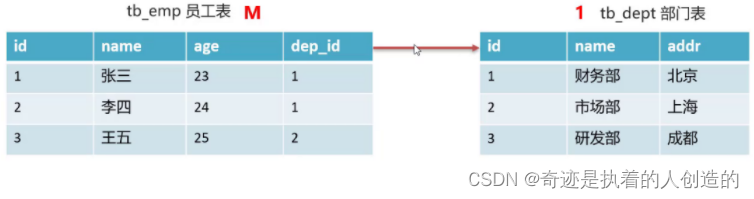
02-mysql高级-
文章目录mysql高级1,约束1.1 概念1.2 分类1.3 非空约束1.4 唯一约束1.5 主键约束1.6 默认约束1.7 约束练习1.8 外键约束1.8.1 概述1.8.2 语法1.8.3 练习2,数据库设计2.1 数据库设计简介2.2 表关系(一对多)mysql高级 今日目标 掌握约束的使用 掌握表关系…...
存储空间占用)
windows 使用everything 查看文件(夹)存储空间占用
起因 总是那个原因,C: D: E:全都红了,下的游戏太多了,然后就这样了,之前也有过不少这种情况.几年前,就在智能手机上见过类似的功能. 大概就是遍历文件系统,统计每个文件的大小,然后父节点记录所有子节点的和,然后可以显示占用百分比之类的. 经过 在windows 上我最开始使用ex…...

2023该好好赚钱了,推荐三个下班就能做的副业
在过去的两年里,越来越多的同事选择辞职创业。许多人通过互联网红利赚到了他们的第一桶金。随着短视频的兴起,越来越多的人吹嘘自己年收入百万,导致很多刚进入职场的年轻人逐渐迷失自我,认为钱特别容易赚。但事实上,80…...

vue3如何进行数据监听watch/watchEffect
我们都知道监听器的作用是在每次响应式状态发生变化时触发,在组合式 API 中,我们可以使用 watch()函数和watchEffect()函数, 当你更改了响应式状态,它可能会同时触发 Vue 组件更新和侦听器回调。 默认情况下,用户创建的侦听器回…...
Wgcloud安装和使用(性能监控)
一、Wgcloud说明 官网:https://www.wgstart.com/ WGCLOUD支持主机各种指标监测(cpu使用率,cpu温度,内存使用率,磁盘容量,磁盘IO,硬盘SMART健康状态,系统负载,连接数量&…...

前端如何实现本地图片上传?
前端如何实现本地图片上传? 摘要 对于学习前端的小伙伴都有一个困惑,就是平常想上手小项目,但碍于不想购买服务器,实践受到了限制。 一般我选择node.js搭建服务器,毕竟基于JavaScript语言,简直不是一家人…...

【基础算法】差分的应用(一维差分和二维差分)
🌹作者:云小逸 📝个人主页:云小逸的主页 📝Github:云小逸的Github 🤟motto:要敢于一个人默默的面对自己,强大自己才是核心。不要等到什么都没有了,才下定决心去做。种一颗树,最好的时间是十年前…...

第49章 API统一集中管理
1 关于统一集中管理API的一些思考 1、统一集中管理是保证工程性项目得保质、保量、成功实施,并对后期维护提供数据支撑的最有效,最节省资源和时间的技能和做法,软件做为一种特殊的工程性项目,也符合上述特性。 2、由于在前台实现中…...

carla0.9.13-UE4添加4轮车模型(Linux系统)
前期准备建模工具:blender:v3.4.1;可以在Ubuntu Software商店直接下载虚拟引擎:carla-UE4 (carla v0.9.13),无需额外安装UE4,carla中自带插件编译carla参照官方文档:https://carla.readthedocs.io/en/0.9.1…...
对比yolov4和yolov3
目录 1. 网络结构的不同 1.1 Backbone 1.1.1 Darknet53 1.1.2 CSPDarknet53 1.2 Neck 1.2.1 FPN 1.2.2 PAN 1.2.3 SPP 1.3 Head 2. 数据增强 2.1 CutMix 2.2 Mosaic 3. 激活函数 4. 损失函数 5. 正则化方法 知识点 记录备忘。 总体而言&…...

Android ServiceManager
1.ServiceManager ServiceManager在init进程启动后启动,用来管理系统中的Service。 一般开机过程分为三个阶段: ①OS级别,由bootloader载入linux内核后,内核开始初始化,并载入built-in的驱动程序,内核完成开机后,载入init process,切换至user-space后,结束内核的循…...
数据挖掘,计算机网络、操作系统刷题笔记53
数据挖掘,计算机网络、操作系统刷题笔记53 2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开 测开的话,你就得学数据库,sql,orac…...

地球板块运动vr交互模拟体验教学提高学生的学习兴趣
海陆变迁是地球演化史上非常重要的一个过程,它不仅影响着地球的气候、地貌、生物多样性等方面,还对人类文明的演化产生了深远的影响。为了帮助学生更加深入地了解海陆变迁的过程和机制,很多高校教育机构开始采用虚拟现实技术进行教学探究。 V…...

【Android玩机】跟大家聊聊面具Magisk的使用(安装、隐藏)
目录:1、Magisk中文网2、隐藏面具和Root(一共3种方法)1、Magisk中文网 (1)首先Magisk有一个中文网,对新手非常友好 (2)这网站里面主要包含:6 部分 (3)按照他给…...

DACS: Domain Adaptation via Cross-domain Mixed Sampling 学习笔记
DACS介绍方法Naive MixingDACSClassMix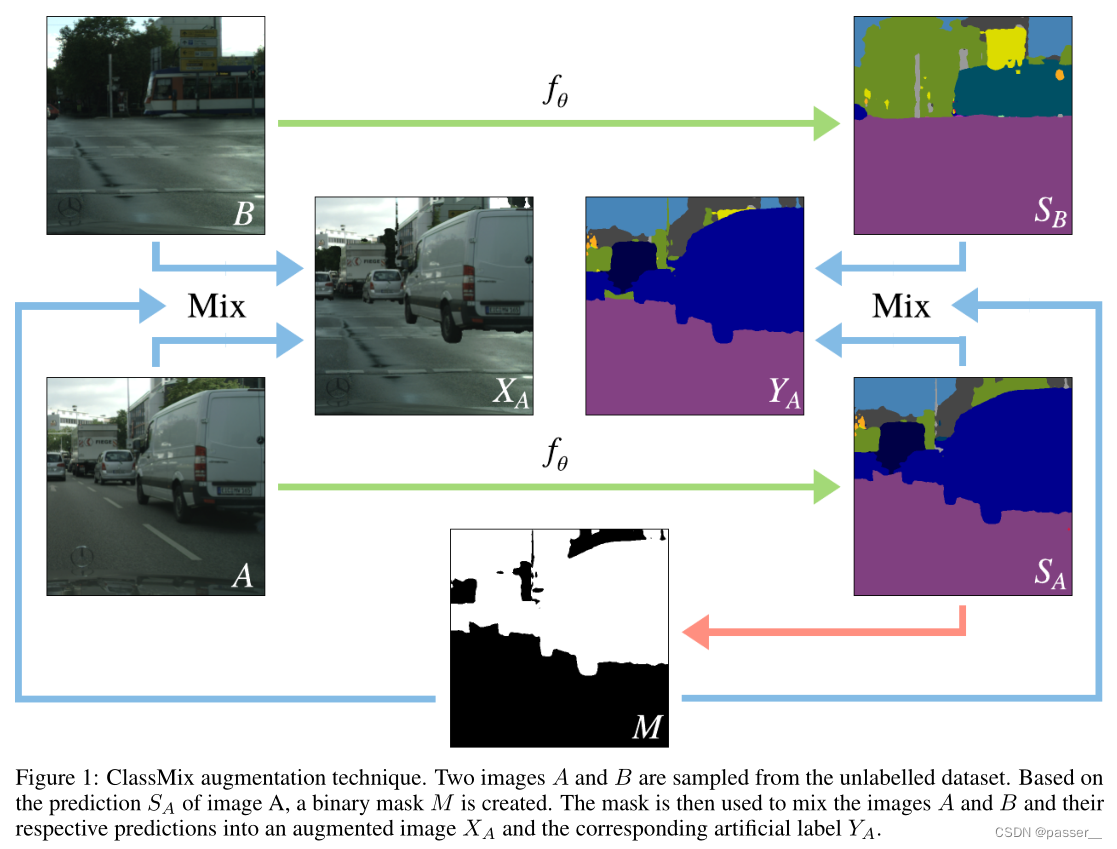算法流程实验结果反思介绍 近年来,基于卷积神经网络的语义分割模型在众多应用中表现出了显著的性能。然而当应用于新的领域时&…...
)
Java 语言特性(面试系列2)
一、SQL 基础 1. 复杂查询 (1)连接查询(JOIN) 内连接(INNER JOIN):返回两表匹配的记录。 SELECT e.name, d.dept_name FROM employees e INNER JOIN departments d ON e.dept_id d.dept_id; 左…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...

4. TypeScript 类型推断与类型组合
一、类型推断 (一) 什么是类型推断 TypeScript 的类型推断会根据变量、函数返回值、对象和数组的赋值和使用方式,自动确定它们的类型。 这一特性减少了显式类型注解的需要,在保持类型安全的同时简化了代码。通过分析上下文和初始值,TypeSc…...

Scrapy-Redis分布式爬虫架构的可扩展性与容错性增强:基于微服务与容器化的解决方案
在大数据时代,海量数据的采集与处理成为企业和研究机构获取信息的关键环节。Scrapy-Redis作为一种经典的分布式爬虫架构,在处理大规模数据抓取任务时展现出强大的能力。然而,随着业务规模的不断扩大和数据抓取需求的日益复杂,传统…...

认识CMake并使用CMake构建自己的第一个项目
1.CMake的作用和优势 跨平台支持:CMake支持多种操作系统和编译器,使用同一份构建配置可以在不同的环境中使用 简化配置:通过CMakeLists.txt文件,用户可以定义项目结构、依赖项、编译选项等,无需手动编写复杂的构建脚本…...
Python训练营-Day26-函数专题1:函数定义与参数
题目1:计算圆的面积 任务: 编写一个名为 calculate_circle_area 的函数,该函数接收圆的半径 radius 作为参数,并返回圆的面积。圆的面积 π * radius (可以使用 math.pi 作为 π 的值)要求:函数接收一个位置参数 radi…...

【实施指南】Android客户端HTTPS双向认证实施指南
🔐 一、所需准备材料 证书文件(6类核心文件) 类型 格式 作用 Android端要求 CA根证书 .crt/.pem 验证服务器/客户端证书合法性 需预置到Android信任库 服务器证书 .crt 服务器身份证明 客户端需持有以验证服务器 客户端证书 .crt 客户端身份…...