Python数据容器:dict(字典、映射)
1、什么是字典
Python中的字典是通过key找到对应的Value(相当于现实生活中通过“字”找到“该字的含义”
我们前面所学习过的列表、元组、字符串以及集合都不能够提供通过某个东西找到其关联的东西的相关功能,字典可以。
例如 这里有一份成绩单,记录了学生的姓名和考试总成绩:
姓名 成绩 王一 77
王二 88 王三 99 现在需要将其通过Python录入至程序中,并可以通过学生姓名检索学生的成绩:
使用字典最为合适,可以通过Key(学生姓名),取到对应的Value(考试成绩):
{"王一":77,"王二":88,"王三":99 }
2、字典的定义
字典同样使用{},不过存储的元素是一个一个的键值对,语法如下:
{key:value, key:value, key:value}
定义空字典:
my_dict = {} # 空字典定义方式1
my_dict = dict() # 空字典定义方式2
字典的key是不允许重复的,当定义了重复的key时,后面的 键值对 会把前面的 键值对 覆盖掉(只保留最后一个)。
字典同集合一样,不可以使用下标索引,但是字典可以通过Key值来取得对应的Value。
字典的key不可以为字典。
字典有如下特点:
1、可以容纳多个数据
2、可以容纳不同类型的数据
3、每一份数据是Keyvalue键值对
4、可以通过Key获取到Value,Key不可重复(重复会覆盖)
5、不支持下标索引
6、可以修改(增加或制除更新元素等)
7、支持for循环,不支持while循环
3、示例代码
# 定义空字典,两种方式 my_dict_empty = dict() my_dict_empty1 = {} """为什么在前面集合处,定义空的集合只有my_set = set()? 因为 ={} 被字典占用了,所以只能使用set() """# 定义字典,键值对:学号:成绩 my_dict = {"2023001": "99", "2023002": "88", "2023003": "77"} print(f"my_dict 的内容是: {my_dict}, 类型是{type(my_dict)}") """输出:my_dict 的内容是: {'2023001': '99', '2023002': '88', '2023003': '77'}, 类型是<class 'dict'> """# 定义重复Key的字典 my_dict_KeyRepeat = {"2023001": "99", "2023002": "88", "2023003": "77", "2023001": "60"} print(f"my_dict_KeyRepeat 的内容是: {my_dict_KeyRepeat }") """输出:my_dict_KeyRepeat 的内容是: {'2023001': '60', '2023002': '88','2023003': '77'}"2023001": "60" 把 "2023001": "99" 覆盖掉了 """# 从字典中基于Key获取Value score = my_dict["2023001"] print(f"学号为2023001的同学的考试成绩为: {score}") # 输出:学号为2023001的同学的考试成绩为: 99 score = my_dict.get("2023002") # 使用get()方法同样可以 print(f"学号为2023002的同学的考试成绩为: {score}") # 输出:学号为2023002的同学的考试成绩为: 88# 定义嵌套字典 """假如有一张成绩单为:姓名 语文 数学 英语王一 99 60 78王二 98 78 91王三 59 66 61…… ……那么这时候使用嵌套字典就很合适了 """ Multiple_subjects_scores = {"王一": {"语文": "99", "数学": "60", "英语": "78"},"王二": {"语文": "98", "数学": "78", "英语": "91"},"王三": {"语文": "59", "数学": "66", "英语": "61"} } # 从嵌套字典中获取数据 someone_score = Multiple_subjects_scores["王一"]["语文"] print(f"王一的语文成绩是{someone_score}") # 输出:王一的语文成绩是99
4、字典的常用操作
操作 语法 结构 新增元素 字典[key] =Value 字典被修改,新增了元素 更新元素 字典[key] =Value 字典被修改,元素被更新
(字典key不可以重复,所以对已存在的key执行新增元素操作,
就是更新Value值)
删除元素 字典.pop(key) 获得指定Key的Value,同时字典被修改,指定Key的数据被删除 清空元素 字典.clear( ) 得到空字典,得到:{} 获取全部
的key值
字典.keys() 得到字典中全部key 遍历字典 for key in 字典: 因为不支持下标索引,所以不支持while循环,只能使用for循环 统计字典内
的元素数量
len(字典) 得到字典的元素数量 # 新增元素 Multiple_subjects_scores = {"王一": {"语文": "99", "数学": "60", "英语": "78"},"王二": {"语文": "98", "数学": "78", "英语": "91"},"王三": {"语文": "59", "数学": "66", "英语": "61"} } Multiple_subjects_scores["王一"]["政治"] = "100" print(f"新增元素后的Multiple_subjects_scores为: Multiple_subjects_scores = {Multiple_subjects_scores}") """输出:新增元素后的Multiple_subjects_scores为: Multiple_subjects_scores = {'王一': {'语文': '99', '数学': '60', '英语': '78', '政治': '100'}, '王二': {'语文': '98', '数学': '78', '英语': '91'}, '王三': {'语文': '59', '数学': '66', '英语': '61'}}王一新增了政治成绩 """# 更新元素 Multiple_subjects_scores["王三"]["语文"] = "88" print(f"更新元素后的Multiple_subjects_scores为: Multiple_subjects_scores = {Multiple_subjects_scores}") """输出:更新元素后的Multiple_subjects_scores为: Multiple_subjects_scores = {'王一': {'语文': '99', '数学': '60', '英语': '78', '政治': '100'}, '王二': {'语文': '98', '数学': '78', '英语': '91'}, '王三': {'语文': '88', '数学': '66', '英语': '61'}}王三的语文成绩从59 改成了 88 """ # 删除元素 Multiple_subjects_scores_Del = {"王一": {'语文': '99', '数学': '60', '英语': '78', '政治': '100'},"王二": {'语文': '98', '数学': '78', '英语': '91'},"王三": {'语文': '88', '数学': '66', '英语': '61'},"王四": {'语文': '82', '数学': '68', '英语': '69'}} Delete_Value_four = Multiple_subjects_scores_Del.pop("王四") # 删除王四整个同学的成绩 Delete_Value_one = Multiple_subjects_scores_Del["王一"].pop("政治") # 注意王一写在了pop的前面 del Multiple_subjects_scores_Del["王二"]["英语"] # 删除王二的英语成绩 print(f"执行完上面三条删除操作后的Multiple_subjects_scores_Del为: "f"Multiple_subjects_scores_Del = {Multiple_subjects_scores_Del}") """输出:执行完上面三条删除操作后的Multiple_subjects_scores_Del为: Multiple_subjects_scores_Del = {'王一': {'语文': '99', '数学': '60', '英语': '78'}, 政治成绩被删除'王二': {'语文': '98', '数学': '78'}, 英语成绩被删除'王三': {'语文': '88', '数学': '66', '英语': '61'}王四整行被删除} """# 获取全部的key值 All_Keys = Multiple_subjects_scores_Del.keys() print(f"Multiple_subjects_scores_Del字典的全部key为: {All_Keys}") # 输出:Multiple_subjects_scores_Del字典的全部key为: dict_keys(['王一', '王二', '王三'])# 遍历字典 print(f"Multiple_subjects_scores_Del字典的key分别为", end=": ") for key in Multiple_subjects_scores_Del:print(key, end=", ") print()print(f"Multiple_subjects_scores_Del字典的Value为", end=": ") for key in Multiple_subjects_scores_Del:print(Multiple_subjects_scores_Del[key], end=", ") print()print(f"Multiple_subjects_scores_Del字典中王一的key为", end=": ") for key in Multiple_subjects_scores_Del["王一"]:print(key, end=", ") print()print(f"Multiple_subjects_scores_Del字典中王一的Value为", end=": ") for key in Multiple_subjects_scores_Del["王一"]:print(Multiple_subjects_scores_Del["王一"][key], end=", ") print() """输出:Multiple_subjects_scores_Del字典的key分别为: 王一, 王二, 王三, Multiple_subjects_scores_Del字典的Value为: {'语文': '99', '数学': '60', '英语': '78'}, {'语文': '98', '数学': '78'}, {'语文': '88', '数学': '66', '英语': '61'}, Multiple_subjects_scores_Del字典中王一的key为: 语文, 数学, 英语, Multiple_subjects_scores_Del字典中王一的Value为: 99, 60, 78, """# 统计字典内的元素数量 count = len(Multiple_subjects_scores_Del) print(f"Multiple_subjects_scores_Del的长度为: {count}") # 输出: Multiple_subjects_scores_Del的长度为: 3
5、键值对
什么是键值对:
键值对是一种数据结构,它由一个唯一的键(Key)和与之关联的值(Value)组成。键用于唯一标识数据,而值则是与键相关联的数据。键值对在编程中被广泛应用,可以用于存储、表示和操作数据。在键值对中,键(Key)是唯一的,它用于标识或索引数据。
通常情况下,键可以是字符串、数字或其他类型的数据。值(Value)则是与键相关联的数据,可以是任意类型的数据,如字符串、数字、布尔值、对象等。通过键,可以快速访问和检索与之关联的值。
使用键值对可以实现快速的数据存储和检索,因为键的唯一性可以确保不会出现重复的键,而值可以根据键进行快速的访问和操作。例如,可以使用键值对来表示字典中的单词和对应的定义,或者用来存储用户的 ID 和相关的用户信息等。
总结起来,键值对是一种由唯一的键和与之关联的值组成的数据结构,用于存储和操作数据。通过键可以快速地访问和检索与之关联的值,使得键值对成为一种常用的数据组织和操作方式。
常见的由键值对组成的结构:
1. 字典(Dictionary):
字典也称“关联数组”、“映射”。字典是Python中内置的数据结构,它使用大括号 `{}` 表示,每个元素都包含一个键和对应的值。字典可以用于存储和管理键值对数据,键是唯一的且不可变,值可以是任意类型的对象。字典的语法:字典={key:value, key:value, key:value}
2. JSON(JavaScript Object Notation):
JSON的语法衍生自JavaScript,但已经成为一种独立于编程语言的通用数据格式,JSON 是一种轻量级的数据交换格式,广泛应用于各种语言中。因其轻量、简洁、易用的特点,JSON广泛应用于Web开发、API设计和数据交换等场景。常见的应用包括将服务器返回的数据以JSON格式传输给前端,或将前端发送的数据以JSON格式传输给服务器。许多API也使用JSON作为数据的传输格式。它的数据结构也是基于键值对的形式。
JSON的语法:在JSON中,数据通过键值对的方式表示,使用大括号 {} 和方括号 [] 来表示对象和数组。
例如,以下是一个简单的JSON示例:
{"name": "John","age": 30,"isStudent": true,"hobbies": ["reading", "music"],"address": {"street": "123 Main St","city": "New York"},"phones": [{"type": "home", "number": "1234567890"},{"type": "work", "number": "9876543210"}] }在上面的示例中,"name": "John" 表示一个键值对,键是 "name",值是 "John"。 "hobbies" 的值是一个包含两个元素的数组。
"address" 的值是一个嵌套的对象。
"phones" 的值是一个包含两个对象元素的数组。
请注意,JSON的语法要求严格遵循上述规则,键必须使用双引号括起来,并且字符串值也必须使用双引号。同时,JSON不支持注释和多行字符串。
3. 命名元组(NamedTuple):
命名元组是一个Python标准库中的数据结构,它是元组的子类,其中每个元素都有一个名称(键)。命名元组可以像元组一样进行索引和切片操作,但是可以通过`<命名元组>.<键名称>`的方式访问元素。
命名元组的语法:
在Python中,创建命名元组的语法使用`collections`模块中的`namedtuple`函数。
创建命名元组的基本语法:from collections import namedtuple # 定义命名元组的类名和字段名 MyTuple = namedtuple('MyTuple', ['field1', 'field2', 'field3']) # 创建命名元组对象 my_tuple = MyTuple('value1', 'value2', 'value3')在上面的示例中,我们首先从`collections`模块导入`namedtuple`函数。然后,使用`namedtuple`函数创建一个命名元组类`MyTuple`,其中`MyTuple`是类的名字,`['field1', 'field2', 'field3']`是字段名的列表。你可以根据需要指定不同的字段名。
一旦我们定义了命名元组类`MyTuple`,我们可以使用这个类来创建命名元组对象。在上面的示例中,我们使用`MyTuple`类创建了一个名为`my_tuple`的命名元组对象,并给每个字段分配了一个值。
可以像访问普通元组一样访问命名元组的字段值,例如`my_tuple.field1`会返回`'value1'`。此外,命名元组还提供了一些其他方法和属性,如`_asdict()`、`_replace()`等,可以进一步操作和处理命名元组对象。
4. 配置文件:
在配置文件中,常使用键值对的形式来表示配置项和相应的值。例如INI文件格式中,使用方括号标记配置项的区域,并使用等号将配置项和值进行分隔。这些结构中的键值对可以用于存储和组织数据,提供了灵活性和可读性,使得代码更易于理解和维护。
配置文件是一种文本文件,用于存储应用程序或系统的配置信息。它通常用于存储各种参数、选项和设置,以便在应用程序运行时进行读取和修改。配置文件的目的是将特定的配置数据与源代码分离,使得可以轻松修改和管理应用程序的行为。配置文件可以包含键值对(key-value)的形式,其中键表示配置项的名称,值表示配置项的对应值。配置文件还可以使用不同的格式,如INI格式、JSON格式、YAML格式等,不同格式的配置文件具有不同的语法和特点。
通过使用配置文件,可以实现以下功能:
- 配置应用程序的默认设置和选项。
- 允许用户根据自己的需求定制应用程序的行为。
- 简化应用程序的部署和配置。
- 将敏感的信息(如数据库密码、API密钥)从源代码中分离,提高安全性。配置文件通常可以手动编辑,也可以通过读取和写入配置文件的代码来进行操作。读取配置文件时,程序可以解析配置文件并将配置项加载到内存中供应用程序使用。修改配置文件时,可以更新配置值或添加新的配置项,以调整应用程序的行为。
5. 关系型数据库(例如MySQL、PostgreSQL、Oracle):
关系型数据库使用表格的形式来存储数据,并使用键值对来表示数据的列名和对应的值。(和字典十分类似)
6. URL参数(Query String):
在URL中,可以通过使用键值对的形式来传递参数。例`https://www.example.com/search?keyword=apple`,其中`keyword`是键,`apple`是对应的值。
URL的组成:
一个URL(Uniform Resource Locator,统一资源定位符)通常包含以下几个部分:
1. 协议(Protocol):URL的协议部分指定了访问资源所使用的协议,比如HTTP、HTTPS、FTP等。协议通常在URL的开头,后跟`://`。
2. 主机名(Host):主机名部分标识了资源所在的主机或服务器的域名或IP地址。主机名通常紧跟在协议之后,并由斜杠或端口号结束。
3. 端口号(Port):端口号是一个可选项,用于标识要连接到的服务器上的特定进程。如果没有显式指定端口号,则使用协议的默认端口号。
4. 路径(Path):路径部分指定了服务器上资源的具体路径或位置。路径以斜杠`/`开头,可以根据需要包含多个目录和文件名称。
5. 查询参数(Query Parameters):查询参数允许在URL中传递附加的参数和数据。查询参数通常以问号`?`开头,多个参数之间以`&`分隔,每个参数由参数名和值组成。
6. 片段标识符(Fragment Identifier):片段标识符允许在URL中指定某个资源的特定片段或锚点位置。片段标识符通常以井号`#`开头。
综上所述,一个完整的URL示例可能如下所示:
https://www.example.com:8080/path/to/resource ?param1=value1¶m2=value2#fragment
其中,协议是`https`,主机名是`www.example.com`,端口号是`8080`,路径是`/path/to/resource`,查询参数是`param1=value1¶m2=value2`,片段标识符是`fragment`。具体的URL结构和含义可以根据不同的协议和实际需求而有所变化。7. HTTP请求头(HTTP Headers):
HTTP请求头包含了一系列的键值对,用来传递额外的信息和控制请求的行为。例如`Content-Type: application/json`,其中`Content-Type`是键,`application/json`是对应的值。
8. 缓存(Cache):
在计算机科学中,缓存是一种用来临时存储数据的技术。缓存常常使用键值对的形式来存储数据,其中键是用来标识数据的唯一值,而值则是要存储的数据本身。
9. 数据存储桶(Data Storage Buckets):
在云计算和分布式系统中,数据存储桶是一种用于存储和组织数据的容器。其中的数据可以使用键值对的形式进行存储和检索,其中键用于唯一标识数据,而值是数据本身。
10.哈希表:
在哈希表中,数据以键值对的形式存储,其中键是数据的唯一标识符,值是与该键关联的数据。通过使用哈希函数,将键映射到哈希表的索引位置,以便更快地访问和检索数据。
哈希表通常用于需要高效的数据查找和检索操作的场景,例如字典、数据库索引等。通过将键进行哈希函数计算,可以将数据均匀地分布到哈希表的不同位置上,从而提供快速的数据访问性能。在哈希表中,键具有唯一性,每个键对应一个值,可以通过键快速定位到对应的值,这使得哈希表成为一种高效的键值对存储和检索的数据结构。
11. 堆(Heap):
堆是一种具有特殊性质的完全二叉树,常用于优先级队列等场景。堆中的每个节点都有一个关键字,其中键可以用来对节点进行排序。堆通常通过键值对的形式来表示,其中键用来排序节点,值用来存储真实的数据。
12. 树(Tree):
树是一种用于存储层次化数据的数据结构,其中每个节点可以包含一个或多个子节点。在一些特定的树结构中,节点可以通过键值对的形式来表示,其中键用于标识节点,值用于存储节点的数据。
相关文章:
)
Python数据容器:dict(字典、映射)
1、什么是字典 Python中的字典是通过key找到对应的Value(相当于现实生活中通过“字”找到“该字的含义” 我们前面所学习过的列表、元组、字符串以及集合都不能够提供通过某个东西找到其关联的东西的相关功能,字典可以。 例如 这里有一份成绩单…...
2023年基因编辑行业研究报告
第一章 行业发展概况 1.1 定义 基因编辑(Gene Editing),又称基因组编辑(Genome Editing)或基因组工程(Genome Engineering),是一项精确的科学技术,可以对含有遗传信息的…...
Spring MVC:请求转发与请求重定向
Spring MVC 请求转发请求重定向附 请求转发 转发( forward ),指服务器接收请求后,从一个资源跳转到另一个资源中。请求转发是一次请求,不会改变浏览器的请求地址。 简单示例: 1.通过 String 类型的返回值…...

按键灯待机2秒后灭掉
修改文件:/device/mediatek/mt6580/init.mt6580.rc chown system system /sys/class/leds/red/triggerchown system system /sys/class/leds/green/triggerchown system system /sys/class/leds/blue/triggerchown system system sys/devices/platform/device_info/…...

SpringBoot通过自定义注解实现日志打印
目录 前言: 正文 一.Spring AOP 1.JDK动态代理 2.Cglib动态代理 使用AOP主要的应用场景: SpringBoot通过自定义注解实现日志打印 一.Maven依赖 二.ControllerMethodLog.class自定义注解 三.Spring AOP切面方法的执行顺序 四.ControllerMethodL…...

代码随想录算法训练营第七天 |151.翻转字符串里的单词
今天是代码随想录的第七天,写了力扣的151.翻转字符串里的单词; 之后或许还要再琢磨琢磨 代码随想录链接 力扣链接 151.翻转字符串里的单词,代码如下: # class Solution: # def reverseWords(self, s: str) -> str: # …...
WEBRTC 发送视频RTP包)
【WebRTC---源码篇】(十:一)WEBRTC 发送视频RTP包
RTPSenderVideo在整个框架中起到重要的作用,它把采集的数据进行编码,并且在流程中会进行将编码后的数据进行RTP打包,最后发送到网络层 RTPSenderVideo::SendVideo //对编码数据打包 bool RTPSenderVideo::SendVideo(int payload_type,absl::optional<VideoCodecType>…...

cmd 90 validate error!(达梦数据库日志报错)
达梦数据库报错 error-cmd 90 validate error! 环境介绍1 解决办法 环境介绍 某生产环境数据库启动后,dm_实例名_202309.log,偶尔报错cmd 90 validate error! 1 解决办法 接口用错了,消息非法,比如用 6 的 JDBC 连 7 或 7 的 …...
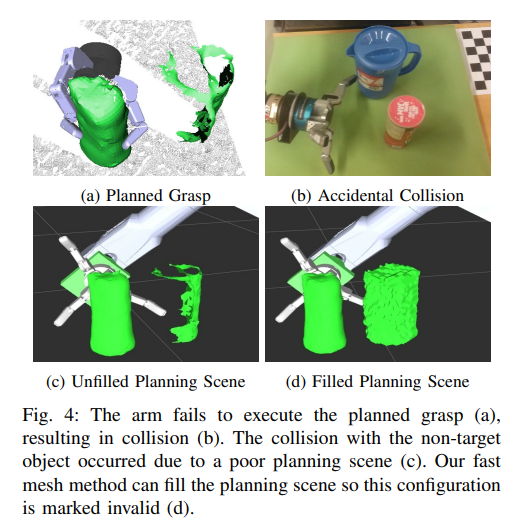
Shape Completion Enabled Robotic Grasping
摘要-这项工作提供了一个架构,使机器人能够通过形状完成抓取规划。形状完成是通过使用3D卷积神经网络(CNN)来完成的。该网络是在我们自己的新的开源数据集上训练的,该数据集包含了从不同视角捕获的超过44万个3D样本。运行时,从单个视角捕获的…...
【C++】构造函数意义 ( 构造函数显式调用与隐式调用 | 构造函数替代方案 - 初始化函数 | 初始化函数缺陷 | 默认构造函数 )
文章目录 一、构造函数意义1、类的构造函数2、构造函数显式调用与隐式调用3、构造函数替代方案 - 初始化函数4、初始化函数缺陷5、默认构造函数6、代码示例 - 初始化函数无法及时调用 一、构造函数意义 1、类的构造函数 C 提供的 构造函数 和 析构函数 作为 类实例对象的 初始化…...
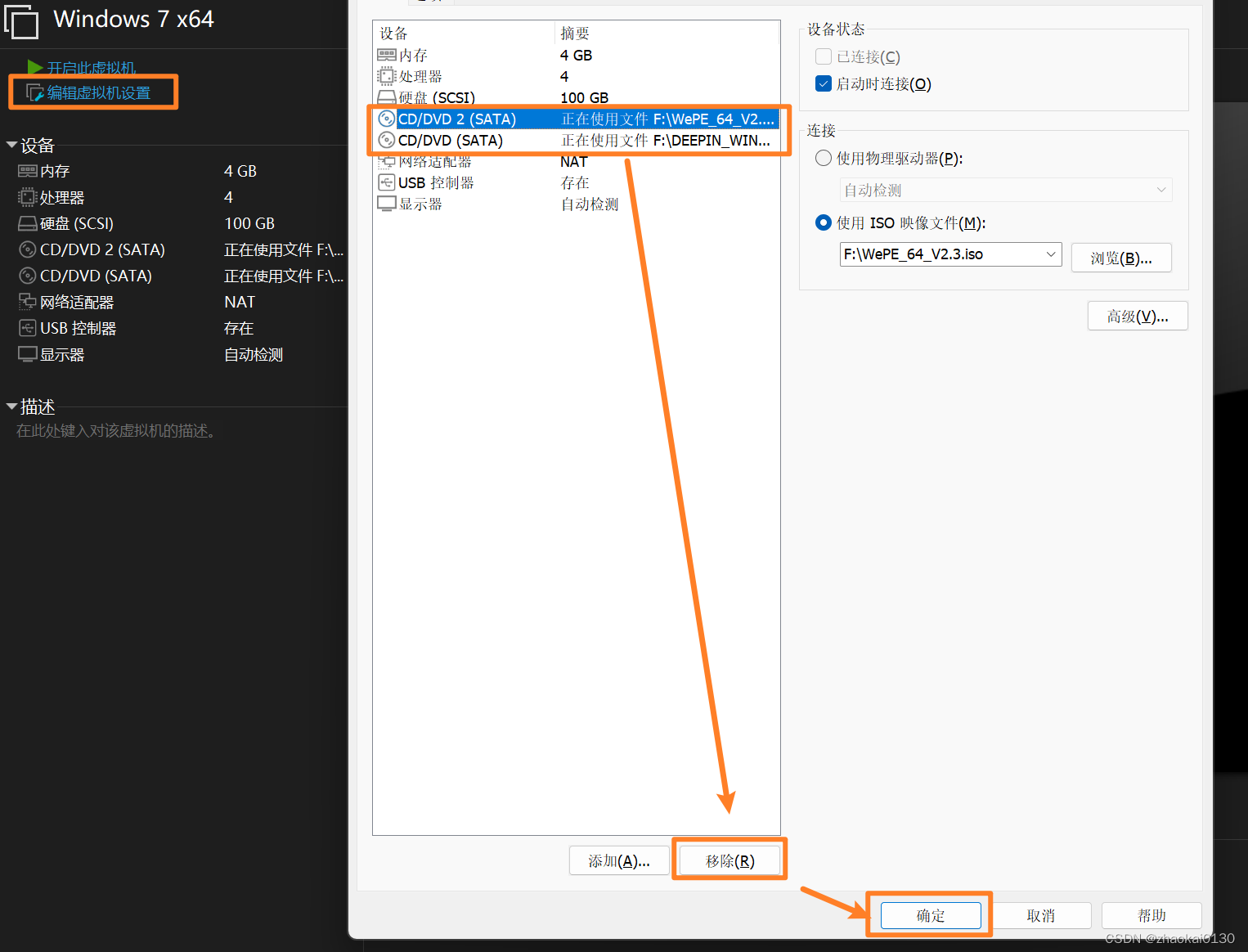
VMware16安装ghost版win7
文章目录 准备工作GHO 文件装机工具 新建虚拟机配置虚拟机还需要一个 CD/DVD PE 安装步骤分区还原挂载 CD/DVD开始还原 还原之后 准备工作 GHO 文件 可以去百度搜索这种文件,我这里是从系统之家下载的deepin win7 ghost 系统 装机工具 因为下载的 ghost 版的 w…...

项目集成swagger,访问不到swagger页面
项目集成swagger 文章目录 前言一、背景二、问题复现1.Full authentication is required to access this resource2.Illegal DefaultValue null for parameter type integer 总结 前言 项目集成swagger这个没啥好整的,maven项目就在pom文件导入依赖,ser…...
变透明的解决方案)
微信小程序怎么隐藏顶部导航栏(navigationBar)变透明的解决方案
怎么隐藏小程序顶部导航栏(navigationBar)? 官网说:Navigation是小程序的顶部导航组件,当页面配置 navigationStyle 设置为 custom 的时候可以使用此组件替代原生导航栏。 那么,我们就知道这种效果是可以…...
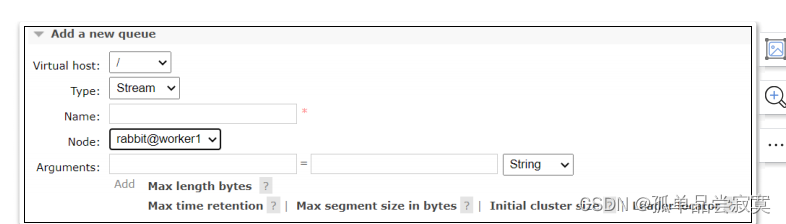
RabbitMQ基础概念-02
RabbitMQ是基于AMQP协议开发的一个MQ产品, 首先我们以Web管理页面为 入口,来了解下RabbitMQ的一些基础概念,这样我们后续才好针对这些基础概念 进行编程实战。 可以参照下图来理解RabbitMQ当中的基础概念: 虚拟主机 virtual hos…...

从构建者到设计者的低代码之路
低代码开发技术,是指无需编码或通过少量代码就可以快速生成应用程序的工具,一方面可降低企业应用开发人力成本和对专业软件人才的需求,另一方面可将原有数月甚至数年的开发时间成倍缩短,帮助企业实现降本增效、灵活迭代。那么&…...

Linux创建进程 及父子进程虚拟空间 多进程GDB调试
父子进程的资源是读时共享,写时拷贝,用到某一个资源,比如说改变变量的值的时候才去拷贝这个变量到一个独立的空间 父子进程的关系: 区别: 1.fork()函数的返回值不同 父进程中:>…...

uni-app 之 表格设置
uni-app 之 表格设置 image.png <view style"padding: 3%; border: #1296db;"><table style"width: 100%; border-collapse: collapse; "><tr style"height: 50px;border: 2px solid;border-color: #F7F7F7;"><td style&qu…...

Linux易混淆知识点
1. 使用 vi 编辑某个文件时,执行删除某行/某几行的操作: dd:删除光标所在行; 6dd:表示删除当前行开始 6 行数据。 ndd: 删除当前行开始的连续 n 行; n1,n2d:删除 n1 到 n2 行&#x…...
移植FlashDB、SFUD到STM32f407
个人上篇文章 搭建STM32F407的SPI-Flash(基于STM32CubeMX)_小刚学長的博客-CSDN博客 主要是解决STM32CubeMX这边的配置,对code端侧是简单介绍了下 实际项目上一般都是拿片外flash存储一些东西,比如一些比较多的配置、参数&…...
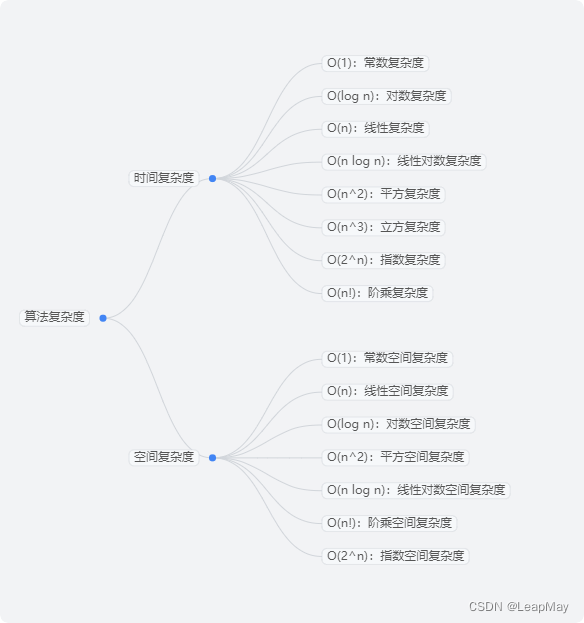
【算法基础】时间复杂度和空间复杂度
目录 1 算法的评价 2 算法复杂度 2.1 时间复杂度(Time Complexity) 2.1.1 如何计算时间复杂度: 2.1.2 常见的时间复杂度类别与示例 2.2 空间复杂度 2.2.1 如何计算空间复杂度 2.2.2 常见的空间复杂度与示例 3 时间复杂度和空间复杂度…...

如何快速集成ButterKnife与ARCore:打造高效增强现实应用
如何快速集成ButterKnife与ARCore:打造高效增强现实应用 【免费下载链接】butterknife Bind Android views and callbacks to fields and methods. 项目地址: https://gitcode.com/gh_mirrors/bu/butterknife ButterKnife是一款强大的Android视图绑定库&…...

浦语灵笔2.5-7B金融场景:K线图+新闻截图→行情解读→投资建议初稿
浦语灵笔2.5-7B金融场景:K线图新闻截图→行情解读→投资建议初稿 1. 引言:当AI分析师看懂K线图和财经新闻 想象一下这个场景:你是一位投资者,面对屏幕上密密麻麻的K线图和铺天盖地的财经新闻,试图从中找出市场的蛛丝…...

开源手机检测大模型DAMO-YOLO效果展示:AP@0.5达88.8%高清检测图集
开源手机检测大模型DAMO-YOLO效果展示:AP0.5达88.8%高清检测图集 1. 引言:当手机检测遇上“火眼金睛” 想象一下,你有一张满是人群的街拍照片,想快速、准确地找出画面里有多少部手机。或者,你正在开发一个智能零售系…...

Kimi-VL-A3B-Thinking真实效果:多轮OSWorld操作系统交互任务执行录屏解析
Kimi-VL-A3B-Thinking真实效果:多轮OSWorld操作系统交互任务执行录屏解析 1. 模型简介与技术亮点 Kimi-VL-A3B-Thinking是一款创新的开源混合专家(MoE)视觉语言模型,在保持高效计算的同时提供了强大的多模态理解能力。这个模型最…...

Arduino 第一部分
一.Arduino IDE界面和设置1.选择开发板型号和端口(1)首先将开发板通过USB线连接到电脑上。需要注意的是,USB线需要插牢,有时候USB线未插牢,开发板上的灯也会亮(2)选择开发板型号①可以通过上方的…...

AD丝印调整终极指南:从文字居中到批量修改的5个工业级技巧
AD丝印调整终极指南:从文字居中到批量修改的5个工业级技巧 在PCB设计的最后阶段,丝印处理往往成为硬件工程师最容易忽视的环节。那些看似微不足道的白色文字和符号,却是电路板可读性和可维护性的关键所在。想象一下,当你的设计进入…...

Git分支管理:Merge与Rebase的实战抉择
1. Git分支管理的核心痛点 每次看到团队仓库里那些错综复杂的分支线,我就想起刚入行时被Git历史图支配的恐惧。上周帮新人排查bug时,发现他为了把feature分支合入develop,竟然生成了7个merge commit——这简直是把版本历史变成了毛线团。相信…...

【LeYOLO】从理论到实践:构建面向边缘计算的超轻量目标检测模型
1. 边缘计算时代的目标检测新挑战 当你用手机拍照时,是否注意过相机会自动框出人脸?这就是典型的目标检测应用。但在智能摄像头、无人机等边缘设备上实现这样的功能,工程师们正面临三大难题:算力捉襟见肘、内存寸土寸金、电量如履…...
)
Spring AOP实战:如何优雅地实现公共字段自动填充(附完整代码)
Spring AOP实战:优雅实现公共字段自动填充的完整指南 在Java企业级应用开发中,数据表设计常常会包含一些重复出现的字段,比如创建时间(create_time)、更新时间(update_time)、创建人(create_user)和更新人(update_user)等。这些字段几乎出现在…...

千问3.5-27B效果展示:音乐专辑封面→风格分析→歌单推荐与文案生成
千问3.5-27B效果展示:音乐专辑封面→风格分析→歌单推荐与文案生成 1. 引言:当AI成为你的音乐品味分析师 想象一下这个场景:你偶然发现一张从未见过的专辑封面,它可能是一张复古的黑胶唱片,也可能是一张充满未来感的…...