机器学习——支持向量机(SVM)
机器学习——支持向量机(SVM)
文章目录
- 前言
- 一、SVM算法原理
- 1.1. SVM介绍
- 1.2. 核函数(Kernel)介绍
- 1.3. 算法和核函数的选择
- 1.4. 算法步骤
- 1.5. 分类和回归的选择
- 二、代码实现(SVM)
- 1. SVR(回归)
- 2. 回归结果可视化
- 3. SVC(分类)
- 3. 分类结果可视化
- 4. 非线性分类
- 总结
前言
支持向量机(SVM)是一种常见的机器学习方法,常用于分类(线性和非线性分类问题),回归问题。本文将详细介绍一下支持向量机算法
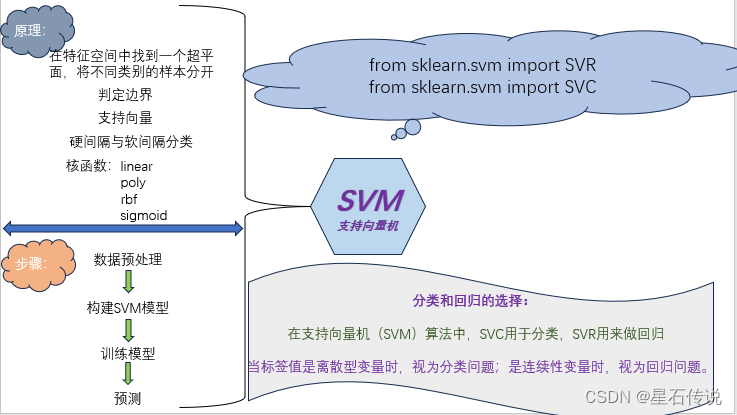
一、SVM算法原理
1.1. SVM介绍
支持向量机(Support Vector Machine,SVM)是一种常用的机器学习算法,SVM可以用于线性和非线性分类问题,回归以及异常值检测
其基本原理是通过在特征空间中找到一个超平面,将不同类别的样本分开,并且使得离超平面最近的样本点到超平面的距离最大化。
以一个二维平面为例,判定边界是一个超平面(在本图中其实是一条线,但是可以将它想象为一个平面乃至更高维形式在二维平面的映射),它是由支持向量所确定的(支持向量是离判定边界最近的样本点,它们决定了判定边界的位置)。
间隔的正中就是判定边界,间隔距离体现了两类数据的差异大小
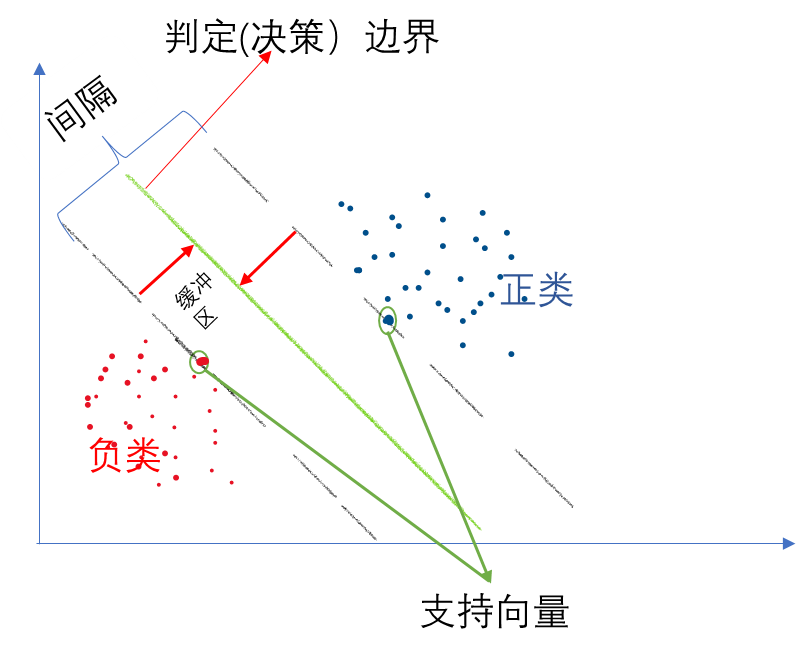
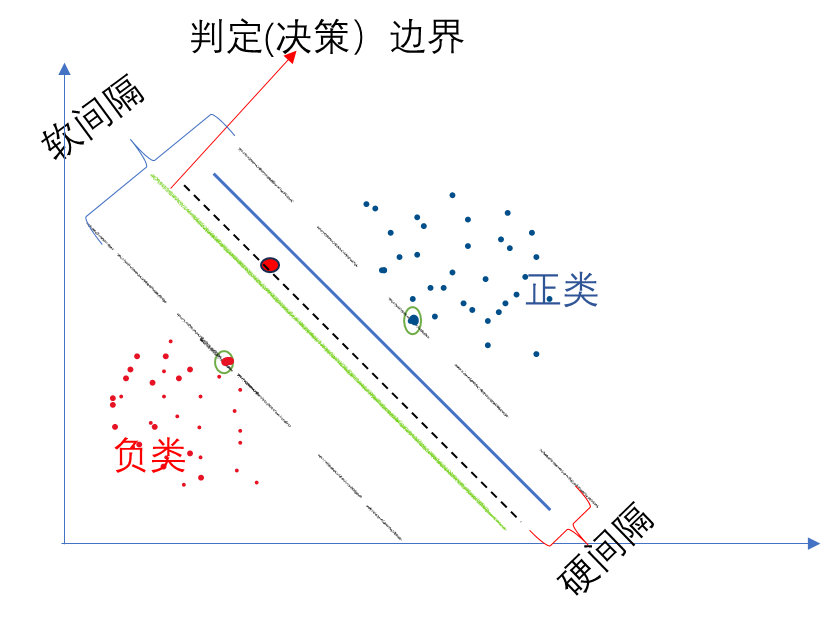
若严格地规定所有的样本点都不在“缓冲区”,都正确的在两边,称为硬间隔分类; 但是在一般情况下,不易实现,这里有两个问题:
第一,它只对线性可分的数据起作用。第二,有异常值的干扰。
为了避免这些问题,可使用软间隔分类:
在保持“缓冲区”尽可能大和避免间隔违规之间找到一个良好的平衡,在sklearn中的SVM类,可以使用超参数 C(惩罚系数),控制了模型的复杂度和容错能力。较小的C值会导致容错能力较高(即更宽的缓冲区),可能会产生更多的错误分类(即间隔违规);较大的C值会导致容错能力较低,可能会产生更少的错误分类。
1.2. 核函数(Kernel)介绍
为什么要引入核函数呢? 因为在SVM中,有时候很难找出一条线或一个超平面来分割数据集,这时候我们就需要升维(把无法线性分割的样本映射到高纬度空间,在高维空间实现分割)
核函数是特征转换函数,它可以将数据映射到高维特征空间中,从而更好地处理非线性关系。
核函数的作用是通过计算两个样本之间的相似度(内积)来替代显式地进行特征映射,从而避免了高维空间的计算开销。
在SVM中,核函数的选择非常重要,它决定了模型能够学习的函数空间。常见的核函数包括:
-
线性核函数(Linear Kernel):最简单的核函数,它在原始特征空间中直接计算内积,适用于线性可分的情况。K(X,y) = (X^T) * y
-
多项式核函数(Polynomial Kernel):通过多项式函数将数据映射到高维空间,可以处理一定程度的非线性关系。(可拟合出复杂的分割超平面,但可选参数太多,阶数高后计算困难,不稳定) K(X,y) = ( (X^T) * y + c ) ^ d , 其中 c 为常数,d 为多项式的阶数。
-
高斯核函数(Gaussian Kernel):也称为径向基函数(Radial Basis Function,RBF),通过高斯分布将数据映射到无穷维的特征空间,可以处理更复杂的非线性关系。形式为 K(x,y) = exp( -|| x-y || ^2 / (2 σ ^2) ) 。
|| x - y || 表示向量 x 和 y 之间的欧氏距离,即它们各个维度差值的平方和的平方根。
σ 是高斯核函数的参数,控制了样本之间相似度的衰减速度。σ 越小,样本之间的相似度下降得越快;σ 越大,样本之间的相似度下降得越慢。 -
sigmoid核函数(Sigmoid Kernel):通过sigmoid函数将数据映射到高维空间,适用于二分类问题。 σ(x) = 1 / (1 + exp(-x))
1.3. 算法和核函数的选择
假设特征数为N,训练数据集的样本个数为W,可按如下规则选择算法:
-
若N相对W较大,使用逻辑回归或线性核函数的SVM算法
-
若N较小,W中等大小(W为N的十倍左右),可使用高斯核函数的SVM算法
-
若N较小,W较大(W为N的五十倍以上),可以使用多项式核函数、高斯核函数的SVM算法
总之 ,数据大的问题,选择复杂一些的模型,反之,选择简单模型。
有关逻辑回归算法的更多信息,请看
机器学习——逻辑回归(LR)
1.4. 算法步骤
SVM算法可以分为以下几个步骤:
-
数据预处理:将数据集划分为训练集和测试集,并进行特征缩放(对数据进行标准化)。
-
构建模型:选择合适的核函数和惩罚系数,构建SVM模型。
-
训练模型:使用训练集对模型进行训练,通过最大化间隔来找到最优的超平面。
-
预测:使用训练好的模型对测试集进行预测。
1.5. 分类和回归的选择
通常情况下,当标签值是离散型变量时,我们将问题视为分类问题,而当标签值是连续性变量时,我们将问题视为回归问题。
在支持向量机(SVM)算法中,SVC用于分类,SVR用来做回归
-
在分类问题中,我们的目标是将输入数据分为不同的离散类别。常见的分类算法包括逻辑回归、决策树、随机森林和支持向量机等。
-
在回归问题中,我们的目标是预测连续性变量的值。回归问题涉及到对输入数据进行建模,以预测一个或多个连续的输出变量。常见的回归算法包括线性回归、决策树回归、支持向量回归和神经网络等。
二、代码实现(SVM)
1. SVR(回归)
使用波士顿房价数据集,其标签值是一个连续型变量,故用SVR来做回归问题
波士顿房价数据集介绍:

#加载波士顿房价数据集
from sklearn.datasets import load_boston
boston = load_boston()
x = boston.data
y = boston.target#数据的划分
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x,y,random_state=42)#标准化
from sklearn import preprocessing
scaler = preprocessing.StandardScaler().fit(x_train)
#保证train数据与test数据是在统一的距离标准下进行的标准化
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)#SVM构建
from sklearn.svm import SVR
#使用多项式核函数
model = SVR(kernel= "poly",degree= 3 ,C=5)
model.fit(x_train,y_train)
#检查得分
print(model.score(x_test,y_test))
# print(model.predict(x_test))#使用高斯核函数
model2 = SVR(kernel="rbf",gamma=0.01,C=5)
# print(model2)
model2.fit(x_train,y_train)
print(model2.score(x_test,y_test))#使用sigmoid核函数
model = SVR(kernel= "sigmoid",gamma=0.01 ,C=5)
model.fit(x_train,y_train)
#检查得分
print(model.score(x_test,y_test))
# print(model.predict(x_test))#使用网格搜索
import numpy as np
from sklearn.model_selection import GridSearchCV
params = {"kernel": ["rbf","sigmoid","poly","linear"],"C": np.arange(1,6),"gamma": np.arange(0,0.5,0.001),"degree":np.arange(1,5)
}
grid_searchcv = GridSearchCV(SVR(),param_grid= params,cv= 5)
grid_searchcv.fit(x_train,y_train)
print(grid_searchcv.best_params_)
print(grid_searchcv.best_score_)
#print(grid_searchcv.cv_results_)
print(grid_searchcv.best_index_)
print(grid_searchcv.best_estimator_)
best_clf = grid_searchcv.best_estimator_
best_clf.fit(x_train,y_train)
print(best_clf.score(x_test,y_test))#结果
{'C': 5, 'degree': 1, 'gamma': 0.058, 'kernel': 'rbf'}
0.7854834638941114
24232
SVR(C=5, degree=1, gamma=0.058)
0.76989712971335132. 回归结果可视化
from sklearn.svm import SVR
best_clf = SVR(kernel= "rbf",degree= 1 ,C=5,gamma=0.058)
best_clf.fit(x_train,y_train)import matplotlib.pyplot as plt
# 使用最佳模型进行预测
y_pred = best_clf.predict(x_test)# 绘制预测值与真实值之间的散点图
plt.scatter(y_test, y_pred)
plt.plot([y_test.min(), y_test.max()], [y_pred.min(), y_pred.max()], 'k--', lw=2)
plt.xlabel('True Values')
plt.ylabel('Predicted Values')
plt.title('SVM Regression - True Values vs Predicted Values')
plt.show()
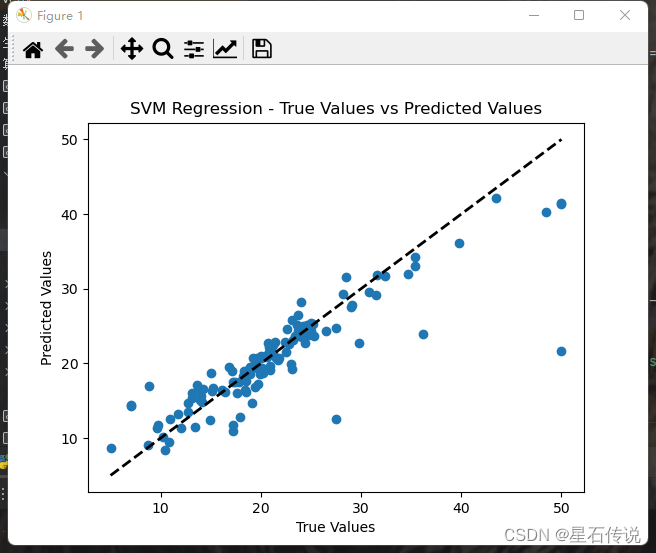
在图中,如果点分布在对角线附近,则表示预测值与真实值较为接近,说明模型的回归效果较好。反之则不好
3. SVC(分类)
使用鸢尾花数据集,因为其标签值为离散型变量,故用SVC来做分类问题
#加载iris数据集
from sklearn.datasets import load_iris
iris = load_iris()
x = iris.data
y = iris.target#数据的划分
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x,y,random_state=42)#标准化
from sklearn import preprocessing
scaler = preprocessing.StandardScaler().fit(x_train)
#保证train数据与test数据是在统一的距离标准下进行的标准化
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)#使用网格搜索
from sklearn.svm import SVC
import numpy as np
from sklearn.model_selection import GridSearchCV
params = {"kernel": ["rbf","sigmoid","poly","linear"],"C": np.arange(1,6),"gamma": np.arange(0,0.5,0.001),"degree":np.arange(1,4)
}
grid_searchcv = GridSearchCV(SVC(),param_grid= params,cv= 5)
grid_searchcv.fit(x_train,y_train)
print(grid_searchcv.best_params_)
print(grid_searchcv.best_score_)
print(grid_searchcv.best_index_)
print(grid_searchcv.best_estimator_)
best_clf = grid_searchcv.best_estimator_
best_clf.fit(x_train,y_train)
print(best_clf.score(x_test,y_test))
print(best_clf.predict(x_test))#结果
{'C': 1, 'degree': 1, 'gamma': 0.133, 'kernel': 'poly'}
0.9640316205533598
534
SVC(C=1, degree=1, gamma=0.133, kernel='poly')
1.0
[1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 10]3. 分类结果可视化
因为鸢尾花数据集有四个特征,所以为了方便可视化,要将数据集进行降维
# 使用PCA进行降维
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
x_pca = pca.fit_transform(x)
#数据的划分
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x_pca,y,random_state=42)#标准化
from sklearn import preprocessing
scaler = preprocessing.StandardScaler().fit(x_train)
#保证train数据与test数据是在统一的距离标准下进行的标准化
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
best_clf = SVC(degree= 1,C= 1,gamma= 0.133,kernel="poly")
best_clf.fit(x_train,y_train)
# 使用最佳模型进行预测
y_pred = best_clf.predict(x_test)# 绘制散点图
sc = plt.scatter(x_test[:, 0], x_test[:, 1], c=y_pred)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('SVM Classification - Predicted Classes')
handles, labels = sc.legend_elements()
plt.legend(handles, labels)
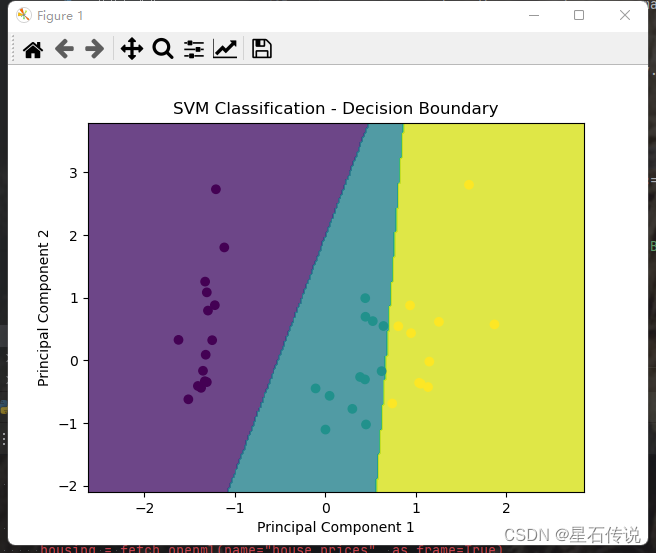
plt.show()# 绘制决策边界图
h = 0.02 # 步长
x_min, x_max = x_test[:, 0].min() - 1, x_test[:, 0].max() + 1
y_min, y_max = x_test[:, 1].min() - 1, x_test[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = best_clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.8)
plt.scatter(x_test[:, 0], x_test[:, 1], c=y_pred)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('SVM Classification - Decision Boundary')
plt.show()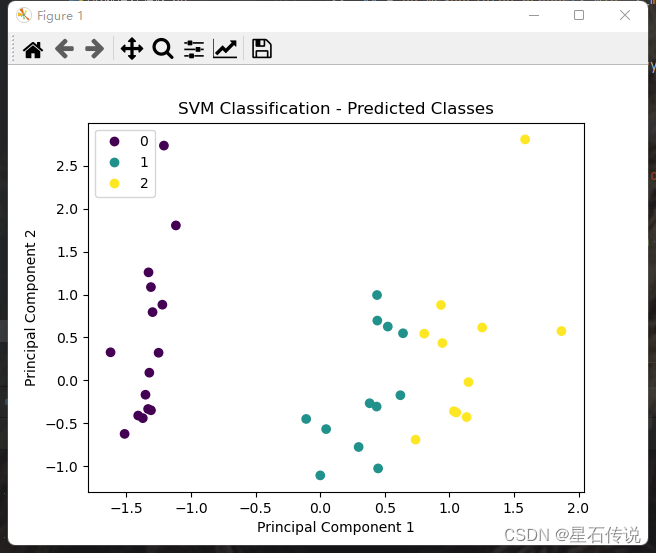
4. 非线性分类
from sklearn.datasets import make_moons
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
plt.style.use("ggplot")
# 生成非线性分类数据
X, y = make_moons(n_samples=200, noise=0.05,random_state=41)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建SVM模型并指定核函数
svm = SVC(kernel='rbf', random_state=42)
svm.fit(X_train, y_train)
y_pred = svm.predict(X_test)# 计算分类准确率
accuracy = accuracy_score(y_test, y_pred)
# print( accuracy)# 绘制分类结果
sc= plt.scatter(X_test[:, 0], X_test[:, 1], c=y_pred, cmap='viridis')
plt.xlabel('X1')
plt.ylabel('X2')
plt.title('Nonlinear Classification')
handles,labels =sc.legend_elements()
plt.legend(handles,labels)
plt.show()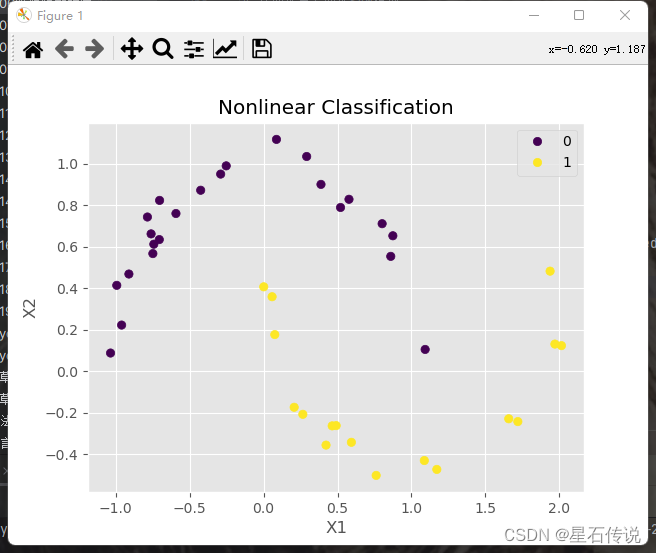
绘制决策边界图
# 绘制决策边界图
def plot_juecebianjie(model, X, y):# 定义绘图边界x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1h = 0.02 # 步长# 生成网格点坐标矩阵xx, yy = np.meshgrid(np.arange(x_min, x_max, h),np.arange(y_min, y_max, h))# 使用模型进行预测Z = model.predict(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)# 绘制等高线图plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral, alpha=0.6)# 绘制数据点sc= plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Spectral)plt.xlabel('X1')plt.ylabel('X2')plt.title('Decision Boundary')handles,labels = sc.legend_elements()plt.legend(handles,labels)plt.show()# 调用函数
plot_juecebianjie(svm, X_test, y_pred)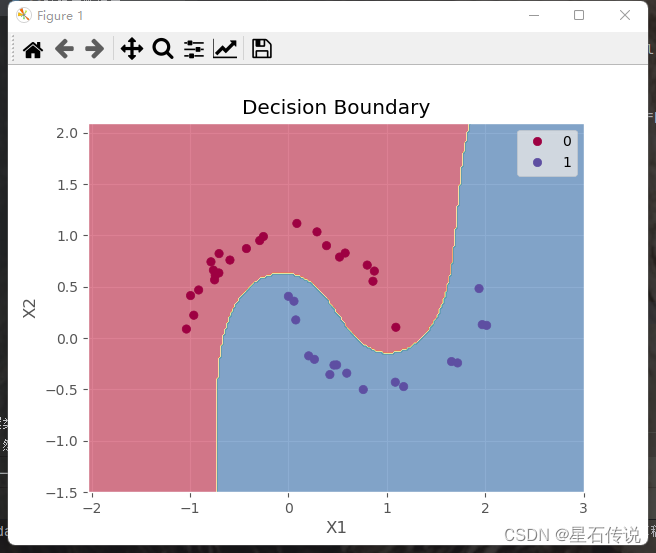
总结
本文在SVM算法原理介绍中:从开始的SVM介绍,到Kernel的介绍,再到算法和核函数的选择,之后就是算法的步骤,以及分类和回归的选择;在代码实现中:亦是分别对SVM中的回归(SVR)和分类(SVC)用代码实现,并可视化结果。
关关雎鸠,在河之洲
–2023-9-4 筑基篇
相关文章:
机器学习——支持向量机(SVM)
机器学习——支持向量机(SVM) 文章目录 前言一、SVM算法原理1.1. SVM介绍1.2. 核函数(Kernel)介绍1.3. 算法和核函数的选择1.4. 算法步骤1.5. 分类和回归的选择 二、代码实现(SVM)1. SVR(回归&a…...

HTTP协议初识·下篇
介绍 承接上篇:HTTP协议初识中篇_清风玉骨的博客-CSDN博客 本篇内容: 长链接 网络病毒 cookie使用&session介绍 基本工具介绍 postman 模拟客户端请求 fiddler 本地抓包的软件 https介绍 https协议原理 为什么加密 怎么加密 CA证书介绍 数字签名介绍…...

c++ 类的实例化顺序
其他类对象有作为本类成员,先构造类中的其他类对象, 释放先执行本对象的析构函数再执行包含的类对象的析构函数 #include <iostream> #include <string.h> using namespace std;class Phone { public:Phone(string name):m_PName(name){…...
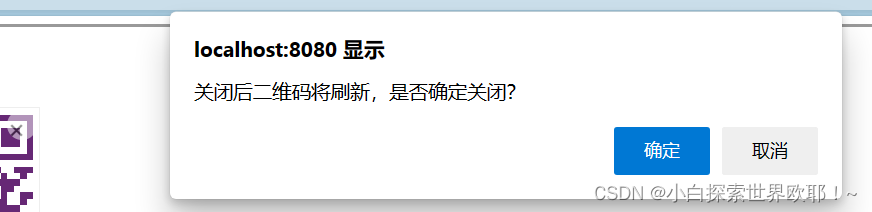
Vue自动生成二维码并可下载二维码
遇到一个需求,需要前端自行生成用户的个人名片分享二维码,并提供二维码下载功能。在网上找到很多解决方案,最终吭哧吭哧做完了,把它整理记录一下,方便后续学习使用!嘿嘿O(∩_∩)O~ 这个小东西有以下功能特点…...
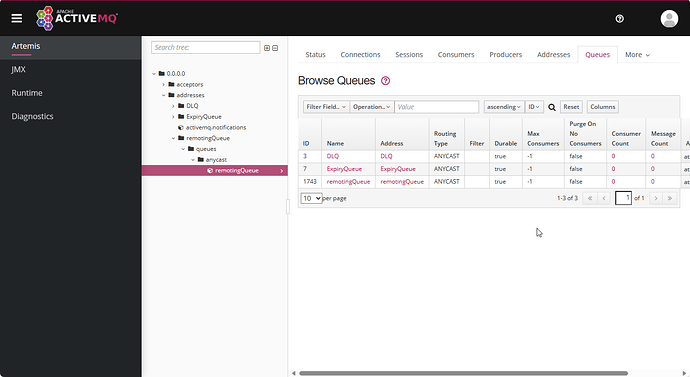
应该下那个 ActiveMQ
最近在搞 ActiveMQ 的时候,发现有 2 个 ActiveMQ 可以下载。 应该下那个呢? JMS 即Java Message Service,是JavaEE的消息服务接口。 JMS主要有两个版本:1.1和2.0。 2.0和1.1相比,主要是简化了收发消息的代码。 所谓…...

【C语言】指针详解(3)
大家好,我是苏貝,本篇博客带大家了解指针(2),如果你觉得我写的还不错的话,可以给我一个赞👍吗,感谢❤️ 目录 一.函数指针数组二.指向函数指针数组的指针(不重要)三.回调函数 一.函…...
告别HR管理繁琐,免费低代码平台来帮忙
编者按:本文着重介绍了使用免费且高效的低代码平台实现的HR管理系统在一般日常人力资源管理工作中的关键作用。 关键词:低代码平台、HR管理系统 1.HR管理系统有什么作用? HR管理系统作为一款数字化工具,可为企业提供全方位的人力资…...

Java开发面试--Redis专区
1、 什么是Redis?它的主要特点是什么? 答: Redis是一个开源的、基于内存的高性能键值对存储系统。它主要用于缓存、数据存储和消息队列等场景。 高性能:Redis将数据存储在内存中,并采用单线程的方式处理请求…...
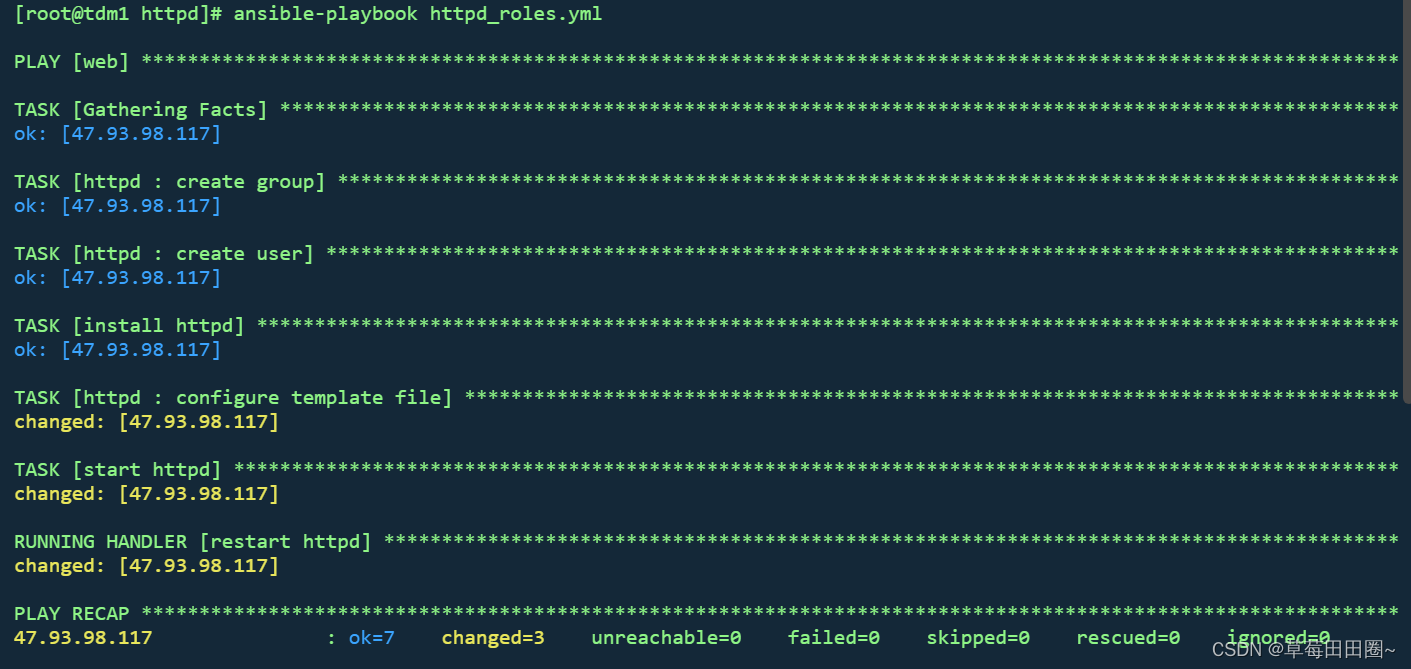
Ansible-roles学习
目录 一.roles角色介绍二.示例一.安装httpd服务 一.roles角色介绍 roles能够根据层次型结构自动装载变量文件,tasks以及handlers登。要使用roles只需在playbook中使用include指令即可。roles就是通过分别将变量,文件,任务,模块以…...
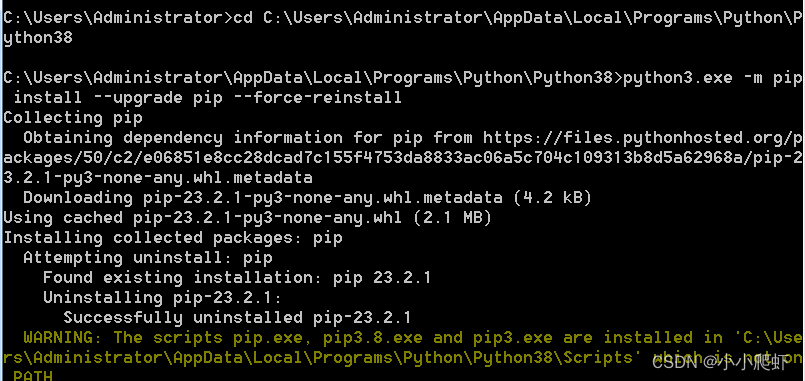
python3如何安装各类库的小总结
我的python3的安装路径是: C:\Users\Administrator\AppData\Local\Programs\Python\Python38 C:\Users\Administrator\AppData\Local\Programs\Python\Python38\python3.exeC:\Users\Administrator\AppData\Local\Programs\Python\Python38\Scripts C:\Users\Admin…...

ffmpeg 特效 转场 放大缩小
案例 ffmpeg \ -i input.mp4 \ -i image1.png \ -i image2.png \ -filter_complex \ [1:v]scale100:100[img1]; \ [2:v]scale1280:720[img2]; \ [0:v][img1]overlay(main_w-overlay_w)/2:(main_h-overlay_h)/2[bkg];\ [bkg][img2]overlay0:0 \ -y output.mp4 -i input.mp4//这…...

【GNN 03】PyG
工具包安装: 不要pip安装 https://github.com/pyg-team/pytorch_geometrichttps://github.com/pyg-team/pytorch_geometric import torch import networkx as nx import matplotlib.pyplot as pltdef visualize_graph(G, color):plt.figure(figsize(7, 7))plt.xtic…...

每日刷题-5
目录 一、选择题 二、算法题 1、不要二 2、把字符串转换成整数 一、选择题 1、 解析:printf(格式化串,参数1,参数2,.….),格式化串: printf第一个参数之后的参数要按照什么格式打印,比如%d--->按照整形方式打印&am…...
)
RNN简介(深入浅出)
目录 简介1. 基本理论 简介 要快速掌握RNN,可以考虑以下步骤: 学习基本理论:了解RNN的原理、结构和工作原理。掌握RNN的输入输出形式、时间步、隐藏状态、记忆单元等关键概念。学习常见的RNN变体:了解LSTM(Long Shor…...

Leetcode137. 某一个数字出现一次,其余数字出现3次
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 给你一个整数数组 nums ,除某个元素仅出现 一次 外,其余每个元素都恰出现 三次 。请你找出并返回那个只出现了一次的元素。 你必须设计并实现线性时间复杂度的算法且使用常数级空…...
)
原子化CSS(Atomic CSS)
UnoCSS,它不是像TailWind CSS和Windi CSS属于框架,而是一个引擎,它没有提供预设的原子化CSS工具类。引用自掘金,文章中实现相同的功能,构建后的体积TailWind 远> Windi > UnoCSS,体积会小很多。 像这种原子性的…...

pandas 筛选数据的 8 个骚操作
日常用Python做数据分析最常用到的就是查询筛选了,按各种条件、各种维度以及组合挑出我们想要的数据,以方便我们分析挖掘。 东哥总结了日常查询和筛选常用的种骚操作,供各位学习参考。本文采用sklearn的boston数据举例介绍。 from sklearn …...
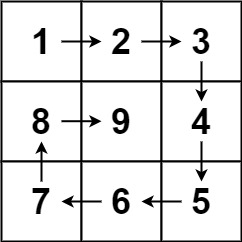
【随想】每日两题Day.3(实则一题)
题目:59.螺旋矩阵|| 给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。 示例 1: 输入:n 3 输出:[[1,2,3],[8,9,4],[7,6,5]]示例 2: …...

阿里后端开发:抽象建模经典案例【文末送书】
文章目录 写作前面1.抽象思维2.软件世界中的抽象3. 经典抽象案例4. 抽象并非一蹴而就!需要不断假设、验证、完善5. 推荐一本书 写作末尾 写作前面 在互联网行业,软件工程师面对的产品需求大都是以具象的现实世界事物概念来描述的,遵循的是人…...
HarmonyOS Codelab 优秀样例——溪村小镇(ArkTS)
一、介绍 溪村小镇是一款展示溪流背坡村园区风貌的应用,包括园区内的导航功能,小火车行车状态查看,以及各区域的风景展览介绍,主要用于展示HarmonyOS的ArkUI能力和动画效果。具体包括如下功能: 打开应用时进入启动页&a…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...
)
Java 语言特性(面试系列2)
一、SQL 基础 1. 复杂查询 (1)连接查询(JOIN) 内连接(INNER JOIN):返回两表匹配的记录。 SELECT e.name, d.dept_name FROM employees e INNER JOIN departments d ON e.dept_id d.dept_id; 左…...
)
postgresql|数据库|只读用户的创建和删除(备忘)
CREATE USER read_only WITH PASSWORD 密码 -- 连接到xxx数据库 \c xxx -- 授予对xxx数据库的只读权限 GRANT CONNECT ON DATABASE xxx TO read_only; GRANT USAGE ON SCHEMA public TO read_only; GRANT SELECT ON ALL TABLES IN SCHEMA public TO read_only; GRANT EXECUTE O…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...

08. C#入门系列【类的基本概念】:开启编程世界的奇妙冒险
C#入门系列【类的基本概念】:开启编程世界的奇妙冒险 嘿,各位编程小白探险家!欢迎来到 C# 的奇幻大陆!今天咱们要深入探索这片大陆上至关重要的 “建筑”—— 类!别害怕,跟着我,保准让你轻松搞…...

适应性Java用于现代 API:REST、GraphQL 和事件驱动
在快速发展的软件开发领域,REST、GraphQL 和事件驱动架构等新的 API 标准对于构建可扩展、高效的系统至关重要。Java 在现代 API 方面以其在企业应用中的稳定性而闻名,不断适应这些现代范式的需求。随着不断发展的生态系统,Java 在现代 API 方…...