GFS文件系统
GFS 分布式文件系统
GlusterFS简介
GlusterFS 是一个开源的分布式文件系统。
由存储服务器、客户端以及NFS/Samba 存储网关(可选,根据需要选择使用)组成。
没有元数据服务器组件,这有助于提升整个系统的性能、可靠性和稳定性。
MFS
传统的分布式文件系统大多通过元服务器来存储元数据,元数据包含存储节点上的目录信息、目录结构等。这样的设计在浏览目录时效率高,但是也存在一些缺陷,例如单点故障。一旦元数据服务器出现故障,即使节点具备再高的冗余性,整个存储系统也将崩溃。而 GlusterFS 分布式文件系统是基于无元服务器的设计,数据横向扩展能力强,具备较高的可靠性及存储效率。
GlusterFS同时也是Scale-Out(横向扩展)存储解决方案Gluster的核心,在存储数据方面具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。
GlusterFS支持借助TCP/IP或InfiniBandRDMA网络(一种支持多并发链接的技术,具有高带宽、低时延、高扩展性的特点)将物理分散分布的存储资源汇聚在一起,统一提供存储服务,并使用统一全局命名空间来管理数据。
GlusterFS特点
1.扩展性和高性能
GlusterFS利用双重特性来提供高容量存储解决方案。
(1)Scale-Out架构允许通过简单地增加存储节点的方式来提高存储容量和性能(磁盘、计算和I/O资源都可以独立增加),支持10GbE和 InfiniBand等高速网络互联。
(2)Gluster弹性哈希(ElasticHash)解决了GlusterFS对元数据服务器的依赖,改善了单点故障和性能瓶颈,真正实现了并行化数据访问。GlusterFS采用弹性哈希算法在存储池中可以智能地定位任意数据分片(将数据分片存储在不同节点上),不需要查看索引或者向元数据服务器查询。
2.高可用性
GlusterFS可以对文件进行自动复制,如镜像或多次复制,从而确保数据总是可以访问,甚至是在硬件故障的情况下也能正常访问。
当数据出现不一致时,自我修复功能能够把数据恢复到正确的状态,数据的修复是以增量的方式在后台执行,几乎不会产生性能负载。
GlusterFS可以支持所有的存储,因为它没有设计自己的私有数据文件格式,而是采用操作系统中主流标准的磁盘文件系统(如EXT3、XFS等)来存储文件,因此数据可以使用传统访问磁盘的方式被访问。
3.全局统一命名空间
分布式存储中,将所有节点的命名空间整合为统一命名空间,将整个系统的所有节点的存储容量组成一个大的虚拟存储池,供前端主机访问这些节点完成数据读写操作。
4.弹性卷管理
GlusterFS通过将数据储存在逻辑卷中,逻辑卷从逻辑存储池进行独立逻辑划分而得到。
逻辑存储池可以在线进行增加和移除,不会导致业务中断。逻辑卷可以根据需求在线增长和缩减,并可以在多个节点中实现负载均衡。
文件系统配置也可以实时在线进行更改并应用,从而可以适应工作负载条件变化或在线性能调优。
5.基于标准协议
Gluster 存储服务支持 NFS、CIFS、HTTP、FTP、SMB 及 Gluster原生协议,完全与 POSIX 标准(可移植操作系统接口)兼容。
现有应用程序不需要做任何修改就可以对Gluster 中的数据进行访问,也可以使用专用 API 进行访问。
GlusterFS 术语
Brick(存储块)
指可信主机池中由主机提供的用于物理存储的专用分区,是GlusterFS中的基本存储单元,同时也是可信存储池中服务器上对外提供的存储目录。
存储目录的格式由服务器和目录的绝对路径构成,表示方法为 SERVER:EXPORT,如 192.168.10.14:/data/mydir/。
Volume(逻辑卷)
一个逻辑卷是卷上进行的。一组 Brick 的集合。卷是数据存储的逻辑设备,类似于 LVM 中的逻辑卷。大部分 Gluster 管理操作是在
FUSE
是一个内核模块,允许用户创建自己的文件系统,无须修改内核代码。
伪文件系统
VFS
内核空间对用户空间提供的访问磁盘的接口。 虚拟端口
Glusterd(后台管理进程)
服务端
在存储群集中的每个节点上都要运行。
GFS 以上虚拟文件系统
模块化堆栈式架构
GlusterFS 采用模块化、堆栈式的架构。
通过对模块进行各种组合,即可实现复杂的功能。例如 Replicate 模块可实现 RAID1,Stripe 模块可实现 RAID0, 通过两者的组合可实现 RAID10 和 RAID01,同时获得更高的性能及可靠性。
GlusterFS 的工作流程
(1)客户端或应用程序通过 GlusterFS 的挂载点访问数据。
(2)linux系统内核通过 VFS API 收到请求并处理。
(3)VFS 将数据递交给 FUSE 内核文件系统,并向系统注册一个实际的文件系统 FUSE,
而 FUSE 文件系统则是将数据通过 /dev/fuse 设备文件递交给了 GlusterFS client 端。
可以将 FUSE 文件系统理解为一个代理。
(4)GlusterFS client 收到数据后,client 根据配置文件的配置对数据进行处理。
(5)经过 GlusterFS client 处理后,通过网络将数据传递至远端的 GlusterFS Server,
并且将数据写入到服务器存储设备上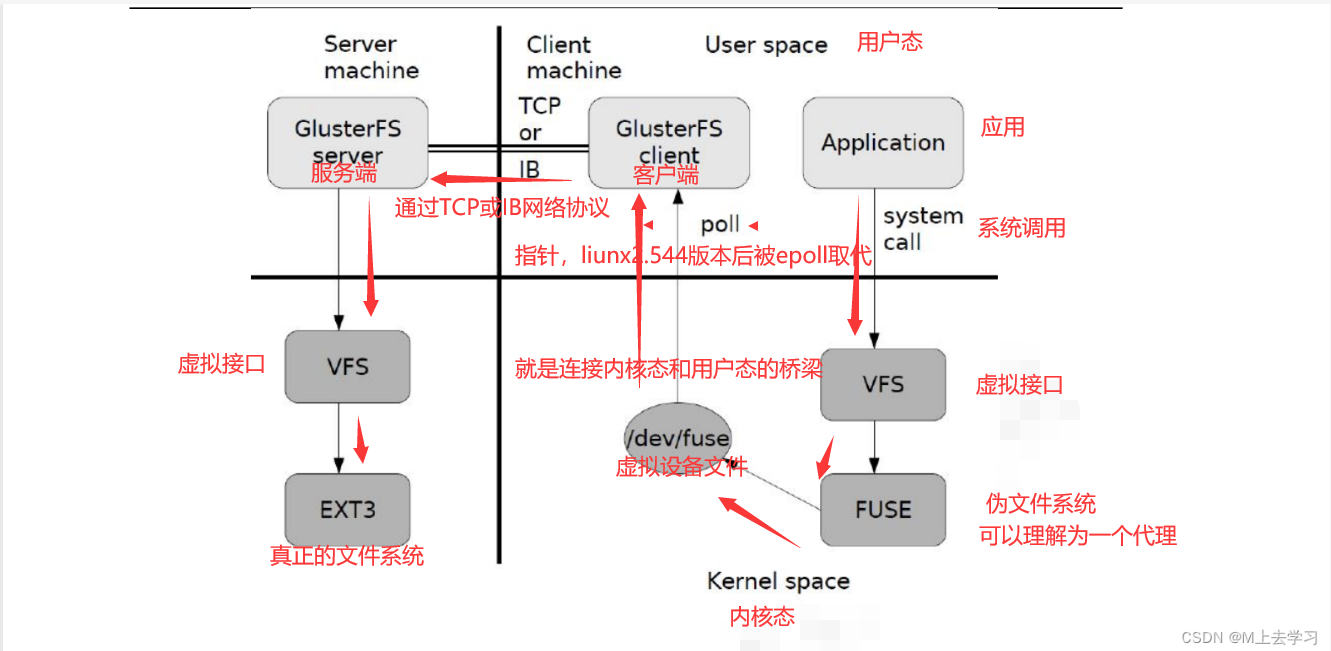
弹性 HASH 算法
弹性 HASH 算法是 Davies-Meyer 算法的具体实现,通过 HASH 算法可以得到一个 32 位的整数范围的 hash 值,
假设逻辑卷中有 N 个存储单位 Brick,则 32 位的整数范围将被划分为 N 个连续的子空间,每个空间对应一个 Brick。
当用户或应用程序访问某一个命名空间时,通过对该命名空间计算 HASH 值,根据该 HASH 值所对应的 32 位整数空间定位数据所在的 Brick。
#弹性 HASH 算法的优点:
保证数据平均分布在每一个 Brick 中。
解决了对元数据服务器的依赖,进而解决了单点故障以及访问瓶颈。
GlusterFS的卷类型
GlusterFS 支持七种卷,即分布式卷、条带卷、复制卷、分布式条带卷、分布式复制卷、条带复制卷和分布式条带复制卷。
1.分布式卷(Distribute volume)
文件通过 HASH 算法分布到所有 Brick Server 上,这种卷是 GlusterFS 的默认卷;以文件为单位根据 HASH 算法散列到不同的 Brick,其实只是扩大了磁盘空间,如果有一块磁盘损坏,数据也将丢失,属于文件级的 RAID0, 不具有容错能力。
在该模式下,并没有对文件进行分块处理,文件直接存储在某个 Server 节点上。 由于直接使用本地文件系统进行文件存储,所以存取效率并没有提高,反而会因为网络通信的原因而有所降低。
#示例原理:
File1 和 File2 存放在 Server1,而 File3 存放在 Server2,文件都是随机存储,一个文件(如 File1)要么在 Server1 上,要么在 Server2 上,不能分块同时存放在 Server1和 Server2 上。
特点
文件分布在不同的服务器,不具备冗余性
更容易和廉价地扩展卷的大小
单点故障会造成数据丢失
依赖底层的数据保护#创建一个名为dis-volume的分布式卷,文件将根据HASH分布在server1:/dir1、server2:/dir2和server3:/dir3中
gluster volume create dis-volume server1:/dir1 server2:/dir2 server3:/dir3
条带卷(Stripe volume)
类似 RAID0,文件被分成数据块并以轮询的方式分布到多个 Brick Server 上,文件存储以数据块为单位,支持大文件存储, 文件越大,读取效率越高,但是不具备冗余性。
#示例原理:
File 被分割为 6 段,1、3、5 放在 Server1,2、4、6 放在 Server2。
条带卷特点
数据被分割成更小块分布到块服务器群中的不同条带区。
分布减少了负载且更小的文件加速了存取的速度。
没有数据冗余。#创建了一个名为stripe-volume的条带卷,文件将被分块轮询的存储在Server1:/dir1和Server2:/dir2两个Brick中
gluster volume create stripe-volume stripe 2 transport tcp server1:/dir1 server2:/dir2
复制卷(Replica volume)
将文件同步到多个 Brick 上,使其具备多个文件副本,属于文件级 RAID 1,具有容错能力。因为数据分散在多个 Brick 中,所以读性能得到很大提升,但写性能下降。
复制卷具备冗余性,即使一个节点损坏,也不影响数据的正常使用。但因为要保存副本,所以磁盘利用率较低。
#示例原理:
File1 同时存在 Server1 和 Server2,File2 也是如此,相当于 Server2 中的文件是 Server1 中文件的副本。
复制卷特点
卷中所有的服务器均保存一个完整的副本。
卷的副本数量可由客户创建的时候决定,但复制数必须等于卷中 Brick 所包含的存储服务器数。
至少由两个块服务器或更多服务器。
具备冗余性。#创建名为rep-volume的复制卷,文件将同时存储两个副本,分别在Server1:/dir1和Server2:/dir2两个Brick中
gluster volume create rep-volume replica 2 transport tcp server1:/dir1 server2:/dir2
分布式条带卷(Distribute Stripe volume)
Brick Server 数量是条带数(数据块分布的 Brick 数量)的倍数,兼具分布式卷和条带卷的特点。 主要用于大文件访问处理,创建一个分布式条带卷最少需要 4 台服务器。
#示例原理:
File1 和 File2 通过分布式卷的功能分别定位到Server1和 Server2。在 Server1 中,File1 被分割成 4 段,其中 1、3 在 Server1 中的 exp1 目录中,2、4 在 Server1 中的 exp2 目录中。在 Server2 中,File2 也被分割成 4 段,其中 1、3 在 Server2 中的 exp3 目录中,2、4 在 Server2 中的 exp4 目录中。
#创建一个名为dis-stripe的分布式条带卷,配置分布式的条带卷时,卷中Brick所包含的存储服务器数必须是条带数的倍数(>=2倍)。Brick 的数量是 4(Server1:/dir1、Server2:/dir2、Server3:/dir3 和 Server4:/dir4),条带数为 2(stripe 2)
gluster volume create dis-stripe stripe 2 transport tcp server1:/dir1 server2:/dir2 server3:/dir3 server4:/dir4
创建卷时,存储服务器的数量如果等于条带或复制数,那么创建的是条带卷或者复制卷;如果存储服务器的数量是条带或复制数的 2 倍甚至更多,那么将创建的是分布式条带卷或分布式复制卷。
分布式复制卷(Distribute Replica volume)
Brick Server 数量是镜像数(数据副本数量)的倍数,兼具分布式卷和复制卷的特点。主要用于需要冗余的情况下。
#示例原理:
File1 和 File2 通过分布式卷的功能分别定位到 Server1 和 Server2。在存放 File1 时,File1 根据复制卷的特性,将存在两个相同的副本,分别是 Server1 中的exp1 目录和 Server2 中的 exp2 目录。在存放 File2 时,File2 根据复制卷的特性,也将存在两个相同的副本,分别是 Server3 中的 exp3 目录和 Server4 中的 exp4 目录。
#创建一个名为dis-rep的分布式复制卷,配置分布式的复制卷时,卷中Brick所包含的存储服务器数必须是复制数的倍数(>=2倍)。Brick 的数量是 4(Server1:/dir1、Server2:/dir2、Server3:/dir3 和 Server4:/dir4),复制数为 2(replica 2)
gluster volume create dis-rep replica 2 transport tcp server1:/dir1 server2:/dir2 server3:/dir3 server4:/dir4
扩展
●条带复制卷(Stripe Replica volume):
类似 RAID 10,同时具有条带卷和复制卷的特点。
●分布式条带复制卷(Distribute Stripe Replicavolume):
三种基本卷的复合卷,通常用于类 Map Reduce 应用
部署 GlusterFS 群集
1.准备工作
Node1节点:20.0.0.50 磁盘:/dev/sdb1 挂载点:/data/sdb1/dev/sdc1 /data/sdc1/dev/sdd1 /data/sdd1/dev/sde1 /data/sde1
Node2节点:20.0.0.60 磁盘:/dev/sdb1 挂载点:/data/sdb1/dev/sdc1 /data/sdc1/dev/sdd1 /data/sdd1/dev/sde1 /data/sde1Node3节点:20.0.0.70 磁盘:/dev/sdb1 挂载点:/data/sdb1/dev/sdc1 /data/sdc1/dev/sdd1 /data/sdd1/dev/sde1 /data/sde1Node4节点:20.0.0.80 磁盘:/dev/sdb1 挂载点:/data/sdb1/dev/sdc1 /data/sdc1/dev/sdd1 /data/sdd1/dev/sde1 /data/sde1客户端节点:20.0.0.90①关闭防火墙
systemctl stop firewalld
setenforce 0②磁盘分区,并挂载
vim /opt/fdisk.sh
#!/bin/bash
NEWDEV=`ls /dev/sd* | grep -o 'sd[b-z]' | uniq`
for VAR in $NEWDEV
doecho -e "n\np\n\n\n\nw\n" | fdisk /dev/$VAR &> /dev/nullmkfs.xfs /dev/${VAR}"1" &> /dev/nullmkdir -p /data/${VAR}"1" &> /dev/nullecho "/dev/${VAR}"1" /data/${VAR}"1" xfs defaults 0 0" >> /etc/fstab
done
mount -a &> /dev/nullchmod +x /opt/fdisk.sh
cd /opt/
./fdisk.sh③修改主机名,配置/etc/hosts文件
#以Node1节点为例(所有的节点都需要):
hostnamectl set-hostname node1
suecho "192.168.10.13 node1" >> /etc/hosts
echo "192.168.10.14 node2" >> /etc/hosts
echo "192.168.10.15 node3" >> /etc/hosts
echo "192.168.10.16 node4" >> /etc/hosts2.安装、启动GlusterFS
(所有node节点上操作)
①.将gfsrepo 软件上传到/opt目录下
unzip gfsrepo.zip
②.创建本地源安装启动服务
cd /etc/yum.repos.d/
mkdir repo.bak
mv *.repo repo.bak
vim glfs.repo
[glfs]
name=glfs
baseurl=file:///opt/gfsrepo
gpgcheck=0
enabled=1yum clean all && yum makecache#yum -y install centos-release-gluster #如采用官方 YUM 源安装,可以直接指向互联网仓库
yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdmasystemctl start glusterd.service
systemctl enable glusterd.service
systemctl status glusterd.service#故障原因是版本过高导致
yum remove glusterfs-api.x86_64 glusterfs-cli.x86_64 glusterfs.x86_64 glusterfs-libs.x86_64 glusterfs-client-xlators.x86_64 glusterfs-fuse.x86_64 -yyum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma
3.添加节点到存储信任池中
#只要在一台Node节点上添加其它节点即可
gluster peer probe node1
gluster peer probe node2
gluster peer probe node3
gluster peer probe node4
#在每个Node节点上查看群集状态
gluster peer status4.创建卷
根据规划创建卷
| 卷名称 | 卷类型 | Brick |
| dis-volume | 分布式卷 | node1(/data/sdb1)、node2(/data/sdb1) |
| stripe-volume | 条带卷 | node1(/data/sdc1)、node2(/data/sdc1) |
| rep-volume | 复制卷 | node3(/data/sdb1)、node4(/data/sdb1) |
| dis-stripe | 分布式条带卷 | node1(/data/sdd1)、node2(/data/sdd1)、node3(/data/sdd1)、node4(/data/sdd1) |
| dis-rep | 分布式复制卷 | node1(/data/sde1)、node2(/data/sde1)、node3(/data/sde1)、node4(/data/sde1) |
①创建分布式卷
#创建分布式卷,没有指定类型,默认创建的是分布式卷
gluster volume create dis-volume node1:/data/sdb1 node2:/data/sdb1 force #查看卷列表
gluster volume list#启动新建分布式卷
gluster volume start dis-volume#查看创建分布式卷信息
gluster volume info dis-volume②创建条带卷
#指定类型为 stripe,数值为 2,且后面跟了 2 个 Brick Server
所以创建的是条带卷
gluster volume create stripe-volume stripe 2 node1:/data/sdc1 node2:/data/sdc1 force
gluster volume start stripe-volume
gluster volume info stripe-volume③创建复制卷
#指定类型为 replica,数值为 2,且后面跟了 2 个 Brick Server
所以创建的是复制卷
gluster volume create rep-volume replica 2 node3:/data/sdb1 node4:/data/sdb1 force
gluster volume start rep-volume
gluster volume info rep-volume④创建分布式条带卷
#指定类型为 stripe,数值为 2,而且后面跟了 4 个 Brick Server,是 2 的两倍
所以创建的是分布式条带卷
gluster volume create dis-stripe stripe 2 node1:/data/sdd1 node2:/data/sdd1 node3:/data/sdd1 node4:/data/sdd1 force
gluster volume start dis-stripe
gluster volume info dis-stripe⑤创建分布式复制卷
指定类型为 replica,数值为 2,而且后面跟了 4 个 Brick Server,是 2 的两倍
所以创建的是分布式复制卷
gluster volume create dis-rep replica 2 node1:/data/sde1 node2:/data/sde1 node3:/data/sde1 node4:/data/sde1 force
gluster volume start dis-rep
gluster volume info dis-rep ##查看当前所有卷的列表
gluster volume list5.部署 Gluster 客户端
(也可直接在某个节点直接测试)
①安装客户端软件
#将gfsrepo 软件上传到/opt目下
unzip gfsrepo.zip②创建本地yum源
cd /etc/yum.repos.d/
mkdir repo.bak
mv *.repo repo.bak
vim glfs.repo
[glfs]
name=glfs
baseurl=file:///opt/gfsrepo
gpgcheck=0
enabled=1yum clean all && yum makecache#安装服务
yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdmasystemctl start glusterd.service
systemctl enable glusterd.service
systemctl status glusterd.service
③创建挂载目录
mkdir -p /test/{dis,stripe,rep,dis_stripe,dis_rep}
ls /test④配置 /etc/hosts 文件
echo "192.168.10.13 node1" >> /etc/hosts
echo "192.168.10.14 node2" >> /etc/hosts
echo "192.168.10.15 node3" >> /etc/hosts
echo "192.168.10.16 node4" >> /etc/hosts ⑤挂载 Gluster 文件系统
#临时挂载
mount.glusterfs node1:dis-volume /test/dis
mount.glusterfs node1:stripe-volume /test/stripe
mount.glusterfs node1:rep-volume /test/rep
mount.glusterfs node1:dis-stripe /test/dis_stripe
mount.glusterfs node1:dis-rep /test/dis_rep
df -Th#永久挂载
vim /etc/fstab
node1:dis-volume /test/dis glusterfs defaults,_netdev 0 0
node1:stripe-volume /test/stripe glusterfs defaults,_netdev 0 0
node1:rep-volume /test/rep glusterfs defaults,_netdev 0 0
node1:dis-stripe /test/dis_stripe glusterfs defaults,_netdev 0 0
node1:dis-rep /test/dis_rep glusterfs defaults,_netdev 0 0
6.测试 Gluster 文件系统
①卷中写入文件,客户端操作
cd /opt
dd if=/dev/zero of=/opt/demo1.log bs=1M count=40
dd if=/dev/zero of=/opt/demo2.log bs=1M count=40
dd if=/dev/zero of=/opt/demo3.log bs=1M count=40
dd if=/dev/zero of=/opt/demo4.log bs=1M count=40
dd if=/dev/zero of=/opt/demo5.log bs=1M count=40
ls -lh /optcp /opt/demo* /test/dis
cp /opt/demo* /test/stripe/
cp /opt/demo* /test/rep/
cp /opt/demo* /test/dis_stripe/
cp /opt/demo* /test/dis_rep/②查看文件分布特点
③破坏性测试
#挂起 node2 节点或者关闭glusterd服务来模拟故障在客户端查看文件是否正常
##### 上述实验测试,凡是带复制数据,相比而言,数据比较安全 #####
#扩展其他的维护命令
1.查看GlusterFS卷
gluster volume list 2.查看所有卷的信息
gluster volume info3.查看所有卷的状态
gluster volume status4.停止一个卷
gluster volume stop dis-stripe5.删除一个卷,注意:删除卷时,需要先停止卷,且信任池中不能有主机处于宕机状态,否则删除不成功
gluster volume delete dis-stripe6.设置卷的访问控制
#仅拒绝
gluster volume set dis-rep auth.deny 192.168.80.100#仅允许
gluster volume set dis-rep auth.allow 192.168.80.*
#设置192.168.80.0网段的所有IP地址都能访问dis-rep卷(分布式复制卷)
相关文章:
GFS文件系统
GFS 分布式文件系统 GlusterFS简介 GlusterFS 是一个开源的分布式文件系统。 由存储服务器、客户端以及NFS/Samba 存储网关(可选,根据需要选择使用)组成。 没有元数据服务器组件,这有助于提升整个系统的性能、可靠性和稳定性。 …...
22 相交链表
相交链表 题解1 快慢双指针改进 (acb bca)题解2 哈希表(偷懒) 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 题目数据 保证 整个链式结构中不存在环。 注意ÿ…...

简历(快速上手)
简历 文章目录 简历简历模板:排版上:内容上:沟通上: 简历在面试中起到关键作用 网申,HR只会花10秒多来看一下 内推,如果简历没优势就只能pass 简历模板: ⽊及简历(推荐! ) : https://resume.mdedit.online 排版上: 尽量简洁,…...
wpf复制xaml及其cs窗体到其他项目 添加现有项,选 .xaml.cs,点添加即可。VS2022
添加现有项,选 LoadingWindow.xaml.cs,点添加即可。...

在线旅游平台步入新时代,携程如何走出自己的路?
今年旅游从线下到线上全方位火了。有统计数据,一季度,光是抖音,旅游达人发布视频数量就高达175万条,播放量1350亿次,收获27亿次点赞。在这一趋势下,许多“不出名”的景区和酒店借势抖音达人完成“出圈”。短…...

java中feign远程调用底层是用Hystrix作为熔断器吗?
在较新的版本中,Feign 默认使用 OpenFeign 作为远程调用的底层实现,并且集成了 Netflix Hystrix 作为熔断器。然而,需要注意的是,自 Feign 10.x 版本开始,默认已不再集成 Hystrix。 在 Feign 中,Hystrix 被…...
Web安全——穷举爆破下篇(仅供学习)
Web安全 一、常见的端口服务穷举1、hydra 密码穷举工具的使用2、使用 hydra 穷举 ssh 服务3、使用 hydra 穷举 ftp 服务4、使用 hydra 穷举 mysql 服务5、使用 hydra 穷举 smb 服务6、使用 hydra 穷举 http 服务7、使用 hydra 穷举 pop3 服务8、使用 hydra 穷举 rdp 服务9、使用…...
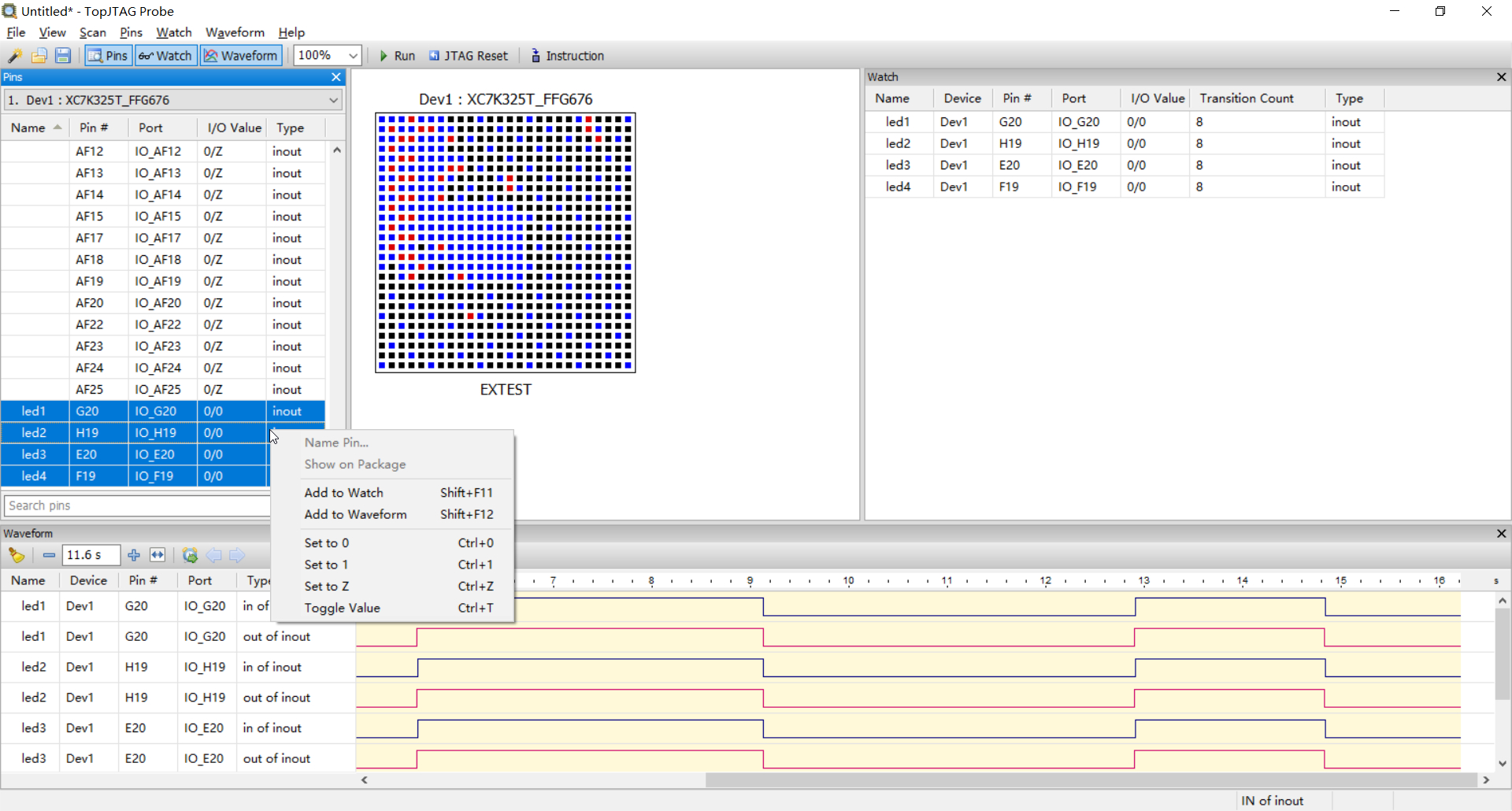
强大的JTAG边界扫描(5):FPGA边界扫描应用
文章目录 1. 获取芯片的BSDL文件2. 硬件连接3. 边界扫描测试4. 总结 上一篇文章,介绍了基于STM32F103的JTAG边界扫描应用,演示了TopJTAG Probe软件的应用,以及边界扫描的基本功能。本文介绍基于Xilinx FPGA的边界扫描应用,两者几乎…...

苍穹外卖集成 Apache POI Java实现Excel文件的读写下载
苍穹外卖 day12 Echats 营业台数据可视化整合_软工菜鸡的博客-CSDN博客 Apache POI - the Java API for Microsoft Documents Project News 16 September 2022 - POI 5.2.3 available The Apache POI team is pleased to announce the release of 5.2.3. Several dependencies …...
iOS逆向:工具安装
二〇二三年〇八月二十三日(2023版,iOS逆向笔记) 对其他APP的实现感兴趣,对技术报以热枕,不去做违反职业道德和违法乱纪的事情,欢迎来到iOS逆向。 工欲善其事必先利其器 ------我说的。 网络不好可配置DNS 1…...
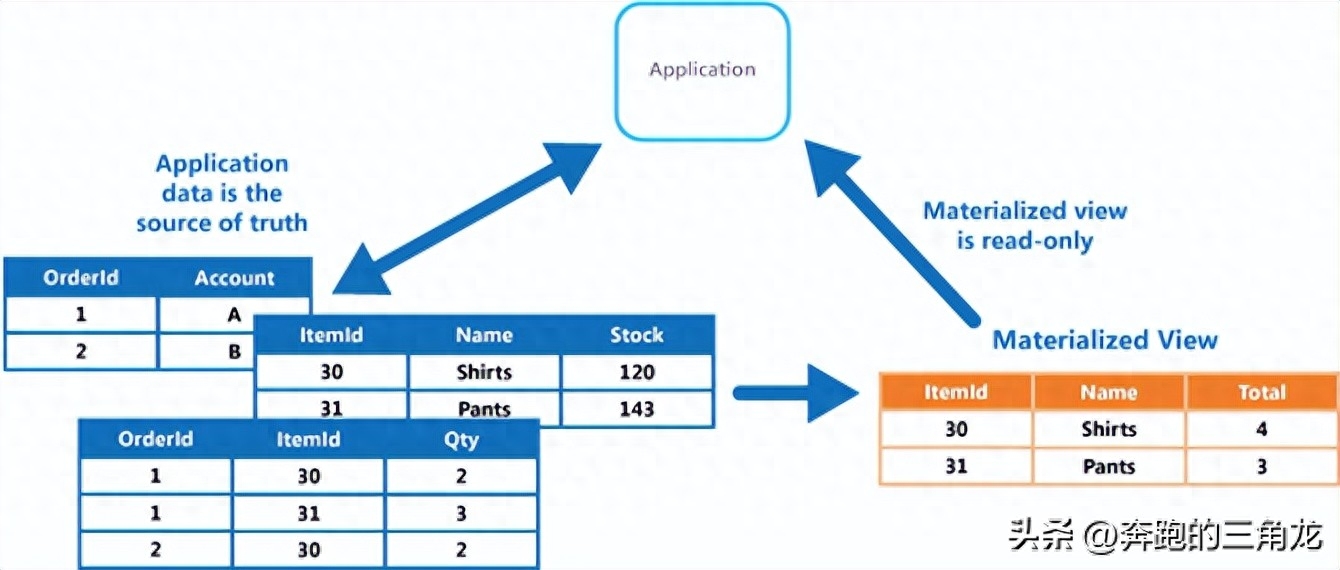
十种数据库缓存相关的技术和机制
数据库的缓存 -- 通过将数据库中的数据或结果集保存在内存或其他快速访问的介质中,能够加快查询响应,减少对磁盘或远程服务器的访问,降低资源消耗。 根据缓存的位置、内容、粒度、更新方式等不同,数据库缓存技术有多种类型和策略。…...

【C++】封装unordered_map和unordered_set(用哈希桶实现)
前言: 前面我们学习了unordered_map和unordered_set容器,比较了他们和map、set的查找效率,我们发现他们的效率比map、set高,进而我们研究他们的底层是由哈希实现。哈希是一种直接映射的方式,所以查找的效率很快…...

面试问题回忆
(1)查看端口 lsof -i:8080 / netstat lsof -i:8080:查看8080端口占用 lsof abc.txt:显示开启文件abc.txt的进程 lsof -c abc:显示abc进程现在打开的文件 lsof -c -p 1234:列出进程号为1234的进程所打开…...
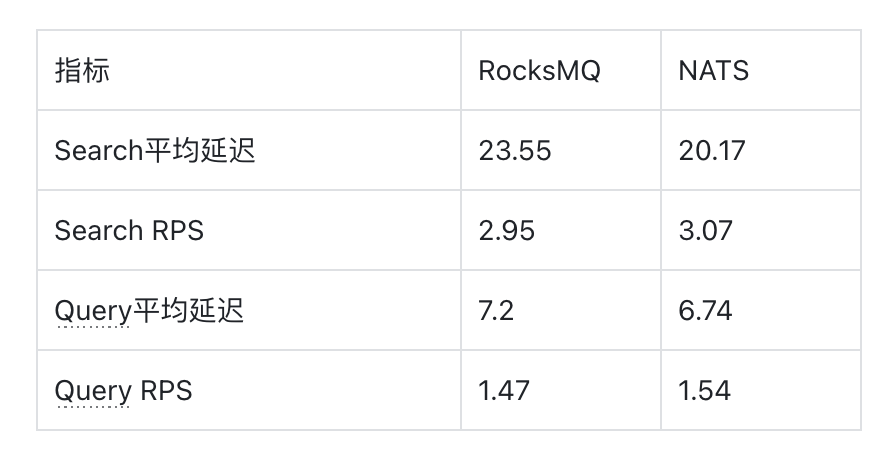
更多场景、更多选择,Milvus 新消息队列 NATS 了解一下
在 Milvus 的云原生架构中,消息队列(Log Broker)可谓任重道远,它不仅要具备流式数据持久性、支持 TT 同步、事件通知等能力,还要确保工作节点从系统崩溃中恢复时增量数据的完整性。 在 Milvus 的架构中,一切…...
如何通过python实现一个web自动化测试框架?
要实现一个web自动化测试框架,可以使用Python中的Selenium库,它是最流行的Web应用程序测试框架之一。以下是一个基本的PythonSelenium测试框架的示例: 1、安装Selenium 在终端中输入以下命令,使用 pip 安装 Selenium:…...

Linux —— 信号阻塞
目录 一,信号内核表示 sigset_t sigprocmask sigpending 二,捕捉信号 sigaction 三,可重入函数 四,volatile 五,SIGCHLD 信号常见概念 实际执行信号的处理动作,称为信号递达Delivery;信…...
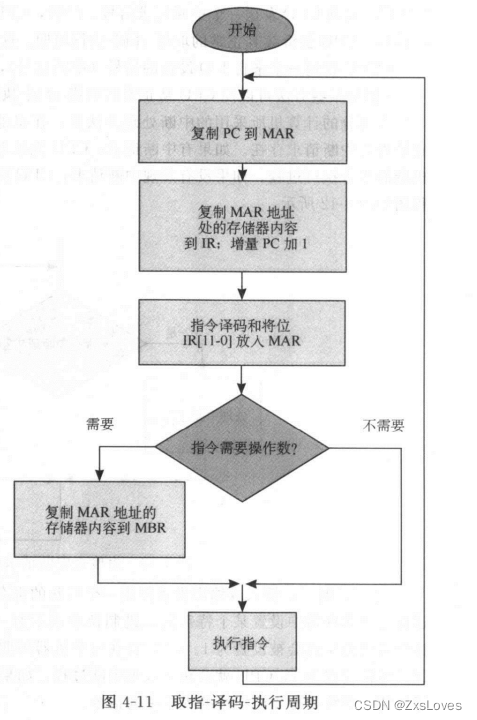
【【萌新编写riscV之计算机体系结构之CPU 总二】】
萌新编写riscV之计算机体系结构之CPU 总二(我水平太差总结不到位) 在学习完软件是如何使用之后 我们接下来要面对的问题是 整个程序是如何运转的这一基本逻辑 中央处理器(central processing unit,CPU)的任务就是负责提取程序指令࿰…...
error:03000086:digital envelope routines::initialization error
项目背景 前端vue项目启动突然报错error:03000086:digital envelope routines::initialization error 我用的开发工具是vscode,node版本是v18.17.0 前端项目版本如下↓ 具体报错如下↓ 报错原因 node版本过高 解决方法 1输入命令 $env:NODE_OPTIONS"--op…...
暴涨130万粉仅用3个月,一招转型成B站热门UP主
- 导语 起号难、找不到内容方向、没流量、没粉丝等等运营困境环绕在创作者之间,近期,有黑马UP主短时间内就在B站涨粉百万,飞升成为热门UP主,以下,飞瓜数据(B站版)剖析黑马UP主运营技巧…...

【Linus】vim的使用:命令模式、底行模式、插入模式、视图模式、替换模式的常用操作介绍
目录 注意:以下操作前提是要确保你输入法是英文模式 一、进入和退出各个模式的方法 1.命令模式 2.底行模式 3.插入模式 4.视图模式 5.替换模式 二、在命令模式中一些常用的操作 1.移动光标 2.删除文字 3.复制 4.替换 5.撤销上一次操作 6.更改 7.跳至指…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

Java如何权衡是使用无序的数组还是有序的数组
在 Java 中,选择有序数组还是无序数组取决于具体场景的性能需求与操作特点。以下是关键权衡因素及决策指南: ⚖️ 核心权衡维度 维度有序数组无序数组查询性能二分查找 O(log n) ✅线性扫描 O(n) ❌插入/删除需移位维护顺序 O(n) ❌直接操作尾部 O(1) ✅内存开销与无序数组相…...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

Java多线程实现之Thread类深度解析
Java多线程实现之Thread类深度解析 一、多线程基础概念1.1 什么是线程1.2 多线程的优势1.3 Java多线程模型 二、Thread类的基本结构与构造函数2.1 Thread类的继承关系2.2 构造函数 三、创建和启动线程3.1 继承Thread类创建线程3.2 实现Runnable接口创建线程 四、Thread类的核心…...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...

处理vxe-table 表尾数据是单独一个接口,表格tableData数据更新后,需要点击两下,表尾才是正确的
修改bug思路: 分别把 tabledata 和 表尾相关数据 console.log() 发现 更新数据先后顺序不对 settimeout延迟查询表格接口 ——测试可行 升级↑:async await 等接口返回后再开始下一个接口查询 ________________________________________________________…...