数分面试题2-牛客
1、面对大方差如何解决
1,AB实验场景下,如果一个指标的方差较大表示它的波动较大,那么实验组和对照组的显著差异可能是因为方差较大即随机波动较大。解决方法有:PSM方法、CUPED(方差缩减)
PSM代表"Propensity Score Matching"(倾向得分匹配),它是一种常用的统计分析方法,用于减少合并数据集时由于非随机分配而引起的处理选择偏差。
PSM倾向值匹配方法(Propensity Score Matching):观测性研究有时无法人为控制干扰因素,因此可能会导致因果推断的偏差。 常规的解决思路是尽量模拟随机试验, 这样实验组与对照组在结果变量上的差异就可归因与实验条件的改变而非干扰因素或协变量施加的影响。
“CUPED"代表"Controlled Uncorrelated Pre-processing and Estimation of Difference”(对照组预处理和差异估计的控制无相关性方法),也称为方差缩减方法。CUPED方法用于降低处理组和对照组之间的方差,并增强估计处理效应的效果。
CUPED方差缩减方法(Controlled-experiment Using Pre-Experiment Data):先分层计算后汇总,举个例子,我们计算对照组和实验组的用户平均使用时长,可以分别按照城市划分,先计算每个城市的用户平均使用时长,然后再按照权重(各城市实验用户)计算总的。(前提是城市这个特征与用户平均使用时长高度相关)
2,机器学习场景下,特征的方差反而越大越好,因为如果一个特征方差为0,那么其实这个特征对于模型来说没有什么意义,所以特征方差大对于模型的训练才是有帮助的
2、KNN、K-Means区别
KNN是分类算法,监督学习,知道了结果去效验结果是否正确。
在KNN算法中,训练集中的每个样本都有一个标签,表示其所属的类别或对应的值。当需要预测新样本的类别或值时,KNN算法会找到训练集中与该新样本最接近的K个邻居,并根据这K个邻居的标签进行决策。
KNN步骤:1,确定k值。2,计算距离 3,根据距离排序 4,决策
1,确定K值:选择一个合适的K值,即决定在预测过程中考虑的邻居数量。
2,计算距离:对于一个新样本,计算它与训练集中每个样本之间的距离。常用的距离度量方法包括欧氏距离、曼哈顿距离、闵可夫斯基距离等。
3,根据距离排序:将训练集中的样本按照与新样本的距离进行排序,选取距离最近的K个邻居。
4,决策:对于分类问题,采用投票法确定新样本的类别,即选择K个邻居中出现最频繁的类别作为新样本的预测类别。对于回归问题,采用平均值法确定新样本的预测值,即将K个邻居的值求平均。
K-Means是聚类算法,它是非监督学习,它需要先自己算去一个结果
K-Means算法的基本思想是通过迭代的方式将数据集分为K个簇(类别),其中K是用户指定的聚类数量。该算法依赖于样本之间的距离度量,通常使用欧氏距离。
k-mean步骤:1,确定k值 2,初始化质心 3,分配样本,4,更新质心 5,重复34,6,输出结果
1,选择聚类数量K:确定希望将数据集分成的簇的数量。
2,初始化质心:从数据集中随机选择K个样本作为质心(每个簇的代表点)。
3,分配样本:对于数据集中的每个样本,计算其与各个质心之间的距离,并将样本分配给与其距离最近的质心所代表的簇。
4,更新质心:对于每个簇,计算该簇中所有样本的平均值或中心点,将其作为新的质心。
5,重复步骤3和步骤4,直到质心不再发生显著的变化或达到预定的迭代次数。
6,输出结果:最终得到K个簇,每个样本都属于其中一个簇。
3、数据分析指标的阈值怎么确定
- 人为划定:根据过往经验设定阈值
- 统计分类:基于统计分类结果设定阈值
- 自动选择:通过数据挖掘方法确定阈值
总结: 人为划定、统计分类、模型自动选择三种方法
对于一些有明确目的或者是凭借过往经验可直接判断的阈值标准,就可以人为划定。这种方法的优势在于简单便捷成本低。
而对于有一定业务知识但是历史经验不足的情况,可以在人为划定的基础上加入统计学原理,用统计分类的思想进行指标阈值确定。这种情况下需要掌握数据的整体情况,了解数据指标的基本分布,根据数据分位数、3-sigma原则、统计指标的拒绝域等进行划分。这种方法既包含了对业务指标有多了解,又用到了统计分析的科学方法,具备科学性和稳定性。
而在数据维度多、指标数量大的情况下,上述两种方法则变得十分困难,此时可以通过机器学习的方法让模型自动调整参数,确定最优阈值。这个过程中最常用的方法有分类、聚类、关联、回归,每种方法下都有多个模型可以进行选择,根据各类模型的评价指标进行参数选择、阈值确定。
4、如何不用自带函数统计一段话每个单词出现的次数
sentence = 'xxx xx x'
words = sentence.split()
dic = {}
for w in words: if w in dic: dic[w] += 1 else: dic[w] = 1
for w, cnt in dic.items(): print('单词%s出现%d'%(w,cnt))
记得处理文本语句时,split()拆分,字典储存值与个数。对于有大小写的情况,可以先用lower函数统一转成小写后进行统计
5、SQL中如何利用replace函数统计给定重复字段在字符串中的出现次数
用替换replace来统计出 现次数.all_string表示原本字符串,target_string表示要计算出现的次数字符串select (length('all_string')-length(replace('all_string','target_string',''))/length('target_string') as cnt
from t
6、统计学的基本方法论,也就是拿到数据怎么分析
统计学是一门综合性的学科,会通过收集、处理、分析、描述等一系列步骤从数据中得出结论。
描述统计和推断统计
1) 描述统计 描述统计通过图表或数学方法,对样本数据进行整理、分析,然后概括总结出反映客观现象的规律。
其中图表描述方法就是使用各类图表在不同的维度下描述数据,比如直方图、饼图、雷达图、散点图等等。
而数学描述方法的分析方法更丰富,常有集中趋势分析、离散程度分析、相关分析三种分析方法。
A. 集中趋势分析 平均数、中数、众数等是集中趋势分析常用来表示数据集中趋势的统计指标,通过这些指标能够反映样本数据的一般水平。
B. 离散程度分析 离中趋势分析主要依赖标准差、方差(协方差)等统计指标来研究数据的离散程度,能够出色地表示数据之间的差异程度。
C. 相关分析 无论是自变量与自变量之间还是自变量与因变量之间都存在潜在地关联性,相关分析探讨的就是变量之间是否具有统计学上的关联性。进行相关分析时,变量数量可以是两个也可以是多个,能够进行单一或多重相关关系分析。
2) 推断统计 推断统计是一种通过样本数据来推断总体特征的统计方法,以部分抽样样本进行延伸推论,并进一步给出推理性结论。
A. 参数估计 顾名思义,参数估计就是根据样本数据对总体参数进行估计的过程,可分为点估计和区间估计两种分析方法。点估计是以样本具体数值为代表数据,区间估计是根据样本数据,计算置信区间及该区间的置信度。
B. 假设检验 假设检验是一种先假设后推理论证检验的思想。首先对总体参数提出一个假设,然后基于样本数据判断该假设是否成立,做出接受还是拒绝该假设的结论。
7、如何用统计学的角度看待新冠疫情
1,描述性统计分析:通过对疫情数据进行描述性统计分析,如计算总感染人数、新病例增长率、疫情期间的死亡率等,可以提供对疫情的概括和总体情况的认识。
2,时间序列分析:使用时间序列分析方法,如ARIMA模型、指数平滑等,来探索和预测疫情的发展趋势。这可以帮助我们了解疫情的变化速度、周期性和长期趋势,以及预测未来的疫情情况。
3,空间分析:通过空间统计学方法,如聚类分析、地理加权回归等,可以研究不同地理区域之间的疫情差异和空间聚集性。这有助于确定高风险区域和资源分配的优先顺序。
4,因果推断:统计学也可以用于因果推断,例如利用断点回归设计来评估特定干预措施对疫情传播的影响。这可以提供有关政策措施和干预措施的实证证据。
5,风险评估和预测建模:使用统计模型和机器学习算法,可以对个体或群体的风险进行评估,并建立预测模型来预测疫情的发展趋势和传播速度。这有助于制定政策和规划资源。
8、简述方差分析概念
方差分析(Analysis of variance,简称ANOVA)为数据分析中常见的统计模型,主要为探讨连续型因变量与类别型自变量的关系,当自变量的因子中包含等于或超过三个类别情况下,检验其各类别间平均数是否相等的统计模式。
9、商城每天的人流量属于什么分布?泊松分布和二项分布的关系?
泊松分布。泊松分布是⼆项分布的近似,当⼆项分布的p很⼩,重复试验次数 n很⼤时,两者分布接近。
二项分布指已知某件事情发⽣的概率是p,那么做n次试验,事情发⽣的次数就服从于二项分布。 泊松分布是指某段连续的时间内某件事情发⽣的次数,⽽且“某件事情”发生所用的时间是可以忽略的
10、100个人,初始各有100块,每人每分钟随机给别人1块钱,问最后的分布
均匀分布:在每个人发钱和得钱的概率及金额完全相等的情况下,最终的结果将是大家的财富值一样。(完全公平情况)
正态分布:根据中心极限定理说明,在适当的条件下,大量相互独立随机变量的均值经适当标准化后依分布收敛于正态分布。房间中的人多次交换金钱后剩余钱数的概率,每次实验均有多个人进行金钱交换。(但此处每个人之间并非独立的,他们手中的财富总值是一个常数)
11、随机误差的分布
正态分布。
随机误差的分布通常基于一个基本假设,即随机误差是独立同分布的。这意味着每个随机误差都是从相同的概率分布中独立地独立地取得的。
中心极限定理中大量独立的随机变量的均值与和均趋向于正态分布
原因:
1,中心极限定理:根据中心极限定理,当大量独立的随机变量加和时,其分布趋向于正态分布。随机误差通常由许多独立的因素相互作用而产生,而这些因素的和可以近似为正态分布。
2,统计模型假设:在许多统计模型中,我们假设随机误差服从正态分布,以便进行参数估计、假设检验和计算置信区间等推断分析。这样假设的好处是它使得分析方法更简单、可靠,并且我们可以利用正态分布的一些特性进行推断。
12、两类错误
第一类错误α叫弃真错误或显著性水平,即原假设为真时却被我们拒绝的概率;第二类错误β叫采伪错误,即原假设为伪我们没有拒绝的概率。在一定样本量的情况下,减小一类错误必然会增大另一类错误,在实践中我们一般会优先控制第一类错误,因为原假设是非常明确的
13、置信区间、置信度
在科学实验中经过多次抽样(一次抽样有多个数据,一次抽样构建一个置信区间),重复构建多次的置信区间中覆盖总体参数真值的次数所占比例为置信度,也称为置信水平或置信系数。
14、相关系数
协方差的大小受变量的相关程度及变量的方差影响,并不能真实反映两个变量的相关程度,而统计学家皮尔逊为了充分反映变量之间线性相关程度,设计了相关系数这一应用广泛的统计指标
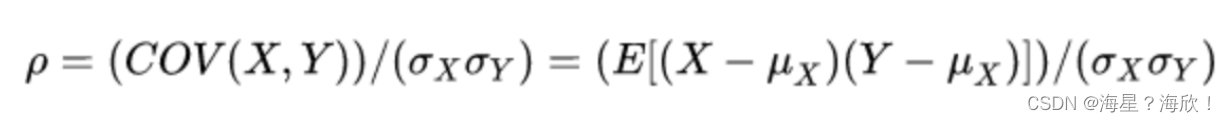
相关系数在协方差基础上进行了标准化,消除了两个变量变化幅度的影响,能够充分反应两个变量的相关关系。与协方差不同的是,相关系数的波动范围是有限的,上下浮动范围是[-1,1]。相关系数越趋近于0,表示两个变量相关程度越弱。相关系数越接近于1,两个变量的正相关程度越高。相关系数越接近于-1,两个变量的负相关程度越高。
15、如何估计样本量
按照功效分析的方法,根据预期的功效、效应值、显著性水平来计算样本大小。
当我们在设计一个实验的时候,需要考虑很多问题,其中一个就是实验流量的分发大小,也就是这个实验中需要需要多少样本才能有意义。 这类问题可以通过功效分析(power analysis)来进行计算,在实验前计算得到所需要的样本量,或者预估在给定样本量下得到不同实验效果的概率。功效分析可以帮助在给定显著性水平的情况下,判断检测到给定效应值时所需的样本大小。
关注四个量:功效、样本大小、效应值、显著性水平,当我们给定任意三个量后,就可以推算出第四个量
功效通过1减去Ⅱ型错误的概率来定义,我们可以把它看作真实效应发生的概率。 4. 效应值指的是在备择或研究假设下效应的量,效应值的表达式依赖于假设检验中使用的统计方法。
步骤:
1,确定研究目标和假设:明确实验研究的目标和假设,包括想要检测的效应大小以及所需的显著性水平。
2,选择适当的统计方法:根据研究问题和数据类型,选择适当的统计方法,比如 t 检验、方差分析、回归分析等。
3,确定显著性水平和统计功效:根据研究设计和领域标准,确定所需的显著性水平(通常为0.05或0.01)和统计功效(通常为0.80或0.90)。
4,估计效应大小和变异性:根据先前的研究结果、相关文献或假设,估计研究中期望的效应大小和总体的变异性。
5,进行功效分析:使用选定的统计方法、显著性水平、统计功效、效应大小和变异性参数,进行功效分析。可以使用统计软件或在线功效分析计算器来进行分析。
6,确定样本量:根据功效分析的结果,确定所需的样本量。通常,需要满足所需的显著性水平和统计功效,并尽量避免样本量过小或过大的情况。
7,考虑实际可行性和资源限制:在确定最终的样本量时,需考虑研究的实际可行性、资源限制以及研究时间和预算等因素。
16、辛普森悖论,以及如何避免这种现象
辛普森悖论:同一组数据,从整体和分组来看,得到的结果完全相反
为什么会出现:数据的整体和部分在结构上呈现了较大的差异,而且存在潜在变量或者混杂因素的影响
牢记:数据的整体有时并不可靠,要通过科学合理的分组来查看具体细致的数据
如何避免:
1.充分考察事件的潜在影响因素和维度,仔细分析因果关系
2.系数消除分组资料基数差异造成的影响
3.实际的应用中,常常引用AB测试来避免该情况,但是要注意的是,AB测试中应保证试验组和对照组里的流量分布均匀且用户质量相同
17、作为出行领域的小玩家,司机端的订单构成是什么样的? 头部优秀司机聚集大量订单,还是订单分布比较发散。
若为较成熟健康的体系中,应为订单分布比较发散;在初期时为头部优秀司机聚集大量订单。
答案解析 :在较健康的供给端体系中,司机端的订单构成应为倒三角或者菱形分布,即头部和腰部司机的订单较多,尾部的订单较少;而在初期时则是头部效应明显,订单集中在头部,后期随着司机和订单量的增多,不可能由头部司机撑起大部分订单的。
18、贝叶斯定理是什么?
贝叶斯定理(Bayes’ theorem)是概率论中的一个定理,描述在已知条件下,某事件的发生概率
条件概率、全概率已知原因求结果、贝叶斯定理已知结果求原因
19、对朴素贝叶斯的理解?
原理:假设数据集各属性之间相互独立,利用贝叶斯公式计算当前特征组合下属于各个类别的概率。
优点:1.算法逻辑简单,易于实现;2.假设各属性之间相互独立,因此算法稳定性好,对于不同类型的数据集,不会呈现太大的差异性。
缺点:由于实际中属性之间相互独立是很难做到的,因此,当属性比较多或者属性之间相关性较大时,算法的分类效果不好
20、两个人相约在8点到9点时间段见面,彼此等15分钟,见不到人就走。两人在8点至9点任一时刻到达目的地,求两人能见面的概率
几何概率问题。画一个坐标轴,xy分别表示甲乙到达的时间。
21、抛硬币直到连续两次出现正面的概率,求扔的期望次数
X=0.5(X+1)+0.50.5(X+2)+0.50.52====>X=6
22、50个红球50个白球放入两个黑箱,怎么分配摸到红球概率最大
第一个箱子放1个红球,其他49个红球和50个白球放进同一个箱子里。选择任意一个箱子的概率都为1/2,第一个箱子拿到红球的概率为1,第二个箱子拿到红球的概率为49/99。1/2(1+49/99)≈0.75
代码跑出来,这样是最优解
23、一个班20个人,至少两个人同一天生日的概率。
20个人生日全不同的概率:C(365,20)/365^20=0.59,至少两个人同一天生日的概率:1-0.59=0.41
24、100次掷硬币60次朝上,可以认为正反概率相等吗?
不可以,样本容量太小
频率是近似值,概率是准确值
25、说一下条件概率的概念
条件概率是指事件A在另外一个事件B已经发生条件下的发生概率。条件概率表示为:P(A|B),读作“在B的条件下A的概率”
26、概率和似然是什么
概率:根据给定的参数求发生某个结果的可能性; 似然:根据发生的结果求某个参数值的可能性
1.概率是给定某⼀参数值,求某⼀结果的可能性的函数。 例如,抛⼀枚匀质硬币,抛10次,6次正⾯向上的可能性多⼤? 解读:“匀质硬币”,表明参数值是0.5,“抛10次,六次正⾯向上”这是⼀个结果,概率(probability)是求这⼀结果的可能性。
2.似然是给定某⼀结果,求某⼀参数值的可能性的函数。 例如,抛⼀枚硬币,抛10次,结果是6次正⾯向上,其是匀质的可能性多⼤? 解读:“抛10次,结果是6次正⾯向上”,这是⼀个给定的结果,问“匀质”的可能性, 即求参数值=0.5的可能性。
27、两个孩子,已知一孩子是男孩,另一孩子是男孩的概率。
1/2或者1/3
答案解析 1/2:两者为独立事件,互不影响,故为1/2;
1/3:如果区分顺序两个孩子可能为:男男,男女,女男,女女;已知其一为男孩,则可能为:男男,男女,女男;男男的概率为1/3
28、假设检验是什么
假设检验是先对总体参数提出一个假设值,然后利用样本信息判断这一假设是否成立;
假设有原假设,备择假设;检验方式有单侧检验和双侧检验;
其步骤通常为:提出原假设与备择假设;从所研究总体中出抽取一个随机样本;构造检验统计量;根据显著性水平确定拒绝域临界值;计算检验统计量与临界值进行比较。
29、假设检验的原理和步骤
假设检验的原理: 小概率事件原理,小概率事件在一次实验中基本是不可能发生的,而一旦发生就有充分的理由拒绝原假设。去证明假设是错误的,从而反证假设的另一面很可能是正确的,运用的是反证法。
步骤:
1,建立原假设和备择假设
2,选择适当的检验统计量:检验统计量是用来度量样本数据与原假设之间的差异或关联程度的统计量,常见的检验统计量包括 t 统计量、F 统计量、卡方统计量等。
3,确定显著性水平:通常表示为α。显著性水平决定了拒绝原假设的临界值,常见的显著性水平包括0.05和0.01。
4,计算检验统计量和p值:使用样本数据计算所选择的检验统计量的值,并据此计算p值。p值是一个表示在原假设成立的条件下,观察到的数据与原假设一致性的概率。p值越小,表示观察到的数据与原假设的不一致程度越大。
5,做出决策:根据p值与显著性水平的比较,对原假设进行决策。常见的决策原则是,如果p值小于显著性水平(p<α),则拒绝原假设,否则接受原假设。拒绝原假设意味着观察到的数据提供了足够的证据支持备择假设。
相关文章:
数分面试题2-牛客
1、面对大方差如何解决 1,AB实验场景下,如果一个指标的方差较大表示它的波动较大,那么实验组和对照组的显著差异可能是因为方差较大即随机波动较大。解决方法有:PSM方法、CUPED(方差缩减) PSM代表"Propensity Score Matchin…...
Android codec2 编码 -- 基于录屏
文章目录 前言android 原生的应用srcreenrecordMediaCodec获取编码数据流程 前言 本篇文章主要是理解Android 12编码的流程, 首先从上层的应用出发理解mediacodec提供给外部API的用法。然后针对每个api 分析编码各个流程中框架中的流程。 熟悉一个框架的流程 可以…...

【Java基础篇 | 面向对象】--- 聊聊什么是多态(上篇)
个人主页:兜里有颗棉花糖 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创 收录于专栏【JavaSE_primary】 本专栏旨在分享学习JavaSE的一点学习心得,欢迎大家在评论区讨论💌 目录 一、什么是多态二、多…...
如何使用 Node.js和Express搭建服务器?
如何使用NodeJs搭建服务器 1. 准备工作1.1 安装Node.js 2. 安装express2.1 初始化package.json2.2 安装express2.3 Express 应用程序生成器 欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段…...

帮公司面试了个要25K的测试,我问了他这些问题...
深耕IT行业多年,我们发现,对于一个程序员而言,能去到一线互联网公司,会给我们以后的发展带来多大的影响。 很多人想说,这个我也知道,但是进大厂实在是太难了,简历投出去基本石沉大海࿰…...
Matlab之创建空数组的多种方法汇总
一、matlab空数组是什么? 在MATLAB中,空数组是指没有元素的数组对象。它可以用于占位或者作为容器,等待后续添加元素。 二、创建空数组的多种方法 1、使用空方括号 [] 创建空矩阵 A []; % 创建一个空双精度矩阵 B logical([]); % 创建一…...
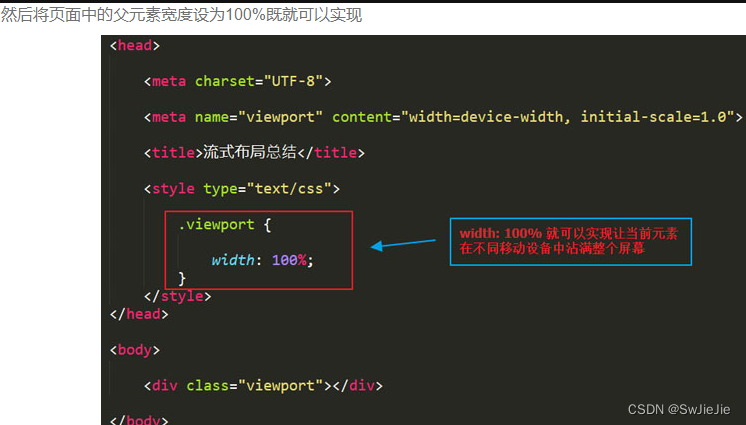
HTML实现移动端布局与页面自适应
我们所说的布局方式,这里我们通常指的是width和height在不同页面情况下面的改变。 常见页面的布局方式有 静态布局 (px布局,就是固定其高宽,不论页面怎样放大缩小,其占领的依旧是,使用px固定了的高宽&…...

CSS3技巧36:backdrop-filter 背景滤镜
CSS3 有 filter 滤镜属性,能给内容,尤其是图片,添加各种滤镜效果。 filter 滤镜详见博文:CSS3中强大的filter(滤镜)属性_css3滤镜_stones4zd的博客-CSDN博客 后续,CSS3 又新增了 backdrop-filter 背景滤镜。 backdr…...

【计算机网络】传输层协议——TCP(上)
文章目录 TCPTCP协议段格式报头和有效载荷如何分离?4位首部长度 TCP可靠性确认应答机制的提出序号和确认序号为什么序号和确认序号在不同的字段? 16位窗口大小 6个标志位标志位本质具体标志位PSHRSTURG 超时重传机制 文章目录 TCPTCP协议段格式报头和有效…...
GO语言网络编程(并发编程)Goroutine池
GO语言网络编程(并发编程)Goroutine池 1. Goroutine池 1.1.1. worker pool(goroutine池) 本质上是生产者消费者模型可以有效控制goroutine数量,防止暴涨需求: 计算一个数字的各个位数之和,例…...

C++面试/笔试准备,资料汇总
文章目录 后端太卷,建议往嵌入式,qt,测试,音视频,C一些细分领域投简历。有任何疑问评论区聊,我看到了回复 C面试/笔试准备,资料汇总自我介绍项目实习尽可能有1.编程语言:一.熟悉C语言…...

【Unity3D】UI Toolkit数据动态绑定
1 前言 本文将实现 cvs 表格数据与 UI Toolkit 元素的动态绑定。 如果读者对 UI Toolkit 不是太了解,可以参考以下内容。 UI Toolkit简介UI Toolkit容器UI Toolkit元素UI Toolkit样式选择器UI Toolkit自定义元素 本文完整资源见→UI Toolkit数据动态绑定。 2 数据…...

微信小程序如何在切换页面后原页面状态不变
在微信小程序中,如果要实现在切换页面后原页面状态不变,可以通过以下几种方式来实现: 使用全局数据:可以将需要保持状态的数据存储在小程序的全局数据中,这样无论切换到哪个页面,都可以通过全局数据来获取…...
)
蓝桥杯官网填空题(生成树)
问题描述 下面是一个 8 个结点的无向图的邻接矩阵表示,其中第 i 行第 j 列表示结点 i 到结点 j 的边长度。当 长度为 0 时表示不存在边。 0 9 3 0 0 0 0 99 0 8 1 4 0 0 03 8 0 9 0 0 0 00 1 9 0 3 0 0 50 4 0 3 0 7 0 60 0 0 0 7 0 5 20 0 0 0 0 5 0 49 0 0 5 6 2…...
Qt Designer UI设计布局小结
目录 前言1 居中布局2 左右布局3 上下布局4 复杂页面布局总结 前言 本文总结了在开发Qt应用程序时使用 Designer 进行UI布局的一些心得体会。Qt Designer是Qt提供的一个可视化界面设计工具,旨在帮助开发人员快速创建和布局用户界面。它提供了丰富的布局管理器和控件…...
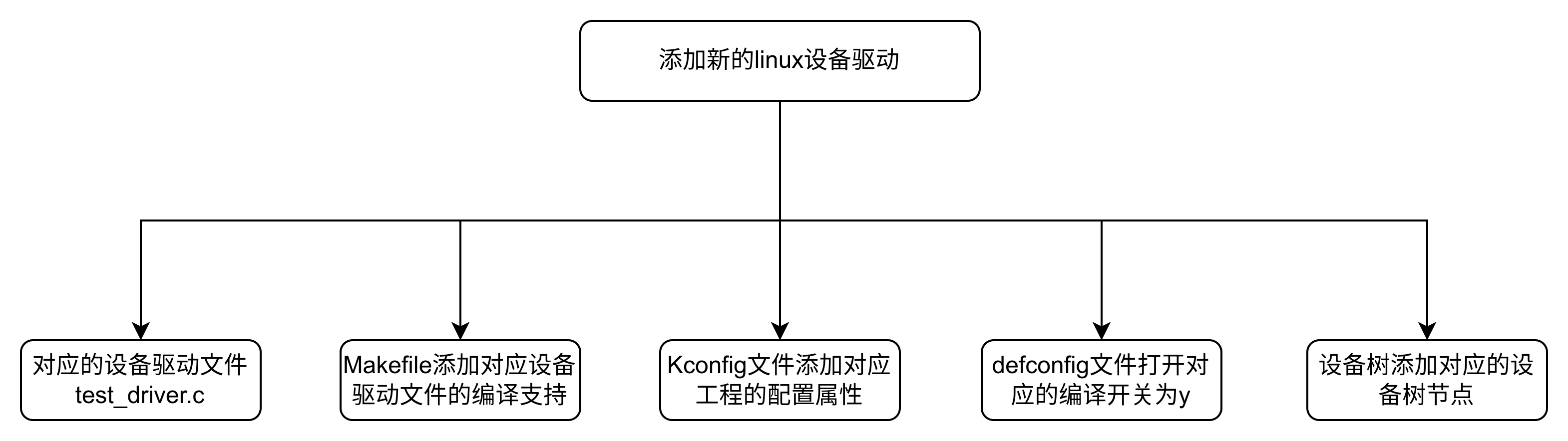
linux设备树节点添加新的复位属性之后设备驱动加载异常问题分析
linux设备树节点添加新的复位属性之后设备驱动加载异常问题分析 1 linux原始设备驱动信息1.1 设备树节点信息1.2 linux设备驱动1.3 makefile1.4 Kconfig1.5 对应的defconfig文件 2 修改之后的linux设备驱动2.1 修改之后的设备树节点信息2.2 原始test_fw.c出现的问题以及原因分析…...
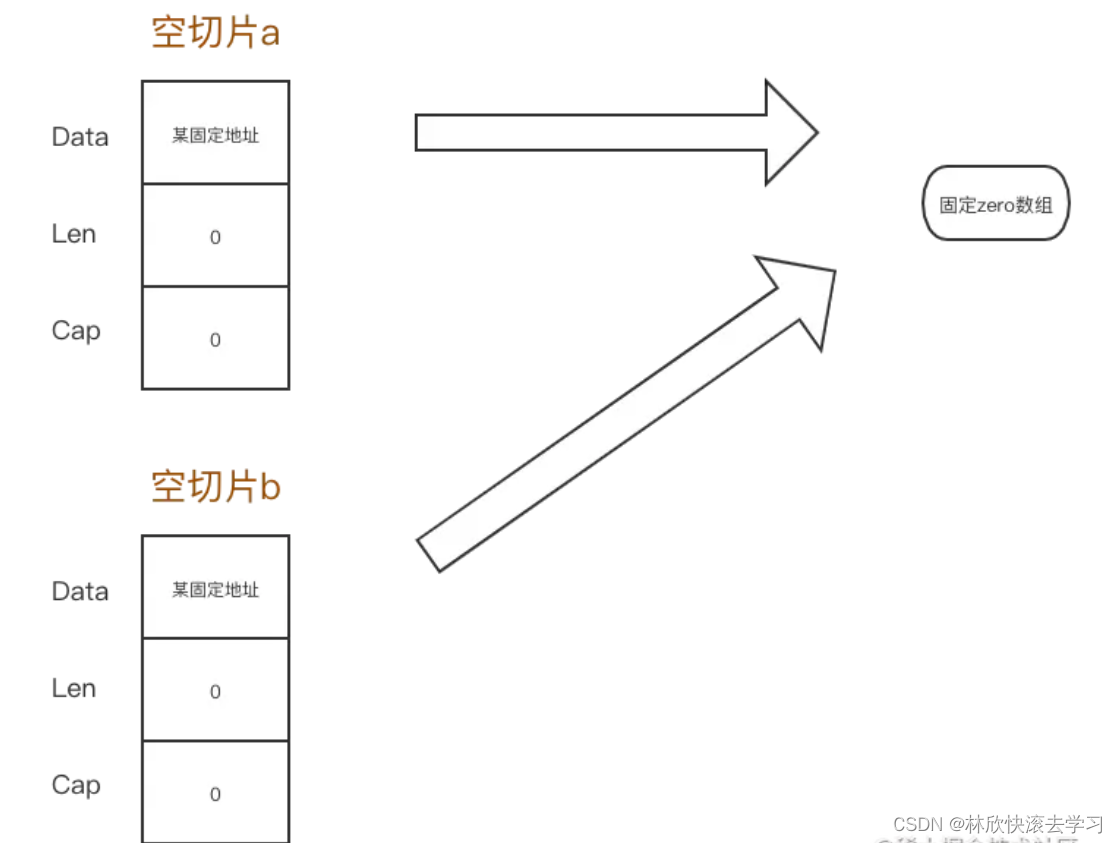
连nil切片和空切片一不一样都不清楚?那BAT面试官只好让你回去等通知了。
连nil切片和空切片一不一样都不清楚?那BAT面试官只好让你回去等通知了。 问题 package mainimport ("fmt""reflect""unsafe" )func main() {var s1 []ints2 : make([]int,0)s4 : make([]int,0)fmt.Printf("s1 pointer:%v, s2 p…...

前端构建工具 webpack 笔记
1、了解 webpack 1、定义:本质上,webpack 是一个用于现代 JavaScript 应用程序的静态模块打包工具,当 webpack 处理应用它会在内部从一个或多个入口点构建一个依赖图(dependency graph),然后将你项目中所程序时,需的…...
.Net MVC 使用Areas后存在相同Controller时报错的解决办法; 从上下文获取请求的Area名及Controller名
先来说个额外的问题:如何在请求上下文(比如过滤器的中)获取请求对应的Area和Controller 名字?(假设请求上下文对象为 filterContext ): 1. 获取Area名: (string)filterContext.RouteData.DataTo…...

docker-compose部署etcd集群
1. docker-compose.yml cat > docker-compose.yml << EOF version: "3.0"networks:etcd-net: # 网络driver: bridge # 桥接模式volumes:etcd1_data: # 挂载到本地的数据卷名driver: localetcd2_data:driver: localetcd3_data:driver:…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

R 语言科研绘图第 55 期 --- 网络图-聚类
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...

STM32---外部32.768K晶振(LSE)无法起振问题
晶振是否起振主要就检查两个1、晶振与MCU是否兼容;2、晶振的负载电容是否匹配 目录 一、判断晶振与MCU是否兼容 二、判断负载电容是否匹配 1. 晶振负载电容(CL)与匹配电容(CL1、CL2)的关系 2. 如何选择 CL1 和 CL…...