基于PyTorch使用LSTM实现新闻文本分类任务
本文参考
PyTorch深度学习项目实战100例
https://weibaohang.blog.csdn.net/article/details/127154284?spm=1001.2014.3001.5501
文章目录
- 本文参考
- 任务介绍
- 做数据的导入
- 环境介绍
- 导入必要的包
- 介绍torchnet和keras
- 做数据的导入
- 给必要的参数命名
- 加载文本数据
- 数据前处理
- 模型训练
- 验证
任务介绍
基于PyTorch使用LSTM实现新闻文本分类任务的概况如下:
任务描述:新闻文本分类是一种常见的自然语言处理任务,旨在将新闻文章分为不同的类别,如政治、体育、科技等。
方法:使用深度学习模型中的LSTM(长短时记忆网络)来处理文本序列数据。LSTM能够捕获文本中的长期依赖关系,适应不定长文本,自动提取特征,适应多类别分类,并在大型数据集上表现出色。
做数据的导入
数据+代码
https://download.csdn.net/download/weixin_55982578/88323618?spm=1001.2014.3001.5503
环境介绍
通俗的说:
直接白嫖 Google colab
优雅的说
Google Colab(Colaboratory)是一种基于云的免费Jupyter笔记本环境,具有以下优点和好处:
免费使用:Colab提供免费的GPU和TPU(Tensor Processing Unit)资源,使用户能够免费运行深度学习和机器学习任务,而无需担心硬件成本。
Google Colab(Colaboratory)是一种基于云的免费Jupyter笔记本环境,具有以下优点和好处:
免费使用:Colab提供免费的GPU和TPU(Tensor Processing Unit)资源,使用户能够免费运行深度学习和机器学习任务,而无需担心硬件成本。
导入必要的包
介绍torchnet和keras
Torchnet 是一个轻量级框架,旨在为 PyTorch 提供一些抽象和实用工具,以简化常见的深度学习研究任务。Torchnet 的设计是模块化和扩展性的,这使得研究者可以更轻松地尝试新的思路和方法。
Keras 是一个开源深度学习框架,最初由François Chollet创建并维护。它是一个高级神经网络API,旨在使深度学习模型的设计和训练变得简单而快速
!pip install torchnet
!pip install keras
import pickle
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
from torch.utils.data import TensorDataset
from torch import optim
from torchnet import meter
from tqdm import tqdm```
做数据的导入
数据+代码
类别
# {0: '法治',
# 1: '国际',
# 2: '国内',
# 3: '健康',
# 4: '教育',
# 5: '经济',
# 6: '军事',
# 7: '科技',
# 8: '农经',
# 9: '三农',
# 10: '人物',
# 11: '社会',
# 12: '生活',
# 13: '书画',
# 14: '文娱'}
给必要的参数命名
# config file
# 模型输入参数,需要自己根据需要调整
num_layers = 1 # LSTM的层数
hidden_dim = 100 # LSTM中的隐层大小
epochs = 50 # 迭代次数
batch_size = 32 # 每个批次样本大小
embedding_dim = 15 # 每个字形成的嵌入向量大小
output_dim = 15 # 输出维度,因为是二分类
lr = 0.01 # 学习率
import torch# 检查是否有可用的GPU
device = torch.device('cuda')
file_path = './news.csv' # 数据路径
input_shape = 80 # 每句话的词的个数,如果不够需要使用0进行填充
加载文本数据
# 加载文本数据
def load_data(file_path, input_shape=20):df = pd.read_csv(file_path, encoding='gbk')# 标签及词汇表labels, vocabulary = list(df['label'].unique()), list(df['brief'].unique())# 构造字符级别的特征string = ''for word in vocabulary:string += word# 所有的词汇表vocabulary = set(string)# word2idx 将字映射为索引 '你':0word2idx = {word: i + 1 for i, word in enumerate(vocabulary)}with open('word2idx.pk', 'wb') as f:pickle.dump(word2idx, f)# idx2word 将索引映射为字 0:'你'idx2word = {i + 1: word for i, word in enumerate(vocabulary)}with open('idx2word.pk', 'wb') as f:pickle.dump(idx2word, f)# label2idx 将正反面映射为0和1 '法治':0label2idx = {label: i for i, label in enumerate(labels)}with open('label2idx.pk', 'wb') as f:pickle.dump(label2idx, f)# idx2label 将0和1映射为正反面 0:'法治'idx2label = {i: labels for i, labels in enumerate(labels)}with open('idx2label.pk', 'wb') as f:pickle.dump(idx2label, f)# 训练数据中所有词的个数vocab_size = len(word2idx.keys()) # 词汇表大小# 标签类别,分别为法治、健康等label_size = len(label2idx.keys()) # 标签类别数量# 序列填充,按input_shape填充,长度不足的按0补充# 将一句话映射成对应的索引 [0,24,63...]x = [[word2idx[word] for word in sent] for sent in df['brief']]# 如果长度不够input_shape,使用0进行填充x = pad_sequences(maxlen=input_shape, sequences=x, padding='post', value=0)# 形成标签0和1y = [[label2idx[sent]] for sent in df['label']]# y = [np_utils.to_categorical(label, num_classes=label_size) for label in y]y = np.array(y)return x, y, idx2label, vocab_size, label_size, idx2word
读取数据返回参数
| 变量名 | 描述 |
|---|---|
| x | 包含了填充后的文本数据(字符索引的序列) |
| y | 包含了标签数据 |
| idx2label | 用于将模型的输出索引映射回标签 |
| vocab_size | 存储词汇表大小 |
| label_size | 存储标签类别数量 |
| idx2word | 用于将字符索引映射回字符 |
生成
| 字典名称 | 描述 |
|---|---|
| word2idx | 字符映射为索引,例如 ‘你’ 映射为 0 |
| idx2word | 索引映射回字符,例如 0 映射回 ‘你’ |
| label2idx | 标签映射为索引,例如 ‘法治’ 映射为 0 |
| idx2label | 索引映射回标签,例如 0 映射回 ‘法治’ |
代码里面提供了可视化的方法
创建LSTM 网路结构
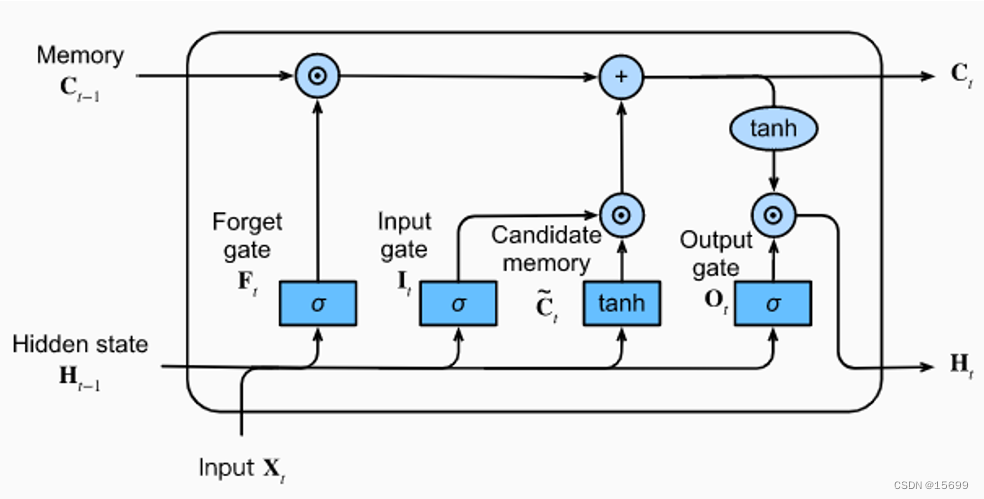
LSTM(Long Short-Term Memory)是一种循环神经网络(Recurrent Neural Network,RNN)的变种,它在处理序列数据时具有很好的性能,特别是在长序列上能够更好地捕捉长期依赖关系。下面是关于LSTM网络结构的说明:
背景:LSTM是为了解决传统RNN中的梯度消失和梯度爆炸问题而提出的。它引入了特殊的记忆单元来维护和控制信息的流动,以更好地捕捉序列数据中的长期依赖关系。
LSTM单元:LSTM网络的基本构建单元是LSTM单元。每个LSTM单元包括以下组件:
- 输入门(Input Gate):控制新信息的输入。
- 遗忘门(Forget Gate):控制过去信息的遗忘。
- 输出门(Output Gate):控制输出的生成。
- 细胞状态(Cell State):用于维护长期依赖关系的记忆。
记忆细胞:LSTM单元内部的细胞状态是其核心。它可以看作一个传送带,可以在不同时间步骤上添加或删除信息。通过输入门、遗忘门和输出门来控制信息的读取、写入和遗忘,以保持对序列中重要信息的长期记忆。
输入门:输入门决定了在当前时间步骤中,新的输入信息中哪些部分将会更新细胞状态。输入门通常由一个Sigmoid激活函数和一个tanh激活函数组成,用于产生0到1之间的权重和-1到1之间的新候选值。
遗忘门:遗忘门决定了哪些信息应该从细胞状态中丢弃。它使用Sigmoid激活函数来产生0到1之间的权重,控制细胞状态中哪些信息应该保留。
输出门:输出门决定了基于当前细胞状态和输入信息,LSTM单元应该输出什么。它使用Sigmoid激活函数来确定输出的哪些部分应该激活,并使用tanh激活函数来生成可能的输出值。
# 定义网络结构
class LSTM(nn.Module):def __init__(self, vocab_size, hidden_dim, num_layers, embedding_dim, output_dim):super(LSTM, self).__init__()self.hidden_dim = hidden_dim # 隐层大小self.num_layers = num_layers # LSTM层数# 嵌入层,会对所有词形成一个连续型嵌入向量,该向量的维度为embedding_dim# 然后利用这个向量来表示该字,而不是用索引继续表示self.embeddings = nn.Embedding(vocab_size + 1, embedding_dim)# 定义LSTM层,第一个参数为每个时间步的特征大小,这里就是每个字的维度# 第二个参数为隐层大小# 第三个参数为LSTM的层数self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers)# 利用全连接层将其映射为2维,即正反面的概率self.fc = nn.Linear(hidden_dim, output_dim)def forward(self, x):# 1.首先形成嵌入向量embeds = self.embeddings(x)# 2.将嵌入向量导入到LSTM层output, (h_n, c_n) = self.lstm(embeds)# 获取输出的形状timestep, batch_size, hidden_dim = output.shape# 3.将其导入全连接层output = output.reshape(-1, hidden_dim)output = self.fc(output) # 形状为batch_size * timestep, 15# 重新调整输出的形状,使其变为 timestep x batch_size x output_dimoutput = output.reshape(timestep, batch_size, -1)# 返回最后一个时间片的输出,维度为 batch_size x output_dimreturn output[-1]数据前处理
# 1.获取训练数据
x, y, idx2label, vocab_size, label_size, idx2word = load_data(file_path, input_shape)# 2.划分训练、测试数据
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.1, random_state=42)# 3.将numpy转成tensor
x_train = torch.from_numpy(x_train).to(torch.int32)
y_train = torch.from_numpy(y_train).to(torch.float32)
x_test = torch.from_numpy(x_test).to(torch.int32)
y_test = torch.from_numpy(y_test).to(torch.float32)# 将训练数据和标签移到GPU上加速
x_train = x_train.to('cuda:0')
y_train = y_train.to('cuda:0')
x_test = x_test.to('cuda:0')
y_test = y_test.to('cuda:0')
使用torch中的Dataloader的方法
# 4.形成训练数据集
train_data = TensorDataset(x_train, y_train)
test_data = TensorDataset(x_test, y_test)# 5.将数据加载成迭代器
train_loader = torch.utils.data.DataLoader(train_data,batch_size,True)test_loader = torch.utils.data.DataLoader(test_data,batch_size,False)
模型训练
# 6.模型训练
model = LSTM(vocab_size=vocab_size, hidden_dim=hidden_dim, num_layers=num_layers,embedding_dim=embedding_dim, output_dim=output_dim)Configimizer = optim.Adam(model.parameters(), lr=lr) # 优化器
criterion = nn.CrossEntropyLoss() # 多分类损失函数model.to(device)
loss_meter = meter.AverageValueMeter()best_acc = 0 # 保存最好准确率
best_model = None # 保存对应最好准确率的模型参数for epoch in range(epochs):model.train() # 开启训练模式epoch_acc = 0 # 每个epoch的准确率epoch_acc_count = 0 # 每个epoch训练的样本数train_count = 0 # 用于计算总的样本数,方便求准确率loss_meter.reset()train_bar = tqdm(train_loader) # 形成进度条for data in train_bar:x_train, y_train = data # 解包迭代器中的X和Yx_input = x_train.long().transpose(1, 0).contiguous()x_input = x_input.to(device)Configimizer.zero_grad()# 形成预测结果output_ = model(x_input).to(device)# 计算损失loss = criterion(output_, y_train.long().view(-1))loss.backward()Configimizer.step()loss_meter.add(loss.item())# 计算每个epoch正确的个数epoch_acc_count += (output_.argmax(axis=1) == y_train.view(-1)).sum()train_count += len(x_train)# 每个epoch对应的准确率epoch_acc = epoch_acc_count / train_count# 打印信息print("【EPOCH: 】%s" % str(epoch + 1))print("训练损失为%s" % (str(loss_meter.mean)))print("训练精度为%s" % (str(epoch_acc.item() * 100)[:5]) + '%')# 保存模型及相关信息if epoch_acc > best_acc:best_acc = epoch_accbest_model = model.state_dict()# 在训练结束保存最优的模型参数if epoch == epochs - 1:# 保存模型torch.save(best_model, './best_model.pkl')# 打印测试集精度
test_accuracy = (model(x_test.long().transpose(1, 0).contiguous()).argmax(axis=1) == y_test.view(-1)).sum() / len(y_test)
print("【训练精度为】%s" % (str(test_accuracy.item() * 100)[:5]) + '%')
验证
# 导入字典,用于形成编码
with open('word2idx.pk', 'rb') as f:word2idx = pickle.load(f)
with open('label2idx.pk', 'rb') as f:label2idx = pickle.load(f)
with open('idx2word.pk', 'rb') as f:idx2word = pickle.load(f)
with open('idx2label.pk', 'rb') as f:idx2label = pickle.load(f)try:# 数据预处理input_shape = 80 # 序列长度,就是时间步大小,也就是这里的每句话中的词的个数# 用于测试的话sent = "陈金英,一位家住浙江丽水的耄耋老人。今年这个年,陈金英过得格外舒心,因为春节前,她耗费10年,凭借自己的努力,不拖不欠,终于还清了所有欠款。"# 将对应的字转化为相应的序号x = [[word2idx[word] for word in sent]]# 如果长度不够180,使用0进行填充x = pad_sequences(maxlen=input_shape, sequences=x, padding='post', value=0)x = torch.from_numpy(x)# 加载模型model_path = './best_model.pkl'model = LSTM(vocab_size=vocab_size, hidden_dim=hidden_dim, num_layers=num_layers,embedding_dim=embedding_dim, output_dim=output_dim)model.load_state_dict(torch.load(model_path, 'cpu'))# 模型预测,注意输入的数据第一个input_shape,就是180y_pred = model(x.long().transpose(1, 0))print('输入语句: %s' % sent)print('新闻分类结果: %s' % idx2label[y_pred.argmax().item()])except KeyError as err:print("您输入的句子有汉字不在词汇表中,请重新输入!")print("不在词汇表中的单词为:%s." % err)弄成函数好调用
def classify_news_sentiment(sent):# 导入字典,用于形成编码with open('word2idx.pk', 'rb') as f:word2idx = pickle.load(f)with open('label2idx.pk', 'rb') as f:label2idx = pickle.load(f)with open('idx2word.pk', 'rb') as f:idx2word = pickle.load(f)with open('idx2label.pk', 'rb') as f:idx2label = pickle.load(f)try:# 数据预处理input_shape = 80 # 序列长度,就是时间步大小,也就是这里的每句话中的词的个数# 将对应的字转化为相应的序号x = [[word2idx[word] for word in sent]]# 如果长度不够180,使用0进行填充x = pad_sequences(maxlen=input_shape, sequences=x, padding='post', value=0)x = torch.from_numpy(x)# 加载模型model_path = './best_model.pkl'model = LSTM(vocab_size=vocab_size, hidden_dim=hidden_dim, num_layers=num_layers,embedding_dim=embedding_dim, output_dim=output_dim)model.load_state_dict(torch.load(model_path, 'cpu'))# 模型预测,注意输入的数据第一个input_shape,就是180y_pred = model(x.long().transpose(1, 0))result_label = idx2label[y_pred.argmax().item()]return result_labelexcept KeyError as err:return f"您输入的句子有汉字不在词汇表中,请重新输入!\n不在词汇表中的单词为:{err}"测试
sent = "陈金英,一位家住浙江丽水的耄耋老人。今年这个年,陈金英过得格外舒心,因为春节前,她耗费10年,凭借自己的努力,不拖不欠,终于还清了所有欠款。"
classify_news_sentiment(sent)
结果
人物
相关文章:
基于PyTorch使用LSTM实现新闻文本分类任务
本文参考 PyTorch深度学习项目实战100例 https://weibaohang.blog.csdn.net/article/details/127154284?spm1001.2014.3001.5501 文章目录 本文参考任务介绍做数据的导入 环境介绍导入必要的包介绍torchnet和keras做数据的导入给必要的参数命名加载文本数据数据前处理模型训…...

Flutter插件的制作和发布
Flutter制作插件有两种方式(以下以android和ios为例): 目录 1.直接在主工程下的android和ios项目内写插件代码:2.创建独立Flutter Plugin项目,制作各端插件后,再引入项目:1. 创建Flutter Plugin…...
【JAVA】异常
作者主页:paper jie 的博客 本文作者:大家好,我是paper jie,感谢你阅读本文,欢迎一建三连哦。 本文录入于《JAVASE语法系列》专栏,本专栏是针对于大学生,编程小白精心打造的。笔者用重金(时间和…...

合同矩阵充要条件
两个实对称矩阵合同的充要条件是它们的正负惯性指数相同。 正惯性指数是矩阵正特征值个数,负惯性指数是矩阵负特征值个数。 即合同矩阵的充分必要条件是特征值的正负号个数相同。 证明: 本论证中的所有矩阵都是对称矩阵。 根据定义,若矩…...
数据分析三剑客之Pandas
1.引入 前面一篇文章我们介绍了numpy,但numpy的特长并不是在于数据处理,而是在它能非常方便地实现科学计算,所以我们日常对数据进行处理时用的numpy情况并不是很多,我们需要处理的数据一般都是带有列标签和index索引的࿰…...

Spring Boot自动装配原理
简介 Spring Boot是一个开源的Java框架,旨在简化Spring应用程序的搭建和开发。它通过自动装配的机制,大大减少了繁琐的配置工作,提高了开发效率。本文将深入探讨Spring Boot的自动装配原理。 自动装配的概述 在传统的Spring框架中…...

VMware Workstation虚拟机网络配置及配置自动启动
目录 一、网络配置二、配置自动启动1.VMware 中配置虚拟机自启动2.系统服务中配置 VMware 服务自启动 一、网络配置 本文将虚拟机 IP 与主机 IP 设置为同一个网段。 点击 “编辑” -> “虚拟网络编辑器(N)…”: 点击 “更改设置”: 将 VMnet0 设置…...

智能语音机器人竞品调研
一、腾讯云-智能客服机器人 链接地址:智能客服机器人_在线智能客服_智能客服解决方案 - 腾讯云 二、阿里云-智能语音机器人 链接地址:智能对话机器人-阿里云帮助中心 链接地址:智能外呼机器人的业务架构_智能外呼机器人-阿里云帮助中心 三、火…...
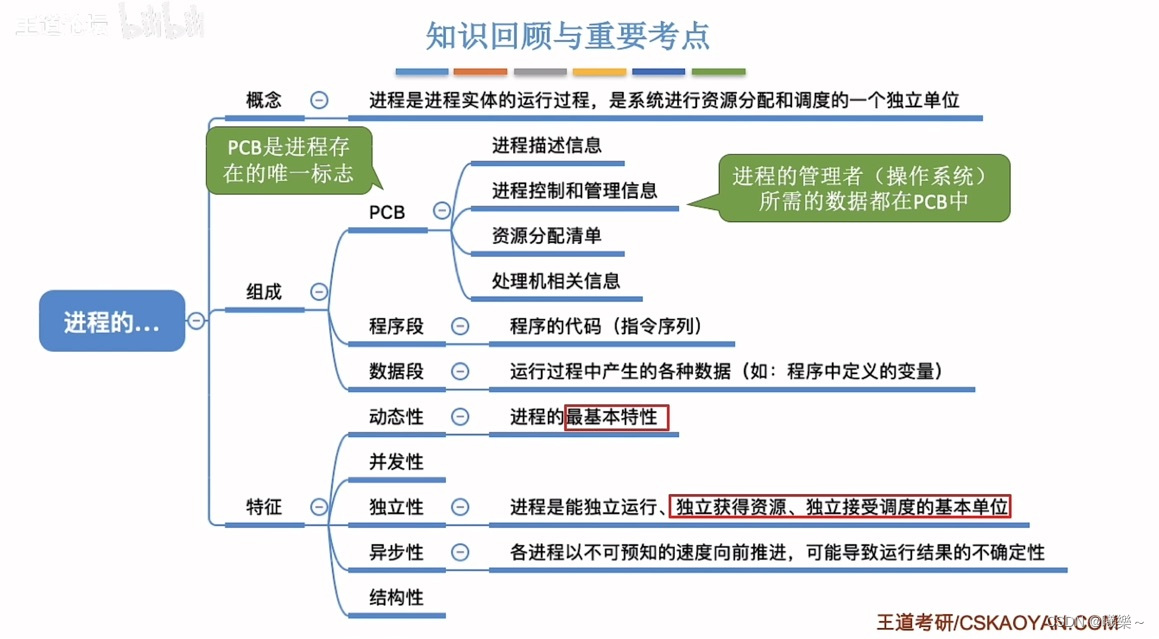
【操作系统】进程的概念、组成、特征
概念组成 程序:静态的放在磁盘(外存)里的可执行文件(代码) 作业:代码+数据+申请(JCB)(外存) 进程:程序的一次执行过程。 …...

大二第二周总结
问题: 想到了之前追的辩论赛,主题是“被误解是表达者的宿命”, 反方认为被误解不是表达者的宿命: 由于表达者表意含混造成误解的可能性是人力可控的,表达者可在真诚沟通的基础之上,根据对方反应不断调整…...

JDK、eclipse软件的安装
一、打开JDK安装包 二、复制路径 三、点击我的电脑,找到环境变量 四、新建环境 变量名:JAVA_HOME 变量值就是刚刚复制的路径 五、在path中建立新变量 双击path 打印以下文字 最后一直双击确定,安装环境完成。 六、双击eclipse 选择好安装…...

235. 二叉搜索树的最近公共祖先 Python
文章目录 一、题目描述示例 1示例 2 二、代码三、解题思路 一、题目描述 给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足…...
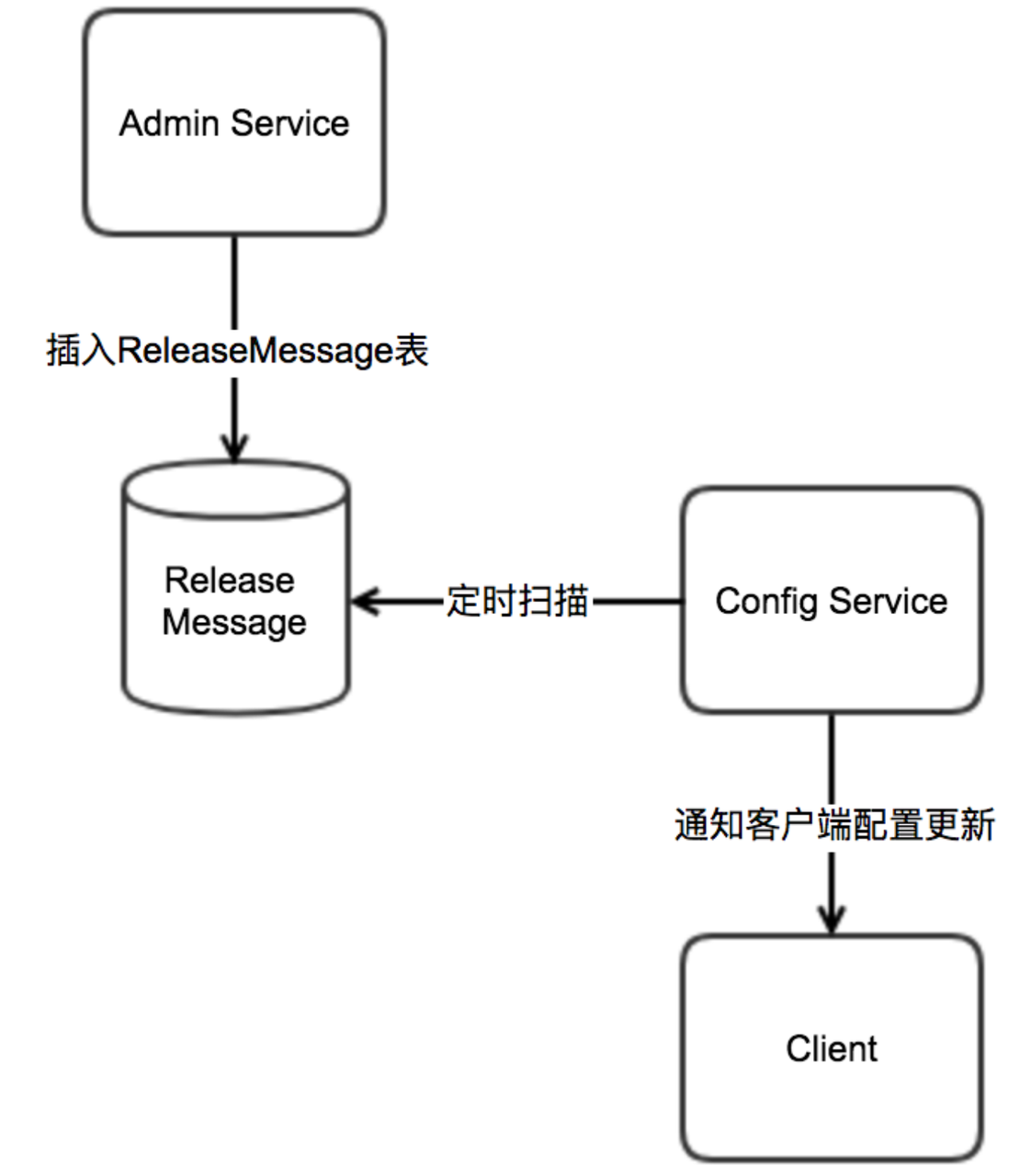
Apollo介绍和入门
文章目录 Apollo介绍配置中心介绍apollo介绍主流配置中心功能特性对比 Apollo简介 入门简单的执行流程Apollo具体的执行流程Apollo对象执行流程分步执行流程 核心概念应用,环境,集群,命名空间企业部署方案灰度发布全量发布 配置发布的原理发送…...
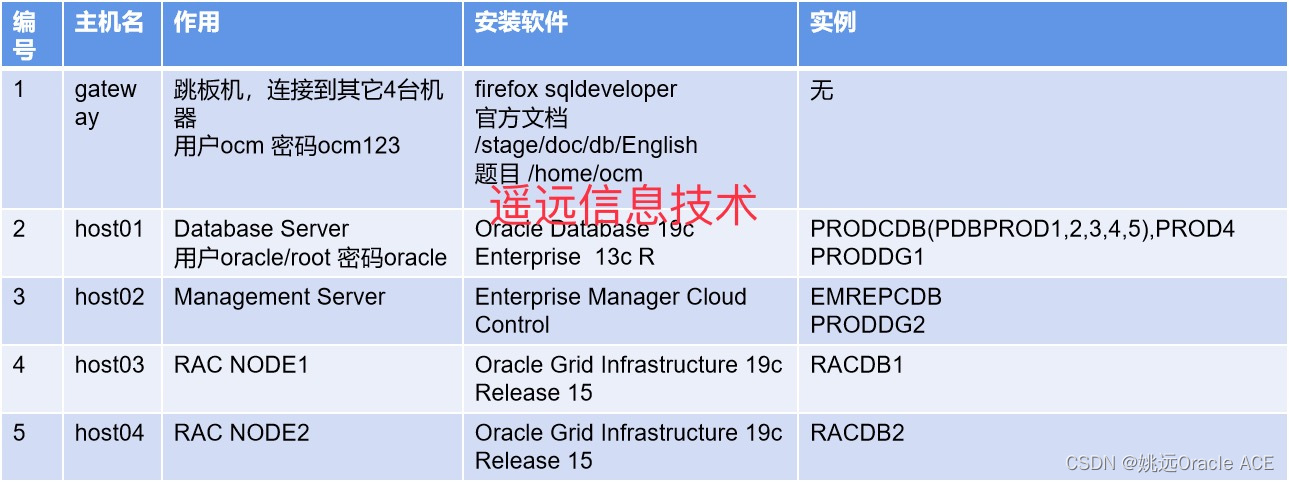
一文看懂Oracle 19c OCM认证考试(需要Oracle OCP证书)
Oracle OCM的认证全称是Oracle Certified Master,是比OCP更高一级的认证,姚远老师的很多OCP学员都对OCM考试有兴趣,这里跟大家做个介绍。 OCM考试全部是上机的实操考试,没有笔试,要到Oracle原厂参加两天的考试。参加1…...
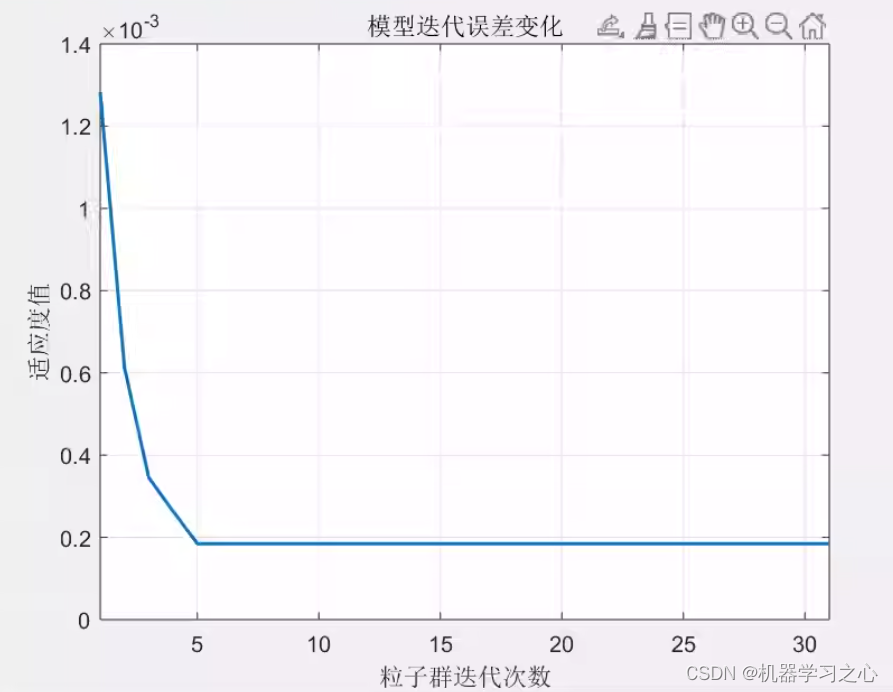
回归预测 | MATLAB实现PSO-SDAE粒子群优化堆叠去噪自编码器多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现PSO-SDAE粒子群优化堆叠去噪自编码器多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现PSO-SDAE粒子群优化堆叠去噪自编码器多输入单输出回归预测(多指标,多图)效果一览…...
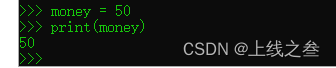
python自学
自学第一步 第一个简单的基础,向世界说你好 启动python 开始 print是打印输出的意思,就是输出引号内的内容。 标点符号必须要是英文的,因为他只认识英文的标点符号。 exit()推出python。 我们创建一个文本文档&…...
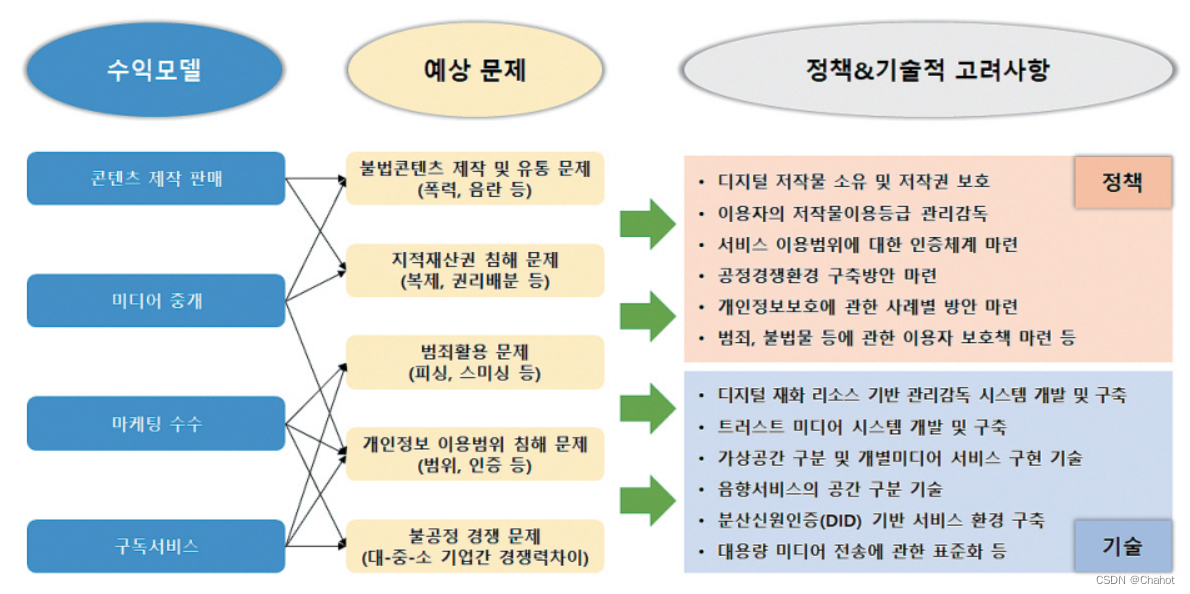
元宇宙安全与著作权相关市场与技术动态:韩国视角
元宇宙市场动态 元宇宙安全与著作权维护技术现状 元宇宙有可能为商业创造巨大价值,尤其是在零售和时尚领域。时尚产品的象征性价值不仅在物理空间中得以保持,在虚拟空间中也是如此。通过元宇宙平台,企业可以开发虚拟产品,降低供…...

springboot整合neo4j--采用Neo4jClient和Neo4jTemplate方式
1.背景 看了spring-boot-starter-data-neo4j的源码之后发现,该starter内已经实现了Neo4jClient和Neo4jTemplate,我们只需要使用Autowire就能直接使用它操作neo4j。 Neo4jClient方式与我的另一篇springboot整合neo4j-使用原生cypher Java API博客方式一样…...
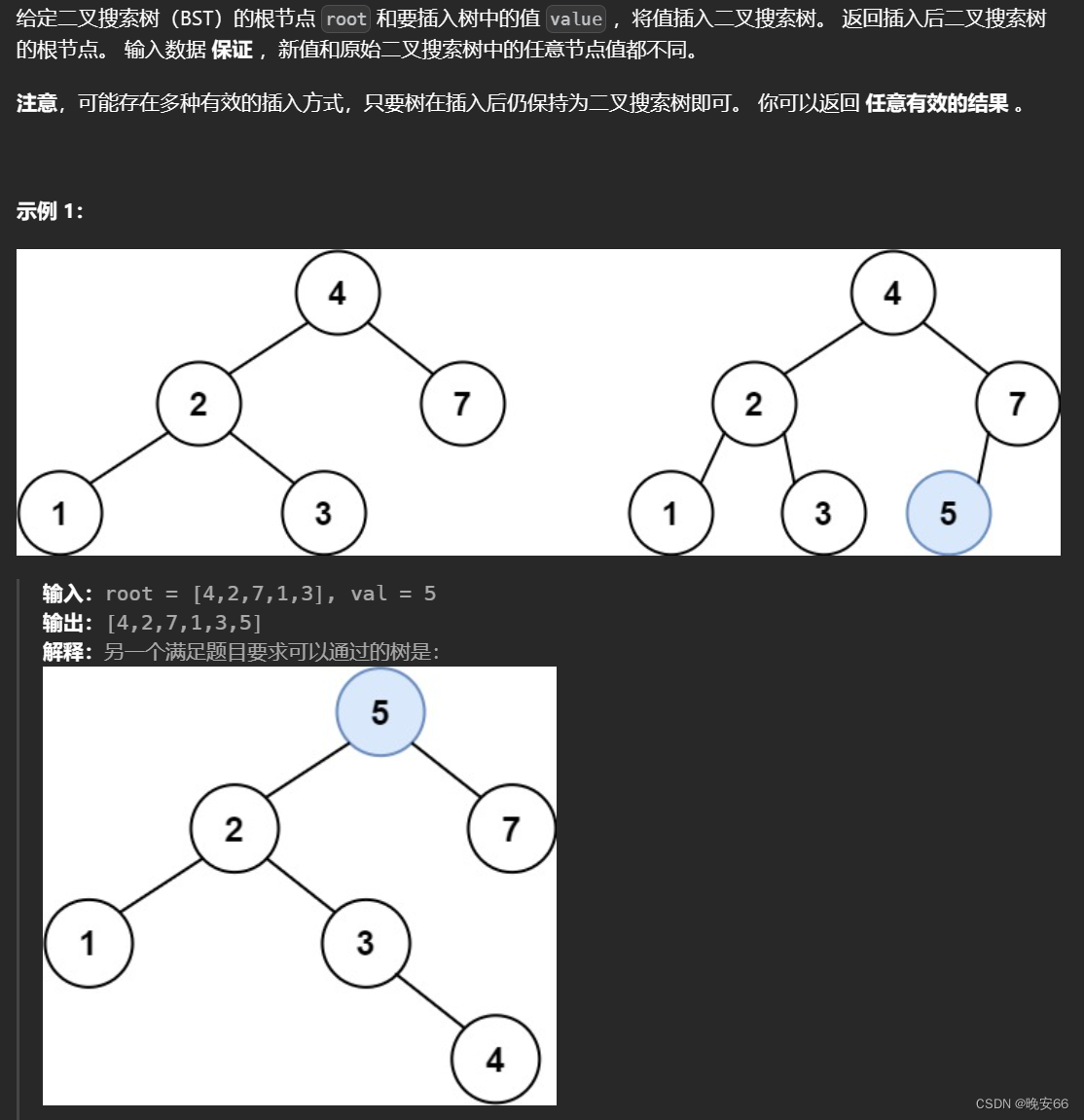
【算法与数据结构】701、LeetCode二叉搜索树中的插入操作
文章目录 一、题目二、解法三、完整代码 所有的LeetCode题解索引,可以看这篇文章——【算法和数据结构】LeetCode题解。 一、题目 二、解法 思路分析:这道题关键在于分析插入值的位置,不论插入的值是什么(插入值和原有树中的键值都…...
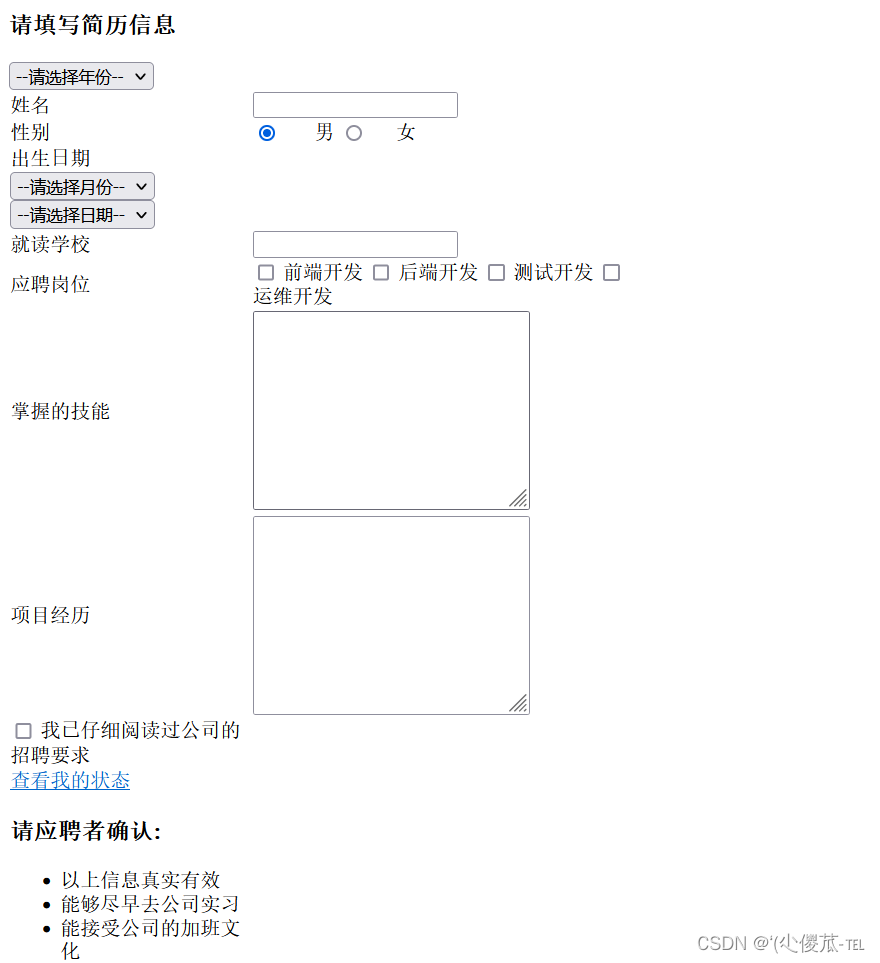
前端--HTML
文章目录 HTML结构快速生成代码框架HTML常见标签 表格标签 编写简历信息 填写简历信息 Emmet 快捷键 HTML 特殊字符 一、HTML结构 1.认识HTML标签 HTML 代码是由 "标签" 构成的. 形如: <body>hello</body> 标签名 (body) 放到 < > 中 大部分标…...
)
C#实战:如何用BarTender 2016实现自动化标签打印(附避坑指南)
C#工业级标签打印自动化实战:BarTender 2016深度整合指南 在制造业和物流仓储领域,标签打印的准确性和效率直接影响着整个生产流程的顺畅度。BarTender作为行业标杆级的标签设计与打印软件,其自动化能力可以显著减少人工干预带来的错误。本文…...

Dify平台集成:Qwen2.5-0.5B Instruct应用开发实战
Dify平台集成:Qwen2.5-0.5B Instruct应用开发实战 1. 引言 想象一下,你是一家中小企业的技术负责人,老板突然要求你在下周前上线一个智能客服系统。传统的方案需要组建算法团队、准备训练数据、调试模型参数,光是想想就让人头疼…...
)
AutoCAD矢量数据导出全攻略:GIS4CAD插件一键转shp/mdb/kml(附安装包)
AutoCAD地理数据高效转换指南:GIS4CAD插件实战技巧 在建筑设计与城市规划领域,AutoCAD工程师经常面临一个棘手问题——如何将精心绘制的矢量数据无缝导入到地理信息系统(GIS)中?传统的手动转换不仅耗时费力,…...

RenderDoc安卓端Vulkan抓帧实战指南
1. 为什么需要安卓端Vulkan抓帧 在移动图形开发过程中,我们经常遇到各种渲染问题:画面闪烁、纹理错误、性能卡顿等等。传统的调试方式往往像盲人摸象,而Vulkan抓帧技术就是给我们装上了一双"透视眼"。我清楚地记得第一次成功抓到帧…...

Phi-3-mini-128k-instruct部署优化:vLLM张量并行+FlashAttention-2加速实测
Phi-3-mini-128k-instruct部署优化:vLLM张量并行FlashAttention-2加速实测 1. 引言:为什么需要优化部署? 如果你尝试过在单张消费级显卡上运行大语言模型,大概率会遇到一个头疼的问题:速度慢,显存不够用。…...

wan2.1-vae镜像CI/CD流水线:GitHub Actions自动构建+GPU集群部署
wan2.1-vae镜像CI/CD流水线:GitHub Actions自动构建GPU集群部署 1. 项目背景与价值 在AI图像生成领域,快速迭代和稳定部署是关键挑战。wan2.1-vae作为基于Qwen-Image-2512模型的文生图平台,需要高效的构建和部署流程来支持其核心功能&#…...
)
从Monitor到SemaphoreSlim:C#同步机制的演进与选择(含性能对比)
从Monitor到SemaphoreSlim:C#同步机制的演进与选择(含性能对比) 在构建高并发C#应用时,开发者的工具箱里有多种同步原语可供选择。从传统的lock关键字到现代的SemaphoreSlim,每种机制都有其独特的适用场景和性能特征。…...

OpenClaw的火爆是否预示着人类即将进入人机协同工作的新阶段,而大多数人还未准备好?
# 当代码遇见道德:给机器人装上“紧箍咒”的技术现实 最近看到不少人在讨论OpenClaw这类机器人系统是否应该内置类似阿西莫夫机器人三定律的约束规则。这个问题挺有意思的,它触及了技术发展中一个很根本的困境:我们创造的工具越来越强大&…...

Qwen-VL实战教程:RTX4090D镜像中通过CLI命令行完成图像问答、描述生成、视觉定位
Qwen-VL实战教程:RTX4090D镜像中通过CLI命令行完成图像问答、描述生成、视觉定位 1. 环境准备与快速开始 Qwen-Image定制镜像是专为RTX4090D显卡优化的多模态大模型推理环境,预装了所有必要的依赖库和工具。这个镜像最大的优势在于开箱即用,…...
)
紧急预警:未做语义等价验证的梯形图转C代码,正悄然导致产线停机率上升42%(附实时校验工具链)
第一章:紧急预警:未做语义等价验证的梯形图转C代码,正悄然导致产线停机率上升42%(附实时校验工具链)工业自动化系统中,PLC梯形图(LAD)向嵌入式C代码的自动转换已成主流开发范式。然而…...