Pytorch学习整理笔记(一)
文章目录
- 数据处理Dataset
- Tensorboard使用
- Transforms
- torchvision数据集使用
- DataLoader使用
- nn.Module的使用
- 神经网络
数据处理Dataset
主要是对Dataset的使用:
- 继承 Dataset
- 实现
init方法,主要是进行一些全局变量的定义,在对其初始化时需要赋值。 - 实现
getitem方法,获取每个数据 - 实现
len方法,获取数据size
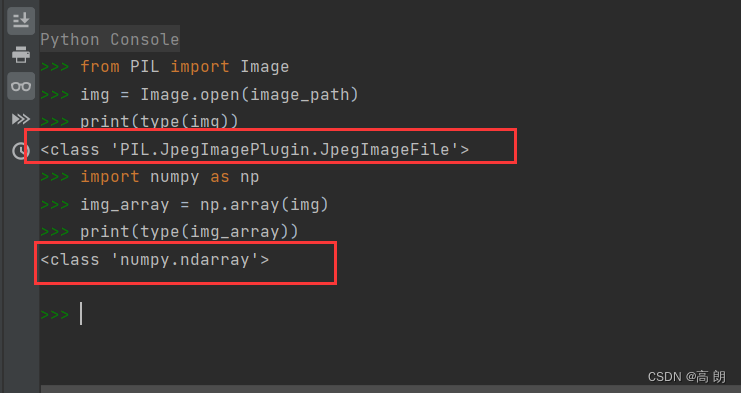
from torch.utils.data import Dataset
from PIL import Image
import osclass MyData(Dataset): # 继承 Datasetdef __init__(self, root_dir, label_dir): # 全局初始化:类申明时进行赋值self.root_dir = root_dirself.label_dir = label_dirself.path = os.path.join(self.root_dir, self.label_dir) # 拼接两个路径self.imge_path = os.listdir(self.path) # 返回这个文件目录下所有文件名--list数组def __getitem__(self, index): # 获取每一个图片img_name = self.imge_path[index]img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)img = Image.open(img_item_path)label = self.label_dirreturn img, labeldef __len__(self): # 返回数据长度return len(self.imge_path)root_dir = "dataset/train"
ants_label_dir = "ants_image"
bees_label_dir = "bees_image"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)train_dataset = ants_dataset + bees_dataset # 可以直接用+整合两个数据集img, label = train_dataset[0] # 获取数据Tensorboard使用
TensorBoard 是Google开发的一个机器学习可视化工具。其主要用于记录机器学习过程,例如:
- 记录损失变化、准确率变化等
- 记录图片变化、语音变化、文本变化等,例如在做GAN时,可以过一段时间记录一张生成的图片
- 绘制模型
主要是add_scalar和add_image的使用:
-
下载Tensorboard:
pip install tensorboard
-
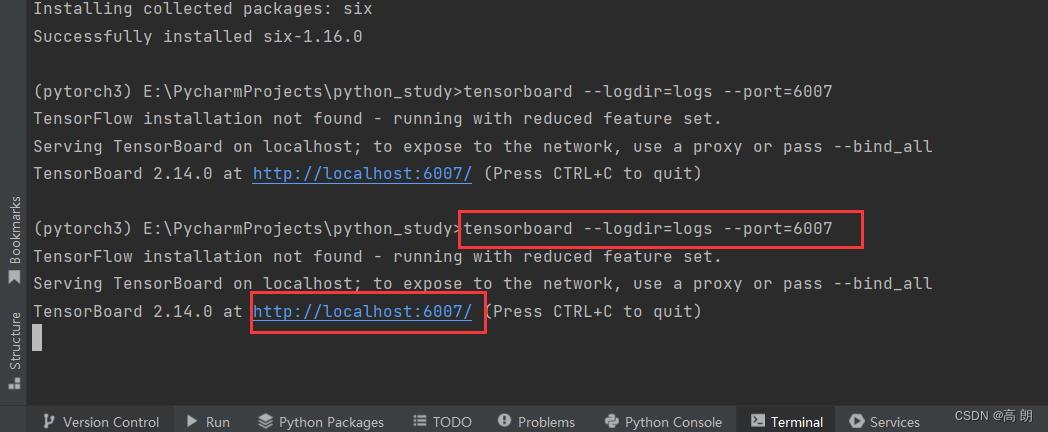
运行检测一些有没有出错:
tensorboard --logdir=logs --port=6007
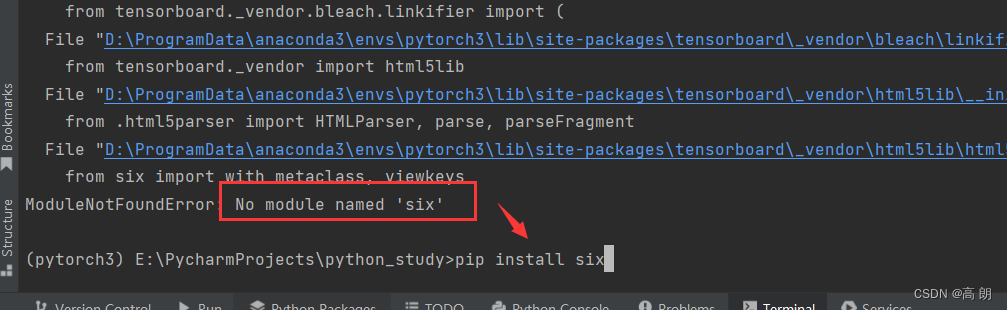
 如果报错例如:
如果报错例如:
-
add_scalar方法:记录损失变化、准确率变化。 -
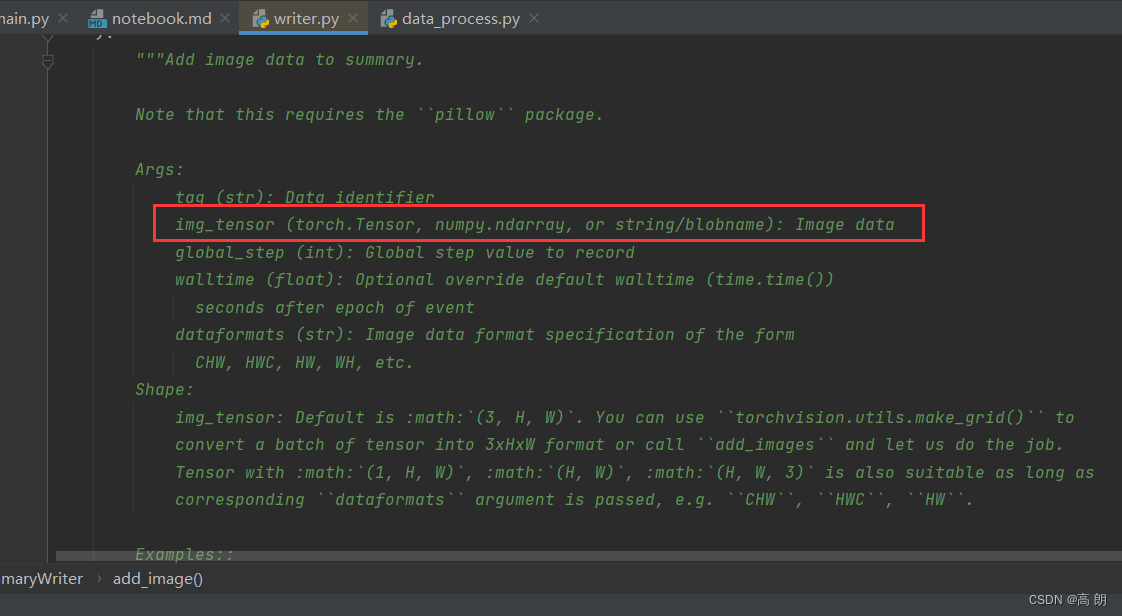
add_image方法:记录图形变化等。需要注意这个方法里面的参数是要求Tensor,ndarray等,并不是图片,需要进行转换。
 转换成ndarray:
转换成ndarray:
 但是这个numpy数据的通道数是在最后,(高,宽,通道),而我们这是方法默认是(通道,高,宽),所以需要修改一下,具体参考下面代码。
但是这个numpy数据的通道数是在最后,(高,宽,通道),而我们这是方法默认是(通道,高,宽),所以需要修改一下,具体参考下面代码。

-
最后记得关闭
close()
# tensorboard : loss函数的生成from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Imagewriter = SummaryWriter("logs") # 事件文件存储在logs下面
image_path = "dataset/train/bees_image/16838648_415acd9e3f.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)writer.add_image("test", img_array, 1, dataformats='HWC') # 默认是通道在前,如果不是则需要dataformats进行设置,改变step进行图像变化# x:scalar_value y: global_step tag: 标题
for i in range(100):writer.add_scalar("y=2*x", 2*i, i)writer.close()
Transforms
可以将transforms理解为一个工具箱:图像预处理方法
例如方法:ToTensor可以将PIL Image or numpy.ndarray这些类型转化为tensor对象,方便后期使用。
import cv2
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms# python的用法-》tensor数据类型
# 通过transforms.ToTensor去看两个问题 :pic (PIL Image or numpy.ndarray): Image to be converted to tensor.
# 1、transforms该如何使用(python)
# 2、为什么我们需要Tensor数据类型# 创键一个PIL对象
img_path = "dataset/train/ants_image/0013035.jpg"
img = Image.open(img_path)writer = SummaryWriter("logs")# 将PIL对象转换为tensor
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)writer.add_image("Tensor_img", tensor_img)# 创建一个numpy.ndarray对象
img_path2 = "dataset/train/ants_image/36439863_0bec9f554f.jpg"
cv_img = cv2.imread(img_path2)
# 将numpy.ndarray对象转换为tensor
tensor_img2 = tensor_trans(cv_img)writer.add_image("Tensor_img", tensor_img2, 2)writer.close()
其他一些常用的:缩放,裁剪,归一等
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transformswriter = SummaryWriter("logs")# ToTensor
img = Image.open("dataset/train/ants_image/6743948_2b8c096dda.jpg")trans_totensor = transforms.ToTensor()
img_tenser = trans_totensor(img)
writer.add_image("ToTensor", img_tenser)# Normalize 标准化
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 均值 标准差 图片是3个
img_norm = trans_norm(img_tenser)
# output[channel] = (input[channel] - mean[channel]) / std[channel]
# (input-0.5)/0.5 = 2*input - 1
# if input[0,1] => output[-1,1]
writer.add_image("Normalize", img_norm)# Resize
trans_resize = transforms.Resize((512, 512)) # 把size 修改为512x512
img_resize = trans_resize(img) # 直接传PIL对象,返回的还是修改了size的PIL对象
img_resize = trans_totensor(img_resize) # 将PIL对象转换为tensor
writer.add_image("Resize", img_resize)# Compose - resize -2 第二种改变size的方式
trans_compose = transforms.Compose([transforms.Resize((32, 32)), # 缩放transforms.ToTensor() # 图片转张量,同时归一化操作,0-255=》0-1])
img_resize_2 = trans_compose(img)
writer.add_image("Resize2", img_resize_2, 1)# RandomCrop 随机裁剪
trans_compose_2 = transforms.Compose([transforms.RandomCrop(32, padding=4), # 随机裁剪transforms.ToTensor() # 图片转张量,同时归一化操作,0-255=》0-1])])
for i in range(10):img_crop = trans_compose_2(img)writer.add_image("Random-crop", img_crop, i)writer.close()torchvision数据集使用
- CIFAR10数据集:相关介绍:https://www.cs.toronto.edu/~kriz/cifar.html
- 下载与测试:
 具体代码:
具体代码:
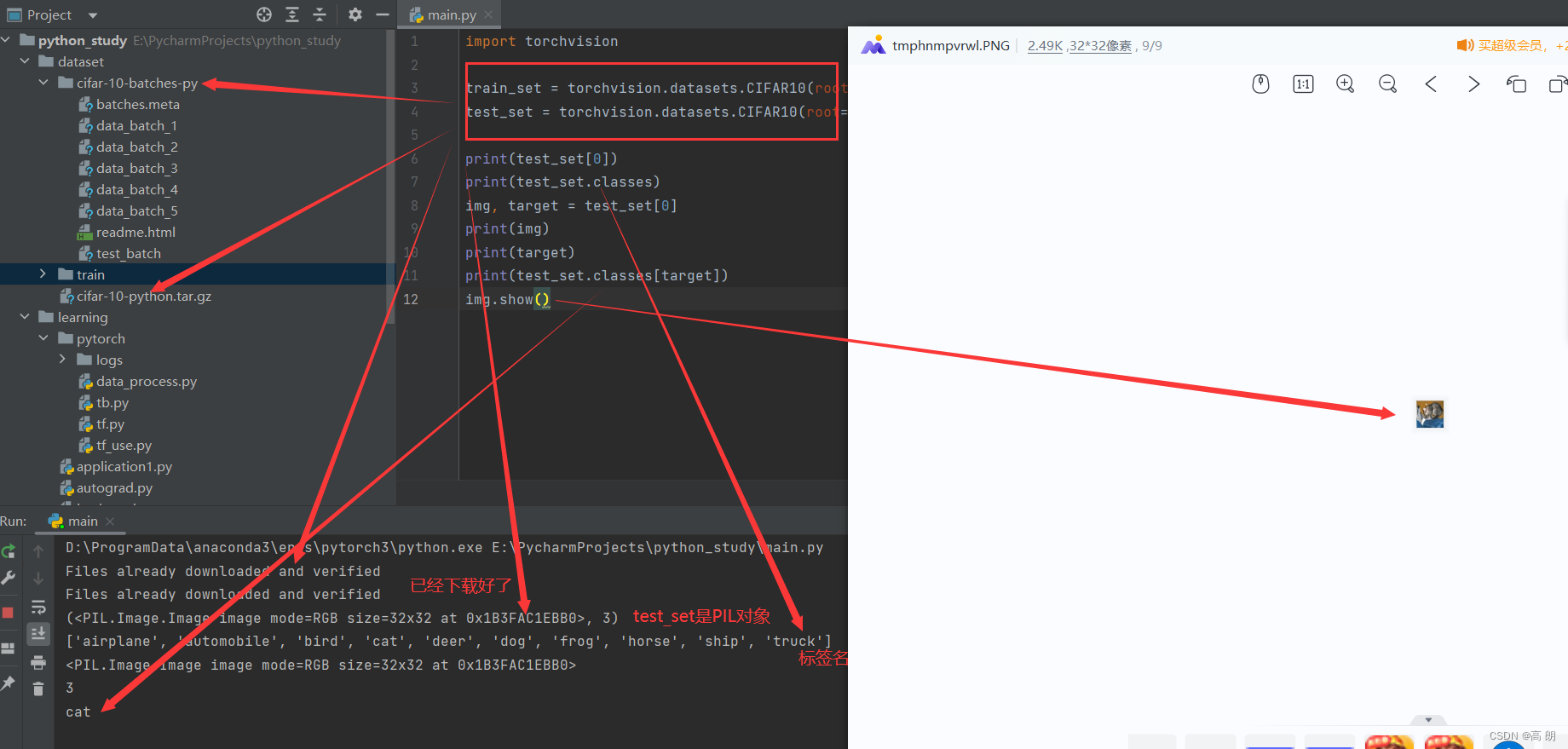
import torchvision
# download 下载 train 训练 root 下载地址
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, download=True)print(test_set[0])
print(test_set.classes)
img, target = test_set[0]
print(img)
print(target)
print(test_set.classes[target])
img.show()
上面生成的数据类型并不是tensor,可以使用transforms对其进行转换:
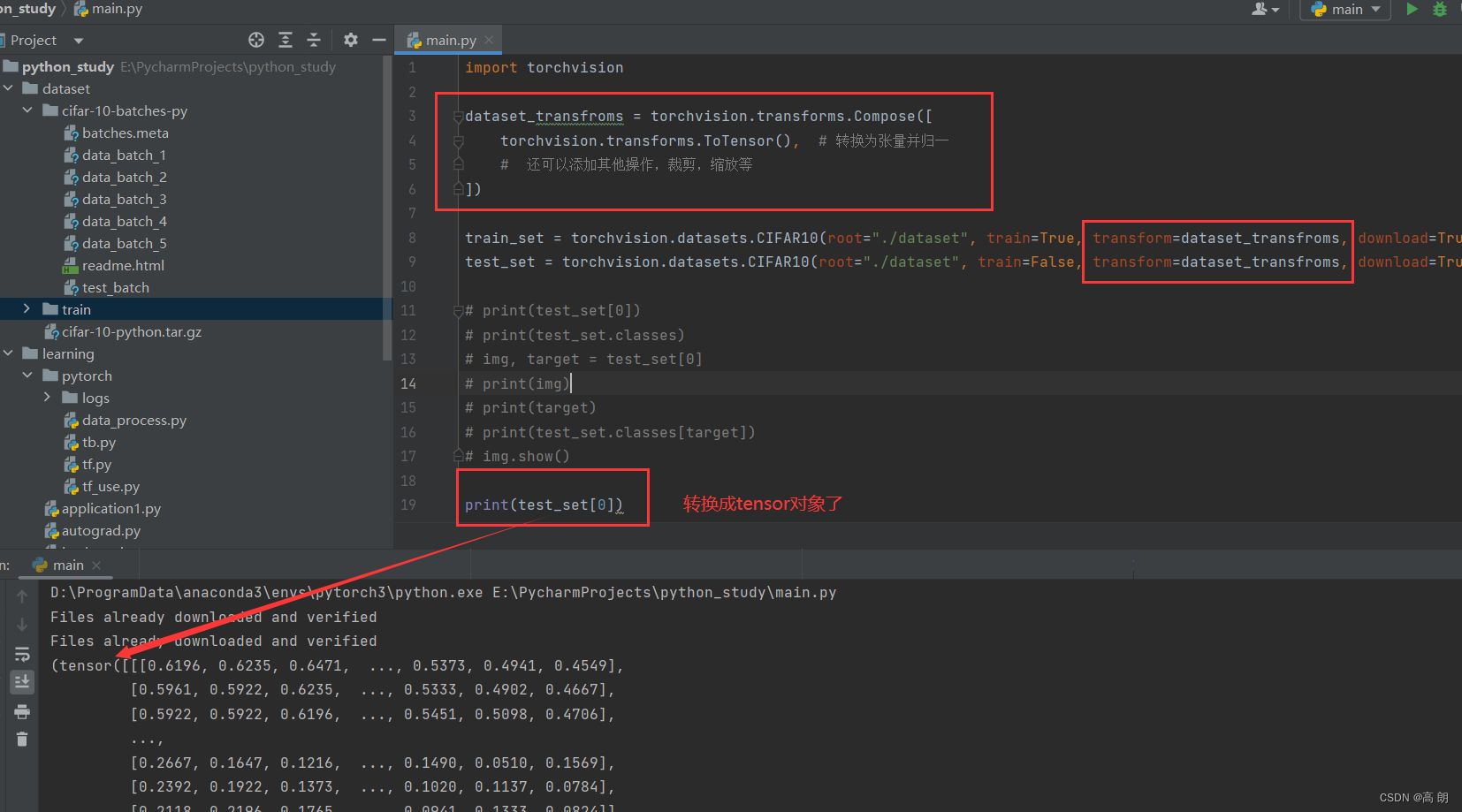
import torchvisiondataset_transfroms = torchvision.transforms.Compose([torchvision.transforms.ToTensor(), # 转换为张量并归一# 还可以添加其他操作,裁剪,缩放等
])train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transfroms, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transfroms, download=True)
print(test_set[0])
- 结合
tensorboard使用:
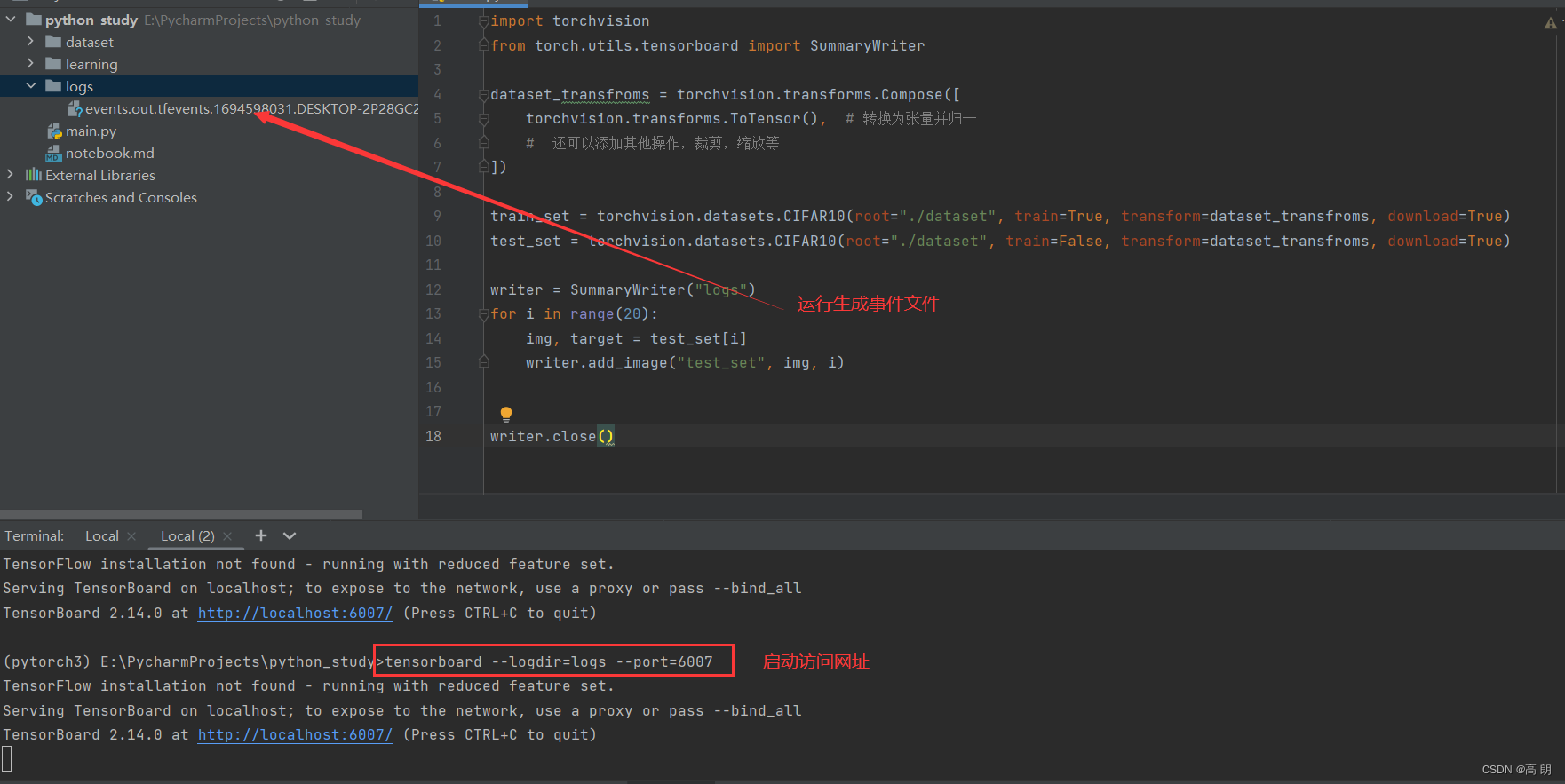
import torchvision
from torch.utils.tensorboard import SummaryWriterdataset_transfroms = torchvision.transforms.Compose([torchvision.transforms.ToTensor(), # 转换为张量并归一# 还可以添加其他操作,裁剪,缩放等
])train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transfroms, download=True)
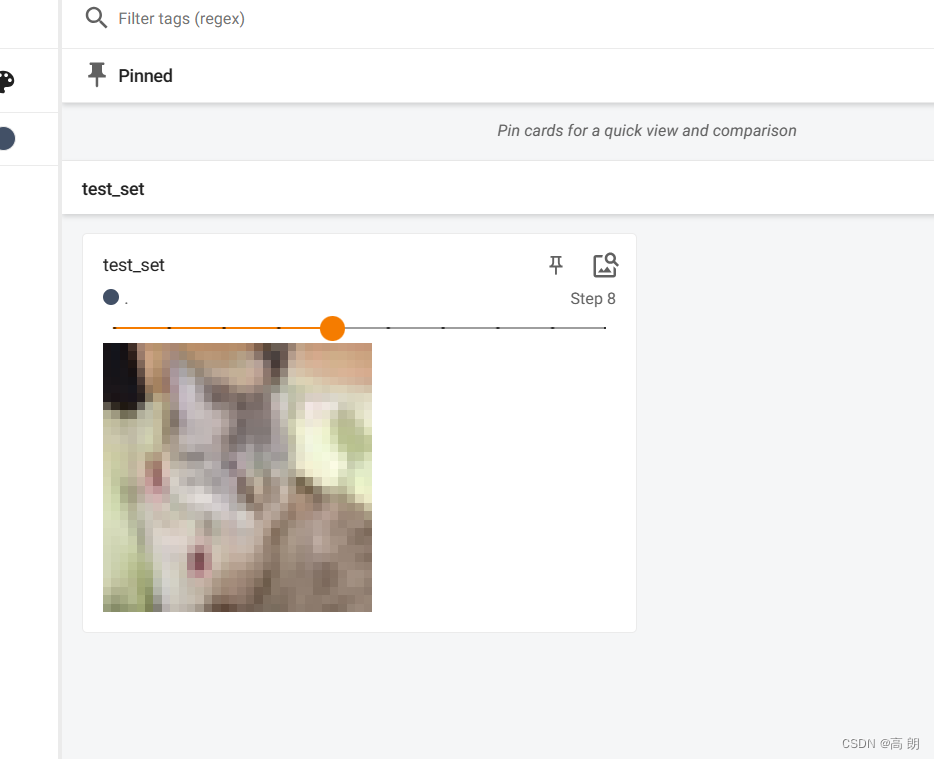
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transfroms, download=True)writer = SummaryWriter("logs")
for i in range(20):img, target = test_set[i]writer.add_image("test_set", img, i)writer.close()
DataLoader使用
Dataset:抽象类可以创建数据集,但是抽象类不能实例化,所以需要构建这个抽象类的子类来创建数据集,并且我们还可以定义自己的继承和重写方法。其中最重要的是len和getitem这两个函数,len能够给出数据集的大小,getitem用于查找数据和标签。(参考最前面dataset部分)DataLoader:处理模型输入数据的一个工具类,可以实现batch和shuffle的读取。- 具体代码操作:
import torchvision
from torch.utils.data import DataLoader# 准备测试数据集
test_data = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor())# batch_size 每个数据块的大小 drop_last 舍弃最后不足数据块大小的数据 shuffle 乱序 num_workers 0默认主线程
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)# 测试数据集第一张大小
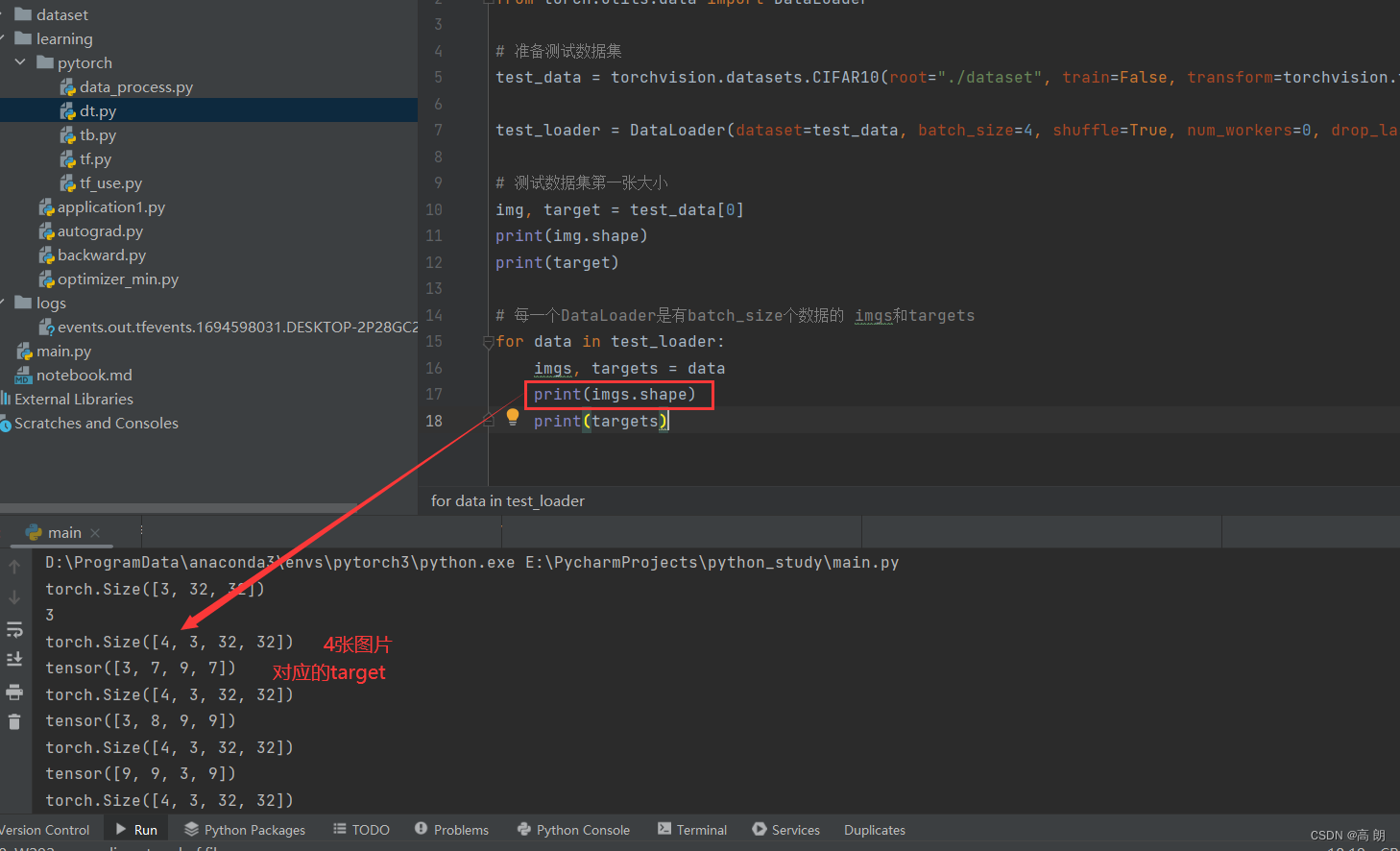
img, target = test_data[0]
print(img.shape)
print(target)# 每一个DataLoader是有batch_size个数据的 imgs和targets
for data in test_loader:imgs, targets = dataprint(imgs.shape)print(targets)
 主要是
主要是DataLoader()里面参数的理解:
dataset: 传入的数据集batch_size: 每个batch有多少个样本shuffle: 在每个epoch开始的时候,对数据进行重新排序num_workers: 这个参数决定了有几个进程来处理data loading。0意味着所有的数据都会被load进主进程。(默认为0)drop_last: 如果设置为True:这个是对最后的未完成的batch来说的,比如你的batch_size设置为64,而一个epoch只有100个样本,那么训练的时候后面的36个就被 扔掉了…如果为False(默认),那么会继续正常执行,只是最后的batch_size会小一点。
nn.Module的使用
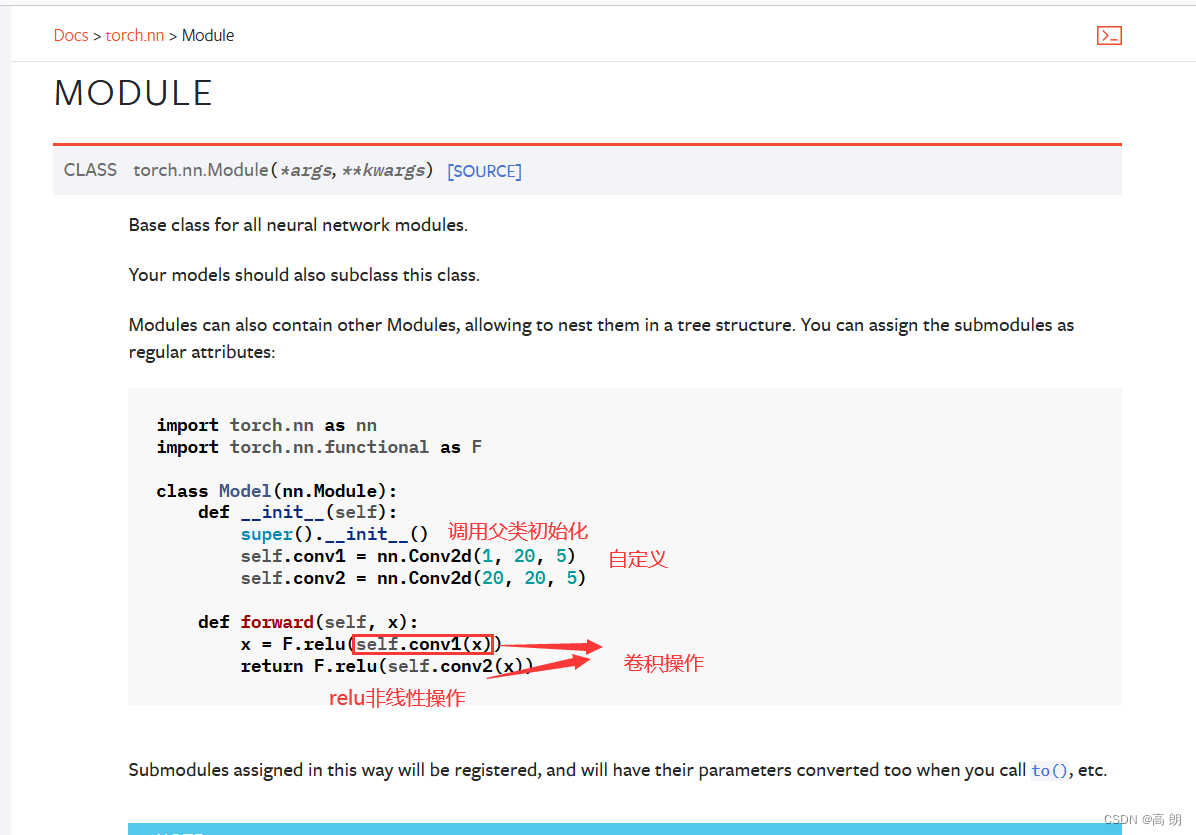
- 官方使用文档:https://pytorch.org/docs/stable/index.html
- 理解什么是卷积操作:没时间整理,可自行搜索或参考官方文档https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
输入图像(5x5) 与卷积核(3x3)的卷积操作代码:调整每次移动的步长
import torch
import torch.nn.functional as Finput = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]])# 卷积核
kernel = torch.tensor([[1, 2, 1],[0, 1, 0],[2, 1, 0]])# input tensor of shape (minibatch,in_channels,iH,iW)(minibatch,in_channels,iH,iW)
# input shape是需要有4个参数,我们上面那个矩阵只有两个,需要reshape
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))# 修改步长stride
output = F.conv2d(input, kernel, stride=1)
output2 = F.conv2d(input, kernel, stride=2)
output3 = F.conv2d(input, kernel, stride=(1, 2))
print(output)
print(output2)
print(output3)# 修改填充padding
output4 = F.conv2d(input, kernel, stride=1, padding=1)
print(output4)
输出:
tensor([[[[10, 12, 12],[18, 16, 16],[13, 9, 3]]]])
tensor([[[[10, 12],[13, 3]]]])
tensor([[[[10, 12],[18, 16],[13, 3]]]])
tensor([[[[ 1, 3, 4, 10, 8],[ 5, 10, 12, 12, 6],[ 7, 18, 16, 16, 8],[11, 13, 9, 3, 4],[14, 13, 9, 7, 4]]]])
- 一些函数中
Parameters参数的理解
stride (int or tuple, optional)–移动的步长,默认1,表示横向和纵向都是1,可以是元组分别控制横向和纵向移动的步长。padding—对输入进行填充,默认是0,也就是不填充,1表示填充一圈(上下左右各填充1行/列)且默认填充数值为0,
神经网络
- 卷积层
相关参数理解:
 搭建简单的卷积操作:
搭建简单的卷积操作:
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True) # 测试数据集
dataloader = DataLoader(dataset, batch_size=64)# 搭建神经网络
class NN(nn.Module):def __init__(self):super(NN, self).__init__()self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)def forward(self, x):x = self.conv1(x)return x# NN((conv1): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1) )
writer = SummaryWriter("logs")
nnn = NN()
step = 0
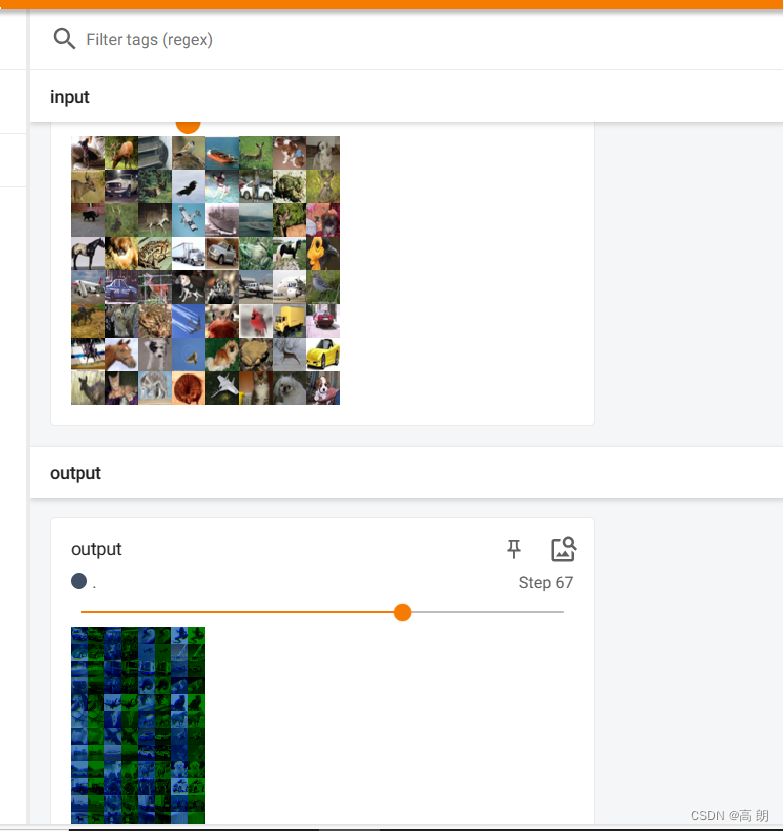
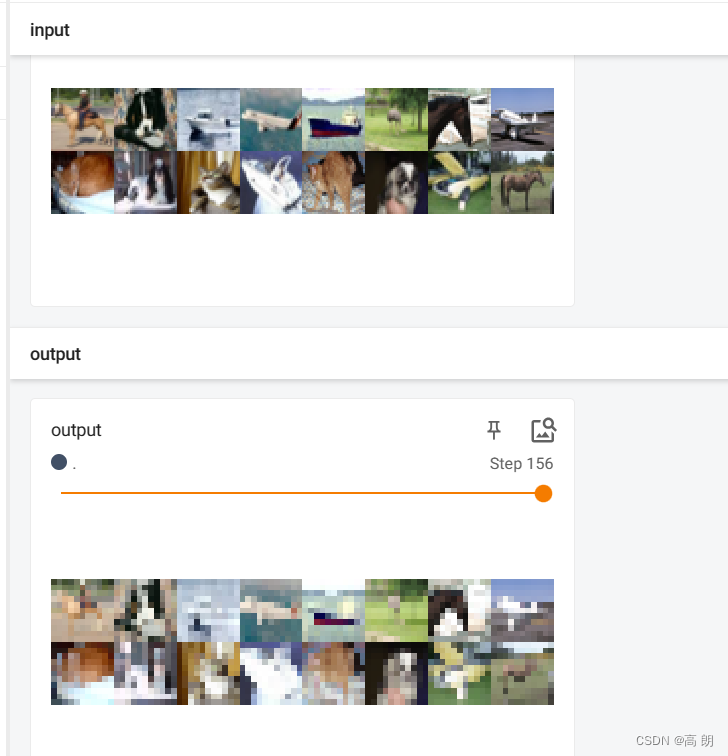
for data in dataloader:imgs, target = dataoutput = nnn(imgs)print(output.shape)# torch.Size([64, 6, 30, 30])writer.add_images("input", imgs, step)# 修改通道数 6-》3 自己计算块output = torch.reshape(output, (-1, 3, 30, 30))writer.add_images("output", output, step)step = step + 1writer.close()
- 最大池化:保留输入特征,减少数据量。https://pytorch.org/docs/stable/generated/torch.nn.MaxPool2d.html#torch.nn.MaxPool2d
卷积是做卷积后所有的和,最大池化是直接取最大值,当池化核遇到不足以全部覆盖时,ceil_mode为true时保留,false舍弃

import torch
from torch import nn
from torch.nn import MaxPool2dinput = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]], dtype=torch.float32)# Input: (N,C,Hin,Win) 修改shape满足输入要求
input = torch.reshape(input, (-1, 1, 5, 5))class NN(nn.Module):def __init__(self):super(NN, self).__init__()self.maxpool1 = MaxPool2d(3, ceil_mode=True)def forward(self, input):output = self.maxpool1(input)return outputnnn = NN()
output = nnn(input)
print(output)
控制台打印:
tensor([[[[2., 3.],[5., 1.]]]])
具体数据集:
import torch
import torchvision.datasets
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10("./data", train=False, download=True,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)class NN(nn.Module):def __init__(self):super(NN, self).__init__()self.maxpool1 = MaxPool2d(3, ceil_mode=True)def forward(self, input):output = self.maxpool1(input)return outputnnn = NN()writer = SummaryWriter("logs")
step = 0
for data in dataloader:imgs, target = datawriter.add_images("input", imgs, step)output = nnn(imgs)writer.add_images("output", output, step)step = step + 1writer.close()
- 非线性激活
常见函数:
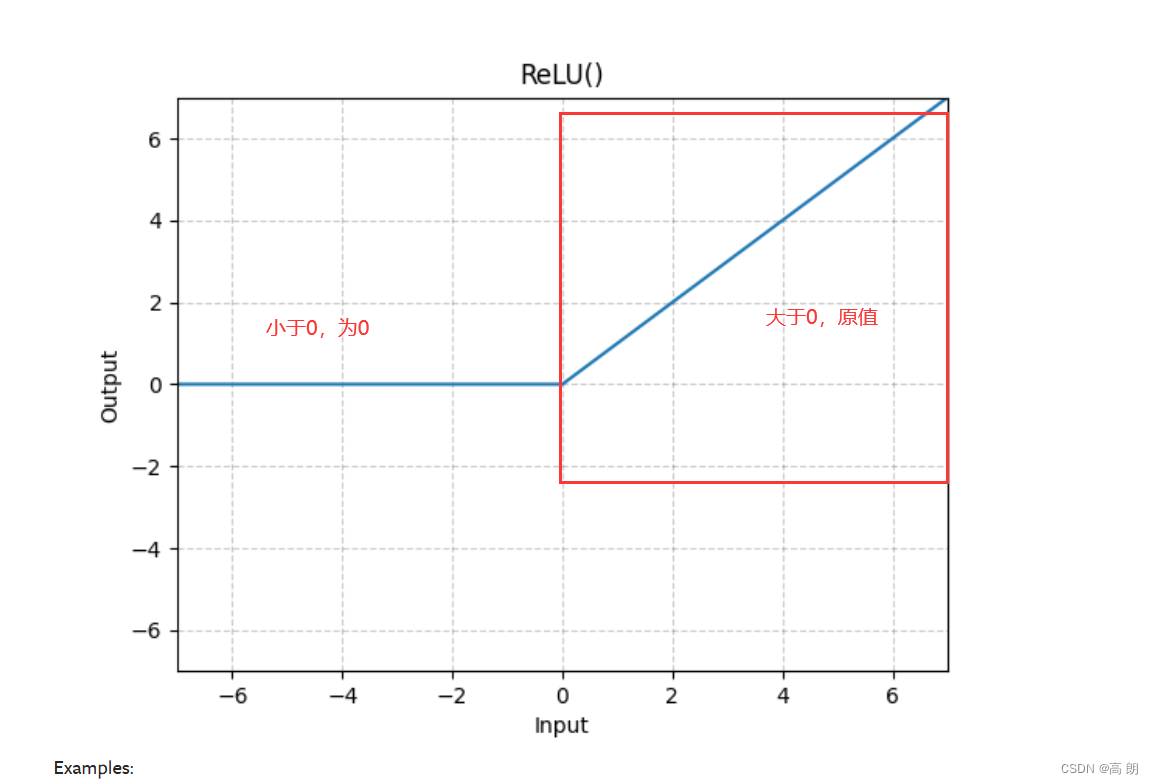
 ReLU函数使用:
ReLU函数使用:
import torch
from torch import nn
from torch.nn import ReLUinput = torch.tensor([[1, -0.5],[-1, 3]])# 指定batch_size
input = torch.reshape(input, (-1, 1, 2, 2))class NN(nn.Module):def __init__(self):super(NN, self).__init__()self.relu1 = ReLU(inplace=False) # inplace:是否把输出的结果替换掉输入input,默认False可不指定def forward(self, input):output = self.relu1(input)return outputnnn = NN()
output = nnn(input)
print(output)输出:
tensor([[[[1., 0.],[0., 3.]]]])
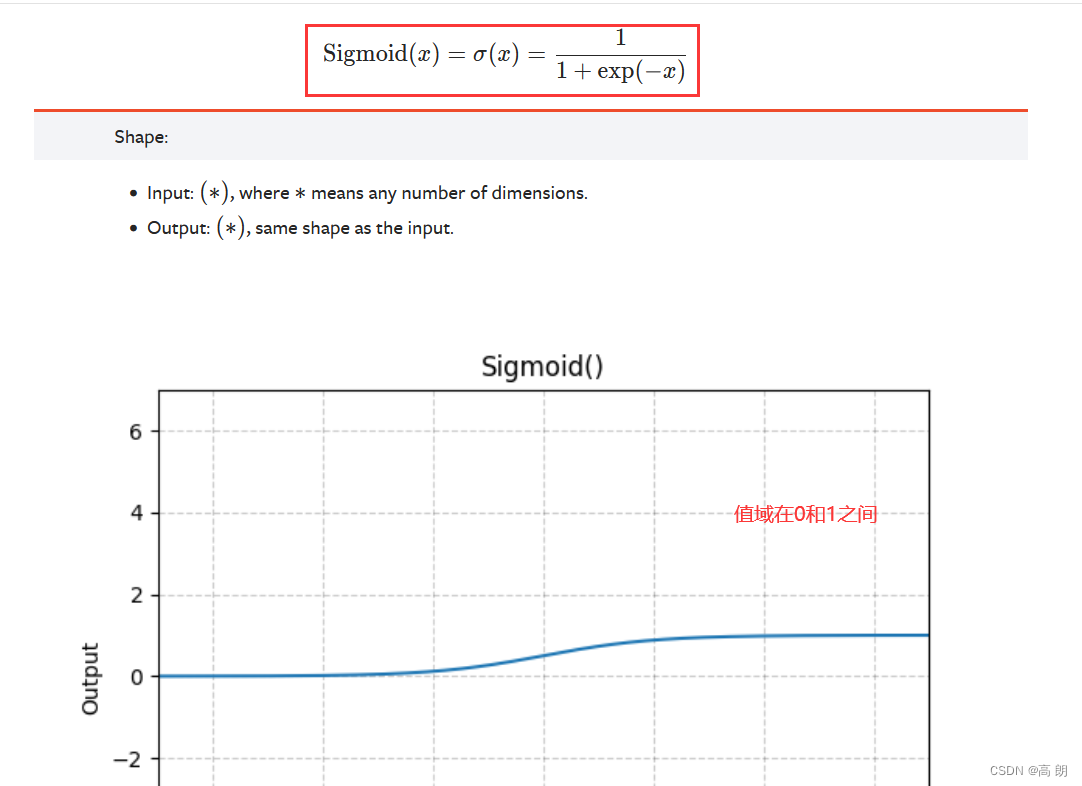
Sigmoid的使用:
import torch
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10("./data", train=False,transform=torchvision.transforms.ToTensor(),download=True)
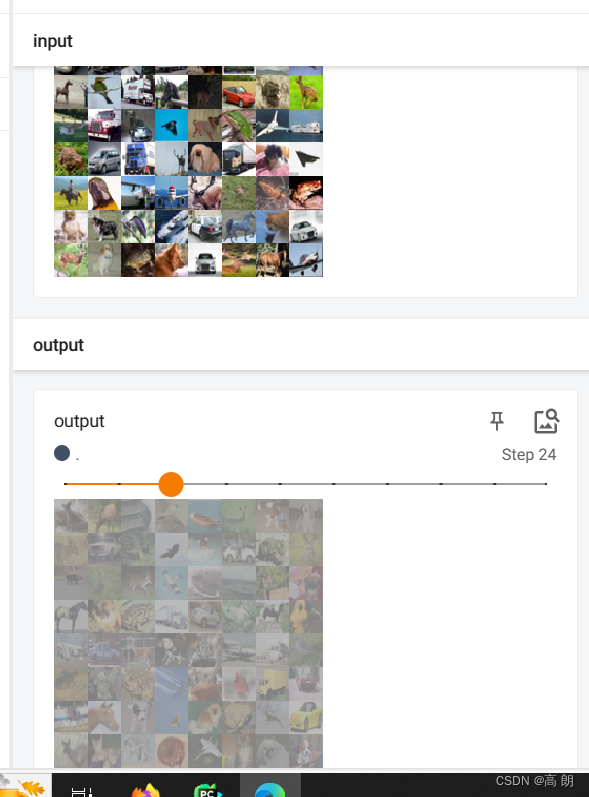
dataloader = DataLoader(dataset, batch_size=64)class NN(nn.Module):def __init__(self):super(NN, self).__init__()self.relu1 = ReLU(inplace=False) # inplace:是否把输出的结果替换掉输入input,默认False可不指定self.sigmoid1 = Sigmoid()def forward(self, input):output = self.sigmoid1(input)return outputnnn = NN()writer = SummaryWriter("logs")
step = 0
for data in dataloader:imgs, target = datawriter.add_images("input", imgs, step)output = nnn(imgs)writer.add_images("output", output, step)step = step + 1writer.close()
- 线性层

import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoaderdataset = torchvision.datasets.CIFAR10("./data", train=False,transform=torchvision.transforms.ToTensor(),download=True)dataloader = DataLoader(dataset, batch_size=64, drop_last=True)class NN(nn.Module):def __init__(self):super(NN, self).__init__()self.linear1 = Linear(196608, 10) # in_features输入的神经元个数 out_features输出神经元个数 bias 是否包含偏置def forward(self, input):output = self.linear1(input)return outputnnn = NN()
for data in dataloader:imgs, target = dataoutput = torch.reshape(imgs, (1, 1, 1, -1)) # 将形状展平,最后一个值语与linear的in_features对应# 上面等价与 torch.flatten(imgs)print(output.shape)output = nnn(output)print(output.shape)Files already downloaded and verified
torch.Size([1, 1, 1, 196608])
torch.Size([1, 1, 1, 10])
torch.Size([1, 1, 1, 196608])
torch.Size([1, 1, 1, 10])
torch.Size([1, 1, 1, 196608])
.....其他部分可参考官方文档:
https://pytorch.org/docs/stable/nn.html#

- 小实战
实现CIFAR 10 model
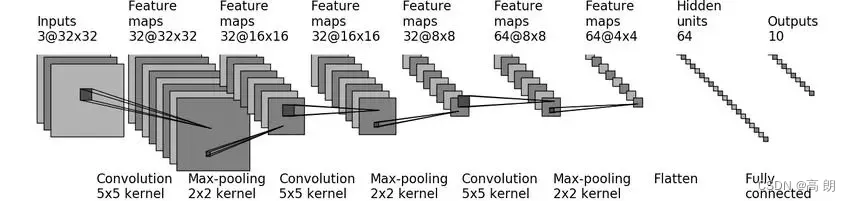 如何计算
如何计算stride和padding这两个参数,其他参数都是已知的输入输出的channel数,以及这个卷积大小都是已知的,通过下图公式可求出两个参数

stride=1和padding=2【padding = (kernel_size-1)/2 保持大小不变的话】
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriterclass NN(nn.Module):def __init__(self):super(NN, self).__init__()# self.conv1 = Conv2d(3, 32, kernel_size=5, stride=1, padding=2)# self.maxpool1 = MaxPool2d(2)# self.conv2 = Conv2d(32, 32, kernel_size=5, stride=1, padding=2)# self.maxpool2 = MaxPool2d(2)# self.conv3 = Conv2d(32, 64, kernel_size=5, stride=1, padding=2)# self.maxpool3 = MaxPool2d(2)# self.flatten = Flatten() # 展平 64*4*4 = 1024个=》通过线性层转化为64=》再通过线性到输出的10# self.linear1 = Linear(1024, 64)# self.linear2 = Linear(64, 10)self.model1 = Sequential(Conv2d(3, 32, kernel_size=5, stride=1, padding=2),MaxPool2d(2),Conv2d(32, 32, kernel_size=5, stride=1, padding=2),MaxPool2d(2),Conv2d(32, 64, kernel_size=5, stride=1, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self, x):# x = self.conv1(x)# x = self.maxpool1(x)# x = self.conv2(x)# x = self.maxpool2(x)# x = self.conv3(x)# x = self.maxpool3(x)# x = self.flatten(x)# x = self.linear1(x)# x = self.linear2(x)x = self.model1(x)return xnnn = NN()
# 检查架构是否有错
input = torch.ones((64, 3, 32, 32))
output = nnn(input)
print(output.shape)writer = SummaryWriter("logs")
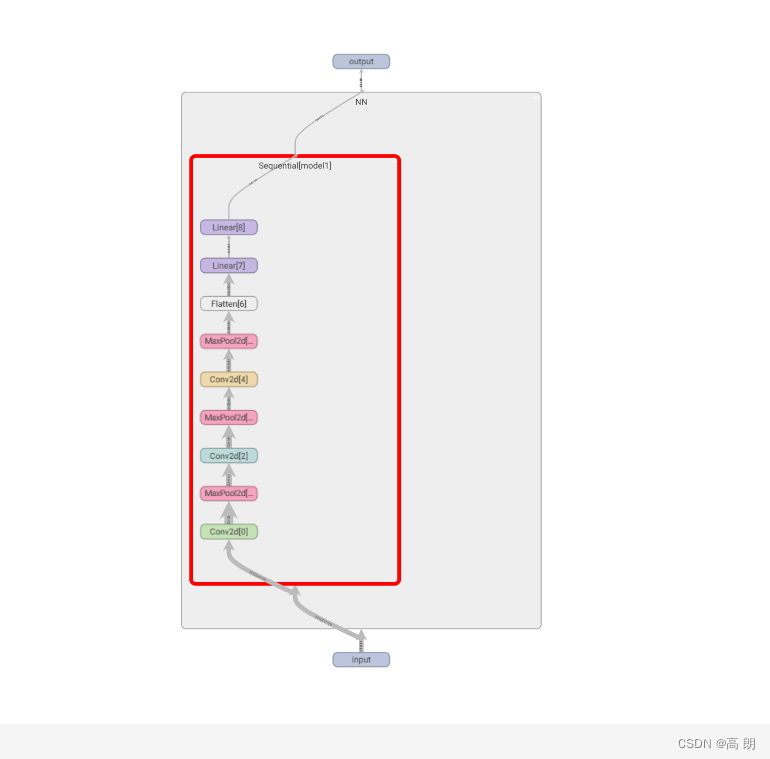
writer.add_graph(nnn, input)
writer.close()
tensorboard 显示的模型:
相关文章:
Pytorch学习整理笔记(一)
文章目录 数据处理DatasetTensorboard使用Transformstorchvision数据集使用DataLoader使用nn.Module的使用神经网络 数据处理Dataset 主要是对Dataset的使用: 继承 Dataset实现init方法,主要是进行一些全局变量的定义,在对其初始化时需要赋…...

paddlespeech asr脚本demo
概述 paddlespeech是百度飞桨平台的开源工具包,主要用于语音和音频的分析处理,其中包含多个可选模型,提供语音识别、语音合成、说话人验证、关键词识别、音频分类和语音翻译等功能。 本文介绍利用ps中的asr功能实现批量处理音频文件的demo。…...

算法分析与设计编程题 递归与分治策略
棋盘覆盖 题目描述 解题代码 // para: 棋盘,行偏移,列偏移,特殊行,特殊列 void dividedCovering(vector<vector<int>>& chessBoard, int dr, int dc, int sr, int sc, int size) {if (size 1) return;size / 2…...

Java的XWPFTemplate工具类导出word.docx的使用
依赖 <!-- word导出 --><dependency><groupId>com.deepoove</groupId><artifactId>poi-tl</artifactId><version>1.7.3</version></dependency><!-- 上面需要的依赖--><dependency><groupId>org.ap…...

Science adv | 转录因子SPIC连接胚胎干细胞中的细胞代谢与表观调控
代谢是生化反应网络的结果,这些反应吸收营养物质并对其进行处理,以满足细胞的需求,包括能量产生和生物合成。反应的中间体被用作各种表观基因组修饰酶的底物和辅助因子,因此代谢与表观遗传密切相关。代谢结合表观遗传涉及疾病&…...
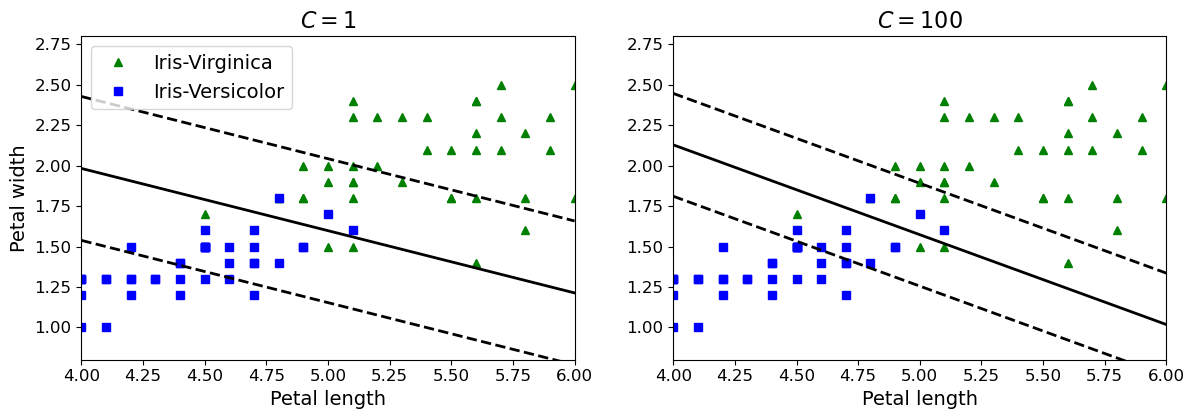
机器学习实战-系列教程7:SVM分类实战2线性SVM(鸢尾花数据集/软间隔/线性SVM/非线性SVM/scikit-learn框架)项目实战、代码解读
🌈🌈🌈机器学习 实战系列 总目录 本篇文章的代码运行界面均在Pycharm中进行 本篇文章配套的代码资源已经上传 SVM分类实战1之简单SVM分类 SVM分类实战2线性SVM SVM分类实战3非线性SVM 3、不同软间隔C值 3.1 数据标准化的影响 如图左边是没…...

DOM渲染与优化 - CSS、JS、DOM解析和渲染阻塞问题
文章目录 DOM渲染面试题DOM的渲染过程DOM渲染的时机与渲染进程的概述浏览器的渲染流程1. 解析HTML生成DOM树:遇到<img>标签加载图片2. 解析CSS生成CSSOM(CSS Object Model): 遇见背景图片链接不加载3. 将DOM树和CSSOM树合并生成渲染树:加载可视节点…...
基于小程序的理发店预约系统
一、项目背景及简介 现在很多的地方都在使用计算机开发的各种管理系统来提高工作的效率,给人们带来很多的方便。计算机技术从很大的程度上解放了人们的双手,并扩大了人们的活动范围,是人们足不出户就可以通过电脑进行各种事情的管理。信息系…...

MD5 算法流程
先通过下面的命令对 md5算法有个感性的认识: $ md5sum /tmp/1.txt 1dc792fcaf345a07b10248a387cc2718 /tmp/1.txt$ md5sum // 从键盘输入,ctrl-d 结束输入 hello, world! 910c8bc73110b0cd1bc5d2bcae782511 -从上面可以看到,一个文件或一…...

TCP/IP协议详解
TCP/IP(Transmission Control Protocol/Internet Protocol,传输控制协议/互联网协议)是互联网的基本协议,也是国际互联网络的基础。 TCP/IP 不是指一个协议,也不是 TCP 和 IP 这两个协议的合称,而是一个协…...
SSM SpringBoot vue快递柜管理系统
SSM SpringBoot vue快递柜管理系统 系统功能 登录 注册 个人中心 快递员管理 用户信息管理 用户寄件管理 配送信息管理 寄存信息管理 开发环境和技术 开发语言:Java 使用框架: SSM(Spring SpringMVC Mybaits)或SpringBoot 前端: vue 数据库:Mys…...

期权交易保证金比例一般是多少?
期权交易是一种非常受欢迎的投资方式之一,它为期权市场带来了更为多样化和灵活化的交易形式。而其中的期权卖方保证金比例是期权交易中的一个重要指标,直接关系到投资者的风险与收益,下文介绍期权交易保证金比例一般是多少?本文来…...

029:vue项目,勾选后今天不再弹窗提示
第029个 查看专栏目录: VUE ------ element UI 专栏目标 在vue和element UI联合技术栈的操控下,本专栏提供行之有效的源代码示例和信息点介绍,做到灵活运用。 (1)提供vue2的一些基本操作:安装、引用,模板使…...

Unet语义分割-语义分割与实例分割概述-001
文章目录 前言1、图像分割和图像识别1.语义分割2.实例分割 2、分割任务中的目标函数定义3.IOU 前言 大纲目录 1、图像分割和图像识别 下面是图像识别和图像分割的区别,图像识别就是识别出来,画个框,右边的是图像分割。 1.语义分割 两张图把…...

Linux常用命令字典篇
Linux命令 1. 翻页查看文件 less [-N] 文件名:可以向后翻页,也可以向前翻页,-N表示显示行号 more 文件名:仅可以向后翻页 2. 端口占用信息查看 netstat -tunlp | grep 端口号:查看端口号对应的信息 lsof i: 端口号…...
 在C++)
__declspec(novtable) 在C++
__declspec(novtable) 在C中接口中广泛应用. 不容易看到它是因为在很多地方它都被定义成为了宏. 比如说ATL活动模板库中的ATL_NO_VTABLE, 其实就是__declspec(novtable). __declspec(novtable) 就是让类不要有虚函数表以及对虚函数表的初始化代码, 这样可以节省运行时间和空间.…...

ChatGPT充值,银行卡被拒绝
目录 前言步骤1. 魔法地址选择2. 选择手机号码(归属地)3. 勾选,服从协议4. 填写信息5. 完善账单地址6. 订阅成功 前言 大家好,今天我在订阅ChatGPT4时,遭遇了银行卡被拒绝的尴尬境地。这里有个技巧,我来给…...
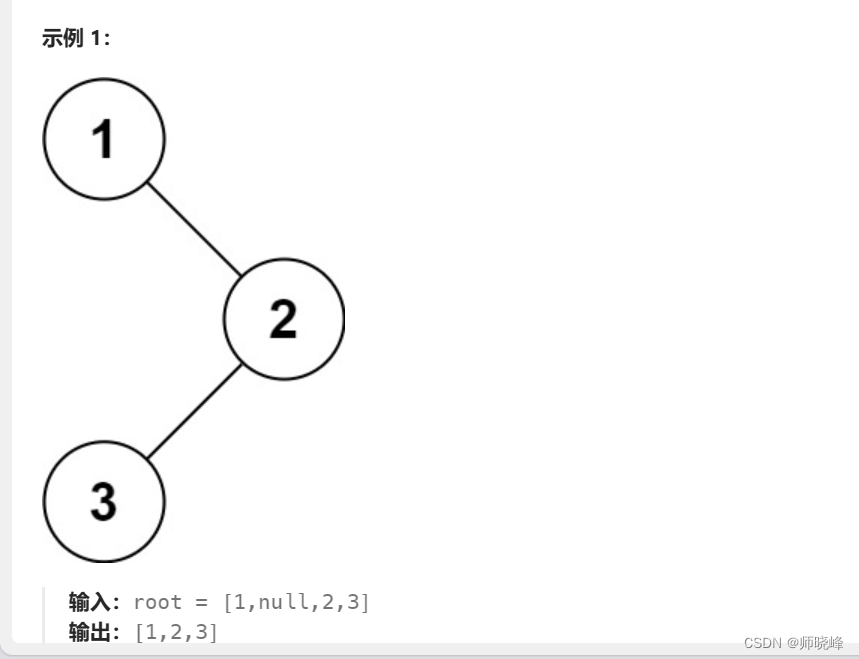
算法通过村第七关-树(递归/二叉树遍历)白银笔记|递归实战
文章目录 前言1. 深入理解前中后序遍历从小到大递推分情况讨论,明确结束条件组合出完整的方法:从大到小 画图推演 总结 前言 提示:没有客观公正的记忆这回事,所有的记忆都是偏见,都是为自己的存活而重组过的经验。--国…...
- 抖音小程序高级功能)
抖音小程序开发教学系列(6)- 抖音小程序高级功能
第六章:抖音小程序高级功能 6.1 抖音小程序的支付功能6.1.1 接入流程6.1.2 注意事项 6.2 抖音小程序的地理位置和地图功能6.2.1 接入流程6.2.2 使用方法 6.3 抖音小程序的实时音视频功能6.3.1 接入流程6.3.2 使用方法 6.4 抖音小程序的小游戏开发6.4.1 基本流程6.4.…...

SpringBoot运行原理
目录 SpringBootApplication ComponentScan SpringBootConfiguration EnableAutoConfiguration 结论 SpringbootApplication(主入口) SpringBootApplication public class SpringbootConfigApplication {public static void main(String[] args) {…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

MPNet:旋转机械轻量化故障诊断模型详解python代码复现
目录 一、问题背景与挑战 二、MPNet核心架构 2.1 多分支特征融合模块(MBFM) 2.2 残差注意力金字塔模块(RAPM) 2.2.1 空间金字塔注意力(SPA) 2.2.2 金字塔残差块(PRBlock) 2.3 分类器设计 三、关键技术突破 3.1 多尺度特征融合 3.2 轻量化设计策略 3.3 抗噪声…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

NFT模式:数字资产确权与链游经济系统构建
NFT模式:数字资产确权与链游经济系统构建 ——从技术架构到可持续生态的范式革命 一、确权技术革新:构建可信数字资产基石 1. 区块链底层架构的进化 跨链互操作协议:基于LayerZero协议实现以太坊、Solana等公链资产互通,通过零知…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...