Python bs4 BeautifulSoup库使用记录
目录
介绍
安装
初始化
解析器 使用方法 优势
Python标准库
lxml HTML
lxml XML
html5lib
格式化输出
对象
tag
Name
多值属性
其他方法
BeautifulSoup
Comment
遍历
子节点
父节点
兄弟节点
回退和前进
搜索
过滤器
字符串
正则表达式
列表
方法
find 和 find_all
像调用find_all()一样调用tag
其他搜索方法
CSS选择器
介绍
bs4 全名 BeautifulSoup,是编写 python 爬虫常用库之一,主要用来解析 html 标签。
安装
pip install bs4初始化
from bs4 import BeautifulSoupsoup = BeautifulSoup("<html>A Html Text</html>", "html.parser")
两个参数:第一个参数是要解析的html文本,第二个参数是使用那种解析器,对于HTML来讲就是html.parser,这个是bs4自带的解析器。
如果一段HTML或XML文档格式不正确的话,那么在不同的解析器中返回的结果可能是不一样的。
解析器 使用方法 优势
Python标准库
BeautifulSoup(html, "html.parser")1、Python的内置标准库2、执行速度适中3、文档容错能力强lxml HTML
BeautifulSoup(html, "lxml")1、速度快2、文档容错能力强lxml XML
BeautifulSoup(html, ["lxml", "xml"])BeautifulSoup(html, "xml")1、速度快2、唯一支持XML的解析器html5lib
BeautifulSoup(html, "html5lib")1、最好的容错性2、以浏览器的方式解析文档3、生成HTML5格式的文档格式化输出
soup.prettify() # prettify 有括号和没括号都可以对象
Beautfiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:tag,NavigableString,BeautifulSoup,Comment。
tag
Tag对象与 xml 或 html 原生文档中的 tag 相同。
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>')tag = soup.btype(tag)# <class 'bs4.element.Tag'>
如果不存在,则返回 None,如果存在多个,则返回第一个。
Name
每个 tag 都有自己的名字
tag.name
# 'b'
Attributestag 的属性是一个字典tag['class']
# 'boldest'tag.attrs
# {'class': 'boldest'}type(tag.attrs)
# <class 'dict'>
多值属性
最常见的多值属性是class,多值属性的返回 list。
soup = BeautifulSoup('<p class="body strikeout"></p>')print(soup.p['class']) # ['body', 'strikeout']print(soup.p.attrs) # {'class': ['body', 'strikeout']}
如果某个属性看起来好像有多个值,但在任何版本的HTML定义中都没有被定义为多值属性,那么Beautiful Soup会将这个属性作为字符串返回。
soup = BeautifulSoup('<p id="my id"></p>', 'html.parser')
print(soup.p['id']) # 'my id'
Text
text 属性返回 tag 的所有字符串连成的字符串。
其他方法
tag.has_attr('id') # 返回 tag 是否包含 id 属性
当然,以上代码还可以写成 ‘id’ in tag.attrs,之前说过,tag 的属性是一个字典。顺便提一下,has_key是老旧遗留的api,为了支持2.2之前的代码留下的。Python3已经删除了该函数。
NavigableString
字符串常被包含在 tag 内,Beautiful Soup 用 NavigableString 类来包装 tag 中的字符串。但是字符串中不能包含其他 tag。
soup = BeautifulSoup(‘Extremely bold’)
s = soup.b.stringprint(s) # Extremely boldprint(type(s)) # <class 'bs4.element.NavigableString'>
BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容。大部分时候,可以把它当作 Tag 对象。但是 BeautifulSoup 对象并不是真正的 HTM L或 XML 的 tag,它没有attribute属性,name 属性是一个值为“[document]”的特殊属性。
Comment
Comment 一般表示文档的注释部分。
soup = BeautifulSoup("<b><!--This is a comment--></b>")comment = soup.b.stringprint(comment) # This is a commentprint(type(comment)) # <class 'bs4.element.Comment'>
遍历
子节点
contents 属性
contents 属性返回所有子节点的列表,包括 NavigableString 类型节点。如果节点当中有换行符,会被当做是 NavigableString 类型节点而作为一个子节点。
NavigableString 类型节点没有 contents 属性,因为没有子节点。
soup = BeautifulSoup("""<div>
<span>test</span>
</div>
""")element = soup.div.contentsprint(element) # ['\n', <span>test</span>, '\n']
children 属性
children 属性跟 contents 属性基本一样,只不过返回的不是子节点列表,而是子节点的可迭代对象。
descendants 属性
descendants 属性返回 tag 的所有子孙节点。
string 属性
如果 tag 只有一个 NavigableString 类型子节点,那么这个 tag 可以使用 .string 得到子节点。
如果一个 tag 仅有一个子节点,那么这个 tag 也可以使用 .string 方法,输出结果与当前唯一子节点的 .string 结果相同。
如果 tag 包含了多个子节点,tag 就无法确定 .string 方法应该调用哪个子节点的内容, .string 的输出结果是 None。
soup = BeautifulSoup("""<div><p><span><b>test</b></span></p>
</div>
""")element = soup.p.stringprint(element) # testprint(type(element)) # <class 'bs4.element.NavigableString'>
特别注意,为了清楚显示,一般我们会将 html 节点换行缩进显示,而在BeautifulSoup 中会被认为是一个 NavigableString 类型子节点,导致出错。上例中,如果改成 element = soup.div.string 就会出错。
strings 和 stripped_strings 属性
如果 tag 中包含多个字符串,可以用 strings 属性来获取。如果返回结果中要去除空行,则可以用 stripped_strings 属性。
soup = BeautifulSoup("""<div><p> </p><p>test 1</p><p>test 2</p>
</div>
""", 'html.parser')element = soup.div.stripped_stringsprint(list(element)) # ['test 1', 'test 2']
父节点
parent 属性
parent 属性返回某个元素(tag、NavigableString)的父节点,文档的顶层节点的父节点是 BeautifulSoup 对象,BeautifulSoup 对象的父节点是 None。
parent 属性递归得到元素的所有父辈节点,包括 BeautifulSoup 对象。
兄弟节点
next_sibling 和 previous_sibling
next_sibling 返回后一个兄弟节点,previous_sibling 返回前一个兄弟节点。直接看个例子,注意别被换行缩进搅了局。
soup = BeautifulSoup("""<div><p>test 1</p><b>test 2</b><h>test 3</h></div>
""", 'html.parser')print(soup.b.next_sibling) # <h>test 3</h>print(soup.b.previous_sibling) # <p>test 1</p>print(soup.h.next_sibling) # Nonenext_siblings 和 previous_siblingsnext_siblings 返回后面的兄弟节点previous_siblings 返回前面的兄弟节点
回退和前进
把html解析看成依次解析标签的一连串事件,BeautifulSoup 提供了重现解析器初始化过程的方法。
next_element 属性指向解析过程中下一个被解析的对象(tag 或 NavigableString)。
previous_element 属性指向解析过程中前一个被解析的对象。
另外还有next_elements 和 previous_elements 属性,不赘述了。
搜索
过滤器
介绍 find_all() 方法前,先介绍一下过滤器的类型,这些过滤器贯穿整个搜索的API。过滤器可以被用在tag的name中,节点的属性中,字符串中或他们的混合中。
示例使用的 html 文档如下:
html = """
<div><p class="title"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a></p>
</div>
"""soup = BeautifulSoup(html, 'html.parser')
字符串
查找所有的标签
soup.find_all(‘b’) # [The Dormouse’s story]正则表达式
传入正则表达式作为参数,返回满足正则表达式的标签。下面例子中找出所有以b开头的标签。
soup.find_all(re.compile("^b")) # [<b>The Dormouse's story</b>]
列表
传入列表参数,将返回与列表中任一元素匹配的内容。下面例子中找出所有标签和标签。
soup.find_all(["a", "b"])
True
True可以匹配任何值,下面的代码查找到所有的tag,但是不会返回字符串节点。
soup.find_all(True)
方法
如果没有合适过滤器,那么还可以自定义一个方法,方法只接受一个元素参数,如果这个方法返回True表示当前元素匹配被找到。下面示例返回所有包含 class 属性但不包含 id 属性的标签。
def has_class_but_no_id(tag):return tag.has_attr('class') and not tag.has_attr('id')print(soup.find_all(has_class_but_no_id))
返回结果:
[<p class="title"><b>The Dormouse's story</b></p>, <p class="story">Once upon a time there were three little sisters; and their names were<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a></p>]
这个结果乍一看不对,标签含有 id 属性,其实返回的 list 中只有2个元素,都是
标签,标签是
标签的子节点。
find 和 find_all
搜索当前 tag 的所有 tag 子节点,并判断是否符合过滤器的条件
语法:
find(name=None, attrs={}, recursive=True, text=None, **kwargs)find_all(name=None, attrs={}, recursive=True, text=None, limit=None, **kwargs)参数:
name:查找所有名字为 name 的 tag,字符串对象会被自动忽略掉。上面过滤器示例中的参数都是 name 参数。当然,其他参数中也可以使用过滤器。attrs:按属性名和值查找。传入字典,key 为属性名,value 为属性值。recursive:是否递归遍历所有子孙节点,默认 True。text:用于搜索字符串,会找到 .string 方法与 text 参数值相符的tag,通常配合正则表达式使用。也就是说,虽然参数名是 text,但实际上搜索的是 string 属性。limit:限定返回列表的最大个数。kwargs:如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作 tag 的属性来搜索。这里注意,如果要按 class 属性搜索,因为 class 是 python 的保留字,需要写作 class_。
Tag 的有些属性在搜索中不能作为 kwargs 参数使用,比如 html5 中的 data-* 属性。
data_soup = BeautifulSoup('<div data-foo="value">foo!</div>')print(data_soup.find_all(data-foo="value"))# SyntaxError: keyword can't be an expression但是可以通过 attrs 参数传递:
data_soup = BeautifulSoup('<div data-foo="value">foo!</div>')print(data_soup.find_all(attrs={"data-foo": "value"}))# [<div data-foo="value">foo!</div>]
而按 class_ 查找时,只要一个CSS类名满足即可,如果写了多个CSS名称,那么顺序必须一致,而且不能跳跃。以下示例中,前三个可以查找到元素,后两个不可以。
css_soup = BeautifulSoup('<p class="body bold strikeout"></p>')print(css_soup.find_all("p", class_="strikeout"))print(css_soup.find_all("p", class_="body"))print(css_soup.find_all("p", class_="body bold strikeout"))# [<p class="body strikeout"></p>]print(css_soup.find_all("p", class_="body strikeout"))print(css_soup.find_all("p", class_="strikeout body"))# []
像调用find_all()一样调用tag
find_all() 几乎是 BeautifulSoup 中最常用的搜索方法,所以我们定义了它的简写方法。BeautifulSoup 对象和 tag 对象可以被当作一个方法来使用,这个方法的执行结果与调用这个对象的 find_all() 方法相同,下面两行代码是等价的:
soup.find_all('b')soup('b')
其他搜索方法
find_parents() 返回所有祖先节点find_parent() 返回直接父节点find_next_siblings() 返回后面所有的兄弟节点find_next_sibling() 返回后面的第一个兄弟节点find_previous_siblings() 返回前面所有的兄弟节点find_previous_sibling() 返回前面第一个兄弟节点find_all_next() 返回节点后所有符合条件的节点find_next() 返回节点后第一个符合条件的节点find_all_previous() 返回节点前所有符合条件的节点find_previous() 返回节点前所有符合条件的节点
CSS选择器
BeautifulSoup支持大部分的CSS选择器,这里直接用代码来演示。
from bs4 import BeautifulSouphtml = """
<html>
<head><title>标题</title></head>
<body><p class="title" name="dromouse"><b>标题</b></p><div name="divlink"><p><a href="http://example.com/1" class="sister" id="link1">链接1</a><a href="http://example.com/2" class="sister" id="link2">链接2</a><a href="http://example.com/3" class="sister" id="link3">链接3</a></p></div><p></p><div name='dv2'></div>
</body>
</html>
"""soup = BeautifulSoup(html, 'lxml')# 通过tag查找
print(soup.select('title')) # [<title>标题</title>]# 通过tag逐层查找
print(soup.select("html head title")) # [<title>标题</title>]# 通过class查找
print(soup.select('.sister'))
# [<a class="sister" href="http://example.com/1" id="link1">链接1</a>,
# <a class="sister" href="http://example.com/2" id="link2">链接2</a>,
# <a class="sister" href="http://example.com/3" id="link3">链接3</a>]# 通过id查找
print(soup.select('#link1, #link2'))
# [<a class="sister" href="http://example.com/1" id="link1">链接1</a>,
# <a class="sister" href="http://example.com/2" id="link2">链接2</a>]# 组合查找
print(soup.select('p #link1')) # [<a class="sister" href="http://example.com/1" id="link1">链接1</a>]# 查找直接子标签
print(soup.select("head > title")) # [<title>标题</title>]print(soup.select("p > #link1")) # [<a class="sister" href="http://example.com/1" id="link1">链接1</a>]print(soup.select("p > a:nth-of-type(2)")) # [<a class="sister" href="http://example.com/2" id="link2">链接2</a>]
# nth-of-type 是CSS选择器# 查找兄弟节点(向后查找)
print(soup.select("#link1 ~ .sister"))
# [<a class="sister" href="http://example.com/2" id="link2">链接2</a>,
# <a class="sister" href="http://example.com/3" id="link3">链接3</a>]print(soup.select("#link1 + .sister"))
# [<a class="sister" href="http://example.com/2" id="link2">链接2</a>]# 通过属性查找
print(soup.select('a[href="http://example.com/1"]'))# ^ 以XX开头
print(soup.select('a[href^="http://example.com/"]'))# * 包含
print(soup.select('a[href*=".com/"]'))# 查找包含指定属性的标签
print(soup.select('[name]'))# 查找第一个元素
print(soup.select_one(".sister"))
相关文章:

Python bs4 BeautifulSoup库使用记录
目录 介绍 安装 初始化 解析器 使用方法 优势 Python标准库 lxml HTML lxml XML html5lib 格式化输出 对象 tag Name 多值属性 其他方法 NavigableString BeautifulSoup Comment 遍历 子节点 父节点 兄弟节点 回退和前进 搜索 过滤器 字符串 正则表达…...
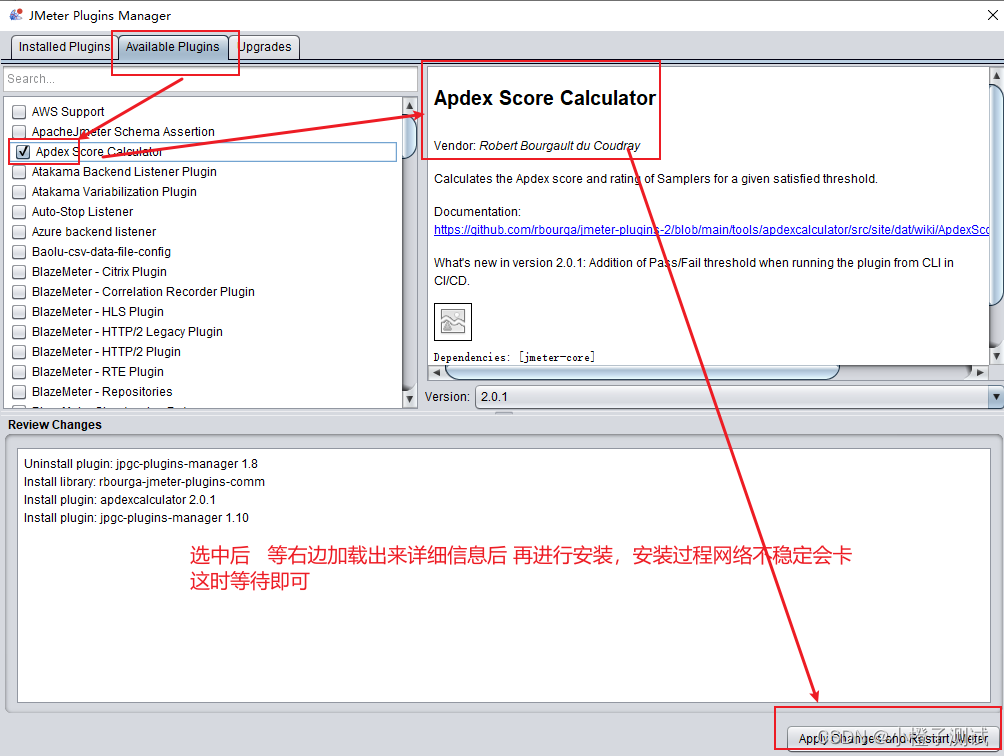
Jmeter系列-插件安装(5)
前言 jmeter4.0以上,如现在最新的5.2.1版本是有集成插件的只需要在官网下载 plugins-manager.jar 包,放在jmeter安装路径的lib/ext目录下即可使用:https://jmeter-plugins.org/install/Install/但并不能满足所有需求,仍然需要安装…...

spring aop源码解析
spring知识回顾 spring的两个重要功能:IOC、AOP,在ioc容器的初始化过程中,会触发2种处理器的调用, 前置处理器(BeanFactoryPostProcessor)后置处理器(BeanPostProcessor)。 前置处理器的调用时机是在容器基本创建完成时ÿ…...
控制物体移动、旋转)
使用Unity的Input.GetAxis(““)控制物体移动、旋转
使用Unity的Input.GetAxis("")控制物体移动、旋转 Input.GetAxis("") 是 Unity 引擎中的一个方法,用于获取游戏玩家在键盘或游戏手柄上输入的某个轴(Axis)的值。这里的 "" 是一个字符串参数,表示要…...

【CSS】画个三角形或圆形或环
首先通过调整边框,我们可以发现一些端倪 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title></head><style>.box{width: 150px;height:150px;border: 50px solid black;}</style&g…...

AI项目六:基于YOLOV5的CPU版本部署openvino
若该文为原创文章,转载请注明原文出处。 一、CPU版本DEMO测试 1、创建一个新的虚拟环境 conda create -n course_torch_openvino python3.8 2、激活环境 conda activate course_torch_openvino 3、安装pytorch cpu版本 pip install torch torchvision torchau…...

记录YDLidar驱动包交叉编译时出现的一点问题
由于一不小心把交叉编译的系统根目录破坏了,所以一股脑将交叉编译系统根目录全删了重新安装,安装后,交叉编译发现ydlidar的ros包驱动出现了库无法链接的错误(刚刚还是好好的),但是又想不起来之前是怎么解决的了,所以还…...

嵌入式学习笔记(32)S5PV210的向量中断控制器
6.6.1异常处理的2个阶段 可以将异常处理分为2个阶段来理解。第一个阶段是异常向量表跳转;第二个阶段是进入了真正的异常处理程序irq_handler之后的部分。 6.6.2回顾:中断处理的第一个阶段(异常向量表跳转阶段)处理 (…...

linux下安装qt、qt触摸屏校准tslib
linux下安装qt 在 Linux 系统下安装 Qt,可以通过以下步骤进行操作:1. 下载 Qt 安装包:首先,你需要从 Qt 官方网站(https://www.qt.io/)下载适用于 Linux 的 Qt 安装包。选择与你的系统和需求相匹配的版本&…...

C++之unordered_map,unordered_set模拟实现
unordered_map,unordered_set模拟实现 哈希表源代码哈希表模板参数的控制仿函数增加正向迭代器实现*运算符重载->运算符重载运算符重载! 和 运算符重载begin()与end()实现 unordered_set实现unordered_map实现map/set 与 unordered_map/unordered_set对比哈希表…...

React Router,常用API有哪些?
react-router React Router是一个用于构建单页面应用程序(SPA)的库,它是用于管理React应用中页面导航和路由的工具。SPA是一种Web应用程序类型,它在加载初始页面后,通过JavaScript来动态加载并更新页面内容࿰…...

JVM类加载和双亲委派机制
当我们用java命令运行某个类的main函数启动程序时,首先需要通过类加载器把类加载到JVM,本文主要说明类加载机制和其具体实现双亲委派模式。 一、类加载机制 类加载过程: 类加载的过程是将类的字节码加载到内存中的过程,主要包括…...

P-MVSNet ICCV-2019 学习笔记总结 译文 深度学习三维重建
文章目录 5 P-MVSNet ICCV-20195.0 主要特点5.1 文章概述5.2 研究方法5.2.1 特征提取5.2.2 学习局域匹配置信5.2.3 深度图预测5.2.4 Loss方程MVSNet系列最新顶刊 对比总结5 P-MVSNet ICCV-2019 深度学习三维重建 P-MVSNet-ICCV-2019(原文、译文、批注) 下载 5.0 主要特点 …...
vueshowpdf 移动端pdf文件预览
1、安装 npm install vueshowpdf -S2、参数 属性说明类型默认值v-model是否显示pdf--pdfurlpdf的文件地址String- scale 默认放大倍数 Number1.2 minscale 最小放大倍数 Number0.8 maxscale 最大放大倍数 Number2 3、事件 名称说明回调参数closepdf pdf关闭事件-pdferr文…...

C#根据excel文件中的表头创建数据库表
C#根据excel文件中的表头创建数据库表 private void button1_Click(object sender, EventArgs e){string tableName tableNameTextBox.Text;string connectionString "";using (OpenFileDialog openFileDialog new OpenFileDialog()){openFileDialog.Filter &quo…...
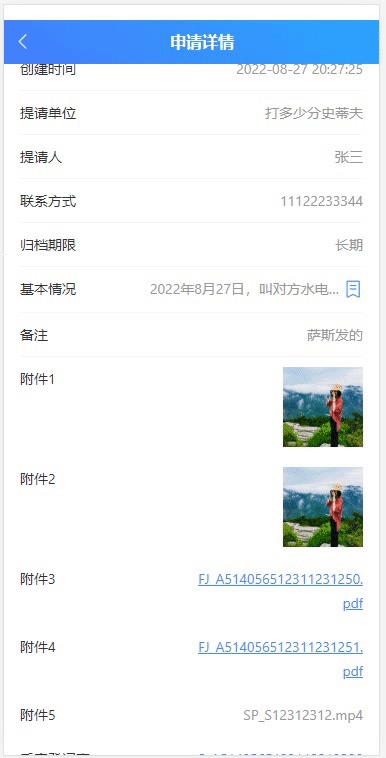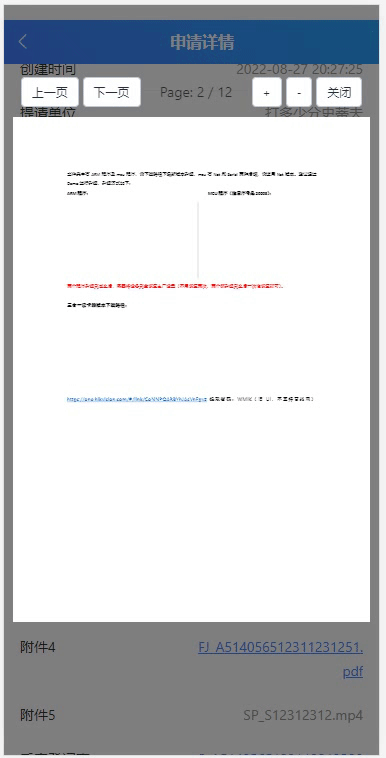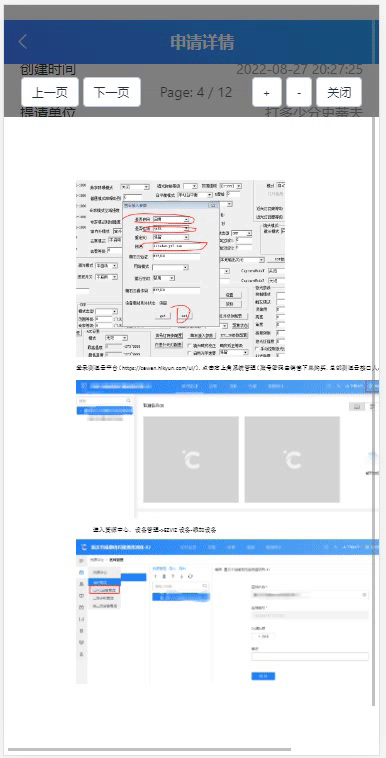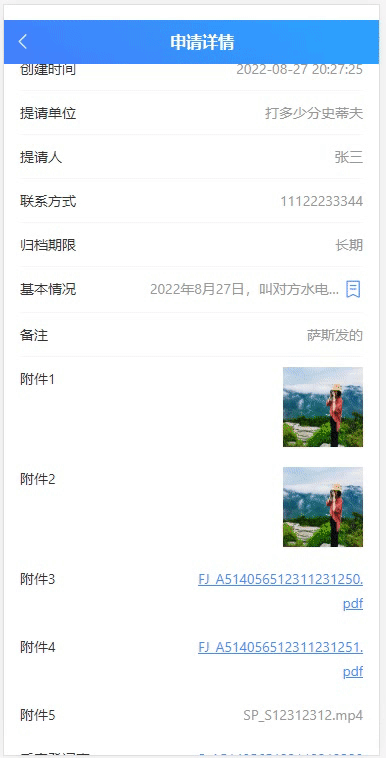
js通过xpath定位元素并且操作元素以下拉框select为例
js也可以使用xpath定位元素,现在实例讲解。 页面上有一个下拉框,里面内容有三个,用F12看一下 一、使用xpath定位这个下拉框select eldocument.evaluate(//select[name"shoppingPreference"], document).iterateNext()二、为下拉框…...
数据类型
目录 1.数值类型 整数类型 int 小数类型 double 2.字符类型 固定长度字符串 char 可变长度字符串 varchar 3.日期时间类型 日期类型:date 日期时间类型:datetime MySQL从小白到总裁完整教程目录:https://blog.csdn.net/weixin_67859959/article…...

vue 模板应用
一,模板应用也就是对DOM的操作 二,如何使用 通过标签里面添加ref 和vue中使用 this.$refs.ref的名字.操作 进行使用 <template><h3>模板引用</h3><div ref"cont" class"cont">{{ content }}</div>&…...
Golang教程与Gin教程合集,入门到实战
GolangGin框架GormRbac微服务仿小米商城项目实战视频教程Docker Swarm K8s云原生分布式部署 介绍: Go即Golang,是Google公司2009年11月正式对外公开的一门编程语言,它不仅拥有静态编译语言的安全和高性能,而 且又达到了动态语言开…...

国家网络安全周 | 天空卫士荣获“2023网络安全优秀创新成果大赛优胜奖”
9月11日上午,四川省2023年国家网络安全宣传周在泸州开幕。在开幕式上,为2023年网络安全优秀创新成果大赛——成都分站赛暨四川省“熊猫杯”网络安全优秀作品大赛中获奖企业颁奖,天空卫士银行数据安全方案获得优秀解决方案奖。 本次比赛由四川…...
)
别再只会用Arduino了!用ESP8266+MicroPython快速搭建你的第一个物联网小项目(附完整代码)
用MicroPython解锁ESP8266的物联网潜能:10分钟搭建温湿度监测系统 当提到物联网开发时,大多数人的第一反应可能是Arduino和C。但今天,我要带你体验一种更高效、更友好的方式——MicroPython。这种基于Python的嵌入式编程语言,让物…...

从NTLM中继到域控接管:ADCS-ESC8漏洞实战解析
1. ADCS-ESC8漏洞概述 ADCS-ESC8是Active Directory证书服务(AD CS)中的一个高危漏洞,它允许攻击者通过NTLM中继攻击获取域控制器证书。这个漏洞的核心在于ADCS默认配置中的Web证书注册页面仅使用HTTP协议且支持NTLM认证,但未启用任何中继攻击防护措施。…...

从零构建STM32 OTA升级系统:BootLoader设计、IAP实现与APP无缝跳转实战
1. 为什么需要OTA升级系统 想象一下你开发的智能硬件产品已经卖出去几千台,突然发现固件有个致命bug需要修复,或者要增加一个用户期待已久的新功能。传统做法是让用户把设备寄回工厂,或者带着设备到维修点刷机——这简直是开发者的噩梦&#…...

C++高性能服务开发:忍者像素绘卷推理引擎封装
C高性能服务开发:忍者像素绘卷推理引擎封装 1. 为什么需要高性能推理引擎 在游戏开发领域,实时生成高质量像素艺术的需求正在快速增长。传统的预渲染方式无法满足玩家对个性化内容和动态场景的需求,而直接使用Python等脚本语言运行的AI模型…...
 - 搜索、分析和可视化,数据全面洞察平台)
Splunk Enterprise 10.2.2 (macOS, Linux, Windows) - 搜索、分析和可视化,数据全面洞察平台
Splunk Enterprise 10.2.2 (macOS, Linux, Windows) - 搜索、分析和可视化,数据全面洞察平台 Search, analysis, and visualization for actionable insights from all of your data 请访问原文链接:https://sysin.org/blog/splunk-10/ 查看最新版。原…...

霜儿-汉服-造相Z-Turbo作品集:看看AI能生成多美的汉服少女图
霜儿-汉服-造相Z-Turbo作品集:看看AI能生成多美的汉服少女图 1. 惊艳开篇:AI汉服艺术的魅力 当传统汉服遇上现代AI技术,会碰撞出怎样的火花?霜儿-汉服-造相Z-Turbo给出了令人惊叹的答案。这个基于Xinference部署的文生图模型服务…...

终极指南:CleanArchitecture项目Angular 17快速升级实战与最佳实践
终极指南:CleanArchitecture项目Angular 17快速升级实战与最佳实践 【免费下载链接】CleanArchitecture Clean Architecture Solution Template for ASP.NET Core 项目地址: https://gitcode.com/GitHub_Trending/cle/CleanArchitecture 如果你正在使用Clean…...

实战指南 — 基于TCGA数据的差异表达分析全流程与可视化呈现
1. TCGA数据获取与准备 第一次接触TCGA数据库时,我被它庞大的数据量震撼到了。作为癌症基因组图谱计划,TCGA收录了33种癌症类型、超过2万例患者的基因组数据。对于肝癌(LIHC)研究来说,这里简直就是一座金矿。 进入TCGA官网后,你会…...

分组网络频率同步互通测试
概述随着3G/4G网络大规模的部署和应用,网络和业务的全IP化发展,分组传送技术将替代SDH/MSTP网络而成为主流的传送承载网络。这时,一方面新的传送网络技术会对网络的同步性能提出相应的要求,另一方面在通信网络由电路交换型向分组交…...

从抓包实战到协议栈:深入解析DDS核心报文与通信机制
1. 从HelloWorld抓包开始认识DDS 第一次接触DDS协议时,很多人会被各种专业术语搞得晕头转向。其实最快的学习方式就是从实际案例入手——就像我当初用Fast DDS的HelloWorld示例做实验那样。这个经典案例包含一个发布者和一个订阅者,正好能展示DDS最核心…...