MySQL基础运维知识点大全
一. MySQL基本知识
1. 目录的功能
通用 Unix/Linux 二进制包的 MySQL 安装下目录的相关功能
| 目录 | 目录目录 |
|---|---|
bin | MySQLd服务器,客户端和实用程序 |
docs | 信息格式的 MySQL 手册 |
man | Unix 手册页 |
include | 包括(头)文件 |
lib | 图书馆 |
share | 用于数据库安装的错误消息、字典和 SQL |
support-files | 其他支持文件 |
2.文件功能
-
db.opt 数据库选项 database option
作用:告诉我们这个库使用的字符串是什么
[root@sc-mysql sc]# cat db.opt default-character-set=utf8 默认字符集 default-collation=utf8_general_ci 默认字符集对应的校对规则->排序的时候使用的 -
索引: index 也是数据,是描述数据的数据,告诉我们数据存放的哪里,一本里的目录->帮助我们可以快速的查询到数据,提升查询的效率
-
使用默认的innodb存储引擎建表产生的文件
- student_info.frm --》表结构文件 frame 框架
- student_info.ibd --》表的数据和索引 后缀ibd就是innodb data
MySQL默认使用的存储引擎是innodb
将MySQL内存里的数据存放到磁盘,将磁盘里的数据读取到内存
存储引擎是捆绑到表上的
-
使用myisam存储引擎建表产生的文件
root@sc 15:38 mysql>create table weicanyu(id int,name varchar(10)) engine=myisam;- weicanyu.frm --》表结构文件 frame 框架
- weicanyu.MYD --》myisam存储引擎存放数据的 data
- weicanyu.MYI --》myisam存储引擎存放索引 index
3.进程间的关系
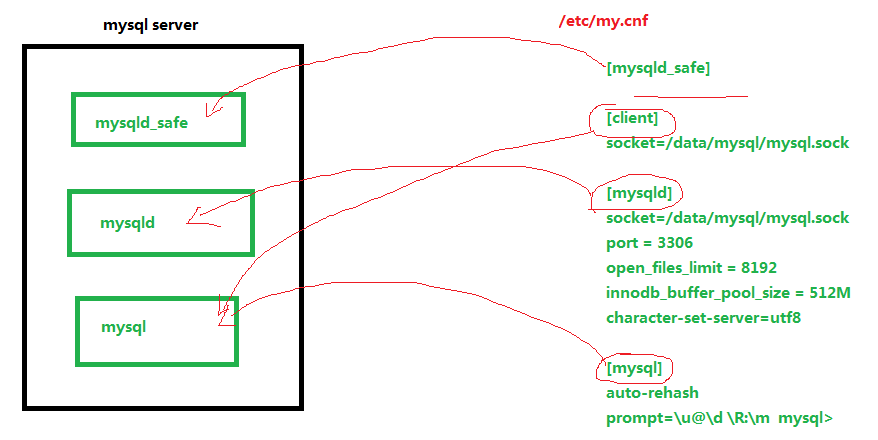
3.1 三个进程
-
mysqld_safe
ysqld_safe是mysqld的父进程,管理mysqld
-
mysqld MySQL的主要进程
-
mysql:是客户端的连接程序->连接到mysqld
3.2 配置文件my.cnf
3.3 进程的6种通信方式
-
socket 是进程是进程之间通信的方式 -->槽
-
1.文件socket
socket=/data/mysql/mysql.sock->实现mysql和mysqld的通信
-
2.网络socket
格式ip:port 192.168.0.163:3309->网络中通过ip地址找到对方,是实现不同的电脑之间的不同的进程之间的通信的
-
-
pipe 管道
-
信号:处理异步事件的方式
kill -9 -
信号量:进程间通信处理同步互斥机制->相当于锁
-
共享内存
-
消息队列
4. 数据类型
4.1 数值
-
整数 int
Unsigned 无符号数 如:40,50,100
signed 有符号数 如:+100,-50类型 存储(字节) 最小值有符号 最小值无符号 最大值有符号 最大值无符号 tinyint 1 -1280127255smallint 2 -3276803276765535mediumint 3 -83886080838860716777215int 4 -2147483648021474836474294967295bigint 8 -2630263-1264-1 -
float 浮点型
有近似值,不精准
-
decimal 定点型
数值非常精确,不会有近似值 -
函数
4.2 字符串
-
char和varchar
char和varchar的区别?
1.存储上的区别char是定长,即存储的时候会根据指定的字符数量存储,不足字符数量的会以空格进行填充,而varchar是变长,只是在后面多填充一个空格。
2.取数据的区别
varchar还是char类型,在读取的时候,都会删除自动填充的空格;不是自动填充的空格varchar会保留
3.允许存储的长度
char长度:0255,varchar长度:065535

-
text
longtext,tinytext,mediumtext,text
-
blob 二进制的文本(图片,音频,视频)
-
enum 枚举
-
set 集合
-
函数
4.3 日期和时间
- year 年
- data 年月日 如:出生
- time 小时分钟秒
- datatime 年月日小时分钟秒 如:考勤
- datetime所能存储的时间范围为:‘1000-01-01 00:00:00.000000’ 到 '9999-12-31 23:59:59.999999
- 对于datatime,不做任何改变,基本上是原样输入和输出
- timestamp 时间戳 年月日时分秒
- timestamp所能存储的时间范围为:‘1970-01-01 00:00:01.000000’ 到 ‘2038-01-19 03:14:07.999999’。
- 对于timestamp,它把客户端插入的时间从当前时区转化为UTC(世界标准时间)进行存储。查询时,将其又转化为客户端当前时区进行返回。
- 注册账号,交易,下订单
5.密码破解
5.1 方法一
-
第1步:停止MySQL进程的运行
[root@mysql-2 mysql]# service mysqld stop Shutting down MySQL.. SUCCESS! -
第2步:修改配置文件
[root@mysql mysql]# vim /etc/my.cnf [mysqld] user=mysql #指定启动MySQL进程的用户 skip-grant-tables #跳过密码验证 #validate-password=off #需要禁用密码复杂性策略 -
第3步:启动MySQL进程
[root@mysql mysql]# service mysqld start 启动MySQL进程 -
第4步:登录MySQL,不接密码
[root@mysql-2 mysql]# mysql -uroot -p mysql> flush privileges; 刷新权限(会加载原来没有加载的权限表--》用户名和密码所在的表user等) mysql> set password for 'root'@'localhost' = 'Sanchuang1234#'; --》修改密码,指定用户名为root@localhost -
第5步:重新修改mysql的配置文件
[mysqld] socket=/data/mysql/mysql.sock #user=mysql --》注释掉 #skip-grant-tables --》注释掉 -
第6步:刷新服务
[root@mysql-2 mysql]# service mysqld restart #重新刷新服务 -
第7步:验证修改密码是否成功
[root@mysql-2 mysql]# mysql -uroot -p'Sanchuang1234#'
5.2 方法二
-
就是使用其他的管理员账号给别的用户重新设置密码,可以在SQLyog里操作
SET PASSWORD FOR 'root'@'localhost' = 'Sanchuang123#'; alter user 'root'@'localhost' identified by 'Sanchuang123#';
6 三个类别
-
数据定义语言DDL
DDL(Data Definition Languages)语句:数据定义语言,这些语句定义了不同的数据段、数据库、表、列、索引等数据库对象的定义。常用的语句关键字主要包括 c r e a t e 、 d r o p 、 a l t e r create、drop、altercreate、drop、alter 等。
-
数据操纵语句DML
DML(Data Manipulation Language)语句:数据操纵语句,用于添加、删除、更新和查询数据库记录(增删改查),并检查数据完整性,常用的语句关键字主要包括 i n s e r t 、 d e l e t e 、 u d p a t e insert、delete、udpateinsert、delete、udpate 和 s e l e c t selectselect 等。
-
数据控制语句DCL
DCL(Data Control Language)语句:数据控制语句,用于控制不同数据段直接的许可和访问级别的语句。这些语句定义了数据库、表、字段、用户的访问权限和安全级别。主要的语句关键字包括 g r a n t 、 d e n y 、 r e v o k e 、 c o m m i t 、 s a v e p o i n t 、 r o l l b a c k grant、deny、revoke、commit、savepoint、rollbackgrant、deny、revoke、commit、savepoint、rollback 等。
二. MySQL命令
1.基本命令
-
关键字不区别大小写,库名和表名区分大小写
-
登录
mysql -uroot -p’123456’ -h 192.168.2.129 -p 3306
-p 指定密码 -h指定ip -P指定端口
-
show processlist 查看有哪些人已经连接到mysql里了
-
help 查询使用手册
-
select 查询操作
- select version();查看MySQL的版本
- select now();查询当前时间
- select * from ejiao1; 查询ejiao1里面的任意字段
- select length()from ejiao1;统计字符储存空间消耗的空间(字节)
- select char_length()from ejiao1;统计字符的长度,字符的个数
-
delete 删除操作
- delete from city_name; 删除整个表里的数据
- delete from city_name where id=9; 添加了条件的删除语句
-
if exists关键字
create database if exists pzz; create databse if not exists pzz;使用后如果创建的数据库可能已经存在,或者是要删除的数据库可能不存在,不进行报错
2. 用户管理
2.1 创建用户
-
create user
root@(none) 16:36 mysql>create user 'liaobo'@'%' identified by '123456';cali@‘%’
% 是通配符,代表任意的字符串 -
查看所有用户
root@(none) 18:31 mysql>select user from mysql.user;
2.2 删除用户
-
drop user 删除用户
root@(none) 16:37 mysql>drop user 'liaobo'@'%'
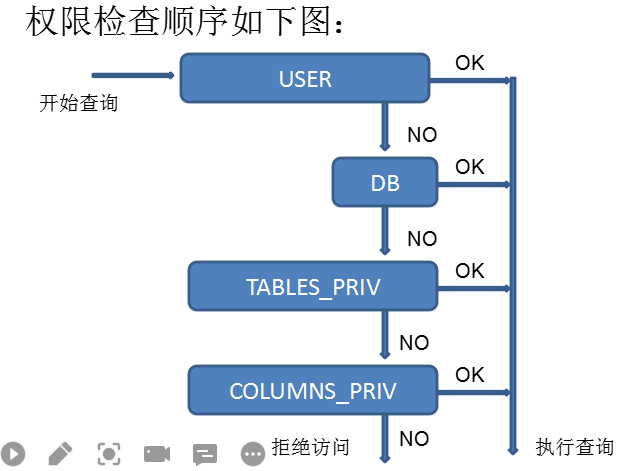
2.3 用户权限
-
权限:全局权限,数据库权限,表权限
- 全局权限 如mysql.user 存放所有的用户名和密码
- 数据库权限 如mysql.db 只能操作某个库
- 表权限 如mysql.table_priv 只能操作某个表;mysql.columns 只能对某个列进行操作
-
grant 授权
root@(none) 16:37 mysql>grant all on *.* to 'liaobo'@'%';grant 是mysql里授权的命令
all 代表授予所有的权限 select insert update delete等
on . 第1个* 代表库 第2个*代表表 所有表所有库
o ‘cali’@‘%’ 给具体的用户-
with grant option 授予授权的权力
grant all on *.* to 'tang3'@'%' with grant option; -
flush privileges 刷新权限
-
-
revoke 取消权限
- 格式:revoke 权限 on 库/表 from 用户名 取消某用户在库或表上面的的什么权限
revoke all on *.* from 'heyachen'@'%';
2.4 四个默认库
-
information_schema 信息库
数据字典库–》资产库,存放MySQL里的资产,例如有多少表,库,视图,触发器,存储过程等
information_schema是一个信息数据库,它保存着关于MySQL服务器所维护的所有其他数据库的信息。(如数据库名,数据库的表,表栏的数据类型与访问权 限等
数据字典–》元数据:描述其他数据的数据
中央情报局(统计局):收录了整个MySQL里的信息(能统计的一切信息) -
performance_schema 性能架构库
主要用于收集数据库服务器性能参数。
执行某些操作会有性能相关的参数
存放MySQL运行起来后相关的数据,例如登陆用户,变量,内存的消耗等 -
sys MySQL系统库
Sys库所有的数据源来自:performance_schema。目标是把performance_schema的把复杂度降低,让DBA能更好的阅读这个库里的内容。让DBA更快的了解DB的运行情况。 -
mysql
存放的是MySQL程序相关的表:登录用户表、时间相关表、db、权限表
mysql的核心数据库,类似于sql server中的master表,主要负责存储数据库的用户、权限设置、关键字等mysql自己需要使用的控制和管理信息
3. 库命令
3.1 建库
-
create database 建库
root@(none) 15:11 mysql>create database sc;
3.2 删除库
-
drop database 删除库
root@xieshan 16:00 scmysql>drop database AOJIAO;
3.3 查看库
-
show databases 展示库列表->相当于ls
root@(none) 15:11 mysql>show databases; -
use sc 进入sc这个库->相当于cd
4. 表命令
4.1 建表
-
create table 建表
root@sc 15:14 mysql>create table student_info(id int,name varchar(20),sex char(10));root@xieshan 15:23 scmysql>create table wang(-> id int not null primary key,-> name varchar(20) not null,-> sex char(1) )-> ;not null 表示不能为空,这个字段primary key 表示这个字段为主键,这个字段里的数据不能重复primary 主要的 -
create temporary table 建临时表
临时表: 只是临时在内存里存在,使用show tables查看不到,用户退出MySQL,马上会删除用户新建的临时表,其他用户不能看到你创建的临时表,只能自己可见。
4.2 查看表
-
show tables 查看表名
root@sc 15:14 mysql>show tables; root@sc 15:14 mysql>show creat table student_info; -
desc 查看表的结构
root@sc 15:16 mysql>desc student_info; -
show create database 查看表的结构
root@(none) 14:45 scmysql>show create database aojiao; -
查看表内容
root@(none) 14:45 scmysql>select * from student;
4.3 insert插入数据
root@xieshan 15:07 scmysql>insert into ejiao1(id,name) values(1,'hepang');
insert into teacher values (1,'LiHong','man');
insert into teacher (id,name) values (2,'WangQin');
insert into teacher values (3,'Bob','man'),(4,'LiLi','woman'); #一次性插入多条数据
4.4 alter修改数据
-
修改表结构
- 增加字段
- alter table Students add sex char(1) ;
- add
- 删除字段
- drop
- 修改字段的类型或者长度
- modify 修改类型
- 修改名字
- alter table Students change name username varchar(30);
- change
- 增加字段
-
修改数据库字符集
- alter database song default character set utf8mb4;
4.5 删除表与数据
-
drop table 删除表与字段
删除表 root@xieshan 16:00 scmysql>drop table chenyulin;删除字段 alter table teacher drop year -
delete删除数据
delete from teacher where id = 1; delete from teacher; #删除所有数据 -
like 复制表的结构
root@hunan 15:20 scmysql>create table new_city like city_name; -
as 复制一个表的结构和数据
root@hunan 15:21 scmysql>create table new_city2 as select * from city_name;
三. 变量和选项
1. 变量
-
系统变量 使用@@进行设置
SET @@auto_increment_offset = 10, -- 设置自增起始值@@auto_increment_increment=10; -- 每次自增10 -
自定义变量 使用@进行设置
root@hunan 15:04 scmysql>set @sg = 'liangliang'; root@hunan 15:05 scmysql>insert into city_name(name) values(@sg)
2.选项约束
选项->字段属性
- signed 有符号整数 unsigned 无符号整数
- not null 不能为空
- zerofill 补零,自动转为为unsigned
- primary key 主键
- 不允许为空,不允许重复
- 分类:复合主键,单列主键
- 设置主键的好处:给表建立索引–》主键索引;在查询数据的时候,先查询索引,然后根据索引去查询数据,速度会非常快
- unique 唯一性约束 不允许重复,空值只能出现一次;以出现很多NULL值
- default 默认值
- auto_increment 自增 初始值为1 步长值(偏移量)默认为1
- if not exists 如果不存在不显示错误
- comment 注释->sqlyog查看
- foreign key 外键
- 多表连接查询使用
- 缺点:产生临时表,进行关联,消耗内存空间和cpu
3. 存储引擎engine
3.1 基本存储引擎
root@hunan 16:02 scmysql>show engines; 查看存储引擎

-
InnoDB 默认存储引擎
表结构:t1.frm 索引和数据:t1.ibd
-
MyISAM
表结构:t1.frm 索引:t1.MYI 数据:t1.MYD
-
csv
csv文件: 是一个文本文件,里面的字段以逗号作为分割符号 --》文件存储的文件 --》数据分析:数据处理和清洗
-
memory 数据保存在内存里,特别适用于适用临时表的场景–》数据分析
-
blackhole
解决了主从复制架构里,让很多的从服务器直接到配置了blackhole存储引擎的master上拿二进制日志,让最上层的master的负载降低-》其实就是帮忙主从架构传递二进制日志,自己不执行二进制日志,只是传递
3.2 Innodb和myisam存储引擎的优缺点
1) 事务支持
**MyISAM不支持事务,而InnoDB支持。**InnoDB的AUTOCOMMIT默认是打开的,即每条SQL语句会默认被封装成一个事务,自动提交,这样会影响速度,所以最好是把多条SQL语句显示放在begin和commit之间,组成一个事务去提交。
MyISAM是非事务安全型的,而InnoDB是事务安全型的,默认开启自动提交,宜合并事务,一同提交,减小数据库多次提交导致的开销,大大提高性能。
2) 存储结构
MyISAM:每个MyISAM在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。.frm文件存储表定义。数据文件的扩展名为.MYD (MYData)。索引文件的扩展名是.MYI (MYIndex)。
InnoDB:所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),InnoDB表的大小只受限于操作系统文件的大小,一般为2GB。
3) 存储空间
MyISAM:可被压缩,存储空间较小。支持三种不同的存储格式:静态表(默认,但是注意数据末尾不能有空格,会被去掉)、动态表、压缩表。
InnoDB:需要更多的内存和存储,它会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引。
4) 可移植性、备份及恢复
MyISAM:数据是以文件的形式存储,所以在跨平台的数据转移中会很方便。在备份和恢复时可单独针对某个表进行操作。
InnoDB:免费的方案可以是拷贝数据文件、备份 binlog,或者用 mysqldump,在数据量达到几十G的时候就相对痛苦了。
5) 表锁差异
MyISAM:只支持表级锁,用户在操作myisam表时,select,update,delete,insert语句都会给表自动加锁,如果加锁以后的表满足insert并发的情况下,可以在表的尾部插入新的数据。
InnoDB:支持事务和行级锁,是innodb的最大特色。行锁大幅度提高了多用户并发操作的新能。但是InnoDB的行锁,只是在WHERE的主键是有效的,非主键的WHERE都会锁全表的。
4.数据库三个核心性能指标
-
TPS(适用innodb):每秒处理的事务数
Transactions Per Second(每秒传输的事物处理个数),即服务器每秒处理的事务数。
TPS包括一条消息入和一条消息出,加上一次用户数据库访问。(业务TPS = CAPS × 每个呼叫平均TPS)
TPS是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
一般的,评价系统性能均以每秒钟完成的技术交易的数量来衡量。系统整体处理能力取决于处理能力最低模块的TPS值。
-
QPS(同时适用与InnoDB和MyISAM 引擎 ):每秒处理的查询数
每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。
对应fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。
-
IOPS 每秒磁盘进行的I/O操作次数
IOPS (Input/Output Per Second)即每秒的输入输出量(或读写次数),是衡量磁盘性能的主要指标之一。IOPS是指单位时间内系统能处理的I/O请求数量,一般以每秒处理的I/O请求数量为单位,I/O请求通常为读或写数据操作请求。
5.字符集
5.1 定义
字符集定义了字符以及字符的编码,规定了字符在数据库中的存储格式,比如占用多少空间,支持那些字符等等。
5.2 MySQL常用字符集
| 字符集 | 长度 | 说明 |
|---|---|---|
| latin1 | 1 | MySQL默认字符集,最早由MySQL使用的字符集 |
| ASCII | 1 | 共收录128个字符,包括空格、标点符号、数字、大小写等 |
| UTF-8 | 3 | 国际通用字符集,收录地球上所有编码,并且在不断扩充。采用变长编码的方式 |
| utf8mb4 | 4 | 完全兼容UTF-8,用四个字节存储更多的字符 |
| GBK | 2 | 支持中文,但是不是国际通用字符集 |
5.3 MySQL字符集操作
-
查看字符集
root@hunan 16:54 mysql>show character set; 查看字符集 root@hunan 16:54 mysql>SHOW variables like '%CHARACTER%'; 查看你正在使用哪些字符集 -
更改默认字符集
alter database 表名 default character set utf8; -
文本类型的数据,会牵涉到字符集->varchar char text
-
继承:库<-表<-列
四. SQL语句
1. selcet 查询
1.1 基本查询
select id,name from student;
-
distinct 查询去重
select distinct sex from student; -
空值查询
select * from student where major is null; select * from student where major is not null;
2.2 where条件查询
-
等于(=)、不等与(<>或!=)
select * from student where sex='man'; select * from student where major<>'Math'; -
大于(>)、小于(<)、大于等于(>=)、小于等于(<=)
select * from student where age >=20; select from student where age>10 and sex='man'; -
与(and)、或(or)、非(not)、异或(xor)
-
介于A和B之间(between A and B)
select * from student where age between 10 and 20;
2.3 like模糊查询
-
select模糊查询所使用的是like与not like关键字
select * from student where name like 'Li_'; select * from student where name like 'Li%'; select * from student where name not like 'Li%';%表示0个或者多个字符,_只表示一个任意的字符 两个\转义
2.4 order by排序查询
select * from student order by age; #默认升序
select * from student order by age desc; #desc降序
-
limit 限制数量
如limit 3 限制三个;limit 3,5 取第三个以后的5个不包括第三个
SELECT * FROM employee ORDER BY salary DESC LIMIT 3; 按照工资从高到低的顺序仅返回前3个结果
2.5 group by分组查询
-
group by单独使用时,后面跟字段名即可
SELECT * FROM user_info GROUP BY name; -
GROUP BY 也可以和 GROUP_CONCAT() 函数一起使用,这样可以把分组的某一字段的每个字段值都显示
SELECT 分组的字段名, GROUP_CONCAT(传入需要全部显示的字段名) FROM 表名 GROUP BY 分组的字段名; -
在数据统计时,GROUP BY 关键字经常和聚合函数一起使用。聚合函数包括:
COUNT(),SUM(),AVG(),MAX()和MIN()COUNT()用来统计记录的条数;SUM()用来计算字段值的总和;AVG()用来计算字段值的平均值;MAX()用来查询字段的最大值;MIN()用来查询字段的最小值。
SELECT sex,COUNT(sex) FROM tb_students_info GROUP BY sex; --统计指定的字段的数量 -
having 可以用来过滤分组的一些信息,类似where
SELECT b, count(*) as c from t1 GROUP BY b HAVING b<100
2. 多表连接查询
连接类型:内连接,外连接,交叉连接
2.1 内连接
基于两个或多个表之间的关联条件,仅返回在所有关联表中都存在匹配的行,不显示不满足条件的行
SELECT columns
FROM table1
INNER JOIN table2 ON table1.column = table2.column;
2.2 外连接
-
左连接(left join) ::用于返回左表中的所有行,以及与右表中匹配的行。如果右表中没有匹配的行,则右表的列将显示为NULL
SELECT columns FROM table1 LEFT JOIN table2 ON table1.column = table2.column; -
右连接(right join):右连接用于返回右表中的所有行,以及与左表中匹配的行。如果左表中没有匹配的行,则左表的列将显示为NULL。
SELECT columns FROM table1 RIGHT JOIN table2 ON table1.column = table2.column;
2.3 交叉连接(笛卡尔积)
交叉连接用于返回两个表的笛卡尔积,即将左表的每一行与右表的每一行进行组合
SELECT columns
FROM table1
CROSS JOIN table2;
2.4 join 语句
-
using关键字
USING关键字用于指定连接的列,这些列在连接的两个表中具有相同的名称。USING关键字仅用于指定连接的列,而不需要在列名前面指定表名或表别名。USING关键字将根据指定的列进行连接,并自动排除重复列。
SELECT * FROM table1 JOIN table2 USING (common_column); -
on关键字
ON关键字用于指定连接的条件,可以根据多个列或表达式进行连接。ON关键字要求在连接条件中明确指定连接的列,包括表名或表别名。ON关键字提供了更灵活的连接选项,可以在连接条件中使用各种逻辑运算符、比较运算符和函数。
SELECT * FROM table1 JOIN table2 ON table1.column1 = table2.column2;
2.5 where
#从student表中查询与“吴刚”来源地相同的所有学生学号、姓名和所属院系。
SELECT st1.ID AS 学号, st1.name AS 姓名, st1.institute AS 所属院系
FROM student AS st1, student AS st2
WHERE st2.name='吴刚'
AND st1.origin=st2.origin;
3. 子查询
如果一个查询语句嵌套在另一个查询语句里面,那么这个查询语句就称之为子查询,子查询不是必须的,可以使用其他的语句代替;
-
根据位置不同,可以分为where型、from型、exists型;
-
根据结果集的行列数不同
标量子查询 结果及只有一行一列 列子查询 结果及只有一列多行 行子查询 结果集有一行多列或多行多列 表子查询 结果集一般为多行多列 - 标量子查询(Scalar Subquery):标量子查询返回的是单个值,可以作为查询语句中的一个常量使用。
- 列子查询(Column Subquery):列子查询返回的是一列数据,可以和主查询的结果进行比较或者连接
- 行子查询(Row Subquery):行子查询返回的是一行数据,可以作为一个整体进行处理或者与其他行进行比较
- 表子查询(Table Subquery):表子查询返回的是一个表或视图,可以嵌套在另一个查询语句中使用。
3.1 where型
where型子查询,是将子查询语句放在where后面
SELECT name
FROM company
WHERE id = (SELECT comid FROM menber WHERE name = '小刘')
3.2 from型
from子查询是把查询结果当成表
SELECT c.name
FROM (SELECT * FROM menber WHERE name = '小刘') t1,company c
WHERE t1.comid = c.id
3.3 exists型
exists是如果子查询语句能够至少查询到一条数据,就返回TRUE,否则就返回FALSE
SELECT cid,cname FROM t_category tc WHERE EXISTS (SELECT * FROM t_product tp WHERE tp.cno = tc.cid)
3.4 in、all、any
-
in
in的意思就是指定的一个值是否在这个集合中,如何在就返回TRUE;否则就返回FALSE了。
SELECT * FROM tb_bookWHERE row_no IN (SELECT row_no FROM tb_row); -
all
all的意思是“对于子查询返回的列中的所有值,如果比较结果为TRUE,则返回TRUE”。
SELECT * FROM tb_bookWHERE row_no >= ALL(SELECT row_no FROM tb_row); -
any
any关键词的意思是“对于子查询返回的列中的任何一个数值,如果比较结果为TRUE,就返回TRUE”;就是任意一个,只要条件满足任意的一个,就返回TRUE。
SELECT * FROM tb_bookWHERE row_no < ANY(SELECT row_no FROM tb_row);
3.5 不相关子查询
子查询的查询条件不依赖于父查询,称为不相关子查询;子查询可以单独运行
3.6 相关子查询
如果子查询的查询条件依赖于父查询,这类子查询称为相关子查询;子查询不可以单独运行,并且先运行外查询再运行子查询。
#找出每个学生超过他自己选修课程的平均成绩的课程号。
SELECT Sno,Cno
FROM SC x
WHERE Grade >= (SELECT AVG(Grade)FROM SC yWHERE y.Sno=x.Sno);#查询工资高于其所在岗位的平均工资的员工
select * from emp e where sal >= (select avg(sal) from emp where job=e.job);
4. 索引
4.1 相关知识
-
作用:加快查询的速度
-
缺点:
- 修改了数据,mysql会去修改索引的,导致mysql的性能下降
- 维护索引的开销是比较大
-
查询的对象:对于主键及唯一性约束,MySQL自动创建索引 ;重复性低的具有高选择性的列适合建立索引
-
底层技术
-
B+ 树索引
btree索引
-
哈希hash索引
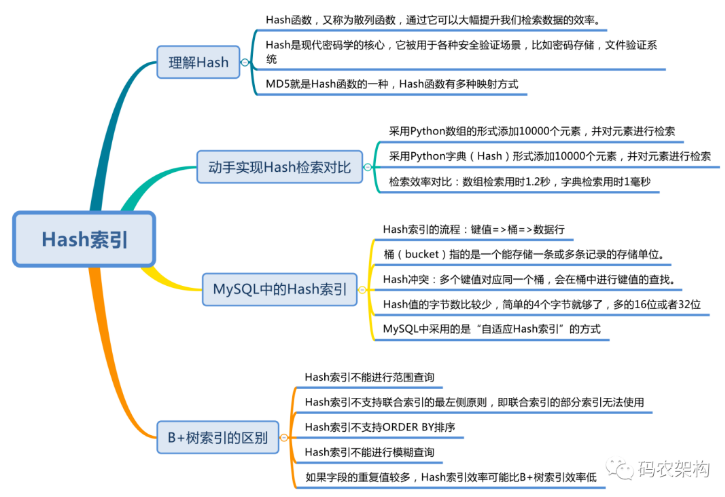
-
4.2 hash索引和B+树索引的区别

4.3 相关命令
-
创建索引
- create index 索引名 on 表名
- alter table 表名 add key(字段名)
-
删除索引:drop index 索引名 on 表名
-
索引类型
-
主键索引:primary 唯一 + not null
-
唯一性索引:unique
-
全文索引:fulltext
-
普通索引
-
复合索引
-
最左匹配原则
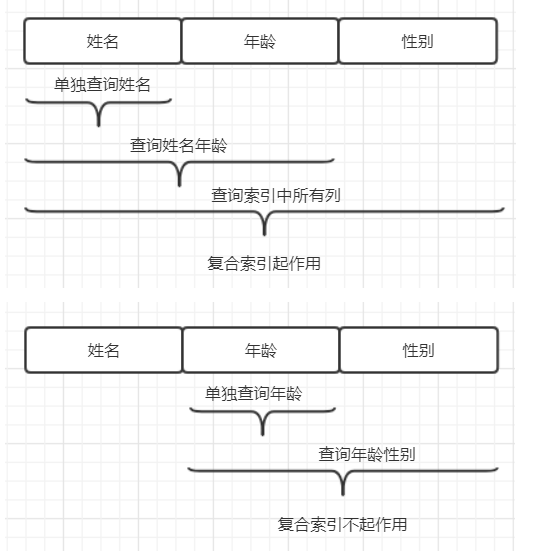
-
-
五.DML和事务
1.DML基本语句
-
insert 插入语句,出现主键冲突不会插入
-
valuse 字句
除了使用字面量,还可以使用函数,计算,标量子查询等
-
-
replace 替代语句,出现主键冲突会替换
-
update 更新语句 需要接where条件,不然全部都会更新
-
delete 删除语句 需要接where条件,不然全部都会一行一行地删除;会产生二进制日志
-
truncate 整张表删除;速度更快,不会产生二进制日志
2.数据库事务
2.1 数据库中的操作
-
commit
-
自动提交功能设置
conn = pymysql.connect(user = 'root',passwd = '1999',db = 'dep2',host = '127.0.0.1',port = 3306,charset = 'utf8',autocommit = True # 自动提交确认 )
-
-
rollback
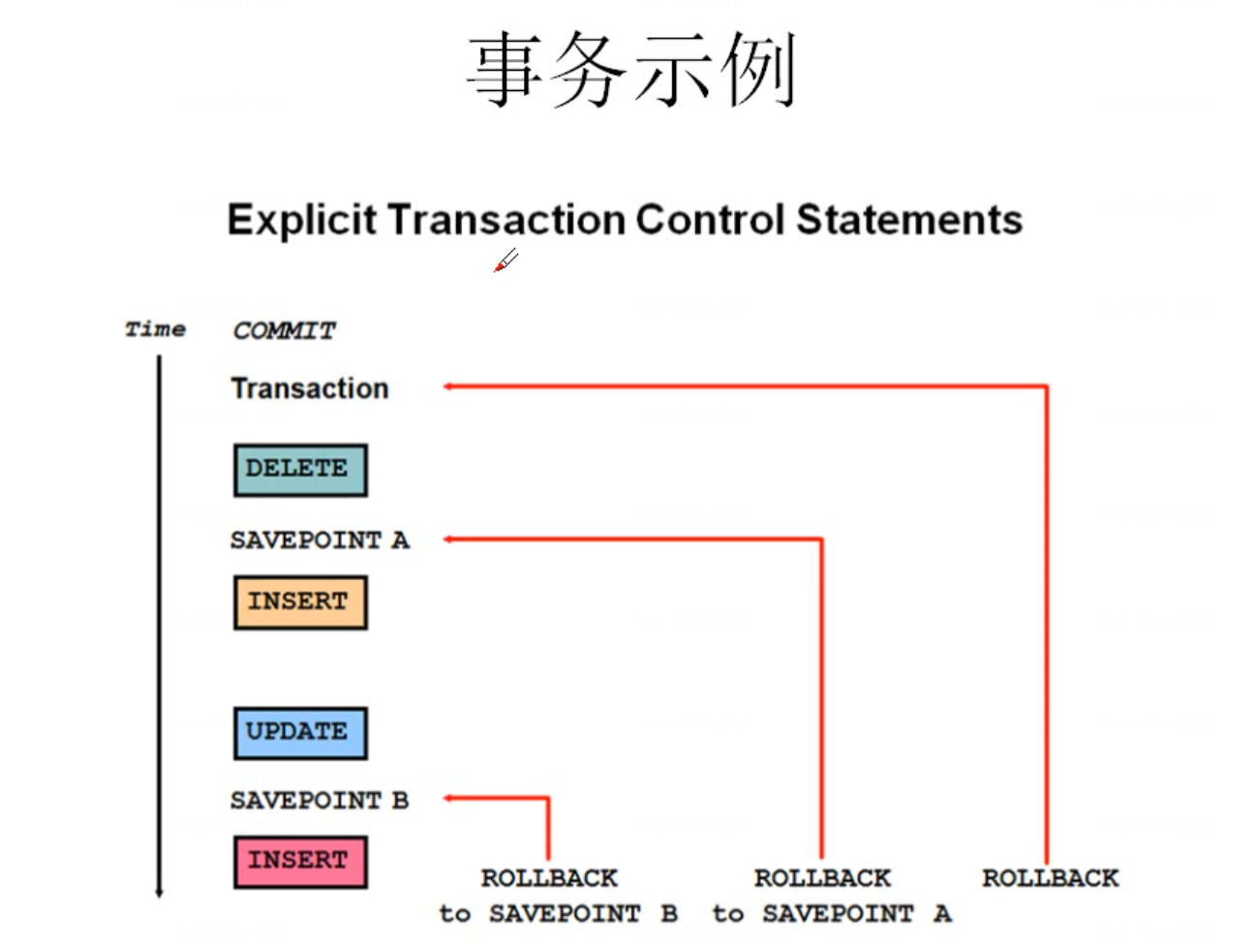
2.2 事务的ACID特性

2.3 并发事务的4个问题
- 脏读
- 不可重复读->重点是修改
- 幻读->新增或删除
- 丢失更新
2.4 解决并发问题的4个隔离级别
-
读未提交
-
读已经提交
-
可重复读
-
可串行化
2.5 锁
2.5.1 根据行为划分
-
读锁
READ:当前会话和其它会话都可以读表,但是不能修改表
-
写锁
WRITE:当前会话可以读写表,但是其它会话既不能读也不能写
注意:当使用lock tables语句时,其后的操作只能访问被锁定的表,而不能访问未被锁定的表
-
共享锁
SELECT * FROM parent WHERE NAME = 'Jones' LOCK IN SHARE MODE; -
排他锁
START TRANSACTION; SELECT * FROM players_copy1 FOR UPDATE;
2.5.2 根据颗粒度划分
-
表锁
-
读锁 read
是共享锁:当前会话能读,其他会话也能读,都不能写
-
写锁 read
是排他锁:当前会话能读写,其他会话不能读也不能写
-
-
行锁
- 读锁: read --》其他事务可以读,不能写 --》共享锁
- 写锁: write --》其他事务不能读,也不能写 --》排他锁
2.5.3 其他的锁
-
死锁
死锁: 在竞争资源的时候,必须满足2个条件,多个进程同时访问,A进程获得了1个条件,B进程获得了第2个条件,A和B都没有同时满足2个条件,互相又都不释放已经掌握的条件,导致2个进程僵死,都不能访问。
如何避免死锁?
1.设计流程,必须先拿到第1个条件,然后才可以去拿第2个条件
2.设计一个单独的进程,去检查是否发生死锁,如果发生了,根据一个算法,权衡利弊,考虑杀死一个进程,释放资源。 -
活锁
在竞争资源的时候,一直得不到,活活被锁住,一直等待
-
悲观锁
悲观锁,正如其名,具有强烈的独占和排他特性。
-
乐观锁
乐观锁机制避免了长事务中的数据库加锁开销(操作员 A和操作员 B 操作过程中,都没有对数据库数据加锁),大大提升了大并发量下的系统整体性能表现
-
互斥锁
六.日志
为什么需要日志?日志用来做什么?
1.用来排错
2.用来做数据分析
3.了解程序的运行情况,是否健康–》了解MySQL的性能,运行情况
1.错误日志 log_err
-
功能
登录失败会记录到错误日志
配置文件出错也会记录
启动过程出问题也会记录 -
存放目录和查看
-
默认开启,存放在数据目录下/data,后缀名是.err
-
查看开启状态
root@(none) 15:42 mysql>show variables like "%err%";
-
-
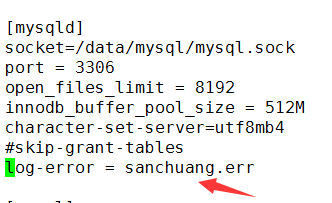
在/etc/my.cnf中配置erro
2.通用日志 general_log
-
功能
记录所有的SQL操作,但是会消耗大量的磁盘空间,cpu,内存
-
存放目录和查看
-
默认不开始,默认存放在数据目录下,名字是主机名.log
-
查看开启状态
root@(none) 15:52 mysql>show variables like "general_log";
-
-
开启并在/etc/my.cnf中配置存放路径
-
临时开启
mysql> set global general_log = 1; -
永久开启
#开启general log general_log #配置存放路径 general_log_file=/data/mysql/sanchuang_mysql_ge.log
-
3. 慢日志 slow query log
-
功能
记录消耗时间比较长的SQL语句,为数据库性能提升提供了线索
面试题:最近数据库压力(负载特别高),客户反应网站或者应用使用特别慢,领导要求你查明原因?
1.SQL语句需要优化,在数据库里启用慢日志,找出执行时间比较长的SQL
2.业务量太大了,硬件已经达到极限了 ,top、glances、dstat -
存放目录和查看
-
默认不开始,存放在数据目录下,名字:主机名+slow.log
-
查看开启状态
root@(none) 15:52 mysql>show variables like "long_query%"; -
查看最低记录时间,默认是10秒
mysql> show variables like "%long_query%";
-
-
开启并在/etc/my.cnf中配置存放路径
#开启slow query log slow_query_log = 1 #配置最低记录时间 long_query_time = 0.001
4. 二进制日志 log_bin
-
二进制的作用
1.恢复数据(增量)
2.主从复制需要使用
3、日志审计场景:用户可以通过二进制日志中的信息来进行审计,判断是否有对数据库进行注入攻击。
-
存放目录/etc/my.cnf和查看日志
-
默认不开始,存放在数据目录下,名字:主机名-bin.00000*
-
sc-mysql-bin.index文件 存放累计有多少个二进制文件的
-
查看开启状态
root@(none) 15:59 mysql>show variables like "log_bin"; -
查看哪个二进制日志正在记录
root@(none) 16:47 mysql>show master status; -
查看二进制日志内容,默认一个二进制文件最大只能一个1G
[root@master mysql]# mysqlbinlog master-bin.000001
-
-
开启二进制日志
#开启二进制日志 log_bin server_id = 1server_id 是服务器的唯一标识,在主从复制的时候使用,每天服务器的id不能一样,不然会导致主从复制失败
-
删除二进制日志
-
清除所有的二进制日志
root@TENNIS 15:15 scmysql>reset master; -
purge 清除
#将指定时间之前的日志清理 root@TENNIS 15:15 scmysql>purge binary logs before ‘2023-08-07’; #将指定日志文件之前的日志清理 root@TENNIS 15:15 scmysql>purge binary logs to 'mysql-bin.000003'; -
自动清除日志

-
-
产生二进制文件
#重启MySQL mysql>service mysqld restart #刷新logs mysql>flush logs -
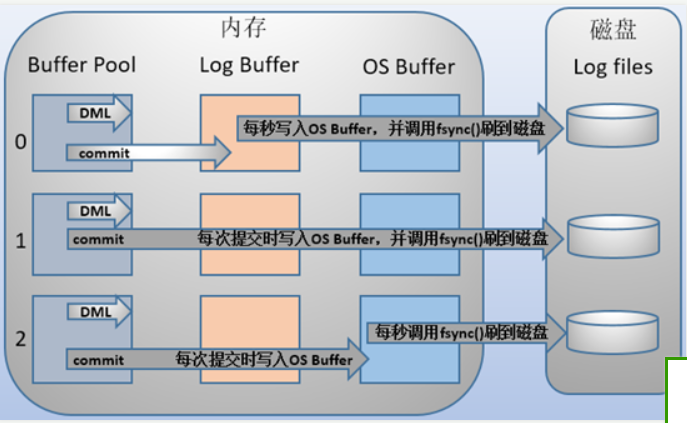
刷盘时机
是指什么时候,通过什么策略将内存日志写入到磁盘中
-
sync_binlog=0
表示刷新binlog时间点由操作系统自身来决定,操作系统自身会每隔一段时间就会刷新缓存数据到磁盘,这个性能最好。–》容易丢失数据
-
sync_binlog=1(MySQL默认刷盘时机)
表示每次事务提交都要调用fsync(),刷新binlog写入到磁盘。–》能快速的存储数据,不容易丢失数据
-
sync_binlog=N
表示N个事务提交,才会调用 fsync()进行一次binlog刷新,写入磁盘。
-
-
SQL注入
通过把SQL命令插入到Web表单提交或输入域名或页面查询的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。
用户(黑客)可以提交一段数据库查询代码,根据程序返回的结果,获得某些他想得知的数据,这就是所谓的SQL Injection,即SQL注入。
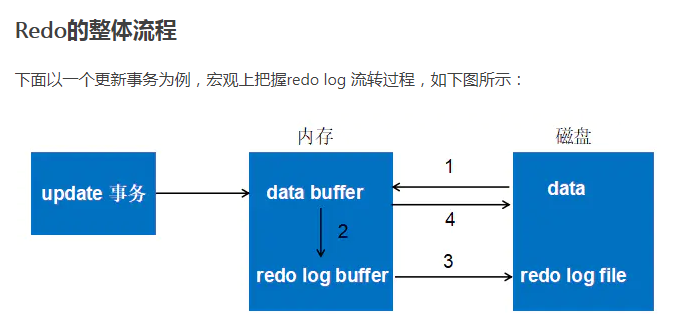
5.redo和undo
-
innodb存储引擎的架构
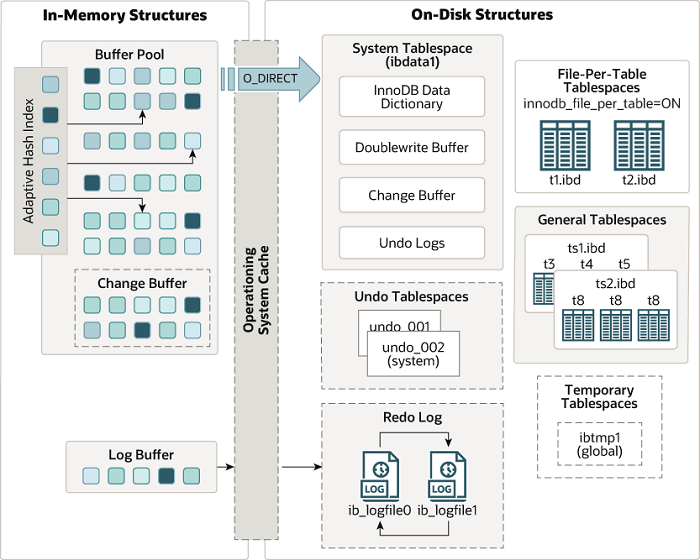
redo log和undo log是innodb 存储引擎产生的日志;先执行redo,然后执行undo
-
redo log:记录的是脏数据的变化(commit事务执行不成功就会redo)–》buffer pool里的
-
作用
MySQL意外宕机重启也不要紧。只要在重启时解析redo log中的事务而后重做一遍。将Buffer Pool中的缓存页重作成脏页。后续再在合适的时机将该脏页刷入磁盘便可。
-
存放位置/data/mysql
ib_logfile0和ib_logfile1
-
-
undo log:记录某数据被修改前的值(rollback事务执行撤销)
-
作用
方便回滚 rollback --》相当于做了一个快照(备份)
-
存放位置/data/mysql
ibdata1
-
七. 备份和还原
1.备份方案
-
完全备份
备份了全部的内容,备份的东西比较多的话,时间比较长
-
增量备份
备份的好处是每次备份需要备份的数据较少,耗时较短,占用的空间较小;坏处是数据恢复比较麻烦
-
差异备份
差异备份最开始进行一次完全备份,但是和增量备份不同的是,每次差异备份都备份和原始的完全备份不同的数据
2.热备
MySQL服务是运行的,最普遍使用的方式
2.1 mysqldump
-
备份库
#全部备份 mysqldump -uroot -p'Sanchuang1234#' --all-databases >all_db.sql #备份几个库 mysqldump --databases db1 db2 db3 > dump.sql mysqldump -uroot -p'Sanchuang1234#' --databases hunan liangliang >hunan_liangliang.sql -
备份表
mysqldump test t1 t3 t7 > dump.sql mysqldump -uroot -p'Sanchuang123#' TENNIS PLAYERS >tennis_players.sql
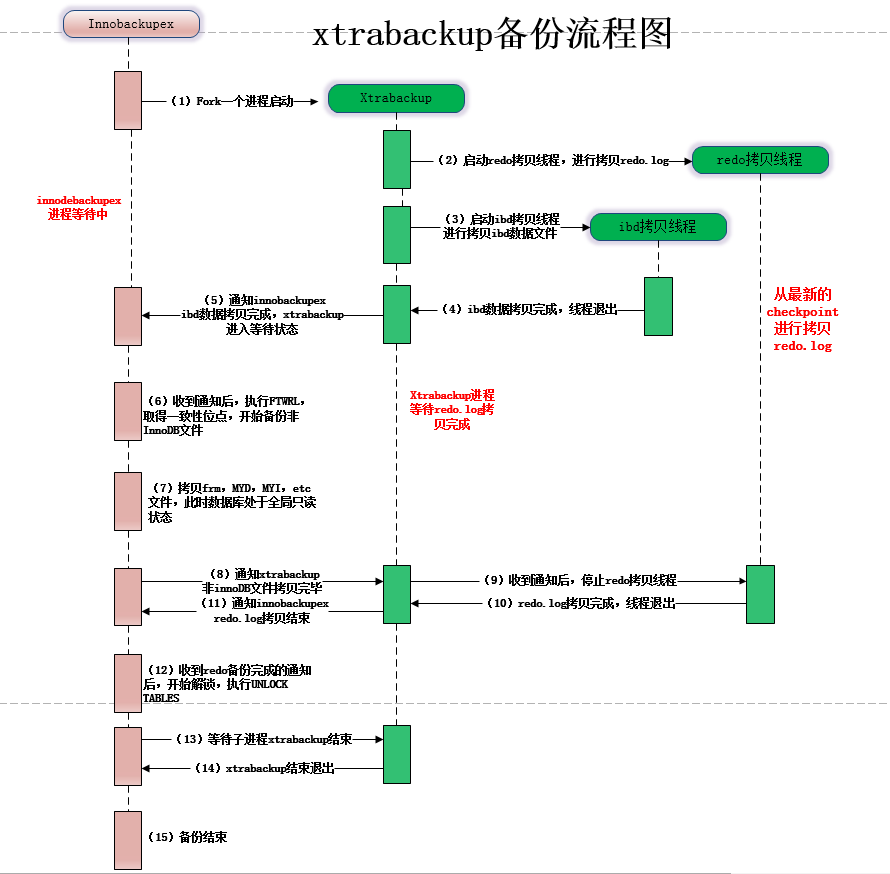
2.2 xtrabackup
xtrabackup备份过程中,先备份innodb表,再备份非innodb表
3.冷备
关闭MySQL服务,不关闭机器
-
scp
-
tar
4.异地备份
4.1 scp
4.2 rsync和sersync
-
简介
- rsync 全称 remote synchronize,即 远程同步
- Sersync可以记录下被监听目录中发生变化的(包括增加、删除、修改)具体某一个文件或者某一个目录的名字,然后使用rsync同步的时候,只同步发生变化的文件或者目录,因此效率更高。
- 主要应用场景为数据体积大,并且文件很多
-
实验操作
-
在备份服务器上操作
1、在备份服务器上,创建备份文件夹/backup
mkdir /backup2、关闭 selinux和Linux防火墙
关闭 selinux [root@sc-mysql2 backup]# getenforce Permissive [root@sc-mysql2 backup]# vim /etc/selinux/config SELINUX=disabled 关闭防火墙 [root@sc-mysql2 backup]# service firewalld stop3、安装rsync服务端软件并且设置开机启动
[root@sc-mysql2 backup]# yum install rsync xinetd -y [root@sc-mysql2 backup]# vi /etc/rc.d/rc.local # #设置开机启动 /usr/bin/rsync --daemon --config=/etc/rsyncd.conf # 添加开机启动[root@sc-mysql2 backup]# chmod +x /etc/rc.d/rc.local [root@sc-mysql2 backup]# systemctl start xinetd #启动xinetdxinetd是一个提供保姆服务的进程,rsync是它照顾的进程
独立的服务:ssh,dhcp,mysql
非独立的服务,非独立的服务需要依赖其他的服务来管理,rsync就是一个非独立的服务,依赖xinetd来管理4、创建rsyncd.conf配置文件
[root@sc-mysql2 backup]# vim /etc/rsyncd.conf 添加下面的配置 uid = root gid = root use chroot = yes max connections = 0 log file = /var/log/rsyncd.log pid file = /var/run/rsyncd.pid lock file = /var/run/rsync.lock secrets file = /etc/rsync.pass motd file = /etc/rsyncd.Motd [back_data] #配置项名称(自定义)path = /backup #备份文件存储地址 -->需要提前在备份服务器上新建,不然后面会报错comment = A directory in which data is storedignore errors = yesread only = nohosts allow = 192.168.98.131 #允许的ip地址(数据源服务器地址)5、创建用户认证文件
$ vi /etc/rsync.pass # 配置文件,添加以下内容,添加允许传输用户和密码sunline:sunline # 格式,用户名:密码,可以设置多个,每行一个用户名:密码sc:sc1234566、设置文件权限
$ chmod 600 /etc/rsyncd.conf #设置文件所有者读取、写入权限 $ chmod 600 /etc/rsync.pass #设置文件所有者读取、写入权限7、启动rsync和xinetd
[root@sc-mysql2 backup]# /usr/bin/rsync --daemon --config=/etc/rsyncd.conf [root@sc-mysql2 backup]# ps aux|grep rsync root 9455 0.0 0.0 114844 584 ? Ss 16:13 0:00 /usr/bin/rsync --daemon --config=/etc/rsyncd.conf root 9457 0.0 0.0 112824 988 pts/0 S+ 16:13 0:00 grep --color=auto rsync[root@sc-mysql2 backup]# systemctl start xinetd [root@sc-mysql2 backup]# ps aux|grep xinetd root 9425 0.0 0.0 25044 584 ? Ss 16:00 0:00 /usr/sbin/xinetd -stayalive -pidfile /var/run/xinetd.pid root 9465 0.0 0.0 112824 988 pts/0 S+ 16:14 0:00 grep --color=auto xinetd8.查看rsync监听的端口号
[root@sc-mysql2 backup]# netstat -anplut -
数据源服务器操作
1、关闭 selinux和防火墙
[root@sc-mysql2 backup]# getenforce Permissive [root@sc-mysql2 backup]# vim /etc/selinux/config SELINUX=disabled[root@sc-mysql2 backup]# service firewalld stop2、安装rsync客户端软件
3、安装rsync服务端软件 [root@sc-mysql2 backup]# yum install rsync xinetd -y [root@sc-mysql2 backup]# vi /etc/rc.d/rc.local # #设置开机启动 /usr/bin/rsync --daemon --config=/etc/rsyncd.conf # 添加开机启动[root@sc-mysql2 backup]# chmod +x /etc/rc.d/rc.local3、创建rsyncd.conf配置文件
[root@sc-mysql backup]# vim /etc/rsyncd.conf log file = /var/log/rsyncd.log pid file = /var/run/rsyncd.pid lock file = /var/run/rsync.lock motd file = /etc/rsyncd.Motd [Sync]comment = Syncuid = rootgid = rootport= 873 [root@sc-mysql2 backup]# systemctl start xinetd #启动(CentOS中是以xinetd来管理rsync服务的)4、创建认证密码文件
[root@sc-mysql backup]# vim /etc/passwd.txt sc123456 #编辑文件,添加以下内容,该密码应与目标服务器中的/etc/rsync.pass中的密码一致 [root@sc-mysql backup]# chmod 600 /etc/passwd.txt #设置文件权限,只设置文件所有者具有读取、写入权限即可5、测试数据同步
数据源服务器192.168.98.131 到备份服务器192.168.98.139之间的数据同步[root@sc-mysql backup]# rsync -avH --port=873 --progress --delete /backup root@192.168.98.139::back_data --password-file=/etc/passwd.txt /backup(要备份的数据源目录 ) root@192.168.98.139::back_data(rsyncd.conf文件配置名称)增加文件,或者删除文件,测试是否可以增量备份
-
接下来安装sersync工具,实现自动的实时的同步–》安装到数据源服务器上
1、修改inotify默认参数(inotify默认内核参数值太小) 修改参数:
临时修改 [root@sc-mysql backup]# sysctl -w fs.inotify.max_queued_events="99999999" fs.inotify.max_queued_events = 99999999 [root@sc-mysql backup]# sysctl -w fs.inotify.max_user_watches="99999999" fs.inotify.max_user_watches = 99999999 [root@sc-mysql backup]# sysctl -w fs.inotify.max_user_instances="65535" fs.inotify.max_user_instances = 65535永久修改参数 [root@sc-mysql backup]# vim /etc/sysctl.conf fs.inotify.max_queued_events=99999999 fs.inotify.max_user_watches=99999999 fs.inotify.max_user_instances=655352、安装sersync
[root@sc-mysql backup]# yum install wget -y [root@sc-mysql backup]# wget http://down.whsir.com/downloads/sersync2.5.4_64bit_binary_stable_final.tar.gz [root@sc-mysql backup]# tar xf sersync2.5.4_64bit_binary_stable_final.tar.gz [root@sc-mysql backup]# mv GNU-Linux-x86/ /usr/local/sersync3、创建rsync
[root@sc-mysql backup]# cd /usr/local/sersync/ [root@sc-mysql sersync]# ls confxml.xml sersync2备份配置文件,防止修改错了,不知道哪里出错,好还原 [root@sc-mysql sersync]# cp confxml.xml confxml.xml.bak [root@sc-mysql sersync]# cp confxml.xml data_configxml.xml [root@sc-mysql sersync]# ls confxml.xml confxml.xml.bak data_configxml.xml sersync2 #data_configxml.xml 是后面需要使用的配置文件4、修改配置 data_configxml.xml 文件
第24行后的配置 <localpath watch="/backup"><remote ip="192.168.2.197" name="back_data"/><!--<remote ip="192.168.8.39" name="tongbu"/>--><!--<remote ip="192.168.8.40" name="tongbu"/>--></localpath><rsync><commonParams params="-artuz"/><auth start="false" users="root" passwordfile="/etc/passwd.txt"/><userDefinedPort start="false" port="874"/><!-- port=874 --><timeout start="false" time="100"/><!-- timeout=100 --><ssh start="false"/>5、启动服务
[root@sc-mysql sersync]# PATH=/usr/local/sersync/:$PATH [root@sc-mysql sersync]# which sersync2 /usr/local/sersync/sersync2[root@sc-mysql sersync]# echo 'PATH=/usr/local/sersync/:$PATH' >>/root/.bashrc [root@sc-mysql sersync]# sersync2 -d -r -o /usr/local/sersync/data_configxml.xml[root@sc-mysql backup]# ps aux|grep sersync验证:去/backup目录下新建一些文件或者文件夹,测试是否在备份服务器上可以看到
6、设置sersync监控开机自动执行
[root@sc-mysql backup]# vim /etc/rc.local /usr/local/sersync/sersync2 -d -r -o /usr/local/sersync/data_configxml.xml
-
-
错误的问题
1.配置文件没有写内容,或者打错
2.两边的服务器没有新建目录/backup -->特别是备份服务器上没有新建/backup-
排错查看日志
[root@sc-mysql2 backup]# cat /var/log/rsyncd.log 2022/08/18 16:13:19 [9455] rsyncd version 3.1.2 starting, listening on port 873 2022/08/18 16:35:08 [9472] name lookup failed for 192.168.2.196: Name or service not known 2022/08/18 16:35:08 [9472] connect from UNKNOWN (192.168.2.196) 2022/08/18 17:16:37 [9532] rsync: chroot /backup2 failed: No such file or directory (2) 错误信息
-
5.恢复备份
5.1 mysqlbinlog
-
根据时间点来恢复
[root@sc-mysql ysql]#mysqlbinlog --start-datetime="2005-04-20 9:55:00" --stop-datetime="2005-04-20 10:05:00" /var/log/mysql/bin.123456 >/tmp/mysql_restore.sql[root@sc-mysql ysql]#mysqlbinlog --start-datetime="2020-08-13 11:50:07" --stop-datetime="2020-08-13 11:50:24" /data/mysql/zabbix-4-centos7-bin.000002 |mysql -uyangst -p'yang123#' -
根据位置号来恢复
[root@sc-mysql ysql]# mysqlbinlog --start-position=154 --stop-position=1063 sc-mysql-bin.000005|mysql -uroot -p'Sanchuang123#'
八. 主从复制
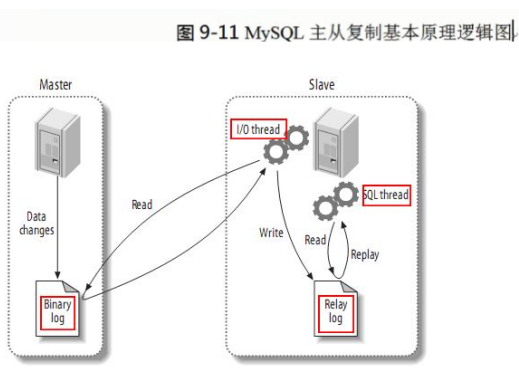
1.主从复制的原理
1.首先在master(主服务器)上开启二进制日志
2.master上数据发生变化,进行DML操作的时候,会产生二进制日志
3.master上的dump线程会通知slave上的IO线程来拿二进制日志,IO线程拿到二进制日志后会写入到slave上的中继日志,然后SQL线程会去读取新产生的中继日志,重演二进制日志里的操作,从而达到slave和master上的数据一模一样,实现数据的一致性。
-
从服务器的master-info文件的作用->给IO线程用的
- 记录master的ip,连接过去复制二进制日志的账号和密码,二进制日志的名字和位置号
- 记录IO线程取日志结束的pos位置号,日志文件的名字
-
从服务器的relay-log.info文件的作用->给SQL线程用的
- 记录SQL线程结束后的中继日志的文件名和位置点
-
主从复制的好处
1.做读写分离,构建一个集群,提高并发,提升性能
2.备份
2.主从复制模式
2.1 异步复制
-
缺点
有延迟,会丢失数据
-
步骤
1.安装好2台数据库服务器的系统,然后安装好MySQL软件
2.在master上开启二进制日志
3.统一2台服务器的基础数据
[root@sc-master ~]# mysqldump -uroot -p'123456' --all-databases >all_db.SQL [root@sc-master ~]# scp all_db.SQL root@192.168.2.197:/root [root@sc-slave ~]# mysql -uroot -p'123456' <all_db.SQL4.清除所有的二进制日志,因为有全备,不需要二进制日志了
root@(none) 11:18 scmysql>reset master; root@(none) 11:19 scmysql>show master status;5.在master上新建一个授权用户,给slave来复制二进制日志
root@(none) 11:19 scmysql>grant replication slave on *.* to 'liaobo'@'%' identified by '123456';6.在slave上配置master info的信息
CHANGE MASTER TO MASTER_HOST='192.168.2.196' , MASTER_USER='renxj', MASTER_PASSWORD='Sanchuang1234#', MASTER_PORT=3306, MASTER_LOG_FILE='sc-master-bin.000001', MASTER_LOG_POS=154;7.查看slave是否配置成功
root@(none) 11:29 mysql>show slave status\G;8.启动slave
root@(none) 11:30 mysql>start slave; root@(none) 11:31 mysql>show slave status\G;9.测试主从复制的效果(主上面建表建库,从上面查看)
-
master.info 和 relay-log.info在哪里?
[root@sc-slave mysql]# pwd /data/mysql [root@sc-slave mysql]# ls *.info master.info relay-log.info [root@sc-slave mysql]# cat master.info [root@sc-slave mysql]# cat relay-log.info
2.2 半同步复制
-
步骤
1.在master上安装配置半同步的插件
root@(none) 09:59 scmysql>INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';2.配置半同步复制超时时间
-
临时设置半同步复制超时时间为1秒,默认为10秒
root@(none) 11:18 scmysql>SET GLOBAL rpl_semi_sync_master_timeout = 1; root@(none) 11:20 scmysql>SET GLOBAL rpl_semi_sync_master_enabled = 1; -
永久配置半同步复制超时时间,修改配置文件
[root@sc-master ~]# vim /etc/my.cnf [mysqld] rpl_semi_sync_master_enabled=1 #添加 rpl_semi_sync_master_timeout=1000 # 1 second 添加
3.刷新mysql服务
[root@sc-master ~]# service mysqld restart4.在从服务器上配置安装半同步的插件
root@(none) 11:22 mysql>INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so'; root@(none) 11:23 mysql>SET GLOBAL rpl_semi_sync_slave_enabled = 1;5.永久修改从服务器上的配置文件
[root@sc-slave ~]# vim /etc/my.cnf [mysqld] rpl_semi_sync_slave_enabled=1 #添加6.刷新mysql服务
[root@sc-slave ~]# service mysqld restart7.在master和slave上执行SQL查看是否激活半同步
root@(none) 11:27 scmysql> SELECT PLUGIN_NAME, PLUGIN_STATUS FROM INFORMATION_SCHEMA.PLUGINS WHERE PLUGIN_NAME LIKE '%semi%'; +----------------------+---------------+ | PLUGIN_NAME | PLUGIN_STATUS | +----------------------+---------------+ | rpl_semi_sync_master | ACTIVE | +----------------------+---------------+8.验证的过程跟异步模式是一样的,在master上建表建库测试,在slave上查看是否生效
-
2.3 同步复制
-
组复制->同步复制实现的技术
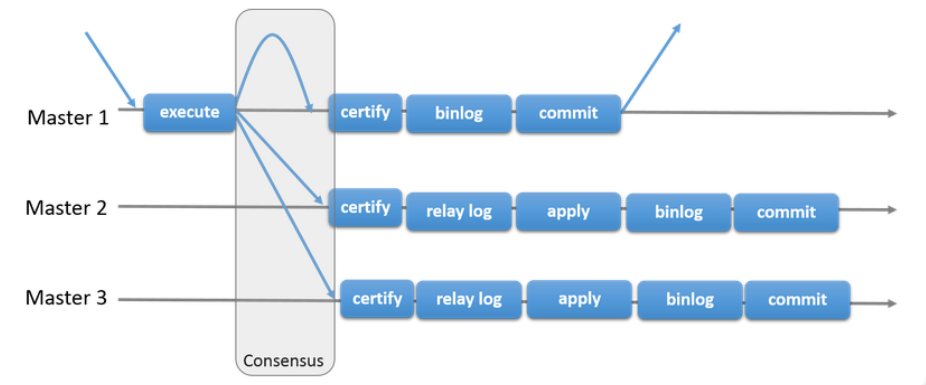
最低3台,最多9台
-
具体操作
https://www.cnblogs.com/kevingrace/p/10260685.html
3 延迟备份
-
步骤
1.停止同步服务
root@(none) 16:37 mysql>stop slave;2.设置延迟时间
root@(none) 16:37 mysql>CHANGE MASTER TO MASTER_DELAY = 10; #延迟10秒3.开始同步时间
root@(none) 16:37 mysql>start slave;4.查看
root@hepang123 11:47 mysql>show slave status\G;
4.主从切换
-
什么时候需要主从切换,主从切换如何实现?
主服务器挂了,需要提升原来的从为主 --》主从切换,故障切换 -
完全手工去操作:
步骤:
1.stop slave
2.reset master
3.开启二进制日志
4.建立授权复制的用户
5.再启动一台机器做从,配置master信息去拉取二进制日志 -
自动实现主从切换
使用脚本实现
1.监控master
在另外一台机器扫描端口:nc 3306
直接访问: mysql -h ip -uroot -p’**’ -e ‘show databases;’
每秒钟监控一次
2.马上执行手工操作的步骤,脚本自动执行 -
如何将网站的写的流量切到新的master上?
1.直接修改web里的代码里的ip,换成新的master的ip
2.修改域名对应的ip为新的master的ip
3.如果使用中间件,需要在中间件里调整
5.GTID主从复制
5.1 GTID简介
-
什么是GTID?
- 全局事务标识符GTID的全称为Global Transaction Identifier,是在整个复制环境中对一个事务的唯一标识。
- 目的在于能够实现主从自动定位和切换,而不像以前需要指定文件和位置。
- 使用GTID复制时,主库上提交事务时创建事务对应的GTID,从库在应用中继日志时用GTID识别和跟踪每个事务。在启动新从库或因故障转移到新主库时可以使用GTID来标识复制的位置,极大地简化了这些任务。–>在新的主从切换的时候,新的从服务器知道哪些事务已经做了,哪些没有做。
-
GTID格式
ceb0ca3d-8366-11e8-ad2b-000c298b7c9a:1-4
-
特点
1、全局唯一,一个事务对应一个GTID
2、替代传统的binlog+pos复制;使用master_auto_position=1自动匹配GTID断点进行复制
3、MySQL5.6开始支持
4、在传统的主从复制中,slave端不用开启binlog;但是在GTID主从复制中,必须开启binlog
5、slave端在接受master的binlog时,会校验GTID值
6、为了保证主从数据的一致性,多线程同时执行一个GTID -
工作原理
1、master更新数据时,会在事务前产生GTID,一同记录到binlog日志中。
2、slave端的i/o 线程将变更的binlog,写入到本地的relay log中。
3、sql线程从relay log中获取GTID,然后对比slave端的binlog是否有记录。
4、如果有记录,说明该GTID的事务已经执行,slave会忽略。
5、如果没有记录,slave就会从relay log中执行该GTID的事务,并记录到binlog。
6、在解析过程中会判断是否有主键,如果没有就用二级索引,如果没有就用全部扫描
5.2 配置基于GTID的半同步主从复制
-
步骤
1.在master上安装配置半同步的插件,再配置
root@(none) 09:59 scmysql>install plugin rpl_semi_sync_master SONAME 'semisync_master.so';#卸载命令 root@(none) 09:59 scmysql>uninstall plugin rpl_semi_sync_master;[root@sc-master ~]# vim /etc/my.cnf
[mysqld] #二进制日志开启 log_bin server_id = 1#开启半同步,需要提前安装半同步的插件 rpl_semi_sync_master_enabled=1 rpl_semi_sync_master_timeout=1000 # 1 second #gtid功能 gtid-mode=ON enforce-gtid-consistency=ON[root@sc-master mysql]# service mysqld restart2.在从服务器上配置安装半同步的插件,配置slave
root@(none) 11:22 mysql>install plugin rpl_semi_sync_slave SONAME 'semisync_slave.so'; root@(none) 11:23 mysql>set global rpl_semi_sync_slave_enabled = 1;[root@sc-slave mysql]# vim /etc/my.cnf
[mysqld] #log bin 二进制日志 log_bin server_id = 2 expire_logs_days = 15 #开启gtid功能 gtid-mode=ON enforce-gtid-consistency=ON log_slave_updates=ON #开启半同步,需要提前安装半同步的插件 rpl_semi_sync_slave_enabled=1[root@sc-slave mysql]# service mysqld restart3.在master上新建一个授权用户,给slave来复制二进制日志
root@(none) 11:19 scmysql>grant replication slave on *.* to 'liaobo'@'192.168.98.%' identified by '123456';4.在slave上配置master info的信息
#停止 root@(none) 16:33 scmysql>stop slave; #清空 root@(none) 16:33 scmysql>reset slave all; #配置 root@(none) 16:33 scmysql>CHANGE MASTER TO MASTER_HOST='192.168.2.197' ,-> MASTER_USER='renxj',-> MASTER_PASSWORD='Sanchuang1234#',-> MASTER_PORT=3306,-> master_auto_position=1; #复制时的位置信息,1表示起点154 #开启 root@(none) 16:33 scmysql>start slave;CHANGE MASTER TO MASTER_HOST='192.168.98.138' , MASTER_USER='master', MASTER_PASSWORD='123456', MASTER_PORT=3306, master_auto_position=1; CHANGE MASTER TO MASTER_DELAY = 60;5.查看
在slave上查看 root@(none) 16:34 scmysql>show slave status\G;在master上查看 root@(none) 16:35 mysql>show variables like "%semi_sync%";在slave上查看 root@(none) 16:35 scmysql>show variables like "%semi_sync%";6.验证GTID的半同步主从复制
-
gtid和组复制的使用场景
业务量小:推荐使用gtid的半同步主从复制,只要2~3台服务器
业务量大: 推荐使用组复制,至少3,5,7,9台服务器
-
log_slave_updates=ON 开启级联同步
但是当我们需要实现级联同步时,即以这样的一个模式,A>B>C实现三级同步时,AB库除了需要设置log-bin参数还需要添加一个参数:log-slave-updates
log-slave-updates参数默认时关闭的状态,如果不手动设置,那么bin-log只会记录直接在该库上执行的SQL语句,由replication机制的SQL线程读取relay-log而执行的SQL语句并不会记录到bin-log,那么就无法实现上述的三级级联同步。
5.3 架构
- 主主复制
- 多实例复制
九. 项目
9.1 简介
项目名称:基于keepalived+gtid半同步主从复制的MySQL集群
项目环境:centos7.9,mysql5.7.30,mysqlrouter8.0.21,keepalived 1.3.5,ansible 2.9.27等
项目描述:
本项目的目的是构建一个高可用的能实现读写分离的高效的MySQL集群,确保业务的稳定,能沟通方便的监控整个集群,同时能批量的去部署和管理整个集群。项目步骤:
1.配置好ansible服务器并建立免密通道,一键安装好5台MySQL服务器系统并安装好半同步相关的插件,在master上导出基础数据到ansible上,发布到所有slave服务器上并导入
2.开启gtid功能,启动主从复制服务,配置延迟备份服务器,从slave1上拿二进制日志
3.在master上创建一个计划任务每天2:30进行数据库的备份脚本,使用rsync+sersync远程同步到slave4异地备份服务器上
4.安装部署mysqlrouter中间件软件,实现读写分离;安装keepalived实现高可用,配置2个vrrp实例实现双vip的高可用功能
5.搭建DNS域名服务器,配置一个域名对应2个vip,实现基于DNS的负载均衡,访问同一URL解析出双vip地址
6.使用sysbench整个MySQL集群的性能(cpu、IO、内存等)进行压力测试,了解系统性能的瓶颈并调优项目心得:
1.一定要规划好整个集群的架构,配置要细心,脚本要提前准备好,边做边修改
2.防火墙和selinux的问题一定要多注意
3.对MySQL的集群和高可用有了深入的理解,对自动化批量部署和监控有了更加多的应用和理解
4.keepalived的配置需要更加细心,对IP地址的规划有了新的认识
5.对双vip有了更深的使用,添加2条负载均衡记录实现dns轮询,达到向2个vip负载均衡器上分流
-
遇到的问题及解决方法:
问题:
1.导入数据的时候GTID问题,先不开启gtid功能,数据导入同步后,再开启gtid功能
2.Slave_IO_Running: No
原因是: slave上的GTIDs编号比master上的还大(意味着slave上的数据比master还新),导致IO线程启动不成功
解决的方法:
在所有slave上清除master信息和slave的信息
reset master
reset slave all -
第9步的计划任务
[root@sc-master backup]# crontab -l 30 2 * * * bash /backup/backup_alldb.sh [root@sc-master backup]# cat backup_alldb.sh #!/bin/bashmkdir -p /backup mysqldump -uroot -p'Sanchuang1234#' --all-databases --triggers --routines --events >/backup/$(date +%Y%m%d%H%M%S)_all_db.SQL scp /backup/$(date +%Y%m%d%H%M%S)_all_db.SQL 192.168.2.103:/backup #可使用rsync远程同步
9.2 mysqlroute
MySQL Router就实现了MySQL的读写分离,对MySQL请求进行了负载均衡;是官方给我们提供的一个读写分离的轻量级MySQL中间件
既然MySQL Router是一个数据库的中间件,那么MySQL Router必须能够分析来自前面客户端的SQL请求是写请求还是读请求,以便决定这个SQL请求是发送给master还是slave,以及发送给哪个master、哪个slave。这样,MySQL Router就实现了MySQL的读写分离,对MySQL请求进行了负载均衡。因此,MySQL Router的前提是后端实现了MySQL的主从复制。
MySQL Router很轻量级,只能通过不同的端口来实现简单的读/写分离,且读请求的调度算法只能使用默认的rr(round-robin)轮询算法。
-
读写分离:将对数据库的增删改查等操作进行分离,读操作往slave上进行,读写操作都可以在master上进行
本质上起到了负载均衡的作用–》读写分离器、负载均衡器 -
目的:是解决大并发的场景下,将流量分散到所有的MySQL服务器上,提升整个MySQL集群的处理能力,避免资源的闲置,提高数据库的响应能力,提高用户使用的满意度->让整个数据库的访问过程非常顺畅,不卡顿。
-
好处:
dba负责数据库的业务,开发人员不需要了解,直接访问读写分离的服务器就可以了
更加好的进行业务上的切割 -
安装部署MySQLrouter
1.上传或者去官方网站下载软件https://dev.mysql.com/get/Downloads/MySQL-Router/mysql-router-community-8.0.23-1.el7.x86_64.rpm
2.安装
[root@mysql-router-1 ~]# rpm -ivh mysql-router-community-8.0.23-1.el7.x86_64.rpm3.修改配置文件
[root@mysql-router-1 ~]# cd /etc/mysqlrouter/ 进入存放配置文件的目录 [root@mysql-router-1 mysqlrouter]# vim mysqlrouter.conf[DEFAULT] logging_folder = /var/log/mysqlrouter runtime_folder = /var/run/mysqlrouter config_folder = /etc/mysqlrouter[logger] level = INFO[keepalive] interval = 60[routing:slaves] #bind_address = 192.168.98.140:7001 bind_address = 0.0.0.0:7001 destinations = 192.168.98.135:3306,192.168.98.138:3306 mode = read-only connect_timeout = 1[routing:masters] #bind_address = 192.168.98.140:7002 bind_address = 0.0.0.0:7002 destinations = 192.168.98.131:3306 mode = read-write connect_timeout = 14.启动MySQL router服务
[root@mysql-router-1 ~]# service mysqlrouter start mysqlrouter监听了7001和7002端口 [root@mysql-router-1 ~]# netstat -anplut|grep mysql tcp 0 0 192.168.2.106:7001 0.0.0.0:* LISTEN 2258/mysqlrouter tcp 0 0 192.168.2.106:7002 0.0.0.0:* LISTEN 2258/mysqlrouter5.在master上创建2个测试账号,一个是读的,一个是写的
root@(none) 15:34 mysql>grant all on *.* to 'write'@'%' identified by '123456'; root@(none) 15:35 mysql>grant select on *.* to 'read'@'%' identified by '123456';6.在客户端上测试读写分离的效果,使用2个测试账号
#实现读功能 [root@node1 ~]# mysql -h 192.168.98.140 -P 7001 -uread -p'123456' #实现写功能 [root@node1 ~]# mysql -h 192.168.98.140 -P 7002 -uwrite -p'123456'读写分离的关键点:其实是用户的权限,让不同的用户连接不同的端口,最后任然要到后端的mysql服务器里去验证是否有读写的权限
mysqlrouter只是做了读写的分流,让应用程序去连接不同的端口–》mysqlrouter只是一个分流的工具
主要是用户权限的控制,有写权限的用户走读的通道也可以写,读的用户走写的通道只能读
9.3 keepalived
9.3.1 介绍
-
high availability(HA) 高可用: 不会有单点故障,一个坏了,另外的能顶替,不影响工作,有备份。
-
3个经典的HA软件:heartbeat、keepalived、HAproxy
-
Keepalived 的2大核心功能:
1.loadbalance 负载均衡LB:ipvs–》lvs软件在linux内核里已经安装,不需要单独安装2.high-availability 高可用HA : vrrp协议
9.3.2 vrrp协议
vrrp协议:虚拟路由器冗余协议
-
介绍
一组路由器协同工作,担任不同的角色,有master角色,也有backup角色
master角色的路由器(的接口)承担实际的数据流量转发任务
Backup路由器侦听Master路由器的状态,并在Master路由器发生故障时,接替其工作,从而保证业务流量的平滑切换。 随时候命,是备胎
-
vip: 虚拟ip ->在一个VRRP 组内的多个路由器接口共用一个虚拟IP地址,该地址被作为局域网内所有主机的缺省网关地址。
-
VRRP协议报文

VRRP协议报文使用固定的组播地址224.0.0.18进行发送
帧的组播地址:目的地址[Destination Address] 01:00:5E:00:00:12 -
vrrp协议工作在网络层
-
vrrp协议的组播地址:
封装角度:
帧: 源mac,目的mac
vrrp协议: 封装
ip协议 -
vrrp协议的工作原理:
选举的过程:
1.所有的路由器或者服务器发送vrrp宣告报文,进行选举,必须是相同vrid和认证密码的,优先级高的服务器或者路由器会被选举为master,其他的机器都是backup
2.master定时(Advertisement Interval)发送VRRP通告报文,以便向Backup路由器告 知自己的存活情况。 默认是间隔1秒
3.接收Master设备发送的VRRP通告报文,判断Master设备的状态是否正常。 如果超过1秒没有收到vrrp报文,就认为master挂了,开始重新选举新的master,vip会漂移到新的master上
9.3.3 脑裂
-
脑裂:多台机器出现vip
-
脑裂原因:
1.vrid(虚拟路由id)不一样
2.网络通信有问题:中间有防火墙阻止了网络之间的选举的过程,vrrp报文的通信
3.认证密码不一样也会出现脑裂 -
脑裂有没有危害?如果有危害对业务有什么影响?
没有危害,能正常访问,反而还有负载均衡的作用
脑裂恢复的时候,还是有影响的,会短暂的中断,影响业务的
9.3.4 keepalived实验
-
配置keepalived的步骤
1.在2台MySQLrouter上都安装keepalived软件,
[root@mysql-router-1 keepalived]# yum install keepalived -y [root@mysql-router-2 keepalived]# yum install keepalived -y2.修改配置文件
#配置介绍 vrrp_instance VI_1 { #定义一个vrrp协议的实例 名字叫VI_1 第一个vrrp实例state MASTER #做master角色interface ens33 #指定监听网络的接口,其实就是vip绑定到那个网络接口上virtual_router_id 151 #虚拟路由器id --》帮派 51是帮派的编号 0~255之间priority 120 #优先级 0~255advert_int 1 #宣告消息的时间间隔 1秒authentication {auth_type PASS #密码认证 passwordauth_pass 1111 #具体密码}virtual_ipaddress { #vip 虚拟ip地址192.168.98.88}[root@mysql-router-1 ~]# cd /etc/keepalived/ [root@mysqlrouter-1 keepalived]# vim keepalived.conf ! Configuration File for keepalivedglobal_defs {notification_email {acassen@firewall.locfailover@firewall.locsysadmin@firewall.loc}notification_email_from Alexandre.Cassen@firewall.locsmtp_server 192.168.200.1smtp_connect_timeout 30router_id LVS_DEVELvrrp_skip_check_adv_addr#vrrp_strictvrrp_garp_interval 0vrrp_gna_interval 0 }vrrp_instance VI_1 {state backupinterface ens33virtual_router_id 80priority 100advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {192.168.98.88} }[root@mysql-router-2 keepalived]# vim keepalived.conf ! Configuration File for keepalivedglobal_defs {notification_email {acassen@firewall.locfailover@firewall.locsysadmin@firewall.loc}notification_email_from Alexandre.Cassen@firewall.locsmtp_server 192.168.200.1smtp_connect_timeout 30router_id LVS_DEVELvrrp_skip_check_adv_addr#vrrp_strictvrrp_garp_interval 0vrrp_gna_interval 0 }vrrp_instance VI_1 {state backupinterface ens33virtual_router_id 80priority 100advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {192.168.98.88} }3.启动服务
[root@mysql-router-1 keepalived]# service keepalived start [root@mysqlrouter-2 keepalived]# service keepalived start4.可以验证vip漂移
关闭master上的keepalived服务
service keepalived stop
在backup服务器上看是否有vip
9.3.5 keepalived的3个进程
- keepalived的3个进程,keepalived进程去封装vrrp协议报文,负责接收和发送
- keepalived正常启动的时候,共启动3个进程:
一个是父进程,负责监控其子进程;一个是VRRP子进程,另外一个是checkers子进程;
两个子进程都被系统watchdog看管,两个子进程各自负责自己的事。
Healthcheck子进程检查各自服务器的健康状况,,例如http,lvs。如果healthchecks进程检查到master上服务不可用了,就会通知本机上的VRRP子进程,让他删除通告,并且去掉虚拟IP,转换为BACKUP状态。

9.3.6 主从切换时如何设置邮件通知
-
/etc/keepalived/keepalived.conf 配置文件中设置(截取部分)
vrrp_script send_mail {script "/mail/sendmail.sh"interval 3 #每隔3秒钟就执行一次这个脚本 }vrrp_instance VI_1 {state MASTERinterface ens33virtual_router_id 80priority 200advert_int 1authentication {auth_type PASSauth_pass 1111} #追踪执行脚本,只要成为master,发送vrrp宣告消息就执行脚本 track_script {send_mail } #notify_master 状态改变为MASTER后执行的脚本 notify_master /mail/master.sh#notify_backup 状态改变为BACKUP后执行的脚本 notify_backup /mail/backup.sh#notify_stop VRRP停止后后执行的脚本 notify_stop /mail/stop.shvirtual_ipaddress {192.168.2.187 }}在vrrp实例里的配置,只要启动keepalived进程就会每隔3秒执行一次/mail/sendmail.sh,不管你是master还是backup;
notify | # (1)任意状态改变后执行的脚本
9.4 keepalived实现双vip功能
-
思路:搞2个vrrp实例,2个vip,2个实例互为主备
-
第1台服务器上的配置
[root@mysql-router-1 keepalived]# cat keepalived.conf ! Configuration File for keepalivedglobal_defs {notification_email {acassen@firewall.locfailover@firewall.locsysadmin@firewall.loc}notification_email_from Alexandre.Cassen@firewall.locsmtp_server 192.168.200.1smtp_connect_timeout 30router_id LVS_DEVELvrrp_skip_check_adv_addr#vrrp_strictvrrp_garp_interval 0vrrp_gna_interval 0 }vrrp_instance VI_1 {state MASTERinterface ens33virtual_router_id 80priority 200advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {192.168.98.88} }vrrp_instance VI_2 {state backupinterface ens33virtual_router_id 81priority 100advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {192.168.98.89} } -
第2台服务器的配置
[root@mysqlrouter-2 keepalived]# cat keepalived.conf ! Configuration File for keepalivedglobal_defs {notification_email {acassen@firewall.locfailover@firewall.locsysadmin@firewall.loc}notification_email_from Alexandre.Cassen@firewall.locsmtp_server 192.168.200.1smtp_connect_timeout 30router_id LVS_DEVELvrrp_skip_check_adv_addr#vrrp_strictvrrp_garp_interval 0vrrp_gna_interval 0 } vrrp_instance VI_1 {state backupinterface ens33virtual_router_id 80priority 100advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {192.168.98.88} }vrrp_instance VI_2 {state masterinterface ens33virtual_router_id 81priority 200advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {192.168.98.89} }
9.5 压力测试工具
-
sysbench
1.使用yum安装,使用epel-release源去安装sysbench[root@nfs-server ~]# yum install epel-release -y [root@nfs-server ~]# yum install sysbench -y2.在master数据库里新建sbtest的库
[root@sc-slave ~]# mysql -uwrite -p'123456' -h 192.168.98.141 -P 7002write@(none) 21:50 mysql>create database sbtest;3.建10个sbtest表
[root@localhost sysbench]# sysbench --mysql-host=192.168.98.141 --mysql-port=7002 --mysql-user=write --mysql-password='123456' /usr/share/sysbench/oltp_common.lua --tables=10 --table_size=10000 prepare4.压力测试
[root@localhost sysbench]# sysbench --threads=4 --time=20 --report-interval=5 --mysql-host=192.168.98.141 --mysql-port=7002 --mysql-user=write --mysql-password='123456' /usr/share/sysbench/oltp_read_write.lua --tables=10 --table_size=100000 run -
mysql性能测试工具——tpcc
1.下载安装包并解压,然后打开目录进行make
wget http://imysql.com/wp-content/uploads/2014/09/tpcc-mysql-src.tgz tar xf tpcc-mysql-src.tar cd tpcc-mysql/src make之后会生成两个二进制工具tpcc_load(提供初始化数据的功能)和tpcc_start(进行压力测试)
[root@nfs-server src]# cd .. [root@nfs-server tpcc-mysql]# ls add_fkey_idx.sql drop_cons.sql schema2 tpcc_load count.sql load.sh scripts tpcc_start create_table.sql README src [root@nfs-server tpcc-mysql]#3、初始化数据库
在master服务器上连接到读写分离器上创建tpcc库,需要在测试的服务器上创建tpcc的库
[root@sc-slave ~]# mysqladmin -uwrite -p'123456' -h 192.168.98.141 -P 7002 create tpcc需要将tpcc的create_table.sql 和add_fkey_idx.sql 远程拷贝到master服务器上
[root@nfs-server tpcc-mysql]# scp create_table.sql add_fkey_idx.sql root@192.168.98.131:/root然后在master服务器上导入create_table.sql 和add_fkey_idx.sql 文件
mysql -uroot -p'123456' tpcc <create_table.sql mysql -uroot -p'123456' tpcc <add_fkey_idx.sql4、加载数据
注意:server是要测试的服务器,db,user,password也是要测的服务器上mysql的信息
./tpcc_load [server] [db] [user] [password] [warehouse]
服务器名 数据库名 用户名 密码 仓库数量
真实测试中,数据库仓库一般不少于100个,如果配置了ssd,建议最少不低于1000个[root@nfs-server tpcc-mysql]# ./tpcc_load 192.168.98.141:7002 tpcc write Sanchuang1234# 1505、进行测试
./tpcc_start -h 192.168.98.141 -p 7002 -d tpcc -u write -p 123456 -w 150 -c 12 -r 300 -l 360 -f test0.log -t test1.log - >test0.out注意:server等信息与步骤4中保持一致
各个参数用法如下:
-h server_host: 服务器名
-P port : 端口号,默认为3306
-d database_name: 数据库名
-u mysql_user : 用户名
-p mysql_password : 密码
-w warehouses: 仓库的数量
-c connections : 线程数,默认为1
-r warmup_time : 热身时间,单位:s,默认为10s , 热身是为了将数据加载到内存。(真实测试中建议热身时间不低于5分钟)
-l running_time: 测试时间,单位:s,默认为20s
-i report_interval: 指定生成报告间隔时长(真实测试中不低于30min)
-f report_file: 测试结果输出文件(一般命名为xxx.log)
-t trx:输出文件out1: 将控制台输出存入文件out1中
相关文章:
MySQL基础运维知识点大全
一. MySQL基本知识 1. 目录的功能 通用 Unix/Linux 二进制包的 MySQL 安装下目录的相关功能 目录目录目录binMySQLd服务器,客户端和实用程序docs信息格式的 MySQL 手册manUnix 手册页include包括(头)文件lib图书馆share用于数据库安装的错…...

javascript获取样式表的规则及读取与写入
CSSStyleSheet是继承了StyleSheet的接口属性,它是用于找当前文档中的<link rel“” href“”…>这样文件的,有以下属性:lenght,cssRules,title,href,type,deleteRule,insertRule等 CSSStyleRule是继承于CSSRule,它是用于找<link re…...

什么是promise?
是JavaScript中用于处理异步操作的一种机制。 异步操作,例如从服务器获取数据、读取文件、执行数据库查询等等。 经典使用:Axios 是一个基于Promise的HTTP客户端 Promise具有三个状态: Pending(待定):Pr…...

从零开始学习软件测试-第45天笔记
monkey事件 事件:对app进行的操作,比如触摸事件,滑动事件...动作:构成一个事件所需要的步骤。 调整事件的百分比 adb shell monkey -p 包名 -v -v --pct-xxx 百分比 次数>输出文件的路径 分析日志有没有报错 到日志中去找…...

visual studio常用快捷键
CtrlM、CtrlO 折叠到定义 CtrlM、CtrlM 折叠当前定义 CtrlM、CtrlA 折叠全部 CtrlK、CtrlD 自动编排代码格式 F12 转到定义 ShiftF12 查看所有定义 ctrl] 转到定义首部或尾部 ctrlX 未选中文本时,剪切/删除光标所在行。ctrlV 未选中文本时,粘贴到…...

数据变换:数据挖掘的准备工作之一
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据…...

Go语言实践案例之简单字典
一、程序要实现效果: 在命令行调用程序的时候,可以在命令行的后面查询一个单词,然后会输出单词的音标和注释。 二、思路分析: 定义一个结构体 DictRequest,用于表示翻译请求的数据结构。其中包含了 TransType&#…...
)
笔试面试相关记录(3)
(1)String String和String.append()的底层实现 C中string append函数的使用与字符串拼接「建议收藏」-腾讯云开发者社区-腾讯云 (tencent.com) String String 在 第二个String中遇到\0就截止,append()的方法则是所有字符都会加在后面。 &…...
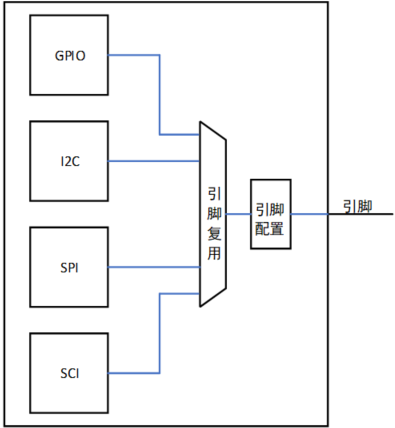
第6章_瑞萨MCU零基础入门系列教程之串行通信接口(SCI)
本教程基于韦东山百问网出的 DShanMCU-RA6M5开发板 进行编写,需要的同学可以在这里获取: https://item.taobao.com/item.htm?id728461040949 配套资料获取:https://renesas-docs.100ask.net 瑞萨MCU零基础入门系列教程汇总: ht…...

开源免费的流程图软件draw.io
2023年9月16日,周六上午 想买微软的visio,但发现不是很值得,因为我平时也不是经常需要画图。 所以我最后还是决定使用开源免费的draw.io来画图 draw.io网页版的网址: Flowchart Maker & Online Diagram Software draw.io的…...
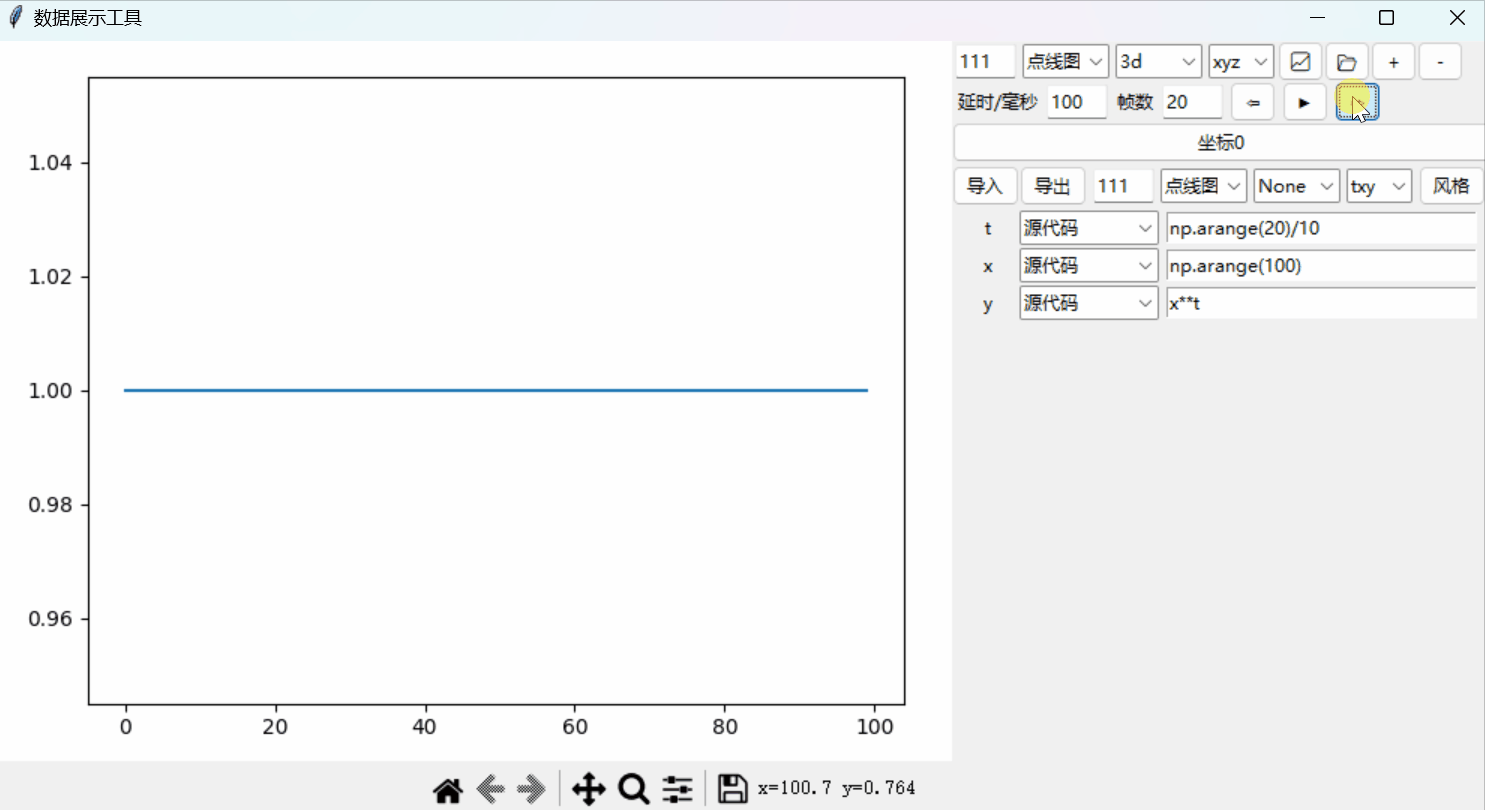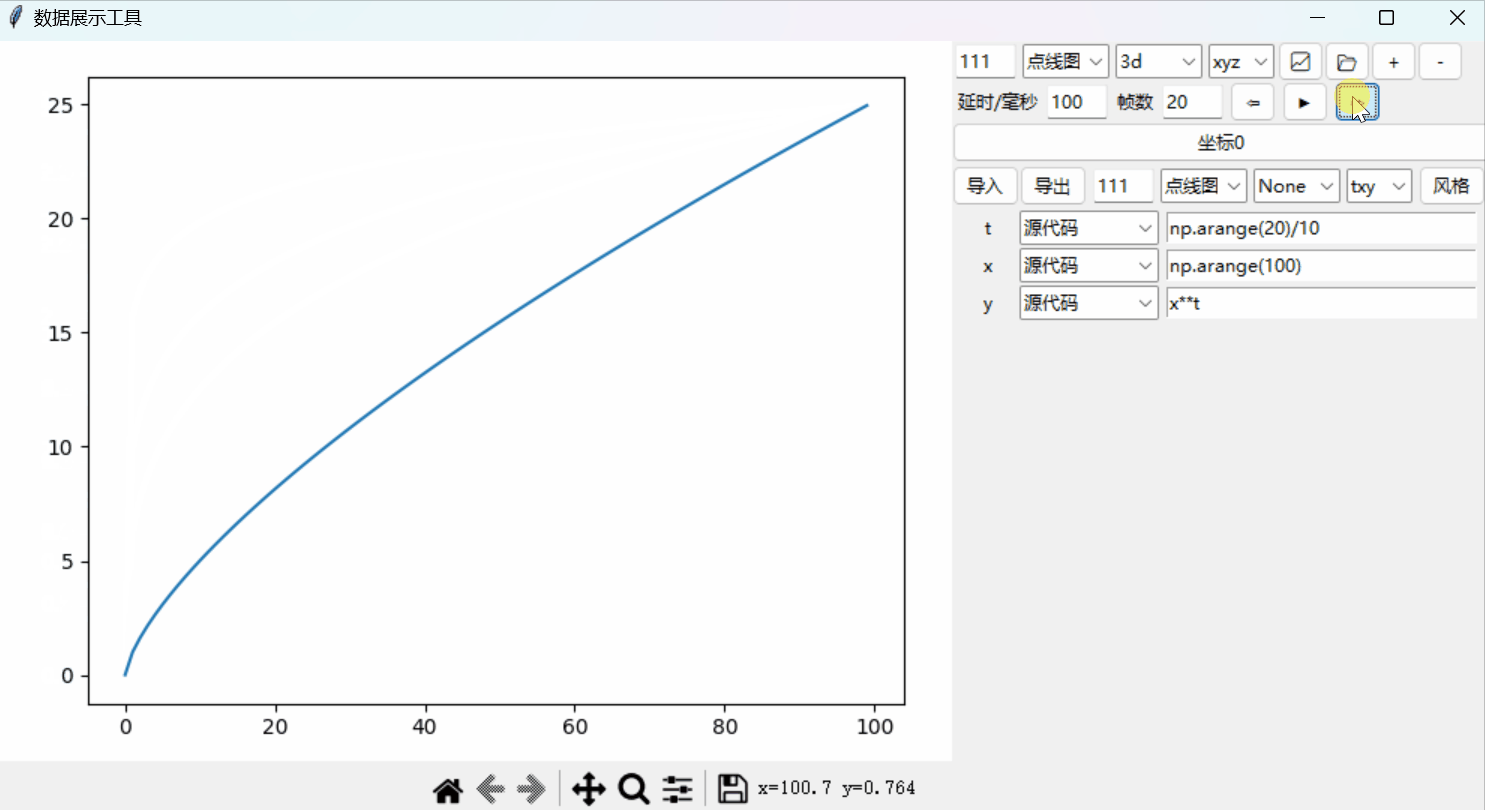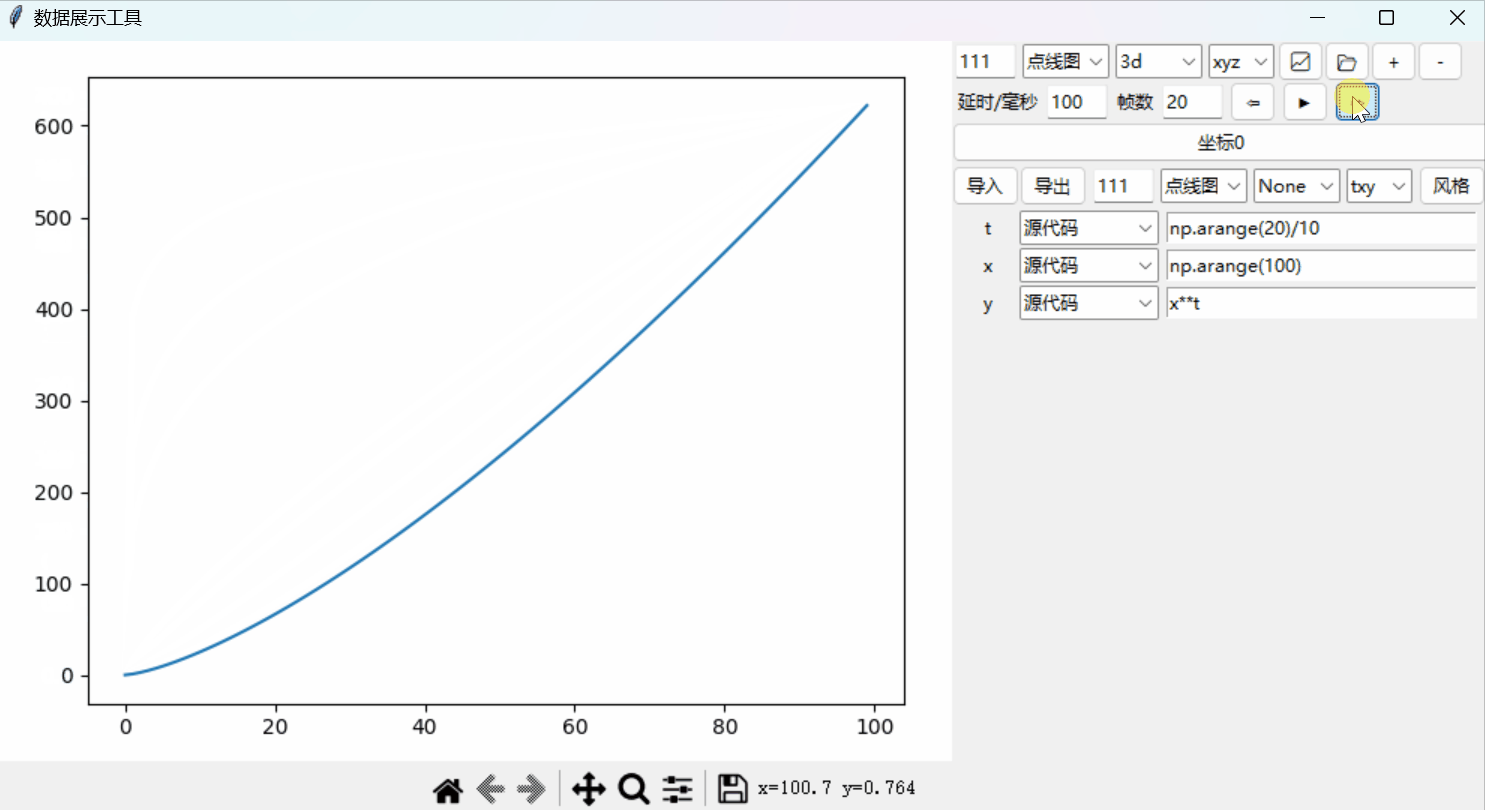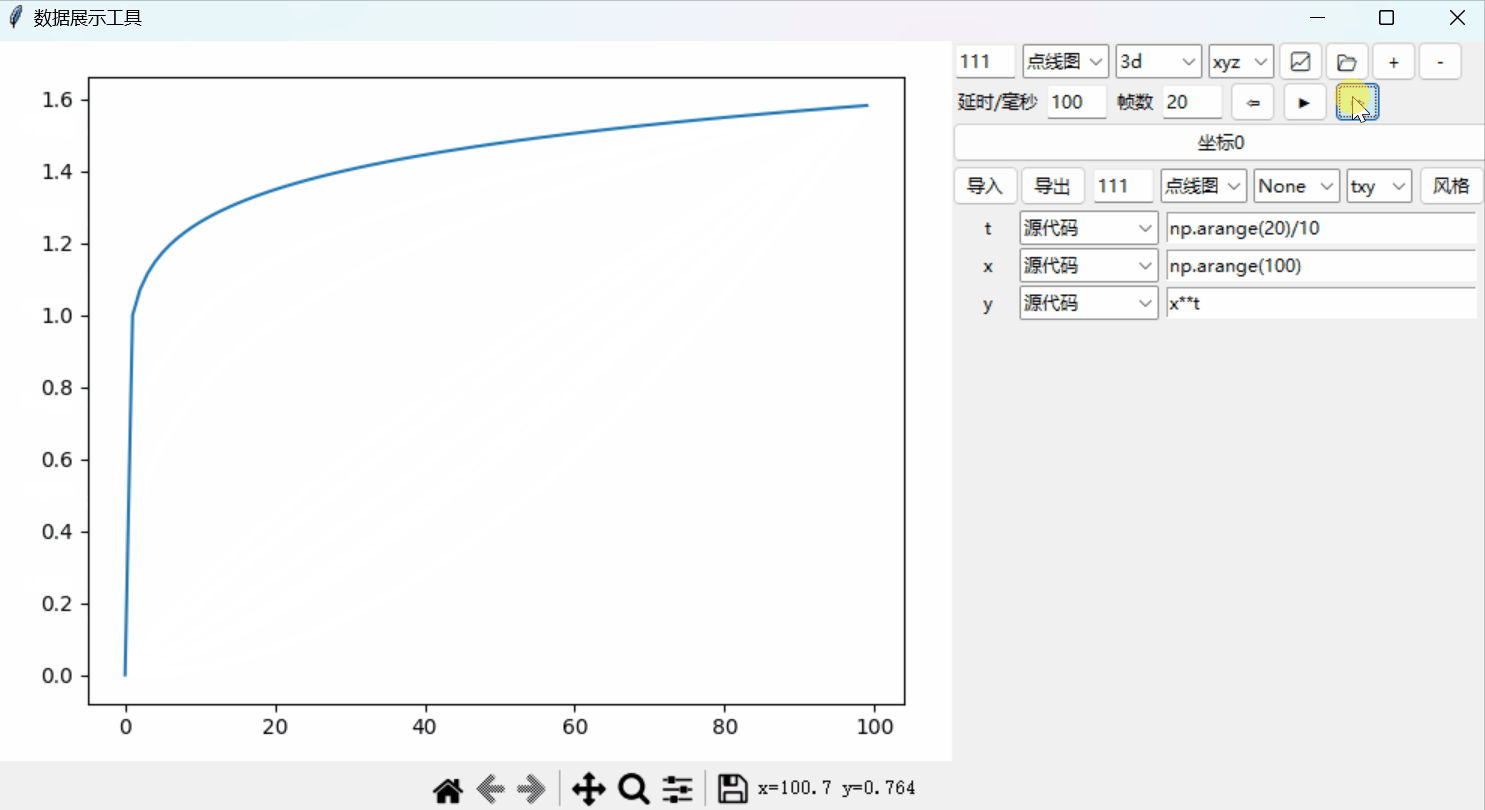
Python绘图系统19:添加时间轴以实现动态绘图
文章目录 时间轴单帧跳转源代码 Python绘图系统: 📈从0开始的3D绘图系统📉一套3D坐标,多个函数📊散点图、极坐标和子图自定义控件:绘图风格📉风格控件📊定制绘图风格坐标设置进阶&a…...
深度解析shell脚本的命令的原理之rm
rm 是 Unix/Linux 系统中的一个基本命令,用于删除文件或目录。以下是对这个命令的深度分析: 基本操作:rm 命令删除一个或多个文件或目录。这是通过从文件系统中移除链接来完成的。在 Unix/Linux 中,文件是通过链接(可以…...
)
RPA机器人流程自动化专题培训大纲(供大家参考使用)
一、RPA机器人流程自动化概述 RPA的定义和发展历程RPA的应用场景和优势RPA与人工智能的关系 二、RPA机器人流程自动化基础知识 RPA的基本原理和技术架构RPA的常用技术和工具RPA的编程语言和开发环境 三、RPA机器人流程自动化实战应用 如何进行业务流程分析与优化如何利用R…...
Python用若干列的数据多条件筛选、去除Excel数据并批量绘制直方图
本文介绍基于Python,读取Excel数据,以一列数据的值为标准,对这一列数据处于指定范围的所有行,再用其他几列数据数值,加以筛选与剔除;同时,对筛选与剔除前、后的数据分别绘制若干直方图ÿ…...
驱动开发,IO多路复用实现过程,epoll方式
1.框架图 被称为当前时代最好用的io多路复用方式; 核心操作:一棵树(红黑树)、一张表(内核链表)以及三个接口; 思想:(fd代表文件描述符) epoll要把检测的事件…...
java在mysql中查询内容无法塞入实体类中,报错 all elements are null
目录 一、问题描述二、解决方案 一、问题描述 java项目中整体配置了mysql的驼峰式字段匹配规则。 mybatis.configuration.map-underscore-to-camel-casetrue由于项目需求,需要返回字段为file_id,file_url,并且放入实体类中,实体…...
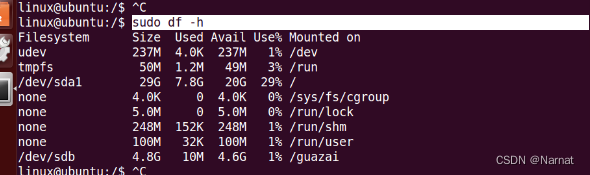
Linux 挂载
挂载需要挂载源和挂载点 虚拟机本身就有的挂源 添加硬件 重启虚拟机 操作程序 sudo fdisk -l //以管理员权限查看电脑硬盘使用情况sudo mkfs.ext4 /dev/sdb //以管理员身份格式化硬盘sudo mkdir guazai //创建挂载文件夹 sudo mount /dev/sdb/guazai //将挂载源接上挂载点 s…...

[面试] 15道最典型的k8s面试题
文章目录 在 Kubernetes 中,有以下常见的资源对象:1.什么是 Kubernetes?它的主要特点是什么?2. Kubernetes 中的 Pod 是什么?它的作用是什么?3.Kubernetes 中的 Deployment 和 StatefulSet 有何区别&#x…...

lintcode 552 · 创建最大数 【算法 数组 贪心 hard】
题目 https://www.lintcode.com/problem/552/description 描述 给出两个长度分别是m和n的数组来表示两个大整数,数组的每个元素都是数字0-9。从这两个数组当中选出k个数字来创建一个最大数,其中k满足k < m n。选出来的数字在创建的最大数里面的位置…...
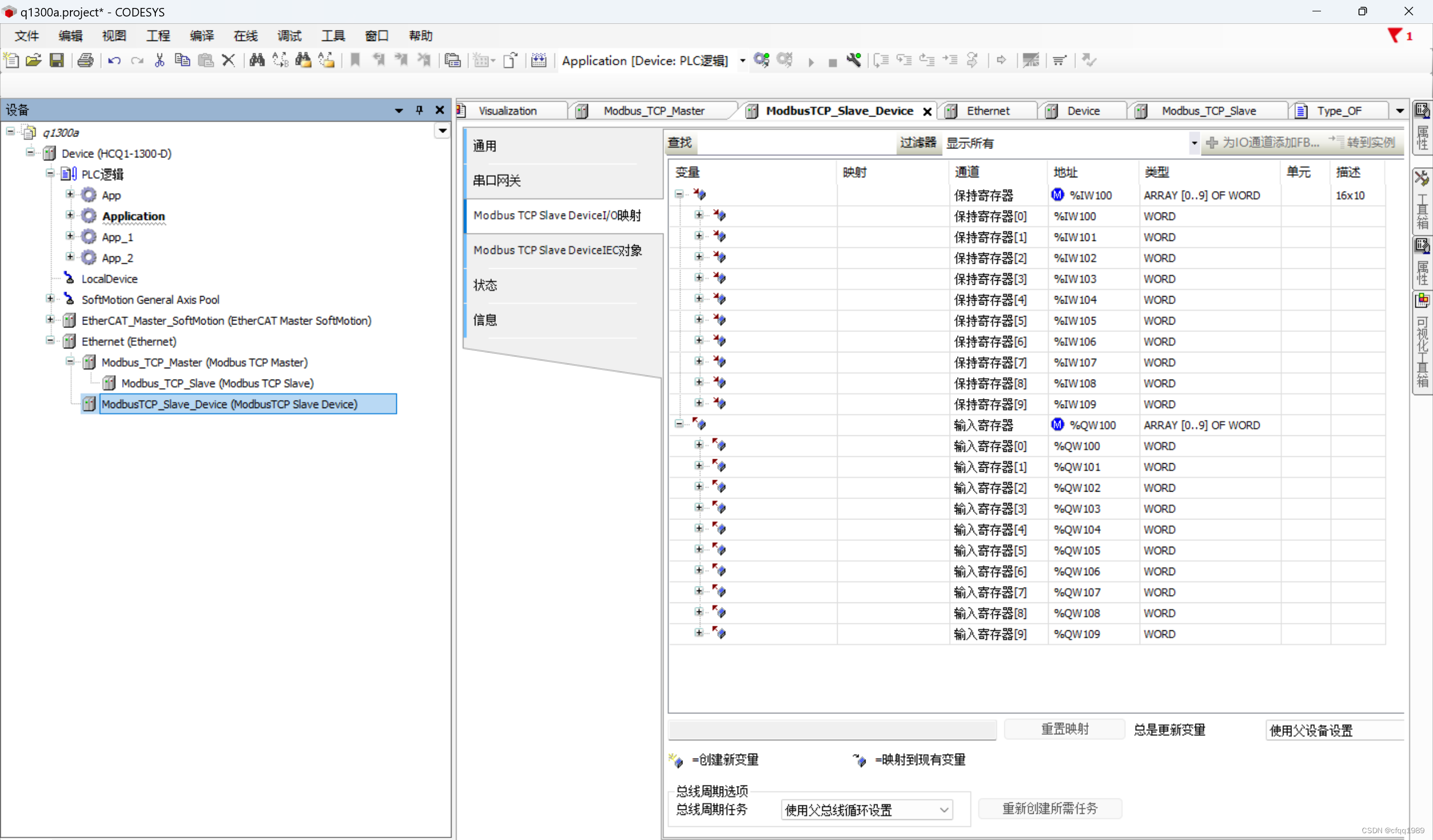
ModbusTCP服务端
1在Device下,添加设备net: 公交车。 2在net下添加 ModbusTCP...

深入解析Hurricane Electric的BGP网络架构与互联策略
1. 从一张图开始:认识Hurricane Electric的全球网络 如果你对网络技术感兴趣,或者自己折腾过服务器、云服务,大概率听说过Hurricane Electric这个名字。很多朋友第一次接触它,可能是在寻找免费的IPv6隧道服务时,那个著…...

Dify 1.0+内网部署全攻略:模型插件离线安装与信创环境适配
1. 为什么需要内网部署Dify? 最近在帮某金融机构部署Dify平台时,遇到了一个典型问题:他们的开发环境完全隔离外网,但业务部门又急需使用大语言模型能力。这让我意识到,很多企业都存在类似需求——在严格的内网环境中部…...

从原理到实战:深度剖析subDomainsBrute的高效子域名爆破引擎
1. 揭开subDomainsBrute的神秘面纱 第一次接触subDomainsBrute是在三年前的一次渗透测试项目中。当时我们需要在短时间内完成一个大型电商平台的子域名发现工作,手动测试效率太低,而常规工具又经常被防火墙拦截。直到同事推荐了这个"神器"&…...
)
用Python模拟Petri网:从标识网到网系统的完整实现(附代码)
用Python模拟Petri网:从标识网到网系统的完整实现(附代码) Petri网作为一种描述离散事件系统的数学模型,在计算机科学、自动化控制等领域有着广泛应用。本文将带您用Python从零实现一个完整的Petri网模拟器,涵盖标识网…...

内窥镜加热器如何选择红外LED加热光源
内窥镜加热器在医疗和工业领域中扮演着关键角色,特别是在低温环境下需要确保内窥镜的正常工作。选择合适的红外LED加热光源对于提高内窥镜的性能和可靠性至关重要。本文将从内窥镜加热方式的发展、红外LED光源的选择、内窥镜加热器的应用案例和方案,以及…...

微电网的功率流计算:基础方法与影响因素
在新型电力系统向“源网荷储”协同转型的背景下,微电网作为整合分布式能源、优化终端能源配置、保障供电安全的核心载体,其运行状态的精准把控是实现高效、稳定、安全运行的前提。功率流计算作为微电网分析、设计、调控与运维的核心基础,本质…...

炸穿 JVM 瓶颈!全网最硬核 JVM 核心参数・线上配置规范与调优 SOP
前言在JDK17成为主流生产环境的今天,90%的线上JVM问题并非代码逻辑缺陷,而是参数配置不合理、内存规划错误、垃圾回收器选型不匹配导致。JVM调优从来不是玄学,而是基于内存模型、垃圾回收机制的标准化工程实践。本文聚焦JDK17环境下JVM核心参…...

react-i18next 国际化支持
一、今日整体工作内容 今天完成的是做了国际化支持,实现中英文语言切换。首先看了官方的 API 文档,它支持不同的编辑器语言。然后我用 React Next 18 引入了相关包,自己维护了一个 locale 键值数组,对应中文和英文字段。 全文国际…...

Retrofit.dart与Dio深度整合:打造高效网络请求架构
Retrofit.dart与Dio深度整合:打造高效网络请求架构 【免费下载链接】retrofit.dart retrofit.dart is an dio client generator using source_gen and inspired by Chopper and Retrofit. 项目地址: https://gitcode.com/gh_mirrors/re/retrofit.dart Retrof…...

【开题答辩全过程】以 基于ssm校园教室设备检修管理系统为例,包含答辩的问题和答案
个人简介一名14年经验的资深毕设内行人,语言擅长Java、php、微信小程序、Python、Golang、安卓Android等开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。感谢大家的…...