pytorch代码实现之动态卷积模块ODConv
ODConv动态卷积模块
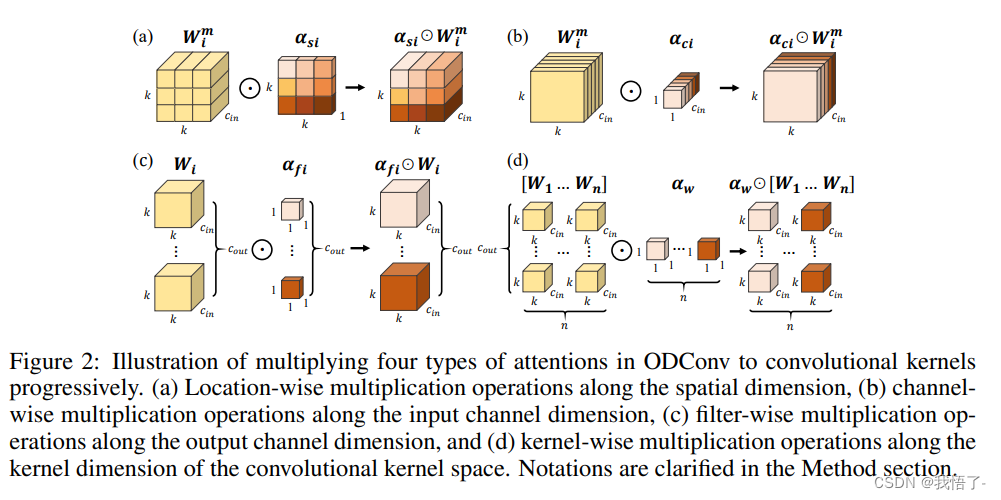
ODConv可以视作CondConv的延续,将CondConv中一个维度上的动态特性进行了扩展,同时了考虑了空域、输入通道、输出通道等维度上的动态性,故称之为全维度动态卷积。ODConv通过并行策略采用多维注意力机制沿核空间的四个维度学习互补性注意力。作为一种“即插即用”的操作,它可以轻易的嵌入到现有CNN网络中。ImageNet分类与COCO检测任务上的实验验证了所提ODConv的优异性:即可提升大模型的性能,又可提升轻量型模型的性能,实乃万金油是也!值得一提的是,受益于其改进的特征提取能力,ODConv搭配一个卷积核时仍可取得与现有多核动态卷积相当甚至更优的性能。
原文地址:Omni-Dimensional Dynamic Convolution
代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.autograd
from models.common import Conv, autopadclass Attention(nn.Module):def __init__(self, in_planes, out_planes, kernel_size, groups=1, reduction=0.0625, kernel_num=4, min_channel=16):super(Attention, self).__init__()attention_channel = max(int(in_planes * reduction), min_channel)self.kernel_size = kernel_sizeself.kernel_num = kernel_numself.temperature = 1.0self.avgpool = nn.AdaptiveAvgPool2d(1)self.fc = Conv(in_planes, attention_channel, act=nn.ReLU(inplace=True))self.channel_fc = nn.Conv2d(attention_channel, in_planes, 1, bias=True)self.func_channel = self.get_channel_attentionif in_planes == groups and in_planes == out_planes: # depth-wise convolutionself.func_filter = self.skipelse:self.filter_fc = nn.Conv2d(attention_channel, out_planes, 1, bias=True)self.func_filter = self.get_filter_attentionif kernel_size == 1: # point-wise convolutionself.func_spatial = self.skipelse:self.spatial_fc = nn.Conv2d(attention_channel, kernel_size * kernel_size, 1, bias=True)self.func_spatial = self.get_spatial_attentionif kernel_num == 1:self.func_kernel = self.skipelse:self.kernel_fc = nn.Conv2d(attention_channel, kernel_num, 1, bias=True)self.func_kernel = self.get_kernel_attentionself._initialize_weights()def _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)if isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)def update_temperature(self, temperature):self.temperature = temperature@staticmethoddef skip(_):return 1.0def get_channel_attention(self, x):channel_attention = torch.sigmoid(self.channel_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)return channel_attentiondef get_filter_attention(self, x):filter_attention = torch.sigmoid(self.filter_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)return filter_attentiondef get_spatial_attention(self, x):spatial_attention = self.spatial_fc(x).view(x.size(0), 1, 1, 1, self.kernel_size, self.kernel_size)spatial_attention = torch.sigmoid(spatial_attention / self.temperature)return spatial_attentiondef get_kernel_attention(self, x):kernel_attention = self.kernel_fc(x).view(x.size(0), -1, 1, 1, 1, 1)kernel_attention = F.softmax(kernel_attention / self.temperature, dim=1)return kernel_attentiondef forward(self, x):x = self.avgpool(x)x = self.fc(x)return self.func_channel(x), self.func_filter(x), self.func_spatial(x), self.func_kernel(x)class ODConv2d(nn.Module):def __init__(self, in_planes, out_planes, k, s=1, p=None, g=1, act=True, d=1,reduction=0.0625, kernel_num=1):super(ODConv2d, self).__init__()self.in_planes = in_planesself.out_planes = out_planesself.kernel_size = kself.stride = sself.padding = autopad(k, p)self.dilation = dself.groups = gself.kernel_num = kernel_numself.attention = Attention(in_planes, out_planes, k, groups=g,reduction=reduction, kernel_num=kernel_num)self.weight = nn.Parameter(torch.randn(kernel_num, out_planes, in_planes//g, k, k),requires_grad=True)self._initialize_weights()self.bn = nn.BatchNorm2d(out_planes)self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())if self.kernel_size == 1 and self.kernel_num == 1:self._forward_impl = self._forward_impl_pw1xelse:self._forward_impl = self._forward_impl_commondef _initialize_weights(self):for i in range(self.kernel_num):nn.init.kaiming_normal_(self.weight[i], mode='fan_out', nonlinearity='relu')def update_temperature(self, temperature):self.attention.update_temperature(temperature)def _forward_impl_common(self, x):# Multiplying channel attention (or filter attention) to weights and feature maps are equivalent,# while we observe that when using the latter method the models will run faster with less gpu memory cost.channel_attention, filter_attention, spatial_attention, kernel_attention = self.attention(x)batch_size, in_planes, height, width = x.size()x = x * channel_attentionx = x.reshape(1, -1, height, width)aggregate_weight = spatial_attention * kernel_attention * self.weight.unsqueeze(dim=0)aggregate_weight = torch.sum(aggregate_weight, dim=1).view([-1, self.in_planes // self.groups, self.kernel_size, self.kernel_size])output = F.conv2d(x, weight=aggregate_weight, bias=None, stride=self.stride, padding=self.padding,dilation=self.dilation, groups=self.groups * batch_size)output = output.view(batch_size, self.out_planes, output.size(-2), output.size(-1))output = output * filter_attentionreturn outputdef _forward_impl_pw1x(self, x):channel_attention, filter_attention, spatial_attention, kernel_attention = self.attention(x)x = x * channel_attentionoutput = F.conv2d(x, weight=self.weight.squeeze(dim=0), bias=None, stride=self.stride, padding=self.padding,dilation=self.dilation, groups=self.groups)output = output * filter_attentionreturn outputdef forward(self, x):return self.act(self.bn(self._forward_impl(x)))
相关文章:
pytorch代码实现之动态卷积模块ODConv
ODConv动态卷积模块 ODConv可以视作CondConv的延续,将CondConv中一个维度上的动态特性进行了扩展,同时了考虑了空域、输入通道、输出通道等维度上的动态性,故称之为全维度动态卷积。ODConv通过并行策略采用多维注意力机制沿核空间的四个维度…...

动态规划:子序列问题(C++)
动态规划:子序列问题 前言子序列问题1.最长递增子序列(中等)2.摆动序列(中等)3.最长递增子序列的个数(中等)4.最长数对链(中等)5.最长定差子序列(中等&#x…...
ORACLE的分区(一)
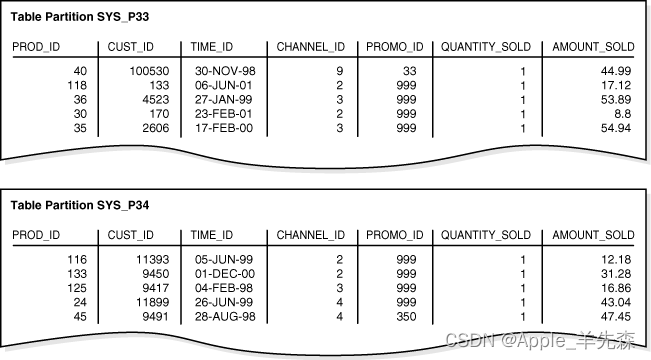
目录 一、分区概念 二、表分区的优点 三、分区策略 一、分区概念 随着时间的发展,一个表的数据会越来越多,当数据量增大的时候我们一般采取建立索引优化索引的方式提高查询速度,但是数据量再次增大即使是索引也无法提高速度,这时…...
【数据结构】C++实现二叉搜索树
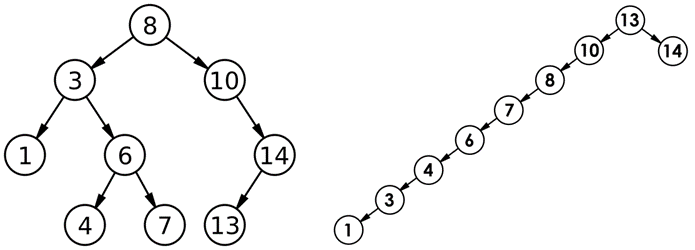
二叉搜索树的概念 二叉搜索树又称为二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树: 若它的左子树不为空,则左子树上所有结点的值都小于根结点的值。若它的右子树不为空,则右子树上所有结点的值都大于根结…...

Python中Mock和Patch的区别
前言: 嗨喽~大家好呀,这里是魔王呐 ❤ ~! python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取 在测试并行开发(TPD)中,代码开发是第一位的。 尽管如此,我们还是要写出开发的测试,…...
sql server 查询某个字段是否有值 返回bool类型
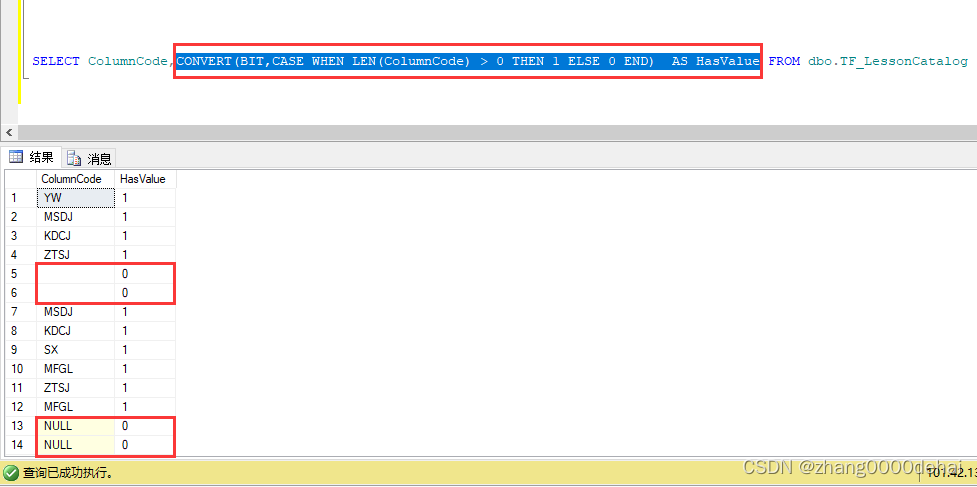
sql server 查询某个字段是否有值 返回bool类型,true 或 false SELECT ColumnCode,CONVERT(BIT,CASE WHEN LEN(ColumnCode) > 0 THEN 1 ELSE 0 END) AS HasValue FROM dbo.TF_LessonCatalog...

紫光展锐5G芯T820 解锁全新应用场景,让机器人更智能
数字经济的持续发展正推动机器人产业成为风口赛道。工信部数据显示,2023年上半年,我国工业机器人产量达22.2万套,同比增长5.4%;服务机器人产量为353万套,同比增长9.6%。 作为国内商用服务机器人领先企业,云…...

秋招前端面试题总结
1、this指向问题,以前总是迷糊,现在总算是一知半解了。应当遵循以下原则,应该就能做对题目了。 如果一个标准函数,也就是非箭头函数,作为某个对象的方法被调用时,那么这个this指向的就是这个对象。涉及到闭…...

【入门篇】ClickHouse 数据类型
文章目录 1. 引言2. ClickHouse 数据类型2.1 基本数据类型2.1.1 整型2.1.2 浮点型2.1.3 字符串型 2.2 复合数据类型2.2.1 数组2.2.2 枚举类型2.2.3 元组2.2.4 Map2.2.5 Nullable 2.3 特殊数据类型2.3.1 日期和时间类型2.3.2 UUID2.3.3 IP 地址2.3.4 AggregateFunction 2.4 数据…...

关于Python数据分析,这里有一条高效的学习路径
无处不在的数据分析 谷歌的数据分析可以预测一个地区即将爆发的流感,从而进行针对性的预防;淘宝可以根据你浏览和消费的数据进行分析,为你精准推荐商品;口碑极好的网易云音乐,通过其相似性算法,为不同的人…...

基于 json-server 工具,模拟实现后端接口服务环境
文章目录 本地配置后端接口一、安装json-server1、安装 JSON 服务器 安装 JSON 服务器2、创建一个db.json包含一些数据的文件(重点)3、启动 JSON 服务器 启动 JSON 服务器4、现在如果你访问http://localhost:3000/posts/1,你会得到 本地配置后…...

想要精通算法和SQL的成长之路 - 课程表II
想要精通算法和SQL的成长之路 - 课程表 前言一. 课程表II (拓扑排序)1.1 拓扑排序1.2 题解 前言 想要精通算法和SQL的成长之路 - 系列导航 一. 课程表II (拓扑排序) 原题链接 1.1 拓扑排序 核心知识: 拓扑排序是专…...
【sgGoogleTranslate】自定义组件:基于Vue.js用谷歌Google Translate翻译插件实现网站多国语言开发
sgGoogleTranslate源码 <template><div :id"$options.name"> </div> </template> <script> export default {name: "sgGoogleTranslate",props: ["languages", "currentLanguage"],data() {return {//…...
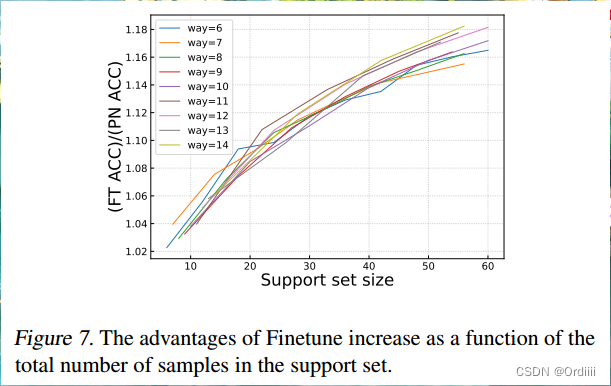
论文总结《A Closer Look at Few-shot Classification Again》
原文链接 A Closer Look at Few-shot Classification Again 摘要 这篇文章主要探讨了在少样本图像分类问题中,training algorithm 和 adaptation algorithm的相关性问题。给出了training algorithm和adaptation algorithm是完全不想关的,这意味着我们…...
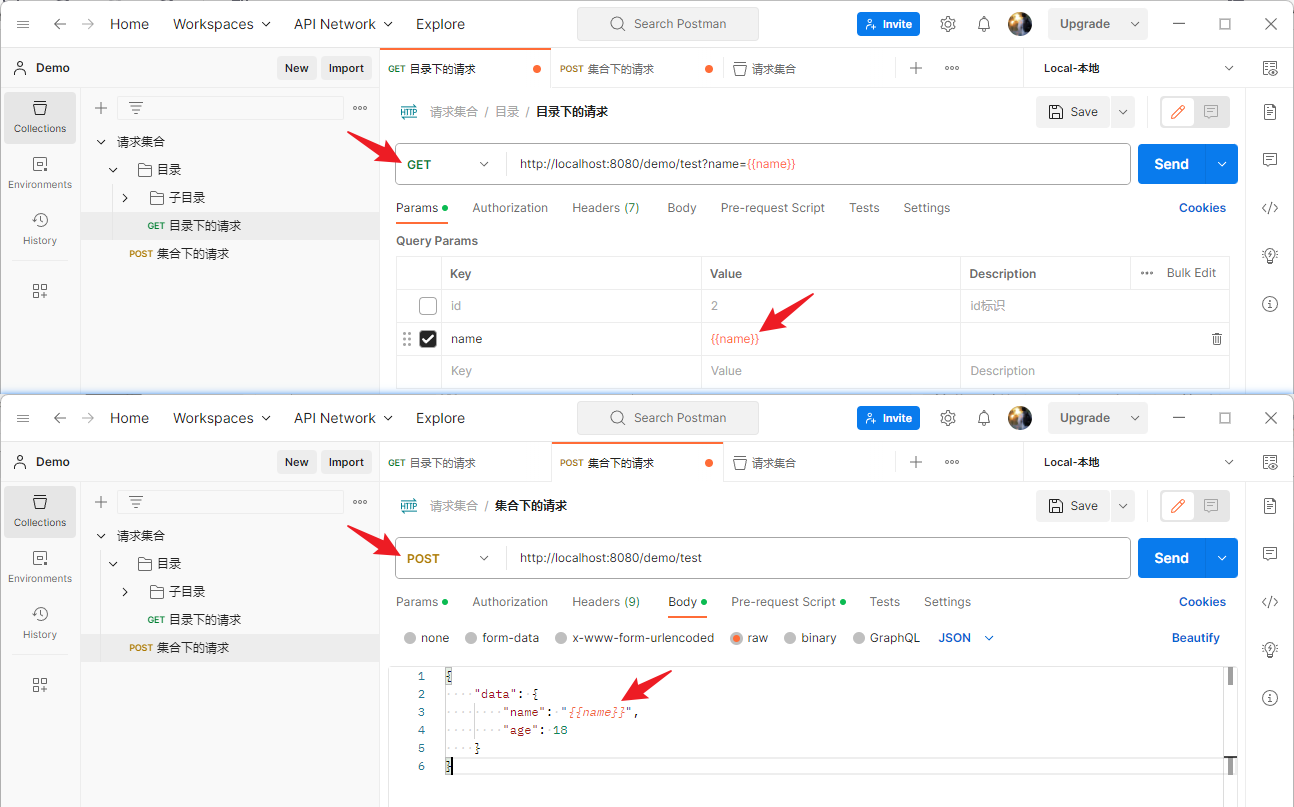
Postman使用_参数设置和获取
文章目录 参数引用内置动态参数手动添加参数脚本设置参数脚本获取参数 参数就像变量一样,它可以是固定的值,也可以是变化的值,比如:会根据一些条件或其他参数进行变化。我们如果要使用该参数就需要引用它。 参数引用 引用动态参数…...

【SQL】优化SQL查询方法
优化SQK查询 一、避免全表扫描 1、where条件中少使用! 或 <>操作符,引擎会放弃索引,进行全表扫描 2、in \or ,用between 或 exist 代替in 3、where 对字段进行为空判断 4、where like ‘%条件’ 前置百分号 5、where …...

Linux-相关操作
2.2.2 Linux目录结构 /:根目录,一般根目录下只存放目录,在Linux下有且只有一个根目录。所有的东西都是从这里开始。当你在终端里输入“/home”,你其实是在告诉电脑,先从/(根目录)开始…...
二十、MySQL多表关系
1、概述 在项目开发中,在进行数据库表结构设计时,会根据业务需求以及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种对应关系 2、多表关系分类 (1࿰…...
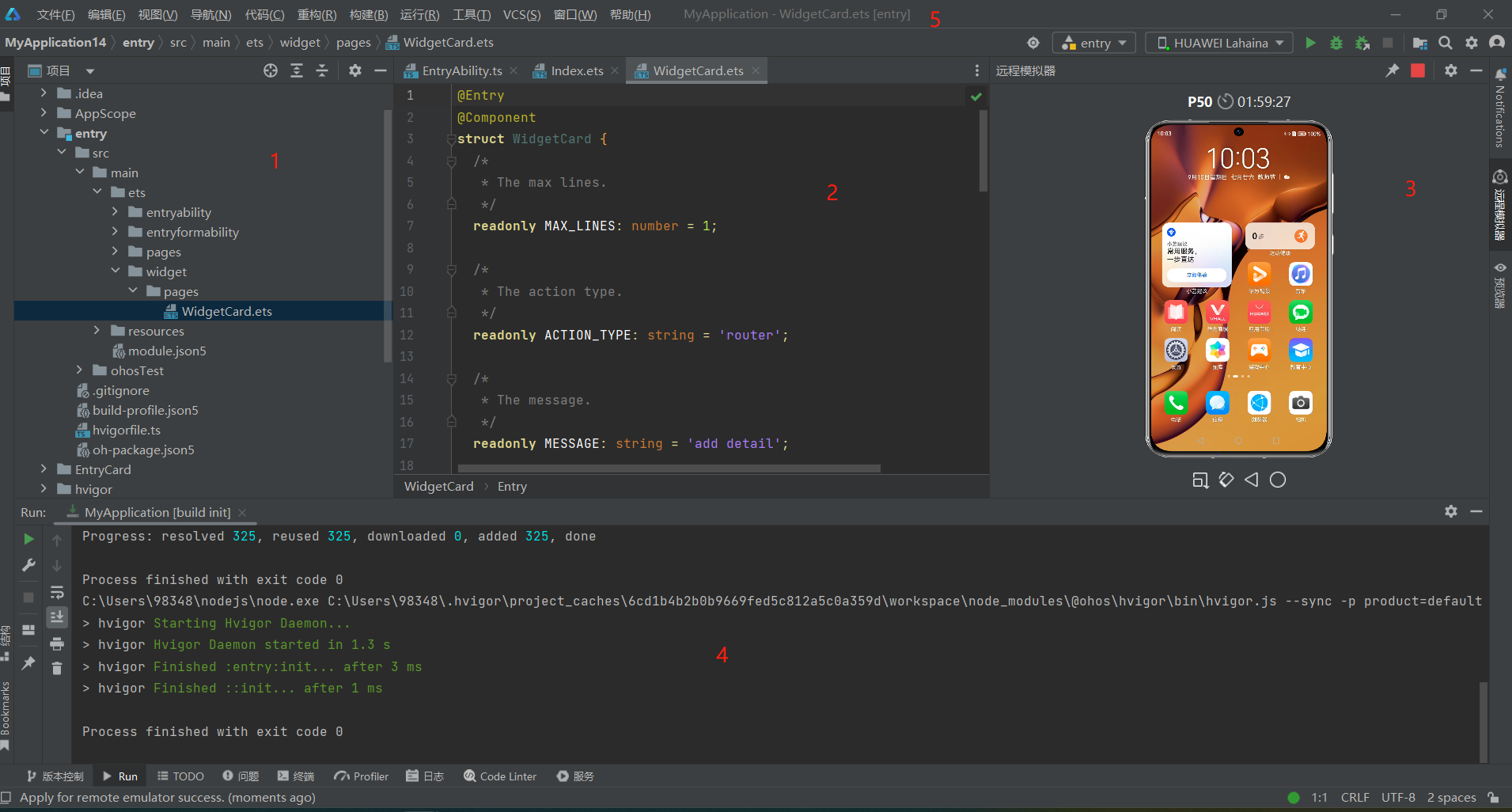
HarmonyOS/OpenHarmony应用开发-DevEco Studio新建项目的整体说明
一、文件-新建-新建项目 二、传统应用形态与IDE自带的模板可供选用与免安装的元服与IDE中自带模板的选择 三、以元服务,远程模拟器为例说明IDE整体结构 1区是工程目录结构,是最基本的配置与开发路径等的认知。 2区是代码开发与修改区,是开发…...
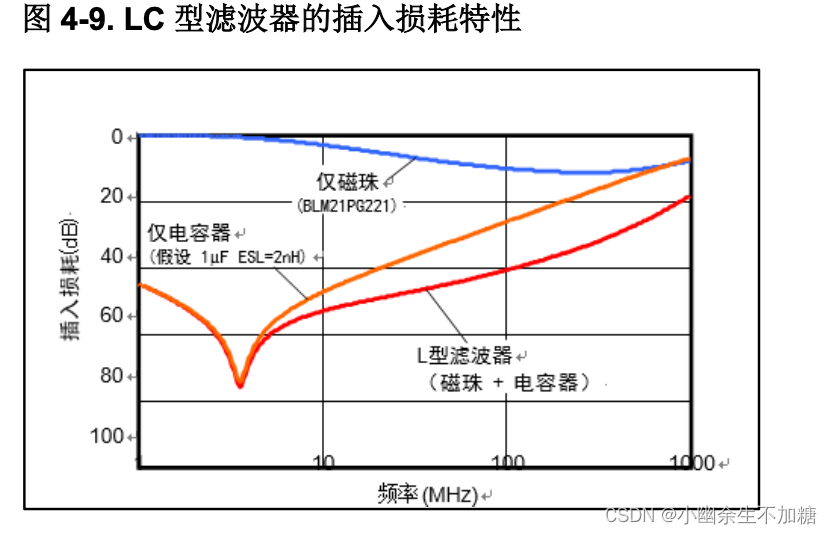
去耦电路设计应用指南(三)磁珠/电感的噪声抑制
(三)磁珠/电感的噪声抑制 1. 电感1.1 电感频率特性 2. 铁氧体磁珠3. LC 型和 PI 型滤波 当去耦电容器不足以抑制电源噪声时,电感器&磁珠/ LC 滤波器的结合使用是很有效的。扼流线圈与铁氧体磁珠 是用于电源去耦电路很常见的电感器。 1. …...

如何通过SRWE实现游戏窗口分辨率自定义:5个高效技巧与实战指南
如何通过SRWE实现游戏窗口分辨率自定义:5个高效技巧与实战指南 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE SRWE(Simple Runtime Window Editor)是一款开源的游戏窗口实时…...
)
MathType 快捷键实战指南——数学建模效率飙升的秘诀(从入门到精通)
1. 为什么你需要掌握MathType快捷键? 如果你经常需要处理数学公式,肯定遇到过这样的场景:为了输入一个简单的积分符号,不得不从工具栏里翻找半天;调整公式对齐时反复用鼠标拖动;修改矩阵维度时逐个单元格调…...

MTKClient终极指南:免费解锁联发科设备的完整刷机解决方案
MTKClient终极指南:免费解锁联发科设备的完整刷机解决方案 【免费下载链接】mtkclient MTK reverse engineering and flash tool 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclient MTKClient是一款专为联发科(MediaTek)芯片设备…...

com0com虚拟串口驱动终极指南:免费创建无限COM端口对,彻底摆脱物理线缆束缚
com0com虚拟串口驱动终极指南:免费创建无限COM端口对,彻底摆脱物理线缆束缚 【免费下载链接】com0com Null-modem emulator - The virtual serial port driver for Windows. Brought to you by: vfrolov [Vyacheslav Frolov](http://sourceforge.net/u/v…...

放心API和4SAPI怎么选?从开发者选型角度看差异
很多开发者在选 Claude API 中转站时,都会遇到一个问题:**到底是选更偏个人友好的放心API,还是选更偏企业级的4SAPI?**这个问题没有标准答案,只有场景答案。---## 一、先给结论如果你的项目处于以下阶段:- …...

好用的AI软件开发选哪家
在当今数字化飞速发展的时代,AI软件已经成为众多企业和个人提升效率、创新业务的重要工具。然而,面对市场上众多的AI软件开发公司,如何选择一家靠谱且好用的公司成为了许多人的困扰。今天,我就为大家推荐广州飞进信息科技有限公司…...

XT2055 双灯显示微型线性电池充电管理芯片
■ 产品概述 XT2055 是一款完善的单节锂电池恒流/恒压线性充电管理芯片。较薄的尺寸和较小的封装使它适用于便携式产品的应用,XT2055 也适用于 USB 的供电电路。得益于内部的MOSFET 结构,在应用上不需要外部电阻和阻塞二极管。在高能量运行和外围温度较高…...

SpringBoot微服务启动遇阻:RedisTemplate Bean缺失的排查与修复指南
1. 问题现象与初步分析 最近在调整SpringBoot微服务项目的Redis配置后,启动时突然遇到一个让人头疼的错误提示: Consider defining a bean of type org.springframework.data.redis.core.RedisTemplate in your configuration.这个错误表面看是Spring容器…...
)
Sora 2 + After Effects 24.4终极联动教程:含LUT自动映射、运动追踪反哺、动态遮罩同步(附独家.jsx插件)
更多请点击: https://intelliparadigm.com 第一章:Sora 2与After Effects 24.4深度整合概览 Adobe After Effects 24.4 正式引入对 OpenAI Sora 2 模型输出格式的原生支持,标志着生成式视频工作流首次在专业后期平台中实现端到端闭环。该整…...

Vexip UI暗黑主题实现:CSS变量与主题切换完全指南 [特殊字符]
Vexip UI暗黑主题实现:CSS变量与主题切换完全指南 🎨 【免费下载链接】vexip-ui A Vue 3 UI library, highly customizability, full TypeScript, performance pretty good. 项目地址: https://gitcode.com/gh_mirrors/ve/vexip-ui 想要为你的Vue…...