LLM 06-大模型架构
LLM 06-大模型架构
6.1 大模型之模型概括
语言模型的一开始就可以被看做是一个黑箱,当前大规模语言模型的能力在于给定一个基于自身需求的prompt就可以生成符合需求的结果。形式可以表达为:
p r o m p t ⇝ c o m p l e t i o n prompt \leadsto completion prompt⇝completion
从数学的角度考虑就对训练数据 (traing data: ( x 1 , … , x L ) (x_{1},…,x_{L}) (x1,…,xL))的概率分布:
t r a i n i n g D a t a ⇒ p ( x 1 , . . . , x L ) . trainingData \Rightarrow p(x_{1},...,x_{L}). trainingData⇒p(x1,...,xL).
在学习内容中中,我们将彻底揭开面纱,讨论大型语言模型是如何构建的。今天的内容将着重讨论两个主题,分别是分词和模型架构:
-
分词:即如何将一个字符串拆分成多个标记。
-
模型架构:我们将主要讨论Transformer架构,这是真正实现大型语言模型的建模创新。
6.2 分词
回顾刚才的内容,语言模型 p p p是一个对标记(token)序列的概率分布,其中每个标记来自某个词汇表 V V V:
[ t h e , m o u s e , a t e , t h e , c h e e s e ] [the, mouse, ate, the, cheese] [the,mouse,ate,the,cheese]
然而,自然语言并不是以标记序列的形式出现,而是以字符串的形式存在(具体来说,是Unicode字符的序列),比如上面的序列的自然语言为“the mouse ate the cheese”。
分词器将任意字符串转换为标记序列:the mouse ate the cheese ⇒ [ t h e , m o u s e , a t e , t h e , c h e e s e ] \Rightarrow [the, mouse, ate, the, cheese] ⇒[the,mouse,ate,the,cheese]
这并不一定是语言建模中最引人注目的部分,但在确定模型的工作效果方面起着非常重要的作用。我们也可以将这个方式理解为自然语言和机器语言的一种显式的对齐。下面我对分词的一些细节进一步的讨论。
6.2.1 基于空格的分词
最简单的解决方案是使用text.split(' ')方式进行分词,这种分词方式对于英文这种按照空格,且每个分词后的单词有语义关系的文本是简单而直接的分词方式。然而,对于一些语言,如中文,句子中的单词之间没有空格:
"我今天去了商店。" \text{"我今天去了商店。"} "我今天去了商店。"
还有一些语言,比如德语,存在着长的复合词(例如Abwasserbehandlungsanlange)。即使在英语中,也有连字符词(例如father-in-law)和缩略词(例如don’t),它们需要被正确拆分。例如,Penn Treebank将don’t拆分为do和n’t,这是一个在语言上基于信息的选择,但不太明显。因此,仅仅通过空格来划分单词会带来很多问题。
那么,什么样的分词才是好的呢?目前从直觉和工程实践的角度来说:
- 首先我们不希望有太多的标记(极端情况:字符或字节),否则序列会变得难以建模。
- 其次我们也不希望标记过少,否则单词之间就无法共享参数(例如,mother-in-law和father-in-law应该完全不同吗?),这对于形态丰富的语言尤其是个问题(例如,阿拉伯语、土耳其语等)。
- 每个标记应该是一个在语言或统计上有意义的单位。
6.2.2 Byte pair encoding
将字节对编码(BPE)算法应用于数据压缩领域,用于生成其中一个最常用的分词器。BPE分词器需要通过模型训练数据进行学习,获得需要分词文本的一些频率特征。
学习分词器的过程,直觉上,我们将每个字符作为自己的标记,并组合那些经常共同出现的标记。整个过程可以表示为:
- 输入:训练语料库(字符序列)。
- 初始化词汇表 V V V为字符的集合。
- 当我们仍然希望V继续增长时:
找到 V V V中共同出现次数最多的元素对 x , x ′ x,x' x,x′。 - 用一个新的符号 x x ′ xx' xx′替换所有 x , x ′ x,x' x,x′的出现。将
- x x ′ xx' xx′添加到V中。
这里举一个例子:
1 [ t , h , e , c , c , a , r ] , [ t , h , e , c , c , a , t ] , [ t , h , e , c , r , a , t ] 1[t, h, e, c, c, a, r],[t, h, e, c, c, a, t],[t, h, e, c, r, a, t] 1[t,h,e,c,c,a,r],[t,h,e,c,c,a,t],[t,h,e,c,r,a,t]
2 [th, e, , c , a , r ] , [ t h , e , u , c , a , t ] , [ t h , e , c , r , a , t ] , c, a, r],[t h, e, u, c, a, t],[t h, e, c, r, a, t] ,c,a,r],[th,e,u,c,a,t],[th,e,c,r,a,t] (th 出现了 3次)
3 [the, ≤ , c , a , r ] \leq, c, a, r] ≤,c,a,r], [the, ⊔ , c , a , t ] , [ \sqcup, c, a, t],[ ⊔,c,a,t],[ the, u , r , a , t ] u, r, a, t] u,r,a,t] (the 出现了 3次)
4 [the, ⊔ , c a , r ] , [ \sqcup, c a, r],[ ⊔,ca,r],[ the, u , c a , t ] , [ u, c a, t],[ u,ca,t],[ the, ⊔ , r , a , t ] \sqcup, r, a, t] ⊔,r,a,t] (ca 出现了 2次)
6.2.2.1 Unicode的问题
Unicode(统一码)是当前主流的一种编码方式。其中这种编码方式对BPE分词产生了一个问题(尤其是在多语言环境中),Unicode字符非常多(共144,697个字符)。在训练数据中我们不可能见到所有的字符。
为了进一步减少数据的稀疏性,我们可以对字节而不是Unicode字符运行BPE算法(Wang等人,2019年)。
以中文为例:
今天 ⇒ [x62, x11, 4e, ca] \text { 今天} \Rightarrow \text {[x62, x11, 4e, ca]} 今天⇒[x62, x11, 4e, ca]
BPE算法在这里的作用是为了进一步减少数据的稀疏性。通过对字节级别进行分词,可以在多语言环境中更好地处理Unicode字符的多样性,并减少数据中出现的低频词汇,提高模型的泛化能力。通过使用字节编码,可以将不同语言中的词汇统一表示为字节序列,从而更好地处理多语言数据。
6.2.3 Unigram model (SentencePiece)
与仅仅根据频率进行拆分不同,一个更“有原则”的方法是定义一个目标函数来捕捉一个好的分词的特征,这种基于目标函数的分词模型可以适应更好分词场景,Unigram model就是基于这种动机提出的。我们现在描述一下unigram模型(Kudo,2018年)。
这是SentencePiece工具(Kudo&Richardson,2018年)所支持的一种分词方法,与BPE一起使用。
它被用来训练T5和Gopher模型。给定一个序列 x 1 : L x_{1:L} x1:L,一个分词器 T T T是 p ( x 1 : L ) = ∏ ( i , j ) ∈ T p ( x i : j ) p\left(x_{1: L}\right)=\prod_{(i, j) \in T} p\left(x_{i: j}\right) p(x1:L)=∏(i,j)∈Tp(xi:j)的一个集合。这边给出一个实例:
- 训练数据(字符串): a b a b c ababc ababc
- 分词结果 T = ( 1 , 2 ) , ( 3 , 4 ) , ( 5 , 5 ) T={(1,2),(3,4),(5,5)} T=(1,2),(3,4),(5,5) (其中 V = { a b , c } V=\{ab,c\} V={ab,c})
- 似然值: p ( x 1 : L ) = 2 / 3 ⋅ 2 / 3 ⋅ 1 / 3 = 4 / 9 p(x_{1:L})=2/3⋅2/3⋅1/3=4/9 p(x1:L)=2/3⋅2/3⋅1/3=4/9
在这个例子中,训练数据是字符串" a b a b c ababc ababc"。分词结果 T = ( 1 , 2 ) , ( 3 , 4 ) , ( 5 , 5 ) T={(1,2),(3,4),(5,5)} T=(1,2),(3,4),(5,5) 表示将字符串拆分成三个子序列: ( a , b ) , ( a , b ) , ( c ) (a,b),(a,b),(c) (a,b),(a,b),(c)。词汇表$ V={ab,c} $表示了训练数据中出现的所有词汇。
似然值 $p(x_{1:L}) $是根据 unigram 模型计算得出的概率,表示训练数据的似然度。在这个例子中,概率的计算为 2 / 3 ⋅ 2 / 3 ⋅ 1 / 3 = 4 / 9 2/3⋅2/3⋅1/3=4/9 2/3⋅2/3⋅1/3=4/9。这个值代表了根据 unigram 模型,将训练数据分词为所给的分词结果 $T $的概率。
unigram 模型通过统计每个词汇在训练数据中的出现次数来估计其概率。在这个例子中, a b ab ab 在训练数据中出现了两次, c c c出现了一次。因此,根据 unigram 模型的估计, p ( a b ) = 2 / 3 , p ( c ) = 1 / 3 p(ab)=2/3,p(c)=1/3 p(ab)=2/3,p(c)=1/3。通过将各个词汇的概率相乘,我们可以得到整个训练数据的似然值为 4 / 9 4/9 4/9。
似然值的计算是 unigram 模型中重要的一部分,它用于评估分词结果的质量。较高的似然值表示训练数据与分词结果之间的匹配程度较高,这意味着该分词结果较为准确或合理。
6.2.3.1 算法流程
- 从一个“相当大”的种子词汇表 V V V 开始。
- 重复以下步骤:
- 给定 V V V ,使用EM算法优化 p ( x ) p(x) p(x) 和 T T T 。
- 计算每个词汇 x ∈ V x∈V x∈V 的 l o s s ( x ) loss(x) loss(x) ,衡量如果将 x x x 从 V V V 中移除,似然值会减少多少。
- 按照 l o s s loss loss 进行排序,并保留 V V V 中排名靠前的80%的词汇。
这个过程旨在优化词汇表,剔除对似然值贡献较小的词汇,以减少数据的稀疏性,并提高模型的效果。通过迭代优化和剪枝,词汇表会逐渐演化,保留那些对于似然值有较大贡献的词汇,提升模型的性能。
6.3 模型架构
到目前为止,我们已经将语言模型定义为对标记序列的概率分布 p ( x 1 , … , x L ) p(x_{1},…,x_{L}) p(x1,…,xL),我们已经看到这种定义非常优雅且强大(通过提示,语言模型原则上可以完成任何任务,正如GPT-3所示)。然而,在实践中,对于专门的任务来说,避免生成整个序列的生成模型可能更高效。
上下文向量表征 (Contextual Embedding): 作为先决条件,主要的关键发展是将标记序列与相应的上下文的向量表征:
[ t h e , m o u s e , a t e , t h e , c h e e s e ] ⇒ ϕ [ ( 1 0.1 ) , ( 0 1 ) , ( 1 1 ) , ( 1 − 0.1 ) , ( 0 − 1 ) ] . [the, mouse, ate, the, cheese] \stackrel{\phi}{\Rightarrow}\left[\left(\begin{array}{c} 1 \\ 0.1 \end{array}\right),\left(\begin{array}{l} 0 \\ 1 \end{array}\right),\left(\begin{array}{l} 1 \\ 1 \end{array}\right),\left(\begin{array}{c} 1 \\ -0.1 \end{array}\right),\left(\begin{array}{c} 0 \\ -1 \end{array}\right)\right]. [the,mouse,ate,the,cheese]⇒ϕ[(10.1),(01),(11),(1−0.1),(0−1)].
正如名称所示,标记的上下文向量表征取决于其上下文(周围的单词);例如,考虑mouse的向量表示需要关注到周围某个窗口大小的其他单词。
-
符号表示:我们将 ϕ : V L → R d × L ϕ:V^{L}→ℝ^{d×L} ϕ:VL→Rd×L 定义为嵌入函数(类似于序列的特征映射,映射为对应的向量表示)。
-
对于标记序列 x 1 : L = [ x 1 , … , x L ] x1:L=[x_{1},…,x_{L}] x1:L=[x1,…,xL], ϕ ϕ ϕ 生成上下文向量表征 ϕ ( x 1 : L ) ϕ(x_{1:L}) ϕ(x1:L)。
6.3.1 语言模型分类
对于语言模型来说,最初的起源来自于Transformer模型,这个模型是编码-解码端 (Encoder-Decoder)的架构。但是当前对于语言模型的分类,将语言模型分为三个类型:编码端(Encoder-Only),解码端(Decoder-Only)和编码-解码端(Encoder-Decoder)。因此我们的架构展示以当前的分类展开。
6.3.1.1 编码端(Encoder-Only)架构
编码端架构的著名的模型如BERT、RoBERTa等。这些语言模型生成上下文向量表征,但不能直接用于生成文本。可以表示为, x 1 : L ⇒ ϕ ( x 1 : L ) x_{1:L}⇒ϕ(x_{1:L}) x1:L⇒ϕ(x1:L)。这些上下文向量表征通常用于分类任务(也呗称为自然语言理解任务)。任务形式比较简单,下面以情感分类/自然语言推理任务举例:
情感分析输入与输出形式: [ [ C L S ] , 他们 , 移动 , 而 , 强大 ] ⇒ 正面情绪 情感分析输入与输出形式:[[CLS], 他们, 移动, 而, 强大]\Rightarrow 正面情绪 情感分析输入与输出形式:[[CLS],他们,移动,而,强大]⇒正面情绪
自然语言处理输入与输出形式: [ [ C L S ] , 所有 , 动物 , 都 , 喜欢 , 吃 , 饼干 , 哦 ] ⇒ 蕴涵 自然语言处理输入与输出形式:[[CLS], 所有, 动物, 都, 喜欢, 吃, 饼干, 哦]⇒蕴涵 自然语言处理输入与输出形式:[[CLS],所有,动物,都,喜欢,吃,饼干,哦]⇒蕴涵
该架构的优势是对于文本的上下文信息有更好的理解,因此该模型架构才会多用于理解任务。该架构的有点是对于每个 x i x{i} xi,上下文向量表征可以双向地依赖于左侧上下文 ( x 1 : i − 1 ) (x_{1:i−1}) (x1:i−1) 和右侧上下文 ( x i + 1 : L ) (x_{i+1:L}) (xi+1:L)。但是缺点在于不能自然地生成完成文本,且需要更多的特定训练目标(如掩码语言建模)。
6.3.1.2 解码器(Decoder-Only)架构
解码器架构的著名模型就是大名鼎鼎的GPT系列模型。这些是我们常见的自回归语言模型,给定一个提示 x 1 : i x_{1:i} x1:i,它们可以生成上下文向量表征,并对下一个标记 x i + 1 x_{i+1} xi+1(以及递归地,整个完成 x i + 1 : L x_{i+1:L} xi+1:L)生成一个概率分布。 x 1 : i ⇒ ϕ ( x 1 : i ) , p ( x i + 1 ∣ x 1 : i ) x_{1:i}⇒ϕ(x_{1:i}),p(x_{i+1}∣x_{1:i}) x1:i⇒ϕ(x1:i),p(xi+1∣x1:i)。我们以自动补全任务来说,输入与输出的形式为, [ [ C L S ] , 他们 , 移动 , 而 ] ⇒ 强大 [[CLS], 他们, 移动, 而]⇒强大 [[CLS],他们,移动,而]⇒强大。与编码端架构比,其优点为能够自然地生成完成文本,有简单的训练目标(最大似然)。缺点也很明显,对于每个 x i xi xi,上下文向量表征只能单向地依赖于左侧上下文 ( x 1 : i − 1 x_{1:i−1} x1:i−1)。
6.3.1.3 编码-解码端(Encoder-Decoder)架构
编码-解码端架构就是最初的Transformer模型,其他的还有如BART、T5等模型。这些模型在某种程度上结合了两者的优点:它们可以使用双向上下文向量表征来处理输入 x 1 : L x_{1:L} x1:L,并且可以生成输出 y 1 : L y_{1:L} y1:L。可以公式化为:
x 1 : L ⇒ ϕ ( x 1 : L ) , p ( y 1 : L ∣ ϕ ( x 1 : L ) ) 。 x1:L⇒ϕ(x1:L),p(y1:L∣ϕ(x1:L))。 x1:L⇒ϕ(x1:L),p(y1:L∣ϕ(x1:L))。
以表格到文本生成任务为例,其输入和输出的可以表示为:
[ 名称 : , 植物 , ∣ , 类型 : , 花卉 , 商店 ] ⇒ [ 花卉 , 是 , 一 , 个 , 商店 ] 。 [名称:, 植物, |, 类型:, 花卉, 商店]⇒[花卉, 是, 一, 个, 商店]。 [名称:,植物,∣,类型:,花卉,商店]⇒[花卉,是,一,个,商店]。
该模型的具有编码端,解码端两个架构的共同的优点,对于每个 x i x_{i} xi,上下文向量表征可以双向地依赖于左侧上下文 ( x 1 : i − 1 x_{1:i−1} x1:i−1) 和右侧上下文 ( x i + 1 : L x_{i+1:L} xi+1:L),可以自由的生成文本数据。缺点就说需要更多的特定训练目标。
6.3.2 语言模型理论
下一步,我们会介绍语言模型的模型架构,重点介绍Transformer架构机器延伸的内容。另外我们对于架构还会对于之前RNN网络的核心知识进行阐述,其目的是对于代表性的模型架构进行学习,为未来的内容增加知识储备。
深度学习的美妙之处在于能够创建构建模块,就像我们用函数构建整个程序一样。因此,在下面的模型架构的讲述中,我们能够像下面的函数一样封装,以函数的的方法进行理解:
T r a n s f o r m e r B l o c k ( x 1 : L ) TransformerBlock(x_{1:L}) TransformerBlock(x1:L)
为了简单起见,我们将在函数主体中包含参数,接下来,我们将定义一个构建模块库,直到构建完整的Transformer模型。
6.3.2.1 基础架构
首先,我们需要将标记序列转换为序列的向量形式。 E m b e d T o k e n EmbedToken EmbedToken函数通过在嵌入矩阵 E ∈ R ∣ v ∣ × d E∈ℝ^{|v|×d} E∈R∣v∣×d中查找每个标记所对应的向量,该向量的具体值这是从数据中学习的参数:
def E m b e d T o k e n ( x 1 : L : V L ) → R d × L EmbedToken(x_{1:L}:V^{L})→ℝ^{d×L} EmbedToken(x1:L:VL)→Rd×L:
- 将序列 x 1 : L x_{1:L} x1:L中的每个标记 x i xi xi转换为向量。
- 返回[Ex1,…,ExL]。
以上的词嵌入是传统的词嵌入,向量内容与上下文无关。这里我们定义一个抽象的 S e q u e n c e M o d e l SequenceModel SequenceModel函数,它接受这些上下文无关的嵌入,并将它们映射为上下文相关的嵌入。
d e f S e q u e n c e M o d e l ( x 1 : L : R d × L ) → R d × L def SequenceModel(x_{1:L}:ℝ^{d×L})→ℝ^{d×L} defSequenceModel(x1:L:Rd×L)→Rd×L:
- 针对序列 x 1 : L x_{1:L} x1:L中的每个元素xi进行处理,考虑其他元素。
- [抽象实现(例如, F e e d F o r w a r d S e q u e n c e M o d e l FeedForwardSequenceModel FeedForwardSequenceModel, S e q u e n c e R N N SequenceRNN SequenceRNN, T r a n s f o r m e r B l o c k TransformerBlock TransformerBlock)]
最简单类型的序列模型基于前馈网络(Bengio等人,2003),应用于固定长度的上下文,就像n-gram模型一样,函数的实现如下:
def F e e d F o r w a r d S e q u e n c e M o d e l ( x 1 : L : R d × L ) → R d × L FeedForwardSequenceModel(x_{1:L}:ℝ^{d×L})→ℝ^{d×L} FeedForwardSequenceModel(x1:L:Rd×L)→Rd×L:
- 通过查看最后 n n n个元素处理序列 x 1 : L x_{1:L} x1:L中的每个元素 x i xi xi。
- 对于每个 i = 1 , … , L i=1,…,L i=1,…,L:
- 计算 h i h_{i} hi= F e e d F o r w a r d ( x i − n + 1 , … , x i ) FeedForward(x_{i−n+1},…,x_{i}) FeedForward(xi−n+1,…,xi)。
- 返回[ h 1 , … , h L h_{1},…,h_{L} h1,…,hL]。
6.3.2.2 递归神经网络
第一个真正的序列模型是递归神经网络(RNN),它是一类模型,包括简单的RNN、LSTM和GRU。基本形式的RNN通过递归地计算一系列隐藏状态来进行计算。
def S e q u e n c e R N N ( x : R d × L ) → R d × L SequenceRNN(x:ℝ^{d×L})→ℝ^{d×L} SequenceRNN(x:Rd×L)→Rd×L:
- 从左到右处理序列 x 1 , … , x L x_{1},…,x_{L} x1,…,xL,并递归计算向量 h 1 , … , h L h_{1},…,h_{L} h1,…,hL。
- 对于 i = 1 , … , L i=1,…,L i=1,…,L:
- 计算 h i = R N N ( h i − 1 , x i ) h_{i}=RNN(h_{i−1},x_{i}) hi=RNN(hi−1,xi)。
- 返回 [ h 1 , … , h L ] [h_{1},…,h_{L}] [h1,…,hL]。
实际完成工作的模块是RNN,类似于有限状态机,它接收当前状态h、新观测值x,并返回更新后的状态:
def R N N ( h : R d , x : R d ) → R d RNN(h:ℝ^d,x:ℝ^d)→ℝ^d RNN(h:Rd,x:Rd)→Rd:
- 根据新的观测值x更新隐藏状态h。
- [抽象实现(例如,SimpleRNN,LSTM,GRU)]
有三种方法可以实现RNN。最早的RNN是简单RNN(Elman,1990),它将 h h h和 x x x的线性组合通过逐元素非线性函数 σ σ σ(例如,逻辑函数 σ ( z ) = ( 1 + e − z ) − 1 σ(z)=(1+e−z)−1 σ(z)=(1+e−z)−1或更现代的 R e L U ReLU ReLU函数 σ ( z ) = m a x ( 0 , z ) σ(z)=max(0,z) σ(z)=max(0,z))进行处理。
def S i m p l e R N N ( h : R d , x : R d ) → R d SimpleRNN(h:ℝd,x:ℝd)→ℝd SimpleRNN(h:Rd,x:Rd)→Rd:
- 通过简单的线性变换和非线性函数根据新的观测值 x x x更新隐藏状态 h h h。
- 返回 σ ( U h + V x + b ) σ(Uh+Vx+b) σ(Uh+Vx+b)。
正如定义的RNN只依赖于过去,但我们可以通过向后运行另一个RNN来使其依赖于未来两个。这些模型被ELMo和ULMFiT使用。
def B i d i r e c t i o n a l S e q u e n c e R N N ( x 1 : L : R d × L ) → R 2 d × L BidirectionalSequenceRNN(x_{1:L}:ℝ^{d×L})→ℝ^{2d×L} BidirectionalSequenceRNN(x1:L:Rd×L)→R2d×L\:
- 同时从左到右和从右到左处理序列。
- 计算从左到右: [ h → 1 , … , h → L ] ← S e q u e n c e R N N ( x 1 , … , x L ) [h→_{1},…,h→_{L}]←SequenceRNN(x_{1},…,x_{L}) [h→1,…,h→L]←SequenceRNN(x1,…,xL)。
- 计算从右到左: [ h ← L , … , h ← 1 ] ← S e q u e n c e R N N ( x L , … , x 1 ) [h←_{L},…,h←_{1}]←SequenceRNN(x_{L},…,x_{1}) [h←L,…,h←1]←SequenceRNN(xL,…,x1)。
- 返回 [ h → 1 h ← 1 , … , h → L h ← L ] [h→_{1}h←_{1},…,h→_{L}h←_{L}] [h→1h←1,…,h→Lh←L]。
注:
- 简单RNN由于梯度消失的问题很难训练。
- 为了解决这个问题,发展了长短期记忆(LSTM)和门控循环单元(GRU)(都属于RNN)。
- 然而,即使嵌入h200可以依赖于任意远的过去(例如,x1),它不太可能以“精确”的方式依赖于它(更多讨论,请参见Khandelwal等人,2018)。
- 从某种意义上说,LSTM真正地将深度学习引入了NLP领域。
6.3.2.3 Transformer
现在,我们将讨论Transformer(Vaswani等人,2017),这是真正推动大型语言模型发展的序列模型。正如之前所提到的,Transformer模型将其分解为Encoder-Only(GPT-2,GPT-3)、Decoder-Only(BERT,RoBERTa)和Encoder-Decoder(BART,T5)模型的构建模块。
关于Transformer的学习资源有很多:
- Illustrated Transformer和Illustrated GPT-2:对Transformer的视觉描述非常好。
- Annotated Transformer:Transformer的Pytorch实现。
强烈建议您阅读这些参考资料。该课程主要依据代码函数和接口进行讲解。
6.3.2.3.1 注意力机制
Transformer的关键是注意机制,这个机制早在机器翻译中就被开发出来了(Bahdananu等人,2017)。可以将注意力视为一个“软”查找表,其中有一个查询 y y y,我们希望将其与序列 x 1 : L = [ x 1 , … , x L ] x_{1:L}=[x_1,…,x_L] x1:L=[x1,…,xL]的每个元素进行匹配。我们可以通过线性变换将每个 x i x_{i} xi视为表示键值对:
( W k e y x i ) : ( W v a l u e x i ) (W_{key}x_{i}):(W_{value}x_{i}) (Wkeyxi):(Wvaluexi)
并通过另一个线性变换形成查询:
W q u e r y y W_{query}y Wqueryy
可以将键和查询进行比较,得到一个分数:
s c o r e i = x i ⊤ W k e y ⊤ W q u e r y y score_{i}=x^{⊤}_{i}W^{⊤}_{key}W_{query}y scorei=xi⊤Wkey⊤Wqueryy
这些分数可以进行指数化和归一化,形成关于标记位置 1 , … , L {1,…,L} 1,…,L的概率分布:
[ α 1 , … , α L ] = s o f t m a x ( [ s c o r e 1 , … , s c o r e L ] ) [α_{1},…,α_{L}]=softmax([score_{1},…,score_{L}]) [α1,…,αL]=softmax([score1,…,scoreL])
然后最终的输出是基于值的加权组合:
∑ i = 1 L α i ( W v a l u e x i ) \sum_{i=1}^L \alpha_i\left(W_{value} x_i\right) i=1∑Lαi(Wvaluexi)
我们可以用矩阵形式简洁地表示所有这些内容:
def A t t e n t i o n ( x 1 : L : R d × L , y : R d ) → R d Attention(x_{1:L}:ℝ^{d×L},y:ℝ^d)→ℝ^d Attention(x1:L:Rd×L,y:Rd)→Rd:
- 通过将其与每个 x i x_{i} xi进行比较来处理 y y y。
- 返回 W v a l u e x 1 : L softmax ( x 1 : L ⊤ W k e y ⊤ W q u e r y y / d ) W_{value} x_{1: L} \operatorname{softmax}\left(x_{1: L}^{\top} W_{key}^{\top} W_{query} y / \sqrt{d}\right) Wvaluex1:Lsoftmax(x1:L⊤Wkey⊤Wqueryy/d)
我们可以将注意力看作是具有多个方面(例如,句法、语义)的匹配。为了适应这一点,我们可以同时使用多个注意力头,并简单地组合它们的输出。
def M u l t i H e a d e d A t t e n t i o n ( x 1 : L : R d × L , y : R d ) → R d MultiHeadedAttention(x_{1:L}:ℝ^{d×L},y:ℝ^{d})→ℝ^{d} MultiHeadedAttention(x1:L:Rd×L,y:Rd)→Rd:
- 通过将其与每个xi与nheads个方面进行比较,处理y。
- 返回 W o u t p u t [ [ Attention ( x 1 : L , y ) , … , Attention ( x 1 : L , y ) ] ⏟ n h e a d s t i m e s W_{output}[\underbrace{\left[\operatorname{Attention}\left(x_{1: L}, y\right), \ldots, \operatorname{Attention}\left(x_{1: L}, y\right)\right]}_{n_{heads}times} Woutput[nheadstimes [Attention(x1:L,y),…,Attention(x1:L,y)]
对于自注意层,我们将用 x i x_{i} xi替换 y y y作为查询参数来产生,其本质上就是将自身的 x i x_{i} xi对句子的其他上下文内容进行 A t t e n t i o n Attention Attention的运算:
def S e l f A t t e n t i o n ( x 1 : L : R d × L ) → R d × L ) SelfAttention(x_{1:L}:ℝ_{d×L})→ℝ_{d×L}) SelfAttention(x1:L:Rd×L)→Rd×L):
- 将每个元素xi与其他元素进行比较。
- 返回 [ A t t e n t i o n ( x 1 : L , x 1 ) , … , A t t e n t i o n ( x 1 : L , x L ) ] [Attention(x_{1:L},x_{1}),…,Attention(x_{1:L},x_{L})] [Attention(x1:L,x1),…,Attention(x1:L,xL)]。
自注意力使得所有的标记都可以“相互通信”,而前馈层提供进一步的连接:
def F e e d F o r w a r d ( x 1 : L : R d × L ) → R d × L FeedForward(x_{1:L}:ℝ^{d×L})→ℝ^{d×L} FeedForward(x1:L:Rd×L)→Rd×L:
- 独立处理每个标记。
- 对于 i = 1 , … , L i=1,…,L i=1,…,L:
- 计算 y i = W 2 m a x ( W 1 x i + b 1 , 0 ) + b 2 y_{i}=W_{2}max(W_{1}x_{i}+b_{1},0)+b_{2} yi=W2max(W1xi+b1,0)+b2。
- 返回 [ y 1 , … , y L ] [y_{1},…,y_{L}] [y1,…,yL]。
对于Transformer的主要的组件,我们差不多进行介绍。原则上,我们可以只需将 F e e d F o r w a r d ∘ S e l f A t t e n t i o n FeedForward∘SelfAttention FeedForward∘SelfAttention序列模型迭代96次以构建GPT-3,但是那样的网络很难优化(同样受到沿深度方向的梯度消失问题的困扰)。因此,我们必须进行两个手段,以确保网络可训练。
6.3.2.3.2 残差连接和归一化
残差连接:计算机视觉中的一个技巧是残差连接(ResNet)。我们不仅应用某个函数f:
f ( x 1 : L ) , f(x1:L), f(x1:L),
而是添加一个残差(跳跃)连接,以便如果 f f f的梯度消失,梯度仍然可以通过$x_{1:L}进行计算:
x 1 : L + f ( x 1 : L ) 。 x_{1:L}+f(x_{1:L})。 x1:L+f(x1:L)。
层归一化:另一个技巧是层归一化,它接收一个向量并确保其元素不会太大:
def L a y e r N o r m ( x 1 : L : R d × L ) → R d × L LayerNorm(x_{1:L}:ℝ^{d×L})→ℝ^{d×L} LayerNorm(x1:L:Rd×L)→Rd×L:
- 使得每个 x i x_{i} xi既不太大也不太小。
我们首先定义一个适配器函数,该函数接受一个序列模型 f f f并使其“鲁棒”:
def A d d N o r m ( f : ( R d × L → R d × L ) , x 1 : L : R d × L ) → R d × L AddNorm(f:(ℝd^{×L}→ℝ^{d×L}),x_{1:L}:ℝ_{d×L})→ℝ^{d×L} AddNorm(f:(Rd×L→Rd×L),x1:L:Rd×L)→Rd×L:
- 安全地将f应用于 x 1 : L x_{1:L} x1:L。
- 返回 L a y e r N o r m ( x 1 : L + f ( x 1 : L ) ) LayerNorm(x_{1:L}+f(x_{1:L})) LayerNorm(x1:L+f(x1:L))。
最后,我们可以简洁地定义Transformer块如下:
def T r a n s f o r m e r B l o c k ( x 1 : L : R d × L ) → R d × L TransformerBlock(x_{1:L}:ℝ^{d×L})→ℝ^{d×L} TransformerBlock(x1:L:Rd×L)→Rd×L:
- 处理上下文中的每个元素 x i x_{i} xi。
- 返回 A d d N o r m ( F e e d F o r w a r d , A d d N o r m ( S e l f A t t e n t i o n , x 1 : L ) ) AddNorm(FeedForward,AddNorm(SelfAttention,x_{1:L})) AddNorm(FeedForward,AddNorm(SelfAttention,x1:L))。
6.3.2.3.3 位置嵌入
最后我们对目前语言模型的位置嵌入进行讨论。您可能已经注意到,根据定义,标记的嵌入不依赖于其在序列中的位置,因此两个句子中的𝗆𝗈𝗎𝗌𝖾将具有相同的嵌入,从而在句子位置的角度忽略了上下文的信息,这是不合理的。
[ t h e , m o u s e , a t e , t h e , c h e e s e ] [ t h e , c h e e s e , a t e , t h e , m o u s e ] [the,mouse,ate,the,cheese] [the,cheese,ate,the,mouse] [the,mouse,ate,the,cheese][the,cheese,ate,the,mouse]
为了解决这个问题,我们将位置信息添加到嵌入中:
def E m b e d T o k e n W i t h P o s i t i o n ( x 1 : L : R d × L ) EmbedTokenWithPosition(x_{1:L}:ℝ^{d×L}) EmbedTokenWithPosition(x1:L:Rd×L):
- 添加位置信息。
- 定义位置嵌入:
- 偶数维度: P i , 2 j = s i n ( i / 1000 0 2 j / d m o d e l ) P_{i,2j}=sin(i/10000^{2j/dmodel}) Pi,2j=sin(i/100002j/dmodel)
- 奇数维度: P i , 2 j + 1 = c o s ( i / 1000 0 2 j / d m o d e l ) P_{i,2j+1}=cos(i/10000^{2j/dmodel}) Pi,2j+1=cos(i/100002j/dmodel)
- 返回 [ x 1 + P 1 , … , x L + P L ] [x_1+P_1,…,x_L+P_L] [x1+P1,…,xL+PL]。
上面的函数中, i i i表示句子中标记的位置, j j j表示该标记的向量表示维度位置。
最后我们来聊一下GPT-3。在所有组件就位后,我们现在可以简要地定义GPT-3架构,只需将Transformer块堆叠96次即可:
G P T − 3 ( x 1 : L ) = T r a n s f o r m e r B l o c k 96 ( E m b e d T o k e n W i t h P o s i t i o n ( x 1 : L ) ) GPT-3(x_{1:L})=TransformerBlock^{96}(EmbedTokenWithPosition(x_{1:L})) GPT−3(x1:L)=TransformerBlock96(EmbedTokenWithPosition(x1:L))
架构的形状(如何分配1750亿个参数):
- 隐藏状态的维度:dmodel=12288
- 中间前馈层的维度:dff=4dmodel
- 注意头的数量:nheads=96
- 上下文长度:L=2048
这些决策未必是最优的。Levine等人(2020)提供了一些理论上的证明,表明GPT-3的深度太深,这促使了更深但更宽的Jurassic架构的训练。
不同版本的Transformer之间存在重要但详细的差异:
- 层归一化“后归一化”(原始Transformer论文)与“先归一化”(GPT-2),这影响了训练的稳定性(Davis等人,2021)。
- 应用了丢弃(Dropout)以防止过拟合。
- GPT-3使用了sparse Transformer(稀释 Transformer)来减少参数数量,并与稠密层交错使用。
- 根据Transformer的类型(Encdoer-Only, Decoder-Only, Encdoer-Decoder),使用不同的掩码操作。
相关文章:

LLM 06-大模型架构
LLM 06-大模型架构 6.1 大模型之模型概括 语言模型的一开始就可以被看做是一个黑箱,当前大规模语言模型的能力在于给定一个基于自身需求的prompt就可以生成符合需求的结果。形式可以表达为: p r o m p t ⇝ c o m p l e t i o n prompt \leadsto compl…...

openGauss学习笔记-71 openGauss 数据库管理-创建和管理普通表-删除表中数据
文章目录 openGauss学习笔记-71 openGauss 数据库管理-创建和管理普通表-删除表中数据 openGauss学习笔记-71 openGauss 数据库管理-创建和管理普通表-删除表中数据 在使用表的过程中,可能会需要删除已过期的数据,删除数据必须从表中整行的删除。 SQL不…...

【k8s】kube-proxy 工作模式
文章目录 Userspace模式:iptables模式:负载均衡(Load Balancing) LB轮询(Round Robin):SessionAffinity:最少连接(Least Connection):IP哈希&…...
Linux:Centos9 《下载-安装》
下载 Download (centos.org)https://www.centos.org/download/ 安装 选择第一个安装centos 根据自己需要的语言环境选择即可 这里选择要安装的磁盘,然后点击完成 这里选择第一个就行带有图形化 然后我们去对这两个进行设置就行 这两个地方自己进行设置就行 耐心等…...

数字化管理平台建设实践
在勘察设计行业,各企业加速推进数字化转型。通过管理要素数字化,不断优化内部组织运营效率;通过生产手段数字化、技术产品数字化,提升服务质量,改善客户体验;通过数字化营销,精准对接市场需求&a…...
之sort)
Linux命令(80)之sort
linux命令之sort 1.sort介绍 linux命令sort用于将文本文件内容以行为单位加以排序;sort命令默认按每行的第一个字符排序,根据首字母的ASCII码值进行升序(从小到大排列)。 sort的默认分隔符是空白(空格和tab),多少空白都算一个分隔符。 2.…...

[k8s] kubectl port-forward 和kubectl expose的区别
kubectl port-forward 和 kubectl expose 是 Kubernetes 命令行工具 kubectl 提供的两种不同方式来公开服务。 kubectl port-forward kubectl port-forward 命令用于在本地主机和集群内部的 Pod 之间建立一个临时的端口转发通道。 该命令将本地机器上的一个端口绑定到集群内部…...
vscode如何设置文件折叠
随着项目的不断迭代开发,复杂度越来越高,配置文件越来越多,导致vscode左侧文件列表展示非常不直观,幸好可以通过文件折叠来简化展示效果,把同类相关的文件折叠在一块展示,方便查看配置文件。配置好后的效果…...

Linux centos7 bash编程训练
训练编写一段代码,打印输出100之内的明7暗7,同时要求每5个数字打印在一行。 此项训练主要是考察for循环的使用,及条件判断表达式的设置和不同写法的应用。 常用的for循环有四种写法(如打印1-100的整数): …...

k8s集群换ip
1.把/etc/kubernetes/*.conf中所有的旧ip换成新ip cd /etc/kubernetes/ find . -type f | xargs sed -i "s/$oldip/$newip/"2.替换$HOME/.kube/config文件中的旧ip为新ip(注意sudo的话需要改root下的) cd $HOME/.kube/ find . -type f | xargs sed -i "s/$old…...

选择HAL库还是标准库
选择HAL库还是标准库呢?HAL库是趋势,标准库不再升级了,转HAL库是大势所趋。HAL库有优点,也有自身的不足,建议初学者还是从标准库入手。 标准库是单片机开发的基本库,它把“用寄存器实现的功能”写成一个函…...

计算机竞赛 机器视觉的试卷批改系统 - opencv python 视觉识别
文章目录 0 简介1 项目背景2 项目目的3 系统设计3.1 目标对象3.2 系统架构3.3 软件设计方案 4 图像预处理4.1 灰度二值化4.2 形态学处理4.3 算式提取4.4 倾斜校正4.5 字符分割 5 字符识别5.1 支持向量机原理5.2 基于SVM的字符识别5.3 SVM算法实现 6 算法测试7 系统实现8 最后 0…...
Mapbox gl HTML经纬度点渲染,动态轨迹播放,自定义图形以及轨迹上显示箭头方向
Mapbox gl HTML经纬度点渲染,动态轨迹播放,自定义图形以及轨迹上显示箭头方向 1. 效果图2. 源码2.1 line.html2.2line_arrow.html 参考 今天要排查个问题,需要显示多个经纬度点连接成线段的方向,于是尝试下展示。 1. mapbox渲染经…...

kubernetes部署(kubeadmin)
文章目录 1.环境准备2. 安装dokcer3.部署cri-docker4.各个节点安装kubeadm等5.整合kubelet和cri-dockerd配置cri-dockerd配置kubelet 6.初始化集群 1.环境准备 环境和软件版本 OS : ubuntu 20.04 container runtime: docker CE 20.10.22 kubernetes 1.24.17 CRI:cr…...

Leetcode168. Excel表列名称
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 题解: 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 代码如下: class Solution {public String convertToTitle(int columnNumber) {StringBuild…...

碎片笔记 | 大模型攻防简报
前言:与传统的AI攻防(后门攻击、对抗样本、投毒攻击等)不同,如今的大模型攻防涉及以下多个方面的内容: 目录 一、大模型的可信问题1.1 虚假内容生成1.2 隐私泄露 二、大模型的安全问题2.1 模型窃取攻击2.2 数据窃取攻击…...
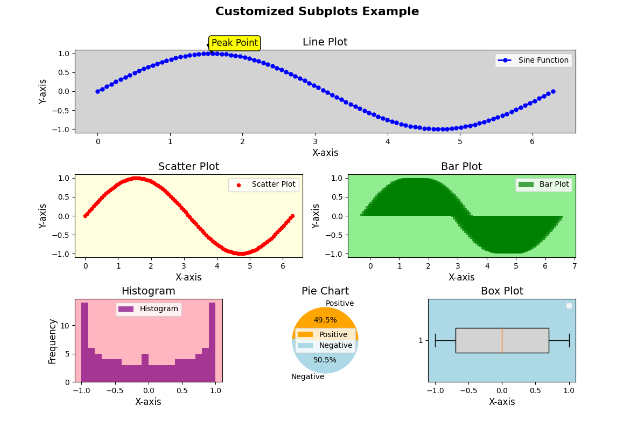
【100天精通Python】Day63:Python可视化_Matplotlib绘制子图,子图网格布局属性设置等示例+代码
目录 1 基本子图绘制示例 2 子图网格布局 3 调整子图的尺寸 4 多行多列的子图布局 5 子图之间的共享轴 6 绘制多个子图类型 7 实战: 绘制一个大图,里面包含6个不同类别的子图,不均匀布局。 绘制子图(subplots)…...
】- UX标注色值带有百分比的使用方法)
【Android常见问题(六)】- UX标注色值带有百分比的使用方法
这里写自定义目录标题 透明度和不透明度的转换对应色值百分比透明度标注 透明度和不透明度的转换 需要不透明度值的,可以自己算:透明度值 不透明度值 100% 如果UI给的视觉稿标注是:颜色#FFFFFF,透明度40% 。那你的计算方式应该…...
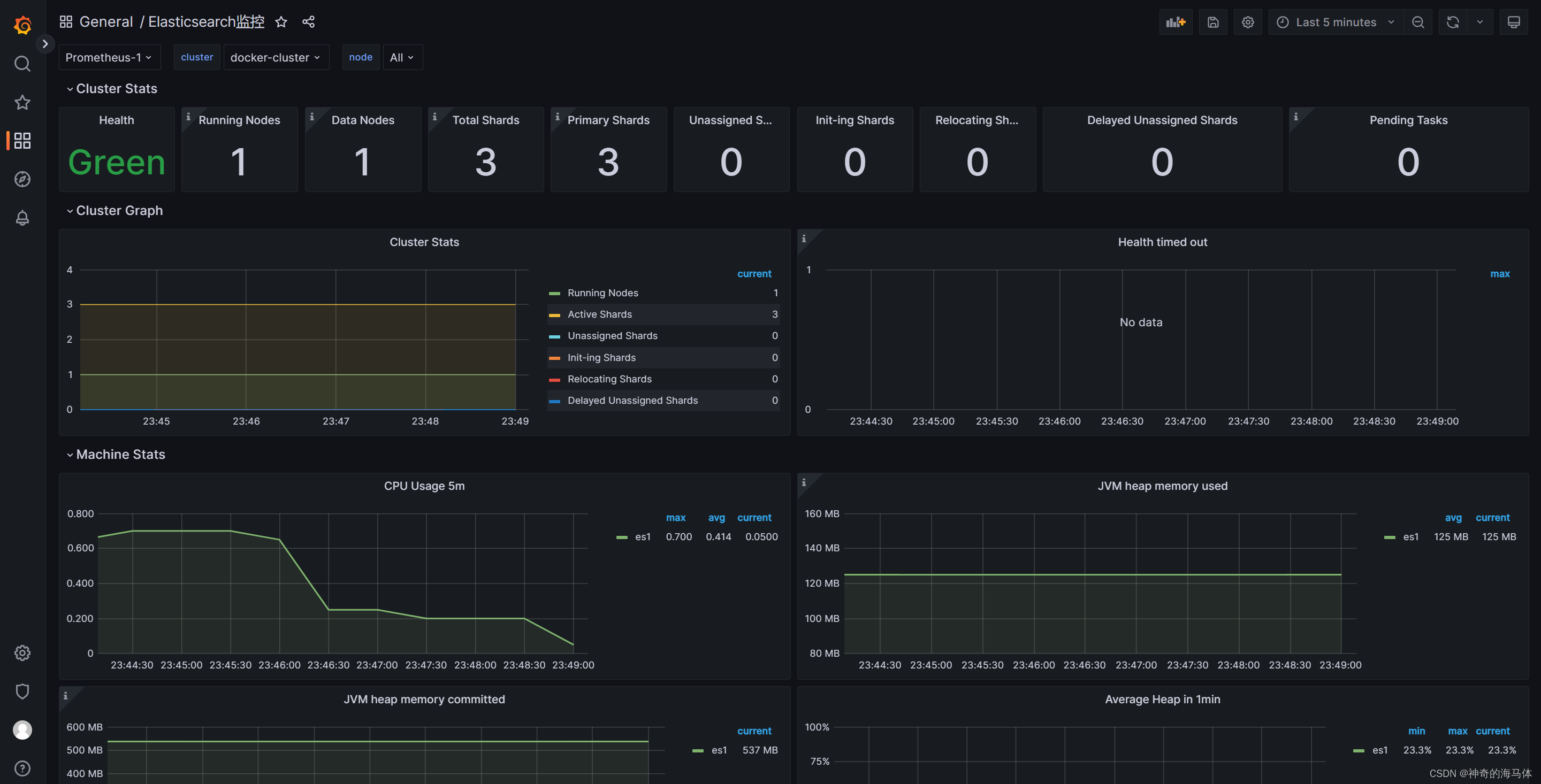
Prometheus+Grafana可视化监控【ElasticSearch状态】
文章目录 一、安装Docker二、安装ElasticSearch(Docker容器方式)三、安装Prometheus四、安装Grafana五、Pronetheus和Grafana相关联六、安装elasticsearch_exporter七、Grafana添加ElasticSearch监控模板 一、安装Docker 注意:我这里使用之前写好脚本进行安装Docke…...
和案例)
Java手写堆排序(Heap Sort)和案例
Java手写堆排序(Heap Sort) 1. 思维导图 下面是使用Mermaid代码绘制的思维导图,用于解释堆排序算法的实现思路原理: #mermaid-svg-cFIgsLSm5LOBm5Gl {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

Java如何权衡是使用无序的数组还是有序的数组
在 Java 中,选择有序数组还是无序数组取决于具体场景的性能需求与操作特点。以下是关键权衡因素及决策指南: ⚖️ 核心权衡维度 维度有序数组无序数组查询性能二分查找 O(log n) ✅线性扫描 O(n) ❌插入/删除需移位维护顺序 O(n) ❌直接操作尾部 O(1) ✅内存开销与无序数组相…...

视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...

【JavaSE】多线程基础学习笔记
多线程基础 -线程相关概念 程序(Program) 是为完成特定任务、用某种语言编写的一组指令的集合简单的说:就是我们写的代码 进程 进程是指运行中的程序,比如我们使用QQ,就启动了一个进程,操作系统就会为该进程分配内存…...

NPOI操作EXCEL文件 ——CAD C# 二次开发
缺点:dll.版本容易加载错误。CAD加载插件时,没有加载所有类库。插件运行过程中用到某个类库,会从CAD的安装目录找,找不到就报错了。 【方案2】让CAD在加载过程中把类库加载到内存 【方案3】是发现缺少了哪个库,就用插件程序加载进…...

为什么要创建 Vue 实例
核心原因:Vue 需要一个「控制中心」来驱动整个应用 你可以把 Vue 实例想象成你应用的**「大脑」或「引擎」。它负责协调模板、数据、逻辑和行为,将它们变成一个活的、可交互的应用**。没有这个实例,你的代码只是一堆静态的 HTML、JavaScript 变量和函数,无法「活」起来。 …...