机器学习第六课--朴素贝叶斯
朴素贝叶斯广泛地应用在文本分类任务中,其中最为经典的场景为垃圾文本分类(如垃圾邮件分类:给定一个邮件,把它自动分类为垃圾或者正常邮件)。这个任务本身是属于文本分析任务,因为对应的数据均为文本类型,所以对于此类任务我们首先需要把文本转换成向量的形式,然后再带入到模型当中。
import pandas as pd
import numpy as np
import matplotlib.mlab as mlab
import matplotlib.pyplot as plt
# 读取spam.csv文件
df = pd.read_csv("/home/anaconda/data/Z_NLP/spam.csv", encoding='latin')
df.head()
# 重命名数据中的v1和v2列,使得拥有更好的可读性
df.rename(columns={'v1':'Label', 'v2':'Text'}, inplace=True)
df.head()
# 把'ham'和'spam'标签重新命名为数字0和1
df['numLabel'] = df['Label'].map({'ham':0, 'spam':1})
df.head()
# 统计有多少个ham,有多少个spam
print ("# of ham : ", len(df[df.numLabel == 0]), " # of spam: ", len(df[df.numLabel == 1]))
print ("# of total samples: ", len(df))
# 统计文本的长度信息,并画出一个histogram
text_lengths = [len(df.loc[i,'Text']) for i in range(len(df))]
plt.hist(text_lengths, 100, facecolor='blue', alpha=0.5)
plt.xlim([0,200])
plt.show()
# 导入英文的停用词库
from sklearn.feature_extraction.text import CountVectorizer
# 构建文本的向量 (基于词频的表示)
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(df.Text)
y = df.numLabel
# 把数据分成训练数据和测试数据
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=100)
print ("训练数据中的样本个数: ", X_train.shape[0], "测试数据中的样本个数: ", X_test.shape[0])
# 利用朴素贝叶斯做训练
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score
clf = MultinomialNB(alpha=1.0, fit_prior=True)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("accuracy on test data: ", accuracy_score(y_test, y_pred))
# 打印混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_pred, labels=[0, 1])
例题:垃圾邮件的分类

总体来讲,朴素贝叶斯分为两个阶段:
- 计算每个单词在不同分类中所出现的概率,这个概率是基于语料库(训练数据)来获得的。
- 利用已经计算好的概率,再结合贝叶斯定理就可以算出对于一个新的文本,它属于某一个类别的概率值,并通过这个结果做最后的分类决策。
先验:
贝叶斯定理

平滑操作---防止也有概率是0,但是贝叶斯乘积永远是0(加1平滑)
另外,在上述过程中可以看到分子的计算过程涉及到了很多概率的乘积,一旦遇到这种情形,就要知道可能会有潜在的风险。比如其中一个概率值等于0,那不管其他概率值是多少,最后的结果一定为0,有点类似于“功亏一篑“的情况,明明出现了很多垃圾邮件相关的单词,就是因为其中的一个概率0,最后判定为属于垃圾邮件的概率为0,这显然是不合理的。为了处理这种情况,有一个关键性操作叫作平滑(smoothing),其中最为常见的平滑方法为加一平滑(add-one smoothing)。
例题:完整的例子:

分子加1,分母加词库的数量

朴素贝叶斯的最大似然估计:

生成模型和判别模型
生成模型是记住所有的特点,所以接下来可以生成新的图片
而判别模型只记得他们之间的区别,所以不能用来生成,只能用来区分
判别模型的初衷是用来解决判别问题,而且只做一件事情(不像生成模型即可以解决分类问题也可以解决生成数据的问题),所以在分类问题上它的效果通常要优于生成模型的。接下来试着从另外一个角度来理解它俩之间的区别。


相关文章:
机器学习第六课--朴素贝叶斯
朴素贝叶斯广泛地应用在文本分类任务中,其中最为经典的场景为垃圾文本分类(如垃圾邮件分类:给定一个邮件,把它自动分类为垃圾或者正常邮件)。这个任务本身是属于文本分析任务,因为对应的数据均为文本类型,所以对于此类任务我们首先…...
基于Java+SpringBoot+Vue的图书借还小程序的设计与实现(亮点:多角色、点赞评论、借书还书、在线支付)
图书借还管理小程序 一、前言二、我的优势2.1 自己的网站2.2 自己的小程序(小蔡coding)2.3 有保障的售后2.4 福利 三、开发环境与技术3.1 MySQL数据库3.2 Vue前端技术3.3 Spring Boot框架3.4 微信小程序 四、功能设计4.1 主要功能描述 五、系统实现5.1 小…...

【校招VIP】前端计算机网络之UDP相关
考点介绍 UDP是一个简单的面向消息的传输层协议,尽管UDP提供标头和有效负载的完整性验证(通过校验和),但它不保证向上层协议提供消息传递,并且UDP层在发送后不会保留UDP 消息的状态。因此,UDP有时被称为不可…...

前缀和实例4(和可被k整除的子数组)
题目: 给定一个整数数组 nums 和一个整数 k ,返回其中元素之和可被 k 整除的(连续、非空) 子数组 的数目。 子数组 是数组的 连续 部分。 示例 1: 输入:nums [4,5,0,-2,-3,1], k 5 输出:7 …...

Android获取系统读取权限
第一步在Androidifest.xml文件中加上授权语句 <uses-permission android:name"android.permission.WRITE_EXTERNAL_STORAGE"/><uses-permission android:name"android.permission.READ_EXTERNAL_STORAGE"/>并且在Application标签下添加 androi…...
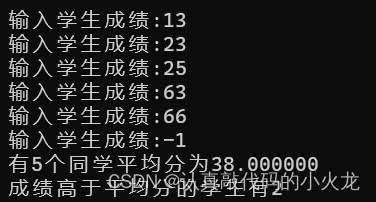
输入学生成绩(最多不超过40),输入为负值时表示输入结束,统计成绩高于平均成绩的学生人数
#include<stdio.h> #define N 40 int scanfscore(int score[N]) {int i -1;do {i;printf("输入学生成绩:");scanf("%d", &score[i]);} while (score[i] > 0);return i; } int average(int score[N], int n) {int j 0;int k 0;double sum …...
【力扣周赛】第 363 场周赛(完全平方数和质因数分解)
文章目录 竞赛链接Q1:100031. 计算 K 置位下标对应元素的和竞赛时代码写法2——手写二进制中1的数量 Q2:100040. 让所有学生保持开心的分组方法数(排序后枚举分界)竞赛时代码 Q3:100033. 最大合金数(二分答…...
RocketMQ的介绍和环境搭建
一、介绍 我也不知道是啥,知道有什么用、怎么用就行了,说到mq(MessageQueue)就是消息队列,队列是先进先出的一种数据结构,但是RocketMQ不一定是这样,简单的理解一下,就是临时存储的…...

【web开发】7、Django(2)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、部门列表二、部门管理(增删改)三、用户管理过渡到modelform组件四、modelform实例:靓号操作五、自定义分页组件六、datepick…...
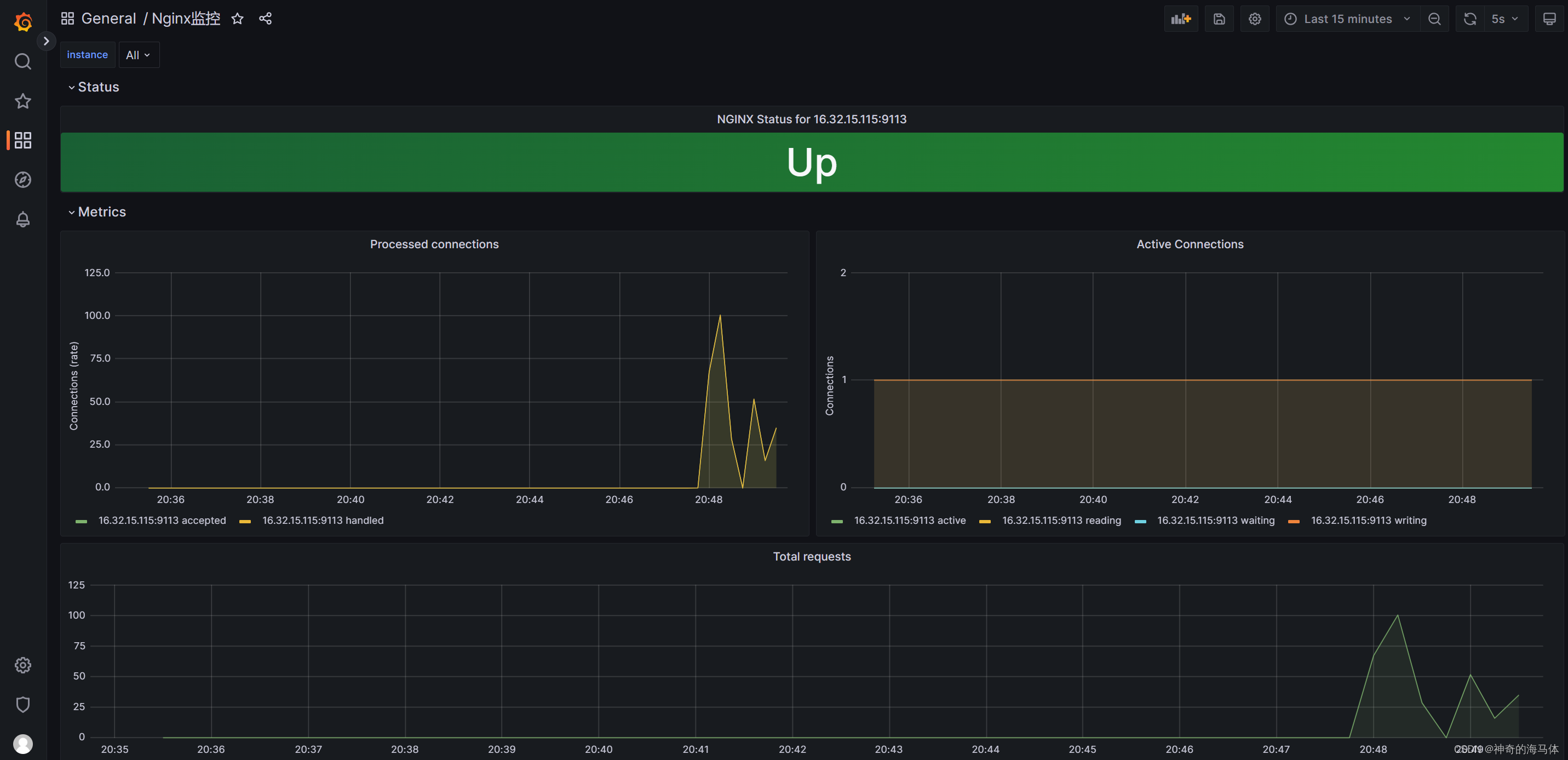
Prometheus+Grafana可视化监控【Nginx状态】
文章目录 一、安装Docker二、安装Nginx(Docker容器方式)三、安装Prometheus四、安装Grafana五、Pronetheus和Grafana相关联六、安装nginx_exporter七、Grafana添加Nginx监控模板 一、安装Docker 注意:我这里使用之前写好脚本进行安装Docker,如果已经有D…...

R 语言的安装教程
一、下载相关软件 1、R 下载 官网:R: The R Project for Statistical Computing 找到中国镜像,下载快 历史版本点击这里 2、Rtools 下载 进入镜像后,点击这里 然后选择与上面下载的R版本相对应的版本即可 3、Rstudio 下载 官网࿱…...
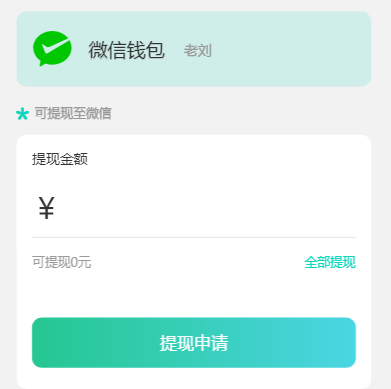
uniapp-提现功能(demo)
页面布局 提现页面 有一个输入框 一个提现按钮 一段提现全部的文字 首先用v-model 和data内的数据双向绑定 输入框逻辑分析 输入框的逻辑 为了符合日常输出 所以要对输入框加一些条件限制 因为是提现 所以对输入的字符做筛选,只允许出现小数点和数字 这里用正则实现的小数点…...
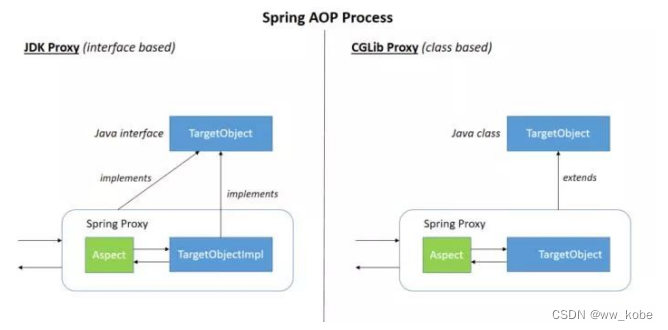
Spring 篇
1、什么是 Spring? Spring是一个轻量级的IOC和AOP容器框架。是为Java应用程序提供基础性服务的一套框架,目的是用于简化企业应用程序的开发,它使得开发者只需要关心业务需求。常见的配置方式有三种:基于XML的配置、基于注解的配置…...
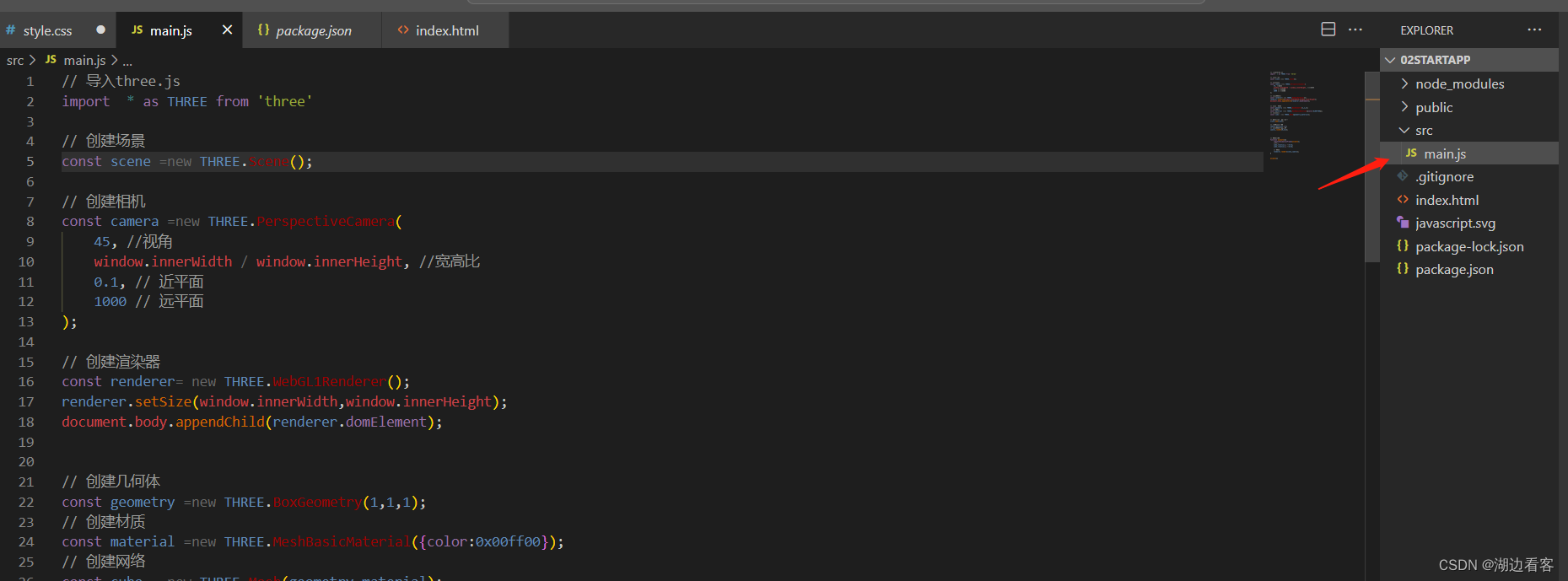
three.js简单3D图形的使用
npm init vitelatest //创建一个vite的脚手架 选择 Vanilla 之后自己处理一下 在main.js中写入 // 导入three.js import * as THREE from three// 创建场景 const scene new THREE.Scene();// 创建相机 const camera new THREE.PerspectiveCamera(45, //视角window.inner…...
)
spark withColumn的使用(笔记)
目录 前言: spark withColumn的语法及使用: 准备源数据演示: 完整实例代码: 前言: withColumn():是Apache Spark中用于DataFrame操作的函数之一,它的作用是在DataFrame中添加或替换列ÿ…...
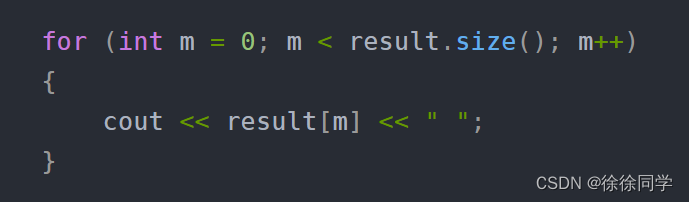
PTA:7-1 线性表的合并
线性表的合并 题目输入样例输出样例 代码解析 题目 输入样例 4 7 5 3 11 3 2 6 3输出样例 7 5 3 11 2 6 代码 #include<iostream> #include<vector> using namespace std;bool checkrep(const vector<int>& arr, int x) {for (int element : arr) {i…...

Spring 的创建和日志框架的整合
目录 一、第一个 Spring 项目 1、配置环境 2、Spring 的 jar 包 Maven 项目导入 jar 包和设置国内源的方法: 3、Spring 的配置文件 4、Spring 的核心 API ApplicationContext 4、程序开发 5、细节分析 (1)名词解释 (2&…...

11-集合和学生管理系统
1.ArrayList 集合和数组的优势对比: 长度可变添加数据的时候不需要考虑索引,默认将数据添加到末尾 1.1 ArrayList类概述 什么是集合 提供一种存储空间可变的存储模型,存储的数据容量可以发生改变 ArrayList集合的特点 长度可以变化…...

C语言进阶指针(3) ——qsort的实现
大家好,我们今天来学习回调函数qsort的实现。 首先让我们打开cplusplus.com找到qsort函数。 我们看到这个函数就可以看到它的头文件和参数信息。 #include<stdlib.h> void qsort (void* base, size_t num, size_t size, int (*compar)(const void*,const voi…...

Rust源码分析——Rc 和 Weak 源码详解
Rc 和 Weak 源码详解 一个值需要被多个所有者拥有 rust中所有权机制在图这种数据结构中,一个节点可能被多个其它节点所指向。那么如何表示图这种数据结构?在多线程中,多个线程可能会持有同一个数据?如何解决这个问题。 Rc rus…...

观成科技:隐蔽隧道工具Ligolo-ng加密流量分析
1.工具介绍 Ligolo-ng是一款由go编写的高效隧道工具,该工具基于TUN接口实现其功能,利用反向TCP/TLS连接建立一条隐蔽的通信信道,支持使用Let’s Encrypt自动生成证书。Ligolo-ng的通信隐蔽性体现在其支持多种连接方式,适应复杂网…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...
:爬虫完整流程)
Python爬虫(二):爬虫完整流程
爬虫完整流程详解(7大核心步骤实战技巧) 一、爬虫完整工作流程 以下是爬虫开发的完整流程,我将结合具体技术点和实战经验展开说明: 1. 目标分析与前期准备 网站技术分析: 使用浏览器开发者工具(F12&…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...
相比,优缺点是什么?适用于哪些场景?)
Redis的发布订阅模式与专业的 MQ(如 Kafka, RabbitMQ)相比,优缺点是什么?适用于哪些场景?
Redis 的发布订阅(Pub/Sub)模式与专业的 MQ(Message Queue)如 Kafka、RabbitMQ 进行比较,核心的权衡点在于:简单与速度 vs. 可靠与功能。 下面我们详细展开对比。 Redis Pub/Sub 的核心特点 它是一个发后…...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...