Hdoop伪分布式集群搭建
文章目录
- Hadoop安装部署
- 前言
- 1.环境
- 2.步骤
- 3.效果图
- 具体步骤
- (一)前期准备
- (1)ping外网
- (2)配置主机名
- (3)配置时钟同步
- (4)关闭防火墙
- (二)正文
- (1)配置hosts列表
- (2)SSH免密钥登录配置
- ①master虚拟机上
- ②slave01虚拟机上
- ③slave02虚拟机上
- ④验证免密登录
- (3)安装JDK
- (4)安装部署Hadoop集群(chenqi用户)
- 1.解压缩包
- 2.配置文件
- 3.创建Hadoop数据目录
- 4.将配置好的hadoop文件夹复制到从节点
- 5.配置Hadoop环境变量
- 6.格式化Hadoop文件目录
- 7.启动Hadoop集群
- (5)测试
- ①Web UI查看集群是否成功启动
- ②运行PI实例检查集群是否成功
Hadoop安装部署
前言
1.环境
- 虚拟机数量:3个 (1个master,2个slave:slave01,slave02)
- 操作系统:Ubuntu 22.04.2
2.步骤

3.效果图
hadoop集群安装部署后,启动集群,效果如下:
效果图1:master虚拟机上,出现这4个进程表示主节点进程启动成功。

效果图2:slave01虚拟机上,出现这3个进程表示从节点进程启动成功。

效果图3:slave02虚拟机上,出现这3个进程表示从节点进程启动成功。

具体步骤
(一)前期准备
首先要确保各台虚拟机能ping通外网
(1)ping外网
在三台虚拟机中使用ping命令,确保各台虚拟机能ping通外网。
(2)配置主机名
将三台主机名分别设置为master,slave01,slave02,便于后期的操作
说明:此处以界面虚拟机master的操作为例,slave01和slave02的操作如法炮制。
不同操作系统可能操作方法不同,百度对应操作即可
-
以下操作需要root用户权限,所以先切换成root用户。
chenqi@localhost:~$ sudo su -
使用vi命令编辑主机名(或使用gedit)。
root@localhost:~# vi /etc/hostname将hostname文件中原来内容替换为master,如果已经是master,可以直接按冒号“:“键,再输入“wq”保存退出
-
临时设置主机名为master。
root@localhost:~# hostname master -
检测主机名是否修改成功,使用bash命令让上一步操作生效。
root@localhost:~# bash -
localhost变为master
(3)配置时钟同步
说明:此处以界面虚拟机master的操作为例,slave01和slave02的操作如法炮制。
不同操作系统可能操作方法不同,百度对应操作即可
Linux服务器运行久了,系统时间就会存在一定的误差,一般情况下可以使用date命令进行时间设置,但在做数据库集群等操作时对多台机器的时间差是有要求的,此时就需要使用ntpdate进行时间同步
-
使用root用户权限
-
执行命令同步,如果没有ntpdate需要先安装:
apt-get install ntpdateroot@master:~# sudo ntpdate cn.pool.ntp.org
(4)关闭防火墙
说明:此处以界面虚拟机master的操作为例,slave01和slave02的操作如法炮制。
不同操作系统可能操作方法不同,百度对应操作即可
-
查看防火墙状态(默认已经关闭防火墙)
root@master:~# sudo ufw status -
两条命令分别是打开防火墙和关闭防火墙)
root@master:~# sudo ufw enable root@master:~# sudo ufw disable
(二)正文
(1)配置hosts列表
说明:此处以界面虚拟机master的操作为例,slave01和slave02的操作如法炮制。
不同操作系统可能操作方法不同,百度对应操作即可
-
运行ifconfig命令,获得当前master虚拟机的ip地址,如图6-10所示是master的ip地址。(用相同方法获得当前slave01和slave02虚拟机的ip地址。)
ifconfig没安装可以先安装,也可以使用ip addr
-
编辑主机名列表文件hosts。将下面三行添加到/etc/hosts文件中,保存退出。
root@master:~# vi /etc/hosts"自己的maser主机地址" master "自己的slave01主机地址" slave01 "自己的slave02主机地址" slave02 -
测试
root@master:~# ping master -c 3 root@master:~# ping slave01 -c 3 root@master:~# ping slave02 -c 3说明:参数-c 3表示只返回三行响应就中止。ping通就代表成功
(2)SSH免密钥登录配置
①master虚拟机上
-
先从root用户,退回到普通用户
root@master:~# su chenqi -
在终端生成密钥,命令如下(一路按回车完成密钥生成)
chenqi@master:~$ ssh-keygen -t rsa
-
生成的密钥在用户根目录中的.ssh子目录中,进入.ssh目录查看

-
执行以下命令复制公钥文件
chenqi@master:~/.ssh$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys -
修改authorized_keys文件的权限
chenqi@master:~/.ssh$ chmod 600 ~/.ssh/authorized_keys -
将专用密钥添加到 ssh-agent 的高速缓存中
chenqi@master:~/.ssh$ ssh-add ~/.ssh/id_rsaCould not open a connection to your authentication agent:
原因:未启动ssh agent
先执行一下ssh-agent bash
-
将authorized_keys文件复制到slave01、slave02虚拟机的zkpk用户的根目录,
chenqi@master:~$ scp ~/.ssh/authorized_keys zkpk@slave01:~/ chenqi@master:~$ scp ~/.ssh/authorized_keys zkpk@slave02:~/
②slave01虚拟机上
-
生成密钥,命令如下(一路点击回车生成密钥)。
chenqi@slave01:~$ ssh-keygen -t rsa -
将authorized_keys文件移动到.ssh目录,
chenqi@slave01:~$ mv authorized_keys ~/.ssh/
③slave02虚拟机上
-
生成密钥,命令如下(一路点击回车生成密钥)。
chenqi@slave02:~$ ssh-keygen -t rsa -
将authorized_keys文件移动到.ssh目录,
chenqi@slave02:~$ mv authorized_keys ~/.ssh/
④验证免密登录
-
在master虚拟机上远程登录slave01
chenqi@master:~$ ssh slave01如果出现如图所示的内容表示免密钥配置成功。

-
退出slave01远程登录
chenqi@slave01:~$ exit -
slave02同理
(3)安装JDK
说明:此处以界面虚拟机master的操作为例,slave01和slave02的操作如法炮制。
不同操作系统可能操作方法不同,百度对应操作即可
-
删除系统自带的jdk(如若出现如图6-21效果,说明系统自带java,需要先卸载)
chenqi@master:~$ rpm -qa | grep java
-
移除系统自带的jdk
root@master:~# yum remove java-1.* -
创建存放jdk文件目录
root@master:~# mkdir /usr/java -
解压JDK压缩包,将/home/chenqi/tgz下的JDK压缩包解压到/usr/java目录下
root@master:~# tar -xzvf /home/chenqi/tar/jdk-8u371-linux-x64.tar.gz -C /usr/javahdoop和jdk的压缩包去官网上下载一个版本下来即可

slave01和02都要解压jdk
-
退出root用户
root@master:~# exit -
配置chenqi用户环境变量。
chenqi@master:~$ vi .profile复制以下内容添加到上面打开的文件.bash_profile中,然后保存退出。
export JAVA_HOME=/usr/java/jdk1.8.0_371/ export PATH=$JAVA_HOME/bin:$PATH -
使环境变量生效
chenqi@master:~$ source /home/chenqi/.profile -
测试是否配置成功
chenqi@master:~$ java -version
(4)安装部署Hadoop集群(chenqi用户)
注意:每个虚拟机上的Hadoop配置基本相同,在master虚拟机上操作,然后复制到slave01、slave02两个虚拟机即可。
1.解压缩包
chenqi@master:~$ tar -xzvf /home/chenqi/tar/hadoop-3.3.6.tar.gz -C /home/chenqi
2.配置文件
• workers : 配置从节点( DataNode )有哪些
• hadoop-env.sh : 配置 Hadoop 的相关环境变量
• core-site.xml : Hadoop 核心配置文件
• hdfs-site.xml : HDFS 核心配置文件
①配置hadoop-env.sh文件
chenqi@master:~$ vi /home/chenqi/hadoop-3.3.6/etc/hadoop/hadoop-env.sh
复制以下内容添加到上面打开的文件hadoop-env.sh中,然后保存退出。
export JAVA_HOME=/usr/java/jdk1.8.0_371/
②配置yarn-env.sh文件。
chenqi@master:~$ vi ~/hadoop-3.3.6/etc/hadoop/yarn-env.sh
复制以下内容添加到上面打开的文件yarn-env.sh中,然后保存退出。
export JAVA_HOME=/usr/java/jdk1.8.0_371/
③配置core-site.xml 文件。
chenqi@master:~$ vi ~/hadoop-3.3.6/etc/hadoop/core-site.xml
复制以下内容替换core-site.xml中的内容,然后保存退出。
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/chenqi/hadoopdata</value> </property>
</configuration>
fs.defaultFS:HDFS的默认访问路径,也是NameNode的访问地址。
hadoop.tmp.dir:Hadoop数据文件的存放目录。该参数如果不配置默认指向/tmp目录,而/tmp目录在系统重启后会自动清空,从而导致Hadoop的文件系统数据丢失。
最后测试的时候如果没有9000端口,将master改成对应的地址
④配置hdfs-site.xml文件。
chenqi@master:~$ vi ~/hadoop-3.3.6/etc/hadoop/hdfs-site.xml
复制以下内容替换hdfs-site.xml中的内容,然后保存退出。
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration> <!-- 测试环境指定HDFS副本的数量1 --><property><name>dfs.replication</name> <value>2</value> </property>
</configuration>
dfs.replication:文件在HDFS系统中的副本数。
dfs.permission.enabled:是否检查用户权限。
dfs.namenoder:NameNode节点数据在本地文件系统的存放位置。
dfs.datanode.data.dir:DataNode节点数据在本地文件系统的存放位置。
⑤配置yarn-site.xml文件。
chenqi@master:~$ vi ~/hadoop-3.3.6/etc/hadoop/yarn-site.xml
6.9.6.2复制以下内容替换yarn-site.xml中的内容,然后保存退出。(如果已经有这样的内容,直接退出。)
<?xml version="1.0"?>
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:18040</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:18030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:18025</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:18141</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:18088</value> </property>
</configuration>
yarn.nodemanager.aux:NodeManager上运行的附属服务,需配置成mapreduce_shuffle才可运行Mapreduce程序。YARN提供了该配置项用于在NodeManager上扩展自定义服务,Mapreduce的Shuffle功能正是一种扩展服务。
yarn.resourcemanager.address:指定ResourceManager所在的节点与访问端口,如果不添加,ResourceManager则默认执行在YARN启动命令的节点上启动。
⑥配置mapred-site.xml文件。
chenqi@master:~$ vi ~/hadoop-3.3.6/etc/hadoop/mapred-site.xml
复制以下内容替换mapred-site.xml中的内容,然后保存退出。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
</configuration>
mapreduce.framework.name:指定 Mapreduce 程序运行在 YARN上
⑦配置workers文件。
chenqi@master:~$ vi ~/hadoop-3.3.6/etc/hadoop/workers
通过workers文件定义数据节点,根据集群规划,我们将两个节点都要作为数据节点,添上:
slave01
slave02
3.创建Hadoop数据目录
chenqi@master:~$ mkdir hadoopdata
4.将配置好的hadoop文件夹复制到从节点
用scp命令将文件夹复制到slave01、slave02上。
注意:因为之前已经配置了免密钥登录,这里可以直接免密钥远程复制。
chenqi@master:~$ scp -r hadoop-3.3.6 chenqi@slave01:~/chenqi@master:~$ scp -r hadoop-3.3.6 chenqi@slave02:~/
复制完成后,可以在slave01和slave02上检验是否复制成功。在用户主目录下ls一下就行
5.配置Hadoop环境变量
说明:此处以界面虚拟机master的操作为例,slave01和slave02的操作如法炮制。
使用vi命令编辑.bash_profile文件。
chenqi@master:~$ vi .profile
复制以下内容添加到.bash_profile末尾,然后保存退出。(如果已经有这样的内容,直接退出。)
#HADOOP
export HADOOP_HOME=/home/chenqi/hadoop-3.3.6
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
使环境变量生效。
chenqi@master:~$ source ~/.profile
6.格式化Hadoop文件目录
注意:此操作在master虚拟机上执行。
格式化命令如下。
chenqi@master:~$ hdfs namenode –format

图6-45 格式化master虚拟机(1)

图 6-46格式化master虚拟机(2)
7.启动Hadoop集群
在master虚拟机上运行start-all.sh命令。(格式化后首次执行此命令,提示输入yes/no时,输入yes。)
chenqi@master:~$ start-all.sh
查看进程是否启动。
注意:前面那些数字是进程号,可能因为自己的实验环境不同而不同。

在slave01虚拟机上的终端执行jps命令,出现如图 :

在slave02虚拟机上的终端执行jps命令,出现如图:
!
(5)测试
①Web UI查看集群是否成功启动
在浏览器地址栏中输入http://master:50070,检查namenode和 datanode 是否正常,如图6-50、6-51、6-52所示。
netstat -ntpl查看自己的

查看集群namenode 和 datanode情况、检查Yarn是否正常

②运行PI实例检查集群是否成功
执行下面的命令。(Pi后面的第一个参数10是Map任务的数量,第二个10是求圆周率Pi的算法的参数。)
[zkpk@master~]$ hadoop jar ~/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 10 10



最后输出:Estimated value of Pi is 3.20000000000000000000,这个值还不够精确,可以通过调整那两个参数逐渐逼近3.1415926……。
问题描述:Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
解决方法:
第一种:在mapred-site.xml中添加以下配置
<property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${hadoop-3.3.6}</value> </property> <property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${hadoop-3.3.6}</value> </property> <property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${hadoop-3.3.6}</value> </property>第二种:如果上述方法不行,采用下面方式
执行下面命令
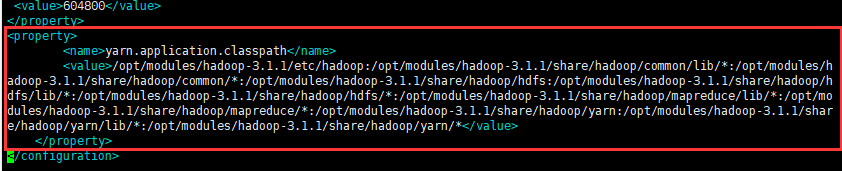
hadoop classpath拿到运行的类的路径,如下图:
在Hadoop安装目录下找到yarn-site.xml文件($HADOOP_HOME/etc/hadoop/yarn-site.xml),把刚才得到的信息配置进去,如下:
<configuration><property><name>yarn.application.classpath</name><value>复制的Hadoop classpath信息</value></property> </configuration>
在所有的Master和Slave节点进行如上设置,设置完毕后重启Hadoop集群,重新运行刚才程序,成功运行。

相关文章:
Hdoop伪分布式集群搭建
文章目录 Hadoop安装部署前言1.环境2.步骤3.效果图 具体步骤(一)前期准备(1)ping外网(2)配置主机名(3)配置时钟同步(4)关闭防火墙 (二)…...

java临时文件
临时文件 有时候,我们程序运行时需要产生中间文件,但是这些文件只是临时用途,并不做长久保存。 我们可以使用临时文件,不需要长久保存。 public static File createTempFile(String prefix, String suffix)prefix 前缀 suffix …...

C++中的<string>头文件 和 <cstring>头文件简介
C中的<string>头文件 和 <cstring>头文件简介 在C中<string> 和 <cstring> 是两个不同的头文件。 <string> 是C标准库中的头文件,定义了一个名为std::string的类,提供了对字符串的操作如size()、length()、empty() 及字…...

安装MySQL
Centos7下安装MySQL详细步骤_centos7安装mysql教程_欢欢李的博客-CSDN博客...

输入学生成绩,函数返回最大元素的数组下标,求最高分学生成绩(输入负数表示输入结束)
scanfscore()函数用于输入学生的成绩 int scanfscore(int score[N])//输入学生的成绩 {int i -1;do {i;printf("输入学生成绩:");scanf("%d", &score[i]);} while (score[i] > 0);return i; } findmax()用于寻找最大值 int findmax(int score[N…...

常用音频接口:TDM,PDM,I2S,PCM
常用音频接口:TDM,PDM,I2S,PCM_tdm音频_沙漠的甲壳虫的博客-CSDN博客 I2S/PCM接口及音频codec_音频pcm接口模块设计-CSDN博客 2个TDM8功放调试ing_周龙(AI湖湘学派)的博客-CSDN博客 数字音频接口时序----IIS、TDM、PCM、PDM_td…...
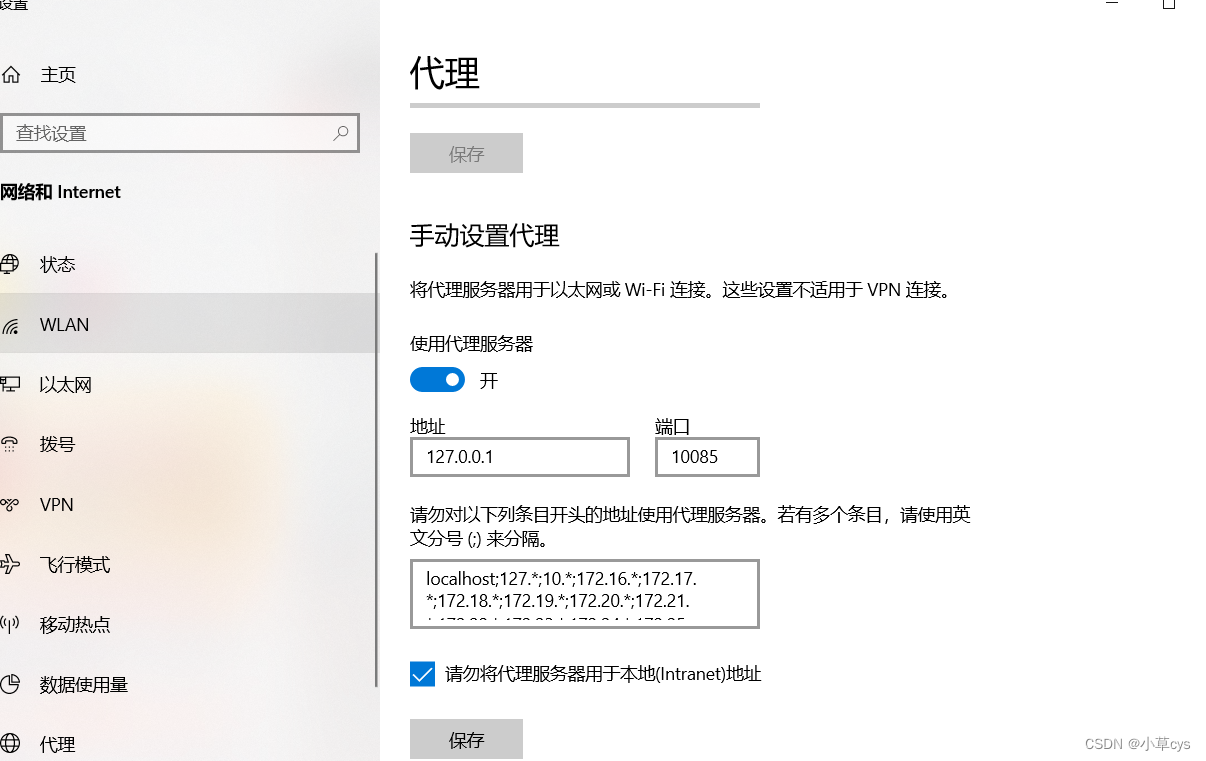
git clone报错Failed to connect to github.com port 443 after 21055 ms:
git 设置代理端口号 git config --global http.proxy http://127.0.0.1:10085 和 git config --global https.proxy http://127.0.0.1:10085 然后就可以成功git clone hugging face的数据集了 如果是https://huggingface.co/datasets/shibing624/medical/tree/main 那么…...
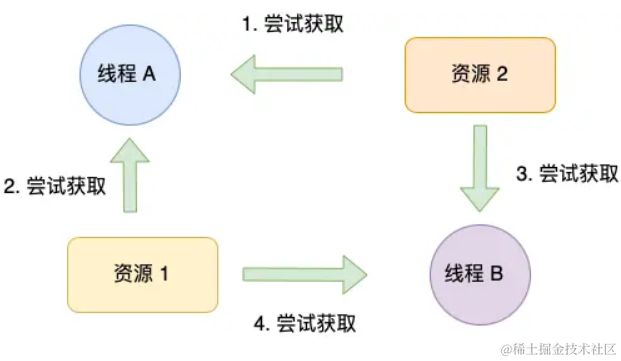
【操作系统】深入浅出死锁问题
死锁的概念 在多线程编程中,我们为了防止多线程竞争共享资源而导致数据错乱,都会在操作共享资源而导致数据错乱,都会在操作共享资源之前加上互斥锁,只有成功获得到锁的线程,才能操作共享资源,获取不到锁的…...

springboot实现webSocket服务端和客户端demo
1:pom导入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId><version>2.2.7.RELEASE</version></dependency>2:myWebSocketClien…...

代码走读: FFMPEG-ffplayer02
AVFrame int attribute_align_arg avcodec_receive_frame(AVCodecContext *avctx, AVFrame *frame) 选取一个音频解码器 和 一个视频解码器分别介绍该解码器功能 音频G722 g722dec.c -> g722_decode_frame 通过 ff_get_buffer 给 传入的 frame 指针分配内存 g722_decode_…...
【数据结构】——排序算法的相关习题
目录 一、选择题题型一 (插入排序)1、直接插入排序2、折半插入排序3、希尔排序 题型二(交换排序)1、冒泡排序2、快速排序 题型三(选择排序)1、简单选择排序~2、堆排序 ~题型四(归并排序…...

C高级day5(Makefile)
一、Xmind整理: 二、上课笔记整理: 1.#----->把带参宏的参数替换成字符串 #include <stdio.h> #include <stdlib.h> #include <string.h> #define MAX(a,b) a>b?a:b #define STR(n) #n int main(int argc, const char *argv…...

Android 系统中适配OAID获取
一、OAID概念 OAID(Open Anonymous Identification)是一种匿名身份识别标识符, 用于在移动设备上进行广告追踪和个性化广告投放。它是由中国移动通信集 团、中国电信集团和中国联通集团共同推出的一项行业标准 OAID值为一个64位的数字 二、…...

差分数组leetcode 2770 数组的最大美丽值
什么是差分数组 差分数组是一种数据结构,它存储的是一个数组每个相邻元素的差值。换句话说,给定一个数组arr[],其对应的差分数组diff[]将满足: diff[i] arr[i1] - arr[i] 对于所有 0 < i < n-1 差分数组的作用 用于高效…...

请求响应状态码
请求与响应&状态码 Requests部分 请求行、消息报头、请求正文。 Header解释示例Accept指定客户端能够接收的内容类型Accept: text/plain, text/htmlAccept-Chars et浏览器可以接受的字符编码集。Accept-Charset: iso-8859-5Accept-Encodi ng指定浏览器可以支持的web服务…...

安卓机型系统美化 Color.xml文件必备常识 自定义颜色资源
color.xml文件是Android工程中用来进行颜色资源管理的文件.可以在color.xml文件中通过<color>标签来定义颜色资源.我们在布局文件中、代码中、style定义中或者其他资源文件中,都可以引用之前在color.xml文件中定义的颜色资源。 将color.xml文件拷到res/value…...
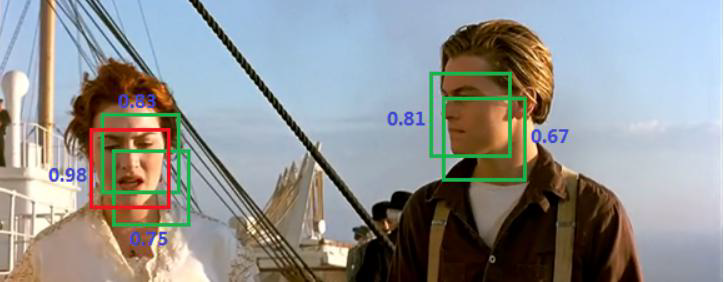
YOLO物体检测-系列教程1:YOLOV1整体解读(预选框/置信度/分类任/回归任务/损失函数/公式解析/置信度/非极大值抑制)
🎈🎈🎈YOLO 系列教程 总目录 YOLOV1整体解读 YOLOV2整体解读 YOLOV1提出论文:You Only Look Once: Unified, Real-Time Object Detection 1、物体检测经典方法 two-stage(两阶段):Faster-rc…...
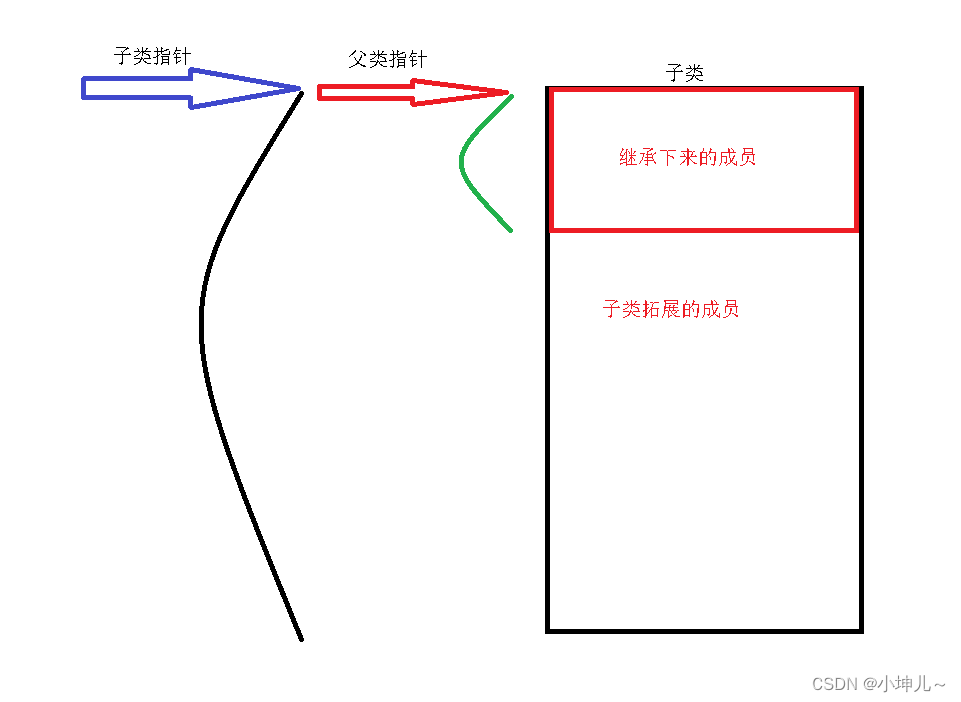
2023/9/12 -- C++/QT
作业 实现一个图形类(Shape),包含受保护成员属性:周长、面积, 公共成员函数:特殊成员函数书写 定义一个圆形类(Circle),继承自图形类,包含私有属性…...
【Purple Pi OH RK3566鸿蒙开发板】OpenHarmony音频播放应用,真实体验感爆棚!
本文转载于Purple Pi OH开发爱好者,作者ITMING 。 原文链接:https://bbs.elecfans.com/jishu_2376383_1_1.html 01注意事项 DevEco Studio 4.0 Beta2(Build Version: 4.0.0.400) OpenHarmony SDK API 9 创建工程类型选择Appli…...

Android rom开发:9.0系统上实现4G wifi 以太网共存
framework层修改网络优先级,4G > wifi > eth 修改patch如下: diff --git a/frameworks/base/services/core/java/com/android/server/connectivity/NetworkAgentInfo.java b/frameworks/base/services/core/java/com/android/server/connectivit…...

若依框架单体应用版:从建表到增删改查,代码生成器实战指南
1. 若依框架单体应用版快速上手 第一次接触若依框架时,我被它的代码生成器功能惊艳到了。作为一个长期奋战在业务开发一线的程序员,最头疼的就是重复编写那些千篇一律的增删改查代码。若依的单体应用版(前后端不分离)特别适合中小…...

骨干网为什么偏爱IS-IS?从报文结构到PRC算法详解运营商级路由协议设计
骨干网为何青睐IS-IS?从协议设计到现网实践的深度解析 在互联网基础设施的底层,运营商骨干网如同数字时代的高速公路系统,承载着全球90%以上的跨域流量。而这条"信息高速公路"的交通指挥系统,则高度依赖IS-IS࿰…...
)
用ESP32-S3做个桌面小玩意:语音助手、GIF时钟和网络摄像头三合一(附开源代码与避坑指南)
ESP32-S3三合一桌面终端:从零构建智能语音助手、动态时钟与摄像监控系统 引言:当极客精神遇见桌面美学 在创客圈里流传着一句话:"如果你桌面上没有至少三个正在吃灰的开发板,说明你不够极客。"而今天我们要做的…...

效率提升:用快马AI构建集成化web终端效率工具面板
效率提升:用快马AI构建集成化web终端效率工具面板 作为一个经常需要操作终端命令的开发者,我一直在寻找提升效率的方法。本地工具如xshell8确实好用,但每次换设备都要重新配置,而且无法轻松分享给团队成员。最近尝试用InsCode(快…...

2026.4.7总结
工作日精进:这个月在心声上看到许多离职的帖子,估计是有很多拿完年终奖离职的。看到别人写的离职感悟,我多少有些共情。当有一天,我离职的时候,我也要写一篇长篇大论。早上HR跟入职一两年的人解读了esop相关政策。这政…...

告别假阳性!用TAGS多模态提示策略,精准提升你的医学影像分割模型性能
告别假阳性!用TAGS多模态提示策略,精准提升你的医学影像分割模型性能 医学影像分割一直是计算机辅助诊断中的核心挑战,尤其是肿瘤这类边界模糊、形态多变的病灶。传统方法依赖大量标注数据和复杂的后处理,而基础模型直接迁移又面临…...

LC327树状数组与归并排序
327. 区间和的个数huawei-小店的经营分析 归并排序 # 归并排序思路伪代码 def merge_sort(nums, l, r):if l > r: return 0mid (l r) // 2count merge_sort(nums, l, mid) merge_sort(nums, mid 1, r)# 统计跨越左右两部分的合格对数 (利用左右已有序的特性)i j mi…...

INS与GPS组合导航EKF算法代码功能说明
三维的组合导航。 ins和卫星的组合导航算法,基于卡尔曼滤波和eskf滤波的都有。 MATLAB源码,有kf和eskf的对比,也有单独的误差,或者输入滤波之后的位移速度等导航参数。 这段程序主要是一个卡尔曼滤波器,用于估计运动物…...

基于Stackelberg博弈与需求响应的光伏用户群内部优化定价模型研究
MATLAB代码:基于Stackelberg博弈的光伏用户群优化定价模型关键词:光伏用户群 内部电价 需求响应 斯塔克伯格博弈 参考文档:《基于Stackelberg博弈的光伏用户群优化定价模型》王程 刘念 仿真平台:MATLAB Cplex 主要内容࿱…...

利用快马平台快速搭建stm32f103c8t6最小系统板LED闪烁原型
最近在做一个嵌入式小项目,用到了经典的stm32f103c8t6最小系统板。作为嵌入式开发新手,最头疼的就是搭建开发环境和写各种初始化代码。不过这次尝试用InsCode(快马)平台后,整个过程顺畅多了,分享下我的经验。 项目背景 stm32f103c…...