Hadoop-Hbase
1. Hbase安装
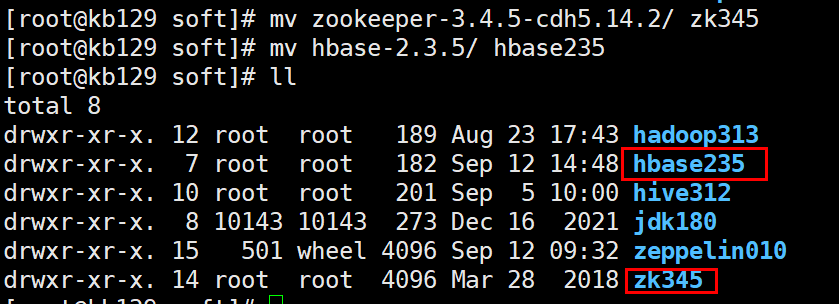
| 1.1 安装zookeeper、 hbase 解压至/opt/soft,并分别改名
配置环境变量并source生效 #ZK export ZOOKEEPER_HOME=/opt/soft/zk345 export PATH=$ZOOKEEPER_HOME/bin:$PATH #HBASE_HOME export HBASE_HOME=/opt/soft/hbase235 export PATH=$HBASE_HOME/bin:$PATH hbase235/conf目录下的 编辑hbase-env.sh:[root@kb129 conf]# vim ./hbase-env.sh export JAVA_HOME=/opt/soft/jdk180
编辑hbase-site.xml [root@kb129 conf]# vim ./hbase-site.xml 拷贝配置文件准备配置zookeeper [root@kb129 conf]# pwd /opt/soft/zk345/conf [root@kb129 conf]# cp zoo_sample.cfg zoo.cfg 创建目录 [root@kb129 conf]# mkdir /opt/soft/zk345/logs [root@kb129 conf]# mkdir /opt/soft/zk345/zkdata
编辑配置文件,增加目录指向 [root@kb129 conf]# vim ./zoo.cfg
追加节点id [root@kb129 conf]# cd ../zkdata/ [root@kb129 zkdata]# echo "0">myid 启动zookeeper [root@kb129 zkdata]# zkServer.sh start
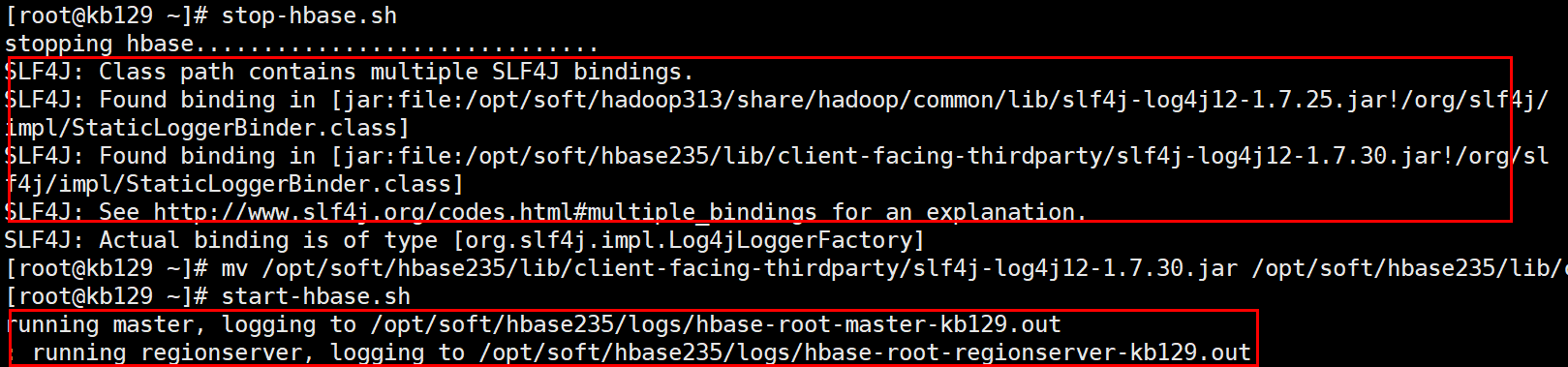
启动hbase (启动前解决Hbase和hadoop中log4j的jar包冲突报错问题:将Hbase中的jar包改名就不会读取,解决掉冲突报错:mv /opt/soft/hbase235/lib/client-facing-thirdparty/slf4j-log4j12-1.7.30.jar /opt/soft/hbase235/lib/client-facing-thirdparty/slf4j-log4j12-1.7.30.jar.bak)
[root@kb129 zkdata]# start-hbase.sh
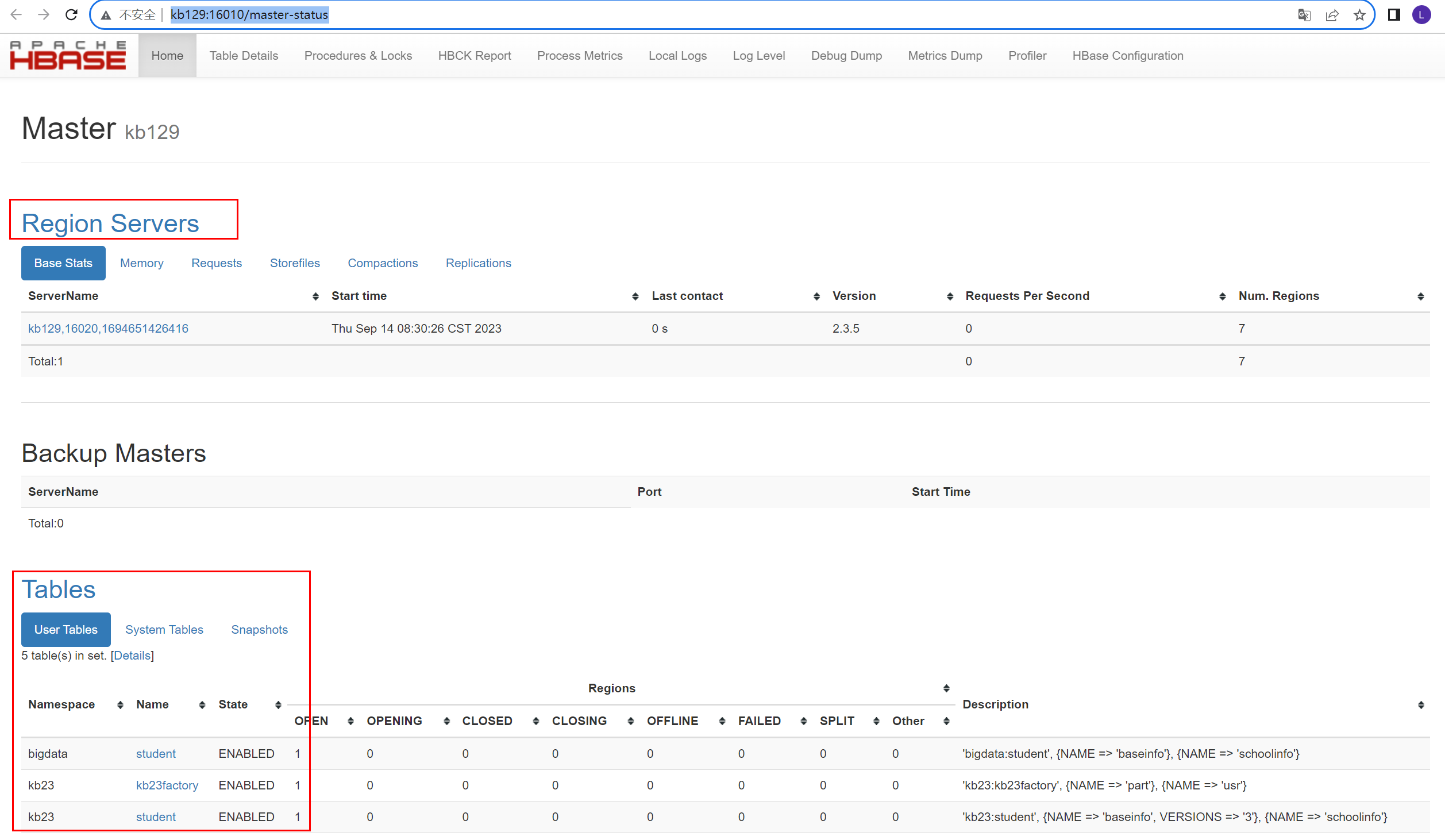
网页访问http://kb129:16010/
|
hbase宕机恢复操作(此操作会删除hbase中数据,慎用!!!)(1)执行stop-hbase.sh关闭hbase进程,或通过kill杀死进程(2)确保hadoop和zookeeper正常运行状态下,进入zookeeper客户端:zkCli.sh(3)删除hbase:rmr /hbase,删除后:ls / ,查看是否已经删除(4)进入hdfs系统,删除hbase指向目录/hbase(5)执行start-hbase.sh,成功恢复hbase |


2.Hbase shell相关操作
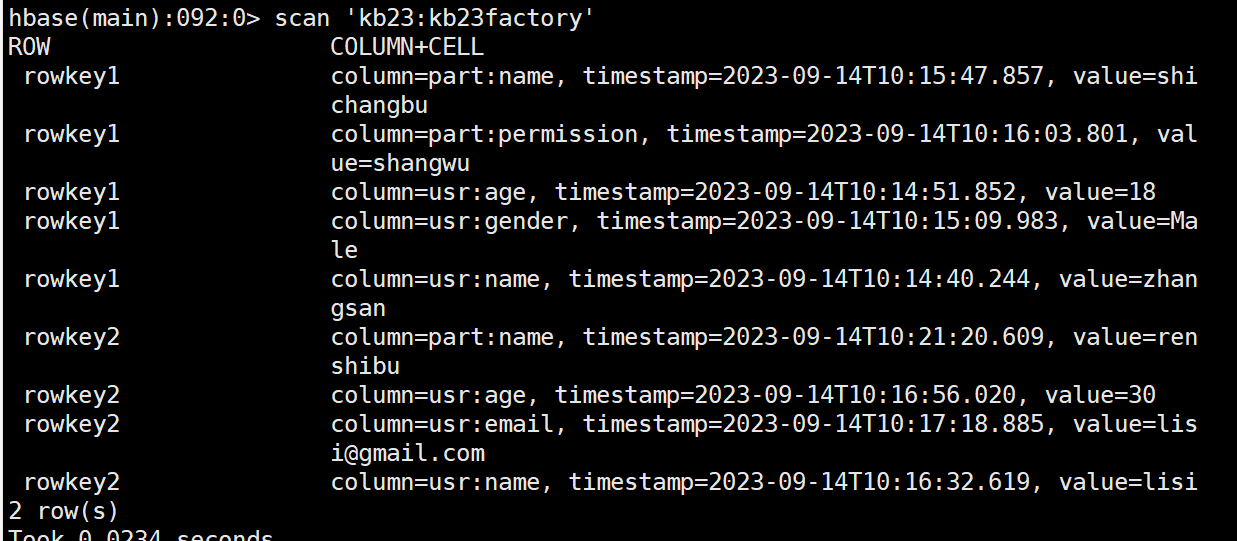
| [root@kb129 conf]# hbase shell 创建命名空间 hbase(main):001:0> create_namespace 'kb23' 查看命名空间 hbase(main):001:0>list _namespace
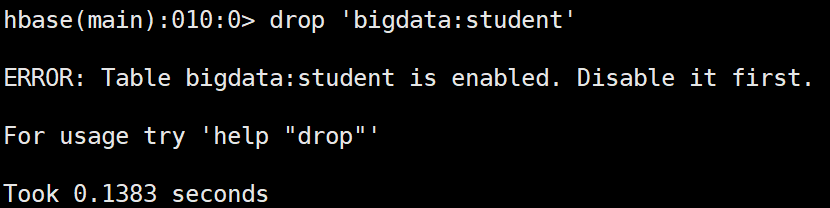
创建表 hbase(main):007:0> create 'bigdata:student','baseinfo','schoolinfo' 查看表 hbase(main):008:0> list_namespace_tables 'bigdata' 查看描述 hbase(main):009:0> desc 'bigdata:student' 删除表之前先禁用表
禁用表 hbase(main):011:0> disable 'bigdata:student' 查看是否禁用/启用 hbase(main):011:0> is_disabled/is_enabled 'bigdata:student' 启用表 hbase(main):011:0> enable 'bigdata:student' 插入数据(原有数据的话会覆盖) hbase(main):006:0> put 'bigdata:student','rowkey1','baseinfo:name','tom' 查看指定rowkey的所有数据 hbase(main):008:0> get 'bigdata:student','rowkey1' COLUMN CELL baseinfo:age timestamp=2023-09-13T14:21:26.095, value=30 baseinfo:name timestamp=2023-09-13T14:21:22.385, value=tom 查看指定列族数据 hbase(main):011:0> get 'bigdata:student','rowkey1','baseinfo' COLUMN CELL baseinfo:age timestamp=2023-09-13T14:21:26.095, value=30 baseinfo:name timestamp=2023-09-13T14:21:22.385, value=tom 查看指定列族中某列数据 hbase(main):012:0> get 'bigdata:student','rowkey1','baseinfo:name' COLUMN CELL baseinfo:name timestamp=2023-09-13T14:21:22.385, value=tom 添加列族 hbase(main):021:0> alter 'kb23:student','teacherinfo' 删除列族 hbase(main):023:0> alter 'kb23:student',{NAME=>'teacherinfo',METHOD=>'delete'} 更改版本个数(VERSIONS默认为1) hbase(main):026:0> alter 'kb23:student',{NAME=>'baseinfo',VERSIONS=>3} 全表扫描 hbase(main):027:0> scan 'kb23:student' 删除指定列族中的列 hbase(main):055:0> delete 'kb23:student','rowkey2','baseinfo:name' 删除所有rowkey2信息 hbase(main):060:0> deleteall 'kb23:student','rowkey2' 查看不同版本信息 hbase(main):070:0> get 'kb23:student','rowkey1',COLUMN=>'baseinfo:name',VERSIONS=>3 查看范围内rowkey的数据(左闭右开) hbase(main):094:0> scan 'kb23:student', {COLUMNS => 'baseinfo:name', STARTROW => 'rowkey',STOPROW=> 'rowkey3'} 查看时使用limit hbase(main):096:0> scan 'kb23:student', {COLUMNS => 'baseinfo:name', STARTROW => 'rowkey',STOPROW=> 'rowkey3', VERSIONS=> 3, LIMIT=> 1} 过滤查找value包含11开头的信息(可查到多个版本) hbase(main):099:0> scan 'kb23:student',FILTER=>"ValueFilter(=,'binary:11')" 过滤查找value包含andemen开头的信息(可查到多个版本) hbase(main):102:0> scan 'kb23:student',FILTER=>"ValueFilter(=,'substring:andemen')" 过滤查找列名birth开头的信息(可查到多个版本) hbase(main):104:0> scan 'kb23:student',FILTER=>"ColumnPrefixFilter('birth')" 多条件AND查询 hbase(main):110:0> scan 'kb23:student',FILTER=>"ColumnPrefixFilter('birth') AND ValueFilter(=,'substring:200')" AND或OR查询 hbase(main):005:0>scan 'kb23:student',FILTER=>"ColumnPrefixFilter('birth') AND (ValueFilter(=,'substring:200')) OR ValueFilter(=,'substring:20')" |

3.Hbase运行原理
| 3.1 HBase物理架构
1)StoreFile 保存实际数据的物理文件,StoreFile以Hfile的形式存储在HDFS上。每个Store会有一个或多个StoreFile(HFile),数据在每个StoreFile中都是有序的。 2)MemStore 写缓存,由于HFile中的数据要求是有序的,所以数据是先存储在MemStore中,排好序后,等到达刷写时机才会刷写到HFile,每次刷写都会形成一个新的HFile。 3)WAL 由于数据要经MemStore排序后才能刷写到HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入MemStore中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。 4)BlockCache 读缓存,每次查询出的数据会缓存在BlockCache中,方便下次查询。 |
| 3.2 写流程
1)Client先访问zookeeper,获取hbase:meta表位于哪个Region Server。 2)访问对应的Region Server,获取hbase:meta表,根据写请求的namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。 3)与目标Region Server进行通讯; 4)将数据顺序写入(追加)到WAL; 5)将数据写入对应的MemStore,数据会在MemStore进行排序; 6)向客户端发送ack; 7)等达到MemStore的刷写时机后,将数据刷写到HFile。 |
| 3.3 MemStore Flush
MemStore刷写时机: 1.当某个memstroe的大小达到了hbase.hregion.memstore.flush.size(默认值128M),其所在region的所有memstore都会刷写。 当memstore的大小达到了 hbase.hregion.memstore.flush.size(默认值128M)* hbase.hregion.memstore.block.multiplier(默认值4)时,会阻止继续往该memstore写数据。 2.当region server中memstore的总大小达到 java_heapsize*hbase.regionserver.global.memstore.size(默认值0.4)*hbase.regionserver.global.memstore.size.lower.limit(默认值0.95), region会按照其所有memstore的大小顺序(由大到小)依次进行刷写。直到region server中所有memstore的总大小减小到上述值以下。 当region server中memstore的总大小达到 java_heapsize*hbase.regionserver.global.memstore.size(默认值0.4)时,会阻止继续往所有的memstore写数据。 3. 到达自动刷写的时间,也会触发memstore flush。自动刷新的时间间隔由该属性进行配置hbase.regionserver.optionalcacheflushinterval(默认1小时)。 4.当WAL文件的数量超过hbase.regionserver.max.logs,region会按照时间顺序依次进行刷写,直到WAL文件数量减小到hbase.regionserver.max.log以下(该属性名已经废弃,现无需手动设置,最大值为32)。 |
| 3.4 读流程
1)Client先访问zookeeper,获取hbase:meta表位于哪个Region Server。 2)访问对应的Region Server,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。 3)与目标Region Server进行通讯; 4)分别在MemStore和Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)。 5)将查询到的新的数据块(Block,HFile数据存储单元,默认大小为64KB)缓存到Block Cache。 6)将合并后的最终结果返回给客户端。 |
| 3.5 StoreFile Compaction 由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能会分布在不同的HFile中,因此查询时需要遍历所有的HFile。为了减少HFile的个数,以及清理掉过期和删除的数据,会进行StoreFile Compaction。 Compaction分为两种,分别是Minor Compaction和Major Compaction。Minor Compaction会将临近的若干个较小的HFile合并成一个较大的HFile,并清理掉部分过期和删除的数据。Major Compaction会将一个Store下的所有的HFile合并成一个大HFile,并且会清理掉所有过期和删除的数据。
|
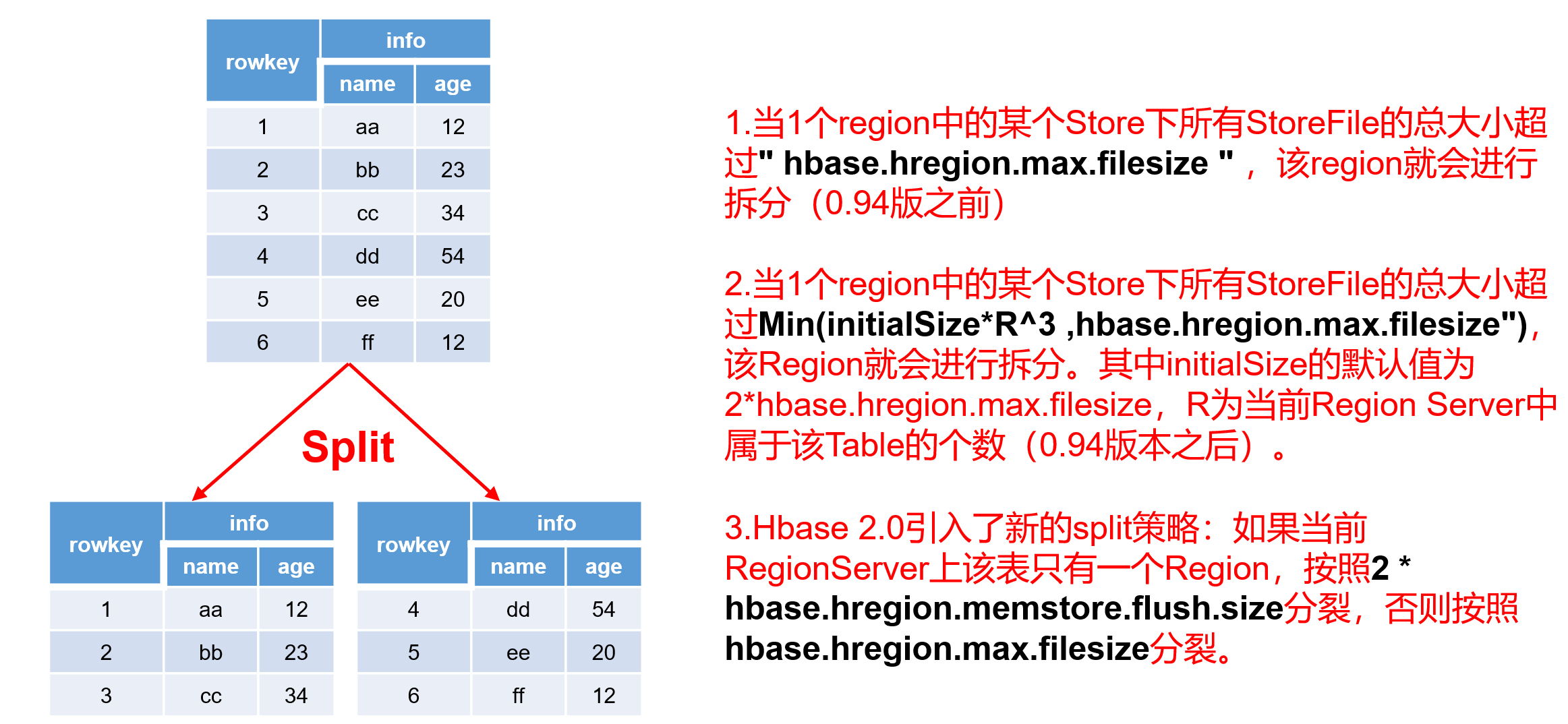
| 3.6 Region Split 默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的Region Server,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的Region Server。 Region Split时机: 1.当1个region中的某个Store下所有StoreFile的总大小超过hbase.hregion.max.filesize (10G),该Region就会进行拆分(0.94版本之前)。 2.当1个region中的某个Store下所有StoreFile的总大小超过Min(initialSize*R^3 ,hbase.hregion.max.filesize"),该Region就会进行拆分。其中initialSize的默认值为2*hbase.hregion.memstore.flush.size,R为当前Region Server中属于该Table的Region个数(0.94版本之后)。 具体的切分策略为: 第一次split:1^3 * 256 = 256MB 第二次split:2^3 * 256 = 2048MB 第三次split:3^3 * 256 = 6912MB 第四次split:4^3 * 256 = 16384MB > 10GB,因此取较小的值10GB 后面每次split的size都是10GB了。 3.Hbase 2.0引入了新的split策略:如果当前RegionServer上该表只有一个Region,按照2 * hbase.hregion.memstore.flush.size分裂,否则按照hbase.hregion.max.filesize分裂。
|






4.hive映射hbase
| hive中创建表格,关联hbase中的表 (1)
(2)rowkey之间不同字段
|


5.Hbase API
| 5.1 pom依赖 |
| 5.2 增删改查等具体操作 |
| 5.3 写缓存 HBase客户端的批量写缓存BufferedMutator HBase的每一个put操作实际上是一个RPC操作,将客户端的数据传输到服务器再返回结果,这只适用于小数据量的操作,如果数据量多的话,每次put都需要建立一次RPC的连接(TCP连接),而建立连接传输数据是需要时间的,因此减少RPC的调用可以提高数据传输的效率,减少建立连接的时间和IO消耗。 HBase的客户端API提供了写缓存区,put的数据一开始放在缓存区内,当数量到达指定的容量或者用户强制提交是才将数据一次性提交到HBase的服务器。这个缓冲区可以通过调用 HTable.setAutoFlush(false) 来开启。而新版HBbase的API中使用了BufferedMutator替换了老版的缓冲区,通过BufferedMutator对象提交的数据自动存放在缓冲区中。 BufferedMutator 通过获取 BufferedMutator 对象,并调用 mutator.mutate(List<Mutation> mutations) 方法来进行批量插入数据。可以使用 Put 类型的对象列表作为 mutations 参数进行插入。BufferedMutator 提供了自动管理缓冲区和写入操作的功能,可以提高插入数据的性能。 |
相关文章:

Hadoop-Hbase
1. Hbase安装 1.1 安装zookeeper、 hbase 解压至/opt/soft,并分别改名 配置环境变量并source生效 #ZK export ZOOKEEPER_HOME/opt/soft/zk345 export PATH$ZOOKEEPER_HOME/bin:$PATH #HBASE_HOME export HBASE_HOME/opt/soft/hbase235 export PATH$HBASE_HOME/b…...

关于不停机发布新版本程序的方式
“不停机发布新版本程序”,暂且这么称呼吧,其实就是所说的滚动发布、灰度发布、金丝雀发布和蓝绿发布。 之所以会总结性地提一下这几个概念,主要是本次出门游历,流浪到了乌兰察布市四王子旗,在这儿遇上了个有趣儿的家伙…...
MeterSphere压测,出现HttpHostConnectException
现象:MeterSphere更换压力机后,压测出现出现HttpHostConnectException 解决方案: net.ipv4.tcp_tw_reuse默认是0或者2,更改为1 net.ipv4.tcp_tw_reuse,表示是否允许重新应用处于TIME-WAIT状态的socket用于新的TCP连…...

cherry-pick
要将dev分支的某次提交给master分支,可以使用以下命令: 1. 切换到dev分支:git checkout dev 2. 查看提交历史,找到要提交给master的某次提交的commit hash(假设为 <commit_hash>) 3. 切换到master…...
opencv形状目标检测
1.圆形检测 OpenCV图像处理中“找圆技术”的使用-图像处理-双翌视觉OpenCV图像处理中“找圆技术”的使用,图像处理,双翌视觉https://www.shuangyi-tech.com/news_224.htmlopencv 找圆心得,模板匹配比霍夫圆心好用 - 知乎1 相比较霍夫找直线算法, 霍夫找…...

k8s中无法获取到nginx-ingress的客户端真实ip地址x-forwarded-for
1.查看阿里云的nginx-ingress配置文档https://help.aliyun.com/document_detail/42205.html 容器K8s配置方案 如果您的服务部署在K8s上,K8s会将真实的客户端IP记录在X-Original-Forwarded-For字段中,并将WAF回源地址记录在X-Forwarded-For字段中。您需要…...
索引实践(2))
MySQL(4)索引实践(2)
一、分页优化 limit 1000 10, 其实不是只查询出10条记录,mysql底层会查询出1100条,然后舍去前1000条 所以,随着页的增多,查询效率会降低 1、可以使用取范围的方式比如id>1000 方式优化 2、使用关联查询优化…...

Kafka【命令行操作】
Kafka 命令行操作 Kafka 主要包括三大部分:生产者、主题分区节点、消费者。 1、Topic 命令行操作 也就是我们 kafka 下的脚本 kafka-topics.sh 的相关操作。 常用命令行操作 参数 描述 --bootstrap-server <String: server toconnect to> 连接的Kafka …...
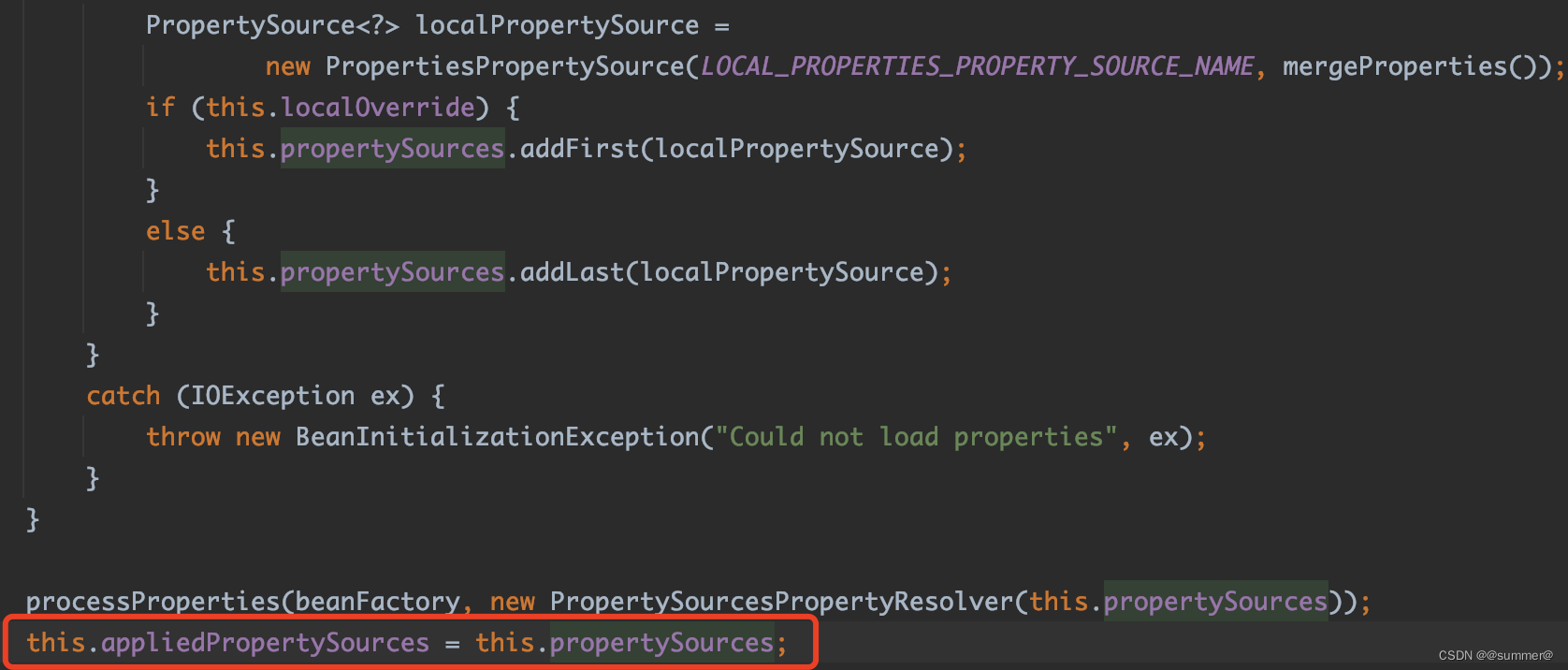
springboot配置注入增强(二)属性注入的原理
一 原理 1 配置的存储 springboot在启动的时候会后构建一个org.springframework.core.env.Environment类型的对象,这个对象就是用于存储配置,如图springboot会在启动的最开始创建一个Environment对象 这个webApplicationType的枚举是在new SpringAppli…...

Android 使用Camera1实现相机预览、拍照、录像
1. 前言 本文介绍如何从零开始,在Android中实现Camera1的接入,并在文末提供Camera1Manager工具类,可以用于快速接入Camera1。 Android Camera1 API虽然已经被Google废弃,但有些场景下不得不使用。 并且Camera1返回的帧数据是NV21…...
)
2024字节跳动校招面试真题汇总及其解答(四)
12.Java的类加载机制 Java的类加载机制是指将描述类的数据从Class文件加载到内存,并对数据进行校验、转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这个过程被称作虚拟机的类加载机制。 类的加载过程分为以下五个阶段: 加载:将Class文件从磁盘读入内存,并…...
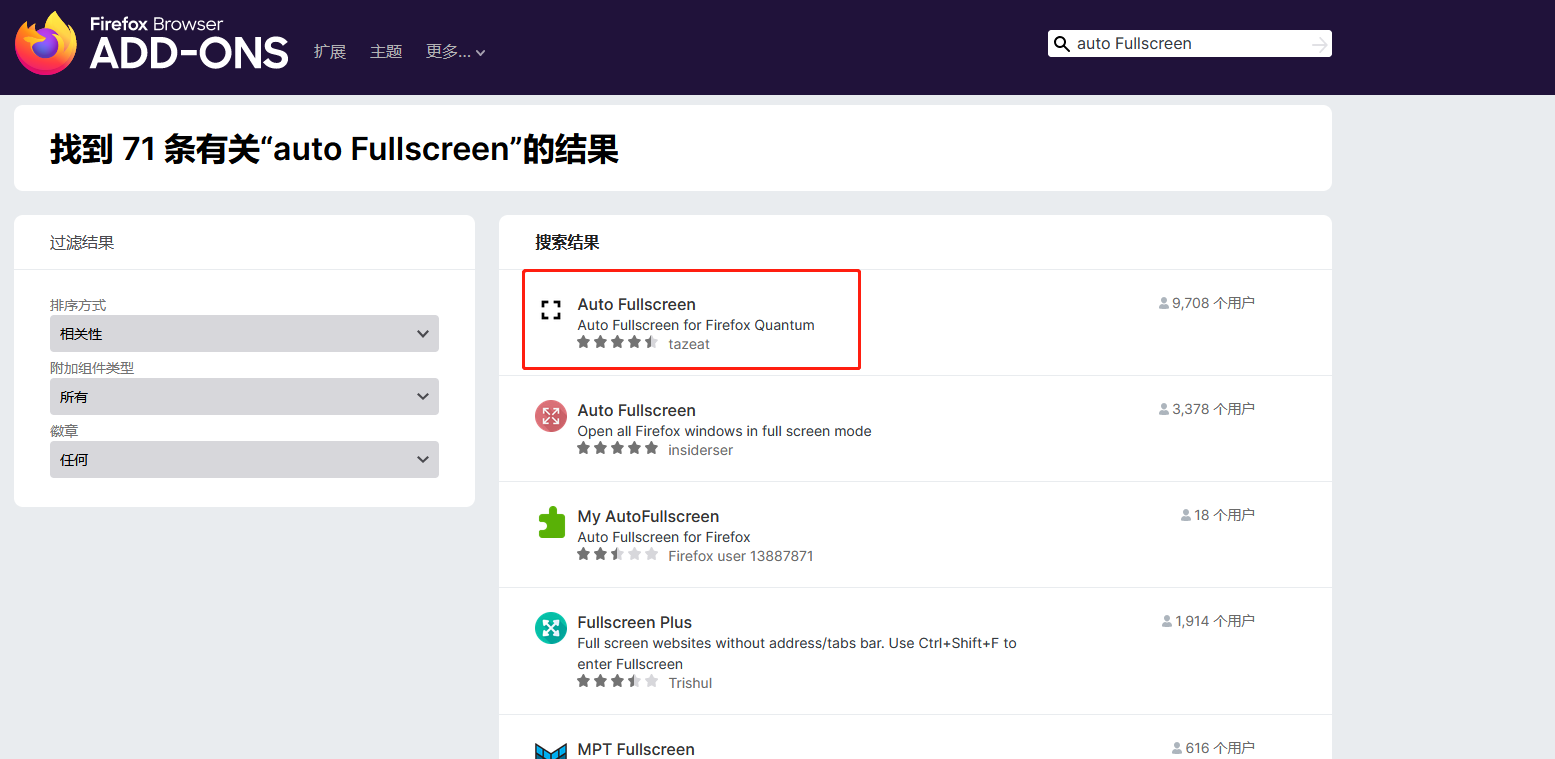
网页的快捷方式打开自动全屏--Chrome、Firefox 浏览器相关设置
Firefox 的全屏方式与 Chrome 不同,Chrome 自带全屏模式以及APP模式,通过简单的参数即可设置,而Firefox暂时么有这个功能,Firefox 的全屏功能可以通过全屏插件实现。 全屏模式下,按 F11 不会退出全屏,鼠标…...
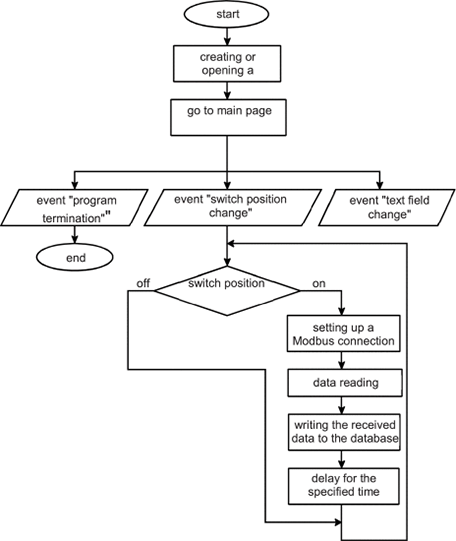
LabVIEW使用ModbusTCP协议构建分布式测量系统
LabVIEW使用ModbusTCP协议构建分布式测量系统 分布式测量系统主要用于监控远程物体。这种系统允许对系统用户获得的数据进行全面的数据收集、处理、存储和组织访问。它们可能包括许多不同类型的传感器。 在任何具有互联网接入的个人计算机上运行的软件都会发送来自传感器的测…...
unity学习第1天
本身也具有一些unity知识,包括Eidtor界面使用、Shader效果实现、性能分析,但对C#、游戏逻辑不太清楚,这次想从开发者角度理解游戏,提高C#编程,从简单的unity游戏理解游戏逻辑,更好的为工作服务。 unity201…...

Spring Boot实现对文件进行压缩下载
在Web应用中,文件下载功能是一个常见的需求,特别是当你需要提供用户下载各种类型的文件时。本文将演示如何使用Spring Boot框架来实现一个简单而强大的文件下载功能。我们将创建一个RESTful API,通过该API,用户可以下载问价为ZIP压…...
Mac专用投屏工具AirServer 7 .27 for Mac中文免费激活版
AirServer 7 .27 for Mac中文免费激活版是一款Mac专用投屏工具,能够通过本地网络将音频、照片、视频以及支持AirPlay功能的第三方App,从 iOS 设备无线传送到 Mac 电脑的屏幕上,把Mac变成一个AirPlay终端的实用工具。 目前最新的AirServer 7.2…...
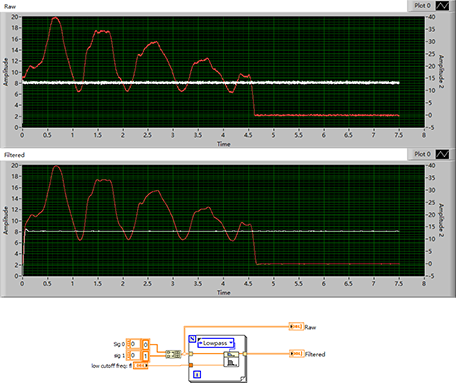
LabVIEW使用巴特沃兹低通滤波器过滤噪声
LabVIEW使用巴特沃兹低通滤波器过滤噪声 设备采集到的数据往往都有噪声,有时候这些数据要做判断使用,如果不处理往往会影响最终的结果。可以使用动态平滑,或者中值滤波等方法。这里介绍使用巴特沃斯低通滤波,也是非常方便的。 下…...
【Realtek sdk-3.4.14b】RTL8197FH-VG和RTL8812F自适应认证失败问题分析及修改
WiFi自适应认证介绍 WiFi 自适应可以理解为针对WiFi的产品,当有外部干扰信号通过,WiFi产品自动停止发出信号一段时间,以达到避让的目的。 问题描述 2.4G和5G WiFi自适应认证失败,信道停止发送信号时间过长,没有在规定时间内停止发包 2.4G截图 问题分析 根据实验室描述可以…...
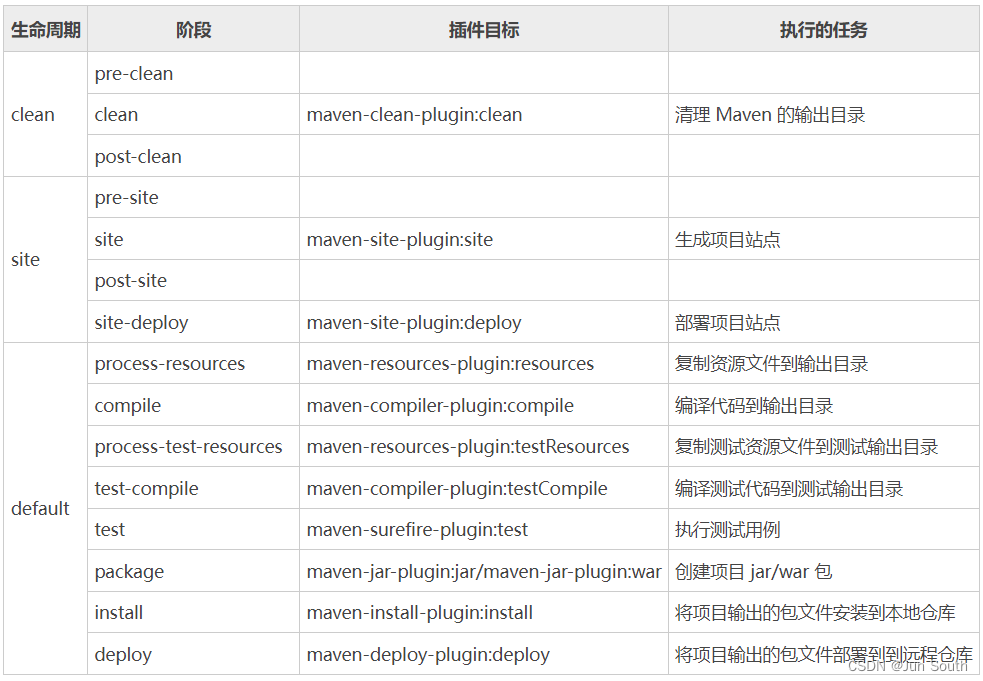
SpringBoot 的版本、打包、Maven
一、SpringBoot 结构、集成 1.1、集成组件 Spring Core:Spring的核心组件,提供IOC、AOP等基础功能,是Spring全家桶的基础。 Spring Boot:一个基于Spring Framework的快速开发框架,可以快速创建独立的、生产级别的…...
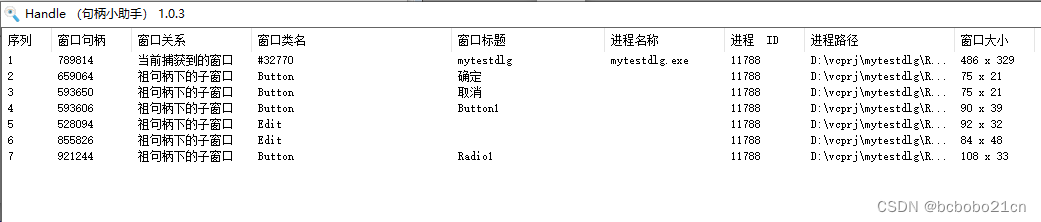
不同类型程序的句柄研究
先做一个winform程序;随便放几个控件; 用窗口句柄查看工具看一下;form和上面的每个控件都有一个句柄; 然后看一下记事本;记事本一共包含三个控件,各自有句柄; 这工具的使用是把右下角图标拖到要…...
)
从连续到离散:用Python小例子复现Mamba SSM的零阶保持离散化(含完整代码)
从连续到离散:用Python小例子复现Mamba SSM的零阶保持离散化(含完整代码) 在深度学习领域,状态空间模型(State Space Model, SSM)因其对序列数据的强大建模能力而备受关注。Mamba作为SSM的最新演进&#x…...

GLM-OCR在跨境电商中的应用:多语言商品说明书OCR→自动翻译预处理
GLM-OCR在跨境电商中的应用:多语言商品说明书OCR→自动翻译预处理 1. 项目概述与背景 跨境电商卖家经常面临一个共同难题:来自不同国家的商品说明书语言各异,手动翻译不仅耗时耗力,还容易出错。传统OCR工具虽然能识别文字&#…...
)
Syncthing中继服务器搭建全攻略:解决公共服务器速度慢的问题(附详细配置步骤)
Syncthing中继服务器搭建实战:突破公共服务器速度瓶颈 周末团队协作时,Syncthing公共中继服务器的龟速让人抓狂——跨国传输一个设计稿居然要两小时。这促使我探索自建中继服务器的方案,实测将同步速度提升8倍。本文将分享从服务器选型到客户…...

二极管单向导电性的秘密:为什么你的电路不工作?可能是二极管接反了!
二极管单向导电性的秘密:为什么你的电路不工作?可能是二极管接反了! 刚接触电子电路的朋友们,一定遇到过这样的困惑:明明按照电路图连接了所有元件,电源也接通了,可电路就是不工作。这时候&…...

从‘发快递’到‘收快递’:手把手拆解RocketMQ 5.x中Producer Group的变迁与最佳实践
从‘发快递’到‘收快递’:手把手拆解RocketMQ 5.x中Producer Group的变迁与最佳实践 在消息中间件的世界里,RocketMQ一直以其高吞吐、低延迟的特性占据着重要地位。随着5.x版本的发布,一个看似微小的改动——生产者匿名化,却在实…...
高效考证解决方案:一次通关的行动蓝图)
信息系统项目管理师(高项)高效考证解决方案:一次通关的行动蓝图
一、 认知破局:理解考试本质与核心挑战信息系统项目管理师(俗称“高项”)是国家软考高级资格,它不仅是职称证书,更是项目投标的硬性门槛(集成/软件企业申报资质、投标时项目经理资格必备)。其核…...

PyTorch 2.8镜像保姆级教程:RTX 4090D下HuggingFace Datasets高效加载
PyTorch 2.8镜像保姆级教程:RTX 4090D下HuggingFace Datasets高效加载 1. 环境准备与快速验证 1.1 镜像基本信息确认 本教程使用的PyTorch 2.8镜像已针对RTX 4090D显卡进行深度优化,主要配置如下: 核心组件:PyTorch 2.8 CUDA…...

GLM-4.1V-9B-Base成本优化指南:GPU显存管理与推理性能调优
GLM-4.1V-9B-Base成本优化指南:GPU显存管理与推理性能调优 1. 为什么需要关注大模型推理成本 大模型在带来强大能力的同时,也伴随着高昂的GPU算力成本。GLM-4.1V-9B-Base作为一款9B参数量的视觉语言大模型,在实际部署中常常面临显存不足、推…...

NVIDIA Profile Inspector 终极指南:免费解锁显卡隐藏性能的完整教程
NVIDIA Profile Inspector 终极指南:免费解锁显卡隐藏性能的完整教程 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 想要让游戏画面更流畅、画质更清晰吗?NVIDIA Profile Inspe…...

YOLO-v8.3实战:用AI识别图片中的物体,5分钟完成你的第一个检测项目
YOLO-v8.3实战:用AI识别图片中的物体,5分钟完成你的第一个检测项目 你是否曾经好奇,那些能自动识别照片中物体的人工智能是如何工作的?想象一下,你拍了一张街景照片,AI不仅能告诉你照片里有汽车、行人和红…...