[deeplearning]pytorch实现softmax多分类问题预测训练
写在前面:俺这两天也是刚刚加入实验室,因为之前的学习过程中用到更多的框架是tensorflow,所以突然上手pytorch多少有些力不从心了。
这两个框架的主要区别在与tensorflow更偏向于工业使用,所以里面的很多函数和类都已经封装得很完整了,直接调用,甚至连w,b等尺寸都会自动调整。但是pytorch更加偏向于学术,。。。。或者说更加偏向于数学,很多功能都需要我们自己手动去实现:
刚刚跟这d2l的课程学习了如何去实现最基本的神经网络和计算,这里使用当时学过的solfmax作为经典案例,作为一个简单的补充,我会在这里面简单讲解一下softmax是怎么实现的,以及一些库函数
纯手动实现:
其实是有一些更高级别的api可以调用,比如损失函数就不用我们自己手写,但是训练的过程还是要的。
1.获取一些数据,这里我们通过一个特殊数据集合来或去数据
#先凑成一个数据集合
batch_size = 256
#这里好像就上面那么恶心了,直接从这个数据集合中获取数据
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)这里注意一个问题,batch_size不是你获取到的全部数据,而是你确定每一批数据的大小
接下来根据这个大小,获取多批数据,然后保存为训练集合以及测试集合
(由于我们这里要的事情非常简单,所以我们不验证)
2.我们开始创建一层神经元,输出为10个分量的估计数值
#初始化参数
num_inputs = 784 #输入,也就是特征值的数目为784
num_outputs = 10 #输出也就是softmax层神经元的数目,10#这段代码用于构建某一层的w和b,并且先将其初始化
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros (num_outputs, requires_grad=True)这里w和b是仅仅是一对数字,而是一个完整的对象,除了基本的数值以外,还能存储一些注入诸如梯度等等信息。代表了这一层神经元的具体情况。
这个layer构建出来的神经元其实就是10个神经元,每个神经元支持的输入为784个特征。
3.创建solftmax函数,这个函数内部将会对神经网络的输出作出一些处理
#创建一个softmax函数,用来完成最后的softmax操作
#X在这里应该是一个10个分量的tensor,下面的函数就是正常的softmax操作
def softmax(X):X_exp = torch.exp(X)partition = X_exp.sum(1, keepdim=True) #沿着列展开的方向求和return X_exp / partition #这里应用了广播机制我们先进行指数化,然后求和,最后使用广播技术(其实这个所谓的广播也算是线性代数计算时候的基本特征了)得到一个(归一化)的tensor(所有分量相加为1,符合我们先是生活中对事物的预测逻辑,比如:连衣裙可能性0.55,鞋子可能性0.25,帽子可能性0.20)
4.然后是定义最核心的预测函数,称之为网络本身到也可以
#定义一个神经网络
#其实说是神经网络,这里只是进行了一个简单的数据变换,然后计算wx+b
#最后计算出来的结果因为是matmul的矩阵乘法,而且w和b本身也是size=10 的 tensor
#所以计算结果也是一样大小的tensor,然后就可以放心进行softmax操作
def net(X):return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
其实这个就是对于十个神经元,然后进行计算操作,得到估计数值
其实直接返回torch.matmul(X.reshape((-1, W.shape[0])), W) + b的话就变化成一个很常见的10线性回归了,在这里可以很清楚的看到softmax实现的是一个激活函数的作用
5.定义损失函数loss function
def cross_entropy(y_hat, y):return - torch.log(y_hat[range(len(y_hat)), y])这个东西稍微有一点点复杂。。。
首先先解释一下这个东西
y_hat[ range(len(y_hat)) , y )
首先要先说明一点就是,y_hat是预测数值,一个二维tensor,比如说其中的第一条数据
[0.22,0.23,0.35.........]这代表的是某一个物体的预测结果,在10个标签中每一种可能性的概率
y则是一个一维tensor,每个分量代表的是该物体到底是什么,是确切数值
而这个[]中携带两个tensor的语法,被称为“高级索引”
#补充一下:这个语法的名字叫做高级索引,是从二维矩阵中选择出一个一维tensor
#第一个tensor是选择哪些行,这里选择所有行
#第二个是选择有哪些列
#在这个数据中我们实现的效果就是
#y-hat是一个二维tensor,每行是一个数据,每一列是对不同类型的预测
#y。。。严格来说是一个一维tensor,每个分量代表第i个数据到底是什么标签
#也就是说这个的逻辑意义是:每条数据猜对的概率?差不多可以这样子理解6.优化/迭代函数
其实这个部分就是我们迭代,gradient descent 时候的操作
所谓的梯度就是求得的偏导数
#优化函数,其实这玩意就是我们的迭代函数,就那个repeat部分的东西,0.1是learning rate
def updater(batch_size):return d2l.sgd([W, b], 0.1, batch_size)
sgd就是d2l包下内置的“随机 gd”函数,这个里面梯度已经保存起来了
7.创建单次训练函数
#把模型训练了
def train_epoch_ch3(net, train_iter, loss, updater): #@save# 将模型设置为训练模式if isinstance(net, torch.nn.Module):net.train()for X, y in train_iter:# loss是已经封装好的损失计算函数l = loss(net(X), y)# 使用定制的优化器和损失函数l.sum().backward() #计算梯度,也就是代价函数导的东西updater(X.shape[0]) #梯度在这里好像是没有传入进来,但是实际上已经保存在w和b中了,对所有的w和b进行迭代计算这个函数执行一次也就是一次训练
8.训练10次
#训练函数def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save"""训练模型(定义见第3章)"""for epoch in range(num_epochs):train_epoch_ch3(net, train_iter, loss, updater) # 直接就是训练了,不验证了#开始训练
num_epochs = 10
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)这里我们直接根据训练集合进行验证
9.最后进行预测以及可视化展示
#预测函数
def predict_ch3(net, test_iter, n=6): #@save"""预测标签(定义见第3章)"""for X, y in test_iter:break# 将真实标签转换为对应的类别名称trues = d2l.get_fashion_mnist_labels(y)# 使用net进行预测,并且寻找预测结果转化为名称preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))#转化为title(还是使用对列生成器语法)titles = [ true +'\n' + pred for true, pred in zip(trues, preds) ]#展示图片d2l.show_images( X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])#展示预测
predict_ch3(net, test_iter)plt.show()
关于在训练和预测的时候我们需要干什么
其实前面也算是写了不少代码了(其实也就是单纯实现了一个单一神经元以及softmax的预测)
这里就简单总结一下,在这个“训练”部分,我们一般都会做一些什么事情:
我们先拿出一个很简单的单一线性回归预测来举个例子
for X, y in data_iter:l = loss(net(X) ,y) #计算这个一批数据(10)个的损失trainer.zero_grad() #清除已经有的梯度l.backward() # 计算损失对当前模型的梯度trainer.step() #根据梯度更新模型参数,梯度下降的根本操作其实看这个代码,我们第一步做的就是遍历,通过一开始设置的数据批次进行分批次的训练
进入某一次训练中的时候,我们要先根据损失函数,计算出这一批的损失
(不同的框架和代码对这个玩应的实现和理解都完全不一样,但是你要记住这个东西的数学本质是损失函数之和,即为这个批次数据的代价函数,我们最后梯度下降的公式,最重要的一个步骤就是对代价函数求偏倒数,这也就是框架中常说的gradient梯度)
然后根据损失,通过一种称之为“反向传递”的技术,计算出偏导
最后这个step,就代表开始训练了
大致架构就是这个样子实现的,如果这个样子还不是太明白具体要做什么,那么我们直接把上面是用softmax技术的东西简化一下再放出来:
#把模型训练了for X, y in train_iter:l = loss(net(X), y) #loss是已经封装好的损失计算函数l.sum().backward() #计算梯度,也就是代价函数导的东西updater(X.shape[0]) #梯度在这里好像是没有传入进来,但是实际上已经保存在w和b中了也是进行分批次的训练
然后计算一下损失,再计算代价函数,对代价函数是用反向传播求偏导数
最后进行训练
最终总结一下,像这样子手动实现一个训练的过程中,我们能做的就是
(1)想办法得到代价函数(也许还要清除之前计算得到的梯度)
(2)获取代价函数的梯度(一般是反向传递)
(3)训练
至于在预测的时候做什么,就是一些预测结果的分析,精度计算什么的,那都是后话了
相关文章:

[deeplearning]pytorch实现softmax多分类问题预测训练
写在前面:俺这两天也是刚刚加入实验室,因为之前的学习过程中用到更多的框架是tensorflow,所以突然上手pytorch多少有些力不从心了。 这两个框架的主要区别在与tensorflow更偏向于工业使用,所以里面的很多函数和类都已经封装得很完…...
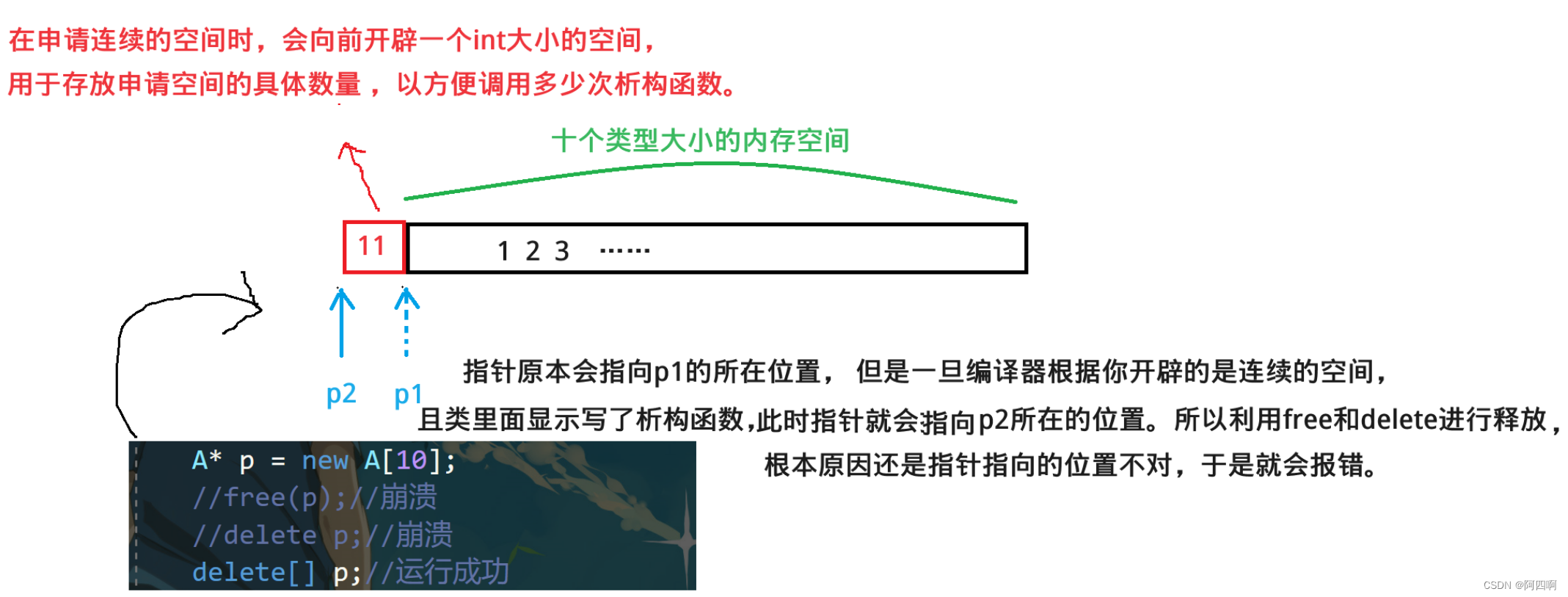
【C++初阶】动态内存管理
👻内容专栏: C/C编程 🐨本文概括: C/C内存分布、C语言动态内存管理、C动态内存管理、operator new与operator delete函数、new和delete的实现原理、定位new表达式、常见面试问题等。 🐼本文作者: 阿四啊 …...

Mac电脑安装Zulu Open JDK 8 使用 spring-kafka 消费不到Kafka Partition中的消息
一、现象描述 使用Mac电脑本地启动spring-kakfa消费不到Kafka的消息,监控消费组的消息偏移量发现存在Lag的消息,但是本地客户端就是拉取不到,通过部署到公司k8s容器上消息却能正常消费! 本地启动的服务消费组监控 公司k8s容器服…...
CodeArts Check代码检查服务用户声音反馈集锦(2)
作者:gentle_zhou 原文链接:CodeArts Check代码检查服务用户声音反馈集锦(2)-云社区-华为云 CodeArts Check(原CodeCheck),是自主研发的代码检查服务。建立在华为30年自动化源代码静态检查技术…...

红帽RHCE9.0学什么内容,新版有什么变化
【微|信|公|众|号:厦门微思网络】 一、红帽公司介绍 红帽是首个(也是全球最大、全球领先)的企业开源软件解决方案提供商,在过去 20 几年里,红帽已经成为开源社区里令人尊敬的成员,赞助了数百个开源项目&…...

线性代数的本质(一)——向量空间
文章目录 向量空间向量及其性质基与维数向量的坐标运算 《线性代数的本质》 - 3blue1brown 高中数学A版选修4-2 矩阵与变换 《线性代数及其应用》(第五版) 《高等代数简明教程》- 蓝以中 向量空间 In the beginning Grant created the space. And Grant said, Let there be vec…...
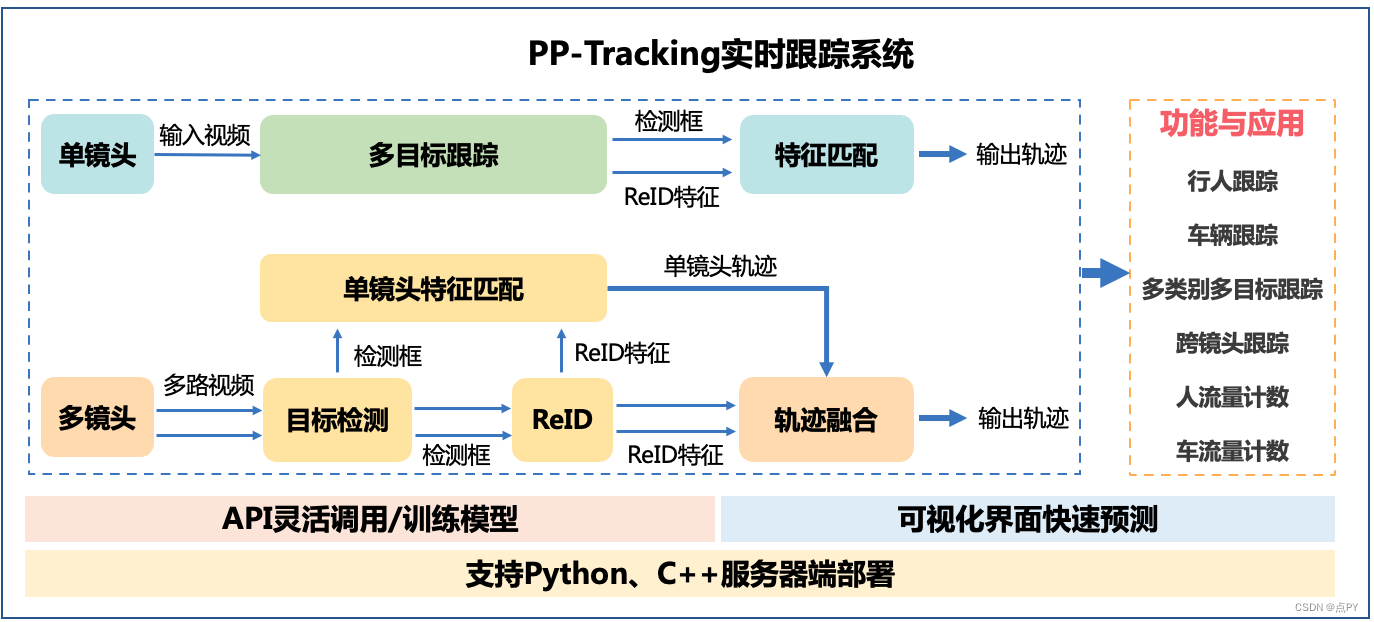
PP-Tracking之C++部署
文章目录 概要环境fastdeploy源码编译PP-Tracking源码编译使用参考概要 PP-Tracking是基于飞桨深度学习框架的业界首个开源实时跟踪系统。针对实际业务的难点痛点,PP-Tracking内置行人车辆跟踪、跨镜头跟踪、多类别跟踪、小目标跟踪及流量计数等能力与产业应用,同时提供可视…...

智慧公厕建设,要以技术为支撑、体验为目的、业务为驱动
#智慧公厕[话题]# #智慧公厕系统[话题]# #智慧公厕厂家[话题]# #智慧公厕驿站[话题]# 在数字化城市与智慧城市的大力推进下,作为社会重要的生活设施,智慧化的公共厕所的建设变得越来越重要。作为城市的基础部件之一,公厕的智慧化建设需要进行…...

通过Sealos 180秒部署一套K8S集群
通过Sealos 180秒部署一套K8S集群 一、主机准备 1.1 主机操作系统说明 序号操作系统及版本备注1CentOS7u9 1.2 主机硬件配置说明 k8s集群CPU及内存最低分别为2颗CPU、2G内存,硬盘建议为100G 需求CPU内存硬盘角色主机名值8C8G1024GBmasterk8s-master01值8C8G1024…...

如何获取美团的热门商品和服务
导语 美团是中国最大的生活服务平台之一,提供了各种各样的商品和服务,如美食、酒店、旅游、电影、娱乐等。如果你想了解美团的热门商品和服务,你可以使用爬虫技术来获取它们。本文将介绍如何使用Python和BeautifulSoup库来编写一个简单的爬虫…...
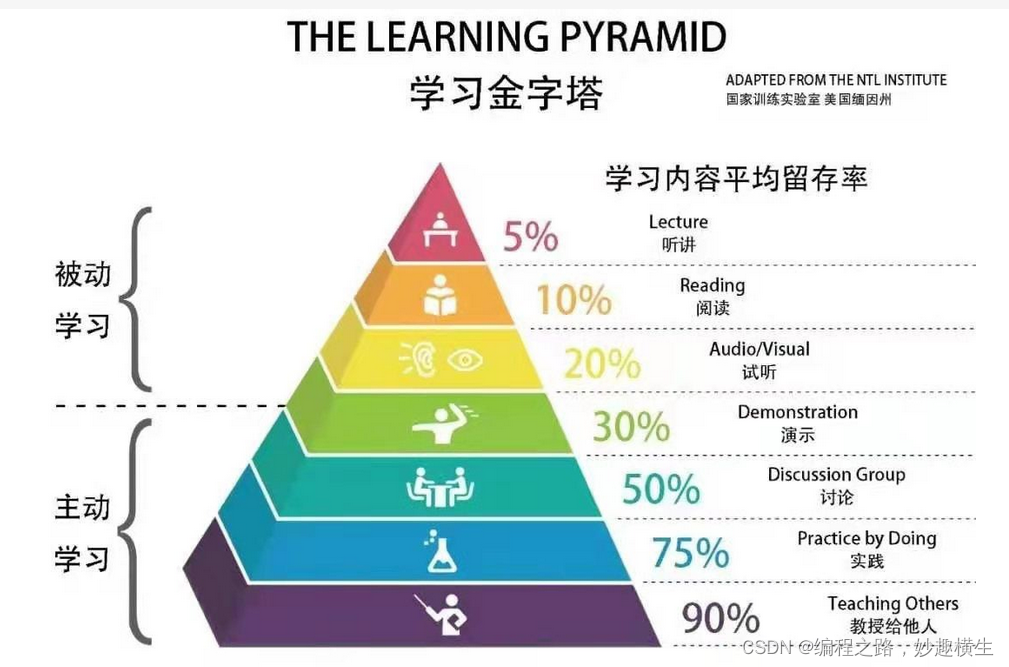
开启编程之门
自我介绍 目前已经大二了,计算机专业在读,是一个热爱编程,做事踏实专注的人。转眼间一年已经过去了,也接触编程一年了,但开始并没有对所学所想进行很好的总结和输出,这一年也有了新的很多感悟与心得&#x…...

【ES】Too many dynamic script compilations within, max: [75/5m]; 问题处理
问题原因 ElasticSearch5分钟内脚本编译的数量不能超过75个。 解决方法 PUT _cluster/settings {"persistent": {"script.max_compilations_rate": "1000/1m"} }参数可以根据自己需要定义,比如10分钟3000个,3000/10m等…...
LED智能家居灯 开关调光 台灯落地灯控制驱动 降压恒流IC AP5191
产品描述 AP5191是一款PWM工作模式,高效率、外围简单、内置功率MOS管,适用于4.5-150V输入的高精度降压LED恒流驱动芯片。输出最大功率150W,最大电流6A。AP5191可实现线性调光和PWM调光,线性调光脚有效电压范围0.55-2.6V.AP5191 工作频率可以…...
贪心算法的思路和典型例题
一、贪心算法的思想 贪心算法是一种求解问题时,总是做出在当前看来是最好的选择,不从整体最优上加以考虑的算法。 二.用贪心算法的解题策略 其基本思路是从问题的某一个初始解出发一步一步地进行,根据某个优化测度,每一步都要确保…...

演讲笔记|《一个ppt者的成长故事》
前言:本文为《说服力:工作型PPT该这样做》作者、秋叶PPT团队成员秦阳于2017年1月15日在北京望界无界空间的演讲内容要点总结。 1. 结构化思考(思考能力) 体系:挖多个坑,多个视角(构建体系 – 获…...

【八大经典排序算法】堆排序
【八大经典排序算法】堆排序 一、概述二、思路解读三、代码实现(大堆为例) 一、概述 堆排序是J.W.J. Williams于1964年提出的。他提出了一种利用堆的数据结构进行排序的算法,并将其称为堆排序。堆排序是基于选择排序的一种改进,通…...
Redis五大基本数据类型
1、字符串类型 字符串类型相当于 java 中的 String 类型。Redis 中的 String 类型以二进制方式存储,不会做任何的编码转换,因此不仅仅可以存储文本数据、整数、普通的字符串、JSON、xml文件,还可以存储图片、视频、音频。String 存储的种类虽…...

AI一点通: OpenAI whisper 在线怎么调用,怎么同时输出时间信息?
OpenAI 语音转文字 whisper API提供了两个端点,即转录和翻译,这基于我们最先进的开源大型v2 Whisper模型。它们可以用来: 将音频转录成音频所在的语言。 翻译并将音频转录成英文。 文件上传目前限制为25 MB,支持以下输入文件类型…...

OpenText EnCase Mobile Investigator 查看、分析和报告被调查手机的证据
OpenText EnCase Mobile Investigator 查看、分析和报告被调查手机的证据 全球83.72%的人口拥有智能手机 OpenText™ EnCase™ Mobile Investigator 使调查人员能够轻松分析、审查和报告与其案件相关的移动设备上的证据。 为什么选择OpenText EnCase Mobile Investigator 预算友…...
【JavaScript】video标签配置及相关事件:
文章目录 一、标签配置:二、事件:三、案例: 一、标签配置: 标签名描述src要播放的路径地址autoplay是否自动播放,默认值是false,(Boolean)loop是否循环播放,默认值是false,…...

失业期PHP程序员极致利用时间的庖丁解
"失业期 PHP 程序员极致利用时间”,常被误解为“疯狂投简历”或“没日没夜地刷 LeetCode”。 但本质上,这是一场**“认知重构”与“资产增值”的特种战役**。 失业不是“空窗期”,而是上帝强行塞给你的**“全脱产战略转型期”**。 在在职…...

游戏化学习与编程实战:CodeCombat让编程学习像玩游戏一样简单
游戏化学习与编程实战:CodeCombat让编程学习像玩游戏一样简单 【免费下载链接】codecombat Game for learning how to code. 项目地址: https://gitcode.com/gh_mirrors/co/codecombat 你是否也曾因枯燥的编程教程而中途放弃?是否希望找到一种既能…...

如何搭建终极游戏串流平台:Sunshine免费开源方案完整指南
如何搭建终极游戏串流平台:Sunshine免费开源方案完整指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想要在任何设备上畅玩PC游戏大作?Sunshine开源游戏…...
)
从电机到USB:一文搞懂嵌入式里的感性负载、容性负载与阻抗匹配(附功率因数校正实例)
从电机到USB:一文搞懂嵌入式里的感性负载、容性负载与阻抗匹配(附功率因数校正实例) 在嵌入式系统设计中,工程师常常需要同时面对两种看似截然不同的挑战:大功率电机驱动的强电控制和高速数字通信的弱电信号处理。当电…...

AutoHotkey-v1.0:Windows自动化效率革命的极简解决方案
AutoHotkey-v1.0:Windows自动化效率革命的极简解决方案 【免费下载链接】AutoHotkey-v1.0 AutoHotkey is a powerful and easy to use scripting language for desktop automation on Windows. 项目地址: https://gitcode.com/gh_mirrors/au/AutoHotkey-v1.0 …...
)
38、【Agent】【OpenCode】本地代理分析(二)
【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除 背景 上篇 blog 【Agent】【OpenCode】本地代…...

企业级应用权限架构设计与实践指南
企业级应用权限架构设计与实践指南 【免费下载链接】react Reactwebpackreduxant designaxiosless全家桶后台管理框架 项目地址: https://gitcode.com/gh_mirrors/reac/react 一、概念解析:权限管理的核心要素 🔍 权限管理是企业级应用的安全基…...

3大场景攻克B站视频下载:Downkyi全功能实战指南
3大场景攻克B站视频下载:Downkyi全功能实战指南 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等)…...

深入解析Kubernetes中的RuntimeClass:容器运行时的“多面手调度器”
前言在Kubernetes集群中,我们通常默认使用containerd或Docker作为容器运行时。但随着业务场景的多样化、安全要求的严苛化以及硬件能力的演进,单一的运行时模型已无法满足所有需求:如何让金融应用运行在强隔离的轻量级虚拟机中,抵…...

猫抓浏览器扩展:3分钟掌握网页视频嗅探下载的终极指南
猫抓浏览器扩展:3分钟掌握网页视频嗅探下载的终极指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到网页上精彩的视频…...